Abstract
Pretrained language models have achieved great success in various natural language understanding (NLU) tasks due to their capacity to capture deep contextualized information in text using pretraining on large-scale corpora. Tokenization plays a significant role in the process of lexical analysis. Tokens become the input for other natural language processing (NLP) tasks, like semantic parsing and language modeling. However, there is a lack of research on the evaluation of the impact of tokenization on the Arabic language model. Therefore, this study aims to address this gap in the literature by evaluating the performance of various tokenizers on Arabic large language models (LLMs). In this paper, we analyze the differences between WordPiece, SentencePiece, and BBPE tokenizers by pretraining three BERT models using each tokenizer while measuring the performance of each model on seven different NLP tasks using 29 different datasets. Overall, the model pretrained with text tokenized using the SentencePiece tokenizer significantly outperforms the other two models that utilize WordPiece and BBPE tokenizers. The results of this paper will assist researchers in developing better models, making better decisions in selecting the best tokenizers, improving feature engineering, and making models more efficient, thus ultimately leading to advancements in various NLP applications.
1. Introduction
In natural language processing (NLP), tokenization is the fundamental preprocessing step for breaking down text into smaller, yet more manageable units called tokens that facilitate machines to appropriately process and generate human language. These tokens can be as small as characters or as long as words. These tokens serve as the building blocks for the sequences that are passed to language models during pretraining or fine-tuning stages. Therefore, the choice of tokenizer significantly impacts the performance of language models [1,2,3,4]. Recently, transformer-based architectures have emphasized the importance of tokenization to limit the vocabulary size, particularly for managing large datasets. Tokenizations are employed in many transformer-based architectures such as BERT [5], DistillBERT [6], GPT-2 [7], and RoBERTa [8].
There are many tokenization algorithms and techniques, including word tokenization, character tokenization, and subword tokenization. Word tokenization algorithms involve splitting the text into individual words, whereas character tokenization represents text as a sequence of individual characters. Subword tokenization is one of the most common tokenization algorithms due to its widespread use with large language models (LLMs). It provides a solution for issues arising from word and character-based tokenization algorithms. Subword tokenization breaks text into units smaller than whole words but that are larger than individual characters. Additionally, it was designed to work for most languages while keeping the vocabulary size manageable. This is because it captures commonalities between words, even in different languages, thus reducing the need for a massive list of unique tokens. Furthermore, the algorithm resolves the issues associated with word-based tokenization such as large vocabulary sizes, out-of-vocabulary tokens, and the different meanings of very similar words. It also overcomes the problems related to character-based tokenization such as long sequences and meaningless individual tokens. However, the subword tokenization approach introduces different types of issues, such as nonsensical subwords. Some of the popular subword-based tokenization algorithms are WordPiece [9], Byte-Pair Encoding (BPE) [10], Unigram [10], Byte-level BPE [11], and SentencePiece [12].
The selection of an appropriate tokenization strategy depends on the specific language and the NLP application. However, there is a critical gap in the literature regarding the influence of various tokenization algorithms on different NLP tasks. According to Bostrom and Durrett [13], there is no direct evaluation of the impact of tokenization over language models like BERT in terms of training efficiency and model performance on different downstream NLP tasks. This lack of investigation presents a significant opportunity to improve the performance of language models on NLP tasks by investigating how various tokenization algorithms would impact language models on different tasks. Moreover, little work has been conducted to evaluate language-specific tokenizers for the Arabic language [1]. Thus, we aim to evaluate the influence of various tokenizers on BERT-based Arabic models, and for this task, we have chosen the most prevalent and widely used tokenizers on the HuggingFace platform: WordPiece, SentencePiece, and BBPE. To the best of our knowledge, this is the first study to evaluate the preference for various tokenizers for Arabic LLMs, particularly BERT-based Arabic models.
Contribution: In this paper, we compare the performance of three subword tokenizers for the Arabic language: WordPiece, SentencePiece, and BBPE. We achieve this by pretraining three separate BERT models, with each using a different tokenizer. We then evaluate the performance of each model on seven different NLP tasks using 29 datasets. The findings of this study will be beneficial to researchers in several ways. They will assist them in developing better models, making informed decisions when selecting the best tokenizers, improving feature engineering techniques, and ultimately leading to more efficient models that advance various NLP applications.
Outline:The remainder of the article is organized as follows. The related works are covered in Section 2. In Section 3, we describe the implementation of the three selected tokenizations. Section 4 describes the experiment and the employed datasets. Section 5 discusses the experiment’s results. Section 6 presents the concluding remarks and future work.
2. Related Works
The literature contains some studies comparing the performance of tokenization algorithms across diverse languages on NLP tasks, including Tunisian Arabic [3], the Turkish language [14], and dialect-agnostic Arabic [1], as well as multilingual applications [15,16]. For example, Mekki et al. [3] compared three tokenization algorithms for the Tunisian Arabic dialect on three machine learning models: conditional random fields, support vector machines, and deep neural networks. The authors used several public datasets such as the Tunisian media corpus [17] and the Tunisian Arabic dialect [18] to compare the model’s performance based on their ability to accurately tokenize text, thus considering the challenges posed by Tunisian Arabic’s morphological complexity. The three models achieved good performance, but the conditional random fields model achieved the best results, with an F measure of 88.9%. In the Turkish language, Erkaya et al. [14] compared the performance of three tokenization algorithms. The three used tokenization algorithms were Byte-pair Encoding [19], WordPiece [20], and the Unigram Language Model [10] on the Open Super-large Crawled Aggregated coRpus (OSCAR) [21]. The results showed that WordPiece tends to produce more single-word tokens, along with morphology-compatible tokens. Also, the authors found that increasing the size of the training corpus for a tokenizer leads to producing more and shorter tokens. In the Arabic language, Alyafeai et al. [1] introduced three new tokenization algorithms for Arabic and then compared them to the other three baselines. The three tokenizers used in the comparison were SentencePiece, Character, and Word tokenizer. The evaluation was conducted on three supervised classification tasks: sentiment analysis, news classification, and poetry classification. Four datasets were employed: AJGT [22], Metrec [23], LABR [24], and DSAC [25]. The result showed that the word tokenizer achieved the best results for small vocabulary sizes only for news classification. However, for small and larger vocabulary sizes, the character tokenizer achieved the best results for poetry classification.
A growing body of research has investigated the impact of different tokenization methods on NLP tasks in multilingual contexts. Domingo et al. [15] conducted several experiments using five different tokenizer algorithms across ten language pairs to evaluate their impact on the quality of the final translation. The five tokenizers employed were SentencePiece, Mecab, StanfordWord Segmenter [26], OpenNMT [27], and Moses [28]. The results showed that tokenization significantly affects the quality of the translation, and the selection of the best tokenizer differs based on the selected language pairs. Also, Rust et al. [16] investigated the performance of multilingual models on nine different languages across five different tasks (NER, SA, QA, Dependency Parsing, and Part-of-Speech Tagging), thus comparing them to their equivalent monolingual model. The paper also investigated the impact of the adopted tokenization approach on the performance of multilingual models on monolingual tasks. The results showed that using a tokenizer that is designed for a particular language significantly improves the model’s performance on downstream tasks for almost every task and language. Moreover, Wei et al. [29] also performed a comparison between byte-level and character-level tokenizers in vocabulary building for multilingual pretrained language models. Several case studies were conducted on the multilingual XNLI tasks in seven languages such as English, Arabic, French, and Russian using the NEZHA architecture [30]. The authors found that the NEZHA model trained with byte-level subwords consistently outperformed the multilingual BERT model [5].
Subword tokenizers have also been explored for various languages and applications. In large language models (LLMs), Chirkova and Troshin [31] investigated the effect of unigram [10] and and BPE [32] subtokenization algorithms on the performance of LLMs trained on source code using the PLBART model [33] as a testing ground. The study revealed that reducing the subtokenization length up to 17% could improve the model training efficiency. Additionally, using the right subtokenizer (in this case: unigram) improved the quality of the trained LLM by 0.5–2%. Similarly, Bostrom and Durrett [13] conducted a study to evaluate the performance of pretrained language models using BPE and unigram tokenizers. They pretrained four RoBERTa-base models: two on an English text corpus of 3 billion tokens and two on a Japanese text corpus of 0.6 billion tokens. Each language group had one model pretrained with BPE tokenization and another with unigram tokenization. They concluded that the English model that used the unigram tokenizer slightly outperformed its counterpart model pretrained with a BPE tokenizer on various NLP tasks. However, the unigram Japanese language model showed a more than 10% improvement over its BPE counterpart in the Japanese QA task. Furthermore, Beinborn and Pinter [34] analyzed the relationship between the output of the tokenizer and the time and accuracy of human performance on a lexical decision task. The results showed that the Unigram produced outputs that were less aligned with human cognition than BPE and WordPiece.
Compared to current related works, there has been limited investigation into the impact of subword tokenizers on the Arabic language. Additionally, there has been limited exploration of how different tokenizers affect LLMs like BERT, particularly for the Arabic language. Thus, this paper aims to bridge this gap by comparing various tokenization algorithms for the Arabic language. We evaluated three subword tokenizers: WordPiece, Byte-Level BPE, and SentencePiece. We pretrained three BERT models using each tokenizer and then evaluated their performance on range of NLP tasks. The outcomes of this paper will assist researchers in developing better models, thus making better decisions in selecting the appropriate tokenizer for their needs, improving feature engineering, and making models more efficient, which will ultimately lead to advancements in various NLP applications.
3. Tokenization
3.1. WordPiece
The WordPiece (WP) tokenizer is a subword tokenization technique originally designed for solving Japanese–Korean segmentation problems in the Google speech recognition system [20]. Wu et al. [9] introduced this tokenization algorithm to maximize the likelihood of the training data when given an evolving word definition. WordPiece selects a symbol pair that will lead to the largest increase in likelihood upon merging. This is similar to the method used by Schuster and Nakajima [20] to handle uncommon/rare words to generate a segmentation for any word. One of the benefits of using the WordPiece algorithm is that it reduces the vocabulary size, thus resulting in more efficient encoding of text data. Additionally, the algorithm is considered a language-agnostic tokenizer, which means that it can be applied to different languages, thus making it adaptable for multilingual applications. First, the algorithm breaks down the input words into individual units called wordpieces. It then counts the most frequently repeated two-character, three-character, and longer sequences in the training corpus. The resulting vocabulary list will contain full words, individual characters, and subwords. To distinguish between a whole word and a subword token, a special symbol, usually ‘##’, is added as a prefix to each subword token. This indicates that the token is part of a larger word rather than a complete word on its own. For example, the sentence “I was uncomfortable” might be split into “I”, “was”, “un”, “##comfortable”. In contrast to BPE, WordPiece selects the one that maximizes the likelihood of the training dataset given the current vocabulary, not the most common symbol pair. The wordpiece tokenizer has been used in many prominent language models such as BERT [5], DistillBERT [6], and in almost all Arabic langauge models such as Arabic-BERT [35], ARBERT [36], AraPoemBERT [37], and CAMELBERT [38].
3.2. Byte-Level BPE (BBPE)
Byte-Pair Encoding (BPE) is a popular subword tokenization algorithm introduced by Sennrich et al. [32]. The pretokenization stage of BPE includes separating the text into words and then creating a set of unique words, along with the frequency of each word in the training text corpus. In the tokenization stage, the algorithm starts by creating a base vocabulary list that contains all the characters and symbols that are in the unique word set. From there, the algorithm starts merging the starting tokens in the base vocabulary list, which are individual characters to form new tokens to be added to the vocabulary list. The algorithm starts by merging the most frequent tokens, and it keeps repeating the merging process until the number of tokens in the vocabulary list reaches the predetermined vocabulary size. The BPE tokenizer was used in the original OpenAI GPT model [39]. Both the BPE and WordPiece algorithms follow a bottom-up approach in building the vocabulary list.
Byte-level BPE (BBPE): BBPE is a recent variation of the original BPE tokenization algorithm introduced by Wang et al. [11]. The main difference between the two is that BBPE builds the base vocabulary list using a 256-byte set instead of actual characters. This approach allows the vocabulary to include all possible based characters while maintaining the overall vocabulary size within a reasonable limit, and it ensures that there is no need for an out-of-vocabulary token. In contrast to Sentencepiece and Wordpiece, BBPE is byte-level, which builds a vocabulary based on bytes encoding, not based on individual characters, in the training data. It also offers a universal vocabulary of bytes, which allows for better handling of many languages and for solving the issue of out-of-vocabulary. The BBPE tokenizer was used in many prominent language models such as GPT2 [39], RoBERTa [8], JABER and SABER [40], and ARAMUS [41].
3.3. SentencePiece
SentencePiece (SP) is an unsupervised subword tokenizer and detokenizer designed for neural-based text processing [12]. Because it is an unsupervised tokenizer, it does not need prelabeled data, and thus, it learns how to segment words directly from raw sentences. SentencePiece is considered to be language-Independent, since it treats the sentences just as sequences of Unicode characters (i.e., it does not extract words based on the whitespace character). It encompasses four main elements: the normalizer, trainer, encoder, and decoder. The task of the normalizer is to convert semantically equivalent Unicode (Unicode- NFKC) characters into their standard forms. The task of the trainer is to train the corpus by learning the subword segmentation strategy. SentencePiece supports two tokenization algorithms—byte pair encoding (BPE) [32] and the unigram language model [10]—to construct the appropriate vocabulary. The task of the encoder is to prepare the text for processing by converting it to a sequence of IDs, while the task of the decoder is to convert the output back to human-readable text. The model starts by creating vocabulary of a predetermined size from the basic character set. Then, a unique ID is assigned to each subword in its vocabulary. In contrast to WordPiece and BPE, SentencePiece adds spaces and nontext symbols in its vocabulary, thus allowing it to tokenize raw text directly. The SentencePiece tokenizer was used in many prominent language models such as ALBERT [42], SaudiBERT [43], XLNet [44], and T5 [45].
4. Experiments
In this section, we present the steps for text preprocessing, the pretraining configurations of the presented models, and the fine-tuning procedures. Additionally, we briefly elaborate on the evaluation metrics used to assess different models and provide a short description of the evaluation datasets used in this study.
All experiments were conducted on a local machine with AMD Ryzen-9 7950x processor, 64 GB DDR5 memory, and two GeForce RTX 4090 GPUs with 24 GB memory each. The software environment was set up on the Ubuntu 22.04 operating system, and we used the HuggingFace Transformers library [46] for pretraining and fine-tuning the models, in addition to downloading many of the datasets used in the experiments from the HuggingFace hub.
4.1. Model Pretraining
The goal of this project is to evaluate the performance of various tokenizers for Arabic LLms. We analyzed the differences between WordPiece (WP), SentencePiece (SP), and Byte-level BPE (BBPE) tokenizers by pretraining three BERT models using each tokenizer (BERT-WP https://huggingface.co/faisalq/bert-base-arabic-wordpiece (accessed on 21 May 2024), BERT-SP https://huggingface.co/faisalq/bert-base-arabic-senpiece (accessed on 21 May 2024), and BERT-BBPE https://huggingface.co/faisalq/bert-base-arabic-bbpe (accessed on 21 May 2024)) while measuring the performance of each model on seven different NLP tasks. The pretraining text corpus underwent a few preprocessing operations using PyArabic [47], a Python library for preprocessing and normalizing Arabic text. The preprocessing steps included only removing diacritics and Arabic letters’ extension (Tatweel), without removing any punctuation, symbol characters, or English words. The final corpus size came out to 35.7 GB (29.6 GB from CC-100-AR [48], and 6.1 GB from Wikipedia dump and Al-Shamela library [49] that was already compiled and made public on Kaggle [50]).
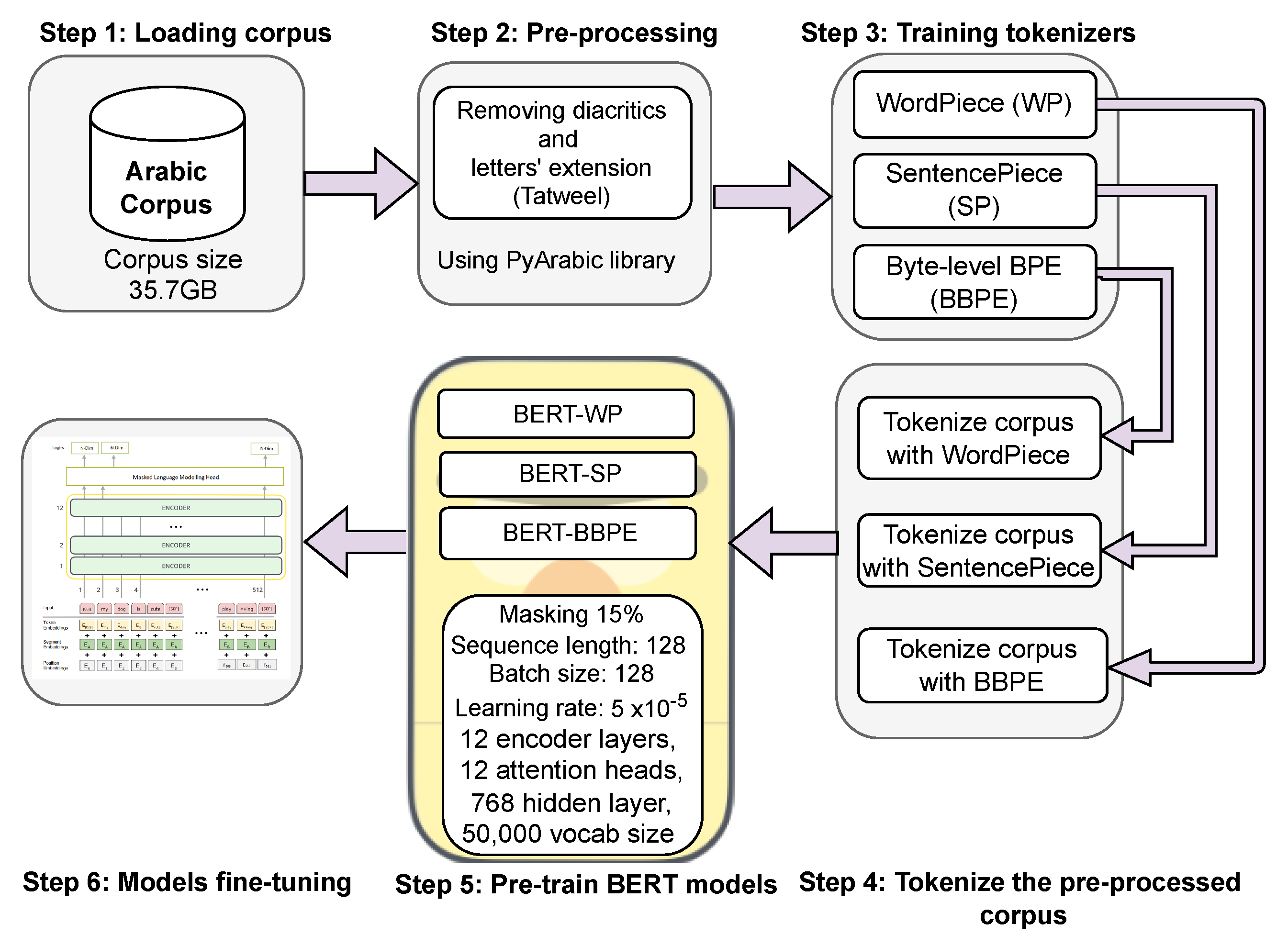
All three models followed the same architecture as the original BERT model, with 12 encoder layers, 12 attention heads per layer, and a hidden layer size of 768 units, and the vocabulary size was set to 50,000 wordpieces. Furthermore, we used the following configurations for pretraining the models: masking 15% of the input tokens, a maximum sequence length of 128, a batch size of 128, and the ‘AdamW’ optimizer, with a learning rate of 5 × . Finally, all three models were pretrained for 2 epochs (around 2 million steps). Figure 1 provides an overview of the text preprocessing and tokenizer preparation steps, along with the model pretraining procedures.
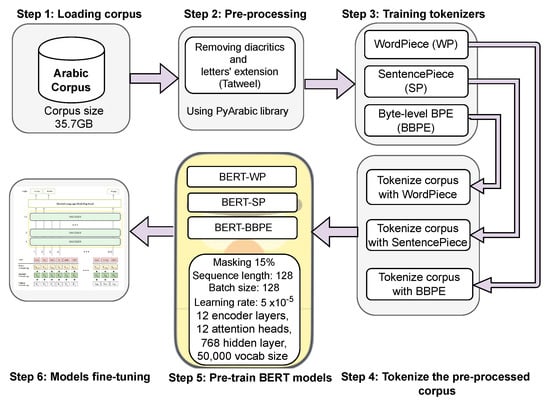
Figure 1.
Overview of text preprocessing, tokenization stages, and BERT model pretraining steps.
4.2. Evaluation Metrics
We evaluated the performance of the new models by measuring their performance across all tasks using the F1 score (1) metric. Additionally, we included the Accuracy (1) metric for the majority of the evaluation tasks, whereas the Exact Match (EM) (5) metric was used only for the QA task. EM is a binary evaluation metric that assesses whether the predicted answer matches the referenced answer or not. The following formulas were used to determine the performance of each classification model:
where is True Positive, is True Negative, is False Positive, and is False Negative. Also, EM represents the average of all individual exact match scores in the set, and T represents the total number of predictions in the set.
4.3. Datasets
In this section, we briefly describe all datasets used for each NLP task. The evaluation process was conducted by measuring the performance of all three models across seven NLP tasks, with a total of 29 datasets. Some datasets were annotated for two or more tasks. Thus, we added an extra identifier in front of the name of those datasets.
4.3.1. Natural Language Inference (NLI) and Stance Detection (SD)
NLI and SD are both subtasks of NLP that deal with understanding the relationships between two sentences associated with a label. However, the NLI task involves determining the relationship between two given sentences. The first sentence is typically called the “premise”, and the second sentence is known as the “hypothesis”. The model’s objective is to classify whether the hypothesis is true (entailment), false (contradiction), or undetermined (neutral) based on the information in the premise. On the other hand, SD involves identifying the author’s stance in a text concerning a specific target. The typical stances identified are ‘favor’, ‘against’, and ‘neutral’. For this task group, we employed five datasets. Four consist of Modern Standard Arabic (MSA) text and one dialectal Arabic (DA) dataset, called Mawqif. Descriptions of employed five datasets are provided below:
- Cross-lingual Natural Language Inference (XNLI): XNLI is a crowdsourced dataset designed to evaluate crosslingual representations [51]. It consists of 393 k sentence pairs, with 2490 in the validation set and 5010 in the test set. Each pair was annotated with one of three labels: entailment, contradiction, or neutral. The dataset has been machine-translated into 14 languages, including Arabic.
- The Multi-Genre Natural Language Inference (MultiNLI): Similarly, MultiNLI is also a crowdsourced dataset designed for crosslingual representations tasks [52]. It consists of 84 k sentence pairs with 21 k in the validation set. The dataset has been machine-translated into 15 languages, including Arabic.
- Arabic Stance Detection dataset (AraStance):AraStance is a collection of Arabic news websites annotated with three fact-checking stances [53]. The dataset consists of 4063 articles covering claims from different domains such as health, politics, and sports.
- Arabic News Stance Corpus (ANS-Stance): ANS-Stance is a collection that includes Arabic news titles, paraphrased titles, and corrupted titles designed for news claim verification and stance prediction [54]. It consists of 3786 titles, with each associated with pairs of claims and evidence.
- A Multi-label Arabic Dataset for Target-specific Stance Detection (Mawqif): Mawqif is a multilabel Arabic dataset that was crawled from Twitter and manually annotated for four different NLP tasks: stance detection, sarcasm detection, sentiment analysis, and text classification [55]. It consists of 4121 tweets in multidialectal Arabic, thus covering three topics: digital transformation, the COVID-19 vaccine, and women’s empowerment.
4.3.2. Sarcasm Detection (SaD)
SaD task typically involves identifying whether a given sentence is sarcastic or not. The task is challenging, because it requires an understanding of subtle hints and context to identify sarcasm. For the SaD task, we employed four datasets, including Mawqif that was briefly described in the NLI and SD task group. All datasets in this task group primarily consist of DA text, along with some MSA text.
- Saudi Dialect Irony Dataset (SaudiIrony): SaudiIrony is a collection of tweets specifically designed to help with detecting irony in the Saudi dialect [56]. The dataset contains about 19,800 tweets.
- iSarcasmEval: iSarcasmEval is a collection of Arabic sarcastic texts specifically designed to help detect intended sarcasm in text [57]. It contains 4887 texts from different dialects such as the Nile Basin, the Gulf area, and North Africa.
- ArSarcasmV2: ArSarcasm is an Arabic SaD dataset [58]. It is an extension of the original ArSarcasm dataset [59]. The expanded corpus contains 15,548 tweets, with each labeled for sarcasm, and which are manually annotated with one of three sentiments: positive, negative, or neutral.
4.3.3. Sentiment Analysis (SA)
In the SA task, the model’s objective is to identify the sentiment of input text data, which can be positive, negative, or sometimes neutral. For this task group, we used six datasets. Two datasets, HARD and ASTD, consist of mixed text in MSA and DA. One dataset, BRAD, consists only of MSA. The other two datasets, Mawqif (briefly described in the NLI and SD task groups) and ArSarcasmV2 (briefly described in the SaD task group), consist of DA. Descriptions of the remaining four datasets are provided below:
- Hotel Arabic-Reviews Dataset (HARD): HARD is a large dataset composed of customer reviews of various hotels that were written in both MSA and various DA forms [60]. The corpus contains 409,562 reviews collected from Booking.com. The dataset contains 2 versions: balanced and unbalanced. The the balanced version contains 105,698 reviews annotated with either positive or negative. In this paper, both versions were included in the experiments.
- Book Reviews in Arabic Dataset (BRAD): BRAD is a large dataset of Arabic book reviews [61] collected from goodreads.com. It contains 510,600 reviews associated with a rating on a scale of 1 to 5 stars for sentiment analysis.
- Arabic Sentiment Tweets Dataset (ASTD): ASTD is a collection of Arabic posts collected from Egyptian Twitter accounts [62]. It contains approximately 10,000 tweets.
4.3.4. Topic Classification (TC)
Topic classification (TC) is a key task in natural language processing. In TC, texts are automatically categorized based on their content. The purpose of this task is to measure the impact of different tokenizers on model performance in analyzing a large body of text. For the TC task, we employed four datasets, all of which consist of news articles written in MSA. Descriptions of the four datasets used are provided below:
- Single-labeled Arabic News Articles Dataset (SANAD): SANAD is a large collection of single-labeled Arabic news articles [63]. It contains 194,797 articles covering different topics such as sports, culture, finance, politics, and medicine. The articles were collected from three different news websites: AlKhaleej, AlArabiya, and Akhbarona. In this paper, we used the AlKhaleej subset labeled into seven categories, and it contains 45 K articles.
- Open Source Arabic Corpora (OSAC): OSAC is a large collection of Arabic datasets that were collected from various sources, including news articles (BBC and CNN Arabic news), cooking recipe books, and religious books [64]. The corpora are divided into three sets: BBC Arabic, CNN Arabic, and OSAC. In total, the corpus contains 22,429 articles covering different topics on economics, astronomy, law, etc. In this paper, we used the CNN Arabic corpus, which contains 5070 articles labeled into 6 different categories: business, entertainment, Middle East news, science and technology, sports, and world news.
- A Moroccan News Articles Dataset (MNAD v2): MNAD is an Arabic dataset that was collected from four Moroccan news articles websites [65]. It contains 418 K articles in total covering 19 different categories such as sports, finance, politics, and business.
- An Arabic News Text (ANTCorp v1.1): ANTCorp is a large collection of Arabic news articles that were collected from Tunisian RSS Feeds [66]. The corpora contain about 6000 articles covering different categories: economy, culture, local News, sports, etc.
4.3.5. Text Classification (TxC)
The text classification (TxC) task is similar to TC, where input texts are categorized into different classes. However, the main difference from TC is that the input text is much shorter, which typically consists of a sentence or two. For the TxC task, we employed seven datasets, including Mawqif, iSarcasmEval, and ArSarcasmV2, which were described previously. All datasets in this group were written in DA, except the ASND dataset. Descriptions of the remaining four datasets are provided below:
- Arabic Social Media News Dataset (ASND): ASND is an Arabic dataset collected from the official Aljazeera news accounts on Twitter, Facebook, and YouTube [67]. It contains about 10 k posts covering different categories such as business, economy, education, politics, spirituality, etc.
- Arabic Influencer Twitter Dataset (AITD): AITD is an Arabic dataset collected from 60 Arab influencers on Twitter [67]. For each influencer, the last 3200 tweets were collected and classified into one of ten categories.
- Dangerous dataset: The Dangerous dataset is an Arabic dataset collected from various Twitter accounts. It includes samples of dangerous speech, such as offensive or hateful language, alongside nondangerous speech [68]. In total, the corpus contains approximately 110.3 million posts collected from 399,000 users.
- Adult content detection: Adult content detection is a collocation of Twitter posts of adult content [69]. In total, the corpora contain about 50 k posts.
4.3.6. Question Answering (QA)
In the QA task, the model is expected to extract the correct answer to a given question from input text passages. For this task, we employed four datasets that contain only MSA text. Descriptions of these datasets are provided below:
- Arabic Reading Comprehension Dataset (ARCD): ARCD is an Arabic QA dataset that was built to solve the issue of open domain factual Arabic QA [70]. It contains 1395 unique question–answer pairs posed by crowdworkers on Wikipedia articles and a machine translation of another Arabic QA dataset. The articles were originally collected from Wikipedia articles written in Arabic.
- Cross-lingual Question Answering Dataset (XQuAD): XQuAD is a benchmark dataset designed to evaluate the preference of crosslingual question answering [71]. It consists of 240 paragraphs and 1190 question–answer pairs developed from SQuAD v1.1 [72]. It covers 11 diverse languages. The dataset has been translated into ten languages: Arabic, Russian, Greek, Turkish, Vietnamese, etc. In this study, we only included the Arabic subset of XQuAD benchmark.
- A Benchmark for Information-Seeking Question Answering (TyDiQA): TyDiQA [73] is a multilingual QA benchmark for 11 different languages, including Arabic. Originally, the dataset consisted of 204 K question–answer pairs. However, we extracted the Arabic subset only, which comprises 15,726 question–answer pairs.
- Evaluating Cross-lingual Extractive Question Answering (MLQA): Similar to XQuAD, MLQA is a benchmark dataset to evaluate the preference of crosslingual question answering [74]. It consists of between 5000 and 6000 question–answering instances in each language, thus presented in SQuAD format in seven languages: Arabic, German, Vietnamese, English, etc. The Arabic subset contains 5852 question–answer pairs.
4.3.7. Named Entity Recognition (NER)
In the NER NLP task, we measure the model’s ability to identify and categorize named entities within unstructured text such as people’s names, locations, dates, and times. For the NER task, we employed six datasets that contain only MSA text. Descriptions of the employed four datasets are provided below:
- Wikipedia-based Fine-grained Arabic Named Entity (NewsFANEGold): NewsFANEGold is a fine-grained Arabic NER corpora that was manually annotated from the Arabic Newswire [75]. It contains 170 K tokens categorized into 88 classes.
- Wikipedia-based Fine-grained Arabic Named Entity Corpus (WikiFANEGold): WikiFANEGold is a fine-grained Arabic NER corpora that was manually annotated from the Arabic Wikipedia [75]. It contains about 500 K tokens that are annotated manually into 102 classes.
- Wikipedia-derived corpus (WDC): WDC is a dataset specifically designed for training models to identify named entities in Arabic text [76]. In the WDC corpus, only sentences with at least three annotated named entity tokens were included. It consists of 165,119 sentences consisting of around 6 M tokens categorized into 9 classes.
- WikiAnn: WikiAnn is a dataset collected from Wikipedia articles in 282 Languages. It was designed for the task of crosslingual naming and linking [77]. The Arabic subset contains 40 K sentences, while the tokens are categorized into 7 classes.
- American and Qatari Modeling of Arabic (AQMAR): AQMAR dataset was collected from Wikipedia for Arabic NER task [78]. It consists of 3000 sentences in four domains: history, science, sports, and technology. The tokens are categorized into 26 classes.
- Arabic NER corpora (ANERcorp): ANERcorp is a dataset designed to be used in Arabic NER tasks [79]. The data were collected from news websites and other web sources [80]. It consists of 316 articles and 150,286 tokens. Each token was annotated based on four categories: person, location, organization, and miscellaneous or other.
5. Results
This section presents the models’ evaluation results across the target NLP tasks. Table 1 presents the results of the models across all datasets employed for NLI and SD tasks. The table includes training and validation sizes for each dataset, along with the number of labels. For this experiment, we trained the BERT model on five datasets. The results indicate that BERT-WP achieved the highest accuracy scores only on the AraStance and Mawqif datasets, with scores of 84.53% and 77.31%, respectively, while BERT-BBPE achieved the highest F1 score on the AraStance dataset alone. However, BERT-SP demonstrated superiority across the majority of datasets, thus achieving the highest accuracy and F1 scores for most tasks, with overall average scores of 75.92% for accuracy and 72.29% for F1. The results suggest that BERT-SP is a more effective tokenizer for NLI and SD tasks compared to BERT-WP and BERT-BBPE. Moreover, no significant differences were observed between the MSA and DA types.

Table 1.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the NLI and SD tasks.
For the SaD task, Table 2 presents the results of BERT models evaluated across all four datasets included. It also provides the details for the training and validation sizes for each dataset. Overall, BERT-SP has outperformed the other two models on the majority of tasks, achieving the highest average accuracy and F1 scores at 79.72% and 69.06%, respectively. BERT-WP achieved the second highest scores for both accuracy and F1, while BERT-BBPE had the lowest overall average scores.
Table 2.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the SaD tasks.
For the SA task, Table 3 shows that the performance of all models was quite similar. We fine-tuned the BERT models on six datasets, each with different training and validation sizes. BERT-SP achieved the highest overall average accuracy and F1 scores, at 74.51% and 69.05%, respectively. Meanwhile, BERT-WP achieved the highest F1 score on four individual datasets and the highest accuracy on three. Moreover, no significant differences were observed between the MSA and DA types.
Table 3.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the SA task.
For the TC task, Table 4 shows that BERT-BBPE achieved a slightly better accuracy score than the other two models. This advantage is due to its better compression rate, which requires fewer tokens when tokenizing specific texts compared to the WordPiece and SentencePiece tokenizers. We will further demonstrate this at the end of this section. This feature is particularly significant, as the input text for the topic classification task often exceeds the maximum allowed sequence length of 128 tokens. However, all three models achieved nearly the same F1, with a score of 86.63%.
Table 4.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the TC task.
For the TcX task, Table 5 shows that BERT-SP outperformed the other two models on the majority of tasks by achieving the highest accuracy score on four out of seven tasks and the highest F1 score on five tasks. Additionally, the model achieved the highest overall average F1 score at 75.34%, thus significantly outperforming the other two models. However, the low average accuracy score is due to the poor performance on the ArSarcasmV2 task, which heavily affected the overall average accuracy.
Table 5.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the TxC task.
For the QA task, Table 6 shows that all three models achieved comparable results across all datasets, which is due to the high complexity of the QA NLP tasks. On average, BERT-SP achieved a slightly better F1 score of 48.03%, while BERT-BBPE recorded the highest EM score at 28.99%.
Table 6.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the QA task.
For the NER task, Table 7 presents the F1 scores for each model on the datasets used. The results indicate that BERT-SP significantly outperformed the other models on five out of six tasks, thus achieving the highest overall average score of 84.04%. This suggests that the SentencePiece tokenizer is the most effective approach for NER tasks, regardless of the size of the dataset or the number of labels.
Table 7.
Comparison of BERT models using different tokenizers: WordPiece (BERT-WP), SentencePiece (BERT-SP), and Byte-level BPE (BERT-BBPE) for the NER task. The results show the F1 score for each model.
In our comparative analysis of BERT models using different tokenizers—WordPiece (BERT-WP), Byte-level BPE (BERT-BBPE), and SentencePiece (BERT-SP)—we measured several performance metrics, including the pretraining time, tokenizer training time, and minimum training loss. Table 8 shows that BERT-BBPE was the most efficient in terms of the training and tokenization time, thus achieving the shortest model pretraining time at 133 GPU hours, tokenizer training time at 6:02 min, and corpus tokenization time at 1:08:41. These results indicate that BERT-BBPE is highly effective in terms of speed and processing efficiency. Additionally, the BBPE tokenizer achieved the best compression rate, thus requiring fewer tokens to encode input texts. However, BERT-BBPE recorded the highest training loss during model pretraining, thus leading it to underperform compared to the other two models in the majority of evaluation tasks, except for the topic classification task, where its efficient compression rate was beneficial.
Table 8.
Comparative performance of BERT models utilizing different tokenization methods: WordPiece, Byte-level BPE, and SentencePiece. Best results in bold.
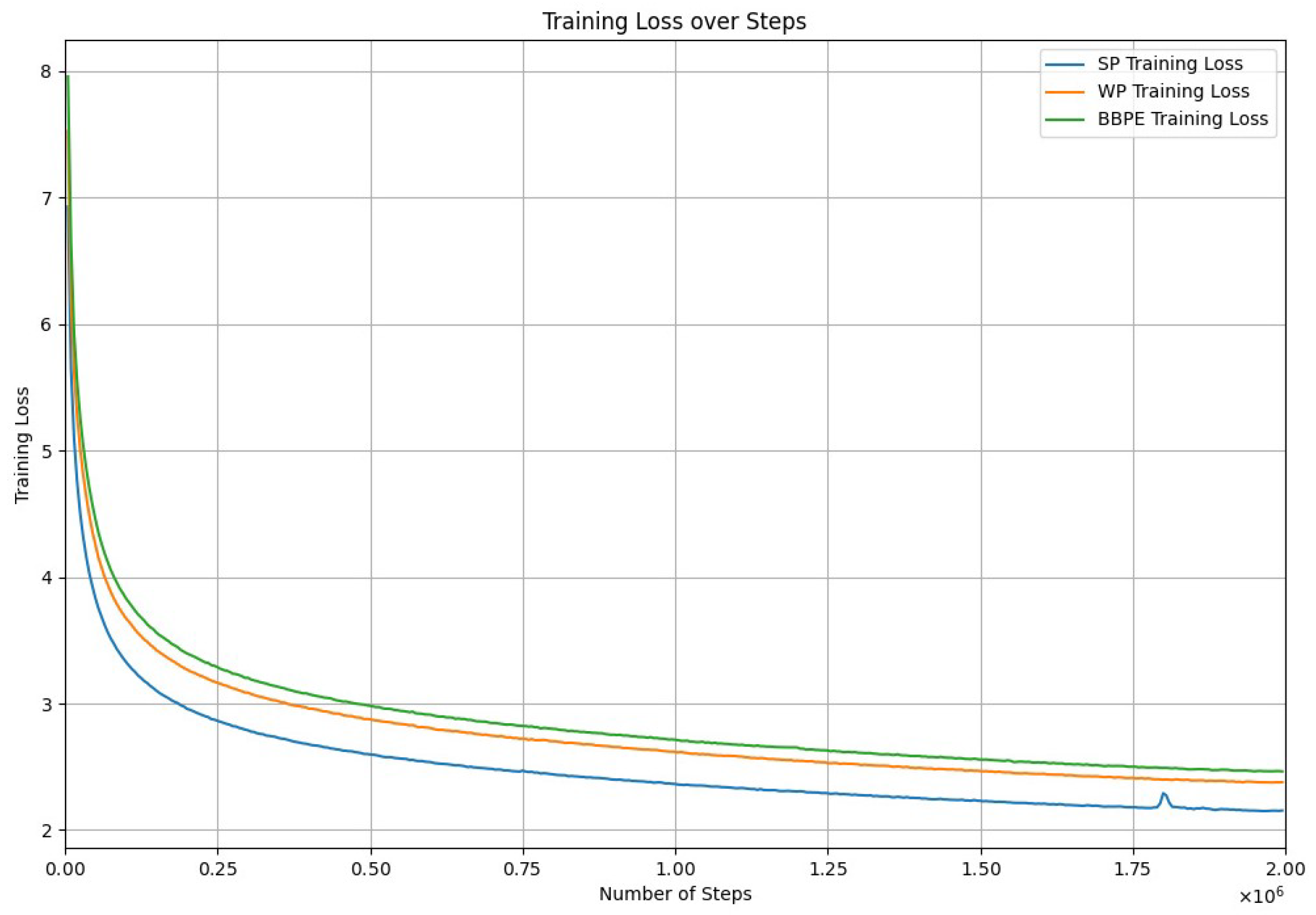
On the other hand, despite its longer tokenization and training time, BERT-SP achieved the lowest training loss at 2.1534 over the same number of training epochs as the other models, thus demonstrating its effectiveness in learning from the training data. Figure 2 illustrates the training loss over the number of steps for each model. In contrast, BERT-WP, while not excelling in any specific category, showed consistent performance across all metrics. This analysis highlights the trade-offs between the tokenizer choice and aspects of the model efficiency, accuracy, and training speed. Both BERT-BBPE and BERT-SP exhibited strengths in different areas of the training process.
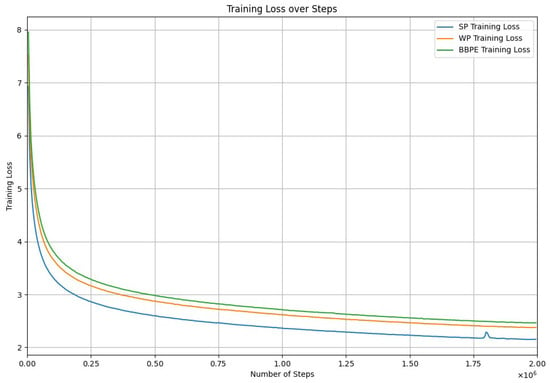
Figure 2.
Pretraining loss over steps for the three BERT models using SentencePiece (SP), Byte-level BPE (BBPE), and WordPiece (WP) tokenizers.
6. Conclusions
Tokenization serves as a crucial foundation for many NLP tasks involving the breakdown of text streams into basic meaningful units called tokens. These tokens are essential inputs for subsequent NLP tasks such as semantic parsing and language modeling. Despite its importance, there is a notable lack of research on how different tokenization approaches affect the performance of Arabic language models. This gap obstructs our understanding of the impact of various tokenization methods on NLP effectiveness and performance. This study addresses this gap by evaluating the effectiveness of three different tokenizers—SentencePiece, WordPiece, and BBPE—by pretraining three Arabic BERT language models (BERT-SP, BERT-WP, and BERT-BBPE). Each model was pretrained using the same corpus and configurations, but they employed different tokenizers. We assessed the impact of each tokenizer by analyzing the performance of each model across seven NLP task groups using 29 Arabic datasets. Our results show that BERT-SP significantly outperformed the other models in most tasks, thus achieving the highest overall average F1 scores: 84.04% in NER, 48.03% in QA, 75.34% in text classification, 69.05% in SA, 69.06% in SaD, and 72.29% in NLI. On the other hand, the BBPE tokenizer demonstrated superior efficiency, thus recording the shortest pretraining time (133 GPU hours), tokenizer training time (6:02 min), and corpus tokenization time (1:08:41). It also achieved the best compression rate, thus requiring fewer tokens per input sequence and enhancing its speed and processing efficiency. This capability allows it to efficiently handle large input texts. Meanwhile, the WordPiece tokenizer showed consistent performance across all evaluated metrics without excelling in any specific area. These findings contribute to the development of more efficient models and better tokenizer selection, thus enhancing feature engineering and overall advancements in NLP applications. Future work should include a more in-depth analysis to understand how various Arabic dialects affect and influence tokenizer performance, as well as evaluating the performance of various tokenizers with generative language models.
Author Contributions
Conceptualization, F.Q. and T.A; Methodology, F.Q.; Software, F.Q.; Validation, F.Q. and T.A.; Formal analysis, F.Q. and T.A.; Investigation, T.A.; Data curation, F.Q.; Writing—original draft, T.A. and F.Q.; Writing—review & editing, T.A. and F.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All three models are publicly available on https://huggingface.co/faisalq/bert-base-arabic-wordpiece, https://huggingface.co/faisalq/bert-base-arabic-senpiece, and https://huggingface.co/faisalq/bert-base-arabic-bbpe, accessed on 21 May 2024. The code files, along with the results, are available on https://github.com/FaisalQarah/TokenizersComparison, accessed on 21 May 2024.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alyafeai, Z.; Al-shaibani, M.S.; Ghaleb, M.; Ahmad, I. Evaluating various tokenizers for Arabic text classification. Neural Process. Lett. 2023, 55, 2911–2933. [Google Scholar] [CrossRef]
- Shapiro, P.; Duh, K. Morphological word embeddings for Arabic neural machine translation in low-resource settings. In Proceedings of the Second Workshop on Subword/Character LEvel Models, New Orleans, LA, USA, 5–7 June 2018; pp. 1–11. [Google Scholar]
- Mekki, A.; Zribi, I.; Ellouze, M.; Belguith, L.H. Tokenization of Tunisian Arabic: A comparison between three Machine Learning models. Acm Trans. Asian -Low-Resour. Lang. Inf. Process. 2023, 22, 194. [Google Scholar] [CrossRef]
- Kamali, D.; Janfada, B.; Shenasa, M.E.; Minaei-Bidgoli, B. Evaluating Persian Tokenizers. arXiv 2022, arXiv:2202.10879. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Kudo, T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, SA, Australia, 15–20 July 2018; pp. 66–75. [Google Scholar] [CrossRef]
- Wang, C.; Cho, K.; Gu, J. Neural machine translation with byte-level subwords. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9154–9160. [Google Scholar]
- Kudo, T.; Richardson, J. Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Bostrom, K.; Durrett, G. Byte pair encoding is suboptimal for language model pretraining. arXiv 2020, arXiv:2004.03720. [Google Scholar]
- Erkaya, E. A Comprehensive Analysis of Subword Tokenizers for Morphologically Rich Languages. Ph.D. Thesis, Bogaziçi University, Istanbul, Türkiye, 2022. [Google Scholar]
- Domingo, M.; García-Martínez, M.; Helle, A.; Casacuberta, F.; Herranz, M. How much does tokenization affect neural machine translation? In Proceedings of the International Conference on Computational Linguistics and Intelligent Text Processing, La Rochelle, France, 7–13 April 2019; pp. 545–554. [Google Scholar]
- Rust, P.; Pfeiffer, J.; Vulić, I.; Ruder, S.; Gurevych, I. How Good is Your Tokenizer? On the Monolingual Performance of Multilingual Language Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers); Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2021; pp. 3118–3135. [Google Scholar] [CrossRef]
- Boujelbane, R.; Ellouze, M.; Béchet, F.; Belguith, L. De l’arabe Standard vers l’Arabe Dialectal: Projection de Corpus et Ressources Linguistiques en vue du Traitement Automatique de L’oral dans les Médias Tunisiens. Revue TAL 2015, Rahma-Boujelbane. Available online: https://shs.hal.science/halshs-01193325/ (accessed on 21 May 2024).
- Younes, J.; Achour, H.; Souissi, E. Constructing linguistic resources for the Tunisian dialect using textual user-generated contents on the social web. In Current Trends in Web Engineering: 15th International Conference, ICWE 2015 Workshops, NLPIT, PEWET, SoWEMine, Rotterdam, The Netherlands, 23–26 June 2015; Revised Selected Papers 15; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–14. [Google Scholar]
- Gage, P. A new algorithm for data compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Schuster, M.; Nakajima, K. Japanese and korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar]
- Abadji, J.; Suárez, P.J.O.; Romary, L.; Sagot, B. Ungoliant: An optimized pipeline for the generation of a very large-scale multilingual web corpus. In Proceedings of the CMLC 2021-9th Workshop on Challenges in the Management of Large Corpora, Virtual, 12 July 2021. [Google Scholar]
- Alomari, K.M.; ElSherif, H.M.; Shaalan, K. Arabic tweets sentimental analysis using machine learning. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Arras, France, 27–30 June 2017; pp. 602–610. [Google Scholar]
- Al-Shaibani, M.S.; Alyafeai, Z.; Ahmad, I. MetRec: A dataset for meter classification of arabic poetry. Data Brief 2020, 33, 106497. [Google Scholar] [CrossRef] [PubMed]
- Aly, M.; Atiya, A. Labr: A large scale arabic book reviews dataset. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 494–498. [Google Scholar]
- Biniz, M. DataSet for Arabic Classification. Mendeley Data 2018, 2. [Google Scholar] [CrossRef]
- Tseng, H.; Chang, P.; Andrew, G.; Jurafsky, D.; Manning, C. A conditional random field word segmenter. In Proceedings of the Fourth SIGHAN Workshop on Chinese Language Processing, Jeju Island, Republic of Korea, 14–15 October 2005. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. Opennmt: Open-source toolkit for neural machine translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions; Association for Computational Linguistics: Kerrville, TX, USA, 2007; pp. 177–180. [Google Scholar]
- Wei, J.; Liu, Q.; Guo, Y.; Jiang, X. Training multilingual pre-trained language model with byte-level subwords. arXiv 2021, arXiv:2101.09469. [Google Scholar]
- Wei, J.; Ren, X.; Li, X.; Huang, W.; Liao, Y.; Wang, Y.; Lin, J.; Jiang, X.; Chen, X.; Liu, Q. Nezha: Neural contextualized representation for chinese language understanding. arXiv 2019, arXiv:1909.00204. [Google Scholar]
- Chirkova, N.; Troshin, S. Codebpe: Investigating subtokenization options for large language model pretraining on source code. arXiv 2023, arXiv:2308.00683. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016. [Google Scholar] [CrossRef]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified pre-training for program understanding and generation. arXiv 2021, arXiv:2103.06333. [Google Scholar]
- Beinborn, L.; Pinter, Y. Analyzing cognitive plausibility of subword tokenization. arXiv 2023, arXiv:2310.13348. [Google Scholar]
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep bidirectional transformers for Arabic. arXiv 2020, arXiv:2101.01785. [Google Scholar]
- Qarah, F. AraPoemBERT: A Pretrained Language Model for Arabic Poetry Analysis. arXiv 2024, arXiv:2403.12392. [Google Scholar]
- Inoue, G.; Alhafni, B.; Baimukan, N.; Bouamor, H.; Habash, N. The interplay of variant, size, and task type in Arabic pre-trained language models. arXiv 2021, arXiv:2103.06678. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 21 May 2024).
- Ghaddar, A.; Wu, Y.; Bagga, S.; Rashid, A.; Bibi, K.; Rezagholizadeh, M.; Xing, C.; Wang, Y.; Duan, X.; Wang, Z.; et al. Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Processing. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 3135–3151. [Google Scholar]
- Alghamdi, A.; Duan, X.; Jiang, W.; Wang, Z.; Wu, Y.; Xia, Q.; Wang, Z.; Zheng, Y.; Rezagholizadeh, M.; Huai, B.; et al. AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing. arXiv 2023, arXiv:2306.06800. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Qarah, F. SaudiBERT: A Large Language Model Pretrained on Saudi Dialect Corpora. arXiv 2024, arXiv:2405.06239. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32, 5753–5763. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Punta Cana, Dominican Republic, 8–12 November 2020; pp. 38–45. [Google Scholar]
- Zerrouki, T. PyArabic, an Arabic Language Library for Python. J. Open Sour. Softw. 2023, 8, 4886. [Google Scholar] [CrossRef]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, É.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-lingual Representation Learning at Scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Seattle, WA, USA, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Al-Shamela Library. Available online: https:///www.shamela.ws/ (accessed on 21 May 2024).
- Arabic BERT Corpus. Available online: https://www.kaggle.com/datasets/abedkhooli/arabic-bert-corpus (accessed on 26 July 2023).
- Conneau, A.; Lample, G.; Rinott, R.; Williams, A.; Bowman, S.R.; Schwenk, H.; Stoyanov, V. XNLI: Evaluating cross-lingual sentence representations. arXiv 2018, arXiv:1809.05053. [Google Scholar]
- Williams, A.; Nangia, N.; Bowman, S.R. A broad-coverage challenge corpus for sentence understanding through inference. arXiv 2017, arXiv:1704.05426. [Google Scholar]
- Alhindi, T.; Alabdulkarim, A.; Alshehri, A.; Abdul-Mageed, M.; Nakov, P. Arastance: A multi-country and multi-domain dataset of arabic stance detection for fact checking. arXiv 2021, arXiv:2104.13559. [Google Scholar]
- Khouja, J. Stance prediction and claim verification: An Arabic perspective. arXiv 2020, arXiv:2005.10410. [Google Scholar]
- Alturayeif, N.S.; Luqman, H.A.; Ahmed, M.A.K. MAWQIF: A Multi-label Arabic Dataset for Target-specific Stance Detection. In Proceedings of the Seventh Arabic Natural Language Processing Workshop (WANLP), Abu Dhabi, United Arab Emirates, 8 December 2022; pp. 174–184. [Google Scholar]
- AlMazrua, H.; AlHazzani, N.; AlDawod, A.; AlAwlaqi, L.; AlReshoudi, N.; Al-Khalifa, H.; AlDhubayi, L. Sa ‘7r: A Saudi Dialect Irony Dataset. In Proceedings of the 5th Workshop on Open-Source Arabic Corpora and Processing Tools with Shared Tasks on Qur’an QA and Fine-Grained Hate Speech Detection, Marseille, France, 20–25 June 2022; pp. 60–70. [Google Scholar]
- Farha, I.A.; Oprea, S.; Wilson, S.; Magdy, W. SemEval-2022 task 6: ISarcasmEval, intended sarcasm detection in English and Arabic. In Proceedings of the 16th International Workshop on Semantic Evaluation 2022, Seattle, WA, USA, 14–15 July 2022; Association for Computational Linguistics: Kerrville, TX, USA, 2022; pp. 802–814. [Google Scholar]
- Farha, I.A.; Zaghouani, W.; Magdy, W. Overview of the wanlp 2021 shared task on sarcasm and sentiment detection in arabic. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kiev, Ukraine, 19 April 2021; pp. 296–305. [Google Scholar]
- Farha, I.A.; Magdy, W. From arabic sentiment analysis to sarcasm detection: The arsarcasm dataset. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 11–16 May 2020; pp. 32–39. [Google Scholar]
- Elnagar, A.; Khalifa, Y.S.; Einea, A. Hotel Arabic-reviews dataset construction for sentiment analysis applications. Intell. Nat. Lang. Process. Trends Appl. 2018, 740, 35–52. [Google Scholar]
- Elnagar, A.; Einea, O. Brad 1.0: Book reviews in arabic dataset. In Proceedings of the 2016 IEEE/ACS 13th International Conference of Computer Systems and Applications (AICCSA), Agadir, Morocco, 29 November–2 December 2016; pp. 1–8. [Google Scholar]
- Nabil, M.; Aly, M.; Atiya, A. Astd: Arabic sentiment tweets dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2515–2519. [Google Scholar]
- Einea, O.; Elnagar, A.; Al Debsi, R. Sanad: Single-label arabic news articles dataset for automatic text categorization. Data Brief 2019, 25, 104076. [Google Scholar] [CrossRef] [PubMed]
- Saad, M.K.; Ashour, W. Osac: Open source arabic corpora. In Proceedings of the 6th ArchEng International Symposiums (EEECS), Opatija, Croatia, 12–15 December 2010; Volume 10, p. 55. [Google Scholar]
- Jbene, M.; Tigani, S.; Saadane, R.; Chehri, A. A Moroccan News Articles Dataset (MNAD) For Arabic Text Categorization. In Proceedings of the 2021 International Conference on Decision Aid Sciences and Application (DASA), Virtual, 7–8 December 2021; pp. 350–353. [Google Scholar]
- Chouigui, A.; Khiroun, O.B.; Elayeb, B. ANT corpus: An Arabic news text collection for textual classification. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 135–142. [Google Scholar]
- Chowdhury, S.A.; Abdelali, A.; Darwish, K.; Soon-Gyo, J.; Salminen, J.; Jansen, B.J. Improving Arabic text categorization using transformer training diversification. In Proceedings of the Fifth Arabic Natural Language Processing Workshop, Barcelona, Spain, 12 December 2020; pp. 226–236. [Google Scholar]
- Alshehri, A.; Nagoudi, E.M.B.; Abdul-Mageed, M. Understanding and detecting dangerous speech in social media. arXiv 2020, arXiv:2005.06608. [Google Scholar]
- Mubarak, H.; Hassan, S.; Abdelali, A. Adult content detection on arabic twitter: Analysis and experiments. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kiev, Ukraine, 19 April 2021; pp. 136–144. [Google Scholar]
- Mozannar, H.; Maamary, E.; El Hajal, K.; Hajj, H. Neural Arabic Question Answering. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 28 July–2 August 2019. [Google Scholar] [CrossRef]
- Artetxe, M.; Ruder, S.; Yogatama, D. On the cross-lingual transferability of monolingual representations. arXiv 2019, arXiv:1910.11856. [Google Scholar]
- Rajpurkar, P.; Zhang, J.; Lopyrev, K.; Liang, P. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250. [Google Scholar]
- Clark, J.H.; Choi, E.; Collins, M.; Garrette, D.; Kwiatkowski, T.; Nikolaev, V.; Palomaki, J. Tydi qa: A benchmark for information-seeking question answering in ty pologically di verse languages. Trans. Assoc. Comput. Linguist. 2020, 8, 454–470. [Google Scholar] [CrossRef]
- Lewis, P.; Oğuz, B.; Rinott, R.; Riedel, S.; Schwenk, H. MLQA: Evaluating cross-lingual extractive question answering. arXiv 2019, arXiv:1910.07475. [Google Scholar]
- Alotaibi, F.; Lee, M. A hybrid approach to features representation for fine-grained Arabic named entity recognition. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 984–995. [Google Scholar]
- Althobaiti, M.; Kruschwitz, U.; Poesio, M. Automatic creation of arabic named entity annotated corpus using wikipedia. In EACL 2014-14th Conference of the European Chapter of the Association for Computational Linguistics, Proceedings of the Student Research Workshop; Association for Computer Linguistics: Kerrville, TX, USA, 2014; pp. 106–115. [Google Scholar]
- Pan, X.; Zhang, B.; May, J.; Nothman, J.; Knight, K.; Ji, H. Cross-lingual name tagging and linking for 282 languages. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers); Association for Computational Linguistics: Kerrville, TX, USA, 2017; pp. 1946–1958. [Google Scholar]
- Mohit, B.; Schneider, N.; Bhowmick, R.; Oflazer, K.; Smith, N.A. Recall-oriented learning of named entities in Arabic Wikipedia. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 162–173. [Google Scholar]
- Benajiba, Y.; Rosso, P.; Benedíruiz, J.M. Anersys: An arabic named entity recognition system based on maximum entropy. In Proceedings of the Computational Linguistics and Intelligent Text Processing: 8th International Conference, CICLing 2007, Mexico City, Mexico, 18–24 February 2007; pp. 143–153. [Google Scholar]
- Obeid, O.; Zalmout, N.; Khalifa, S.; Taji, D.; Oudah, M.; Alhafni, B.; Inoue, G.; Eryani, F.; Erdmann, A.; Habash, N. CAMeL tools: An open source python toolkit for Arabic natural language processing. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 7022–7032. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).