Abstract
In the medical field, hematoxylin and eosin (H&E)-stained histopathology images of cell nuclei analysis represent an important measure for cancer diagnosis. The most valuable aspect of the nuclei analysis is the segmentation of the different nuclei morphologies of different organs and subsequent diagnosis of the type and severity of the disease based on pathology. In recent years, deep learning techniques have been widely used in digital histopathology analysis. Automated nuclear segmentation technology enables the rapid and efficient segmentation of tens of thousands of complex and variable nuclei in histopathology images. However, a challenging problem during nuclei segmentation is the blocking of cell nuclei, overlapping, and background complexity of the tissue fraction. To address this challenge, we present MIU-net, an efficient deep learning network structure for the nuclei segmentation of histopathology images. Our proposed structure includes two blocks with modified inception module and attention module. The advantage of the modified inception module is to balance the computation and network performance of the deeper layers of the network, combined with the convolutional layer using different sizes of kernels to learn effective features in a fast and efficient manner to complete kernel segmentation. The attention module allows us to extract small and fine irregular boundary features from the images, which can better segment cancer cells that appear disorganized and fragmented. We test our methodology on public kumar datasets and achieve the highest AUC score of 0.92. The experimental results show that the proposed method achieves better performance than other state-of-the-art methods.
1. Introduction
The segmentation of nuclei from histopathologic images has been a major focus of the cancer research community. Millions of tissue biopsies are performed annually, representing the most accurate method of cancer diagnosis. The most critical aspect of tissue biopsy is the analysis of nuclei in pathological images. Their shape and distribution within the organ determines cell type, tissue morphology and cancer category. This has significant implications in the diagnosis, severity and treatment of cancer. However, manual segmentation is tedious and incorporates the subjectivity of the observer. A large amount of fully annotated histopathological data can be empirically quantified by recent computerized techniques. It has advantage of being less time-consuming than doctors’ manual review and providing prior advice. Particularly for routinely stained hematoxylin and eosin sections, since differences in nuclear and cytoplasmic morphology and stain density, the nucleus overlap and occlusion, inter- and intra- nucleus inhomogeneity, background complexity, and image artifacts [1]. So Pre-processing of the original data is also an essential part before solving the nucleus segmentation. Computerized techniques to efficiently identify nuclear and subsequent detailed analysis quickly can help physicians diagnose conditions to save time and avoid subjective errors.
In many U-net structures, the same convolutional module is used to extract features, which tends to extract too many bloated semantic features in the shallow layer and not enough in the deep layer. We would like to make appropriate optimizations in the structure and depth of the network. In this work, we focus on adopting different methods in different depth convolutional layers. Nuclear segmentation is a relatively simple binary classification task. The network channels of MIU-net is reduced to half of the routine U-net network [2]. Shallow layers use single convolution modules, and deep layers combine inception and resnet ideas [3]. We adopt residual connections and different sizes kernels to extract features in deep layers. The function of the attention module is to train for the region of interest in the decoder process [4]. In this paper, we attempt to use the U-net as our baseline and make some modifications to it. This module can achieve state-of-the-art performance compared to the original U-net and other variants on kumar dataset. We have improved performance by adding the attention mechanism to the original U-net, improving the inception module, and appropriately reducing the number of channels. We have obtained the appropriate range of parameter quantity, taking into account both parameter quantity and accuracy.
- The pre-processing part combined the advantages of various data enhancement to make the histopathology images clearer and higher contrast.
- A new network architecture is proposed, which has a certain robustness and efficiency while reducing parameters and maintaining good segmentation performance.
- The modules of the proposed architecture address challenges, focusing on a robust modified inception block and attention block that segment touching nuclei and accurately detecting nuclei with variable shapes.
2. Related Work
A large number of scientific studies have been conducted on semantic segmentation of pixel-level pathology pictures by conventional methods [5,6,7,8]. The adaptive threshold method is an innovation on the method of setting the threshold manually. The threshold setting is simple and easy to implement, but the segmentation effect is terrible and sensitive to image noise [9]. Watershed segmentation is prone to the phenomenon of excessive segmentation [10]. Automatic Bayesian algorithm achieves high accuracy [11]. There is fuzzy clustering [12], graph-based segmentation methods [13], and so on.
Automatic analysis of medical images based on deep convolutional neural networks has attracted much interest owing to its excellent performance. We will summarize the most recent advances in nuclear segmentation of histopathological images. U-net is a landmark work where the basic framework is a encoder-decoder convolutional neural network with skip connections. It has a symmetric network structure with feature extraction in the front part and upsampling in the second part, using skip connections to fuse the location information at the bottom with the deep semantic information [14]. The advantage of it is simple and efficient and has become the backbone of almost all primary medical image segmentation methods. There are many structural variants of U-net. Nested U-net can fuse networks of different depths and produce flexible feature fusion schemes [15]. Attention mechanisms are effective for nuclear segmentation. The hard attention mechanism directly removes useless target and only trains the most important foreground nuclei. The soft attention mechanism can process channels, spatial and mixed domain. Channel attention mechanism suppresses irrelevant channels, models the importance of each feature, and for different tasks can be assigned features based on the input. [16]. Spatial attention mechanism first locates the pixel points relevant to the task and then proceeds an affine transformation or obtains the weights. [17]. The U-net with attention module allows more accurate features extraction for the foreground cell nucleus fraction [18]. The one with rcnn module is generalized from the target detection domain and extracts features with a sliding window of selective search [19]. U2-net uses U-net structures inside multiple encoding and decoding processes. Then combines the results of more U-net outputs. Finally merger results [20]. The context encoding network apply dense dilated convolution to extract features using different scales of the field of view, and multiple pooling modules reduce the complexity of the model [21].
New network architectures or multi-branching tasks applied to different kinds of medical images. HoVer-net can process classification tasks according to cell nucleus ground classification labels and better handles joining-up nucleus pixels. It puts forward horizontal distance gradient technique to settle problems [22]. A novel deep contour-aware network portray clear contour lines to separate cell nuclei instance, which intelligently integrates contextual information with auxiliary supervision. Then it constructed a depth contour-aware network by fusing complementary information with appearance and contour of the cell nucleus [23]. Neural network architecture uses graph structure to analyze bone age presented in X-rays [24]. A characteristic pyramidal network was used in the retinal classification of lesions caused by diabetes and grading of lesion levels [25]. Multimodal and single-modal feature reconstruction in brain CT scans for efficient multiple branching tasks [26]. MIU-net can use a variety of modules to improve segmentation efficiency. Furthermore, the use of publicly available datasets, which are annotated by professional physicians, further enhances the challenge results.
3. Methodology
3.1. Network Design
The structure of the MIU-net is shown in Figure 1. The overall architecture of the network is similar to a traditional U-net, using a five-layer deep, symmetric u-shaped structure. We use different numbers of convolutions and kernel sizes in the shallow and deep layers, intending to extract features flexibly and balance network consumption. In the downsampling process, the three-channel input image is first passed through three single convolution modules, then through two double convolution modules and inception modules to extract deep semantic information more precisely. The overall number of channels in the encoding stage is reduced by half contrasted to the conventional U-net, and the image is halved in size after each downsampling. We cropped the original shot in the pre-processing stage to be able to accommodate the five-times split image size. In the upsampling process, we used bilinear interpolation to restore the image resolution, and then the feature maps from the encoding stage were skip-connected. The feature map conducts attention learning before the last two skip-connected. It avoids redundant information from being activated in the low-level encoding stage and reduces jump connections of redundant information. The final feature map is downscaled to obtain a single-channel grayscale map.
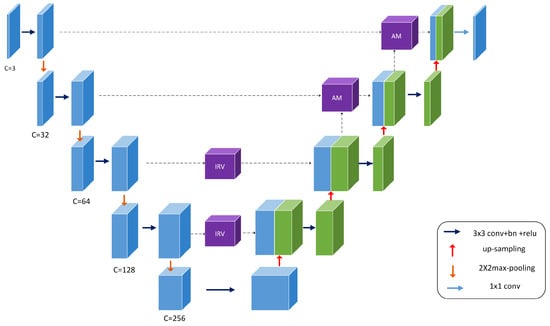
Figure 1.
Overview of the proposed MIU-net architecture.
3.2. Convolution Stage
Each convolutional module is possessed with convolution, batch normalization, dropout and leakyrelu activation function. Parameter select a kernel size of 3 × 3, stride of 1 and padding of 1. The dropout parameter is selected as 0.3. The leakyrelu function prevent the neurons from not learing after relu function enters the negative interval. The dropout reduce overfitting phenomenon.
3.3. Modified Inception Stage
Inception of Google’s proposed uses convolution kernels of different sizes and different numbers of channels for convolution and supervision in dimension [3]. The network determines its filter combinations, pooling layers, and other parameters. 1 × 1 reduces the amount of computation, forming a bottleneck layer, shrinking network channels and then increasing. By building wisely bottleneck layer , it can shrink down the representation size significantly without hurt network performance and saves a lot of computation.
The inception mechanism emphasizes that wideth of network and different size of kernels help optimize network performance in Figure 2. Large convolution kernels can extract more abstract features and provide a wider field of view, and small convolution kernels can concentrate on small targets to identify target pixels in detail. The module parallels three processes, which increase the network span and improve the scale adaptability. In the first part, we adopt a residual idea for diminishing network overfitting. In the second part, we linear features after dimensionality reduction and 5 × 5 feature extracted by convolution Then set appropriate dropout parameters and bottleneck layer. In the third part, we divide kernel 5 × 5 into 1 × 5 and 5 × 1. The computing cost of the original reduces 1/25.
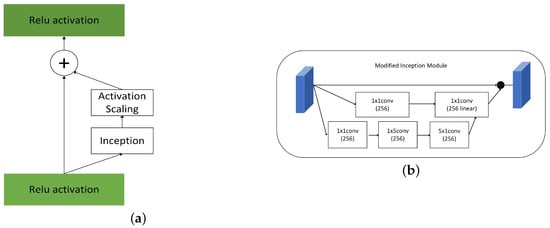
Figure 2.
(a) Inception (b) Modified Inception Module.
3.4. Attention Stage
The purpose of the attention mechanism is to highlight salient features while neglecting irrelevant context. The module in Figure 3 is used later in the fusion process of the two features. This attention structure extracts small and elaboration features of the image-which is very important in histopathology images, where the absence of even a tiny feature can lead to loss of small cell nuclei at the margins of the figure.
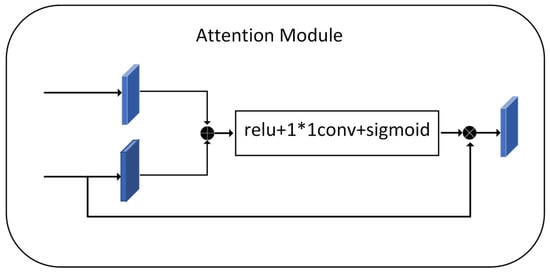
Figure 3.
Attention Module.
Before concatenating, we need to adjust the output features of the encoding to generate a gating signal that reflects the significance of the features at different spatial locations. Fusion of the features extracted by the encoder and the feature maps after the upsampling process with the decoder, keeping the exact resolution. The feature map is then reduced by 1 × 1 convolution to introduce nonlinearity to better fit the relevance of the channels. Relu adds nonlinearity. Sigmoid maps the values in the feature map to between 0 and 1 that assign weights to the pixels values of the nucleus at different locations, responding to the fraction of pixels belonging to the nucleus. Finally, we obtain an attention feature map. The essence is to weight the current feature map using the feature map with higher semantic features, focusing more on the foreground, which is the nucleus part.
4. Experimental Setup
4.1. Datasets
Kumar dataset comprised 30 tissues images, each of size 1000 × 1000, containing 21,623 hand-annotated nuclear boundaries. Each 1000 × 1000 image in this dataset was extracted from a separate whole slide image (WSI) (scanned at 40×) of an individual patient downloaded from TCGA [27]. 40× represents the magnification of the microscope. These images came from 18 different hospitals. The annotators were engineering students, and an expert pathologist examinated of annotation quality. Our annotations included both epithelial and stromal nuclei. For overlapping nuclei, we assigned each multi-nuclear pixel to the largest nucleus containing that pixel. All the images we used were RGB three-channel images.
Because most existing datasets are annotated for nuclei instance segmentation. Since our task is the binary classification task of nucleus, we extract the black-and-white label map suitable for binary classification from the xml file.
Correct and meticulous implementation of Pre-processing is very important for automatic diagnosis. Contrast Limited Adaptive Histogram Equalization(CLAHE) is used to improve contrast of the input images, rejecting noise [28]. Three channels of RGB images are divided into appropriately sized blocks, and then threshold is selected for equaliztion. It maps the pixel values of original photos to the new histogram in a balanced way. Gamma correction enhances the correction of gray areas in order to distinguish details of gray images. Vahadane [29] only normalize for brightness and coloring without damaging images texture part. Suitable Pre-processing methods will enhance the robustness of training model in Figure 4.
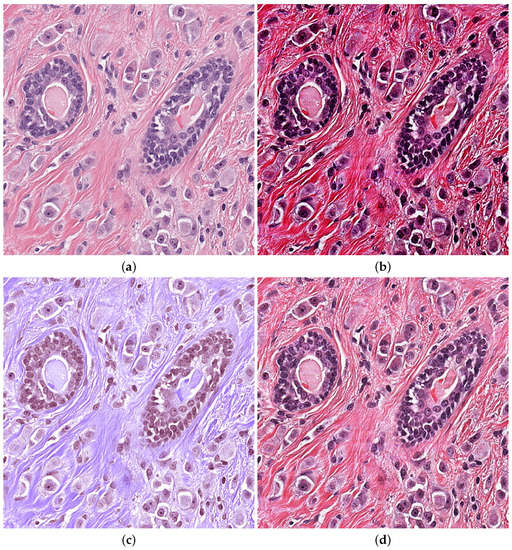
Figure 4.
Pre-processing H&E images (a) Original image (b) CLAHE (c) Vahadane (d) Gamma.
Kumar dataset contains multiple organs. We selected the pathological image of the breast for testing. The Pre-processing of Vahadane lost mang nuclei edge and the intensity of contrast was insufficient, which brought a large amount of calculation consumption. The gamma correction method works better on the grayscale image. The advantage of CLAHE is that the contrast intensity is very high, and it has a good enhancement effect on marginal nuclei and independent large nuclei. So we choose CLAHE methods.
4.2. Implementation Details
All the experiments are conducted on an NVIDIA GTX 3080Ti GPU. To make input image what is crop to 992 × 992 conforms five times of downsampling. Data augmentation includes random flip and random rotation [30]. We selected cross validation for the train and test dataset, which set accounted for 20% of the training set and fixed random state.
We develop MIU-net using Pytorch framework. We apply a combination of dice loss and binary cross entropy (BCE) to train model.
We chose to use conventional BCE for binary classification and Dice, which is commonly used for semantic segmentation. Dice is equivalent to examining from the global level, which can solve the problem of unbalanced samples well. However, disadvantage is that backpropagation is instability. BCE examines from the pixel level and learns effectively for small samples. Because nuclei of the dataset are more equally distributed. So the weight of dice loss is assigned to 0.5, and the weight of bce is assigned to 1. The loss between the prediction and the target y is formulated as [31]:
All models are optimized by RMSprop with learning rate 1 × , momentum 0.9, The batchsize is set 3. We used automatic mixed precision training, trained with warm-up, and updated the learning rate at each step. It was shown in Table 1

Table 1.
Experiments hyperparameters.
4.3. Evaluation Metrics
All the pixel points are divided into two channels after onehot, which are the foreground channel and the background channel. We conducted a series of experiments on public datasets to evaluate the proposed network. Evaluation indicators are visualization effects and specific numerical indicators. We chose Dice Similarity Coefficient (DSC) and Hausdorff Distance (HD) to measure the segmentation performance.
DSC is usually used to calculate the similarity of two samples in the range of 0 to 1. The closer value is to 1, the more similar the automatic segmentation is to the manual annotation segmentation. DSC implies precision and recall, which are equal to F1 in value.
where TP represents the accurately segmented region, FP represents error nuclei region, FN represents error background region.
Hausdorff Distance (HD) is also a commonly segmentation metric in medical image. HD is mainly applied to measure the segmentation accuracy of nuclei boundary. We use tools of surface-distance to calculate HD. A and B stands for two sets of points on the edge of the nucleus. Hausdorff distance measures the contour similarity. Let , , the HD between these two point sets is defined as:
5. Experimental Results and Discussion
The scalar AUC measures accuracy of binary classification model, which achieves a good balance sensitivity and specifity. We make quantitative analysis for performance indicators and qualitative analysis for visual effects in Figure 4. After 120 eopchs, we selected unlearned pathological maps for testing, and carried out visualization processing and processing of the resulting data.
Kumar datasets only have 30 training images that contain almost 1000 nuclei in every picture. The difficulty lies in tightly fitting, overlapping, and clumping of nuclei, which can be followed up with more effective data enhancement or applying large models such as vit to extract nuclei feature that using chunked encoding [32,33,34].
We compared our performance with other different structrues. The experimental visual results are listed in Figure 5. Visual images show that nucleus part of the foreground is more excellent after training. Through the red box above, we can see the dense areas of nuclei in the upper left and lower right of the box. In the dense ring region with many overlapping nuclei, our network can segment effectively. The network can accurately distinguish clear edges and interiors of nuclei for independent nuclei in dispersive regions. The periphery of the concentrated area in the red box can be segmented into separate nuclei compared to the other frames. In the region of independent nuclei, we also identified independent nuclei better than the mainstream model, and segmented more nuclei. The experimental data also reflect this. Our net is an improvement over the mainstream model in the dense areas of most concern. The periphery of the concentrated area in the red box can be segmented into separate nuclei compared to the other frames. However, some of the smaller nuclei were missed and over-segmented (incorrectly splitting a large nuclei into multiple smaller nuclei) some larger nuclei.
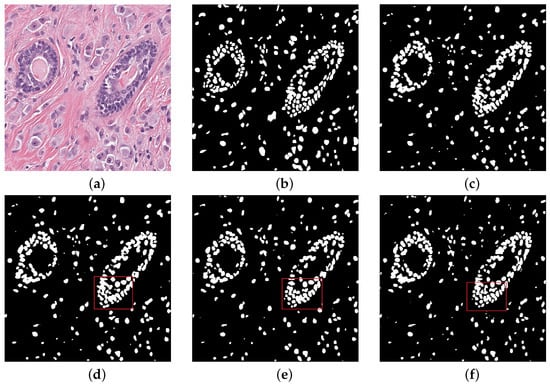
Figure 5.
Qualitative comparisons (a) Histopathology image (b) Ground truth (c) Nested UNet (d) Attention UNet (e) RCNN UNet (f) MIU-net.
Table 2 shows Kumar dataset performance comparison between the proposed method and other advanced methods. Through DSC scores, we see that our proposed method exceeds other mainstream methods. We has an faint advantage on nuclei-dense origin. AUC metric demonstrates to achieve the highest score. 0.92 of AUC score is a few points higher than Attention U-net and RCNN U-net. It avoids the problem of sample imbalance and better identification foreground and background.
Table 2.
Experiments in comparison to many traditional methods.
Compared with Nested U-net and Attention U-net, MIU-net has more parameters that reach 45.26 MB. It mainly adds convolution kernels of different sizes in the deep layer. As the number of channels in the feature graph is more than that in the shallow layer, so the number of parameters increases significantly. RCNN U-net has parameters that reach 97.28 MB. Due to the use of recurrent residual module, random structure is used in every downsampling and upsampling process, which will be a large number pixel points overlap, even adding residuals to reduce the amount of computation, but parameters is still huge. The score of our model is DSC 0.821, HD 51.0, which is higher than DSC of traditional Attention U-net. The inner and outer edges of the nucleus achieve better segmentation result.
Table 3 shows ablation experiments results. We conducted ablation experiments on the model. The baseline model is unet. The addition of two modules shows a practical improvement in segmentation accuracy. After adding the attention module separately, it shows that the attention mechanism expression is a little better on top of HD, with 1.2 more. This indicates that the attention mechanism is applied to the edge of the nucleus for better learning. While in the final accuracy score, the two are similar and mechanisms plays the same role in improving performance. The highest score was achieved in the final model that combines the two modules, and our model proved effective.
Table 3.
Ablation Experiments Results.
Class activation mapping is a visual thermodynamic chart that has certain explanatory functions for net. It overlays highly abstract category feature maps for visualization to obtain heat maps. One of the most essential techniques is global average pooling, which locates feature pixels. We conducted class activation mapping that only does activation mapping of the nuclei. The heat map is better to observe which patches are important, and give different weights to the deep feature map, to sum up to obtain saliency map. Figure 6 show that activation was performed in two nucleus-dense regions, while the other models did not identify the nucleus-dense regions. In comparison, activation was performed in two relatively non-dense nucleus regions. The second example has the correct activation in the nuclear edge region of the ring, giving more weight to the ring region, and a small area outside the ring is also activated. While other models only activate the outer region of the ring without identifying the important nucleus of the ring. This indicates that our network is better focused on cancerous nuclei, which gradually reduces reliance of manual annotation and timely monitoring effectiveness of net learning.

Figure 6.
Class activation mapping (a,d) Histopathology image (b,e) U-net (c,f) MIU-net.
Figure 7 illustrate the overlaid segmented mask of one of the test images in the kumar dataset for some models. Some nets unable to detect all ground masked nuclei in the picture, was unable to detect shape variability of nuclei, and missed some touching nuclei. Our architectures used made many accurate detections. The boundary distribution of touching nuclei is very close to each other, which can easily result in the ability to split two or more contact nuclei. These results indicated that the main challenge of semantic segmentation of the nucleus in irregular shape of the nucleus and separation of multiple nuclei with overlap. Our models has a good advantage compared to the base model in addressing these challenges.
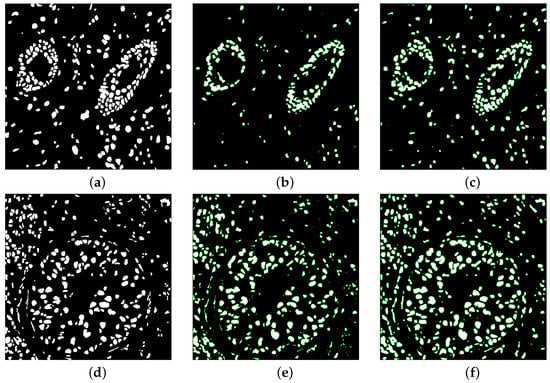
Figure 7.
Overlaid segmented mask (a,d) Ground truth (b,e) U-net (c,f) MIU-net.
In Figure 8, loss converges to stability at about 75 epochs, and the numerical value is stable below 0.1. Bce and dice loss are combined in loss to carry out weighted calculation for both small targets and large areas. Loss fluctuates in the early stage.
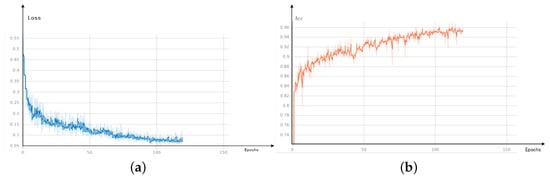
Figure 8.
Visual results (a) loss (b) Acc.
The definition of Acc indicator is to divide the number of correctly predicted pixels by the total number of pixels in the picture.
As Acc result, it also about 75 epochs to reach stability, and the final numerical value is stable at roughly 0.96.
6. Conclusions
Segmentation allows us to focus on specific areas of interest and extract detailed information to help clinicians make accurate diagnoses.
We achieved this by changing the number of channels, adding an attention module, and an inception module into a regular U-net. The attention module can focus more on small targets, such as splitting up individual nuclei in the periphery of densely packed cells. The inception module can expand the receptive field at a deep level. The overall network structure can extract simple information in the shallow layer and complex semantic information in the deep layer. In the decoding process, an attention mechanism is used to strengthen the feature fusion part. We demonstrate that MIU-net is robust and efficient. All the modules in the network play an appropriate role and improve segmentation accuracy.
In our future work, we will try to fully employ the information from the nuclear boundary and center of mass, especially in overlapping or poorly defined nuclei. Since the two test sets given by the data set include different organ tissues, the test indexes that are more suitable for nuclear overlap and contact are selected. The new network structure will apply to a wider range of pathology medical datasets, further broaden the application range and enhance generalization capability. Models use fewer parameters and iterations to complete simple binary classification tasks efficiently.
Author Contributions
Investigation, J.L.; Writing—riginal draft, J.L.; Supervision, X.L.; Funding acquisition, X.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wan, T.; Zhao, L.; Feng, H.; Li, D.; Tong, C.; Qin, Z. Robust nuclei segmentation in histopathology using ASPPU-Net and boundary refinement. Neurocomputing 2020, 408, 144–156. [Google Scholar] [CrossRef]
- Valanarasu, J.M.J.; Patel, V.M. UNeXt: MLP-based Rapid Medical Image Segmentation Network. arXiv 2022, arXiv:2203.04967. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Li, X.; Jiang, Y.; Li, M.; Yin, S. Lightweight attention convolutional neural network for retinal vessel image segmentation. IEEE Trans. Ind. Inform. 2020, 17, 1958–1967. [Google Scholar] [CrossRef]
- Salvi, M.; Molinari, F. Multi-tissue and multi-scale approach for nuclei segmentation in H&E stained images. Biomed. Eng. Online 2018, 17, 1–13. [Google Scholar]
- Nguyen, L.; Tosun, A.B.; Fine, J.L.; Lee, A.V.; Taylor, D.L.; Chennubhotla, S.C. Spatial statistics for segmenting histological structures in H&E stained tissue images. IEEE Trans. Med. Imaging 2017, 36, 1522–1532. [Google Scholar]
- Mouelhi, A.; Rmili, H.; Ali, J.B.; Sayadi, M.; Doghri, R.; Mrad, K. Fast unsupervised nuclear segmentation and classification scheme for automatic allred cancer scoring in immunohistochemical breast tissue images. Comput. Methods Programs Biomed. 2018, 165, 37–51. [Google Scholar] [CrossRef]
- Taheri, S.; Fevens, T.; Bui, T.D. Robust nuclei segmentation in cyto-histopathological images using statistical level set approach with topology preserving constraint. In Medical Imaging 2017: Image Processing; SPIE: Bellingham, WA, USA, 2017; Volume 10133, pp. 353–361. [Google Scholar]
- Petushi, S.; Garcia, F.U.; Haber, M.M.; Katsinis, C.; Tozeren, A. Large-scale computations on histology images reveal grade-differentiating parameters for breast cancer. BMC Med. Imaging 2006, 6, 14. [Google Scholar] [CrossRef]
- Veta, M.; Van Diest, P.J.; Kornegoor, R.; Huisman, A.; Viergever, M.A.; Pluim, J.P. Automatic nuclei segmentation in H&E stained breast cancer histopathology images. PLoS ONE 2013, 8, e70221. [Google Scholar]
- Naik, S.; Doyle, S.; Agner, S.; Madabhushi, A.; Feldman, M.; Tomaszewski, J. Automated gland and nuclei segmentation for grading of prostate and breast cancer histopathology. In Proceedings of the 2008 5th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Paris, France, 14–17 May 2008; pp. 284–287. [Google Scholar]
- Bai, X.; Sun, C.; Sun, C. Cell segmentation based on FOPSO combined with shape information improved intuitionistic FCM. IEEE J. Biomed. Health Inform. 2018, 23, 449–459. [Google Scholar] [CrossRef]
- Kost, H.; Homeyer, A.; Molin, J.; Lundström, C.; Hahn, H.K. Training nuclei detection algorithms with simple annotations. J. Pathol. Inform. 2017, 8, 21. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning In Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Zhang, T.; Gao, S.; Liu, J. Ce-net: Context encoder network for 2d medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Graham, S.; Vu, Q.D.; Raza, S.E.A.; Azam, A.; Tsang, Y.W.; Kwak, J.T.; Rajpoot, N. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 2019, 58, 101563. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Qi, X.; Yu, L.; Dou, Q.; Qin, J.; Heng, P.A. DCAN: Deep contour-aware networks for object instance segmentation from histology images. Med. Image Anal. 2017, 36, 135–146. [Google Scholar] [CrossRef]
- Li, X.; Jiang, Y.; Liu, Y.; Zhang, J.; Yin, S.; Luo, H. RAGCN: Region Aggregation Graph Convolutional Network for Bone Age Assessment From X-Ray Images. IEEE Trans. Instrum. Meas. 2022, 71, 4006412. [Google Scholar] [CrossRef]
- Li, X.; Jiang, Y.; Zhang, J.; Li, M.; Luo, H.; Yin, S. Lesion-attention pyramid network for diabetic retinopathy grading. Artif. Intell. Med. 2022, 126, 102259. [Google Scholar] [CrossRef]
- Li, X.; Jiang, Y.; Li, M.; Zhang, J.; Yin, S.; Luo, H. MSFR-Net: Multi-modality and single-modality feature recalibration network for brain tumor segmentation. Med. Phys. 2022. [Google Scholar] [CrossRef]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A dataset and a technique for generalized nuclear segmentation for computational pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef] [PubMed]
- Azzuni, H.; Ridzuan, M.; Xu, M.; Yaqub, M. Color Space-based HoVer-Net for Nuclei Instance Segmentation and Classification. arXiv 2022, arXiv:2203.01940. [Google Scholar]
- Yıldırım, Z.; Hançer, E.; Samet, R.; Mali, M.T.; Nemati, N. Effect of Color Normalization on Nuclei Segmentation Problem in H&E Stained Histopathology Images. In Proceedings of the 2022 30th Signal Processing and Communications Applications Conference (SIU), Safranbolu, Turkey, 15–18 May 2022; pp. 1–4. [Google Scholar]
- Wang, H.; Xie, S.; Lin, L.; Iwamoto, Y.; Han, X.H.; Chen, Y.W.; Tong, R. Mixed transformer u-net for medical image segmentation. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 2390–2394. [Google Scholar]
- Bu, Z. Multi-structure segmentation for renal cancer treatment with modified nn-UNet. arXiv 2022, arXiv:2208.05241. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Valanarasu, J.M.J.; Oza, P.; Hacihaliloglu, I.; Patel, V.M. Medical transformer: Gated axial-attention for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 36–46. [Google Scholar]
- Wang, W.; Chen, C.; Ding, M.; Yu, H.; Zha, S.; Li, J. Transbts: Multimodal brain tumor segmentation using transformer. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Strasbourg, France, 27 September–1 October 2021; pp. 109–119. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).