
Fusion of Multiple Attention Mechanisms and Background Feature Adaptive Update Strategies in Siamese Networks for Single-Object Tracking

Abstract
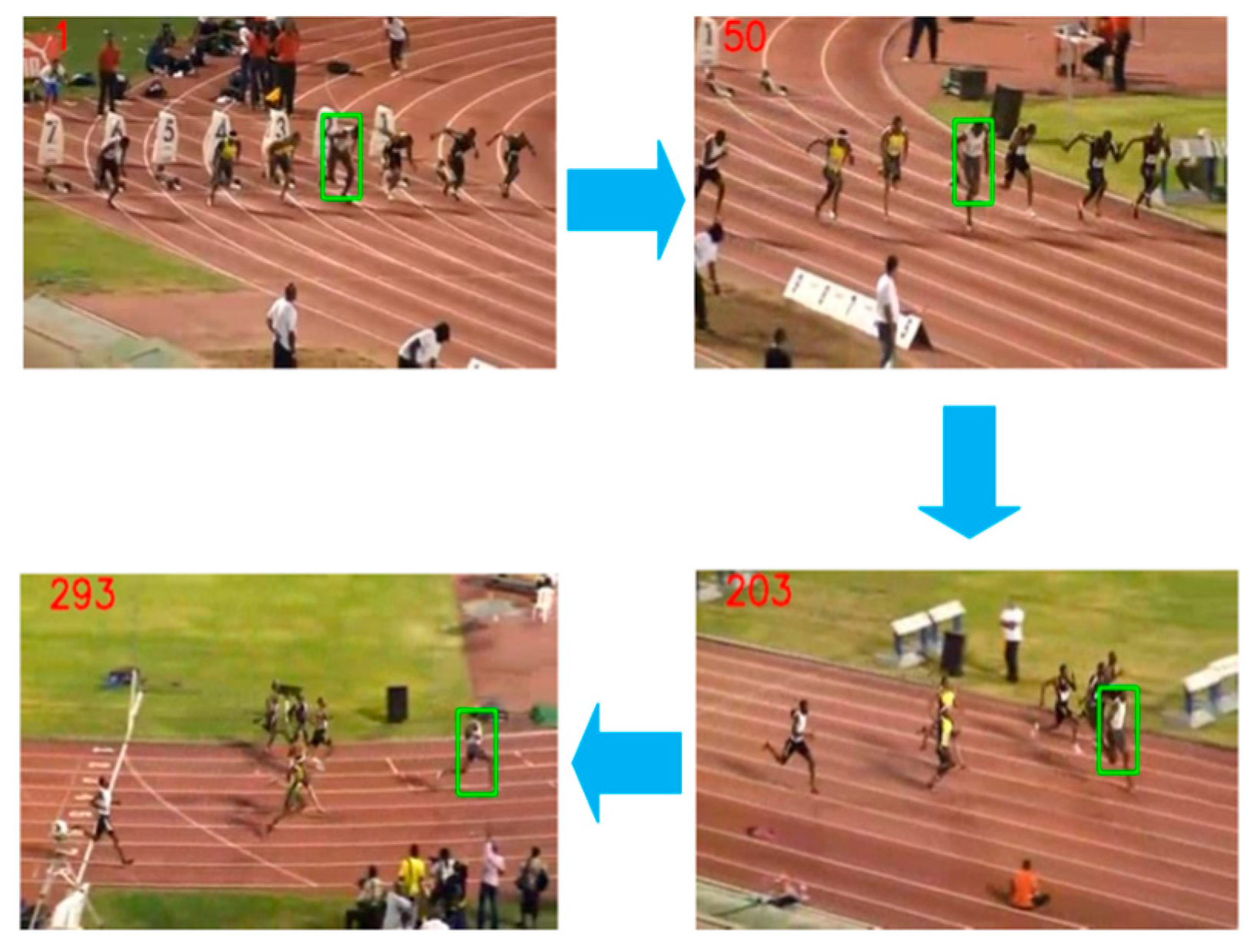
1. Introduction
- (1)
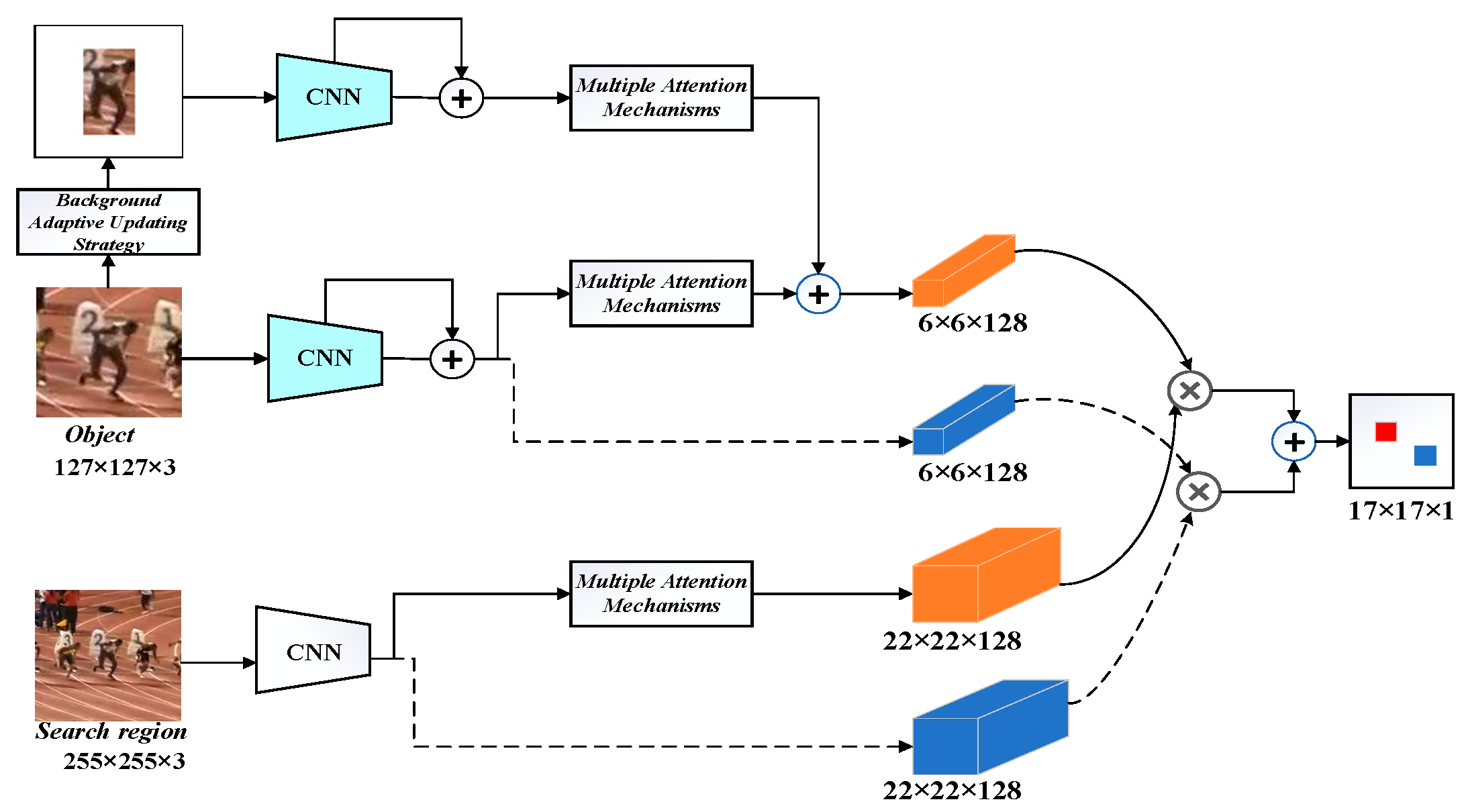
- We designed a backbone feature extraction network with a small convolutional kernel and hopping layer connection feature fusion. It can not only effectively extract the deep semantic features of the object, but also fuse the mid-level features with the deep features through the hopping layer connection, which is conducive to the enhancement of the feature expression ability of the network. Meanwhile, utilizing 3 × 3 and 1 × 1 small convolution kernels for convolution operation can increase the depth of the network while reducing the network parameters.
- (2)
- A background feature adaptive updating strategy was proposed in our algorithm and applied to the processing of the object template. First, after the object template is processed through the background feature adaptive updating strategy, it highlights the object features and weakens the background features so that the object features form a sharp contrast with the background features, so that the algorithm can fully distinguish the object and background features in the object template. Then, the object features obtained after processing through the background feature adaptive updating strategy, and then through the backbone feature extraction network and multiple attention mechanisms, are linearly fused with another object feature that has not been processed through the background feature adaptive updating strategy. Then through the backbone feature extraction network and multiple attention mechanisms, the algorithm’s ability to discriminate between the object features and the background features can be effectively enhanced.
- (3)
- The fusion of multiple attention mechanisms is proposed in our algorithm, which consists of an improved hybrid attention mechanism connected in parallel with the CA attention mechanism. Applying it to the object template branch and the search region branch enables the algorithm to locate and recognize the tracking object more precisely, and makes the algorithm adaptively learn to focus on the channel, spatial, and coordinate feature information of the tracking object, thus improving the attention ability and precision of the algorithm.
- (4)
- In our algorithm, we propose a response fusion operation, a mutual correlation operation, where the original object features are convolved with the original search region features, and the object features after multiple attention mechanisms are convolved with the search region features after multiple attention mechanisms, and the results of the two convolutional mutual correlations are linearly fused to obtain the final response map in order to enrich the output response of the algorithm.
2. Research Work
2.1. Siamese Network Framework
2.2. Adaptive Updating Strategy for Background Features
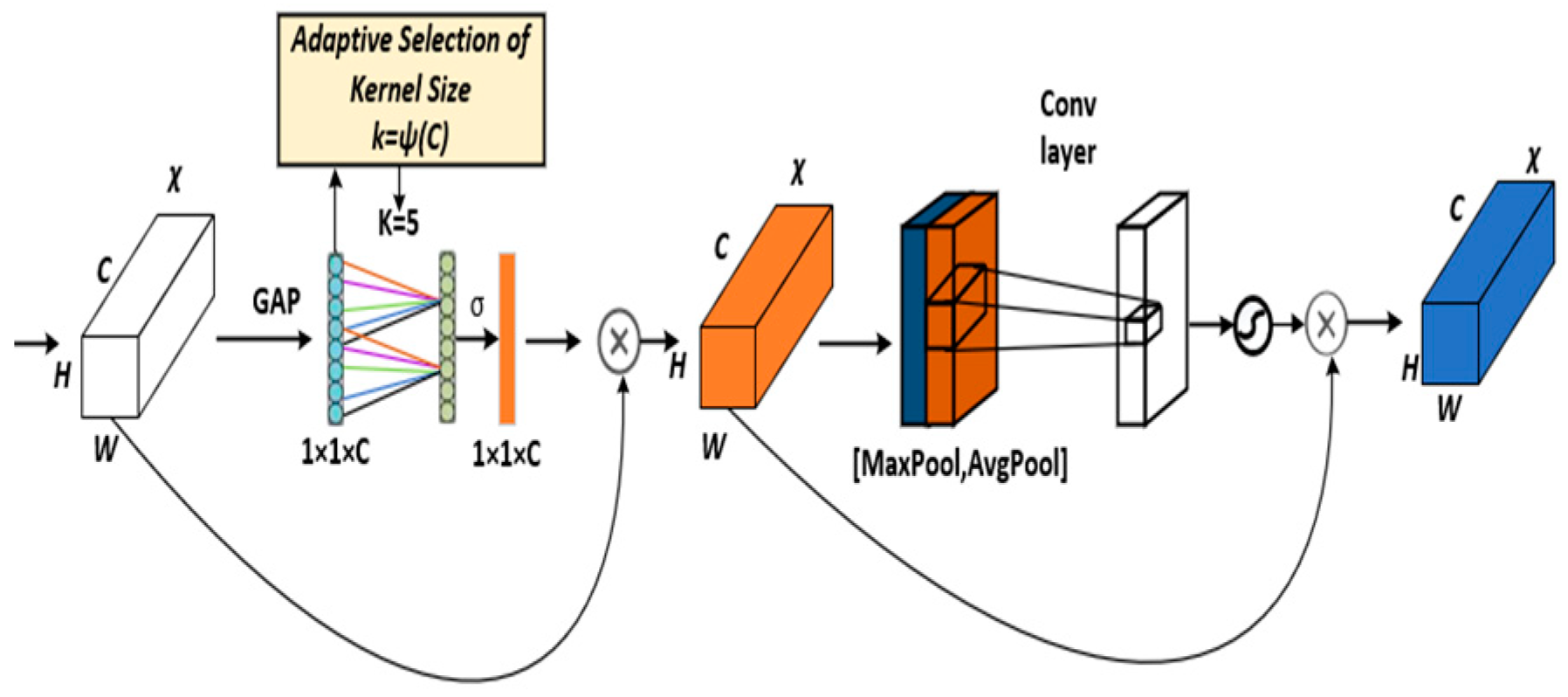
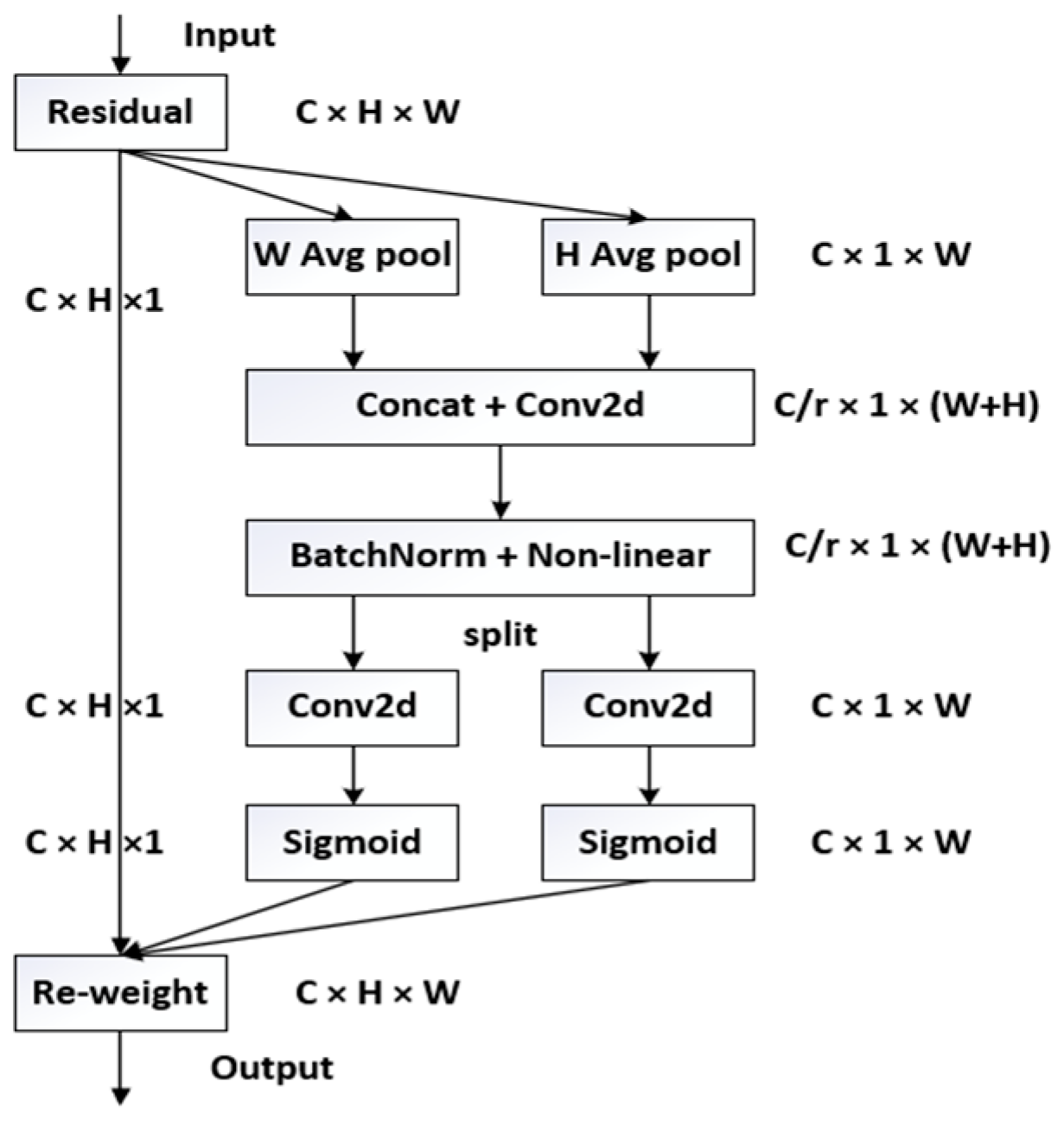
2.3. Fusion of Multiple Attention Mechanisms
2.4. Response Fusion Operations after Convolutional Inter-Correlation
3. Training and Testing of Algorithms
4. Algorithm Test Results
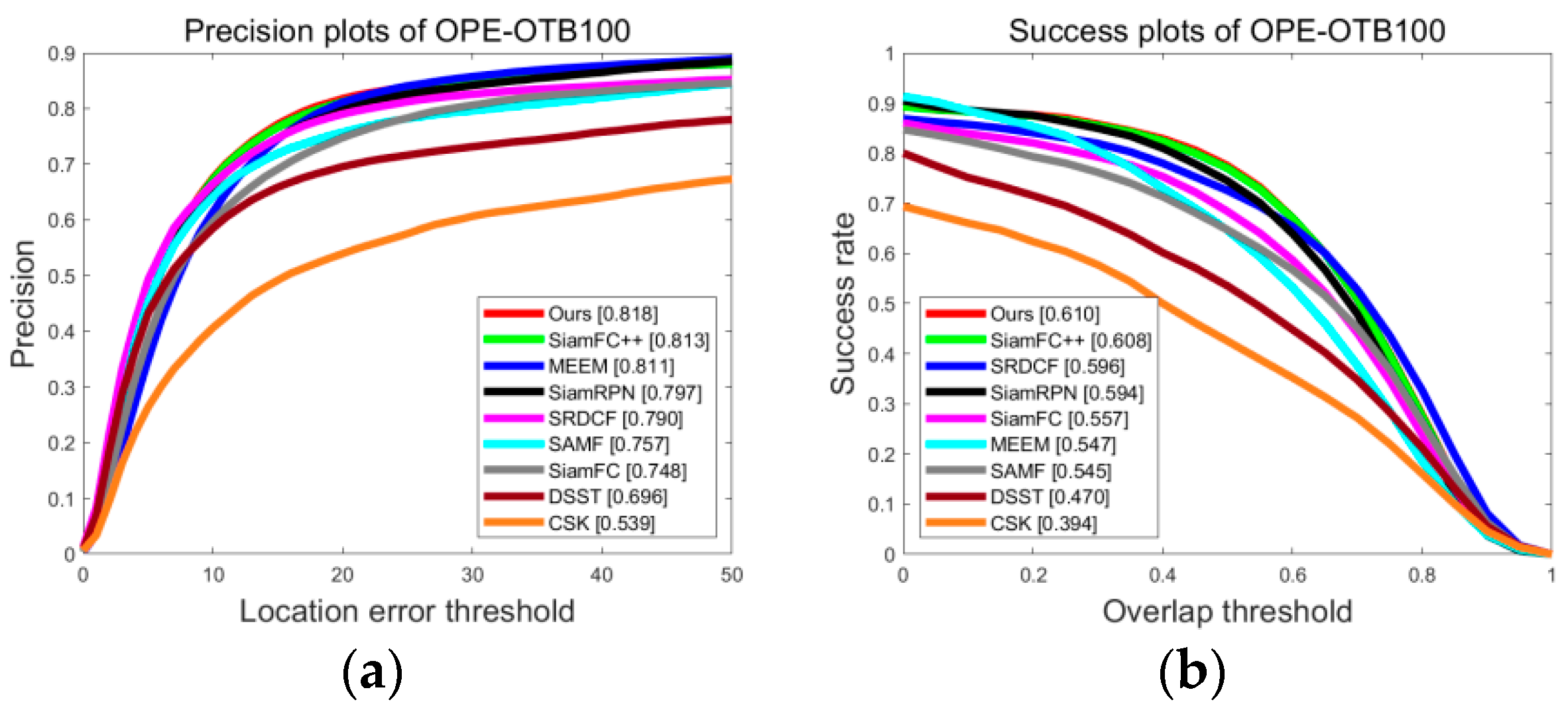
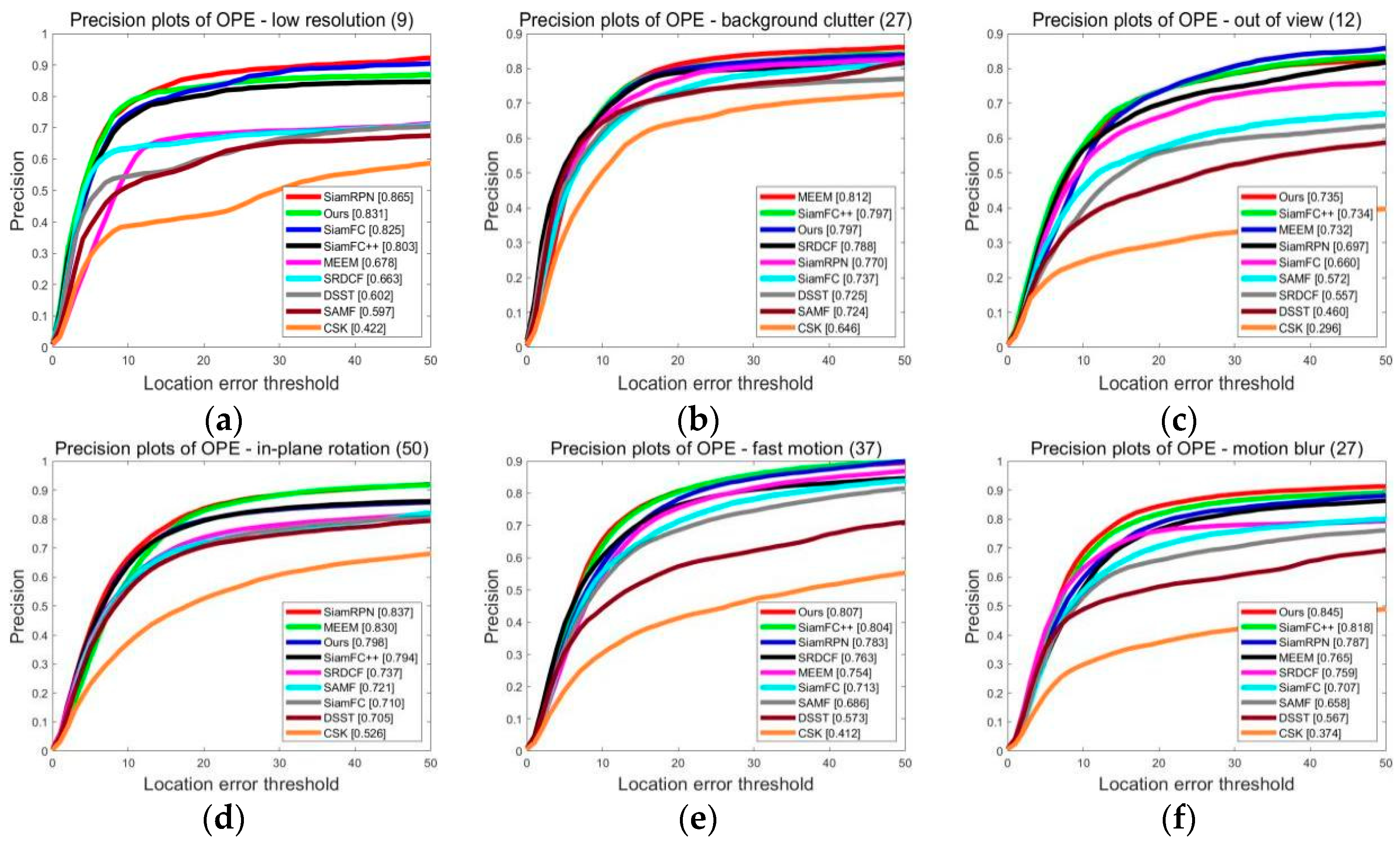
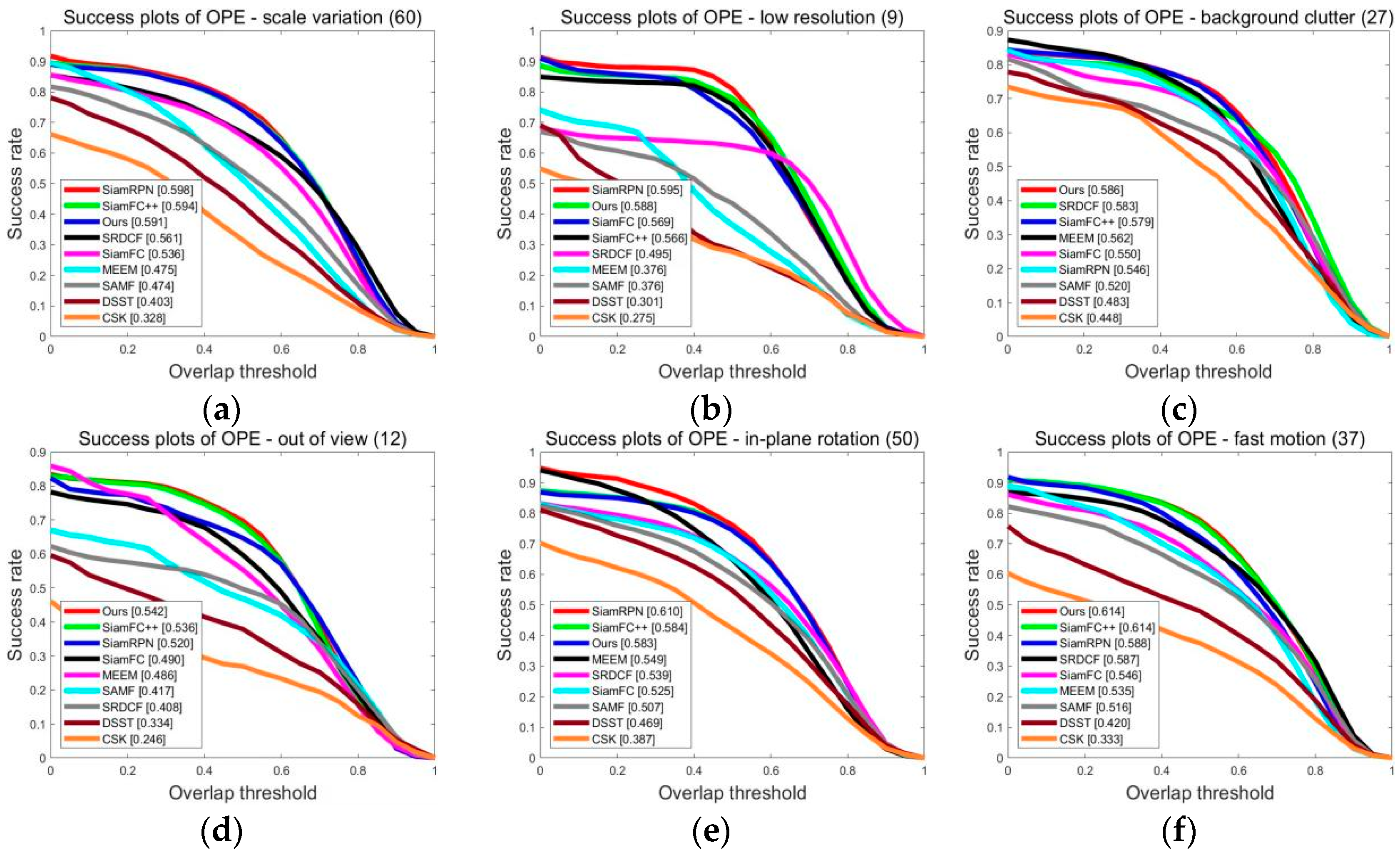
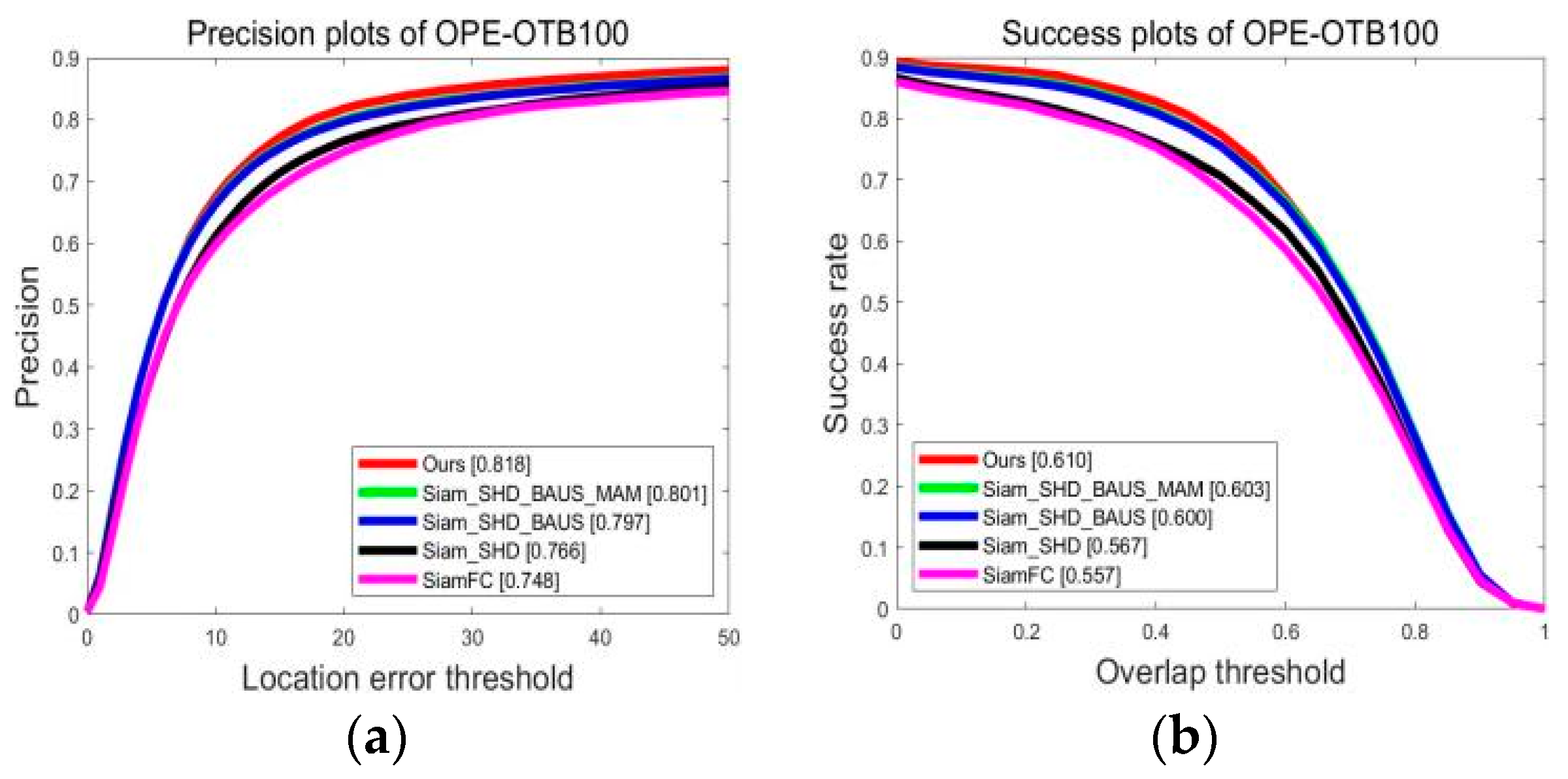
4.1. OTB Dataset Test Results and Analysis
4.2. VOT Dataset Test Results and Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yilmaz, A.; Javed, O.; Shah, M. Object Tracking: A Survey. ACM Comput. Surv. 2006, 38, 13. [Google Scholar] [CrossRef]
- Li, P.X.; Wang, D.; Wang, L.J.; Lu, H. Deep visual tracking: Review And experimental comparison. Pattern Recognit. 2018, 76, 323–338. [Google Scholar] [CrossRef]
- Zheng, C.; Usagawa, T. A rapid webcam-based eye tracking method for human computer interaction. In Proceedings of the 2018 International Conference on Control, Automation and Information Sciences (ICCAIS), Hangzhou, China, 24–27 October 2018; pp. 133–136. [Google Scholar]
- Sarcinelli, R.; Guidolini, R.; Cardoso, V.B.; Paixão, T.M.; Berriel, R.F.; Azevedo, P.; De Souza, A.F.; Badue, C.; Oliveira-Santos, T. Handling pedestrians in self-driving cars using image tracking and alternative path generation with Frenét frames. Comput. Graph. 2019, 84, 173–184. [Google Scholar] [CrossRef]
- Wu, Y.; Lim, J.; Yang, M.-H. Online object tracking: A benchmark. In Proceedings of the 2013 IEEE International Conference on Computer Vision and Pattern Recogintion (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Cheng, J.; Wang, J.; Lu, H. Real-time visual tracking via Incremental Covariance Tensor Learning. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 1631–1638. [Google Scholar]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recogintion (CVPR), Hilton Head, SC, USA, 15 June 2000; pp. 142–149. [Google Scholar]
- Comaniciu, D.; Ramesh, V.; Meer, P. Kernel-based object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 564–577. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking using Adaptive Correlation Filters. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, IEEE, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the Circulant Structure of Tracking-by-Detection with Kernels. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Florence, Italy, 2012; pp. 702–715. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; IEEE: Santiago, Chile, 2015; pp. 3074–3082. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the 2005 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Li, Y.; Zhu, J. A scale adaptive kernel correlation filter tracker with feature integration. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–7 and 12 September 2014; Springer: Cham, Switzerland, 2014; pp. 254–265. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; Lecun, Y.; Moore, C.; Sackinger, E.; Shah, R. Signature verification using a “Siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-convolutional siamese networks for object tracking. In Proceedings of the Computer Vision—ECCV 2016 Workshops (ECCV), Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 850–865. [Google Scholar]
- Abdelpakey, M.H.; Shehata, M.S.; Mohamed, M.M. DensSiam: End-to-end densely-siamese network with self-attention model for object tracking. In International Symposium on Visual Computing; Springer: Cham, Switzerland, 2018; pp. 463–473. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region network. In Proceedings of the 2018 IEEE/CVF Conference of Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with object estimation guidelines. In Proceedings of the 34th AAAI Conference on Artificial Intelligence (AAAI-20), New York, NY, USA, 7–12 February 2020; pp. 12549–12556. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, Y.; Zhang, X. SiamVGG: Visual Tracking using Deeper Siamese Networks. arXiv 2019, arXiv:arXiv.1902.02804. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, L.; Bertinetto, L.; Hu, W.; Torr, P.H.S. Fast Online Object Tracking and Segmentation: A Unifying Approach. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1328–1338. [Google Scholar] [CrossRef]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-end representation learning for correlation filter based tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015. [Google Scholar]
- Chaudhari, S.; Polatkan, G.; Ramanath, R.; Mithal, V. An attentive survey of attention models. arXiv 2019, arXiv:1904.02874. [Google Scholar] [CrossRef]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for realtime object tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4834–4843. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the Computer Vision—ECCV 2018 (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient channel attention for deep convolutional neural network. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Huang, L.; Zhao, X.; Huang, K. GOT-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1562–1577. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Fan, B.; Peng, Y. Adaptive Scale Correlation Filter Tracker with Feature Fusion. In Proceedings of the 30th Chinese Conference on Control and Decision Making, Shenyang, China, 9–11 June 2018. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust Tracking via Multiple Experts Using Entropy Minimization. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate Scale Estimation for Robust Visual Tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Li, B.; Maybank, S. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. J. Comput. Sci. Technol. 2024, 39, 691–714. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pfugfelder, R.; Zajc, L.C.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking VOT2018 challenge results. In Proceedings of the Computer Vision—ECCV 2018 Workshops (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–53. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Definition Layer | Layer | Kernel Size | Stride/Channel | Template | Search |
|---|---|---|---|---|---|
| Input | /3 | 127 × 127 | 255 × 255 | ||
| conv1 | CONV1-BN | 3 × 3 | 1/64 | 125 × 125 | 253 × 253 |
| CONV2-BN | 3 × 3 | 1/128 | 123 × 123 | 251 × 251 | |
| CONV3-BN-ReLu | 1 × 1 | 1/64 | 123 × 123 | 251 × 251 | |
| MaxPool | 2 × 2 | 2/64 | 61 × 61 | 125 × 125 | |
| conv2 | CONV4-BN | 3 × 3 | 1/128 | 59 × 59 | 123 × 123 |
| CONV5-BN | 1 × 1 | 1/64 | 59 × 59 | 123 × 123 | |
| CONV6-BN-ReLu | 3 × 3 | 1/128 | 57 × 57 | 121 × 121 | |
| MaxPool | 2 × 2 | 2/128 | 28 × 28 | 60 × 60 | |
| conv3 | CONV7-BN | 3 × 3 | 1/256 | 26 × 26 | 58 × 58 |
| CONV8-BN | 1 × 1 | 1/128 | 26 × 26 | 58 × 58 | |
| CONV9-BN-ReLu | 3 × 3 | 1/256 | 24 × 24 | 56 × 56 | |
| MaxPool | 2 × 2 | 2/256 | 12 × 12 | 28 × 28 | |
| conv4 | CONV10-BN | 3 × 3 | 1/512 | 10 × 10 | 26 × 26 |
| CONV11-BN | 1 × 1 | 1/256 | 10 × 10 | 26 × 26 | |
| CONV12-BN | 3 × 3 | 1/512 | 8 × 8 | 24 × 24 | |
| CONV13-BN-ReLu | 1 × 1 | 1/256 | 8 × 8 | 24 × 24 | |
| conv5 | CONV14 | 3 × 3 | 1/256 | 6 × 6 | 22 × 22 |
| Tracking Algorithms | Ours | SiamFC | SiamFC++ | SiamRPN | MEEM | SAMF | CSK |
| Average Running Speed (FPS) | 60 | 86 | 90 | 160 | 6 | 7 | 362 |
| Tracking Algorithms | EAO | Precision | Robustness |
|---|---|---|---|
| Our | 0.229 | 0.511 | 0.514 |
| MEEM | 0.192 | 0.463 | 0.534 |
| siamFC | 0.188 | 0.503 | 0.585 |
| DCFNet | 0.182 | 0.470 | 0.543 |
| SRDCF | 0.119 | 0.490 | 0.974 |
| DSST | 0.079 | 0.395 | 1.452 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, W.; Meng, F.; Yu, C.; You, A. Fusion of Multiple Attention Mechanisms and Background Feature Adaptive Update Strategies in Siamese Networks for Single-Object Tracking. Appl. Sci. 2024, 14, 8199. https://doi.org/10.3390/app14188199
Feng W, Meng F, Yu C, You A. Fusion of Multiple Attention Mechanisms and Background Feature Adaptive Update Strategies in Siamese Networks for Single-Object Tracking. Applied Sciences. 2024; 14(18):8199. https://doi.org/10.3390/app14188199
Chicago/Turabian StyleFeng, Wenliang, Fanbao Meng, Chuan Yu, and Anqing You. 2024. "Fusion of Multiple Attention Mechanisms and Background Feature Adaptive Update Strategies in Siamese Networks for Single-Object Tracking" Applied Sciences 14, no. 18: 8199. https://doi.org/10.3390/app14188199
APA StyleFeng, W., Meng, F., Yu, C., & You, A. (2024). Fusion of Multiple Attention Mechanisms and Background Feature Adaptive Update Strategies in Siamese Networks for Single-Object Tracking. Applied Sciences, 14(18), 8199. https://doi.org/10.3390/app14188199