Abstract
Person re-identification (Re-ID) is a technique for identifying target pedestrians in images or videos. In recent years, owing to the advancements in deep learning, research on person re-identification has made significant progress. However, current methods mostly focus on salient regions within the entire image, overlooking certain hidden features specific to pedestrians themselves. Motivated by this consideration, we propose a novel person re-identification network. Our approach integrates pedestrian edge features into the representation and utilizes edge information to guide global context feature extraction. Additionally, by modeling the internal relationships between different parts of pedestrians, we enhance the network’s ability to capture and understand the interdependencies within pedestrians, thereby improving the semantic coherence of pedestrian features. Ultimately, by fusing these multifaceted features, we generate comprehensive and highly discriminative representations of pedestrians, significantly enhancing person Re-ID performance. Experimental results demonstrate that our method outperforms most state-of-the-art approaches in person re-identification.
1. Introduction
Person re-identification (Re-ID) is a significant task in computer vision. It aims to address the problem of retrieving and matching the same individual across different camera views in a cross-camera environment, i.e., retrieving a given person from a large set of images. This technology achieves tracking and localization of specific pedestrian targets within large-scale video surveillance networks by extracting and comparing their features captured by various surveillance cameras. Re-ID holds crucial theoretical value and offers extensive practical applications in domains such as public safety, intelligent transportation, and smart cities.
Traditional pedestrian re-identification methods primarily rely on manually designed feature representations and similarity measurement techniques. These methods typically start by extracting low-level or mid-level features from pedestrian images, such as color histograms, texture features, and local descriptors (e.g., SIFT, HOG). Subsequently, they utilize metrics like Euclidean distance, Mahalanobis distance, or cosine similarity for feature matching [1,2,3]. However, these approaches exhibit significant limitations: (1) Limited Feature Representation: Manually designed features often struggle to comprehensively and effectively capture the complexity and diversity of pedestrian characteristics. This limitation becomes especially pronounced in complex scenarios involving variations in lighting, occlusion, and pose changes. (2) Shallow Feature-Based Distance Metrics: Distance metrics based on shallow features may fail to accurately reflect the deep semantic similarity among pedestrians. Consequently, this can lead to reduced recognition performance across different viewpoints and scenes.
The introduction of deep learning into the field of pedestrian re-identification undoubtedly provides novel perspectives and powerful tools for addressing this complex problem. Leveraging deep neural networks, particularly convolutional neural networks (CNNs), allows us to progressively extract high-level abstract features representing pedestrian identities from raw pixel-level data. This overcomes the limitations of traditional methods in terms of feature expressiveness. Currently, the steps involved in deep learning-based pedestrian re-identification are as follows: during the training phase, a deep CNN model is employed for end-to-end learning on pedestrian images. This model directly extracts discriminative feature representations from input images. Network weights are adjusted based on label feedback, and after multiple iterations, a mature network is formed. Widely used pre-trained models such as ResNet [4], VGG [5], and PCB [6] serve as the foundation, with fine-tuning to adapt them specifically to the task of pedestrian re-identification. In the evaluation phase, the trained network is utilized to extract features from both probe and gallery images. The goal is to match these features and select the top-n images with the highest similarity as the target pedestrian image. Researchers have proposed various methods to enhance network recognition accuracy from different perspectives. To improve the recognition accuracy of the network, researchers have proposed a variety of methods to improve network performance from different perspectives, such as data augmentation [7], feature fusion [8,9], feature sorting [10,11], and so on, and have achieved impressive results.
While pedestrian re-identification (Re-ID) based on convolutional neural networks (CNNs) has achieved commendable performance, it still faces numerous challenges in real-world scenarios. These challenges arise due to factors such as insufficient data volume, variations in lighting conditions, occlusions, diverse poses, varying resolutions, and background interference. Figure 1 illustrates some typical examples of these challenges.

Figure 1.
Challenges in person re-identification. (a) illumination change, (b) resolution change, (c) pose change, and (d) occlusion.
In these typical challenges, background interference is the most common phenomenon. This is because nearly all pedestrian images in open scenes contain a substantial amount of background, which affects the weight distribution of the network during training and consequently impacts person re-identification (Re-ID) performance. Attention networks can guide the network to focus on salient regions in the image, partially mitigating the impact of background interference. However, attention networks can only focus on specific areas and cannot precisely distinguish pedestrian boundaries, thus failing to eliminate background interference. Especially for complex backgrounds or images where the background occupies a significant portion of the frame, attention networks still fall short of ideal performance. Therefore, accurately identifying the pedestrian foreground in the image and performing feature extraction operations within the foreground region represents a potential method to reduce background interference and enhance person re-identification performance [12].
Furthermore, deep learning methods have a strong demand for data. However, in practical scenarios of pedestrian re-identification, obtaining a large amount of well-annotated cross-camera pedestrian data is challenging due to privacy protection and high annotation costs. Given the current limited dataset size, further mining of useful information hidden in images not only enhances feature representation capabilities and model accuracy but also addresses the issue of insufficient data. Pedestrian edges typically represent abrupt changes in brightness or color in images, revealing object contours, textures, shapes, and structures with rich detail features. Although edge features have been widely applied in areas such as object detection, image segmentation, and image enhancement, they are rarely considered in pedestrian re-identification. Introducing edge features into pedestrian re-identification tasks and studying their impact on performance is meaningful. Additionally, the relationships between different parts of pedestrian images constitute another typical hidden feature. These relationships reflect internal dependencies among different semantic components of pedestrians, including rich spatial and connectivity features. Combining these internal relational features with other high-level features (such as local textures and global colors) can provide a more comprehensive description of pedestrian appearance, thereby improving re-identification accuracy and robustness.
Motivated by the considerations mentioned above, we propose a novel person Re-ID network that leverages edge-enhanced feature extraction and part-level relationships. Our method integrates global features, edge features, and part-level relationships to achieve precise person matching. In the preprocessing stage, we utilize a fine-tuned fully convolutional network (FCN) to extract binary pedestrian masks from pedestrian images. Subsequently, we perform two key feature extraction processes within the foreground region: (1) Edge-Enhanced Global Feature Extraction: We employ an effective edge detection algorithm to generate pedestrian edge images. These edge images are combined with the original input images. Two deep learning network branches are used to extract pedestrian edge features and global features, respectively. Mutual information exchange between these features enhances the extraction of global features. (2) Inter-part Feature Extraction: We extract the foreground part of the features from (1) and divide it into non-overlapping sub-features along the horizontal direction based on semantics. Descriptors are constructed to reveal the relative relationships between different parts of pedestrians. Finally, we use a well-designed feature fusion layer to deeply integrate the aforementioned diverse features. By combining global structural consistency with local detail differences, we create highly discriminative representations of pedestrians. These fused feature vectors are used for cross-camera person re-identification, which effectively improves the accuracy and robustness of the system.
The main contributions of this paper are as follows:
- We propose an innovative person re-identification network that uniquely combines the richness of global features with the specificity of edge-enhanced details and the relationship among different body parts. By doing so, it not only captures the holistic appearance of individuals but also emphasizes fine-grained details and the structural relationships between various body segments. This comprehensive feature extraction strategy leads to a more robust and discriminative representation for pedestrian re-identification tasks.
- We propose an Edge-enhanced Feature Extraction Module (EFEM) that leverages dual deep learning network branches to independently capture the contour details and the comprehensive attributes of pedestrians. Facilitating information exchange between these distinct feature sets, significantly amplifies the system’s ability to extract and understand the global contextual features of pedestrians, leading to an enriched and more robust global representation.
- We propose an Inter-part Relationship Extraction Module (IREM) to extract the interdependence between pedestrian local features. This module aims at the main area of pedestrians, where we use a semantic-based soft segmentation strategy to subdivide the area into several different parts, and then carefully extract and analyze the associated features between these separate segments. The module significantly enhances the ability of the model to understand and interpret local features with higher accuracy, so that it can more effectively deal with the complex challenges related to cross-perspective changes and partial occlusion.
- We verified the performance of the network on three mainstream datasets, including Market-1501, DukeMTMC-reID, and MSMT17. The experimental results show that our method achieves optimal or near-optimal performance on multiple data sets, which proves the effectiveness of our proposed method.
The organization of the paper is as follows: Section 2 presents related work, Section 3 states the problem, Section 4 provides a detailed description of the proposed method, Section 5 presents the experimental setup and results, and finally, Section 6 concludes the article and offers prospects for future research.
2. Related Works
2.1. Deep Learning for Person Re-ID
Benefiting from rapid advancements in computer technology, pedestrian re-identification based on deep learning has become the predominant research direction and has yielded significant achievements. Its core research approach involves employing deep learning methodologies for feature vector extraction, followed by metric learning techniques to discriminate these feature vectors, thereby quantifying the discrepancies between images and refining the model through iterative training with ample annotated data. In the realm of pedestrian re-identification, global features are favored due to their intuitive representation and ease of learning, making them the most commonly used discriminative features. While global features are convenient for learning, they do not yield optimal results in pedestrian re-identification tasks due to issues such as occlusion and misalignment in pedestrian images. Consequently, researchers have incorporated local features into these tasks, utilizing both local and global characteristics as the identifiers of pedestrians [13]. In [14,15], a multi-stream recognition network based on the fusion of local and global features was proposed. This approach extracts global features from the original image and local features from each segmented body region, subsequently merging these to generate the final prediction. Another study [16] introduced a multi-part feature network that employs the Position Attention Module (PAM) to learn spatial feature dependencies and extract contextual information from local elements, alongside the Efficient Channel Attention (ECA) mechanism to capture cross-channel feature interactions. By combining temporal, spatial, and channel features, this method offers a more expressive feature representation. A different study [17] presented a novel methodology that integrates both global and local pedestrian features by modeling spatial relationships between patches using Graph Neural Networks (GNNs) to capture bodily structure information. It further incorporates a scoring function to explore correspondences among local features, thereby alleviating reliance on external information such as body pose.
2.2. Attention-Based Re-ID
The attention mechanism emulates the human visual and cognitive systems, guiding deep learning models to focus on vital information in pedestrian images during the learning process. By incorporating attention mechanisms, neural networks can assign different weights to various features, thereby automatically learning and selectively emphasizing key information in the input features, enhancing model performance and generalization capabilities. Commonly employed attentions include spatial attention, channel attention, mixed attention, and multi-scale attention. Ref. [18] introduces a channel attention selection mechanism that, by explicitly modeling inter-channel dependencies, calibrates features of each channel, achieving image alignment without requiring additional annotation information. Ref. [19] proposes a new pedestrian feature attention module that learns attention at the local region part level across multiple scales, fusing these weighted attentions into a global feature, yielding more robust representations. Ref. [20] presents an attention mechanism capable of perceiving global structural information, first extracting global contextual information from feature maps via global average pooling, then devising a relational matrix to model inter-feature dependencies. This approach, which considers not only the significance of local features but also their mutual relationships among different features, outperforms existing methodologies. Ref. [21] introduces a Heterogeneous Local Graph Attention Network (HLGAT), integrating attention into graph neural networks by dynamically weighting node features in graphs to construct a local feature map for each input image. This graph structure accounts for both the spatial adjacency of local features and semantic correlations between features. Acknowledging the importance of features at different scales for pedestrian re-identification, this method fuses features across various scales following the local graph attention module, enabling the model to comprehend and compare pedestrian images at multiple granularity levels. Ref. [22] devises a method to enhance group-based pedestrian re-identification performance through multiple attention-learning context graphs. The method incorporates multi-attention mechanisms, including Self-Attention, Inter-Attention, and Group-Attention, to, respectively, capture individual pedestrian feature representations, interactions among pedestrians, and the overall contextual information of groups, finally aggregating all features to form a group-level representation.
2.3. Part-Based Re-ID
Part-based Re-ID is a pedestrian re-identification strategy grounded in part-based analysis, which segments pedestrian images into distinct sections through techniques such as image cropping, pedestrian segmentation, and keypoint localization. Extracting and fusing features from these different parts enhances feature expressiveness, thereby boosting the performance of pedestrian re-identification. These methodologies effectively address the limitations of global features and exhibit heightened robustness against variations in pose and illumination. Ref. [6] introduces a Part-based Convolutional Baseline (PCB), partitioning images into six segments and employing Refined Part Pooling (RPP) to mitigate anomalies arising from uniform segmentation, a practice widely referenced in subsequent studies. Ref. [23] integrates this concept into Graph Convolutional Networks, proposing the Part-Guided Graph Convolution Network (PGCN), which extracts local features from pedestrian parts, constructs adjacency matrices based on similarity to explore relationships among local features of identical parts across different images and diverse parts within the same image, enriching pedestrian feature representation. Another study, [24], presents a multi-branch network that uniformly divides feature maps horizontally to extract fine-grained part features, followed by fusion with global and attribute features via a multitask learning strategy, yielding a more comprehensive pedestrian feature profile. Ref. [25] applies part features to unsupervised pedestrian re-identification, devising a Part-based Pseudo Label Refinement (PPLR) framework. This approach refines global feature pseudo labels using ensemble predictions of part features, mitigating noise in pedestrian feature clustering and reducing the impact of noisy labels. Lastly, [26] proposes a Part-based Representation Enhancement (PRE) network to tackle pedestrian re-identification under occlusion. This network partitions pedestrian images into seven sections, leveraging a Part Relation Aggregation module for autonomous exploration of the subject’s visibility. It reinforces the uniqueness of local features through feature completion and reverse fusion strategies. At the testing stage, concatenating global features with reconstructed local features yields high-performance identification results.
2.4. Mask-Based Re-ID
Instance segmentation is an image segmentation technique aimed at labeling each object instance in an image and generating a pixel-level segmentation mask for each instance. With the success of deep learning in instance segmentation tasks, researchers have applied instance segmentation to pedestrian re-identification tasks, achieving promising results. In their pioneering work, Ref. [12] successfully introduced binary masks into individual Re-ID tasks and proposed region-level contrastive learning, achieving state-of-the-art results on three public datasets (including MARS, Market-1501, and CUHK03). Ref. [27] proposed a mask-based deep sorting neural network that combines sorting with masks, further mitigating interference from similar negative samples during ranking result generation. Additionally, Ref. [28] presented a real-time person re-identification system called ReID-DeePNet. They developed a segmentation pipeline that fuses Mask R-CNN and GrabCut algorithms for pedestrian image segmentation. Subsequently, they extracted discriminative feature representations from segmented pedestrian images using two different deep learning models: CNN and DBN, achieving significant performance.
3. Problem Statement
The prevailing approach in pedestrian re-identification involves feeding the entire image into a neural network and then extracting image features through multiple layers of neural networks. By comparing the similarity of different image features, it is determined whether the target pedestrian is present. However, this recognition process faces the following challenges:
Existing methods based on the entire pedestrian image unavoidably introduce background information. Extracting only the pedestrian foreground as input is a natural way to mitigate background interference. Ideally, using a clean pedestrian foreground devoid of any background would significantly enhance pedestrian recognition accuracy. Unfortunately, there is currently no mature pedestrian extraction network specifically designed for pedestrian re-identification. The mainstream pedestrian instance segmentation networks cannot accurately extract the pedestrian foreground. Extracted pedestrian foregrounds suffer from issues such as background information and missing features, leading to discrepancies between segmented and true pedestrian foregrounds. Relying solely on imprecise segmentation results as input for pedestrian re-identification not only fails to improve recognition accuracy but may even degrade performance to some extent. To address these challenges, one potential approach is to incorporate pedestrian masks as an additional input dimension. These masks not only include the pedestrian’s contour information but also provide approximate location details within the image. By utilizing masks as input, we can enrich the feature information used for pedestrian recognition.
Pedestrian image edges typically represent abrupt changes in brightness or color within an image. These edges can reveal object contours, textures, shapes, and structures, containing rich detail features. While edge features have been widely applied in fields such as object detection, image segmentation, and image enhancement, they are currently underexplored in the domain of pedestrian re-identification. Introducing edge features into pedestrian re-identification tasks and studying their impact on re-identification performance is meaningful.
Different parts of pedestrians exhibit unique semantic features, and there exists a natural intrinsic connection between these parts. Exploring the inherent relationships among different body parts of the same pedestrian contributes to enriching their features. Some scholars have proposed using hard segmentation to divide pedestrian images into distinct parts, thereby investigating the relationships among these segments. However, hard segmentation compromises the semantic integrity of different pedestrian body parts. Besides, each segmented part contains substantial background information, which adversely affects the extraction of component features.
4. Method
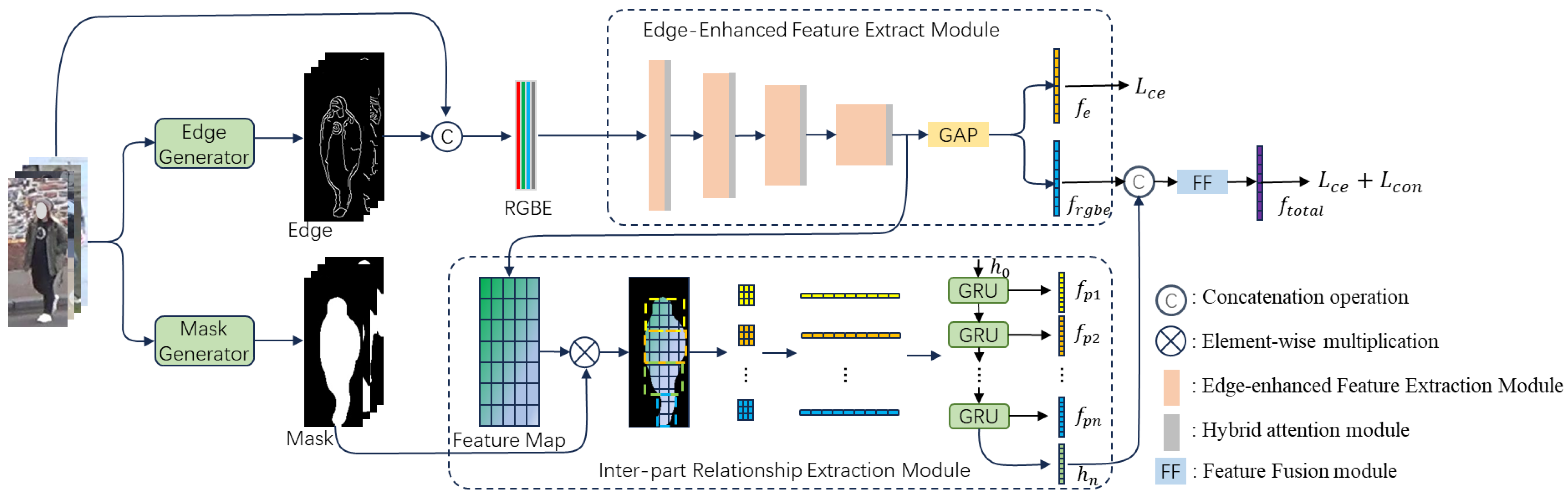
To address the aforementioned issues and extract more discriminative pedestrian features, we propose an edge-enhanced global feature extraction and inter-part relationship-based network. The network combines various features, including global features, edge features, and inter-part dependency features to enhance feature representation. The network architecture is illustrated in Figure 2. Specifically, we employ a pre-trained fully convolutional network (FCN) to extract pedestrian masks. Subsequently, we extract pedestrian features through two modules:
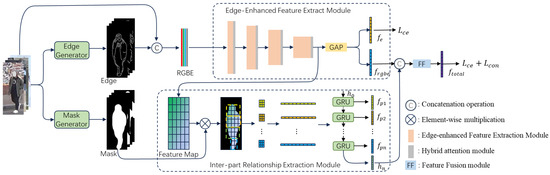
Figure 2.
The overall structure of the proposed network.
Edge-enhanced Feature Extraction Module (EFEM). We utilize the Canny algorithm to generate pedestrian edges corresponding to the mask regions, then fuse these edges with the RGB image, and extract the features of the fused image through the feature extraction network.
Inter-part Relationship Extraction Module (IREM). Combined with semantic segmentation, we divide the features of the foreground region into multiple parts and capture the relationship between different parts through an RNN network.
The features extracted by the two modules are fused to generate the final pedestrian representation, which is then classified using a classification layer.
Below, we will provide a detailed introduction to various components of the network.
4.1. Mask Generator
In recent years, deep learning has achieved significant success in the field of image semantic segmentation, with numerous networks now capable of effectively segmenting pedestrians in images. In this study, many researchers have applied semantic segmentation techniques to the domain of person re-identification. Specifically, we utilize a pre-trained FCN [29] to extract pedestrian masks. These masks highlight the regions corresponding to pedestrians in the input images. Given a batch of pedestrian images as input , is the batch size, is the channel, denotes the height, and denotes the width; the process of extracting pedestrian masks using an FCN can be expressed as follows:
where denotes the FCN network.
4.2. Edge Generator
The Canny edge detection algorithm [30] is a classical approach for extracting edges from images. Although various edge extraction techniques, including neural network-based approaches, are currently available, the Canny algorithm remains widely adopted in numerous computer vision systems due to its reliability and straightforward implementation. The Canny algorithm employs a multi-stage process to accurately locate a wide range of edges while utilizing Gaussian filtering to suppress noise, thereby minimizing the impact of noise on edge detection outcomes and preventing false detections. The typical design for the size of the Gaussian filter kernel is given by the expression , where represents the half-width of the kernel. This choice of kernel size ensures effective noise reduction while preserving relevant edge information.
In the given expression, where , represents the pixel coordinates, and denotes the standard deviation. Generally, the size of the Gaussian filter kernel increases with . A larger kernel size in the Canny operator results in lower sensitivity to noise but may introduce greater errors in edge detection.
Using the Canny algorithm, we extract the image edges denoted as . By applying the pedestrian mask to these extracted image edges, we obtain the corresponding pedestrian edges, represented as . This relationship can be expressed as follows:
4.3. Edge-Enhanced Feature Extraction Module
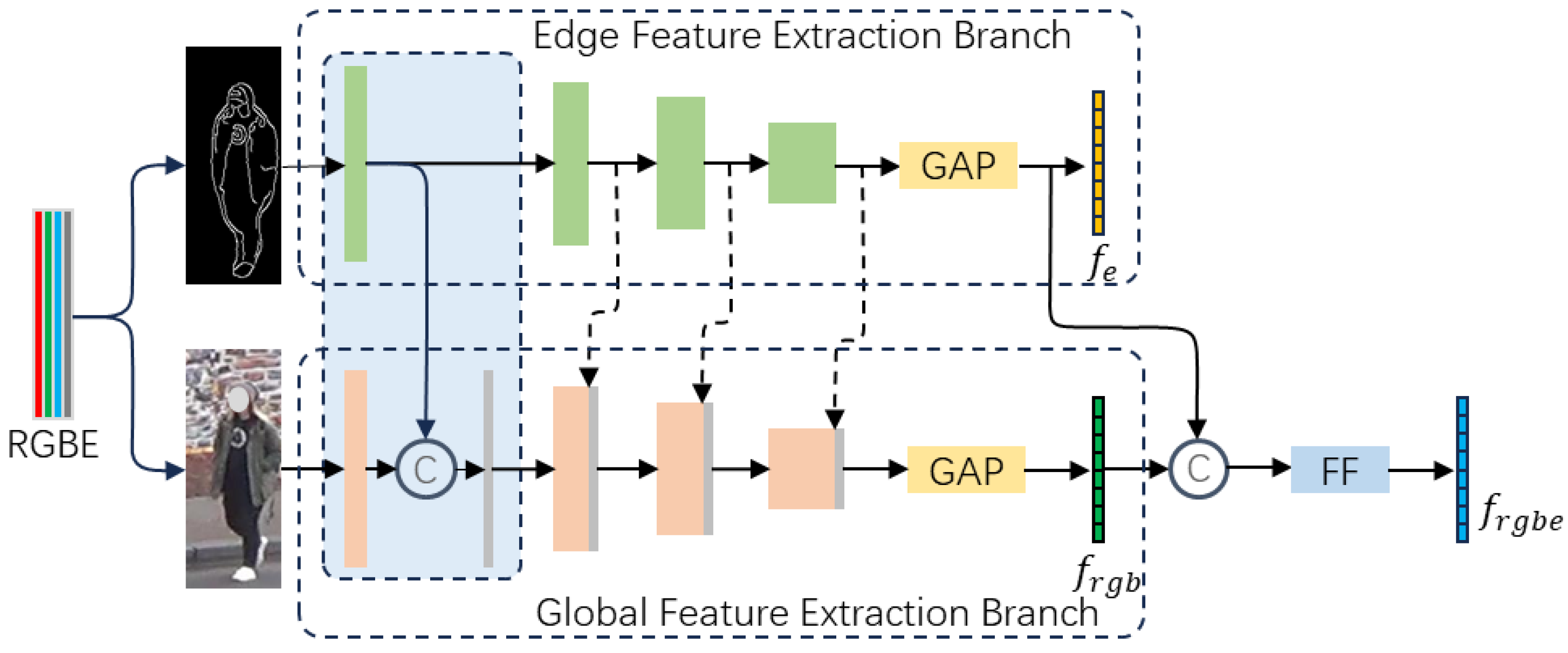
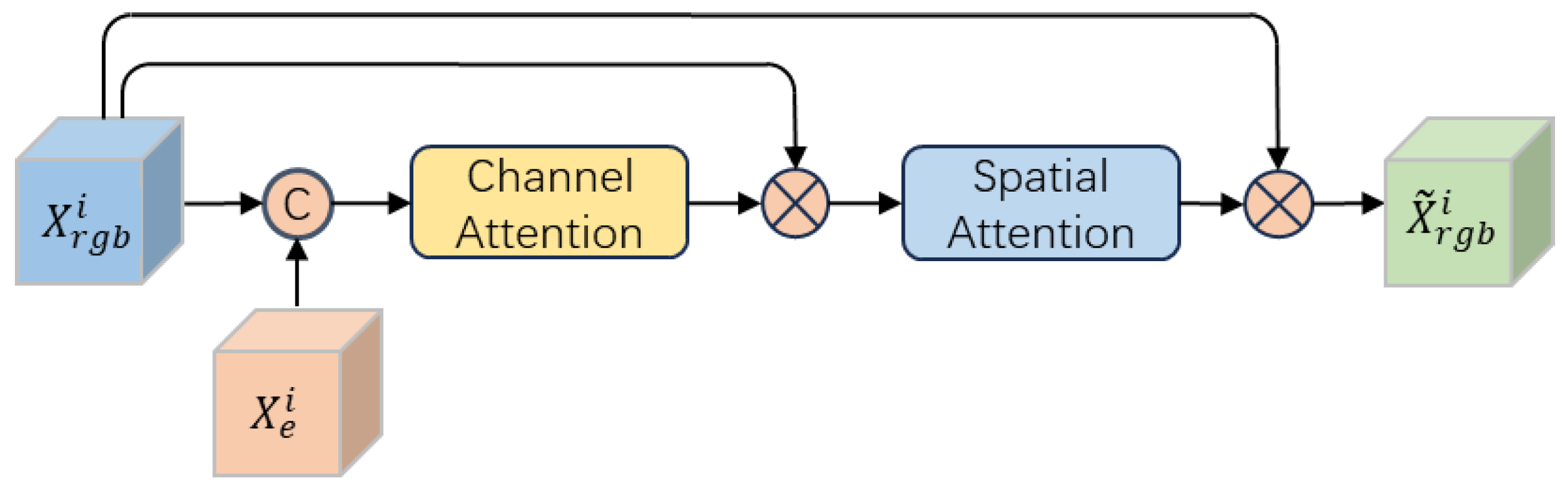
Considering the distinct characteristics of global features and edge features, we employ a dual-branch network architecture to separately extract features from the original image and the corresponding edge image. As shown in Figure 3, these branches are called the Global Feature Extraction Branch and the Edge Feature Extraction Branch . During the feature learning process, edge features are incorporated into corresponding layers of the Global Feature Extraction Branch, aiming to enhance the network’s ability to extract global features. Specifically, to efficiently learn deep features of the image and mitigate the issue of gradient vanishing during training, ResNet-50 is used as the backbone network of the Global Feature Extraction Branch, while ResNet-18 is used as the backbone network of the Edge Feature Extraction Branch. In addition, considering that features in different channels and regions have different importance, we added a hybrid attention module to the global feature extraction branch. As shown in Figure 4, the hybrid attention module consists of a channel attention block and a spatial attention block. It dynamically assigns greater weights to important channels and regions in the features, allowing the network to learn critical information while ignoring less relevant details. Finally, global features and edge features are fused by a feature fusion module (see Section 4.5 for a detailed description) to obtain the output features of this module, which enhances the comprehensive feature representation.
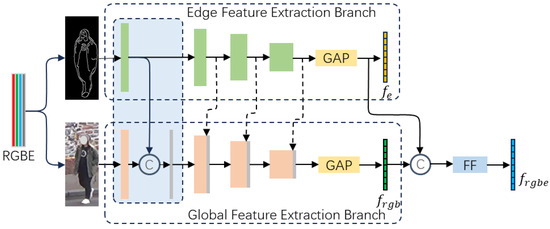
Figure 3.
Edge-enhanced Feature Extraction Module.
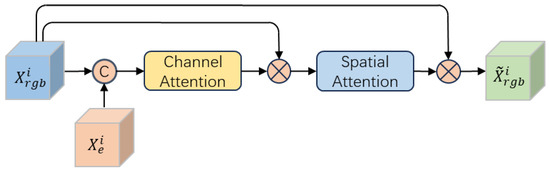
Figure 4.
Hybrid attention module.
The channel attention block includes a global average pooling layer, a global maximum pooling layer, a convolutional layer, and a sigmoid function. The spatial attention block comprises a cross-channel average pooling layer, a cross-channel maximum pooling layer, a convolutional layer, and another sigmoid function. For a given global feature map and edge feature map output from the i-th layer of the network, , . and are first concatenated along the channel dimension. The concatenated features are then subjected to global average pooling and global max pooling operations, respectively. The pooled features are concatenated along the channel dimension and fed into a convolutional layer, where the number of input channels is , and the number of output channels is . Finally, the convolution features are activated using a sigmoid function and expanded via broadcasting along the spatial dimension to match the dimensions of . The channel attention map can be expressed as follow:
here, is the channel attention map, denotes broadcast operation along the spatial dimension, denotes the sigmoid function, represents the concatenation operation, represents the convolutional layer with a kernel size of , and represent the global average pooling layer and the global maximum pooling layer, respectively.
Embedding into through element-wise multiplication, the embedded feature can be expressed as , where denotes element-wise multiplication. The features are used as the input for the spatial attention block. First, undergoes both cross-channel average pooling and cross-channel max pooling on . The pooled features are concatenated along the channel dimension and fed into a convolution layer, followed by activation using a sigmoid function and expanded via broadcasting along the channels dimension to match the dimensions of . The spatial attention can be represented by the following equation:
here is the spatial attention map, denotes broadcast operation along the channel dimension, represents the convolutional layer with a kernel size of , and represent the cross-channel average pooling layer and the cross-channel maximum pooling layer, respectively.
The output of and after the hybrid attention module can be expressed as follows:
here, represents the feature map obtained after applying hybrid attention to and .
4.4. Inter-Part Relationship Extraction Module
Pedestrian Feature Segmentation. The purpose of this module is to segment pedestrian features horizontally into multiple parts and then capture the relationships between different parts using an RNN network. However, we have observed that in open pedestrian scenes, pedestrians do not always occupy the entire image; instead, they often only occupy a small region of the image. Therefore, we map the pedestrian mask to the deep feature space , resulting in a new mask . Based on , we extract pedestrian-specific features from as , and then further divide the pedestrian features horizontally into multiple parts.
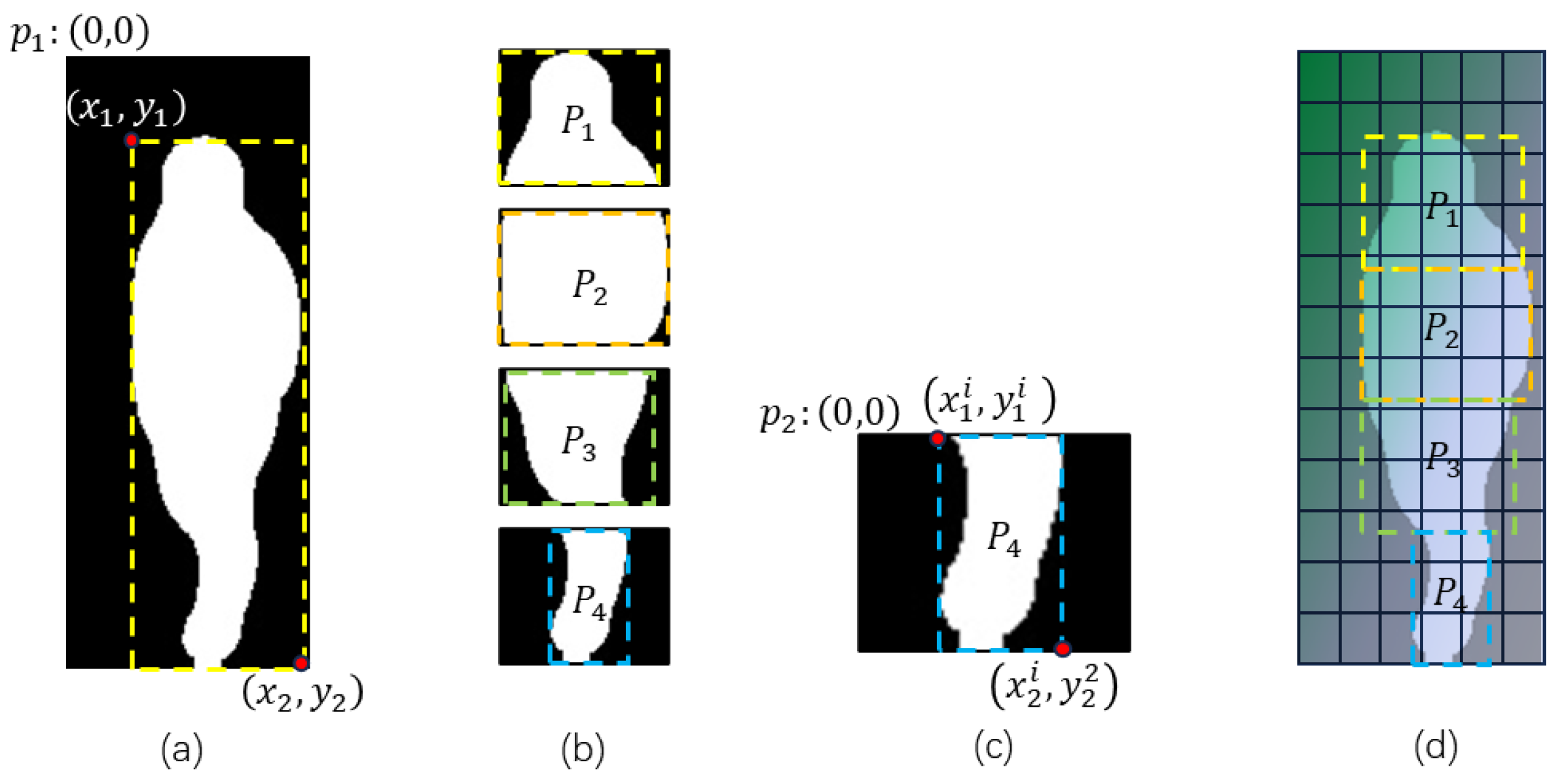
Figure 5 illustrates the process of pedestrian feature segmentation. First, we seek the smallest rectangular bounding box, denoted as , that covers the binary mask with values equal to 1. Assuming the top-left corner of is at coordinate , the coordinates of relative to are given by , where represents the top-left corner, and represents the bottom-right corner. Next, we divide horizontally into equal parts. The -th part, denoted as , has coordinates relative to given by the following:
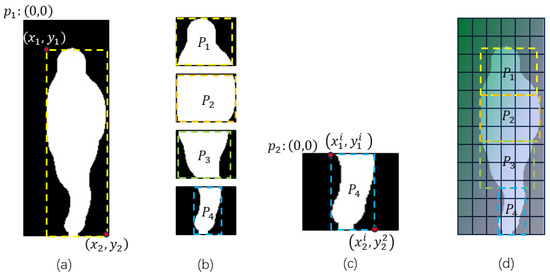
Figure 5.
Pedestrian feature map segmentation (take as an example). (a) Region of interest (ROI), (b) split the ROI into N parts, (c) part ROI (take as an example), and (d) mapping part ROIs to the feature map.
For each , we find the smallest rectangular bounding box, denoted as , that covers the corresponding region in the mask with values equal to 1. Assuming the top-left corner of is at coordinate , the coordinates of relative to are given by the following:
Then, the coordinates of relative to are as follows:
Finally, by mapping to the feature space , we obtain the pedestrian features corresponding to the respective regions.
Inter-part Relationship Modeling. Components based on foreground segmentation contain rich local features of pedestrians, and there are also potential dependencies between different components. In this research paper, we construct a feature extraction network for inter-component features using Gated Recurrent Units (GRU) to capture the dependencies between different components. GRU is an effective variant of recurrent neural networks (RNNs), and shares similarities with Long Short-Term Memory (LSTM) networks. By introducing gating mechanisms to control information flow, GRU effectively addresses the challenge of long-term dependencies inherent in traditional RNNs [31]. Notably, GRU exhibits comparable performance to LSTM while having a simpler structure and fewer parameters [32], making it a valuable tool in practical applications, particularly within the field of image processing.
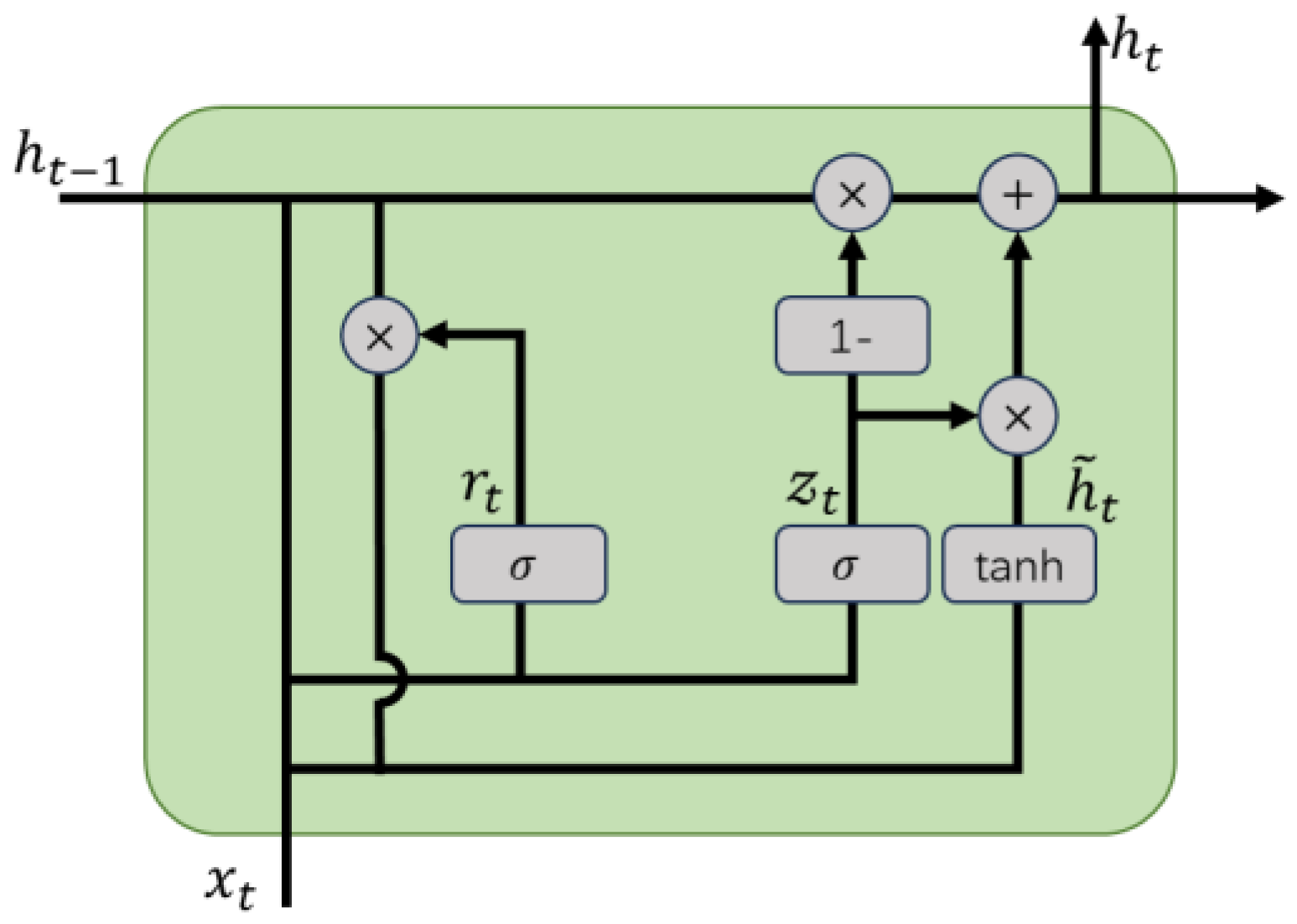
The structure of a Gated Recurrent Unit (GRU), as illustrated in Figure 6, comprises two essential components: the Reset Gate and the Update Gate. The reset gate determines how much of the previous hidden state should be retained when combining it with new input information. It controls the balance between preserving past context and adapting to new data. The update gate regulates how much of the previous hidden state should influence the current state. It allows us to control the extent to which the new state is a continuation of the old one. The details can be expressed by the following equation:
where is the input at time , is the hidden state of the layer at time or the initial hidden state at time 0, is the hidden state at time , is the candidate hidden state at time , and and are the reset gate and update gate, respectively. is the sigmoid function, and is the tanh function.
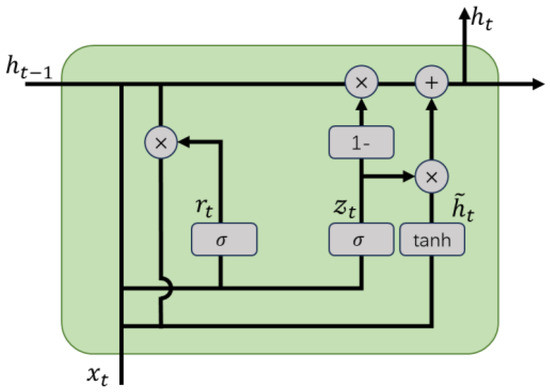
Figure 6.
GRU Structure.
Due to the different and irregular shapes of each segment after segmentation, they cannot be directly used as input for convolutional neural networks. Therefore, to adapt to the input requirements of GRU (Gated Recurrent Unit), we borrowed the ROI Align (Region of Interest Align) method. This method maps the segmented features to the same size and further transforms each part’s features into vector space. These spatial vectors contain all the information about that part. Next, we sort the feature vectors of different parts from top to bottom and input them sequentially into a 4-layer bidirectional GRU network. The hidden state units of the last GRU layer contain internal relationship features of all components. We take the hidden state from the last GRU layer as the output feature.
4.5. Feature Fusion
As shown in Figure 2, we concatenate the feature vectors (with dimension ) generated by the EFEM with the feature vectors (with dimension ) generated by the IREM. The concatenated feature vector is then nonlinearly transformed using a fully connected layer (FC layer) to map it to a feature vector of dimension , and it is further subjected to a probabilistic operation called Dropout, which randomly discards part of the node outputs during the training process with a retention rate of . The final feature vector output is denoted as :
where denotes column-wise concatenation, is the weight matrix of the fully connected layer, is the bias vector, denotes the activation function, and denotes the Dropout operation, where each element is retained with a probability of .
Finally, the feature vector is classified into classes using a softmax classification layer:
where and correspond to the weight vector and bias associated with class c, respectively. represents the probability of belonging to class , and given the feature vector , the sum of probabilities across all classes is equal to 1.
4.6. Loss Function
Cross-Entropy Loss. In this study, we employ the cross-entropy loss to quantify the discrepancy between predicted labels and ground truth labels. In practical applications, models often exhibit overconfidence when predicting that a sample belongs to a particular class for one-hot encoded labels. This overconfidence can lead to excessive sensitivity to noise in the training data, thereby impairing the model’s generalization ability. Label smoothing can mitigate this issue by reducing the probability of the true labels from 1 to a value less than 1 and distributing the remaining probability evenly among other classes. This reduces the risk of overfitting and enhances the model’s generalization capability. Suppose the actual label distribution for an image is denoted as , and after label smoothing, the modified label distribution becomes the following:
where is the total number of pedestrians ID and is a hyperparameter that controls label smoothing.
Calculate the cross-entropy loss using the smoothed label distribution as follows:
where, is the number of samples, is the smoothed true label distribution, and is the probability that the -th sample belongs to the -th category.
Triplet Loss. In our approach, we employ the hard triplet loss to assess the similarity between features. The formulation is as follows:
where, , , represent the i-th anchor sample, its corresponding positive sample, and negative samples, respectively. , represent the feature vectors of the anchor, positive, and negative samples, respectively. and represent the distances between positive samples and the distances between negative samples, respectively. is a non-negative hyperparameter that represents the minimum distance by which the distance between positive samples is expected to be smaller than the distance between negative samples, signifies the hinge function, which retains the original value when the value inside the parentheses is greater than 0; otherwise, it is set to 0. The optimization objective of the triplet loss is to minimize the difference between the two distances, i.e., . In this way, the triplet loss encourages the positive samples to move closer to each other in the feature space while pushing the negative samples farther away, thus enhancing the discriminative power of the model [33].
We combine the aforementioned losses to optimize the network parameters, and the final loss can be expressed as follows:
where and are hyperparameters that control the loss balance.
5. Experiments
5.1. Experiment Setting
5.1.1. Datasets
We selected three commonly used pedestrian re-identification datasets, namely Market-1501 [34], DukeMTMC-reID [35], and MSMT17 [36], to validate the proposed method. Market-1501, released by Tsinghua University in 2015, comprises 32,668 images of 1501 distinct pedestrians captured from different time frames and viewing angles. The DukeMTMC-reID dataset, collected by Duke University and published in 2017, includes 36,411 images of 1812 pedestrians captured by eight cameras. The MSMT17 dataset, released by Microsoft Research Asia in 2018, contains 126,441 images of 4101 different pedestrians. Table 1 shows the details of the three datasets and Figure 2 gives some example images from the datasets.

Table 1.
Datasets details induction.
5.1.2. Evaluation Matrix
In this paper, we adopt Rank-1 accuracy and mean average precision (mAP) as performance evaluation metrics for the model. These are commonly used indicators to assess the accuracy of person re-identification. Rank-1 accuracy represents the probability that the first image in the search results is the correct match. mAP combines both precision and recall. It reflects the overall retrieval performance of the system. It is important to note that all evaluations in this article do not utilize the re-rank technique.
5.1.3. Implementation Details
Backbone. We adopt the ResNet-50 network as the backbone, and to better accommodate our proposed method, we made several customized modifications to the backbone network. First, we set the of the network’s initial layer to 4. Second, we adjusted the of the conv2 layer and the downsample layer in Layer4 of the network to 1. Third, during the training, we set the of the fully connected (FC) layer to match the number of IDs in the corresponding dataset.
Training Models. In the training process, the following settings were applied: First, a mini batch of P (P = 64) images were randomly selected from the dataset. Then, the following preprocessing steps were applied to each image in this mini batch: The images were first resized to , followed by data augmentation techniques such as horizontal flipping, random erasing, and color enhancement. Finally, the pixel values of the images were normalized to have a mean of 0 and a variance of 1. To effectively train the neural network model, we used the Adam optimizer to optimize the model parameters, with weight decay and momentum factors set to 5 × 10−4 and 0.9, respectively. Additionally, we employed a joint learning rate adjustment strategy: For the first ten epochs, we used warm-up techniques to increase the learning rate from 1 × 10−6 to 0.05. After the warm-up, we applied a cosine annealing learning rate adjustment technique, gradually decreasing the learning rate from 0.05 over 1/4 of a cosine cycle until reaching the minimum value. The change in learning rate can be expressed using the following formula:
where is the current epoch during the training.
In addition, we set the number of pedestrian split N to 8 and the balance parameters α and to 0.3 and 0.7, respectively [37]. The Canny edge generator is implemented using the canny function from the Kornia library with the following parameter settings: low_threshold = 0.2, high_threshold = 0.7, and kernel_size = 3. All other parameters are kept as default.
5.2. Experimental Results and Analysis
5.2.1. Ablation Study
To evaluate the effectiveness of each component of the proposed method, we conduct an ablation study on the Market-1501 dataset. Specifically, the backbone network in Figure 1 is used as the baseline. Sequentially, the EFEM and IREM are applied to the baseline, respectively, to review their respective contributions to performance improvement. Furthermore, the EFEM and IREM are applied to the baseline at the same time to demonstrate the synergy between the two modules. All experiments are carried out under the same training configuration to ensure a consistent basis for comparison.
The ablation study results are summarized in Table 2. Compared to the baseline, both EFEM and IREM exhibit significant performance improvements, with EFEM enhancing Rank-1 accuracy by 1.3% and mAP accuracy by 1.8%, while IREM boosts Rank-1 accuracy by 2.6% and mAP accuracy by 2.9%. When employed concurrently, they lead to an increase in Rank-1 accuracy by 4.2% and mAP accuracy by 5.0%. This can be attributed to the fact that both EFEM and IREM focus on pedestrian areas, effectively alleviating the background differences in images of the same person captured by different cameras. In addition, the edge features and inter-part relationships are combined into pedestrian representation, which enriches the feature set and enhances the distinguishing ability of the model.
Table 2.
The ablation experimental results on the Market-1501 dataset.
5.2.2. Comparison with Other Mainstream Re-ID Methods
To validate the efficacy of our proposed method, we conducted experiments on the Market-1501, DukeMTMC-reID, and MSMT17 datasets, and compared the results with the current state-of-the-art person Re-ID methods summarized in Table 3. Among these methods, refs. [38,39,40,41] are attention-based methods, wherein [38,39] employ first-order attention to guide the network’s focus onto salient features within pedestrian images, whereas [40,41] leverage higher-order attention mechanisms to mimic and harness high-order statistical information, thereby enhancing the network’s capability to distinguish similar features. Refs. [6,24,42,43,44,45] exemplify part-based Re-ID methodologies, wherein pedestrians are segmented into distinct parts based on predefined rules, and then extract features from different segments and fuse them to enrich the feature representation. Specifically, ref. [42] is driven by pose estimation, while [6,24,43,44,45] rely on manually defined partitions. Methods [12,27,46,47,48,49] incorporate pedestrian masks and utilize the image foreground as input to mitigate background interference. Refs. [50,51,52] incorporate attribute information of pedestrians into the network, further enhancing feature representation. Refs. [53,54,55,56,57,58,59,60] improve the re-identification performance through alignment, interaction, and aggregation operations on multi-dimensional features. The following is a detailed comparison of the experimental results on each dataset.
Table 3.
Performance comparison of our method with current representative methods on Market-1501, DukeMTMC-reID, and MSMT17. The best results are shown in red bold, and the second-best in blue bold.
Results on Market-1501. Our method achieves the best Rank-1 accuracy of 96.7% and the second-highest mAP accuracy of 90.1% on the Market-1501 dataset. Ref. [58] reports a second-best Rank-1 accuracy of 96.1%, albeit with a mAP accuracy of 88.0%, which is 1.9% lower than ours. Meanwhile, ref. [24] attains the optimal mAP accuracy of 92.1%, but its Rank-1 accuracy stands at 94.5%, trailing ours by 2.2%.
Results on DukeMTMC-reID. Despite the greater challenges posed by this dataset, which encompasses a broader range of viewpoint variations and illumination differences, our proposed method demonstrates strong performance as well. On the DukeMTMC-ReID dataset, our method achieves the top-ranking accuracy of 90.3% on the Rank-1 metric, marking a new state-of-the-art by outperforming the previous best method by a margin of 0.3%. In terms of mAP, our method attains 81.4% accuracy, which is 5.1% lower than the optimal performance but it still significantly outperforms the other existing methods and holds the second-best place.
Results on MSMT17. Our method also shows remarkable performance on the larger and more complex MSMT17 dataset, achieving 79.2% Rank-1 accuracy and 55.3% mAP accuracy. Although [59] obtained the optimal Rank-1 accuracy of 79.5%, which is 0.3% higher than ours, its mAP accuracy is 52.5%, which is 2.8% lower than our method. In addition, ref. [58] achieved the highest mAP accuracy of 55.7%, which is 0.4% higher than our method. Nevertheless, our approach is at least 2.4% higher than all other methods, ensuring the second-best position in terms of overall performance.
In summary, our method achieves optimal or near-optimal results in large-scale datasets and complex environments. These experiments prove the effectiveness and versatility of the method, which lays a solid theoretical foundation and technical support for its implementation in the real-world scene.
5.3. Visualization
5.3.1. Feature Maps Visualization
To clearly demonstrate the effectiveness of the method introduced in this paper, we randomly selected pedestrian images from the Market-1501 dataset for feature extraction. Subsequently, we visualized the extracted feature maps. As shown in Figure 7, Figure 7a shows the original pedestrian images, Figure 7b shows the feature maps extracted by the baseline, and Figure 7c shows the feature maps extracted by our proposed method. In these visualization images, we use chromatic gradients to indicate the different levels of attention paid by the neural network to different parts of the image. Specifically, the dark red color indicates that the network pays the most attention to the region, while the dark blue color indicates that the network pays the least attention to the region, thus creating a clear contrast.

Figure 7.
Feature map visualization. (a) Original images. (b) Feature maps extracted by baseline. (c) Feature maps extracted by our method.
As shown in Figure 7, the baseline model tends to focus on large regions of the image where pedestrians might be present, but it fails to effectively focus on the pedestrians themselves or fully consider potential auxiliary information. This limitation restricts the overall feature extraction capability. In contrast, our method integrates pedestrian boundary information, allowing us not only to locate pedestrian positions from a global perspective and effectively focus on the pedestrians themselves, but also to capture subtle differences at the local level, revealing more detailed pedestrian features. Notably, the introduction of the IREM enhances the semantic coherence and depth of feature extraction by deepening the understanding of spatial relationships between different parts of the pedestrian. In summary, compared to the baseline, our approach generates richer and more discriminative feature representations, significantly improving the performance in person re-identification tasks.
5.3.2. Visualization of Retrieval Results
To directly demonstrate the retrieval performance of the method proposed in this paper, we randomly select a series of sample images from the query set of the Market-1501 dataset and retrieve them from the gallery set. The retrieval results are shown in Figure 8. In the visual representation, we use green bounding boxes to highlight correct retrieval and red bounding boxes to highlight incorrect retrieval. The experimental results show that our method can accurately retrieve the target image in most cases, exhibiting good robustness and accuracy. This result strongly demonstrates the effectiveness of our proposed method.

Figure 8.
Visualization of retrieval results.
While our method achieves accurate target recognition overall, there are still occasional instances where the system incorrectly recognizes different pedestrians as the same one. This problem is particularly evident when pedestrians exhibit highly similar foreground features. The remarkable similarity of physical features across individuals poses a challenge for the system to make accurate judgments. This finding highlights the necessity to further explore and optimize our method, especially in terms of extracting and exploiting local features and their relationships more efficiently for objects that look very similar.
6. Conclusions
In this study, we innovatively design a pedestrian Re-ID network based on edge-enhanced global features and inter-part relations. The uniqueness of our method is the fusion of edge features into the pedestrian representation, leveraging edge information to enhance the extraction of global contextual features. Subsequently, a hybrid attention module is used to guide the model to focus on key features in the image to extract more discriminative features. The Inter-part Relationship Extraction Module further enhances the model’s ability to capture and understand the interdependencies between adjacent regions in pedestrian images, improving the semantic consistency of pedestrian features. Ultimately, by integrating these multifaceted features, we generate comprehensive and highly distinctive pedestrian representations. These well-designed modules enable our proposed network to capture more detailed and distinctive features, which significantly improves person Re-ID performance. Experimental results demonstrate that our method outperforms most state-of-the-art methods in person re-identification.
In the future, we intend to conduct a more in-depth investigation into the information embedded in pedestrian images and explore how to fully leverage this information to further enhance model performance. We aim to apply these advancements to more open and challenging person re-identification scenarios, thereby contributing to technological progress in this field.
Author Contributions
Conceptualization, C.Z.; methodology, C.Z.; software, C.Z.; validation, C.Z.; formal analysis, W.Z.; investigation, W.Z.; resources, J.M.; writing—original draft preparation, C.Z.; writing—review and editing, J.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar] [CrossRef]
- Hirzer, M.; Beleznai, C.; Roth, P.M.; Bischof, H. Person re-identification by descriptive and discriminative classification. In Proceedings of the 17th Scandinavian Conference on Image Analysis (SCIA’11), Ystad, Sweden, 1 May 2011; Springer: Berlin/Heidelberg, Germany; pp. 91–102. [Google Scholar]
- Li, W.; Zhao, R.; Wang, X. Human reidentification with transferred metric learning. In Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Republic of Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 31–44. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline). In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 501–518. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13001–13008. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Liu, Y. Multi-scale feature fusion network for person re-identification. IET Image Process. 2020, 14, 4614–4620. [Google Scholar] [CrossRef]
- Pan, S.; Feng, W.; Chong, Y. Attribute-Guided Global and Part-Level Identity Network for Person Re-Identification. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2250011. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking Person Re-identification with k-Reciprocal Encoding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3652–3661. [Google Scholar]
- Kim, K.; Byeon, M.; Choi, J.Y. Re-ranking with ranking-reflected similarity for person re-identification. Pattern Recognit. Lett. 2019, 128, 326–332. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-Guided Contrastive Attention Model for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar] [CrossRef]
- Li, W.; Zhu, X.; Gong, S. Person re-identification by deep joint learning of multi-loss classification. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 2194–2200. [Google Scholar]
- Hu, L.; Hong, C.; Zeng, Z.; Wang, X. Two-stream person re-identification with multi-task deep neural networks. Mach. Vis. Appl. 2018, 29, 947–954. [Google Scholar] [CrossRef]
- Ghorbel, M.; Ammar, S.; Kessentini, Y.; Jmaiel, M.; Chaari, A. Fusing Local and Global Features for Person Re-identification Using Multi-stream Deep Neural Networks. In Proceedings of the Mediterranean Conference on Pattern Recognition and Artificial Intelligence, Hammamet, Tunisia, 20–22 December 2020; Springer: Cham, Switzerland, 2020; pp. 73–85. [Google Scholar] [CrossRef]
- Saber, S.; Meshoul, S.; Amin, K.; Pławiak, P.; Hammad, M. A Multi-Attention Approach for Person Re-Identification Using Deep Learning. Sensors 2023, 23, 3678. [Google Scholar] [CrossRef]
- Zhang, J.; Ainam, J.P.; Song, W.; Zhao, L.; Wang, X.; Li, H. Learning global and local features using graph neural networks for person re-identification. Signal Process. Image Commun. 2022, 107, 116744. [Google Scholar] [CrossRef]
- Guo, T.; Wang, D.; Jiang, Z.; Men, A.; Zhou, Y. Deep Network with Spatial and Channel Attention for Person Re-identification. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yan, Y.; Ni, B.; Liu, J.; Yang, X. Multi-level attention model for person re-identification. Pattern Recognit. Lett. 2019, 127, 156–164. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3183–3192. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, H.; Liu, S. Person Re-identification using Heterogeneous Local Graph Attention Networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12131–12140. [Google Scholar] [CrossRef]
- Yan, Y.; Qin, J.; Ni, B.; Chen, J.; Liu, L.; Zhu, F.; Zheng, W.; Yang, X.; Shao, L. Learning Multi-Attention Context Graph for Group-Based Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7001–7018. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Zhang, H.; Liu, S.; Xie, Y. Part-guided graph convolution networks for person re-identification. Pattern Recognit. 2021, 120, 108115. [Google Scholar] [CrossRef]
- Peng, Y.; Li, W.; Li, Y.; Pei, Y.; Guo, Y. Multi-task person re-identification via attribute and part-based learning. Multimed. Tools Appl. 2022, 81, 11221–11237. [Google Scholar] [CrossRef]
- Cho, Y.H.; Kim, W.J.; Hong, S.; Yoon, S. Part-based Pseudo Label Refinement for Unsupervised Person Re-identification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 7298–7308. [Google Scholar]
- Yan, G.; Wang, Z.; Geng, S.; Yu, Y.; Guo, Y. Part-Based Representation Enhancement for Occluded Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4217–4231. [Google Scholar] [CrossRef]
- Qi, L.; Huo, J.; Wang, L.; Shi, Y.; Gao, Y. A Mask Based Deep Ranking Neural Network for Person Retrieval. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 496–501. [Google Scholar] [CrossRef]
- Mohammed, H.J.; Al-Fahdawi, S.; Al-Waisy, A.S.; Zebari, D.A.; Ibrahim, D.A.; Mohammed, M.A.; Kadry, S.; Kim, J. ReID-DeePNet: A Hybrid Deep Learning System for Person Re-Identification. Mathematics 2022, 10, 3530. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef] [PubMed]
- Khan, R.; Islam, S.; Kanwal, K.; Iqbal, M.; Hossain, M.I.; Ye, Z.F. A Deep Neural Framework for Image Caption Generation Using GRU-Based Attention Mechanism. arXiv 2022, arXiv:2203.01594. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. LSTM and GRU Neural Network Performance Comparison Study: Taking Yelp Review Dataset as an Example. In Proceedings of the 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Shanghai, China, 12–14 June 2020; pp. 98–101. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 17–35. [Google Scholar] [CrossRef]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep filter pairing neural network for person re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, W.; Ma, J. Neighboring-Part Dependency Mining and Feature Fusion Network for Person Re-Identification. IEEE Access. 2023, 11, 49760–49771. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A Multi-task Attentional Network with Curriculum Sampling for Person Re-Identification. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 384–400. [Google Scholar] [CrossRef]
- Li, W.; Zhu, X.; Gong, S. Harmonious Attention Network for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; 2018; pp. 2285–2294. [Google Scholar] [CrossRef]
- Chen, B.; Deng, W.; Hu, J. Mixed High-Order Attention Network for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019; pp. 371–381. [Google Scholar] [CrossRef]
- Fang, P.; Zhou, J.; Roy, S.; Petersson, L.; Harandi, M. Bilinear Attention Networks for Person Retrieval. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019; pp. 8029–8038. [Google Scholar] [CrossRef]
- Su, C.; Li, J.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Pose-Driven Deep Convolutional Model for Person Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3980–3989. [Google Scholar] [CrossRef]
- Wei, L.; Zhang, S.; Yao, H.; Gao, W.; Tian, Q. GLAD: Global–Local-Alignment Descriptor for Scalable Person Re-Identification. IEEE Trans. Multimed. 2019, 21, 986–999. [Google Scholar] [CrossRef]
- Zhang, Y.; Gu, X.; Tang, J.; Cheng, K.; Tan, S. Part-Based Attribute-Aware Network for Person Re-Identification. IEEE Access 2019, 7, 53585–53595. [Google Scholar] [CrossRef]
- Li, L.; Dang, J.; Wang, Y.; Wang, S.; Zhang, Z. Part-Based Bilinear CNN For Person Re-Identification. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 368–374. [Google Scholar] [CrossRef]
- Tay, C.-P.; Roy, S.; Yap, K.-H. AANet: Attribute Attention Network for Person Re-Identifications. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7127–7136. [Google Scholar] [CrossRef]
- Zhang, B.; Li, Y.; Chen, H.; Sun, J. Improving Person Re-identification by Mask Guiding and Part Pooling. In Proceedings of the 2020 12th International Conference on Machine Learning and Computing (ICMLC ‘20), Shenzhen, China, 15–17 February 2020; pp. 301–306. [Google Scholar] [CrossRef]
- Lian, S.; Hu, H. Mask-guided class activation mapping network for person re-identification. Electron. Lett. 2020, 56, 1416–1418. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, W.; Liu, J.; Qi, G.-J.; Tian, Q.; Li, H. An End-to-End Foreground-Aware Network for Person Re-Identification. IEEE Trans. Image Process. 2021, 30, 2060–2071. [Google Scholar] [CrossRef]
- Lin, Y.; Zheng, L.; Zheng, Z.; Wu, Y.; Hu, Z.; Yan, C.; Yang, Y. Improving person re-identification by attribute and identity learning. Pattern Recognit. 2019, 95, 151–161. [Google Scholar] [CrossRef]
- Luo, J.; Liu, Y.; Gao, C.; Sang, N. Learning What and Where from Attributes to Improve Person Re-Identification. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 165–169. [Google Scholar] [CrossRef]
- Li, S.; Yu, H.; Hu, R. Attributes-aided part detection and refinement for person re-identification. Pattern Recogn. 2020, 97, 107016. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. SVDNet for Pedestrian Retrieval. In Proceedings of the 2017 IEEE International Con-ference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3820–3828. [Google Scholar] [CrossRef]
- Zheng, Z.; Zheng, L.; Yang, Y. Pedestrian Alignment Network for Large-scale Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 3037–3045. [Google Scholar] [CrossRef]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Interaction-And-Aggregation Network for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9309–9318. [Google Scholar] [CrossRef]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J. Joint Discriminative and Generative Learning for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2133–2142. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October 2019; pp. 3701–3711. [Google Scholar] [CrossRef]
- Jin, X.; Lan, C.; Zeng, W.; Wei, G.; Chen, Z. Semantics-Aligned Representation Learning for Person Re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11173–11180. [Google Scholar] [CrossRef]
- He, L.; Liu, W. Guided Saliency Feature Learning for Person Re-identification in Crowded Scenes. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 357–373. [Google Scholar] [CrossRef]
- Zhou, Y.; Qin, Y.; Wang, S.; Huang, Z.; Zhang, D. Person Re-Identification Based on Instance Segmentation and Pose Estimation. In Proceedings of the 2023 IEEE 6th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), Haikou, China, 18–20 August 2023; pp. 584–589. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).