


FAPR: An Adaptive Approach to Link Failure Recovery in SDN with High Speed and Low Interruption Rate

Abstract
:1. Introduction
- (1)
- FAPR adopts the proactive link failure recovery scheme to ensure fast recovery speed after link failures. The recovery time required by our proposed scheme is reduced by compared with the purely reactive scheme.
- (2)
- FAPR uses the reactive link failure recovery scheme to promise high usability of backup paths. More specifically, it pre-calculates and stores backup paths for network links to reduce a portion of the calculation latency after link failures, and optimizes backup paths before they are dispatched to minimize unnecessary resource consumption.
- (3)
- FAPR analyzes characteristics of the affected flows and allocates suitable paths from the stored backup paths, reducing the possibility of blockage or interruption in the subsequent forwarding process. Specifically, the interruption rate of flows after failure recovery is reduced by and compared with the reactive and proactive schemes, respectively. As a result, this helps to improve the quality of network services.
2. Related Work
2.1. Proactive Approaches
2.2. Reactive Approaches
3. Motivation
3.1. Concept of Flow
3.2. Analysis of Two Classical Schemes
3.3. Proposed Scheme
4. Design of Proposed Scheme: FAPR
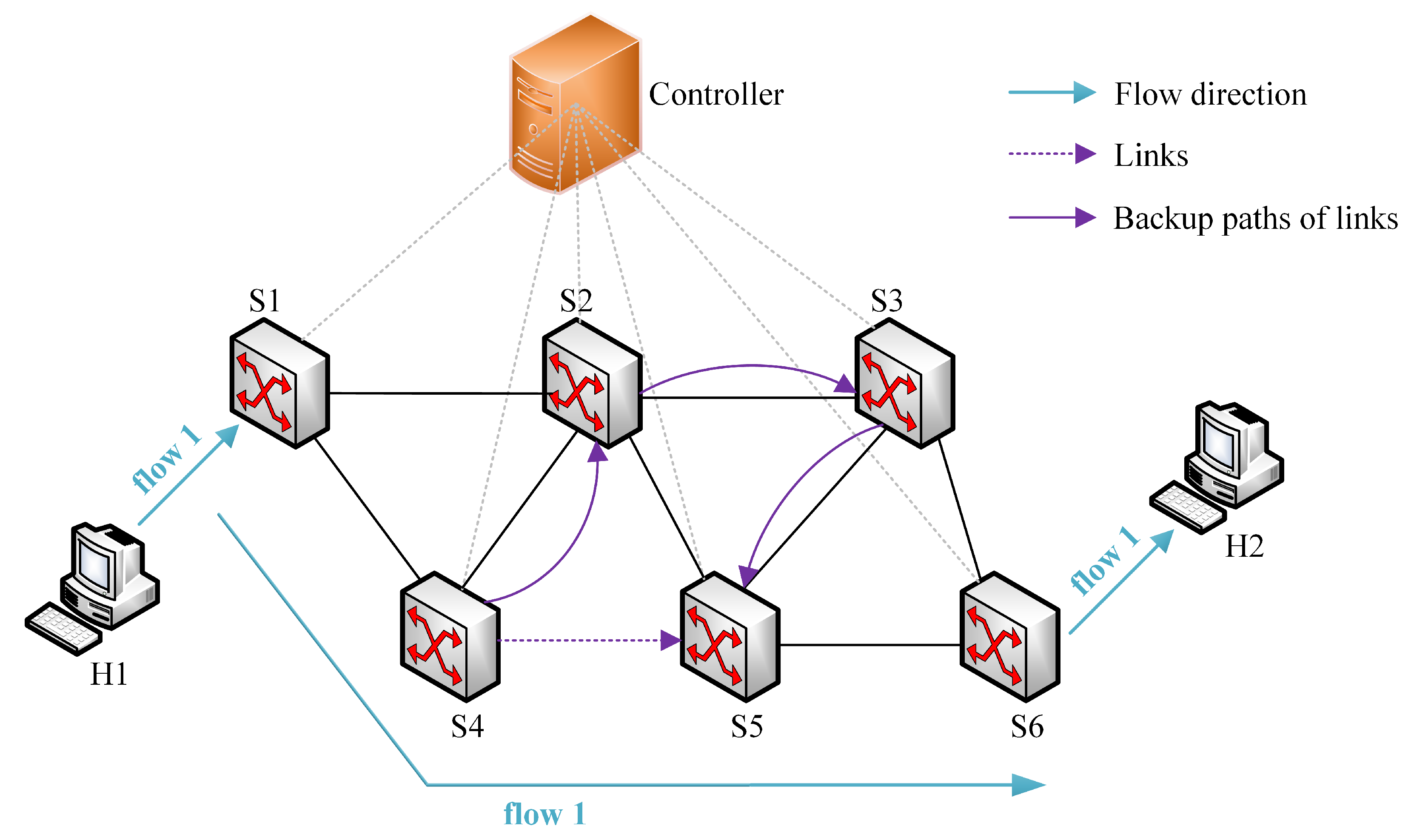
4.1. FAPR Overview
4.2. Proactive Part
4.3. Reactive Part
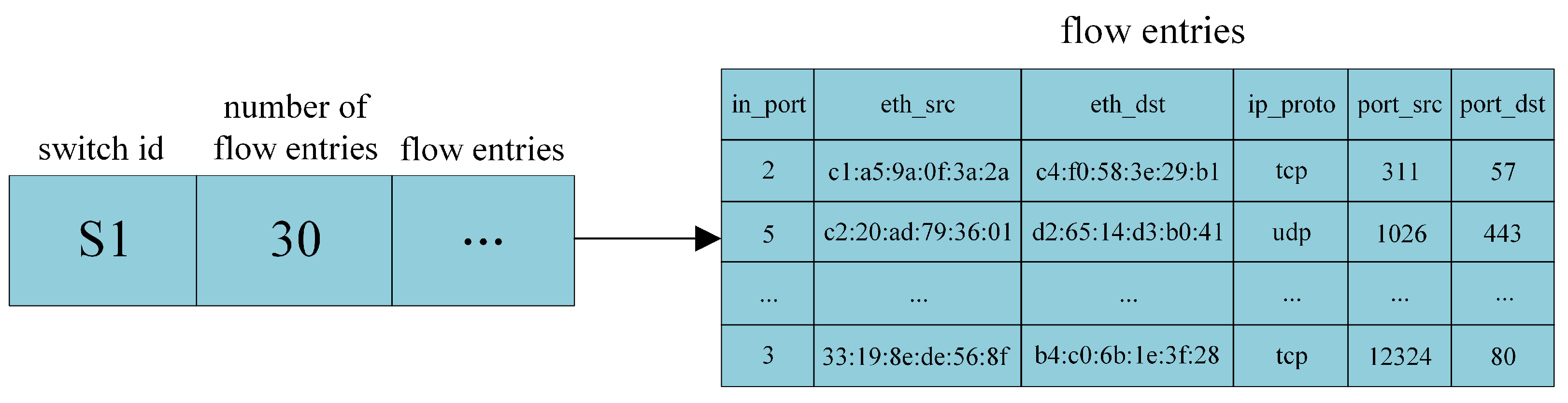
4.3.1. Data Collection Module
4.3.2. Backup Path Generation Module
4.3.3. Failure Detection Module
4.3.4. Flow Analysis Module
4.3.5. Backup Path Allocation Module
4.4. Network Model
4.5. Algorithms and Formulation
4.5.1. Broadcast Storm Suppression Algorithm
| Algorithm 1 Broadcast storm suppression algorithm |
|
4.5.2. Optimized K-Shortest Paths Algorithm
4.5.3. Backup Path Overlap Removal Algorithm
| Algorithm 2 Backup path overlap removal algorithm |
|
4.5.4. Formulation of Backup Path Allocation
4.5.5. Bandwidth Estimation Method
4.5.6. Latency Estimation Method
5. Performance Evaluation
5.1. Simulation Environment
5.2. Comparison Methods
5.3. Simulation Results
5.3.1. Failure Recovery Time
5.3.2. Interruption Rate
5.3.3. Number of Backup Flow Rules
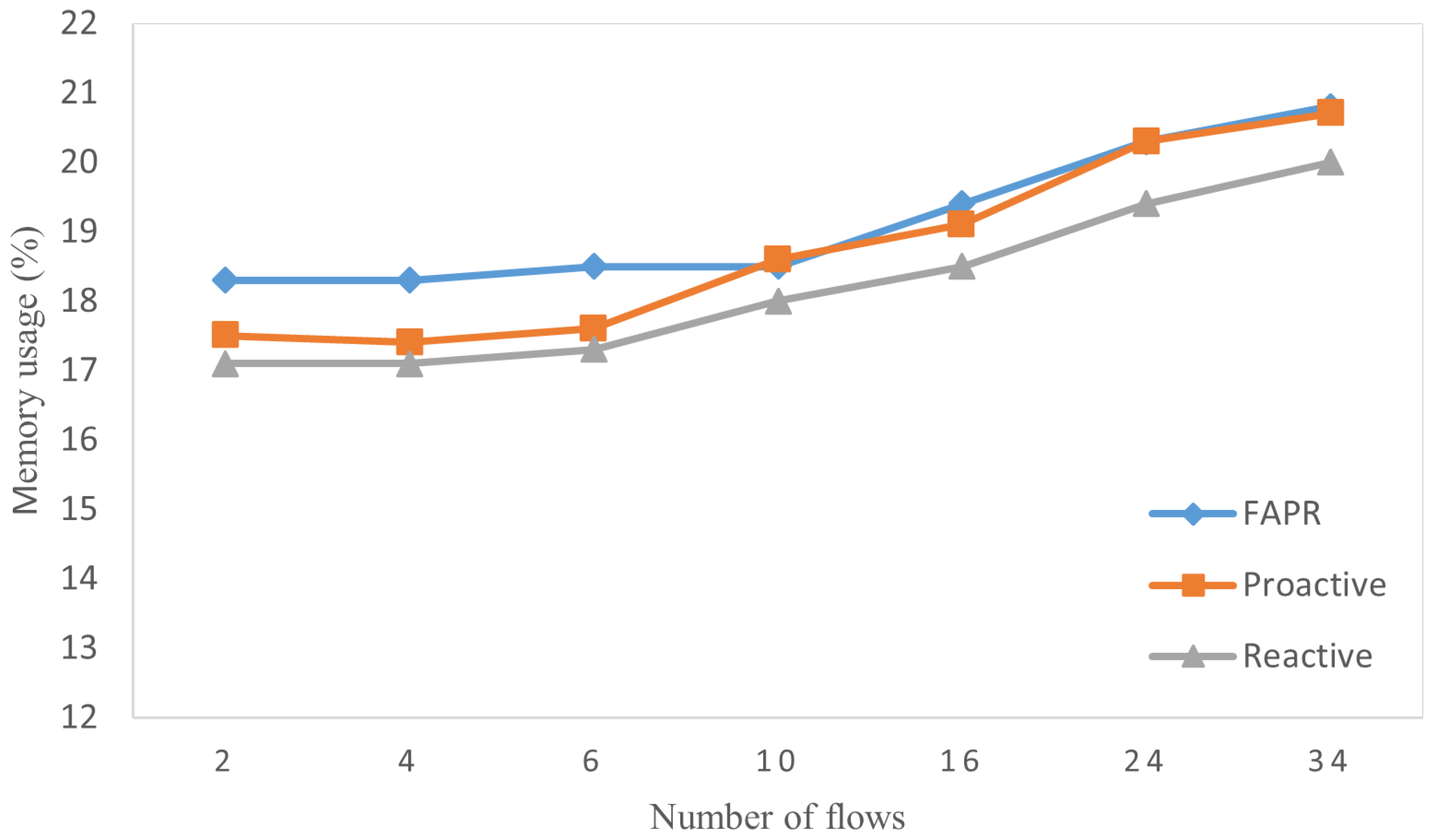
5.3.4. CPU and Memory Utilization
6. Conclusions and Future Work
- (1)
- FAPR keeps a stable and fast failure recovery speed no matter how the number of flows varies, reducing over compared with the reactive scheme.
- (2)
- FAPR corresponds to the minimum interruption rate, which is reduced by and compared with the reactive and proactive schemes, respectively.
- (3)
- FAPR only installs essential backup flow rules in switches in advance, and keeps the CPU and memory usages almost stable.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| G | Network topology |
| V | The switch set |
| E | The link set |
| The link between switch i and switch j | |
| A flow on link | |
| The set of on link | |
| A backup path for link | |
| The set of for link | |
| The backup path allocated for flow | |
| The set of on link | |
| The result of processing using backup path overlap removal algorithm | |
| The set of on link | |
| The original path of flow | |
| The set of on link | |
| A certain data packet of flow f |
References
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling innovation in campus networks. SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Anerousis, N.; Chemouil, P.; Lazar, A.A.; Mihai, N.; Weinstein, S.B. The Origin and Evolution of Open Programmable Networks and SDN. IEEE Commun. Surv. Tutor. 2021, 23, 1956–1971. [Google Scholar] [CrossRef]
- Kazmi, S.H.A.; Qamar, F.; Hassan, R.; Nisar, K.; Chowdhry, B.S. Survey on Joint Paradigm of 5G and SDN Emerging Mobile Technologies: Architecture, Security, Challenges and Research Directions. Wirel. Pers. Commun. 2023, 130, 2753–2800. [Google Scholar] [CrossRef]
- Khorsandroo, S.; Sánchez, A.G.; Tosun, A.S.; Arco, J.; Doriguzzi-Corin, R. Hybrid SDN evolution: A comprehensive survey of the state-of-the-art. Comput. Netw. 2021, 192, 107981. [Google Scholar] [CrossRef]
- Raghavan, B.; Casado, M.; Koponen, T.; Ratnasamy, S.; Ghodsi, A.; Shenker, S. Software-defined internet architecture: Decoupling architecture from infrastructure. In Proceedings of the 11th ACM Workshop on Hot Topics in Networks, Redmond, WA, USA, 29–30 October 2012; pp. 43–48. [Google Scholar] [CrossRef]
- Khan, N.; Salleh, R.B.; Koubaa, A.; Khan, Z.; Khan, M.K.; Ali, I. Data plane failure and its recovery techniques in SDN: A systematic literature review. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 176–201. [Google Scholar] [CrossRef]
- Keshari, S.K.; Kansal, V.; Kumar, S. A Systematic Review of Quality of Services (QoS) in Software Defined Networking (SDN). Wirel. Pers. Commun. 2021, 116, 2593–2614. [Google Scholar] [CrossRef]
- Sahoo, K.S.; Puthal, D.; Tiwary, M.; Rodrigues, J.J.; Sahoo, B.; Dash, R. An early detection of low rate DDoS attack to SDN based data center networks using information distance metrics. Future Gener. Comput. Syst. 2018, 89, 685–697. [Google Scholar] [CrossRef]
- Hu, T.; Yi, P.; Guo, Z.; Lan, J.; Zhang, J. Bidirectional Matching Strategy for Multi-Controller Deployment in Distributed Software Defined Networking. IEEE Access 2018, 6, 14946–14953. [Google Scholar] [CrossRef]
- Theodorou, T.; Mamatas, L. CORAL-SDN: A software-defined networking solution for the Internet of Things. In Proceedings of the 2017 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Berlin, Germany, 6–8 November 2017; pp. 1–2. [Google Scholar] [CrossRef]
- Adrichem, N.L.V.; Asten, B.J.V.; Kuipers, F.A. Fast Recovery in Software-Defined Networks. In Proceedings of the 2014 Third European Workshop on Software Defined Networks, Budapest, Hungary, 1–3 September 2014; pp. 61–66. [Google Scholar] [CrossRef]
- Muthumanikandan, V.; Valliyammai, C. A survey on link failures in software defined networks. In Proceedings of the 2015 Seventh International Conference on Advanced Computing (ICoAC), Chennai, India, 15–17 December 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Rehman, A.U.; Aguiar, R.L.; Barraca, J.P. Fault-Tolerance in the Scope of Software-Defined Networking (sdn). IEEE Access 2019, 7, 124474–124490. [Google Scholar] [CrossRef]
- Grzimek, B.; Thoney, D.A.; Loiselle, P.V.; Schlager, N.; Hutchins, M. Grzimek’s Animal Life Encyclopedia, 2nd ed.; Thomson Gale: Detroit, MI, USA, 2003. [Google Scholar]
- Padma, V.; Yogesh, P. Proactive Failure Recovery in OpenFlow Based Software Defined Networks. In Proceedings of the 2015 3rd International Conference on Signal Processing, Communication and Networking (ICSCN), Chennai, India, 26–28 March 2015. [Google Scholar]
- Huang, H.; Guo, S.; Wu, J.; Li, J. Green DataPath for TCAM-Based Software-Defined Networks. IEEE Commun. Mag. 2016, 54, 194–201. [Google Scholar] [CrossRef]
- Li, H.; Li, Q.; Jiang, Y.; Zhang, T.; Wang, L. A declarative failure recovery system in software defined networks. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Amarasinghe, H.; Jarray, A.; Karmouch, A. Fault-tolerant IaaS management for networked cloud infrastructure with SDN. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Ling, J.; Zhou, J.; Zhang, W. Link Failure Recovery in SDN: High Efficiency, Strong Scalability and Wide Applicability. J. Circuit Syst. Comp. 2018, 27, 1850087. [Google Scholar] [CrossRef]
- Desai, M.; Nandagopal, T. Coping with link failures in centralized control plane architectures. In Proceedings of the 2010 Second International Conference on COMmunication Systems and NETworks (COMSNETS 2010), Bangalore, India, 5–9 January 2010; pp. 1–10. [Google Scholar] [CrossRef]
- Kempf, J.; Bellagamba, E.; Kern, A.; Jocha, D.; Takacs, A.; Skoldstrom, P. Scalable fault management for OpenFlow. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6606–6610. [Google Scholar] [CrossRef]
- Ramos, R.M.; Martinello, M.; Esteve Rothenberg, C. SlickFlow: Resilient source routing in Data Center Networks unlocked by OpenFlow. In Proceedings of the 38th Annual IEEE Conference on Local Computer Networks, Sydney, NSW, Australia, 21–24 October 2013; pp. 606–613. [Google Scholar] [CrossRef]
- Ramos, R.M.; Martinello, M.; Rothenberg, C.E. Data Center Fault-Tolerant Routing and Forwarding: An Approach Based on Encoded Paths. In Proceedings of the 2013 Sixth Latin-American Symposium on Dependable Computing, Rio de Janeiro, Brazil, 1–5 April 2013; pp. 104–113. [Google Scholar] [CrossRef]
- Reitblatt, M.; Canini, M.; Guha, A.; Foster, N. FatTire: Declarative fault tolerance for software-defined networks. In Proceedings of the Second ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking, Hong Kong, China, 16 August 2013; pp. 109–114. [Google Scholar] [CrossRef]
- Petroulakis, N.E.; Spanoudakis, G.; Askoxylakis, I.G. Fault Tolerance Using an SDN Pattern Framework. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Cascone, C.; Sanvito, D.; Pollini, L.; Capone, A.; Sansò, B. Fast failure detection and recovery in SDN with stateful data plane: Fast failure detection and recovery in SDN with stateful data planes. Int. J. Netw. Manag. 2017, 27, e1957. [Google Scholar] [CrossRef]
- Isyaku, B.; Bin Abu Bakar, K.; Nagmeldin, W.; Abdelmaboud, A.; Saeed, F.; Ghaleb, F.A. Reliable Failure Restoration with Bayesian Congestion Aware for Software Defined Networks. Comput. Syst. Sci. Eng. 2023, 46, 3729–3748. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. OpenFlow: Meeting carrier-grade recovery requirements. Comput. Commun. 2013, 36, 656–665. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Fast failure recovery for in-band OpenFlow networks. In Proceedings of the 2013 9th International Conference on the Design of Reliable Communication Networks (DRCN), Budapest, Hungary, 4–7 March 2013; pp. 52–59. [Google Scholar]
- Borokhovich, M.; Schiff, L.; Schmid, S. Provable data plane connectivity with local fast failover: Introducing openflow graph algorithms. In Proceedings of the Third Workshop on Hot Topics in Software Defined Networking, Chicago, IL, USA, 22 August 2014; pp. 121–126. [Google Scholar] [CrossRef]
- Pfeiffenberger, T.; Du, J.L.; Arruda, P.B.; Anzaloni, A. Reliable and flexible communications for power systems: Fault-tolerant multicast with SDN/OpenFlow. In Proceedings of the 2015 7th International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 27–29 July 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Thorat, P.; Raza, S.M.; Kim, D.S.; Choo, H. Rapid recovery from link failures in software-defined networks. J. Commun. Netw. 2017, 19, 648–665. [Google Scholar] [CrossRef]
- Kim, H.; Schlansker, M.; Santos, J.R.; Tourrilhes, J.; Turner, Y.; Feamster, N. CORONET: Fault tolerance for Software Defined Networks. In Proceedings of the 2012 20th IEEE International Conference on Network Protocols (ICNP), Austin, TX, USA, 30 October–2 November 2012; pp. 1–2. [Google Scholar] [CrossRef]
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. Enabling fast failure recovery in OpenFlow networks. In Proceedings of the 2011 8th International Workshop on the Design of Reliable Communication Networks (DRCN), Krakow, Poland, 10–12 October 2011; pp. 164–171. [Google Scholar] [CrossRef]
- Nguyen, K.; Minh, Q.T.; Yamada, S. A Software-Defined Networking Approach for Disaster-Resilient WANs. In Proceedings of the 2013 22nd International Conference on Computer Communication and Networks (ICCCN), Nassau, Bahamas, 30 July–2 August 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Li, J.; Hyun, J.; Yoo, J.H.; Baik, S.; Hong, J.W.K. Scalable failover method for Data Center Networks using OpenFlow. In Proceedings of the 2014 IEEE Network Operations and Management Symposium (NOMS), Krakow, Poland, 5–9 May 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Y.; Beheshti, N.; Tatipamula, M. On Resilience of Split-Architecture Networks. In Proceedings of the 2011 IEEE Global Telecommunications Conference—GLOBECOM 2011, Houston, TX, USA, 5–9 December 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, K.; Kim, M.; Kim, H.; Chwa, H.S.; Lee, J.; Shin, I. Fault-Resilient Real-Time Communication Using Software-Defined Networking. In Proceedings of the 2019 IEEE Real-Time and Embedded Technology and Applications Symposium (RTAS), Montreal, QC, Canada, 16–18 April 2019; pp. 204–215. [Google Scholar] [CrossRef]
- Tajiki, M.M.; Shojafar, M.; Akbari, B.; Salsano, S.; Conti, M.; Singhal, M. Joint failure recovery, fault prevention, and energyefficient resource management for real-time SFC in fog-supported SDN. Comput. Netw. 2019, 162, 106850. [Google Scholar] [CrossRef]
- Liang, D.; Liu, Q.; Yan, B.; Hu, Y.; Zhao, B.; Hu, T. Low interruption ratio link fault recovery scheme for data plane in software-defined networks. Peer-to-Peer Netw. Appl. 2021, 14, 3806–3819. [Google Scholar] [CrossRef]
- Yuan, B.; Jin, H.; Zou, D.; Yang, L.T.; Yu, S. A Practical Byzantine-Based Approach for Faulty Switch Tolerance in Software-Defined Networks. IEEE Trans. Netw. Serv. Manag. 2018, 15, 825–839. [Google Scholar] [CrossRef]
- Song, S.; Park, H.; Choi, B.Y.; Choi, T.; Zhu, H. Control Path Management Framework for Enhancing Software-Defined Network (SDN) Reliability. IEEE Trans. Netw. Serv. Manag. 2017, 14, 302–316. [Google Scholar] [CrossRef]
- Bhatia, J.; Kakadia, P.; Bhavsar, M.; Tanwar, S. SDN-Enabled Network Coding-Based Secure Data Dissemination in VANET Environment. IEEE Internet Things 2020, 7, 6078–6087. [Google Scholar] [CrossRef]
- Narimani, Y.; Zeinali, E.; Mirzaei, A. QoS-aware resource allocation and fault tolerant operation in hybrid SDN using stochastic network calculus. Phys. Commun. 2022, 53, 101709. [Google Scholar] [CrossRef]
- Nunes, B.A.A.; Mendonca, M.; Nguyen, X.N.; Obraczka, K.; Turletti, T. A Survey of Software-Defined Networking: Past, Present, and Future of Programmable Networks. IEEE Commun. Surv. Tutor. 2014, 16, 1617–1634. [Google Scholar] [CrossRef]
- Eppstein, D. Finding the k Shortest Paths. Available online: https://ics.uci.edu/~eppstein/pubs/Epp-SJC-98.pdf (accessed on 7 January 2024).











| Argument | Value | Description |
|---|---|---|
| ipv4_src | IPv4 address | IPv4 source address |
| ipv4_dst | IPv4 address | IPv4 destination address |
| transport_proto | Interger 8bit | Transport protocol |
| tcp/udp_src | Integer 16bit | TCP/UDP source port |
| tcp/udp_dst | Integer 16bit | TCP/UDP destination port |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, H.; Chen, J.; Qiu, X.; Zhang, X.; Cui, M. FAPR: An Adaptive Approach to Link Failure Recovery in SDN with High Speed and Low Interruption Rate. Appl. Sci. 2024, 14, 4719. https://doi.org/10.3390/app14114719
Qin H, Chen J, Qiu X, Zhang X, Cui M. FAPR: An Adaptive Approach to Link Failure Recovery in SDN with High Speed and Low Interruption Rate. Applied Sciences. 2024; 14(11):4719. https://doi.org/10.3390/app14114719
Chicago/Turabian StyleQin, Haijun, Jue Chen, Xihe Qiu, Xinyu Zhang, and Meng Cui. 2024. "FAPR: An Adaptive Approach to Link Failure Recovery in SDN with High Speed and Low Interruption Rate" Applied Sciences 14, no. 11: 4719. https://doi.org/10.3390/app14114719