
NeuChain+: A Sharding Permissioned Blockchain System with Ordering-Free Consensus



Abstract
1. Introduction
- We propose a cross-shard transaction processing protocol, cross-reserve, which utilizes deterministic concurrency control to avoid costly commit protocols.
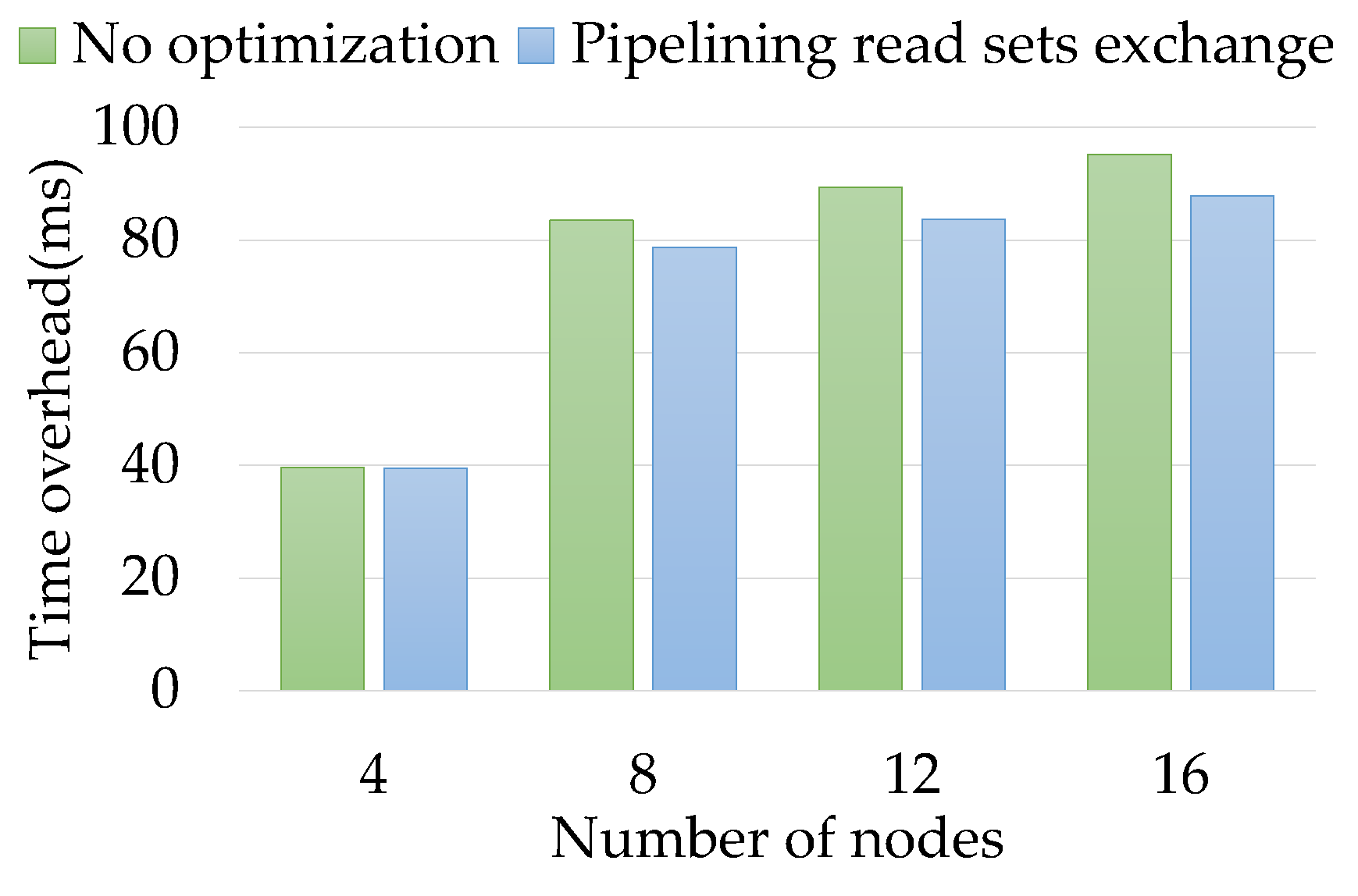
- We pipeline and parallelize the read sets transmission during transaction execution to further reduce cross-shard commit latency.
- We propose the sharding—EV architecture, which enhances horizontal scalability while achieving high throughput by eliminating explicit ordering.
- We implement a sharding blockchain prototype, NeuChain+, based on our team’s previous work, NeuChain. Experimental results show that the throughput of NeuChain+ is approximately 2.9× that of NeuChain and outperforms other state-of-the-art blockchain systems with – throughput under the SmallBank workload.
2. Background and Motivation
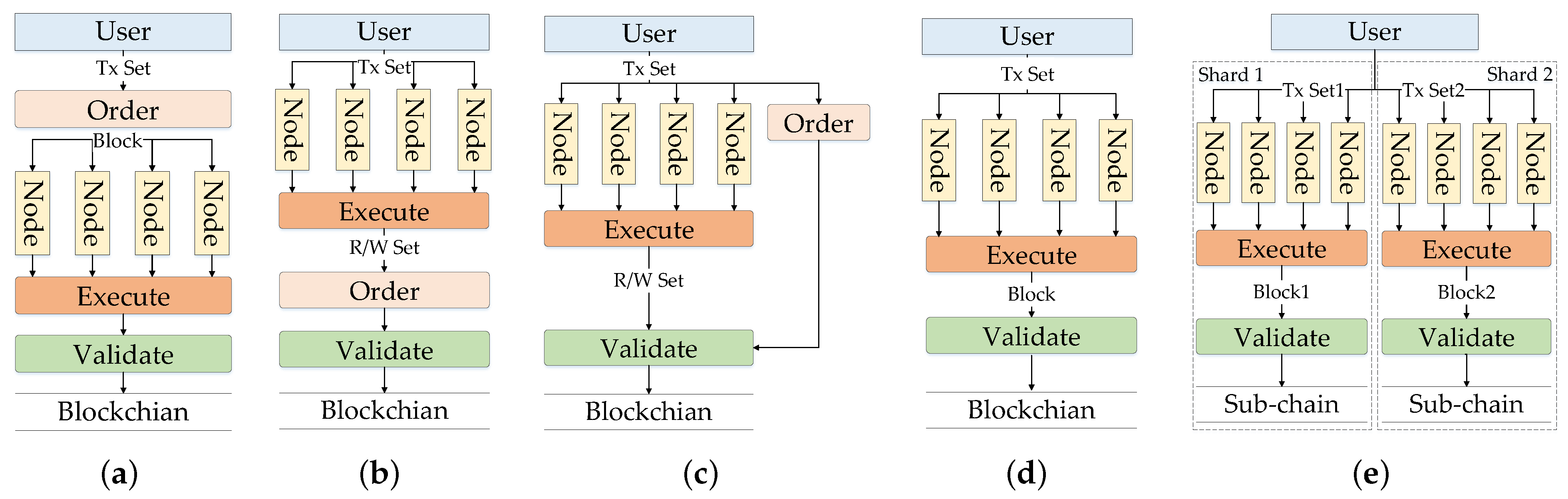
2.1. OEV Architecture
- After receiving transactions from clients, the consensus leader batches these transactions into a block and determines the execution order of these transactions so that each node can obtain the same results. The consensus leader also pre-executes these transactions to ensure their validity.
- The block is then replicated to other follower nodes. Since block execution is performed locally, a node must execute the block based on the given order to update its local ledger. Otherwise, if two nodes execute these transactions in a different order, their local ledger copies will be inconsistent.
- Meanwhile, the node validates the block and its contained transactions to prevent faulty behaviors by the leader node.
2.2. EOV Architecture
- A transaction is executed based on a snapshot of the ledger and obtains a read–write set. Since the ledger is not modified during the execution phase, transactions can be executed concurrently and distributed evenly to all nodes (i.e., different nodes execute disjoint transaction sets).
- The executed transactions are batched into blocks to obtain a global consistent order.
- Similar to the OEV architecture, transactions are validated in serial order to ensure consistent results. If records read by a transaction have been modified (stale read), the transaction must abort. Otherwise, its write set is applied to the ledger.
2.3. OEPV Architecture
2.4. EV Architecture
- All nodes independently receive user transaction requests and then exchange transactions through multiple parallel consensus instances. When a node collects the complete transaction set from all other nodes, it executes these transactions according to the deterministic rule and generates blocks.
- After completion of execution, the execution results are returned to the user, and signatures verifying the execution results are exchanged among nodes.
- Insight. The EV architecture employs deterministic concurrency control, which can determine the order of transactions without additional coordination. Therefore, when employing blockchain sharding to the EV architecture, the order of cross-shard transactions can be determined in advance, and no additional coordination is required during transaction execution, eliminating the costly commit protocols. Therefore, we propose the sharding–EV architecture based on the EV architecture, as shown in Figure 2e.
3. NeuChain+ Design
3.1. System Model
- Network model. NeuChain+ assumes the partial synchrony model [44]. The network is mostly synchronized, but unstable and asynchronous scenarios can also happen. When the network is unstable, an unknown global stabilization time (GST) exists, during which the system operates asynchronously. Once the GST is reached, the system transitions to a synchronous state. At this time, messages are guaranteed to arrive within Δ.
- Threat model. NeuChain+ adopts the Byzantine fault-tolerance (BFT) model, where faulty nodes can behave arbitrarily. We denote the number of faulty nodes in a shard as f and the minimum number of nodes in this shard as . NeuChain+ adopts a public-key infrastructure (PKI), where each node has a public–private key pair for signing and verifying messages.
3.2. System Overview
- Client proxy. The client proxy receives transactions involving its shard from clients. To determine which block the transactions belong to, it batches them and requests an epoch number from the epoch server. Each transaction is then assigned a globally unique transaction ID for deterministic intrablock ordering. The client proxy then uses atomic broadcast (e.g., PBFT or Raft) to exchange its transactions with other intrashard client proxies, ensuring the integrity and consistency of transactions. Notably, the client proxy acts as both the leader of the broadcast instance initiated by itself and as the follower of other broadcast instances initiated by other client proxies within the same shard.
- Epoch server. The epoch server generates monotonically increasing epoch numbers and assigns them to transaction batches generated by client proxies. The epoch server can be a trusted single node or a fault-tolerant cluster containing multiple epoch servers. Notably, only the increment of the epoch number requires consensus, and the epoch number assignment can be performed concurrently with this consensus to reduce latency.
- Block server. The block server only stores transactions that access records on its local shard, forming a subchain. A block server corresponds with a client proxy that accepts transactions. It uses deterministic concurrency control to execute transactions concurrently to generate read–write sets for validation. Each block server maintains a shared read–write reserve table, which only reserves transactions that can be committed in the current , ensuring a serializable isolation level. After execution, the cross-shard transactions use cross-reserve (detail in Section 5) to guarantee atomicity.
3.3. System Workflow
3.3.1. Preparation Phase
3.3.2. Execution Phase
3.3.3. Validation Phase
4. Deterministic Transaction Execution
4.1. Read Sets Transmission
4.2. Pipeline Optimization
| Algorithm 1 Pipelining read sets transmission. | ||
| Input: The reading shard state database snapshot − 1], the cross-shard transaction T | ||
| with remote read-write dependencies of epoch n | ||
| Output: The read-write set {} | ||
| 1: | function Execute(T) ▹ In reading shard | |
| 2: | { execute operation of T base on − 1]; | |
| 3: | Send with epoch n to all Block Servers in writing shard; | |
| 4: | function ReadSetReceiver(T) ▹ In writing shard | |
| 5: | Initialize reading result ; | |
| 6: | if receive the same over f + 1 then | |
| 7: | ; | |
| 8: | T.notify(); | |
| 9: | function Execute(T) ▹ In writing shard | |
| 10: | if RR[accountreq] != NULL then ▹ if received | |
| 11: | execute operation of T base on − 1] and RR[accountreq]; | |
| 12: | else | |
| 13: | T.wait(); | |
5. Cross-Shard Transaction Processing Protocol
5.1. Merging Reserve Table
| Algorithm 2 Merging reserve table based on deterministic execution. | |
| Input: The read-write set {} | |
| Output: A complete reserve table containing accounts involved in cross-shard transactions | |
| 1: | Initialize read reserve table ; |
| 2: | Initialize write reserve table ; |
| 3: | Initialize cross read list ; |
| 4: | Initialize cross write list ; |
| 5: | function Reserve(T) ▹ After T completes execution |
| 6: | for do |
| 7: | [w.] = min([w.], T.); |
| 8: | if T is cross-shard transaction then |
| 9: | .insert(w.); |
| 10: | for do |
| 11: | [r.] = min([r.], T.); |
| 12: | if T is cross-shard transaction then |
| 13: | .insert(r.); |
| 14: | function MergingSender( ) ▹ After completing all intra-shard reservations |
| 15: | for do |
| 16: | .insert(<]>); |
| 17: | for do |
| 18: | .insert(<]>); |
| 19: | Broadcast to all other shard; |
| 20: | function MergingReceiver( ) |
| 21: | if receive the same of a shard over f + 1 then |
| 22: | for do |
| 23: | ; |
| 24: | for do |
| 25: | ; |
5.2. Transaction Conflict Detection
| Algorithm 3 Detect conflict. | ||
| Input: A complete reserve table containing accounts involved in cross-shard transactions, | ||
| A set of transactions of epoch n | ||
| Output: The commit set and abort set of transactions of epoch n | ||
| 1: | for do | |
| 2: | for do | |
| 3: | if [w.] < T. then | |
| 4: | Abort T and continue; | |
| 5: | for do | |
| 6: | if [r.] < T. then | |
| 7: | Abort T and continue; | |
| 8: | Commit T; | |
- An example of the transaction of account amalgamating. It is convenient for readers to better understand the entire processing of cross-shard transactions. This is a detailed description of the transaction of account amalgamating as an example. In this example, there are two shards: Shard containing accounts A, B, and C, and Shard containing accounts D and E. As depicted in Figure 5, the transaction set to be sent by the client includes the transaction amalgamate(C, D) and other intrashard transactions. Amalgamate(C, D) is aimed at merging accounts C and D. It comprises four operations, referred to subsequently as Op1−4, which are to obtain the balance of C, obtain the balance of D, update the balance of C to 0, and update the balance of D to the sum of the original balances of C and D. The client divides the complete transaction set into two subtransaction sets and sends them to and Shard , respectively. After the preparation phase, amalgamate(C, D) is assigned to the Epoch N and is also assigned a unique . During the execution phase, the intrashard block server executes this transaction deterministically. It is noteworthy that for cross-shard transactions like amalgamate(C, D), operations are executed based solely on the accounts contained within the local shard. Specifically, executes only and , while executes only and . However, since depends on the read set of , it cannot be executed directly, but if has completed execution and sent the read set to , then it can directly read the prereceived read set from the local cache for executing (according to Algorithm 1). Otherwise, it is temporarily pended and continues to execute other transactions. After the deterministic execution is completed, cross-reserve first generates the intrashard reserve table (according to Algorithm 2, Lines 5–13, the bold words in Figure 5). In this example, reserves the update of C from amalgamate(C, D), while reserves the update of D from the other transaction. After merging reserve tables of cross-reserve (according to Algorithm 2, Lines 14–25), the reserve tables in both shards have the same row of C and D (the gray words in Figure 5). and conduct conflict detection based on the complete reserve table (according to Algorithm 3). According to the deterministic rule, this transaction exists with a WAW dependency. As a result, amalgamate(C, D) ultimately is aborted.
6. Analysis
6.1. Time Complexity Analysis of Algorithms
6.2. Cross-Reserve Security and Liveness Analysis
- Send the tampered read sets or reserve table to other shards to affect security;
- Perform no read sets transmission or merging of reserve tables to some or all block servers to affect liveness;
- Do not follow deterministic rule reserve or malicious conflict detection to tamper with the local blocks to affect security.
7. Evaluation
- Implementation. We implemented a NeuChain+ prototype based on NeuChain [46] with C++14. We leveraged the braft [47] library for intrashard consensus. We employed the RSA digital signature and SHA256 to ensure data integrity and authenticity of messages. We employed key-value database LevelDB [48] as the state database and the file system to store blocks. The state database maintains the ledger view of the current epoch of the shard subchain, and transaction execution is based on this view snapshot. We employed ZeroMQ [49] and protocol buffers [50] to implement message transport between physical nodes. We used Blockbench [42] as the test tool. We also leveraged pipelining and batching optimizations [25] to enhance performance.
- Competitors. We compared NeuChain+ to state-of-the-art systems, including NeuChain [25], Fabric [9], Fabric# [51], FastFabric [52], ResilientDB [20], and a BFT-distributed database, Basil [53]. Moreover, to show the efficiency of our sharding strategy, we also compared NeuChain+ with a sharding permissioned blockchain, Meepo [37].
- Setup. We deployed 12 nodes on Aliyun [54] in the same data center. Each node is an ecs.hfc6.4xlarge instance with an Intel Xeon Platinum 8269CY 3.1GHz 16-core processor, 32GB RAM, and 10 Gbps bandwidth. In Fabric, Fabric#, and FastFabric, four nodes are orderers, and eight nodes are peers. Basil requires running on nodes; hence, we deployed Basil on 12 nodes. For ResilientDB, we deployed it on eight nodes. For Meepo, we deployed it on eight nodes. Due to the trustworthiness within the consortium member, each shard can deploy on a single node. In NeuChain+ and NeuChain, each client proxy corresponds to one block server and runs on the same node. We deployed four nodes for epoch servers and eight for client proxies and block servers. By default, NeuChain+ runs on two shards, and each shard is deployed on four nodes of client proxies and block servers.
- Workload. We employed two of the most popular workloads: SmallBank [43] and YCSB [55]. The SmallBank workload is a benchmark for online transaction processing (OLTP) workloads. It consists of three tables (account, checking, and saving). It simulates various fundamental transactions in banking applications, including six types of transactions: transfer, query, account amalgamating, check writing, saving update, and checking update. It is configured with 100,000 accounts, and the transactions follow a uniform distribution. The YCSB workload uses a table containing 1,000,000 records, with each record consisting of 10 attributes, each 100 bytes in size. Read operations access entire records, while write operations access only one attribute of a single record at a time. The experiments used YCSB-A (50% read operations, 50% write operations), YCSB-B (95% read operations, 5% write operations), and YCSB-C (100% read operations). All YCSB transactions followed a Zipf distribution with a skew factor of 0.99. The cross-shard transaction rate depends on the number of shards, which was 16.6%, 22.2%, and 25% under two, three, and four shards, respectively.
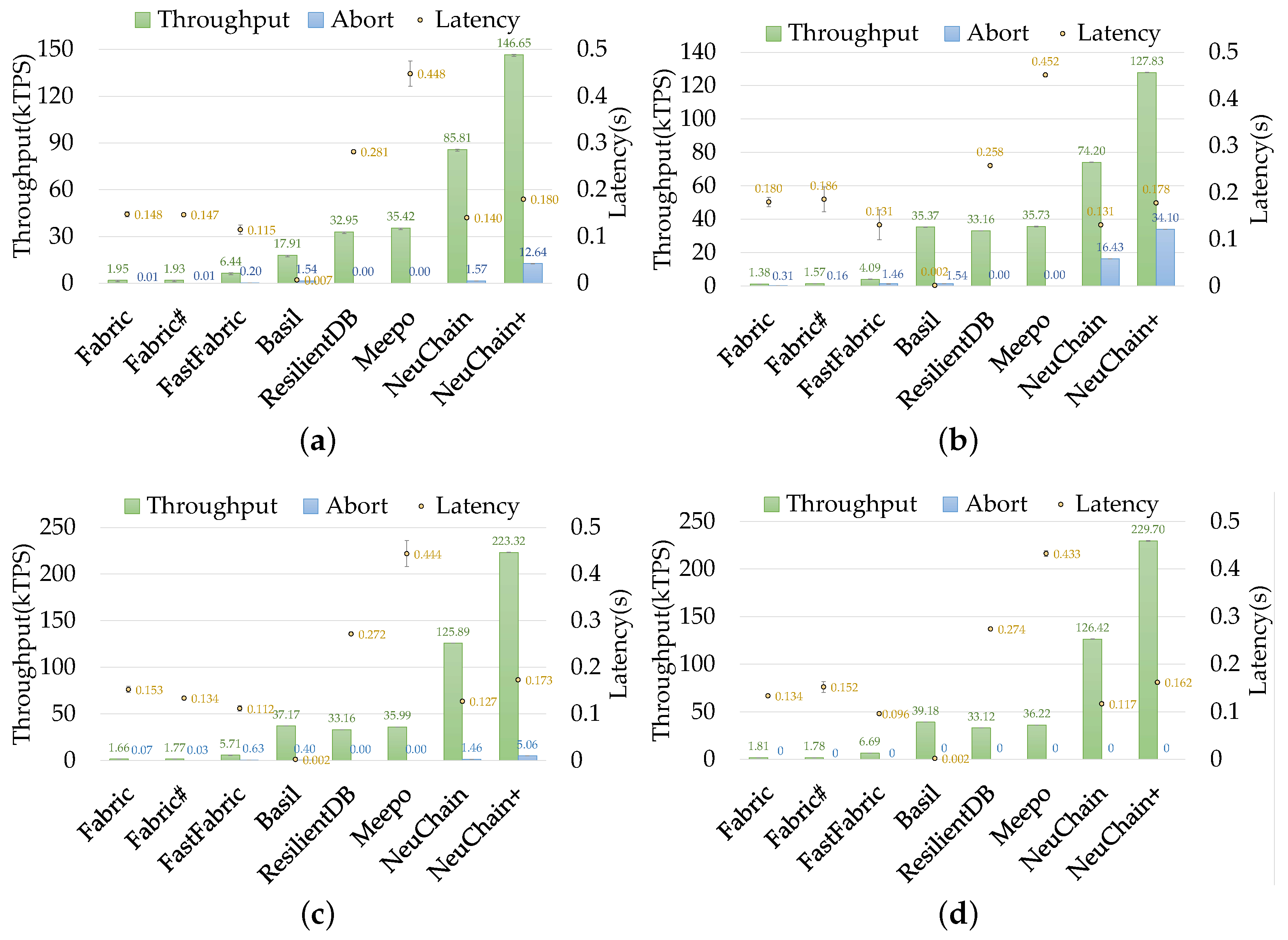
7.1. Overall Performance
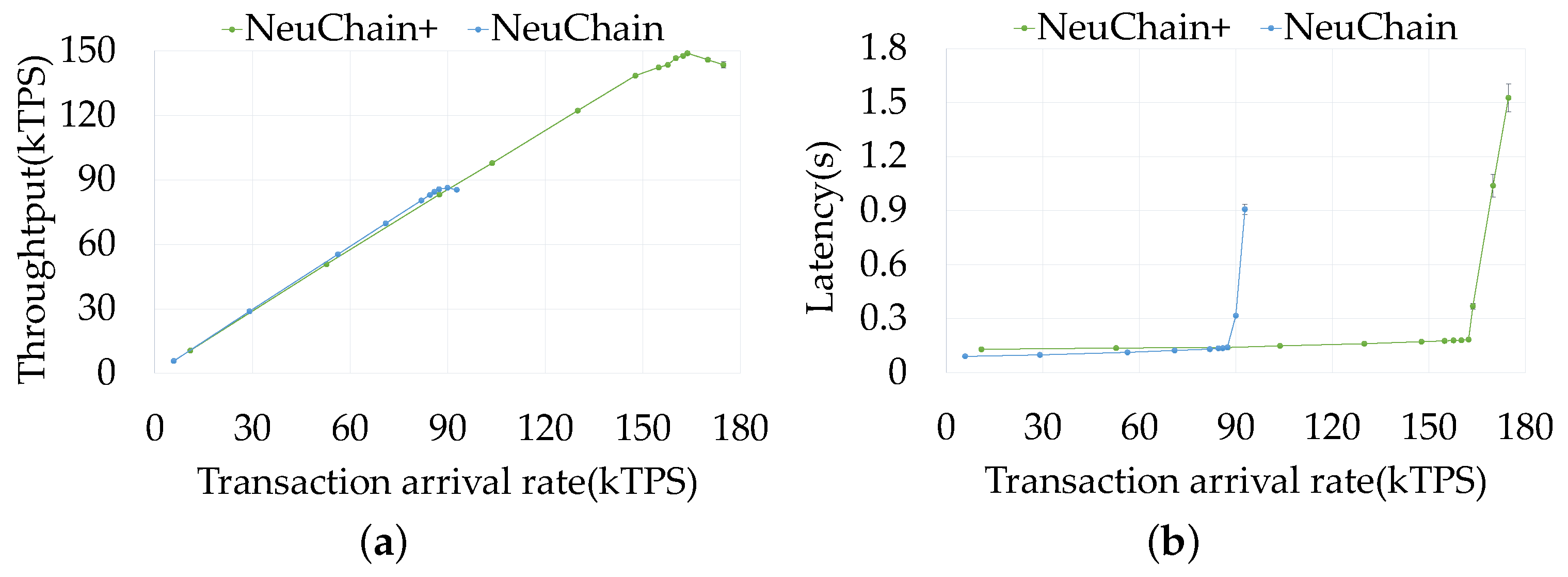
7.2. Varying Transaction Arrival Rates
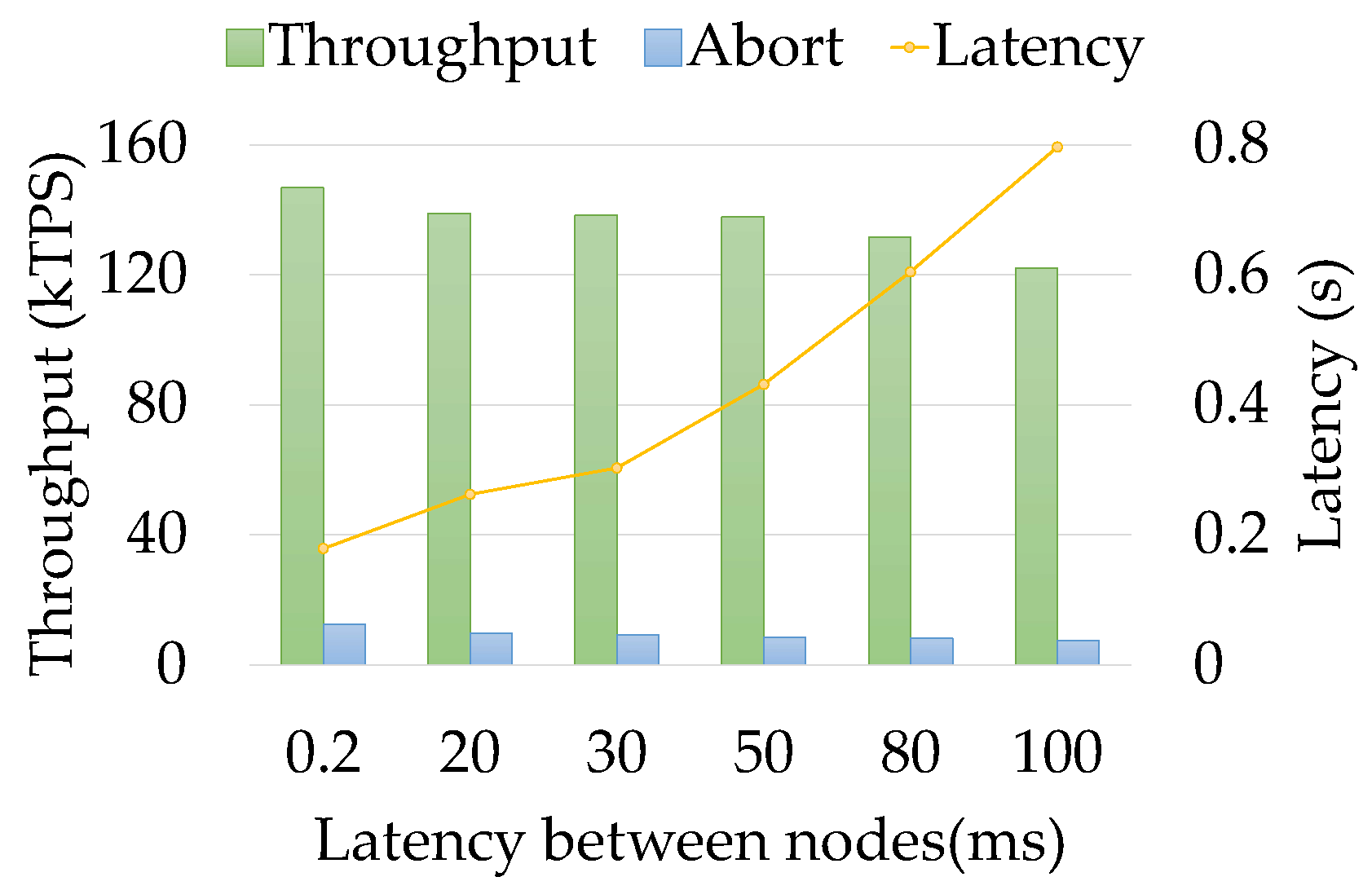
7.3. Varying Network Latency
7.4. Scalability Comparison
7.5. Cross-Shard Transaction Processing Overhead
- Summary of results. Experimental results show that NeuChain+ addresses the scalability issues of nonsharding and previous sharding blockchains. Under 16 nodes, the throughput was that of NeuChain, and the storage overhead was only 30.9% of NeuChain. Compared to Meepo, NeuChain+ in the situation of storage sharding in each node and nontrustworthiness among all nodes, achieved higher throughput and 61% lower latency. Compared with nonsharding blockchains under eight shards, NeuChain+ outperformed state-of-the-art blockchain systems with – throughput.
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Truong, V.T.; Le, L.; Niyato, D. Blockchain Meets Metaverse and Digital Asset Management: A Comprehensive Survey. IEEE Access 2023, 11, 26258–26288. [Google Scholar] [CrossRef]
- Kamble, S.S.; Gunasekaran, A.; Subramanian, N.; Ghadge, A.; Belhadi, A.; Venkatesh, M. Blockchain technology’s impact on supply chain integration and sustainable supply chain performance: Evidence from the automotive industry. Ann. Oper. Res. 2023, 327, 575–600. [Google Scholar] [CrossRef]
- Elisa, N.; Yang, L.; Chao, F.; Cao, Y. A framework of blockchain-based secure and privacy-preserving E-government system. Wirel. Networks 2023, 29, 1005–1015. [Google Scholar] [CrossRef]
- Ray, P.P. Web3: A comprehensive review on background, technologies, applications, zero-trust architectures, challenges and future directions. Internet Things Cyber Phys. Syst. 2023, 3, 213–248. [Google Scholar] [CrossRef]
- Satija, S.; Mehra, A.; Singanamalla, S.; Grover, K.; Sivathanu, M.; Chandran, N.; Gupta, D.; Lokam, S. Blockene: A high-throughput blockchain over mobile devices. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Virtual, 4–6 November 2020; pp. 567–582. [Google Scholar]
- Ulm, G.; Smith, S.; Nilsson, A.; Gustavsson, E.; Jirstrand, M. OODIDA: On-board/off-board distributed real-time data analytics for connected vehicles. Data Sci. Eng. 2021, 6, 102–117. [Google Scholar] [CrossRef]
- Di Vaio, A.; Varriale, L. Blockchain technology in supply chain management for sustainable performance: Evidence from the airport industry. Int. J. Inf. Manag. 2020, 52, 102014. [Google Scholar] [CrossRef]
- Tapscott, A.; Tapscott, D. How blockchain is changing finance. Harv. Bus. Rev. 2017, 1, 2–5. [Google Scholar]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Enyeart, D.; Ferris, C.; Laventman, G.; Manevich, Y.; et al. Hyperledger fabric: A distributed operating system for permissioned blockchains. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; pp. 1–15. [Google Scholar]
- Visa Fact Sheet: What You Need to Know about One of the World’s Largest Payments Companies. 2018. Available online: https://www.visa.co.uk/dam/VCOM/download/corporate/media/visanet-technology/aboutvisafactsheet.pdf (accessed on 17 May 2024).
- Amiri, M.J.; Agrawal, D.; Abbadi, A.E. CAPER: A cross-application permissioned blockchain. Proc. VLDB Endow. 2019, 12, 1385–1398. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical byzantine fault tolerance and proactive recovery. ACM Trans. Comput. Syst. (TOCS) 2002, 20, 398–461. [Google Scholar] [CrossRef]
- Ongaro, D.; Ousterhout, J. In search of an understandable consensus algorithm. In Proceedings of the 2014 USENIX Annual Technical Conference (USENIX ATC 14), Philadelphia, PA, USA, 19–20 June 2014; pp. 305–319. [Google Scholar]
- Eyal, I.; Gencer, A.E.; Sirer, E.G.; Van Renesse, R. {Bitcoin-NG}: A scalable blockchain protocol. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 45–59. [Google Scholar]
- Bentov, I.; Pass, R.; Shi, E. Snow White: Provably secure proofs of stake. IACR Cryptol. ePrint Arch. 2016, 2016, 1–62. [Google Scholar]
- Kiayias, A.; Russell, A.; David, B.; Oliynykov, R. Ouroboros: A provably secure proof-of-stake blockchain protocol. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 357–388. [Google Scholar]
- Miller, A.; Xia, Y.; Croman, K.; Shi, E.; Song, D. The honey badger of BFT protocols. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 31–42. [Google Scholar]
- Yin, M.; Malkhi, D.; Reiter, M.K.; Gueta, G.G.; Abraham, I. HotStuff: BFT consensus with linearity and responsiveness. In Proceedings of the 2019 ACM Symposium on Principles of Distributed Computing, Toronto, ON, Canada, 29 July–2 August 2019; pp. 347–356. [Google Scholar]
- Gilad, Y.; Hemo, R.; Micali, S.; Vlachos, G.; Zeldovich, N. Algorand: Scaling byzantine agreements for cryptocurrencies. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 51–68. [Google Scholar]
- Gupta, S.; Rahnama, S.; Hellings, J.; Sadoghi, M. Resilientdb: Global scale resilient blockchain fabric. arXiv 2020, arXiv:2002.00160. [Google Scholar] [CrossRef]
- Gupta, S.; Hellings, J.; Sadoghi, M. Rcc: Resilient concurrent consensus for high-throughput secure transaction processing. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1392–1403. [Google Scholar]
- Stathakopoulou, C.; Pavlovic, M.; Vukolić, M. State machine replication scalability made simple. In Proceedings of the Seventeenth European Conference on Computer Systems, Rennes, France, 5–8 April 2022; pp. 17–33. [Google Scholar]
- Qi, J.; Chen, X.; Jiang, Y.; Jiang, J.; Shen, T.; Zhao, S.; Wang, S.; Zhang, G.; Chen, L.; Au, M.H.; et al. Bidl: A high-throughput, low-latency permissioned blockchain framework for datacenter networks. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, Virtual, 26–29 October 2021; pp. 18–34. [Google Scholar]
- Nathan, S.; Govindarajan, C.; Saraf, A.; Sethi, M.; Jayachandran, P. Blockchain meets database: Design and implementation of a blockchain relational database. arXiv 2019, arXiv:1903.01919. [Google Scholar] [CrossRef]
- Peng, Z.; Zhang, Y.; Xu, Q.; Liu, H.; Gao, Y.; Li, X.; Yu, G. Neuchain: A fast permissioned blockchain system with deterministic ordering. Proc. VLDB Endow. 2022, 15, 2585–2598. [Google Scholar] [CrossRef]
- Luu, L.; Narayanan, V.; Zheng, C.; Baweja, K.; Gilbert, S.; Saxena, P. A secure sharding protocol for open blockchains. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 17–30. [Google Scholar]
- Kokoris-Kogias, E.; Jovanovic, P.; Gasser, L.; Gailly, N.; Syta, E.; Ford, B. Omniledger: A secure, scale-out, decentralized ledger via sharding. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–24 May 2018; pp. 583–598. [Google Scholar]
- Zamani, M.; Movahedi, M.; Raykova, M. Rapidchain: Scaling blockchain via full sharding. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 931–948. [Google Scholar]
- Al-Bassam, M.; Sonnino, A.; Bano, S.; Hrycyszyn, D.; Danezis, G. Chainspace: A sharded smart contracts platform. arXiv 2017, arXiv:1708.03778. [Google Scholar]
- Hellings, J.; Sadoghi, M. Byshard: Sharding in a byzantine environment. Proc. VLDB Endow. 2021, 14, 2230–2243. [Google Scholar] [CrossRef]
- Dang, H.; Dinh, T.T.A.; Loghin, D.; Chang, E.C.; Lin, Q.; Ooi, B.C. Towards scaling blockchain systems via sharding. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 123–140. [Google Scholar]
- Mohan, C.; Lindsay, B.; Obermarck, R. Transaction management in the R* distributed database management system. ACM Trans. Database Syst. (TODS) 1986, 11, 378–396. [Google Scholar] [CrossRef]
- Özsu, M.T.; Valduriez, P. Principles of Distributed Database Systems; Springer: Berlin/Heidelberg, Germany, 1999; Volume 2. [Google Scholar]
- Wang, J.; Wang, H. Monoxide: Scale out blockchains with asynchronous consensus zones. In Proceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), Boston, MA, USA, 26–28 March 2019; pp. 95–112. [Google Scholar]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://assets.pubpub.org/d8wct41f/31611263538139.pdf (accessed on 20 October 2021).
- Wood, G. Ethereum: A secure decentralised generalised transaction ledger. Ethereum Proj. Yellow Pap. 2014, 151, 1–32. [Google Scholar]
- Zheng, P.; Xu, Q.; Zheng, Z.; Zhou, Z.; Yan, Y.; Zhang, H. Meepo: Sharded consortium blockchain. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 1847–1852. [Google Scholar]
- Huang, H.; Peng, X.; Zhan, J.; Zhang, S.; Lin, Y.; Zheng, Z.; Guo, S. Brokerchain: A cross-shard blockchain protocol for account/balance-based state sharding. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 1968–1977. [Google Scholar]
- Hong, Z.; Guo, S.; Zhou, E.; Zhang, J.; Chen, W.; Liang, J.; Zhang, J.; Zomaya, A. Prophet: Conflict-Free Sharding Blockchain via Byzantine-Tolerant Deterministic Ordering. In Proceedings of the IEEE INFOCOM 2023—IEEE Conference on Computer Communications, New York, NY, USA, 17–20 May 2023; pp. 1–10. [Google Scholar]
- De Angelis, S.; Aniello, L.; Baldoni, R.; Lombardi, F.; Margheri, A.; Sassone, V. PBFT vs proof-of-authority: Applying the CAP theorem to permissioned blockchain. In Proceedings of the CEUR Workshop Proceedings. CEUR-WS, Milan, Italy, 7 May 2022; Volume 2058. [Google Scholar]
- Kung, H.T.; Robinson, J.T. On optimistic methods for concurrency control. ACM Trans. Database Syst. (TODS) 1981, 6, 213–226. [Google Scholar] [CrossRef]
- Dinh, T.T.A.; Wang, J.; Chen, G.; Liu, R.; Ooi, B.C.; Tan, K.L. Blockbench: A framework for analyzing private blockchains. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 1085–1100. [Google Scholar]
- Cahill, M.J.; Röhm, U.; Fekete, A.D. Serializable isolation for snapshot databases. ACM Trans. Database Syst. (TODS) 2009, 34, 1–42. [Google Scholar] [CrossRef]
- Dwork, C.; Lynch, N.; Stockmeyer, L. Consensus in the presence of partial synchrony. J. ACM (JACM) 1988, 35, 288–323. [Google Scholar] [CrossRef]
- Lu, Y.; Yu, X.; Cao, L.; Madden, S. Aria: A Fast and Practical Deterministic OLTP Database; Massachusetts Institute of Technology (MIT): Cambridge, MA, USA, 2020. [Google Scholar]
- NeuChain: A Fast Permissioned Blockchain System with Deterministic Ordering. 2023. Available online: https://github.com/iDC-NEU/NeuChain (accessed on 30 June 2022).
- braft: An Industrial-Grade C++ Implementation of RAFT Consensus Algorithm. 2023. Available online: https://github.com/baidu/braft (accessed on 15 July 2022).
- LevelDB: A Fast Key-Value Storage Library. 2021. Available online: https://github.com/google/leveldb (accessed on 7 July 2022).
- ZeroMQ: A High-Performance Asynchronous Messaging Library. 2023. Available online: https://github.com/zeromq/cppzmq (accessed on 4 July 2022).
- Protocol Buffers: The Language-Neutral, Platform-Neutral Extensible Mechanisms for Serializing Structured Data. 2023. Available online: https://github.com/protocolbuffers/protobuf (accessed on 4 July 2022).
- Ruan, P.; Loghin, D.; Ta, Q.T.; Zhang, M.; Chen, G.; Ooi, B.C. A transactional perspective on execute-order-validate blockchains. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 543–557. [Google Scholar]
- Gorenflo, C.; Lee, S.; Golab, L.; Keshav, S. FastFabric: Scaling hyperledger fabric to 20,000 transactions per second. Int. J. Netw. Manag. 2020, 30, e2099. [Google Scholar] [CrossRef]
- Suri-Payer, F.; Burke, M.; Wang, Z.; Zhang, Y.; Alvisi, L.; Crooks, N. Basil: Breaking up BFT with ACID (transactions). In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles, Virtual, 26–29 October 2021; pp. 1–17. [Google Scholar]
- Alibaba Cloud: Cloud Computing Services. 2024. Available online: https://www.alibabacloud.com/zh?_p_lc=1 (accessed on 15 April 2024).
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking cloud serving systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Architecture | Consensus | Shard Fault | Total Fault | Ledger Model | State Sharding | Cross-Shard Transaction | Throughput | Latency |
|---|---|---|---|---|---|---|---|---|---|
| Elastico | OEV | PBFT | 33% | 25% | UTXO | False | - | 48 kTPS | 800 s |
| OmniLedger | OEV | ByzCoinX | 33% | 25% | UTXO | True | 2PC | >100 kTPS | 1.38 s |
| Rapidchain | OEV | 50%BFT | 50% | 33% | UTXO | True | 2PC | 7.3 kTPS | 8 s |
| Chainspace | OEV | MOD-SmaRt | 33% | 25% | Object | True | 2PC | 350 TPS | 0.1 s |
| Monoxide | OEV | Chu-ko-nu | 33% | 50% | Account/balance | True | Eventual atomicity | 11.7 kTPS | 15 s |
| ByShard | OEV | PBFT | 33% | 33% | UTXO | True | 2PC | 20 kTPS | 1 s |
| Meepo | OEV | PoA [40] | 33% | 25% | Account/balance | True | cross-epoc and cross-call | 124.6 kTPS | 0.52 s |
| BrokerChain | OEV | PBFT | 33% | 33% | Account/balance | True | Broker | 3 kTPS | 14.9 s |
| PROPHET | OEV | PBFT | 33% | 33% | Account/balance | True | Reconnaissance coalition | 1.2 kTPS | 2.5 s |
| AHL [31] | EOV | AHL | 33% | 33% | General workload | True | 2PC | 3 kTPS | 18 s |
| NeuChain | EV | PBFT Raft | - | 33% | Account/balance | - | - | 85.7 kTPS | 0.14 s |
| NeuChain+ | EV | PBFT Raft | 33% | 33% | Account/balance | True | Cross-reserve | 247 kTPS | 0.19 s |
| Type | Description | Error Case |
|---|---|---|
| WAW | Transactions and simultaneously write to . | Concurrent writes by and lead to an indeterminate final result. |
| RAW | writes to , followed by reading from . | Due to snapshot-based reading, reads outdated data. |
| WAR | reads from , followed by writing to . | None. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Li, X.; Peng, Z.; Zhang, Y.; Yu, G. NeuChain+: A Sharding Permissioned Blockchain System with Ordering-Free Consensus. Appl. Sci. 2024, 14, 4897. https://doi.org/10.3390/app14114897
Gao Y, Li X, Peng Z, Zhang Y, Yu G. NeuChain+: A Sharding Permissioned Blockchain System with Ordering-Free Consensus. Applied Sciences. 2024; 14(11):4897. https://doi.org/10.3390/app14114897
Chicago/Turabian StyleGao, Yuxiao, Xiaohua Li, Zeshun Peng, Yanfeng Zhang, and Ge Yu. 2024. "NeuChain+: A Sharding Permissioned Blockchain System with Ordering-Free Consensus" Applied Sciences 14, no. 11: 4897. https://doi.org/10.3390/app14114897
APA StyleGao, Y., Li, X., Peng, Z., Zhang, Y., & Yu, G. (2024). NeuChain+: A Sharding Permissioned Blockchain System with Ordering-Free Consensus. Applied Sciences, 14(11), 4897. https://doi.org/10.3390/app14114897