
RiQ-KGC: Relation Instantiation Enhanced Quaternionic Attention for Complex-Relation Knowledge Graph Completion



Abstract
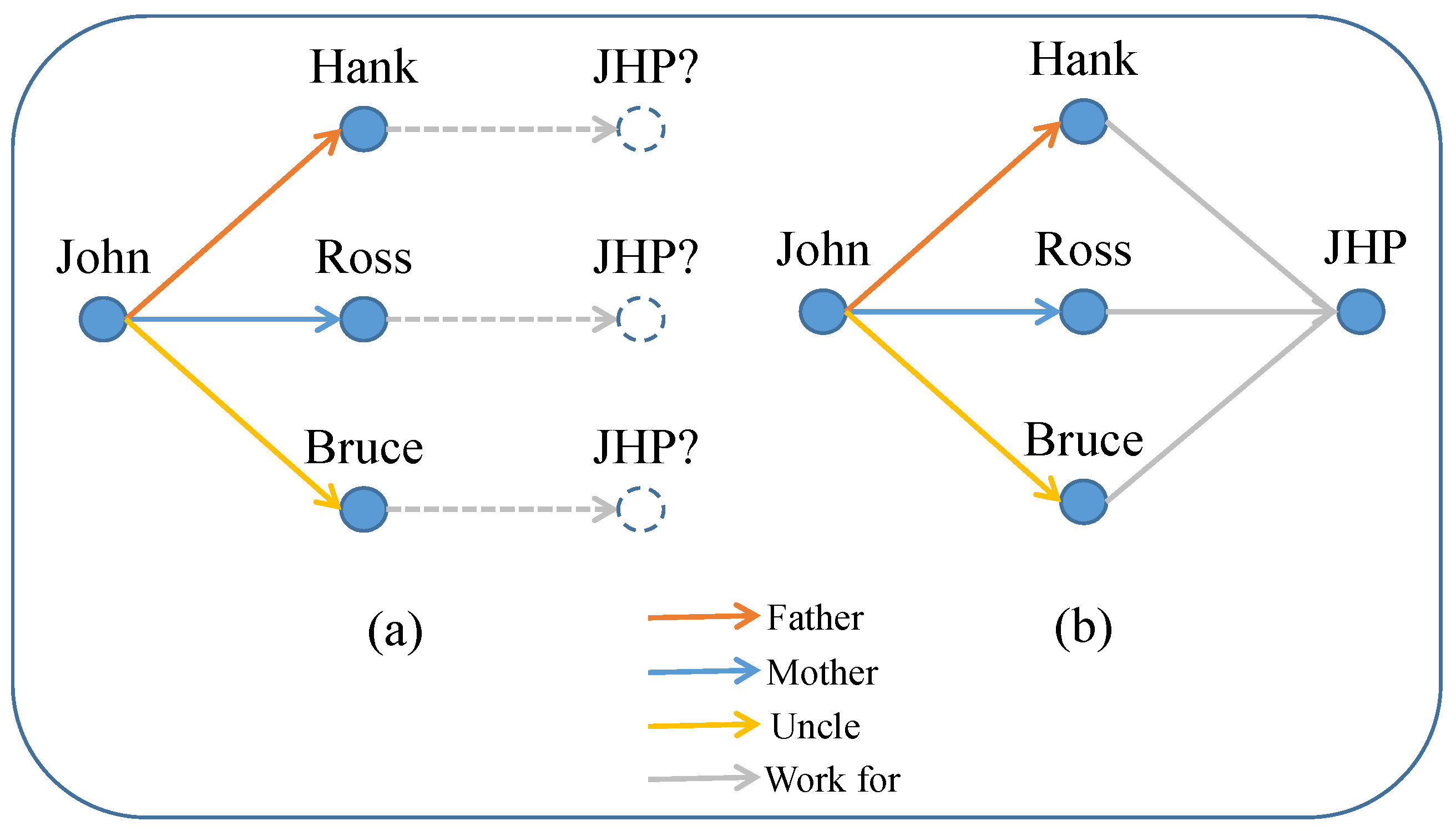
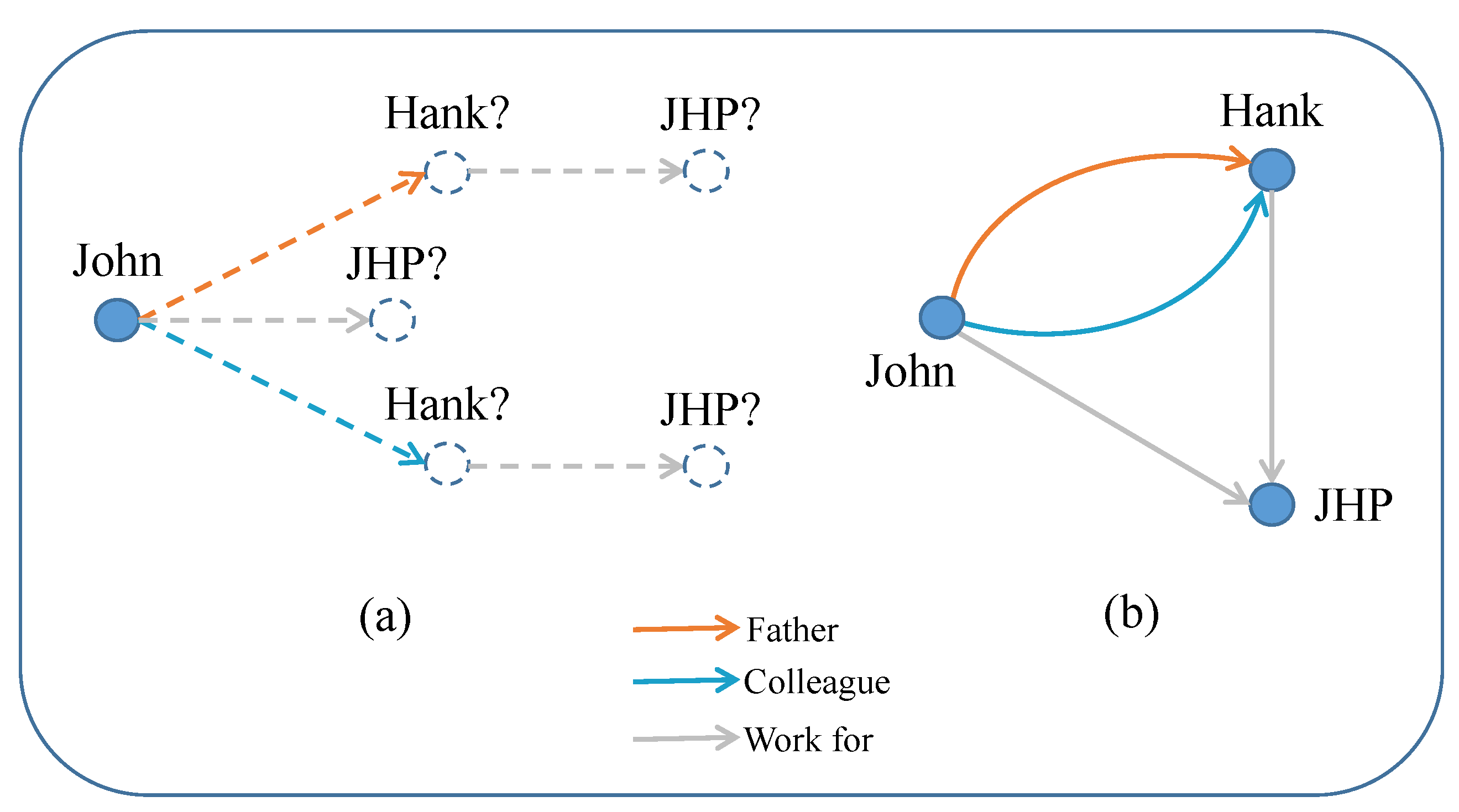
1. Introduction
- We present RiQ-KGC, a hierarchical multi-head attention network framework that embeds KGs in quaternion spaces and constructs graph embeddings using geometric information.
- We propose a novel relation instantiation method that utilizes contextual information to transform relations, making them express transformation patterns unique to their corresponding triple context.
- We conduct theoretical and empirical analyses that demonstrate the competitiveness of RiQ-KGC against numerous existing models.
2. Related Work
2.1. Machine-Learning-Based Model
2.2. Deep-Learning-Based Model
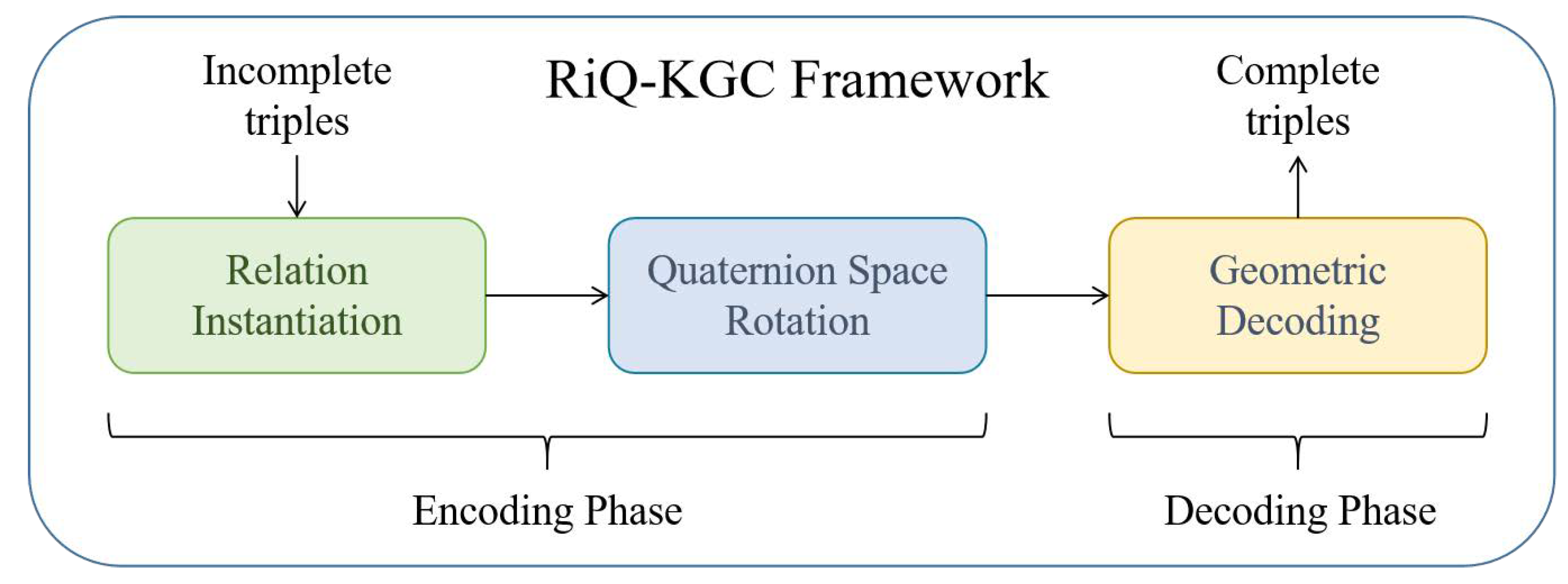
3. Methodology
3.1. Quaternion for Link Prediction
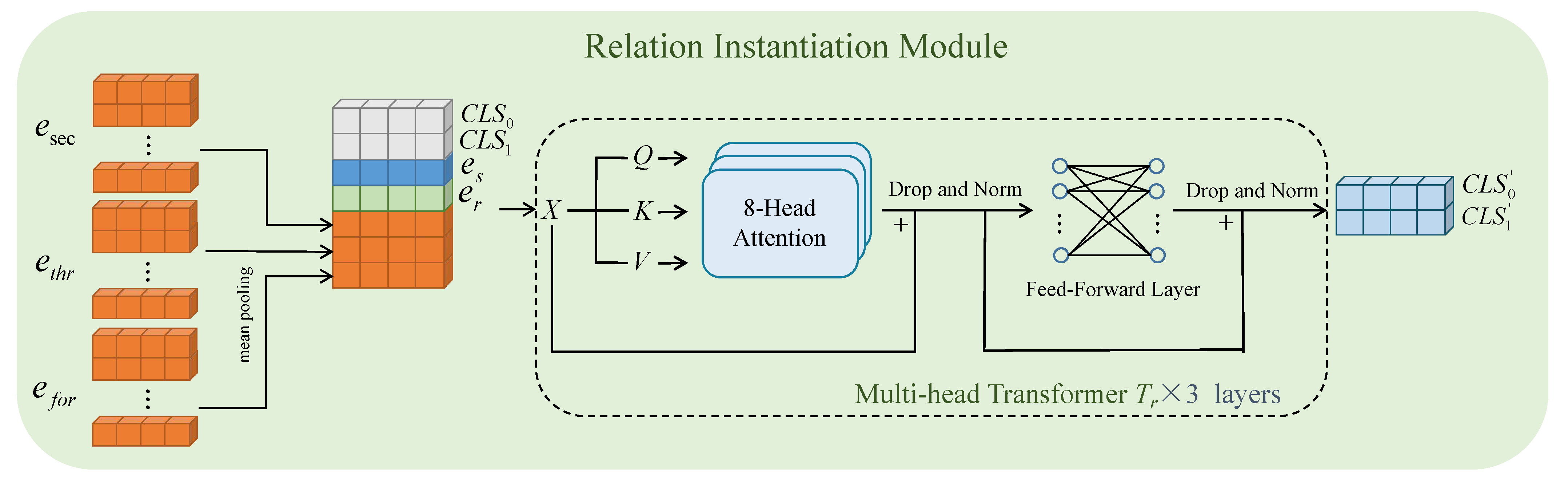
3.2. Relation Instantiation
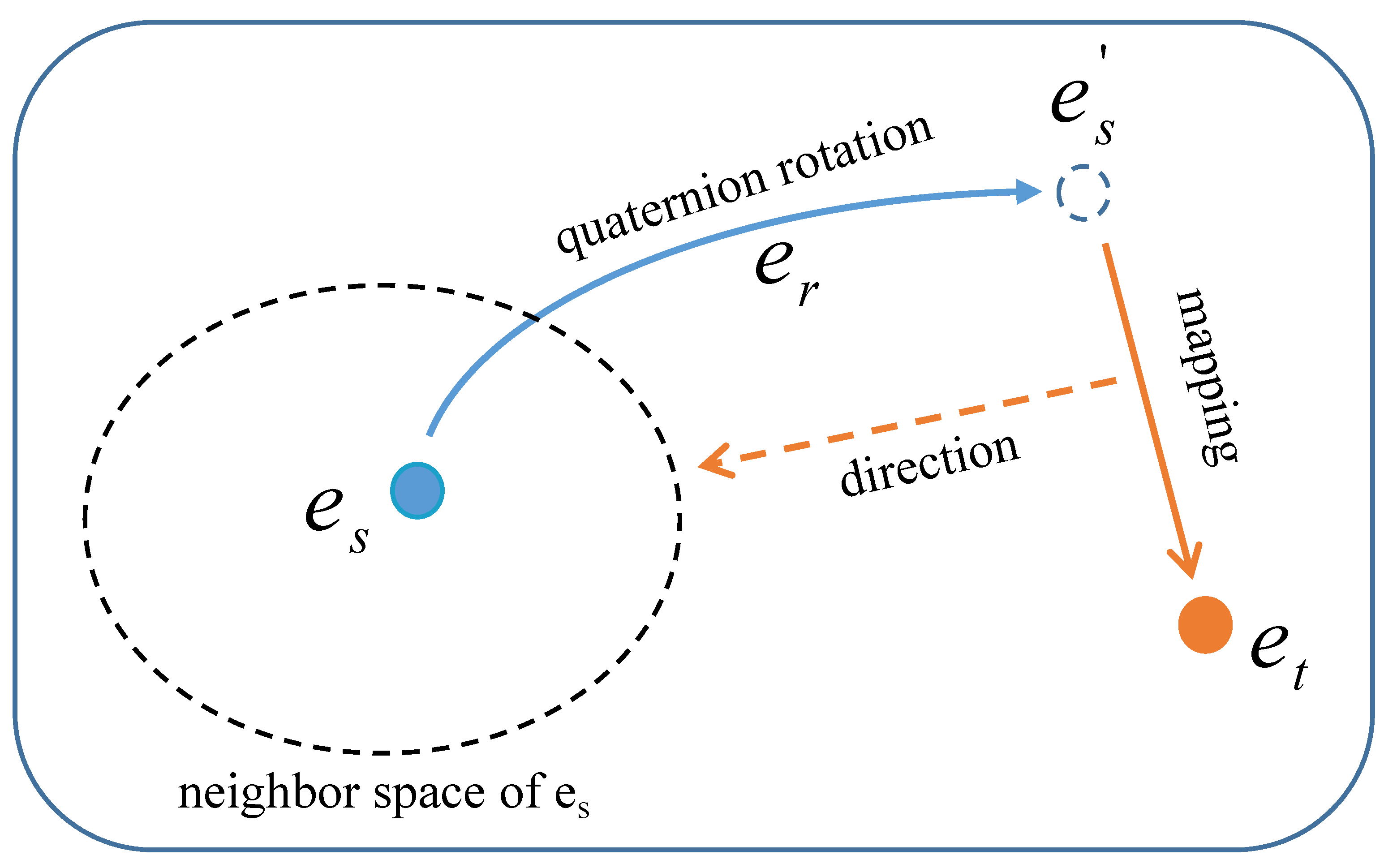
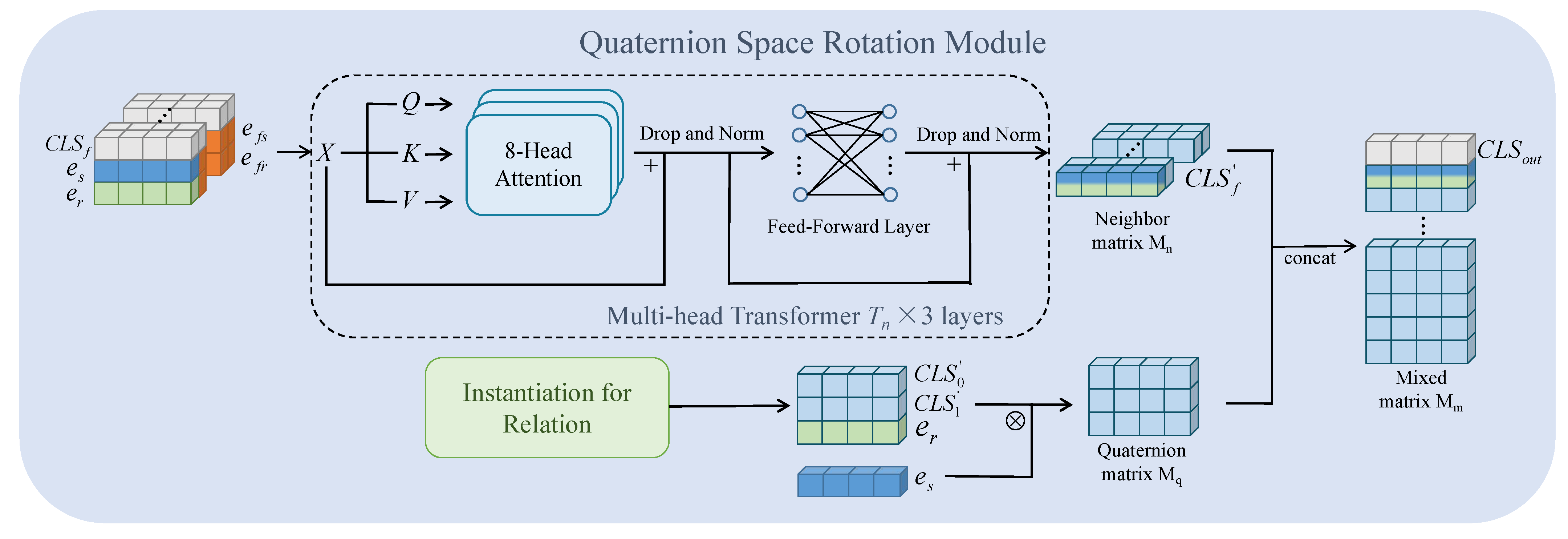
3.3. Quaternion Space Rotation
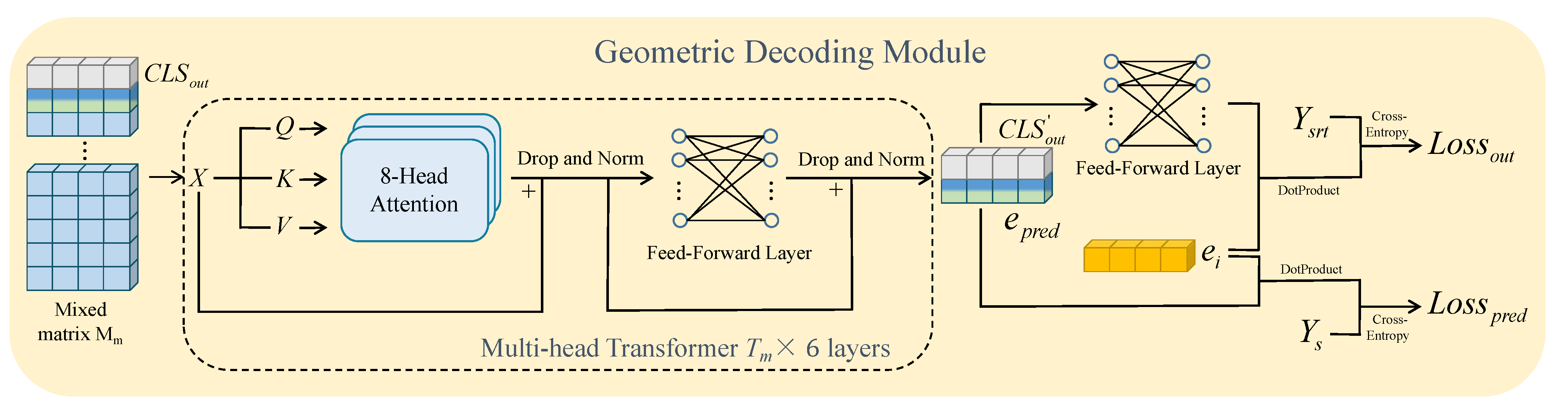
3.4. Geometric Decoding
4. Experiments and Numerical Results
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Evaluation Metrics
4.1.3. Baselines
4.1.4. Implementation Details
4.2. Comparison with Existing Methods
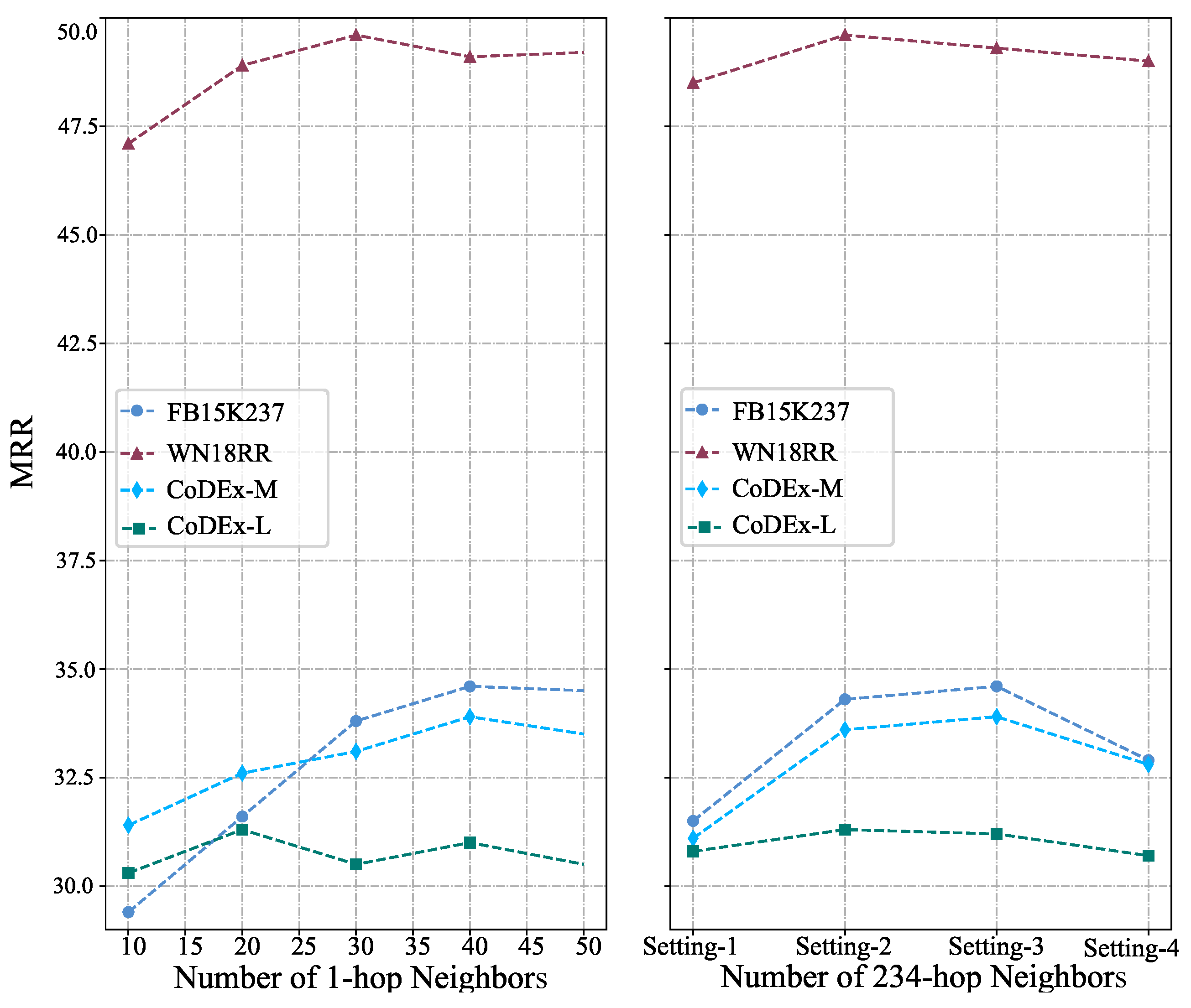
4.3. Parameter Evaluation
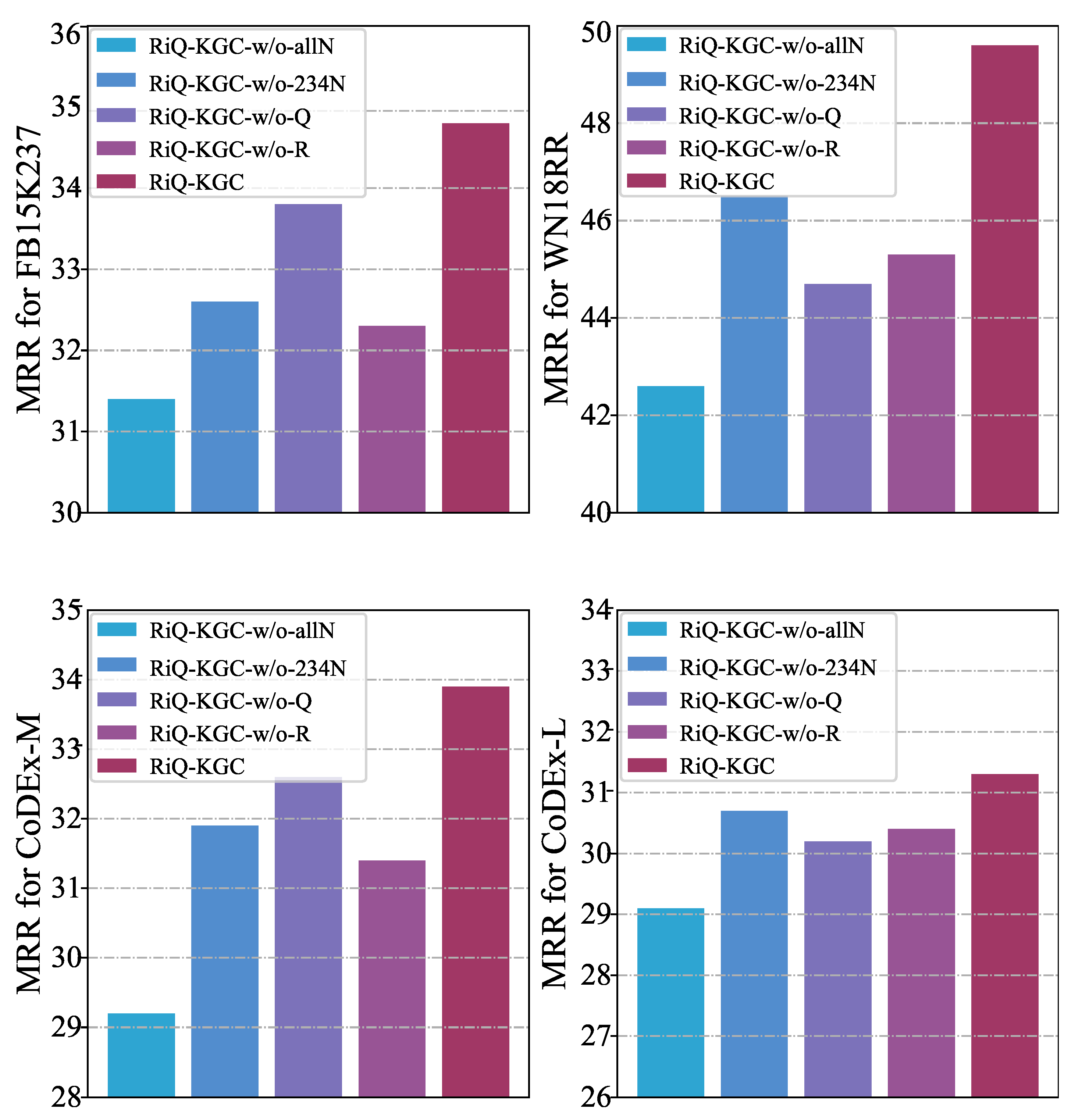
4.4. Ablation Studies
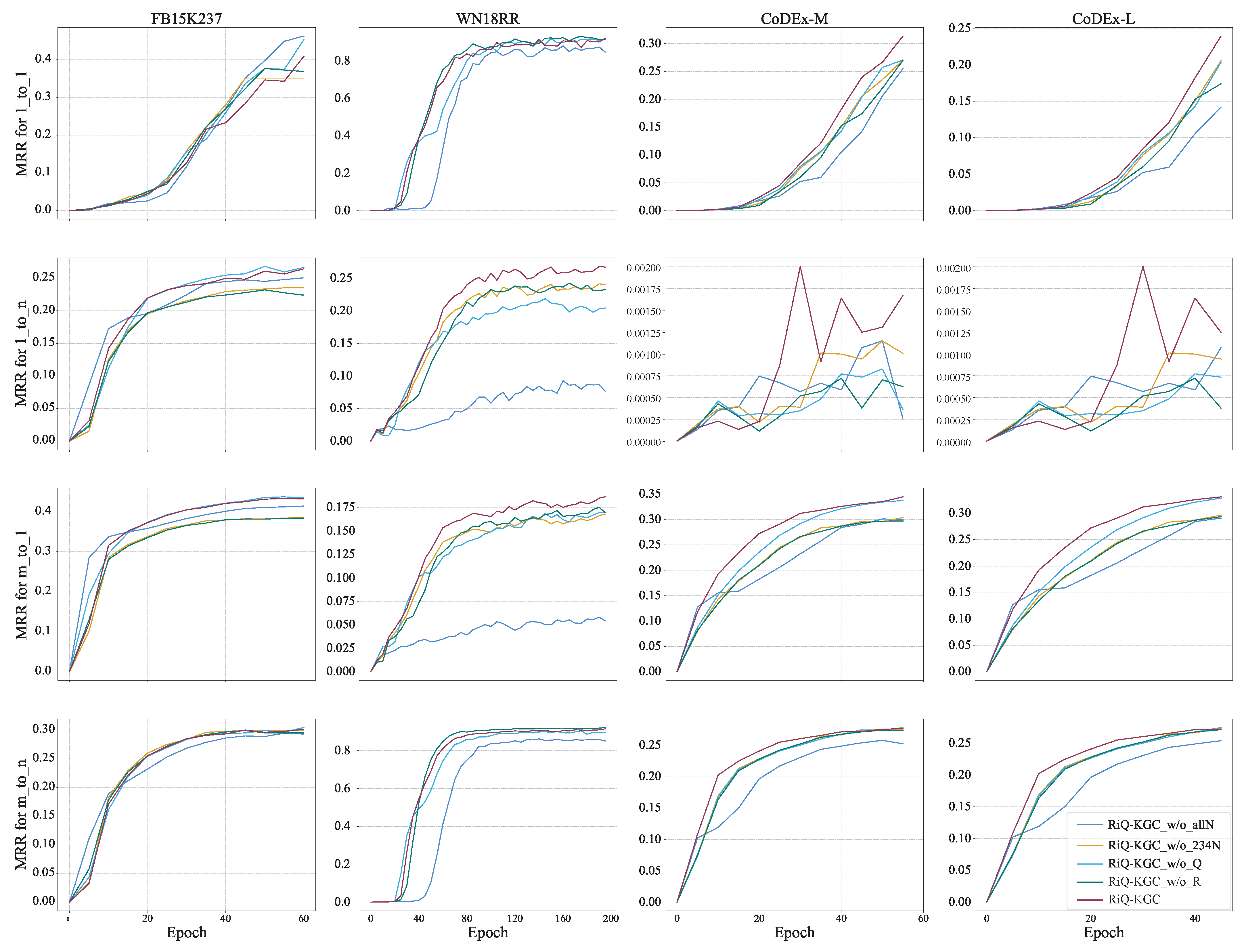
4.5. Modeling Capability for Complex Relation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hayashi, H.; Hu, Z.; Xiong, C.; Neubig, G. Latent Relation Language Models. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7911–7918. [Google Scholar]
- Verga, P.; Sun, H.; Soares, L.B.; Cohen, W.W. Adaptable and Interpretable Neural MemoryOver Symbolic Knowledge. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3678–3691. [Google Scholar]
- Song, X.; Li, J.; Cai, T.; Yang, S.; Yang, T.; Liu, C. A survey on deep learning based knowledge tracing. Knowl. Based Syst. 2022, 258, 110036. [Google Scholar] [CrossRef]
- Bi, X.; Nie, H.; Zhang, G.; Hu, L.; Ma, Y.; Zhao, X.; Yuan, Y.; Wang, G. Boosting question answering over knowledge graph with reward integration and policy evaluation under weak supervision. Inf. Process. Manag. 2023, 60, 103242. [Google Scholar] [CrossRef]
- Hu, X.; Xu, J.; Wang, W.; Li, Z.; Liu, A. A graph embedding based model for fine-grained POI recommendation. Neurocomputing 2021, 428, 376–384. [Google Scholar] [CrossRef]
- Liu, H.; Tong, Y.; Han, J.; Zhang, P.; Lu, X.; Xiong, H. Incorporating Multi-Source Urban Data for Personalized and Context-Aware Multi-Modal Transportation Recommendation. IEEE Trans. Knowl. Data Eng. 2022, 34, 723–735. [Google Scholar] [CrossRef]
- Wang, X.; Cui, P.; Wang, J.; Pei, J.; Zhu, W.; Yang, S. Community Preserving Network Embedding. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 203–209. [Google Scholar]
- Nie, F.; Zhu, W.; Li, X. Unsupervised Large Graph Embedding. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31, pp. 2422–2428. [Google Scholar]
- Yan, J.; Gu, Z.; Jiang, Z.; Gao, C.; Yang, J. Persistent Graph Stream Summarization For Real-time Graph Analytics. World Wide Web J. 2023, 31, 7911–7918. [Google Scholar]
- Yi, P.; Li, J.; Choi, B.; Bhowmick, S.S.; Xu, J. FLAG: Towards Graph Query Autocompletion for Large Graphs. Data Sci. Eng. 2022, 7, 175–191. [Google Scholar] [CrossRef]
- Liu, P.; Wang, X.; Fu, Q.; Yang, Y.; Li, Y.F.; Zhang, Q. KGVQL: A knowledge graph visual query language with bidirectional transformations. Knowl.-Based Syst. 2022, 250, 108870. [Google Scholar] [CrossRef]
- Shaalan, K. A Survey of Arabic Named Entity Recognition and Classification. Comput. Linguist. 2014, 40, 469–510. [Google Scholar] [CrossRef]
- Wu, H.; Song, C.; Ge, Y.; Ge, T. Link Prediction on Complex Networks: An Experimental Survey. Data Sci. Eng. 2022, 7, 253–278. [Google Scholar] [CrossRef] [PubMed]
- Miller, G.A. WordNet: A Lexical Database for English. Communications 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Vrandecic, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Communications 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, X.; Wang, C.; Li, J. Explainable Link Prediction in Knowledge Hypergraphs. In Proceedings of the 31st ACM International Conference on Information and Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 262–271. [Google Scholar]
- Zhang, Y.; Sheng, M.; Zhou, R.; Wang, Y.; Han, G.; Zhang, H.; Xing, C.; Dong, J. HKGB: An Inclusive, Extensible, Intelligent, Semi-auto-constructed Knowledge Graph Framework for Healthcare with Clinicians’ Expertise Incorporated. Inf. Process. Manag. 2020, 57, 102324. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2787–2795. [Google Scholar]
- Sun, Z.; Deng, Z.; Nie, J.; Tang, J. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kim, B.; Hong, T.; Ko, Y.; Seo, J. Multi-Task Learning for Knowledge Graph Completion with Pre-trained Language Models. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1737–1743. [Google Scholar] [CrossRef]
- Chen, S.; Liu, X.; Gao, J.; Jiao, J.; Zhang, R.; Ji, Y. HittER: Hierarchical Transformers for Knowledge Graph Embeddings. In Proceedings of the Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 10395–10407. [Google Scholar] [CrossRef]
- Zhang, S.; Tay, Y.; Yao, L.; Liu, Q. Quaternion Knowledge Graph Embeddings. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 2731–2741. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar] [CrossRef]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 2071–2080. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T.A. Holographic Embeddings of Knowledge Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1955–1961. [Google Scholar]
- Ebisu, T.; Ichise, R. TorusE: Knowledge Graph Embedding on a Lie Group. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1819–1826. [Google Scholar]
- Cao, Z.; Xu, Q.; Yang, Z.; Cao, X.; Huang, Q. Dual Quaternion Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 6894–6902. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, T.M. Multi-relational Poincaré Graph Embeddings. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4465–4475. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6901–6914. [Google Scholar] [CrossRef]
- Jia, Y.; Lin, M.; Wang, Y.; Li, J.; Chen, K.; Siebert, J.; Zhang, G.Z.; Liao, Q. Extrapolation over temporal knowledge graph via hyperbolic embedding. CAAI Trans. Intell. Technol. 2023, 8, 418–429. [Google Scholar] [CrossRef]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2D Knowledge Graph Embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Balazevic, I.; Allen, C.; Hospedales, T.M. Hypernetwork Knowledge Graph Embeddings. In Proceedings of the 28th International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Volume 11731, pp. 553–565. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Huang, X.; Li, J.; Min, G. GNN-based long and short term preference modeling for next-location prediction. Inf. Sci. 2023, 629, 1–14. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wang, B.; Shen, T.; Long, G.; Zhou, T.; Wang, Y.; Chang, Y. Structure-Augmented Text Representation Learning for Efficient Knowledge Graph Completion. In Proceedings of the WWW ’21: The Web Conference, Ljubljana, Slovenia, 19–23 April 2021; pp. 1737–1748. [Google Scholar] [CrossRef]
- Lv, X.; Lin, Y.; Cao, Y.; Hou, L.; Li, J.; Liu, Z.; Li, P.; Zhou, J. Do Pre-trained Models Benefit Knowledge Graph Completion? In A Reliable Evaluation and a Reasonable Approach. In Proceedings of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 3570–3581. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, W.; Wei, Z.; Liu, J. SimKGC: Simple Contrastive Knowledge Graph Completion with Pre-trained Language Models. In Proceedings of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 4281–4294. [Google Scholar] [CrossRef]
- Youn, J.; Tagkopoulos, I. KGLM: Integrating Knowledge Graph Structure in Language Models for Link Prediction. In Proceedings of the 12th Joint Conference on Lexical and Computational Semantics, Toronto, ON, Canada, 13–14 July 2023; pp. 217–224. [Google Scholar] [CrossRef]
- Lacroix, T.; Usunier, N.; Obozinski, G. Canonical Tensor Decomposition for Knowledge Base Completion. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2869–2878. [Google Scholar]
- Toutanova, K.; Chen, D. Observed versus latent features for knowledge base and text inference. In Proceedings of the Continuous Vector Space Models and their Compositionality, Beijing, China, 31 July 2015; pp. 57–66. [Google Scholar] [CrossRef]
- Bollacker, K.D.; Evans, C.; Paritosh, P.K.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Safavi, T.; Koutra, D. CoDEx: A Comprehensive Knowledge Graph Completion Benchmark. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 8328–8350. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Broscheit, S.; Ruffinelli, D.; Kochsiek, A.; Betz, P.; Gemulla, R. LibKGE—A knowledge graph embedding library for reproducible research. In Proceedings of the Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 165–174. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Head entity, relation, and tail entity in a KG triple | |
| Embeddings of and t, respectively | |
| Embeddings of the source entity in a given incomplete triple | |
| Embeddings of the predicted entity obtained by quaternion transform | |
| Embeddings of the second-hop, third-hop, and fourth-hop neighbors | |
| Embeddings of the first-hop neighbor’s entity and relation | |
| Different flag vectors | |
| Output of and | |
| A multi-head Transformer for relation instantiation | |
| A multi-head Transformer for quaternion space rotation | |
| A multi-head Transformer for geometric decoding |
| Datasets | Training | Validation | Test | ||
|---|---|---|---|---|---|
| FB15K-237 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| CoDEx-M | 17,050 | 51 | 185,584 | 10,310 | 10,311 |
| CoDEx-L | 77,951 | 69 | 551,193 | 30,622 | 30,622 |
| Datasets | 1-Hop | 1-Hop Dropout | 2-Hop | 3-Hop | 4-Hop |
|---|---|---|---|---|---|
| FB15K-237 | 40 | 0.3 | 50 | 150 | 500 |
| WN18RR | 30 | 0.5 | 30 | 100 | 250 |
| CoDEx-M | 40 | 0.3 | 50 | 150 | 500 |
| CoDEx-L | 20 | 0.5 | 30 | 100 | 250 |
| FB15K-237 | WN18RR | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 |
| DisMult [27] | 0.241 | 0.155 | 0.263 | 0.419 | 0.430 | 0.390 | 0.440 | 0.490 |
| RotatE [20] | 0.338 | 0.241 | 0.375 | 0.476 | 0.428 | 0.492 | 0.571 | |
| QuatE [23] | 0.311 | 0.221 | 0.342 | 0.495 | 0.436 | 0.500 | 0.564 | |
| MuRP [33] | 0.335 | 0.243 | 0.367 | 0.518 | 0.495 | 0.566 | ||
| MuRE [33] | 0.336 | 0.245 | 0.370 | 0.521 | 0.475 | 0.436 | 0.487 | 0.554 |
| ConvE [36] | 0.325 | 0.237 | 0.356 | 0.501 | 0.430 | 0.400 | 0.440 | 0.520 |
| HypER [37] | 0.520 | 0.465 | 0.436 | 0.477 | 0.522 | |||
| MTL-KGC [21] | 0.267 | 0.172 | 0.298 | 0.458 | 0.331 | 0.203 | 0.383 | 0.597 |
| StAR [41] | 0.296 | 0.205 | 0.322 | 0.482 | 0.401 | 0.243 | 0.491 | |
| KGLM [44] | 0.289 | 0.200 | 0.314 | 0.468 | 0.467 | 0.330 | ||
| RiQ-KGC (ours) | 0.572 | |||||||
| FB15K-237 | WN18RR | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | MRR | H@1 | H@3 | H@10 | MRR | H@1 | H@3 | H@10 |
| TransE [19] | 0.303 | 0.223 | 0.336 | 0.454 | 0.187 | 0.116 | 0.218 | 0.317 |
| RESCAL [29] | 0.317 | 0.244 | 0.347 | 0.456 | 0.304 | 0.331 | 0.419 | |
| ComplEx [28] | 0.294 | 0.237 | 0.318 | 0.400 | ||||
| ConvE [36] | 0.318 | 0.239 | 0.355 | 0.464 | 0.303 | 0.240 | 0.330 | 0.420 |
| TuckER [45] | 0.328 | 0.360 | 0.458 | |||||
| RiQ-KGC (ours) | ||||||||
| Second-Hop | Third-Hop | Fourth-Hop | |
|---|---|---|---|
| Setting-1 | 10 | 25 | 60 |
| Setting-2 | 30 | 100 | 250 |
| Setting-3 | 50 | 150 | 500 |
| Setting-4 | 80 | 200 | 750 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Ning, B.; Jiang, S.; Zhou, X.; Li, G.; Ma, Q. RiQ-KGC: Relation Instantiation Enhanced Quaternionic Attention for Complex-Relation Knowledge Graph Completion. Appl. Sci. 2024, 14, 3221. https://doi.org/10.3390/app14083221
Wang Y, Ning B, Jiang S, Zhou X, Li G, Ma Q. RiQ-KGC: Relation Instantiation Enhanced Quaternionic Attention for Complex-Relation Knowledge Graph Completion. Applied Sciences. 2024; 14(8):3221. https://doi.org/10.3390/app14083221
Chicago/Turabian StyleWang, Yunpeng, Bo Ning, Shuo Jiang, Xin Zhou, Guanyu Li, and Qian Ma. 2024. "RiQ-KGC: Relation Instantiation Enhanced Quaternionic Attention for Complex-Relation Knowledge Graph Completion" Applied Sciences 14, no. 8: 3221. https://doi.org/10.3390/app14083221
APA StyleWang, Y., Ning, B., Jiang, S., Zhou, X., Li, G., & Ma, Q. (2024). RiQ-KGC: Relation Instantiation Enhanced Quaternionic Attention for Complex-Relation Knowledge Graph Completion. Applied Sciences, 14(8), 3221. https://doi.org/10.3390/app14083221