
Structure–Activity Relationship (SAR) Modeling of Mosquito Repellents: Deciphering the Importance of the 1-Octanol/Water Partition Coefficient on the Prediction Results

Abstract
:1. Introduction
2. Materials and Methods
2.1. Mosquito Repellent Activity
2.2. Molecular Descriptors
2.3. Statistical Tools
2.4. Performance Evaluation Metrics
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sato, S. Plasmodium—A brief introduction to the parasites causing human malaria and their basic biology. J. Physiol. Anthropol. 2021, 40, 1, Erratum in J. Physiol. Anthropol. 2021, 40, 3. [Google Scholar] [CrossRef]
- WHO. World Malaria Report 2022; World Health Organization: Geneva, Switzerland, 2022. Available online: https://www.who.int/teams/global-malaria-programme/reports/world-malaria-report-2022 (accessed on 13 March 2024).
- Bhatt, S.; Gething, P.W.; Brady, O.J.; Messina, J.P.; Farlow, A.W.; Moyes, C.L.; Drake, J.M.; Brownstein, J.S.; Hoen, A.G.; Sankoh, O.; et al. The global distribution and burden of dengue. Nature 2013, 496, 504–507. [Google Scholar] [CrossRef]
- Messina, J.P.; Brady, O.J.; Golding, N.; Kraemer, M.U.G.; Wint, G.R.W.; Ray, S.E.; Pigott, D.M.; Shearer, F.M.; Johnson, K.; Earl, L.; et al. The current and future global distribution and population at risk of dengue. Nat. Microbiol. 2019, 9, 1508–1515. [Google Scholar] [CrossRef]
- World Health Organization. Vector-Borne Diseases. 2024. Available online: https://www.who.int/news-room/fact-sheets/detail/vector-borne-diseases (accessed on 15 March 2024).
- Fontenille, D.; Lagneau, C.; Lecollinet, S.; Lefait-Robin, R.; Setbon, M.; Tirel, B.; Yébakima, A. La Lutte Antivectorielle en France/Disease Vector Control in France; IRD Edition: Marseille, France, 2009. [Google Scholar]
- Onen, H.; Luzala, M.M.; Kigozi, S.; Sikumbili, R.M.; Muanga, C.-J.K.; Zola, E.N.; Wendji, S.N.; Buya, A.B.; Balciunaitiene, A.; Viškelis, J.; et al. Mosquito-borne diseases and their control strategies: An overview focused on green synthesized plant-based metallic nanoparticles. Insects 2023, 14, 221. [Google Scholar] [CrossRef]
- Debboun, M.; Frances, S.P.; Strickman, D.A. Insect Repellents Handbook, 2nd ed.; CRC Press: Boca Raton, CA, USA, 2020. [Google Scholar]
- Afify, A.; Betz, J.F.; Riabinina, O.; Lahondère, C.; Potter, C.J. Commonly used insect repellents hide human odors from Anopheles mosquitoes. Curr. Biol. 2019, 29, 3669–3680.e5. [Google Scholar] [CrossRef]
- Stanczyk, N.M.; Brookfield, J.F.Y.; Ignell, R.; Logan, J.G.; Field, L.M. Behavioral insensitivity to DEET in Aedes aegypti is a genetically determined trait residing in changes in sensillum function. Proc. Natl. Acad. Sci. USA 2010, 107, 8575–8580. [Google Scholar] [CrossRef]
- Deletre, E.; Martin, T.; Duménil, C.; Chandre, F. Insecticide resistance modifies mosquito response to DEET and natural repellents. Parasites Vectors 2019, 12, 89. [Google Scholar] [CrossRef]
- Yang, L.; Norris, E.J.; Jiang, S.; Bernier, U.R.; Linthicum, K.J.; Bloomquist, J.R. Reduced effectiveness of repellents in a pyrethroid-resistant strain of Aedes aegypti (Diptera: Culicidae) and its correlation with olfactory sensitivity. Pest Manag. Sci. 2020, 76, 118–124. [Google Scholar] [CrossRef]
- da Costa, K.S.; Galúcio, J.M.; da Costa, C.H.S.; Santana, A.R.; Dos Santos Carvalho, V.; do Nascimento, L.D.; Lima e Lima, A.H.; Neves Cruz, J.; Alves, C.N.; Lameira, J. Exploring the potentiality of natural products from essential oils as inhibitors of odorant-binding proteins: A structure- and ligand-based virtual screening approach to find novel mosquito repellents. ACS Omega 2019, 4, 22475–22486. [Google Scholar] [CrossRef]
- Portilla-Pulido, J.S.; Castillo-Morales, R.M.; Barón-Rodríguez, M.A.; Duque, J.E.; Mendez-Sanchez, S.C. Design of a repellent against Aedes aegypti (Diptera: Culicidae) using in silico simulations with AaegOBP1 protein. J. Med. Entomol. 2020, 57, 463–476. [Google Scholar] [CrossRef]
- Neto, M.F.A.; Campos, J.M.; Cerqueira, A.P.M.; de Lima, L.R.; Da Costa, G.V.; Ramos, R.D.S.; Junior, J.T.M.; Santos, C.B.R.; Leite, F.H.A. Hierarchical virtual screening and binding free energy prediction of potential modulators of Aedes aegypti odorant-binding protein 1. Molecules 2022, 27, 6777. [Google Scholar] [CrossRef] [PubMed]
- Liggri, P.G.V.; Pérez-Garrido, A.; Tsitsanou, K.E.; Dileep, K.V.; Michaelakis, A.; Papachristos, D.P.; Pérez-Sánchez, H.; Zographos, S.E. 2D finger-printing and molecular docking studies identified potent mosquito repellents targeting odorant binding protein 1. Insect Biochem. Mol. Biol. 2023, 157, 103961. [Google Scholar] [CrossRef] [PubMed]
- Karcher, W.; Devillers, J. Practical Applications of Quantitative Structure-Activity Relationships (QSAR) in Environmental Chemistry and Toxicology; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1990. [Google Scholar]
- Devillers, J.; Karcher, W. Applied Multivariate Analysis in SAR and Environmental Studies; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Sorkun, M.C.; Koelman, J.M.V.A.; Er, S. Pushing the limits of solubility prediction via quality-oriented data selection. iScience 2020, 24, 101961. [Google Scholar] [CrossRef]
- Dearden, J.C.; Rotureau, P.; Fayet, G. QSPR prediction of physico-chemical properties for REACH. SAR QSAR Environ. Res. 2013, 24, 279–318. [Google Scholar] [CrossRef] [PubMed]
- Rácz, A.; Bajusz, D.; Héberger, K. Modelling methods and cross-validation variants in QSAR: A multi-level analysis. SAR QSAR Environ. Res. 2018, 29, 661–674. [Google Scholar] [CrossRef] [PubMed]
- Jorgensen, W.L.; Duffy, E.M. Prediction of drug solubility from structure. Adv. Drug Deliv. Rev. 2002, 54, 355–366. [Google Scholar] [CrossRef] [PubMed]
- Devillers, J. Calculation of octanol/water partition coefficients for pesticides: A comparative study. SAR QSAR Environ. Res. 1999, 10, 249–262. [Google Scholar] [CrossRef] [PubMed]
- Devillers, J. 2D and 3D structure-activity modelling of mosquito repellents: A review. SAR QSAR Environ. Res. 2018, 29, 693–723. [Google Scholar] [CrossRef] [PubMed]
- Devillers, J.; Larghi, A.; Sartor, V.; Setier-Rio, M.-L.; Lagneau, C.; Devillers, H. Nonlinear SAR modelling of mosquito repellents for skin application. Toxics 2023, 11, 837. [Google Scholar] [CrossRef]
- Knipling, E.F.; McAlister, L.C.; Jones, H.A. Results of Screening Tests with Materials Evaluated as Insecticides, Miticides, and Repellents at the Orlando, Fla., Laboratory, April 1942 to April 1947; USDA Publication E-733; United States Department of Agriculture, Agriculture Research Administration, Bureau of Entomology and Plant Quarantine: Orlando, FL, USA, 1947. [Google Scholar]
- Devillers, J. Neural Networks in QSAR and Drug Design; Academic Press: London, UK, 1996. [Google Scholar]
- Moriguchi, I.; Hirono, S.; Liu, Q.; Nakagome, I.; Matsushita, Y. A simple method of calculating octanol/water partition coefficient. Chem. Pharm. Bull. 1992, 40, 127–130. [Google Scholar] [CrossRef]
- Moriguchi, I.; Hirono, S.; Nakagome, I.; Hirano, H. Comparison of reliability of log P values for drugs calculated by several methods. Chem. Pharm. Bull. 1994, 42, 976–978. [Google Scholar] [CrossRef]
- Meylan, W.M.; Howard, P.H. Atom/fragment contribution method for estimating octanol-water partition coefficients. J. Pharm. Sci. 1995, 84, 83–92. [Google Scholar] [CrossRef]
- Devillers, J.; Sartor, V.; Doucet, J.P.; Doucet-Panaye, A.; Devillers, H. In silico prediction of mosquito repellents for clothing application. SAR QSAR Environ. Res. 2022, 33, 239–257. [Google Scholar] [CrossRef]
- Pérez-Pereira, A.; Carvalho, A.R.; Carrola, J.S.; Tiritan, M.E.; Ribeiro, C. Integrated approach for synthetic cathinone drug prioritization and risk assessment: In silico approach and sub-chronic studies in Daphnia magna and Tetrahymena thermophila. Molecules 2023, 28, 2899. [Google Scholar] [CrossRef]
- Naik, P.K.; Sindhura; Singh, T.; Singh, H. Quantitative structure-activity relationship (QSAR) for insecticides: Development of predictive in vivo insecticide activity models. SAR QSAR Environ. Res. 2009, 20, 551–566. [Google Scholar] [CrossRef] [PubMed]
- Sinclair, C.J.; Boxall, A.B.A. Assessing the ecotoxicity of pesticide transformation products. Environ. Sci. Technol. 2003, 37, 4617–4625. [Google Scholar] [CrossRef]
- Fang, H.; Tong, W.; Shi, L.M.; Blair, R.; Perkins, R.; Branham, W.; Hass, B.S.; Xie, Q.; Dial, S.L.; Moland, C.L.; et al. Structure-activity relationships for a large diverse set of natural, synthetic, and environmental estrogens. Chem. Res. Toxicol. 2001, 14, 280–294. [Google Scholar] [CrossRef]
- Devillers, J.; Balaban, A.T. Topological Indices and Related Descriptors in QSAR and QSPR; Gordon and Breach Science Publishers: Amsterdam, The Netherlands, 1999. [Google Scholar]
- Balaban, A.T. Highly discriminating distance-based topological index. Chem. Phys. Lett. 1982, 89, 399–404. [Google Scholar] [CrossRef]
- Bertz, S.H. The first general index of molecular complexity. J. Am. Chem. Soc. 1981, 103, 3599–3601. [Google Scholar] [CrossRef]
- Kier, L.B.; Hall, L.H. Molecular connectivity VII: Specific treatment of heteroatoms. J. Pharm. Sci. 1976, 65, 1806–1809. [Google Scholar] [CrossRef]
- Kier, L.B.; Hall, L.H. An electrotopological-state index for atoms in molecules. Pharm. Res. 1990, 7, 801–807. [Google Scholar] [CrossRef] [PubMed]
- Chicco, D.; Warrens, M.J.; Jurman, G. The Matthews correlation coefficient (MCC) is more informative than Cohen’s Kappa and Brier score in binary classification assessment. IEEE Access 2021, 9, 78368–78381. [Google Scholar] [CrossRef]
- Thusberg, J.; Olatubosun, A.; Vihinen, M. Performance of mutation pathogenicity prediction methods on missense variants. Hum. Mutat. 2011, 32, 358–368. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Li, Y.; Yang, J.-Y.; Shen, H.-B.; Yu, D.-J. GPCR-drug interactions prediction using random forest with drug-association-matrix-based post-processing procedure. Comput. Biol. Chem. 2016, 60, 59–71. [Google Scholar] [CrossRef] [PubMed]
- Verheyen, G.R.; Braeken, E.; Van Deun, K.; Van Miert, S. Evaluation of in silico tools to predict the skin sensitization potential of chemicals. SAR QSAR Environ. Res. 2017, 28, 59–73. [Google Scholar] [CrossRef] [PubMed]
- Benfenati, E.; Golbamaki, A.; Raitano, G.; Roncaglioni, A.; Manganelli, S.; Lemke, F.; Norinder, U.; Lo Piparo, E.; Honma, M.; Manganaro, A.; et al. A large comparison of integrated SAR/QSAR models of the Ames test for mutagenicity. SAR QSAR Environ. Res. 2018, 29, 591–611. [Google Scholar] [CrossRef] [PubMed]
- Hughes, M.G.; Glasby, T.M.; Hanslow, D.J.; West, G.J.; Wen, L. Random forest classification method for predicting intertidal wetland migration under sea level rise. Front. Environ. Sci. 2022, 10, 749950. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Branco, P.; Torgo, L.; Ribeiro, R.P. A survey of predictive modeling on imbalanced domains. ACM Comput. Surv. 2016, 1, 31. [Google Scholar] [CrossRef]
- Akosa, J.S. Predictive Accuracy: A Misleading Performance Measure for Highly Imbalanced Data. In Proceedings of the SAS Global Forum 2017, Orlando, FL, USA, 2–5 April 2017; paper 942. Available online: https://support.sas.com/resources/papers/proceedings17/0942-2017.pdf (accessed on 30 March 2024).
- García, V.; Mollineda, R.A.; Sánchez, J.S. A new performance evaluation method for two-class imbalanced problems. In Structural, Syntactic, and Statistical Pattern Recognition; da Vitoria Lobo, N., Kasparis, T., Georgiopoulos, M., Roli, F., Kwok, J.T., Anagnostopoulos, G.C., Loog, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 917–925. [Google Scholar]
- Khater, H.F.; Selim, A.M.; Abouelella, G.A.; Abouelella, N.A.; Murugan, K.; Vaz, N.P.; Govindarajan, M. Commercial mosquito repellents and their safety concerns. In Malaria; Kasenga, F.H., Ed.; IntechOpen Limited: London, UK, 2019; Available online: https://www.intechopen.com/chapters/68538 (accessed on 30 March 2024).
- Pridgeon, J.W.; Bernier, U.R.; Becnel, J.J. Toxicity comparison of eight repellents against four species of female mosquitoes. J. Am. Mosq. Control Assoc. 2009, 25, 168–173. [Google Scholar] [CrossRef]
- Hansch, C.; Leo, A. Exploring QSAR: Fundamentals and Applications in Chemistry and Biology; American Chemical Society: Washington, DC, USA, 1995. [Google Scholar]
- World Health Organization. Ethyl Butylacetylaminopropionate Also Known as IR3535®, 3-(N-acetyl-N-butyl)Aminopropionic Acid Ethyl Ester; WHO Specifications and Evaluations for Public Health Pesticides; World Health Organization: Geneva, Switzerland, 2006; p. 26. Available online: https://archive.epa.gov/osa/hsrb/web/pdf/whoir3535evaluationapril2006.pdf (accessed on 13 March 2024).
- European Chemicals Agency. Regulation (EU) No 528/2012 Concerning the Making Available on the Market and Use of Biocidal products. Icaridin. Product-Type 19 (Repellents and Attractants). Assessment Report. December 2019; ECHA: Helsinki, Finland, 2019; p. 84. Available online: https://echa.europa.eu/documents/10162/58d77648-e39e-6498-e743-d64df39cdc24 (accessed on 13 March 2024).
- European Chemicals Agency. Directive 98/8/EC Concerning the Placing Biocidal Products on the Market. N,N-diethyl-meta-toluamide (DEET). Product-Type 19 (Repellents and Attractants). Assessment Report. 11 March 2010; ECHA: Helsinki, Finland, 2010; p. 43. Available online: https://echa.europa.eu/documents/10162/a9b111f6-37b7-c179-dce4-361b6217484d (accessed on 13 March 2024).
- Ali, A.; Cantrell, C.L.; Bernier, U.R.; Duke, S.O.; Schneider, J.C.; Agramonte, N.M.; Khan, I. Aedes aegypti (Diptera: Culicidae) biting deterrence: Structure-activity relationship of saturated and unsaturated fatty acids. J. Med. Entomol. 2012, 49, 1370–1378. [Google Scholar] [CrossRef] [PubMed]
- Jahn, A.; Kim, S.Y.; Choi, J.-H.; Kim, D.-D.; Ahn, Y.-J.; Yong, C.S.; Kim, J.S. A bioassay for mosquito repellency against Aedes aegypti: Method validation and bioactivities of DEET analogues. J. Pharm. Pharmacol. 2010, 62, 91–97. [Google Scholar] [CrossRef] [PubMed]
- Suryanarayana, M.V.; Pandey, K.S.; Prakash, S.; Raghuveeran, C.D.; Dangi, R.S.; Swamy, R.V.; Rao, K.M. Structure-activity relationship studies with mosquito repellent amides. J. Pharm. Sci. 1991, 80, 1055–1057. [Google Scholar] [CrossRef] [PubMed]
- Iovinella, I.; Mandoli, A.; Luceri, C.; D’Ambrosio, M.; Caputo, B.; Cobre, P.; Dani, F.R. Cyclic acetals as novel long-lasting mosquito repellents. J. Agric. Food Chem. 2023, 71, 2152–2159. [Google Scholar] [CrossRef] [PubMed]
- Boeckh, J.; Breer, H.; Geier, M.; Hoever, F.P.; Krüger, B.W.; Nentwig, G.; Sass, H. Acylated 1,3-aminopropanols as repellents against bloodsucking arthropods. Pest. Sci. 1996, 48, 359–373. [Google Scholar] [CrossRef]
- Leal, W.S. The enigmatic reception of DEET—The gold standard of insect repellents. Curr. Opin. Insect Sci. 2014, 6, 93–98. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.-I.; Tak, J.-H.; Seo, J.K.; Park, S.R.; Kim, J.; Boo, K.-H. Repellency of veratraldehyde (3,4-dimethoxy benzaldehyde) against mosquito females and tick nymphs. Appl. Sci. 2021, 11, 4861. [Google Scholar] [CrossRef]
- Katritzky, A.R.; Dobchev, D.A.; Tulp, I.; Karelson, M.; Carlson, D.A. QSAR study of mosquito repellents using Codessa Pro. Bioorg. Med. Chem. Lett. 2006, 16, 2306–2311. [Google Scholar] [CrossRef] [PubMed]
- Paluch, G.; Grodnitzky, J.; Bartholomay, L.; Coats, J. Quantitative structure–activity relationship of botanical sesquiterpenes: Spatial and contact repellency to the yellow fever mosquito, Aedes aegypti. J. Agric. Food Chem. 2009, 57, 7618–7625. [Google Scholar] [CrossRef]
- Wang, Z.; Song, J.; Chen, J.; Song, Z.; Shang, S.; Jiang, Z.; Han, Z. QSAR study of mosquito repellents from terpenoid with a six-member ring. Bioorg. Med. Chem. Lett. 2008, 18, 2854–2859. [Google Scholar] [CrossRef]
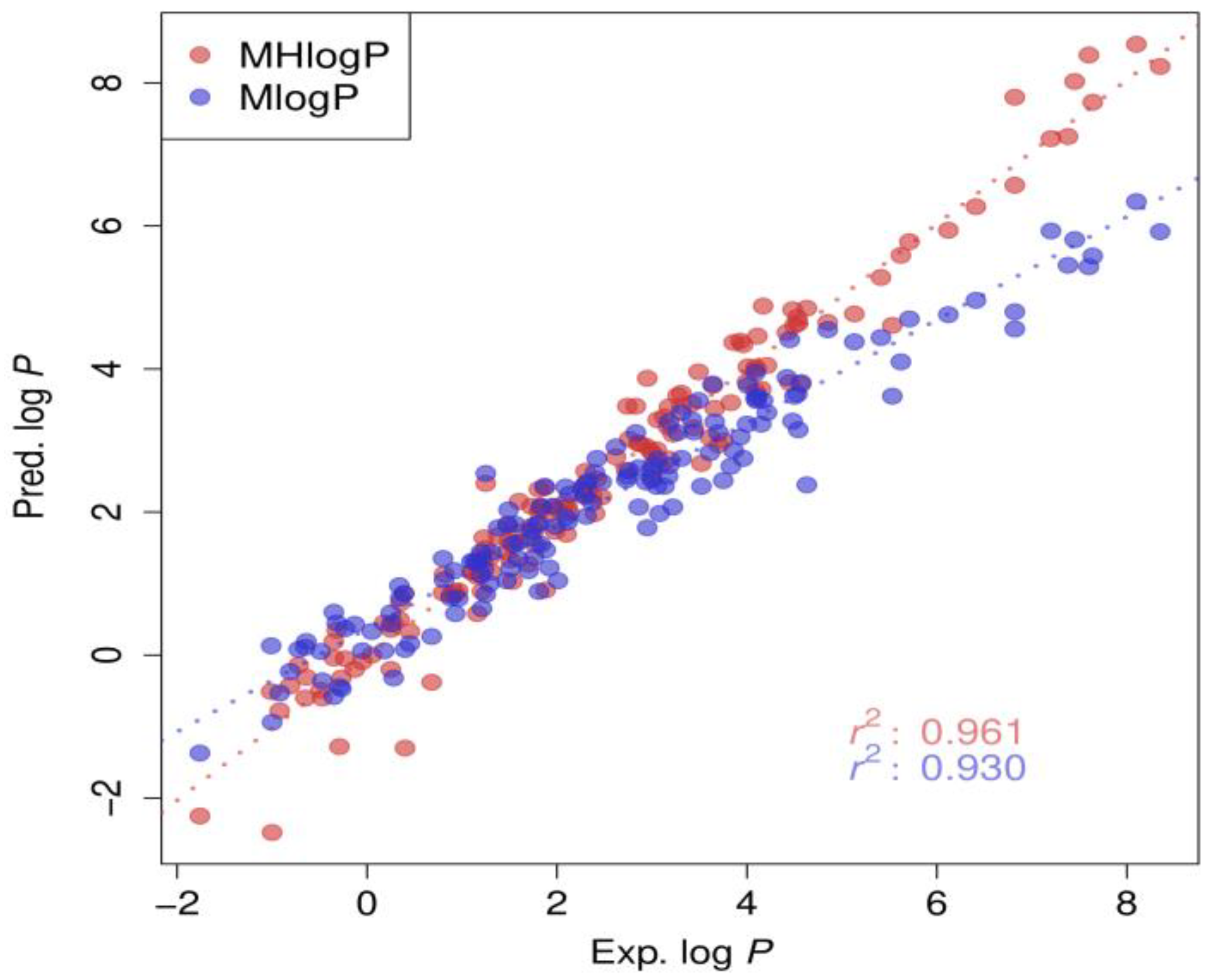


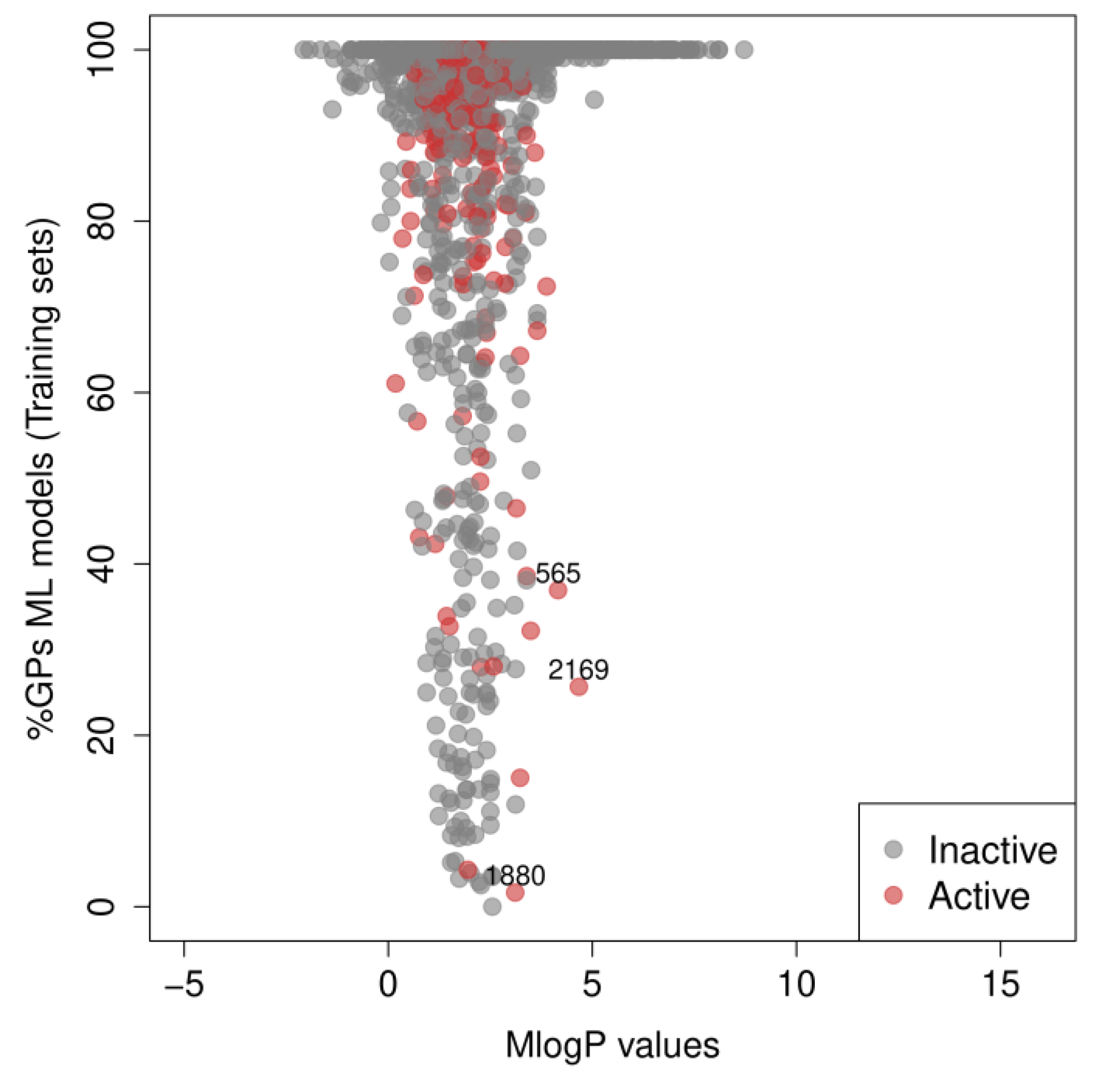


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | ML1-To | ML1-Tr | ML1-Ts |
|---|---|---|---|
| TP 1 | 302 | 262 | 40 |
| TN | 1681 | 1332 | 349 |
| FP | 172 | 132 | 40 |
| FN | 16 | 11 | 5 |
| Sensitivity | 0.950 | 0.960 | 0.889 |
| Specificity | 0.907 | 0.910 | 0.897 |
| Accuracy | 0.913 | 0.918 | 0.896 |
| MCC | 0.733 | 0.756 | 0.618 |
| F1 | 0.763 | 0.786 | 0.640 |
| AUC | 0.948 | 0.954 | 0.920 |
| G-Mean | 0.928 | 0.934 | 0.893 |
| Dominance | 0.043 | 0.050 | −0.008 |
| Metrics | MH1-To | MH1-Tr | MH1-Ts |
|---|---|---|---|
| TP 1 | 300 | 261 | 39 |
| TN | 1693 | 1341 | 352 |
| FP | 160 | 123 | 37 |
| FN | 18 | 12 | 6 |
| Sensitivity | 0.943 | 0.956 | 0.867 |
| Specificity | 0.914 | 0.916 | 0.905 |
| Accuracy | 0.918 | 0.922 | 0.901 |
| MCC | 0.742 | 0.765 | 0.619 |
| F1 | 0.771 | 0.795 | 0.645 |
| AUC | 0.954 | 0.958 | 0.928 |
| G-Mean | 0.928 | 0.936 | 0.886 |
| Dominance | 0.030 | 0.040 | −0.038 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Devillers, J.; Devillers, H. Structure–Activity Relationship (SAR) Modeling of Mosquito Repellents: Deciphering the Importance of the 1-Octanol/Water Partition Coefficient on the Prediction Results. Appl. Sci. 2024, 14, 5366. https://doi.org/10.3390/app14135366
Devillers J, Devillers H. Structure–Activity Relationship (SAR) Modeling of Mosquito Repellents: Deciphering the Importance of the 1-Octanol/Water Partition Coefficient on the Prediction Results. Applied Sciences. 2024; 14(13):5366. https://doi.org/10.3390/app14135366
Chicago/Turabian StyleDevillers, James, and Hugo Devillers. 2024. "Structure–Activity Relationship (SAR) Modeling of Mosquito Repellents: Deciphering the Importance of the 1-Octanol/Water Partition Coefficient on the Prediction Results" Applied Sciences 14, no. 13: 5366. https://doi.org/10.3390/app14135366