
Health State Prediction Method Based on Multi-Featured Parameter Information Fusion
Abstract
:1. Introduction
2. Methods
2.1. Bi-LSTM
2.2. SOM
- 1.
- Stochastically initialize the network weight.
- 2.
- The input vibration signal feature vector is . Calculate the Euclidean distance between the neurons in the topology layer and . The formula is as follows:where is the weight vector between neurons in the topology layer.
- 3.
- The neuron with the smallest distance is selected as the winning neuron C and the set of its neighborhood neurons is given.
- 4.
- Weight learning to correct the weights of the output neuron C and its neighborhood neurons.where is the gain function.
- 5.
- Train steps 2–5, until the maximum number of training sessions is reached.
- 6.
- Calculate the distance between the input feature vector and the winning unit C at each time point, Minimum Quantization Error ().where is the weight vector of the winning unit. Since there are many burrs and perturbations in the calculated , the accuracy of the prediction will be affected if it is directly used as HI; therefore, this paper decomposes the into db5 wavelet packets and uses the low-dimensional trend term as the HI curve.
- Obtain the filter coefficients for the db5 wavelet: Let the original signal be . The low-pass filter coefficients of the db5 wavelet are . The high-pass filter coefficients areLow-frequency component:High-frequency component:
- Recursive decomposition: Apply the low-pass and high-pass filters again to each new component A and D and continue the decomposition to obtain more detailed frequency components. Repeat the steps until a predetermined level of decomposition is reached.
- Reconstructing the signal: wavelet packet reconstruction is the inverse of the decomposition process, where the signal is reduced by reconstructing filters for the low- and high-frequency components.
2.3. K-Means Clustering
- Initialize the center of mass: divide the dataset into algorithmic k classes and select k data points as initial centroids.
- Calculate the Euclidean distance from each data point to the center of mass and assign the data points to the class nearest to the center of mass.where denotes the location of the center of gravity of the jth class. To optimize the clustering results, the criterion should be minimized.
- Update the center of mass: recalculate the centers of mass of the individual classes already obtained. Calculate the Euclidean distance from each data point to the center of mass and assign the data points to the class nearest to the center of mass.
- Repeat steps 2–3 until the algorithm converges and the centers of mass to which all samples belong no longer change.
2.4. Particle Swarm Optimization Algorithm
- Population initialization: randomly initialize the position and velocity of the particles and calculate the fitness value of each particle; initialize the particle parameters such as the number, maximum number of iterations, and learning factor.
- Velocity and position update: each particle has two key attributes: position and velocity. The position of a particle indicates the location of an unknown solution in space, and its velocity is the direction and step size of moving in space. The position of each particle is evaluated by the fitness function to guide the search for the particle. The update formula is as follows:where, is the velocity of particle at moment t, is the position of the particle at moment it, and is the current found individual best position of the particle. is the overall optimal position of all the particles, and is the inertia weights, which are used for controlling the searching range of the particle. and are the individual and population balance factors, respectively, and t is the number of iterations. and are random numbers taking values between [0, 1] to increase the randomness of the search. The particle velocity variation is shown in Figure 5.
- Individual and population optimal solution updating: in each iteration, each particle records its own position; if the updated individual position is better than before, then it is the individual optimal position; if the updated global position is later than before, then, it is the global optimal position.
- Termination condition: when the maximum number of iterations is reached to meet the convergence criteria, the algorithm terminates and outputs the global optimal position and the optimal fitness value.
3. Improved BiLSTM Modle Optimized by PSO
4. Data Description and Pre-Processing
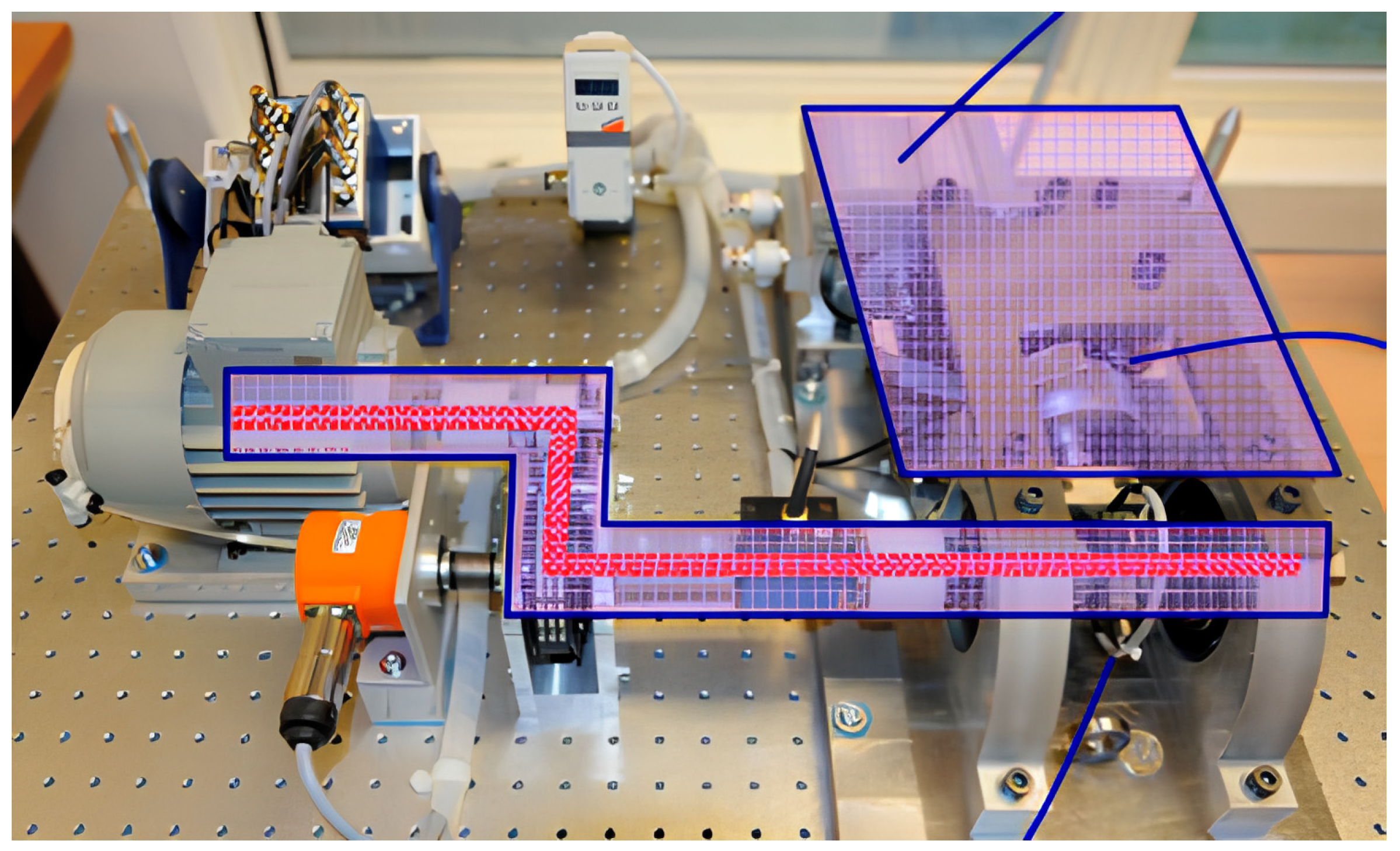
4.1. Data Descriptions
4.2. Data Preprocessing
4.2.1. Feature Extraction
4.2.2. Feature Fusion
- The selected degradation-sensitive features are normalized.
- Training set and test set: take the first 502 sets of data as the training set and the last 502 sets as the test set.
- The SOM network was trained, the input dimension was 15, the output dimension was 25, the learning rate was 0.80, the number of training sessions was 100, and the between the input feature vector and the winning neuron was computed for each sampling point. Input the test set features into the trained SOM network and calculate the from the figure. There are a lot of burrs in the , which will affect the accuracy of the prediction, so the is decomposed by the db5 wavelet packets, and the low-frequency trend term is used as the HI. The result is shown in Figure 10.
4.2.3. Health Status
5. Experimental Verification
5.1. Predictive Modeling Based on PSO-BILSTM
5.2. Experimental Research
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, Y.; Rao, M.; Feng, K.; Zuo, M.J. Physics-Informed LSTM hyperparameters selection for gearbox fault detection. Mech. Syst. Signal Process. 2022, 171, 108907. [Google Scholar] [CrossRef]
- Yu, X.; Ding, E.; Chen, C.; Liu, X.; Li, L. A novel characteristic frequency bands extraction method for automatic bearing fault diagnosis based on Hilbert Huang transform. Sensors 2015, 15, 27869–27893. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Peng, Z.; Liu, R.; Chen, C. Research on multi-fault diagnosis method based on time domain features of vibration signals. Sensor 2022, 22, 8164. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Li, S.; Xin, Y.; An, Z. Gear fault intelligent diagnosis based on frequency-domain feature extraction. J. Vib. Eng. Technol. 2019, 7, 159–166. [Google Scholar] [CrossRef]
- Jiang, W.; Xie, C.; Zhuang, M.; Shou, Y.; Tang, Y. Sensor data fusion with z-numbers and its application in fault diagnosis. Sensors 2016, 16, 1509. [Google Scholar] [CrossRef] [PubMed]
- Yin, Y.; Liu, F.; Zhou, X.; Li, Q. An efficient data compression model based on spatial clustering and principal component analysis in wireless sensor networks. Sensors 2015, 15, 19443–19465. [Google Scholar] [CrossRef] [PubMed]
- Widodo, A.; Yang, B.S. Application of nonlinear feature extraction and support vector machines for fault diagnosis of induction motors. Expert Syst. Appl. 2007, 33, 241–250. [Google Scholar] [CrossRef]
- Zhou, H.; Chen, J.; Dong, G.; Wang, H.; Yuan, H. Bearing fault recognition method based on neighbourhood component analysis and coupled hidden Markov model. Mech. Syst. Signal Process. 2016, 66, 568–581. [Google Scholar] [CrossRef]
- Stief, A.; Ottewill, J.R.; Baranowski, J.; Orkisz, M. A PCA and two-stage Bayesian sensor fusion approach for diagnosing electrical and mechanical faults in induction motors. IEEE Trans. Ind. Electron. 2019, 66, 9510–9520. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, Y.; Li, P.; Su, S. Entropy feature fusion-based diagnosis for railway point machines using vibration signals based on kernel principal component analysis and support vector machine. IEEE Intell. Transp. Syst. Mag. 2023, 15, 96–108. [Google Scholar] [CrossRef]
- Yaman, O. An automated faults classification method based on binary pattern and neighborhood component analysis using induction motor. Measurement 2021, 168, 108323. [Google Scholar] [CrossRef]
- Zhou, Y.; Yan, S.; Ren, Y.; Liu, S. Rolling bearing fault diagnosis using transient-extracting transform and linear discriminant analysis. Measurement 2021, 178, 109298. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, J.; Wei, B.; Chen, W.; Xu, S. Investigating the construction, training, and verification methods of k-means clustering fault recognition model for rotating machinery. IEEE Access 2020, 8, 196515–196528. [Google Scholar] [CrossRef]
- Liu, Y.; Ge, Z. Weighted random forests for fault classification in industrial processes with hierarchical clustering model selection. J. Process Control 2018, 64, 62–70. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, H. Fault diagnosis of VRF air-conditioning system based on improved Gaussian mixture model with PCA approach. Int. J. Refrig. 2020, 118, 1–11. [Google Scholar] [CrossRef]
- Yiakopoulos, C.T.; Gryllias, K.C.; Antoniadis, I.A. Rolling element bearing fault detection in industrial environments based on a K-means clustering approach. Expert Syst. Appl. 2011, 38, 2888–2911. [Google Scholar] [CrossRef]
- Lin, X.; Wu, H.; Ye, B.; Xu, B.; Tao, W. Dynamic equivalent modeling of motors based on improved hierarchical clustering algorithm. J. Electr. Eng. Technol. 2019, 14, 1139–1150. [Google Scholar] [CrossRef]
- Wang, S.; Wang, Z.; Cheng, X.; Zhang, Z. A double-layer fault diagnosis strategy for electric vehicle batteries based on Gaussian mixture model. Energy 2023, 281, 128318. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Peng, H. Diagnostic Method for Short Circuit Faults at the Generator End of Ship Power Systems Based on MWDN and Deep-Gated RNN-FCN. J. Mar. Sci. Eng. 2023, 11, 1806. [Google Scholar] [CrossRef]
- Zhang, J.; Feng, Y.; Zhang, J.; Li, Y. The Short Time Prediction of the Dst Index Based on the Long-Short Time Memory and Empirical Mode Decomposition–Long-Short Time Memory Models. Appl. Sci. 2023, 13, 11824. [Google Scholar] [CrossRef]
- Ahmad, T.; Zhang, D. A data-driven deep sequence-to-sequence long-short memory method along with a gated recurrent neural network for wind power forecasting. Energy 2022, 239, 122109. [Google Scholar] [CrossRef]
- Zollanvari, A.; Kunanbayev, K.; Bitaghsir, S.A.; Bagheri, M. Transformer fault prognosis using deep recurrent neural network over vibration signals. IEEE Trans. Instrum. Meas. 2020, 70, 2502011. [Google Scholar] [CrossRef]
- Jiang, T.; Liu, Y. A short-term wind power prediction approach based on ensemble empirical mode decomposition and improved long short-term memory. Comput. Electr. Eng. 2023, 110, 108830. [Google Scholar] [CrossRef]
- Liu, Y.; Gan, H.; Cong, Y.; Hu, G. Research on fault prediction of marine diesel engine based on attention-LSTM. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2023, 237, 508–519. [Google Scholar] [CrossRef]
- Qiang, Z.; Jieying, G.; Junming, L.; Ying, T.; Shilei, Z. Gearbox fault diagnosis using data fusion based on self-organizing map neural network. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720923476. [Google Scholar] [CrossRef]
- Peng, X.; Zhang, B. Ship motion attitude prediction based on EMD-PSO-LSTM integrated model. J. Coast. Isl. Technol. 2019, 27, 421–426. [Google Scholar]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, IEEE Catalog Number: CPF12PHM-CDR, Spokane, WA, USA, 17–19 June 2012; pp. 1–8. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Starting Value | Optimal Value |
|---|---|---|
| Training Optimizer | Adam | |
| Maximum number of iteration rounds | 1000 | |
| Batch size | 50 | |
| Initial learning rate | 0.01 | 0.0748 |
| Dropout loss function | 0.2 | |
| Hidden layer neuron | 50 | 156 |
| Network layer | 1 | 2 |
| Regularization factor | 1.6164 × 10−5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, X.; Rong, Y.; Li, L.; He, W.; Lv, M.; Sun, S. Health State Prediction Method Based on Multi-Featured Parameter Information Fusion. Appl. Sci. 2024, 14, 6809. https://doi.org/10.3390/app14156809
Yin X, Rong Y, Li L, He W, Lv M, Sun S. Health State Prediction Method Based on Multi-Featured Parameter Information Fusion. Applied Sciences. 2024; 14(15):6809. https://doi.org/10.3390/app14156809
Chicago/Turabian StyleYin, Xiaojing, Yao Rong, Lei Li, Weidong He, Ming Lv, and Shiqi Sun. 2024. "Health State Prediction Method Based on Multi-Featured Parameter Information Fusion" Applied Sciences 14, no. 15: 6809. https://doi.org/10.3390/app14156809