Abstract
This study introduces a novel recommender system that integrates academic performance and socio-demographic variables to provide personalised and contextually relevant recommendations for university degree selection. The system aims to optimise the alignment between students’ profiles and potential academic programmes by utilising advanced machine learning models, including XGBoost, Random Forest, GLMNET, and KNN. The research addresses a critical gap identified in the literature, where most existing systems rely solely on academic data, neglecting the significant impact of socioeconomic factors on educational decision-making. The proposed system demonstrates superior predictive accuracy through rigorous cross-validation and hyperparameter tuning compared to simpler models, such as linear regression. The results show that integrating socio-demographic data enhances the relevance of the recommendations, supporting students in making more informed choices. This approach contributes to educational equity by ensuring that guidance is tailored to each student’s unique circumstances, aligning with the sustainable development goal of quality education. The findings highlight the value of incorporating a comprehensive data-driven approach to improve educational outcomes and support more equitable decision-making processes.
1. Introduction
The selection of a university programme is a critical decision for students, with significant implications for their future academic and professional success. The existing recommender systems for higher education primarily focus on academic data, such as grades and test scores, to guide programme selection. However, this narrow focus overlooks the broader context in which students make these decisions. According to Kamal et al. [1], previous studies have largely neglected the impact of socioeconomic factors—such as family status, household income, and parental occupation—on educational outcomes. These external influences are crucial in shaping a student’s academic journey and long-term success.
Our research aims to fill this gap by introducing a recommender system that integrates academic and socioeconomic information to provide more holistic and personalised guidance for students choosing their university careers. This approach acknowledges the findings of previous studies, as summarised in Table 1, which highlight the significance of socioeconomic variables in the decision-making process for selecting a university programme. For example, research by Fouad et al. [2] and Columbu et al. [3] underscores the influence of family and socioeconomic factors on students’ educational choices across different cultural contexts.
By incorporating these diverse data points into our machine learning models, our system not only enhances the accuracy of recommendations but also contributes to educational equity by considering the varied socioeconomic realities of students. This approach addresses the need identified in recent systematic reviews for developing hybrid and context-specific recommendation systems that can offer more informed and personalised guidance, ultimately improving educational outcomes for a broader range of students. Moreover, career indecision in college students is predicted by a greater identity moratorium and diffusion, less maternal acceptance, and fewer years in college [4]. Consequently, a student satisfied with their professional choice is likely to perform better academically, thereby improving the efficiency of the study group. Data generated by former students regarding their career choices and academic performance can be used to create a decision-making framework that incorporates intrinsic factors of the learning process, such as standardised test results, and extrinsic factors, such as type of school and parent’s education and occupation.

Table 1.
Socioeconomic variables in educational recommender systems.
Table 1.
Socioeconomic variables in educational recommender systems.
| Article | Insights |
|---|---|
| Fouad, N.A., Kim, S.Y., Ghosh, A., Chang, W.H., Figueiredo, C. (2016) [5] | Family influence on career decision-making is consistent across the United States and India, and family influence is correlated to family obligation, work volition, work values, calling, and occupational engagement. |
| Columbu, S., Porcu, M., Sulis, I. (2021) [3] | Students’ university choices are influenced by the university, field of study, and other factors, with socioeconomic indicators playing a significant role in their decision-making process. |
| Olmos-Gómez, M.D.C., Luque-Suárez, M., Becerril-Ruiz, D., Cuevas-Rincón, J.M. (2021) [6] | Parents significantly influence their children’s career decisions, with gender and socioeconomic status also playing a significant role in their choice of the Spanish Baccalaureate programme and career path. |
| Duong, M.Q., Nguyen, V.T., Bach, T.N.D., Ly, B.N., Le, T.Y.D. (2023) [7] | Socioeconomic status and the university’s internal environment factors, such as curricula and facilities, positively and negatively affect postgraduate students’ decisions. |
| Koçak, O., Ak, N., Erdem, S.S., Sinan, M., Younis, M.Z., Erdoğan, A. (2021) [8] | Family influence and academic satisfaction positively impact career decision-making, self-efficacy, and happiness in university students. |
| Kim, S.Y., Ahn, T., Fouad, N. (2016) [2] | Family influences, such as informational and financial support, significantly relate to life satisfaction in South Korean college students, accounting for 57% of the variance. |
| Nieuwenhuis, M., Manstead, A.S., Easterbrook, M.J. (2019) [9] | Social identity factors significantly explain higher education choices among low-status group members, with disadvantaged students more likely to apply to selective universities. |
| Parker, P.D., Schoon, I., Tsai, Y.M., Nagy, G., Trautwein, U., Eccles, J.S. (2012) [10] | Socioeconomic status is a key predictor of university entry, while gender influences major selection. Achievement and self-concept in both maths and English positively predict university entry. |
In this context, our study proposes a machine-learning model to recommend university degrees for new students. By applying data science techniques to standardised high school and college test results and incorporating socioeconomic variables, the model predicts students’ academic performance on standardised tests at the end of college. This allows for recommendations as to the career paths that will likely result in better performance. This work has practical applications for any student deciding which career to pursue and offers universities an advancement in student counselling by using records from former students to generate helpful information for future professionals.
The remainder of this article is structured as follows: Section 2 reviews the relevant literature supporting our recommender system’s development. Section 3 describes the theoretical framework, including the modelling approach for the recommender system. Section 4 presents the machine learning approach and strategies to prevent overfitting and ensure generalizability. Section 5 presents the results, highlighting the models’ performance and the findings’ practical implications. Section 6 discusses the results by comparing them with previous studies. Subsequently, Section 7 discusses the study’s limitations and proposes future research directions. Finally, Section 8 concludes the article, summarising the key contributions and potential impact of our research.
2. Related Work
Recommender systems are potent tools that can offer personalised filtering and recommendation services that influence the transformation of educational data into educational knowledge. Currently, educational organisations need to face and in some cases lead the development, management, and adaptation that the new trends in recommender systems incorporate. These new challenges in the educational field need to offer personalised learning paths using recommendations and suggestions that involve students, professors, and administrative areas and that are performed by automatic tools with a deep understanding of educational requirements and the educational domain. In [11], different tasks of a recommender system (collaborative filtering, content-based filtering, knowledge-based algorithms, and hybrid techniques) are described to clarify their functioning and to set the convergence between their specificities and educational requirements.
2.1. Foundations of Recommender Systems
One of the advantages of learning processes in modern life is that nformation can be personalised even more than could be achieved in the past. There are many aspects to consider in the process of adapting learning materials and the learning environment to a specific profile, one of which is the use of recommender systems (RSs). Each time new technologies related to data treatment are proposed, in addition the creation of new, more accurate recommendation algorithms is advocated, since they facilitate learning in a more effective way. These works are especially devoted to solving some common limitations in the education field. When a student enters a virtual learning space, usually she expects to find, among other things, resources that have some relationship to her profile not only as a student, but to her affective and personality traits that are conducive to her own way of learning [12].
From a theoretical point of view, according to its taxonomy, in education there are various elements that we could recommend. However, in respect to the incipient use of recommender systems in the field of e-education, no taxonomy has been clearly defined for fulfilling such task. Most works deal mainly with recommending courses, actions, tutoring, open educational resources, adaptive content, exercise types, numbers of questions, levels of difficulty, etc. Depending on the kind of items to be recommended, the RS techniques applied can be very diverse. For instance, in some studies, Data Mining (DM) and association rules (ARs) have been utilized, while meta recommendation systems, machine learning techniques, artificial intelligence, ontology-driven systems, etc., have been proposed for recommending other items, such as, for example, activities to be performed, courses, etc. [13].
2.2. Types of Recommender Systems in Education
Recommender systems have been used in different domains and for different application purposes. It has become increasingly pertinent to use them within educational environments. There are various types of recommender systems. These can be classified into content-based, collaborative filtering, and hybrid systems. Hybrid systems are able to benefit from the advantages of both collaborative filtering and content-based techniques, while counteracting their limitations—a cold start for collaborative filtering and also less diversification for content-based methods [14]. From an educational standpoint, the three categories (content-based, collaborative filtering, and hybrid) can be further broken down to provide educational systems based on the learning resources to be recommended (e.g., peer-reviewed articles, blog posts, or textbooks), the user data that need to be collected for the recommendations, or the resources to be recommended within the user interface/app [15,16].
As mentioned above, recommender systems can be based on content, which is useful to recommend resources similar to ones the user has read or discovered by themselves. Collaborative filtering can be used to make recommendations based on the past behaviour of other users. Finally, a hybrid approach to recommender system development has been suggested, which combines collaborative approaches and content-based filtering, to make use of the strengths of both. Model-based methods have been developed. Memory-based methods, on the other hand, store and manipulate the entire user–item interaction data to generate predictions. Hybrid systems are, by definition, designed to combine the recommendations generated by the different types of models. Hybrid systems have generally performed better than either model-based or memory-based systems in the literature. More recently, there is a move to using machine learning models for generating the data for the hybrid, and they have been shown to generate good performance [17].
2.3. Application of Recommender Systems in Educational Settings
In recent years, recommendation systems in the educational field have gained significant popularity, encompassing various stages of the student’s relationship with academic institutions. From a high-level perspective, there are systems designed for university enrolment recommendations. These educational recommender systems aim to enhance the relevance of proposed study programmes to students’ interests. Specifically, their objectives include mapping students’ interests to a broad range of available courses to ensure they find courses that match their learning needs [18]. With recent developments in the availability of online content, there is a growing need for systems that perform a data analysis to find the best match for students based on their unique interests and capabilities [19]. Researchers have conducted numerous studies to develop systems that fill this gap using intelligent information processing techniques, such as recommender systems.
Throughout the literature, various approaches leverage recommender system techniques, including collaborative filtering [20], content-based filtering, and hybrid recommender systems based on fuzzy systems [21] and complex machine learning models [22]. Each approach collects and analyses students’ historical behaviours, interests, or performance measurements to provide personalised recommendations. For example, collaborative filtering assumes that measuring the degree of similarity between users’ experiences can help identify items of interest. Suppose two students tend to enrol in similar courses. In that case, it is likely that if student A receives a good grade in a particular course, student B will also perform well, as they have demonstrated similar academic behaviours in the academic records [10]. However, these methods often fall short in contexts where student capabilities, learning curves, and backgrounds are highly diverse, leading to issues like data sparsity and limited generalizability in recommendations.
Conversely, content-based approaches incorporate textual data from users’ previous histories. Unlike collaborative filtering, content-based systems do not suffer from issues related to data matrix sparsity. However, these approaches require mechanisms to transform text features such as tags, keywords, and topics into vectors [23]. For instance, a content-based recommender system effectively assists prospective students in Bangladesh choose top-K private universities based on several parameters, achieving high accuracy [12]. After creating vector representations, content-based approaches use cosine similarity to determine the degree of similarity between users. However, these systems often neglect critical external influences on a student’s educational journey, such as family income, parental occupation, and other socioeconomic factors.
Moreover, hybrid frameworks combine complex models to generate personalised recommendations. Machine learning applications incorporating deep neural networks have produced robust and accurate recommendations. Natural language processing techniques, such as latent Dirichlet allocation (LDA) and latent semantic analysis (LSA), are also used to process extensive textual profiles to understand the semantics of the information used in the recommendation process [24]. Despite their advantages, textual features often contain inherent biases and uncertainties. Researchers have widely adopted fuzzy logic systems to handle these issues, which model vagueness logically and provide heuristic rules [25]. This approach supports the present research’s development by incorporating a student’s perspective through text analysis.
In educational recommender systems, fuzzy logic consistently mitigates vagueness by using linguistic variables and can be combined with other approaches, such as clustering, to find concrete user similarities. For instance, fuzzy rules can better interpret user ratings on specific items, offering greater flexibility in handling demographic data [26].
However, collaborative filtering does not perform well in specific domains, particularly in educational contexts where students have diverse capabilities, learning curves, and core strengths. The sparsity of data matrices indicating users’ degrees of collaboration further degrades the performance of collaborative filtering approaches in educational recommender systems [27]. To address this, researchers have developed hybrid recommendation frameworks that combine multiple methods to enhance robustness and accuracy.
A context-aware recommender system based on fuzzy logic was proposed to generate personalised recommendations by assessing each user’s performance [28]. This model calculates the required contexts for applying fuzzy logic based on the learners’ assessment scores and the time to complete the assessment. Additionally, novel fuzzy-based recommender systems leverage family tree-based fuzzy inference systems to capture critical concepts in user profiles and the available courses, improving neighbours’ semantic and content similarities for personalised recommendations [19].
Ontology-based approaches have also been explored to develop recommendation engines. These approaches transform human-generated information into machine-readable language, which is then used in machine learning-based solutions. For instance, ontology-based recommender systems have been proposed to better guide students in higher education systems by assessing their strengths, weaknesses, interests, and abilities. These systems collect data explicitly from user profiles and implicitly from surveys conducted with graduate students. Machine learning methods create and cluster profile models of graduate students, which are then used in hybrid recommendation engines [29].
Furthermore, deep learning-based recommendation frameworks have been developed for e-learning platforms. These models use K-Nearest Neighbour (KNN) and collaborative filtering approaches to find similar students with comparable learning capabilities. Other frameworks incorporate sentimental and cognitive analysis and learning style categorisation to generate personalised course recommendations [30].
Overall, intelligent, personalised course-advising models and hybrid recommendation systems combining collaborative and content-based filtering, optimised with genetic algorithms, have significantly improved recommendation reliability and performance. These advancements in recommendation system technologies offer practical applications for students and educational institutions, enhancing the guidance provided to students in their course registration processes [31]. However, the course recommendation approach differs from that of recommending a study programme; therefore, considering context affects the recommender system’s structure.
3. Theoretical Framework
Academic processes generate much contextual data, such as academic performance and demographic and financial information. Thus, universities and colleges have tutors who carry out accompaniment processes to advise students on the most relevant careers according to their academic profile. However, a tutor cannot manage all the information from the thousands of previous students about whom there is information about their chosen career and academic performance; in addition, tutors can generate a bias based on their relationship with the students or their own experiences and beliefs.
Previous recommender systems for university programme selection have predominantly relied on academic data such as grades and standardised test scores to generate recommendations. While these systems can be effective in specific contexts, they often need to account for the broader factors that influence a student’s educational and career decisions. By contrast, our approach integrates academic and socioeconomic data, offering several key advantages, especially in countries with a lower Human Development Index (HDI).
In many countries with a low HDI, the information available to students for making informed decisions about university programmes is often limited and not easily accessible. This lack of comprehensive, open information can hinder students’ ability to choose programmes that align with their academic strengths and personal circumstances. Integrating socioeconomic variables—such as family income, parental occupation, and educational background—into our system provides a more holistic understanding of a student’s context. This allows for academically appropriate recommendations and is better suited to the student’s socioeconomic reality, thereby improving the relevance and practicality of the guidance provided.
For instance, in regions where students may face financial constraints or a limited access to educational resources, our system can recommend programmes that match the student’s academic abilities and can consider factors like potential financial limitations and the personal fit between the student and the university. This is particularly important in contexts where such information is not readily available, as it empowers students to make informed and feasible decisions given their personal and economic circumstances.
Additionally, by addressing educational equity, our approach helps mitigate the barriers faced by students from disadvantaged backgrounds, who may not have the same support or resources as their peers. The integration of socioeconomic data enables the system to identify programmes that provide additional support or resources, helping to level the playing field and promote more equitable educational outcomes.
For the present study, we articulate a dataset where the academic and socio-demographic information of the students in the final stage of secondary school and university is related. The dataset comprises the results of standardised tests administered to students at the end of their high school and college education. Therefore, a supervised learning model was employed to train various algorithms to predict university exam results based on data from the high school stage. In addition, the key variables that determine the results in the standardised examination of the university stage were determined. To facilitate the application of the model, the results are provided as recommendations that students, tutors, or universities can utilise. This information is intended to aid in making one of the most critical decisions in a person’s life: selecting a university career.
The vector {X1, X2, … Xn} gives the data structure, representing the input variables for the model, and “y” means the student’s average result on the university standardised test. The output “y” is a continuous vector from 0 to 300. Hence, the proposed recommendation system can be structured as a forecasting model, wherein the implicit relationship between the model’s input and response variables is articulated in Equation (1).
where “f” is an algorithm associated with a supervised machine learning model used to make predictions based on the training dataset, and epsilon represents the error arising from the discrepancy between the actual value and the value predicted by the supervised model. Thus, the recommendation of studies is associated with the degree that presents a higher value of Ypred for a new student “Xnew” due to the function Ypred = f(Xnew).
y = f(X1, X2, …, Xn) + ε,
In our study, a novel approach is provided to structure a recommendation system for students, using longitudinal information of the student from the high school stage until the completion of university. Consequently, the paper answers the following questions:
- −
- How to generate recommendations of careers to study at university for new students based on academic and socio-demographic data?
- −
- What features have the most significant impact on the recommendation of which career to study?
- −
- Which machine learning model offers the best prediction performance?
4. Materials and Methods
It is difficult to anticipate which supervised model will be the one that will achieve a better fit to the data a priori; this condition is known as the No Free Lunch theorem. The algorithms with a greater theoretical prediction capacity have less or no capacity of explaining the relationships between the input and output variables. Thus, four algorithms with different fitting approaches will be used: Random Forest, XGBoost, GLMNET, and KNN.
Random Forest (RF) is an ensemble machine learning technique capable of performing classification and regression tasks that involve training many decision trees. The scores of individual trees are combined through a majority vote in the case of classification or by averaging in the case of regression. It has the advantages of no parameter tuning and being robust enough to overfit. Random Forest is efficient when applied to a large amount of data with many attributes and is currently one of the most widely used classification algorithms in the prediction models.
Extreme Gradient Boosting, or XGBoost, is an implementation of gradient boosting, an ensemble of decision trees where new trees are trained to predict the residuals of the existing trees. It has become one of the most popular machine learning algorithms due to its good performance and superior speed. XGBoost was originally implemented in C++, and several wrappers for other programming languages are currently offered. Among these, the R implementation used in this study appears to be the most popular because the R package is available as open-source and is actively maintained.
K-Nearest Neighbours (KNN) is a non-parametric method for classification and regression tasks. It avoids overfitting, especially with smaller datasets. KNN classifies data points based on their neighbours, making it intuitive and straightforward. It does not assume any data distribution, allowing it to adapt to various data types. KNN is computationally efficient and serves as a baseline for comparing complex algorithms. It is a valuable tool in machine learning, serving as a benchmark for evaluating sophisticated models.
Generalised Linear Models Regularised, or GLMNET is a versatile package that implements regularised generalised linear models. It can deal with high-dimensional challenges and can be used for binary classification, multiclass classification, multi-response problems, or time-to-event models. Its implementation uses the coordinate descent approach combined with warm starts, leading to a significant speedup. It is more memory-efficient than the other available techniques that fit LASSO (L1-penalized) models. The implementation used in this study is based on the package from [32].
An important aspect to consider when creating machine learning models is achieving a high model generalisation. Therefore, the algorithms have strategies to achieve robust results and maximise generalisation to avoid overfitting. For example, the GLMNET model uses the Lasso (L1) and Ridge [L2] regularisation techniques, increasing the generalisation capacity of the model. In addition, in the XGBOOST, GLMNET and Random Forest models, a grid search was used to identify the optimal fit of the data (See Table 2). For the decision tree model, the pruning technique involves trimming the branches of the tree that have little importance and are likely to represent noise in the data. Consequently, the XGBOOST and Random Forest algorithms internally perform a feature selection process due to their random way of incorporating variables in the creation of trees.
Table 2.
Classification models’ tuning and final parameters.
4.1. Proposed Modelling Structure
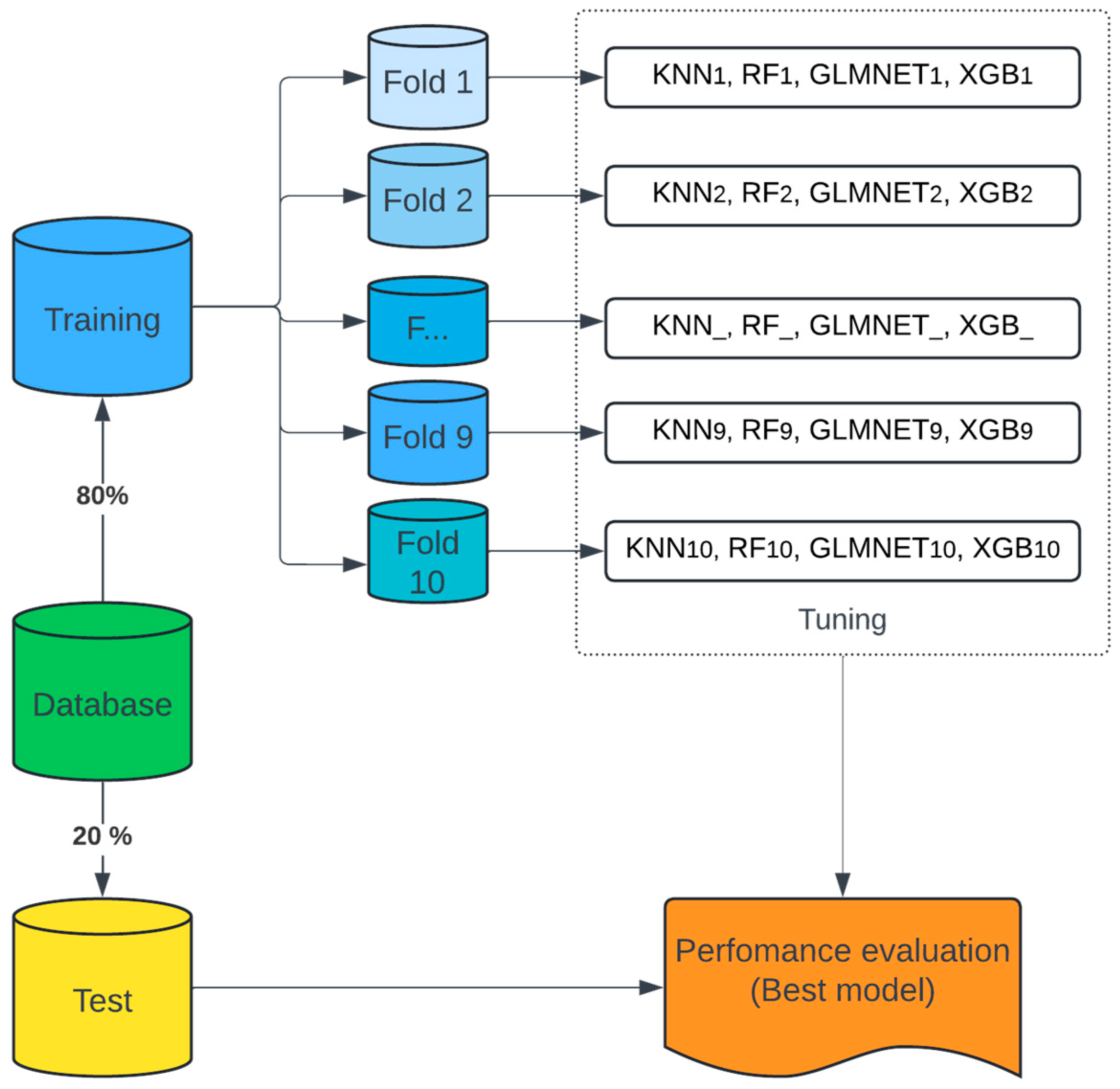
This study proposes the creation of five machine learning models to generate suggestions as to which professional path a student should pursue. The method is determined by dividing the first dataset into 80% training and 20% testing (See Figure 1). The training technique was designed using a 10-fold cross-validation scheme, in which the dataset is split randomly into ten equal halves. Nine are utilised as the training set, with the remaining one is the testing set. The mean value of the predictive outcomes from the ten rounds is used to evaluate the algorithm.
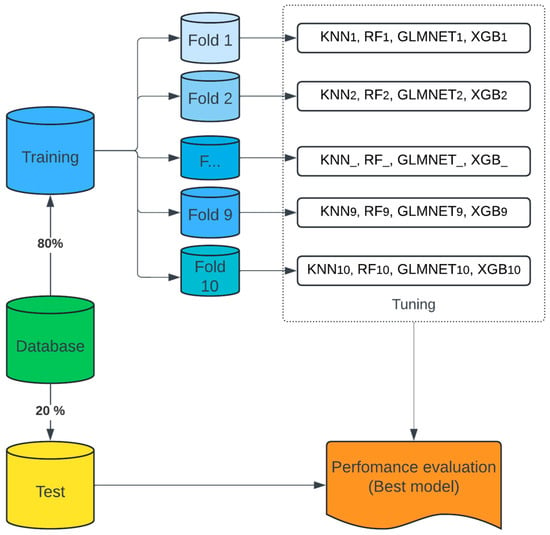
Figure 1.
Cross-validation approach.
The model’s input variables represent student information. They are classified into three categories: information on standardised test results, socioeconomic information in high school, and information on standardised test results in college. Table 3 shows the structure, category, and description of the variables.
Table 3.
Study variables.
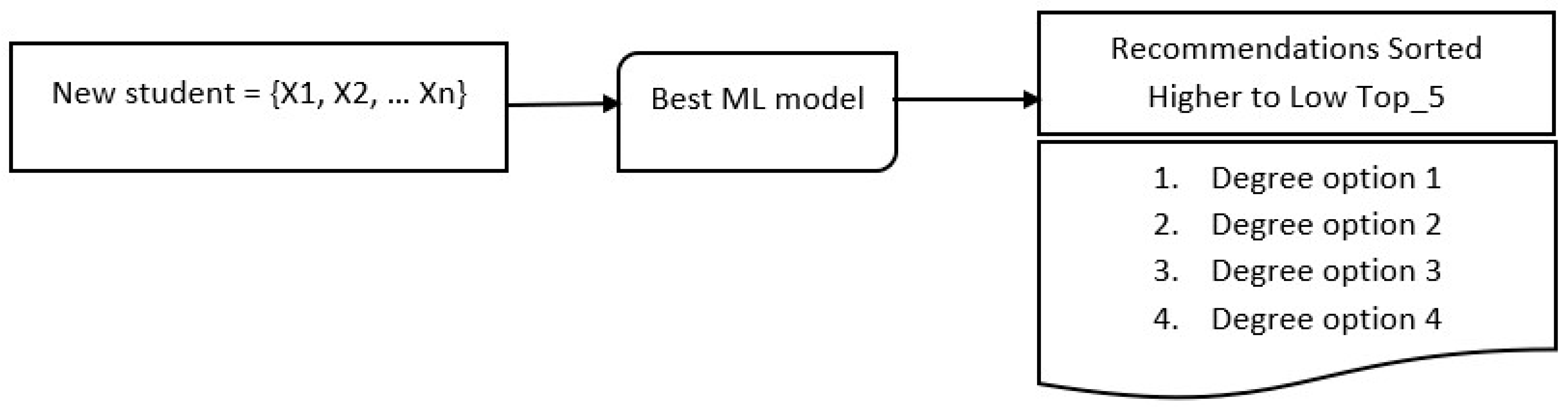
In operationalising the model, a new student enters their academic results and social variables into the model and thus receives recommendations for the careers for which a better performance is projected in the Saber Pro university exam results. Figure 2 represents the operational flow in which the algorithm recommends degree options.
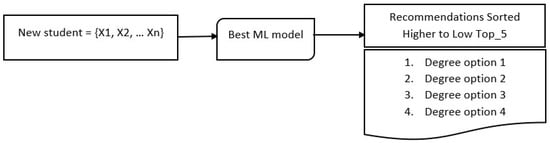
Figure 2.
Predictions structure.
4.2. Data
Data were collected from the Colombian Education Institute (ICFES) [33] and included the records of undergraduate students who took the Saber11 (high school) and Saber Pro (university) exams from 2006 to 2019. These data are made publicly available by ICFES for research and analysis. The comprehensive database contains 921,041 results from high school and university standardised tests. The dataset encompasses 102 focus options covering various categories such as engineering, literature, science, and art. Additionally, it includes socioeconomic information such as parents’ education and occupations, type of school, academic calendar, gender, and department of residence. Consequently, the recommender system will be represented by fourteen variables, as outlined in Table 3. Eight categorical variables are derived from demographic information and the student’s background. This information was sourced from the ICFES repository, with the standardised test result designated as the target variable at the university level.
4.3. Data Preprocessing
The first challenge in constructing the dataset was integrating information from the high school (Saber_11) and university (Saber_Pro) stages of the students’ academic journey into a single vector, a task complicated by the fact that the data originated from separate databases without consistent identification numbers across both stages. To address this issue, a multi-step process was employed to match records between the Saber_11 and Saber_Pro datasets, primarily using secondary identifiers such as names and dates of birth. When students took the Saber_Pro exam multiple times to improve their scores, the highest score obtained was retained to ensure the most representative data was used for analysis. During the data-cleaning process, it was observed that approximately 2% of the Saber_Pro results had zero scores across all the evaluated components; these cases were considered outliers and were subsequently removed from the final dataset, as they likely did not represent legitimate exam attempts and could have skewed the analysis. In addition to handling missing data and outliers, inconsistencies were identified and resolved by ensuring all records were uniformly processed and any contradictory information—such as duplicate records or mismatches in student identifiers—was reconciled, thus preserving the integrity of the data before it was used in the model-training process.
4.4. Descriptive Data Analysis
Table 4 shows the statistical summary for the 921,041 records adjusted by gender in the database for the fourteen years of the study. As shown in Table 4, the gender distribution is 58% female and 42% male. Moreover, the median and mean values for all modules evaluated are higher for men than women.
Table 4.
RSME results.
4.5. Performance Metrics
Metrics and comparison structures are needed to identify improvement patterns in the regression model that presents the best performance in different situations. These metrics are called performance indicators; they will give an idea of the general performance of the prediction models of the standardised exam results—a well-fitted regression model results in predicted values close to the observed data values. The base model, which uses the mean for each predicted value, would generally be used without informative predictor variables. Therefore, the fit of a proposed regression model should be better than the fit of the base model, considered as a model capable of generating information beyond the average value.
Root Mean Square Value
The RMSE (Root Mean Square Error) is the square root of the residuals’ variance, indicating the model’s absolute fit to the data by measuring how close the observed data points are to the model’s predicted values. As an absolute measure of fit, RMSE can be interpreted similarly to the standard deviation of the unexplained variance, sharing the same units as the response variable. Lower RMSE values denote a better fit. RMSE is an effective measure of the model’s predictive accuracy and is the most critical criterion for assessing fit when prediction is the model’s primary objective. Generally, to evaluate the quality of the fit, the model’s RMSE value should be significantly lower than the standard deviation of the response variable. The RMSE is calculated by Equation (2).
5. Results
In this study, a recommender system based on machine learning algorithms was built using the R [34] programming language within the Caret package [35]. Caret is a sophisticated library that develops supervised learning modelling, with tools for the preprocessing and cross-validation of data. Random Forest [36], XGBoost [37], GLMNET [32], and KNN supported the recommender system. To train the proposed model, ten folds were created to experiment with the predictions and evaluate each algorithm’s performance; the training stage results are listed in Table 5. The average value of the ten folds was calculated as the algorithm’s overall prediction performance. As shown in Table 5, the mean RMSE values for XGBoost, RF, GLMNET, and KNN are 30.1, 45.0, 41.1, and 51.1, respectively.
Table 5.
Cross-validation results.
Therefore, considering that the standard deviation of the output variable is 70.4 and comparing the RMSE results shown in Table 5, the model with the best performance in the training stage is XGBOOST with an RMSE value of 30.1, followed by the GLMNET algorithm with an RMSE value of 41.1. Consequently, it is essential to analyse the model’s consistency; again, XGBoost is the algorithm with the lowest standard deviation value, followed by GLMNET.
The predictions of the standardised tests at university in this study are used to recommend a degree to study; therefore, a high capacity for prediction generates confidence that the recommendations created serve as objective support for decision-making.
5.1. Model Testing
Section 4 explained that 30% of the data was reserved for the supervised learning models’ validation phase. During the validation stage, XGBoost demonstrated a strong performance on previously unseen data, achieving an RMSE of 30.1, which was the best among the models evaluated. The RMSE values for the four algorithms implemented in the recommender system are all lower than the standard deviation of the testing dataset used for the respective models. These results demonstrate that these four models perform well in predicting standardised test results. However, the XGBoost algorithm surpasses the other models (XGBoost vs. GLMNET, RF, and KNN) in terms of performance.
5.2. Explainable Artificial Intelligence (XAI) Approach
The Root Mean Square Error (RMSE) is a crucial metric for evaluating the accuracy of the predictive models. Thus, lower RMSE values indicate that the model’s predictions closely match the actual outcomes, leading to more reliable student recommendations. However, while RMSE is highly effective for assessing the predictive power of models, it is not necessarily well known to most people and may not serve as a clear guide for decision-making. Along with RMSE, our recommender system proposes an Explainable Artificial Intelligence (XAI) approach to ensure students understand the reasoning behind the recommendations. For instance, if a student has a specific academic and socioeconomic profile, the system might suggest pursuing a degree in Engineering. This recommendation would be justified by explaining, “Based on your profile, the system recommends studying Engineering, as it is the field where you are projected to achieve the highest score on the Saber Pro university exam, with an estimated 350/400 points. In comparison, other options like Mathematics (315/400 points) and Biology (310/400 points) also show strong potential but are slightly lower. This recommendation is generated using data from over 900,000 students, considering your high school academic performance and socioeconomic information, to assist you in making this important life decision”. This level of explanation, enabled by XAI, not only enhances the student’s comprehension of the recommendation but also fosters trust in the system. The student can see exactly how their unique profile influenced the recommendation, increasing the transparency and knowledge involved in the decision-making process.
6. Discussion
Developing and evaluating a recommender system for predicting standardised test results and recommending suitable undergraduate degrees based on academic and socio-demographic data presents a significant advancement in educational technology. Our study leverages a combination of machine learning algorithms to enhance students’ decision-making processes. This discussion compares our findings with those of previous studies and highlights the unique contributions of our research.
To begin with, Bhumichitr implemented collaborative filtering and ALS for elective course recommendations, achieving an accuracy of 86%. While that approach focused on course selection, our system extends to degree recommendations using a broader set of variables, including socio-demographic data, enhancing the recommendations’ contextual relevance [38].
Similarly, Khanam and Alkhaldi used a Random Forest regression model to classify universities based on student preferences and voting data. Although their system focused on graduate admissions, it parallels our use of Random Forest in predicting undergraduate degree suitability, highlighting the versatility and effectiveness of this algorithm [39].
Moreover, Esteban developed a hybrid recommendation system combining collaborative and content-based filtering with genetic optimisation to recommend courses. Their success in integrating multiple criteria underscores the importance of using diverse data points, a strategy we also employed to capture a comprehensive view of student profiles [40]. While the current system effectively uses advanced models to improve recommendation accuracy, there is room for further optimisation. For example, exploring deep learning techniques or ensemble methods could potentially enhance the system’s performance.
In addition, Samin and Azim applied probabilistic topic models for course and supervisor recommendations, focusing on the faculty’s past publications and research interests. Our system similarly uses historical academic data but extends this to include socio-demographic factors, thus broadening the scope and potential impact of the recommendations [41].
Furthermore, Slim proposed a framework for recommending academic programmes, courses, and instructors using collaborative filtering and non-negative matrix factorisation. While their system focused on optimising course schedules, our approach aimed at predicting standardised test results and recommending degrees, thereby supporting long-term academic planning [42].
Likewise, Ognjanovic used institutional data and the Analytical Hierarchy Process (AHP) to predict course selections. Similarly, our study utilises institutional data but expands its use to recommend undergraduate degrees, thus providing more holistic support for academic decisions [43]. Besides, the AHP allows for a natural interpretation of the recommendation results. In our system, the explainability of the recommendations could be further refined to ensure that students fully understand the reasoning behind the suggestions. This could involve incorporating more sophisticated Explainable AI (XAI) techniques to make the decision-making process even more transparent and user-friendly.
Additionally, George and Lal employed a personalised approach to course recommendation using ontology and sequential pattern mining. Our system also emphasises personalisation by incorporating socio-demographic factors, ensuring that recommendations align closely with individual student profiles [44].
Moreover, Zayed investigated supervised machine learning techniques for recommending undergraduate programmes using academic history and job market data. Our study similarly uses machine learning but focuses on standardised test predictions and degree recommendations, providing a comprehensive tool for student support [18].
Consequently, the average RMSE for the linear regression model was 72.1 during cross-validation. This indicates that while linear regression provides a baseline for predictive accuracy, it may struggle to capture our dataset’s complex, non-linear relationships between variables. In contrast, XGBoost can identify intricate interaction patterns among variables due to its ability to build decision trees iteratively, optimizing the model’s performance at each step. Additionally, XGBoost’s regularisation parameters help prevent overfitting, delivering more accurate and robust predictions than simpler models like linear regression.
In summary, our study stands out by integrating both academic and socio-demographic data to provide holistic recommendations. We achieved a robust prediction model by employing advanced machine learning algorithms such as XGBoost, Random Forest, GLMNET, and KNN. Including variables such as parental education, school type, and regional data enhances the accuracy and relevance of our recommendations, offering a significant improvement over systems that rely solely on academic performance data.
7. Limitations and Future Research
The dataset represents diverse student populations that are limited due to its specific population and educational context. Therefore, socioeconomic status and academic performance may not have the same impact across different educational systems. Including demographic variables like ethnicity, parental education, and rural/urban residence would provide a better understanding of how these factors influence educational and career decisions. The current dataset is limited to a specific educational system, which may differ from others in curriculum and assessment methods. Incorporating data from diverse systems would reveal how different structures and policies affect student outcomes and the recommender system. Future research should include datasets from multiple systems and a wider range of demographic variables to address these limitations. Transfer learning techniques could also be applied to adapt the model to different systems, improving its applicability.
Secondly, although robust, the prediction models employed in this study depend on the quality and accuracy of the input data. Any inconsistencies or inaccuracies in the standardised test results or socio-demographic information can affect the recommender system’s performance. Thus, ensuring high-quality data collection and preprocessing is crucial for the system’s reliability.
Thirdly, while the machine learning algorithms (XGBoost, Random Forest, GLMNET, and KNN) have shown solid predictive capabilities, they also require significant computational resources and expertise to implement and maintain. This may pose a challenge for some educational institutions with limited technical resources. Future research should explore more efficient algorithms and methods to reduce the computational burden without compromising accuracy.
Additionally, the temporal scope of the data, which spans from 2006 to 2019, presents another limitation. To articulate the dataset, it is necessary to trace the students’ academic performance from their high school years through to their university education. This process requires at least five years to obtain a high school student’s university-standardised exam results. Consequently, there is an inherent delay in the availability of comprehensive data, which may impact the timeliness and relevance of the study’s findings. Future studies should consider strategies to mitigate this delay, such as employing longitudinal data collection methods, to ensure more timely and applicable insights.
8. Conclusions
This study presents a significant advancement in educational technology by developing and evaluating a recommender system designed to predict standardised test results and recommend suitable undergraduate degrees based on a combination of academic and socio-demographic data. Our approach leverages advanced machine learning algorithms, specifically XGBoost, Random Forest, GLMNET, and KNN, to enhance students’ decision-making.
Firstly, integrating academic and socio-demographic variables, such as parental education, school type, and regional data, proved crucial in improving the accuracy and contextual relevance of the recommendations. This holistic approach addresses the limitations of previous systems that relied solely on academic performance data, offering a more comprehensive tool for student support.
Our findings demonstrate that machine learning models, particularly XGBoost and Random Forest, exhibit a robust performance in predicting standardised test outcomes and recommending undergraduate degrees. These models significantly outperform simpler algorithms, highlighting the importance of employing sophisticated techniques to achieve a high accuracy in educational recommendations.
Further optimisation techniques could be employed to address computational efficiency, especially given the complexity of integrating and processing large datasets. For instance, model compression techniques such as quantisation or pruning could reduce the computational load without significantly compromising the model’s accuracy. Moreover, deploying the system on cloud-based platforms that offer scalable computing resources could help manage the computational demands of real-time data processing and model updates.
Incorporating these strategies into future system iterations would enhance its real-time applicability and ensure it remains computationally efficient and scalable. By focusing on these areas, we can continue to improve the system’s ability to provide accurate, timely, and contextually relevant recommendations to students, ultimately supporting better educational outcomes.
In conclusion, the proposed recommender system supports students in making informed academic decisions and aligns with the broader educational objectives of reducing gender disparities and ensuring equal access to education. Future research can explore the integration of real-time data and the continuous improvement of recommendation algorithms to further refine the system’s predictive capabilities. Expanding the system to include personalised learning paths and career counselling features could offer more excellent value to students and educational institutions.
Overall, this study contributes to the ongoing efforts to harness the power of data science and machine learning in education, aiming to improve educational outcomes and promote equity in access to quality education.
Author Contributions
Conceptualisation, E.J.D.-D. and R.H.-N.; methodology, E.J.D.-D. and R.H.-N.; software, E.J.D.-D.; validation, E.J.D.-D. and R.H.-N.; formal analysis, E.J.D.-D.; data curation, E.J.D.-D.; writing—original draft preparation, E.J.D.-D. and R.H.-N.; writing—review and editing, E.J.D.-D. and R.H.-N.; visualisation, E.J.D.-D.; supervision, R.H.-N. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by research grants PID2022-137849OB-I00 funded by MICIU/AEI/10.13039/501100011033 and by the ERDF, EU. The APC was funded by Universidad del Magdalena, Colombia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The final compilation of the data utilised in this study is available in the Mendeley Data repository [33]. Researchers and interested parties can access the dataset for further analysis and replication studies.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kamal, N.; Sarker, F.; Rahman, A.; Hossain, S.; Mamun, K.A. Recommender System in Academic Choices of Higher Education: A Systematic Review. IEEE Access 2024, 12, 35475–35501. [Google Scholar] [CrossRef]
- Kim, S.; Ahn, T.; Fouad, N. Family Influence on Korean Students’ Career Decisions: A Social Cognitive Perspective. J. Career Assess. 2016, 24, 513–526. [Google Scholar] [CrossRef]
- Columbu, S.; Porcu, M.; Sulis, I. University Choice and the Attractiveness of the Study Area: Insights on the Differences amongst Degree Programmes in Italy Based on Generalised Mixed-Effect Models. Socioecon. Plann. Sci. 2021, 74, 100926. [Google Scholar] [CrossRef]
- Guerra, A.L.; Braungart-Rieker, J.M. Predicting Career Indecision in College Students: The Roles of Identity Formation and Parental Relationship Factors. Career Dev. Q. 1999, 47, 255–266. [Google Scholar] [CrossRef]
- Fouad, N.A.; Kim, S.; Ghosh, A.; Chang, W.; Figueiredo, C. Family Influence on Career Decision Making: Validation in India and the United States. J. Career Assess. 2016, 24, 197–212. [Google Scholar] [CrossRef]
- Olmos-Gómez, M.d.C.; Luque-Suárez, M.; Becerril-Ruiz, D.; Cuevas-Rincón, J.M. Gender and Socioeconomic Status as Factors of Individual Differences in Pre-University Students’ Decision-Making for Careers, with a Focus on Family Influence and Psychosocial Factors. Int. J. Environ. Res. Public Health 2021, 18, 1344. [Google Scholar] [CrossRef]
- Duong, M.-Q.; Nguyen, V.-T.; Bach, T.-N.-D.; Ly, B.-N.; Le, T.-Y.-D. Influence of Socioeconomic Status and University’s Internal Environment Factors on University-Choice Decisions of Postgraduate Students in Vietnam. Int. J. Educ. Pract. 2023, 11, 218–231. [Google Scholar] [CrossRef]
- Koçak, O.; Ak, N.; Erdem, S.S.; Sinan, M.; Younis, M.Z.; Erdoğan, A. The Role of Family Influence and Academic Satisfaction on Career Decision-Making Self-Efficacy and Happiness. Int. J. Environ. Res. Public Health 2021, 18, 5919. [Google Scholar] [CrossRef]
- Nieuwenhuis, M.; Manstead, A.S.R.; Easterbrook, M.J. Accounting for Unequal Access to Higher Education: The Role of Social Identity Factors. Group Process. Intergroup Relat. 2019, 22, 371–389. [Google Scholar] [CrossRef]
- Parker, P.D.; Schoon, I.; Tsai, Y.-M.; Nagy, G.; Trautwein, U.; Eccles, J.S. Achievement, Agency, Gender, and Socioeconomic Background as Predictors of Postschool Choices: A Multicontext Study. Dev. Psychol. 2012, 48, 1629–1642. [Google Scholar] [CrossRef]
- Nabizadeh, A.H.; Leal, J.P.; Rafsanjani, H.N.; Shah, R.R. Learning Path Personalization and Recommendation Methods: A Survey of the State-of-the-Art. Expert Syst. Appl. 2020, 159, 113596. [Google Scholar] [CrossRef]
- Liu, T.; Wu, Q.; Chang, L.; Gu, T. A Review of Deep Learning-Based Recommender System in e-Learning Environments. Artif. Intell. Rev. 2022, 55, 5953–5980. [Google Scholar] [CrossRef]
- Urdaneta-Ponte, M.C.; Mendez-Zorrilla, A.; Oleagordia-Ruiz, I. Recommendation Systems for Education: Systematic Review. Electronics 2021, 10, 1611. [Google Scholar] [CrossRef]
- Nallamala, S.H.; Bajjuri, U.R.; Anandarao, S.; Prasad, D.D.D.; Mishra, D.P. A Brief Analysis of Collaborative and Content Based Filtering Algorithms Used in Recommender Systems. IOP Conf. Ser. Mater. Sci. Eng. 2020, 981, 022008. [Google Scholar] [CrossRef]
- Afoudi, Y.; Lazaar, M.; Al Achhab, M. Hybrid Recommendation System Combined Content-Based Filtering and Collaborative Prediction Using Artificial Neural Network. Simul. Model. Pract. Theory 2021, 113, 102375. [Google Scholar] [CrossRef]
- Parthasarathy, G.; Sathiya Devi, S. Hybrid Recommendation System Based on Collaborative and Content-Based Filtering. Cybern. Syst. 2023, 54, 432–453. [Google Scholar] [CrossRef]
- Aljunid, M.F.; Huchaiah, M.D. An Efficient Hybrid Recommendation Model Based on Collaborative Filtering Recommender Systems. CAAI Trans. Intell. Technol. 2021, 6, 480–492. [Google Scholar] [CrossRef]
- Zayed, Y.; Salman, Y.; Hasasneh, A. A Recommendation System for Selecting the Appropriate Undergraduate Program at Higher Education Institutions Using Graduate Student Data. Appl. Sci. 2022, 12, 12525. [Google Scholar] [CrossRef]
- Yan, L.; Liu, Y. An Ensemble Prediction Model for Potential Student Recommendation Using Machine Learning. Symmetry 2020, 12, 728. [Google Scholar] [CrossRef]
- Han, J.; Jo, J.; Ji, H.; Lim, H. A Collaborative Recommender System for Learning Courses Considering the Relevance of a Learner’s Learning Skills. Clust. Comput. J. Netw. Softw. Tools Appl. 2016, 19, 2273–2284. [Google Scholar] [CrossRef]
- Gogo, K.O.; Nderu, L.; Mwangi, R.W. Fuzzy Logic Based Context Aware Recommender for Smart E-Learning Content Delivery. In Proceedings of the 2018 5th International Conference on Soft Computing & Machine Intelligence (ISCMI), Nairobi, Kenya, 21–22 November 2018; pp. 114–118. [Google Scholar]
- Yanes, N.; Mostafa, A.M.; Ezz, M.; Almuayqil, S.N. A Machine Learning-Based Recommender System for Improving Students Learning Experiences. IEEE Access 2020, 8, 201218–201235. [Google Scholar] [CrossRef]
- Mokarrama, M.; Khatun, S.; Arefin, M. A Content-Based Recommender System for Choosing Universities. Turk. J. Electr. Eng. Comput. Sci. 2020, 28, 2128–2142. [Google Scholar] [CrossRef]
- Touimi, Y.B.; Hadioui, A.; Faddouli, N.E.; Bennani, S. Intelligent Chatbot-LDA Recommender System. Int. J. Emerg. Technol. Learn. IJET 2020, 15, 4–20. [Google Scholar] [CrossRef]
- Alghamdi, S.; Alzhrani, N.; Algethami, H. Fuzzy-Based Recommendation System for University Major Selection. In Proceedings of the 11th International Joint Conference on Computational Intelligence (IJCCI 2019), Vienna, Austria, 17–19 September 2019; pp. 317–324. [Google Scholar]
- Aditya, A.; Purwiantono, F.E. The Application of Fuzzy-Analytical Hierarchy Process Method for Majors Selection at Public Universities. J. Inform. Telecommun. Eng. 2020, 3, 240–251. [Google Scholar] [CrossRef]
- Singh, M. Scalability and Sparsity Issues in Recommender Datasets: A Survey. Knowl. Inf. Syst. 2020, 62, 1–43. [Google Scholar] [CrossRef]
- Boyinbode, O.; Fatoke, T. Context-Aware Recommender System for Adaptive Ubiquitous Learning. Int. J. Mob. Learn. Organ. 2021, 15, 409–426. [Google Scholar] [CrossRef]
- Amane, M.; Aissaoui, K.; Berrada, M. ERSDO: E-Learning Recommender System Based on Dynamic Ontology. Educ. Inf. Technol. 2022, 27, 7549–7561. [Google Scholar] [CrossRef]
- Nagaraj, P.; Saiteja, K.; Ram, K.K.; Kanta, K.M.; Aditya, S.K.; Muneeswaran, V. University Recommender System Based on Student Profile Using Feature Weighted Algorithm and KNN. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; pp. 479–484. [Google Scholar]
- Tilahun, L.A.; Sekeroglu, B. An Intelligent and Personalized Course Advising Model for Higher Educational Institutes. SN Appl. Sci. 2020, 2, 1635. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Regularization Paths for Generalized Linear Models via Coordinate Descent. J. Stat. Softw. 2010, 33, 1. [Google Scholar] [CrossRef]
- DeLaHoz-Domínguez, E.J. Colombian Student Exam Records (High School & University)—Mendeley Data. Available online: https://data.mendeley.com/drafts/fsvt9dr3ww (accessed on 9 September 2024).
- R Core Team. R: A Language and Environment for Statistical Computing; R Core Team: Vienna, Austria, 2013. [Google Scholar]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V. Package ‘Xgboost’, R Version 090; CRAN: Vienna, Austria, 2019. [Google Scholar]
- Bhumichitr, K.; Channarukul, S.; Saejiem, N.; Jiamthapthaksin, R.; Nongpong, K. Recommender Systems for University Elective Course Recommendation. In Proceedings of the 2017 14th International Joint Conference on Computer Science and Software Engineering (JCSSE), Nakhon Si Thammarat, Thailand, 12–14 July 2017; pp. 1–5. [Google Scholar]
- Khanam, Z.; Alkhaldi, S. An Intelligent Recommendation Engine for Selecting the University for Graduate Courses in KSA: SARS Student Admission Recommender System. In Proceedings of the Inventive Computation Technologies; Smys, S., Bestak, R., Rocha, Á., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 711–722. [Google Scholar]
- Esteban, A.; Zafra, A.; Romero, C. Helping University Students to Choose Elective Courses by Using a Hybrid Multi-Criteria Recommendation System with Genetic Optimization. Knowl.-Based Syst. 2020, 194, 105385. [Google Scholar] [CrossRef]
- Samin, H.; Azim, T. Knowledge Based Recommender System for Academia Using Machine Learning: A Case Study on Higher Education Landscape of Pakistan. IEEE Access 2019, 7, 67081–67093. [Google Scholar] [CrossRef]
- Slim, A.; Hush, D.; Ojha, T.; Abdallah, C.; Heileman, G.; El-Howayek, G. An Automated Framework to Recommend A Suitable Academic Program, Course and Instructor. In Proceedings of the 2019 IEEE Fifth International Conference on Big Data Computing Service and Applications (BigDataService), Newark, CA, USA, 4–9 April 2019; pp. 145–150. [Google Scholar]
- Ognjanovic, I.; Gasevic, D.; Dawson, S. Using Institutional Data to Predict Student Course Selections in Higher Education. Internet High. Educ. 2016, 29, 49–62. [Google Scholar] [CrossRef]
- George, G.; Lal, A.M. A Personalized Approach to Course Recommendation in Higher Education. Int. J. Semantic Web Inf. Syst. IJSWIS 2021, 17, 100–114. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).