
HandFormer: A Dynamic Hand Gesture Recognition Method Based on Attention Mechanism

Abstract
:1. Introduction
- (1)
- This paper proposes a deep neural network that fuses a CNN and Transformer model by embedding spatial attention convolution and temporal attention convolution into the Transformer model.
- (2)
- The spatial features of each frame of the input gesture are extracted, and the temporal features are fused into the channel information in the channel dimension; then, the temporal and spatial features of the temporal features are extracted.
- (3)
- The proposed method is tested on three datasets. The experimental results show that the proposed method has reference value and high robustness for applications in real-time human–computer interaction and control, sign language recognition, and other fields.
2. Related Works
2.1. Hand Gesture Recognition Datasets
2.2. Dynamic Hand Gesture Recognition
3. Method
3.1. MetaFormer
3.2. Spatial Attention Former Block (SAFB)
3.3. Temporal Attention Former Block (TAFB)
4. Results
4.1. Datasets
4.2. Experimental Settings
4.3. Results on Jester Dataset
4.4. Results on NVGesture Dataset
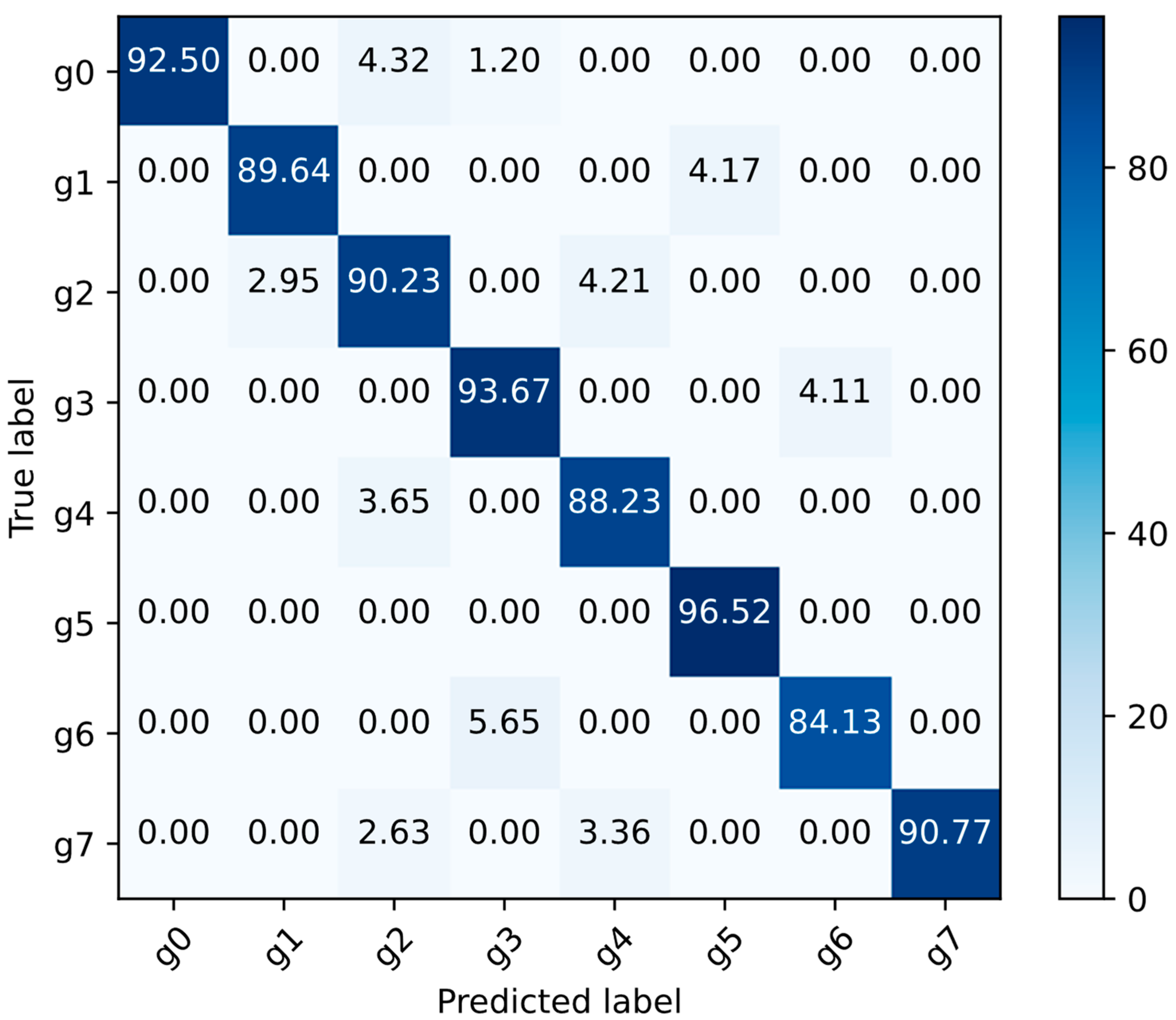
4.5. Results on Self-Built Dataset
4.6. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kowdiki, M.; Khaparde, A. Adaptive hough transform with optimized deep learning followed by dynamic time warping for hand gesture recognition. Multimed. Tools Appl. 2022, 81, 2095–2126. [Google Scholar] [CrossRef]
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand Gesture Recognition Based on Computer Vision: A Review of Techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef]
- Kim, Y.; Baek, H. Preprocessing for Keypoint-Based Sign Language Translation without Glosses. Sensors 2023, 23, 3231. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online detection and classifification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 4207–4215. [Google Scholar]
- Min, Y.; Zhang, Y.; Chai, X.; Chen, X. An efficient pointlstm for point clouds based gesture recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Abavisani, M.; VaeziJoze, H.R.; Patel, V.M. Improving the performance of unimodal dynamic hand gesture recognition with multimodal training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1165–1174. [Google Scholar]
- Joze, H.R.V.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal transfer module for CNN fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Y.; Cao, C.; Cheng, J.; Lu, H. EgoGesture: A New Dataset and Benchmark for Egocentric Hand Gesture Recognition. IEEE Trans. Multimed. (T-MM) 2018, 20, 1038–1050. [Google Scholar] [CrossRef]
- Cao, C.; Zhang, Y.; Wu, Y.; Lu, H.; Cheng, J. Egocentric Gesture Recognition Using Recurrent 3D Convolutional Neural Networks with Spatio-temporal Transformer Modules. In Proceedings of the IEEE International Conference On Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Köpüklü, O.; Gunduz, A.; Neslihan, K.; Rigoll, G. Real-time hand gesture detection and classification using convolutional neural networks. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019. [Google Scholar]
- Materzynska, J.; Berger, G.; Bax, I.; Memisevic, R. The jester dataset: A large-scale video dataset of human gestures. In Proceedings of the IEEE/CVF International Conference Computer Vision Workshop, Seoul, Republic of Korea, 7–28 October 2019; pp. 2874–2882. [Google Scholar]
- Kopuklu, O.; Neslihan, K.; Gerhard, R. Motion fused frames: Data level fusion strategy for hand gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhou, B.; Andonian, A.; Oliva, A.; Torralba, A. Temporal relational reasoning in videos. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Sincan, O.M.; Keles, H.Y. AUTSL: A Large Scale Multi-modal Turkish Sign Language Dataset and Baseline Methods. IEEE Access 2020, 8, 181340–181355. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Sun, B.; Wang, L.; Bai, Y.; Li, K.; Fu, Y. Skeleton aware multi-modal sign language recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Novopoltsev, M.; Verkhovtsev, L.; Murtazin, R.; Milevich, D.; Zemtsova, I. Fine-tuning of sign language recognition models: A technical report. arXiv 2023, arXiv:2302.07693. [Google Scholar]
- Li, D.; Rodriguez, C.; Yu, X.; Li, H. Word-level deep sign language recognition from video: A new large-scale dataset and methods comparison. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Khaleghi, L.; Sepas-Moghaddam, A.; Marshall, J.; Etemad, A. Multi-view video-based 3D hand pose estimation. IEEE Trans. Artif. Intell. 2022, 1–14. [Google Scholar] [CrossRef]
- Khaleghi, L.; Joshua, M.; Ali, E. Learning Sequential Contexts using Transformer for 3D Hand Pose Estimation. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), IEEE, Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Liu, J.; Wang, Y.; Tian, M. Dynamic Gesture Recognition Network based on Multi-scale spatio-temporal feature Fusion. J. Electron. Inf. Technol. 2022, 44, 1–9. [Google Scholar] [CrossRef]
- Chen, X.; She, Q.; Zhang, B.; Ma, Y.; Zhang, J. Based on attention to guide the airspace image convolution SRU dynamic gesture recognition. Control Decis. 2023, 1–9. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Howard Andrew, G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Hu, J.; Li, S.; Gang, S. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.-F.; Paluri, M. Convnet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhang, W.; Wang, J.; Lan, F. Dynamic hand gesture recognition based on short-term sampling neural networks. IEEE/CAA J. Autom. Sin. 2020, 8, 110–120. [Google Scholar] [CrossRef]
- Sharir, G.; Asaf, N.; Lihi, Z.-M. An image is worth 16x16 words, what is a video worth? arXiv 2021, arXiv:2103.13915. [Google Scholar]
- Zhang, C.; Zou, Y.; Chen, G.; Gan, L. Pan: Towards fast action recognition via learning persistence of appearance. arXiv 2020, arXiv:2008.03462. [Google Scholar]
- Yang, X.; Pavlo, M.; Jan, K. Making convolutional networks recurrent for visual sequence learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitionx, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 1–14. [Google Scholar] [CrossRef]
- Min, Y.; Chai, X.; Zhao, L.; Chen, X. FlickerNet: Adaptive 3D Gesture Recognition from Sparse Point Clouds. BMVC 2019, 2, 1–13. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Release Year | Characteristics |
|---|---|---|
| NVGesture [6] | 2016 | Front-facing cameras, gesture interaction in driving scenarios |
| EgoGesture [10] | 2017 | Egocentric |
| Jester [13] | 2019 | Front-facing cameras, hand gesture interaction |
| AUTSL [16] | 2020 | Sign language, multimodal |
| WLASL [20] | 2020 | Sign language |
| MuViHand [21] | 2021 | 3D synthetic gesture |
| Method | FLOPs (G) | Parameters (M) | Accuracy (%) | F1-Score (%) | Sensitivity (%) | Only Specificity (%) |
|---|---|---|---|---|---|---|
| R3D-34 [29] | 25.420 | 63.791 | 85.48 | - | - | - |
| R(2 + 1)D-34 [30] | 25.813 | 63.748 | 84.75 | 91.20 | 86.30 | 89.21 |
| STSNN [31] | - | - | 95.73 | 96.33 | 87.20 | 91.36 |
| STAM [32] | 137.464 | 104.807 | 88.94 | 90.02 | 90.63 | 92.55 |
| PAN [33] | 9.128 | 23.866 | 90.74 | 94.56 | 88.96 | 91.04 |
| DRX3D [14] | - | - | 96.60 | 95.21 | 91.23 | 93.33 |
| SlowFast [19] | 13.176 | 35.17 | 87.62 | 90.04 | 94.44 | 96.22 |
| CvT-MTAM [23] | 11.544 | 26.979 | 92.26 | 96.66 | 89.30 | 90.64 |
| Ours | 5.766 | 21.485 | 96.72 | 97.2 | 94.38 | 96.76 |
| Method | Mode | Accuracy (%) | F1-Score (%) | Sensitivity (%) | Only Specificity (%) |
|---|---|---|---|---|---|
| R3DCNN [6] | IR image | 63.5 | 73.35 | 75.62 | 73.22 |
| R3DCNN [6] | Optical flow | 77.8 | 78.42 | 79.53 | 80.63 |
| R3DCNN [6] | Depth video | 80.3 | 83.12 | 85.14 | 84.53 |
| PreRNN [34] | Depth video | 84.4 | 85.66 | 85.97 | 86.57 |
| MTUT [8] | Depth video | 84.9 | 85.48 | 88.52 | 89.91 |
| PointNet++ [35] | Point clouds | 63.9 | 71.53 | 74.31 | 72.11 |
| FlickerNet [36] | Point clouds | 86.3 | 88.56 | 89.04 | 90.10 |
| PointLSTM [7] | Point clouds | 87.9 | 89.97 | 90.65 | 91.18 |
| Human [6] | RGB video | 88.4 | 90.45 | 91.56 | 92.56 |
| MMTM [9] | RGB video + optical flow | 84.85 | 88.61 | 88.09 | 90.28 |
| STSNN [31] | RGB video + optical flow | 85.13 | 91.23 | 92.61 | 93.61 |
| Ours | RGB video + optical flow | 92.16 | 92.49 | 92.55 | 93.94 |
| Method | Accuracy (%) |
|---|---|
| PoolFormer [5] | 77.50 |
| 3PoolFB + 3SAFB + 6SAFB + 3SAFB | 88.82 |
| 3PoolFB + 3SAFB + 6SAFB + 3TAFB | 96.72 |
| 3PoolFB + 3SAFB + 6TAFB + 3TAFB | 91.47 |
| 3PoolFB + 3TAFB + 6TAFB + 3TAFB | 86.16 |
| Method | Accuracy (%) |
|---|---|
| PoolFormer [5] | 77.50 |
| 3PoolFB + 3SAFB + 3SAFB + 3TAFB | 89.82 |
| 3PoolFB + 3SAFB + 6SAFB + 3TAFB | 96.72 |
| 3PoolFB + 6SAFB + 6SAFB + 6TAFB | 95.17 |
| 3PoolFB + 6SAFB + 6SAFB + 3TAFB | 95.56 |
| Method | Accuracy (%) |
|---|---|
| PoolFormer [5] | 77.50 |
| Remove Spatial Attention | 89.82 |
| Remove Temporal Attention | 91.22 |
| Remove Spatial and Temporal Attention | 82.31 |
| Ours | 96.72 |
| Method | Characteristics |
|---|---|
| MTUT [8] | Unimodal, multimodal training, unimodal data, 3D convolution |
| GRX3D [14] | Motion Fused Frames, data-level fusion, convolutional neural network |
| SlowFast [28] | SlowFast network, two streams, 3D convolution |
| PointLSTM [7] | Point cloud, LSTM, CNN, unimodal data |
| Ours | Fusion of CNN with Transformer, multimodal data, lite, attention mechanism |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wang, F. HandFormer: A Dynamic Hand Gesture Recognition Method Based on Attention Mechanism. Appl. Sci. 2023, 13, 4558. https://doi.org/10.3390/app13074558
Zhang Y, Wang F. HandFormer: A Dynamic Hand Gesture Recognition Method Based on Attention Mechanism. Applied Sciences. 2023; 13(7):4558. https://doi.org/10.3390/app13074558
Chicago/Turabian StyleZhang, Yun, and Fengping Wang. 2023. "HandFormer: A Dynamic Hand Gesture Recognition Method Based on Attention Mechanism" Applied Sciences 13, no. 7: 4558. https://doi.org/10.3390/app13074558
APA StyleZhang, Y., & Wang, F. (2023). HandFormer: A Dynamic Hand Gesture Recognition Method Based on Attention Mechanism. Applied Sciences, 13(7), 4558. https://doi.org/10.3390/app13074558