1. Introduction
Humans have access to a wide range of verbal and nonverbal cues from nature with which to communicate their emotions. Our emotions greatly influence our social relationships. Emotions are complex mental states that comprise subjective experience, pathological and physiologic responses, and other factors [
1,
2]. They are consistent responses to events based on some stimuli, and the intensity of response varies from human to human. Human Emotion Recognition (HER) has several exciting application areas such as human–computer interaction to better understand and respond to human-centric events, affect-sensitive systems for autism therapy, chat-bots in call centres, in the entertainment industry, and so on. Such applications can potentially alter the way we interact with computers in our daily lives [
3,
4,
5].
Humans can express emotions both verbally and non-verbally. The expression of verbal emotions is limited and typically indicated by known words, idioms, or phrases, whereas nonverbal emotions can be shown more diversely. Nonverbal emotions can be revealed through physiological indications, facial expressions, speech, gestures, etc. For many decades, psychologists and scientists have extensively explored the field of human sentiment analysis to understand human emotions [
6,
7,
8,
9]. On the one hand, psychologists probe human emotions from the perspective of social psychology as “emotions naturally emerge out of the core principles of evolutionary psychology” [
10]. However, scientists from other fields, such as the medical sciences, hardware design engineering, computer science, etc., investigate emotions to comprehend how the brain functions, to create new, improved hardware, and to create intelligent systems to assess, forecast, and identify human affective states.
With the rapid advancement of consumer electronics, it is now feasible to capture human emotions using various technologies (including smart devices). This includes, but is not limited to, vision sensors to capture facial expressions or record human gait in the form of videos [
11,
12], speech-based emotions recognition [
13,
14,
15], electroencephalograms (EEG) to record the electrical activity of the brain [
16,
17], and wearable inertial sensors to capture human gait data under different affective states [
16]. Facial expressions, being the most prominent artefact of intimate emotions, have been extensively explored [
18]. Although facial expression-based emotions prediction has improved significantly over time, environment and occlusion-invariant facial expression-based emotions recognition systems are still very challenging, especially given the COVID-19 situation where it is recommended to wear face masks. Moreover, recording facial data raises serious privacy concerns and hence cannot be used in practical applications. Furthermore, facial expressions are not trustworthy indicators of emotion since they may be manipulated and are not generated as a result of a particular feeling [
19].
Wearable inertial sensors, such as smart fitness bands, smartwatches, smart in-soles, etc., have turned into a key enabling technology for a wide variety of applications. They are low cost, do not impose any environmental constraints, and have been widely used in human gait analysis, healthcare and health monitoring, and sports activities [
20,
21,
22,
23,
24]. The inertial gait data collected via wearable gadgets have been analysed to better understand human motion from a variety of perspectives such as estimating soft-biometrics such as gender, age, and height [
25,
26], predicting emotions [
19,
27,
28], classification of terrains and ground surfaces [
29], human activity recognition [
30,
31], cognitive impairment and fall detection [
32,
33,
34], and even person re-identification [
35,
36].
Body posture and movement are the most independent forms of expressing human emotions, as opposed to facial expressions, which may be altered and hence faked. Much research suggests that the kinematics of walking can convey emotional states [
19,
37,
38,
39,
40,
41]. However, most prior research either deals with a restricted range of emotions or has marginally poor classification accuracies and hence cannot be employed in practical applications [
27,
42,
43].
The work at hand presents a CNN-RNN-based deep learning model, which can predict emotions from human gait using low-level kinematic signals. To train the model, we used an inertial-based emotions dataset collected in one of our previous studies [
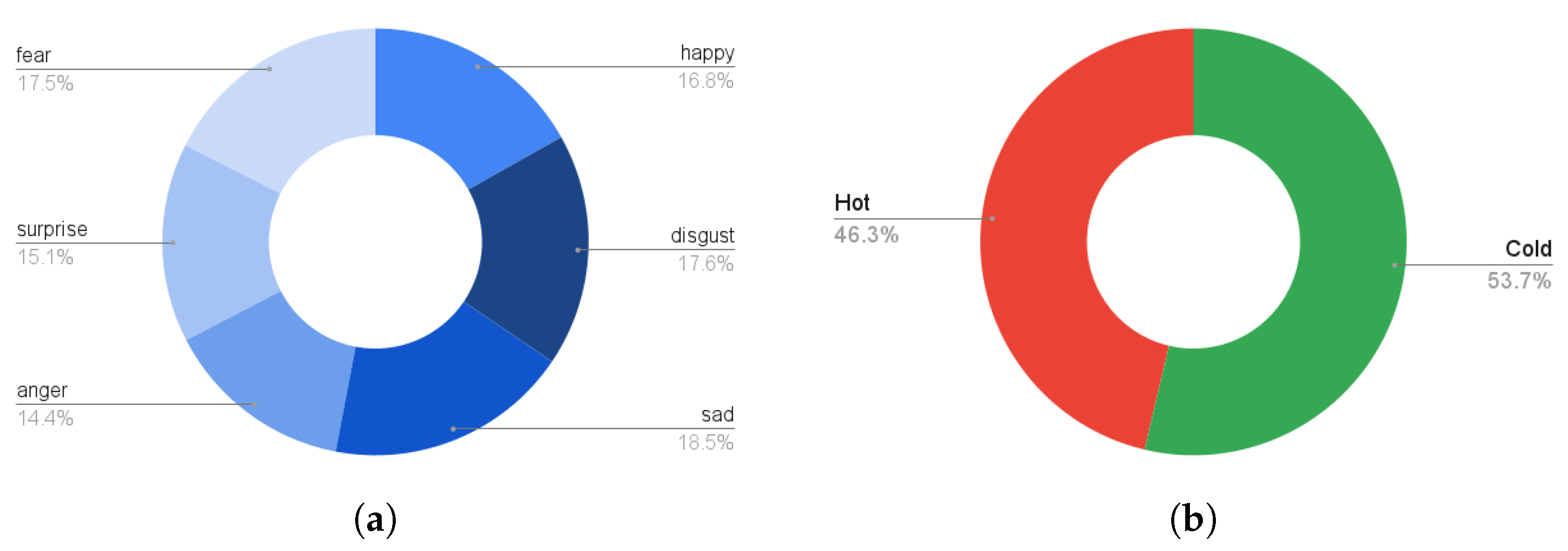
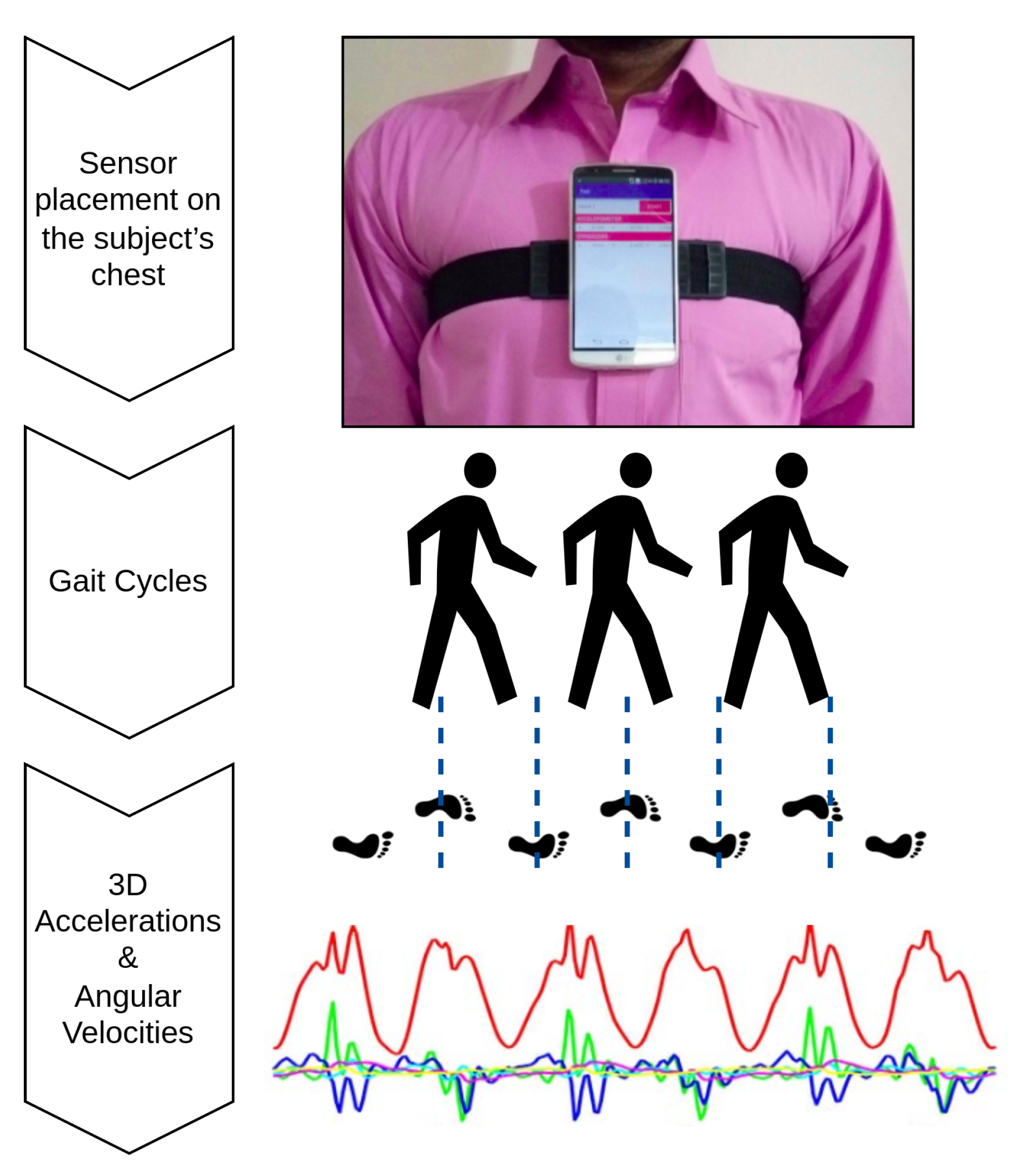
19]. An autobiographical memories paradigm was employed for emotional stimuli to collect the emotional data. A chest-mounted smartphone with on-board inertial sensors (tri-axial accelerometer and tri-axial gyroscope) was used to capture gait data from 40 healthy volunteers for six fundamental human emotions, including anger, happy, disgust, sad, fear, and surprise. Subjects were instructed to recollect a prior significant incident and walk straight twice for 10-meters back and forth for each emotion. This resulted in a 40-m walk for each mood.
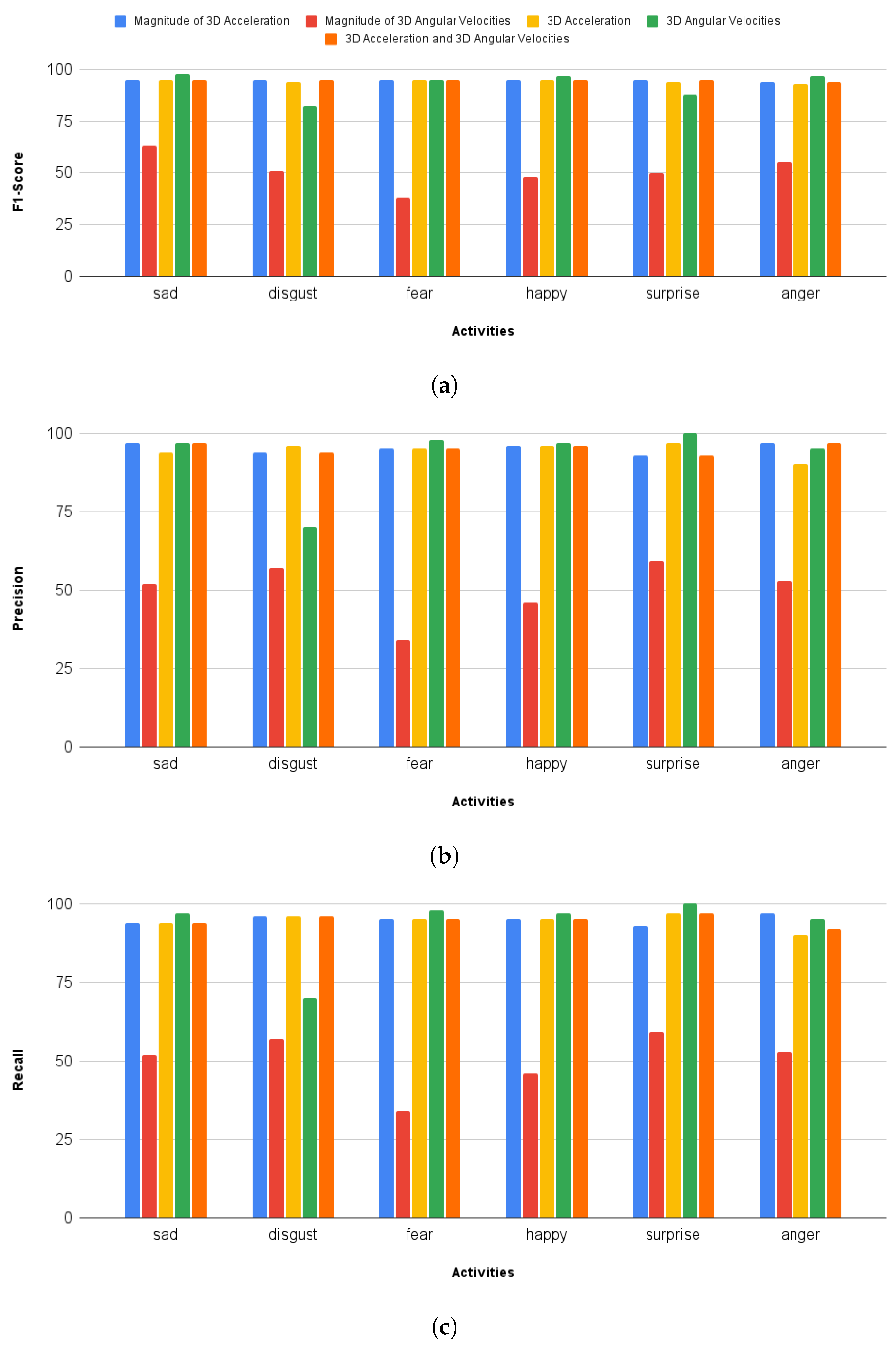
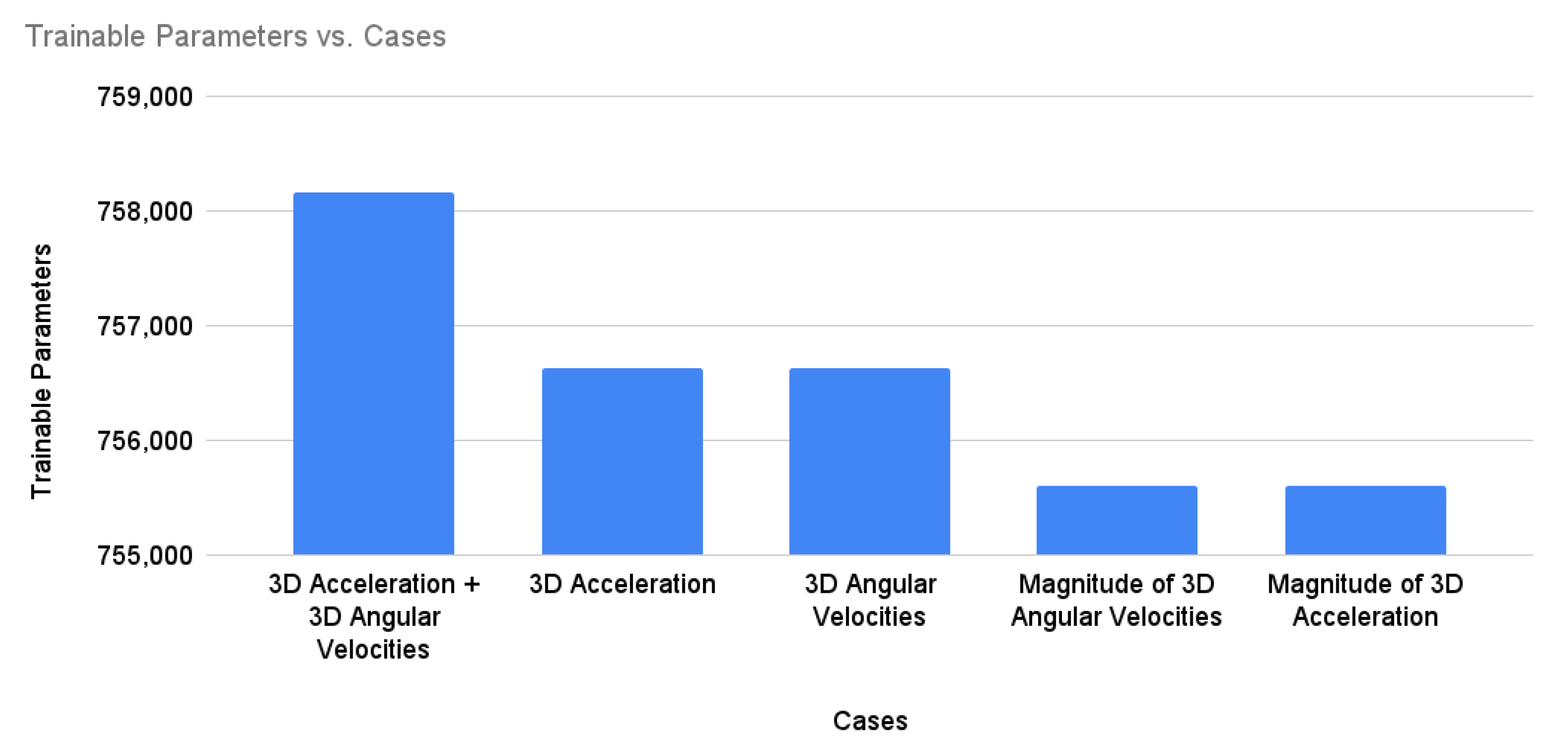
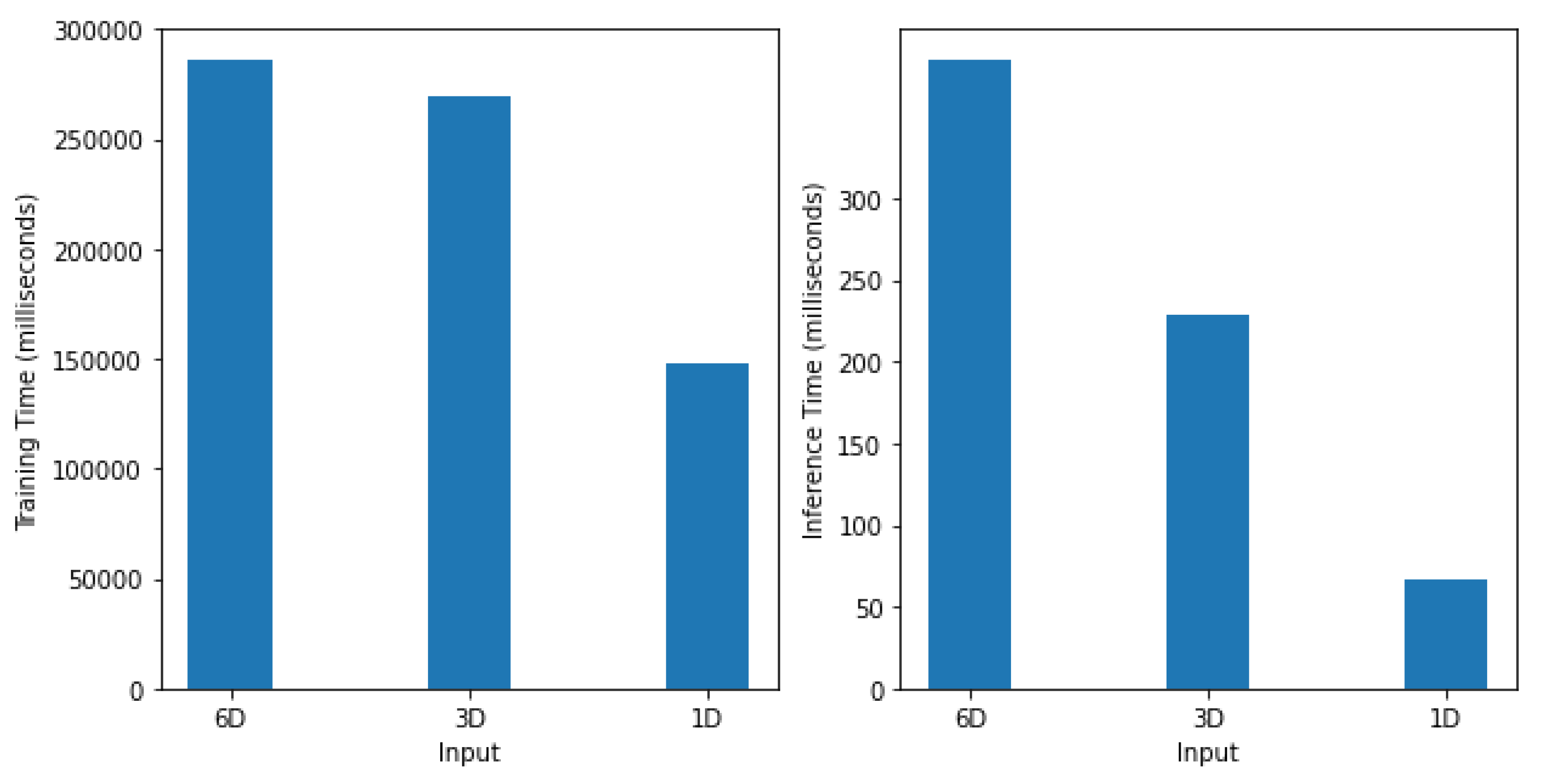
During the design of the deep model, a key factor was reducing the model’s complexity to speed up the learning process. To this end, we proposed the computation of the magnitude of 3D accelerations () from the raw signals in the pre-processing step. This reduces the input space from 3D to 1D. Similarly, we compute the magnitude of 3D angular velocities () from the raw signals, which reduces the input space from 3D to 1D. The proposed model was separately trained and validated with and . For the sake of comparison, the proposed model was validated with a 3D input space (3D accelerations and 3D angular velocities) as well as a 6D input space (6D accelerations and angular velocities). During experimentation, it was observed that the reduction of input size to 1D ( or ) significantly reduces the computation time as compared to 3D or 6D input sizes. Furthermore, the proposed methodology also outperforms existing state-of-the-art approaches. The following are the significant contributions of this work:
We present a CNN-RNN deep architecture (inspired by InceptionResNet CNN and BiGRU models) where we proposed a novel approach of dense connections employing 1 × 1 convolutions from raw input to the BiGRU model (see
Section 4);
We proposed a reduction in the input space by utilising 1D magnitudes of 3D accelerations and 3D angular velocities (
,
), which result in lower processing requirements as well as better results (
Section 4 and
Section 5);
The proposed deep model was trained and evaluated with different input sizes (1D–6D) for the sake of comparison and the best results are reported (
Section 5);
The proposed model was compared with the existing approaches and it was observed that the proposed model outperforms the state-of-the-art approaches (
Section 6.1).
The rest of the article is organised as follows:
Section 2 discusses related literature,
Section 3 describes the dataset used in this study;
Section 4 explains the methodology including pre-processing, the proposed model, the training procedure, and the model’s complexity;
Section 5 presents the results computed with different input sizes, and
Section 6 concludes the article.
2. Literature Review
Emotion recognition based on inertial sensor data and machine or deep learning entails collecting data on bodily movements and gestures associated with various emotions using sensors such as accelerometers and gyroscopes. These data are subsequently analysed by AI systems to precisely detect an individual’s emotional state.
There are various advantages of using inertial sensors and AI for emotion recognition over traditional approaches such as facial expression analysis or self-reporting. They can give a more objective and accurate assessment of emotions, even when people are attempting to conceal their emotions.
Accurate assessment of the emotional state of a user is vital for improving machine–user interactions. Smart wearable devices are the right choice for emotional estimation because of ease of use, mobility, privacy, and the ubiquity of IMUs in these devices. In this context, Zhang et al. [
27] investigated the use of smart wristbands with built-in accelerometers to identify three human emotions: neutral, angry, and happy. A population of 123 subjects was used to collect emotional data and traditional machine-learning classifiers were used for training and validation. They reported the best classification accuracy of 81.2%. The dataset proposed in this study includes only the data of Chinese subjects and data on only three emotions were collected.
Piskioulis et al. [
37] described a method for emotion recognition based on non-intrusive mobile sensing employing accelerometer and gyroscope sensor data supplied by cellphones. To monitor the players’ sensor data while playing the game, an Android OS sensor log app was employed, and a prototype gaming software was created. Data from 40 participants were analysed and used to train classifiers for two emotions: happiness and impatience. The validation investigation found that the accuracy for joy is 87.90% and the accuracy for frustration is 89.45%. This study only deals with two types of emotions.
Reyana et al. [
38] designed a system for emotion recognition based on physiological inputs. Body sensors such as muscle pressure sensors, heartbeat sensors, accelerometers, and capacitive sensors were used to gather signals. There were four classes: happy, sad, furious, and neutral. The suggested approach achieved the following percentages of accuracy for emotional states: happy 80%, sad 70%, angry 90%, and neutral 100%. The study considered only three basic emotions.
Quiroz et al. [
42] performed emotion recognition based on smart bands inertial sensors data. The dataset collected was based on 50 volunteers. The volunteers were given audio-visual stimuli to enter a state and then were requested to walk. The presented study only dealt with two classes—happy and sad. The accuracy achieved was 75%.
Gravina and Li used sensor and feature-level fusion techniques based on body-worn inertial sensors attached to users’ wrists and a pressure detection module put on the seat to construct a system that identifies and monitors in-seat actions [
44]. They concentrated on four major emotional activities: frustration, sadness, curiosity, and happiness. Their findings revealed that integrating temporal and frequency-domain data from all sensors resulted in outstanding classification accuracies (about 99.0%).
A complete system for ambient assisted living was proposed by Costa et al. [
8] to alter the environment of the living based on the emotions of the elderly. They developed a smart band to measure electrodermal activity, temperature, heart rate, and mobility. They proposed a neural network consisting of fully connected layers which were trained on 18 features to classify eight different emotions, i.e., happiness, contempt, anger, disgust, fear, sadness, neutral, and surprise. They reported 20% of misclassification cases. The study proposed collecting data on eight emotions but made use of multiple sensors including heart rate and temperature sensors which are usually not available in smart-wearable devices.
The study by Cui et al. [
43] employed a smartphone’s onboard tri-axial accelerometer attached to the wrist and ankle of the subjects to collect data for three emotions: happy, neutral, and anger. They extracted 114 features using principal component analysis (PCA). Different classical machine learning classifiers were trained and they found that the support vector machine (SVM) performed best. They also provided a comparison of emotional identification using wrist versus ankle data. They reported the best classification accuracy of 85% and also showed that the emotions prediction from the ankle sensor is much higher than from the wrist sensor.
Hashmi et al. [
19] collected emotion data from smartphones’ onboard IMUs for six different emotions: anger, sad, happy, fear, disgust, and surprise. They demonstrated a manually-built feature set that comprised elements from the time, frequency, and wavelet domains. They concluded that time, frequency, and wavelet domain characteristics may be employed to train various supervised learning models. The best classification accuracy for all six emotions is stated to be 86.45%.
In the majority of the studies above, the number of classes is limited excluding the study [
19] which deals with the case of classifying six activities.
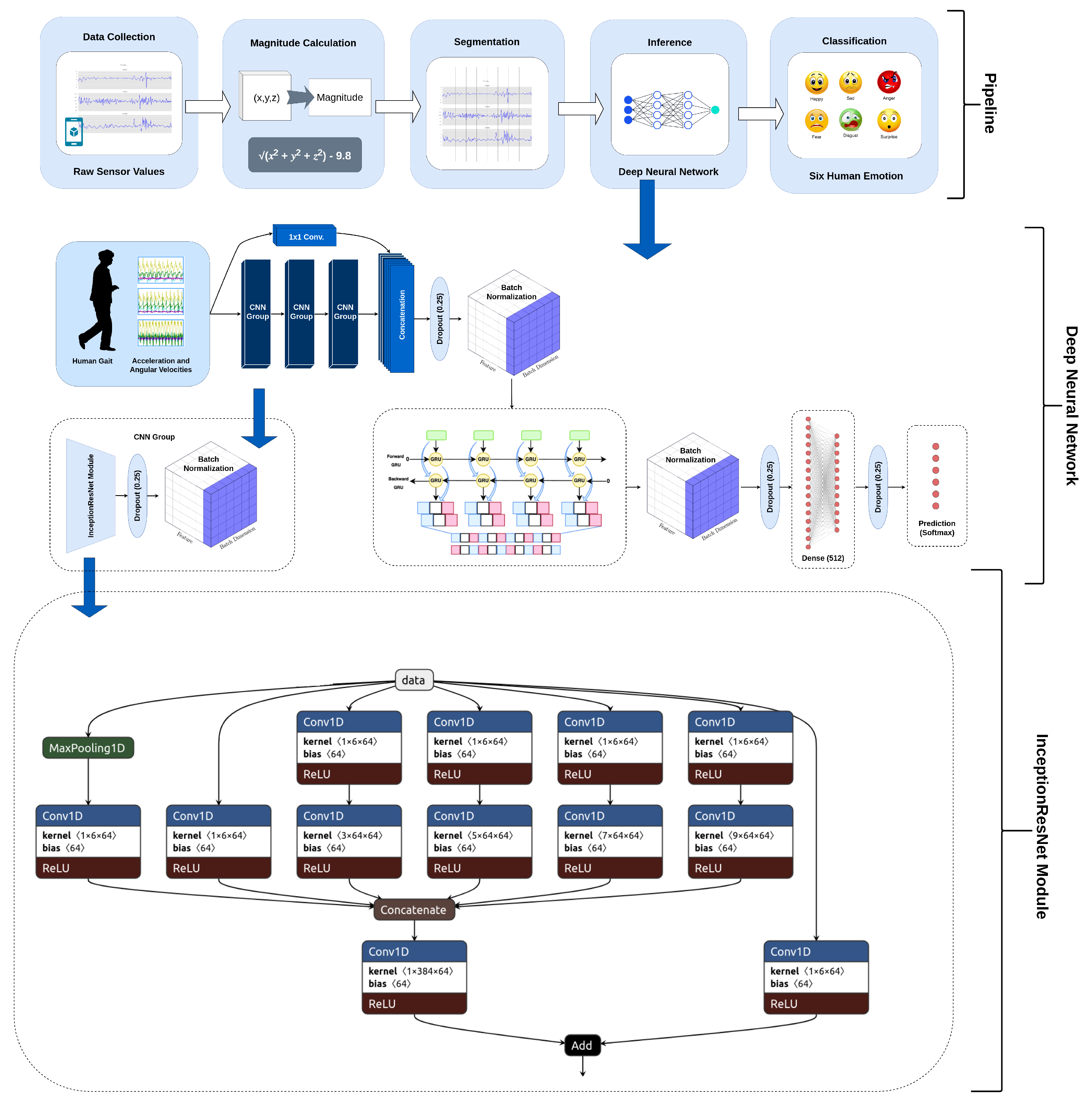
4. Methodology
In this section, we will discuss the proposed methodology. We will start with thepPre-processing (
Section 4.1) where we describe the computation of the magnitudes of 3D accelerations and 3D angular velocities. Then, the proposed deep architecture is explained (
Section 4.2). Afterwards, the model training process is described (
Section 4.3). The complete flow of the suggested approach is depicted in
Figure 3.
4.1. Pre-Processing
A critical goal of the proposed work was minimizing computational complexity, making it more suitable for Internet of Things (IoT) applications and real-time systems. One way to minimize the system’s complexity is to reduce the input size [
49]. The main advantage of 1D magnitudes is the removal of the sensor’s orientation effect. Such an effect is noticeable when the sensor is attached to a joint with higher degrees of freedom, e.g., a wrist-mounted smartwatch or smart band. In this context, we proposed computing a 1D magnitude from 3D accelerations and 3D angular velocities, i.e., reducing the input size from 3D to 1D. The magnitude of the three-dimensional accelerations was calculated as follows. Let
,
,
be 3D accelerations, then the magnitude of the 3D accelerations,
, is given as:
The gravitational constant, 9.8, was subtracted from the magnitude to remove the effect of gravity.
Similarly, let
,
,
be 3D angular velocities, then the magnitude of the 3D angular velocities,
, is given as:
The and were separately fed into the deep learning model for training and validation.
4.2. The Architecture
The proposed architecture for classifying human emotions consists of the Convolutional Neural Network – Recurrent Neural Network (CNN-RNN) model. The CNN-RNN models were first proposed for image-captioning applications [
50], where the CNN models are used to extract visual features from images followed by the recurrent units such as the gated recurrent unit (GRU) [
51] or long short term memory (LSTM) [
52] to generate captions. The model we proposed comprises two InceptionResNet [
53] inspired CNN modules built on a bidirectional RNN [
54], consisting of a bidirectional-GRU with 128 units (see
Figure 3). The feature map created by the CNN module was concatenated with the raw signals through a connection of a 1 × 1 convolutional layer. To keep the spatial dimensions identical, we used 1 × 1 convolution operations. A total of 64, 1 × 1 kernels were applied to the raw sensor data. This concatenation was inspired by DenseNet [
55], which is an image classification model. The benefit of InceptionNet [
56] is that it has variable-sized kernels that enable it to detect features of different sizes. Similarly, the ResNet [
57], or having a residual connection, lets the model learn the identity; thus, the model is capable of bypassing a module if it does not contribute to classification. For the sequential data, RNNs perform better; therefore, the feature map generated by the CNN modules is given to the bidirectional GRU. The motivation behind introducing the dense connection was that, if CNNs are of no benefit, the raw sensor data are still processed by RNNs resulting in a better classification accuracy. To the best of our knowledge, this type of dense connection, where a feature map generated by CNNs is concatenated with the raw signals, has never before been experimented with for any kind of classification problem. In our experimentation, we found that this significantly improves the performance of the entire model.
Figure 3 shows the overall proposed architecture and presents the InceptionResNet modules that are incorporated into the model.
The proposed model has five different kernels, i.e., 1 × 1, 1 × 3, 1 × 5, 1 × 7, and 1 × 9. The input is convolved with 64, 1 × 1 kernels before applying 10 kernels of sizes 1 × 3, 1 × 5, 1 × 7, and 1 × 9. This reduces the overall complexity of the model as pointed out in the existing literature [
58]. We tested it by adding different-sized kernels sequentially, which improves the performance significantly. The selection of the number of kernels and their spatial dimensions were based on empirical results (see
Section 5.3). Moreover, the addition of a max-pool also improves performance. The feature map generated by the kernels and max-pool was then concatenated. The final output was then passed to 64 kernels of 1 × 1 convolutions to change the spatial dimensions. The input feature map was also passed through 64, 1 × 1 kernels, and feature maps generated from both were then added. The overall architecture has three such modules in it, which were selected by empirical analysis.
The batch normalization and dropout were set to 0.25, and were applied after each module and to the feature map generated by the Bi-GRU units. This significantly reduces the training time. The feature vector generated by Bi-GRU was then reshaped and flattened before passing it to a fully connected layer of 512 neurons. The number of neurons in the dense layer was also selected empirically. A dropout of 0.25 was then applied for the sake of regularization.
4.3. Training Process
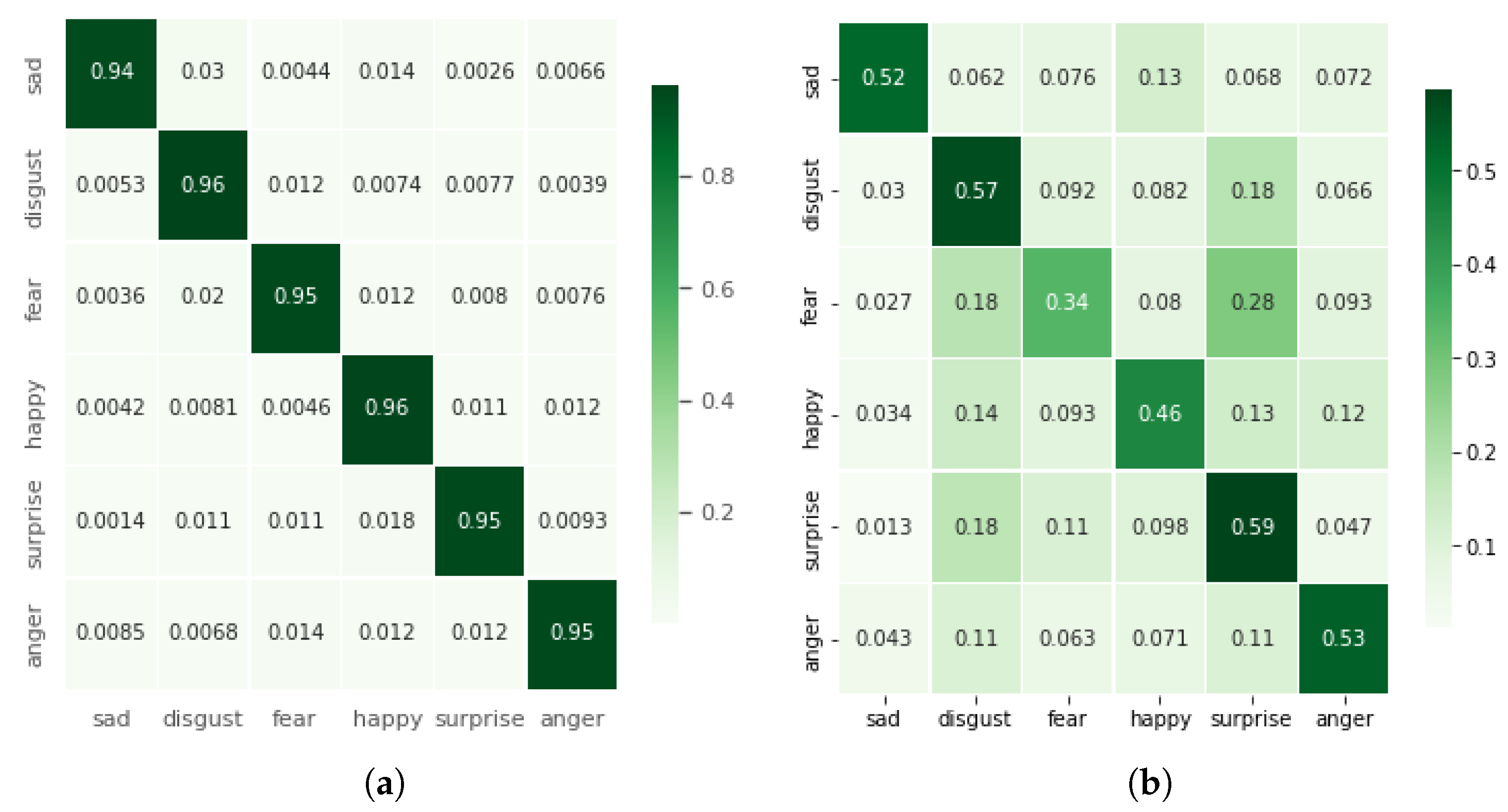
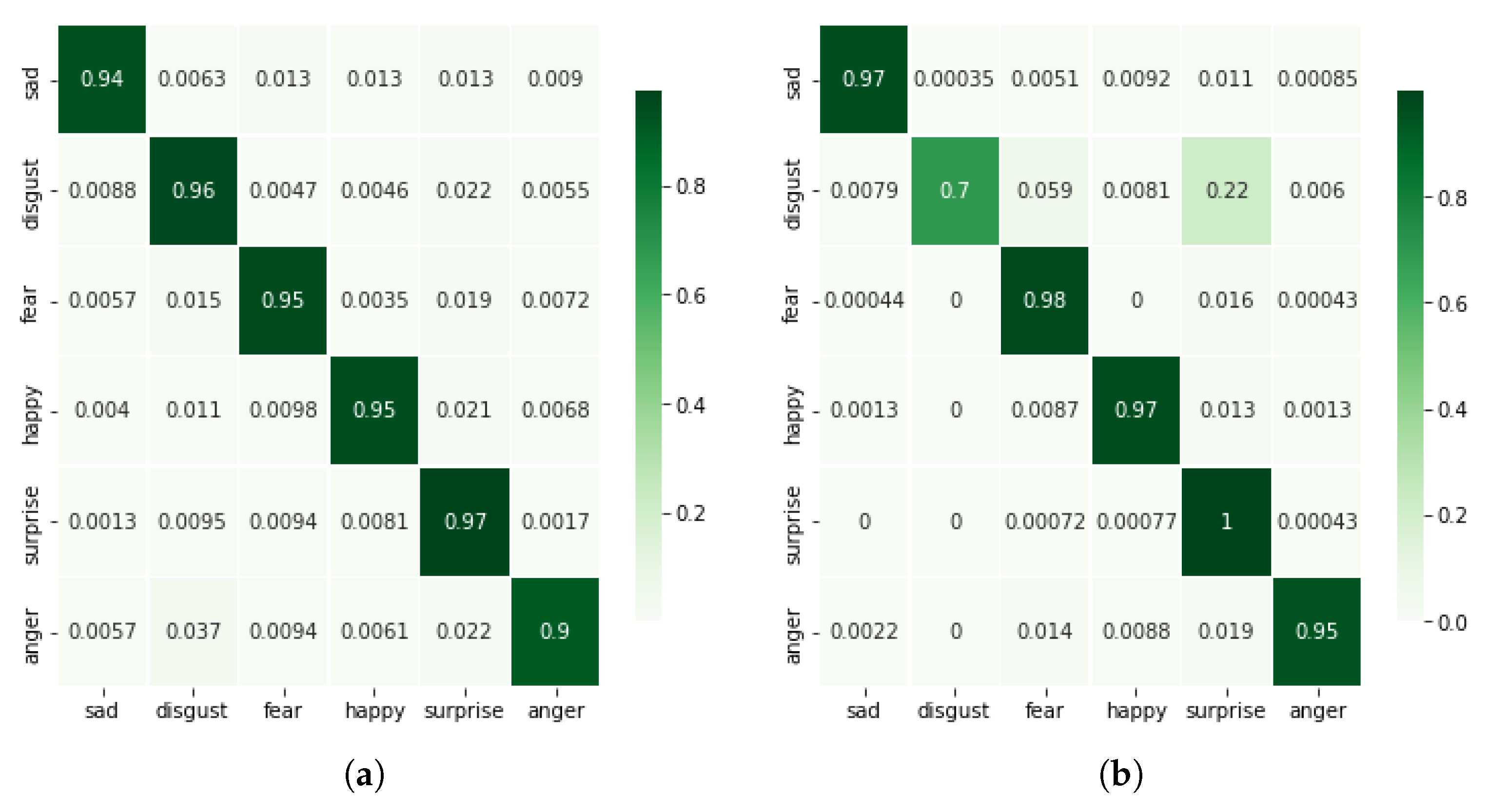
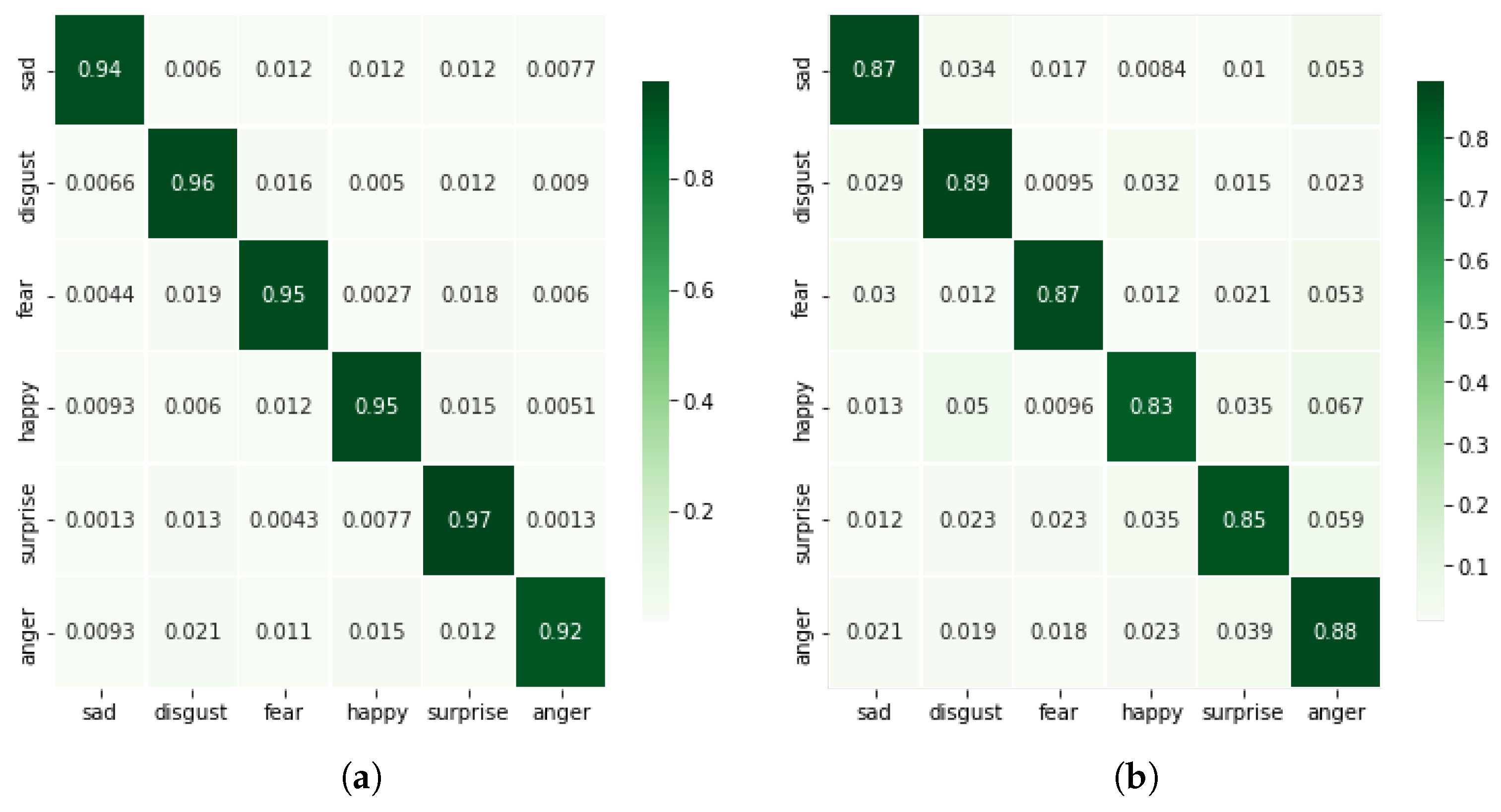
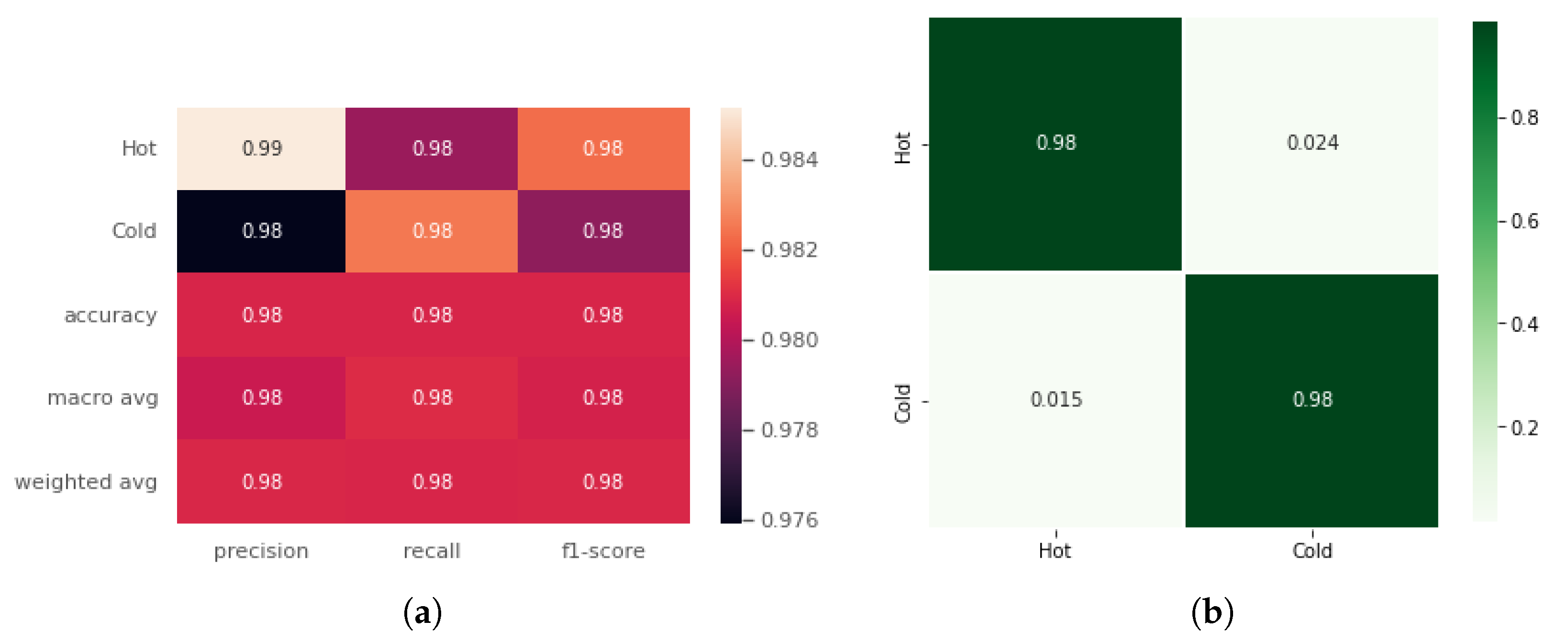
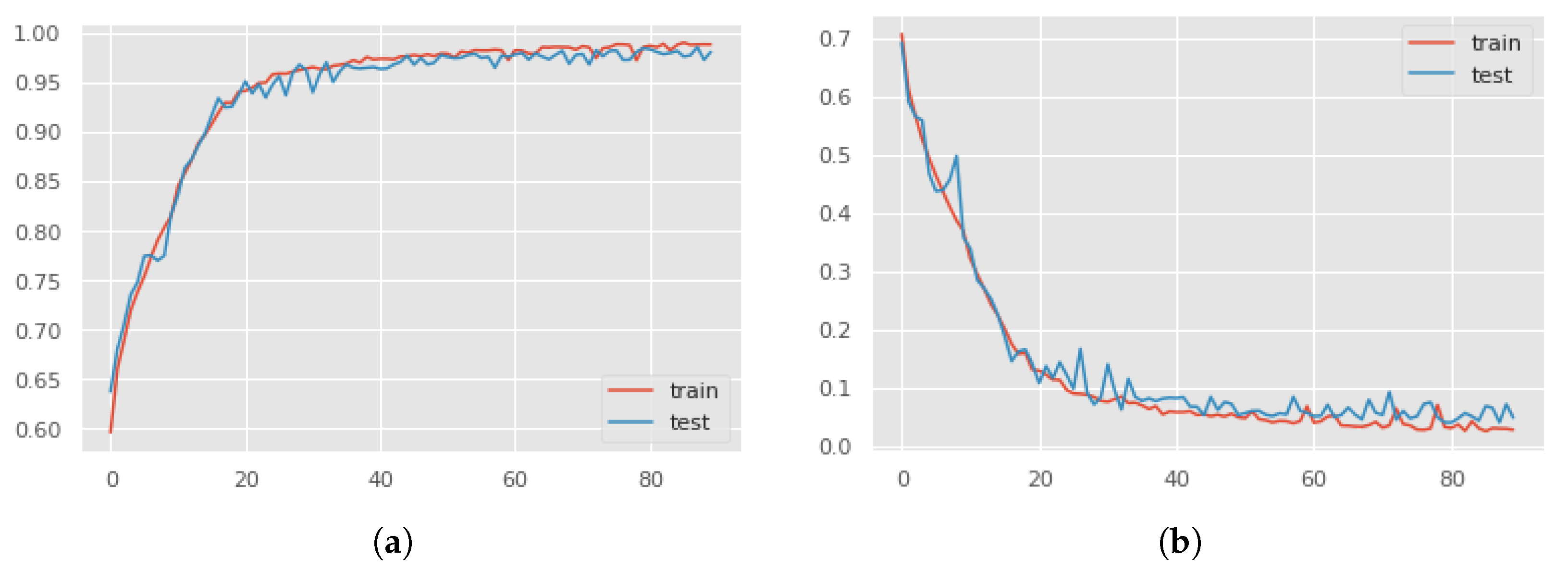
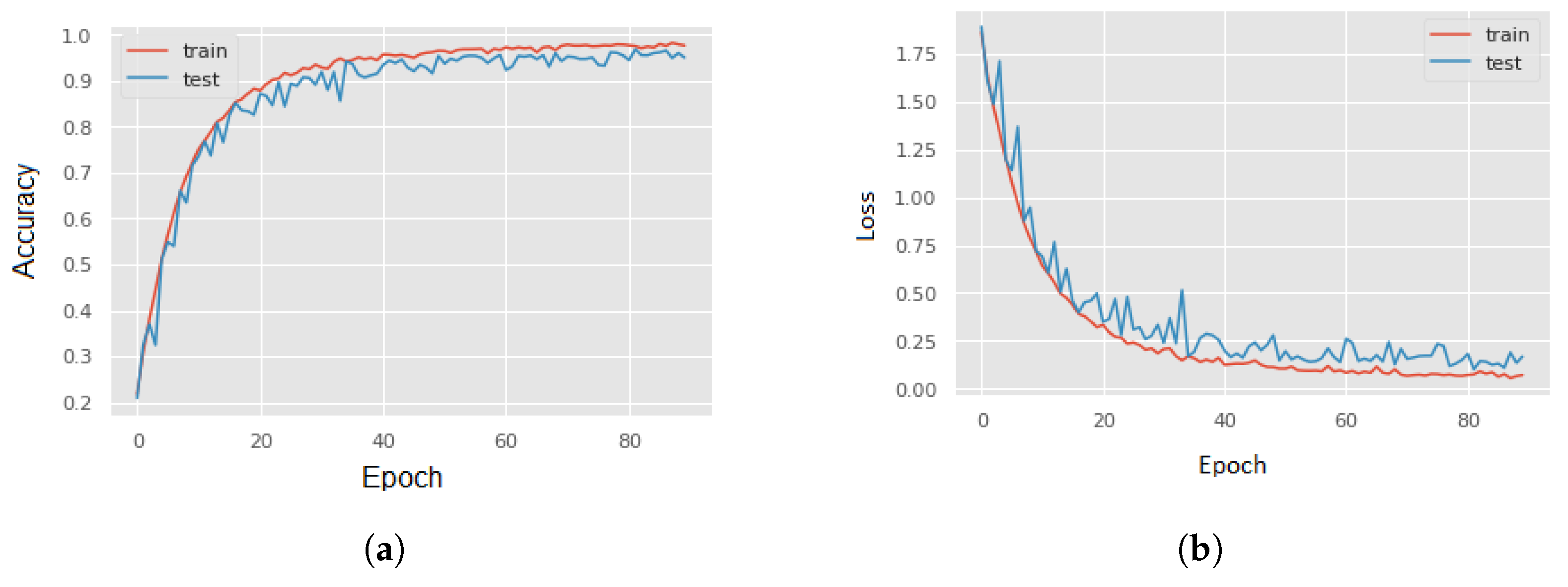
For all of the investigations, Google Colaboratory’s runtime GPUs were used. The experiment was carried out entirely with Python using Keras 2.4.3 and Tensorflow 2.4.0 to build the model. Seaborn and Sklearn were used to visualize and compute the confusion matrices and performance reports. A 10-fold cross-validation technique was employed for validation. The batch size was set to 64, and the epoch count was set at 120. The number of epochs was determined empirically by observing the accuracy and loss graphs for training and testing. To minimize loss, the neural network weights and the learning rate should be adjusted. We learned how to adjust the weights or learning rate of our neural network using an optimizer. We experimented with several optimizers, including “Adam”, “Momentum”, “RMSprob”, and others, and found that “Adam” performed the best in comparison with another optimizer.
6. Conclusions
We presented a unique CNN-RNN deep learning model for classifying human emotional states using body-mounted inertial sensors. Our experiments have demonstrated that decreasing the input space not only reduces the model’s complexity but also gives the best classification accuracies. The input space can be reduced by computing the magnitude of 3D accelerations or 3D angular velocities. Our results show a classification accuracy above 95% with the magnitude of 3D accelerations (), i.e., 1D input signal. For the sake of comparison, we also trained and validated the proposed deep model with 3D input signals (3D accelerations, 3D angular velocities) and 6D input signals (6D accelerations and angular velocities). The results were computed on a multi-emotions inertial dataset collected in one of our previous studies, which covers six basic emotions, i.e., disgust, happy, anger, surprise, sad, and fear.
6.1. Comparison with Existing Approaches
A detailed comparison with the existing studies is given in
Table 6. It can be observed that the most related work is [
19], in which they proposed a set of manually-crafted features which are used to train different supervised learning models. We have used the same dataset to train our proposed deep learning model and achieved the best classification accuracy of 95% using the 1D input signal.
6.2. Limitations and Future Work Directions
We essentially worked on six basic emotions–disgust, happy, anger, surprise, sad, fear. However, a variety of micro-expressions such as pain, pleasure, joy, etc., exist. Extending the dataset with a wider range of emotions is an important future direction, which will help in developing better deep models to estimate and understand human emotions on the fly. Similarly, the demographic diversity of the subject is another important direction of future work to analyze emotions from a demographic perspective. Additionally, for practical applications, developing a real-time, edge-based emotions prediction system developed over the node (e.g., a smartwatch) is another crucial aspect to be worked on in the future.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}