Abstract
The occurrence of flight risks and accidents is closely related to pilot workload. Effective detection of pilot workload has been a key research area in the aviation industry. However, traditional methods for detecting pilot workload have several shortcomings: firstly, the collection of metrics via contact-based devices can interfere with pilots; secondly, real-time detection of pilot workload is challenging, making it difficult to capture sudden increases in workload; thirdly, the detection accuracy of these models is limited; fourthly, the models lack cross-pilot generalization. To address these challenges, this study proposes a large language model, WorkloadGPT, which utilizes low-interference indicators: eye movement and seat pressure. Specifically, features are extracted in 10 s time windows and input into WorkloadGPT for classification into low, medium, and high workload categories. Additionally, this article presents the design of an appropriate text template to serialize the tabular feature dataset into natural language, incorporating individual difference prompts during instance construction to enhance cross-pilot generalization. Finally, the LoRA algorithm was used to fine-tune the pre-trained large language model ChatGLM3-6B, resulting in WorkloadGPT. During the training process of WorkloadGPT, the GAN-Ensemble algorithm was employed to augment the experimental raw data, constructing a realistic and robust extended dataset for model training. The results show that WorkloadGPT achieved a classification accuracy of 87.3%, with a cross-pilot standard deviation of only 2.1% and a response time of just 1.76 s, overall outperforming existing studies in terms of accuracy, real-time performance, and cross-pilot generalization capability, thereby providing a solid foundation for enhancing flight safety.
1. Introduction
Aviation safety has always been a critical issue and an ongoing challenge. As the aviation industry advances, the requirements for ensuring flight safety have become increasingly stringent. Research indicates that under high workload conditions, pilots’ reaction times and decision-making accuracy significantly decline, thereby raising the risk of operational errors [1]. To mitigate flight accidents induced by high workloads, optimizing the cockpit display interface layout has become an essential design requirement in the aviation industry. Complex cockpit display interfaces, filled with numerous flight readings and instrument data, must be properly designed to accommodate pilots’ workload levels; otherwise, they may adversely affect flight safety [2,3]. Consequently, measuring pilot workload has become an integral part of aircraft design. This assessment not only aids in monitoring pilots’ states but also guides the optimization of cockpit display interfaces in avionics systems. By precisely adjusting display technologies, interface layouts, information presentation, and control arrangements, pilots can receive the most critical information at crucial moments, enhancing aviation safety. Additionally, real-time workload monitoring systems can serve as auxiliary tools for pilot training, aiding pilots in understanding and adapting to workload patterns in different flight scenarios [4].
Methods for identifying workload primarily include task performance evaluation, subjective assessment, and physiological measurement [5]. Task performance evaluation and subjective assessment are post-task measurement methods conducted after task completion. In contrast, physiological measurement enables real-time workload monitoring by tracking fluctuations in physiological parameters, allowing the collection of operational data including the behavior patterns of pilots under various workload conditions. These real-time workload data can be used to optimize cockpit interface design, aligning it more closely with ergonomic principles and thereby enhancing flight safety.
However, most methods based on physiological measurement rely on contact-based devices [6,7,8]. The foreign body sensation caused by wearing these physiological data collection devices significantly affects the participants’ operational behavior. Previous studies on models based on physiological measurement have often used deep learning algorithms or neural networks, such as convolutional neural networks (CNNs) [9] and multimodal deep learning [10]. When cognitive workload is divided into low, medium, and high levels, the accuracy typically ranges from 65% to 80% [11,12,13], leaving room for improvement. During workload detection process, the feature data detected by the devices are usually stored in tabular form, and the inherent characteristics of these tabular feature data may be the reason for the limited accuracy of workload classification models [14]. Tabular feature data lack local features and have a weaker ability to integrate multiple data types; compared with text or image data, the number of features is relatively limited [15]. These factors make the processing of tabular feature data more complex, increasing the difficulty of developing accurate and reliable workload classification models.
Additionally, obtaining sufficient experimental samples to train complex deep learning models through human–machine interaction experiments presents significant challenges. Previous studies typically involved approximately 20–30 participants, generating around 800–3000 samples [16,17,18]. Such a sample size may lead to overfitting and generalization issues, and it is necessary to augment the dataset. A major drawback of current data augmentation methods is the inability to ensure the quality of generated data, potentially leading to low-confidence samples that do not accurately represent real data distribution [19]. Therefore, there is an urgent need to establish a stable and reliable data augmentation method.
Recently, large language models (LLMs) have undergone extensive pre-training on massive textual corpora, exhibiting exceptional performance across a spectrum of text classification and generation tasks. Comprehensive pre-training on extensive datasets, coupled with the deployment of sophisticated deep neural network architectures like transformers, enables these LLMs to effectively understand and manage complex contexts [20]. The superior generalizability of LLMs further amplifies their potential across a broader array of classification tasks. Therefore, large language models are expected to surmount the limitations of prior workload detection algorithms.
This study developed a large language model, WorkloadGPT, for identifying pilot workload based on low-interference indicators. These low-interference indicators include average gaze duration, number of fixations, number of saccades, number of blinks, average saccadic amplitude, left pupil diameter, right pupil diameter, and center of gravity offset rate. Workload is classified into three levels: low, medium, and high (label = 1, label = 2, label = 3). Due to the extensive pre-training knowledge and strong learning capabilities of large language models, WorkloadGPT excels in handling long-range dependencies and complex contextual information, thereby demonstrating outstanding performance in identifying pilot workload. The main contributions of this study are as follows:
- This method uses low-interference monitoring indicators, collecting data in 10 s time windows for model input. Compared with previous monitoring solutions, the low-interference devices impose less disturbance on pilots and enable real-time detection of pilot workload;
- This article introduces a GAN-Ensemble-based data augmentation technique that performs feature sampling through a generative adversarial network (GAN). The soft voting ensemble learning model is used to iteratively apply pseudo-labels to the sampled feature data. This algorithm can generate synthetic features that closely resemble real data while introducing necessary variability, ensuring the stability and robustness of data augmentation;
- This research proposes WorkloadGPT to recognize pilot workload. It employs the explained text template method to construct formatted instances. This method includes hints and variables regarding individual pilot differences in the ‘instruction’ of the formatted instances. Results indicate that WorkloadGPT excels in accuracy, real-time performance, and cross-pilot generalization.
The remainder of this paper is organized as follows: Section 2 reviews related studies. Section 3 introduces WorkloadGPT. Section 4 explains the experimental design and dataset. Section 5 presents the research results. Section 6 discusses the findings and limitations. Finally, Section 7 concludes the paper.
2. Literature Review
2.1. Methods for Recognizing Workload
2.1.1. Subjective Measurement and Task Performance Measurement
Subjective measurement reflects the true feelings of the operator through self-assessment questionnaires [21]. A major limitation of subjective measures is that they can assess only the overall experience of workload, not the changes in workload during task execution [22]. Task performance measurement is based on the premise that task performance reflects the psychological and physiological burden experienced by individuals during task execution. However, it has been argued that the relationship between workload, task performance, and physiological and psychological responses remains unclear [23,24].
2.1.2. Physiological Measurement
Zheng, L. et al. [6] established an artificial neural network (ANN) model to recognize workload using heart rate variability (HRV) and galvanic skin response (GSR), with an accuracy of 73%. Lim, W. L. et al. [25] developed a support vector machine (SVM) model with an accuracy of 69%, based on electroencephalography (EEG). Additionally, Han, S.Y. et al. [26] utilized a multimodal deep learning (MDL) network architecture, integrating information from EEG, electrocardiography (ECG), respiratory (RESP) data, and electrodermal activity (EDA). He, D. [27] used k-nearest neighbor (KNN), SVM, feedforward neural networks (FNNs), recurrent neural networks (RNNs), and random forest (RF) to classify three levels of workload for 33 drivers in a driving simulator. They found that combining eye-tracking data with physiological data significantly improved the classification accuracy. Rahman, H. [28] developed a non-contact method to classify driver workload using physiological parameters extracted from facial video images and vehicular parameters from controller area networks. They employed four machine learning algorithms—logistic regression (LR), SVM, linear discriminant analysis (LDA), and neural networks (NNs)—for classification. They concluded that the classification accuracy of non-contact camera data was comparable to, and often better than, traditional sensor data, due to fewer artifacts. Zhang, X. [29] developed a fuzzy neural network (FNN) model to assess pilot workload by integrating flight data with physiological data (including heart rate and respiratory rate). They achieved an accuracy of 75% in distinguishing different workload levels.
Although these methods can identify workload, they also have certain limitations. For instance, measuring indicators such as ECG, EEG, and GSR may interfere with pilot performance. In contrast, low-interference monitoring techniques can assess workload with minimal disruption to the pilot. For example, Filippini, C. investigated a methodology focused on remote evaluations of peripheral neurovegetative activity using thermal infrared imaging, where the emotional state classified from thermal signal analysis was compared with that recognized by a facial action coding system [30]. Additionally, eye-tracking devices and pressure cushions can also represent low-interference monitoring technologies. Jacob and Karn stated that eye-tracking devices can accurately record eye movements without disrupting tasks, making them effective for workload assessment [31]. While pressure cushions have not yet been used for workload detection, they have been widely applied in monitoring the cognitive state of drivers [32,33,34].
Under the category of low-interference devices, such as eye-tracking devices and pressure cushions, the following key metrics are commonly collected. The average fixation duration [35] and the number of fixations [36] are critical indicators of a pilot’s attention and concentration; longer fixation durations and increased fixation counts may suggest higher cognitive demands as the pilot focuses more intently on specific tasks or instruments. Similarly, the number of saccades [37] and the saccadic amplitude [38] can indicate workload levels; higher counts and larger amplitudes may suggest that the pilot is scanning the environment more frequently or shifting focus between different cockpit displays, both of which are associated with cognitive load. The number of blinks [39], often inversely correlated with cognitive load, is another significant indicator. A lower blink frequency might indicate increased cognitive demands as the pilot maintains focus, while a higher blink frequency could suggest fatigue or reduced workload. Additionally, as the pilot processes more information under high mental load conditions, the pupil diameter [40] may dilate due to cognitive strain. Finally, the center of pressure shift rate [41], derived from seat pressure data, reflects the pilot’s physical movement, with larger shifts potentially indicating increased physical and mental workload or discomfort.
Moreover, most previous studies recognized workload based on overall task difficulty, without accounting for continuous fluctuations in workload within the task. Establishing a method for real-time monitoring of continuous workload fluctuations within tasks is beneficial for designing safer and more efficient human–machine interaction systems. For instance, it can improve the design of the human–machine interface to control the workload caused by complicated digital information display.
2.2. Application of Large Language Models in Recognition Tasks
Large language models (LLMs), constructed using deep neural networks and trained with large datasets through self-supervised learning strategies, have emerged as sophisticated tools in the realm of language modeling [42]. Inferential computation via LLMs, based on numerous complex recognition tasks, facilitates the easier capture of characteristics inherent in these tasks. Hegselmann, S. et al. [43] developed a framework called TabLLM based on LLMs and experimentally assessed it, finding it to excel in the recognition of tabular data and outperform advanced algorithms like Extreme Gradient Boosting (XGBoost). Fang, X. et al. [44], in their survey on LLM applications in tabular data, highlighted the capabilities of LLMs in pre-trained knowledge transfer, context reasoning, and multi-step inference, which significantly improve accuracy and flexibility in data processing. Zhang, Y. et al. [45] proposed an adaptive boosting framework called Recurrence Generative Pre-trained Transformer (RGPT), specifically designed for text recognition using LLMs; results showed that RGPT exceeded average human performance in text classification tasks.
2.3. Tabular Data Sets and Serialization Methods
Tabular data refers to structured data organized in a table format, consisting of rows and columns. Each row represents a unique record, while each column represents a specific attribute of the data [43]. The structure of tabular data can vary significantly, including different orientations (horizontal or vertical), hierarchies (flat or nested), and formats of values (text, numbers, date/time, formulas, etc.). The experimental results of this study, as well as the constructed feature datasets, are all in tabular data format. These datasets include multidimensional feature variables with numerical values, and the first row of each tabular dataset contains the names of the feature variables in text format.
Table serialization is the process of converting table data into a linear, sequential text format, which is crucial when applying large language models to tabular datasets. Common serialization methods include row-wise serialization of table data, a technique adopted in many approaches such as TaPas [46], TableFormer [47], and TURL [48]. Additionally, TaPEx [49] uses special tokens to represent table components such as headers, TABBIE [50] serializes tables in both row and column formats, while TableGPT [51] employs a template-based method to serialize attribute–value pairs in each table record. These methods effectively transform tabular data into a format suitable for processing by large language models.
2.4. Fine-Tuning Methods
Research indicates that instruction fine-tuning significantly improves model performance on complex tasks [52]. Experiments have demonstrated that even with very limited data, applying instruction fine-tuning and training across datasets can enhance model generalization. Ma, Z. et al. [53] developed an instruction adjustment framework called LLaMoCo for fine-tuning LLMs specifically for given optimization problems. Experiments show that the CodeGen (350M) model fine-tuned using the LLaMoCo framework outperformed models like GPT-4 Turbo on a set of given problems, indicating that fine-tuning enhances the adaptability and generalization of LLMs. Tribes, C. et al. [54] highlighted that optimizing hyperparameters is crucial to the performance of instruction fine-tuning techniques like low-rank adaptation (LoRA). LoRA can substantially reduce both training duration and resource utilization while preserving or enhancing task-specific performance.
2.5. Data Augmentation for Small-Sample Datasets
Data augmentation is a crucial technique in machine learning and deep learning, especially for dealing with small-sample datasets. It plays a pivotal role in enhancing the performance of large language models (LLMs) in recognition tasks by expanding the diversity and quantity of training data, thereby improving the models’ ability to generalize and perform accurately across various contexts.
Synthetic minority oversampling technique (SMOTE) is the most widely used oversampling method to balance imbalanced data in machine learning. SMOTE arbitrarily creates new instances of the minority class from the nearest neighbors of that class [55]. Time-series synthetic minority oversampling technique (TSMOTE) generates new data through linear interpolation, which may produce data points that do not conform to the actual distribution [56]. Generative adversarial networks (GANs) are a class of deep learning models that consist of a generator and a discriminator, which are trained simultaneously through adversarial processes, with the generator aiming to create realistic data and the discriminator working to distinguish between real and generated data, thereby improving the quality of the generated outputs [57]. CTGAN, a method based on generative adversarial networks (GANs), can generate synthetic tabular data conforming to actual distributions, making it suitable for scenarios with diverse data types and complex relationships [58].
However, GAN-based methods struggle to capture the latent associations between attribute sets and class labels in relational data. To address this issue, Zhang, C. et al. [59] proposed an end-to-end self-training scheme called quality-aware self-training (QAST) for synthesizing rare relational data. QAST generates labeled synthetic data using GAN-based synthesis and pseudo-labeling. It ensures feature quality with a classifier committee and assigns semantic labels through majority voting by pre-trained classifiers.
3. Methods
This study proposes WorkloadGPT, an innovative approach that utilizes a large language model (LLM) for the detection of pilot workload. The model structure is shown in Figure 1. This study utilized the pre-trained ChatGLM3-6B model as the foundational architecture and employed low-rank adaptation (LoRA) for fine-tuning.
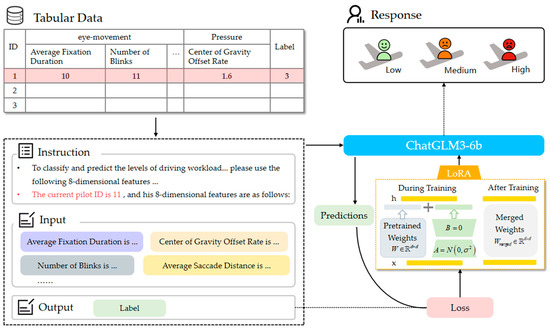
Figure 1.
The architecture of the entire model.
The input to the model was a tabular dataset containing the following eight-dimensional feature variables: Average Gaze Duration, Number of Fixations, Number of Saccades, Number of Blinks, Average Saccadic Amplitude, Left Pupil Diameter, Right Pupil Diameter, and Center of Gravity Offset Rate. During the training process, these tabular training data were serialized into a natural language format to construct a formatted instance dataset, allowing seamless input into a large language model. Specifically, the feature variable “Pilot ID” and explanations emphasizing individual pilot differences were included in the “Instruction” part of the formatted instance dataset to enhance the model’s generalization ability across different pilots.
3.1. Construction of the Formatted Instance Dataset
The performance of LLMs is highly sensitive to the precise details of natural language input [60,61]. Consequently, the construction of the formatted instance dataset significantly impacts model performance. In the “Instruction” section, this study describes the recognition task and includes information about individual pilot differences and the pilot ID. In the “Input” section, the pilot’s eight-dimensional features are included, and four different serialization formats of varied complexity are explored. All these serialization methods can be applied to new recognition tasks with minimal human effort. These four methods were evaluated for generating natural text closely aligned with the training distribution of LLMs, thereby enhancing the performance of fine-tuning large language models. In the “Output” section, labels corresponding to the pilot workload (low, medium, and high levels corresponding to labels 1, 2, and 3, respectively) are provided.
The methods of constructing the formatted instance dataset are described in Table 1 and Table 2. The formatted instances were constructed using the D1–D4 formats. These instances were then used to train large language models. After training, the models were tested on the same validation set. Model accuracy was used to evaluate the performance of each construction format, and the evaluation results are shown in Table 3. The comparison of results showed that the D3 format was the best for constructing the formatted instance dataset.

Table 1.
Examples of Formatting Construction Methods.
Table 2.
Types of Formatted Instance Datasets.
Table 3.
Comparison Results of the Four Formatted Instances.
The specific content included in D3 was as follows. Finally, all tabular data were converted into formatted instances according to the D3 format and stored in a JSON file to be used as a fine-tuning training set.
{
“instruction”: “To classify and predict the levels of pilot workload (high, medium, low) based on eye movement features and center of gravity shift rates, please use the following 8-dimensional features obtained from a flight simulation experiment. The workload classification labels range from 1 to 3, representing low, medium, and high workload, respectively. The current pilot ID is 11, and his 8-dimensional features are as follows:”;
“input”: “The average fixation duration (reflecting the driver’s concentration level) is 0.13403726. The number of fixations (indicating the frequency of the driver’s eye movements away from the focus of attention) is 4, the numbers of saccades are 7, the number of blinks is 6. The saccadic amplitude (reflecting the amplitude of the driver’s eye movements) is 114.895099. The left pupil diameter is 0.007033175, the right pupil diameter is 0.007331769. The center of pressure shift rate (indicating the extent of the driver’s body movement) is 1.575175968.”;
“output”: “3”
}
3.2. LoRA Fine-Tuning
This study employed the low-rank adaptation (LoRA) model as the fine-tuning method. LoRA has been demonstrated to effectively fine-tune large language models with minimal computational overhead while preserving the knowledge acquired during pre-training [62]. In workload recognition tasks, such as those explored in this study, the data predominantly consists of tabular data. The LoRA method offers distinct advantages for recognizing this type of data using large language models, which are not achievable with other fine-tuning approaches:
- Capturing structural relationships: In classifying tabular data, it is crucial to understand and interpret the intrinsic structural relationships within the table [1]. Although traditional large language models like GPT excel in handling textual data, they often struggle to adequately process the structured elements inherent in tabular data when directly applied. While this study formatted the tabular data into natural language, the formatted instances still retained certain structural relationships. To enhance the model’s capabilities in this area, LoRA incorporates low-rank matrices into the transformer layers, thereby improving the model’s ability to understand and process the data relationships within these formatted instances;
- Reducing the need for parameter tuning: Classification tasks involving tabular data often require extensive parameter tuning and model fine-tuning, which are resource-intensive for traditional large pre-trained models. LoRA addresses this issue by freezing the original model weights and solely modifying the added low-rank matrices, significantly reducing the number of parameters that require adjustments [63]. This approach not only lowers computational demands but also accelerates the model iteration process, enabling efficient tuning even under resource constraints;
- Suitability for resource-constrained environments: This method is particularly well-suited for use in environments with limited computational and storage resources, while maintaining the performance and flexibility of the model. Consequently, LoRA can operate efficiently under resource constraints, achieving effective fine-tuning without compromising model performance.
After multiple rounds of experiments and parameter tuning, this study determined the key parameters as shown in Table 4.
Table 4.
Key Parameters for LoRA Adaptation to ChatGLM3-6B Model.
3.3. Model Deployment, Training, and Testing Applications
3.3.1. Model Deployment and Training
Before formal training, the dataset containing data from 20 pilots was divided into a training set (pilot IDs 1–16) and a validation set (pilot IDs 17–20). These sets were then serialized and transformed into formatted instances. The deployment and training of the WorkloadGPT model was carried out on the LLaMA-Factory platform.
Figure 2 shows that the loss function value gradually decreased and stabilized during the training process, reflecting a good training outcome.
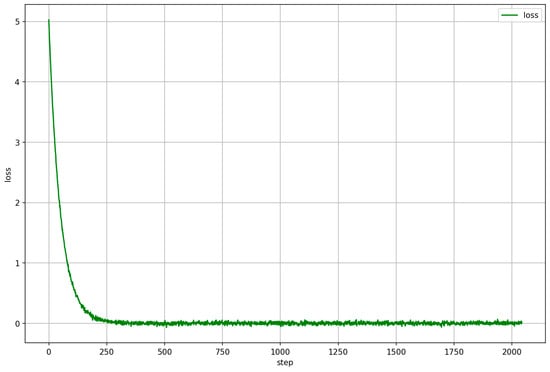
Figure 2.
Loss function curve chart.
3.3.2. Model Testing and Application
During the local testing and application of WorkloadGPT via API calls, the specific parameter settings were as Table 5.
Table 5.
Key Parameters for Model Evaluation.
4. Data
4.1. Data Collection
4.1.1. Flight Simulation Equipment
This study employed the X-Plane11 flight simulator (manufactured by Laminar Research, a company based in Columbia, SC, USA), recognized as one of the most advanced simulation software in the field [64,65,66]. Certified by the Federal Aviation Administration (FAA) for use in pilot training when paired with certified hardware, X-Plane facilitates a highly realistic training environment. The experimental setup was enhanced with professional-grade equipment, including triple-screen displays, a flight seat with VRS flight joystick support, a civil aviation cockpit chair (A10C t16000mx56tca), flight joysticks, Thrustmaster TCA Boeing throttle quadrants, and Thrustmaster TPR rudder pedals (manufactured by Guillemot Corporation, headquartered in Carentoir, France).
4.1.2. Flight Operations
In the flight simulation experiments, weather conditions were manipulated through dynamic parameter settings, affecting both the visual environment and task difficulty. This, in turn, significantly influenced the pilot’s workload. Additionally, different flight missions impacted the pilot’s workload. To elicit various levels of pilot workload, this study designed three simulated flight tasks: A, B, and C, with progressively increasing difficulty. Illustrations of the three flight tasks are shown in Figure 3.

Figure 3.
Three simulated flight tasks.
In Task A, pilots operated a single-engine light aircraft, taking off and climbing to 1500 m with tutorial guidance, maintaining the altitude briefly.
For Tasks B and C, preset conditions included a temperature of 59.1°F, sea-level pressure of 29.92 inches of mercury, and cloud layers between 1500 and 30,000 feet. Wind layers were at 6000, 4000, and 2000 feet, with standing water on the runway. The simulation was carried out at Runway Ranch, starting on Runway 18 with a 3-nautical-mile approach.
Task B involved flying a Boeing-Cessna Skyhawk in favorable weather, starting 3 nautical miles away at 3 km altitude, and landing on the runway at 10:30. Conditions included broken cumulus clouds, heavy precipitation, storms, 10-knot wind speeds, moderate turbulence, and 20 km visibility.
Task C, similar to Task B, was executed under adverse weather conditions, starting at 18:00 with stratus clouds, severe precipitation and storms, 20-knot wind speeds, maximum moderate turbulence, and 10 km visibility, resulting in increased workload due to reduced visibility.
4.1.3. Data Collection Using Low-Interference Devices and the NASA-TLX Scale
The low-interference devices used in this study are listed in the Table 6. Low-interference devices detected measurements including eye movement and seat pressure. Additionally, EEG and ECG data were used to label the pilot workload for these low-interference devices.
Table 6.
List of Low-Interference Devices.
NASA-TLX is a subjective tool designed to allow participants to subjectively assess the workload they experience during each task. After completing a task, participants were required to fill out the NASA-TLX questionnaire. The specific calculation process included:
NASA-TLX comprises six subscales: mental demand, physical demand, temporal demand, performance, effort, and frustration. Each participant’s total workload score was determined by a weighted average of these dimension scores, with higher scores indicating greater workload. In this model, represents the total score for workload assessment; denotes the score selected by the participant for the -th dimension; indicates the number of times the -th item is chosen from among 15 pairs. The overall workload score was calculated through a weighted average of the dimension scores, providing a quantitative measure of the workload experienced by participants in each task.
4.2. Participants and Experimental Procedure
The study enrolled a total of 20 participants, selected according to the recruitment standards for civil aviation pilots in China [67]. The specific details were as follows:
- Gender: The participants comprised 18 males and two females.
- Age: All participants were within the age range of 20 to 24 years.
- Height: Participants were required to be at least 168 cm tall.
- Weight: Participants’ weight had to comply with the body mass index (BMI) standards set for civil aviation pilot recruitment [67].
- Visual Acuity: All participants had a visual acuity (including corrected vision) of 0.8 or higher.
- Prior to the experiment, all participants were familiarized with the operational procedures of the flight simulator and had acquired the basic skills necessary for simulated flight, ensuring they were capable of competently performing the tasks required for this study.
During the formal experiment, each participant completed three sub-tasks labeled A, B, and C. Once the experimental setup was fully prepared, participants were instructed to complete the three tasks sequentially. After completing each sub-task, they were required to fill out a NASA-TLX questionnaire.
Informed consent was obtained from all participants. The experimental protocol received approval from the Institutional Ethics Committee of Tongji University.
4.3. Data Pre-Preprocessing
4.3.1. Seat Pressure Indicator
The output from seat pressure sensors was represented as a 32 × 32 matrix, capturing the dynamics of pressure at a sampling rate of 20 Hz. By analyzing this pressure distribution matrix, the center of gravity at any given moment can be identified, along with the rate of shift of the center of gravity. This analysis allows for the computation of the average center of pressure shift rate every 10 s.
The above formula is the calculation formula for the center of gravity shift rate. In the formula, and represent the rows and columns of the matrix, respectively, denoting the pressure value at row and column . and are the horizontal and vertical coordinates of the centroid after the matrix coordinates have been normalized. is the sampling frequency of the device, is the total duration, represents the centroid shift rate within a 10-s time window, and indicates the time window number for acquiring physiological measurement data.
4.3.2. Eye Movement Indicator
This study employed a telemetry-based eye-tracker to extract seven eye movement indicators, as shown in Figure 4. Gaze fixation was determined over intervals exceeding 100 milliseconds; if the Euclidean distance between gaze coordinates at adjacent timestamps was less than 50, the instance was considered a fixation. Since browsing behavior was not considered in this experiment, eye movements during non-fixation periods were classified as saccades. Saccade amplitude is defined as the Euclidean distance between the centers of two fixation points.

Figure 4.
The eye movement indicators extracted in this study.
4.3.3. ECG
After extracting physiological indicators from ECG and EEG, the mean values of these indicators for each subtask of the flight simulation experiment were calculated. These were then correlated with the pilot workload scores derived from the NASA-TLX scale for each subtask.
The process of ECG indicator extraction was as follows, ultimately obtaining the average heart rate generated every 10 s, denoted as HR.
- Signal Denoising:
The collected ECG signal often contains various types of noise, including white noise, motion artifacts, power line interference (electromagnetic interference from power lines, typically occurring at 50 Hz or 60 Hz frequencies), myoelectric interference (interference caused by electrical signals generated from muscle activity affecting measurement devices), and baseline drift (low-frequency noise caused by the drift of the baseline in a measurement system). To preprocess the ECG signal and remove these noises, we applied different filtering techniques:
- Band-pass filtering to remove power line interference;
- Low-pass filtering to remove myoelectric interference;
- High-pass filtering to remove baseline drift noise;
- Wavelet thresholding denoising to remove white noise and motion artifacts.
- 2.
- Indicator Extraction:
Once the ECG signal had been denoised, the next step involved extracting the R peaks of the QRS (Q wave, R wave, S wave) complex and determining the R-R intervals. This process used a differential thresholding method, combining thresholding with differential operations. The steps were as follows:
- First-order differentiation:
This step identifies all inflection points in the ECG signal;
- Second-order differentiation:
This step finds all peak points in the ECG signal;
- Threshold determination:
This step calculates the threshold value to identify the R peaks [68].
By following these steps, we were able to extract the R peaks of the QRS complex. The RR intervals were then determined, allowing us to calculate the average heart rate every 10 s.
The correlation analysis results demonstrated a strong positive correlation (r > 0.85) between the average heart rate and subjective scales, effectively indicating the magnitude of the workload.
4.3.4. EEG
The preprocessing of EEG data was carried out using EEGLAB [69], adhering to the following steps:
- Subject Training:
Beginning with writing the channel files necessary for whole-brain analysis, this step ensured that all relevant channels were accurately defined and prepared for subsequent data collection and analysis;
- 2.
- Initialization of Hardware and Software:
All required hardware and software devices were turned on and configured to ensure proper data acquisition. This included setting up EEG recording equipment and software platforms to capture brain activity signals accurately;
- 3.
- Task Execution:
During Tasks A, B, and C, EEG signals were collected, using the average power of the whole brain as a reference. This step helped in normalizing the data and ensured that variations in brain activity were accurately captured;
- 4.
- Signal Filtering:
- Band-pass filtering: A band-pass filter of 0.1–40 Hz was applied to extract EEG frequency band signals. This filter was designed to capture the relevant EEG signal frequencies while excluding frequencies outside this range;
- Notch filtering: A notch filter operating at 50 Hz was to remove interference caused by power line frequency; this step was crucial for eliminating common electrical noise present in the EEG data;
- 5.
- Signal Isolation and Artifact Removal:
- Isolating independent signal sources: Techniques such as independent component analysis (ICA) were used to isolate statistically independent signal sources within the EEG data.
- Artifact removal: Artifacts such as blinks and muscle movements were removed based on the characteristics of the source signals. This step was essential for ensuring that the data accurately reflected brain activity rather than external noise.
- 6.
- Frequency Separation:
A Fourier transform was performed on the preprocessed EEG signals to separate the data into different frequency bands, specifically targeting the alpha, beta, and theta frequency bands. This step was critical for analyzing the specific components of brain activity relevant to the study.
Based on the method described by GS, S.K. et al. [70], the 10 s average power of frequency bands from the frontal channels (FP1, FP2) and temporal channels (T7, T8)—denoted as E—was utilized as the workload characteristic value. This value was normalized for each participant to account for inter-subject variability. Statistical analysis demonstrated a strong positive correlation between E and subjective scale scores (r > 0.9), confirming its effectiveness in accurately representing workload.
4.4. Labeling Method
Based on previous analysis of EEG and ECG data, it is known that the characteristics of these indicators are significantly correlated with workload. Therefore, this study used E and HR to label the dataset, composed of eye movement and pressure indicators, with workload tags in 10 s time windows.
First, as shown in Figure 5a, an E-HR scatter plot was drawn, with vector arrows of different colors representing the data from various sample points. The plot indicates a significant positive correlation among individual participants. Next, a principal component analysis (PCA) was performed on the dataset composed of E and HR, revealing that the first principal component accounted for the majority of the variance. The loading calculations showed that both E and HR had identical loadings of 0.7071 on the first principal component, indicating that the main features of the dataset were distributed along the y = x direction. Consequently, using the K-means method, the data points were clustered into three categories based on their E and HR values along the characteristic direction.
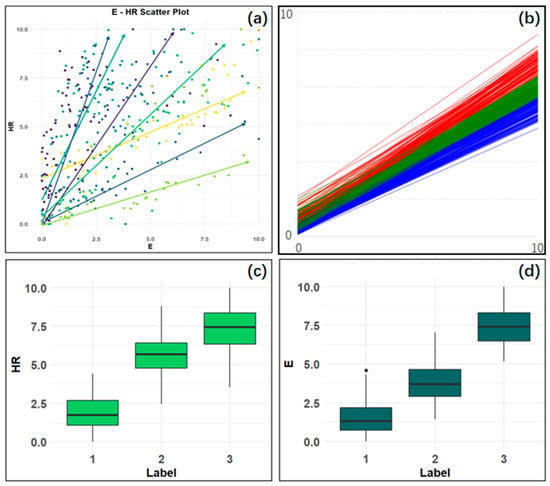
Figure 5.
(a) E-HR scatter plot; (b) parallel coordinates plot of E and HR values; (c) box plot of HR, (d) box plot of E.
Figure 5b displays a parallel coordinates plot containing the values of E and HR, aimed at visualizing the results of the PCA. In this plot, each colored line represents a data point in the dataset across the two variables, E and HR. Each vertical axis represents one of these variables, and lines connecting the data points’ values on these axes form a representation of each data point. Different colored lines indicate different categories obtained through the K-means clustering method.
Finally, the box plots shown in Figure 5c,d illustrate that both HR and E increased with higher workload labels. Therefore, each sample point is labeled with the corresponding cognitive load: low (label = 1), medium (label = 2), or high (label = 3). Ultimately, the dataset comprised 20 participants, with a 10 s time window, containing eight low-interference features (average gaze duration, number of fixations, number of saccades, number of blinks, average saccadic amplitude, left pupil diameter, right pupil diameter, and center of gravity offset rate) and their corresponding workload labels.
4.5. Data Augmentation
In this study involving 20 participants, we obtained a total of 1073 data points through experiments using a 10 s time window. The sample size was relatively small. Small sample datasets can cause large language models to overfit, making it difficult for models to learn universally applicable linguistic patterns, thereby weakening their generalization capabilities. Additionally, the choices and adjustments of model architectures in small-sample environments are restricted, which may compromise performance. Therefore, employing data augmentation techniques to expand the small sample dataset before training large language models is essential. Traditional data augmentation algorithms like Mixup, which use linear operations, can mitigate the scarcity of data in rare classes but may lead to performance instability due to their randomness [71]. To address the aforementioned small-sample dilemma and the limitations of traditional data augmentation methods, this study proposes a novel data augmentation approach: GAN-Ensemble. Compared with traditional data augmentation techniques, GAN-Ensemble can generate synthetic features that are highly similar to real data while introducing the necessary variability to ensure data diversity and authenticity. Through iterative pseudo-label generation and retraining, this method exhibits adaptability. Furthermore, by maintaining feature distribution and utilizing ensemble learning for pseudo-label generation, the algorithm ensures the robustness and stability of the data augmentation process.
The GAN-Ensemble data augmentation method involves generating features using the GAN algorithm and subsequently applying pseudo-labeling techniques to assign labels to the GAN-generated feature data. Initially, during the data partitioning phase of the original feature dataset T0, pilots with IDs 1–16 were assigned to the training set (T1), while pilots with IDs 17–20 were assigned to the validation set (T2). Subsequently, during the feature augmentation process, each pilot’s data was augmented separately to maintain inter-pilot variability. Finally, the original experimental data were used to train a soft voting ensemble learning model, which included base learners such as random forest, support vector machine, and gradient boosting tree. This soft voting ensemble learning model was then used for the subsequent generation of pseudo-labels. The overall workflow is shown in Figure 6.
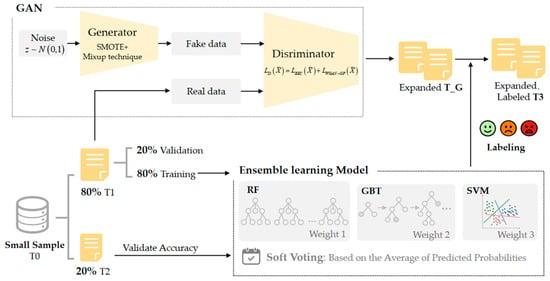
Figure 6.
Workflow of the GAN-Ensemble data augmentation method.
4.5.1. Using GAN for Feature Augmentation
The generative adversarial network (GAN) algorithm consists of two parts: the generator and the discriminator:
- (1)
- Generator design
The goal of the generator is to produce high-quality synthetic features that approximate the true data distribution. The input to the generator typically consists of high-dimensional random noise vectors. To enhance the quality and diversity of these seeds, this study incorporates random noise from a standard normal distribution, the SMOTE algorithm [57], and the Mixup technique [72] to generate these seeds:
- Random noise from a standard normal distribution: Initial seeds are generated through high-dimensional random noise vectors, utilizing the standard normal distribution to introduce randomness. This enhances the diversity of the seeds but may also lead to instability in seed quality.
- SMOTE algorithm: SMOTE generates more realistic samples by interpolating between neighboring real samples within the same category. This method improves the quality of the seeds but limits their diversity.where ~Uniform (0,1).
- Mixup technique: According to the study [72], Mixup creates new synthetic samples by performing linear interpolation in both feature and label spaces between two randomly selected samples. Applying this method to the generation of seeds for the generator not only enhances the diversity of the seeds but also maintains a certain level of quality.where ~Beta(,).
Unlike standard GANs that rely on a single method for generating synthetic data, our GAN-Ensemble combines random noise, SMOTE, and Mixup to generate seeds for the GAN. This hybrid approach ensures that the generator receives high-quality and diverse inputs, enabling it to learn a more accurate data distribution. This is particularly beneficial during the initial training phase when the generator is still learning, and it is crucial for both the stability of the training process and the quality of the generated data.
The training of the generator includes the use of reconstruction loss for supervised learning. This loss function aims to minimize the Euclidean distance between the generated samples and the original samples. The expression for the loss function is as follows:
where represents the normalized original experimental sample set [73] and denotes the synthetic sample set generated by the generator.
- (2)
- Discriminator design
The task of the discriminator is to distinguish between generated and real samples. This is a binary classification task, where the discriminator performs its judgment function by calculating the probability that a sample belongs to the real data set. The loss functions used are binary cross entropy (BCE) and Wasserstein distance with gradient penalty (WGAN-GP) [59], as follows:
where, represents the discrimination loss, is the BCE loss, and is the Wasserstein distance with gradient penalty. The expressions for and are as follows:
where, represents the probability that sample belongs to the original data. equals 1 when the sample comes from the original data, and equals 1 when the sample is synthesized by the generator.
Here, represents the original loss, and is the penalty loss.
By using a combination of normalized original samples x and generated samples z, the gradient of the discriminator is reduced to 1. The formula is as follows:
The data for each pilot in T1 were expanded to 10 times their original quantity, resulting in a feature dataset T_G. To evaluate the distribution differences of all features before and after data augmentation with GAN, the Jensen–Shannon (JS) divergence between T1 and T_G was calculated. The test results are shown as follows in Table 7.
Table 7.
Results of Jensen–Shannon Divergence Calculations.
The Jensen–Shannon divergence was close to zero, indicating a high degree of similarity between distributions. Consequently, this suggested that the distribution of features remained highly similar before and after data augmentation.
4.5.2. Iterative Pseudo-Labeling
Next, dataset T1 was partitioned into a training set and a testing set at a ratio of 8:2. Subsequently, an ensemble learning model was trained using five-fold cross-validation to label the feature dataset T_G. A soft voting mechanism was employed to obtain the prediction probabilities from each base learner. The final prediction was determined by selecting the label associated with the highest average probability. The trained initial model, referred to as M0, was then evaluated for accuracy using the validation set T2, achieving an accuracy rate of λ0.
Next, the following steps were repeated:
Step 1: Initially, model M0 was applied to the feature dataset T_G to generate pseudo-labels, resulting in dataset T3.
Step 2: Subsequently, datasets T3 and T1 were merged and this combined dataset was partitioned into a training set and a testing set in an 8:2 ratio. The ensemble learning model was designated as M1 and further training was carried out.
Step 3: The accuracy of model M1 was evaluated using validation set T2, denoted as λ1.
Steps 1, 2, and 3 were repeated until the accuracy measure λ stabilized and no longer exhibited significant changes. The flowchart of this process is shown in Figure 7.
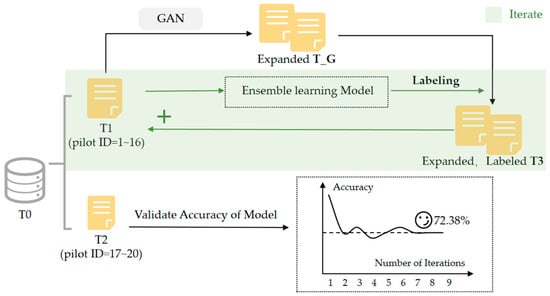
Figure 7.
Data Augmentation Process Diagram.
After nine iterations, the final model M9 achieved an accuracy of 85.37%. This model was used to assign pseudo-labels to the feature dataset T_G, denoted as Tk. Dataset Tk was then merged with dataset T1, resulting in a combined dataset of 9020 records (8200 from Tk plus 820 from T1). This merged dataset served as the training set Tx for fine-tuning the large language model, with dataset T2 designated as the test set.
5. Results
WorkloadGPT achieved a high accuracy of 87.3% on the validation set T2, with an operational time of only 1.76 s, demonstrating both high precision and real-time performance. Additionally, the standard deviation of classification accuracy across different pilots was less than 2%, indicating that the model exhibited excellent generalization and stability.
Further evaluation of the model’s classification performance was conducted using a confusion matrix, as shown in Table 8.
Table 8.
Confusion Matrix Results.
Several key metrics were derived from the confusion matrix, including precision, recall, and the F1 score, to evaluate the model’s performance. Among these, the F1 score is particularly used to assess the model’s accuracy in binary classification tasks. It represents the harmonic mean of precision and recall, providing a balanced measure between the two. The calculated precision, recall, and F1 scores for each class are summarized in Figure 8.
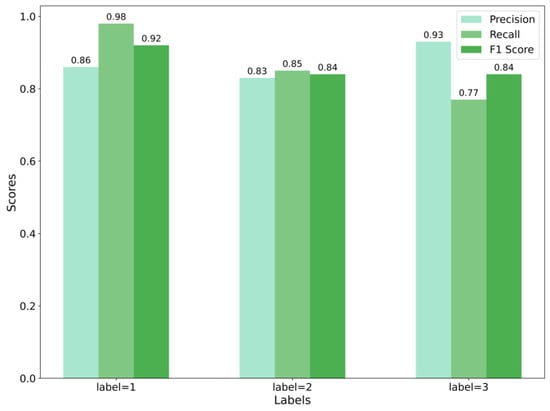
Figure 8.
Precision, recall, and F1 score by label.
For label = 1, the model showed excellent performance with a precision of 0.86 and a recall of 0.98, resulting in a high F1 score of 0.92, indicating high accuracy and sensitivity. For label = 2, the model achieved a precision of 0.83 and a recall of 0.85, yielding an F1 score of 0.84, suggesting good performance but with potential for reducing false positives. For label = 3, the model attained the highest precision of 0.93, but a lower recall of 0.77, leading to an F1 score of 0.84, indicating strong accuracy but with room for improvement in recall. Overall, these metrics suggest that the model performed well, with specific areas for enhancement in distinguishing between certain labels.
6. Discussion
This study conducted an in-depth analysis of the following three questions to thoroughly explore the current research and the developed WorkloadGPT model:
- Q1: Comparison between other methods and WorkloadGPT: How effective is WorkloadGPT?
- Q2: How does WorkloadGPT perform in terms of generalization across different pilots?
- Q3: What advantages does this study have compared to previous studies?
6.1. Comparison between Other Methods and WorkloadGPT (Q1)
This study established comparison models using random forest, support vector machine (SVM), K-nearest neighbors (KNNs), gradient goosting decision tree (GBDT), and a few-shot logic applied with ChatGPT-4 to evaluate their performance against WorkloadGPT.
Random Forest: Random forest is an ensemble learning method that improves the accuracy and stability of a model by constructing multiple decision trees and combining their predictions. The model’s structure consists of several independently trained decision trees, and the final classification result is determined by majority voting. In this model, the number of decision trees (n_estimators) was set to 150, the maximum number of features considered at each split (max_features) was set to 3, and the maximum depth of the decision trees was left unrestricted (i.e., defaulting to none), as is typical.
Support Vector Machine: Support vector machine (SVM) is a widely used supervised learning model for classification problems. It works by finding the optimal hyperplane that maximizes the margin between different classes. In this study, a linear kernel function (kernel = ‘linear’) was used to create the SVM model, which was then trained on the training set. The regularization parameter C was set to the default value of 1 to balance training error and generalization ability.
KNNs: K-nearest neighbors (KNNs) is a supervised learning model used for classification problems. It works by calculating the distance between the input sample and the training samples, then selecting the K nearest neighbors to vote on the classification. In this model, the features were first standardized and the KNNs model was then trained. The number of neighbors (K) was set to 5, and Euclidean distance was used as the distance metric to optimize classification performance.
GBDT: Gradient boosting decision tree (GBDT) is a powerful ensemble learning method that improves model accuracy and stability by constructing a series of decision trees and iteratively optimizing the prediction errors of each tree. After standardizing the features, the GBDT model was trained. In this model, the learning rate was set to 0.004, the maximum depth of the decision trees was set to 6, the subsample ratio and the ratio of random sampling for each tree were both set to 0.8, and the number of decision trees was set to 120. These settings achieved a good balance between model complexity and training time.
All models were tested on the same validation set, using data from pilot IDs 17–20. The classification accuracy for each model is detailed in Figure 9.
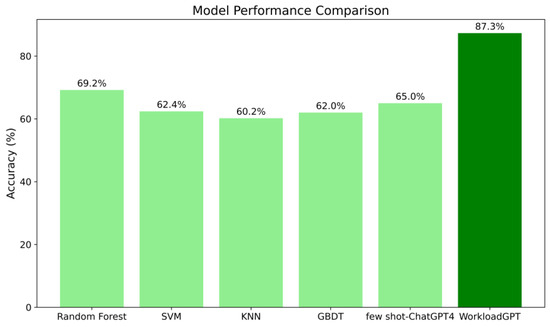
Figure 9.
Comparison of results from different models.
In terms of accuracy, only WorkloadGPT exceeded 80%, outperforming the second most accurate model, random forest, by 18.1%. This indicates WorkloadGPT’s significant advantage in accuracy compared with the other algorithms. Specifically, compared was ChatGPT-4, which utilizes few-shot learning methods, WorkloadGPT improved the model accuracy by 12.3%, with a runtime of only 1.76 s, demonstrating rapid response and strong real-time performance. This comprehensive performance enhancement was probably a reflection of ChatGPT-4’s lack of pre-training knowledge in the specific domain of pilot workload. Therefore, training a large language model specifically for pilot workload recognition is essential.
6.2. Generalization of WorkloadGPT across Pilots (Q2)
During the development of WorkloadGPT, pilot IDs were added as variables in the “instruction” part of the formatted instances, along with relevant prompts indicating “pilots have individual differences.” After training and fine-tuning, WorkloadGPT achieved an accuracy of 87.3% on a validation set, with a cross-pilot standard deviation of accuracy of about 2.1%, demonstrating its strong generalization capability.
In previous studies, generalization was typically achieved through specific algorithm designs:
CNN-DG [74]: The CNN-DG model for cross-pilot workload recognition (CWR) leverages convolutional neural networks (CNNs) and domain generalization (DG) to overcome CWR challenges. It consists of three primary components: a deep feature extractor, a label classifier, and a domain generalizer. The model enhances domain generalizability through adversarial training.
Kmeans + SVM [75]: The K-means + SVM model integrates k-means clustering with support vector machines (SVMs) to mitigate individual differences in workload assessments. It comprises two main components: a clustering module and a classification module. Initially, the clustering module groups participants based on physiological data features. Subsequently, the classification module uses SVM within each cluster to classify and predict data.
Using the same training and validation sets as WorkloadGPT, CNN-DG and Kmeans + SVM were trained and tested. The results are shown in Figure 10. For CNN-DG, the cross-pilot standard deviation was 1.9%, but the accuracy was only 63.7%. This could have been due to the adversarial training process overlooking key factors that influence workload classification. Consequently, the model failed to adequately learn the essential features required to distinguish between different workload states, resulting in low model accuracy.
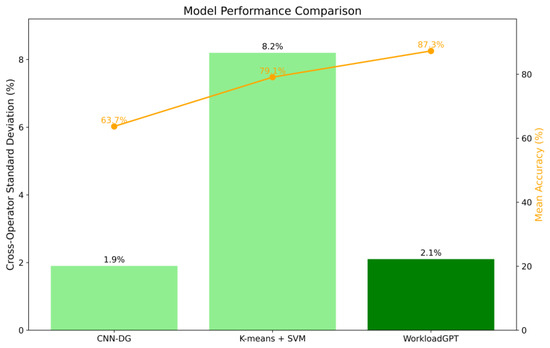
Figure 10.
Evaluation results of cross-pilot generalization for different models.
On the other hand, Kmeans + SVM resulted in a cross-pilot standard deviation of 8.2% and a mean accuracy of 79.1%. The cross-pilot standard deviation was nearly four times higher than that of WorkloadGPT, and the model’s accuracy was also lower than WorkloadGPT. The suboptimal performance of the Kmeans + SVM model may be attributed to several factors. Firstly, the k-means algorithm requires pre-specifying the number of clusters, which is difficult to determine accurately in practical applications, leading to poor clustering performance. Secondly, k-means is sensitive to the initial cluster centers, and different initializations can affect the model’s stability and predictive performance. Additionally, the complexity and diversity of individual differences make it challenging for simple clustering and classification methods to capture all relevant information comprehensively. Furthermore, imbalanced data distribution and noise can also reduce the model’s performance.
In contrast, WorkloadGPT employs an end-to-end approach, achieving robust generalization efficiently and with high quality, effectively addressing the limitations of the aforementioned models.
Firstly, WorkloadGPT ensures that the large language model focuses on individual differences by including prompts in the training dataset, capturing key features that are crucial for classification predictions and have generalizability. This approach overcomes the limitations of previous methods that failed to comprehensively capture useful information, effectively capturing the characteristics of different pilots.
Secondly, WorkloadGPT avoids the inherent issues of the k-means clustering algorithm, which requires pre-specifying the number of clusters—a challenging task to determine accurately in practical applications, potentially leading to suboptimal clustering results. Additionally, WorkloadGPT does not rely on initial cluster centers, thus avoiding inconsistencies in clustering outcomes due to different initializations, thereby enhancing the model’s stability and predictive performance.
Additionally, WorkloadGPT demonstrates greater robustness in handling high-dimensional and heterogeneous physiological data. By employing an end-to-end approach, WorkloadGPT can directly extract features from raw data, reducing the negative impact of imbalanced data distribution and noise on model performance. Compared with traditional methods, WorkloadGPT exhibits higher accuracy and consistency when processing complex data.
6.3. Comparison with Previous Studies (Q3)
In this section, this study is compared with previous research in terms of data type, feature selection methods, classification models, sample size, number of categories, real-time capability, number of participants, and accuracy (ACC). The comparison results are shown in Table 9.
Table 9.
Comparison of Different Studies.
Firstly, previous studies have predominantly used high-interference devices for data collection. For instance, Caliskan, S.G. et al. [76] utilized EDA, ECG, and RESP data, while Khanam, F. et al. [7] and Salimi, N. et al. [8] employed EEG data. In contrast, this study utilized the low-interference eye movement indicator and seat pressure indicator, effectively reducing interference with pilot operations.
Secondly, common feature selection methods in past research have included ANOVA, Pearson correlation coefficient, and discrete wavelet transform (DWT), which extract features by analyzing variance, correlation, and signal characteristics. This study, however, did not perform explicit feature selection but has adopted an end-to-end modeling approach, fully utilizing raw data and introducing individual difference cues during the construction of formatted instances. This enhances the model’s cross-pilot generalization. This end-to-end method allows the model to accurately capture key features affecting workload classification, thereby improving the model’s accuracy and consistency in complex dynamic scenarios.
Additionally, the real-time detection of driving workload has been challenging in previous research. This study extracted features using a 10 s time window and input them into WorkloadGPT for classification, with a model response time of only 1.76 s, demonstrating strong real-time performance.
Finally, this study employed a three-level cognitive workload classification standard (low, medium, high), with WorkloadGPT achieving an accuracy of 87.3%, significantly higher than the 70–80% range reported in previous studies [6,7,8]. Unlike prior models that relied on classical machine learning algorithms or ensemble structures, this study innovatively applies a large language model to address pilot workload classification, presenting a novel solution. Despite the limited sample size and number of participants in this study, the proposed GAN-Ensemble data augmentation method provides a robust foundation for model development.
6.4. Limitations and Future Work
6.4.1. Limitations
This study also has some limitations. The number of participants in the experiment was small. Although data augmentation was used, it might have been insufficient to comprehensively cover the characteristics of pilot driving; therefore, there is more room for improvement in the model’s generalization and accuracy. Additionally, during the testing phase, WorkLoadGPT occasionally experienced catastrophic forgetting and misunderstandings of user queries. Fortunately, these issues were rare.
6.4.2. Future Work
- Expansion of Participant Pool: Future research will involve recruiting a larger and more diverse group of participants. By including pilots with different levels of experience, from various regions, and with different physiological characteristics, the model can be trained on a more comprehensive dataset. This approach is expected to enhance the model’s generalization across different pilot populations and improve its overall accuracy.
- Advanced Data Augmentation Techniques: To further address the limitations of the current data augmentation methods, future work will explore more sophisticated techniques such as variational autoencoders (VAEs) [77] and adversarial training [78]. These methods could create richer and more varied synthetic data that better represent the nuances of pilot workload, ultimately leading to a more robust model.
- Mitigation of Catastrophic Forgetting: To tackle the problem of catastrophic forgetting, future iterations of WorkloadGPT will incorporate continual learning strategies. Techniques such as elastic weight consolidation (EWC) [79] and memory-aware synapses (MASs) [80] can be applied to protect previously learned knowledge while allowing the model to adapt to new data.
- Enhancement of Instruction Understanding: The introduction of instruction vectors (IVs) [81] will be refined and optimized. By maintaining and possibly expanding the computational graph related to the IVs during training, the model can improve its ability to retain and correctly apply instructions from prior tasks when learning new ones. Additionally, experimenting with different architectures that better integrate IVs might reduce instances of misinterpretation.
- Incorporation of Real-World Scenarios: Future work will also involve testing the model in more complex and dynamic real-world scenarios, possibly integrating with live flight data. This will help assess the model’s performance in practical applications and provide valuable feedback for further development.
7. Conclusions
Real-time monitoring of pilot workload is crucial for aiding in cockpit interface design, supporting pilot training and evaluation, and enhancing flight safety. However, current pilot workload detection faces significant challenges. Against this backdrop, this study proposes WorkloadGPT, a novel approach utilizing a large language model to address the classification of pilot workload. The model achieved an accuracy of 87.3% and a response time of only 1.76 s, representing a significant improvement in both model accuracy and response speed compared with previous studies. Moreover, WorkloadGPT demonstrated a cross-pilot standard deviation of only 2.1% on a validation set composed entirely of data from unfamiliar pilots, indicating strong cross-pilot generalization performance. This study also leverages low-interference devices, including the eye movement indicator and seat pressure indicator, to establish a connection with pilot workload, effectively reducing interference during workload detection. By inputting these low-interference indicators into the model within a 10 s time window, the model ensures real-time detection of pilot workload. Additionally, an efficient data augmentation method, GAN-Ensemble, is introduced to address the issue of small sample sizes. This method reliably ensures the efficiency and quality of data augmentation, thereby enhancing the overall model performance.
This model can be used not only in providing new benchmarks for the evaluation of flight training and missions, but also in assisting in the design and improvement of flight dashboards and cockpit functions. The outcomes of this study provide a novel solution for pilot workload recognition, with significant theoretical and practical value.
Author Contributions
Conceptualization, L.Y. and Y.G.; methodology, Y.G. and L.Y.; software, Y.G. and J.S.; validation, Y.G.; formal analysis, Y.G. and Y.L.; investigation, Y.G., Y.L., J.S. and X.W.; resources, L.Y.; data curation, Y.G. and Y.L.; writing—original draft preparation, Y.G. and J.S.; writing—review and editing, L.Y. and X.S.; visualization, X.W.; supervision, L.Y. and X.S.; project administration, L.Y.; funding acquisition, L.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research is funded by the National Natural Science Foundation Project under Grant 52302442.
Institutional Review Board Statement
The study was approved by the Institutional Ethics Com mittee of Tongji University for studies involving humans with the approval number tjdxsro82 on 15 April 2024.
Informed Consent Statement
Informed consent was obtained from all participants involved in the study.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request. Due to confidentiality agreements, access to the raw data may be restricted.
Acknowledgments
Thanks to the College of Transportation Engineering at Tongji University for providing ample experimental resources, and to all the participants for their diligence, responsibility, and high level of cooperation in completing the experiments. Lastly, we would like to express our gratitude for the assistance of ChatGPT-4.0 in performing grammar checks during the preparation of this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wickens, C.D. Situation awareness and workload in aviation. Curr. Dir. Psychol. Sci. 2002, 11, 128–133. [Google Scholar] [CrossRef]
- Guo, X.; Liu, B. Cockpit information required by advanced fighter pilots for displays in taxiing take-off. Chin. J. Ergon. 2002, 8, 1–7. [Google Scholar]
- Wei, Z.M.; Wanyan, X.R.; Zhuang, D.M. Measurement and evaluation of mental workload for aircraft cockpit display interface. J. Beijing Univ. Aeronaut. Astronaut. 2014, 40, 86. [Google Scholar] [CrossRef]
- Kale, U.; Rohács, J.; Rohács, D. Operators’ load monitoring and management. Sensors 2020, 20, 4665. [Google Scholar] [CrossRef] [PubMed]
- Khosla, A.; Khandnor, P.; Chand, T. A comparative analysis of signal processing and classification methods for different applications based on EEG signals. Biocybern. Biomed. Eng. 2020, 40, 649–690. [Google Scholar] [CrossRef]
- Zheng, L.; Qiao, X.; Ni, T.; Yang, W.; Li, Y. Driver cognitive loads based on multi-dimensional information feature analysis. China J. Highw. Transp. 2021, 34, 240–250. [Google Scholar]
- Khanam, F.; Hossain, A.B.M.A.; Ahmad, M. Electroencephalogram-based cognitive load level classification using wavelet decomposition and support vector machine. Brain-Comput. Interfaces 2023, 10, 1–15. [Google Scholar] [CrossRef]
- Salimi, N.; Barlow, M.; Lakshika, E. Mental Workload Classification Using Short Duration EEG Data: An Ensemble Approach Based on Individual Channels. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence (SSCI), Xiamen, China, 6–9 December 2019; pp. 393–398. [Google Scholar] [CrossRef]
- Khan, M.J.; Hong, M.J.; Hong, K.S. Decoding of four movement directions using hybrid NIRS-EEG brain-computer interface. Front. Hum. Neurosci. 2014, 8, 244. [Google Scholar] [CrossRef]
- Fazli, S.; Mehnert, J.; Steinbrink, J.; Curio, G.; Villringer, A.; Müller, K.R.; Blankertz, B. Enhanced performance by a hybrid NIRS–EEG brain computer interface. NeuroImage 2012, 59, 519–529. [Google Scholar] [CrossRef]
- Abibullaev, B.; An, J.; Moon, J.I. Neural network classification of brain hemodynamic responses from four mental tasks. Int. J. Optomechatron. 2011, 5, 340–359. [Google Scholar] [CrossRef]
- Hennrich, J.; Herff, C.; Heger, D.; Schultz, T. Investigating deep learning for fNIRS based BCI. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; IEEE: New York, NY, USA, 2015; pp. 2844–2847. [Google Scholar] [CrossRef]
- Trakoolwilaiwan, T.; Behboodi, B.; Lee, J.; Kim, K.; Choi, J.W. Convolutional neural network for high-accuracy functional near-infrared spectroscopy in a brain–computer interface: Three-class classification of rest, right-, and left-hand motor execution. Neurophotonics 2018, 5, 011008. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Zhang, L.; Wang, L.; Xu, M.; Qi, H.; Wan, B.; Ming, D.; Hu, Y. A hybrid brain-computer interface combining the EEG and NIRS. In Proceedings of the 2012 IEEE International Conference on Virtual Environments Human-Computer Interfaces and Measurement Systems (VECIMS), Tianjin, China, 2–4 July 2012; IEEE: New York, NY, USA, 2012; pp. 159–162. [Google Scholar] [CrossRef]
- Lee, M.H.; Fazli, S.; Mehnert, J.; Lee, S.W. Hybrid brain-computer interface based on EEG and NIRS modalities. In Proceedings of the 2014 International Winter Workshop on Brain-Computer Interface (BCI), Jeongseon, Republic of Korea, 17–19 February 2014; IEEE: New York, NY, USA, 2014; pp. 1–2. [Google Scholar] [CrossRef]
- Wu, F.; Wang, Q.; Bian, J.; Ding, N.; Lu, F.; Cheng, J.; Dou, D.; Xiong, H. A survey on video action recognition in sports: Datasets, methods and applications. IEEE Trans. Multimed. 2022, 25, 7943–7966. [Google Scholar] [CrossRef]
- Ru, Y.; Wei, Z.; An, G.; Chen, H. Combining data augmentation and deep learning for improved epilepsy detection. Front. Neurol. 2024, 15, 1378076. [Google Scholar] [CrossRef]
- Zhou, J.; Yu, K.; Chen, F.; Wang, Y.; Arshad, S.Z. Multimodal behavioral and physiological signals as indicators of cognitive load. In The Handbook of Multimodal-Multisensor Interfaces: Signal Processing, Architectures, and Detection of Emotion and Cognition, 2nd ed.; Oviatt, S., Schuller, B., Eds.; Association for Computing Machinery: New York, NY, USA, 2018; Volume 2, pp. 287–329. [Google Scholar] [CrossRef]
- Rashid, H.; Tanveer, M.A.; Khan, H.A. Skin lesion classification using GAN based data augmentation. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Berlin, Germany, 23–27 July 2019; IEEE: New York, NY, USA, 2019; pp. 916–919. [Google Scholar] [CrossRef]
- Liu, Y.; He, H.; Han, T.; Zhang, X.; Liu, M.; Tian, J.; Zhang, Y.; Wang, J.; Gao, X.; Zhong, T.; et al. Understanding LLMs: A comprehensive overview from training to inference. arXiv 2024, arXiv:2401.02038. [Google Scholar] [CrossRef]
- Li, L.-P.; Liu, Z.-G.; Zhu, H.-Y.; Zhu, L.; Huang, Y.-C. Functional Near-Infrared Spectroscopy in the Evaluation of Urban Rail Transit Drivers’ Mental Workload under Simulated Driving Conditions. Ergonomics 2019, 62, 406–419. [Google Scholar] [CrossRef]
- Gao, Q.; Wang, Y.; Song, F.; Li, Z.; Dong, X. Mental Workload Measurement for Emergency Operating Procedures in Digital Nuclear Power Plants. Ergonomics 2013, 56, 1070–1085. [Google Scholar] [CrossRef]
- Stevens, C.A.; Morris, M.B.; Fisher, C.R.; Myers, C.W. Profiling Cognitive Workload in an Unmanned Vehicle Control Task with Cognitive Models and Physiological Metrics. Mil. Psychol. 2023, 35, 507–520. [Google Scholar] [CrossRef]
- Moray, N. Mental Workload since 1979. Int. Rev. Ergon. 1988, 2, 123–150. [Google Scholar]
- Lim, W.L.; Sourina, O.; Wang, L.P. STEW: Simultaneous Task EEG Workload Data Set. IEEE Trans. Neural Syst. Rehabil. Eng. 2018, 26, 2106–2114. [Google Scholar] [CrossRef]
- Han, S.Y.; Kwak, N.S.; Oh, T.; Lee, S.W. Classification of Pilots’ Mental States Using a Multimodal Deep Learning Network. Biocybern. Biomed. Eng. 2020, 40, 324–336. [Google Scholar] [CrossRef]
- He, D.; Wang, Z.; Khalil, E.B.; Donmez, B.; Qiao, G.; Kumar, S. Classification of Driver Cognitive Load: Exploring the Benefits of Fusing Eye-Tracking and Physiological Measures. Transp. Res. Rec. J. Transp. Res. Board 2022, 2676, 670–681. [Google Scholar] [CrossRef]
- Rahman, H.; Ahmed, M.; Barua, S.; Begum, S. Non-Contact-Based Driver’s Cognitive Load Classification Using Physiological and Vehicular Parameters. Biomed. Signal Process. Control 2020, 55, 101634. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Qiu, Z.; Bao, J.; Zhang, Y. Adaptive Neuro-Fuzzy Fusion of Multi-Sensor Data for Monitoring a Pilot’s Workload Condition. Sensors 2019, 19, 3629. [Google Scholar] [CrossRef]
- Filippini, C.; Spadolini, E.; Cardone, D. Facilitating the Child–Robot Interaction by Endowing the Robot with the Capability of Understanding the Child Engagement: The Case of Mio Amico Robot. Int. J. Soc. Robot. 2021, 13, 677–689. [Google Scholar] [CrossRef]
- Jacob, R.J.K.; Karn, K.S. Commentary on Section 4—Eye Tracking in Human-Computer Interaction and Usability Research: Ready to Deliver the Promises. In The Mind’s Eye: Cognitive and Applied Aspects of Eye Movement Research; Hyönä, J., Radach, R., Deubel, H., Eds.; Elsevier: Amsterdam, The Netherlands, 2003; pp. 573–605. [Google Scholar]
- Tan, H.Z.; Slivovsky, L.A.; Pentland, A. A Sensing Chair Using Pressure Distribution Sensors. IEEE/ASME Trans. Mechatron. 2001, 6, 261–268. [Google Scholar] [CrossRef]
- Andreoni, G.; Santambrogio, G.C.; Rabuffetti, M.; Pedotti, A. Method for the Analysis of Posture and Interface Pressure of Car Drivers. Appl. Ergon. 2002, 33, 511–522. [Google Scholar] [CrossRef]
- Lantoine, P.; Lecocq, M.; Bougard, C.; Dousset, E.; Marqueste, T.; Bourdin, C.; Allègre, J.M.; Bauvineau, L.; Mesure, S. Car Seat Impact on Driver’s Sitting Behavior and Perceived Discomfort during Prolonged Real Driving on Varied Road Types. PLoS ONE 2021, 16, e0259934. [Google Scholar] [CrossRef]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Rayner, K. Eye Movements in Reading and Information Processing: 20 Years of Research. Psychol. Bull. 1998, 124, 372. [Google Scholar] [CrossRef]
- Di Stasi, L.L.; Renner, R.; Staehr, P.; Helmert, J.R.; Velichkovsky, B.M.; Cañas, J.J.; Catena, A.; Pannasch, S. Saccadic Peak Velocity Sensitivity to Variations in Mental Workload. Aviat. Space Environ. Med. 2010, 81, 413–417. [Google Scholar] [CrossRef] [PubMed]
- Bahill, A.T.; Clark, M.R.; Stark, L. The Main Sequence, a Tool for Studying Human Eye Movements. Math. Biosci. 1975, 24, 191–204. [Google Scholar] [CrossRef]
- Stern, J.A.; Boyer, D.; Schroeder, D. Blink Rate: A Possible Measure of Fatigue. Hum. Factors 1994, 36, 285–297. [Google Scholar] [CrossRef] [PubMed]
- Beatty, J. Task-Evoked Pupillary Responses, Processing Load, and the Structure of Processing Resources. Psychol. Bull. 1982, 91, 276. [Google Scholar] [CrossRef] [PubMed]
- Van Erp, J.B.; Van Veen, H.A. Vibrotactile In-Vehicle Navigation System. Transp. Res. Part F Traffic Psychol. Behav. 2004, 7, 247–256. [Google Scholar] [CrossRef]
- Zhang, Q.; Gui, T.; Zheng, R.; Huang, X. The Theory and Practice of Large Language Models. Available online: https://intro-llm.github.io/ (accessed on 17 May 2024).
- Hegselmann, S.; Buendia, A.; Lang, H.; Agrawal, M.; Jiang, X.; Sontag, D. TabLLM: Few-Shot Classification of Tabular Data with Large Language Models. arXiv 2022, arXiv:2210.10723. Available online: https://arxiv.org/abs/2210.10723 (accessed on 17 May 2024).
- Fang, X.; Xu, W.; Tan, F.A.; Zhang, J.; Hu, Z.; Qi, Y.; Nickleach, S.; Socolinsky, D.; Sengamedu, S.; Faloutsos, C. Large Language Models (LLMs) on Tabular Data: Prediction, Generation, and Understanding—A Survey. arXiv 2024, arXiv:2402.17944. Available online: https://arxiv.org/abs/2402.17944 (accessed on 17 May 2024).
- Zhang, Y.; Wang, M.; Ren, C. Pushing the Limit of LLM Capacity for Text Classification. arXiv 2024, arXiv:2402.07470. Available online: https://arxiv.org/abs/2402.07470 (accessed on 17 May 2024).
- Herzig, J.; Nowak, P.K.; Müller, T.; Piccinno, F.; Eisenschlos, J.M. TaPas: Weakly Supervised Table Parsing via Pre-Training. arXiv 2020, arXiv:2004.02349. [Google Scholar]
- Nassar, A.; Livathinos, N.; Lysak, M.; Staar, P. Tableformer: Table Structure Understanding with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4614–4623. [Google Scholar]
- Deng, X.; Sun, H.; Lees, A.; Wu, Y.; Yu, C. Turl: Table Understanding through Representation Learning. ACM SIGMOD Rec. 2022, 51, 33–40. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, B.; Guo, J.; Ziyadi, M.; Lin, Z.; Chen, W.; Lou, J.G. TAPEX: Table Pre-Training via Learning a Neural SQL Executor. arXiv 2021, arXiv:2107.07653. [Google Scholar]
- Iida, H.; Thai, D.; Manjunatha, V.; Iyyer, M. Tabbie: Pretrained Representations of Tabular Data. arXiv 2021, arXiv:2105.02584. [Google Scholar]
- Gong, H.; Sun, Y.; Feng, X.; Qin, B.; Bi, W.; Liu, X.; Liu, T. TableGPT: Few-shot table-to-text generation with table structure reconstruction and content matching. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1978–1988. [Google Scholar]
- Xu, X. Mental-LLM: Leveraging Large Language Models for Mental Health Prediction via Online Text Data. arXiv 2023, arXiv:2307.14385. Available online: https://arxiv.org/abs/2307.14385 (accessed on 17 May 2024). [CrossRef]
- Ma, Z.; Guo, H.; Chen, J.; Peng, G.; Cao, Z.; Ma, Y.; Gong, Y.-J. LLaMoCo: Instruction Tuning of Large Language Models for Optimization Code Generation. arXiv 2024, arXiv:2403.01131. Available online: https://arxiv.org/abs/2403.01131 (accessed on 17 May 2024).
- Tribes, C.; Benarroch-Lelong, S.; Lu, P.; Kobyzev, I. Hyperparameter Optimization for Large Language Model Instruction-Tuning. arXiv 2024, arXiv:2312.00949. Available online: https://arxiv.org/abs/2312.00949 (accessed on 17 May 2024).
- Hussain, L.; Lone, K.J.; Awan, I.A.; Abbasi, A.A.; Pirzada, J. Detecting Congestive Heart Failure by Extracting Multimodal Features with Synthetic Minority Oversampling Technique (SMOTE) for Imbalanced Data Using Robust Machine Learning Techniques. Waves Random Complex Media 2022, 32, 1079–1102. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J. Generative Adversarial Networks (GANs) Challenges, Solutions, and Future Directions. ACM Comput. Surv. 2021, 54, 63. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular Data Using Conditional GAN. arXiv 2019, arXiv:1907.00503. [Google Scholar] [CrossRef]
- Zhang, C.; Hou, Y.; Chen, K.; Cao, S.; Fan, G.; Liu, J. Quality-aware self-training on differentiable synthesis of rare relational data. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 6602–6611. [Google Scholar] [CrossRef]
- Hajikhani, A.; Cole, C. A critical review of large language models: Sensitivity, bias, and the path toward specialized AI. Quant. Sci. Stud. 2024, 1–22. [Google Scholar] [CrossRef]
- Loya, M.; Sinha, D.A.; Futrell, R. Exploring the Sensitivity of LLMs’ Decision-Making Capabilities: Insights from Prompt Variation and Hyperparameters. arXiv 2023, arXiv:2312.17476. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar] [CrossRef]
- Sui, Y.; Zhou, M.; Zhou, M.; Han, S.; Zhang, D. Table meets llm: Can large language models understand structured table data? A benchmark and empirical study. In Proceedings of the 17th ACM International Conference on Web Search and Data Mining, Merida, Mexico, 4–8 March 2024; pp. 645–654. [Google Scholar] [CrossRef]
- Rao, S.B.; Chatterjee, A.; Kanistras, K. System identification of an unmanned aerial vehicle with actuated wingtips. J. Intell. Robot. Syst. 2022, 105, 11. [Google Scholar] [CrossRef]
- Zeng, G.; Jia, H.; Li, J.; Pan, S.; Zheng, L. Design of UAV 3D visual simulation system based on X-plane. In Proceedings of the International Conference on Autonomous Unmanned Systems, Xi’an, China, 23–25 September 2022; Springer Nature: Singapore, 2022; pp. 1194–1203. [Google Scholar] [CrossRef]
- Garcia, R.; Barnes, L. Multi-uav simulator utilizing x-plane. In Proceedings of the 2nd International Symposium on UAVs, Reno, NV, USA, 8–10 June 2009; Springer: Dordrecht, The Netherlands, 2010; pp. 393–406. [Google Scholar] [CrossRef]
- Hörmann, H.J. Development of selection methods for civil aviation student pilots. Part I: Comparison of aptitude testscores between China and Germany. Psychol. Sci. China 1999, 22, 26–29. [Google Scholar]
- Popov, A.; Ivanko, K. Introduction to biomedical signals and biomedical imaging. In Advances in Artificial Intelligence; Academic Press: Cambridge, MA, USA, 2024; pp. 1–57. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed]
- GS, S.K.; Sampathila, N.; Tanmay, T. Wavelet based machine learning models for classification of human emotions using EEG signal. Meas. Sens. 2022, 24, 100554. [Google Scholar] [CrossRef]
- Guo, H. Nonlinear mixup: Out-of-manifold data augmentation for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 4044–4051. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar] [CrossRef]
- Maron, H.; Ben-Hamu, H.; Serviansky, H.; Lipman, Y. Provably powerful graph networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2019; Volume 32. [Google Scholar]
- Zhou, Y.; Gong, P.; Wang, P.; Wen, X.; Zhang, D. Cross-operator Cognitive Workload Recognition Based on Convolutional Neural Network and Domain Generalization. J. Electron. Inform. Technol. 2023, 45, 2796–2805. [Google Scholar]
- Chen, J.; Zhang, Q.; Cheng, L.; Gao, X.; Ding, L. A cognitive load assessment method considering individual differences in eye movement data. In Proceedings of the 2019 IEEE 15th International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 295–300. [Google Scholar]
- Caliskan, S.G.; Bilgin, M.D.; Polatli, M. Nonlinear analysis of electrodermal activity signals for healthy subjects and patients with chronic obstructive pulmonary disease. Australas. Phys. Eng. Sci. Med. 2018, 41, 487–494. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. Available online: https://arxiv.org/abs/1312.6114 (accessed on 24 August 2024).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming Catastrophic Forgetting in Neural Networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Aljundi, R.; Babiloni, F.; Elhoseiny, M.; Rohrbach, M.; Tuytelaars, T. Memory Aware Synapses: Learning What (Not) to Forget. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 139–154. [Google Scholar]
- Jiang, G.; Li, Z.; Jiang, C.; Xue, S.; Zhou, J.; Song, L.; Lian, D.; Wei, Y. Interpretable Catastrophic Forgetting of Large Language Model Fine-Tuning via Instruction Vector. arXiv 2024, arXiv:2406.12227. Available online: https://arxiv.org/abs/2406.12227 (accessed on 24 August 2024).















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).