1. Introduction
In the contemporary era, the exponential proliferation of multimedia content has led to a precipitously rising interest in the domain of multimodal data interpretation among academic scholars. This discipline encompasses the evaluation of data through diverse channels, such as visual and textual streams [
1,
2,
3]. A pivotal and emergent subfield in this realm is the study of multimodal emotional analysis, which involves deciphering human sentiments as manifested across diverse communication modalities. This avenue of innovation has witnessed escalating momentum within the scholarly domain over the past few years. Multimodal frameworks endorse an interactive paradigm that emulates human dialogue by permitting the concurrent utilization of multiple data ingestion and emission channels. The liberty to opt for an array of these modalities cultivates a more anthropomorphic dialogue experience, enhancing user immersion and communication efficacy. A significant body of scholarly work has been dedicated to exploring sentiment discernment in the written content [
4,
5], facial affective interpretation [
6,
7], and auditory emotional cognition [
8,
9]. Nevertheless, scrutiny of these outcomes indicates that inquiries centered on singular modes have encountered a particular impasse, prompting amplified scholarly interest in the utilization of multimodal methodology. Amalgamating ancillary data from pictorial and textual sources can augment the fidelity of affective discernment, and thus foster the evolution of machines equipped with empathic faculties. The domain of multimodal affective identification encompasses an extensive array of implementations such as human–machine interfacing, automated detection systems, intelligent playthings, protective mechanisms, service dispensation, and linguistic transposition. Within the realm of multimodal emotion recognition, the paramount phases encompass the derivation of distinguishing attributes and the amalgamation of these elements across diverse modalities. The objective of attribute derivation is to discern the vital constituents of signals, formulate vector representations predicated on these constituents, and employ them to classify pertinent emotions. This process streamlines the subsequent phases of the emotion discernment task [
10]. Prior investigations typically derived features intrinsic to each modality, such as lexical representations from textual data [
11], temporal acoustic attributes from vocal utterances [
12], and visual cues from facial imagery [
13]. Existing extraction methodologies include techniques such as Fourier transformation, wavelet transformation, and high-order cross processes, which can be collectively categorized as low-level feature extraction methods. However, given the dichotomy between human affective states and low-level attributes, these extraction strategies may not be adequately robust for multimodal emotion identification. Conversely, deep learning methodologies can detect the dispersion attributes of datasets by integrating basal characteristics, thereby constructing a more abstract, superior-level portrayal of information. Furthermore, multimodal amalgamation, which entails merging data obtained from various channels, profoundly affects the efficiency and outcomes of multimodal emotional discernment [
14,
15]. This amalgamation procedure provides supplementary data, consequently improving the fidelity of emotional identification. Therefore, conceptualizing a more advanced fusion strategy is imperative to yield a superior optimized discriminative feature representation for multimodal emotion recognition.
Emotional expressions often manifest as distinct energy patterns in spectrograms, particularly in auditory formats like speech. These patterns display specific distributions of energy across different frequencies, making them identifiable when analyzed through spectrograms. Convolutional neural networks (CNNs) are particularly adept at emphasizing areas in the data that exhibit high energy levels or sudden transitions. This capability is advantageous for emotion analysis, as CNNs effectively capture emotions that appear rapidly and with marked intensity. Such focused analysis enables the model to discern between subtle and robust emotional cues, which is crucial in situations where emotions may intensify suddenly or peak briefly, thus ensuring a thorough understanding of the emotional landscape.
Text also serves as a crucial medium for expressing and deciphering emotions. Unlike spoken words and physical expressions that often provide direct emotional cues, written language offers nuanced indicators through word choice, phrasing, and punctuation, enabling authors to convey a wide spectrum of emotions, from joy and excitement to sadness and despair. However, a major challenge in developing text-based models is the need for extensive, relevant data. The effectiveness and accuracy of these models depend heavily on the availability and accessibility of large, task-specific datasets. The greater the dataset’s size and diversity, the more effectively the model can generalize and adapt to real-world scenarios.
To address this challenge, the application of transfer learning and/or the utilization of pre-trained models have emerged as promising solutions. These techniques leverage the knowledge gained from one task and apply it to a related task, potentially reducing the need for extensive datasets specific to each challenge.
Our study introduced a multimodal emotion-recognition system that combines speech and text data. First, a speech module was crafted using CNNs to extract patterns from the mel spectrograms, to produce a fully connected (FC) layer. This method excels in revealing intricate details in the time and frequency domains.
Next, we employed a pre-trained BERT-based model for our text component. BERT’s 12-layer bidirectional structure offers a profound understanding of textual semantics. Leveraging BERT’s extensive training on large-scale datasets allows for a more enriched emotional representation. Post-BERT processing involved an FC layer for reducing dimensionality, a Bi-GRU for contextual understanding, and another FC layer to link features to specific emotions. These refined outputs were fed into our fusion module, thereby strengthening our emotion-detection mechanism.
Finally, the fusion process involves an attention-based mechanism to balance the speech and text contributions. It allocates attention scores, prioritizing the most pertinent modality based on the context. We standardized the feature dimensions using an FC layer for unbiased attention allocation. The consolidated features were then passed through a softmax layer to classify the embedded emotion, ensuring comprehensive emotion analysis. This study introduced several vital contributions that deserve special emphasis. The research:
Unveiled an innovative multimodal emotion-detection method that surpassed the precision of prevailing benchmark models. This groundbreaking technique will facilitate future studies on emotion detection;
Innovatively leveraged convolutional neural networks and a fully connected layer to extract mel spectrogram features, offering enhanced accuracy and bridging the divide between raw speech and emotional nuances;
Employed a pre-trained BERT-based model to encode textual data effectively, capitalizing on its bidirectional transformer encoders to capture context-rich semantic information;
Employed an attention-based fusion mechanism for a bimodal system that emphasizes speech and text, dynamically prioritizes modalities, standardizes feature vectors, and utilizes multistage processing to enhance sentiment classification accuracy.
Conducted comprehensive tests on two benchmark datasets, CMU-MOSEI and MELD, where the outcomes clearly highlighted the superior performance of our approach in emotion recognition.
This article is arranged as follows.
Section 2 provides a summary of pertinent research in the realm of multimodal emotion recognition.
Section 3 describes the overall scheme of the proposed model.
Section 4 presents an exhaustive account of the dataset used in the experiment, accompanied by the results and essential analyses, and the model’s efficacy is discussed. Finally, the conclusions are presented.
3. Proposed Multimodal Emotion-Recognition Approach
Figure 1 illustrates how the proposed method harnesses the potential of both the speech and text modalities for emotion recognition. This approach acknowledges the rich and complex information conveyed through spoken words, as well as the nuanced meanings captured in written text. By integrating these modalities, the method aims to achieve a more comprehensive and accurate understanding of emotional states. It leverages the strengths of both the speech and text analyses, potentially improving the efficacy of emotion-recognition systems. Specifically, emotional expressions extracted from both text and speech are introduced into a fusion module. The output derived from the fusion module is subsequently introduced into an FC layer. This step allows the consolidation of high-dimensional multimodal features. The final part of this process includes the application of a softmax layer, which computes the probabilities corresponding to different emotions. Each component of the emotion-recognition pipeline is explored in detail in the following subsections.
3.1. Speech Module
To leverage the benefits of mel spectrogram features, our speech module includes a series of convolutional neural networks preceding a fully connected layer. This design captures the intricate patterns within the mel spectrogram, and for enhanced performance and accuracy, ensures that the convolutional layers effectively extract the spatial characteristics, which are then synthesized in the fully connected layer. Specifically, we drew inspiration from the work outlined in [
31], and adapted the architecture by implementing changes tailored to our objectives. This allowed us to build on established ideas while incorporating our unique modifications to better suit the needs of the proposed multimodal emotion-recognition approach.
Figure 2 presents an in-depth depiction of the speech module architecture.
Initially, we utilized the “Librosa” library [
32] to procure the mel spectrogram features from the raw speech data. The extracted features were then channeled into two distinct convolutional layers that ran concurrently. These layers are specifically designed to capture and highlight patterns from both the time and frequency domains, ensuring a comprehensive analysis of the audio signal characteristics. We employed two simultaneous convolutional layers as our initial layers, with kernel sizes of (10, 2) and (2, 8). After padding, the output from each convolutional layer yielded eight channels. The outputs were merged, resulting in a combined 16-channel representation for further processing. Subsequently, four additional convolutional layers were employed to produce an 80-channel representation, which was forwarded to the fully connected layer for further analysis and processing. Following each convolutional layer, we incorporated a batch normalization (BN) layer coupled with a rectified linear unit (ReLU) activation function to enhance the stability and performance of the network. Moreover, convolutional layers 1 and 2 preceded a max-pooling operation with a kernel size of two that reduced data dimensionality and further streamlined processing.
Throughout these convolutional layers, the kernel size remained consistent at 3 × 3 with a stride of one. However, as we progressed from convolutional layers 1 and 4, the number of input channels started at 16 and doubled, subsequently increasing in increments of 16, ultimately reaching 80 output channels in convolutional layer 4. This structured increment in channels suggests a hierarchical feature extraction process, wherein each subsequent layer aims to extract more complex and nuanced features from the input.
3.2. Text Module
The origin of textual modality can be traced back to the process of transcribing uttered speech. This involves converting spoken words into written forms, thereby creating a textual representation that can be easily analyzed and interpreted. This is a crucial step in the data-preparation phase for emotion recognition and other natural language processing tasks. Using a written transcript of spoken language, various text analysis techniques can be applied to extract meaningful features such as sentiment, tone, and other linguistic characteristics that could indicate emotional states. This extends our ability to understand and analyze the emotions expressed through the tone and inflection of speech and the choice of words and phrases, their arrangement, and other textual elements. Several strategies have been used to extract features from textual modalities. In the proposed approach, we employ a series of techniques, as depicted in
Figure 3.
Specifically, our methodology is initiated by utilizing a pre-trained BERT-based model [
17] to encode textual data. The BERT-based model comprises 12 layers of transformer encoders. These transformer encoders are exceptional since they allow the consideration of context from both directions; that is, left-to-right and right-to-left, for every layer of the model. The bidirectional nature of transformer encoders aids in capturing context more effectively, thereby providing a robust and nuanced understanding of a text’s semantic meaning. It is worth noting that by leveraging a pre-trained BERT-based model, we gained from the model’s extensive learning previously undergone on a massive corpus of text. This helps generate more meaningful and accurate representations of our textual data, which is especially beneficial when dealing with complex emotion-recognition tasks. In essence, using the pre-trained BERT-based model for text encoding sets a strong foundation for our proposed approach, offering the capacity to extract valuable insights from the text, thereby significantly improving the proposed emotion-recognition system’s performance.
After leveraging the BERT-based model, an FC layer was used. This layer simplifies the BERT-generated high-dimensional vectors into 100 dimensions, creating compact yet effective representations termed the utterance features of the text modality. This process aids in managing computational complexity and overfitting, while retaining essential textual information, serving as a robust basis for emotion-recognition analysis. After feature reduction, a bidirectional gated recurrent unit (Bi-GRU) was used to encode all utterances, capturing past and future dialogue information. Such bidirectional processing bolsters the model’s understanding of the context within a conversation. The Bi-GRU hidden states were set to 100 dimensions, in line with our prior feature reduction, ensuring consistency and capturing vital temporal and contextual dialogue information. After processing through the Bi-GRU layer, the resulting outputs were fed into the FC layer. This layer functioned as a translator, converting high-level features into dimensions representing different emotional categories. This was a critical bridge linking the complex features generated by the Bi-GRU to various emotion classes, thereby boosting the efficacy of our emotion-recognition system. The output generated from the FC layer was channeled into the fusion module.
To train the text module in our emotion-recognition system, we followed a robust approach. This involved running 300 epochs with 30 data batches. To prevent overfitting, we applied a dropout of 0.3 and L2 regularization with a weight of 0.0001. For efficient training, we used the Adam optimizer with an initial learning rate of 0.0005, which decayed at a rate of 0.0001.
3.3. Fusion Module and Classification
When classifying sentiments, not every modality contributes relevance or significance to the same degree. Different modalities such as text, speech, and facial expressions offer unique aspects of emotional insight. However, their contributions to sentiment classification vary significantly. Some may have a more pronounced influence, whereas others may make only subtle contributions. This discrepancy arises because of the inherent differences in the types of information that these modalities encapsulate, as well as the varying capacities with which they express emotional cues. Therefore, when designing a multimodal system for sentiment classification, accounting for the diverse significance levels of the different modalities and strategically balancing their integration to achieve optimal performance is crucial.
In the fusion module of our proposed multimodal emotion-recognition approach, we incorporated an attention-based fusion mechanism, as outlined in existing research [
33]. This sophisticated approach allowed our system to assign varying degrees of importance to different modalities during the fusion process. The intention is to focus more heavily on the modalities that are considered most significant for a given context or dataset. This strategic prioritization helps refine the system output, enabling it to yield more accurate and contextually appropriate results in sentiment classification tasks. The research outlined in [
33] incorporated three distinct modalities—audio, visual, and textual—to generate an attention score for each modality and determine its relevance to the final output. In contrast, our approach operates on a bimodal system, focusing solely on speech and text modalities. Despite this, our model effectively assigned attention scores to each of these two modalities, allowing for the dynamic allocation of significance based on their inherent contributions to the emotion-recognition task.
Before inputting the feature vectors from the speech and text modalities into the attention network, their dimensions were uniform. This was accomplished using an FC layer of size n. By implementing this layer, we could effectively transform feature vectors into equal dimensions, thereby ensuring that each modality was represented equally when processed in the attention network. This step was vital for maintaining fairness and balance in the allocation of attention weights between the two modalities.
Consider
as the standardized feature set, where “
” represents the acoustic features, and “
” denotes the textual features. Here, the dimensionality of each feature set has been equalized to size “n”, resulting in “F” belonging to the dimensional space
. Optimal performance was achieved when the value o of n was set to 250. The attention weight vector, denoted as
, and the fused multimodal feature vector, referred to as
, were calculated using the following procedures:
where
,
,
, and
. The resulting output, denoted as
, signified the combined multimodal feature vector. This composite representation was then processed through a fully connected layer, which acted as an intermediary step to consolidate the high-dimensional multimodal features to be more manageable. Subsequently, a softmax layer was employed to finalize the speech emotion classification task. The softmax layer worked by outputting a probability distribution over predefined emotional categories, thus determining the most likely emotion to be present in the speech. This multistage process ensured a thorough evaluation of multimodal features, and effectively identifies nuanced emotional content within a given speech input.
4. Results and Discussion
4.1. Datasets
To validate the efficacy of the proposed model, two well-established datasets, namely, MELD MELD [
34] and CMU-MOSEI [
35], were employed. These datasets, which are rich in multimodal emotional content, provide a comprehensive foundation for evaluating a model’s proficiency in multimodal emotion-recognition tasks. Further details regarding the characteristics of these datasets and their contributions to the assessment of the model are discussed below.
4.1.1. MELD
MELD is a large-scale multimodal dataset specifically designed to enhance emotion-recognition research. Developed by refining and augmenting the EmotionLines dataset, MELD includes data from various modalities such as text, audio, and visual cues, which are further associated with six different emotional categories.
The MELD dataset is unique since it is derived from the popular television series, “Friends”. This source provides real-life conversations among multiple speakers, which are inherently dynamic and rich in emotional expressions. The dataset includes a large number of dialogue instances, capturing over 1400 items of dialogue and 13,000 utterances from the series.
Each utterance in the MELD dataset is annotated using emotion and sentiment labels. The six emotions are anger, disgust, joy, sadness, surprise, and neutrality as depicted in
Figure 4. The dataset also contains sentiment labels, such as positive, negative, and neutral.
4.1.2. CMU-MOSEI
The CMU-MOSEI dataset is an extensive multimodal compilation of conversational video data dedicated to emotion recognition. This dataset includes more than 23,000 video fragments extracted from 1000 distinct sessions involving over 1200 contributors. The video entries are accompanied by speech transcripts, auditory and visual characteristics, and labels signifying varying degrees of valence and arousal. The CMU-MOSEI dataset classifies emotions into six categories: anger, happiness, sadness, disgust, fear, and surprise. The dataset encompasses a wide variety of emotional samples: anger (4600), sadness (5601), disgust (3755), surprise (2055), happiness (10,752), and fear (1803) as depicted in
Figure 5. This variety ensures a comprehensive representation of emotional states, facilitating a more robust and accurate analysis in subsequent emotion-recognition studies.
4.2. Implementation Configuration
Our model outcomes are represented using the Accuracy and F1-score metrics on the CMU-MOSEI dataset and the WA and WF1-score metrics on the MELD dataset, owing to the inherent disparity among different emotions [
34,
36].
The weighted accuracy, which is identical to the mean recall across all emotion categories, provides an understanding of the model’s performance considering the imbalance between different classes.
To evaluate our model fairly and objectively using the MELD and CMU-MOSEI datasets, we employed a robust training procedure, as explained in [
37]. This involved restructuring the original datasets and subsequently dividing the data into training and testing subsets (
Table 1), allocating 80% of the data for training and 20% for testing.
This methodology ensured a comprehensive and detailed evaluation of the performance of the proposed model. This procedure yielded 10,676 training samples and 2674 testing samples from the MELD dataset. Similarly, for the CMU-MOSEI dataset, 22,851 training and 5715 testing samples were obtained. Unlike the methodology outlined in [
38], we did not implement 10-fold cross-validation in our study. This choice was driven by the practical complications associated with deploying cross-validation on deep-learning models, considering the extensive time and computational resources required.
The proposed model was subjected to an extensive training and testing regimen of over 300 epochs using batches of 32. To execute these deep learning tasks efficiently we used an Nvidia GeForce RTX 3090, Nvidia, Santa Clara, CA, USA, 24 GB graphics processing unit coupled with an Intel Core i7-13700K 10-Core Processor, Intel, Santa Clara, CA, USA. The Ubuntu platform was complemented by 128 GB of RAM, and this provided a robust and high-performance computational environment for model training and evaluation.
4.3. Recognition Performances
In multimodal emotion recognition, several studies have used various datasets and modalities to evaluate the effectiveness of their methodologies. A crucial aspect of these evaluations lies in performance metrics such as accuracy and F1-score, which provide insights into their efficacy and reliability.
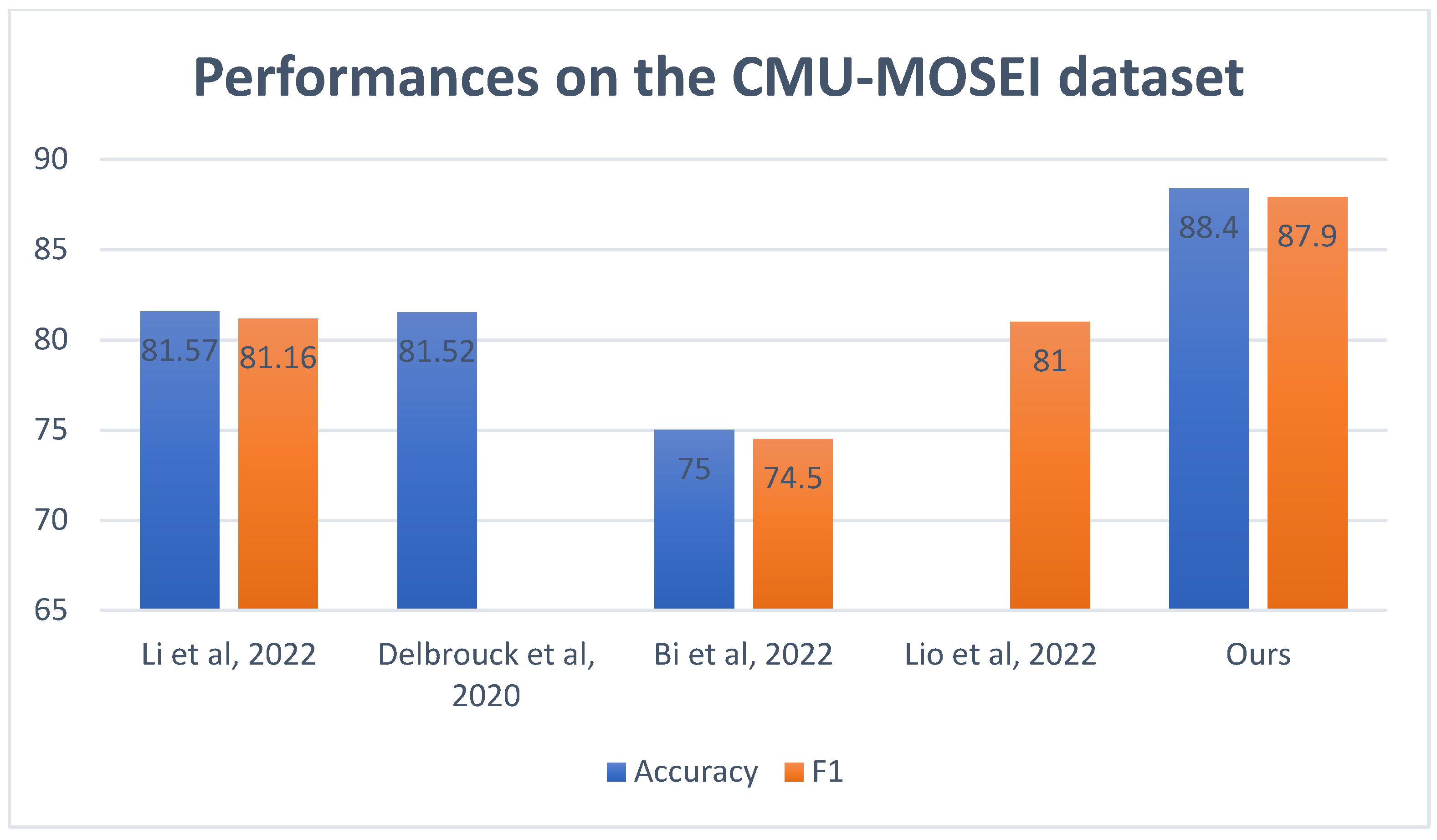
Table 2 and
Figure 6 present a comparative analysis of emotion-recognition studies using multimodal data. Focusing on the performance metrics of the Accuracy and F1-score, we observed a range of results. Li et al. [
39] reported a commendable accuracy of 81.57% and an F1-score of 81.16%. Close on its heels came Delbrouck et al. [
40] with an accuracy of 81.52%, though their F1-score is not provided. A slight dip is seen in Bi et al. [
41], who recorded an accuracy of 75.0% and an F1-score of 74.5%. Lio et al. [
24] only offered an F1-score of 81.0%, omitting accuracy data. Remarkably, our method, denoted as Ours, outperforms the referenced studies with an accuracy of 83.2% and an F1-score of 82.9%. Moreover, training and validation Loss (a) and accuracy (b) performances on the CMU-MOSEI dataset were illustrated in the
Figure 7. This suggests that our methodology is competitive, and also potentially sets a new benchmark in the realm of emotion recognition using the specified modality.
Following our earlier evaluation of the CMU-MOSEI dataset, we further expanded our comparative analysis to include the results of the MELD dataset, another key benchmark in the domain of emotion recognition. This additional comparison is vital to ensure the robustness and adaptability of the proposed system across diverse datasets.
Table 3 and
Figure 8 present the performance metrics of various studies on the MELD dataset. Each of these studies consistently employs the “Speech + Text” modality. Guo et al. [
11] developed a list with a WA of 54.79% and WF1 of 48.96%. Interestingly, while Soumya et al. [
42] and Sharma et al. [
43] only disclosed their WF1 scores at 65.8% and 53.42%, respectively, Lian et al. [
44] presented a more comprehensive result with a WA of 65.59% and a WF1 of 64.50%. Significantly, our approach surpasses these metrics with a leading WA of 66.81% and WF1 of 66.12%. Moreover, training and validation Loss (a) and accuracy (b) performances on the MELD dataset were illustrated in the
Figure 9. This further consolidation of the MELD dataset underscores the efficiency and superiority of the proposed methodology for multimodal emotion recognition.
4.4. Discussion
In this study, we introduced a multimodal emotion-recognition approach that leverages both the speech and text modalities to better understand emotional states. From the experiments and results presented, several key insights emerged that provide a comprehensive understanding of the potential and efficacy of the proposed model.
Our multimodal emotion-recognition system is designed with an advanced architecture that integrates convolutional neural networks (CNNs) for processing mel spectrograms in the speech module and a pre-trained BERT model for the text module. This approach provides a significant advantage by extracting crucial temporal, frequency, and semantic features essential for a nuanced understanding of emotional expressions. The CNNs in the speech module utilize specific kernel sizes to capture a broad range of acoustic properties effectively, while the 12-layer bidirectional structure of BERT analyzes textual context from both directions, ensuring deep semantic comprehension.
Further enhancing our model, hierarchical feature processing is employed within both modules. In the speech module, the layer-by-layer refinement of features through increasing channel numbers allows for the detailed extraction of acoustic signals. Similarly, in the text module, features processed by BERT are dimensionally reduced and contextually enriched through subsequent layers, including a fully connected layer and a Bi-GRU, optimizing the use of textual information for emotion recognition.
The fusion of these processed features is managed by a dynamic attention-based mechanism, which adjusts the contributions of each modality based on their relevance to the current context. This not only improves the system’s accuracy but also its adaptability, as the attention mechanism prioritizes modalities dynamically, enhancing performance in complex scenarios. Additionally, standardizing feature dimensions prior to fusion ensures equitable treatment of modalities, preventing bias and maintaining balance in attention allocation.
Robust training protocols further strengthen the system, involving 300 epochs with strategic dropout and L2 regularization to prevent overfitting, thereby enhancing the model’s generalizability and performance. This rigorous training approach maximizes the advantages offered by our sophisticated model design, ensuring that the system is capable of performing emotion recognition with exceptional accuracy and sensitivity to context.
This architecture, coupled with strategic feature processing and dynamic modality fusion, positions our emotion-recognition system at the forefront of technological advancements, offering a powerful tool for accurately deciphering complex emotional states from multiple data sources.
While the integration of these sophisticated models provides a robust framework for emotion recognition, it introduces substantial complexity and computational demands. This complexity can hinder real-time application and scalability, particularly in environments lacking extensive computational resources. Additionally, the reliance on large, annotated datasets for training these advanced models can limit their applicability in scenarios where such data are scarce.
Compared to existing works, which may rely on simpler or unimodal approaches, our system achieves superior accuracy and contextual sensitivity but at the cost of increased computational overhead and data dependency. For example, traditional systems might use simpler statistical techniques or shallow learning models that, while less computationally intensive, fail to capture the depth of emotional context provided by our CNN and BERT-based architecture.
As we aim to enhance the capabilities of our multimodal emotion-recognition system, addressing its current limitations is essential. Future research should focus on optimizing the model to reduce computational demands, enabling real-time processing and making the system suitable for deployment on devices with limited computational capabilities. Techniques such as model distillation or the development of lightweight versions of BERT could maintain high accuracy while reducing resource requirements. Additionally, integrating additional modalities such as physiological signals [
45] and facial expressions could enrich the emotion-recognition process. This expansion would involve developing new fusion techniques capable of effectively handling the complexity and diversity of data from these sources. Another critical area of focus is improving data efficiency by reducing dependency on large, annotated datasets. Exploring methods like transfer learning, few-shot learning, and synthetic data generation could enhance the system’s robustness and facilitate its application in data-scarce environments. Finally, adapting the system for specific emotional recognition tasks tailored to different cultural contexts or specialized domains requires flexible and scalable model configurations. Investigating modular approaches and domain-specific adaptations will enable more targeted and effective emotion recognition, enhancing the system’s utility across various global and professional settings. By pursuing these strategic areas, our research will not only overcome existing challenges, but also expand the practical utility and reach of our emotion-recognition system, ensuring it continues to lead in the field of affective computing.
5. Conclusions
In this study, we delved deeply into a multimodal approach, consolidating speech and text, to develop a potent and efficient emotion-recognition system. The robust architecture, from convolutional neural networks for speech to the pre-trained BERT-based model for text, ensures a comprehensive analysis of inputs. Our attention-based fusion mechanism stands out, demonstrating its ability to discern and weight the contributions from each modality. As emotion recognition evolves, methodologies such as ours will facilitate future innovations, showcasing the potential for multimodal integration. Although our system has garnered commendable outcomes on the CMU-MOSEI and MELD datasets, it has certain limitations. First, although using a pre-trained model provides the advantage of leveraging extensive training on a vast corpus of text, it may not always perfectly align with specific domain requirements. Certain nuances or domain-specific emotional cues in a dataset may not be captured efficiently. Second, the system design incorporates several layers, including convolutional layers, transformer encoders, FC layers, and attention mechanisms. This complexity can introduce significant computational demands that may not be feasible for real-time applications or systems with limited computational resources. Therefore, this study paves the way for numerous potential avenues for future research. Thus, future studies should design lightweight architectures or employ model quantization and pruning techniques to render the system feasible for real-time applications. Moreover, we aim to develop models that recognize cultural nuances in emotional expressions to ensure that they are universally applicable.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}