
A Multi-Performance Reliability Evaluation Approach Based on the Surrogate Model with Cluster Mixing Weight
Abstract
:1. Introduction
- Devising a multi-performance reliability analysis algorithm appropriate for complicated mechanical assets with various failure modes;
- Promoting efficiency in balancing the calculation cost and accuracy of the proposed cluster surrogate model to a great extent;
- Generating a mixing weight channel to investigate the different contributions to overall reliability corresponding to diverse practical engineering scenarios.
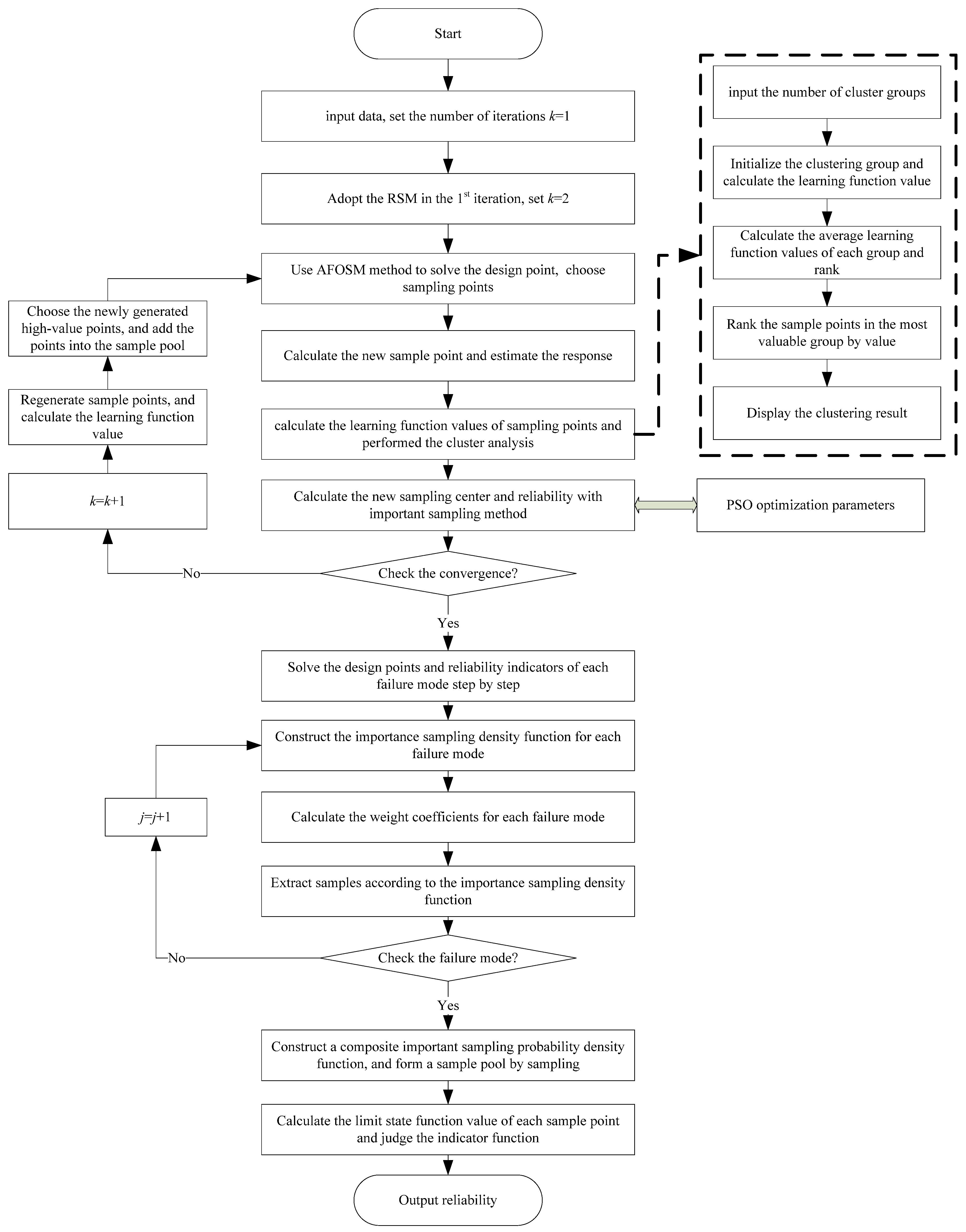
2. Cluster-Based Sample Inheritance Statement
2.1. Overview of Kriging Model
2.2. Parameters Optimization
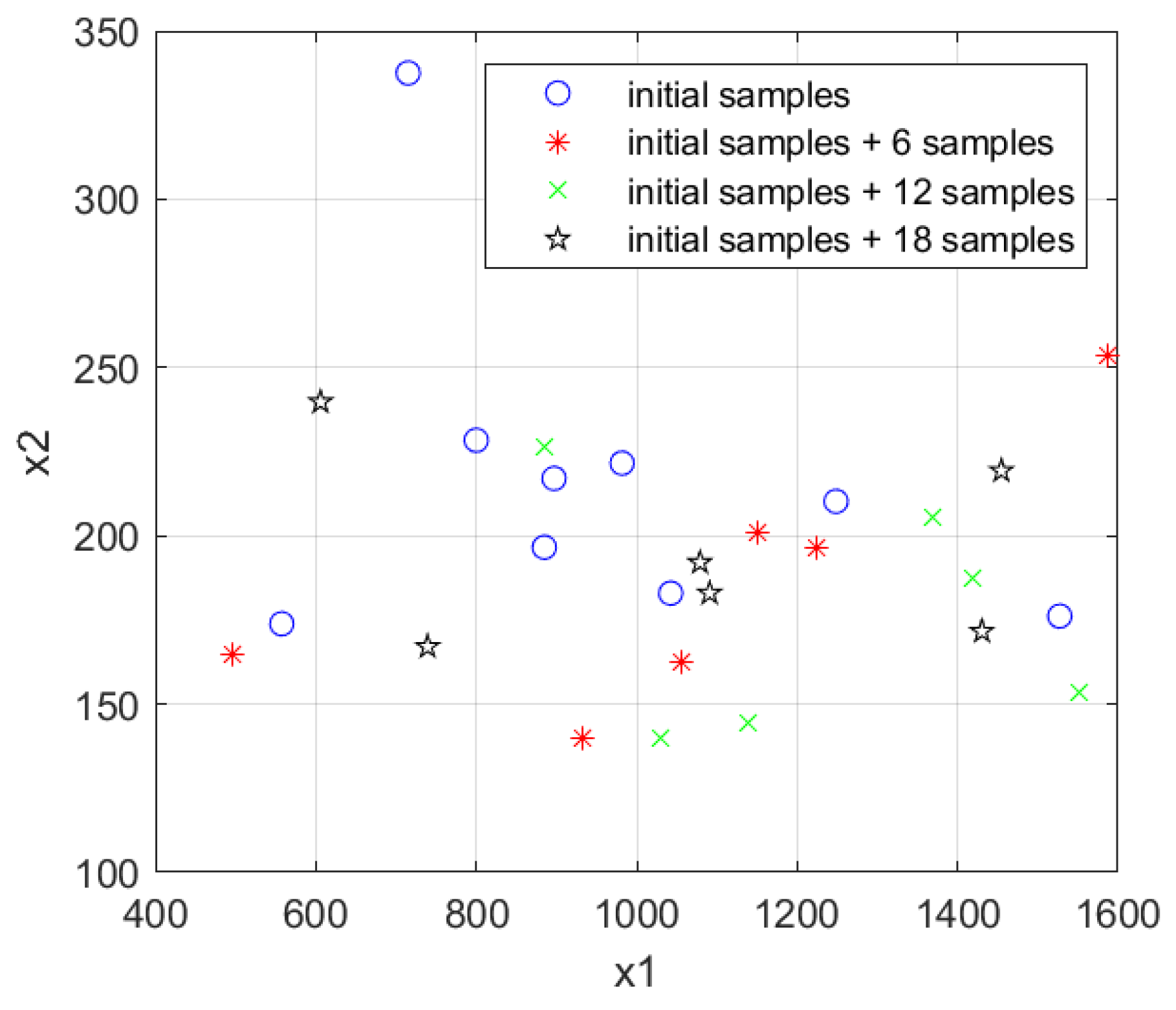
2.3. Sample Inheritance
2.4. Learning Function Construction
3. Calculation of Mixing Weight Importance Sampling Model
4. Algorithm Designing for Multi-Performance Reliability Analysis
5. Case Studies
5.1. Numerical Experiment A: A Highly Nonlinear System
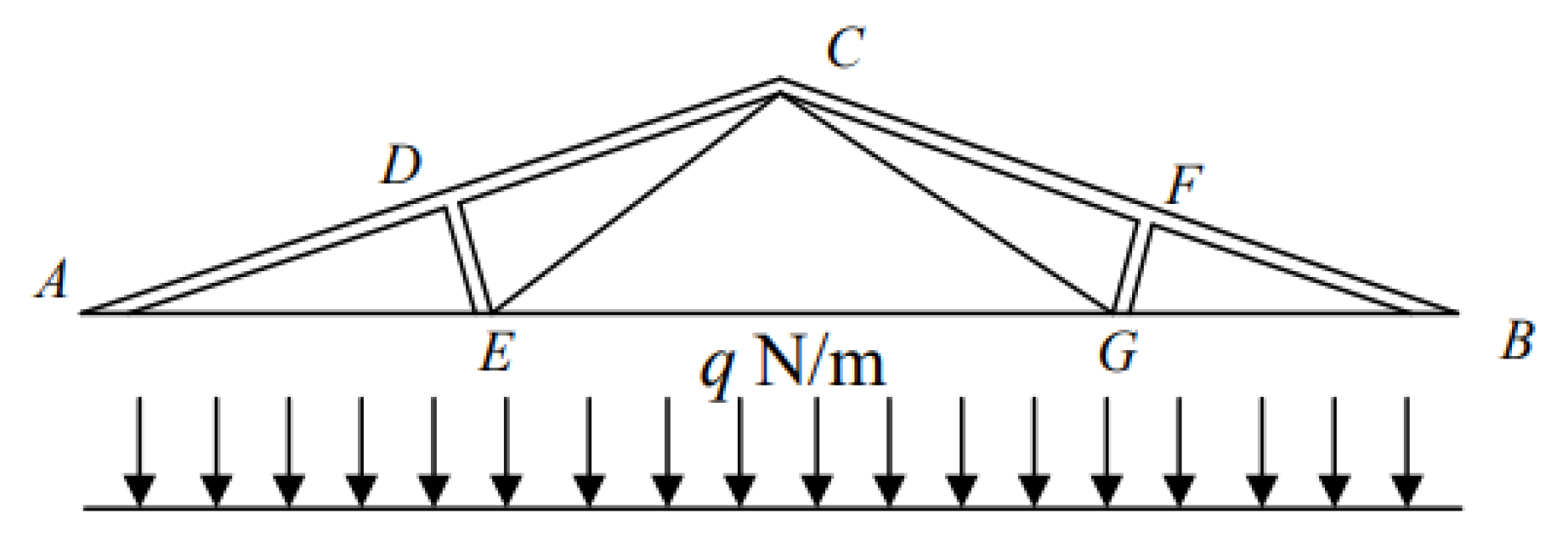
5.2. Engineering Experiment A: A Series Industrial System
5.3. Engineering Experiment B: A Turbine Disc
- Material properties, such as the elastic modulus, density and Poisson’s ratio of the materials utilized in roulette and pins, can reflect the material uncertainties;
- Roulette speed can reflect the uncertainty of centrifugal force;
- Uncertainties exist in the assembly force at the connection between the pin and blade.
6. Conclusions
- The local optimal issue has been avoided via employing the particle swarm optimization algorithm in the surrogate mode construction within the proposed approach; furthermore, the proposed sample inheritance and active learning strategies promote convergence efficiency to a great extent;
- The proposed Kriging surrogate model combined with the importance sampling approach has overcome the nonlinear and implicit challenges when handling diverse limit state functions, which reduces the complexity of structural simulation calculation noticeably;
- The proposed mixing weight with the importance sampling channel, considering the contribution of each single failure mode to the overall failure probability, is applied to the reliability analysis of several cases, which indicates a higher accuracy and computation efficiency, especially when the structural functions are nonlinear.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Acronyms and notations | |
| RSM | Response Surface Method |
| PCE | Polynomial Chaos Expansion |
| RBF | Radial Basis Function |
| SVM | Support Vector Machine |
| ANN | Artificial Neural Network |
| Design variable | |
| the performance response of the system | |
| importance sampling density function | |
| the failure probability of the i-th failure mode | |
References
- Hu, X.Y.; Wang, R.P.; Wang, X.; Fu, Y.T. Recent development of safety and reliability analysis technology for model-based complex system. Acta Aeronaut. Astronaut. Sin. 2020, 41, 523436. [Google Scholar] [CrossRef]
- Afshari, S.S.; Enayatollahi, F.; Xu, X.; Liang, X. Machine learning-based methods in structural reliability analysis: A review. Reliab. Eng. Syst. Safety 2022, 219, 108223. [Google Scholar] [CrossRef]
- Wang, J.; Ma, X.; Yang, L.; Qiu, Q.; Shang, L.; Wang, J. A hybrid inspection-replacement policy for multi-stage degradation considering imperfect inspection with variable probabilities. Reliab. Eng. Syst. Saf. 2024, 241, 109629. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, S.; Peng, R.; Qiu, Q.; Yang, L. An inspection-based replacement planning in consideration of state-driven imperfect inspections. Reliab. Eng. Syst. Saf. 2023, 232, 109064. [Google Scholar] [CrossRef]
- Han, T.; Liu, C.; Yang, W.; Jiang, D. Deep transfer network with joint distribution adaptation: A new intelligent fault diagnosis framework for industry application. ISA Trans. 2020, 97, 269–281. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Huang, X.; Zhang, T. Review Of The Application Of Deep Learning In Health Management. In Proceedings of the 2021 Global Reliability and Prognostics and Health Management (PHM-Nanjing), Nanjing, China, 15–17 October 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Lu, S.; He, Q.; Wang, J. A review of stochastic resonance in rotating machine fault detection. Mech. Syst. Signal Process. 2019, 116, 230–260. [Google Scholar] [CrossRef]
- Yi, P.; Yang, W.; Xie, D. Reliability analysis of engineering structure based on surrogate model. J. Dalian Univ. Technol. 2018, 58, 269–276. [Google Scholar] [CrossRef]
- Breig, S.J.M.; Luti, K.J.K. Response surface methodology: A review on its applications and challenges in microbial cultures. Mater. Today Proc. 2021, 42, 2277–2284. [Google Scholar] [CrossRef]
- Li, P.; Li, H.; Huang, Y.; Yang, S.; Yang, H.; Liu, Y. A high sparse response surface method based on combined bases for complex products optimization. Adv. Eng. Softw. 2019, 129, 1–12. [Google Scholar] [CrossRef]
- Lu, N.; Li, Y.F.; Huang, H.Z.; Mi, J.; Niazi, S.G. AGP-MCS+D: An active learning reliability analysis method combining dependent Gaussian process and Monte Carlo simulation. Reliab. Eng. Syst. Saf. 2023, 240, 109541. [Google Scholar] [CrossRef]
- Faraji, J.; Aslani, M.; Hashemi-Dezaki, H.; Ketabi, A.; De Grève, Z.; Vallée, F. Reliability Analysis of Cyber–Physical Energy Hubs: A Monte Carlo Approach. IEEE Trans. Smart Grid 2024, 15, 848–862. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, J.; You, L.; Ye, N. Structural reliability calculation method based on improved weighted response surface. J. Beijing Univ. Aeronaut. Astronaut. 2021, 47, 1638–1645. [Google Scholar] [CrossRef]
- You, L.; Zhang, J.; Zhou, S.; Du, X. A new method for fatigue reliability calculation of aero-engine limited life parts. Acta Aeronaut. Astronaut. Sin. 2019, 40, 223228. [Google Scholar] [CrossRef]
- Gong, Y.; Zhang, J.; Wu, Z.; Chu, G.; Fan, X.; Huang, Y. Reliability algorithm of composite structure based on active learning basisadaptive PC-Kriging model. Acta Aeronaut. Astronaut. Sin. 2024, 45, 428982. (In Chinese) [Google Scholar]
- Yang, N.; Yao, X.; Das, P.K. Application of response surface method for reliability analysis of stiffened laminated plates. Ships Offshore Struct. 2015, 10, 653–659. [Google Scholar] [CrossRef]
- Zhao, W.; Su, G.-S.; Hu, L.-H. Reliability Analysis of Suspension Bridge Using Gaussian Process Based Response Surface Method. Adv. Mater. Res. 2014, 860, 2970–2974. [Google Scholar]
- Li, D.Q.; Zheng, D.; Cao, Z.J.; Tang, X.S.; Phoon, K.K. Response surface methods for slope reliability analysis: Review and comparison. Eng. Geol. 2016, 203, 3–14. [Google Scholar] [CrossRef]
- Wang, D.; Qiu, H.; Gao, L.; Jiang, C. A Subdomain uncertainty-guided Kriging method with optimized feasibility metric for time-dependent reliability analysis. Reliab. Eng. Syst. Saf. 2024, 243, 109839. [Google Scholar] [CrossRef]
- Chen, Z.; He, J.; Li, G.; Yang, Z.; Wang, T.; Du, X. Fast convergence strategy for adaptive structural reliability analysis based on kriging believer criterion and importance sampling. Reliab. Eng. Syst. Saf. 2024, 242, 109730. [Google Scholar] [CrossRef]
- Yang, S.; Meng, D.; Wang, H.; Yang, C. A novel learning function for adaptive surrogate-model-based reliability evaluation. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2024, 382, 20220395. [Google Scholar] [CrossRef]
- Han, Z.; Huang, Z. An Interpolation Method for Karhunen-Loeve Expansion of Random Field Discretization. CMES-Comput. Model. Eng. Sci. 2024, 138, 245–272. [Google Scholar] [CrossRef]
- Liu, Z.; Choe, Y. Data-driven sparse polynomial chaos expansion for models with dependent inputs. J. Saf. Sci. Resil. 2023, 4, 358–365. [Google Scholar] [CrossRef]
- Yu, C.; Lv, X.; Huang, D.; Jiang, D. Reliability-based design optimization of offshore wind turbine support structures using RBF surrogate model. Front. Struct. Civ. Eng. 2023, 17, 1086–1099. [Google Scholar] [CrossRef]
- Mukherjee, S.; Sivakumar Babu, G.L. Probabilistic Evaluation of the Uplift Capacity of Transmission Tower Foundations Using Reinforced Anchors. Int. J. Geomech. 2023, 23, 04023203. [Google Scholar] [CrossRef]
- Hu, J.; Wang, B.; Di, K.; Zou, J.; Ren, D.; Zhao, J. Self-healing FBG sensor network fault-detection based on a multi-class SVM algorithm. Opt. Express 2023, 31, 41313–41325. [Google Scholar] [CrossRef]
- Zhu, H.; Shi, Y. Displacement Self-Sensing Control of Permanent Magnet Assisted Bearingless Synchronous Reluctance Motor Based on Least Square Support Vector Machine Optimized by Improved NSGA-II. IEEE Trans. Ind. Electron. 2024, 71, 1201–1211. [Google Scholar] [CrossRef]
- Liu, J.-Q.; Feng, Y.-W.; Lu, C.; Pan, W.-H. Decomposed-coordinated framework with intelligent extremum network for operational reliability analysis of complex system. Reliab. Eng. Syst. Saf. 2024, 242, 109752. [Google Scholar] [CrossRef]
- Gao, Z.; Fu, Z.; Wen, M.; Guo, Y.; Zhang, Y. Physical informed neural network for thermo-hydral analysis of fire-loaded concrete. Eng. Anal. Bound. Elem. 2024, 158, 252–261. [Google Scholar] [CrossRef]
- Liu, H.; Li, S.; Huang, X.; Ding, P.; Jiang, Z. Adaptive stochastic configuration network ensemble for structural reliability analysis. Expert Syst. Appl. 2024, 237, 121633. [Google Scholar] [CrossRef]
- Harrou, F.; Hittawe, M.M. Road Traffic Modeling and Management: Using Statistical Monitoring and Deep Learning; Elsevier: Amsterdam, The Netherlands, 2021. [Google Scholar] [CrossRef]
- Harrou, F.; Zeroual, A.; Hittawe, M.M.; Sun, Y. Chapter 6—Recurrent and Convolutional Neural Networks for Traffic Management. In Road Traffic Modeling and Management; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar] [CrossRef]
- Zhang, Y.; Mazen Hittawe, M.; Katterbauer, K.; Marsala, A.F.; Knio, O.M.; Hoteit, I. Joint seismic and electromagnetic inversion for reservoir mapping using a deep learning aided feature-oriented approach. In SEG Technical Program Expanded Abstracts 2020; Society of Exploration Geophysicists: Houston, TX, USA, 2020. [Google Scholar] [CrossRef]
- Hittawe, M.M.; Sidibe, D.; Meriaudeau, F. Bag of words representation and SVM classifier for timber knots detection on color images. In Proceedings of the 14th IAPR International Conference on Machine Vision Applications (MVA), Tokyo, Japan, 18–22 May 2015. [Google Scholar] [CrossRef]
- Echard, B.; Gayton, N.; Lemaire, M. AK-MCS: An active learning reliability method combining Kriging and Monte Carlo Simulation. Struct. Saf. 2011, 33, 145–154. [Google Scholar] [CrossRef]
- Li, G.; Zhang, K. A combined reliability analysis approach with dimension reduction method and maximum entropy method. Struct. Multidiscip. Optim. 2011, 43, 121–134. [Google Scholar] [CrossRef]
- Bichon, B.J.; Eldred, M.S.; Swiler, L.P.; Mahadevan, S.; McFarland, J.M. Efficient Global Reliability Analysis for Nonlinear Implicit Performance Functions. AIAA J. 2008, 46, 2459–2468. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient Global Optimization of Expensive Black-Box Functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Hu, Z.; Du, X. Mixed efficient global optimization for time-dependent reliability analysis. J. Mech. Des. 2015, 137, 051401. [Google Scholar] [CrossRef]
- Aloise, D.; Deshpande, A.; Hansen, P.; Popat, P. NP-hardness of Euclidean sum-of-squares clustering. Mach. Learn. 2009, 75, 245–248. [Google Scholar] [CrossRef]
- Song, Z.; Lu, Z.; Zhou, C. A Novel and Efficient Subset Simulation (SubSim) Method for Obtaining Cumulative Distribution Function (CDF) of Structural Response and Its Application. J. Northwestern Polytech. Univ. 2011, 29, 542–547. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Number of Iterations | Reliability Index | Probability of Failure | Relative Error/% |
|---|---|---|---|---|
| Monte Carlo | 108 | 2.341625 | 0.0096 | - |
| Response Surface | 30 | 2.388398 | 0.008461 | 1.83 |
| Kriging model | 7 | 2.330912 | 0.009879 | 0.62 |
| Proposed approach | 3 | 2.346199 | 0.009483 | 0.41 |
| Method | Number of Sample Points | Reliability Index | Probability of Failure | Relative Error/% |
|---|---|---|---|---|
| Monte Carlo | 106 | 2.271446 | 0.01156 | - |
| Importance sampling | 4000 | 2.258733 | 0.01195 | 3.374 |
| Proposed approach | 1500 | 2.282497 | 0.01123 | 2.855 |
| Random Variables | Physical Significance | Mean Value | Standard Deviation | Unit |
|---|---|---|---|---|
| E1 | Elastic modulus of roulette | 123,000 | 3000 | MPa |
| ε1 | Poisson’s ratio of roulette | 0.33 | 0.015 | / |
| ρ1 | Density of roulette | 4.48 | 0.2 | g/cm3 |
| E2 | Elastic modulus of pin | 219,000 | 6000 | MPa |
| ε2 | Poisson’s ratio of pin | 0.3 | 0.015 | / |
| ρ2 | Density of pin | 7.76 | 0.3 | g/cm3 |
| n | Rotational speed | 1000 | 10 | rad/s |
| F | Assembly force | 21.928 | 0.01 | kN |
| Smax | Fatigue strength of material | 703.84 | / | MPa |
| Iteration | Number of Sample Points | E1 | ε1 | ρ1 | E2 | ε2 | ρ2 | n | F | Smax |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 123,000 | 0.330 | 4.480 | 219,000 | 0.300 | 7.760 | 1000 | 21.928 | 801.16 |
| 2 | 120,000 | 0.330 | 4.480 | 219,000 | 0.300 | 7.760 | 1000 | 21.928 | 801.25 | |
| 3 | 123,000 | 0.315 | 4.480 | 219,000 | 0.300 | 7.760 | 1000 | 21.928 | 800.81 | |
| … | … | … | … | … | … | … | … | … | … | |
| 2 | 18 | 121,149.492 | 0.347 | 4.521 | 218,251.976 | 0.288 | 7.746 | 1127.9 | 91.934 | 837.75 |
| 19 | 118,149.492 | 0.347 | 4.521 | 218,251.976 | 0.288 | 7.746 | 1127.9 | 91.934 | 838.21 | |
| … | … | … | … | … | … | … | … | … | … | |
| 3 | 35 | 121,152.780 | 0.351 | 4.531 | 217,800.072 | 0.292 | 8.047 | 1137.6 | 21.932 | 840.61 |
| 36 | 118,152.780 | 0.351 | 4.531 | 217,800.072 | 0.292 | 8.047 | 1137.6 | 21.932 | 843.50 | |
| … | … | … | … | … | … | … | … | … | … | |
| 4 | … | … | … | … | … | … | … | … | … | … |
| 67 | 121,065.224 | 0.354 | 4.554 | 216,893.977 | 0.295 | 7.745 | 1159.5 | 21.931 | 847.23 | |
| 68 | 121,065.224 | 0.354 | 4.554 | 216,893.977 | 0.295 | 7.745 | 1159.5 | 21.941 | 844.44 |
| Method | Number of Sample Points | Reliability Index | Probability of Failure | Relative Error/% |
|---|---|---|---|---|
| Monte Carlo | 106 | 2.141422 | 0.01612 | - |
| Response surface + Importance sampling | 256 | 2.157586 | 0.01548 | 3.9702 |
| Proposed approach | 68 | 2.131111 | 0.01654 | 2.6055 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, X.; Wang, J.; Zhang, J.; Ni, Z. A Multi-Performance Reliability Evaluation Approach Based on the Surrogate Model with Cluster Mixing Weight. Appl. Sci. 2024, 14, 5813. https://doi.org/10.3390/app14135813
Fan X, Wang J, Zhang J, Ni Z. A Multi-Performance Reliability Evaluation Approach Based on the Surrogate Model with Cluster Mixing Weight. Applied Sciences. 2024; 14(13):5813. https://doi.org/10.3390/app14135813
Chicago/Turabian StyleFan, Xiaoduo, Jiantai Wang, Jianguo Zhang, and Ziqi Ni. 2024. "A Multi-Performance Reliability Evaluation Approach Based on the Surrogate Model with Cluster Mixing Weight" Applied Sciences 14, no. 13: 5813. https://doi.org/10.3390/app14135813