
Blockchain Traceability Process for Hairy Crab Based on Cuckoo Filter

Abstract
:1. Introduction
2. Filter Technical Analysis
2.1. Bloom Filter
2.2. Cuckoo Filter
3. ECMI Model
4. Experimental Validation
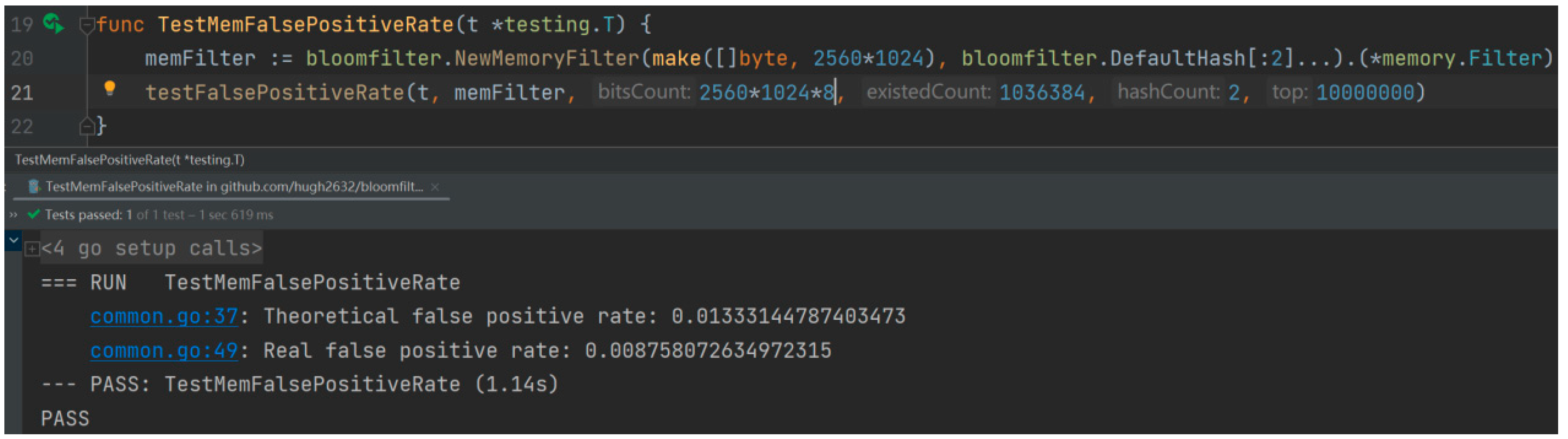
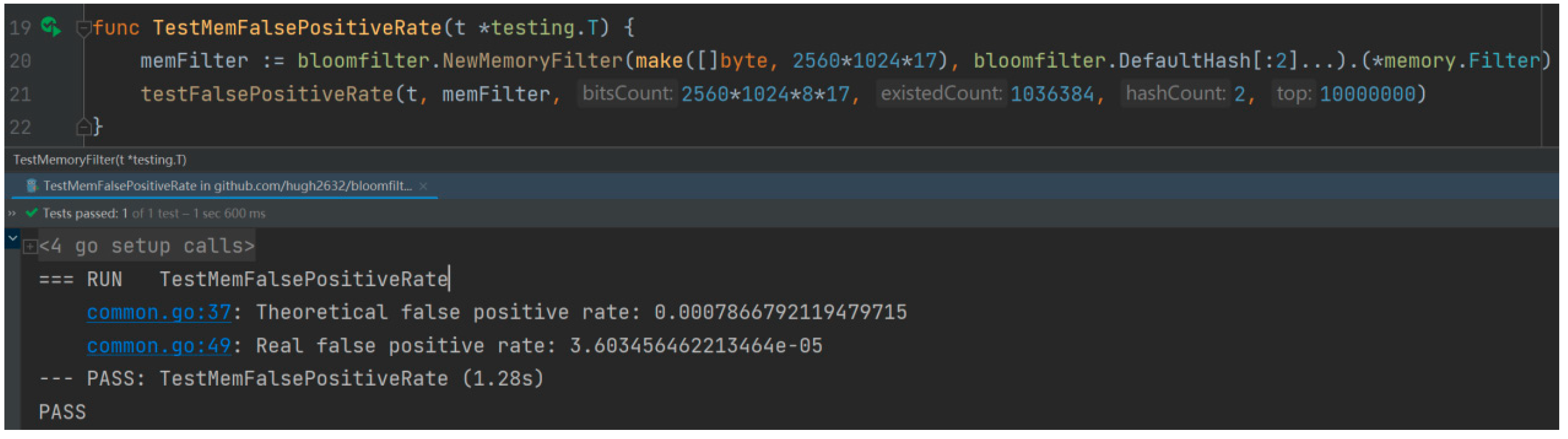
4.1. Experimental Purpose
4.2. Experimental Procedure and Analysis of Results
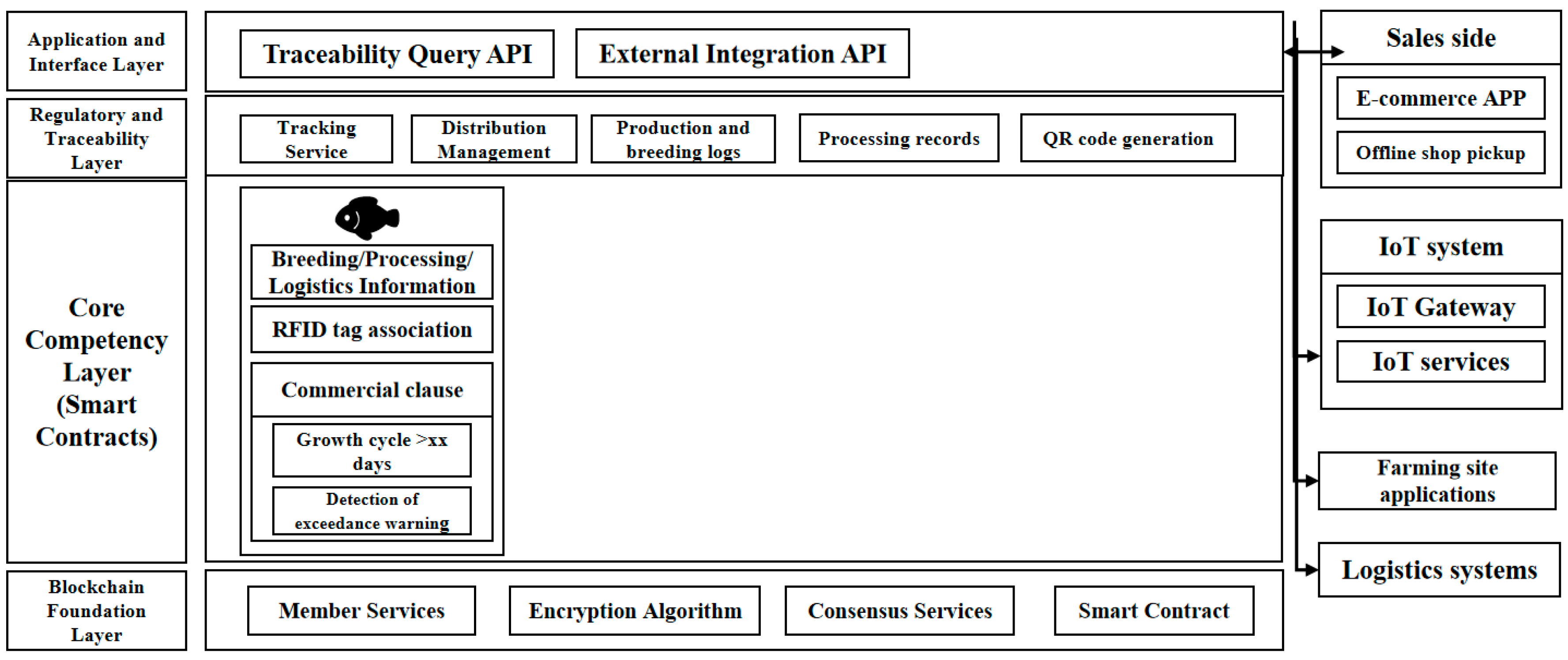
5. Hairy Crab Full-Chain Traceability
5.1. Construction of Traceability Information Table for Each Link of Traceability Process
5.2. Hairy Crab Full-Chain Traceability Process
5.3. Hairy Crab Traceability Platform
6. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zeng, Y.W.; Song, Y.X.; Lin, X.Z. Ruminations on some issues of digital village construction in China. China Rural. Econ. 2021, 4, 21–35. [Google Scholar]
- Lin, W.; Huang, X.; Fang, H.; Wang, V.; Hua, Y.; Wang, J.; Yin, H.; Yi, D.; Yau, L. Blockchain Technology in Current Agricultural Systems: From Techniques to Applications. IEEE Access 2020, 8, 143920–143937. [Google Scholar] [CrossRef]
- Yang, X.; Li, M.; Yu, H.; Wang, M.; Xu, D.; Sun, C. A Trusted Blockchain-Based Traceability System for Fruit and Vegetable Agricultural Products. IEEE Access 2021, 9, 36282–36293. [Google Scholar] [CrossRef]
- Prashar, D.; Jha, N.; Jha, S.; Lee, Y.; Joshi, G.P. Blockchain-Based Traceability and Visibility for Agricultural Products: A Decentralized Way of Ensuring Food Safety in India. Sustainability 2020, 12, 3497. [Google Scholar] [CrossRef]
- Yao, Q.; Zhang, H. Improving Agricultural Product Traceability Using Blockchain. Sensors 2022, 22, 3388. [Google Scholar] [CrossRef]
- Aung, M.M.; Chang, Y.S. Traceability in a food supply chain: Safety and quality perspectives. Food Control. 2014, 39, 172–184. [Google Scholar] [CrossRef]
- Tian, F. A supply chain traceability system for food safety based on HACCP, blockchain & Internet of things. In Proceedings of the International Conference on Service Systems and Service Management, Dalian, China, 16–18 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Dabbene, F.; Gay, P.; Tortia, C. Traceability issues in food supply chain management: A review. Biosyst. Eng. 2014, 120, 65–80. [Google Scholar] [CrossRef]
- Tian, F. An agri-food supply chain traceability system for China based on RFID & blockchain technology. In Proceedings of the 13th International Conference on Service Systems and Service Management (ICSSSM), Kunming, China, 24–26 June 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Scholten, H.; Verdouw, C.N.; Beulens, A.; Van der Vorst, G.A. Defining and Analyzing Traceability Systems in Food Supply Chains. In Woodhead Publishing Series in Food Science, Technology and Nutrition, Advances in Food Traceability Techniques and Technologies; Espiñeira, M., Santaclara, F., Eds.; Woodhead Publishing: Cambridge, UK, 2016; pp. 9–33. ISBN 9780081003107. [Google Scholar] [CrossRef]
- Mileti, A.; Arduini, D.; Watson, G.; Giangrande, A. Blockchain Traceability in Trading Biomasses Obtained with an Integrated Multi-Trophic Aquaculture. Sustainability 2023, 15, 767. [Google Scholar] [CrossRef]
- Liu, H.; Xue, J.; Tang, J.; Jiang, T.; Chen, X.; Yang, J. Taste Attributes of the “June Hairy Crab” Juveniles of Chinese Mitten Crab (Eriocheir sinensis) in Yangcheng Lake, China—A Pilot Study. Fishes 2022, 7, 128. [Google Scholar] [CrossRef]
- Liu, H.; Fu, C.; Ding, G.; Fang, Y.; Yun, Y.; Norra, S. Effects of hairy crab breeding on drinking water quality in a shallow lake. Sci. Total Environ. 2019, 662, 48–56. [Google Scholar] [CrossRef]
- Akella, G.K.; Wibowo, S.; Grandhi, S.; Mubarak, S. A systematic review of blockchain technology adoption barriers and enablers for smart and sustainable agriculture. Big Data Cogn. Comput. 2023, 7, 86. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, J.; Cao, K. Interaction between joining platform blockchain technology and channel encroachment for fresh agricultural product firms. Int. Trans. Oper. Res. 2024, 31, 3565–3591. [Google Scholar] [CrossRef]
- Tsai, F.; Tran, D.H.; Nguyen, P.H.; Lin, M.H. Interval-valued hesitant fuzzy DEMATEL-based blockchain technology adoption barriers evaluation methodology in agricultural supply chain management. Sustainability 2023, 15, 4686. [Google Scholar] [CrossRef]
- Bosona, T.; Gebresenbet, G. The role of blockchain technology in promoting traceability systems in agri-food production and supply chains. Sensors 2023, 23, 5342. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/time tradeoffs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Chazelle, B.; Kilian, J.; Rubinfeld, R.; Tal, A. The bloomier filter: An efficient data structure for static support lookup tables. In Proceedings of the Fifteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 11–13 January 2004; pp. 30–39. [Google Scholar]
- Luo, L.; Guo, D.; Ma, R.T.; Rottenstreich, O.; Luo, X. Optimizing bloom filter: Challenges, solutions, and comparisons. IEEE Commun. Surv. Tutor. 2018, 21, 1912–1949. [Google Scholar] [CrossRef]
- Tarkoma, S.; Rothenberg, C.E.; Lagerspetz, E. Theory and practice of bloom filters for distributed systems. IEEE Commun. Surv. Tutor. 2011, 14, 131–155. [Google Scholar] [CrossRef]
- Geravand, S.; Ahmadi, M. Bloom filter applications in network security: A state-of-the-art survey. Comput. Netw. 2013, 57, 4047–4064. [Google Scholar] [CrossRef]
- Rottenstreich, O.; Keslassy, I. The bloom paradox: When not to use a bloom filter. IEEE/ACM Trans. Netw. 2014, 23, 703–716. [Google Scholar] [CrossRef]
- Guo, D.; Wu, J.; Chen, H.; Yuan, Y.; Luo, X. The dynamic bloom filters. IEEE Trans. Knowl. Data Eng. 2009, 22, 120–133. [Google Scholar] [CrossRef]
- Yang, J.; Jia, W.; Gao, Z.; Guo, Z.; Zhou, Y.; Pan, Z. Cuckoo-Store Engine: A Reed–Solomon Code-Based Ledger Storage Optimization Scheme for Blockchain-Enabled IoT. Electronics 2023, 12, 3328. [Google Scholar] [CrossRef]
- Zhao, Y.; Dai, W.; Wang, S.; Xi, L.; Wang, S.; Zhang, F. A Review of Cuckoo Filters for Privacy Protection and Their Applications. Electronics 2023, 12, 2809. [Google Scholar] [CrossRef]
- Cui, J.; Zhang, J.; Zhong, H.; Xu, Y. SPACF: A secure privacy-preserving authentication scheme for VANET with cuckoo filter. IEEE Trans. Veh. Technol. 2017, 66, 10283–10295. [Google Scholar] [CrossRef]
- Reviriego, P.; Larrabeiti, D. Denial of service attack on cuckoo filter based networking systems. IEEE Commun. Lett. 2020, 24, 1428–1432. [Google Scholar] [CrossRef]
- Breslow, A.D.; Jayasena, N.S. Morton filters: Fast, compressed sparse cuckoo filters. VLDB J. 2020, 29, 731–754. [Google Scholar] [CrossRef]
- Kumar, M.; Rawat, T.K. Optimal fractional delay-IIR filter design using cuckoo search algorithm. ISA Trans. 2015, 59, 39–54. [Google Scholar] [CrossRef]
- Reviriego, P.; Apple, J.; Larrabeiti, D.; Liu, S.; Lombardi, F. On the Privacy of Adaptive Cuckoo Filters: Analysis and Protection. IEEE Trans. Inf. Forensics Secur. 2024, 19, 5867–5879. [Google Scholar] [CrossRef]
- Fan, B.; Andersen, D.G.; Kaminsky, M.; Mitzenmacher, M.D. Cuckoo filter: Practically better than bloom. In Proceedings of the International Conference on Emerging Networking Experiments and Techno-logies, Los Angeles, CA, USA, 9–12 December 2014; pp. 75–88. [Google Scholar]
- Chen, H.; Liao, L.; Jin, H.; Wu, J. The dynamic cuckoo filter. In Proceedings of the International Conference on Network Protocols, Toronto, ON, Canada, 10 October 2017; pp. 1–10. [Google Scholar]
- Zhang, F.; Chen, H.; Jin, H.; Reviriego, P. logarithmic dynamic cuckoo filter. In Proceedings of the 37th IEEE International Conference on Data Engineering, Chania, Greece, 19–22 April 2021; pp. 948–959. [Google Scholar]
- Huang, K.; Yang, T. Additive and subtractive cuckoo filters. In Proceedings of the International Symposium on Quality of Service, Hang Zhou, China, 15–17 June 2020; pp. 1–10. [Google Scholar]
- Cheng, L.; Lv, Z.; Alfarraj, O.; Tolba, A.; Yu, X.; Ren, Y. Secure cross-chain interaction solution in multi-blockchain environment. Heliyon 2024, 10, e28861. [Google Scholar] [CrossRef]
- Ou, W.; Huang, S.; Zheng, J.; Zhang, Q.; Zeng, G.; Han, W. An overview on cross-chain: Mechanism, platforms, challenges and advances. Comput. Netw. 2022, 218, 109378. [Google Scholar] [CrossRef]
- Mao, H.; Nie, T.; Sun, H.; Shen, D.; Yu, G. A survey on cross-chain technology: Challenges, development, and prospect. IEEE Access 2022, 11, 45527–45546. [Google Scholar] [CrossRef]
- He, Y.; Zhang, C.; Wu, B.; Yang, Y.; Xiao, K.; Li, H. A cross-chain trusted reputation scheme for a shared charging platform based on blockchain. IEEE Internet Things J. 2021, 9, 7989–8000. [Google Scholar] [CrossRef]
- Falazi, G.; Breitenbücher, U.; Leymann, F.; Schulte, S. Cross-Chain Smart Contract Invocations: A systematic multi-vocal literature review. ACM Comput. Surv. 2024, 56, 1–38. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, Z.; Wang, G.; Yuan, Y. Efficient cross-chain transaction processing on blockchains. Appl. Sci. 2022, 12, 4434. [Google Scholar] [CrossRef]
- Duan, L.; Sun, Y.; Ni, W.; Ding, W.; Liu, J.; Wang, W. Attacks against cross-chain systems and defense approaches: A contemporary survey. IEEE/CAA J. Autom. Sin. 2023, 10, 1647–1667. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| OS | Windows 11 (64-bit) |
| CPU | Intel 13th Gen Core i9-13900HX 24 Core |
| RAM | 16 GB (4800 MHz) |
| Hard Drive | 1024 GB (PCIe SSD) |
| Graphics Board | NVIDIA NVIDIA GeForce RTX 4060 Laptop GPU (8188 MB) |
| Language | go1.20.4 windows/amd64 |
| Compilers | GoLand 2023.1.2 |
| Segment | Traceability Information |
|---|---|
| Breeding Process | Crab Fry Information, Feed Information, Water Quality Information, Farm Information, Supplier Qualification Information |
| Processing Stage | Weight of Hairy Crabs, Order Information, Factory Temperature and Humidity Information, Processing Time, Processing Batch, Factory Address, Product Name |
| Transport Links | Transportation Carriage Data, Driver Information, Vehicle Information, Transportation Date, Cargo Weight, Order Information, Transportation Route |
| Sales Process | Sales Manager, Consumer Information, Product Information, Inventory Time, Sales Time, Sales Location |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Jiang, W. Blockchain Traceability Process for Hairy Crab Based on Cuckoo Filter. Appl. Sci. 2024, 14, 8027. https://doi.org/10.3390/app14178027
Tian S, Jiang W. Blockchain Traceability Process for Hairy Crab Based on Cuckoo Filter. Applied Sciences. 2024; 14(17):8027. https://doi.org/10.3390/app14178027
Chicago/Turabian StyleTian, Shiyu, and Wenbao Jiang. 2024. "Blockchain Traceability Process for Hairy Crab Based on Cuckoo Filter" Applied Sciences 14, no. 17: 8027. https://doi.org/10.3390/app14178027