Abstract
Images captured in rainy weather conditions often suffer from contamination, resulting in blurred or obscured objects, which can significantly impact detection performance due to the loss of identifiable texture and color information. Moreover, the quality of the detection model plays a pivotal role in determining detection outcomes. This study adopts a dual perspective, considering both pre-trained models and training data. It employs 15 image augmentation techniques, combined with neural style transfer (NST), CycleGAN, and an analytical method, to synthesize images under rainy conditions. The Real-Time Detection Transformer (RTDETR) and YOLOv8 pre-trained models are utilized to establish object detection frameworks tailored for rainy weather conditions. Testing is carried out using the DAWN (Detection in Adverse Weather Nature) dataset. The findings suggest compatibility between the pre-trained detection models and various data synthesis methods. Notably, YOLOv8 exhibits better compatibility with CycleGAN data synthesis, while RTDETR demonstrates a stronger alignment with the NST and analytical approaches. Upon the integration of synthesized rainy images into model training, RTDETR demonstrates significantly enhanced detection accuracy compared to YOLOv8, indicating a more pronounced improvement in performance. The proposed approach of combining RTDETR with NST in this study shows a significant improvement in Recall (R) and mAP50-95 by 16.35% and 15.50%, respectively, demonstrating the robust rainy weather resilience of this method. Additionally, RTDETR outperforms YOLOv8 in terms of inference speed and hardware requirements, making it easier to use and deploy in real-time applications.
1. Introduction
The continuous development and widespread adoption of deep learning technology have significantly advanced the field of computer vision. Object detection, a core task in computer vision, holds promising applications across various domains. For instance, in autonomous driving, object detection aids in identifying pedestrians, vehicles, and obstacles on the road, thereby enabling intelligent driving and accident prevention [1,2,3]. In intelligent surveillance systems, object detection facilitates real-time recognition and tracking of specific targets by surveillance cameras, thereby enhancing security and monitoring efficiency [4,5,6]. The broad application of deep learning technology has led to ongoing optimization and enhancement of object detection algorithms, improving their accuracy, robustness, and efficiency. Through the training of deep neural networks, object detection algorithms can learn rich feature representations from vast image data, enabling precise identification and localization of objects across different classes. As a result, we anticipate the emergence of more precise and efficient object detection algorithms to address the diverse needs of practical application scenarios, ultimately bringing greater convenience and security to people’s lives and work.
Improving object detection performance under adverse weather conditions is crucial for automated visual systems, making it a focal point in computer vision research. Approaches to handling the influence of adverse weather conditions on object detection tasks can generally be categorized into two groups: data-driven methods and image restoration methods. Data-driven approaches aim to train object detection models specifically tailored to varying weather conditions using images affected by adverse weather. However, a significant challenge with such methods lies in acquiring a large and diverse dataset of images captured under adverse weather conditions. Traditional methods involve collecting real images, which is expensive, time-consuming, and often leads to insufficient generalization of trained models, thereby limiting their applicability. Image augmentation and synthesis techniques have emerged as pivotal advancements for data-driven approaches, particularly with the advent of deep learning. These techniques facilitate effective extraction of additional information from existing data, enabling the generation of new images or modifications to existing ones. Consequently, they enhance the robustness of object detection models to adverse weather conditions.
Deep learning-based image generation methods, due to their ability to extract deep visual information from images for synthesis, produce images that better meet user needs. Therefore, these methods have become some of the primary approaches for simulating images under adverse weather conditions. Among them, the generative adversarial network (GAN) and its variants are widely employed methods. Of these methods, CycleGAN, proposed by Zhu et al. [7], effectively addresses the challenge of precise matching training samples in pix2Pix and enables training using unpaired samples. CycleGAN extends the potential applications of GAN in various domains, such as autonomous driving research, by mitigating data scarcity issues under adverse weather conditions [8,9,10,11,12], as well as in closed-circuit television (CCTV) surveillance systems [13], construction site image dataset creation with diverse weather conditions [14], and synthetic sample generation for model training to address the scarcity of specific samples, such as flood scenarios [15]. Moreover, CycleGAN enhances limited day–night image data for creating paired datasets in industrial inspection applications [16] and in medical applications [17].
Neural style transfer (NST) is another notable method. The pioneering work by Gatys et al. [18] showcased the remarkable capabilities of the convolutional neural network (CNN) in artistic image creation by separating and recombining image content and style. NST has since become a popular topic in academic literature and industrial applications [19]. Studies have explored the effects of style transfer-based data transformation on CNN classifier accuracy, particularly in automobile detection under adverse winter weather conditions [20]. Additionally, NST has been used to create a stylized version of the COCO (Common Objects in Context) dataset, mimicking images obtained from thermal imagers [21], and enhancing object detection models for personal protective equipment (PPE) detection by generating extreme conditions such as low light, strong light, dust, fog, and rain [22].
An alternative approach to enhance object detection accuracy under adverse weather conditions is noise removal techniques, also called image restoration. This method involves preprocessing images before object detection to improve image quality and eliminate noise. During this preprocessing phase, a noise removal module is established prior to the object detection module. This module is trained to remove noise generated by adverse weather conditions from the images, restoring them to cleaner versions. This method can generally be classified into three categories [23]. The first category involves establishing a noise removal module using physical and mathematical models or deep learning networks [24,25,26,27,28], followed by utilizing a pre-trained object detection model for detection tasks. The second and third categories consider the loss of object detection accuracy when establishing the noise removal module, incorporating the detection results into the design of the loss function partially or entirely. In the second category, the parameters of the pre-trained object detection model are learnable [29,30,31,32], while in the third category, they remain fixed [23,33].
YOLO series of models represent the most widely used approach to date. From YOLOv1 to YOLOv9, this series of models has played a pivotal role in the field of object detection, with various variants based on each version. YOLOv1, introduced by Redmon et al. in 2015 [34], was notable for its ability to simultaneously perform object class classification and bounding box prediction, earning recognition for its speed and efficiency. In 2017, YOLOv2 [35] was introduced, further refining YOLOv1 by introducing the Darknet-19 architecture and a series of techniques, resulting in improved model performance, comparable speed, and support for a greater number of object classes. YOLOv3 [36], introduced in 2018, adopted the Darknet-53 backbone architecture, further enhancing model efficiency. YOLOv4 [37], introduced in 2020 by Bochkovskiy et al., introduced the CSPDarknet53 backbone architecture and multiple new techniques, including Mosaic data augmentation and a new anchor-free detection head, aimed at improving detection accuracy. In 2022, the team presented YOLOv7 [38], which adopted the Extended Effective Layer Aggregation Network (E-ELAN) and RepVGG, enhancing network learning capabilities through shuffling and merging cardinalities without disrupting the original gradient path. Following this, YOLOv9 [39] was unveiled in 2024, introducing groundbreaking technologies such as Programmable Gradient Information (PGI) and the General Efficient Layer Aggregation Network (GELAN), achieving significant improvements in efficiency, accuracy, and adaptability. YOLOv5 [40], proposed by Glen Jocher, founder and CEO of Ultralytics, in 2020 modified the CSPDarknet53 backbone network, improving upon aspects of YOLOv4. It was developed in PyTorch instead of Darknet and incorporated the Ultralytics algorithm AutoAnchor. In 2023, YOLOv8 [41] was introduced, featuring advanced backbone and neck structures, as well as an anchor-free segmentation head from Ultralytics, along with optimized accuracy and speed balance, making it suitable for various real-time object detection tasks. YOLOv6 [42], proposed by Meituan in 2022, combined backbone blocks such as RepVGG or CSPStackRep and utilized enhanced quantization techniques such as post-training quantization and channel-level distillation to achieve faster and more accurate detectors.
The Vision Transformer (ViT) is a deep learning model based on the Transformer architecture, first proposed by Dosovitskiy et al. [43] in 2020 in the paper “An Image Is Worth 16 × 16 Words: Transformers for Image Recognition”. This study explores the application of the Transformer architecture in image classification tasks, introducing a novel approach of slicing images into fixed-sized patches and feeding them into a Transformer model for processing, instead of using a traditional convolutional neural network (CNN). The research demonstrates that the Transformer architecture can achieve comparable performance to a traditional CNN in image classification, laying the foundation for the development and subsequent applications of ViT models in the field of image processing.
DETR (Detection Transformer), proposed by Carion et al. [44] in 2020, is a model for end-to-end object detection using the Transformer architecture. The DETR model eliminates the need for traditional components, such as anchor boxes and non-maximum suppression (NMS), in conventional object detection algorithms by leveraging attention mechanisms, directly encoding and predicting object positions using Transformers. Deformable DETR, introduced by Zhu et al. [45] in 2020, integrates deformable mechanisms into the Transformer model, enabling the model to flexibly adjust receptive fields to adapt to objects of different scales and shapes, thereby better capturing and understanding the actual shapes and positions of objects in images. Conditional DETR, proposed by Meng et al. [46] in 2021, learns conditional space queries from decoder embeddings for decoder multi-head cross-attention. This approach reduces the spatial range for different regions used for target classification and box regression, thereby reducing reliance on content embeddings and simplifying the training process. Real-Time Detection Transformer (RTDETR), introduced by Lv et al. [47] in 2023, designs an efficient hybrid encoder to effectively handle multi-scale features by decoupling intra-scale interaction and cross-scale fusion. Additionally, it proposes IoU-aware query selection to improve the initialization of target queries. Moreover, the proposed detector supports flexible adjustment of inference speed using different decoder layers without the need for retraining, facilitating practical applications of real-time object detection.
In addition to the object detection methods mentioned earlier, several innovative approaches have been proposed in the research community. Ren et al. [48] in 2015 introduced Faster R-CNN, which incorporated a region proposal network (RPN) for swift feature extraction and object localization. Liu et al. [49] in 2016 streamlined the process with the Single Shot MultiBox Detector (SSD) by enabling direct object classification and localization across multiple feature maps. Fu et al. [50] in 2017 enhanced SSD with the Deconvolutional Single Shot Detector (DSSD), using deconvolutional layers to improve feature map resolution. Introduced by Cai and Vasconcelos [51] in 2018, Cascade Mask R-CNN is a high-performance framework for object detection and instance segmentation. It improves on Mask R-CNN by incorporating a cascading strategy, enhancing performance in handling small objects or objects within complex backgrounds. Zhang et al. [52] in 2020 presented adaptive training sample selection (ATSS) to automatically select positive and negative samples according to statistical characteristics of objects to improve the performance of anchor-based and anchor-free detectors. Chen et al. [53] in 2020 introduced RepPointsV2, capturing nuanced object shapes. Sun et al. [54] in 2021 revolutionized object detection with Sparse R-CNN, simplifying detection processes with learned proposals. In the field of object detection based on visual data, the clarity of texture and distinct color contrast in images is crucial for learning visual features for accurate prediction. However, in outdoor environments, such as those encountered in applications like autonomous driving or surveillance systems, adverse weather conditions inject noise into images, leading to blurriness, decreased visibility, or obstruction of crucial information about objects. As a result, the degradation of visual features in images reduces the accuracy of object detection. Adverse weather conditions in image recognition typically refer to phenomena such as rain, snow, fog, and dust storms. Given Taiwan’s geographical location, encountering rainy seasons or typhoon climates throughout the year is common. Therefore, among adverse weather conditions, rainfall is one of the most severe factors affecting image recognition applications. Consequently, developing object detection models adapted to rainy weather conditions is a valuable research issue, not limited to Taiwan alone. This study will focus on the data-driven domain to evaluate rainy weather image generation and detection models, aiming to develop object detection models for rainy weather conditions.
Here are the main contributions of this study: (1) To the best of our knowledge, this research marks the inaugural endeavor to formulate an object detection model tailored to rainy weather conditions using RTDETR. (2) By leveraging image augmentation and synthesis techniques to generate rainy weather noise, we augmented real data for model training, mitigating the constraints associated with the scarcity of authentic rainy weather images. This approach is particularly advantageous for bespoke detection models, enabling them to glean insights from diverse and intricate rainy weather imagery, thereby enhancing their generalization capability during deployment. (3) Through a comprehensive evaluation of rainy weather image generation methods and detection models, we discerned that the selection of a rainy weather image generation method should hinge upon the characteristics of the specific detection model. (4) RTDETR exhibits exceptional prowess in discerning object features from rainy weather images. Relative to YOLOv8, it manifests superior proficiency in training object detection models with heightened accuracy under rainy weather conditions. (5) Our findings underscore the efficacy of amalgamating a pre-trained RTDETR model with neural style transfer to generate rainy weather images for training purposes, delineating a robust and dependable data-driven methodology for crafting rainy weather object detection models.
2. Related Work
In light of the research content and thematic inquiry of this study, this section undertakes a comprehensive review, centering on data-driven methodologies, particularly emphasizing the utilization of deep learning-based image synthesis techniques to enhance object detection precision. In 2019, Volk et al. [48] pioneered a methodology integrating deep maps, OpenGL, and a convolutional neural network (CNN) to synthetically generate diverse rain patterns. This approach aimed to systematically evaluate and refine deep neural networks (DNNs) by exposing them to a wide array of simulated rain scenarios. The methodology comprised two fundamental phases: initial training of the neural network on a foundational dataset, followed by a robustness assessment through synthetic rain simulations. Consequently, the original dataset underwent augmentation with synthetic rain patterns, encompassing variations in luminance, rainfall intensity, and the impact of rain droplets on surfaces. During the evaluation phase, parameters governing synthetic rain synthesis were meticulously explored, culminating in dataset expansion during the optimization phase. This involved integrating images depicting identified key synthetic rain variations. Subsequently, the neural network underwent retraining using the augmented dataset, resulting in enhanced performance under diverse environmental conditions. Notably, this approach yielded significant improvements in object detection accuracy, as evidenced by substantial enhancements in average precision (AP) scores on the KITTI dataset, with Faster-RCCN and YOLOv3 achieving notable performance gains of 4.37 and 7.33 percentage points, respectively.
In 2020, a novel method was introduced by [49], leveraging a combination of generative adversarial network (GAN) and physics-based rendering (PBR) techniques for synthesizing rainy weather images. Validation using YOLOv2 confirmed substantial improvements in object detection accuracy. Similarly, in 2021, [12] explored the feasibility of generating synthetic weather images using a generative adversarial network (GAN). Subsequent studies investigated the use of CycleGAN to generate synthetic adverse weather data [9], resulting in performance enhancements in object detection models under real adverse conditions. Among various detection models, YOLOv5 emerged as a preferred choice due to its superior performance, achieving high mAP scores under different weather conditions. Furthermore, developments such as the NST-YOLOv5 model [22] demonstrated significant improvements in detecting personal protective equipment (PPE) for construction workers, particularly under extreme weather conditions.
In 2024, a study by [50] utilized the CycleGAN model to generate images under rainy and foggy weather conditions for Maritime Surveillance Systems’ object detection. The research validated the approach by retraining pre-trained models, including YOLOv5, Faster R-CNN, and DETR, with the results indicating superior performance of YOLOv5 compared to DETR. Additionally, Gupta et al. [51], in the same year, employed image augmentation and synthesis techniques to generate adverse weather images, including fog, rain, and snow. Initially, original images were collected and subjected to analytical, GAN, and style-transfer methods to generate adverse weather images. Subsequently, different augmentation strategies were applied to both original and synthetically generated images under adverse weather conditions. Finally, the pre-trained YOLOv5-l model was employed to train object detection models, demonstrating the potential of synthetic weather augmentation, with style transfer networks particularly impactful. Furthermore, exploration of adverse weather denoising methods revealed the delicate balance between noise reduction and detection accuracy, underscoring the inherent complexity of this task. Despite facing challenges posed by adverse weather conditions, the research emphasizes the continuous potential for advancements in target detection and denoising techniques, positioning this study as a cornerstone toward more robust and reliable computer vision systems capable of operating under various weather conditions.
Based on the literature review presented, the research in this area is deemed worthy of further exploration. Notably, the study revealed that the impact of incorporating synthetic rainfall images on model detection accuracy is not universally consistent, emphasizing the importance of the image synthesis method employed. Additionally, the diversity of rainy weather images is influenced by the entire training data augmentation process, while the choice of pre-trained models significantly influences detection outcomes. Furthermore, the predominance of studies focusing on YOLO series detectors highlights a research gap concerning Transformer-based detection models. Motivated by these insights, this study aims to propose a novel data-driven approach to construct object detection models under rainy weather conditions, emphasizing the generation of training data and the selection of pre-trained models, with the goal of achieving significant advancements in this field and providing valuable insights for interested researchers.
3. Methodology
The motivation of this study is to train a detection model that can overcome the adverse effects on object detection caused by rainy weather conditions while maintaining the robustness and reliability of the model. Considering many downstream tasks of object detection, as the objects to be detected are not included in commonly used pre-trained models, such as COCO dataset models only containing specific 80 categories, retraining the model in such cases is unavoidable. We were inspired by this to aim to train a detection model that can adapt to rainy weather conditions. However, images under rainy conditions are relatively scarce compared to those under normal weather conditions, both in quantity and diversity of objects. This limitation makes it challenging to use real images under rainy conditions for model training. Thanks to advancements in image augmentation and synthesis techniques, this study generates realistic rainy images as training data through these techniques.
RTDETR and YOLOv8 were chosen as novel object detection models in this study. RTDETR combines Transformer and CNN into a hybrid detection model, inspired by the successful application of Transformers in the field of natural language processing. It transforms the object detection problem into an attention mechanism problem, modeling the relationships between objects in images through self-attention mechanisms. YOLOv8 directly predicts bounding boxes and class probabilities using deep CNN. It is an improved version of YOLOv5, optimized for network structure, data augmentation, and training techniques to achieve better detection performance. The choice of model significantly affects the detection accuracy of the detection model. Currently, common detection models under rainy conditions are mostly based on the YOLO series, with less exploration of Transformer-based models.
Therefore, this study not only explores different image generation methods under rainy weather conditions but also analyzes two detection methods, RTDETR and YOLOv8, with vastly different model structures. We aimed to investigate the detection performance of different combinations of training data and models, attempting to propose a robust and reliable model training method to overcome the impact of rainy weather conditions on object detection accuracy. The research process is illustrated in Figure 1.
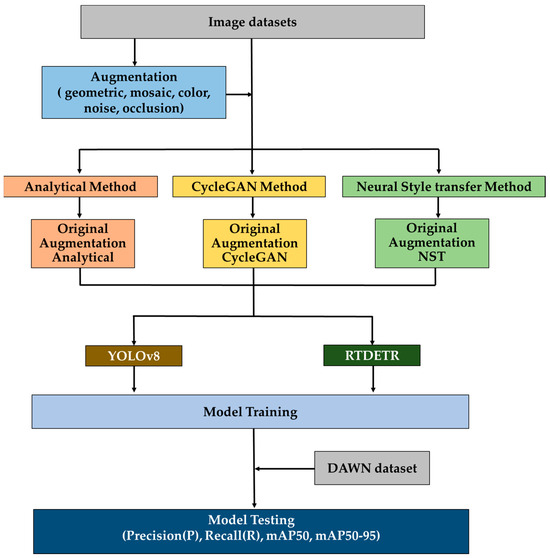
Figure 1.
Architecture of the methodology.
3.1. Image Augmentation
The general process of image augmentation involves collecting the required images, such as original images and synthetic images, and then performing augmentation [51]. However, such a strategy may lead to a lack of diversity or insufficient rainy images due to the random selection of images for augmentation. Therefore, in this study, we adopted a strategy of performing image augmentation first and then generating rainy images comprehensively to ensure that each original image and its augmented counterparts have corresponding images under rainy conditions. In total, this study collected 5322 images of good weather conditions, referred to as original images, all of which were sourced from openly accessible datasets, such as the COCO dataset, and have been annotated for object detection. To increase the diversity of training data and improve the model’s generalization ability, we utilized the Albumentations v.1.3.0 software to apply image augmentation techniques to these original images as shown in Figure 2. These techniques include:

Figure 2.
Image augmentation in this study.
- Geometric transformations: applying Affine, HorizontalFlip, Perspective, SafeRotation, and Scale transformations to introduce samples with different angles and proportions.
- Color adjustments: using ColorJitter and HueSaturation to adjust the tone, brightness, and contrast parameters of the original images to simulate different lighting conditions.
- Occlusion: adding CoarseDropout, Shadow, SunFlare, and Spatter to simulate common occlusion scenarios in the real world.
- Mosaic: concatenating multiple original images together, then cropping and rearranging the concatenated images to generate new images, thereby increasing the diversity of the data.
- Noise and blur: applying GaussNoise, PixelDropout, and Blur to increase the blur and noise in the original images.
By applying these data augmentation techniques, we generated a total of 16,003 augmented images. In theory, a larger number of training images can enhance detection performance, but this also increases computational complexity. There is no specific rule in the literature regarding how many training images are required. In this study, since multiple augmentation methods were employed, 1000 images were randomly selected from the original images for each method for augmentation. Additionally, 2003 images were generated for the Mosaic method. In total, there are 21,325 images, including 5322 original images and 16,003 augmented images, which will serve as the basis for generating rainy weather images.
3.2. Rainy Image Generation
Generally speaking, different image generation methods have their own advantages and limitations, and the choice of an appropriate method depends on specific application scenarios and requirements. Inspired by the work of [51], this study selected three methods: analytical synthesis, CycleGAN, and neural style transfer, to compare their effects on the object detection capability of trained models when generating rainy images as shown in Figure 3. In this study, based on 5322 original images and 16,003 augmented images, rainy weather condition images were generated using the aforementioned methods. Each method produced 21,325 images, resulting in a total of 42,650 images for training, including original images, augmented images, and rainy images.

Figure 3.
Schematic diagrams of rainy image generation by different methods.
3.2.1. Analytical Method
This method is based on physical principles and mathematical models, aiming to simulate specific effects of rainy weather. It involves modeling physical phenomena such as raindrops, splashes, and water flow, and then applying these models to image generation. This method typically requires in-depth knowledge of physics and complex computational models, but the generated images may have higher realism and physical plausibility. The RandomRain function from the Albumentations library was employed to replicate the visual effects of rainy weather in images. Parameters were meticulously configured, encompassing variables such as the slant angle of raindrops (ranging from −10 to 10 degrees), raindrop length (fixed at 20 pixels), and width (set to 1 pixel). Furthermore, we specified the color of raindrops as (200, 200, 200), denoting a light gray hue. The blur value was calibrated to 7, while the brightness coefficient was fine-tuned to 0.7. Rainfall patterns were stratified into three categories: drizzle, heavy, and torrential. Notably, the slant angle of raindrops and the rainfall pattern for each generated image were randomly assigned, ensuring the emulation of diverse precipitation scenarios with varying magnitudes and distribution patterns.
3.2.2. CycleGAN
It is based on a generative adversarial network (GAN), capable of generating target domain images corresponding to a set of source domain images. During the model training process, CycleGAN usually trains two generators and two discriminators, each responsible for mapping between domains and distinguishing between real and generated images. Through training, CycleGAN can learn the correspondence between source domain images and target domain images. In this study, the approach of using CycleGAN to generate rainy weather images, thereby learning the mapping relationship between clear and rainy weather images, is similar to the method described in [51]. The designed generator architecture consists of two downsampling blocks, nine ResNet blocks, and two upsampling blocks, while the discriminator adopts the PatchGAN-based structure, including a ConvNet with three hidden layers. Rainy weather images from the Boreas dataset [52] were utilized for training. The model was trained with parameters set as 100 epochs, batch size of 2, and Adam optimizer.
3.2.3. Neural Style Transfer
This technique is a CNN-based approach used to generate a new image with a specific artistic style or visual effect by combining the style of one image with the content of another image. Pre-trained CNNs are employed to extract the features of both the content and style images. The content image represents the structure and shape we aim to preserve, while the style image embodies the desired stylistic characteristics (such as colors, textures, brushstrokes, etc.) to be applied to the content image. In this study, we utilized a pre-trained VGG19 model trained on the ImageNet dataset to extract content and style features. The content loss is computed using mean squared error (MSE) loss, while the style loss is calculated using Gram matrices. The content loss measures the difference between the content features of the generated image and those of the content image, whereas the style loss quantifies the disparity between the style features of the generated image and those of the style image. We employed the LBFGS optimizer for iterative optimization, aiming to produce a final image that retains the main structural elements of the content image while simulating the visual style of the style image.
3.3. YOLOv8 and RTDETR
YOLOv8 [41], developed and released by Ultralytics, the same company behind YOLOv5, aims to provide a high-performance and efficient solution for object detection tasks. Built on the forefront advancements in deep learning and computer vision, it offers unparalleled performance in terms of speed and accuracy. Its streamlined design makes it suitable for various applications and easily adaptable to different hardware platforms, from edge devices to cloud APIs. Compared to previous versions of YOLO, YOLOv8 introduces new design philosophies and technologies to enhance the model’s accuracy and speed. It has been optimized in model architecture, data augmentation, and network design, among other aspects, resulting in outstanding results in object detection tasks. YOLOv8 not only performs well in general object detection tasks but also finds applications in various domains such as autonomous driving, industrial inspection, and object recognition.
RTDETR [47], developed by Baidu, is a real-time end-to-end detector based on the DETR architecture, achieving outstanding performance in speed and accuracy. Its development primarily addresses a significant improvement needed in YOLO detectors, namely the requirement for post-processing non-maximum suppression (NMS), which is often difficult to optimize and not robust enough, leading to detection speed delays. DETR eliminates the need for post-processing NMS and is a Transformer-based end-to-end object detector. However, compared to the YOLO series detectors, DETR detectors are much slower, which does not manifest the advantage of “NMS-free” in terms of speed.
The development of RTDETR aims to address the aforementioned issues and explore real-time end-to-end detectors, intending to design a real-time detector based on the excellent architecture of DETR to fundamentally solve the speed delay problem caused by NMS for real-time detectors. It is the first real-time end-to-end object detector. Specifically, RTDETR designs an efficient hybrid encoder to efficiently handle multi-scale features by decoupling intra-scale interactions and cross-scale fusion. It also proposes an IoU-aware query selection mechanism to optimize the initialization of decoder queries. Additionally, RTDETR supports flexible adjustment of inference speed by using different decoder layers without the need for retraining, which contributes to the practical application of real-time object detectors.
3.4. Model Training and Testing
To evaluate the impact of incorporating rainy images into the training dataset on object detection performance, this study designed four distinct training datasets: (1) original images combined with augmented images, (2) original images combined with augmented images and rainy images generated using the analytical method, (3) original images combined with augmented images and rainy images generated using the CycleGAN method, and (4) original images combined with augmented images and rainy images generated using the neural style transfer method. Regarding pre-trained models, RTDETR-x and YOLOv8-x were chosen, as they have the largest number of parameters and thus the best feature extraction capability. Therefore, a total of 8 detection models were trained, representing different combinations of the aforementioned data and pre-trained models as outlined in Table 1. During model training, 80% of the data was used for training and 20% for validation. The training process consisted of 100 epochs with a batch size of 16, and AdamW was employed as the optimizer. The hardware configuration for the experiment includes an Intel(R) Core(TM) i7-14700KF processor, Microsoft Windows 11 Pro, 64.0 GB of memory, and an NVIDIA GeForce RTX 4060 Ti 16 GB GPU.

Table 1.
The trained object detection models.
For independent testing, real rainy images were used to evaluate the detection capability. The DAWN [53] (Detection in Adverse Weather Nature) dataset was selected for this purpose, which is well-known and commonly used for testing. This dataset contains approximately 1000 images captured under adverse weather conditions, including rain, fog, snow, and sand. It encompasses diverse traffic environments such as urban, highway, and freeway, and provides annotations for both images and object bounding boxes. Hence, it is frequently utilized for evaluating the performance of detection models in autonomous driving vehicles and intelligent visual surveillance systems, especially under adverse weather conditions. Given this study’s focus on addressing the deterioration of object detection capability under rainy weather conditions, images under rainy weather from DAWN dataset were chosen for testing.
Four object detection evaluation metrics, namely Precision (P), Recall (R), mAP50, and mAP50-95, were utilized to assess the detection accuracy of different models. Precision indicates the accuracy of detected objects, Recall measures the model’s ability to identify all instances of objects in the images, mAP50 calculates the mean average precision at an IoU threshold of 0.50, and mAP50-95 computes the average of mean average precision across IoU thresholds ranging from 0.50 to 0.95. These metrics not only evaluate the model’s ability to correctly detect object categories, but also assess the localization accuracy of detection boxes. Frame per second (FPS), giga floating point operations (GFLOPs), and parameters are metrics used to evaluate the inference speed and computational efficiency of models, which are particularly useful for considering the deployment of real-time detection models.
4. Results and Discussion
This section evaluates the detection capabilities of the eight trained object detection models in this study, focusing on several aspects: whether the proposed method is effective, which method of generating rainy images enhances model recognition ability, the adaptability of RTDETR and YOLOv8 to the generated rainy image data, and the improvement in detection capabilities after adding rainy images as training data. The DAWN dataset mainly consists of vehicles such as cars, motorcycles, and pedestrians on the road. Therefore, these three categories are evaluated for detection accuracy. Considering that the number of instances varies among classes in rainy images, a weighted average is used to evaluate the overall accuracy of each metric. In other words, classes with more instances have higher weights, while classes with fewer instances have lower weights. We believe that this approach provides a fair and objective representation of model performance compared to simple averages.
Table 2 presents the testing results of the eight trained object detection models in this study. RTDETRx_non and YOLOv8x_non represent the object detection models using only original and augmentation images. The bold detection accuracy metric values indicate the best detection accuracy achieved by the corresponding model in that metric. The results show that RTDETRx_NST has the best performance in this study, followed by RTDETRx_A and then YOLOv8x_CG. These three models, when compared with their corresponding RTDETRx_non and YOLOv8x_non, demonstrate a significant improvement in object detection accuracy when rainy images are included in the training data. However, it is worth noting that this effect is not observed in the RTDETRx_CG, YOLOv8x_A, and YOLOv8x_NST models. Among the pre-trained models, YOLOv8x_CG exhibits the best object detection capability compared to other pre-trained YOLOv8x models. However, the rainy images generated using CycleGAN do not yield outstanding performance when applied to the pre-trained RTDETRx model.
Table 2.
Object detection results for RTDETR with different training datasets.
Regarding the performance of pre-trained models, it is evident that RTDETRx_non and YOLOv8x_non have respective advantages in different metrics when rainy images are not included. RTDETRx_non demonstrates better category prediction ability, while YOLOv8x_non shows better detection sensitivity. However, when rainy images are added to the training data, significant differences emerge. Undoubtedly, the performance of pre-trained RTDETRx models stands out, especially the RTDETRx_NST and RTDETRx_A models, which both exhibit a significant improvement in object detection accuracy under rainy conditions.
Compared to YOLOv8x, RTDETRx demonstrates advantages in real-time performance and hardware deployment requirements. The higher FPS of RTDETRx indicates its ability to process images and generate detection results more quickly, which is crucial for real-time object detection applications. Additionally, RTDETRx has lower GFLOPs and parameter counts, suggesting greater efficiency in computation and storage. Therefore, deploying RTDETRx models in resource-constrained environments is easier and more efficient compared to YOLOv8x.
We further used RTDETRx_non and YOLOv8x_non as baselines to calculate the improvement in detection performance for each rainy model. The results presented in Table 3 clearly confirm our hypothesis for this study: that no single method of generating rainy images is suitable for all pre-trained models. Additionally, the choice of pre-trained model is equally important. Training the same dataset with different pre-trained models can lead to vastly different results. The ability of pre-trained RTDETRx models to extract useful information for object recognition under the interference of rainy conditions, despite the degradation of visual feature information, is evidently superior to YOLOv8. We attribute this result to the contribution of Transformer characteristics. Compared to YOLOv8, RTDETR utilizes global information from images for object detection, rather than relying solely on local information like YOLOv8. These differences have minimal impact on object detection performance when images are clean. However, under rainy weather conditions, where images become blurred and objects are obscured or interfered with, the advantages of RTDETRx are highlighted.
Table 3.
Improvement in performance for different object detection models.
It can be observed that both RTDETR_NST and RTDETR_A demonstrate positive improvements in three out of four indicators. The only regret is that each model fails to exhibit a significant improvement in one indicator. However, the significance of the models’ contributions to our study is not diminished by this. From the table, improvements of 13.89% and 15.50%, respectively, are achieved by these two models in terms of the mAP50-95 indicator. Additionally, a high improvement rate of 16.35% in the Recall (R) indicator is shown by RTDETR_NST. This suggests that the sensitivity of object detection is significantly enhanced by the model, and it provides more accurate object positioning under rainy weather conditions, which is meaningful for an object detection model.
Based on the results of this study, we further infer that Transformer-based pre-trained object detection models are more suitable for establishing rainy weather object detection models compared to pre-trained models from the YOLO series. Additionally, training models using rainy image generation methods paired with the neural style transfer and analytical methods is recommended as one of the approaches.
5. Conclusions
This study provides significant insights into improving the performance of object detection models under rainy conditions. Firstly, we explored for the first time the training of rainy weather object detection models using pre-trained RTDETR models, comparing them with YOLOv8. The approach we used to generate training data ensured a diverse set of rainy images, crucial for achieving accurate models. Secondly, we evaluated the models’ performance using three different methods for generating rainy images and found that no single method could be universally applied to all pre-trained object detection models, posing a challenging question for future research. Furthermore, we recommend integrating RTDETR with the neural style transfer or analytical methods to enhance the performance of rainy weather object detection models, providing valuable insights for practical applications. Specifically, combining with neural style transfer yields significant improvements of 16.35% in Recall (R) and 15.50% in mAP50-95, demonstrating the robustness of this approach against rainy conditions and highlighting the excellence of the proposed method in this study.
Using image generation techniques to construct training data under rainy weather conditions is an efficient method of data collection. While obtaining real rainy images through long-term observation is possible, it still has its limitations. It is understandable that collecting images of various objects in rainy conditions is more challenging than in clean environments. However, advancements in image generation technology bring hope. Similar to the approach in this study, we can first augment clean images to generate diverse images and then apply rainy weather effects to all clean and augmented images using image generation methods. These effects can be adjusted through parameters to simulate various rain intensities, from light drizzles to heavy storms. Such training data strengthen the robustness and reliability of object detection models in terms of accuracy. Therefore, we believe this is a research area worthy of further exploration.
It is worth noting that the results of this study are valuable both in academic research and practical applications. In academia, we expanded the understanding of rainy weather object detection models and proposed new training methods and performance evaluation strategies. In practical applications, our research findings can be applied to various scenarios requiring object detection in rainy environments, such as self-driving cars and smart city surveillance systems. These application areas stand to benefit from the effective methods and technologies proposed in this study, enhancing system performance and reliability. Overall, the results of this study make important contributions to the modeling of rainy weather object detection models, offering valuable insights and guidance for future research and applications.
Author Contributions
Conceptualization, C.-Y.H., Y.-C.C. and T.-T.C.; methodology, C.-Y.H., Y.-C.C. and T.-T.C.; software, Y.-C.C., T.-T.C. and T.-H.L.; validation, C.-Y.H., Y.-C.C., T.-T.C., T.-Y.C. and F.-S.N.; formal analysis, Y.-C.C., C.-Y.H., T.-T.C. and T.-H.L.; investigation, Y.-C.C., C.-Y.H. and T.-T.C.; resources, T.-T.C., C.-Y.H., T.-Y.C., F.-S.N. and M.-H.C.; data curation, Y.-C.C., C.-Y.H., T.-T.C. and T.-H.L.; writing—original draft preparation, Y.-C.C., C.-Y.H. and T.-T.C.; writing—review and editing, Y.-C.C., C.-Y.H., T.-T.C., T.-Y.C., F.-S.N. and M.-H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. DAWN can be found here: [https://data.mendeley.com/datasets/766ygrbt8y/3], accessed on 10 April 2024. Boreas can be found here: [https://www.boreas.utias.utoronto.ca/#/download], accessed on 1 March 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Jia, X.; Tong, Y.; Qiao, H.; Li, M.; Tong, J.; Liang, B. Fast and accurate object detector for autonomous driving based on improved YOLOv5. Sci. Rep. 2023, 13, 9711. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Li, C.; Peng, Y.; Ru, H. MCS-YOLO: A multiscale object detection method for autonomous driving road environment recognition. IEEE Access 2023, 11, 22342–22354. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Ball, J.E. Deep learning-based image 3-d object detection for autonomous driving. IEEE Sens. J. 2023, 23, 3378–3394. [Google Scholar] [CrossRef]
- Wang, G.; Ding, H.; Duan, M.; Pu, Y.; Yang, Z.; Li, H. Fighting against terrorism: A real-time CCTV autonomous weapons detection based on improved YOLO v4. Digit. Signal Process. 2023, 132, 103790. [Google Scholar] [CrossRef]
- Ahn, Y.; Choi, H.; Kim, B.S. Development of early fire detection model for buildings using computer vision-based CCTV. J. Build. Eng. 2023, 65, 105647. [Google Scholar] [CrossRef]
- Hentati-Sundberg, J.; Olin, A.B.; Reddy, S.; Berglund, P.-A.; Svensson, E.; Reddy, M.; Kasarareni, S.; Carlsen, A.A.; Hanes, M.; Kad, S. Seabird surveillance: Combining CCTV and artificial intelligence for monitoring and research. Remote Sens. Ecol. Conserv. 2023, 9, 568–581. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Porav, H.; Maddern, W.; Newman, P. Adversarial Training for Adverse Conditions: Robust Metric Localisation Using Appearance Transfer. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1011–1018. [Google Scholar]
- Teeti, I.; Musat, V.; Khan, S.; Rast, A.; Cuzzolin, F.; Bradley, A. Vision in adverse weather: Augmentation using CycleGANs with various object detectors for robust perception in autonomous racing. arXiv 2022, arXiv:2201.03246. [Google Scholar]
- Musat, V.; Fursa, I.; Newman, P.; Cuzzolin, F.; Bradley, A. Multi-weather city: Adverse weather stacking for autonomous driving. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2906–2915. [Google Scholar]
- Uricar, M.; Krizek, P.; Sistu, G.; Yogamani, S. SoilingNet: Soiling Detection on Automotive Surround-View Cameras. arXiv 2019, arXiv:1905.01492. [Google Scholar]
- Rothmeier, T.; Huber, W. Let it Snow: On the Synthesis of Adverse Weather Image Data. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3300–3306. [Google Scholar]
- Jin, K.-H.; Kang, K.-S.; Shin, B.-K.; Kwon, J.-H.; Jang, S.-J.; Kim, Y.-B.; Ryu, H.-G. Development of robust detector using the weather deep generative model for outdoor monitoring system. Expert Syst. Appl. 2023, 234, 120984. [Google Scholar] [CrossRef]
- Chang, K.-C.; Liao, Y.-D.; Kuo, C.-Y. Enhancing Recognition Accuracy of Urban Flooding by Generating Synthetic Samples Using CycleGAN. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics—Taiwan, Taipei, Taiwan, 6–8 July 2022; pp. 357–358. [Google Scholar]
- Son, D.-M.; Kwon, H.-J.; Lee, S.-H. Enhanced Night-to-Day Image Conversion Using CycleGAN-Based Base-Detail Paired Training. Mathematics 2023, 11, 3102. [Google Scholar] [CrossRef]
- Chen, K.; Li, H.; Li, C.; Zhao, X.; Wu, S.; Duan, Y.; Wang, J. An Automatic Defect Detection System for Petrochemical Pipeline Based on Cycle-GAN and YOLO v5. Sensors 2022, 22, 7907. [Google Scholar] [CrossRef] [PubMed]
- Bothra, D.; Shetty, R.; Bhagat, S.; Patil, M. ColorAI-automatic image Colorization using CycleGAN. Int. J. Sci. Res. Eng. Manag. 2021, 5, 1–4. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Jing, Y.; Yang, Y.; Feng, Z.; Ye, J.; Yu, Y.; Song, M. Neural Style Transfer: A Review. arXiv 2017, arXiv:1705.04058. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Goel, A. Cross-Domain Image Classification through Neural-Style Transfer Data Augmentation. arXiv 2019, arXiv:1910.05611. [Google Scholar]
- Cygert, S.; Czyzewski, A. Style Transfer for Detecting Vehicles with Thermal Camera. In Proceedings of the 2019 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 18–20 September 2019; pp. 218–222. [Google Scholar]
- Ding, Y.; Luo, X. Personal Protective Equipment Detection in Extreme Construction Conditions. In Proceedings of the Computing in Civil Engineering 2023, Corvallis, OR, USA, 25–28 June 2023; pp. 672–679. [Google Scholar]
- Fan, Y.; Wang, Y.; Wei, M.; Wang, F.L.; Xie, H. FriendNet: Detection-Friendly Dehazing Network. arXiv 2024, arXiv:2403.04443. [Google Scholar]
- Narasimhan, S.G.; Nayar, S.K. Chromatic framework for vision in bad weather. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 15 June 2000; Volume 1, pp. 598–605. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Qian, R.; Tan, R.T.; Yang, W.; Su, J.; Liu, J. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2482–2491. [Google Scholar]
- Li, S.; Ren, W.; Zhang, J.; Yu, J.; Guo, X. Single image rain removal via a deep decomposition–composition network. Comput. Vis. Image Underst. 2019, 186, 48–57. [Google Scholar] [CrossRef]
- Liu, W.; Ren, G.; Yu, R.; Guo, S.; Zhu, J.; Zhang, L. Image-adaptive YOLO for object detection in adverse weather conditions. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 1792–1800. [Google Scholar]
- Zhang, K.; Yan, X.; Wang, Y.; Qi, J. Adaptive Dehazing YOLO for Object Detection. In International Conference on Artificial Neural Networks; Springer: Cham, Switzerland, 2023; pp. 14–27. [Google Scholar]
- Wang, Y.; Yan, X.; Zhang, K.; Gong, L.; Xie, H.; Wang, F.L.; Wei, M. Togethernet: Bridging image restoration and object detection together via dynamic enhancement learning. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2022; Volume 41, pp. 465–476. [Google Scholar]
- Wang, K.; Wang, T.; Qu, J.; Jiang, H.; Li, Q.; Chang, L. An End-to-End Cascaded Image Deraining and Object Detection Neural Network. arXiv 2022, arXiv:2202.11279. [Google Scholar] [CrossRef]
- Qiu, Y.; Lu, Y.; Wang, Y.; Jiang, H. IDOD-YOLOV7: Image-dehazing YOLOV7 for object detection in low-light foggy traffic environments. Sensors 2023, 23, 1347. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:240213616. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 2 May 2023).
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 2 May 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:220902976. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:201011929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision–ECCV 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:201004159. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. Detrs beat yolos on real-time object detection. arXiv 2023, arXiv:230408069. [Google Scholar]
- Volk, G.; Müller, S.; Von Bernuth, A.; Hospach, D.; Bringmann, O. Towards robust CNN-based object detection through augmentation with synthetic rain variations. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 285–292. [Google Scholar]
- Tremblay, M.; Halder, S.S.; de Charette, R.; Lalonde, J.-F. Rain rendering for evaluating and improving robustness to bad weather. arXiv 2020, arXiv:2009.03683. [Google Scholar] [CrossRef]
- Chen, M.; Sun, J.; Aida, K.; Takefusa, A. Weather-aware object detection method for maritime surveillance systems. Future Gener. Comput. Syst. 2024, 151, 111–123. [Google Scholar] [CrossRef]
- Gupta, H.; Kotlyar, O.; Andreasson, H.; Lilienthal, A.J. Robust Object Detection in Challenging Weather Conditions. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 7523–7532. [Google Scholar]
- Burnett, K.; Yoon, D.J.; Wu, Y.; Li, A.Z.; Zhang, H.; Lu, S.; Qian, J.; Tseng, W.-K.; Lambert, A.; Leung, K.Y. Boreas: A multi-season autonomous driving dataset. Int. J. Robot. Res. 2023, 42, 33–42. [Google Scholar] [CrossRef]
- Kenk, M.A.; Hassaballah, M. DAWN: Vehicle Detection in Adverse Weather Nature Dataset. arXiv 2020, arXiv:2008.05402. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Luo, P. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14454–14463. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).