


Machinery Fault Signal Detection with Deep One-Class Classification
Abstract
:1. Introduction
- The deep OCC methods can achieve superior fault detection performance, although raw time-series signals are directly used as input data. In general, for more effectively analyzing the time-series signals, signal processing techniques (e.g., short-time Fourier transform (STFT [32,33]) or wavelet transform [34]) are used to transform the raw signals. However, these signal-processing techniques require additional user-specified hyperparameters, which should be carefully determined. In contrast, the deep OCC methods do not need any signal processing techniques. This implies the efficiency of the deep OCC methods in handling the raw time-series signal data.
- In the deep OCC methods, more useful features for fault signal detection can be simultaneously extracted along with minimizing loss function on anomaly detection tasks. By doing so, the fault signal detection performance can be improved.
- Finally, we applied the deep OCC methods to the widely used benchmark fault signal datasets and the signal dataset collected from our own rolling element experimental platform. By doing so, the effectiveness and applicability of the deep neural network-based methods to real fault signal detection problems can be confirmed.
2. Related Works
2.1. One-Class Classification Methods
2.2. Deep Neural Network-Based One-Class Classification Methods
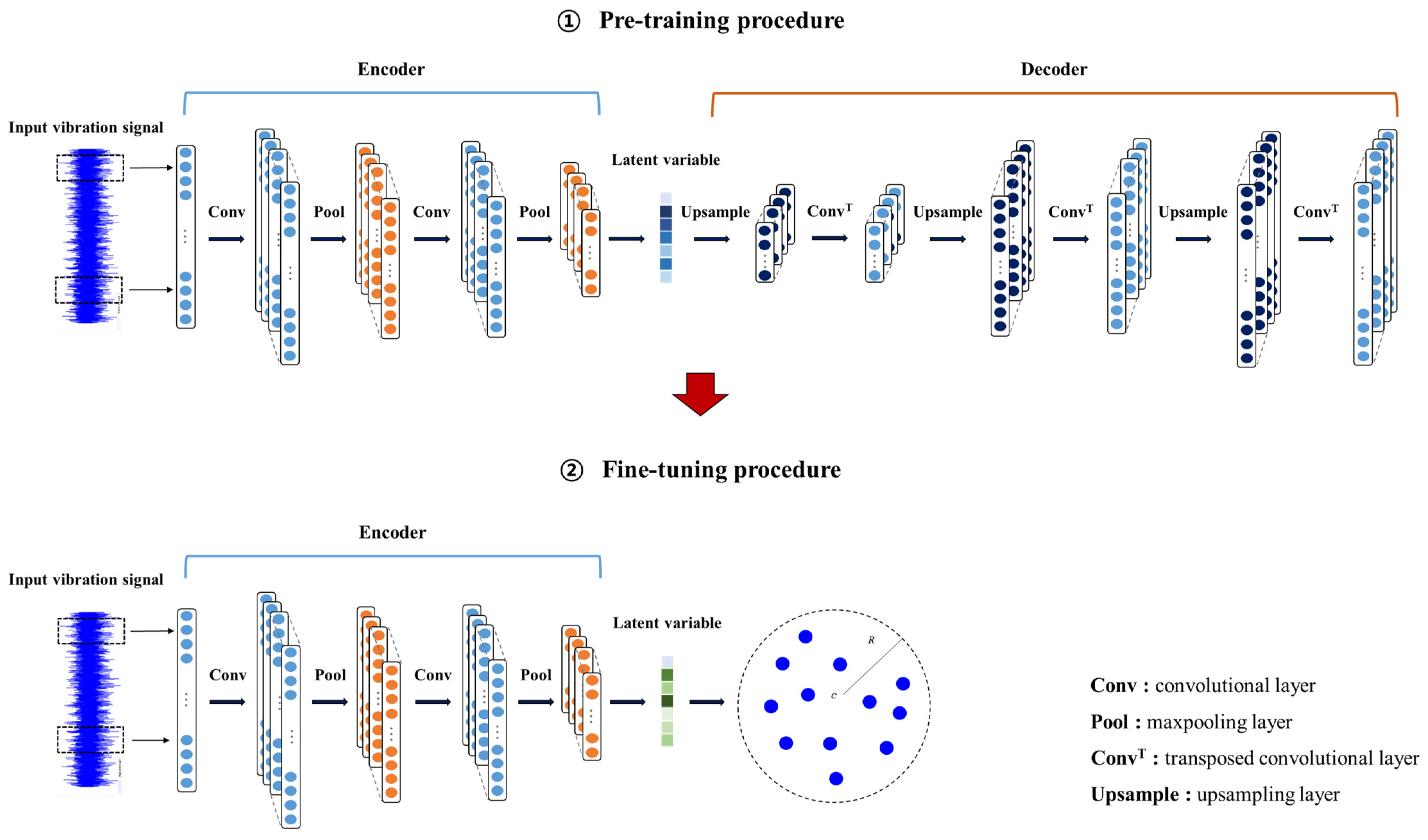
3. Fault Signal Detection with Deep Support Vector Data Description
- (1)
- Soft-boundary deep SVDD
- (2)
- One-class deep SVDD
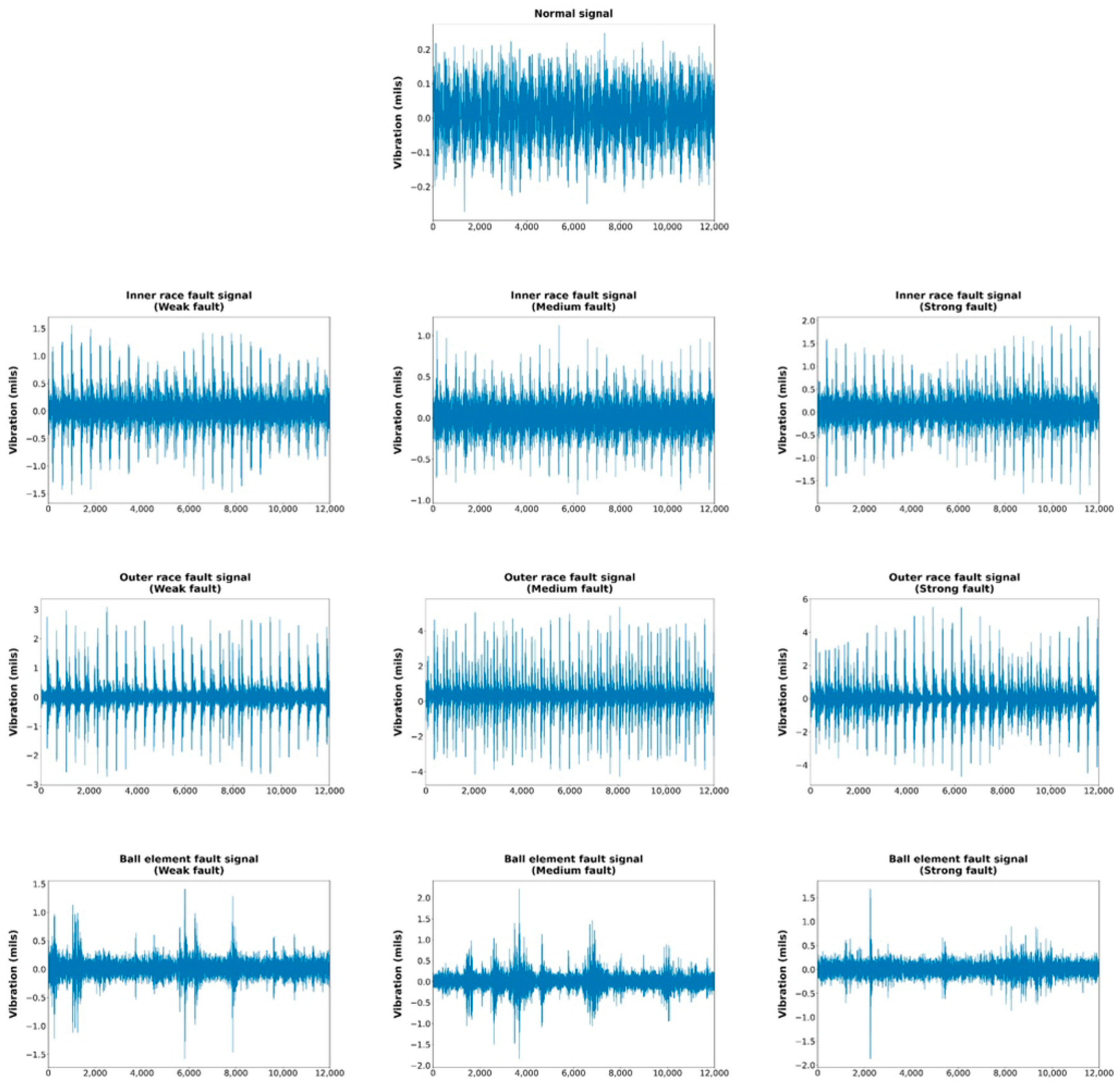
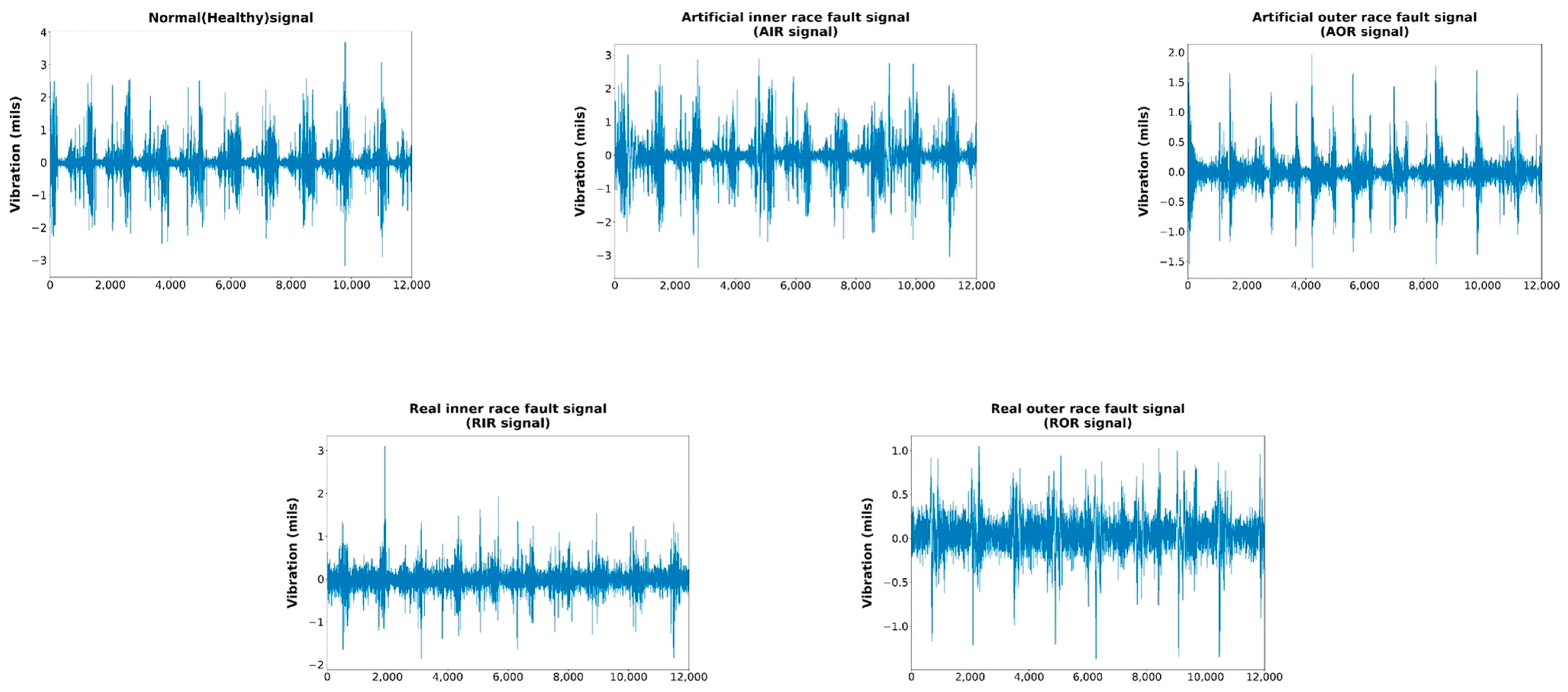
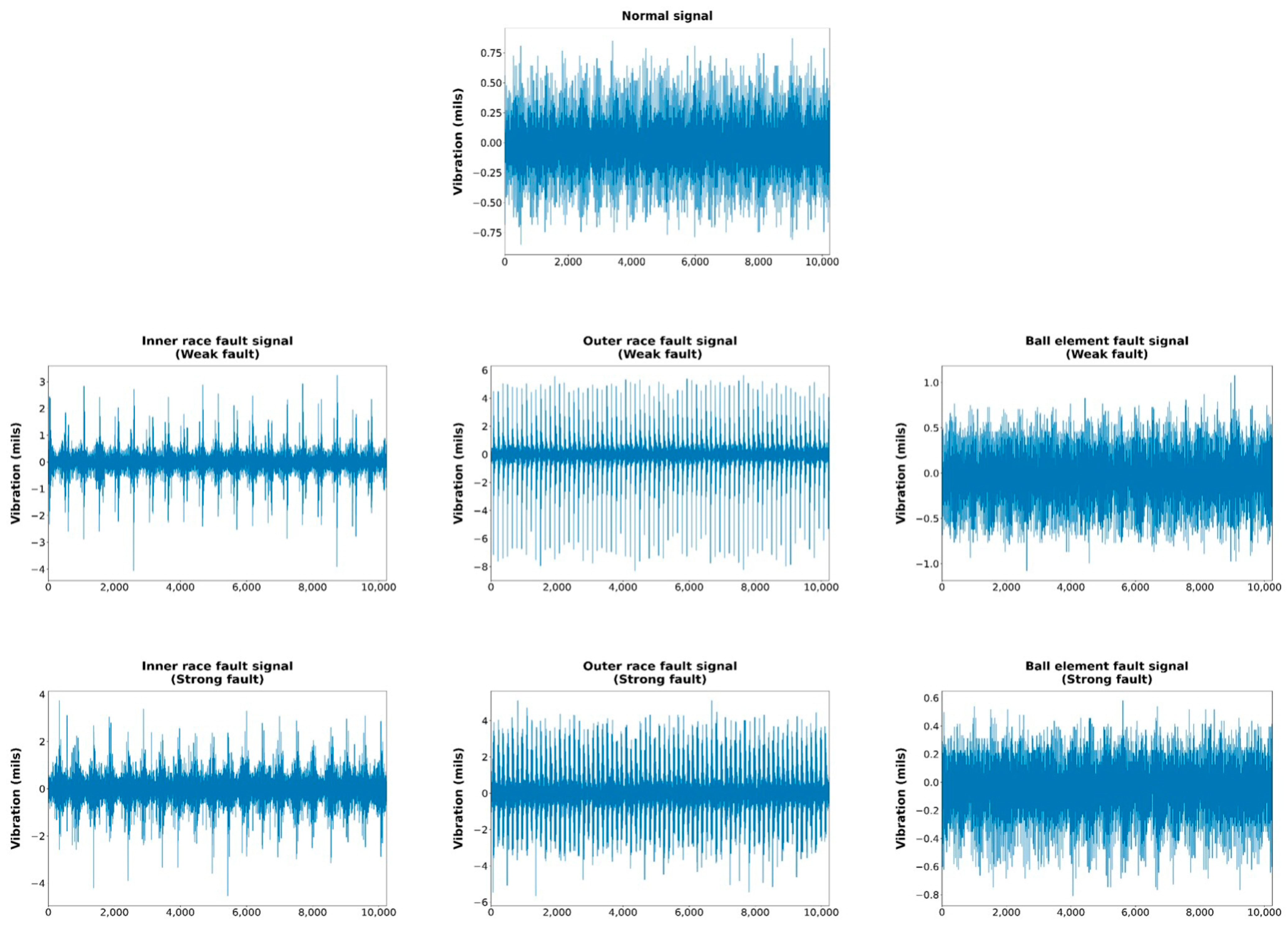
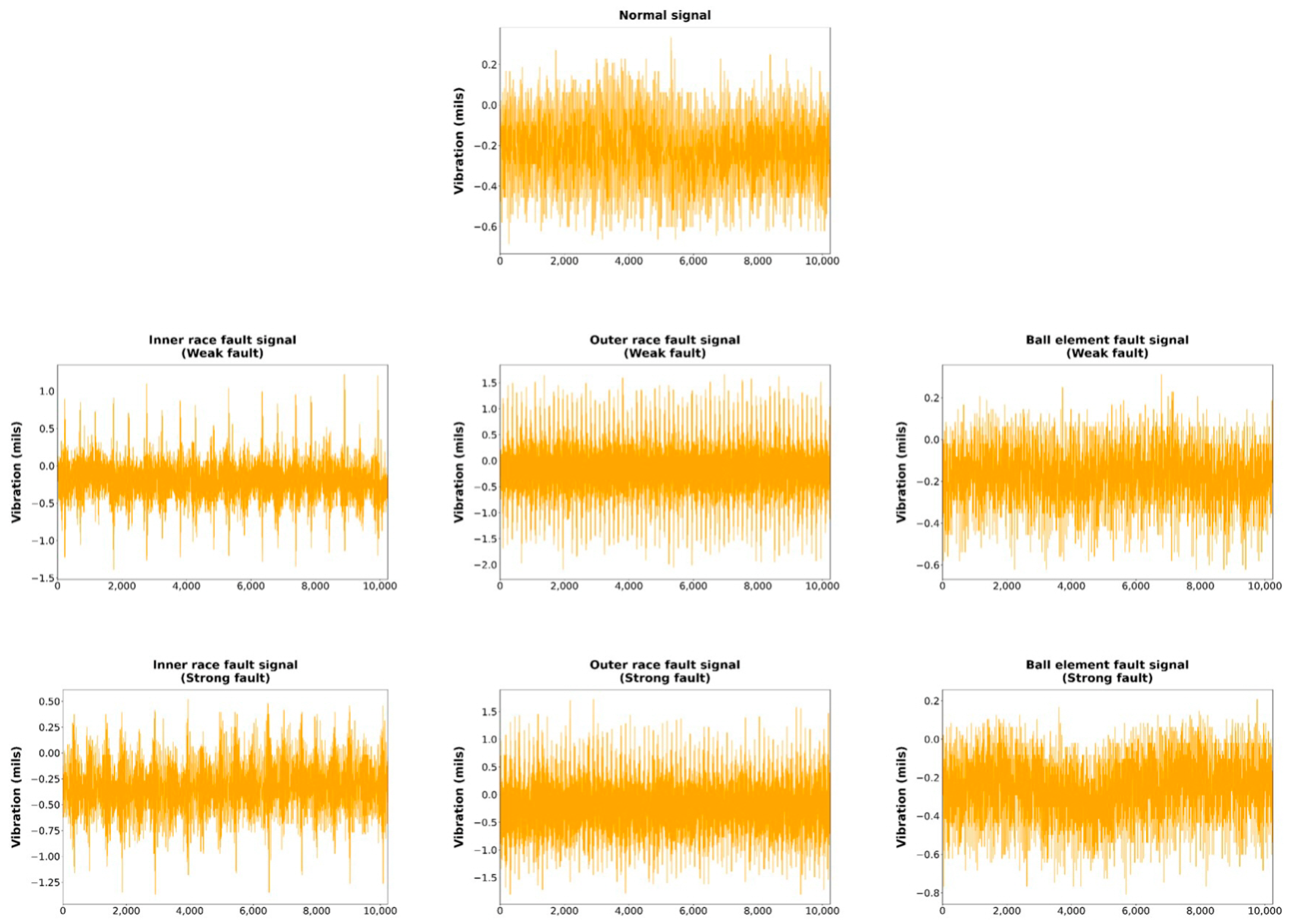
4. Experimental Study
4.1. Experimental Settings
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, S.; Goyal, D.; Dang, R.K.; Dhami, S.S.; Pabla, B.S. Condition based maintenance of bearings and gears for fault detection–A review. Mater. Today Proc. 2018, 5, 6128–6137. [Google Scholar] [CrossRef]
- Kim, J.; Ahn, Y.; Yeo, H. A comparative study of time-based maintenance and condition-based maintenance for optimal choice of maintenance policy. Struct. Infrastruct. Eng. 2016, 12, 1525–1536. [Google Scholar] [CrossRef]
- Wu, S.; Zuo, M.J. Linear and nonlinear preventive maintenance models. IEEE Trans. Reliab. 2010, 59, 242–249. [Google Scholar]
- Yang, S.K. A condition-based failure-prediction and processing-scheme for preventive maintenance. IEEE Trans. Reliab. 2003, 52, 373–383. [Google Scholar] [CrossRef]
- Yang, B.S. An intelligent condition-based maintenance platform for rotating machinery. Expert Syst. Appl. 2012, 39, 2977–2988. [Google Scholar]
- Yang, S.K.; Liu, T.S. A Petri net approach to early failure detection and isolation for preventive maintenance. Qual. Reliab. Eng. Int. 1998, 14, 319–330. [Google Scholar] [CrossRef]
- Jardine, A.K.; Lin, D.; Banjevic, D. A review on machinery diagnostics and prognostics implementing condition-based maintenance. Mech. Syst. Signal Process. 2006, 20, 1483–1510. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Goyal, D.; Pabla, B.S. Condition based maintenance of machine tools—A review. CIRP J. Manuf. Sci. Technol. 2015, 10, 24–35. [Google Scholar] [CrossRef]
- Lee, J.; Ardakani, H.D.; Yang, S.; Bagheri, B. Industrial big data analytics and cyber-physical systems for future maintenance & service innovation. Procedia CIRP 2015, 38, 3–7. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Ruff, L.; Vandermeulen, R.; Goernitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Li, W.; Shang, Z.; Gao, M.; Qian, S.; Zhang, B.; Zhang, J. A novel deep autoencoder and hyperparametric adaptive learning for imbalance intelligent fault diagnosis of rotating machinery. Eng. Appl. Artif. Intell. 2021, 102, 104279. [Google Scholar] [CrossRef]
- Shao, S.; Wang, P.; Yan, R. Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 2019, 106, 85–93. [Google Scholar] [CrossRef]
- Baydar, N.; Ball, A. Detection of gear failures via vibration and acoustic signals using wavelet transform. Mech. Syst. Signal Process. 2003, 17, 787–804. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, G.; Tang, S.; Wang, R.; Su, H.; Wang, C. Acoustic signal-based fault detection of hydraulic piston pump using a particle swarm optimization enhancement CNN. Appl. Acoust. 2022, 192, 108718. [Google Scholar] [CrossRef]
- Zhang, J.; Sun, Y.; Guo, L.; Gao, H.; Hong, X.; Song, H. A new bearing fault diagnosis method based on modified convolutional neural networks. Chin. J. Aeronaut. 2020, 33, 439–447. [Google Scholar] [CrossRef]
- Krawczyk, B.; Woźniak, M.; Cyganek, B. Clustering-based ensembles for one-class classification. Inf. Sci. 2014, 264, 182–195. [Google Scholar] [CrossRef]
- Yu, J.; Kang, J. Clustering ensemble-based novelty score for outlier detection. Eng. Appl. Artif. Intell. 2023, 121, 106164. [Google Scholar] [CrossRef]
- Yu, J.; Do, H. Proximity-based density description with regularized reconstruction algorithm for anomaly detection. Inf. Sci. 2024, 654, 119816. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. A new approach to intelligent fault diagnosis of rotating machinery. Expert Syst. Appl. 2008, 35, 1593–1600. [Google Scholar] [CrossRef]
- Lei, Y.; Zuo, M.J. Gear crack level identification based on weighted K nearest neighbor classification algorithm. Mech. Syst. Signal Process. 2009, 23, 1535–1547. [Google Scholar] [CrossRef]
- Shen, Z.; Chen, X.; Zhang, X.; He, Z. A novel intelligent gear fault diagnosis model based on EMD and multi-class TSVM. Measurement 2012, 45, 30–40. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. WIREs Comp. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Schölkopf, B.; Smola, A.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Berlin, Germany, 8–10 October 1997. [Google Scholar]
- Lu, W.; Wang, X.; Yang, C.; Zhang, T. A novel feature extraction method using deep neural network for rolling bearing fault diagnosis. In Proceedings of the 27th Chinese Control and Decision Conference, Qingdao, China, 23–25 May 2015. [Google Scholar]
- Zhang, Y.; Zhou, T.; Huang, X.; Cao, L.; Zhou, Q. Fault diagnosis of rotating machinery based on recurrent neural networks. Measurement 2021, 171, 108774. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, H.; Peng, J. Low-rank reconstruction-based autoencoder for robust fault detection. Control Eng. Pract. 2022, 123, 105156. [Google Scholar] [CrossRef]
- Chalapathy, R.; Menon, A.K.; Chawla, S. Anomaly detection using one-class neural networks. arXiv 2019, arXiv:1802.06360. [Google Scholar]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Gröchenig, K. Foundations of Time-Frequency Analysis; Birkhäuser: Boston, MA, USA, 2001. [Google Scholar]
- Sejdić, E.; Djurović, I.; Jiang, J. Time–frequency feature representation using energy concentration: An overview of recent advances. Digital Signal Process. 2009, 19, 153–183. [Google Scholar] [CrossRef]
- Ogden, R.T. Essential Wavelets for Statistical Applications and Data Analysis; Birkhäuser: Boston, MA, USA, 1997. [Google Scholar]
- Chen, G.; Zhang, X.; Wang, Z.J.; Li, F. Robust support vector data description for outlier detection with noise or uncertain data. Knowl.-Based Syst. 2015, 90, 129–137. [Google Scholar] [CrossRef]
- Ghafoori, C.Z.; Erfani, S.M.; Rajasegarar, S.; Bezdek, J.C.; Karunasekera, S.; Leckie, C. Efficient unsupervised parameter estimation for one-class support vector machines. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5057–5070. [Google Scholar] [CrossRef]
- Yu, J.; Kang, S. Clustering-based proxy measure for optimizing one-class classifiers. Pattern Recognit. Lett. 2019, 117, 37–44. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008. [Google Scholar]
- Chen, L.; Xu, G.; Zhang, S.; Yan, W.; Wu, Q. Health indicator construction of machinery based on end-to-end trainable convolution recurrent neural networks. J. Manuf. Syst. 2020, 54, 1–11. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: New York, NY, USA, 2018. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the International Conference on Artificial Neural Networks, Berlin, Germany, 14–17 June 2011. [Google Scholar]
- Schlegl, T.; Seeböck, P.; Waldstein, S.M.; Schmidt-Erfurth, U.; Langs, G. Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. In Proceedings of the International Conference on Information Processing in Medical Imaging, Boone, NC, USA, 25–30 June 2017. [Google Scholar]
- Luo, W.; Liu, W.; Lian, D.; Tang, J.; Duan, L.; Peng, X.; Gao, S. Video anomaly detection with sparse coding inspired deep neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1070–1084. [Google Scholar] [CrossRef]
- Bergman, L.; Hoshen, Y. Classification-based anomaly detection for general data. arXiv 2020, arXiv:2005.02359. [Google Scholar]
- Tack, J.; Mo, S.; Jeong, J.; Shin, J. Csi: Novelty detection via contrastive learning on distributionally shifted instances. In Proceedings of the Advances in Neural Information Processing Systems, Virtual Conference, 6–12 December 2020. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Ruff, L.; Vandermeulen, R.A.; Görnitz, N.; Binder, A.; Müller, E.; Müller, K.R.; Kloft, M. Deep semi-supervised anomaly detection. arXiv 2019, arXiv:1906.02694. [Google Scholar]
- Li, D.; Zhang, J.; Zhang, Q.; Wei, X. Classification of ECG signals based on 1D convolution neural network. In Proceedings of the IEEE International Conference on e-Health Networking, Applications and Services, Dalian, China, 12–15 October 2017. [Google Scholar]
- Yu, J.; Zhou, X. One-dimensional residual convolutional autoencoder based feature learning for gearbox fault diagnosis. IEEE Trans. Ind. Inf. 2020, 16, 6347–6358. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.K.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the PHM Society European Conference, Bilbao, Spain, 5–8 July 2016. [Google Scholar]
- Liang, P.; Wang, W.; Yuan, X.; Liu, S.; Zhang, L.; Cheng, Y. Intelligent fault diagnosis of rolling bearing based on wavelet transform and improved ResNet under noisy labels and environment. Eng. Appl. Artif. Intell. 2022, 115, 105269. [Google Scholar] [CrossRef]
- Sun, J.; Liu, Z.; Wen, J.; Fu, R. Multiple hierarchical compression for deep neural network toward intelligent bearing fault diagnosis. Eng. Appl. Artif. Intell. 2022, 116, 105498. [Google Scholar] [CrossRef]
- Liu, B.; Xiao, Y.; Philip, S.Y.; Hao, Z.; Cao, L. An efficient approach for outlier detection with imperfect data labels. IEEE Trans. Knowl. Data Eng. 2013, 26, 1602–1616. [Google Scholar] [CrossRef]
- Conover, W.J. Practical Nonparametric Statistics, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn Res. 2008, 9, 2579–2605. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rotating Speed | Vertical Load | |
|---|---|---|
| Scenario 1 | 1797 RPM | 0 HP (No pressure) |
| Scenario 2 | 1772 RPM | 1 HP |
| Scenario 3 | 1750 RPM | 2 HP |
| Scenario 4 | 1730 RPM | 3 HP |
| The Number of Target Signals (Normal Signals) | The Number of All Fault Signals | |
|---|---|---|
| Scenario 1 | 952 | 6108 |
| Scenario 2 | 1888 | 5160 |
| Scenario 3 | 1892 | 5172 |
| Scenario 4 | 1896 | 5180 |
| Rotating Speed | Radial Force | Load Torque | |
|---|---|---|---|
| Scenario 1 | 1500 RPM | 1000 N | 0.7 Nm |
| Scenario 2 | 900 RPM | 1000 N | 0.7 Nm |
| Scenario 3 | 1500 RPM | 1000 N | 0.1 Nm |
| Scenario 4 | 1500 RPM | 400 N | 0.7 Nm |
| The Number of Target Signals (Normal Signals) | The Number of All Fault Signals | |
|---|---|---|
| Scenario 1 | 2500 | 51,660 |
| Scenario 2 | ||
| Scenario 3 | ||
| Scenario 4 |
| Signal Types | The Number of Target Signals (Normal Signals) | The Number of All Fault Signals |
|---|---|---|
| Vibration | 4850 | 21,050 |
| Acoustic |
| Case | Architecture | Batch Size | Optimizer (Learning Rate) |
|---|---|---|---|
| CWRU dataset (Case 1) | 8 × (5 × 1)-filters + max pooling + Leaky ReLU 4 × (5 × 1)-filters + max pooling + Leaky ReLU Dense layer of 16 units (i.e., the number of latent features (q) is 16) | 32 | Adam optimizer ( = 0.005) |
| PU dataset (Case 2) | 8 × (5 × 1)-filters + max pooling + Leaky ReLU 4 × (5 × 1)-filters + max pooling + Leaky ReLU Dense layer of 16 units (i.e., the number of latent features (q) is 16) | 128 | |
| Rolling element experiment platform dataset (Case 3) | 8 × (5 × 1)-filters + max pooling + Leaky ReLU 4 × (5 × 1)-filters + max pooling + Leaky ReLU Dense layer of 16 units (i.e., the number of latent features (q) is 16) | 128 |
| Methods | CWRU Dataset (Case 1) | PU Dataset (Case 2) | Rolling Element Experiment Platform Dataset (Case 3) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 | Scenario 1 | Scenario 2 | Scenario 3 | Scenario 4 | Vibration Signals | Acoustic Signals | |
| PCA + KDE | 1.000 (0.000) | 0.986 (0.005) | 0.992 (0.005) | 0.993 (0.001) | 0.340 (0.006) | 0.790 (0.005) | 0.780 (0.005) | 0.827 (0.004) | 0.665 (0.005) | 0.603 (0.009) |
| PCA + IF | 0.995 (0.002) | 0.994 (0.000) | 0.994 (0.000) | 0.994 (0.000) | 0.349 (0.036) | 0.782 (0.007) | 0.778 (0.013) | 0.822 (0.004) | 0.722 (0.003) | 0.618 (0.004) |
| PCA + SVDD | 1.000 (0.000) | 0.994 (0.000) | 0.994 (0.000) | 0.994 (0.000) | 0.393 (0.101) | 0.791 (0.005) | 0.776 (0.017) | 0.825 (0.004) | 0.735 (0.003) | 0.637 (0.005) |
| AE + KDE | 0.883 (0.172) | 0.548 (0.047) | 0.524 (0.031) | 0.391 (0.054) | 0.681 (0.015) | 0.730 (0.036) | 0.733 (0.024) | 0.748 (0.023) | 0.519 (0.113) | 0.534 (0.023) |
| AE + IF | 0.870 (0.168) | 0.084 (0.097) | 0.092 (0.102) | 0.122 (0.044) | 0.707 (0.009) | 0.748 (0.012) | 0.749 (0.013) | 0.746 (0.008) | 0.264 (0.124) | 0.551 (0.025) |
| AE + SVDD | 0.858 (0.159) | 0.286 (0.118) | 0.530 (0.085) | 0.535 (0.084) | 0.717 (0.011) | 0.684 (0.057) | 0.650 (0.082) | 0.700 (0.042) | 0.412 (0.165) | 0.530 (0.038) |
| CAE + KDE | 0.978 (0.028) | 0.993 (0.001) | 0.993 (0.001) | 0.993 (0.002) | 0.987 (0.001) | 0.847 (0.054) | 0.869 (0.015) | 0.867 (0.054) | 0.921 (0.009) | 0.801 (0.042) |
| CAE + IsoForest | 0.962 (0.072) | 0.998 (0.036) | 0.988 (0.036) | 0.974 (0.072) | 0.980 (0.002) | 0.860 (0.046) | 0.883 (0.026) | 0.870 (0.061) | 0.924 (0.009) | 0.819 (0.061) |
| CAE + SVDD | 0.976 (0.047) | 0.985 (0.042) | 0.999 (0.001) | 0.974 (0.072) | 0.980 (0.004) | 0.877 (0.038) | 0.895 (0.024) | 0.882 (0.056) | 0.794 (0.048) | 0.622 (0.070) |
| ReSAE | 0.992 (0.001) | 0.996 (0.002) | 0.996 (0.003) | 0.994 (0.000) | 0.068 (0.011) | 0.347 (0.022) | 0.320 (0.017) | 0.358 (0.024) | 0.809 (0.038) | 0.569 (0.021) |
| ReCAE | 0.999 (0.002) | 0.999 (0.001) | 0.998 (0.002) | 0.998 (0.001) | 0.048 (0.001) | 0.327 (0.003) | 0.303 (0.002) | 0.333 (0.003) | 0.732 (0.002) | 0.569 (0.007) |
| AnoGAN | 0.765 (0.024) | 0.567 (0.036) | 0.570 (0.037) | 0.604 (0.095) | 0.216 (0.116) | 0.452 (0.139) | 0.399 (0.101) | 0.417 (0.207) | 0.722 (0.014) | 0.691 (0.042) |
| Soft-boundary deep SVDD (AE pre-trained) | 0.980 (0.005) | 0.994 (0.003) | 0.985 (0.002) | 0.989 (0.003) | 0.792 (0.007) | 0.823 (0.007) | 0.760 (0.004) | 0.791 (0.007) | 0.819 (0.079) | 0.643 (0.091) |
| One-class deep SVDD (AE pre-trained) | 0.980 (0.005) | 0.993 (0.003) | 0.985 (0.003) | 0.988 (0.004) | 0.775 (0.005) | 0.793 (0.007) | 0.762 (0.003) | 0.759 (0.006) | 0.859 (0.103) | 0.683 (0.028) |
| Soft-boundary deep SVDD (CAE pre-trained; Proposed) | 0.985 (0.026) | 1.000 (0.000) | 1.000 (0.000) | 1.000 (0.000) | 0.991 (0.001) | 0.936 (0.007) | 0.941 (0.008) | 0.940 (0.007) | 0.985 (0.002) | 0.912 (0.011) |
| One-class deep SVDD (CAE pre-trained; Proposed) | 1.000 (0.000) | 1.000 (0.000) | 1.000 (0.000) | 1.000 (0.000) | 0.991 (0.001) | 0.939 (0.006) | 0.944 (0.002) | 0.939 (0.009) | 0.985 (0.004) | 0.922 (0.014) |
| Methods | Average Rank | p-Value | Hypothesis (α = 0.01) |
|---|---|---|---|
| One-class deep SVDD (CAE pre-trained; Proposed) | 1.1 | - | - |
| Soft-boundary deep SVDD (CAE pre-trained; Proposed) | 1.9 | 0.1056 | Not reject |
| CAE + IsoForest | 5.9 | 0.0059 | Reject |
| CAE + KDE | 6.0 | 0.0058 | Reject |
| CAE + SVDD | 6.7 | 0.0020 | Reject |
| PCA + SVDD | 6.8 | 0.0089 | Reject |
| Soft-boundary deep SVDD (AE pre-trained) | 7.8 | 0.0020 | Reject |
| PCA + IF | 7.9 | 0.0058 | Reject |
| One-class deep SVDD (AE pre-trained) | 8.2 | 0.0020 | Reject |
| PCA + KDE | 8.6 | 0.0092 | Reject |
| ReSAE | 9.9 | 0.0059 | Reject |
| ReCAE | 10.0 | 0.0059 | Reject |
| AnoGAN | 12.7 | 0.0020 | Reject |
| AE + KDE | 13.1 | 0.0020 | Reject |
| AE + IF | 13.5 | 0.0020 | Reject |
| AE + SVDD | 13.6 | 0.0020 | Reject |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoon, D.; Yu, J. Machinery Fault Signal Detection with Deep One-Class Classification. Appl. Sci. 2024, 14, 221. https://doi.org/10.3390/app14010221
Yoon D, Yu J. Machinery Fault Signal Detection with Deep One-Class Classification. Applied Sciences. 2024; 14(1):221. https://doi.org/10.3390/app14010221
Chicago/Turabian StyleYoon, Dosik, and Jaehong Yu. 2024. "Machinery Fault Signal Detection with Deep One-Class Classification" Applied Sciences 14, no. 1: 221. https://doi.org/10.3390/app14010221
APA StyleYoon, D., & Yu, J. (2024). Machinery Fault Signal Detection with Deep One-Class Classification. Applied Sciences, 14(1), 221. https://doi.org/10.3390/app14010221