
An Intelligent Real-Time Driver Activity Recognition System Using Spatio-Temporal Features



Abstract
1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Contribution
- We develop a real-time end-to-end deep learning system that synergistically combines TimeDis-CNN and LSTM models to detect drivers’ behavioral patterns in real vehicle settings. Unlike prior studies that heavily depend on complex feature extraction, the proposed system does not require any major pre-processing steps and performs well in a complex and cluttered background environment with reduced computational cost. Moreover, nodding off to sleep and fainting while driving, which are considered to be two of the major leading causes of road traffic accidents, are studied.
- In contrast to most existing works, we also address nighttime recognition in addition to daytime. An important note is that, although the number of drivers decreases substantially at night, the number of traffic accidents occurring at night is significantly higher than during the daytime, and human errors and distractions are involved in most accidents. As such, this work considered thermal IR images to study the driver behavior during nighttime conditions.
- We collect naturalistic adequate datasets to effectively study driver activity and report a real-time implementation system for both day- and nighttime scenarios. The designed end-to-end LRCN model directly works on the raw sequential images received from the RGBDT sensor module and automatically extracts the optimal features to execute the final recognition and detection system.
2. Experiment Setup and Data Collection
2.1. Data Collection
- Non-distracted driving: driving with both hands on the wheel.
- Drinking: the participant drinking a plastic bottle while driving.
- Talking: the driver engages in conversation with the passenger by raising their right arm hand from the wheel.
- Controlling: when a driver is interacting with a navigation system, radio, and dashboard.
- Looking outside: looking completely outside in the left direction while driving.
- Texting: the participant manually dials or writes a text while driving.
- Smoking: smoking while driving.
- Head nodding: when the driver is nodding off to sleep.
- Fainting: corresponds to when the driver’s head and body are completely down.
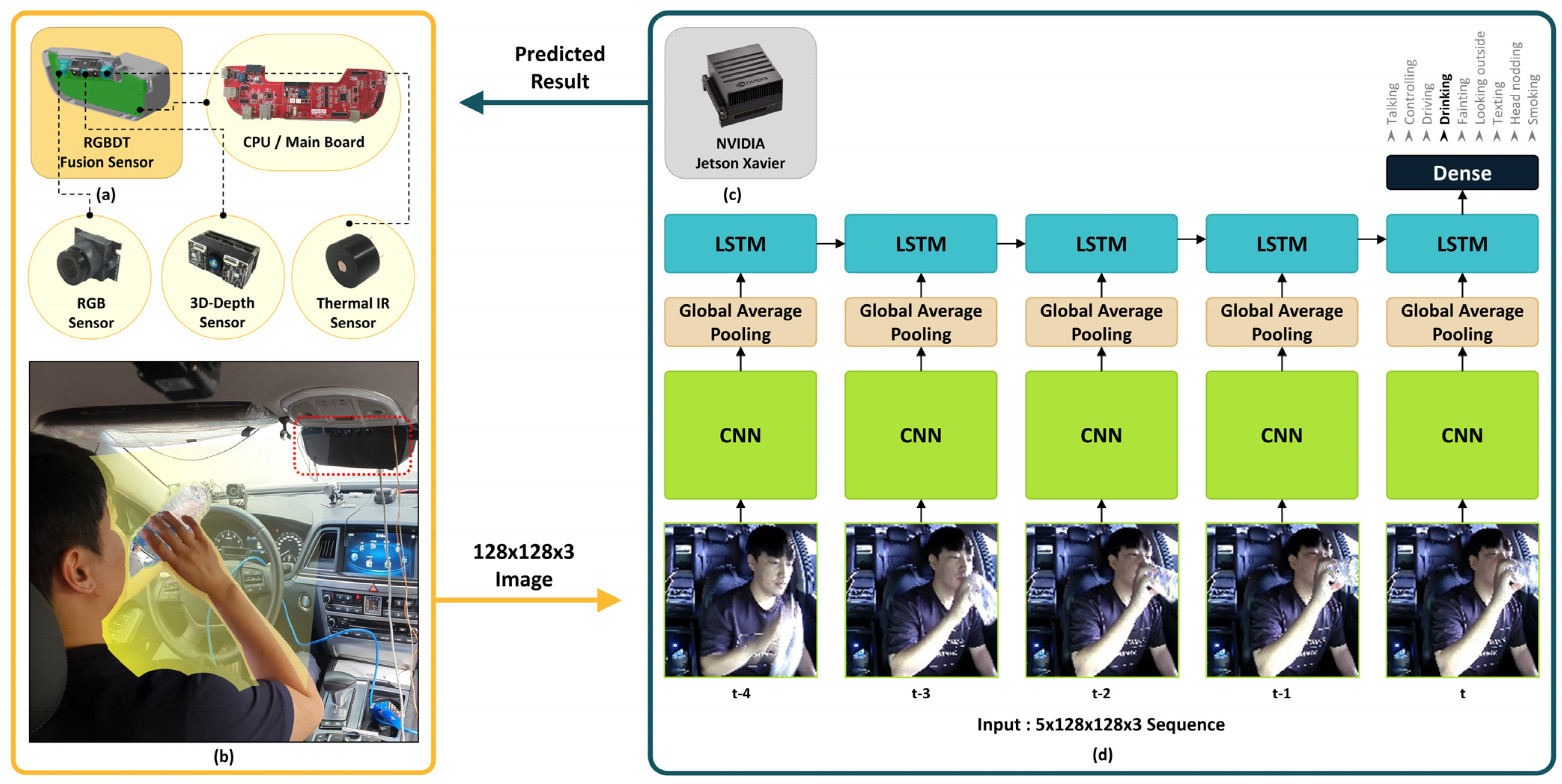
2.2. RGBDT Module Sensor
3. Methodology
3.1. Input Data Pre-Processing
3.2. Proposed Model Framework
3.3. Spatial Feature Extraction
3.4. Long Short-Term Memory Network for Sequence Inputs
3.5. The Designed LRCN Model
3.6. Model Training
3.7. Experiment Environment
4. Results and Evaluation
4.1. Evaluation of the LRCN Model Based on Train–Test Split
4.2. Evaluation of the LRCN Model Based on Seven-Fold Cross Validation
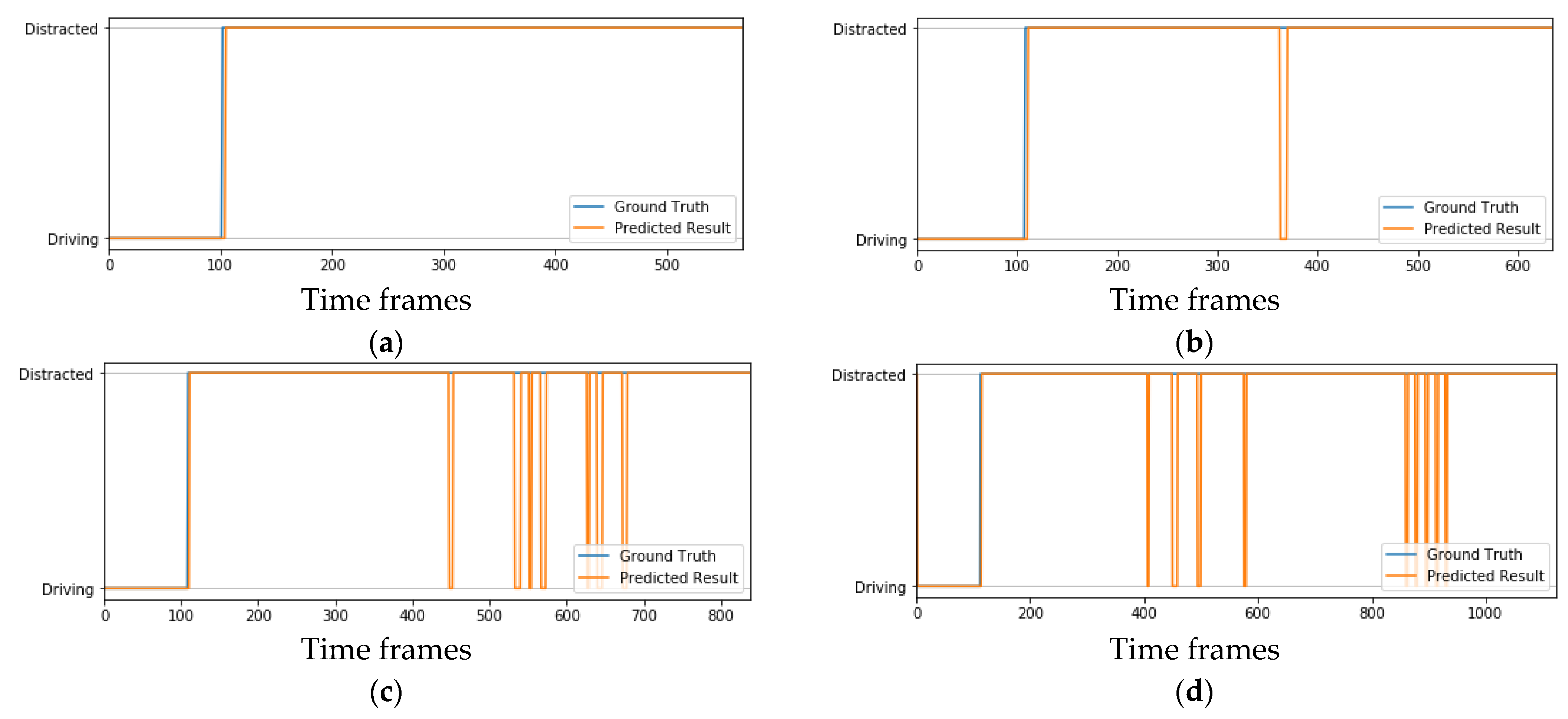
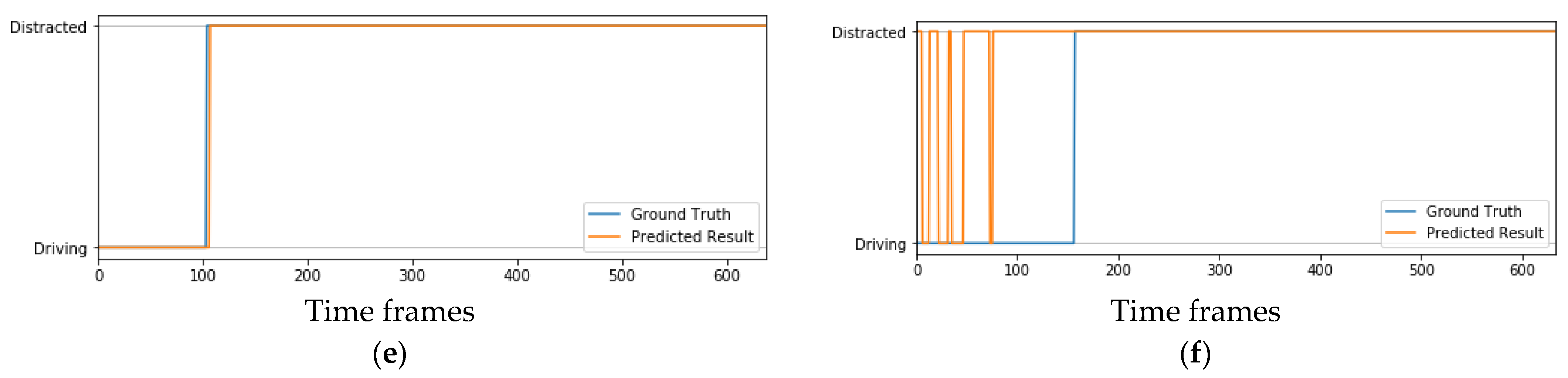
4.3. Binary Driver Distraction Classification
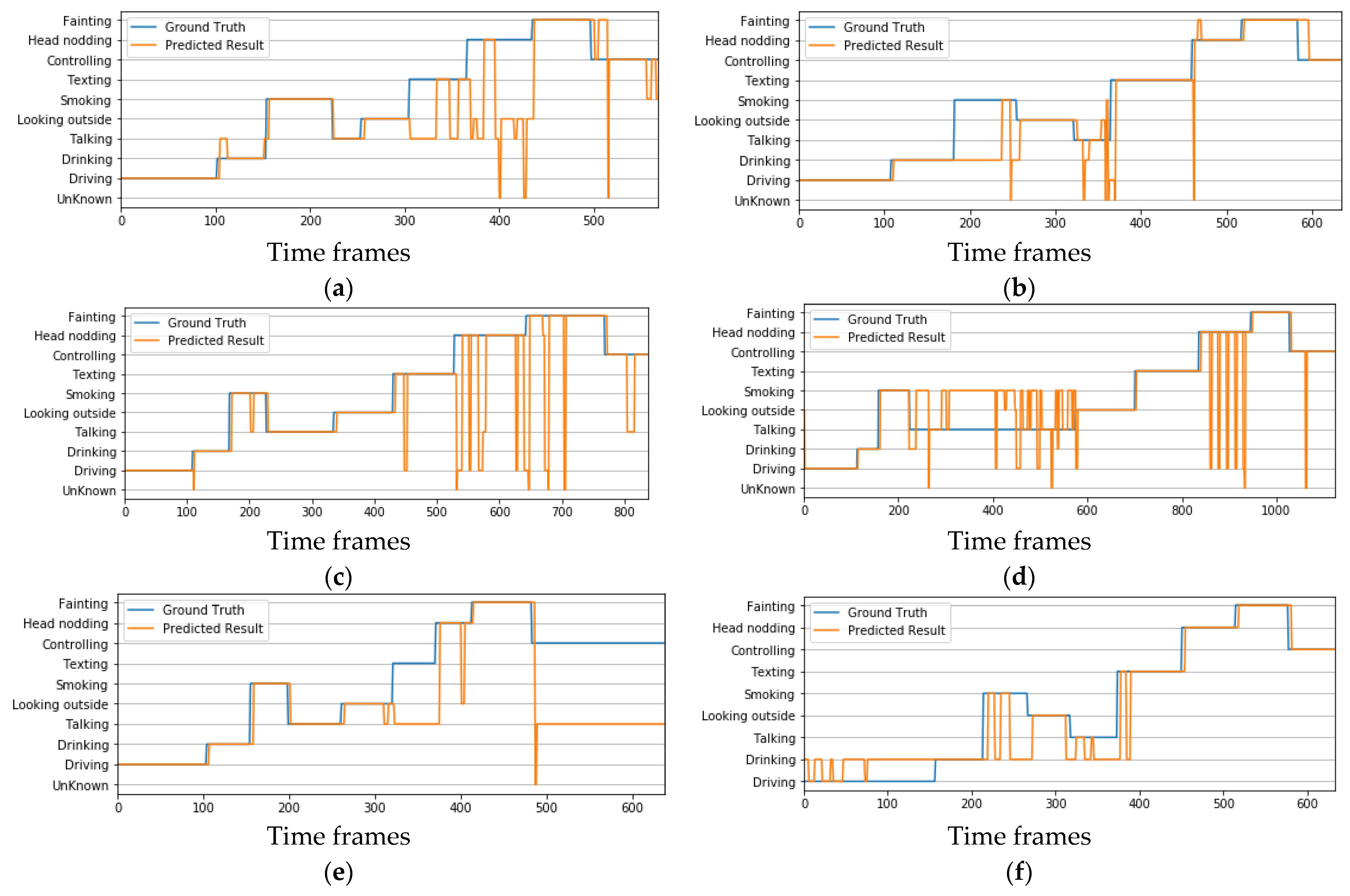
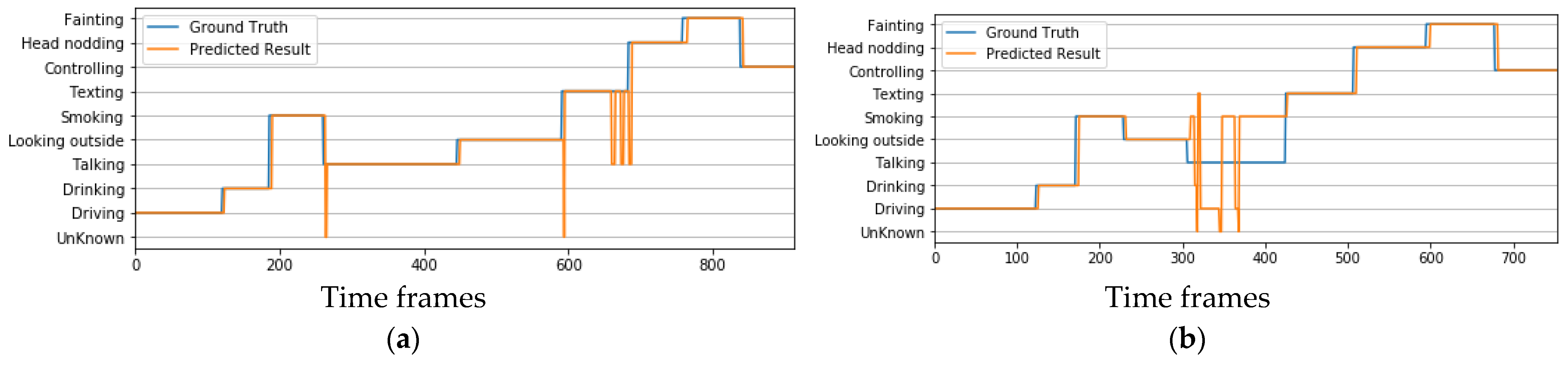
4.4. Real-Time Implementation
4.5. Comparison with Existing Approaches
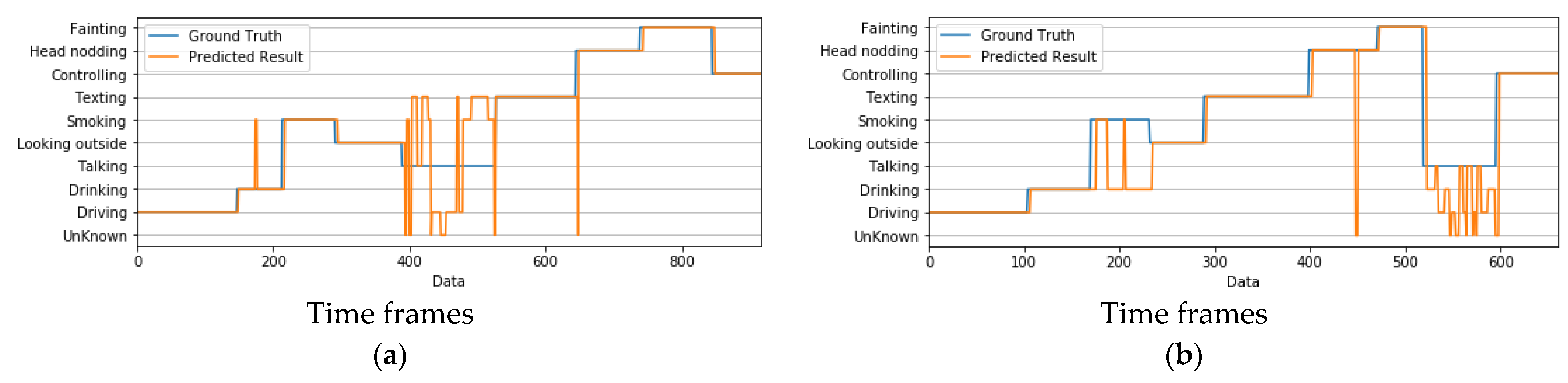
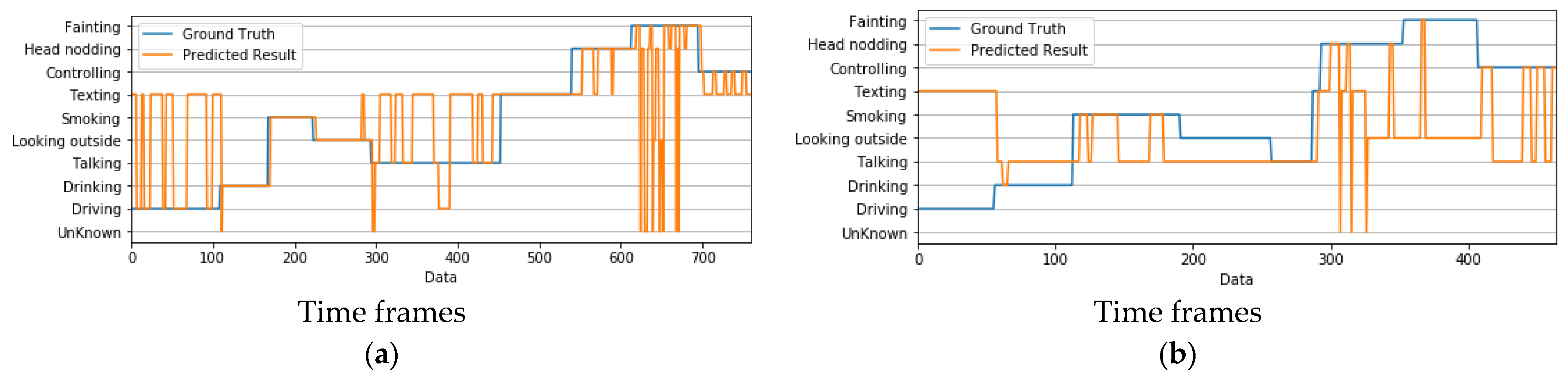
4.6. Failure Analysis of the Proposed System
5. Discussions and Conclusions
5.1. Discussion
5.2. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Trainable Parameter | Feature Memory |
|---|---|---|---|
| Input layer | 0 | 0.24 M | |
| Conv2D 1 | 1792 | 5 M | |
| Conv2D 2 | 36,928 | 5 M | |
| MaxPooling2D | 0 | 1 M | |
| Conv2D 2 | 73,856 | 2.5 M | |
| Conv2D 2 | 147,584 | 2.5 M | |
| MaxPooling2D | 0 | 0.5 M | |
| Conv2D 3 | 295,168 | 1 M | |
| Conv2D 3 | 590,080 | 1 M | |
| Conv2D 3 | 590,080 | 1 M | |
| MaxPooling2D | 0 | 0.32 M | |
| Conv2D 4 | 118,016 | 0.65 M | |
| Conv2D 4 | 2,359,808 | 0.65 M | |
| Conv2D 5 | 2,359,808 | 0.65 M | |
| MaxPooling2D | 0 | 0.8 K | |
| Conv2D 5 | 2,359,808 | 0.1 M | |
| Conv2D 5 | 2,359,808 | 0.1 M | |
| Conv2D 5 | 2,359,808 | 0.1 M | |
| MaxPooling2D | 0 | 40 K | |
| TimeDis | 14,714,688 | 12.5 K | |
| LSTM | 256 | 787,456 | 0.2 K |
| Dense | 1024 | 263,168 | 1 K |
| BN | 1024 | 4096 | 1 K |
| Dropout | 1024 | 0 | 1 K |
| Dense | 512 | 524,800 | 0.5 K |
| BN | 512 | 2048 | 0.5 K |
| Dropout | 512 | 0 | 0.5 K |
| Dense | 9 | 4617 | - |
| Total | - | 16 M | 90 M |
| Number of Frames | Test Accuracy (%) |
|---|---|
| 3 frames | 69.6 |
| 4 frames | 86.7 |
| 5 frames | 88.7 |
| 6 frames | 88.1 |
References
- Road Traffic Injuries. Available online: https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries (accessed on 27 June 2021).
- NHTSA Statistics. Available online: https://www.nhtsa.gov/book/countermeasures-that-work/distracted-driving/understanding-problem (accessed on 27 June 2021).
- Lee, J.D. Dynamics of Driver Distraction: The process of engaging and disengaging. Ann. Adv. Automot. Med. 2014, 58, 24–32. [Google Scholar] [PubMed]
- Vehicle Safety. Available online: https://www.cdc.gov/niosh/motor-vehicle/distracted-driving/index.html (accessed on 29 June 2021).
- Ahlstrom, C.; Kircher, K.; Kircher, A. A Gaze-Based Driver Distraction Warning System and Its Effect on Visual Behavior. IEEE Trans. Intell. Transp. Syst. 2013, 14, 965–973. [Google Scholar] [CrossRef]
- Kang, H.-B. Various approaches for driver and driving behavior monitoring: A review. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013. [Google Scholar]
- Murphy-Chutorian, E.; Trivedi, M.M. Head Pose Estimation and Augmented Reality Tracking: An Integrated System and Evaluation for Monitoring Driver Awareness. IEEE Trans. Intell. Transp. Syst. 2010, 11, 300–311. [Google Scholar] [CrossRef]
- Braunagel, C.; Kasneci, E.; Stolzmann, W.; Rosenstiel, W. Driver-activity recognition in the context of conditionally autonomous driving. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015. [Google Scholar]
- Ohn-Bar, E.; Martin, S.; Tawari, A.; Trivedi, M.M. Head, Eye, and Hand Patterns for Driver Activity Recognition. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 660–665. [Google Scholar]
- Jiménez, P.; Bergasa, L.M.; Nuevo, J.; Hernández, N.; Daza, I.G. Gaze Fixation System for the Evaluation of Driver Distractions Induced by IVIS. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1167–1178. [Google Scholar] [CrossRef]
- Jin, L.; Niu, Q.; Jiang, Y.; Xian, H.; Qin, Y.; Xu, M. Driver Sleepiness Detection System Based on Eye Movements Variables. Adv. Mech. Eng. 2013, 5, 648431. [Google Scholar] [CrossRef]
- Bergasa, L.M.; Nuevo, J.; Sotelo, M.A.; Barea, R.; Lopez, M.E. Real-time system for monitoring driver vigilance. IEEE Trans. Intell. Transp. Syst. 2006, 7, 63–77. [Google Scholar] [CrossRef]
- Singh, H.; Bhatia, J.S.; Kaur, J. Eye tracking based driver fatigue monitoring and warning system. In Proceedings of the India International Conference on Power Electronics 2010 (IICPE2010), New Delhi, India, 28–30 January 2011. [Google Scholar]
- Sigari, M.-H.; Fathy, M.; Soryani, M. A driver face monitoring system for fatigue and distraction detection. Int. J. Veh. Technol. 2013, 2013, 263983. [Google Scholar] [CrossRef]
- Teyeb, I.; Jemai, O.; Zaied, M.; Amar, C.B. A novel approach for drowsy driver detection using head posture estimation and eyes recognition system based on wavelet network. In Proceedings of the IISA, The 5th International Conference on Information, Intelligence, Systems and Applications (IISA), Chania, Greece, 7–9 July 2014. [Google Scholar]
- Jemai, O.; Teyeb, I.; Bouchrika, T.; Ben Amar, C. A Novel Approach for Drowsy Driver Detection Using Eyes Recognition System Based on Wavelet Network. Int. J. Recent Contrib. Eng. Sci. IT (iJES) 2013, 1, 46–52. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, E.; Wang, F.-Y. Driver Activity Recognition for Intelligent Vehicles: A Deep Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 5379–5390. [Google Scholar] [CrossRef]
- Osman, O.A.; Hajij, M.; Karbalaieali, S.; Ishak, S. A hierarchical machine learning classification approach for secondary task identification from observed driving behavior data. Accid. Anal. Prev. 2019, 123, 274–281. [Google Scholar] [CrossRef]
- Mousa, S.R.; Bakhit, P.R.; Ishak, S. An extreme gradient boosting method for identifying the factors contributing to crash/near-crash events: A naturalistic driving study. Can. J. Civ. Eng. 2019, 46, 712–721. [Google Scholar] [CrossRef]
- Bakhit, P.R.; Osman, O.A.; Guo, B.; Ishak, S. A distraction index for quantification of driver eye glance behavior: A study using SHRP2 NEST database. Saf. Sci. 2019, 119, 106–111. [Google Scholar] [CrossRef]
- Ashley, G.; Osman, O.A.; Ishak, S.; Codjoe, J. Investigating Effect of Driver-, Vehicle-, and Road-Related Factors on Location-Specific Crashes with Naturalistic Driving Data. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 46–56. [Google Scholar] [CrossRef]
- Bakhit, P.R.; Guo, B.; Ishak, S. Crash and Near-Crash Risk Assessment of Distracted Driving and Engagement in Secondary Tasks: A Naturalistic Driving Study. Transp. Res. Rec. J. Transp. Res. Board 2018, 2672, 245–254. [Google Scholar] [CrossRef]
- Osman, O.A.; Hajij, M.; Bakhit, P.R.; Ishak, S. Prediction of Near-Crashes from Observed Vehicle Kinematics using Machine Learning. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 463–473. [Google Scholar] [CrossRef]
- Berri, R.A.; Silva, A.G.; Parpinelli, R.S.; Girardi, E.; Arthur, R. A pattern recognition system for detecting use of mobile phones while driving. In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014. [Google Scholar]
- Yan, C.; Coenen, F.; Zhang, B. Driving posture recognition by convolutional neural networks. IET Comput. Vis. 2016, 10, 103–114. [Google Scholar] [CrossRef]
- Ahlstrom, C.; Georgoulas, G.; Kircher, K. Towards a Context-Dependent Multi-Buffer Driver Distraction Detection Algorithm. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4778–4790. [Google Scholar] [CrossRef]
- Yan, S.; Teng, Y.; Smith, J.S.; Zhang, B. Driver behavior recognition based on deep convolutional neural networks. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016. [Google Scholar]
- Majdi, M.S.; Ram, S.; Gill, J.T.; Rodríguez, J.J. Drive-net: Convolutional network for driver distraction detection. In Proceedings of the 2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI), Las Vegas, NV, USA, 8–10 April 2018. [Google Scholar]
- Abouelnaga, Y.; Eraqi, H.M.; Moustafa, M.N. Real-time distracted driver posture classification. arXiv 2017, arXiv:1706.09498. [Google Scholar]
- Zhang, C.; Li, R.; Kim, W.; Yoon, D.; Patras, P. Driver Behavior Recognition via Interwoven Deep Convolutional Neural Nets with Multi-Stream Inputs. arXiv 2018, arXiv:1811.09128. [Google Scholar] [CrossRef]
- Baheti, B.; Gajre, S.; Talbar, S. Detection of distracted driver using convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tran, D.; Do, H.M.; Sheng, W.; Bai, H.; Chowdhary, G. Real-time detection of distracted driving based on deep learning. IET Intell. Transp. Syst. 2018, 12, 1210–1219. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Moyà, G.; Jaume-i-Capó, A.; Varona, J. Dealing with sequences in the RGBDT space. arXiv 2018, arXiv:1805.03897. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Akilan, T.; Wu, Q.J.; Safaei, A.; Huo, J.; Yang, Y. A 3D CNN-LSTM-Based Image-to-Image Foreground Segmentation. IEEE Trans. Intell. Transp. Syst. 2019, 21, 959–971. [Google Scholar] [CrossRef]
- Schmidhuber, J.; Hochreiter, S. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Hinton, G.E. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Celine, C.; Fakhri, K. Driver distraction detection and recognition using RGB-D sensor. arXiv 2015, arXiv:1502.00250. [Google Scholar]
- Li, N.; Carlos, B. Detecting drivers’ mirror-checking actions and its application to maneuver and secondary task recognition. IEEE Trans. Intell. Transp. Syst. 2016, 17, 980–992. [Google Scholar] [CrossRef]
- Liang, Y.; Reyes, M.L.; Lee, J.D. Real-Time Detection of Driver Cognitive Distraction Using Support Vector Machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 340–350. [Google Scholar] [CrossRef]
- Miyaji, M.; Danno, M.; Kawanaka, H.; Oguri, K. Drivers cognitive distraction detection using AdaBoost on pattern recognition basis. In Proceedings of the 2008 IEEE International Conference on Vehicular Electronics and Safety, Columbus, OH, USA, 22–24 September 2008. [Google Scholar]
- Martin, S.; Ohn-Bar, E.; Tawari, A.; Trivedi, M.M. Understanding head and hand activities and coordination in naturalistic driving videos. In Proceedings of the 2014 IEEE Intelligent Vehicles Symposium Proceedings, Dearborn, MI, USA, 8–11 June 2014. [Google Scholar]
- Liang, Y.; Lee, J.D. A hybrid Bayesian Network approach to detect driver cognitive distraction. Transp. Res. Part C: Emerg. Technol. 2014, 38, 146–155. [Google Scholar] [CrossRef]
- Martin, M.; Roitberg, A.; Haurilet, M.; Horne, M.; Reiß, S.; Voit, M.; Stiefelhagen, R. Drive&Act: A Multi-modal Dataset for Fine-grained Driver Behavior Recognition in Autonomous Vehicles. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]








| Model | Test Accuracy (%) |
|---|---|
| TimeDis VGG16+LSTM | 86.53 |
| VGG16 | 77.08 |
| TimeDis ResNet50+LSTM | 77.46 |
| ResNet50 | 65.83 |
| TimeDis MobileNet+LSTM | 78.84 |
| MobileNet | 68.57 |
| TimeDis Xception+LSTM | 73.29 |
| Xception | 70.12 |
| DenseNet169 | 74.65 |
| NASNet-Mobile | 66.92 |
| InceptionResNetV2 | 66.68 |
| Metrics | Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Fold-6 | Fold-7 | Average |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 90.1 | 85.60 | 88.6 | 78.7 | 94.6 | 92.9 | 90.6 | 88.7 |
| Precision (%) | 86.7 | 82.7 | 85.9 | 83.7 | 95.6 | 89.4 | 91.6 | 87.9 |
| Recall (%) | 82.3 | 81.9 | 87.7 | 87.2 | 93.8 | 88.3 | 88.1 | 87.0 |
| F1-Score (%) | 83.5 | 80.1 | 86.2 | 82.8 | 94.6 | 88.6 | 89.4 | 86.5 |
| Metrics | Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Fold-6 | Fold-7 | Average |
|---|---|---|---|---|---|---|---|---|
| Accuracy (%) | 94.9 | 82.9 | 96.7 | 95.3 | 96.4 | 86.9 | 93.8 | 92.4 |
| Precision (%) | 92.9 | 78.2 | 95.9 | 93.7 | 97.2 | 86.4 | 95.3 | 91.4 |
| Recall (%) | 92.6 | 75.2 | 96.3 | 92.7 | 95.9 | 85.0 | 93.4 | 90.2 |
| F1-Score (%) | 92.3 | 74.9 | 96.4 | 92.2 | 96.3 | 84.6 | 94.0 | 90.1 |
| RGB Images | IR Images | |||||
|---|---|---|---|---|---|---|
| Driver State | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Talking | 78.4 | 78.7 | 76.1 | 90.1 | 95.1 | 92.4 |
| Controlling | 85.0 | 87.3 | 83.6 | 95.4 | 96.7 | 95.6 |
| Driving | 95.0 | 87.0 | 89.4 | 98.0 | 98.9 | 98.6 |
| Drinking | 92.4 | 92.1 | 92.3 | 93.9 | 94.6 | 93.7 |
| Fainting | 86.4 | 84.4 | 84.3 | 89.1 | 84.9 | 86.0 |
| Looking outside | 86.9 | 88.7 | 87.4 | 94.6 | 99.1 | 96.6 |
| Texting | 93.1 | 96.3 | 94.7 | 98.3 | 93.0 | 95.3 |
| Head nodding | 84.7 | 81.1 | 81.7 | 82.7 | 75.0 | 77.4 |
| Smoking | 89.4 | 88.1 | 88.6 | 81.3 | 74.1 | 75.7 |
| Image Type | Fold-1 | Fold-2 | Fold-3 | Fold-4 | Fold-5 | Fold-6 | Fold-7 | Average | |
|---|---|---|---|---|---|---|---|---|---|
| RGB Images | Driving | 98.9 | 85.8 | 88.7 | 45.0 | 99.0 | 97.9 | 92.6 | 86.8 |
| Distracted | 96.2 | 96.5 | 98.4 | 99.8 | 97.1 | 98.3 | 96.5 | 97.7 | |
| Average | 97.4 | 91.1 | 95.5 | 83.3 | 97.5 | 98.1 | 95.1 | 93.9 | |
| IR Images | Driving | 96.1 | 98.4 | 100.0 | 98.5 | 99.2 | 100.0 | 100.0 | 98.9 |
| Distracted | 99.6 | 98.8 | 99.8 | 99.7 | 99.2 | 99.9 | 100.0 | 99.6 | |
| Average | 99.1 | 98.7 | 99.9 | 99.5 | 99.3 | 99.9 | 100.0 | 99.2 |
| Approaches | Accuracy | Participants | Platform | Operation | |
|---|---|---|---|---|---|
| Daytime | Nighttime | ||||
| GMM segmentation and transfer learning [17] | Recognition: 81.6% Binary classification: 91.4% | 10 drivers | Real Vehicle | ||
| InterCNN with MobileNet [30] | Recognition: 73.9%—9class, Recognition: 81.66%—5class | 50 drivers | Mockup car (Simulator) | ||
| VGG16 with regularization [31] | Recognition: 96.3% (Train–Test Split) | 31 drivers | Real Vehicle | ||
| AlexNet,VGG16, GoogleNet, and ResNet [33] | Recognition: 86–92% | 10 drivers | Simulator | ||
| AdaBoost classifier and Hidden Markov Model [45] | Recognition: 85.0%, Binary classification: 89.8% | 8 drivers | Simulator | ||
| Modified SVM, KNN, and RUSBoost [46] | Recognition: 66.7~87.7% | 20 drivers | Real Vehicle | ||
| Our proposed model | Recognition: 88.7% for RGB images and 92.4% for night-time datasets. Binary classification: 93.9% for RGB images and 99.2% for nighttime datasets. | 35 drivers | Real Vehicle | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kidu, T.; Song, Y.; Seo, K.-W.; Lee, S.; Park, T. An Intelligent Real-Time Driver Activity Recognition System Using Spatio-Temporal Features. Appl. Sci. 2024, 14, 7985. https://doi.org/10.3390/app14177985
Kidu T, Song Y, Seo K-W, Lee S, Park T. An Intelligent Real-Time Driver Activity Recognition System Using Spatio-Temporal Features. Applied Sciences. 2024; 14(17):7985. https://doi.org/10.3390/app14177985
Chicago/Turabian StyleKidu, Thomas, Yongjun Song, Kwang-Won Seo, Sunyong Lee, and Taejoon Park. 2024. "An Intelligent Real-Time Driver Activity Recognition System Using Spatio-Temporal Features" Applied Sciences 14, no. 17: 7985. https://doi.org/10.3390/app14177985
APA StyleKidu, T., Song, Y., Seo, K.-W., Lee, S., & Park, T. (2024). An Intelligent Real-Time Driver Activity Recognition System Using Spatio-Temporal Features. Applied Sciences, 14(17), 7985. https://doi.org/10.3390/app14177985