Abstract
Emergencies in gas pipeline networks can lead to significant loss of life and property, necessitating extensive professional knowledge for effective response and management. Effective emergency response depends on specialized knowledge, which can be captured efficiently through domain-specific lexicons. The goal of this research is to develop a specialized lexicon that integrates domain-specific knowledge to improve emergency management in gas pipeline networks. The process starts with an enhanced version of Term Frequency–Inverse Document Frequency (TF-IDF), a statistical method used in information retrieval, combined with filtering logic to extract candidate words from investigation reports. Simultaneously, we fine tune the Chinese Bidirectional Encoder Representations from Transformers (BERT) model, a state-of-the-art language model, with domain-specific data to enhance semantic capture and integrate domain knowledge. Next, words with similar meanings are identified through word similarity analysis based on standard terminology and risk inventories, facilitating lexicon expansion. Finally, the domain-specific lexicon is formed by amalgamating these words. Validation shows that this method, which integrates domain knowledge, outperforms models that lack such integration. The resulting lexicon not only assigns domain-specific weights to terms but also deeply embeds domain knowledge, offering robust support for cause analysis and emergency management in gas pipeline networks.
1. Introduction
Gas pipeline networks are essential for energy supply in urbanization, social activities, and residential life [1]. Additionally, managing safety and assessing risks in these networks are crucial for urban stability and public safety [2]. Urban gas pipeline networks, components of life-supporting infrastructure, primarily transport and distribute gas to residential, commercial, and industrial users, meeting their daily gas needs [3]. Despite their importance, these networks pose significant risks [4]. Emergencies in gas pipeline networks can have impacts on health, the environment, and societal structures. Gas leaks can lead to explosions and fires, posing direct threats to individuals near the incident site [5]. Such leaks also contribute to air pollution [6]. When the gas does not ignite, unburned methane can also cause suffocation or poisoning. Severe network emergencies can disrupt traffic, damage infrastructure, and affect community services and economic activities [7]. Gas pipeline safety is a major challenge for many countries, including China, the United States, and the United Kingdom. The main challenges are low digitalization in enterprises and inefficient sharing of safety and emergency information [8]. In China, gas pipeline safety is moving towards intelligent systems, emphasizing the use of multi-source data for risk perception, early warning, risk assessment, intelligent analysis, and decision making [9].
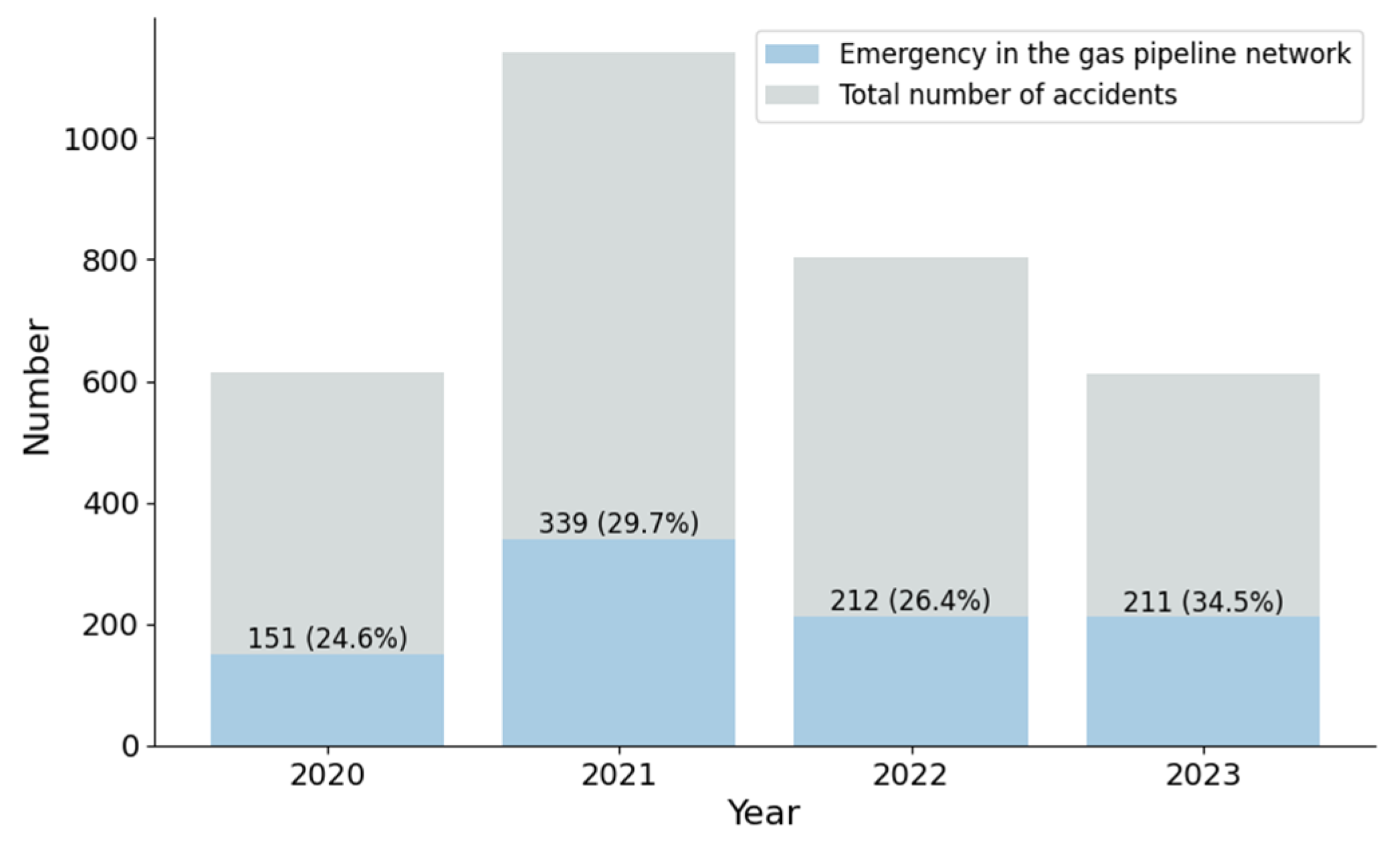
In recent years, numerous critical emergencies in gas pipeline networks have led to significant losses. Investigation reports from various provinces and cities outline several recent events. On 20 September 2023, around 2:45 p.m., Zhongsheng Shengbo Group Co., Ltd. (Anshan, China) was excavating a drainage pipeline at 80 Zhonghua South Road, Rongyu Community, Tiedong District. The construction team accidentally breached a gas pipeline, triggering a flash explosion that damaged the Huaqing Pool bathhouse and injured four people. The incident resulted in direct economic losses estimated at approximately CNY 2.7273 million. On 13 August 2023, around 7:05 a.m., a gas explosion at the intersection of Fenghuang Street and Jiafang Road in Gaomi City, Weifang, caused two deaths and two injuries, with economic losses estimated at approximately CNY 6.94 million. On 15 January 2023, at about 1:25 p.m., an explosion and subsequent fire occurred at Panjin Haoye Chemical Co., Ltd. (Panjin, China) during a pressurized sealing operation on the inlet pipeline of the alkylation unit’s water washing tank, resulting in 13 deaths and 35 injuries. This accident caused direct economic damage estimated at approximately CNY 87.99 million. Figure 1 shows the frequency and proportion of these emergencies within all reported gas accidents. Although not exhaustive, data from the Safety Management Committee of the China Urban Gas Association clearly highlight the severity of these emergencies in gas pipeline networks.
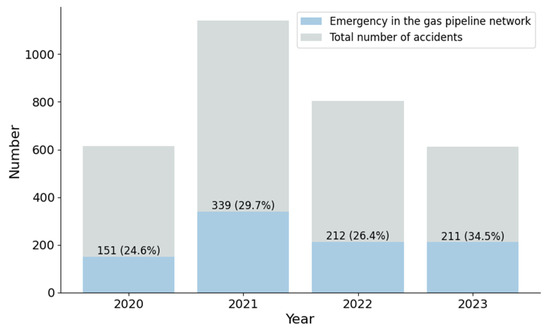
Figure 1.
Number and proportion of emergencies in China’s gas pipeline networks, 2020–2023, compared to all gas-related accidents.
Emergencies in gas pipeline networks exhibit distinctive characteristics. Typically originating in confined areas, these emergencies can escalate rapidly due to the flammable and explosive nature of gas, causing extensive damage [10]. Managing such events requires broad emergency management skills and specialized technical expertise, especially in detecting gas leaks and repairing pipelines [11]. Effective prevention and response strategies for gas pipeline emergencies rely critically on robust monitoring systems and proactive early warning mechanisms, as timely detection is essential to averting disasters [12]. Developing a domain-specific lexicon is crucial in natural language processing, as it encapsulates essential knowledge of a specific field [13]. This task is pivotal not only for comprehending domain-specific knowledge but also for tracking domain evolution, carrying significant theoretical and practical value [14]. The advancement of natural language processing technology has markedly diminished the need for manual involvement in creating these lexicons [15].
An interactive approach has been introduced in the field of terminology lexicon construction for creating user-centric lexicons aimed at text analysis [16]. This method leverages human–machine interaction to precisely capture user requirements and intentions, enhancing the lexicon’s relevance and accuracy. The innovative algorithm can efficiently grasp an analyst’s intent with minimal data, enhancing both the efficiency of the construction process and the quality of the lexicon. Although this approach functions with minimal interactions, practical application limits on the number of interactions might impinge on the lexicon’s comprehensiveness and scope.
Deep learning has greatly impacted lexicon construction, evidenced by the development of a domain terminology lexicon using Chinese Wikipedia [17]. This approach integrates the Word2vec model with Wikipedia’s link structure, enriching and refining domain terminology representations. Neural networks have notably expanded the lexicon’s scope and utility. The method’s effectiveness was proven in the automotive sector, highlighting its strengths in creating domain-specific lexicons. While this approach performed well in the automotive sector, its adaptability across different fields requires further investigation and validation.
Reducing human intervention represents a significant advancement in technology. A novel method has been introduced for building Chinese domain-specific vocabularies via new word recommendations [18]. This method ingeniously addresses new word discovery sparsity using enhanced mutual information and branch entropy techniques, improving low-frequency term identification. It significantly alleviates the need for expert reviews, streamlining the construction of domain lexicons via automated processes. The success of new word recommendations depends heavily on the quality and breadth of domain-specific corpora, with corpus selection and pre-processing being crucial.
Domain lexicons are crucial for model optimization, as particularly demonstrated in news classification. Research shows that using bigram-based lexicons to classify unseen news data yields efficient and accurate results. Extending these lexicons to include bigrams and trigrams can marginally enhance accuracy [19]. Researchers have developed a lexicon learning algorithm using projected dual reconstruction for cross-domain recognition [20]. This approach creates class-specific sub-lexicons that maintain inherent connections between source and target domain data, incorporating label consistency constraints and classifier training. Despite its innovation, the algorithm’s high time complexity and intricate optimization present challenges to broader applicability.
In conclusion, significant progress has been achieved across various research areas, including the development of domain-specific lexicon construction methods, the enhancement of human–computer interactions, the reduction of human labor, the integration of deep learning techniques, and the optimization and evaluation of lexicons to improve classification model efficacy. Despite these advancements, several challenges remain, notably the high computational demands, stringent data pre-processing requirements, and the limited cross-domain applicability of these methods. In the context of emergencies in gas pipeline networks—a sector that heavily relies on human input—the lack of a tailored lexicon represents a significant gap. Creating a domain-specific lexicon for this area could critically enhance efforts in risk assessment, causal analysis, emergency decision making, risk monitoring, and early warning systems.
Pre-training technology aims to develop general models using large datasets, which can be fine tuned for various downstream applications [21]. BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model based on the Transformer architecture, which converts textual data into high-dimensional dense vectors [22]. BERT encodes semantic information of input texts using self-attention, generating word embeddings and processing them across multiple Transformer layers to capture contextual details, ultimately producing vectors for each word or sentence. These vectors encapsulate rich semantic and contextual details, enabling a better understanding of word polysemy and nuances across different contexts. The Chinese BERT model, pre-trained on a large corpus of Chinese text, has emerged as a versatile architecture capable of handling a wide range of natural language processing (NLP) tasks [23]. Chinese word embeddings as input features have proven effective in NLP applications and real-world challenges, including entity relation extraction, word similarity measurement, and disease identification.
TF-IDF (Term Frequency–Inverse Document Frequency) is a widely used method for keyword extraction [24]. By calculating the TF-IDF value for each word, significant keywords within a specific document can be identified [25]. Since its inception, TF-IDF has been extensively applied to the construction of domain-specific lexicons. Research indicates that TF-IDF effectively identifies keywords and excels in automatically generating domain-specific vocabularies. As text analysis techniques have advanced, TF-IDF has been optimized to enhance domain-specific lexicon accuracy, especially with large-scale corpora. Recent research has explored integrating TF-IDF with other NLP techniques to enhance domain-specific lexicon construction efficiency and effectiveness.
This paper presents a domain-specific lexicon encompassing standard terminology, risk inventories, and emergency-related terms for natural gas pipeline networks. It quantifies the relevance of these terms and evaluates their interrelationships within the domain. Creating this domain lexicon offers several advantages, including improved precision in natural language processing systems’ understanding of specialized texts. It also serves as a valuable resource for knowledge discovery and data mining. Additionally, the lexicon aids in feature engineering, enabling models to process and interpret domain-specific data effectively. Establishing a domain-specific lexicon for gas pipeline emergencies enhances management capabilities and supports rigorous cause analysis, risk assessments, and emergency response strategy development. The innovations of this study include the following:
- We developed a specialized domain-specific lexicon for emergencies in gas pipeline networks after extensively reviewing the literature and consulting with field experts. To our knowledge, this is the first lexicon specifically focused on this area.
- We trained a Chinese pre-trained model specifically for emergencies in gas pipeline networks, successfully extracting semantic nuances from substantial domain-specific data.
- We introduced a hybrid method that enhances the traditional TF-IDF technique with deep learning to incorporate domain knowledge more effectively. Initially, statistical methods filtered out less relevant terms, followed by deep learning to further develop and enhance the lexicon with detailed domain knowledge.
This paper is divided into five sections. The first section outlines the necessity and significance of developing a specialized lexicon for gas pipeline emergencies. The second section details the materials and methods used. The third section presents the research findings and analysis. The fourth section discusses the practical implications of the research. The final section provides a summary and outlook.
2. Materials and Methods
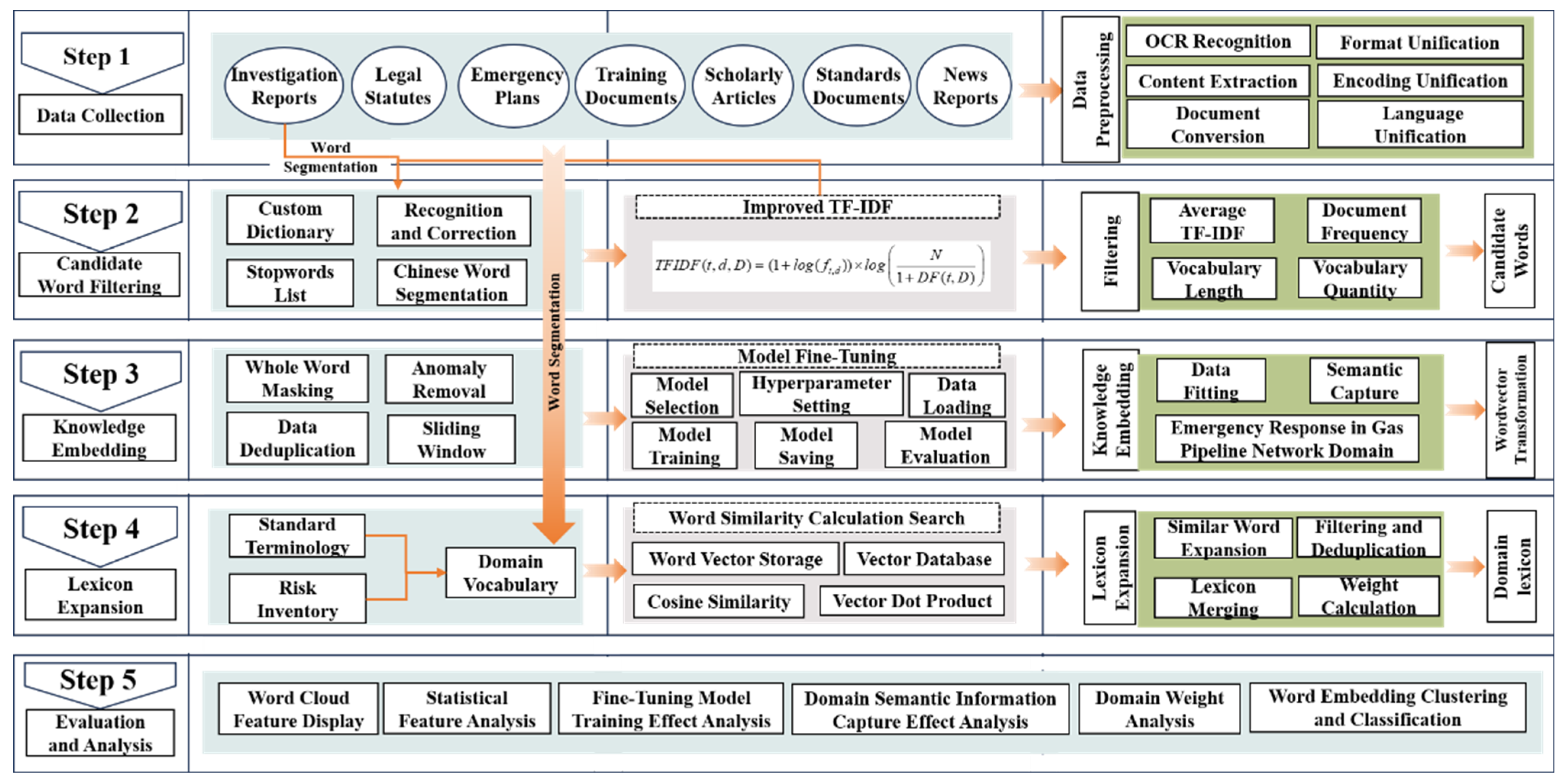
Developing a specialized lexicon for gas pipeline emergencies requires integrating diverse data sources and types. In the practical management of such events, standards and risk inventories serve as essential tools for risk assessment [26]. To achieve this, we utilized enhanced TF-IDF methods and BERT-based pre-training technologies. These pre-training techniques enable profound extraction of semantic insights from domain knowledge, leveraging specialized information in standards and risk inventories. The lexicon was evaluated through a holistic appraisal, covering metrics like entry volume, semantic depth, and the effectiveness of classification and clustering. This research consists of five main steps, as shown in Figure 2.
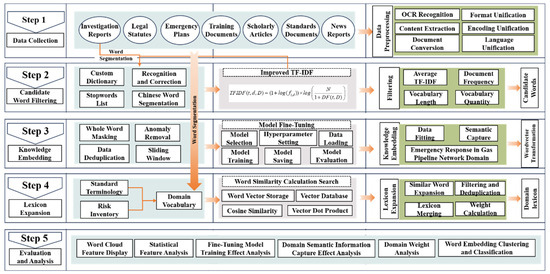
Figure 2.
Framework for constructing and validating a domain-specific lexicon for emergency response in gas pipeline networks.
Step 1: Data Collection and Processing, This study, focusing on gas pipeline emergencies, requires collecting extensive network-related data. The primary data sources include survey reports from government entities, internal data from a specific gas company, and data obtained through web scraping. The data are pre-processed to convert them into a format ready for analysis. To facilitate future use, the processed data are stored in HDF5 format, a versatile and efficient file format designed for handling large, complex datasets.
Step 2: Construction and Selection of Candidate Words. Use Jieba, a specialized tool for Chinese text segmentation, to process data and compute the TF-IDF matrix. Candidate words are identified using specific filtering rules.
Step 3: Learning the Domain Knowledge Embedding Model. The word embedding model is fine tuned with domain-specific data to capture deeper semantic information. To achieve the goal of lexicon construction, we used pre-processed data to create a cloze task with whole words for fine tuning the pre-trained model. After this, the pre-trained model was enriched with domain-specific semantic information relevant to gas pipeline emergencies.
Step 4: Expansion and Construction of the Domain-Specific Lexicon. Word similarity is determined by calculating the cosine similarity of word vectors. In this study, the lexicon is expanded by identifying words similar to established standards and terms in risk inventories.
Step 5: Evaluation and Visualization of the Lexicon. The constructed lexicon undergoes comprehensive analysis and evaluation, focusing on quantitative and qualitative aspects.
2.1. Data Collection and Processing
Data on gas pipeline network emergencies are typically stored as textual or numerical records, especially safety-related documents, which are too extensive for manual processing. Advances in natural language processing technologies have significantly improved text processing techniques, enabling automated handling of textual data and facilitating the digitization of domain-specific knowledge [27]. Numerous countries have established dedicated agencies or websites for managing emergency event data. These platforms provide access to high-quality structured or semi-structured data. Examples include the Pipeline and Hazardous Materials Safety Administration (PHMSA) [28], the Major Accident Hazards Bureau (MAHB) of the Joint Research Centre [29], and the European Gas Pipeline Incident Data Group (EGIG) [30], each maintaining specialized databases. Table 1 provides examples of various data sources related to gas pipeline network accidents.

Table 1.
Summary of gas pipeline network database resources.
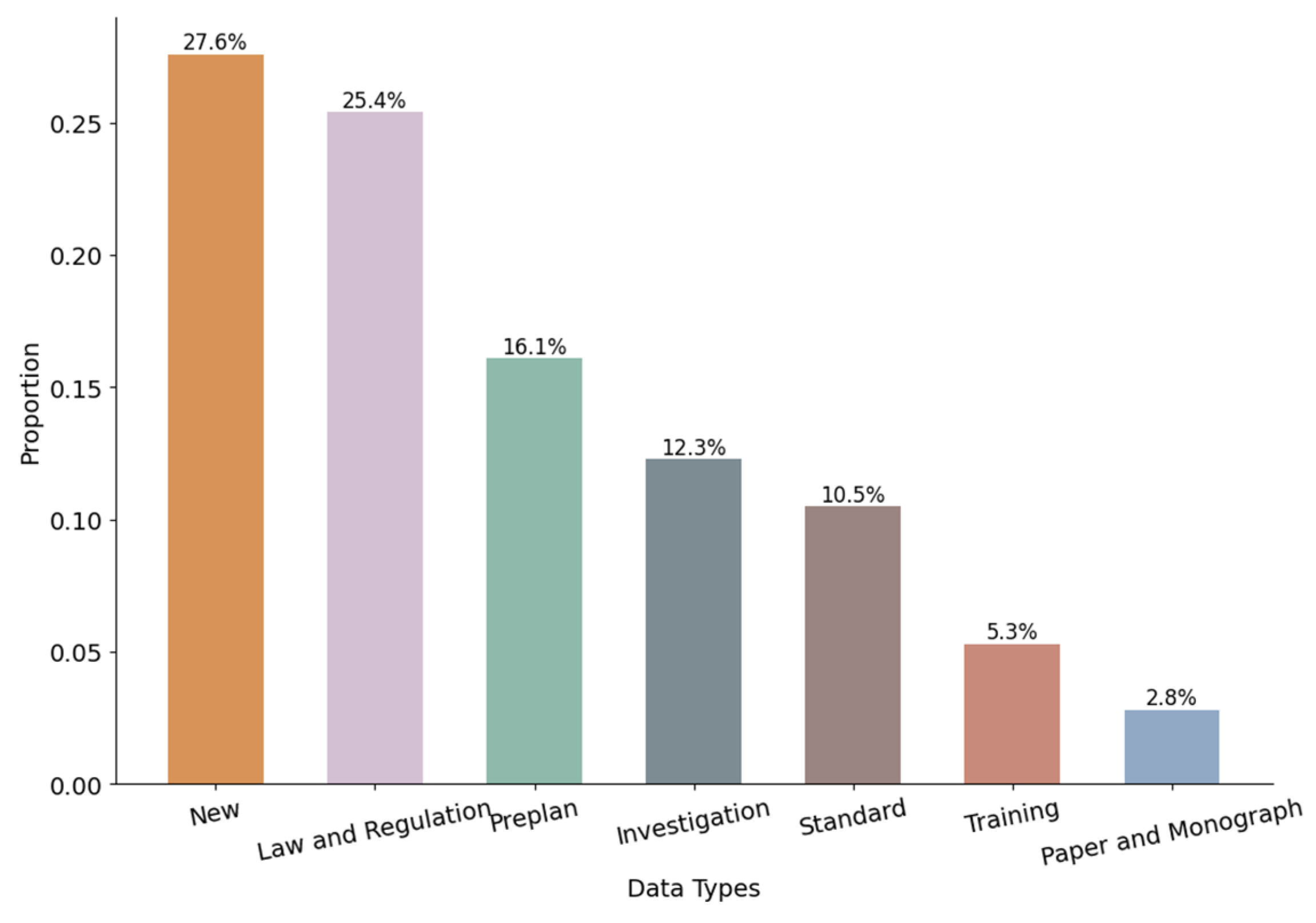
At present, China lacks a dedicated regulatory authority or department tasked with developing systems or platforms specifically designed for the collection and analysis of gas pipeline accident data. Emergency data are mainly held by relevant gas companies and specialized investigation teams, with most detailed investigation report data remaining unpublished. This paper extends existing databases by incorporating diverse sources, such as investigation reports from Chinese gas pipelines, legal statutes, emergency plans, training documents, scholarly articles, standards, and news, creating a dataset specifically for emergencies in Chinese gas networks. Investigation reports mainly come from public documents issued by emergency management departments in various provinces and cities, supplemented by additional data from web scraping. Information regarding laws and regulations is sourced from the national legal database. Emergency plans and training materials mainly come from industry websites and specific gas companies, collected through web scraping. The standards literature is obtained from the National Standard Information Public Service Platform using web scraping. News data are extensively collected from Sina Weibo using scraping techniques, while scholarly articles are sourced from open-access academic websites.
2.1.1. Standard Collection and Terminology Extraction
Standards are established norms and guidelines defining technical specifications and procedures. Countries and regions typically maintain their own standardization bodies tasked with the creation, publication, and oversight of these standards. Nationally, entities like the Standardization Administration of China and the American National Standards Institute play pivotal roles. Regionally, organizations such as the European Committee for Standardization and the Asia-Pacific Economic Cooperation’s Subcommittee on Standards and Conformance are crucial. Internationally, major standardization bodies such as the International Organization for Standardization (ISO) [31], the International Telecommunication Union (ITU) [32], and the International Electrotechnical Commission (IEC) [33] contribute to global standards across various sectors.
In China, the standards framework comprises national, industry, local, enterprise, and group standards. The National Standard Information Public Service Platform is a commonly used platform for these standards. Standard terminology refers to uniform terms and definitions used within specific fields or in the standards documents. Standards have well-defined and clear constitutive elements, with core technical components being highly specialized, complex, and filled with numerous proprietary terms and professional terminology specific to the gas industry.
The standardized terms within these documents often include multiple nested terms with blurred boundaries. Due to copyright regulations, acquiring the full text of these standards is challenging. During the acquisition of standard data, some documents were purchased from standard platforms, some were obtained from a gas company, and others were from the official website of the Ministry of Housing and Urban-Rural Development of the People’s Republic of China. Ultimately, 589 standard documents related to gas pipeline networks were collected. Table 2 presents examples of relevant Chinese standards for gas pipeline networks. These terms are usually presented in dedicated sections of the standards documents, including both the terms and their detailed explanations. Given the structured nature of these documents, iconic markers, such as section beginnings and endings, are used as reference points. We used Python tools to extract paragraphs containing standard terminology. After screening and deduplication, we retained only the terms relevant to standard terminology, storing them in TXT format as a standard terminology lexicon.
Table 2.
Examples of standards and terminology for gas pipeline networks.
2.1.2. Risk Inventory Collection and Processing
The risk inventory for gas pipeline networks includes potential hazards that could impact the safety, stability, and efficiency of the gas supply. These risks arise from technological, environmental, operational, and external factors. The Safety Production Committee and other government agencies issue risk inventories for various sectors.
We collected these inventories from the Safety Production Technical Committee, industry-specific WeChat accounts, and Google searches. A total of 209 risk records pertaining to gas pipeline networks were collected. Table 3 presents a partial list of identified risks. Subsequently, we segmented and filtered the identified risk sources and criteria.
Table 3.
Risk inventory examples.
2.1.3. Domain Data Collection and Processing
Considering that most of the data are stored in PDF format, with much of them being non-editable text, technologies like Optical Character Recognition (OCR) and document format conversion were mainly used to extract content from the data sources. Subsequently, a data cleaning process was implemented, which involved handling special symbols, correcting paragraph anomalies, and normalizing data encoding schemes. Considering the errors found in the OCR-processed text, the pycorrector tool was used for corrections, with manual review helping to identify and rectify textual errors. Overall, we collected 2134 records related to emergencies in gas pipeline networks from 2002 to 2023, totaling about 4.95 gigabytes of data. The distribution of these data types is shown in Figure 3.
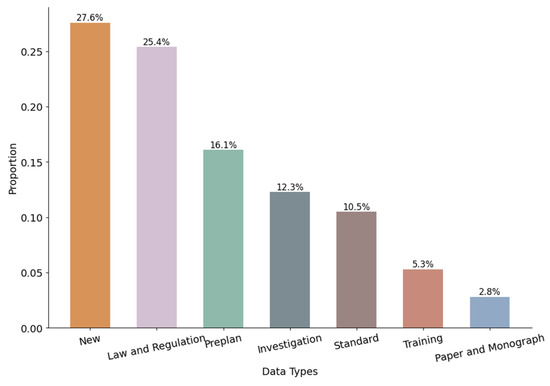
Figure 3.
Distribution of data.
2.2. Candidate Word Set Construction
After analyzing the impact of the stop word list and the user-defined dictionary, we selected Jieba as our primary text segmentation tool [38]. The TF-IDF algorithm, widely used in information retrieval and text mining, evaluates the significance of a word within a dataset. The importance of a word increases with its frequency in a document but decreases with its prevalence across the corpus [39]. The TF-IDF algorithm comprises two components: term frequency (TF) and inverse document frequency (IDF).
Term frequency (TF) is the frequency of a word’s appearance in a document, serving as the initial computation of its weight. Inverse document frequency (IDF) assesses the overall importance of a word within the corpus.
Here, indicates the frequency of the term in the document , and reflects how many times the term appears in the document. Compared to the traditional method of simply counting word occurrences, which calculates TF as the raw count of how many times term appears in document d, this approach uses logarithmic scaling to reduce the impact of high-frequency words [40]. While the traditional TF effectively captures term frequency, it tends to assign disproportionately high weights to very frequent words, overshadowing the significance of less frequent but potentially more informative terms. To address this, the improved method applies a logarithmic scale to the calculation, smoothing term frequencies. This adjustment diminishes the dominance of high-frequency words while preserving the significance of low-frequency words, allowing for a more balanced representation of content.
We use a modified approach to calculate the inverse document frequency (IDF).
Here, represents the inverse document frequency (IDF) of the word across the document collection . The total number of documents within the document collection is represented by , and indicates the number of documents that contain the specified term. Additionally, this method includes a plus-one smoothing term, ensuring that, even in extreme cases (e.g., when a word appears in all documents), a meaningful IDF value is produced. This approach seeks to reduce the influence of high-frequency terms while enhancing the significance of rare terms. Given the rarity of gas pipeline emergencies, we have selected these calculation methods to more accurately represent their infrequency and importance. Additionally, this method incorporates a plus-one smoothing term to ensure that, even in extreme cases (e.g., when a term appears in all documents), a meaningful IDF value is produced. This prevents the weight from dropping to zero, thereby avoiding the potential loss of crucial information.
TF-IDF is a statistical technique that calculates the weight of terms. The TF-IDF matrix aids in assessing the importance of specific terms in domain data. However, these measures alone are not enough to effectively pinpoint key risk factors. This paper utilizes a dual-logic approach with the TF-IDF matrix, analyzing both documents and their TF-IDF values to conduct this filtering. The implementation was performed in Python, including data pre-processing steps like Chinese word segmentation. By sorting and filtering TF-IDF values, words with higher scores were chosen as candidates for the domain-specific dictionary.
2.3. Domain-Specific BERT Fine Tuning
The Masked Language Model (MLM) is crucial in the pre-training phase of BERT [23]. In this research, we developed a Chinese whole-word masking task to enhance the model’s adaptation to domain-specific data, particularly for emergencies in gas pipeline networks. This fine tuning method utilizes BERT’s ability to learn contextual information by masking certain words in the input and predicting these obscured words. During the whole-word masking phase, we first use the Jieba tokenizer, a Chinese word segmentation tool, to segment the input text and identify complete words. After establishing word boundaries, we apply a whole-word masking strategy, masking all characters within a selected word simultaneously. This approach better aligns with the characteristics of the Chinese language, especially in processing multi-character words, as it more effectively preserves semantic information and enhances the model’s adaptability to complex linguistic structures.
During the vocabulary selection phase, we used a random sampling strategy to decide which words to mask in each input sequence. Specifically, a certain proportion of words in each sequence is randomly selected for masking, ensuring variation in masked words across different sequences. This approach improves the model’s generalization ability. Approximately 15% of the words in each input sequence are randomly selected for masking. These pre-processed text data are then used as inputs for the model. The model outputs a probability distribution for each word in the vocabulary, tailored to each masked position. During this phase, all model parameters, including those established during pre-training and any additional parameters introduced, are trainable [22]. BERT fine tuning was implemented in Python using Hugging Face’s Transformers library, with custom domain-specific data processing steps.
2.4. Lexicon Expansion
Through pre-training on large-scale text corpora, the BERT model develops word embeddings enriched with contextual information. Following domain-specific fine tuning, the model is better equipped to align with domain-specific data [41]. It processes input data using a pre-trained model to generate embeddings for each word. Through pre-training on large-scale text corpora, the BERT model develops word embeddings enriched with contextual information.
Common methods for measuring similarity are cosine similarity and Euclidean distance [42]. Cosine similarity, which evaluates the directional similarity between two vectors without considering their magnitudes, is particularly prevalent [43]. This characteristic makes it highly suitable for measuring similarity in high-dimensional spaces.
Here, represents the dot product of vectors and . and denote the magnitudes of vectors and , respectively.
Pre-trained models excel at discerning subtle nuances in word meanings with high precision. Additionally, these models provide the flexibility to choose the most suitable configuration for specific needs. During the implementation process, the vocabulary was expanded by extracting words similar to those identified using the previous method.
3. Results
To validate the lexicon’s effectiveness and suitability for the domain, we conduct a thorough analysis and evaluation. This evaluation covers three main areas: lexicon size, acquisition of domain-specific semantic information, and word clustering effectiveness.
Figure 4 shows a word cloud, visually depicting the relative importance of each word in the context of emergencies in gas pipeline networks. The figure emphasizes words such as “construction”, “operation”, “pipeline”, “gas pipe”, “natural gas”, “excavation”, and “excavator” for their significant domain relevance.

Figure 4.
Visualization of the lexicon development process for emergency response in gas pipeline networks. (a) TF-IDF candidate; (b) standards and risk inventory; (c) domain lexicon.
The size of the lexicon reflects its coverage to a certain extent. Our research involved a detailed statistical analysis of Chinese words processed at various stages. Considering the importance of specific terms, we selected the top 200 words based on their average TF-IDF values. From a risk inventory, we identified 69 critical risk factors. Additionally, 1414 standard terms were extracted from gas pipeline network-related standards. Our custom-trained model allowed us to enrich the lexicon by adding 3429 synonyms and related terms identified through semantic similarity. After merging and removing duplicates, the final lexicon contained 4646 terms. Since single Chinese characters often fail to convey domain-specific relevance and our model was trained on whole words, we excluded all individual characters.
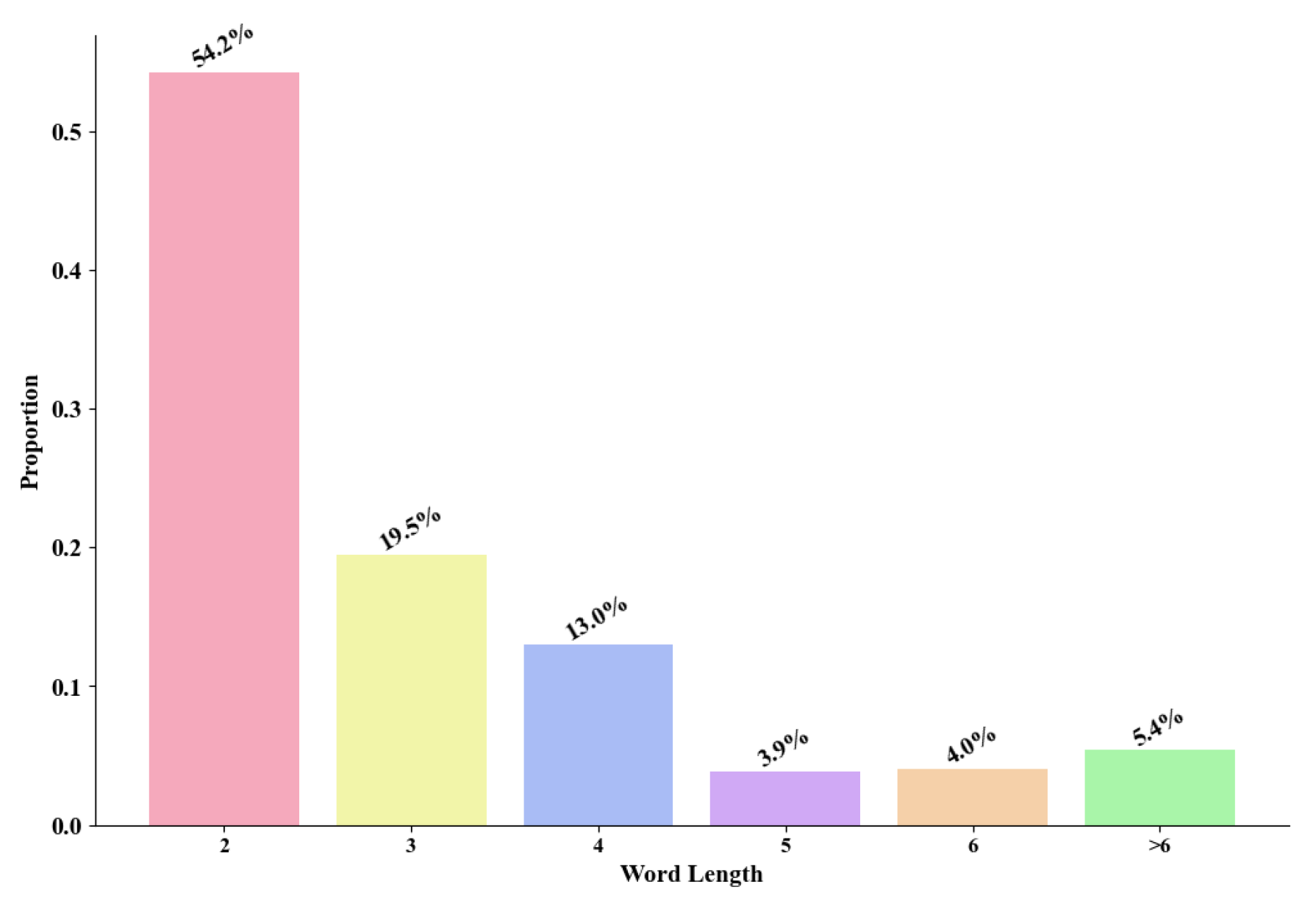
Figure 5 illustrates the word length information within the developed dictionary. Bi-character words make up 54% of the vocabulary, while words longer than two characters account for about 46%. This distribution reflects both the linguistic tendencies of the Chinese language and the specific characteristics of sudden gas pipeline events. In general Chinese usage, bi-character words are predominant. However, in the context of gas pipeline emergencies, terms often extend beyond two characters to describe related equipment and procedural measures, resulting in a significant proportion of multi-character words.
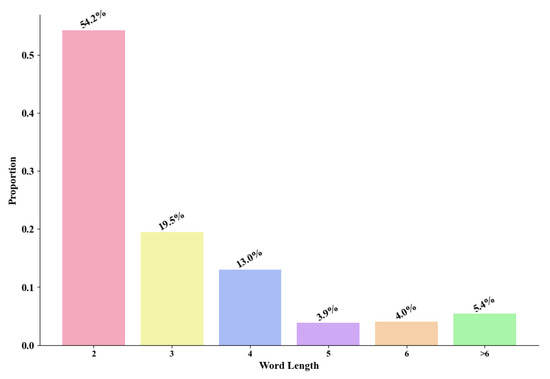
Figure 5.
Word length statistics in the lexicon developed for gas pipeline emergency scenarios.
The data reveal that words consisting of up to four characters dominate the lexicon, while those exceeding six characters comprise 5.4% of the total, as shown in Figure 5. Among the entries, the longest term “焊机内无压冷却时间或移除焊机后冷却时间” (time for pressure-free cooling inside the welder or after its removal) is often used in welding pipe operations, which are critical for gas pipeline emergencies.
The word length distribution within the lexicon reveals distinct patterns specific to gas pipeline emergency scenarios. Notably, shorter words dominate the lexicon, with those consisting of two to four characters being the most prevalent. This trend reflects a preference for concise language in emergency management, where brief terms, commonly used nouns, and verbs are crucial for the rapid and clear communication of key information. Conversely, the frequency of words with five or more characters decreases significantly as word length increases. These longer terms, often representing complex concepts or specialized terminology, appear less frequently but are crucial in certain contexts, particularly when describing intricate technical processes or specific risks.
This word length distribution has significant implications for the development and optimization of a gas pipeline emergency lexicon. It suggests that effective communication in emergency scenarios relies heavily on concise, easily understood words, while longer, specialized terms are essential in more complex situations. To enhance emergency response efficiency, future research and applications should focus on ensuring a thorough inclusion of shorter words and improving the understanding and application of longer terms, especially in conveying technical terms and details.
Table 4 presents a comparison between the domain-specific dictionary developed in this study and those from comparable works. In terms of data scale, our dictionary is derived from gas pipeline network standards and risk lists, leading to a more specialized and extensive dataset. Additionally, in terms of methodology, I employed an enhanced TF-IDF algorithm, which improves the identification of domain-specific vocabulary while maintaining the effectiveness of traditional TF-IDF. Furthermore, my dictionary employs the BERT model as the primary model, which, compared to the Word2Vec or Skip-gram models used in other studies, provides superior contextual understanding and more accurate semantic representation, making it particularly well-suited for processing complex domain-specific texts.
Table 4.
Comparison of the domain-specific lexicon developed in this paper with lexicons from other fields.
3.1. Candidate Words
This study implements a multi-tiered filtering logic to sift through keywords extracted from gas pipeline network incident reports using refined TF-IDF values. The initial filtering stage ranks words based on their average TF-IDF values, prominently retaining the top 200 words within the “document-word” matrix. The subsequent filtering stage considers the frequency of word occurrences across documents, with a threshold that retains words appearing in more than 10% of the documents. This method ensures that only the most relevant terms are included in the analysis.
The third filtering tier uses a customized user dictionary and a research-specific stop words list. The stop words list is designed to exclude terms that, despite having high occurrence values, contribute little to substantive analysis. The user dictionary focuses on preserving terms crucial for understanding gas pipeline emergencies, which might not be prevalent in the dataset and are hard for algorithms to identify. To enhance word segmentation accuracy, we developed a specialized stop words list for sudden gas pipeline events, drawing on the most widely used open-source Chinese stop words lists—those from Baidu, Sogou, and the Harbin Institute of Technology—combined with initial segmentation results from Jieba.
In this research, candidate words for the lexicon were sourced from reports on gas pipeline network accidents. Table 5 displays 30 terms associated with emergencies in gas pipeline networks alongside their respective TF-IDF values. The table highlights key terms, such as “construction”, “operation”, “liquefied petroleum gas”, “pipeline”, and “production”, noted for their frequent appearance and distinctiveness in the dataset. These findings underscore their pivotal role in the context of gas pipeline incidents. Terms such as “liquefied petroleum gas”, “natural gas”, “gas pipe”, and “pipeline” suggest connections to the petroleum and natural gas industries, particularly concerning aspects of construction and pipeline management. Additionally, terms such as “safety”, “emergency”, “deflagration”, and “explosion” emphasize their importance in emergency management and accident prevention, particularly in gas-related construction environments. Other terms such as “management”, “inspection”, “plan”, and “construction site” reflect in-depth discussions in the documents about project management and operational strategies at the sites.
Table 5.
Examples of candidate words and corresponding TF-IDF values.
3.2. Expanded Lexicon
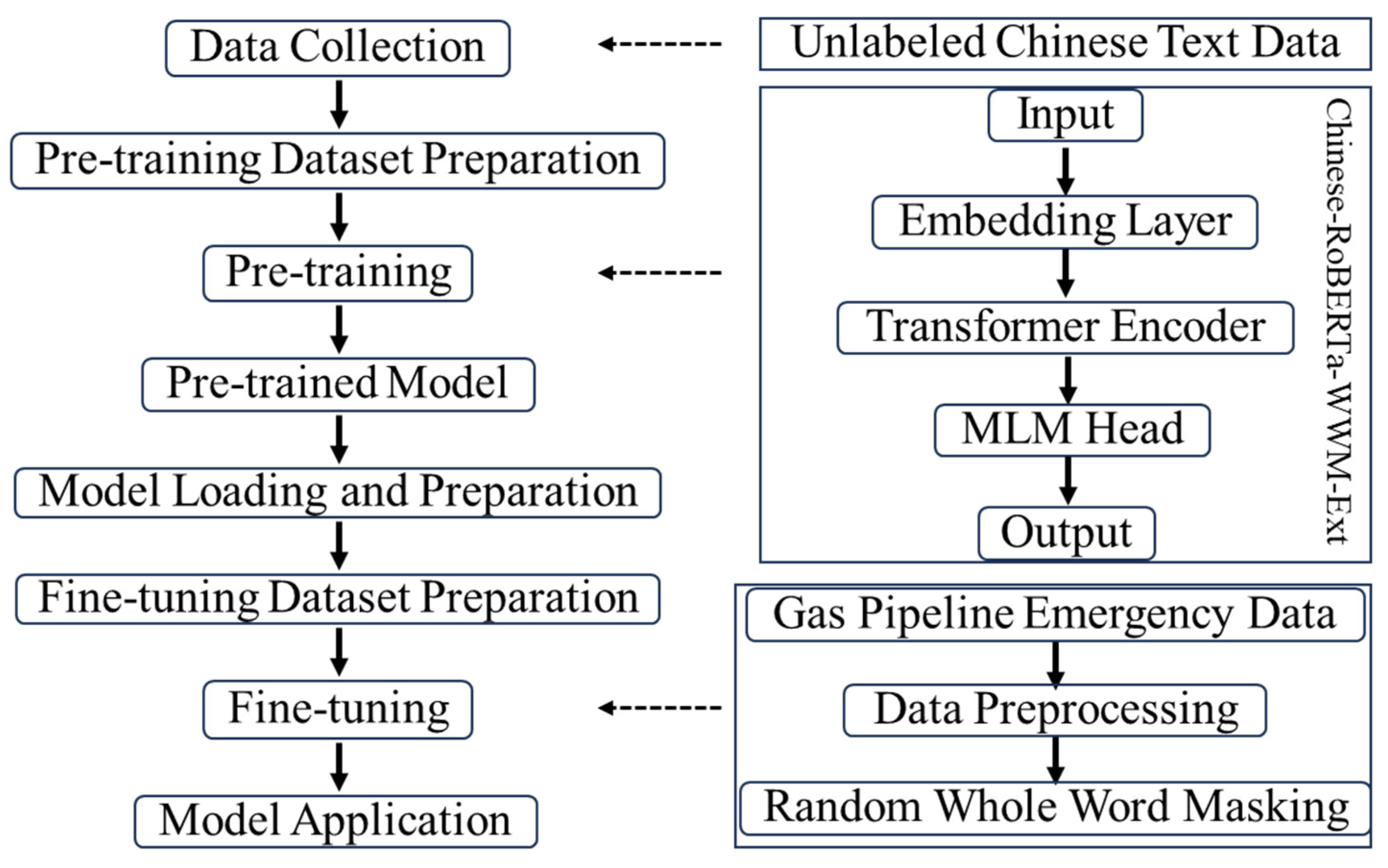
Fine tuning pre-trained models for specific domains is crucial to maximizing their effectiveness. Pre-trained models acquire substantial basic semantic knowledge from large volumes of unlabeled data, and fine tuning with domain-specific data enables more accurate extraction of semantic information relevant to a particular domain. Figure 6 illustrates the comprehensive process employed in this study, from pre-training to fine tuning, and finally to application, using the BERT model. During the pre-training phase, the model initially undergoes language modeling through self-supervised learning. Specifically, the “Whole Word Masking” (WWM) strategy is applied to mask Chinese text, ensuring that entire words, rather than individual characters, are masked simultaneously. Upon completing the pre-training, the model is fine tuned for specific downstream tasks, with its parameters being adjusted to enhance performance on these tasks.
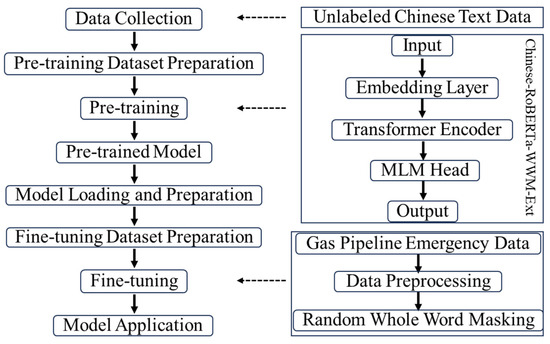
Figure 6.
Chinese-RoBERTa-WWM-Ext model architecture and fine-tuning steps.
In our research, we fine tuned the Chinese-RoBERTa-WWM-Ext model [49]. This model is configured with key parameters, including a hidden layer size of 768, 12 hidden layers, and 12 attention heads, equipping it with the capacity to discern nuanced linguistic relationships. It addresses nonlinear complexities using the GELU activation function. We implemented a dropout rate of 0.1 to reduce overfitting and set the maximum positional embeddings at 512, allowing for the processing of extended text sequences. The model employs absolute positional embeddings to enhance its comprehension of sequence positioning. The minimum setting for layer normalization is established to ensure numerical stability. Throughout the training and inference phases, features such as outputting historical states and caching capabilities were activated to augment training efficiency and accelerate inference rates. These carefully calibrated parameters facilitate a deeper understanding and generation of language, significantly bolstering support for natural language processing tasks.
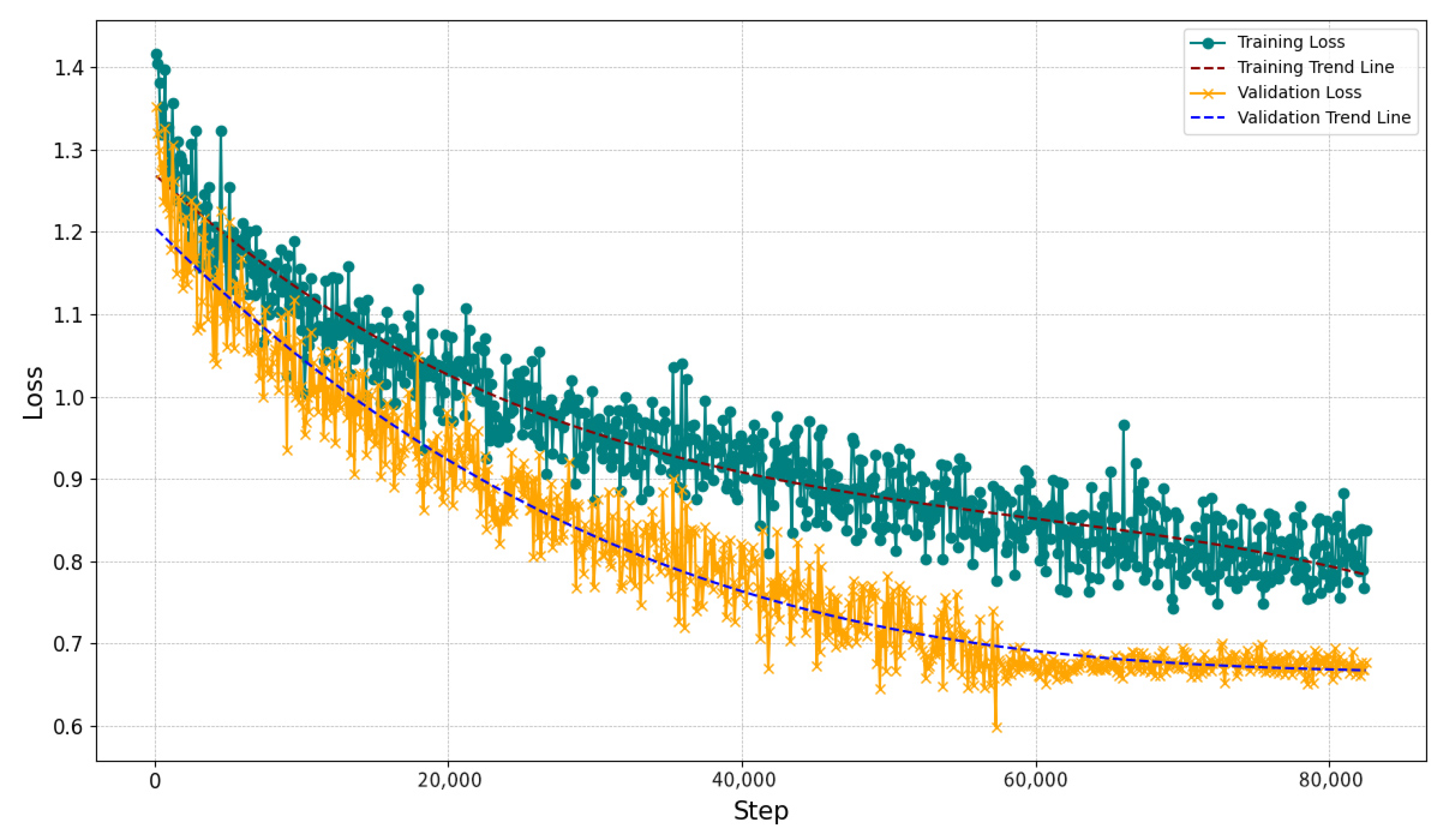
The model completed all 82,524 training steps by the 6th cycle, with each cycle lasting approximately 6 h, 20 min, and 12 s. Figure 7 shows the model’s training loss and trend line, illustrating a pronounced downward trend throughout the fine-tuning process. This pattern signifies the model’s adaptation to the training data, as evidenced by the continual decline in loss values. Initially, the training loss was 1.4 but quickly dropped below 1.0 after a sharp early decrease. The greatest loss reduction occurred within the first 10,000 steps of early training. During this period, the model rapidly adjusts to the training dataset from its initial random weight configurations. As training progresses, the reduction in loss slows, suggesting the model is approaching its performance limits after learning simpler patterns. Beyond approximately 20,000 steps, the loss curve stabilizes between 0.8 and 1.0. The training loss gradually reduced from 1.4 to around 0.8 through iterations. This indicates significant error reduction and effective fitting. Although there were fluctuations in loss during early training, they diminished over time, demonstrating the model’s strong convergence and reduced error. These fluctuations are likely due to batch-to-batch variability or the model’s adjustment to more complex patterns. The dashed trend line illustrates this decline, confirming the model’s effective and stable fine tuning. Additionally, the consistent decrease in training loss and stability in later stages indicates successful model optimization and parameter adjustments. These outcomes suggest that hyperparameters, like the learning rate and batch size, were effectively set for optimal learning. Future research could build on these findings by refining the model’s structure and parameters to explore further loss reduction and generalization improvements.
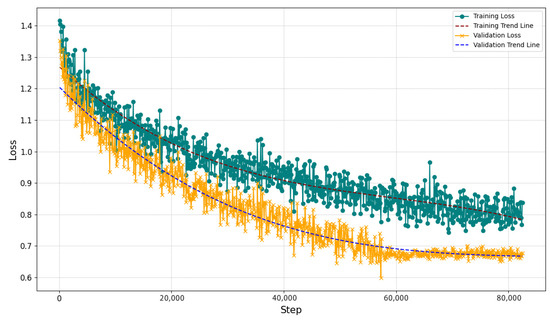
Figure 7.
The trend of training loss over training steps during the domain-specific fine tuning process.
In this study, we chose not to explicitly partition the dataset into training and validation sets. This decision was informed by the specific nature of our task, which emphasizes fine tuning the language model rather than performing a traditional supervised learning task. Given that the pre-training and fine tuning processes are designed to enhance the model’s performance on unlabeled data, the use of a validation set was considered unnecessary at this stage. However, to mitigate any potential shortcomings of this approach, we introduced a gas pipeline network case matching task as an auxiliary method to assess the model’s effectiveness. This task involves inputting the textual description of an incident case and generating the most similar historical event as an output. Table 6 presents an example of a historical case matching result, where the analysis indicates that these similar cases share commonalities with the input case in terms of geographic location, incident outcomes, causes, and other relevant factors.
Table 6.
Results of matching similar historical cases.
According to the National Gas Accident Analysis Report, the majority of gas pipeline network accidents are primarily caused by third-party construction, pipeline corrosion, and other related factors, collectively accounting for more than half of the reported incidents [50]. Considering that the primary causes of gas pipeline emergencies stem from external impacts, human activities, and environmental factors, we selected representative causes from these categories and identified the ten most similar terms using cosine similarity. Table 7 shows that terms closely related to “third-party construction” mainly involve construction-related aspects like “construction personnel”, “engineering construction”, and “construction site”, all demonstrating high similarity scores. Notably, the highest similarity score was 0.794868, demonstrating the model’s capability to precisely identify activities and entities associated with “third-party construction”.
Table 7.
Examples of the 10 words most similar to the sample terms.
Moreover, terms linked to “pipeline corrosion” cover specialized areas, such as various corrosion types (“metal corrosion”, “soil corrosion”), and specific concepts, like “corrosion depth” and “corrosion prevention”. This suggests that the model not only grasps the fundamental concept of “corrosion” but also identifies how it manifests across various materials and environmental conditions, with similarity scores ranging from 0.790442 to 0.822075. This indicates the model’s proficiency in recognizing specialized technical terms. Furthermore, the term “non-compliant operations” and related terms like “violative operations” (similarity 0.971644) show high similarity, emphasizing the model’s sensitivity to norm violations. This highlights the model’s enhanced sensitivity to breaches of conduct norms. Additionally, terms such as “operational error” and “mistaken operation” further demonstrate the model’s ability to detect inappropriate actions and their potential consequences. Overall, the model displays a high level of accuracy and sophistication in semantic understanding, adeptly identifying and linking closely related specialized terms and their subtle differences.
During the lexicon expansion, this article integrated three types of terms from previous steps: candidate terms from survey reports using an enhanced TF-IDF approach, risk terms from a risk inventory, and standard terms from established standards. Utilizing these types, the nearest five words for each term were determined using a cosine similarity method applied through a finely tuned pre-trained model. These methods merged four categories of terms into an initial lexicon tailored to gas pipeline network emergencies. Following this, deduplication, screening, and error correction processes were applied, resulting in the final domain-specific lexicon.
3.3. Impact Analysis
This study developed a domain-specific lexicon for terms related to emergencies in gas pipeline networks and assigned a specific weight to each term. Table 8 reused the same terms as a previous table for comparative analysis. The comparison shows increased TF-IDF values for most terms in the latter table. For example, TF-IDF values increased, such as “construction” from 0.87825 to 0.98185, “production” from 0.75127 to 0.94400, and “installation” from 0.61668 to 1.01146. This increase may indicate a higher frequency or greater distinctiveness of these terms in the relevant document corpus. Conversely, the TF-IDF value for “excavator” dropped significantly from 0.58360 to 0.23351, likely indicating a decrease in specificity or an increase in general usage within the final document collection. The TF-IDF value for “emergency” increased from 0.58144 to 1.17261, suggesting heightened specificity and importance. Significant increases in the TF-IDF values for “safety” and “gas” indicate a heightened focus on these concepts within the domain.
Table 8.
Evaluation table of term importance within the lexicon.
The causes of emergencies in gas pipeline networks are diverse and complex, with considerable interactions among various factors. Analyzing causes is crucial for assessing network vulnerability, conducting dynamic risk assessments, managing risks, evaluating accident consequences, studying disaster mechanisms, and analyzing accident impacts. To assess the effectiveness of the domain-specific lexicon, we introduced a task to visualize the reduced dimensionality of word embeddings for causes of emergencies in gas pipeline networks. These data and their identifiers are detailed in Table 9.
Table 9.
List of causes and corresponding identifiers for emergencies in gas pipeline networks.
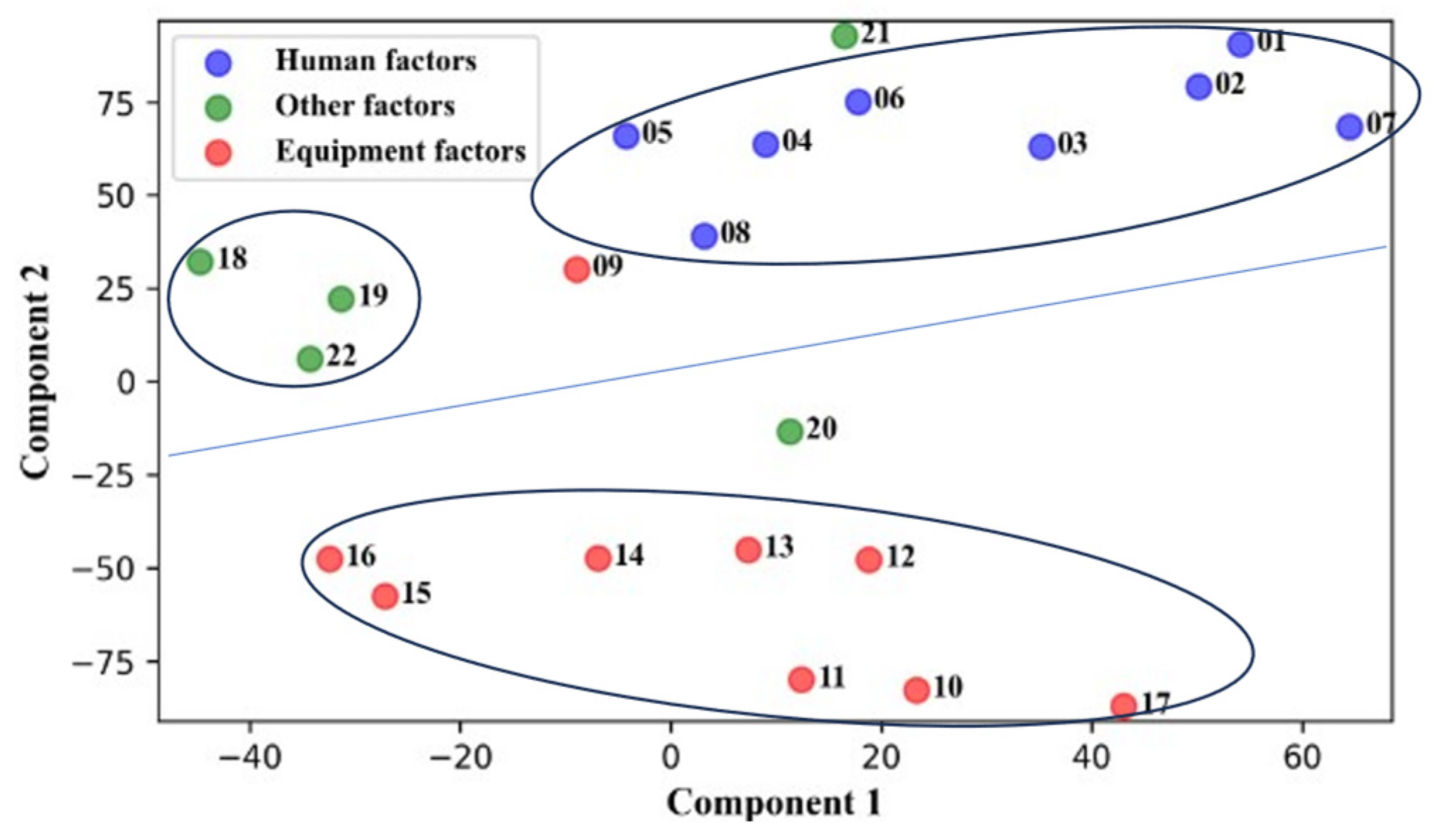
Emergencies in gas pipeline networks are categorized by human-related factors, equipment-related factors, and other factors. Initially, word embeddings are generated for these causes, and then their dimensionality is reduced to two dimensions using t-SNE. The results are shown in Figure 8. Distinct spatial separations among points of different colors are evident, with equipment-related factors (red) typically in different regions from human-related factors (blue) and other factors (green). Clustering, represented by ellipses, shows that most points within each cluster share the same color, indicating a high degree of internal consistency and excellent clustering quality. The figure may also display some boundary or outlier points situated on the borders between different colored zones or distant from the primary clusters. These occurrences suggest complex structures in higher-dimensional spaces or unique characteristics of some data points that are hard to detect.
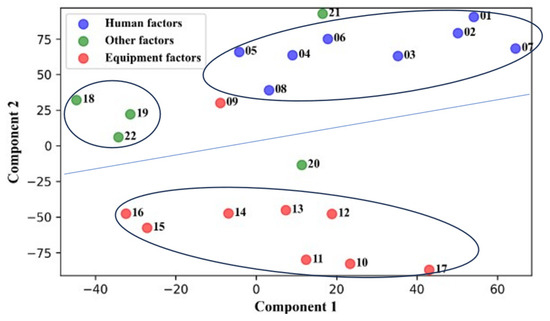
Figure 8.
Two-dimensional visualization of clusters in word embeddings.
4. Discussion
Developing a specialized domain lexicon is crucial for digitizing the field, enhancing human–computer interaction, and applying deep learning techniques. Despite their high visibility and impact, gas pipeline emergencies currently lack a customized domain lexicon for effective response.
This paper proposes a method for constructing a gas pipeline emergency lexicon by integrating word embedding and statistical techniques. The main tasks include collecting standards and risk lists, fine tuning a pre-trained model to capture the semantic information, and constructing a domain-specific lexicon.
Regarding content coverage, the lexicon developed in this study includes investigation reports, laws and regulations, emergency plans, training materials, academic papers, standards and specifications, and news reports, covering various aspects of gas pipeline emergency response.
Regarding scale, the lexicon boasts advantages in both quantity and diversity of words, with distinct semantic differentiation among different word types, indicating that the proposed model effectively captures domain-specific information.
Regarding effectiveness, the lexicon enhances the digitization of domain knowledge, enabling rapid search and understanding of relevant information, thereby providing a foundational tool for responding to gas pipeline emergencies.
Regarding presentation, the lexicon includes domain-specific words, their respective weights, and the degree of similarity between words. In future research, this lexicon can be applied to improve emergency cause identification, result prediction, and knowledge graph construction, which are also our next research focus.
This lexicon is crucial for responding to gas pipeline emergencies, encompassing early warning and risk identification, accident cause analysis and response, and risk assessment and management. This domain lexicon can be applied to accurately identify causes, automate knowledge graph construction, and quantitatively assess risks.
The domain-specific lexicon from this study is available upon request. Interested researchers or practitioners are encouraged to contact the authors directly. We are pleased to provide access to the lexicon and support its application in advancing emergency management practices in gas pipeline networks. Incorporating this lexicon into these platforms may enhance critical functions such as risk analysis, decision making, and incident management. The lexicon supports various phases of emergency response, including early warning, real-time incident management, and post-incident analysis. This integration can lead to more precise decision making and effective risk management, potentially strengthening the overall emergency preparedness and response capabilities of organizations dealing with gas pipeline networks.
Although this study introduces a promising approach to constructing a gas pipeline emergency lexicon, certain limitations exist. Data sources, such as investigation reports and standards, may not fully capture all relevant aspects of gas pipeline incidents, potentially leading to gaps in the lexicon. Additionally, despite efforts to fine tune the BERT model with domain-specific data, capturing the precise semantic nuances of specialized terms remains challenging, potentially affecting the lexicon’s accuracy. Furthermore, the methods used for term extraction and word similarity analysis might not fully address issues like polysemy and synonymy, potentially impacting the reliability of the lexicon. These limitations highlight areas for future research, including expanding data sources, improving model precision, and developing more sophisticated semantic analysis techniques to enhance the lexicon’s effectiveness and applicability.
5. Conclusions
This study presents a methodology for developing a specialized lexicon for emergency incidents in gas pipeline networks. The method not only integrates standard terminology and risk inventory knowledge but also combines statistical-based approaches with pre-trained models. Analysis shows that the resulting domain-specific lexicon is highly applicable in its intended context.
This research aims to significantly improve emergency management in gas pipeline networks. The lexicon supports cause analysis, a critical component of emergency response, by encompassing an extensive array of domain-specific terms. The TF-IDF values, a statistical measure of term relevance, indicate the importance of specific terms in this domain, supporting cause analysis. Furthermore, this lexicon facilitates domain knowledge acquisition and aids in decision categorization within emergency decision-making systems. Given its domain-specific attributes, the lexicon is expected to enhance domain knowledge graph development and improve named entity recognition accuracy.
This study makes significant progress in constructing a domain-specific lexicon for gas pipeline emergencies, though certain limitations remain. The breadth of data sources, challenges in capturing precise semantics, and difficulties in term extraction and analysis highlight areas needing improvement. Future research will address these issues by expanding data sources, improving model precision, and refining semantic analysis. These efforts aim to enhance the lexicon’s comprehensiveness and reliability, ensuring its broader applicability and effectiveness in real-world scenarios.
Author Contributions
Conceptualization, X.Z. and Y.H.; methodology, X.Z.; software, X.Z.; validation, T.Q., W.W. and Y.W.; formal analysis, X.Z.; investigation, Y.H.; resources, Y.W.; data curation, W.W.; writing—original draft preparation, X.Z.; writing—review and editing, Y.H.; visualization, X.Z.; supervision, Y.H.; project administration, W.W.; funding acquisition, Y.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Program of China, grant number 2020YFC1511701, and the Beijing Municipal Science and Technology Plan Project, grant numbers Z221100005222024 and Z221100005222020.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Inside China’s 2023 Natural Gas Development Report. Available online: https://www.energypolicy.columbia.edu/inside-chinas-2023-natural-gas-development-report/ (accessed on 9 May 2024).
- Zheng, D.; Zhang, J.; Liu, Z.; Liu, Q.; Liu, C.; Yao, W.; Li, M. Effects of Pipeline Pressure on Diffusion Characteristics of Leaked Natural Gas in Tunnel Space. ACS Omega 2023, 8, 10235–10241. [Google Scholar] [CrossRef]
- Wang, W.; Mou, D.; Li, F.; Dong, C.; Khan, F. Dynamic Failure Probability Analysis of Urban Gas Pipeline Network. J. Loss Prev. Process Ind. 2021, 72, 104552. [Google Scholar] [CrossRef]
- Li, J.; Yan, M.; Yu, J. Evaluation on Gas Supply Reliability of Urban Gas Pipeline Network. Eksploat. Niezawodn.—Maint. Reliab. 2018, 20, 471–477. [Google Scholar] [CrossRef]
- Tian, F.-J.; Chen, J.K.C. Ranking the Social-Impact Factors for Major Security Emergency of Oil and Gas Pipelines in Urban. In Proceedings of the 2016 Portland International Conference on Management of Engineering and Technology (PICMET), Honolulu, HI, USA, 4–8 September 2016; pp. 2067–2076. [Google Scholar] [CrossRef]
- Varsegova, E.; Dresvyannikova, E.; Osipova, L.; Sadykov, R. Damage Areas during Emergency Depressurization of a Gas Pipeline. E3S Web Conf. 2019, 140, 06007. [Google Scholar] [CrossRef]
- Heidarysafa, M.; Kowsari, K.; Barnes, L.; Brown, D. Analysis of Railway Accidents’ Narratives Using Deep Learning. In Proceedings of the 2018 International Conference on Big Data, Orlando, FL, USA, 17–20 December 2018; pp. 1446–1453. [Google Scholar] [CrossRef]
- Xu, H.; Li, Y.; Zhou, T.; Lan, F.; Zhang, L. An overview of the oil and gas pipeline safety in China. J. Ind. Saf. 2024, 1, 100003. [Google Scholar] [CrossRef]
- Song, X.Y.; Li, X.R.; Liang, Z.Q.; Li, R. Research on the Demand for Emergency Rescue Materials and the Optimization of Rescue Points in Gas Pipeline Leakage and Explosion. J. Saf. Environ. 2024, 24, 1136–1142. [Google Scholar] [CrossRef]
- Zhou, X.; Yang, D.; Chen, X.; Fang, L. Dynamic Evolution Computing of Leakage and Diffusion from Pipeline Gas and Risk Analysis. Int. J. Environ. Sci. Technol. 2023, 20, 6091–6102. [Google Scholar] [CrossRef]
- Chen, X.; Lin, W.; Liu, C.; Yang, F.; Guo, Y.; Li, X.; Yuan, S.; Reniers, G. An Integrated EDIB Model for Probabilistic Risk Analysis of Natural Gas Pipeline Leakage Accidents. J. Loss Prev. Process Ind. 2023, 83, 105027. [Google Scholar] [CrossRef]
- Parlak, B.O.; Yavasoglu, H.A. A Comprehensive Analysis of In-Line Inspection Tools and Technologies for Steel Oil and Gas Pipelines. Sustainability 2023, 15, 2783. [Google Scholar] [CrossRef]
- Shaukat, K.; Hameed, I.A.; Luo, S.; Javed, I.; Iqbal, F.; Faisal, A.; Masood, R.; Usman, A.; Shaukat, U.; Hassan, R.; et al. Domain Specific Lexicon Generation through Sentiment Analysis. Int. J. Emerg. Technol. Learn. (IJET) 2020, 15, 190–204. [Google Scholar] [CrossRef]
- Cheng, Y.; Huang, Y. Research and Development of Domain Dictionary Construction System. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 1162–1165. [Google Scholar]
- Ren, W.; Zhang, H.; Chen, M. A Method of Domain Dictionary Construction for Electric Vehicles Disassembly. Entropy 2022, 24, 363. [Google Scholar] [CrossRef] [PubMed]
- Kohita, R.; Yoshida, I.; Kanayama, H.; Nasukawa, T. Interactive construction of user-centric dictionary for text analytics. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 789–799. [Google Scholar]
- Zhang, Y.; Li, B.; Lv, X.; Sun, N.; Tian, J.-J. Research on domain term dictionary construction based on Chinese Wikipedia. DEStech Trans. Comput. Sci. Eng. 2018, 3. [Google Scholar] [CrossRef] [PubMed]
- Duan, J.; Wang, M.; Guan, Y.; Lin, Q. A method for building Chinese domain lexicon based on new words recommendation. In Proceedings of the 2022 3rd International Conference on Computer Science and Management Technology (ICCSMT), Shanghai, China, 18–20 November 2022; pp. 516–522. [Google Scholar]
- Sood, M.; Kaur, H.; Gera, J. Creating domain-based dictionary and its evaluation using classification accuracy. In Proceedings of the 2021 8th International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 17–19 March 2021; pp. 341–347. [Google Scholar]
- Han, N.; Wu, J.; Fang, X.; Teng, S.; Zhou, G.; Xie, S.; Li, X. Projective double reconstructions based dictionary learning algorithm for cross-domain recognition. IEEE Trans. Image Process. 2020, 29, 9220–9233. [Google Scholar] [CrossRef]
- Luo, X.; Deng, Z.; Yang, B.; Luo, M.Y. Pre-trained language models in medicine: A survey. Artif. Intell. Med. 2024, 154, 102904. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–9 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for Chinese BERT. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Rose, R.L.; Puranik, T.G.; Mavris, D.N.; Rao, A.H. Application of structural topic modeling to aviation safety data. Reliab. Eng. Syst. Saf. 2022, 224. [Google Scholar] [CrossRef]
- Na, X.; Ling, M.; Liu, Q.; Li, W.; Deng, Y. An improved text mining approach to extract safety risk factors from construction accident reports. Saf. Sci. 2021, 138, 105216. [Google Scholar]
- Yi, R.; Zhang, T.; Xing, X.; Ma, W.; Zhang, K.; Liu, W. Construction of a disaster and accident domain dictionary integrating standard knowledge. China Stand. 2022, 15, 88–94+117. [Google Scholar]
- Pillai, P.; Ryali, S.; Maniar, H.; Mangsuli, P.; Abubakar, A. NLP Applications in the Oil and Natural Gas Industry. In Proceedings of the Second International Meeting for Applied Geoscience & Energy, Houston, TX, USA, 28 August–1 September 2022; Society of Exploration Geophysicists and American Association of Petroleum: Houston, TX, USA, 2022; pp. 1956–1960. [Google Scholar] [CrossRef]
- Liu, G.; Boyd, M.; Yu, M.; Halim, S.Z.; Quddus, N. Identifying Causality and Contributory Factors of Pipeline Incidents by Employing Natural Language Processing and Text Mining Techniques. Process Saf. Environ. Prot. 2021, 152, 37–46. [Google Scholar] [CrossRef]
- Huang, J.; Chang, K.C.-C.; Xiong, J.; Hwu, W. Measuring Fine-Grained Domain Relevance of Terms: A Hierarchical Core-Fringe Approach. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 1694–1703. [Google Scholar] [CrossRef]
- Abdoul Nasser, A.H.; Ndalila, P.D.; Mawugbe, E.A.; Emmanuel Kouame, M.; Arthur Paterne, M.; Li, Y. Mitigation of Risks Associated with Gas Pipeline Failure by Using Quantitative Risk Management Approach: A Descriptive Study on Gas Industry. J. Mar. Sci. Eng. 2021, 9, 1098. [Google Scholar] [CrossRef]
- International Organization for Standardization. Available online: https://www.iso.org/home.html (accessed on 31 July 2024).
- International Telecommunication Union. Available online: https://www.itu.int:443/zh/Pages/default.aspx (accessed on 31 July 2024).
- International Electrotechnical Commission. Available online: https://www.iec.ch/homepage (accessed on 31 July 2024).
- Standard for Safety Inspection of Urban Gas Facilities; Zhejiang Provincial Department of Housing and Urban-Rural Development: Hangzhou, Zhejiang, 2020.
- Technical Specification for Trenchless Rehabilitation and Replacement Engineering of City Gas Pipe; Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2011.
- Technical Specification for Leak Detection of City Gas Piping System; Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2014.
- Technical Specification for Control of External Corrosion on Under-Ground Gas Pipeline of Steel in Area of Cities and Towns; Ministry of Housing and Urban-Rural Development of the People’s Republic of China: Beijing, China, 2014.
- Xu, H.; Liu, Y.; Shu, C.-M.; Bai, M.; Motalifu, M.; He, Z.; Wu, S.; Zhou, P.; Li, B. Cause Analysis of Hot Work Accidents Based on Text Mining and Deep Learning. J. Loss Prev. Process Ind. 2022, 76, 104747. [Google Scholar] [CrossRef]
- Deng, C.; Yu, H.; Fan, G.; Zhu, H. Sentiment Analysis of Chinese Texts for Gas Customer Service Hotline. J. East China Univ. Sci. Technol. Nat. Sci. Ed. 2019, 45, 140–147. [Google Scholar]
- Hu, J.; Huang, R.; Xu, F. Data mining in coal-mine gas explosion accidents based on evidence-based safety: A case study in China. Sustainability 2022, 14, 16346. [Google Scholar] [CrossRef]
- Zhang, B.; Yao, X.; Li, H.; Aini, M. Chinese Medical Named Entity Recognition Based on Expert Knowledge and Fine-Tuning Bert. In Proceedings of the 2023 IEEE International Conference on Knowledge Graph, ICKG, Shanghai, China, 1–2 December 2023; IEEE: New York, NY, USA, 2023; pp. 84–90. [Google Scholar]
- Babić, K.; Guerra, F.; Martinčić-Ipšić, S.; Meštrović, A. A comparison of approaches for measuring the semantic similarity of short texts based on word embeddings. J. Inf. Organ. Sci. 2020, 44, 231–246. [Google Scholar] [CrossRef]
- Steck, H.; Ekanadham, C.; Kallus, N. Is cosine-similarity of embeddings really about similarity? In Proceedings of the ACM on Web Conference 2024, Singapore, 13–17 May 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 887–890. [Google Scholar]
- Wang, L.X. Research on the construction of a domain dictionary and its application in public safety event identification. J. Inf. Explor. 2020, 02, 13–20. [Google Scholar]
- Fan, H.W.; Fan, S.X.; Li, B.; Feng, C.Y.; Luo, H.M. Research on the construction method of professional dictionaries in the field of power dispatching. Electr. Power Inf. Commun. Technol. 2021, 57, 57–65. [Google Scholar] [CrossRef]
- Huang, J.Y.; Sun, R.Y. Construction of a dictionary in the field of commodity trading. J. Beijing Inf. Sci. Technol. Univ. (Nat. Sci. Ed.) 2022, 71, 71–75. [Google Scholar] [CrossRef]
- Chen, J.; Xi, N.L.; Li, J.M.; Wan, X.R. Construction of a sentiment dictionary in the field of education by integrating Skip-gram and R-SOPMI. J. Appl. Sci. 2023, 870, 870–880. [Google Scholar]
- Xu, Y.; Wei, W.; Wang, Z. Development of a Chinese Tourism Technical Word List Based on Corpus Analysis. In Chinese Lexical Semantics; Springer: Singapore, 2024; pp. 405–419. [Google Scholar]
- Xu, Z. RoBERTa-Wwm-Ext Fine-Tuning for Chinese Text Classification. In Proceedings of the 2021 International Conference on Asian Language Processing (IALP), Singapore, 23–25 October 2021; pp. 216–220. [Google Scholar]
- National Gas Accident Analysis Report for the First Half of 2023; Urban and Rural Construction: Newcastle, South Africa, 2023; pp. 18–23.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).