

Methods and Applications of Space Understanding in Indoor Environment—A Decade Survey



Abstract
:1. Introduction
- a customized SLR on the topic of room segmentation and classification,
- three interdisciplinary taxonomies for the research done so far and summarizing research findings,
- extended discussion of the application scenarios of found solutions,
- description of observed challenges and research directions that need further analysis.
2. Review Methodology and Conduction
2.1. Research Questions (RQ)
2.2. Filtering Criteria
2.3. Search Query and Data Sources
- Association for Computing Machinery Digital Library (ACM DL),
- Institute of Electrical and Electronics Engineers Xplore (IEEE Explore),
- Digital Bibliography & Library Project (dblp),
- Scopus,
- Elsevier Science Direct (SD),
- Springer Link (SL).
2.4. Review Protocol
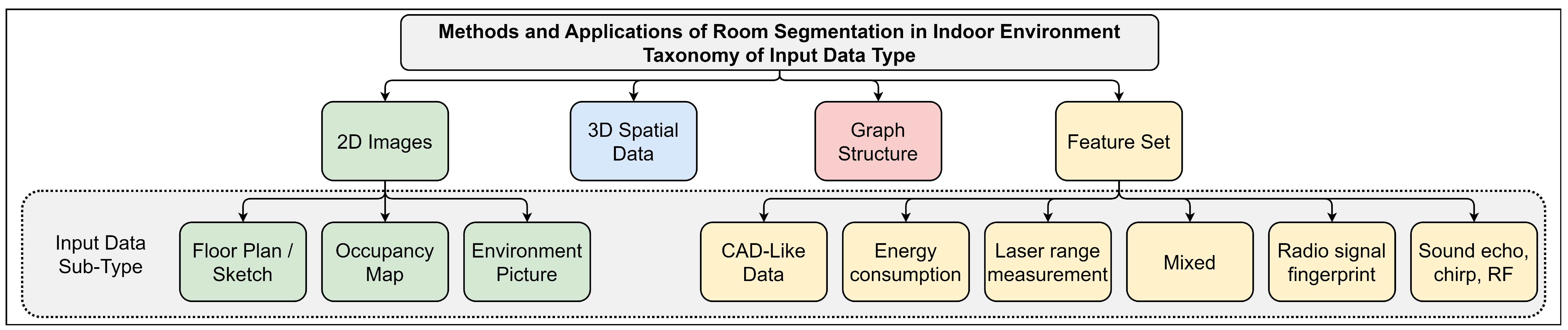
3. Taxonomy of Input Data Types
3.1. Taxonomy Presentation
- 2D Images,
- 3D Spatial Data,
- Graph Structures,
- Mixed Feature Sets.
3.2. Taxonomy Discussion
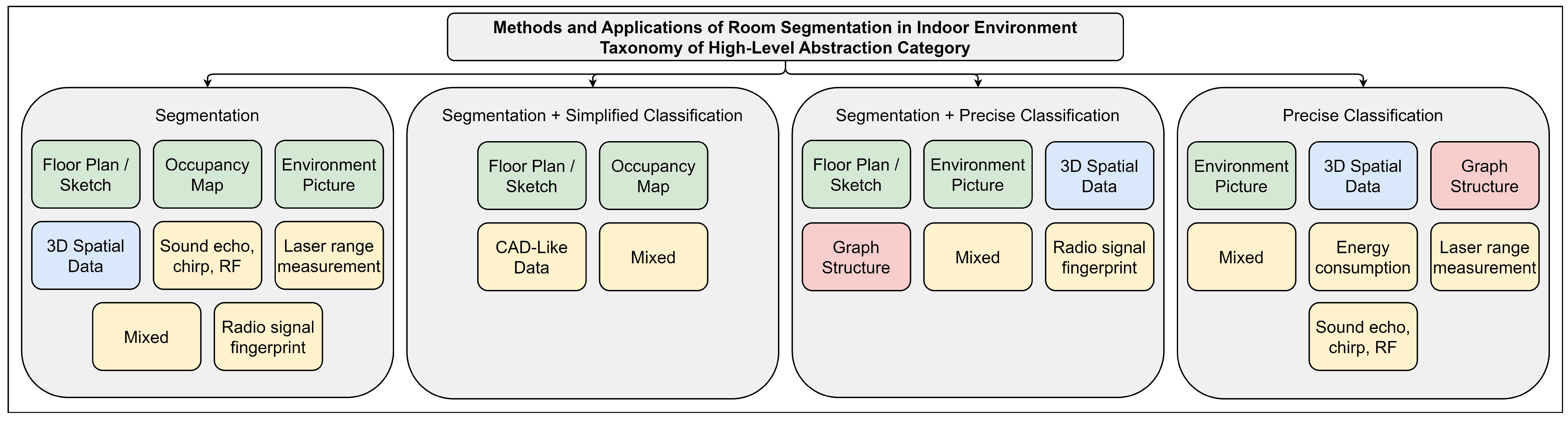
4. Taxonomy of High-Level Abstraction Category of Performed Process
4.1. Taxonomy Presentation
4.2. Taxonomy Discussion
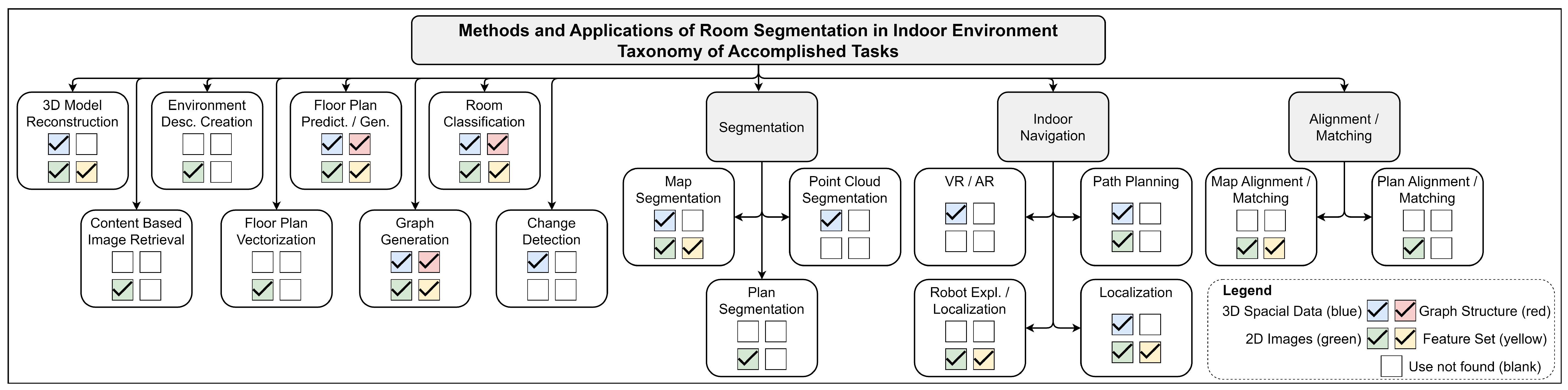
5. Taxonomy of Accomplished Tasks
5.1. Taxonomy Presentation
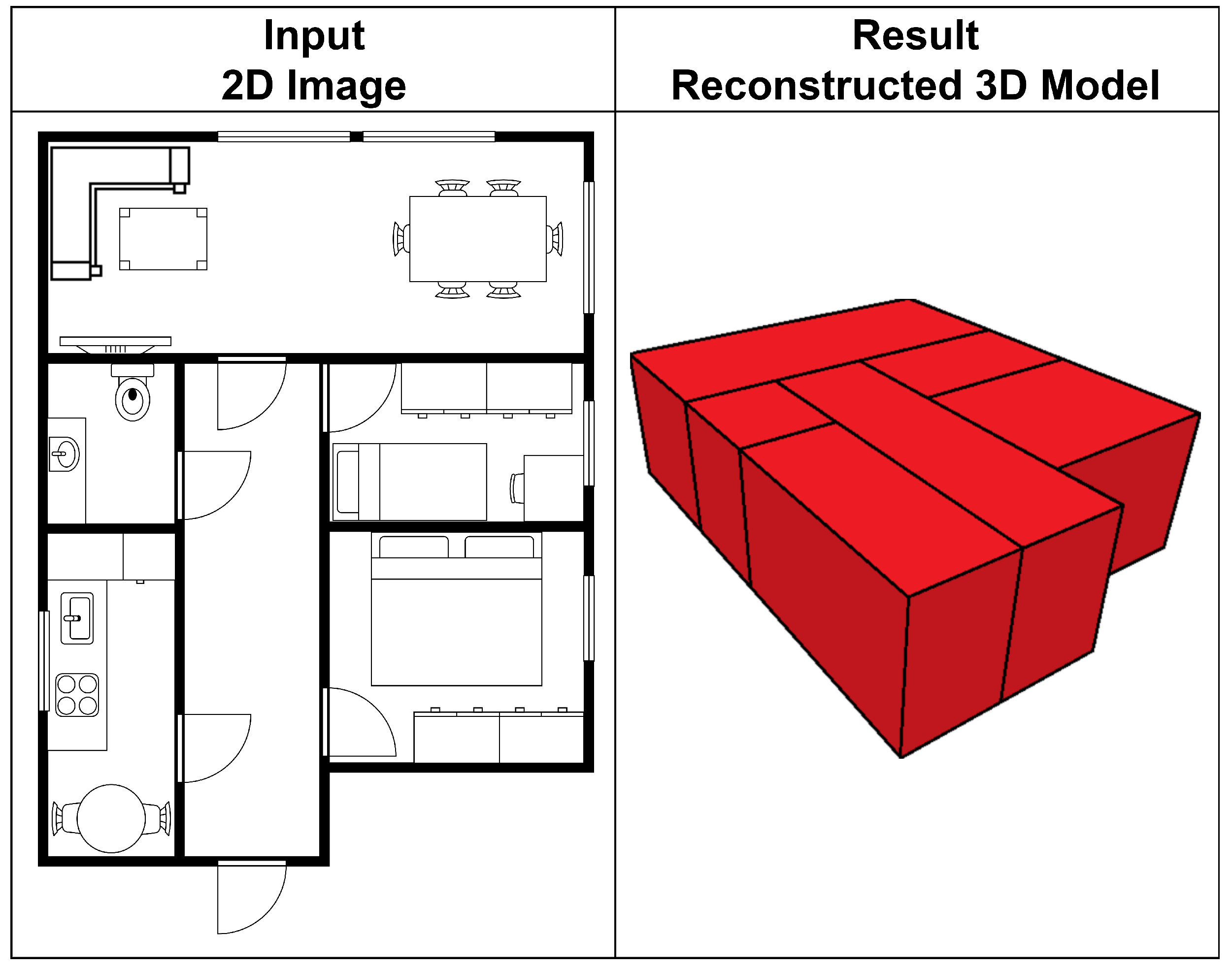
5.1.1. 3D Model Reconstruction
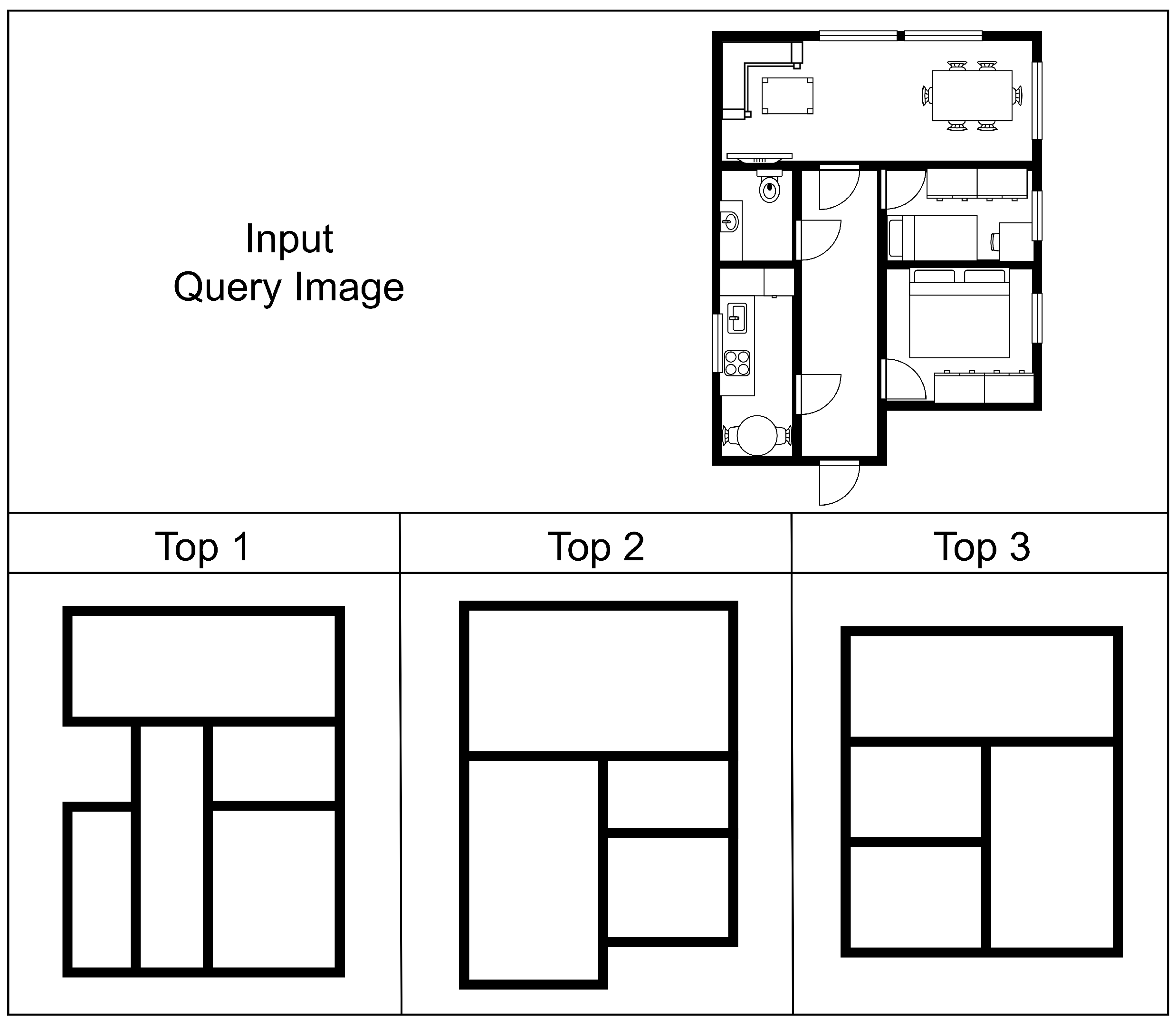
5.1.2. Content-Based Image Retrieval (CBIR)
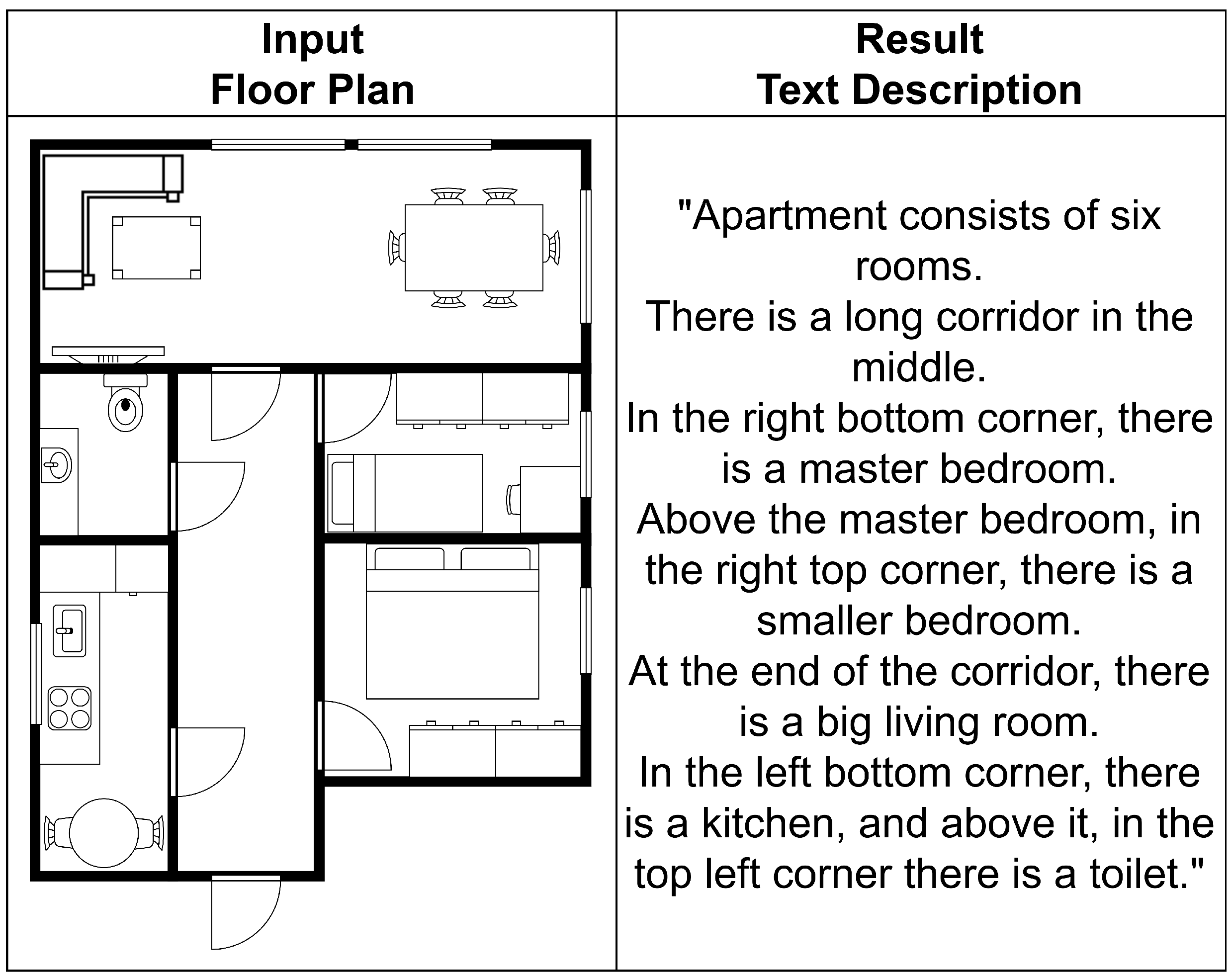
5.1.3. Environment Description Creation
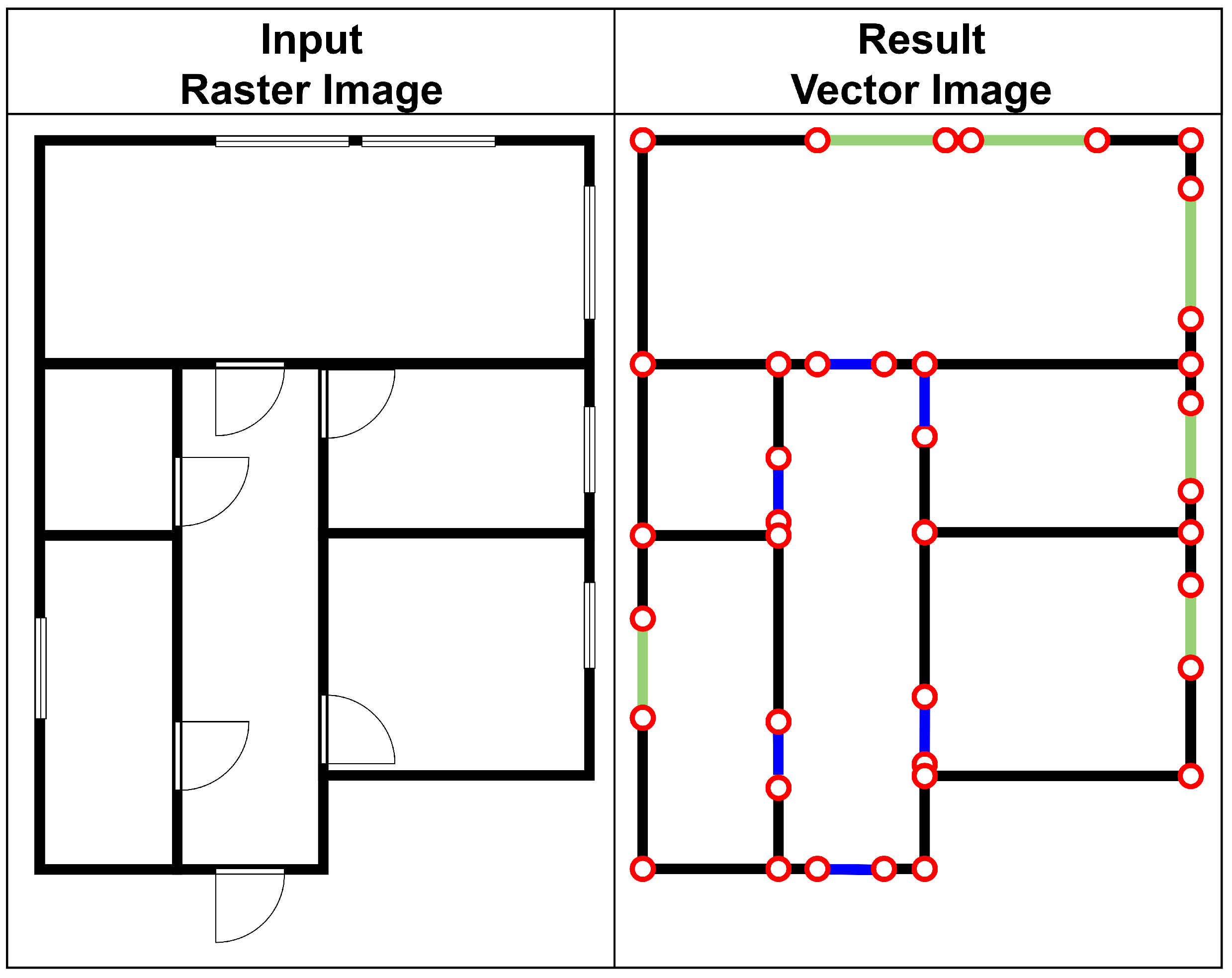
5.1.4. Floor Plan Vectorization
5.1.5. Floor Plan Prediction/Generation
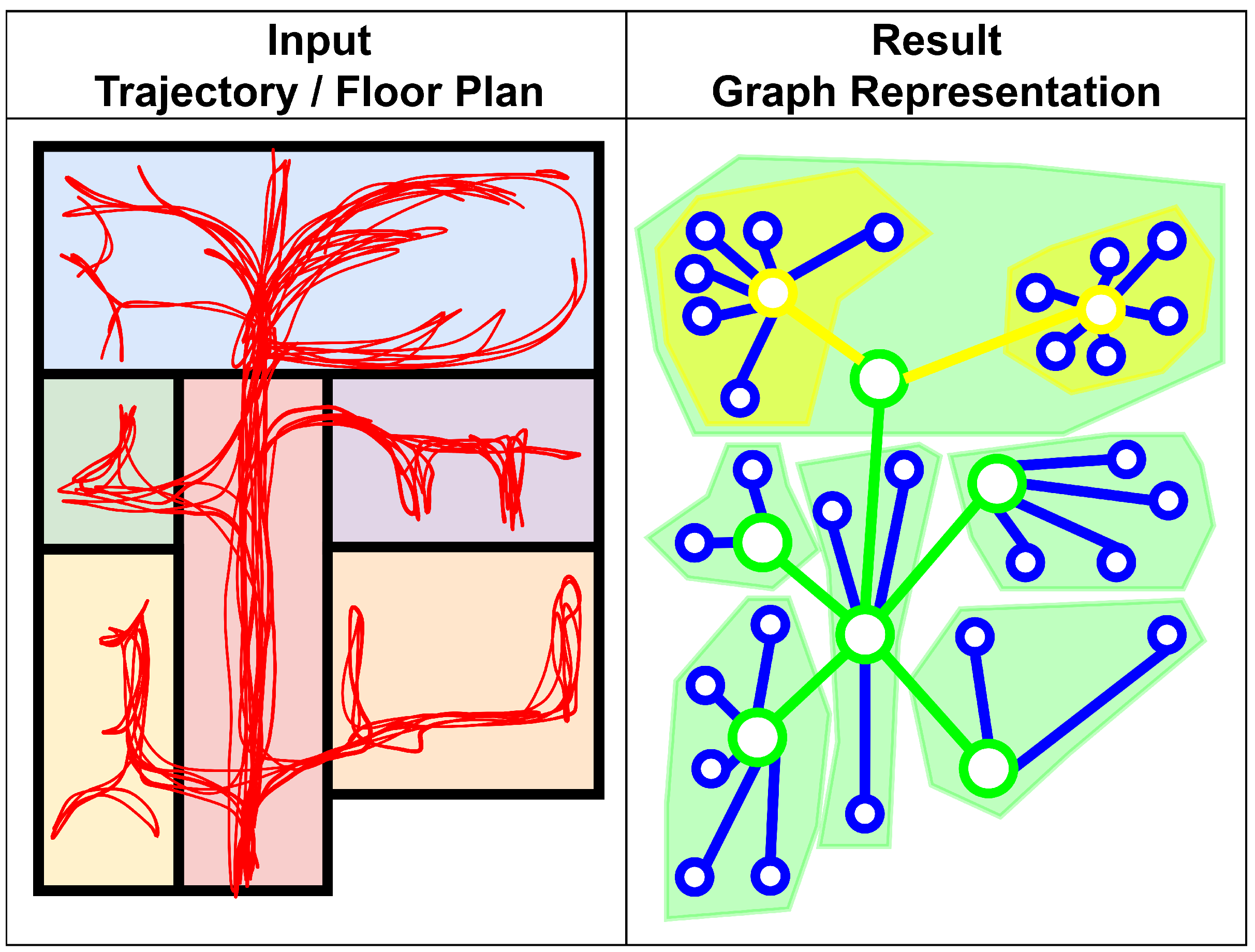
5.1.6. Graph Generation
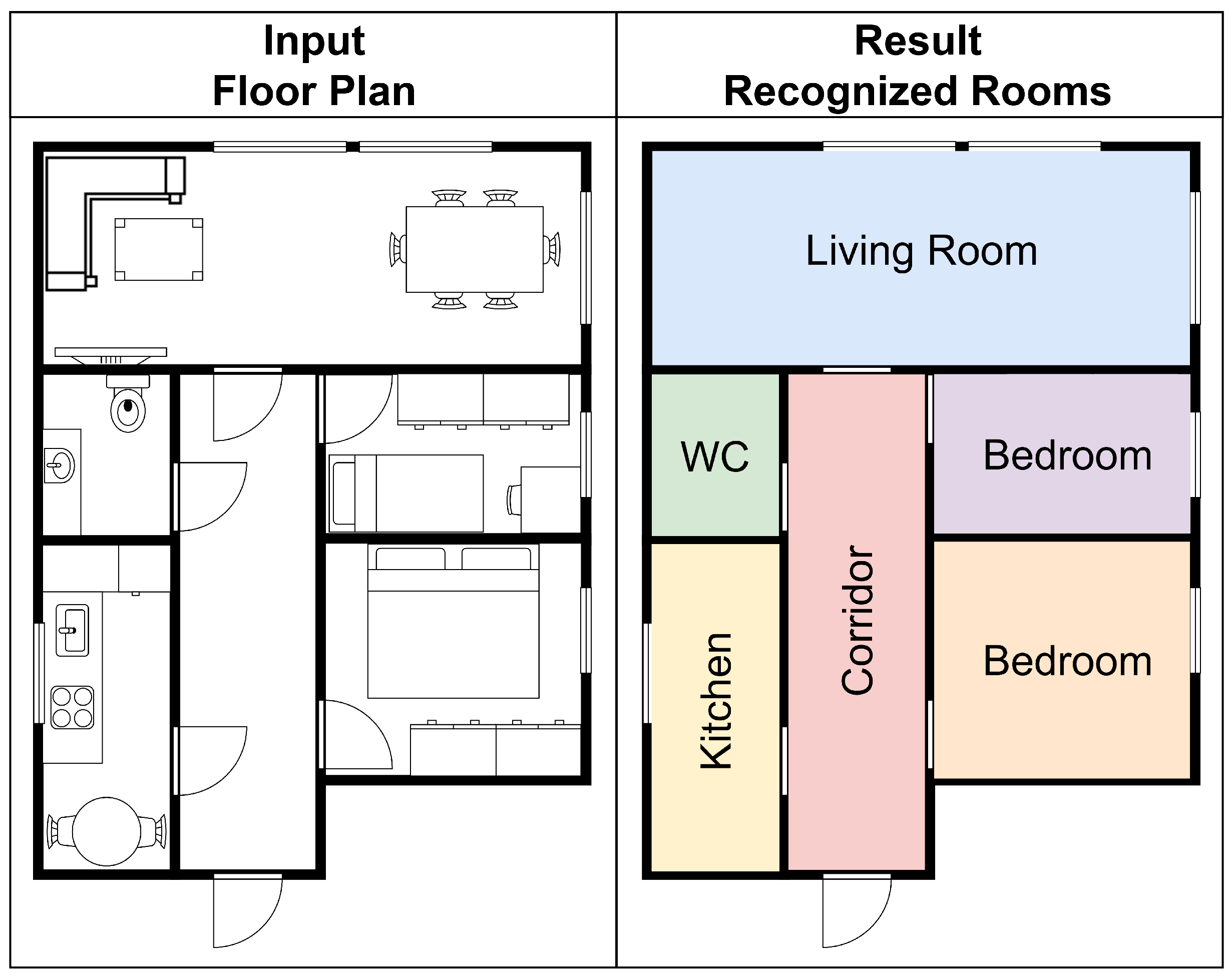
5.1.7. Room Classification
5.1.8. Change Detection
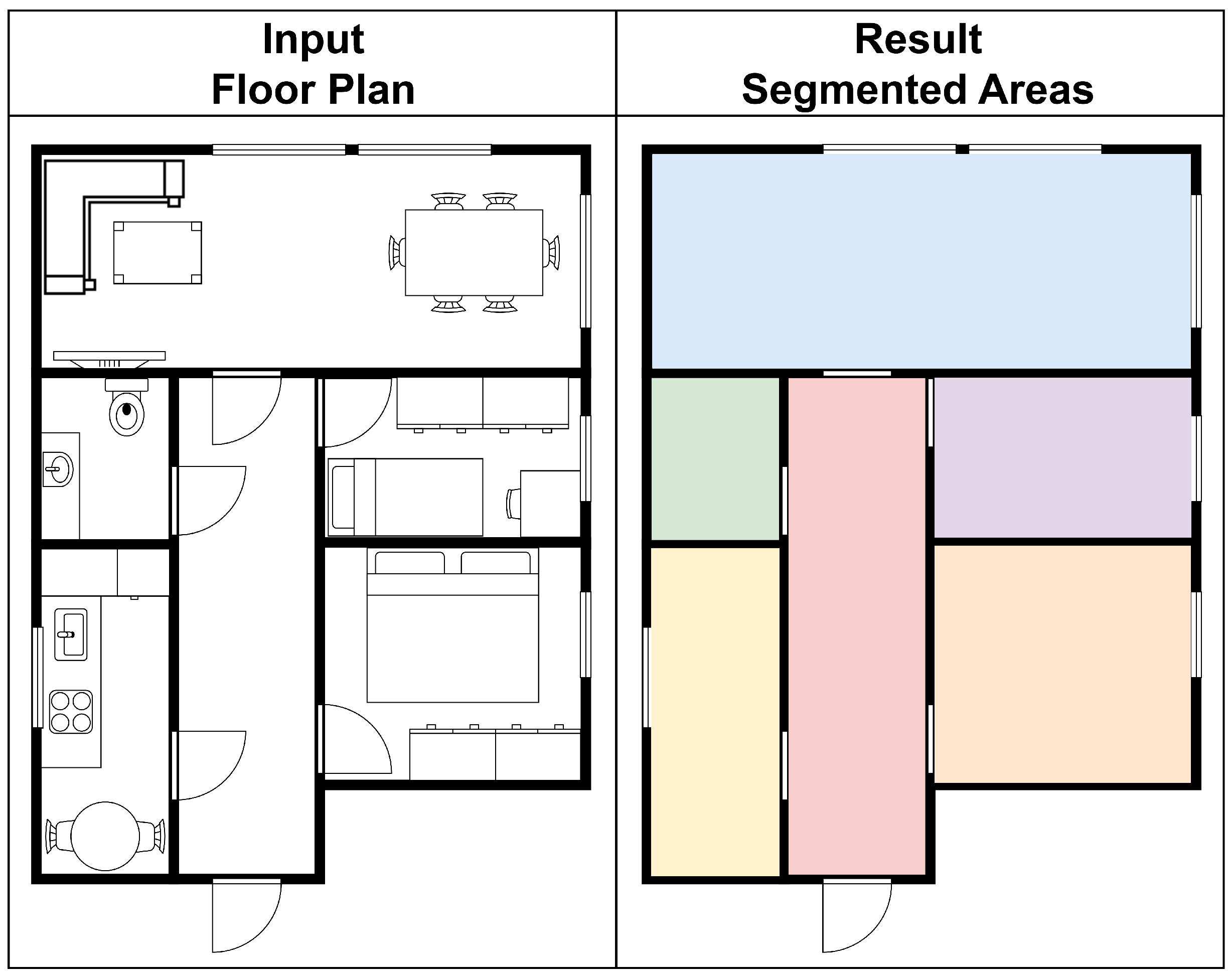
5.1.9. Segmentation
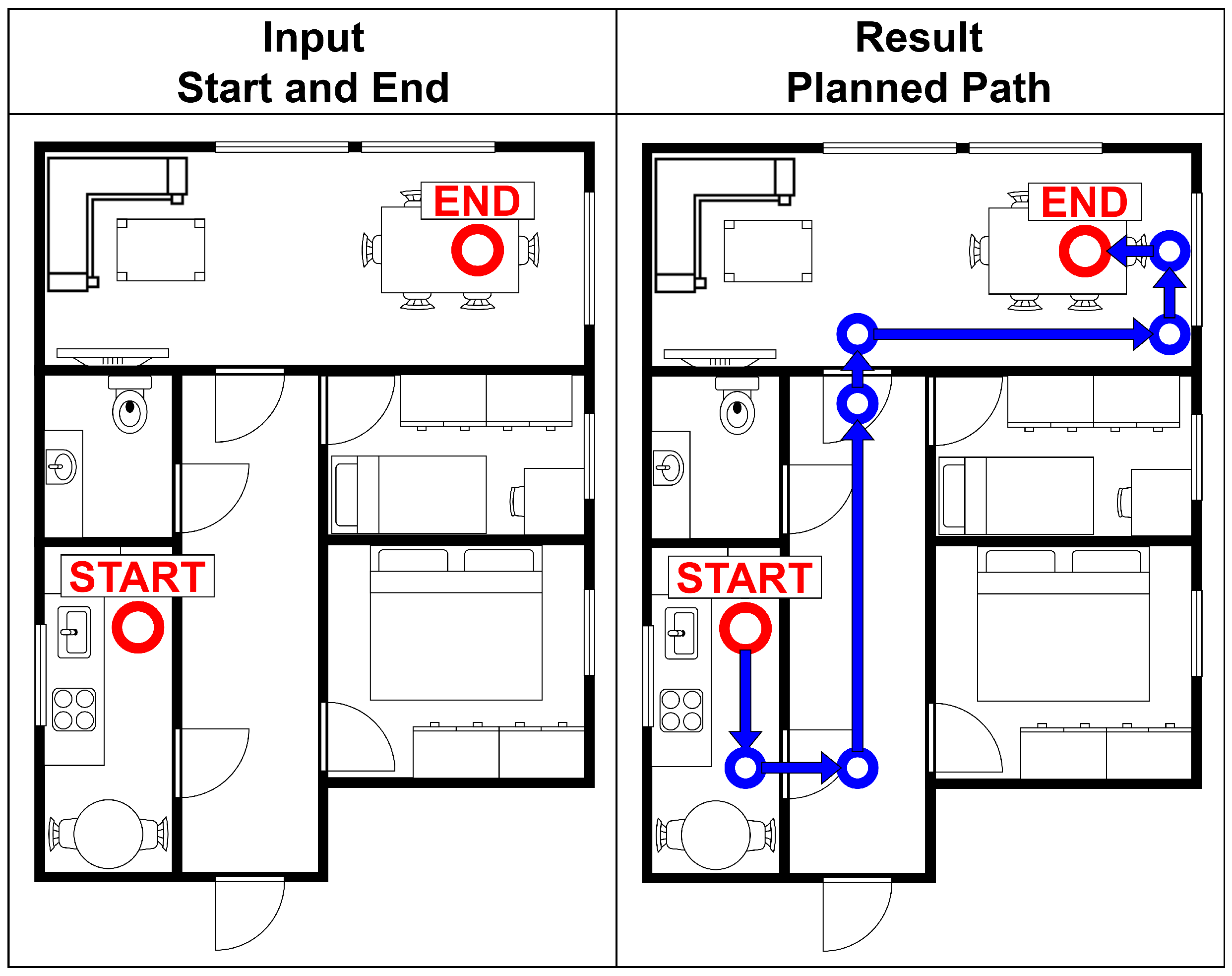
5.1.10. Indoor Navigation
5.1.11. Alignment/Matching
5.2. Taxonomy Summary and Discussion
6. Bibliometrics Analysis
7. Challenges
8. Newest Trends and Place for Future Work
9. Summary
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ACM | Association for Computing Machinery |
| AGG | Attributed Graph Grammar |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| AR | Augmented Reality |
| BIM | Building Information Modeling |
| BLS | Backpack Laser Scanner |
| BNC | Bayesian Network Classifier |
| BoW | Bag Of Words |
| CAD | Computer Aided Design |
| CBIR | Content-Based Image Retrieval |
| CNN | Convolutional Neural Network |
| DBLP | Digital Bibliography and Library Project |
| DCEL | Doubly-Connected Edge List |
| DL | Deep Learning |
| DSFL | Discriminative and Shareable Feature Learning |
| DuDe | Dual Space Decomposition |
| EC | Exclusion Criteria |
| EDT | Euclidean Distance Transformation |
| ESN | Echo State Network |
| GAN | Generative Adversarial Network |
| GAT | Graph Attention Network |
| GCN | Graph Convolutional Network |
| GMM | Gaussian Mixture Model |
| GNN | Graph Neural Network |
| GVG | Generalized Voronoi Graph |
| IC | Inclusion Criteria |
| IIoT | Industrial Internet of Things |
| IMU | Inertial measurement unit |
| IoT | Internet of Things |
| ISODATA | Iterative Self-Organizing Data Analysis Technique Algorithm |
| MCL | Monte Carlo Localization |
| MCMC | Markov Chain Monte Carlo |
| MDL | Minimum Description Length |
| ML | Machine Learning |
| MLN | Markov Logic Networks |
| MLP | Multi-Layer Perception |
| MLS | Mobile Laser Scanner |
| OCR | Optical Character Recognition |
| OTC | Oriented Texture Curves |
| RAG | Region Adjacency Graph |
| RNN | Recurrent Neural Network |
| RQ | Research Question |
| RSS | Received Signal Strength |
| SD | Science Direct |
| SL | Springer Link |
| SLAM | Simultaneous Localization And Mapping |
| SLR | Systematic Literature Review |
| SLS | Static Laser Scanner |
| SVM | Support Vector Machine |
| UAV | Unmanned Aerial Vehicle |
| VR | Virtual Reality |
References
- Bormann, R.; Jordan, F.; Li, W.; Hampp, J.; Hagele, M. Room segmentation: Survey, implementation, and analysis. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1019–1026. [Google Scholar] [CrossRef]
- Gimenez, L.; Hippolyte, J.L.; Robert, S.; Suard, F.; Zreik, K. Review: Reconstruction of 3D building information models from 2D scanned plans. J. Build. Eng. 2015, 2, 24–35. [Google Scholar] [CrossRef]
- Kang, Z.; Yang, J.; Yang, Z.; Cheng, S. A review of techniques for 3D reconstruction of indoor environments. ISPRS Int. J. Geo-Inf. 2020, 9, 330. [Google Scholar] [CrossRef]
- Mackenzie, H.; Dewey, A.; Drahota, A.; Kilburn, S.; Kalra, P.R.; Fogg, C.; Zachariah, D. Systematic reviews: What they are, why they are important, and how to get involved. J. Clin. Prev. Cardiol. 2012, 1, 193–202. [Google Scholar]
- Gough, D.; Oliver, S.; Thomas, J. An Introduction to Systematic Reviews, 2nd ed.; SAGE: London, UK, 2017. [Google Scholar]
- Grant, M.J.; Booth, A. A typology of reviews: An analysis of 14 review types and associated methodologies: A typology of reviews. Maria J. Grant Andrew Booth 2009, 26, 91–108. [Google Scholar] [CrossRef]
- Xiao, Y.; Watson, M. Guidance on Conducting a Systematic Literature Review. J. Plan. Educ. Res. 2019, 39, 93–112. [Google Scholar] [CrossRef]
- Santos, F.; Moreira, A.; Costa, P. Towards extraction of topological maps from 2D and 3D occupancy grids. In Proceedings of the Progress in Artificial Intelligence, Azores, Portugal, 9–12 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8154, pp. 307–318, ISBN 978-3-642-40668-3. [Google Scholar] [CrossRef]
- Mura, C.; Mattausch, O.; Villanueva, A.J.; Gobbetti, E.; Pajarola, R. Robust Reconstruction of Interior Building Structures with Multiple Rooms under Clutter and Occlusions. In Proceedings of the 2013 International Conference on Computer-Aided Design and Computer Graphics, Hong Kong, China, 16–18 November 2013; pp. 52–59. [Google Scholar] [CrossRef]
- Borrmann, D.; Nüchter, A.; Ðakulović, M.; Maurović, I.; Petrović, I.; Osmanković, D.; Velagić, J. A mobile robot based system for fully automated thermal 3D mapping. Adv. Eng. Inform. 2014, 28, 425–440. [Google Scholar] [CrossRef]
- Maurović, I.; ðakulović, M.; Petrović, I. Autonomous Exploration of Large Unknown Indoor Environments for Dense 3D Model Building. IFAC Proc. Vol. 2014, 47, 10188–10193. [Google Scholar] [CrossRef]
- Mura, C.; Mattausch, O.; Villanueva, A.J.; Gobbetti, E.; Pajarola, R. Automatic room detection and reconstruction in cluttered indoor environments with complex room layouts. Comput. Graph. 2014, 44, 20–32. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Wessel, R.; Tamke, M.; Klein, R. Automatic generation of structural building descriptions from 3D point cloud scans. In Proceedings of the GRAPP 2014—Proceedings of the 9th International Conference on Computer Graphics Theory and Applications, Lisbon, Portugal, 5–8 January 2014; SciTePress: Setúbal, Portugal, 2014; pp. 120–127. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Wessel, R.; Klein, R. Towards the extraction of hierarchical building descriptions from 3D indoor scans. In Proceedings of the Eurographics Workshop on 3D Object Retrieval, EG 3DOR, Strasbourg, France, 6 April 2014; Veltkamp, R., Tabia, H., B.B.V.J.P., Eds.; Eurographics Association: Cambridge, MA, USA, 2014. [Google Scholar] [CrossRef]
- Swadzba, A.; Wachsmuth, S. A detailed analysis of a new 3D spatial feature vector for indoor scene classification. Robot. Auton. Syst. 2014, 62, 646–662. [Google Scholar] [CrossRef]
- Macher, H.; Landes, T.; Grussenmeyer, P. Point clouds segmentation as base for as-built BIM creation. ISPRS Ann. Photogramm. Remote. Sens. Spat. Inf. Sci. 2015, 2, 191–197. [Google Scholar] [CrossRef]
- Turner, E.; Cheng, P.; Zakhor, A. Fast, automated, scalable generation of textured 3D models of indoor environments. IEEE J. Sel. Top. Signal Process. 2015, 9, 409–421. [Google Scholar] [CrossRef]
- Turner, E.; Zakhor, A. Automatic Indoor 3D Surface Reconstruction with Segmented Building and Object Elements. In Proceedings of the Proceedings—2015 International Conference on 3D Vision, 3DV 2015, Lyon, France, 19–22 October 2015; Brown, M., Kosecka, J., T.C., Eds.; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2015; pp. 362–370. [Google Scholar] [CrossRef]
- Ikehata, S.; Yang, H.; Furukawa, Y. Structured Indoor Modeling. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1323–1331. [Google Scholar] [CrossRef]
- Armeni, I.; Sener, O.; Zamir, A.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D semantic parsing of large-scale indoor spaces. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 1534–1543. [Google Scholar] [CrossRef]
- Manfredi, G.; Devin, S.; Devy, M.; Sidobre, D. Autonomous Apartment Exploration, Modelling and Segmentation for Service Robotics. IFAC-PapersOnLine 2016, 49, 120–125. [Google Scholar] [CrossRef]
- Martínez-Gómez, J.; Morell, V.; Cazorla, M.; García-Varea, I. Semantic localization in the PCL library. Robot. Auton. Syst. 2016, 75, 641–648. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Wessel, R.; Klein, R. Automatic reconstruction of parametric building models from indoor point clouds. Comput. Graph. 2016, 54, 94–103. [Google Scholar] [CrossRef]
- Liu, Q.; Li, R.; Hu, H.; Gu, D. Using semantic maps for room recognition to aid visually impaired people. In Proceedings of the 2016 22nd International Conference on Automation and Computing (ICAC), Colchester, UK, 7–8 September 2016; pp. 89–94. [Google Scholar] [CrossRef]
- Jung, J.; Stachniss, C.; Kim, C. Automatic Room Segmentation of 3D Laser Data Using Morphological Processing. SPRS Int. J. Geo-Inf. 2017, 6, 206. [Google Scholar] [CrossRef]
- Macher, H.; Landes, T.; Grussenmeyer, P. From point clouds to building information models: 3D semi-automatic reconstruction of indoors of existing buildings. Appl. Sci. 2017, 7, 1030. [Google Scholar] [CrossRef]
- Murali, S.; Speciale, P.; Oswald, M.; Pollefeys, M. Indoor Scan2BIM: Building information models of house interiors. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 6126–6133. [Google Scholar] [CrossRef]
- Nikoohemat, S.; Peter, M.; Oude Elberink, S.; Vosselman, G. Exploiting Indoor Mobile Laser Scanner Trajectories for Semantic Interpretation of Point Clouds. In Proceedings of the ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Wuhan, China, 18–22 September 2017; Copernicus GmbH: Göttingen, Germany, 2017; Volume 4, pp. 355–362. [Google Scholar] [CrossRef]
- Wang, R.; Xie, L.; Chen, D. Modeling indoor spaces using decomposition and reconstruction of structural elements. Photogramm. Eng. Remote. Sens. 2017, 83, 827–841. [Google Scholar] [CrossRef]
- Xie, L.; Wang, R. Automatic indoor building reconstruction from mobile laser scanning data. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, 42, 417–422. [Google Scholar] [CrossRef]
- Ambruş, R.; Claici, S.; Wendt, A. Automatic Room Segmentation From Unstructured 3-D Data of Indoor Environments. IEEE Robot. Autom. Lett. 2017, 2, 749–756. [Google Scholar] [CrossRef]
- Bobkov, D.; Kiechle, M.; Hilsenbeck, S.; Steinbach, E. Room segmentation in 3D point clouds using anisotropic potential fields. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 727–732. [Google Scholar] [CrossRef]
- Brucker, M.; Durner, M.; Ambrus, R.; Marton, Z.; Wendt, A.; Jensfelt, P.; Arras, K.; Triebel, R. Semantic Labeling of Indoor Environments from 3D RGB Maps. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA; pp. 1871–1878. [Google Scholar] [CrossRef]
- Elseicy, A.; Nikoohemat, S.; Peter, M.; Elberink, S. Space subdivision of indoor mobile laser scanning data based on the scanner trajectory. Remote Sens. 2018, 10, 1815. [Google Scholar] [CrossRef]
- Jung, J.; Stachniss, C.; Ju, S.; Heo, J. Automated 3D volumetric reconstruction of multiple-room building interiors for as-built BIM. Adv. Eng. Inform. 2018, 38, 811–825. [Google Scholar] [CrossRef]
- Li, L.; Su, F.; Yang, F.; Zhu, H.; Li, D.; Zuo, X.; Li, F.; Liu, Y.; Ying, S. Reconstruction of three-dimensional (3D) indoor interiors with multiple stories via comprehensive segmentation. Remote Sens. 2018, 10, 1281. [Google Scholar] [CrossRef]
- Magri, L.; Fusiello, A. Reconstruction of interior walls from point cloud data with min-hashed J-Linkage. In Proceedings of the Proceedings—2018 International Conference on 3D Vision, 3DV 2018, Verona, Italy, 5–8 September 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 131–139. [Google Scholar] [CrossRef]
- Nikoohemat, S.; Peter, M.; Elberink, S.; Vosselman, G. Semantic interpretation of mobile laser scanner point clouds in Indoor Scenes using trajectories. Remote Sens. 2018, 10, 1754. [Google Scholar] [CrossRef]
- Zheng, Y.; Peter, M.; Zhong, R.; Elberink, S.; Zhou, Q. Space subdivision in indoor mobile laser scanning point clouds based on scanline analysis. Sensors 2018, 18, 1838. [Google Scholar] [CrossRef] [PubMed]
- Sharma, O.; Pandey, J.; Akhtar, H.; Rathee, G. Navigation in AR based on digital replicas. Vis. Comput. 2018, 34, 925–936. [Google Scholar] [CrossRef]
- Cui, Y.; Li, Q.; Dong, Z. Structural 3D reconstruction of indoor space for 5G signal simulation with mobile laser scanning point clouds. Sensors 2018, 11, 2262. [Google Scholar] [CrossRef]
- Cui, Y.; Li, Q.; Yang, B.; Xiao, W.; Chen, C.; Dong, Z. Automatic 3-D Reconstruction of Indoor Environment with Mobile Laser Scanning Point Clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3117–3130. [Google Scholar] [CrossRef]
- Koeva, M.; Nikoohemat, S.; Elberink, S.; Morales, J.; Lemmen, C.; Zevenbergen, J. Towards 3D indoor cadastre based on change detection from point clouds. Remote Sens. 2019, 11, 1972. [Google Scholar] [CrossRef]
- Maset, E.; Magri, L.; Fusiello, A. Improving automatic reconstruction of interior walls from point cloud data. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, 42, 849–855. [Google Scholar] [CrossRef]
- Nikoohemat, S.; Diakité, A.; Zlatanova, S.; Vosselman, G. INDOOR 3D MODELING and FLEXIBLE SPACE SUBDIVISION from POINT CLOUDS. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, 4, 285–292. [Google Scholar] [CrossRef]
- Ochmann, S.; Vock, R.; Klein, R. Automatic reconstruction of fully volumetric 3D building models from oriented point clouds. ISPRS J. Photogramm. Remote Sens. 2019, 151, 251–262. [Google Scholar] [CrossRef]
- Previtali, M.; Barazzetti, L.; Roncoroni, F. Automated Detection and Layout Regularization of Similar Features in Indoor Point Cloud. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, 42, 631–638. [Google Scholar] [CrossRef]
- Shi, W.; Ahmed, W.; Li, N.; Fan, W.; Xiang, H.; Wang, M. Semantic geometric modelling of unstructured indoor point cloud. ISPRS Int. J. Geo-Inf. 2019, 8, 9. [Google Scholar] [CrossRef]
- Tang, S.; Zhang, Y.; Li, Y.; Yuan, Z.; Wang, Y.; Zhang, X.; Li, X.; Zhang, Y.; Guo, R.; Wang, W. Fast and automatic reconstruction of semantically rich 3D indoor maps from low-quality RGB-D sequences. Sensors 2019, 19, 533. [Google Scholar] [CrossRef] [PubMed]
- Wang, P.; Cheng, J.; Feng, W. An approach for construct semantic map with scene classification and object semantic segmentation. In Proceedings of the 2018 IEEE International Conference on Real-Time Computing and Robotics, RCAR 2018, Kandima, Maldives, 1–5 August 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 270–275. [Google Scholar] [CrossRef]
- Yang, F.; Li, L.; Su, F.; Li, D.; Zhu, H.; Ying, S.; Zuo, X.; Tang, L. Semantic decomposition and recognition of indoor spaces with structural constraints for 3D indoor modelling. Autom. Constr. 2019, 106, 102913. [Google Scholar] [CrossRef]
- Yang, F.; Zhou, G.; Su, F.; Zuo, X.; Tang, L.; Liang, Y.; Zhu, H.; Li, L. Automatic indoor reconstruction from point clouds in multi-room environments with curved walls. Sensors 2019, 19, 3798. [Google Scholar] [CrossRef] [PubMed]
- He, Z.; Hou, J.; Schwertfeger, S. Furniture Free Mapping using 3D Lidars. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 583–589. [Google Scholar] [CrossRef]
- Nikoohemat, S.; Diakité, A.; Zlatanova, S.; Vosselman, G. Indoor 3D reconstruction from point clouds for optimal routing in complex buildings to support disaster management. Autom. Constr. 2020, 113, 103109. [Google Scholar] [CrossRef]
- Otero, R.; Frías, E.; Lagüela, S.; Arias, P. Automatic gbXML modeling from LiDAR data for energy studies. Remote Sens. 2020, 12, 2679. [Google Scholar] [CrossRef]
- Rusli, I.; Trilaksono, B.R.; Adiprawita, W. RoomSLAM: Simultaneous Localization and Mapping With Objects and Indoor Layout Structure. IEEE Access 2020, 8, 196992–197004. [Google Scholar] [CrossRef]
- Ryu, M.; Oh, S.; Kim, M.; Cho, H.; Son, C.; Kim, T. Algorithm for generating 3d geometric representation based on indoor point cloud data. Appl. Sci. 2020, 10, 8073. [Google Scholar] [CrossRef]
- Phalak, A.; Badrinarayanan, V.; Rabinovich, A. Scan2Plan: Efficient Floorplan Generation from 3D Scans of Indoor Scenes. arXiv 2020. Available online: http://arxiv.org/abs/2003.07356 (accessed on 28 April 2024).
- Frías, E.; Balado, J.; Díaz-Vilariño, L.; Lorenzo, H. Point Cloud Room Segmentation Based on Indoor Spaces and 3D Mathematical Morphology. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2020, 44, 49–55. [Google Scholar] [CrossRef]
- Ai, M.; Li, Z.; Shan, J. Topologically consistent reconstruction for complex indoor structures from point clouds. Remote Sens. 2021, 13, 3844. [Google Scholar] [CrossRef]
- Cai, Y.; Fan, L. An efficient approach to automatic construction of 3d watertight geometry of buildings using point clouds. Remote Sens. 2021, 13, 1947. [Google Scholar] [CrossRef]
- Fang, H.; Lafarge, F.; Pan, C.; Huang, H. Floorplan generation from 3D point clouds: A space partitioning approach. ISPRS J. Photogramm. Remote Sens. 2021, 175, 44–55. [Google Scholar] [CrossRef]
- He, Z.; Sun, H.; Hou, J.; Ha, Y.; Schwertfeger, S. Hierarchical topometric representation of 3D robotic maps. Auton. Robot. 2021, 45, 755–771. [Google Scholar] [CrossRef]
- Hübner, P.; Weinmann, M.; Wursthorn, S.; Hinz, S. Automatic voxel-based 3D indoor reconstruction and room partitioning from triangle meshes. ISPRS J. Photogramm. Remote Sens. 2021, 181, 254–278. [Google Scholar] [CrossRef]
- Wang, Y.; Ramezani, M.; Mattamala, M.; Fallon, M. Scalable and elastic LiDAR reconstruction in complex environments through spatial analysis. In Proceedings of the 2021 10th European Conference on Mobile Robots, ECMR 2021—Proceedings, Bonn, Germany, 31 August–3 September 2021; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Yang, F.; Che, M.; Zuo, X.; Li, L.; Zhang, J.; Zhang, C. Volumetric Representation and Sphere Packing of Indoor Space for Three-Dimensional Room Segmentation. ISPRS Int. J. Geo-Inf. 2021, 10, 739. [Google Scholar] [CrossRef]
- Yang, J.; Kang, Z.; Zeng, L.; Hope Akwensi, P.; Sester, M. Semantics-guided reconstruction of indoor navigation elements from 3D colorized points. ISPRS J. Photogramm. Remote Sens. 2021, 173, 238–261. [Google Scholar] [CrossRef]
- Cai, R.; Li, H.; Xie, J.; Jin, X. Accurate floorplan reconstruction using geometric priors. Comput. Graph. 2022, 102, 360–369. [Google Scholar] [CrossRef]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Nießner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. arXiv 2017. Available online: http://arxiv.org/abs/1709.06158 (accessed on 28 April 2024).
- Blöchliger, F.; Fehr, M.; Dymczyk, M.; Schneider, T.; Siegwart, R. Topomap: Topological Mapping and Navigation Based on Visual SLAM Maps. arXiv 2018. Available online: http://arxiv.org/abs/1709.05533 (accessed on 28 April 2024).
- Chen, J.; Liu, C.; Wu, J.; Furukawa, Y. Floor-SP: Inverse CAD for Floorplans by Sequential Room-Wise Shortest Path. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2661–2670. [Google Scholar] [CrossRef]
- Carrera, V.J.L.; Zhao, Z.; Braun, T.; Li, Z.; Neto, A. A real-time robust indoor tracking system in smartphones. Comput. Commun. 2018, 117, 104–115. [Google Scholar] [CrossRef]
- Matez-Bandera, J.; Monroy, J.; Gonzalez-Jimenez, J. Efficient semantic place categorization by a robot through active line-of-sight selection. Knowl.-Based Syst. 2022, 240, 108022. [Google Scholar] [CrossRef]
- Liu, N.; Lin, B.; Yuan, L.; Lv, G.; Yu, Z.; Zhou, L. An Interactive Indoor 3D Reconstruction Method Based on Conformal Geometry Algebra. Adv. Appl. Clifford Algebras 2018, 28, 73. [Google Scholar] [CrossRef]
- Weinmann, M.; Wursthorn, S.; Weinmann, M.; Hübner, P. Efficient 3D Mapping and Modelling of Indoor Scenes with the Microsoft HoloLens: A Survey. PFG 2021, 89, 319–333. [Google Scholar] [CrossRef]
- Franz, S.; Irmler, R.; Rüppel, U. Real-time collaborative reconstruction of digital building models with mobile devices. Adv. Eng. Inform. 2018, 38, 569–580. [Google Scholar] [CrossRef]
- Gao, R.; Zhao, M.; Ye, T.; Ye, F.; Wang, Y.; Bian, K.; Wang, T.; Li, X. Jigsaw: Indoor Floor Plan Reconstruction via Mobile Crowdsensing. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, MobiCom’14, Maui, HI, USA, 7–11 September 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 249–260. [Google Scholar] [CrossRef]
- Liu, C.; Wu, J.; Furukawa, Y. FloorNet: A unified framework for floorplan reconstruction from 3D scans. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; Volume 11210, pp. 203–219. [Google Scholar] [CrossRef]
- Liu, H.; Yang, Y.L.; AlHalawani, S.; Mitra, N.J. Constraint-aware interior layout exploration for pre-cast concrete-based buildings. Vis. Comput. 2013, 29, 663–673. [Google Scholar] [CrossRef]
- Luperto, M.; D’Emilio, L.; Amigoni, F. A generative spectral model for semantic mapping of buildings. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4451–4458. [Google Scholar] [CrossRef]
- Luperto, M.; Riva, A.; Amigoni, F. Semantic classification by reasoning on the whole structure of buildings using statistical relational learning techniques. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Singapore, 29 May–3 June 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 2562–2568. [Google Scholar] [CrossRef]
- Luperto, M.; Amigoni, F. Predicting the global structure of indoor environments: A constructive machine learning approach. Auton. Robot. 2019, 43, 813–835. [Google Scholar] [CrossRef]
- Nauata, N.; Chang, K.H.; Cheng, C.Y.; Mori, G.; Furukawa, Y. House-GAN: Relational Generative Adversarial Networks for Graph-Constrained House Layout Generation. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12346, pp. 162–177. [Google Scholar] [CrossRef]
- Paudel, A.; Dhakal, R.; Bhattarai, S. Room Classification on Floor Plan Graphs using Graph Neural Networks. arXiv 2021. Available online: http://arxiv.org/abs/2108.05947 (accessed on 28 April 2024).
- Wang, Z.; Sacks, R.; Yeung, T. Exploring graph neural networks for semantic enrichment: Room-type classification. Autom. Constr. 2022, 134, 104039. [Google Scholar] [CrossRef]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Automatic Room Detection and Room Labeling from Architectural Floor Plans. In Proceedings of the 2012 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, QLD, Australia, 27–29 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 339–343. [Google Scholar] [CrossRef]
- Heras, L.P.d.l.; Ahmed, S.; Liwicki, M.; Valveny, E.; Sánchez, G. Statistical segmentation and structural recognition for floor plan interpretation - Notation invariant structural element recognition. IJDAR 2014, 17, 221–237. [Google Scholar] [CrossRef]
- Liu, Z.; Von Wichert, G. Extracting semantic indoor maps from occupancy grids. Robot. Auton. Syst. 2014, 62, 663–674. [Google Scholar] [CrossRef]
- Camozzato, D.; Dihl, L.; Silveira, I.; Marson, F.; Musse, S. Procedural floor plan generation from building sketches. Vis. Comput. 2015, 31, 753–763. [Google Scholar] [CrossRef]
- Goncu, C.; Madugalla, A.; Marinai, S.; Marriott, K. Accessible On-Line Floor Plans. In Proceedings of the 24th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, WWW’15, Florence, Italy, 18–22 May 2015; pp. 388–398. [Google Scholar] [CrossRef]
- de las Heras, L.P.; Terrades, O.R.; Lladós, J. Attributed Graph Grammar for floor plan analysis. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 726–730. [Google Scholar] [CrossRef]
- Sharma, D.; Chattopadhyay, C.; Harit, G. A unified framework for semantic matching of architectural floorplans. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2422–2427. [Google Scholar] [CrossRef]
- Zhang, X.; Wong, A.K.S.; Lea, C.T. Automatic Floor Plan Analysis for Adaptive Indoor Wi-Fi Positioning System. In Proceedings of the 2016 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 15–17 December 2016; pp. 869–874. [Google Scholar] [CrossRef]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 358–361. [Google Scholar] [CrossRef]
- Madugalla, A.; Marriott, K.; Marinai, S. Partitioning Open Plan Areas in Floor Plans. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 47–52. [Google Scholar] [CrossRef]
- Goyal, S.; Chattopadhyay, C.; Bhatnagar, G. Plan2Text: A framework for describing building floor plan images from first person perspective. In Proceedings of the Proceedings—2018 IEEE 14th International Colloquium on Signal Processing and its Application, CSPA 2018, Penang, Malaysia, 9–10 March 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 35–40. [Google Scholar] [CrossRef]
- Sharma, D.; Chattopadhyay, C. High-level feature aggregation for fine-grained architectural floor plan retrieval. IET Comput. Vis. 2018, 12, 702–709. [Google Scholar] [CrossRef]
- Yamasaki, T.; Zhang, J.; Takada, Y. Apartment Structure Estimation Using Fully Convolutional Networks and Graph Model. In Proceedings of the 2018 ACM Workshop on Multimedia for Real Estate Tech, Association for Computing Machinery, RETech’18, Yokohama, Japan, 11 June 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Goyal, S.; Bhavsar, S.; Patel, S.; Chattopadhyay, C.; Bhatnagar, G. Sugaman: Describing floor plans for visually impaired by annotation learning and proximity-based grammar. IET Image Process. 2019, 13, 2623–2635. [Google Scholar] [CrossRef]
- Kalervo, A.; Ylioinas, J.; Häikiö, M.; Karhu, A.; Kannala, J. CubiCasa5K: A Dataset and an Improved Multi-Task Model for Floorplan Image Analysis. arXiv 2019. Available online: http://arxiv.org/abs/1904.01920 (accessed on 28 April 2024).
- Zeng, Z.; Li, X.; Yu, Y.K.; Fu, C.W. Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention. arXiv 2019. Available online: http://arxiv.org/abs/1908.11025 (accessed on 28 April 2024).
- Mewada, H.K.; Patel, A.V.; Chaudhari, J.P.; Mahant, K.K.; Vala, A. Automatic room information retrieval and classification from floor plan using linear regression model. IJDAR 2020, 23, 253–266. [Google Scholar] [CrossRef]
- Madugalla, A.; Marriott, K.; Marinai, S.; Capobianco, S.; Goncu, C. Creating Accessible Online Floor Plans for Visually Impaired Readers. ACM Trans. Access. Comput. 2020, 13, 1–37. [Google Scholar] [CrossRef]
- Dong, S.; Wang, W.; Li, W.; Zou, K. Vectorization of floor plans based on EdgeGAN. Information 2021, 12, 206. [Google Scholar] [CrossRef]
- Foroughi, F.; Wang, J.; Nemati, A.; Chen, Z.; Pei, H. MapSegNet: A Fully Automated Model Based on the Encoder-Decoder Architecture for Indoor Map Segmentation. IEEE Access 2021, 9, 101530–101542. [Google Scholar] [CrossRef]
- Gan, Y.; Wang, S.Y.; Huang, C.E.; Hsieh, Y.C.; Wang, H.Y.; Lin, W.H.; Chong, S.N.; Liong, S.T. How Many Bedrooms Do You Need? A Real-Estate Recommender System from Architectural Floor Plan Images. Sci. Program. 2021, 2021, 9914557. [Google Scholar] [CrossRef]
- Goyal, S.; Chattopadhyay, C.; Bhatnagar, G. Knowledge-driven description synthesis for floor plan interpretation. IJDAR 2021, 24, 19–32. [Google Scholar] [CrossRef]
- Lu, Z.; Wang, T.; Guo, J.; Meng, W.; Xiao, J.; Zhang, W.; Zhang, X. Data-driven floor plan understanding in rural residential buildings via deep recognition. Inf. Sci. 2021, 567, 58–74. [Google Scholar] [CrossRef]
- Murugan, G.; Moyal, V.; Nandankar, P.; Pandithurai, O.; Pimo, E.S.J. A novel CNN method for the accurate spatial data recovery from digital images. Mater. Today Proc. 2021, 80, 1706–1712. [Google Scholar] [CrossRef]
- Park, S.; Kim, H. 3dplannet: Generating 3D models from 2d floor plan images using ensemble methods. Electronics 2021, 10, 2729. [Google Scholar] [CrossRef]
- Lv, X.; Zhao, S.; Yu, X.; Zhao, B. Residential floor plan recognition and reconstruction. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16712–16721. [Google Scholar] [CrossRef]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Improved Automatic Analysis of Architectural Floor Plans. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, ICDAR 2011, Beijing, China, 18–21 September 2011; IEEE Computer Society: Washington, DC, USA, 2011; pp. 864–869. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, D.; Von Wichert, G. 2D Semantic Mapping on Occupancy Grids. In Proceedings of the German Conference on Robotics, Munich, Germany, 21–22 May 2012; p. 6. [Google Scholar]
- Ahmed, S.; Weber, M.; Liwicki, M.; Langenhan, C.; Dengel, A.; Petzold, F. Automatic analysis and sketch-based retrieval of architectural floor plans. Pattern Recognit. Lett. 2014, 35, 91–100. [Google Scholar] [CrossRef]
- Paladugu, A.; Tian, Q.; Maguluri, H.; Li, B. Towards building an automated system for describing indoor floor maps for individuals with visual impairment. Cyber-Phys. Syst. 2016, 1, 132–159. [Google Scholar] [CrossRef]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3D building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Liu, C.; Wu, J.; Kohli, P.; Furukawa, Y. Raster-to-Vector: Revisiting Floorplan Transformation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 2214–2222. [Google Scholar] [CrossRef]
- Sandelin, F.; Sjöberg, K. Semantic and Instance Segmentation of Room Features in Floor Plans using Mask R-CNN; Uppsala University, Department of Information Technology: Uppsala, Sweden, 2019. [Google Scholar]
- Goyal, S.; Mistry, V.; Chattopadhyay, C.; Bhatnagar, G. BRIDGE: Building Plan Repository for Image Description Generation, and Evaluation. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1071–1076. [Google Scholar] [CrossRef]
- Jang, H.; Yu, K.; Yang, J. Indoor reconstruction from floorplan images with a deep learning approach. ISPRS Int. J. Geo-Inf. 2020, 9, 65. [Google Scholar] [CrossRef]
- Kim, S.; Park, S.; Kim, H.; Yu, K. Deep Floor Plan Analysis for Complicated Drawings Based on Style Transfer. J. Comput. Civ. Eng. 2020, 35. [Google Scholar] [CrossRef]
- Surikov, I.; Nakhatovich, M.; Belyaev, S.; Savchuk, D. Floor plan recognition and vectorization using combination unet, faster-rcnn, statistical component analysis and ramer-douglas-peucker. In Proceedings of the Computing Science, Communication and Security, Gujarat, India, 26–27 March 2020; Springer: Singapore, 2020; Volume 1235, pp. 16–28, ISBN 9789811566479. [Google Scholar] [CrossRef]
- Zhang, Y.; He, Y.; Zhu, S.; Di, X. The Direction-Aware, Learnable, Additive Kernels and the Adversarial Network for Deep Floor Plan Recognition. arXiv 2020. Available online: http://arxiv.org/abs/2001.11194 (accessed on 28 April 2024).
- Liu, Z.; von Wichert, G. A Generalizable Knowledge Framework for Semantic Indoor Mapping Based on Markov Logic Networks and Data Driven MCMC. arXiv 2020. Available online: http://arxiv.org/abs/2002.08402 (accessed on 28 April 2024).
- Kim, H.; Kim, S.; Yu, K. Automatic Extraction of Indoor Spatial Information from Floor Plan Image: A Patch-Based Deep Learning Methodology Application on Large-Scale Complex Buildings. ISPRS Int. J. Geo-Inf. 2021, 10, 828. [Google Scholar] [CrossRef]
- Song, J.; Yu, K. Framework for indoor elements classification via inductive learning on floor plan graphs. ISPRS Int. J. Geo-Inf. 2021, 10, 97. [Google Scholar] [CrossRef]
- Hellbach, S.; Himstedt, M.; Bahrmann, F.; Riedel, M.; Villmann, T.; Böhme, H.J. Some Room for GLVQ: Semantic Labeling of Occupancy Grid Maps. In Proceedings of the Advances in Self-Organizing Maps and Learning Vector Quantization—Proceedings of the 10th International Workshop, WSOM 2014, Mittweida, Germany, 2–4 July 2014; Villmann, T., Schleif, F.M., Kaden, M., Lange, M., Eds.; Advances in Intelligent Systems and Computing. Springer: Berlin/Heidelberg, Germany, 2014; Volume 295, pp. 133–143. [Google Scholar] [CrossRef]
- Luperto, M.; Quattrini Li, A.; Amigoni, F. A system for building semantic maps of indoor environments exploiting the concept of building typology. In RoboCup 2013: Robot World Cup XVII; Springer: Berlin/Heidelberg, Germany, 2014; Volume 8371, pp. 504–515. ISBN 9783662444672. [Google Scholar] [CrossRef]
- Fermin-Leon, L.; Neira, J.; Castellanos, J. TIGRE: Topological graph based robotic exploration. In Proceedings of the 2017 European Conference on Mobile Robots, ECMR 2017, Paris, France, 6–8 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef]
- Kakuma, D.; Tsuichihara, S.; Ricardez, G.; Takamatsu, J.; Ogasawara, T. Alignment of Occupancy Grid and Floor Maps Using Graph Matching. In Proceedings of the Proceedings—IEEE 11th International Conference on Semantic Computing, ICSC 2017, San Diego, CA, USA, 30 January–1 February 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 57–60. [Google Scholar] [CrossRef]
- Kleiner, A.; Baravalle, R.; Kolling, A.; Pilotti, P.; Munich, M. A solution to room-by-room coverage for autonomous cleaning robots. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vancouver, BC, Canada, 24–28 September 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 5346–5352. [Google Scholar] [CrossRef]
- Fermin-Leon, L.; Neira, J.; Castellanos, J.A. Incremental contour-based topological segmentation for robot exploration. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2554–2561. [Google Scholar] [CrossRef]
- Hang, M.; Lin, M.; Li, S.; Chen, Z.; Ding, R. A multi-strategy path planner based on space accessibility. In Proceedings of the 2017 IEEE International Conference on Robotics and Biomimetics, ROBIO 2017, Macau, Macao, 5–8 December 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 2154–2161. [Google Scholar] [CrossRef]
- Liu, B.; Zuo, L.; Zhang, C.H.; Liu, Y. An approach to graph-based grid map segmentation for robot global localization. In Proceedings of the 2018 IEEE International Conference on Mechatronics and Automation, ICMA 2018, Changchun, China, 5–8 August 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2018; pp. 1812–1817. [Google Scholar] [CrossRef]
- Mielle, M.; Magnusson, M.; Lilienthal, A. A method to segment maps from different modalities using free space layout maoris: Map of ripples segmentation. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 4993–4999. [Google Scholar] [CrossRef]
- Hiller, M.; Qiu, C.; Particke, F.; Hofmann, C.; Thielecke, J. Learning Topometric Semantic Maps from Occupancy Grids. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 4190–4197. [Google Scholar] [CrossRef]
- Luperto, M.; Arcerito, V.; Amigoni, F. Predicting the layout of partially observed rooms from grid maps. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2017; pp. 6898–6904. [Google Scholar] [CrossRef]
- Schwertfeger, S.; Yu, T. Room Detection for Topological Maps. arXiv 2019. Available online: http://arxiv.org/abs/1912.01279 (accessed on 28 April 2024).
- Hou, J.; Yuan, Y.; Schwertfeger, S. Area Graph: Generation of Topological Maps using the Voronoi Diagram. In Proceedings of the 2019 19th International Conference on Advanced Robotics (ICAR), Belo Horizonte, Brazil, 2–6 December 2019; pp. 509–515. [Google Scholar] [CrossRef]
- Tien, M.; Park, Y.; Jung, K.H.; Kim, S.Y.; Kye, J.E. Performance evaluation on the accuracy of the semantic map of an autonomous robot equipped with P2P communication module. Peer-to-Peer Netw. Appl. 2020, 13, 704–716. [Google Scholar] [CrossRef]
- Zheng, T.; Duan, Z.; Wang, J.; Lu, G.; Li, S.; Yu, Z. Research on Distance Transform and Neural Network Lidar Information Sampling Classification-Based Semantic Segmentation of 2D Indoor Room Maps. Sensors 2020, 21, 1365. [Google Scholar] [CrossRef]
- Luperto, M.; Kucner, T.P.; Tassi, A.; Magnusson, M.; Amigoni, F. Robust Structure Identification and Room Segmentation of Cluttered Indoor Environments from Occupancy Grid Maps. arXiv, 2022. Available online: http://arxiv.org/abs/2203.03519(accessed on 28 April 2024).
- Shi, L.; Kodagoda, S.; Dissanayake, G. Application of semi-supervised learning with Voronoi Graph for place classification. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 2991–2996. [Google Scholar] [CrossRef]
- Sjoo, K. Semantic map segmentation using function-based energy maximization. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 4066–4073. [Google Scholar] [CrossRef]
- Capobianco, R.; Gemignani, G.; Bloisi, D.; Nardi, D.; Iocchi, L. Automatic extraction of structural representations of environments. In Intelligent Autonomous Systems 13; Springer: Cham, Switzerland, 2015; Volume 302, pp. 721–733. ISBN 9783319083377. [Google Scholar] [CrossRef]
- Liu, M.; Colas, F.; Oth, L.; Siegwart, R. Incremental topological segmentation for semi-structured environments using discretized GVG. Auton. Robot. 2015, 38, 143–160. [Google Scholar] [CrossRef]
- Goeddel, R.; Olson, E. Learning semantic place labels from occupancy grids using CNNs. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3999–4004. [Google Scholar] [CrossRef]
- Hou, J.; Kuang, H.; Schwertfeger, S. Fast 2D map matching based on area graphs. In Proceedings of the IEEE International Conference on Robotics and Biomimetics, ROBIO 2019, Dali, China, 6–8 December 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 1723–1729. [Google Scholar] [CrossRef]
- Rubio, F.; Martínez-Gómez, J.; Flores, M.J.; Puerta, J.M. Comparison between Bayesian network classifiers and SVMs for semantic localization. Expert Syst. Appl. 2016, 64, 434–443. [Google Scholar] [CrossRef]
- Ursic, P.; Mandeljc, R.; Leonardis, A.; Kristan, M. Part-based room categorization for household service robots. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 2287–2294. [Google Scholar] [CrossRef]
- Fleer, D. Human-Like Room Segmentation for Domestic Cleaning Robots. Robotics 2017, 6, 35. [Google Scholar] [CrossRef]
- Young, J.; Basile, V.; Suchi, M.; Kunze, L.; Hawes, N.; Vincze, M.; Caputo, B. Making Sense of Indoor Spaces Using Semantic Web Mining and Situated Robot Perception. In Proceedings of the The Semantic Web: ESWC 2017 Satellite Events, Portorož, Slovenia, 28 May–1 June 2017; Springer: Cham, Switzerland, 2017; Volume 10577, pp. 299–313. [Google Scholar] [CrossRef]
- Pintore, G.; Ganovelli, F.; Pintus, R.; Scopigno, R.; Gobbetti, E. 3D floor plan recovery from overlapping spherical images. Comp. Visual Media 2018, 4, 367–383. [Google Scholar] [CrossRef]
- Pintore, G.; Ganovelli, F.; Pintus, R.; Scopigno, R.; Gobbetti, E. Recovering 3D Indoor Floor Plans by Exploiting Low-cost Spherical Photography. In Pacific Graphics Short Papers; The Eurographics Association: Eindhoven, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Othman, K.; Rad, A. An indoor room classification system for social robots via integration of CNN and ECOC. Appl. Sci. 2019, 9, 470. [Google Scholar] [CrossRef]
- Balaska, V.; Bampis, L.; Boudourides, M.; Gasteratos, A. Unsupervised semantic clustering and localization for mobile robotics tasks. Robot. Auton. Syst. 2020, 131, 103567. [Google Scholar] [CrossRef]
- Sadeghi, F.; Tappen, M.F. Latent Pyramidal Regions for Recognizing Scenes. In Proceedings of the Computer Vision—ECCV 2012, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2021; pp. 228–241. [Google Scholar] [CrossRef]
- Erkent, O.; Bozma, I. Place representation in topological maps based on bubble space. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3497–3502. [Google Scholar] [CrossRef]
- Ranganathan, A. PLISS: Labeling places using online changepoint detection. Auton Robot 2012, 32, 351–368. [Google Scholar] [CrossRef]
- Parizi, S.N.; Oberlin, J.G.; Felzenszwalb, P.F. Reconfigurable models for scene recognition. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 2775–2782. [Google Scholar] [CrossRef]
- Sadovnik, A.; Chen, T. Hierarchical object groups for scene classification. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1881–1884. [Google Scholar] [CrossRef]
- Mozos, O.; Mizutani, H.; Kurazume, R.; Hasegawa, T. Categorization of Indoor Places Using the Kinect Sensor. Sensors 2012, 12, 6695–6711. [Google Scholar] [CrossRef] [PubMed]
- Juneja, M.; Vedaldi, A.; Jawahar, C.; Zisserman, A. Blocks That Shout: Distinctive Parts for Scene Classification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 923–930. [Google Scholar] [CrossRef]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. OTC: A Novel Local Descriptor for Scene Classification. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 377–391. [Google Scholar] [CrossRef]
- Zuo, Z.; Wang, G.; Shuai, B.; Zhao, L.; Yang, Q.; Jiang, X. Learning Discriminative and Shareable Features for Scene Classification. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 552–568. [Google Scholar] [CrossRef]
- Jie, Z.; Yan, S. Robust Scene Classification with Cross-Level LLC Coding on CNN Features. In Proceedings of the Computer Vision—ACCV 2014, Singapore, 1–5 November 2014; Cremers, D., Reid, I., Saito, H., Yang, M.H., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 376–390. [Google Scholar] [CrossRef]
- Mesnil, G.; Rifai, S.; Bordes, A.; Glorot, X.; Bengio, Y.; Vincent, P. Unsupervised Learning of Semantics of Object Detections for Scene Categorization. In Proceedings of the Pattern Recognition Applications and Methods, Lisbon, Portugal, 10–12 January 2015; Fred, A., De Marsico, M., Eds.; Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2014; pp. 209–224. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Dixit, M.; Chen, S.; Gao, D.; Rasiwasia, N.; Vasconcelos, N. Scene classification with semantic Fisher vectors. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2974–2983. [Google Scholar] [CrossRef]
- Pintore, G.; Garro, V.; Ganovelli, F.; Gobbetti, E.; Agus, M. Omnidirectional image capture on mobile devices for fast automatic generation of 2.5D indoor maps. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar] [CrossRef]
- Cruz, E.; Rangel, J.C.; Gomez-Donoso, F.; Bauer, Z.; Cazorla, M.; Garcia-Rodriguez, J. Finding the Place: How to Train and Use Convolutional Neural Networks for a Dynamically Learning Robot. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Simonsen, C.; Thiesson, F.; Philipsen, M.; Moeslund, T. GENERALIZING FLOOR PLANS USING GRAPH NEURAL NETWORKS. In Proceedings of the Proceedings—International Conference on Image Processing, ICIP, Anchorage, AK, USA, 19–22 September 2021; IEEE Computer Society: Washington, DC, USA; pp. 654–658. [Google Scholar] [CrossRef]
- Wei, Q.; Wei, Q.; Liu, Y.; Guan, Q.; Liu, D. Data-driven room classification for office buildings based on echo state network. In Proceedings of the the 27th Chinese Control and Decision Conference (2015 CCDC), Qingdao, China, 23–25 May 2015; pp. 2602–2607. [Google Scholar] [CrossRef]
- Shi, G.; Zhao, B.; Li, C.; Wei, Q.; Liu, D. An echo state network based approach to room classification of office buildings. Neurocomputing 2019, 333, 319–328. [Google Scholar] [CrossRef]
- Uršič, P.; Kristan, M.; Skočaj, D.; Leonardis, A. Room classification using a hierarchical representation of space. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1371–1378. [Google Scholar] [CrossRef]
- Turner, E.; Zakhor, A. Floor plan generation and room labeling of indoor environments from laser range data. In Proceedings of the 2014 International Conference on Computer Graphics Theory and Applications (GRAPP), Lisbon, Portugal, 5–8 January 2014; pp. 1–12. [Google Scholar]
- Turner, E.; Zakhor, A. Multistory floor plan generation and room labeling of building interiors from laser range data. In Proceedings of the Computer Vision, Imaging and Computer Graphics—Theory and Applications, Berlin, Germany, 11–14 March 2015; Springer: Berlin/Heidelberg, Germany, 2015; Volume 550, pp. 29–44, ISBN 9783319251165. [Google Scholar] [CrossRef]
- Ursic, P.; Leonardis, A.; Skocaj, D.; Kristan, M. Hierarchical spatial model for 2D range data based room categorization. In Proceedings of the Proceedings—IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 4514–4521. [Google Scholar] [CrossRef]
- He, X.; Liu, H.; Huang, W. Room categorization using local receptive fields-based extreme learning machine. In Proceedings of the 2017 2nd International Conference on Advanced Robotics and Mechatronics, ICARM 2017, Hefei and Tai’an, China, 27–31 August 2017; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2016; pp. 620–625. [Google Scholar] [CrossRef]
- Wu, H.; Tian, G.h.; Li, Y.; Zhou, F.y.; Duan, P. Spatial semantic hybrid map building and application of mobile service robot. Robot. Auton. Syst. 2014, 62, 923–941. [Google Scholar] [CrossRef]
- Hardegger, M.; Roggen, D.; Tröster, G. 3D ActionSLAM: Wearable Person Tracking in Multi-Floor Environments. Pers. Ubiquit. Comput. 2015, 19, 123–141. [Google Scholar] [CrossRef]
- Rojas Castro, D.; Revel, A.; Ménard, M. Document image analysis by a mobile robot for autonomous indoor navigation. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 156–160. [Google Scholar] [CrossRef]
- Loch-Dehbi, S.; Dehbi, Y.; Gröger, G.; Plümer, L. Prediction of Building Floorplans Using Logical and Stochastic Reasoning Based on Sparse Observations. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2016, 4, 265–270. [Google Scholar] [CrossRef]
- Dehbi, Y.; Loch-Dehbi, S.; Plümer, L. Parameter Estimation and Model Selection for Indoor Environments Based on Sparse Observations. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, 4, 303–310. [Google Scholar] [CrossRef]
- Loch-Dehbi, S.; Dehbi, Y.; Pl mer, L. Estimation of 3D indoor models with constraint propagation and stochastic reasoning in the absence of indoor measurements. ISPRS Int. J. Geo-Inf. 2017, 6, 90. [Google Scholar] [CrossRef]
- Dehbi, Y.; Gojayeva, N.; Pickert, A.; Haunert, J.H.; Plümer, L. Room shapes and functional uses predicted from sparse data. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2018, 4, 33–40. [Google Scholar] [CrossRef]
- Shahbandi, S.G.; Magnusson, M.; Iagnemma, K. Nonlinear Optimization of Multimodal Two-Dimensional Map Alignment With Application to Prior Knowledge Transfer. IEEE Robot. Autom. Lett. 2018, 3, 2040–2047. [Google Scholar] [CrossRef]
- Hu, X.; Fan, H.; Noskov, A.; Zipf, A.; Wang, Z.; Shang, J. Feasibility of using grammars to infer room semantics. Remote Sens. 2019, 11, 1535. [Google Scholar] [CrossRef]
- Zhou, R.; Lu, X.; Zhao, H.S.; Fu, Y.; Tang, M.J. Automatic Construction of Floor Plan with Smartphone Sensorsb. J. Electron. Sci. Technol. 2019, 17, 13–25. [Google Scholar] [CrossRef]
- Pronobis, A.; Jensfelt, P. Large-scale semantic mapping and reasoning with heterogeneous modalities. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 4–18 May 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3515–3522. [Google Scholar] [CrossRef]
- Kostavelis, I.; Charalampous, K.; Gasteratos, A. Online Spatiotemporal-Coherent Semantic Maps for Advanced Robot Navigation. In Proceedings of the 5th Workshop on Planning, Perception and Navigation for Intelligent Vehicles, in Conjunction with the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–8 November 2013. [Google Scholar]
- Hemachandra, S.; Walter, M.R.; Tellex, S.; Teller, S. Learning spatial-semantic representations from natural language descriptions and scene classifications. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2623–2630. [Google Scholar] [CrossRef]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place Categorization and Semantic Mapping on a Mobile Robot. arXiv 2015. Available online: http://arxiv.org/abs/1507.02428 (accessed on 28 April 2024).
- Kostavelis, I.; Charalampous, K.; Gasteratos, A.; Tsotsos, J.K. Robot navigation via spatial and temporal coherent semantic maps. Eng. Appl. Artif. Intell. 2016, 48, 173–187. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic maps from multiple visual cues. Expert Syst. Appl. 2017, 68, 45–57. [Google Scholar] [CrossRef]
- Liu, M.; Chen, R.; Li, D.; Chen, Y.; Guo, G.; Cao, Z.; Pan, Y. Scene Recognition for Indoor Localization Using a Multi-Sensor Fusion Approach. Sensors 2017, 17, 2847. [Google Scholar] [CrossRef]
- Luo, R.C.; Chiou, M. Hierarchical Semantic Mapping Using Convolutional Neural Networks for Intelligent Service Robotics. IEEE Access 2018, 6, 61287–61294. [Google Scholar] [CrossRef]
- Jin, C.; Elibol, A.; Zhu, P.; Chong, N.Y. Semantic Mapping Based on Image Feature Fusion in Indoor Environments. In Proceedings of the 2021 21st International Conference on Control, Automation and Systems (ICCAS), Jeju, Republic of Korea, 12–15 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 693–698. [Google Scholar] [CrossRef]
- Schäfer, J. Practical concerns of implementing machine learning algorithms for W-LAN location fingerprinting. In Proceedings of the 2014 6th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), St. Petersburg, Russia, 6–8 October 2014; pp. 310–317. [Google Scholar] [CrossRef]
- Laska, M.; Blankenbach, J.; Klamma, R. Adaptive indoor area localization for perpetual crowdsourced data collection. Sensors 2020, 20, 1443. [Google Scholar] [CrossRef]
- Peters, N.; Lei, H.; Friedland, G. Name That Room: Room Identification Using Acoustic Features in a Recording. In Proceedings of the 20th ACM International Conference on Multimedia. Association for Computing Machinery, MM’12, Nara, Japan, 29 October–2 November 2012; pp. 841–844. [Google Scholar] [CrossRef]
- Song, Q.; Gu, C.; Tan, R. Deep Room Recognition Using Inaudible Echos. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 135. [Google Scholar] [CrossRef]
- Au-Yeung, J.; Banavar, M.K.; Vanitha, M. Room Classification using Acoustic Signals. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Resuli, N.; Skubic, M.; Kovaleski, S. Learning Room Structure and Activity Patterns Using RF Sensing for In-Home Monitoring of Older Adults. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 2054–2061. [Google Scholar] [CrossRef]
- Dziwis, D.; Zimmermann, S.; Lübeck, T.; Arend, J.M.; Bau, D.; Pörschmann, C. Machine Learning-Based Room Classification for Selecting Binaural Room Impulse Responses in Augmented Reality Applications. In Proceedings of the 2021 Immersive and 3D Audio: From Architecture to Automotive (I3DA), Bologna, Italy, 8–10 September 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Walter, M.; Hemachandra, S.; Homberg, B.; Tellex, S.; Teller, S. Learning Semantic Maps from Natural Language Descriptions. In Proceedings of the Robotics: Science and Systems IX; Robotics: Science and Systems Foundation, Berlin, Germany, 24–28 June 2013. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Wang, Y.; Funk, N.; Ramezani, M.; Papatheodorou, S.; Popovic, M.; Camurri, M.; Leutenegger, S.; Fallon, M. Elastic and Efficient LiDAR Reconstruction for Large-Scale Exploration Tasks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2016; pp. 5035–5041. [Google Scholar] [CrossRef]
- Carrera, J.L.; Li, Z.; Zhao, Z.; Braun, T.; Neto, A. A Real-Time Indoor Tracking System in Smartphones. In Proceedings of the 19th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems. 151 Association for Computing Machinery, MSWiM’16, Malta, Malta, 13–17 November 2016; pp. 292–301. [Google Scholar] [CrossRef]
- Coughlan, J.; Yuille, A. Manhattan World: Compass direction from a single image by Bayesian inference. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; IEEE: Piscataway, NJ, USA, 2016; Volume 2, pp. 941–947. [Google Scholar] [CrossRef]
- Frasconi, P.; Costa, F.; De Raedt, L.; De Grave, K. kLog: A Language for Logical and Relational Learning with Kernels. Artif. Intell. 2014, 217, 117–143. [Google Scholar] [CrossRef]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Inductive Representation Learning on Large Graphs. arXiv 2018. [Google Scholar] [CrossRef]
- Du, J.; Zhang, S.; Wu, G.; Moura, J.M.F.; Kar, S. Topology Adaptive Graph Convolutional Networks. arXiv 2018. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017. [Google Scholar] [CrossRef]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. arXiv 2018. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2018. Available online: http://arxiv.org/abs/1905.11946 (accessed on 28 April 2024).
- Lin, K.S. Adaptive WiFi positioning system with unsupervised map construction. Electron. Comput. Eng. 2015, b1514560. [Google Scholar] [CrossRef]
- Ball, G.H.; Hall, D.J. Isodata, a Novel Method of Data Analysis and Pattern Classification; Stanford Research Institute: Menlo Park, CA, USA, 1965. [Google Scholar]
- Roth, S.D. Ray casting for modeling solids. Comput. Graph. Image Process. 1982, 18, 109–144. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [PubMed]
- Bastian, M.; Heymann, S.; Jacomy, M. Gephi: An Open Source Software for Exploring and Manipulating Networks. In Proceedings of the International AAAI Conference on Web and Social Media, San Jose, CA, USA, 17–20 May 2009; Volume 3, pp. 361–362. [Google Scholar]
- Zhu, B.; Fan, X.; Gao, X.; Xu, G.; Xie, J. A heterogeneous attention fusion mechanism for the cross-environment scene classification of the home service robot. Robot. Auton. Syst. 2024, 173, 104619. [Google Scholar] [CrossRef]
- Yang, L.; Ye, J.; Zhang, Y.; Wang, L.; Qiu, C. A semantic SLAM-based method for navigation and landing of UAVs in indoor environments. Knowl.-Based Syst. 2024, 293, 111693. [Google Scholar] [CrossRef]
- Shaharuddin, S.; Abdul Maulud, K.N.; Syed Abdul Rahman, S.A.F.; Che Ani, A.I.; Pradhan, B. The role of IoT sensor in smart building context for indoor fire hazard scenario: A systematic review of interdisciplinary articles. Internet Things 2023, 22, 100803. [Google Scholar] [CrossRef]
- Mahmoud, M.; Chen, W.; Yang, Y.; Li, Y. Automated BIM generation for large-scale indoor complex environments based on deep learning. Autom. Constr. 2024, 162, 105376. [Google Scholar] [CrossRef]
- Sommer, M.; Stjepandić, J.; Stobrawa, S.; Soden, M.V. Automated generation of digital twin for a built environment using scan and object detection as input for production planning. J. Ind. Inf. Integr. 2023, 33, 100462. [Google Scholar] [CrossRef]
- Zheng, Y.; Xu, Y.; Shu, S.; Sarem, M. Indoor semantic segmentation based on Swin-Transformer. J. Vis. Commun. Image Represent. 2024, 98, 103991. [Google Scholar] [CrossRef]
- Han, Y.; Zhou, Z.; Li, W.; Feng, J.; Wang, C. Exploring building component thermal storage performance for optimizing indoor thermal environment—A case study in Beijing. Energy Build. 2024, 304, 113834. [Google Scholar] [CrossRef]
- Pachano, J.E.; Fernández-Vigil Iglesias, M.; Peppas, A.; Fernández Bandera, C. Enhancing self-consumption for decarbonization: An optimization strategy based on a calibrated building energy model. Energy Build. 2023, 298, 113576. [Google Scholar] [CrossRef]
- Deng, M.; Fu, B.; Menassa, C.C.; Kamat, V.R. Learning-Based personal models for joint optimization of thermal comfort and energy consumption in flexible workplaces. Energy Build. 2023, 298, 113438. [Google Scholar] [CrossRef]
- Roumi, S.; Zhang, F.; Stewart, R.A.; Santamouris, M. Indoor environment quality effects on occupant satisfaction and energy consumption: Empirical evidence from subtropical offices. Energy Build. 2024, 303, 113784. [Google Scholar] [CrossRef]
- Sulaiman, M.H.; Mustaffa, Z. Using the evolutionary mating algorithm for optimizing the user comfort and energy consumption in smart building. J. Build. Eng. 2023, 76, 107139. [Google Scholar] [CrossRef]
- Wei, Y.; Du, M.; Huang, Z. The effects of energy quota trading on total factor productivity and economic potential in industrial sector: Evidence from China. J. Clean. Prod. 2024, 445, 141227. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Title | Description |
|---|---|---|
| EC1 | Published before 2012 | To keep the research up to date, the survey conducted was focused on the newest methodologies—from the last decade only. |
| EC2 | Duplicated article | As we searched multiple publication databases, the same article could be found in many different sources but was supposed to be analyzed only once. |
| EC3 | Not written in English | English was chosen as the only accepted language. It was important to check the whole paper, as it happened to find results with English titles and abstracts but foreign language content. |
| EC4 | Not concerning a topic, at least potentially related to the room segmentation or classification | Although we used a precise search query, the found papers’ relevance was not guaranteed. We checked them manually and verified if the general topic of the article discussed floor plan analysis, spatial data processing methods, or at least an issue that could lead to room segmentation in any different type of data. |
| EC5 | Full text not found | Reliable paper analysis requires the publications to be read and understood. Titles or abstracts alone were not enough. |
| EC6 | Does not describe the process in detail | Papers without a precise description of the methodology used were rejected. The presentation of only the research results was not enough to fully answer the research questions. |
| EC7 | Describes only ideas, discussions, or interviews | The objective of this study was to include publications of substantial value and precise descriptions of the papers. They were required to be implemented reliably, tested, and their results had to be available. |
| IC1 | The topic must indicate the, at least potential, use in the indoor environment | This paper focuses on closed spaces, which can segment rooms inside of a building, not areas outside of it. This criterion filtered out solutions dedicated to large-scale outdoor applications, like the analysis of aerial photos. |
| IC2 | Method must include some form of automated processing | The idea is to compare systems of somehow unsupervised data processing. Descriptions of fully manual processes, design guidelines, or manually carried out reports were omitted. |
| IC3 | Article must reference at least 10 other papers | As the survey should be based only on reliable and scientifically important articles, analyzed papers were expected to be based on at least ten reviewed references. |
| IC4 | Solution must process room—or higher structure—level data | We want to filter out solutions focused on internal single-room analysis. An example of such a scenario was the furniture segmentation task or wall décor recognition. To fulfill this criterion, the algorithm had to be able to segment at least one instance of a room or one class for the whole room needed to be recognized. |
| IC5 | Article must describe the achieved performance and datasets used | Only papers with reliable results presentations were accepted. To fulfill this criterion, a description of the performance evaluation method had to be presented. The public availability of the datasets was not required, but their description was. |
| Input Data Type | Subtype | Found Papers |
|---|---|---|
| 3D Spatial Data (68 + 3) | - | [8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78] |
| Graph Structure (5 + 2) | - | [79,80,81,82,83,84,85] |
| 2D Images (51 + 36) | Floor Plan / Sketch (26 + 15) | [86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126] |
| Occupancy Map (17 + 6) | [1,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148] | |
| Environment Picture (8 + 15) | [149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,170,171] | |
| Feature set (25 + 9) | CAD-Like Data (1 + 0) | [172] |
| Energy Consumption (2 + 0) | [173,174] | |
| Laser Range Measurements (5 + 0) | [175,176,177,178,179] | |
| Mixed (10 + 9) | [180,181,182,183,184,185,186,187,188,189,190,191,192,193,194,195,196,197,198] | |
| Radio Signal Fingerprint (2 + 0) | [199,200] | |
| Sound echo, chirp, RF (5 + 0) | [201,202,203,204,205] |
| High-Level Solution Category | ||||
|---|---|---|---|---|
| Data Type | Segmentation | Segmentation + Simplified Classification | Segmentation + Precise Classification | Precise Classification |
| Floor Plan/Sketch | [86,87,88,90,91,92,93,94,95,96,97,103,108,113,116,118,120,121,122,124,125] | [102,106,110,126] | [89,98,99,100,101,104,105,107,109,111,112,114,115,117,119,123] | - |
| Occupancy Map | [1,129,130,131,132,134,135,137,138,139,142,145,146,148] | [127,128,133,136,140,141,143,144,147] | - | - |
| Environment Picture | [151,153,154,170] | - | [156] | [149,150,152,155,157,158,159,160,161,162,163,164,165,166,167,168,169,171] |
| 3D Spatial | [8,9,10,11,12,13,14,16,17,18,19,20,21,23,25,26,27,28,29,30,31,32,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,51,52,53,54,55,57,58,59,60,61,62,63,64,65,66,67,68,70,71,74,75,76,77] | - | [22,24,33,50,56,69,78] | [15,72,73] |
| Laser Range Measurement | [176,177] | - | - | [175,178,179] |
| Mixed | [181,182,183,184,185] | [189] | [180,187,190,191,192,193,194,195,197,198] | [186,188,196] |
| Radio Signal Fingerprint | [200] | - | [199] | - |
| Sound Echo, Chirp, RF | [204] | - | - | [201,202,203,205] |
| CAD-Like Data | - | [172] | - | - |
| Graph | - | - | [79,80,82,83] | [81,84,85] |
| Energy | - | - | - | [173,174] |
| Processed Data Type | |||||
|---|---|---|---|---|---|
| Task | Section | 3D Spacial Data | 2D Images | Graph Structure | Feature Set |
| 3D Model Reconstruction | Section 5.1.1 | [9,10,11,12,17,18,20,21,23,26,27,28,29,30,35,36,42,45,46,47,48,49,51,52,54,55,57,60,61,63,64,74,75,76] | [94,110,111,116,154] | - | [195] |
| CBIR | Section 5.1.2 | - | [97,98,114] | - | - |
| Environment Desc. Creation | Section 5.1.3 | - | [90,95,96,99,103,107,115,119] | - | - |
| Floor Plan Vectorization | Section 5.1.4 | - | [104,117,120,122] | - | - |
| Floor Plan Predict./Gen. | Section 5.1.5 | [8,25,31,33,37,44,53,58,62,68,71,78] | [89,151,153,170] | [79,83] | [77,172,176,177,183,184,185,189,204] |
| Graph Generation | Section 5.1.6 | [13,14,19,67] | [138,139] | [80,82] | [180,190,191,194] |
| Room Classification | Section 5.1.7 | [15,73] | [143,149,150,152,155,157,158,159,160,161,162,163,164,165,166,167,168,169] | [81,84,85] | [173,174,175,178,179,186,188,201,202,203,205] |
| Change Detection | Section 5.1.8 | [43] | - | - | - |
| Map Segmentation | Section 5.1.9 | [50] | [1,82,127,128,135,136,140,141,142,144,145,146,147] | - | [192,193,197,198,206] |
| Plan Segmentation | - | [86,87,88,91,100,101,102,105,106,108,109,112,113,118,121,123,124,125,126] | - | - | |
| Point Cloud Segmentation | [16,32,34,38,39,41,59,65,66,69,207,208] | - | - | - | |
| VR/AR | Section 5.1.10 | [40] | - | - | - |
| Robot Expl./Localization | - | [129,131,132,134,156,171] | - | [182] | |
| Path Planning | [70] | [133] | - | - | |
| Localization | [22,56] | [93] | - | [24,181,196,199,200,209] | |
| Map Alignment/Matching | Section 5.1.11 | - | [187] | - | [130,148] |
| Plan Alignment/Matching | - | [92] | - | - | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pokuciński, S.; Mrozek, D. Methods and Applications of Space Understanding in Indoor Environment—A Decade Survey. Appl. Sci. 2024, 14, 3974. https://doi.org/10.3390/app14103974
Pokuciński S, Mrozek D. Methods and Applications of Space Understanding in Indoor Environment—A Decade Survey. Applied Sciences. 2024; 14(10):3974. https://doi.org/10.3390/app14103974
Chicago/Turabian StylePokuciński, Sebastian, and Dariusz Mrozek. 2024. "Methods and Applications of Space Understanding in Indoor Environment—A Decade Survey" Applied Sciences 14, no. 10: 3974. https://doi.org/10.3390/app14103974
APA StylePokuciński, S., & Mrozek, D. (2024). Methods and Applications of Space Understanding in Indoor Environment—A Decade Survey. Applied Sciences, 14(10), 3974. https://doi.org/10.3390/app14103974