Abstract
This study presents a modified compensating observer control strategy for nonlinear multi-agent systems affected by unknown hysteresis signal loops. Compared to conventional high-gain observers, this approach introduces a novel compensation signal, effectively reducing the tracking error of traditional observers. Then, by utilizing a backstepping method, an adaptive output feedback controller is designed, such that the tracking error converges to the small neighborhood around the origin. Simulation experiments with and without the compensation term demonstrate that this control strategy can effectively reduce error, but it increases input chattering to some extent.
1. Introduction
The coordinated control of multi-agent systems has emerged as a pivotal area of contemporary research, driven by the proliferation of distributed network resources and the imperative for collaboration among various mechanical devices [1,2,3]. Key aspects of such systems encompass group interaction and communication, coordination and cooperation, and conflict resolution. A prominent example of these concepts is the multi-flight simulator system [4]. Additionally, multi-agent systems have notable applications in the healthcare sector [5].
Exploration of multi-agent systems has yielded numerous methodologies and control strategies aimed at ensuring consistent stability. For instance, dynamic surface control combined with a first-order low-pass filter has been utilized to address the inherent “differential explosion” issue in traditional recursive methods [6,7,8,9]. While this method simplifies computational complexity, it also introduces errors associated with filter computation and increases the number of control parameters, potentially compromising transient performance management. Recent research [10] has attempted to resolve the algebraic loop problem intrinsic to the backstepping method, thereby ensuring transient tracking performance, albeit at the cost of increased control complexity due to the introduction of new variables.
In addressing the problem of unknown states in high-order multi-agent systems, observers are often employed. Among these, the use of high-gain observers is a common research approach [11,12]. Through the application of such observers, disturbances within the system, including external input disturbances, system coupling, and other factors, can be effectively managed [13,14,15,16,17]. These mechanisms ensure the stability of the entire closed-loop system while optimizing the tracking performance of each subsystem. Various types of observers employ different methodologies; for example, interval observers utilize neural networks, resilient control techniques, and fuzzy equations to estimate unmeasurable states of the system [18]. By narrowing the interval width, this method ensures that the closed-loop system remains semi-globally ultimately bounded, allowing for a convergence of tracking and observation errors within a small neighborhood near the origin [19]. Similar developments have been documented in discrete systems [20]. Optimizations of high-gain observers involve dimensionality reduction, as seen in the current literature [21,22] where the observer model’s complexity is optimized within manageable limits while ensuring that all closed-loop signals are ultimately bounded under the influence of a continuously differentiable switching function. Therefore, building upon the research foundation of high-gain observers, this study considers the addition of compensatory terms to achieve error reduction and structural simplification.
Furthermore, with the expansion of material science applications, particularly in multi-agent systems equipped with intelligent materials, significant challenges arise. For example, piezoelectric ceramics and ionic polymer metal composites have gained attention due to their exceptional performance and desirable physical characteristics [23]. However, these materials also exhibit performance deficiencies, such as non-smoothness, nonlinearity, and hysteresis, which can significantly impact the precision and stability of control systems, particularly due to the effects of hysteresis signals and coupling characteristics [24]. To address nonlinear hysteresis inputs, two primary strategies are typically employed. The first strategy involves mitigating hysteresis effects through the development of an adaptive hysteresis inverse controller [25]. The second strategy, similar to the methods outlined in [26], employs an adaptive algorithm to reduce the impacts of hysteresis by modeling it with both linear and nonlinear components. Commonly referenced models include the dead zone hysteresis model, the Prandtl–Ishlinskii (PI) hysteresis model, and the Bouc–Wen hysteresis model. This study discusses the processing of hysteresis signals using the Prandtl–Ishlinskii model. The specific work content is as follows:
- (1)
- This study introduces a modified compensating observer scheme. By incorporating this compensatory mechanism, the proposed method effectively reduces tracking errors and confines them to a small region near zero while ensuring stability, compared to traditional control schemes.
- (2)
- Unlike most output feedback systems, the system investigated in this study involves unknown parameters, nonlinear coupling, and hysteresis interference, and the proposed compensating observer has more practical significance.
The proposed scheme in this study demonstrates superior performance in handling nonlinear multi-agent systems through numerical simulations and case studies while maintaining low computational complexity. This provides new insights and methods for controlling nonlinear multi-agent systems and lays a foundation for future research directions. By comparing with existing mainstream control strategies, this study not only highlights the advantages of the new method but also reveals its potential limitations in practical applications, thereby providing valuable references for further optimization and improvement.
The remainder of this paper is organized as follows. Section 2 outlines the relevant background information, problem models, assumptions, and lemmas necessary for understanding the subsequent analysis. In Section 3, we propose a decentralized adaptive output feedback backstepping approach that incorporates a high-gain observer. Section 4 provides a comprehensive stability analysis, which substantiates the stability and tracking capabilities of the system. Finally, Section 5 corroborates the effectiveness of our proposed design through simulation results based on an example presented earlier in the paper.
2. Establishing the Problem Model
2.1. Preliminaries
According to the principles of the graph theory presented in [10,11,12], the relationship among followers is represented here by a directed topological graph , where denotes the set of nodes, defines the set of edges, and is the adjacency matrix. If node can send data to node , then ; otherwise, . To facilitate system analysis, we employ the following lemmas and inequality theorems.
Lemma 1
[5]. The following formula is valid as long as there exist normal numbers , , and and a symmetrical positive definite matrix , where is the identity matrix. :
Lemma 2
[17]. There is a positive definite matrix that meets the following requirements if matrix is a Hurwitz matrix:
Lemma 3
[9]. The following inequality is met for any and (where represents the set of real numbers):
Theorem 1.
Young’s inequality:
The parameters that are already in place are known positive design parameters. The other parameters will be determined later.
2.2. Basic Model and Problem Hypothesis
We consider a set of nonlinear systems defined as follows. First, Equation (6) delineates the state equation:
Let denote the -th state variable of the -th subsystem, where and . The actual output of the -th subsystem is . Here, the smooth nonlinear function vectors and are known, as is the lower triangular nonlinear function matrix . The matrix is a known function matrix, while and are unknown, non-zero constant parameters. The structure of the matrix is as follows:
where is an input for hysteresis. The Prandtl–Ishlinskii model was selected as the hysteresis model in this study. The relevant formula and mathematical model are as follows:
In the expression , the function is a continuous, non-negative known function, while is an unknown, non-zero constant. This equation represents an area-based hysteresis model.
The design parameter serves as the upper limit of integration. In practical analysis, the influence of can be neglected when approaches infinity (). Consequently, both and are bounded, and is determined by experimental data. As a result, the functions are also bounded. Thus, the range of is constrained to , or .
This formulation describes the saturation play operator . The expression uses and , respectively, as the input and output of symmetrical hysteresis, which is constrained by the curve and represented by a well-known, continuous, non-decreasing function. Here, indicates the hysteresis threshold:
Next, we provide a monotone input signal, which is monotone in the interval , and select the parameter number using the formula above, as follows:
In this way, the hysteresis model diagram shown in Figure 1 can be obtained.
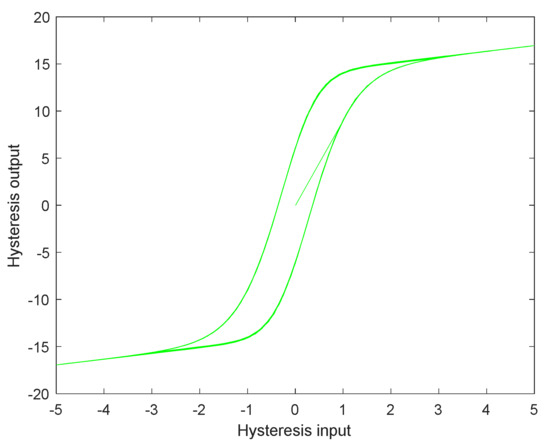
Figure 1.
PI hysteresis input relation model diagram.
The hysteresis effect set in this study has an upper and lower limit, as shown in Figure 1. Here, we use the parameter to represent the range of the hysteresis effect, which is . The parameter represents the last term of the hysteresis effect, and the parameter represents the minimum value of the hysteresis effect. Here, H = 20, h = −20.
Remark 1.
The hysteresis phenomenon represents one of the most prevalent nonlinear influences in real systems. However, the existing literature on hysteresis research, such as the research in [5,7,9,13,17,23], has not yet proposed efficient solutions. Therefore, this study continues to focus on hysteresis phenomena as the subject of analysis.
We suggest the following presumptions for the current system to simplify system analysis.
Proposition 1.
The output of the theory leader and its derivatives ( and ) are known, bounded, and smooth functions. The simulation will provide this function’s information.
Proposition 2.
Let the parameter in the equation of state be a normal integer that can satisfy the following expression to maintain generality using the Hurwitz Equation (14):
Remark 2
[27]. As the polynomial is a Hurwitz polynomial, the positivity of coefficients ensures that the real parts of the roots (zeroes) of the system are negative, thereby guaranteeing system stability.
Proposition 3.
The leader transmits at least one directed spanning tree to the follower in the directed graph composed of system (7).
Proposition 4.
If a smooth and integrable bounded positive function exists, the following expression (20) is fulfilled:
3. Controller Design and Derivation
3.1. Design of the Gain Compensation Observer
We devised a number of compensation gain filters in the manner described below to estimate the unknown state of the nonlinear multi-agent system (7):
The factors in this case have values of , and , which correspond to the observer’s design parameters. The dynamic gain of the filter is , and its expression is , while the dynamic gain at position denotes a favorable design feature. A function with slick positive elements is represented by . A positive design parameter, represented by , will be explained subsequently. The gain begins with a number of .
We estimate the status as
The definition error is , and its derivative is expressed as
Transformation of this error is achieved as follows:
We next define the Lyapunov equation as an expression of and and combine Formulas (14)–(18):
Remark 3.
Compared to the methods described in [28,29], the quadratic form employed in this study not only exhibits fundamental quadratic characteristics but also offers a simpler form and more favorable mathematical properties. The convex nature of quadratic functions facilitates easier analysis and the derivation of system stability and convergence properties, as well as controller design.
Proposition 5.
There exists a smooth non-negative function that fulfills . The dynamic gain is subjected to the flattening function whose word is according to us.
The compensation component and hysteresis effect can be reduced as follows by combining Lemma 1, Lemma 2, Proposition 5, and the aforementioned theorems:
Remark 4.
The primary purpose of introducing T is to compensate for the self-interference term in the traditional high-gain observer, thereby reducing the impact of interference terms and consequently decreasing observational errors.
On the other hand, , where represents a finite parameter. Finally, we can obtain the following:
Remark 5.
The value of M is very small due to the influence of observer compensation, dynamic gains, and related parameters, which are consistently greater than 1. This fact corresponds with the stability proof content, ensuring the validity of the stability analysis.
Remark 6.
The selection criterion for is to ensure that the value of this expression is minimized, ideally approaching the value of . The purpose of this design is to ensure that the value of is sufficiently small, which will be further explained in the stability analysis section.
3.2. Controller Design
In this section, a controller is constructed by utilizing the adaptive backstepping method with a gain compensation observer. Subsystems are recursively designed.
Step 1:
The tracking error is defined as . The origin of the phrase is
The following changes were made:
Substituting Equations (31) and (32) into (30) yields
where and are positive design parameters. Then, we synchronously set . Here, is an unknown parameter and is a positive design parameter.
Next, we apply Formula (34):
At the same time, we set the auxiliary controller as
where is the known normal number; is the estimated value; and , is the estimated value of the unknown parameter . Additionally, , are estimates of unknown parameter .
According to inequality Theorem 1, the two parameters are scaled as follows:
The Lyapunov equation can be changed into the following shape by defining the new parameter . The expression of this function is defined below:
Step 2:
As above, we set the Lyapunov function under the condition of and obtain the following expression according to Formula (34):
One can then derive the following equation from the auxiliary controller:
In addition, we define the expression of the following parameters:
Then, we can obtain the following expression:
At this time, we use inequality Theorem 1 again:
This theorem is then substituted into the Lyapunov equation, and the following parameters are defined:
The expression of the auxiliary controller can be obtained with Formula (44):
where is positive design parameter.
Substituting Formula (44) into (39), we can obtain the expression of the Lyapunov equation as
Step 3: .
The following formula can be obtained using the same inversion calculation method:
Step 4: .
This section adds the function and hysteresis input environment. The input is defined as follows:
The expression of is the same as that in Formula (46). Next, we set the Lyapunov function to (50)
The expression can be obtained by substituting the above parameters into the following calculation:
Let the parameter value be
In combination with Equation (51), the final expression of the Lyapunov equation can be obtained as follows:
4. Stability Analysis
This section is dedicated to analyzing the stability and tracking performance of the proposed control scheme. The globally stable operation and precise tracking capabilities of the closed-loop, decentralized, adaptive control system are ensured by incorporating a specially designed high-gain compensation observer.
Remark 7.
Consider a closed-loop system composed of the controlled system (7), the hysteresis signal (11), the compensation filter (14), the update law (24), and Equations (31) and (33). Next, select appropriate values for the gain’s positive design parameters , , , , and . The tracking error of each subsystem within the closed-loop decentralized control system converges to an arbitrarily small residual set, while all signals remain globally uniformly bounded.
Remark 8.
Notably, the proposed approach can effectively handle a wider range of interference signals, and system (7) encompasses more interference factors than systems in the existing literature. Thus, this system represents a broader category of multi-agent systems. The following are the key certification elements.
To summarize, let the Lyapunov function of the whole be , where the value is .
Next, use Young’s inequality, inequality Theorem 1, to extend and reduce Formula (55), as shown below:
Because of the universal existence of , parameter and the following equations are designed:
Combining (55)–(58), we can obtain Formula (59):
Then, set the parameters in dynamic gain as follows:
where is set to 0.5 in the simulation. The following outcomes can be obtained using this setting technique, which effectively reduces the interference of parameter variables:
For Formula (59), we selected the design parameters to meet the standard requirements:
where is the positive term parameter designed in this study. Combining this formula with Formula (59), we can obtain
Next, solve the integral inequality:
In addition, when , the limit value can be obtained:
Here, the parameters , , , and are bounded. Through the design process of Formulas (22)–(34), we can obtain expressions of the following main variables:
The adjusted observer parameter is also bounded, as both the expected value and dynamic gain are bounded according to our theoretical framework. Once the parameters of the compensatory observer, such as , , , and , are confirmed to be finite, it can be demonstrated that the state variable and the auxiliary controller are also bounded. As a result, the integral discrepancy shown in Equation (62) can be resolved as follows:
Ultimately, variables and are unrelated to one another. Through properly increasing , , , , and , the larger value of in Formula (59) can be selected. This step provides all remaining evidence.
Remark 9.
The compensation-based control strategy effectively reduces errors by lowering the key system parameters . With appropriately chosen design parameters, the system errors can be reduced to zero under specific conditions.
5. Simulation Examples and a System Analysis of Control Strategies
This section presents two cases to illustrate the feasibility of our design strategy using numerical examples and gear system models. The objective of this control strategy is to progressively align each subsystem’s actual output with its desired output by utilizing an adaptive control law , developed through a compensatory observer control scheme. In this context, the differential equation defines the optimal output .
5.1. Numerical Example
We consider the following second-order numerical system:
where . The remaining parameters are all set to zero.
To validate the effectiveness of the control strategy, we set the initial state of the control system to zero and compare the simulation results between the compensation observer control scheme and the traditional observer control scheme.
The compensatory observer control scheme proposed in this design introduces a compensation term into the traditional observer. Consequently, the traditional observer control scheme follows the observer structure shown in Equation (67), but without the compensation term. To ensure a fair comparison, all other parameters remain identical:
Figure 2 presents the compensation observer control strategy, while Figure 3 illustrates the traditional controller control strategy. The error range in Figure 2b is smaller, indicating better tracking performance. This result further validates the superiority of the compensation observer control strategy.
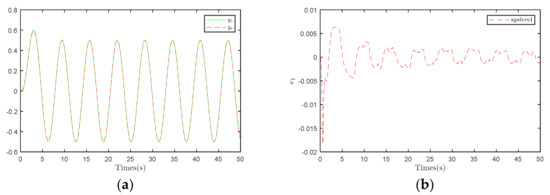
Figure 2.
Results under the compensation control strategy. (a) Trajectory tracking diagram of System 1. (b) System 1 output error.
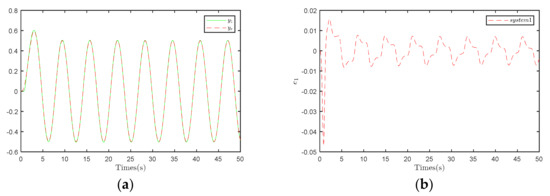
Figure 3.
Results under the traditional control strategy. (a) Trajectory tracking diagram of System 1. (b) System 1 output error.
Comparing the input waveforms between Figure 4 and Figure 5 indicates that under both control strategies, the input waveform of the overall system exhibits periodic variations. However, under the compensation strategy, the system input presents localized oscillations. This result represents a drawback of the control scheme, indicating a limitation in its ability to mitigate localized oscillations in the system input.
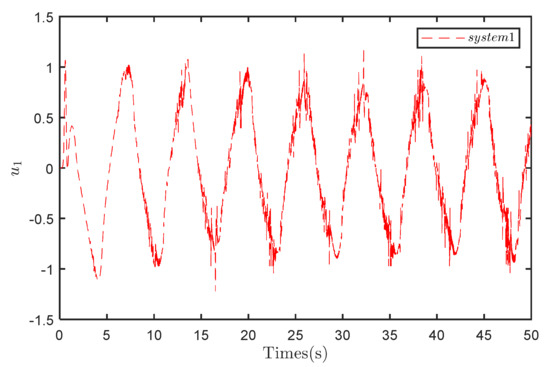
Figure 4.
Input to System 1 under the compensation control strategy.
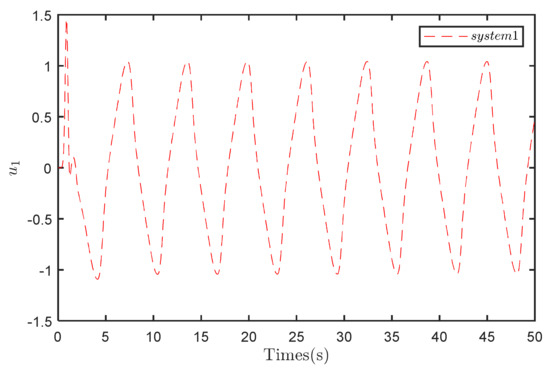
Figure 5.
Input to System 1 under the traditional control strategy.
The dynamic behavior depicted in Figure 6, showing periodic states of the system output in three-dimensional state space, indicates the stable periodic responses of the system to certain inputs or initial conditions, indirectly suggesting a degree of stability in the system.
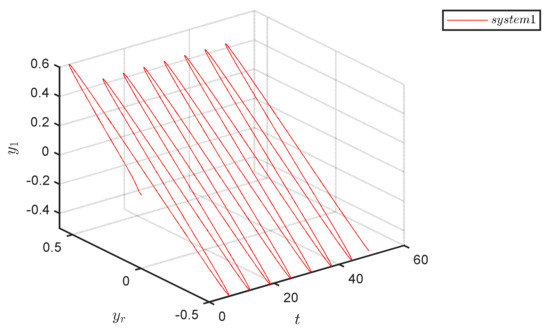
Figure 6.
State space tracking performance of System 1.
As shown in Figure 7a, the derivative of the dynamic gain exhibits periodic oscillations. This phenomenon is similar to observations in Figure 7b. Additionally, the waveforms of and trend towards zero, indicating that the integrated values of these parameters are bounded. This characteristic may reflect the stability of the system dynamics, as the integrated values of the parameters are constrained, leading to limited variations in the system state within a finite range.
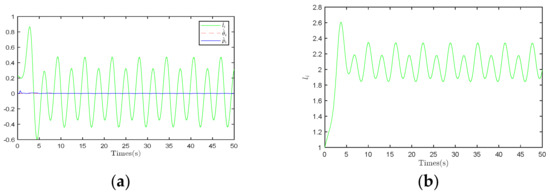
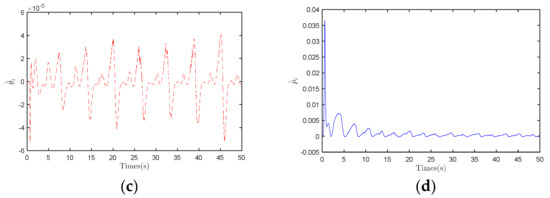
Figure 7.
Results under the compensation control strategy. (a) Derivation of three parameters of System 1. (b) Waveform diagram of parameter . (c) Waveform diagram of parameter . (d) Waveform diagram of parameter .
Based on the results shown in Figure 8, the waveforms of and are nearly identical, indicating that the observer can accurately track and predict the system’s state variables. This result demonstrates that the observer effectively estimates the system state in dynamic environments, thereby providing a necessary foundation for the performance of the stringent controller.
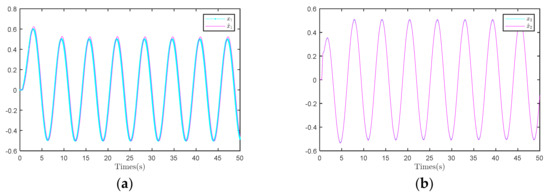
Figure 8.
Comparison of observer performance. (a) and in System 1; (b) and in System 1.
5.2. Pratical Example
In this section, we employ a dual-motor coupled control system as an example of the simulation. The instance model of this control system is illustrated in Figure 9. Here, we treat the two motors as independent agents within a multi-agent system. Each agent is independently controlled, and overall stability is achieved by coordinating the two agents via controllers or information transmission.

Figure 9.
A dual-motor coupled control system.
The physical meanings of the parameters are as follows: is the drive rotation angle, and is the load rotation angle, which are represented by and , respectively. is the moment of inertia of the load, is the moment of inertia of the driver, is the gear tooth ratio, is the damping of the driver, is the load damping, and is the torsional elastic constant.
The state equation of the system is
In Formula (68) of subsystem 2,
In Formula (69) in subsystem 3,
Next, we set the parameter values as follows:
To summarize, the simulation operation effect of the system can be obtained as follows:
Comparing Figure 10 with Figure 11 yields a consistent conclusion, indicating that employing the compensation observer control strategy can further reduce tracking errors. This finding underscores the efficacy of the compensation observer control strategy in enhancing the system’s tracking performance.
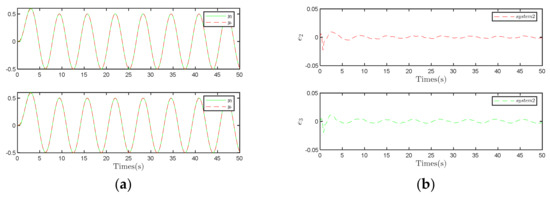
Figure 10.
Results under the compensation control strategy. (a) Trajectory tracking diagram of System 2 and 3. (b) System 2 and 3 output error.
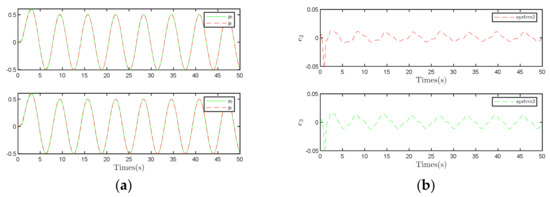
Figure 11.
Results under the traditional control strategy. (a) Trajectory tracking diagram of System 2 and 3. (b) System 2 and 3 output error.
A comparative analysis of Figure 12 and Figure 13 similarly reveals an inherent flaw in the compensation observer control strategy: the exacerbation of input oscillations. This observation highlights a limitation of the compensational observer control strategy, indicating its tendency to amplify input oscillations. However, the degree of oscillation amplification is relatively mild and remains within an acceptable range.
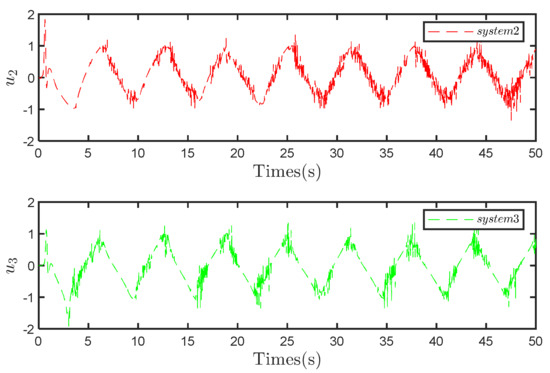
Figure 12.
Input to System 2 and 3 under the compensation control strategy.
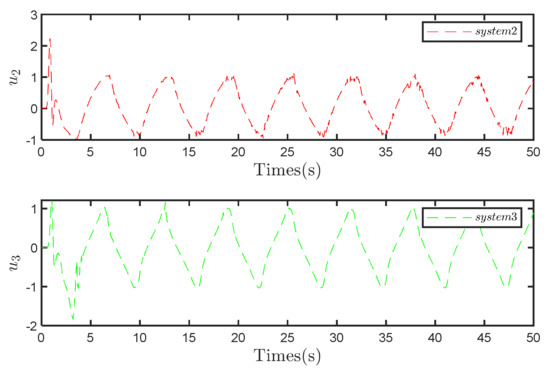
Figure 13.
Input to System 2 and 3 under the traditional control strategy.
Figure 14 graphically depicts the trajectories of Systems 2 and 3 within the state space, indicating a nearly complete overlap between them. This significant overlap not only underscores the high effectiveness of the control strategy in tracking the desired trajectory but also confirms the existence of a stable periodic response in both systems. The results from the comparative experiments further support these findings.
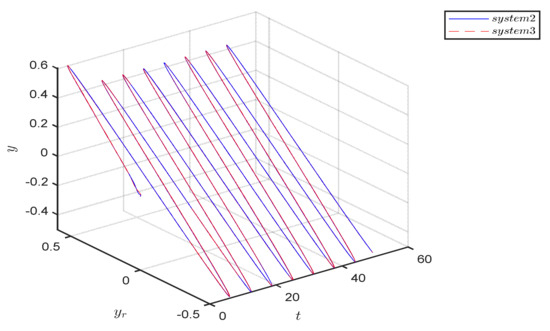
Figure 14.
State space tracking performance of system 2 and 3.
Figure 15 presents the actual and estimated values of the first state variable. Here, the overlap between and , as well as that between and , indicates that the observer can closely match the true state of the system. The superior fitting accuracy of the second state variable can be observed in Figure 16, as indicated by the minimal deviation between and , as well as and . This level of precision in estimating the second state variable highlights the enhanced performance of the observer in multi-dimensional settings, which is crucial to effectively control multi-agent systems.
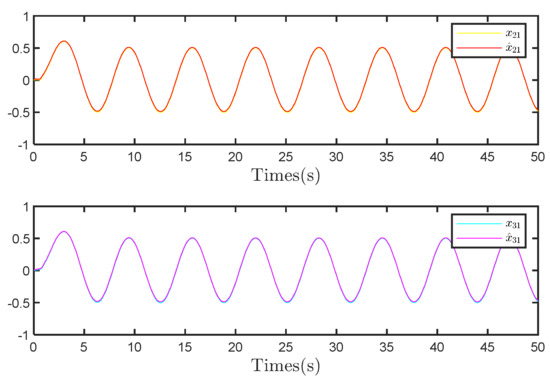
Figure 15.
The comparison of observer performance.
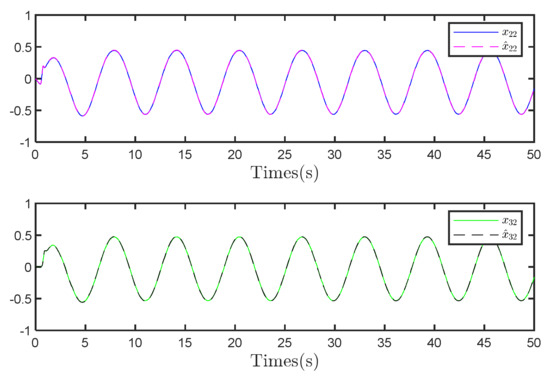
Figure 16.
The comparison of observer performance.
6. Conclusions and Further Research
This study introduced a modified compensatory observation scheme that markedly differs from traditional observation methods and was specifically designed for a class of nonlinear multi-agent systems influenced by an unknown hysteresis signal loop. This innovative approach not only significantly reduces tracking errors but also substantially enhances overall system tracking performance. However, we observed that under certain conditions, the compensatory observer control strategy may inadvertently increase input oscillations. Although these oscillations are relatively mild, it is essential to consider their potential impacts on overall system control and stability.
Future research will focus on further optimizing the system’s design. This includes detailed studies on parameter adjustments, structural enhancements, sensor layout optimization, and other aspects. These efforts aim to refine the compensatory observation scheme, minimize any adverse effects, and improve the robustness and reliability of the control strategy. Ultimately, such advancements will contribute to significant technological progress and development in related fields.
Author Contributions
Algorithm derivation, Z.L.; simulation model, Y.L.; paper writing and editing, Z.L.; paper conception and ideas, Z.L. and Y.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China No. 61703269.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to privacy.
Acknowledgments
The authors would like to thank all of the authors cited in this article and the anonymous referees for their helpful suggestions.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Montagna, S.; Castro Silva, D.; Henriques Abreu, P.; Ito, M.; Schumacher, M.I.; Vargiu, E. Autonomous Agents and Multi-Agent Systems Applied in Healthcare. Artif. Intell. Med. 2019, 96, 142–144. [Google Scholar] [CrossRef] [PubMed]
- Cong, Z. Distributed ESO Based Cooperative Tracking Control for High-Order Nonlinear Multiagent Systems with Lumped Disturbance and Application in Multi Flight Simulators Systems. ISA Trans. 2018, 74, 217–228. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Chen, M.Z.Q.; Gao, Z.; Wu, C.W.; Lin, Z. Special Issue on “Distributed Coordination Control for Multi-Agent Systems in Engineering Applications”. ISA Trans. 2017, 71, 1–2. [Google Scholar] [CrossRef] [PubMed]
- De Wilde, P.; Briscoe, G. Stability of Evolving Multiagent Systems. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2011, 41, 1149–1157. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Fang, Z.; Li, Y. Global Decentralized Output Feedback Control for Interconnected Time Delay Systems with Saturated PI Hysteresis. J. Frankl. Inst. 2020, 357, 5460–5484. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Cui, G.; Xu, S.; Ma, Q.; Li, Y.; Zhang, Z. Prescribed Performance Distributed Consensus Control for Nonlinear Multi-Agent Systems with Unknown Dead-Zone Input. Int. J. Control 2017, 91, 1053–1065. [Google Scholar] [CrossRef]
- Gong, A.; Xie, X.; Yue, D.; Xia, J. Multi-instant observer design of discrete-time fuzzy systems via an enhanced gain-scheduling mechanism. IEEE Trans. Cybern. 2022, 53, 2876–2885. [Google Scholar] [CrossRef] [PubMed]
- Hua, C.; Liu, S.; Li, Y.; Guan, X. Distributed adaptive output feedback leader-following consensus control for nonlinear multiagent systems. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 4309–4317. [Google Scholar] [CrossRef]
- Huang, D.; Yang, C.; Pan, Y.; Cheng, L. Composite learning enhanced neural control for robot manipulator with output error constraints. IEEE Trans. Ind. Inform. 2019, 17, 209–218. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Z.; Ge, S.S. Dynamic Gain Reduced-Order Observer-Based Global Adaptive Neural-Network Tracking Control for Nonlinear Time-Delay Systems. IEEE Trans. Cybern. 2022, 53, 7105–7114. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Liu, J.; Huang, Z.; Peng, Y.; Pu, H.; Ding, L. Adaptive impedance control of human–robot cooperation using reinforcement learning. IEEE Trans. Ind. Electron. 2017, 64, 8013–8022. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, L.; Yu, J. Adaptive finite-time consensus tracking for nonstrict feedback nonlinear multi-agent systems with unknown control directions. IEEE Access 2019, 7, 155262–155269. [Google Scholar] [CrossRef]
- Liu, Y.H. Adaptive dynamic surface asymptotic tracking for a class of uncertain nonlinear systems. Int. J. Robust Nonlinear Control 2018, 28, 1233–1245. [Google Scholar] [CrossRef]
- Liu, Y.J.; Tong, S. Barrier Lyapunov functions-based adaptive control for a class of nonlinear pure-feedback systems with full state constraints. Automatica 2016, 64, 70–75. [Google Scholar] [CrossRef]
- Liu, Y.J.; Tong, S. Barrier Lyapunov functions for Nussbaum gain adaptive control of full state constrained nonlinear systems. Automatica 2017, 76, 143–152. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, Y. Global adaptive output feedback tracking for a class of non-linear systems with unknown backlash-like hysteresis. IET Control Theory Appl. 2014, 8, 927–936. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, Y.; Huang, R. Decentralised adaptive output feedback control for interconnected nonlinear systems preceded by unknown hysteresis. Int. J. Control 2015, 88, 1712–1725. [Google Scholar] [CrossRef]
- Schwartz, M.; Krebs, S.; Hohmann, S. Guaranteed State Estimation Using a Bundle of Interval Observers with Adaptive Gains Applied to the Induction Machine. Sensors 2021, 21, 2584. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Lu, J.; Li, Z.; Xu, S. Robust Adaptive Distributed Dynamic Surface Consensus Tracking Control for Nonlinear Multi-Agent Systems with Dynamic Uncertainties. J. Frankl. Inst. 2016, 353, 4785–4802. [Google Scholar] [CrossRef]
- Tao, G.; Kokotovic, P.V. Adaptive control of plants with unknown hystereses. IEEE Trans. Autom. Control. 1995, 40, 200–212. [Google Scholar] [CrossRef]
- Tong, S.; Li, Y.; Liu, Y. Observer-based adaptive neural networks control for large-scale interconnected systems with nonconstant control gains. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1575–1585. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Shen, H.; Xie, X.; Hayat, T.; Alsaadi, F.E. Robust Adaptive Neural Control for Pure-Feedback Stochastic Nonlinear Systems with Prandtl–Ishlinskii Hysteresis. Neurocomputing 2018, 314, 169–176. [Google Scholar] [CrossRef]
- Ye, W.; Aghili, F.; Wu, J.; Su, C.-Y. Robust Adaptive Control of Uncertain Systems Preceded with Unknown Hysteresis Actuators. In Proceedings of the 2021 IEEE 7th International Conference on Control Science and Systems Engineering (ICCSSE), Qingdao, China, 30 July–1 August 2021; pp. 23–28. [Google Scholar]
- Zhao, W.; Liu, Y.; Liu, L. Observer-based adaptive fuzzy tracking control using integral barrier Lyapunov functionals for a nonlinear system with full state constraints. IEEE/CAA J. Autom. Sin. 2021, 8, 617–627. [Google Scholar] [CrossRef]
- Zhou, M.; Zhang, Y.; Ji, K.; Zhu, D. Model Reference Adaptive Control Based on KP Model for Magnetically Controlled Shape Memory Alloy Actuators. J. Appl. Biomater. Funct. Mater. 2017, 15, 31–37. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Liu, Y.; Zhang, G.; Li, H.; Liu, H. Novel Dynamic Surface Funnel Control for Input Delay Nonlinear Systems. Control. Theory Appl. 2022, 39, 1426–1432. [Google Scholar]
- Hosseinzadeh, M.; Yazdanpanah, M.J. Performance enhanced model reference adaptive control through switching non-quadratic Lyapunov functions. Syst. Control Lett. 2015, 76, 47–55. [Google Scholar] [CrossRef]
- Tao, G. Model reference adaptive control with L 1+ α tracking. Int. J. Control 1996, 64, 859–870. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).