1. Introduction
In the Chinese classification system for mental disorders, social anxiety disorder falls under the category of neurosis. The Chinese Society of Psychiatry’s CCMD-3 defines anxiety disorders, including social anxiety disorder, as a type of neurosis characterized by extreme and irrational fear of external objects or environments [
1]. Despite recognizing the irrationality of their fears, individuals with this disorder cannot avoid experiencing anxiety attacks, which are typically accompanied by noticeable anxiety and autonomic nervous system symptoms. Patients either make great efforts to avoid the objects or situations that trigger their fear or endure them with anxiety. The corresponding diagnostic criteria for social anxiety disorder describe symptoms such as a primary fear of social environments (such as eating or speaking in public, attending parties or meetings, or fear of making embarrassing gestures) and interpersonal interactions (such as interacting with others in public, avoiding eye contact, or fearing scrutiny when faced with a crowd).
In contrast, the American classification system DSM-IV places social anxiety disorder or social anxiety disorder under the umbrella of anxiety disorders. The DSM-IV characterizes social anxiety disorder as a persistent and excessive fear of one or more social or performance situations, where the individual is exposed to unfamiliar individuals or potential scrutiny. The individual fears acting in a way that may be embarrassing or humiliating and exhibits symptoms of anxiety. Currently, the specific causes of social anxiety disorder are unclear, but it is likely influenced by multiple factors such as genetics, environment, biology, and psychology.
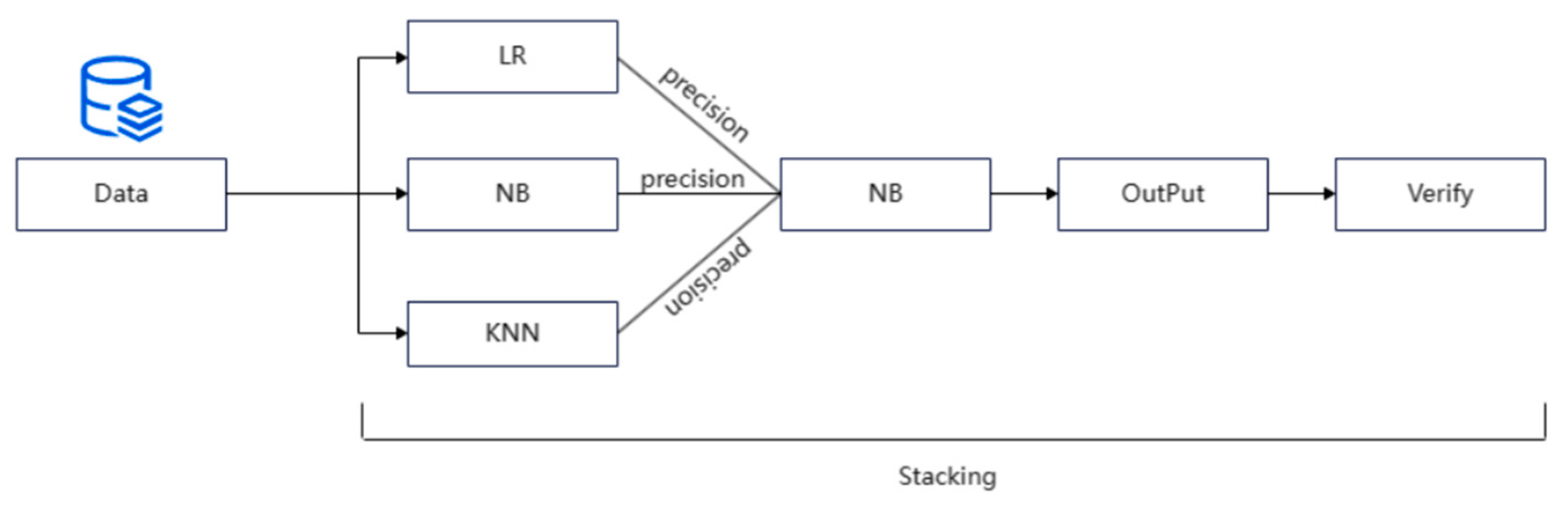
In this study, data were collected through questionnaire surveys to identify social anxiety disorder within a student population. Multiple mainstream machine learning algorithms were employed to find the most optimal algorithm for detection. Ultimately, a stacked model was built by combining logistic regression, Naive Bayes, and k-Nearest Neighbor (KNN) algorithms, which yielded better prediction results compared to individual algorithms. However, it is important to note that the subjective nature of data collected through questionnaire surveys presents limitations. Therefore, the authors suggest the establishment of a comprehensive information collection system in schools. Additionally, mainstream machine learning algorithms have their inherent limitations. Nevertheless, this study provides insights for seeking the most optimal algorithm for identifying social anxiety disorder.
2. Related Studies
The classification model for social anxiety disorder is a fundamental model that categorizes individuals into patients and non-patients, and the effectiveness of this classification is crucial for the subsequent treatment of social anxiety disorder. For example, Al-Ezzi et al. proposed the fusion of EEG with other techniques such as fMRI and magnetoencephalography (MEG) to improve effectiveness beyond the use of EEG alone, ultimately enhancing the selection process for treatment plans and exploring the potential of EEG measurements in early diagnosis and phenotypic examination of social anxiety disorder [
2]. Boukhechba et al. used non-invasive mobile sensing technology to passively assess the level of social anxiety among college students and developed a social anxiety prediction model based on automatically generated Global Positioning System (GPS) data. They employed a neural network-based prediction approach to longitudinally track college students, extract daily activity features, and predict social anxiety symptoms [
3]. Gong et al. proposed examining subtle behaviors of individuals with social anxiety during engagement in various forms of social interaction using smartphone sensors and how these behaviors vary with location changes. They found that individuals with higher (vs. lower) social anxiety symptoms exhibited more movement, as tracked by accelerometers, particularly in unfamiliar locations (i.e., not at home or work) [
4]. There are also some deep learning-based models, such as those analyzing patient behavioral data in virtual reality (VR) environments, that can aid researchers in understanding patient fear responses and adjusting VR environments to better accommodate patient needs [
5]. Wiederhold et al. mentioned that leveraging virtual reality in healthcare, using mobile VR technology to alleviate anxiety and pain, will gradually become a future trend in social anxiety disorder treatment [
6].
Furthermore, researchers have proposed using thermography as a passive medium to analyze physiologically related signals associated with emotional states, avoiding the discomfort of attaching physiological signal sensors to the skin and providing more realistic experimental data and better experimental results [
7]. Additionally, many applications of emotion recognition in human–computer interactions currently rely on visual information, typically based on facial expressions. However, the expression of emotional states through facial expressions is fundamentally a voluntary control process, and since humans have not yet learned to use this channel when interacting with robotic technologies, there is an urgent need to exploit channels of emotional information that humans cannot directly control. Researchers have proposed that emotion computation based on thermal infrared imaging may address this issue. This validated technology facilitates non-invasive monitoring of physiological parameters and can infer emotional states from them [
8]. Moreover, Fathi et al. proposed a clinical decision support system for diagnosing social anxiety disorder, which is particularly suitable for SAD diagnosis [
9].
Many algorithms and advanced technologies have also been applied to the treatment of social anxiety disorder, showing diverse trends. These include virtual reality therapy, cognitive behavioral therapy, and online therapy, among others. For example, virtual reality therapy utilizes virtual social environments created using virtual reality technology to gradually expose patients to social situations, thereby alleviating symptoms of social anxiety disorder [
10]. In a study on cognitive behavioral therapy (CBT) and machine learning, researchers analyzed patient data from internet-based CBT (ICBT) using machine learning algorithms such as Support Vector Machine (SVM) and Random Forest to predict treatment response and outcomes [
11]. Lin et al. studied the effects of cognitive behavioral group therapy (CBGT) on social anxiety patients’ emotion regulation self-efficacy and found that CBGT can improve social anxiety symptoms and enhance patients’ emotion regulation self-efficacy, making it an effective method for treating social anxiety [
12]. Additionally, virtual reality technology, as an emerging comprehensive artificial intelligence technology, possesses important features such as multi-sensory perception, presence, interactivity, and autonomy, which can effectively address potential issues in exposure to real-life situations during cognitive behavioral therapy. Therefore, researchers have studied virtual reality exposure therapy (VRET) and found it to be an acceptable treatment for social anxiety disorder patients, with significant and lasting therapeutic effects. However, in long-term follow-ups, the efficacy of VRET may decrease compared to in vivo exposure [
13].
In recent years, stacking ensemble learning models in machine learning have been applied to study student populations, providing insights for finding the optimal algorithm for predicting social anxiety disorder. For example, Yang et al. first applied the Jenks Natural Breaks algorithm for feature classification and then used the Apriori algorithm to analyze feature associations based on the classification results to discover behavior features that are correlated with students’ mental health status. They ultimately constructed a Particle Difference Neural Network (PDNN) model for predicting students’ mental health status. The proposed model outperformed traditional machine learning and deep learning models, converging quickly, and more accurately predicting students’ mental health status [
14]. Similarly, Suri proposed a stacking fusion model based on Random Forest, logistic regression, and Adaboost, and designed and implemented a psychological crisis early warning system based on this model [
15]. Additionally, Zhang et al. constructed a stacking ensemble learning model using multiple algorithms to predict student performance in blended learning. The model consists of polynomial Naive Bayes, AdaBoost, and Gradient Boosting as primary learners and logistic regression as the secondary learner, forming a two-layer fusion framework [
16].
In this article, we will apply stacked machine learning models to the prediction of social phobia in student groups, and their advantages are very obvious. Firstly, they improve prediction accuracy: stacked ensemble learning models can combine multiple different prediction models (such as decision trees, support vector machines, etc.) to produce a stronger and more complex prediction model. In this way, we can take advantage of the advantages of each single model while avoiding its disadvantages, so as to improve the accuracy of social fear prediction of student groups. Secondly, the robustness is improved: stackable machine learning models can reduce the sensitivity of a single model to data noise or outliers. If there are some outliers or noises in the training data, these outliers or noises may have a negative impact on the training of a single model. However, in stack-integrated learning, each single model will produce a prediction result, which will be further integrated in the top-level model, thus reducing the impact of individual model outliers or noise. And using our model does not require too much data, so it can be applied in schools.
However, we still have some limitations that need to be further addressed, such as the limitations of data sources and samples and the lack of consideration of multidimensional factors, which will be the direction of our further research.



 and
and 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}