Abstract
Key–value stores (KV stores) are becoming popular in both academia and industry due to their high performance and simplicity in data management. Unlike traditional database systems such as relational databases, KV stores manage data in key–value pairs and do not support relationships between the data. This simplicity enables KV stores to offer higher performance. To further improve the performance of KV stores, high-performance storage devices such as solid-state drives (SSDs) and non-volatile memory express (NVMe) SSDs have been widely adopted. These devices are intended to expedite data processing and storage. However, our studies indicate that, due to a lack of multi-thread-oriented programming, the performance of KV stores is far below the raw performance of high-performance storage devices. In this paper, we analyze the performance of existing KV stores utilizing high-performance storage devices. Our analysis reveals that the actual performance of KV stores is below the potential performance that these storage devices could offer. According to the profiling results, we argue that this performance gap is due to the coarse-grained locking mechanisms of existing KV stores. To alleviate this issue, we propose a multi-threaded compaction operation that leverages idle threads to participate in I/O operations. Our experimental results demonstrate that our scheme can improve the performance of KV stores by up to 16% by increasing the number of threads involved in I/O operations.
1. Introduction
Key–value stores (KV stores) are used in many industry and academic applications due to their simplicity and high performance [1,2,3,4,5,6,7]. KV stores are non-relational databases that store, retrieve, and manage data as a collection of key–value pairs. Each key in a KV store serves as a unique identifier for accessing its associated value. Both keys and values can be simple data types like strings or numbers, as well as more complex structures such as JSON objects or binary data. Unlike relational databases (RDBs), which rely on predefined schemas like tables composed of fields with well-defined data types, KV stores provide a schemaless structure, allowing for simple and flexible data storage without the need for predefined schemas. Due to their simplicity of managing data and the relationship between data, KV stores are used in many different layers of operating systems, including KV store-based file systems [8,9,10,11,12,13]. As KV stores are adapted to a wide variety of applications, it is becoming important to improve the performance of KV stores running on new upcoming hardware.
In recent years, advancements in hardware, such as multi-core CPUs and high-performance storage devices, have been introduced to improve application performance. However, these hardware innovations require corresponding optimizations in the software stack to fully leverage the hardware’s capabilities. For instance, multi-core CPUs require parallelization of the existing software stack to take full advantage of the increased number of cores. Similarly, high-performance storage devices need more aggressive polling-based, multi-threaded I/O operations to exploit their fast response time and concurrency features. Without proper optimization in the software stack, the potential benefits offered by the emerging hardware may be lost. In some cases, the overall performance of the application could remain unchanged or even degrade due to mismatches between the hardware capabilities and the existing software stack.
To handle these issues, previous studies have optimized the I/O stack to fully exploit the high-performance capabilities of multi-core CPUs and emerging storage devices. IceFS [14] and SpanFS [15] leverage hardware capabilities by partitioning the journaling file system. SpanFS consists of a collection of micro file system services known as domains. It distributes files and directories across these domains and delegates I/O operations to the corresponding domain to avoid lock contention. It also exploits device parallelism for shared data structures and parallelizes file system services. IceFS enables performing concurrent I/O operations by separating the file system into directory subtrees. Son et al. [16] optimized the journaling and checkpointing operations of the existing file system by utilizing idle application threads to participate in the I/O operation. ScaleFS [17] introduced a per-core operation log within the file system to improve scalability across multiple cores. MAX [18] introduced a multi-core-friendly log-structured file system to exploit flash parallelism by scaling user I/O operations with newly designed semaphores. These studies concentrate on optimizing the I/O stack within operating systems, particularly improving file system scalability. In contrast, our approach aims to optimize performance independently of underlying systems (e.g., file systems) by utilizing idle computing resources within the KV store to accelerate I/O operations.
We first analyze the I/O operations performed in the existing KV store, focusing on the widely used KV store RocksDB [19,20], to identify the performance bottleneck. Our analysis of the I/O path in RocksDB reveals that background I/O operations, such as flush and compaction, cause stalls during foreground I/O operations. As a result, even with an increased number of threads allocated to handle foreground I/O operations, most of these threads remain in a wait state until the background jobs are completed. To address this issue, we focus on the compaction procedure—one of the background I/O operations occurring in the KV store—where multiple files need to be read to sort key–value pairs. This procedure involves numerous recursive read operations, but the existing implementation of RocksDB utilizes only a single thread for these read operations. To optimize this, we enable concurrent file read operations by creating a read buffer and prefetching files into a temporary read buffer.
We implement our scheme within the existing RocksDB and evaluate its performance using the db_bench benchmark, varying the number of threads and using different machines. The experimental results demonstrate that our scheme improves the performance of KV stores by parallelizing I/O operations utilizing idle computing resources.
In summary, our main contributions are as follows:
- We analyze the I/O path and scalability within the existing KV store, RocksDB.
- We design parallel read operations to accelerate background jobs, optimizing the KV store for multi-core CPUs and high-performance storage devices.
- We demonstrate that our proposed scheme improves the overall performance of the KV store by involving idle computing resources in I/O operations.
The rest of this paper is organized as follows:
Section 2 discusses the related work. Section 3 describes the background and presents the analysis performance of RocksDB with high-performance storage devices using various configurations. Section 4 presents the design of our scheme to fully utilize hardware capabilities. Section 5 shows the experimental results. Section 6 explains the limitations of the study and discusses future work. Section 7 concludes the paper.
2. Related Work
2.1. Optimizing Software Stack for High-Performance Storage Devices
There have been many studies on utilizing new storage devices to improve the performance of KV stores. KVSSD [21] is a new SSD design that supports LSM-tree compaction and flush operation inside the flash transition layer (FTL) of the SSD to reduce the write amplification. iLSM [22] introduced an SSD that implements LSM-tree with key–value separation, which was originally introduced in WiscKey [23], by modifying the SSD firmware. To provide near-data processing capability, iLSM designed a new protocol for key–value interfaces at the user, kernel, and storage device levels. Pengfei et al. [24] proposed a low-overhead hashing design that utilizes a non-volatile memory as persistent memory.
Our study is in line with these studies [21,22,24] since we try to optimize the performance of KV stores. However, in contrast, our study focuses on the KV store layer itself, rather than the underlying storage device.
2.2. Optimizing Key–Value Stores
There have been many studies on improving the performance of KV stores by improving concurrency. FASTER [25] is a concurrent key–value store design for update-intensive workloads. It manages a separate lock-free data region for the frequent update operation. Liu et al. [26] improve the performance of KV stores by separating compaction and flush operation to separate disks. Sun et al. [27] accelerate background I/O operations by offloading compaction to FPGA. SpanDB [3] and P2KVS [4] notice the overhead caused by coarse-grained write-ahead logging (WAL). To provide scalability, SpanDB parallelizes the WAL operation to engage multiple threads by leveraging SPDK [28] interfaces. P2KVS launches multiple key–value instances to handle concurrent foreground requests by distributing them to different key–value engines.
Our study is in line with these studies [25,26] in improving the performance of KV stores by supporting concurrency. However, in contrast, our study tries to improve concurrency in a global function call and support various storage devices.
3. Background and Motivation
3.1. High-Performance Storage Devices
With the advancement of flash memory, flash-based SSDs and NVMe SSDs are widely used and are rapidly replacing traditional tape-based storage and magnetic hard disk drives (HDDs). SSDs offer significantly faster throughput and lower latency compared to HDDs and have no moving parts, which enhances their durability and endurance.
A key difference that must be considered in the software stack is that SSDs are typically equipped with multiple channels. In contrast to HDDs, where multiple requests from the host are serialized into a single queue and handled once at a time, SSDs can handle multiple requests simultaneously. This capability arises from the architecture of SSDs, which connect multiple chips (groups of flash cells) to multiple channels. Although each channel can accept only one request at a time, the presence of multiple channels allows for simultaneous access to different chips.
This parallelism in SSDs enables the host to issue requests in a parallel and concurrent manner, rather than a serialized manner. However, existing applications and I/O stacks are optimized for HDDs, and thus, are designed to issue requests in a serialized manner. This approach only utilizes a single channel, despite the storage device’s ability to handle requests across multiple channels. Therefore, a new approach is required to fully exploit the potential of multiple channels in storage devices by employing multiple threads to issue I/O requests in a parallel and concurrent manner.
3.2. Existing I/O Path Analysis of RocksDB
As RocksDB is a widely used KV store, it is important to fully understand its I/O path and examine how the KV stores are implemented to support high performance and data robustness.
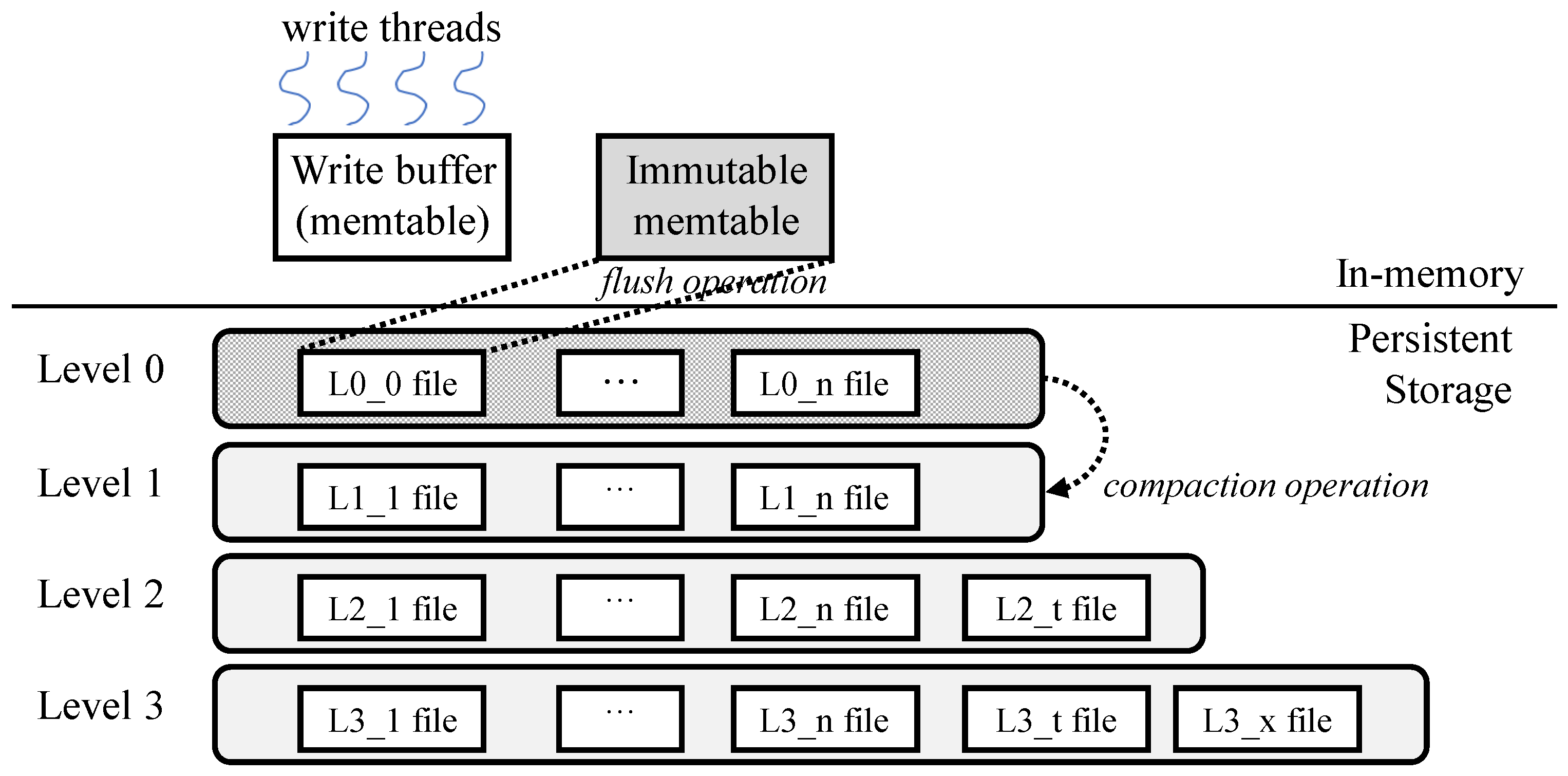
Figure 1 illustrates the existing architecture of RocksDB. Incoming insert operations store key–value pairs in the in-memory write buffer, known as the memtable. When the memtable becomes immutable due to accumulating sufficient key–value pairs, background job—specifically, the flush operation—stores the immutable memtable as a level 0 file in persistent storage. RocksDB organizes these files, which store key–value pairs, into multiple levels based on data access recency. Since duplicate keys are not allowed within a certain level and key–value pairs are stored in order within each level, the compaction job continuously performs read and write operations to manage the number of files at each level. This process ensures that the number of files remains constant at each level, thereby maintaining the desired characteristics of the KV store across all levels.
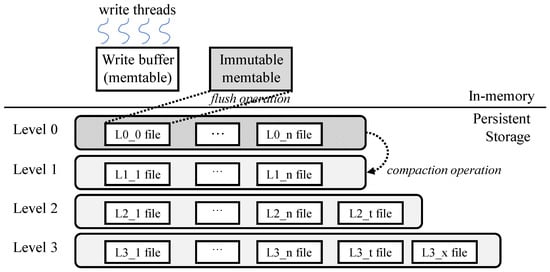
Figure 1.
RocksDB architecture [7,29].
Algorithm 1 presents a pseudocode representation of the existing I/O path in RocksDB during an insert operation.
| Algorithm 1 Existing I/O path pseudocode |
|
As shown, RocksDB initiates the insert operation with the DoWrite() function. In this function, the first thread to arrive is selected as the leader thread (lines 2–12). The leader thread acquires a lock and performs preprocessing operations (PreprocessWrite()) to handle the write operation (lines 3–9). It then checks the write controller to determine whether the write operation can proceed, taking into account the status of background operations (line 5). For example, if the flush operation is too slow and there is not enough memtable for inserting new key–value pairs, the leader thread waits for the flush job to complete, allowing the memtable to become available. Another background job, the compaction job, also causes stalls in foreground operations. As new key–value pairs continue to arrive, the compaction job is executed to keep the number of files in level 0 below a certain threshold, which may cause the leader thread to wait until space becomes available in level 0. In other words, if the system is in a state where new key–value pairs cannot be inserted due to ongoing background I/O operations, the operations of the leader thread are stalled (lines 5–8). In summary, the overall progress of the foreground insert operation is heavily dependent on the performance of background jobs. If progress is possible, the leader thread proceeds with foreground I/O operations, such as writing to the write-ahead log and flushing the key–value pairs in the memtable to the non-volatile storage device (lines 10–12).
In contrast, threads that are not selected as the leader thread are stalled, waiting for the leader thread’s operations to complete. This means that, despite the availability of a large number of threads —a trend that is increasing with the growth of CPU cores —only a single thread is responsible for executing the actual I/O operations. This limitation not only reduces the efficiency of I/O operations but also hampers the overall progress of insert operations within the KV store. The insert operation is delayed until sufficient space is available to temporarily store the key–value pairs. This clearly indicates that the current implementation of RocksDB is not optimized for multi-core CPUs and high-performance storage devices.
3.3. Existing KV Store Performance Analysis
In this section, we analyze the performance of the existing RocksDB when used with multi-core CPUs and high-performance storage devices, focusing on various configuration parameters that affect scalability. We use db_bench benchmark, which is included as part of RocksDB and widely used for evaluating the performance of KV stores [30,31]. The experiments are conducted on a machine equipped with an Intel Xeon E5-2620 v4 processor (Intel, Santa Clara, CA, USA) and 32 GB of memory. For storage, we use a Samsung 960 NVMe SSD (Samsung, Suwon-si, Republic of Korea) with a capacity of 512 GB. The evaluation parameters used in the experiments are described in Section 5.1.
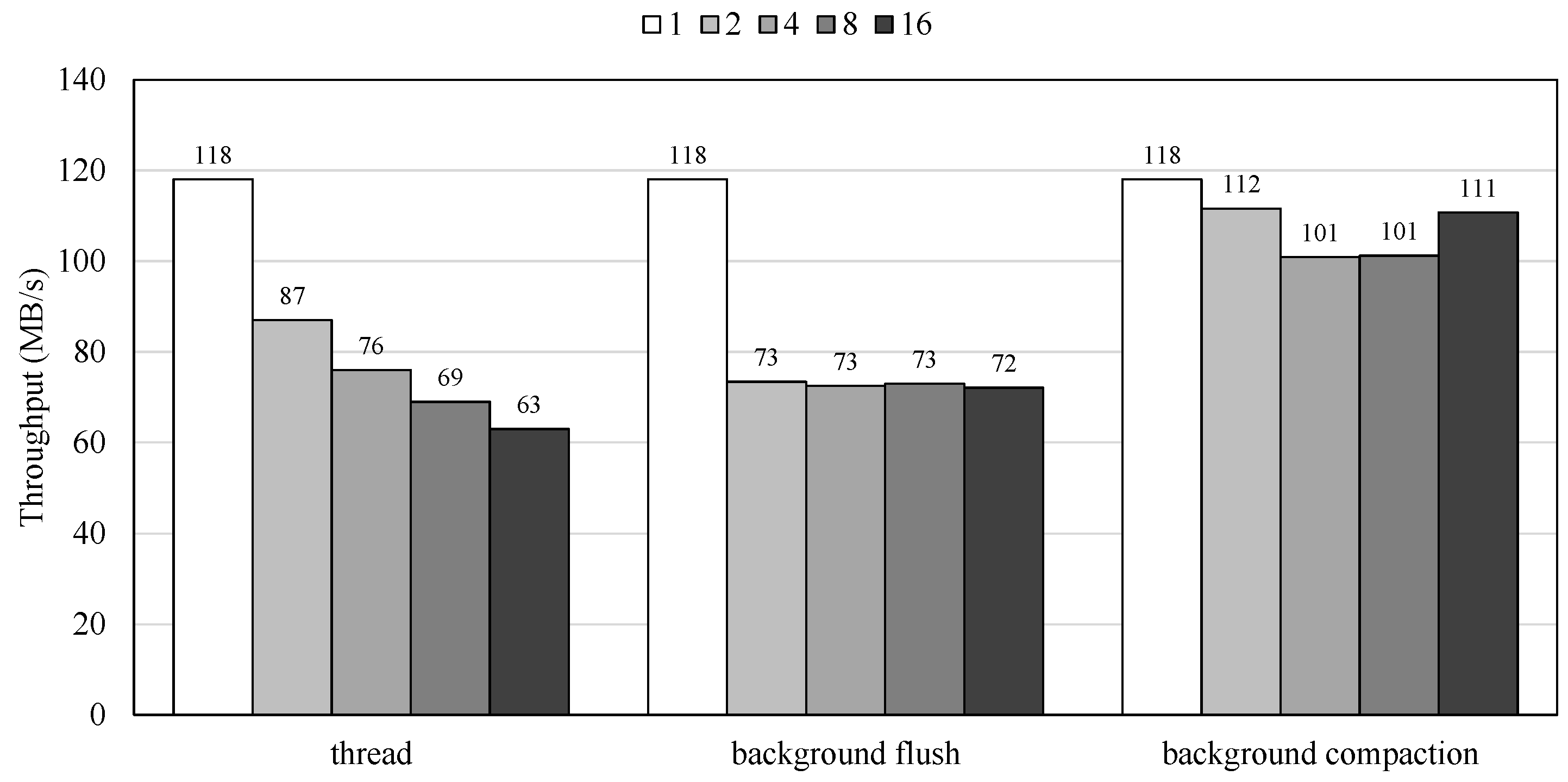
Figure 2 presents the performance of RocksDB with varying numbers of application threads, background flush threads, and background compaction threads. By increasing the number of threads, we increase the number of application threads requesting I/O operations from RocksDB. As illustrated in the figure, RocksDB’s performance not only fails to improve but actually decreases as the number of threads increases. This occurs because only a single leader thread is responsible for foreground I/O operations, while other non-leader threads often remain idle or compete for locks, leading to increased lock contention as the thread count rises. Since the number of threads corresponds to the number of threads involved in inserting key–value pairs, the experimental results indicate that the current RocksDB implementation is not optimized for modern multi-core CPUs.
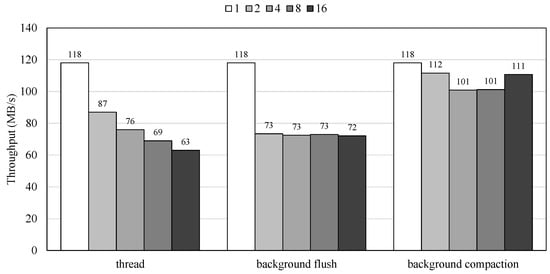
Figure 2.
Performance of KV store with increasing number of threads for foreground I/O operations and background flush and compaction operations.
We also measure RocksDB’s performance with increasing numbers of background flush and compaction threads. Figure 2 includes performance results based on varying the number of threads for background jobs. As previously mentioned, foreground I/O operations are heavily impacted by flush and compaction jobs. Therefore, we analyze the effects of increasing the number of background job threads. While increasing the number of flush and compaction threads could theoretically improve performance, the results show that RocksDB’s performance does not improve with more compaction threads and actually degraded with additional flush threads. Similar to the earlier findings in Figure 2, which showed decreased performance with an increasing number of foreground operation threads, these results indicate that a single thread handles actual I/O operations while other threads either remain idle or exacerbate lock contention, leading to diminished performance with more flush threads.
In summary, this section demonstrates RocksDB’s performance under different configurations intended to increase parallelism and concurrency by adding more threads. However, as shown in all figures, increasing the number of application, flush, and compaction threads generally does not improve performance and often reduces it. These findings suggest that the current implementation of RocksDB is not optimized for multi-core CPUs and high-performance storage devices, indicating a need for a new approach to fully leverage the potential of emerging hardware.
4. Design and Implementation
In this section, we present our scheme to efficiently utilize emerging hardware. We propose a scheme that utilizes idle threads to participate in I/O operations, thereby taking advantage of both high numbers of core counts in CPUs and the multiple channels within storage devices.
4.1. Design
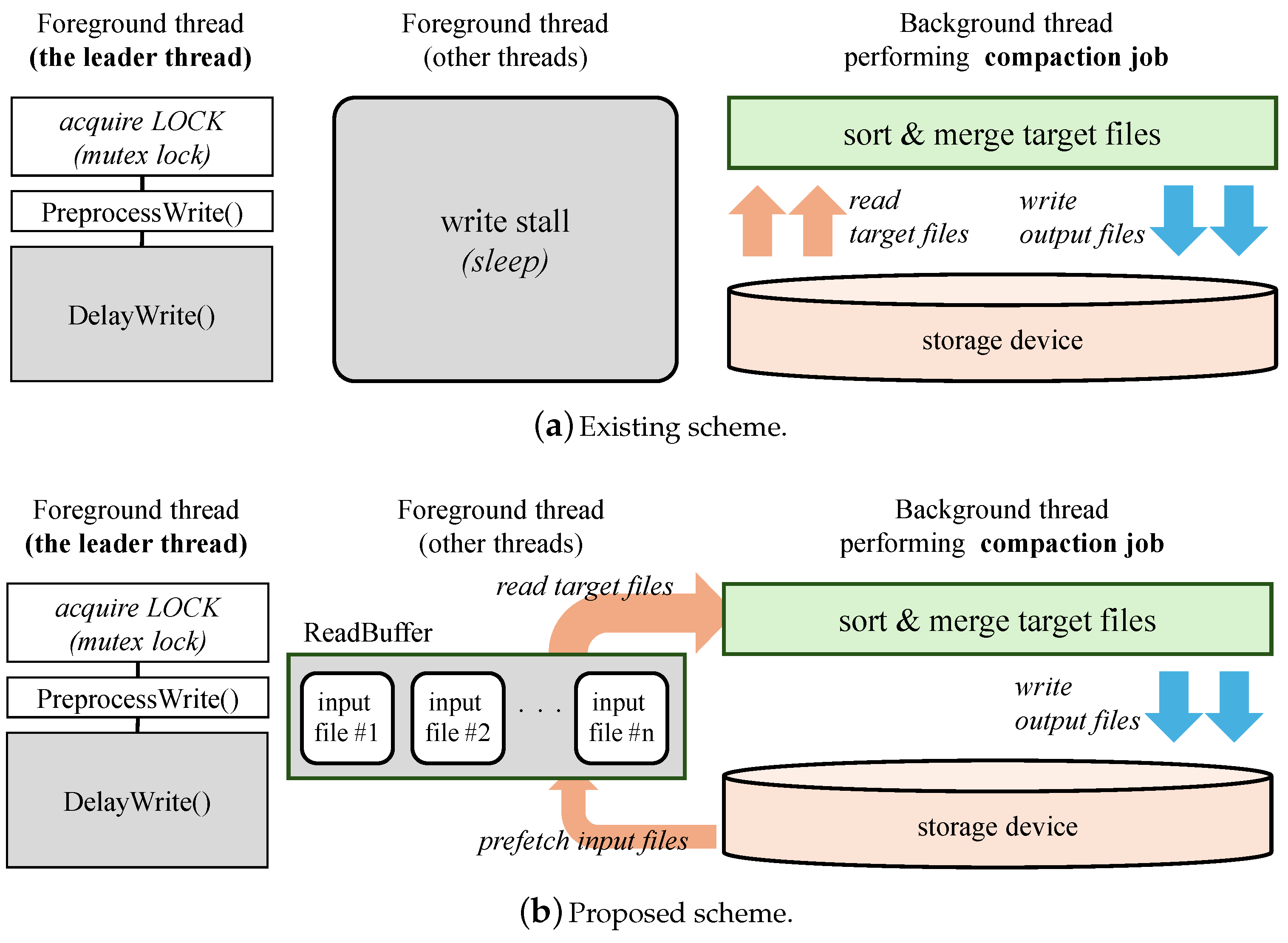
Figure 3 illustrates the overall design of the proposed scheme. The top part depicts the existing scheme, while the bottom part presents our proposed scheme. In the existing scheme, as discussed in Section 3, only a single thread is selected as the leader and is solely responsible for handling foreground I/O operations, such as insert operations.
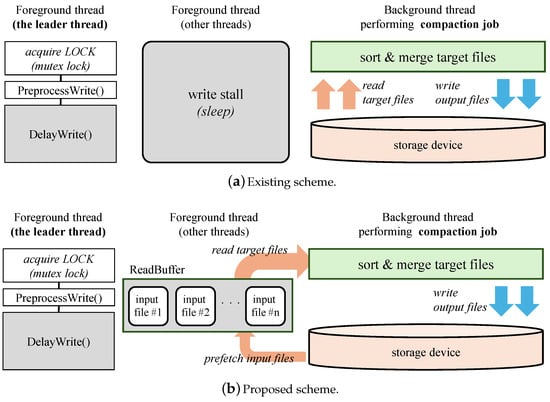
Figure 3.
Overall design of the existing and proposed schemes.
During flush and compaction operations, the thread initiating the operation first acquires the data to be sorted and written to the storage device. In the flush operation, the data are already in memory, as the sorted data are received from the user and formed into a table in memory, known as a memtable, as illustrated in Figure 1. In contrast, during compaction, the data must be retrieved from the storage device by locating the files containing keys in the target range and reading them into memory. However, because these I/O operations are not performed in parallel, increasing the number of flush or compaction threads does not improve the performance of RocksDB, as shown in Figure 2.
In our proposed scheme, we expedite background I/O operations by involving threads that are not selected as the leader, utilizing them during their idle states. To achieve this, we adopt a technique commonly used in file system optimization for scalability [15,16]. Instead of having these threads sleep or contend for locks, we enable them to participate in the I/O operations. Given our focus on multi-core systems, we believe that there will be a sufficient number of application threads available for I/O operations, rather than being idle. This approach increases the number of threads involved in I/O operations without incurring the overhead associated with thread creation.
As shown in Figure 3a, in the existing design, threads allocated for foreground I/O operations, except a leader thread, remain in a wait state. Furthermore, if the write controller delays the execution of the leader thread (during the execution of DelayWrite()) due to intensive background I/O operations, all threads allocated for foreground I/O operations will remain idle. Our key idea is accelerating background jobs that delay foreground I/O operations by parallelizing I/O operations using threads that would otherwise be in a wait state.
To implement this, we first identify the files that need to be read during the compaction operation. As shown in the example in Figure 3b, the input files #1 through #n are identified as containing the target key range for the compaction job. We also allocate a temporary read buffer to hold the prefetched target input files. Instead of waiting, the threads originally allocated for foreground I/O operations are now engaged in these background jobs. Consequently, while the leader thread handles foreground jobs such as PreprocessWrite(), other threads assist by concurrently reading the target input files and loading their contents into the preallocated read buffer. This approach allows the background thread to expedite the compaction process by accessing data from the in-memory read buffer rather than from the storage device, resulting in reduced stall time during foreground I/O operations. Our scheme effectively utilizes the high core count of the CPU and the parallelism provided by emerging storage devices.
4.2. Implementation
We implement the proposed scheme in RocksDB version 5.13. To enable foreground idle threads to participate in background I/O operations, we introduce a global data structure called ReadQueue. Algorithm 2 represents the pseudocode for the process in which multiple threads add or remove information about files that need to be read into the ReadQueue, facilitating concurrent I/O operations. One of the background jobs, the compaction job, adds information about files requiring read I/O operations (lines 1–7). The main procedure of the compaction job is performed in the function ProcessKeyValueCompaction(), which begins by identifying compaction target files that need to be read from storage devices (line 2). Since all files stored on the storage devices are sorted, the target files are read sequentially to merge and re-sort valid data. In other words, while all target files for compaction must eventually be read, they are not read all at once. For instance, if six files with file numbers 1 through 6 are selected as compaction targets, the process begins with file number 1. Files 2 and 3, which store overlapping key ranges, should be read first, but the read operations for files 4, 5, and 6 are delayed until the merge and re-sorting operations for the preceding key ranges are completed. The proposed scheme manages information about files that must eventually be read in the global queue, allowing idle threads to perform I/O operations in advance, which must be performed eventually.
| Algorithm 2 Pseudocode for the proposed scheme. |
|
As shown in Algorithm 1 (lines 6–7, 14–15), all threads allocated for foreground I/O operations are stalled and wait for the background jobs to complete. In the proposed scheme, before the threads allocated to foreground I/O operations enter a waiting state, they first check the global queue to see if there are any files requiring read I/O for background jobs (lines 9, 14–23). In the PrefetchQueueData() function, we first check whether the global queue is empty. If the queue is empty, it indicates that other threads have already read the target files and there is no remaining work. In this case, since no additional work is needed, the function returns, and the thread checks again to determine whether waiting is still necessary (lines 10–11). If the queue is not empty, a file is selected from the global queue for reading (lines 17–22). At this point, to avoid duplicate read operations by multiple threads, a thread acquires a lock, reads the file information, and updates the status of the file to indicate that the read operation is in progress. After selecting a file, the thread allocates space in the read buffer so that the file can be preloaded, and the data contained in the file are read into memory. Once the read operations are complete, the status is updated, and the file information is removed from the global queue to prevent duplication I/O operations.
Our implementation is available as open-source software at https://github.com/hkim-snu/rocksdb-parallel.git (accessed on 16 July 2024).
5. Evaluation
5.1. Experimental Setup
We conduct experiments using db_bench benchmark provided by RocksDB. While db_bench benchmark offers multiple benchmark scenarios, we select the fillrandom workload to evaluate our scheme because fillrandom incurs the high I/O processing overhead. The fillrandom workload first generates keys in random order, and then, inserts the generated random key–value pairs into the pre-configured database location. The key and value sizes used are 16 B and 16 KB, respectively. We generate and inserted 625,000 key–value pairs into RocksDB.
Table 1 presents the evaluation parameters used in this study. Parameter values not listed in the table are set to their default values [20]. The parameters max_background_flushes and max_background_compactions indicate the number of threads allocated for flush and compaction jobs, respectively. To verify the effectiveness of the proposed scheme, we conduct experiments with varying numbers of threads allocated for foreground I/O operations.

Table 1.
Evaluation parameters.
We use two different machines in the following experiments to evaluate RocksDB’s performance. The machine specifications are provided in Table 2. I/O operations were configured as direct by setting the parameter values use_direct_io_for_flush_and_compaction and use_direct_reads to true, thereby avoiding the overhead associated with transferring data through the kernel. We implement our scheme in RocksDB version 5.13 on Linux kernel 4.17.0 version, using the ext4 file system.
Table 2.
Machine specifications.
5.2. Performance Results
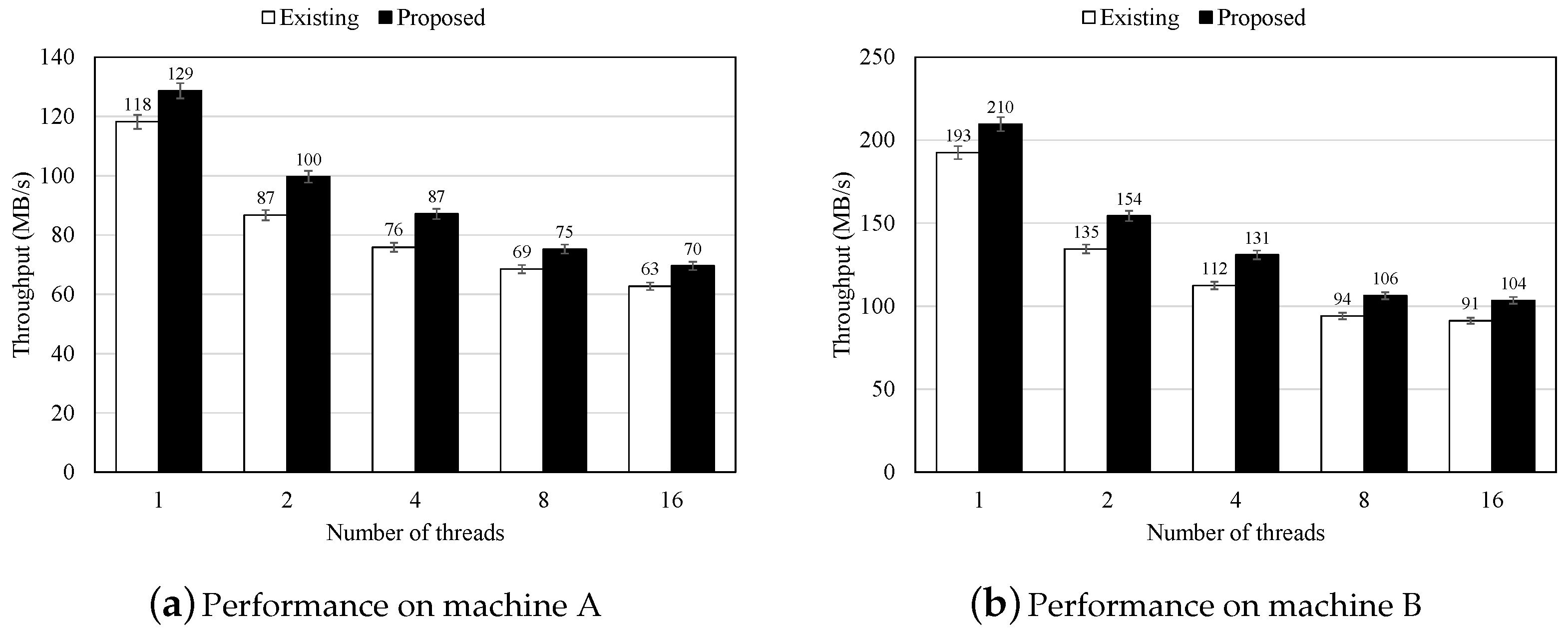
Figure 4 illustrates the performance of RocksDB with both the existing and proposed schemes on two different machines. As depicted, the proposed scheme improves RocksDB’s performance by up to 16% across a range of thread counts, from 1 to 16, on both machines. Specifically, on machine A, the proposed scheme improves performance by 9%, 15%, 15%, 10%, and 11% when 1, 2, 4, 8, and 16 threads are allocated for foreground I/O operations, respectively. On machine B, the proposed scheme yields performance improvements of 9%, 15%, 16%, 13%, and 13% for the same thread allocations.
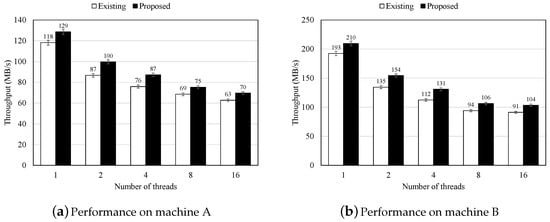
Figure 4.
Performance of KV store with the original and proposed schemes on different machines.
The performance gains result from utilizing idle computing resources to participate in I/O operations rather than merely waiting for the completion of background jobs. By leveraging threads originally scheduled for foreground I/O operations, the thread allocated to background jobs can concentrate on processing data fetched from the read buffer during compaction. This approach reduces the time required, as the thread responsible for the background job can read data from a prefetched memory region instead of directly from the storage device. Additionally, the proposed scheme not only accelerates overall processing performance but also reduces lock contention among threads attempting to become the leader during foreground I/O operations. However, as shown in the figure, the performance gains diminish when using 8 or 16 threads compared to 2 or 4 threads on both machines. Increasing the number of threads does not yield proportional performance improvements. This is because, as the thread count increases, the overhead associated with acquiring locks during foreground I/O operations and becoming the leader thread also increases.
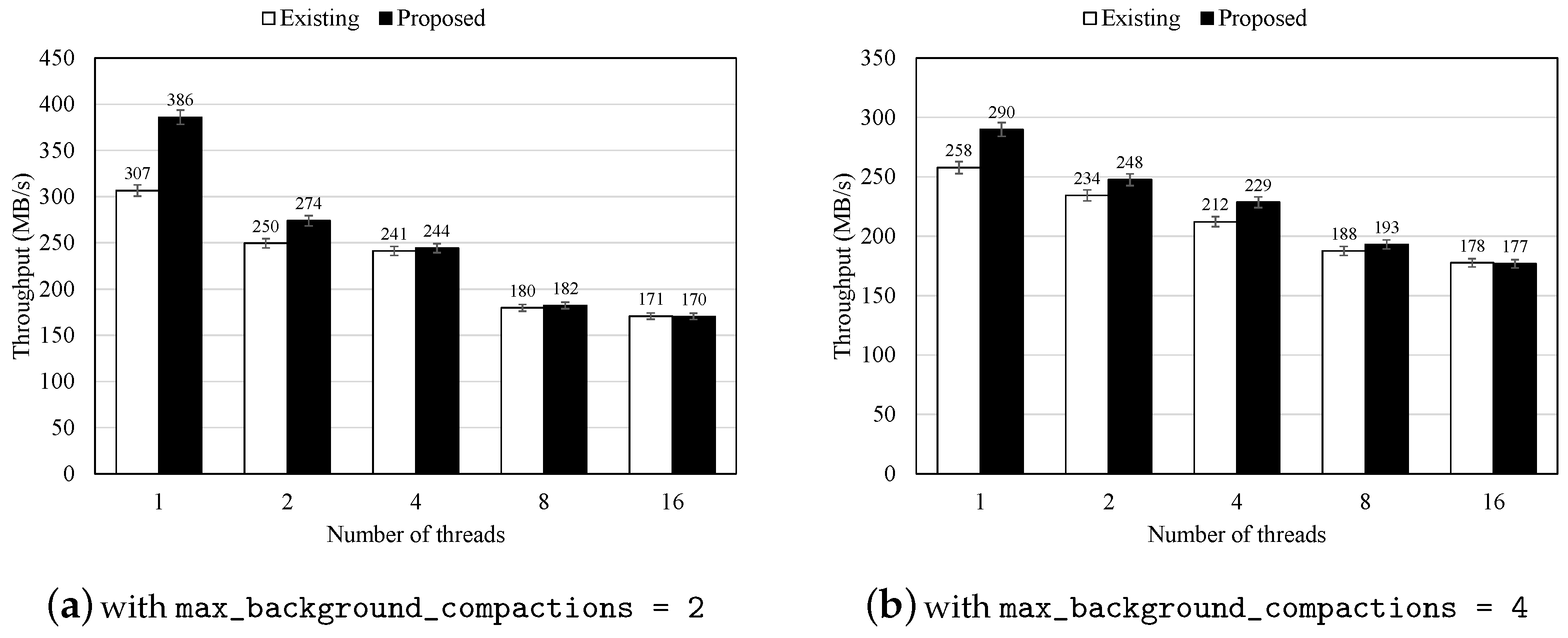
Furthermore, to assess the effectiveness of the proposed scheme with an increasing number of background threads, we measure performance by varying the max_background_compactions parameter to 2 and 4. Since our scheme is designed to perform concurrent read operations on files required for compaction, we focused on adjusting the number of threads allocated to compaction jobs. Figure 5 presents the performance results with varying numbers of background threads. The results indicate that the proposed scheme improves performance by accelerating the background compaction job through concurrent reading of target files while reducing delays during foreground I/O operations.
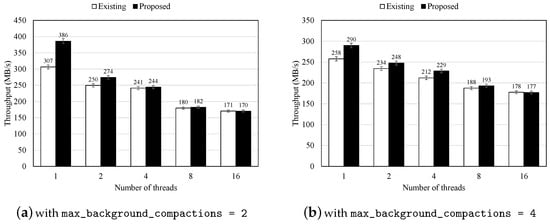
Figure 5.
Performance of KV store with the original and proposed schemes with a different number of compaction threads (performed on machine B).
In summary, our evaluation demonstrates that the proposed scheme can effectively improve the performance of KV stores when a high number of threads are used in conjunction with emerging fast storage devices.
6. Limitation and Future Work
One limitation of our proposed scheme is its reliance on idle computing resources to participate in I/O operations. While this approach can lead to performance gains, these gains diminish as the number of threads allocated for foreground I/O operations increases. As discussed in Section 5.2, as a large number of threads are allocated for foreground I/O operations, contention for acquiring lock to become the leader thread becomes significant. To address this issue, our scheme could be enhanced by incorporating lock-free data structures and operations using atomic instructions, as introduced in [16].
For future work, our scheme has the potential to be extended to applications that intermittently require a large amount of I/O operations within a short period. For example, in log-structured file systems, the garbage collection process is triggered when free space falls below a certain threshold. During garbage collection, valid data must be read, and space occupied by invalid data must be reclaimed, both of which demand numerous I/O operations. Additionally, other operations are typically stalled while garbage collection is performed. Our scheme could reduce stall time by utilizing idle resources to assist in garbage collection within multi-core systems, thereby improving overall system efficiency.
7. Conclusions
In this paper, we propose a multi-threaded I/O operation scheme for KV stores to improve performance. Our analysis reveals that the main cause of performance degradation is the lack of scalability in handling I/O operations. While multiple threads are allocated to manage foreground I/O operations, only a single thread performs these tasks, forcing all other threads to wait until this operation is completed, which significantly hinders overall system performance. To address this issue, we utilize idle computing resources to accelerate I/O operations. Specifically, we engage these idle threads to perform background I/O operations that would otherwise delay the execution of foreground tasks. In this way, we effectively reduce the waiting time and increase the efficiency of the I/O handling process.
Previous studies [14,15,16,17,18] have also attempted to enhance performance by increasing parallelism through the use of idle computing resources. These studies have mainly focused on file systems within operating systems, meaning that their performance improvements are only realized when operating within such systems. Although the potential benefits of the proposed scheme may be limited in resource-constrained systems, our study leverages idle resources allocated at the application level, allowing the proposed method to achieve performance gains without being constrained by the underlying system architecture. Our experimental results demonstrate that the proposed scheme improves the KV store performance by up to 16% compared to the existing KV store.
Author Contributions
Conceptualization, S.K. and H.K.; methodology, S.K. and H.K.; software, H.K.; validation, H.K.; formal analysis, S.K. and H.K.; investigation, S.K. and H.K.; resources, S.K. and H.K.; data curation, S.K. and H.K.; writing—original draft preparation, S.K.; writing—review and editing, H.K.; visualization, S.K. and H.K.; supervision, H.K.; project administration, H.K.; funding acquisition, H.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (No. RS-2023-00240734).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Marmol, L.; Sundararaman, S.; Talagala, N.; Rangaswami, R.; Devendrappa, S.; Ramsundar, B.; Ganesan, S. NVMKV: A Scalable and Lightweight Flash Aware Key-Value Store. In Proceedings of the 6th USENIX Workshop on Hot Topics in Storage and File Systems, Philadelphia, PA, USA, 17–18 June 2014. [Google Scholar]
- Drolia, U.; Mickulicz, N.; Gandhi, R.; Narasimhan, P. Krowd: A key-value store for crowded venues. In Proceedings of the 10th International Workshop on Mobility in the Evolving Internet Architecture, Paris, France, 7 September 2015; pp. 20–25. [Google Scholar]
- Chen, H.; Ruan, C.; Li, C.; Ma, X.; Xu, Y. SpanDB: A fast, Cost-Effective LSM-tree based KV store on hybrid storage. In Proceedings of the 19th USENIX Conference on File and Storage Technologies, Online, 23–25 February 2021; pp. 17–32. [Google Scholar]
- Lu, Z.; Cao, Q.; Jiang, H.; Wang, S.; Dong, Y. p2kvs: A portable 2-dimensional parallelizing framework to improve scalability of key-value stores on ssds. In Proceedings of the Seventeenth European Conference on Computer Systems, Rennes, France, 5–8 April 2022; pp. 575–591. [Google Scholar]
- Zhao, J.; Pan, Y.; Zhang, H.; Lin, M.; Luo, X.; Xu, Z. InPlaceKV: In-place update scheme for SSD-based KV storage systems under update-intensive Worklaods. Clust. Comput. 2024, 27, 1527–1540. [Google Scholar] [CrossRef]
- Yan, B.; Zhu, J.; Jiang, B. Limon: A Scalable and Stable Key-Value Engine for Fast NVMe Devices. IEEE Trans. Comput. 2023, 72, 3017–3028. [Google Scholar] [CrossRef]
- Yu, J.; Noh, S.H.; Choi, Y.R.; Xue, C.J. ADOC Automatically Harmonizing Dataflow Between Components in Log-Structured Key-Value Stores for Improved Performance. In Proceedings of the 21st USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 21–23 February 2023; pp. 65–80. [Google Scholar]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 2008, 26, 4. [Google Scholar] [CrossRef]
- Lakshman, A.; Malik, P. Cassandra: A decentralized structured storage system. ACM SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Im, J.; Bae, J.; Chung, C.; Lee, S. PinK: High-speed In-storage Key-value Store with Bounded Tails. In Proceedings of the 2020 USENIX Annual Technical Conference, Online, 15–17 July 2020; pp. 173–187. [Google Scholar]
- Koo, J.; Im, J.; Song, J.; Park, J.; Lee, E.; Kim, B.S.; Lee, S. Modernizing file system through in-storage indexing. In Proceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation, Online, 14–16 July 2021; pp. 75–92. [Google Scholar]
- Zhang, Y.; Zhou, J.; Min, X.; Ge, S.; Wan, J.; Yao, T.; Wang, D. PetaKV: Building Efficient Key-Value Store for File System Metadata on Persistent Memory. IEEE Trans. Parallel Distrib. Syst. 2022, 34, 843–855. [Google Scholar] [CrossRef]
- Cai, T.; Chen, F.; He, Q.; Niu, D.; Wang, J. The matrix KV storage system based on NVM devices. Micromachines 2019, 10, 346. [Google Scholar] [CrossRef] [PubMed]
- Lu, L.; Zhang, Y.; Do, T.; Al-Kiswany, S.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. Physical Disentanglement in a {Container-Based} File System. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 81–96. [Google Scholar]
- Kang, J.; Zhang, B.; Wo, T.; Yu, W.; Du, L.; Ma, S.; Huai, J. SpanFS: A scalable file system on fast storage devices. In Proceedings of the 2015 USENIX Annual Technical Conference, Santa Clara, CA, USA, 8–10 July 2015; pp. 249–261. [Google Scholar]
- Son, Y.; Kim, S.; Yeom, H.Y.; Han, H. High-performance transaction processing in journaling file systems. In Proceedings of the 16th USENIX Conference on File and Storage Technologies, Oakland, CA, USA, 12–15 February 2018; pp. 227–240. [Google Scholar]
- Bhat, S.S.; Eqbal, R.; Clements, A.T.; Kaashoek, M.F.; Zeldovich, N. Scaling a file system to many cores using an operation log. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 69–86. [Google Scholar]
- Liao, X.; Lu, Y.; Xu, E.; Shu, J. Max: A {Multicore-Accelerated} File System for Flash Storage. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 21), Online, 14–16 July 2021; pp. 877–891. [Google Scholar]
- Borthakur, D. Under the Hood: Building and Open-Sourcing RocksDB. Facebook Engineering Notes. 2013. Available online: https://engineering.fb.com/2013/11/21/core-infra/under-the-hood-building-and-open-sourcing-rocksdb/ (accessed on 16 July 2024).
- A Library That Provides an Embeddable, Persistent Key-Value Store for Fast Storage. Available online: https://github.com/facebook/rocksdb (accessed on 16 July 2024).
- Wu, S.M.; Lin, K.H.; Chang, L.P. KVSSD: Close integration of LSM trees and flash translation layer for write-efficient KV store. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition, Dresden, Germany, 19–23 March 2018; pp. 563–568. [Google Scholar]
- Lee, C.G.; Kang, H.; Park, D.; Park, S.; Kim, Y.; Noh, J.; Chung, W.; Park, K. iLSM-SSD: An intelligent LSM-tree based key-value SSD for data analytics. In Proceedings of the 2019 IEEE 27th International Symposium on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS), Rennes, France, 21–25 October 2019; pp. 384–395. [Google Scholar]
- Lu, L.; Pillai, T.S.; Gopalakrishnan, H.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. Wisckey: Separating keys from values in ssd-conscious storage. ACM Trans. Storage (TOS) 2017, 13, 1–28. [Google Scholar] [CrossRef]
- Zuo, P.; Hua, Y.; Wu, J. Write-optimized and high-performance hashing index scheme for persistent memory. In Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2018; pp. 461–476. [Google Scholar]
- Chandramouli, B.; Prasaad, G.; Kossmann, D.; Levandoski, J.; Hunter, J.; Barnett, M. FASTER: A concurrent key-value store with in-place updates. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 275–290. [Google Scholar]
- Liu, L.; Wang, H.; Zhou, K. An optimized implementation for concurrent LSM-structured key-value stores. In Proceedings of the 2018 IEEE International Conference on Networking, Architecture and Storage, Chongqing, China, 11–14 October 2018; pp. 1–8. [Google Scholar]
- Sun, X.; Yu, J.; Zhou, Z.; Xue, C.J. FPGA-based compaction engine for accelerating LSM-tree key-value stores. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering, Dallas, TX, USA, 20–24 April 2020; pp. 1261–1272. [Google Scholar]
- Intel. SPDK: Storage Performance Development Kit. Available online: https://spdk.io/ (accessed on 16 July 2024).
- Meta Platforms, Inc. RocksDB|A Persistent Key-Value Store|RocksDB. Available online: https://rocksdb.org/ (accessed on 16 July 2024).
- Guz, Z.; Li, H.H.; Shayesteh, A.; Balakrishnan, V. NVMe-over-fabrics performance characterization and the path to low-overhead flash disaggregation. In Proceedings of the 10th ACM International Systems and Storage Conference, Haifa, Israel, 22–24 May 2017; p. 16. [Google Scholar]
- Zion, I.B. Key-value FTL over open channel SSD. In Proceedings of the 12th ACM International Conference on Systems and Storage, Haifa, Israel, 3–5 June 2019; p. 192. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).