1. Introduction
Sentiment classification is a classic research topic in natural language processing (NLP), with promising application and research prospects. For instance, sentiment polarity analysis of product and service reviews can help businesses identify and resolve problems, enhancing user experience. It can also serve as a tool for public sentiment monitoring, analyzing people’s comments on specific events to understand their emotional reactions and respond accordingly. Additionally, sentiment analysis can be used for mental health monitoring, helping individuals track their emotional state and detect mental disorders. In the field of chatbots, this technology can assist robots to promptly capture the emotions of interlocutors, facilitating deeper human–machine conversations. Furthermore, sentiment analysis can be applied in cross-cultural communication, reducing misunderstandings caused by cultural differences and enhancing communication and comprehension among people in a multilingual environment.
An effective sentiment classification system must be able to predict the sentiment polarity of a text quickly and accurately, such as negative, neutral, or positive. Some previous research has treated sentiment classification as a general text classification task and utilized classic classification methods. Many methods based on statistics [
1,
2], dictionary and rule-based [
3,
4], as well as shallow machine learning models [
5,
6] provide solutions for this task. In recent years, deep learning has attracted widespread attention, and three typical frameworks, namely convolutional neural networks (CNNs) [
7], recurrent neural networks (RNNs) [
8], and transformers [
9], have also shown their abilities in this task. However, sentiment classification is different from other text classification tasks. It is a domain-specific issue. This implies that the same expression can convey different sentiment polarities or effects across domains. For instance, the word “simple” may serve as a synonym for “not rich” and “handy” when describing breakfasts in a hotel and the use of an electrical appliance, respectively. Even the same meaning can have varying sentiments across different domains. For the sentence “This skirt is very beautiful, but the camera on my phone is subpar”, it’s positive in the clothing domain, but negative in the phone domain. One simple method to resolve this issue is to train domain-specific classifiers for different domains. Nonetheless, they frequently require a large number of labeled samples to ensure satisfactory performance. In addition, it is impractical to create a sufficient labeled sample set for each domain.
Thus, some studies have started to explore how to leverage data from multiple domains to improve the classification accuracies of domain-specific sentiment classifiers. Multi-task learning, which can achieve mutual benefits from different tasks by learning them together, offers fresh prospects to this matter. By simultaneously training multiple domain-specific classifiers, a number of models extract both shared and domain-specific features for sentiment classification. These methods can be roughly divided into two categories. One category uses independent components to learn shared and domain-specific features [
10], like a neural network containing a shared layer and other task-specific layers. The other category uses a general model structure [
11], such as a neural network used to generate a feature pool and then attention or other techniques applied to extract the features required for domain-specific sentiment classification from the pool.
Although the aforementioned methods are efficient, we observe that they only concentrate on domain-related features and cannot directly model the relative importance of the features. In fact, this is essential for sentiment classification, particularly when a sentence contains descriptions from multiple aspects and the corresponding polarities are inconsistent. Consider the following three reviews:
“The food at this restaurant is delicious and reasonably priced.”
“This restaurant has poor service and an unpleasant atmosphere.”
“The food at this restaurant is delicious and reasonably priced, but the service and atmosphere are poor. Overall, you can give it a try.”
The first review is obviously positive, because it has the words “delicious” and “reasonably priced”. The second review is negative, because neither the service nor the atmosphere are satisfactory. For the third review, if we only notice the first sentence, it may be difficult to determine its polarity. This is because it includes inconsistent polarity among the service, environment, taste, and price. However, when we see the final sentence “Overall, you can try it”, we know this customer recommends the restaurant, regardless of what was said earlier, which indicates that some sentiment information is more important than others. Inspired by this observation, we design a novel attention neural network that can automatically choose the crucial information, such as the final sentence of the third review. In contrast to reviews with consistent polarity, reviews with inconsistent polarity are common in natural language corpora and are always a challenge for sentiment classification.
To further model the relative importance of domain-related sentiment features, we constructed an attention-pooling neural network for multi-domain sentiment classification(AP-MDSC). It consists of two core components: an attention weight matrix composed of feature-wise gates, and a min-pooling layer over the attention weight matrix. On the Amazon multi-domain sentiment analysis dataset, the effectiveness of our proposed model and other traditional sentiment classification classifiers is evaluated.
The following are our main contributions:
- (1)
proposing an attention mechanism for multi-domain sentiment classification to take both the relative importance of features and the influence of the domain information into account, and expanding the set of existing attention mechanisms.
- (2)
integrating attention with min-pooling to generate sharp probabilistic attention weights over words in a sentence to select salient features. To the best of our knowledge, the constructed model is distinct from other existing attention neural networks.
- (3)
According to our experimental results, our model can obtain better performance on the Amazon sentiment analysis dataset at different scales.
The rest of this article is organized as follows. In the
Section 2, we present some important works in sentiment classification, cutting-edge attention and pooling techniques, and multi-domain scenarios. Then, we provide a detailed introduction of the proposed method, AP-MDSC, in the
Section 3, which consists of the basic framework, attention-pooling technology, and model training approach. The evaluation is conducted in the
Section 4, and the overall work is summarized in the
Section 5.
3. Methods
To directly model the ranking of emotional information, we propose a attention-pooling neural network for multi-domain sentiment classification called AP-MDSC. We will introduce it in two parts: one is a general neural network framework for the sentiment classification task, and the other is a novel attention mechanism with a pooling technique to improve the model performance. It is worth noting that the pooling operation in our model is not performed on the feature maps but on an attention weight matrix, and instead of using conventional max pooling and mean pooling, min pooling is employed. Now, we offer an overview of the model architecture and the attention mechanism proposed.
3.1. Overall Framework
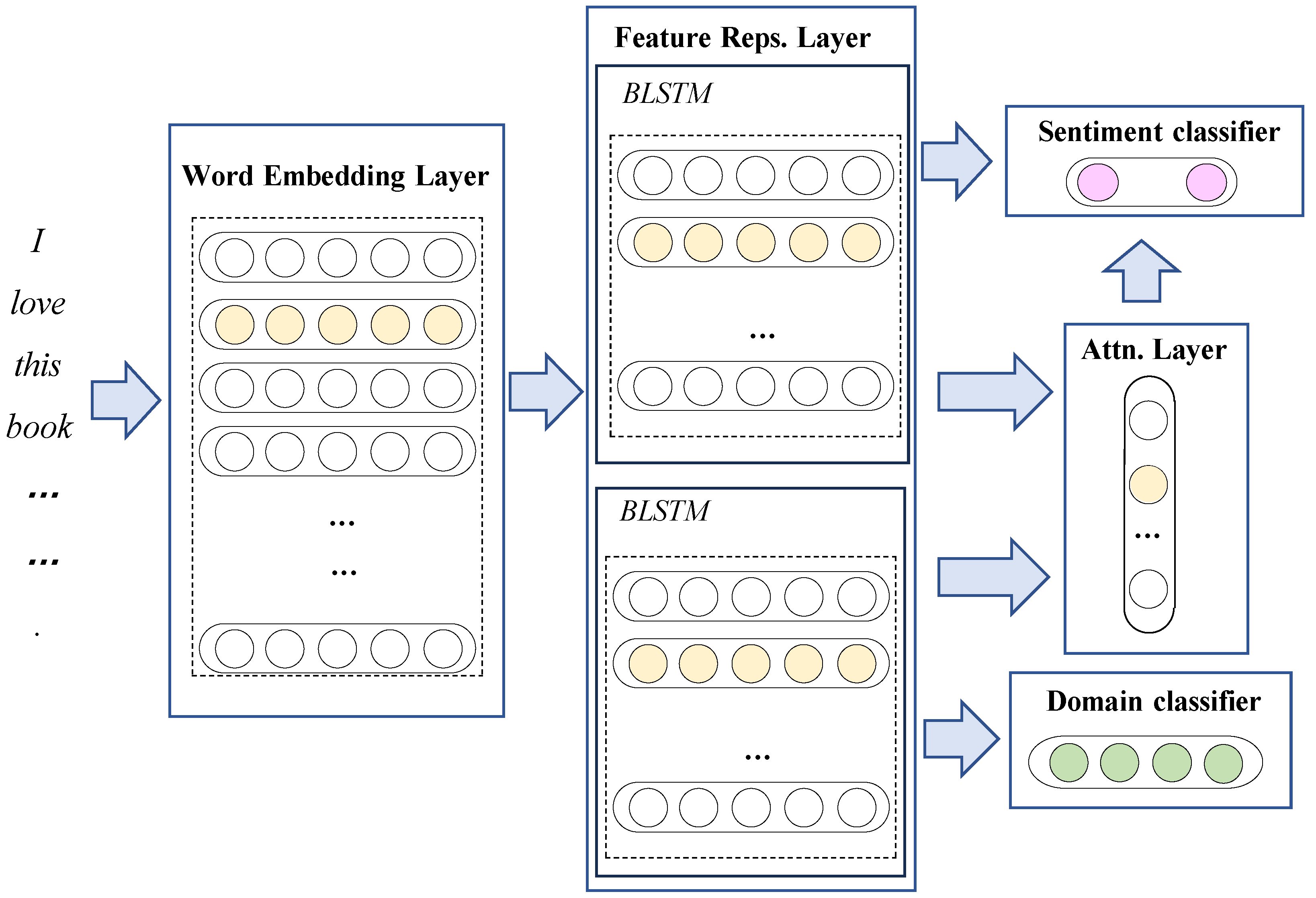
We adopt the general framework illustrated in
Figure 1 to accomplish the multi-domain sentiment classification task, which is composed of four components: a word-embedding layer, domain feature representation and sentiment feature layers, an attention layer, and domain and sentiment classifiers.
Word-embedding layer:converting words into dense vector representations to reflect semantic and syntactic information between words.
Feature representation layer: generating domain features and sentiment features from the obtained word embeddings for domain and sentiment classification.
Attention layer: deciding how to extract the features required for the target task, which is a critical mechanism for the attention neural network and directly affects the model performance.
Classifiers: categorizing input data into predefined domain and sentiment classes based on learned features.
Specifically, we assume that the one-hot vector representations of an input text are represented as
. Initially,
X is passed through the word-embedding layer to produce a set of embedding vectors,
,
, and
.
A is the word-embedding matrix, where
D and
V represent the dimension of the word embedding and the size of the dictionary, respectively. Then, the word-embedding vectors are conveyed to a domain module. In the domain module, inputs are transformed into context-aware vector representations via a bidirectional LSTM (BiLSTM) [
39] layer, which can be expressed by the following formulae:
where
are hidden states consisting of the forward states
and backward states
from BiLSTM. The internal structure of a cell in LSTM is described by the following formulae:
In the formulae above,
,
, and
denote the forget gate, the input gate, and the output gate, which are used to regulate the influence of historical inputs and the current input, as well as the current information output at time
i, respectively, according to the previous hidden state
and present word embbeding
.
and
are referred to as the unit state.
denotes the sigmoid function.
v and
b with different subscripts represent the projection matrix and the bias, respectively. At this point, the domain representation of the input text
is the last hidden state of the input text, and it is converted to a probability distribution on the domain labels, which is as follows:
where
is the mapping of
into a predicted domain label
.
Then, the word embeddings and the domain representation are fed into another BiLSTM and the attention layer in the sentiment module. The word embeddings are converted into context-aware hidden states
via the BiLSTM, and then the hidden states and the domain representation interact to produce attention weights
at the attention layer as follows:
where
f is a fusion function. It is defined as a linear projection in DAM. Our work proposes a new method of information interaction, which will be thoroughly introduced in the next subsection. Once
has been determined, the weighted sum over
, which also represents the text vector
v, is calculated as follows:
Finally, another mapping function
is used to predict a sentiment label
according to the text representation, i.e.,
3.2. Proposed Attention Mechanism
According to our analysis, when there is a conflict in the polarity of emotional information within a sentence, the relative importance of these conflicting emotions is crucial for determining the overall polarity of the sentence. To fit this relationship, we propose an attention mechanism distinguished from other works. This mechanism uses an attention weight matrix to store the relative importance scores between input elements and then employs pooling techniques to select the attention distribution over each element.
Figure 2 shows the attention generation process in this mechanism.
First, on the input text domain representation
generated in the domain module and the hidden states
H generated in the sentiment module, an attention matrix is created that reflects the relative importance of the input elements. This is obtained by comparing the elements at each moment with those at other moments, which is expressed as follows:
where
f,
and
correspond to one-layer feed-forward neural networks that are used to merge domain information with hidden states at all time steps.
and
are concatenated with
to form domain-aware hidden states at times
i and
j, respectively, then the hidden state at time
i is used as the key point and compared with the hidden state at time
j to generate a gate
. Ideally, this value should be 0 or 1 to indicate whether
i is selected after comparison. In our method, the activation function in
f is set to Sigmoid to complete this function. After each hidden state is compared with other hidden states, a matrix
is generated.
However, we note that in our method, the values in S are subject to a significant restriction; that is, the sum of and must be equal to 1, because if the th element is selected between the th element and the th element, then the th element cannot be selected, and vice versa.
Accordingly, we assume that there are two triangular mask matrices,
and
, which are expressed as follows:
Next, the attention matrix is updated as follows:
where
is the updated attention matrix,
S and
are the initial attention matrix and its transpose,
J is the all-ones matrix, and · denotes element-wise multiplication. Through the above transformation, it can be ensured that in matrix
U, the sum of
and
is equal to 1, except for the elements on the diagonal.
After that,
U passes through a min-pooling layer and a Softmax layer to generate the attention probability distribution
. This step is crucial for our method, because the min-pooling layer is used to achieve the function of “if one element cannot be more significant than others, it will not be the focus of attention”. When using other pooling layers such as a max-pooling layer or a mean pooling layer, this function is difficult to implement. The process is expressed in the following formula:
where min-pooling is performed on the first dimension of the matrix to determine the importance of the
th element, represented by the attention weight
. It is converted to
through a Softmax transformation.
Afterward, we can use Formulas (12) and (13) to calculate the input text features required for sentiment classification and complete this task accordingly.
3.3. Training
In our model, the objective function is a linear combination of the loss functions of sentiment classification and domain classification. We suppose there are
K domains, with each containing
N samples. The objective function is expressed as follows:
where
represents all inputs and parameters;
and
denote the true sentiment label and domain label, respectively, of the
th sample in the
th domain; and
and
correspond to the predicted sentiment label and domain label, respectively. The cross-entropy loss function is denoted by
L. Because the primary task is sentiment classification and the auxiliary task is domain classification,
is introduced to control the participation rate of the domain classification task.
4. Experiments
In this section, we evaluate the performance of the proposed model on the Amazon multi-domain sentiment analysis dataset and compare it to other multi-domain sentiment analysis methods.
4.1. Experimental Settings
Datasets: the Amazon dataset provided by Blitzer et al. is a public English sentiment analysis dataset containing over 20 domains. We focus on four domains, namely books, DVDs, kitchen, and electronics, and we use 1000 positive samples (labelled as 1) from positive.reviews and 1000 negative samples (labelled as 0) from negative.reviews in each domain for our experiments. The selected labeled samples in each domain are randomly divided into training data, validation data, and testing data in a 7:2:1 ratio.
Table 1 displays the statistics of the datasets. Because some sentences in the Amazon dataset are too long, we set a length threshold so that the part of the sentence that exceeds this threshold is truncated.
Implementation details: The experiments were conducted on a computer equipped with an Intel Core i7 processor, 64 GB of RAM (Santa Clara, CA, USA), and a NVIDIA GeForce RTX 1080 GPU (Santa Clara, CA, USA) running on the Ubuntu operating system (v.24.04). The Python language was employed for programming, the data were processed with the NumPy and NLTK libraries, and our models were built using the Keras platform (v.3.4.1) for all experiments.
For training, an adaptive learning rate method (ADADELTA) [
40] is selected to update the parameters in AP-MDSC, and the initial learning rate is set to 0.1. If the validation loss does not improve after 3 epochs of training, the learning rate is reduced. Simultaneously, if the loss cannot be reduced further within 5 epochs, early stopping is implemented. Considering the overfitting problem, the word-embedding and output layers utilize a dropout layer with a rate of 0.2. The dimension of the hidden states is 100, and the batch size is 64. For the Amazon dataset, 300D Glove [
41] pretrained vectors are used as initial word-embedding vectors for words in the Glove dictionary; otherwise, randomly initialized embedding vectors are employed. Each experiment is carried out 10 times, and the average accuracy is recorded.
Baselines: We compare the proposed AP-MDSC with the classic supervised sentiment classification methods in a single domain and across all domains, including least squares (LS-single, LS-all), support vector machine (SVM-single, SVM-all),and LSTM methods (LSTM-single, LSTM-all). Considering that our model is based on multi-domain data, some typical multi-task learning methods are also compared, including MTL-DNN, MTL-CNN, MTL-SM, MDSC-Com, RMTL, MTL-Graph, CSMC, AP-MTL, NeuroSent, and DAM. To further investigate the model’s performance on datasets composed of varying domains, we have also defined the DMA-x and AP-MDSC-x series models, where x denotes the number of domains on which the model is trained and tested. For instance, when x equals 2, the model utilizes data from the book and DVD domains, and so on. If experiments are conducted on the classic four domains (books, DVDs, kitchen, electronics, and music), we can also use DAM and AP-MDSC to denote these setups.
4.2. Performance Evaluation
Table 2 summarizes the experimental results of our model and baseline models trained on the Amazon dataset.
A detailed analysis of the results can be given as follows:
(1) AP-MDSC versus traditional sentiment classification models: It is shown in
Table 2 that our model obtains significant improvements compared to all single-domain sentiment classification methods, including LS-single, SVM-single, and LSTM-single. We speculate that the main reason is that those models only use single-domain data for training and cannot acquire general knowledge from other datasets. Compared to sentiment classification models that use all domain data indiscriminately, such as LS-all, SVM-all, and LSTM-all, our model achieves higher classification accuracy across all domains. This is because, although the models can gain general knowledge from a larger set of training data, they do not leverage domain information to filter out the sentiment features required for specific domains.
(2) AP-MDSC versus other multi-task learning models: As shown in
Table 2, our model outperforms other multi-task-based models, whether in terms of performance within a single domain or the average performance across the entire dataset, except for DAM. According to the analysis of DAM, these multi-task-based methods have various shortcomings, such as not fully considering the relationships between different domains or ignoring shared sentiment knowledge, while DAM can extract domain-related features from a shared feature pool at the feature level using domain attention, reducing the need to design a specific layer for each task. In contrast to DAM, although AP-MDSC does not achieve the best performance in all domains, it can achieve the best overall performance. This suggests that our proposed approach can improve multi-domain sentiment classification by simulating the ranking of the elements in the input text. Overall, the experimental results show that AP-MDSC is a powerful multi-domain sentiment classification algorithm.
4.3. Comparative Experiments in Datasets with Different Domains
To further verify the performance of our model, we compare the performance of AP-MDSC and DAM on different numbers of domains.
Table 3 presents their average sentiment classification accuracies as the number of domains increases from two to five (books, DVDs, kitchen, electronics, and music).
As shown in
Table 3, both DAM and AP-MDSC generally perform better as the number of domains increases. As previously discussed, the expansion of domains can provide more shared knowledge in most cases. In addition, the average classification accuracy of AP-MDSC is higher than that of DAM, regardless of the number of domains. These results demonstrate that the attention mechanism used in AP-MDSC can effectively use the ranking of elements to obtain salient sentiment features. However, we also observed that as the number of domains increases, the performance advantage of AP-MDSC decreases. We believe that for multi-task learning problems such as multi-domain sentiment analysis, an increase in the number of domains can lead to more conflicts between tasks, to which AP-MDSC is particularly sensitive. This is a topic worthy of study, and we plan to explore it in future work.
4.4. Pooling Techniques
According to our analysis in the third section, using min-pooling in AP-MDSC can help extract significant features for sentiment classification, which is different from the more general use of max-pooling and mean-pooling in many other attention models.
Table 4 shows the testing accuracy of the AP-MDSC model on the Amazon sentiment classification dataset with three different pooling techniques while keeping all other network structures and settings unchanged.
As shown in
Table 4, using the min-pooling layer results in a better performance on the dataset than using the mean-pooling and max-pooling layers. This validates our previous analysis result that when calculating the distribution of attention at each moment in AP-MDSC. If a word is less important than others, it should be given less attention; specifically, the corresponding attention weight should be smaller. Therefore, adopting the min-pooling layer is more reasonable than using the other two pooling layers. The choice of pooling technique is one of the keys to efficiently performing multi-domain sentiment analysis tasks for our model.
4.5. Inverse Events
As mentioned in the previous analysis, we set the sum of
and
to be 1 in the matrix
U in AP-MDSC. This is because in our work,
represents the relative importance of words at time
i and time
j. When a word at time
i is selected, the word at time
j cannot be selected naturally, and vice versa. This is different from other attention models for this task.
Table 4 shows the test accuracy on the dataset when considering inverse events.
As shown in
Table 5, the test accuracy of AP-MDSC (U-limited) is higher than that of AP-MDSC (U-unlimited). This also verifies the rationality of the method our model uses to calculate the matrix
U.
4.6. Computational Costs
The training times of AP-MDSC and DAM during each epoch with an increasing number of domains are shown in
Table 6.
Table 6 shows that as the size of the sample data increases, the training time costs of AP-MDSC and DAM increase gradually. Compared with DAM, the growth of the time cost of AP-MDSC during each epoch is slight, never exceeding 10%. Given the improvement in classification precision, we regard AP-MDSC as a good multi-domain sentiment classification model.
4.7. Visualization of Attention Weights
Figure 3 shows the distribution of attention weights on a test sample from the DVD domain, which is as follows:
“This is an excellent film, which unfortunately has not been given a decent treatment by the distributor. I was very disappointed in the quality of the release-the picture quality is poor inter-titles appear to be missing, and the score which has been added is just a reptition of long synth chords that don’t match the action on-screen. It’s a shame, because a film like this one deserves much better.”
We mark words with negative emotions in blue, words with positive emotions in red, and randomly generate colors for other words. The sizes of the words are based on the attention weights assigned. The greater the weight, the larger the font size, and vice versa.
Based on
Figure 3, it is clear that, except for the initial position, the most prominent words are the blue word “unfortunately” and the red word “decent”. The most prominent sentence is the first one, followed by the last one. In the first sentence, the emotional words are “unfortunately”, “excellent”, and “decent”. However, it is evident that “excellent”, which describes “film”, is paid relatively less attention by our attention mechanism. This indicates that, by contrasting it with other words in the context, it is judged that “excellent” is not important. Then, there is the contrast between “unfortunately” and “decent”, where an important phrase “not been given” stands between them. Although these words are neutral when taken individually, the model’s context-aware capability allows it to understand the emotional information of “not been given decent treatment” as a whole. Similarly, in the last sentence, the negative emotion word “shame” and the positive emotion word “better” are included, but the understanding of “better” needs to be combined with the context; i.e., “deserves much better.” The large sections of description in the middle are allocated relatively little attention; compared to the first and last sentences, they have less influence on determining the emotional polarity of the review.



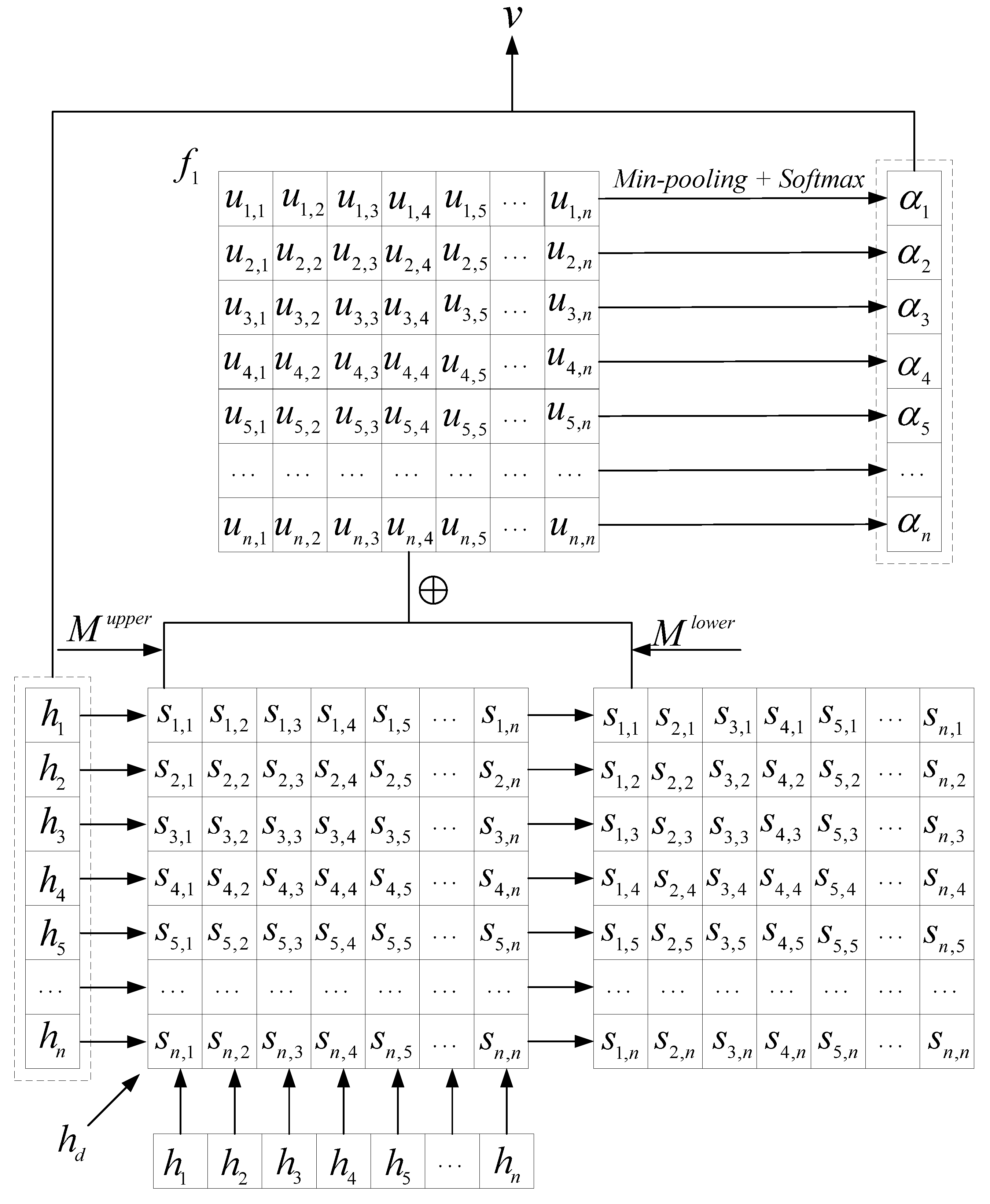


{kind=link}
{kind=link}
{kind=link}