

A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective
Abstract
:1. Introduction
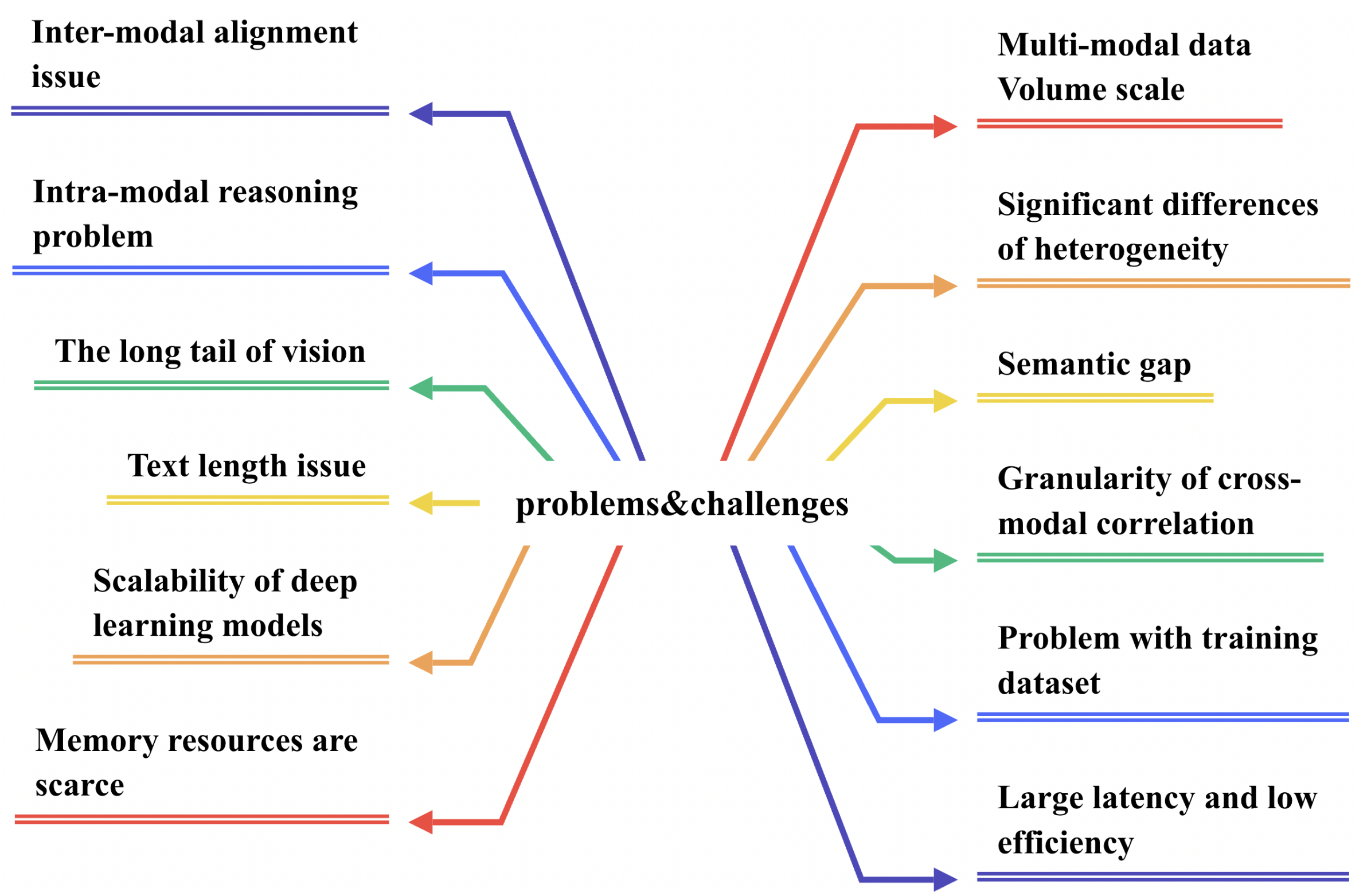
- 1.
- Multi-modal data volume: Uni-modal retrieval cannot keep up with the increasing expansion of multi-modal data.
- 2.
- Significant differences in the manifestation of heterogeneity: There is an issue with evaluating the content correlation between modal data and computing their similarity.
- 3.
- Semantic gaps: The bottom-up semantics in feature analysis between separate modalities are called semantic gaps.
- 4.
- Scalability of deep learning models: Adding new datasets, retraining the model, and recalculating all take a long period and need incremental learning.
- 5.
- Problem with training datasets: There are missing data, loose data, fewer data labels, and noisy data. Because the volume of particular cross-modal retrieval datasets is now relatively tiny, multi-modal retrieval datasets that are large in scale and a universal representation must be collected.
- 6.
- Granularity of cross-modal correlation: Researchers must connect information at the fine-grained and coarse-grained levels and pay close attention to contextual information.
- 7.
- Text length issue: The textual duration in cross-modal retrieval may be too lengthy or too short to prevent it from expressing complete meaning.
- 8.
- Long tail of vision: Raw data in the vision domain often follow a long-tail distribution, with most samples originating from only a small number of classes.
- 9.
- Intra-modal reasoning problem: The fine-grained information in the modal is semantically dependent, posing an intra-modal reasoning challenge.
- 10.
- Inter-modal alignment issue: Fine-grained information alignment and fragment alignment are examples of inter-modal alignment issues.
- 11.
- Scarce memory resources: When dealing with vast amounts of data, real-valued representation techniques suffer from expensive computing costs and great space requirements.
- 12.
- Large latency and low efficiency in retrieval: Extracting region features or other characteristics might be time-consuming, resulting in delayed retrieval results.
- We summarize various open issues and challenges.
- We concentrated on methodologies with a full-cycle deep learning process, which addresses a gap in existing works. Our approach incorporates innovative techniques and references that are absent in prior surveys.
- This paper provides a comprehensive summary and comparative analysis of disparate cross-modal representations at every pre-training stage.
- We present a comprehensive description of benchmark datasets and evaluation metrics that are critical.
2. Overview of Cross-Modal Retrieval
3. Fine-Grained Deep Learning Methodologies
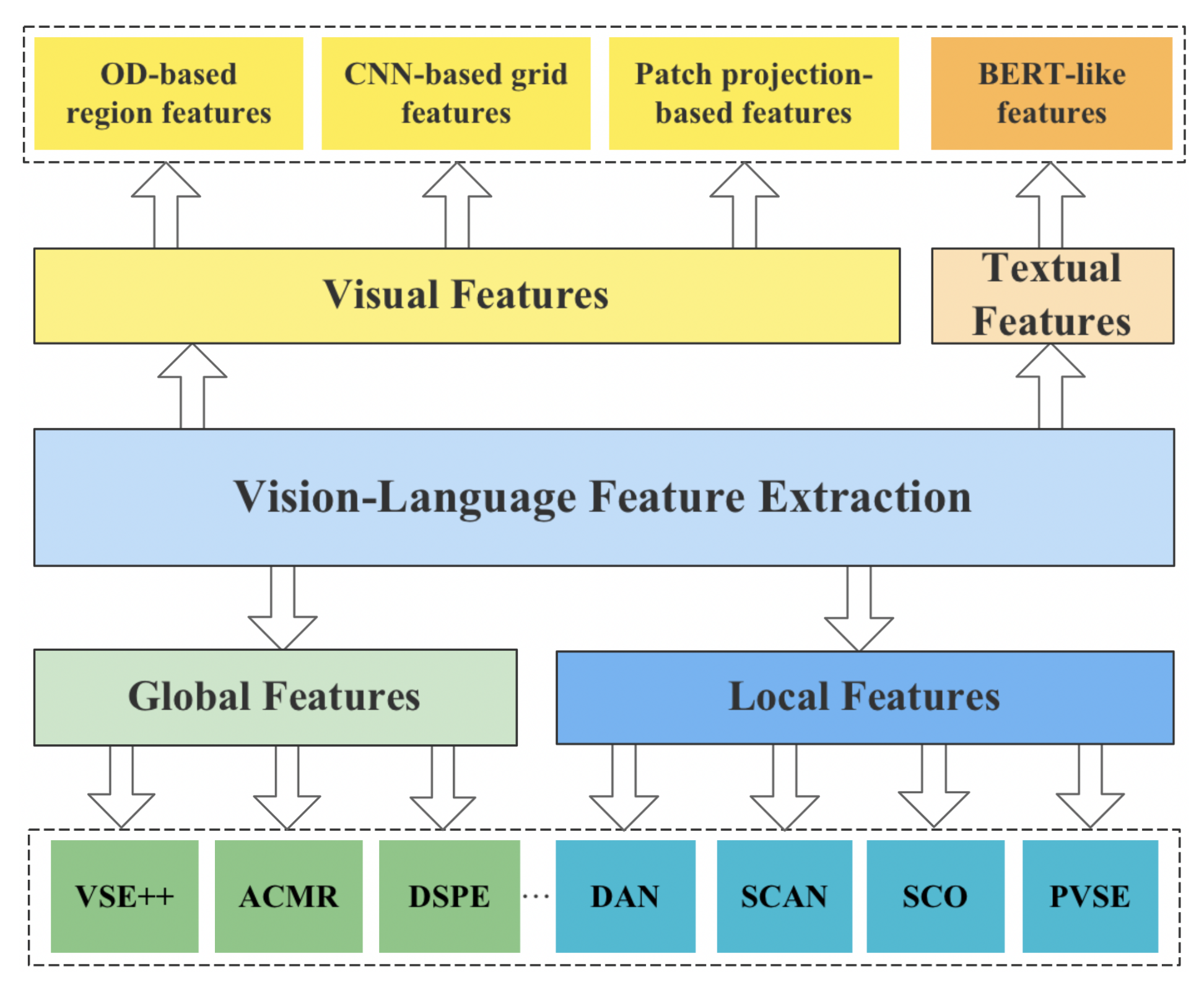
3.1. Feature Engineering
3.2. Cross-Modal Interaction
3.3. Pre-Training Tasks
3.4. Unified V-L Architecture
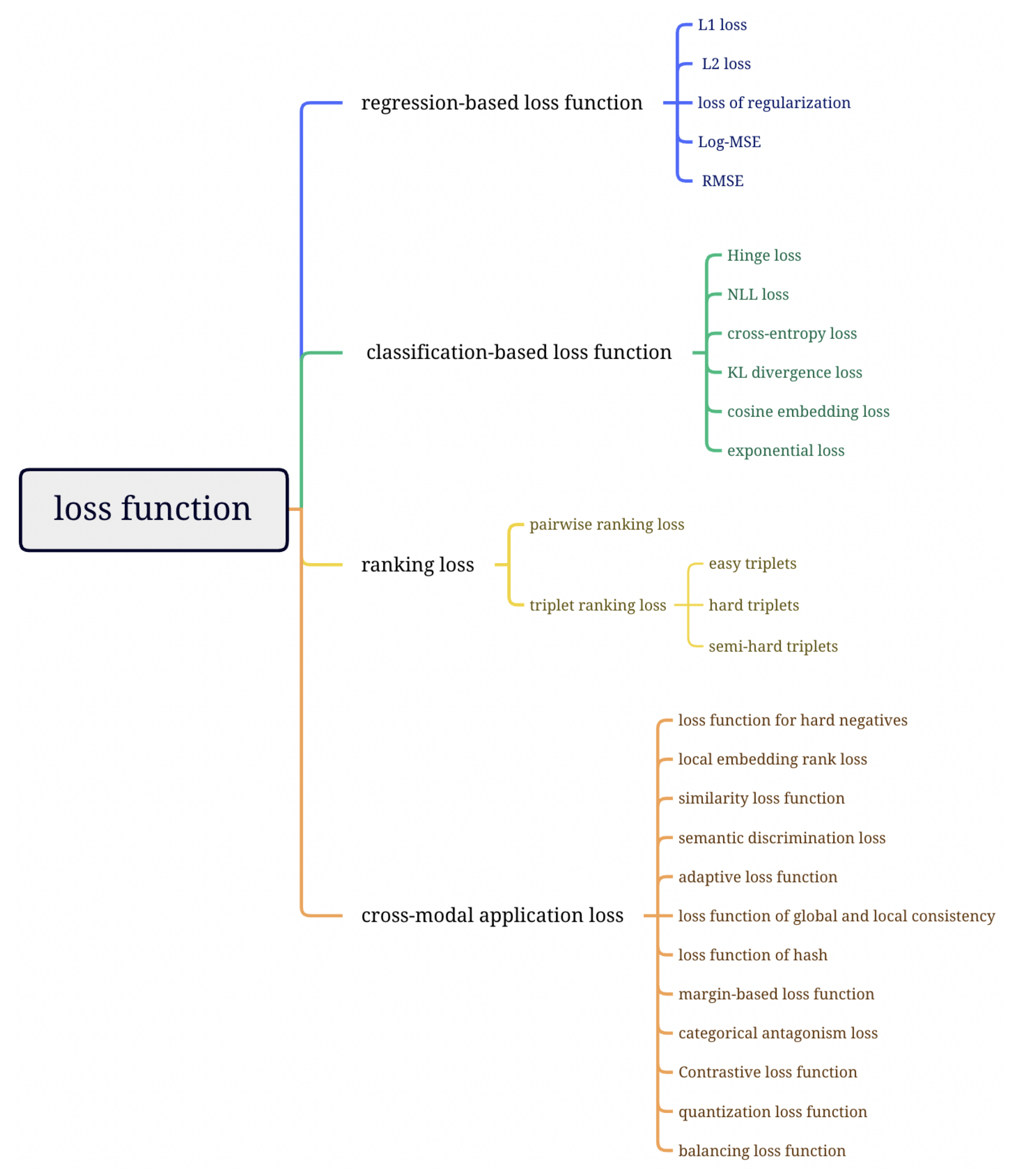
4. Loss Function
5. Evaluation Metrics
6. Benchmark Datasets
6.1. Cross-Modal Datasets
6.2. Comparison on Flickr 30k and MS-COCO Datasets
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaur, P.; Pannu, H.S.; Malhi, A.K. Comparative analysis on cross-modal information retrieval: A review. Comput. Sci. Rev. 2021, 39, 100336. [Google Scholar] [CrossRef]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Feng, F.; Wang, X.; Li, R. Cross-modal retrieval with correspondence autoencoder. In Proceedings of the 22nd ACM International Conference on Multimedia, Lisboa, Portugal, 14 October 2022; pp. 7–16. [Google Scholar]
- Wang, K.; Yin, Q.; Wang, W.; Wu, S.; Wang, L. A comprehensive survey on cross-modal retrieval. arXiv 2016, arXiv:1607.06215. [Google Scholar]
- Peng, Y.X.; Zhu, W.W.; Zhao, Y.; Xu, C.S.; Huang, Q.M.; Lu, H.Q.; Zheng, Q.H.; Huang, T.j.; Gao, W. Cross-media analysis and reasoning: Advances and directions. Front. Inf. Technol. Electron. Eng. 2017, 18, 44–57. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Huang, X.; Zhao, Y. An overview of cross-media retrieval: Concepts, methodologies, benchmarks, and challenges. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 2372–2385. [Google Scholar] [CrossRef] [Green Version]
- Ou, W.; Liu, B.; Zhou, Y.; Xuan, R. Survey on the cross-modal retrieval research. J. Guizhou Norm. Univ. (Nat. Sci.) 2018, 36, 114–120. [Google Scholar]
- Li, Z.; Huang, Z.; Xu, X. A review of the cross-modal retrieval model and feature extraction based on representation learning. J. China Soc. Sci. Tech. Inf. 2018, 37, 422–435. [Google Scholar]
- Ayyavaraiah, M.; Venkateswarlu, B. Joint graph regularization based semantic analysis for cross-media retrieval: A systematic review. Int. J. Eng. Technol. 2018, 7, 257–261. [Google Scholar] [CrossRef] [Green Version]
- Ayyavaraiah, M.; Venkateswarlu, B. Cross media feature retrieval and optimization: A contemporary review of research scope, challenges and objectives. In Proceedings of the International Conference On Computational Vision and Bio Inspired Computing, Coimbatore, India, 19–20 November 2019; pp. 1125–1136. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H.W. Unified language model pre-training for natural language understanding and generation. Adv. Neural Inf. Process. Syst. 2019, 32, 13063–13075. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Winn, J.; Criminisi, A.; Minka, T. Object categorization by learned universal visual dictionary. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–20 October 2005; Volume 2, pp. 1800–1807. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Venice, Italy, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 2019, 32, 13–23. [Google Scholar]
- Tan, H.; Bansal, M. Lxmert: Learning cross-modality encoder representations from transformers. arXiv 2019, arXiv:1908.07490. [Google Scholar]
- Huang, Z.; Zeng, Z.; Huang, Y.; Liu, B.; Fu, D.; Fu, J. Seeing out of the box: End-to-end pre-training for vision-language representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12976–12985. [Google Scholar]
- Shen, S.; Li, L.H.; Tan, H.; Bansal, M.; Rohrbach, A.; Chang, K.W.; Yao, Z.; Keutzer, K. How Much Can CLIP Benefit Vision-and-Language Tasks? arXiv 2021, arXiv:2107.06383, 6383. [Google Scholar]
- Huang, Z.; Zeng, Z.; Liu, B.; Fu, D.; Fu, J. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv 2020, arXiv:2004.00849. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural Inf. Process. Syst. 2021, 34, 38. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Yu, F.; Tang, J.; Yin, W.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. Ernie-vil: Knowledge enhanced vision-language representations through scene graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 3208–3216. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 2015; pp. 3128–3137. [Google Scholar]
- Carvalho, M.; Cadène, R.; Picard, D.; Soulier, L.; Thome, N.; Cord, M. Cross-modal retrieval in the cooking context: Learning semantic text-image embeddings. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 35–44. [Google Scholar]
- Liu, Y.; Wu, J.; Qu, L.; Gan, T.; Yin, J.; Nie, L. Self-supervised Correlation Learning for Cross-Modal Retrieval. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Kim, W.; Son, B.; Kim, I. Vilt: Vision-and-language transformer without convolution or region supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Cui, Y.; Yu, Z.; Wang, C.; Zhao, Z.; Zhang, J.; Wang, M.; Yu, J. ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross-and Intra-modal Knowledge Integration. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 15 July 2021; pp. 797–806. [Google Scholar]
- Cai, Z.; Kwon, G.; Ravichandran, A.; Bas, E.; Tu, Z.; Bhotika, R.; Soatto, S. X-DETR: A Versatile Architecture for Instance-wise Vision-Language Tasks. arXiv 2022, arXiv:2204.05626. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. Visualbert: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 104–120. [Google Scholar]
- Li, W.; Gao, C.; Niu, G.; Xiao, X.; Liu, H.; Liu, J.; Wu, H.; Wang, H. Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning. arXiv 2020, arXiv:2012.15409. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-scale adversarial training for vision-and-language representation learning. Adv. Neural Inf. Process. Syst. 2020, 33, 6616–6628. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11336–11344. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Sun, S.; Chen, Y.C.; Li, L.; Wang, S.; Fang, Y.; Liu, J. Lightningdot: Pre-training visual-semantic embeddings for real-time image-text retrieval. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 982–997. [Google Scholar]
- Xu, H.; Yan, M.; Li, C.; Bi, B.; Huang, S.; Xiao, W.; Huang, F. E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning. arXiv 2021, arXiv:2106.01804. [Google Scholar]
- Qi, D.; Su, L.; Song, J.; Cui, E.; Bharti, T.; Sacheti, A. Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data. arXiv 2020, arXiv:2001.07966. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5579–5588. [Google Scholar]
- Lu, H.; Fei, N.; Huo, Y.; Gao, Y.; Lu, Z.; Wen, J.R. COTS: Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval. arXiv 2022, arXiv:2204.07441. [Google Scholar]
- Lin, J.; Men, R.; Yang, A.; Zhou, C.; Zhang, Y.; Wang, P.; Zhou, J.; Tang, J.; Yang, H. M6: Multi-Modality-to-Multi-Modality Multitask Mega-transformer for Unified Pretraining. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Virtual, 14 August 2021; pp. 3251–3261. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Chen, H.; Ding, G.; Liu, X.; Lin, Z.; Liu, J.; Han, J. Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12655–12663. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Wang, Z.; Wang, W.; Zhu, H.; Liu, M.; Qin, B.; Wei, F. Distilled Dual-Encoder Model for Vision-Language Understanding. arXiv 2021, arXiv:2112.08723. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Mei, T. X-linear attention networks for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10971–10980. [Google Scholar]
- Lee, K.H.; Chen, X.; Hua, G.; Hu, H.; He, X. Stacked cross attention for image-text matching. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 201–216. [Google Scholar]
- Wang, Z.; Liu, X.; Li, H.; Sheng, L.; Yan, J.; Wang, X.; Shao, J. Camp: Cross-modal adaptive message passing for text-image retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5764–5773. [Google Scholar]
- Wei, X.; Zhang, T.; Li, Y.; Zhang, Y.; Wu, F. Multi-modality cross attention network for image and sentence matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10941–10950. [Google Scholar]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Liu, Z.; Zeng, M.; et al. An Empirical Study of Training End-to-End Vision-and-Language Transformers. arXiv 2021, arXiv:2111.02387. [Google Scholar]
- Ji, Z.; Wang, H.; Han, J.; Pang, Y. SMAN: Stacked multimodal attention network for cross-modal image-text retrieval. IEEE Trans. Cybern. 2020, 52, 1086–1097. [Google Scholar] [CrossRef] [PubMed]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. Vse++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; Shen, H.T. Adversarial cross-modal retrieval. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 154–162. [Google Scholar]
- Wang, L.; Li, Y.; Lazebnik, S. Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5005–5013. [Google Scholar]
- Nam, H.; Ha, J.W.; Kim, J. Dual attention networks for multimodal reasoning and matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 299–307. [Google Scholar]
- Huang, Y.; Wu, Q.; Song, C.; Wang, L. Learning semantic concepts and order for image and sentence matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6163–6171. [Google Scholar]
- Song, Y.; Soleymani, M. Polysemous visual-semantic embedding for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1979–1988. [Google Scholar]
- Qu, L.; Liu, M.; Wu, J.; Gao, Z.; Nie, L. Dynamic modality interaction modeling for image-text retrieval. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; pp. 1104–1113. [Google Scholar]
- Gur, S.; Neverova, N.; Stauffer, C.; Lim, S.N.; Kiela, D.; Reiter, A. Cross-modal retrieval augmentation for multi-modal classification. arXiv 2021, arXiv:2104.08108. [Google Scholar]
- Zhou, M.; Yu, L.; Singh, A.; Wang, M.; Yu, Z.; Zhang, N. Unsupervised Vision-and-Language Pre-training via Retrieval-based Multi-Granular Alignment. arXiv 2022, arXiv:2203.00242. [Google Scholar]
- Xu, X.; Song, J.; Lu, H.; Yang, Y.; Shen, F.; Huang, Z. Modal-adversarial semantic learning network for extendable cross-modal retrieval. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Seattle, WA, USA, 10–13 December 2018; pp. 46–54. [Google Scholar]
- Wang, L.; Li, Y.; Huang, J.; Lazebnik, S. Learning two-branch neural networks for image-text matching tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 394–407. [Google Scholar] [CrossRef] [Green Version]
- Cornia, M.; Baraldi, L.; Tavakoli, H.R.; Cucchiara, R. A unified cycle-consistent neural model for text and image retrieval. Multimed. Tools Appl. 2020, 79, 25697–25721. [Google Scholar] [CrossRef]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Auto-encoding scene graphs for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10685–10694. [Google Scholar]
- Zhen, L.; Hu, P.; Wang, X.; Peng, D. Deep supervised cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10394–10403. [Google Scholar]
- Chun, S.; Oh, S.J.; De Rezende, R.S.; Kalantidis, Y.; Larlus, D. Probabilistic embeddings for cross-modal retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8415–8424. [Google Scholar]
- Cheng, M.; Sun, Y.; Wang, L.; Zhu, X.; Yao, K.; Chen, J.; Song, G.; Han, J.; Liu, J.; Ding, E.; et al. ViSTA: Vision and Scene Text Aggregation for Cross-Modal Retrieval. arXiv 2022, arXiv:2203.16778. [Google Scholar]
- Hu, P.; Zhen, L.; Peng, D.; Liu, P. Scalable deep multimodal learning for cross-modal retrieval. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 635–644. [Google Scholar]
- Gupta, T.; Kamath, A.; Kembhavi, A.; Hoiem, D. Towards General Purpose Vision Systems: An End-to-End Task-Agnostic Vision-Language Architecture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16399–16409. [Google Scholar]
- Ni, M.; Huang, H.; Su, L.; Cui, E.; Bharti, T.; Wang, L.; Zhang, D.; Duan, N. M3p: Learning universal representations via multitask multilingual multimodal pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3977–3986. [Google Scholar]
- Cho, J.; Lei, J.; Tan, H.; Bansal, M. Unifying vision-and-language tasks via text generation. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 1931–1942. [Google Scholar]
- Yang, Z.; Gan, Z.; Wang, J.; Hu, X.; Ahmed, F.; Liu, Z.; Lu, Y.; Wang, L. Crossing the Format Boundary of Text and Boxes: Towards Unified Vision-Language Modeling. arXiv 2021, arXiv:2111.12085. [Google Scholar]
- Gao, D.; Jin, L.; Chen, B.; Qiu, M.; Li, P.; Wei, Y.; Hu, Y.; Wang, H. Fashionbert: Text and image matching with adaptive loss for cross-modal retrieval. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 2251–2260. [Google Scholar]
- Gu, J.; Cai, J.; Joty, S.R.; Niu, L.; Wang, G. Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7181–7189. [Google Scholar]
- Shi, Y.; Chung, Y.J. Efficient Cross-Modal Retrieval via Deep Binary Hashing and Quantization. U.S. Patent App. 16/869,408, 31 December 2022. [Google Scholar]
- Yin, X.; Chen, L. A Cross-Modal Image and Text Retrieval Method Based on Efficient Feature Extraction and Interactive Learning CAE. Sci. Program. 2022, 2022, 1–12. [Google Scholar] [CrossRef]
- Wei, J.; Yang, Y.; Xu, X.; Zhu, X.; Shen, H.T. Universal weighting metric learning for cross-modal retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6534–6545. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. Hcmsl: Hybrid cross-modal similarity learning for cross-modal retrieval. Acm Trans. Multimed. Comput. Commun. Appl. (Tomm) 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Wang, X.; Chen, L.; Ban, T.; Usman, M.; Guan, Y.; Liu, S.; Wu, T.; Chen, H. Knowledge graph quality control: A survey. Fundam. Res. 2021, 1, 607–626. [Google Scholar] [CrossRef]
- Zhong, F.; Wang, G.; Chen, Z.; Xia, F.; Min, G. Cross-modal retrieval for CPSS data. IEEE Access 2020, 8, 16689–16701. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Zhu, Y. Visual Relationship Detection with Contextual Information. Comput. Mater. Contin. 2020, 63, 1575–1589. [Google Scholar]
- Jiang, B.; Yang, J.; Lv, Z.; Tian, K.; Meng, Q.; Yan, Y. Internet cross-media retrieval based on deep learning. J. Vis. Commun. Image Represent. 2017, 48, 356–366. [Google Scholar] [CrossRef] [Green Version]
- Chua, T.S.; Tang, J.; Hong, R.; Li, H.; Luo, Z.; Zheng, Y. Nus-wide: A real-world web image database from national university of singapore. In Proceedings of the ACM International Conference on Image and Video Retrieval, Santorini Island, Greece, 1 January 2009; pp. 1–9. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Winn, J. The pascal visual object classes challenge 2012 (voc2012) development kit. Pattern Anal. Stat. Model. Comput. Learn. Tech. Rep. 2011, 8, 1–32. [Google Scholar]
- Rasiwasia, N.; Costa Pereira, J.; Coviello, E.; Doyle, G.; Lanckriet, G.R.; Levy, R.; Vasconcelos, N. A new approach to cross-modal multimedia retrieval. In Proceedings of the 18th ACM International Conference on Multimedia, Lisboa, Portugal, 14 October 2010; pp. 251–260. [Google Scholar]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2text: Describing images using 1 million captioned photographs. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framing image description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef] [Green Version]
- Xiong, W.; Wang, S.; Zhang, C.; Huang, Q. Wiki-cmr: A web cross modality dataset for studying and evaluation of cross modality retrieval models. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft coco captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Peng, Y.; Xie, L. A new benchmark and approach for fine-grained cross-media retrieval. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1740–1748. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 8430–8439. [Google Scholar]
- Changpinyo, S.; Sharma, P.; Ding, N.; Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3558–3568. [Google Scholar]
- Zhang, Q.; Lei, Z.; Zhang, Z.; Li, S.Z. Context-aware attention network for image-text retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3536–3545. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual semantic reasoning for image-text matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4654–4662. [Google Scholar]
- Qu, L.; Liu, M.; Cao, D.; Nie, L.; Tian, Q. Context-aware multi-view summarization network for image-text matching. In Proceedings of the 28th ACM International Conference on Multimedia, Virtual, 12–16 October 2020; pp. 1047–1055. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dual-Stream Models | Single-Stream Models |
|---|---|
| 2019-ViLBERT [24] | 2019-VisualBERT [38] |
| 2019-LXMERT [25] | 2020-UNITER [39] |
| 2020-UNIMO [40] | 2020-Oscar [30] |
| 2020-ViLLA [41] | 2020-Unicoder-VL [42] |
| 2021-ALBEF [29] | 2020-VL-BERT [43] |
| 2021-LightningDot [44] | 2020-E2E-VLP [45] |
| 2021-CLIP [27] | 2020-ImageBERT [46] |
| 2021-ALIGN [47] | 2020-Pixel-BERT [28] |
| 2021-ERNIE-ViL [31] | 2021-ViLT [35] |
| 2019-WenLan1.0(RoBERTa-base) [17] | 2021-VinVL [48] |
| 2022-COTS [49] | 2021-M6 [50] |
| Pre-Training Type | Task Name |
|---|---|
| Vision-Based Tasks |
MOC: masked object classification MRFR: masked region feature regression MRM: masked region modeling MFR: masked feature regression MFC: masked feature classification MRC: masked region classification MIM: masked image modeling |
| Text-Based Tasks |
MLM: masked language modeling NSP: next sentence prediction WRA: word region alignment PLM: permuted language modeling CLTR: cross-lingual text recovery TLM: translation language modeling |
| Cross-Modal Tasks |
VLM: visual-linguistic matching ITM: image text matching MTL: multi-task learning CMCL: cross-modal contrastive Learning CMTR: cross-modal text recovery PrefixLM: prefix language modeling DAE: denoising autoencoding ITCL: image-text contrastive learning MRTM: masked region-to-token modeling VTLM: visual translation language modeling |
| Pros of Universal Representation | Improved Accuracy: It reduces the computational resources and training time needed, making retrieval faster and more efficient. |
| Pros of Universal Representation | Better Generalization: A universal representation can lead to better generalization. This can improve performance and reduce the need for large amounts of training data. |
| Pros of Universal Representation | Increased Efficiency: A universal representation reduces the computational cost of developing and training models. Instead of creating separate models for each task, the model can be trained and used for multiple tasks. |
| Cons of Universal Representation | Increased Complexity: A universal representation is a complex and challenging task that requires a significant cost of time and resources. Developing cross-modal retrieval model may require expertise from multiple domains and may involve complex algorithms and architectures. |
| Cons of Universal Representation | Loss of Modality-Specific Information: Combining multiple modalities into a single model, some modality-specific information may be lost. This may reduce the accuracy of the cross-modal retrieval that require fine-grained features. |
| Cons of Universal Representation | Limited Interpretability: A universal representation may be difficult to interpret, making it challenging to understand the interactions between vision and language. This lack of interpretability may be a concern for applications. |
| Pros of Unified Generation Model | Generation Ability: A unified generation model can generate outputs in one modality based on inputs from another modality, which can be useful for cross-modal retrieval. |
| Pros of Unified Generation Model | Better Performance: A unified generation model can provide better performance in cross-modal retrieval compared to separate models for different modalities. The unified model can capture the complex relationships between different modalities more effectively. |
| Cons of Unified Generation Model | Limited Flexibility: A unified generation model is not as flexible as traditional models in handling different modalities. The model generates representations for all modalities, which may not be optimal for specific modalities. |
| Cons of Unified Generation Model | Increased Complexity of Training: Although training a unified generation model may take less time, the complexity of training the model may be higher. The model generates representations for multiple modalities, which can be a more challenging task. |
| Cons of Unified Generation Model | Increased Risk of Overfitting: A unified generation model is more prone to overfitting. The model generates representations for multiple modalities simultaneously, which may overfit if the training data are not sufficiently diverse. |
| Name | Number | Description |
|---|---|---|
| NUS-WIDE [92] | 269,648 | Every image includes 2 to 5 label claims on average. |
| https://www.image-net.org/ (accessed on 1 January 2022) | 14,197,122 | ImageNet aims at classification, positioning, and detection task evaluation. |
| Pascal VOC 2007 [93] | 9963 | It includes training, validation, and test and marks 24,640 objects. |
| Pascal VOC 2012 [94] | 11,530 | Each image is tagged with 20 categories of objects, including people, animals, vehicles, and furniture. Each image has an average of 2.4 objects. |
| Wikipedia [95] | 2866 | The most-often used dataset for retrieval study is Wikipedia, which consists of entries with relevant picture–text pairs. |
| SBU Caption [96] | 1,000,000 | Image captions are a retrieval task containing 1 million image URLs and title pairs. Humans write the captions, which are then filtered to leave only those with at least two nouns, noun–verb pairs, or verb–adjective pairs. |
| Flickr 8k [97] | 8092 | Each image is accompanied by five human-generated subtitles that focus on humans or animals performing an action. |
| Wiki-CMR [98] | 74,961 | A web cross-modality dataset includes written paragraphs, photos, and hyperlinks. |
| Flickr 30k [99] | 31,783 | The images are accompanied by 1,58,915 captions gathered through crowdsourcing. |
| MS-COCO [100] | 3,28,000 | The dataset contains 25,00,000 annotated occurrences. The collection contains artifacts from 91 different categories. |
| Visual Genome [101] | 108,077 | There are about 5.4 million captions given to picture areas. It contains around 2.8 million labels for object properties in the picture and approximately 2.3 million labels for object connections. |
| PKU FG-XMedia [102] | 50,000 | Over 50,000 samples are included in the PKU FG-XMedia collection, comprising 11,788 graphics, 8000 texts, 18,350 videos, and 12,000 audios. It has different media kinds, a precise granularity of categories, and multiple data sources. |
| Conceptual Caption [103] | 3,000,000 | The photographs and descriptions are gathered from the Internet, and they feature a diverse spectrum of emotions. The captions are derived from the HTML alt element of each picture. |
| Objects 365 [104] | 630,000 | The collection includes 630,000 photos from 365 categories and up to 10 million frames. It is distinguished by its cast scale, excellent quality, and good generalizability. |
| https://storage.googleapis.com/openimages/web/index.html (accessed on 1 January 2022) | 9,000,000 | Open Images is a library of 9 million collection including image-level labels, 15,851,536 bounding boxes, 2,785,498 segmentation masks, visual connections, 675,155 localized narratives, and 59,919,574 image-level labels. |
| M6 [50] | 100,000,000 | It is the most-extensive dataset of a Chinese multi-modal pre-training model, with 1.9 T pictures and 292 G texts. |
| Conceptual 12M [105] | 12,000,000 | It includes a much greater spectrum of visual concepts than the Conceptual Captions dataset, used for image captioning model pre-training and end-to-end training. |
| Models | Pretrain Images | Flickr 30k (1K Test Set) | R_SUM | |||||
|---|---|---|---|---|---|---|---|---|
| TR@1 | TR@5 | TR@10 | IR@1 | IR@5 | IR@10 | |||
| SCAN | - | 67.4 | 90.3 | 95.6 | 48.5 | 77.7 | 85.2 | 464.7 |
| CAAN | - | 70.1 | 91.6 | 97.2 | 52.8 | 79.0 | 97.9 | 488.6 |
| VSRN | - | 71.3 | 90.6 | 96.0 | 54.7 | 81.8 | 88.2 | 482.6 |
| MMCA | - | 74.2 | 92.8 | 96.4 | 54.8 | 81.4 | 87.8 | 487.4 |
| CAMRA | - | 78.0 | 95.1 | 97.9 | 60.3 | 85.9 | 91.7 | 508.9 |
| DIME | - | 81.0 | 95.9 | 98.4 | 63.6 | 88.1 | 93.0 | 520.0 |
| UNITER | 4 M | 87.3 | 98.0 | 99.2 | 75.6 | 94.1 | 96.8 | 551.0 |
| VILLA | 4 M | 87.9 | 97.5 | 98.8 | 76.3 | 94.8 | 96.5 | 552.8 |
| ALIGN | 1.8 B | 95.3 | 99.8 | 100 | 84.9 | 97.4 | 98.6 | 576 |
| UNIMO | 5.7 M | 89.4 | 98.9 | 99.8 | 78 | 94.2 | 97.1 | 557.4 |
| VLC | 5.6 M | 89.2 | 99.2 | 99.8 | 72.4 | 93.4 | 96.5 | 550.5 |
| Models | Pretrain Images | MS-COCO (5K Test Set) | R_SUM | |||||
|---|---|---|---|---|---|---|---|---|
| TR@1 | TR@5 | TR@10 | IR@1 | IR@5 | IR@10 | |||
| UNITER | 4 M | 65.70 | 88.60 | 93.80 | 52.90 | 79.90 | 88.00 | 468.90 |
| ViLT | 4 M | 61.50 | 86.30 | 92.70 | 42.70 | 72.90 | 83.10 | 439.20 |
| ALBEF | 4 M | 73.10 | 91.40 | 96.00 | 56.8 | 81.50 | 89.20 | 488.00 |
| TCL | 4 M | 75.60 | 92.80 | 96.70 | 59 | 83.20 | 89.90 | 497.20 |
| VLC | 5.6 M | 71.30 | 91.20 | 95.80 | 50.70 | 78.90 | 88.00 | 475.90 |
| ALIGN | 1.8 B | 77.00 | 93.50 | 96.90 | 59.90 | 83.30 | 89.80 | 500.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Zhu, L.; Shi, L.; Mo, H.; Tan, S. A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective. Appl. Sci. 2023, 13, 4571. https://doi.org/10.3390/app13074571
Wang S, Zhu L, Shi L, Mo H, Tan S. A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective. Applied Sciences. 2023; 13(7):4571. https://doi.org/10.3390/app13074571
Chicago/Turabian StyleWang, Suping, Ligu Zhu, Lei Shi, Hao Mo, and Songfu Tan. 2023. "A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective" Applied Sciences 13, no. 7: 4571. https://doi.org/10.3390/app13074571
APA StyleWang, S., Zhu, L., Shi, L., Mo, H., & Tan, S. (2023). A Survey of Full-Cycle Cross-Modal Retrieval: From a Representation Learning Perspective. Applied Sciences, 13(7), 4571. https://doi.org/10.3390/app13074571