
Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based)



Abstract
:1. Introduction
- Bidirectional Context: Bert offers a comprehensive, context-based understanding of word meanings.
- Sequential Processing: RNN is particularly adept at identifying the order and flow of words in a sequence.
- Enhanced Accuracy: Combining Bert’s contextual embeddings with RNN’s sequential modeling improves text classification accuracy.
- Improved Generalization: The combined model enhances the ability to generalize across different text types.
2. Related Work
3. Proposed Methodology
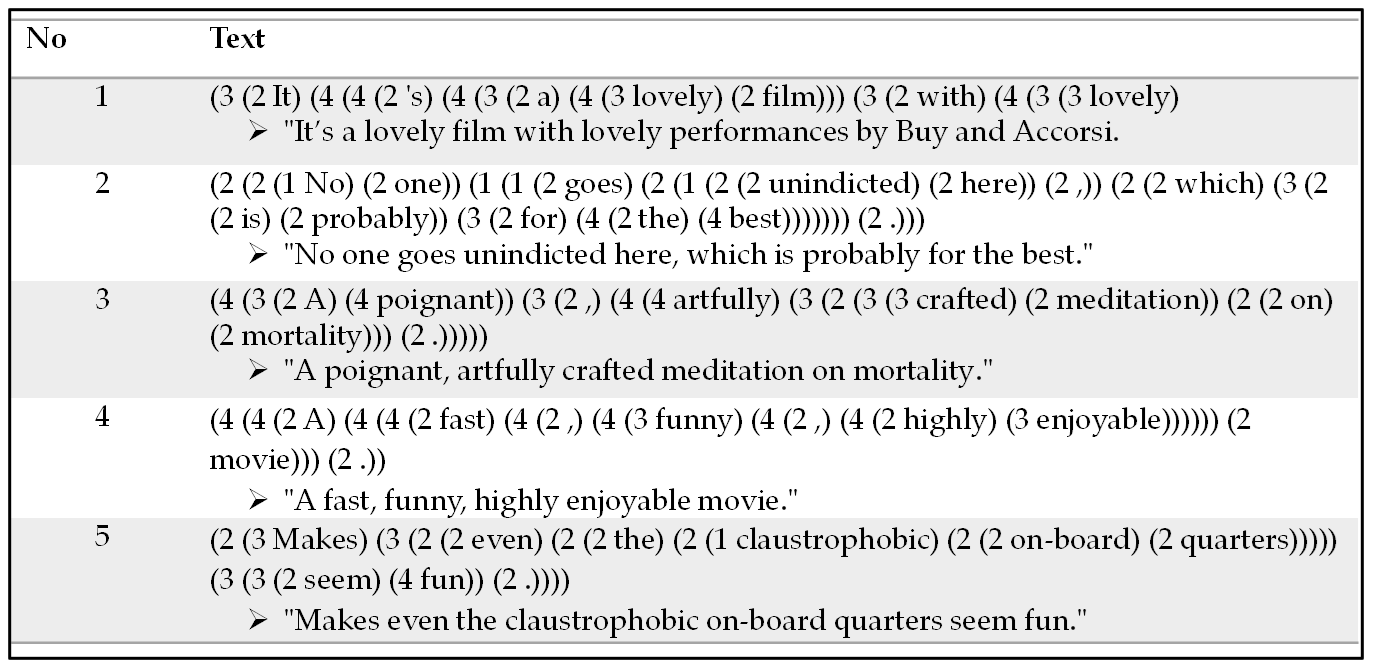
3.1. Dataset Structure
3.2. Bert Model Structure
3.2.1. Input Layer
- Text Preprocessing: The input layer begins by receiving the raw text data, which may include unstructured text from various sources such as documents, social media posts, or reviews. It performs initial preprocessing tasks such as removing punctuation, handling capitalization, and tokenizing the text into individual words or sub-word units.
- Tokenization: Once the text has been preprocessed, the input layer applies tokenization, which breaks the text into discrete units called tokens. These tokens typically correspond to words, subwords, or characters, depending on the tokenization strategy chosen. In the case of Bert, WordPiece Tokenization is commonly used, where the text is segmented into subword units based on a predefined vocabulary.
- Token Representation: After tokenization, each token is mapped to a unique numeric representation using an embedding lookup table. This process converts the textual tokens into dense vector representations, often called word embeddings or token embeddings. These embeddings capture semantic information about the tokens and facilitate the model’s understanding of the input text.
- Sequence padding: To ensure uniform input dimensions, the input layer can apply sequence padding to the tokenized text. This involves adding padding tokens (usually zeros) to shorter sequences to ensure that all input sequences have the same length. Padding allows for efficient batch processing and matrix computation within the neural network architecture.
3.2.2. Bert Encoding Layer
- Contextual Embeddings: In contrast to traditional word embeddings, which assign fixed representations to individual words irrespective of context, the Bert encoding layer generates contextual embeddings. These embeddings capture the nuanced meanings of words within the context of the entire input sequence, thereby enabling the model to comprehend subtle semantic nuances and disambiguate polysemous words.
- Transformer Architecture: The Bert encoding layer employs the Transformer architecture, a self-attention mechanism that enables the capture of long-range dependencies and contextual relationships within the input text. Through the use of multi-head self-attention mechanisms and position-wise feedforward networks, Bert is capable of effectively processing input sequences, thereby capturing both local and global contextual information.
- Pre-trained Language Representations: Bert is typically pre-trained on large-scale text corpora using unsupervised learning objectives, such as masked language modeling and next sentence prediction. During pre-training, Bert learns to encode text into rich, contextualized representations by optimizing for various language understanding tasks. These pre-trained representations serve as a foundation for downstream tasks, including text classification, enabling the model to leverage extensive linguistic knowledge acquired during pre-training.
- Fine-tuning for Specific Tasks: While Bert’s pre-trained representations capture general linguistic patterns, the encoding layer can be fine-tuned on task-specific data through supervised learning. This process involves updating the parameters of the Bert model using labeled data from the target task, such as sentiment analysis. This adaptation of the model’s representations enhances performance on specific classification tasks.
- High-dimensional Vector Representations: The Bert encoding layer outputs high-dimensional vector representations for each token in the input sequence. These representations typically have hundreds of dimensions, capturing a wealth of information about the semantics, syntax, and context of the input text. The richness of these representations enables downstream layers of the model to make informed decisions during classification tasks.
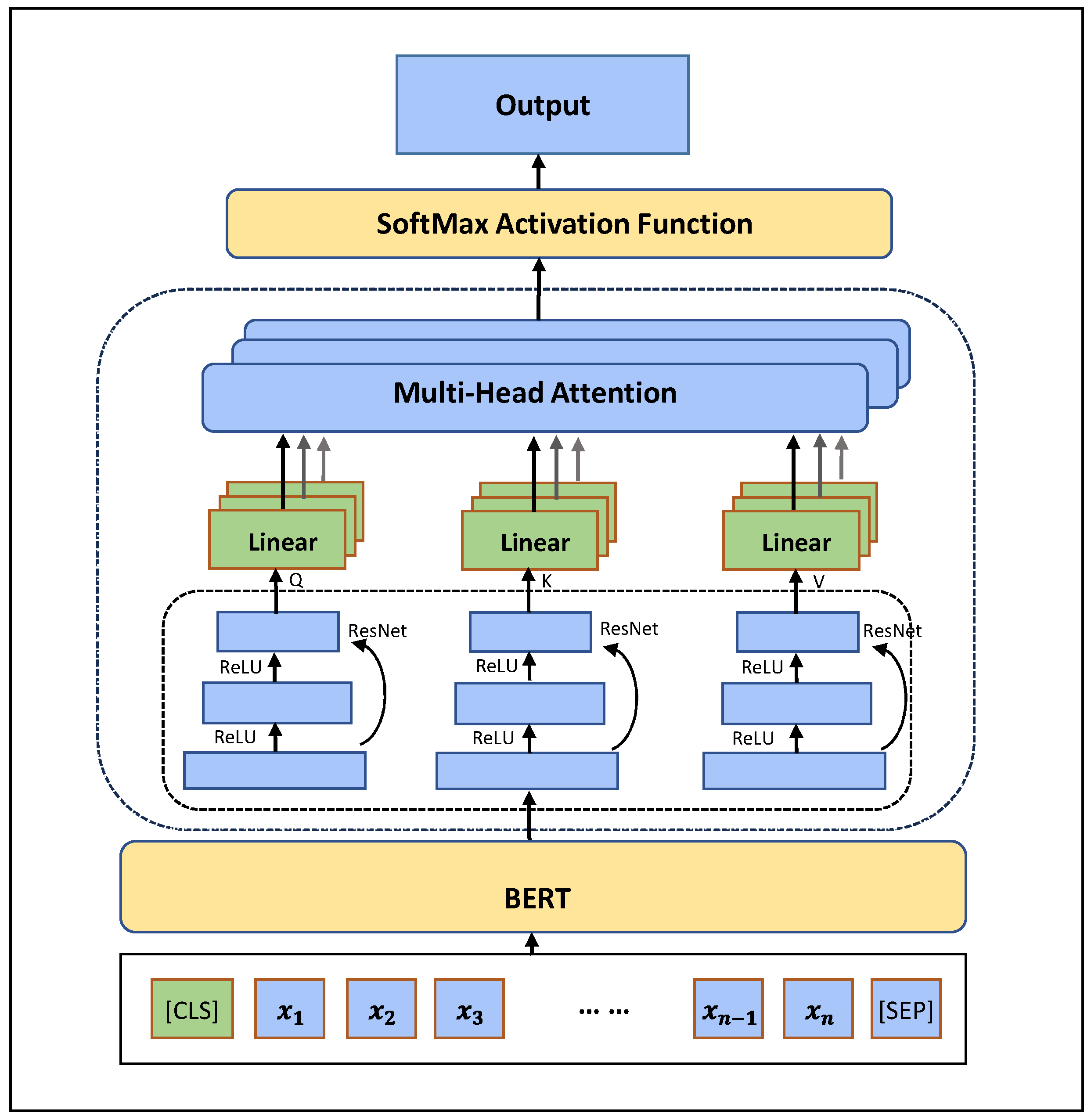
3.2.3. The Fully Connected Layers
- Multi-scale Feature Extraction: The incorporation of multiple fully connected layers enables the model to extract text features at varying scales or levels of abstraction. Each fully connected layer can capture distinct aspects of the input text, ranging from fine-grained details to higher-level semantic information. This multi-scale feature extraction facilitates the model’s ability to discern intricate patterns and semantic nuances present in the text across different levels of granularity.
- Dimensionality Transformation: Fully connected layers facilitate the transformation of feature vector representations from one dimension to another. This transformation serves two primary purposes. Dimensionality Expansion: In some cases, fully connected layers increase the dimensionality of the feature vector representation, allowing it to capture more complex patterns and relationships within the input text.
- Dimensionality Reduction: Conversely, fully connected layers can also reduce the dimensionality of the feature vector representation, condensing it into a lower-dimensional space while retaining essential information. Dimensionality reduction techniques, such as principal component analysis (PCA) or feature selection, are employed with the objective of preserving the most salient features of the input text while reducing computational complexity and mitigating the risk of overfitting.
- Nonlinear Transformation: Fully connected layers typically incorporate nonlinear activation functions, such as ReLU (Rectified Linear Unit) or sigmoid functions, to introduce nonlinearity into the feature transformation process. This nonlinearity enables the model to capture complex relationships and interactions between different features, enhancing its capacity to model intricate textual patterns and semantic structures.
- Feature Fusion and Abstraction: As the feature vectors propagate through the fully connected layers, they undergo successive transformations that fuse and abstract information from the input text. By iteratively combining and refining features across multiple layers, the model learns to extract hierarchical representations of the input text, gradually transitioning from raw textual data to high-level semantic abstractions.
3.2.4. Residual Networks
- Performance Enhancement: ResNet layers are renowned for their ability to facilitate the training of very deep neural networks. By incorporating residual connections, where the output of one layer is added to the input of another, ResNet layers alleviate the vanishing gradient problem encountered in deep networks. This enables more efficient gradient flow during training, facilitating the learning of intricate patterns and representations within the input text.
- Stability Improvement: The residual connections within the ResNet layer introduce skip connections that bypass certain layers in the network. This allows the model to retain information from earlier layers, mitigating the risk of information loss or degradation as the input propagates through successive layers. Consequently, ResNet layers promote greater stability and robustness in the model’s predictions, reducing the likelihood of overfitting and improving generalization performance.
- Detailed Information Capture: By summing the outputs of different fully connected layers with the input vectors, the ResNet layer effectively integrates detailed information from multiple scales and abstraction levels. This enables the model to capture fine-grained textual features and semantic nuances present in the input text, enhancing its discriminative power and expressive capacity.
- Hierarchical Feature Fusion: The residual connections within the ResNet layer enable hierarchical feature fusion, allowing the model to combine information from different layers and abstraction levels. This facilitates the integration of both low-level and high-level features, enabling the model to capture complex relationships and interactions within the input text.
3.2.5. The Output Layer
- The integration of the mechanism output is as follows: the output of the preceding layers, which frequently includes the contextual embeddings derived from Bert as well as the aggregated information from the residual network, serves as the input to the output layer.
- Fully Connected Transformation: The input from the preceding layers undergoes transformation through one or more fully connected layers within the output layer. These fully connected layers serve to further distill and refine the learned representations, enabling the model to extract high-level features and patterns relevant to the classification task at hand.
- Softmax Activation: Following the transformation through fully connected layers, the output of the final fully connected layer is passed through a softmax activation function. The softmax function computes the probability distribution over the possible classes or categories, assigning a probability score to each class. This probability distribution reflects the model’s confidence in each class, with higher probabilities indicating stronger predictions.
- Classification Output: The final step in the output layer involves the classification of the input text based on the computed probability distribution. The class with the highest probability score is selected as the predicted class label for the input text. This classification output serves as the model’s prediction for the sentiment, category, or label associated with the input text, enabling downstream applications to utilize the model’s insights for decision-making or analysis.
- Training and Optimization: During the training phase, the output layer is optimized to minimize the discrepancy between the predicted probability distribution and the ground truth labels. This is typically achieved through the use of a loss function, such as cross-entropy loss, which quantifies the difference between the predicted probabilities and the true labels.
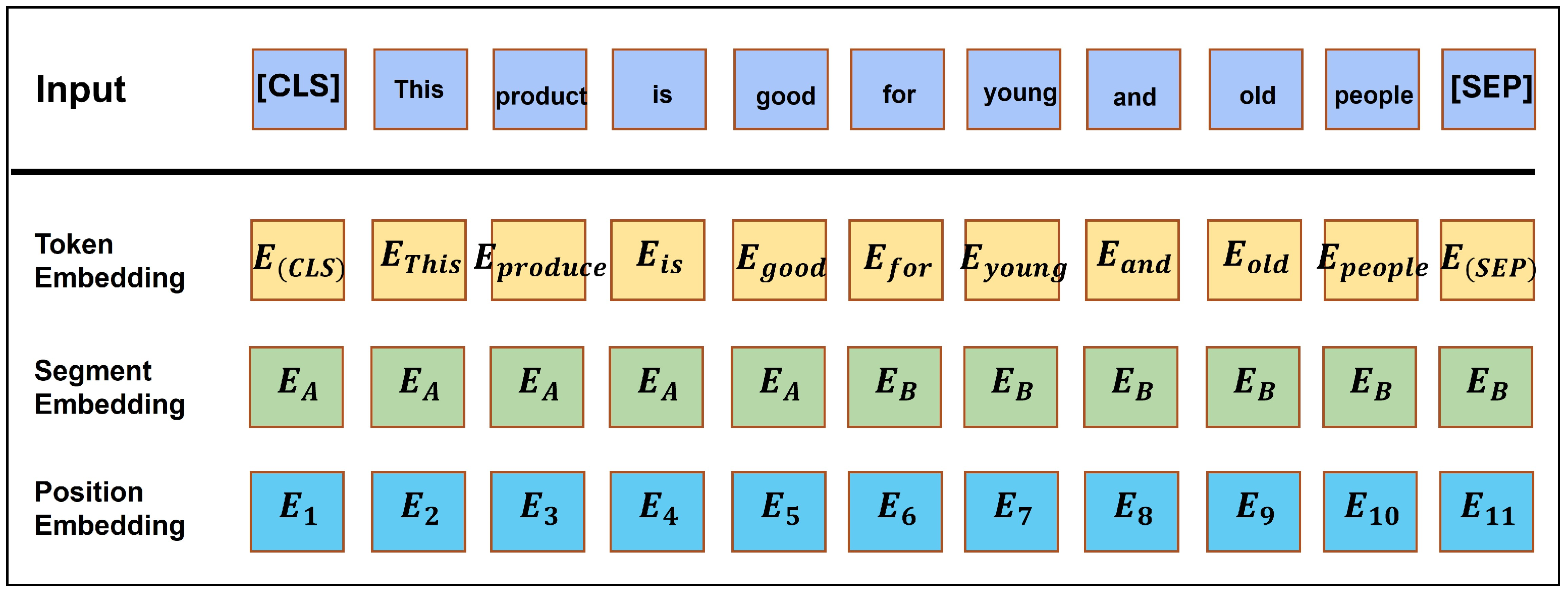
3.2.6. Word Embedding with Bert Layer
- Word Vectors: These embeddings represent individual tokens (words or subwords) within the input sentence. Each token is mapped to a corresponding vector representation, which is learned during pre-training. This representation encodes semantic information about the token’s meaning and context.
- Segment Vectors: Bert employs segment vectors to process input sequences comprising multiple sentences or segments. These vectors assign a unique identifier to each token, indicating its segment or sentence of origin. This enables the model to distinguish between different segments and consider their contextual relevance during processing.
- Location Embedding Vectors: In addition to word and segment embeddings, Bert incorporates location embedding vectors to encode positional information within the input sequence.
3.3. Bert and K-Nearest Neighbor Based (Bert_KNN_Based) Model
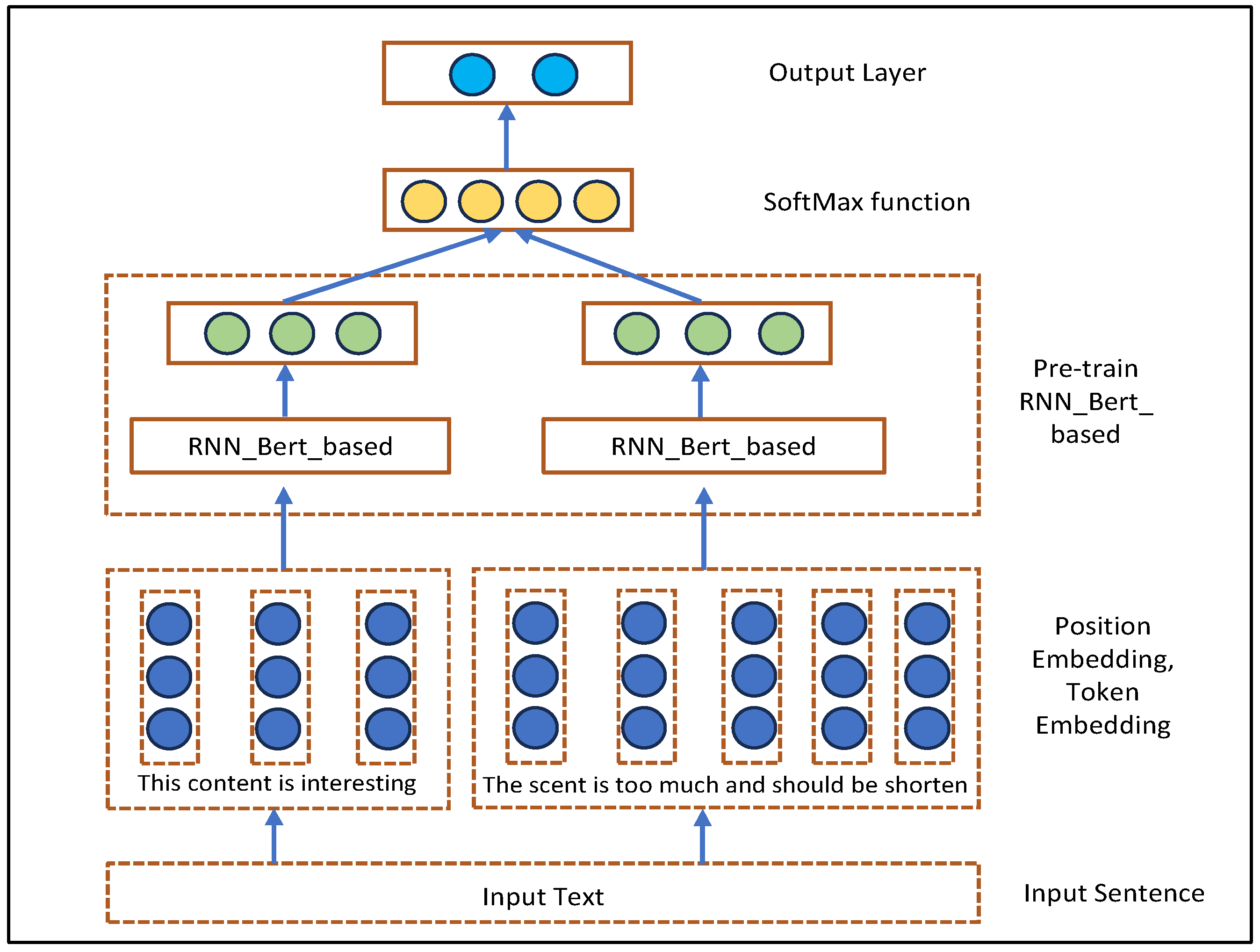
3.4. Proposed Bert and Recurrent Neural Network Based (RNN_Bert_b)
3.5. Algorithm Flow of TextCNN + RoBERTa and RNN_Bert_Based
| Algorithm 1 TextCNN + RoBERTa | |||||
| 1: | Data: X_train_text, y_train, X_test_text | ||||
| 2: | Result: Trained Hybrid Model, Predictions | ||||
| 3: | Initialize TextCNN model: | ||||
| 4: | TextCNN (The size of word embeddings, 2D convolutional layers, classification output) | ||||
| 5: | Initialize RoBERTa model: | ||||
| 6: | roberta_model = loads a pre-trained RoBERTa model | ||||
| 7: | hybrid_model = creates a hybrid model by combining a TextCNN mode | ||||
| 8: | Training parameters: | ||||
| 9: | Learning rate = , Epochs = 5, and Batch_size = 16, 32 | ||||
| 10: | Loss function and optimizer: | ||||
| 11: | criterion = Binary Cross-Entropy Loss () | ||||
| 12: | optimizer = Adam | ||||
| 13: | Training loop: | ||||
| 14: | for epoch in range(epochs): do | ||||
| 15: | hybrid_model.train() | ||||
| 16: | For | ||||
| 17: | i in tqdm(range(0, len(X_train_text), batch_size)): | ||||
| Do | |||||
| 18: | Text input batch = X_train_text, (i: i+batch_size) | ||||
| 19: | Inputs for the RoBERTa batch = additional input features for RoBERTa | ||||
| 20: | labels_batch = True labels for the current batch of data. | ||||
| 21: | clears the old gradients from the previous iteration() | ||||
| 22: | Runs the current batch through the hybrid model, producing predictions. | ||||
| 23: | loss = computes the loss via Binary Cross-Entropy Loss () | ||||
| 24: | backpropagation () | ||||
| 25: | optimizer.step() | ||||
| 26: | end | ||||
| 27: | end | ||||
| 28: | Evaluate the hybrid model: | ||||
| 29: | hybrid model: | ||||
| 30: | Disables gradient calculation to save memory and computations (): | ||||
| 31: | Extracts the input_ids from the test data | ||||
| 32: | inputs other required parameters by the RoBERTa model (like attention masks or token type IDs) | ||||
| 33: | Converts the binary predictions to integer values 0 (negative) or 1 (positive) | ||||
| 34: | Metrics calculation | ||||
| Algorithm 2 RNN_Bert_based | ||||||
| 1: | Data: X_train_text, y_train, X_test_text | |||||
| 2: | Result: Trained RNN_Bert_based, Predictions | |||||
| 3: | Initialize RNN_Bert_based model: | |||||
| 4: | Bert (Setting up parameters for Bert model) | |||||
| 5: | Initialize Bertmodel: | |||||
| 6: | Bert_model = loads a pre-trained Bert model | |||||
| 7: | Integrated_model = Integrated_Model l (Bert_model, RNN_model) | |||||
| 8: | Training parameters: | |||||
| 9: | Learning rate = , Epochs = 5, and Batch_size = 16, 32 | |||||
| 10: | Loss function and optimizer: | |||||
| 11: | criterion = Cross Entropy Loss () | |||||
| 12: | optimizer = Adam | |||||
| 13: | Training loop: | |||||
| 14: | for epoch in range(epochs): do | |||||
| 15: | Model Training | |||||
| 16: | For (Trains the model for a specified number of epochs until validation accuracy improves.) | |||||
| 17: | i in tqdm (range(0, len(X_train_text), batch_size)): | |||||
| Do | ||||||
| 18: | Data: An RNN model with layers, Weight , pruning rate , training epoch | |||||
| 19: | For i to & epoch to do | |||||
| 20: | ||||||
| 21: | normal training | |||||
| 22: | % Weight prunning | |||||
| 23: | labels_batch = True labels for the current batch of data. | |||||
| 24: | labels_batch = y_train[i: i + batch_size] | |||||
| 25: | Optimizer = Adam | |||||
| 26: | loss = Cross Entropy Loss () | |||||
| 27: | loss.backward() | |||||
| 28: | optimizer.step() | |||||
| 29: | end | |||||
| 30: | end | |||||
| 31: | end | |||||
| 32: | Metrics calculation: outputs = binary predictions to integer values 0 (negative) or 1 (positive) | |||||
4. Experiment Result and Analysis
4.1. Datasets and Evaluation Metrics
4.2. Experiments and Parameter Settings
- Bert was introduced by Google in 2018 and has revolutionized natural language understanding tasks. It is based on the Transformer architecture and trained on two unsupervised tasks: Masked Language Model (MLM) and Next Sentence Prediction (NSP). Bert is capable of understanding context by considering both the left and right context of a word. Nevertheless, it is constrained by the fixed-length input limitation inherent to its token-based approach.
- The TextCNN + RoBERTa (Convolutional Neural Networks for Efficient Text Classification and Robus Bidirectional Encoder Representations from Transformers) was proposed by [14], which can adapt convolutional neural networks (CNNs). It was originally designed for image data to handle text data. CNNs are effective at capturing local patterns, which makes them well-suited for tasks where n-grams (sequences of words) are of importance. RoBERTa is an enhanced version of Bert that was developed to refine the original Bert model through optimized pre-training. In 2019, Facebook AI introduced RoBERTa, which modifies Bert in several ways to achieve enhanced performance on a range of NLP tasks. The combination of TextCNN and RoBERTa offers several benefits, including the following:
- Complementary Strengths: While RoBERTa demonstrates proficiency in discerning contextual relationships within textual data, it may exhibit a deficiency in identifying specific local patterns, such as n-grams, that are pivotal for certain tasks. In contrast, TextCNN demonstrates a high proficiency in capturing local patterns, although it is less adept at grasping the intricate contextual nuances that RoBERTa is capable of discerning.
- Enhanced Feature Representation: The combination of these models allows for the exploitation of RoBERTa’s profound, context-aware representations, which are augmented by the capacity of TextCNN to discern salient local features. The combination of these models may result in enhanced classification performance, particularly in tasks where both global context and local patterns are of significance.
- The TextCNN + RoBERTa hybrid model is an innovative approach that effectively integrates the strengths of convolutional neural networks and transformer-based architectures, resulting in a robust and efficient solution for text classification tasks. This combination enables the model to capture both local and global features in text data, which may result in enhanced performance across a diverse range of NLP applications.
- XLNet, which was introduced by Google in 2019, represents an improvement upon Bert’s bidirectional context understanding. It employs a permutation-based approach, leveraging an autoregressive model similar to the Transformer-XL architecture. This enables the capture of bidirectional context without the need for masked language modeling. The enhanced bidirectional context understanding results in enhanced performance on various downstream tasks.
- ALBERT (A Lite BERT), which was proposed by Google in 2019, is designed to reduce the computational cost of Bert while maintaining or even improving its performance. This is achieved by factorizing the embedding parameters and applying cross-layer parameter sharing. ALBERT also introduces two novel training strategies: Sentence Order Prediction and Cross-Example Loss, which are intended to further enhance its performance. ALBERT reduces the number of parameters compared to Bert by sharing parameters across layers. In Bert, each layer has its own set of parameter weights, but ALBERT reuses the same parameters for each layer. This significantly reduces the total number of parameters, making the model smaller and faster. It splits the large vocabulary embedding matrix into two smaller matrices, which also helps in reducing the model size. This factorization decouples the size of the hidden layers from the size of the vocabulary embeddings, allowing for a smaller overall footprint.
4.3. Experimental Results
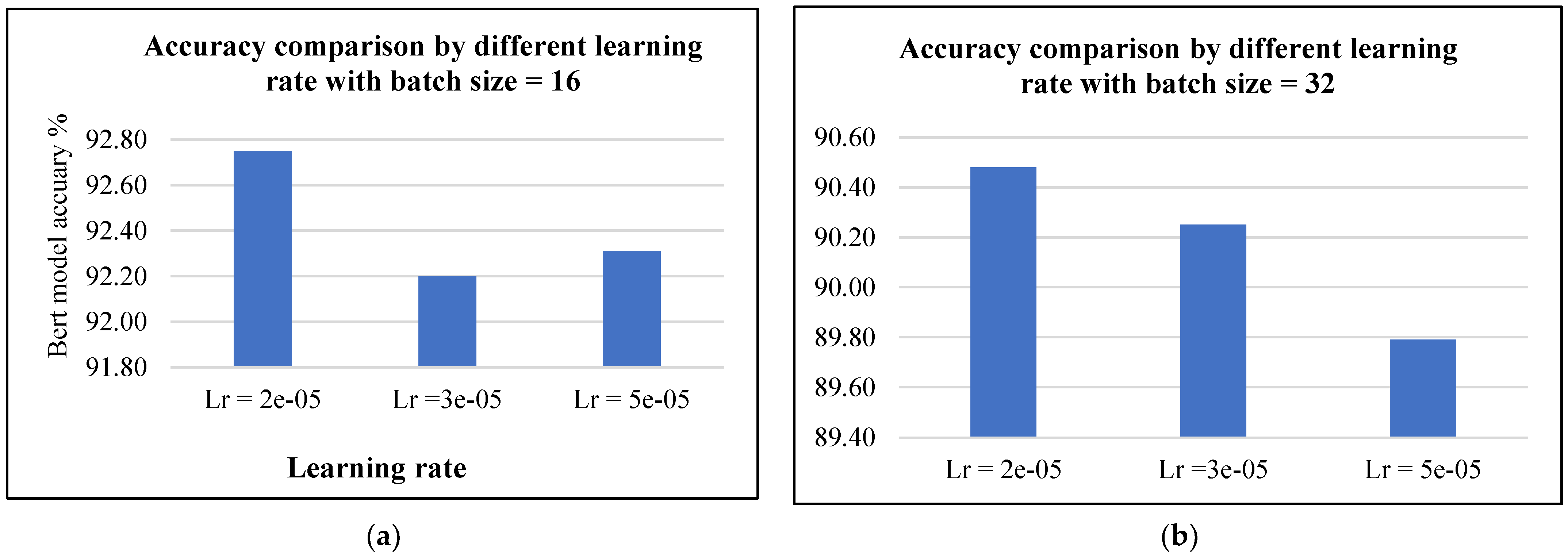
4.3.1. Bert-Based Method with Different Learning Rates and Batch Sizes
4.3.2. KNN_Bert_Based Method
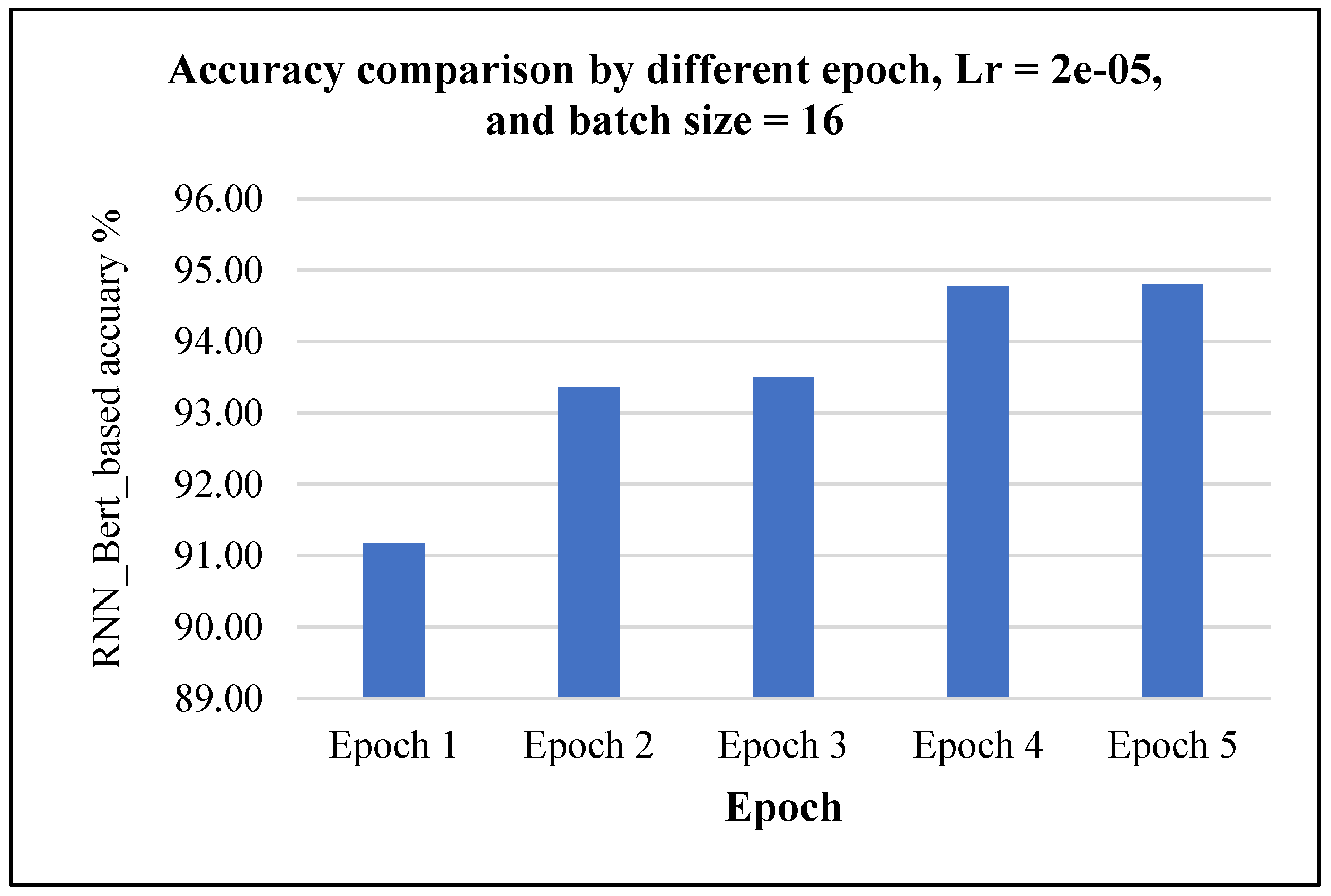
4.3.3. Proposed RNN_Bert_Based Method
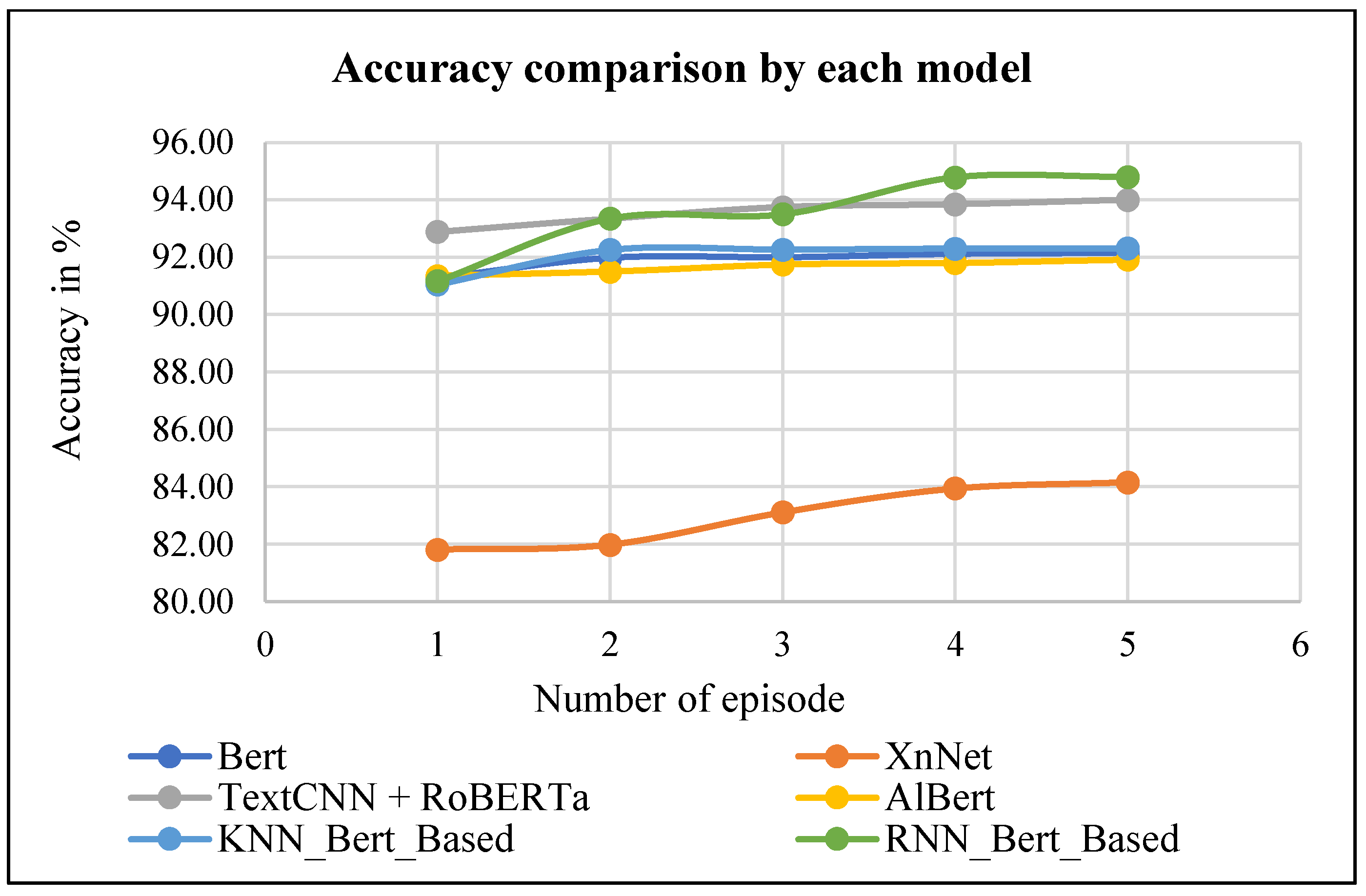
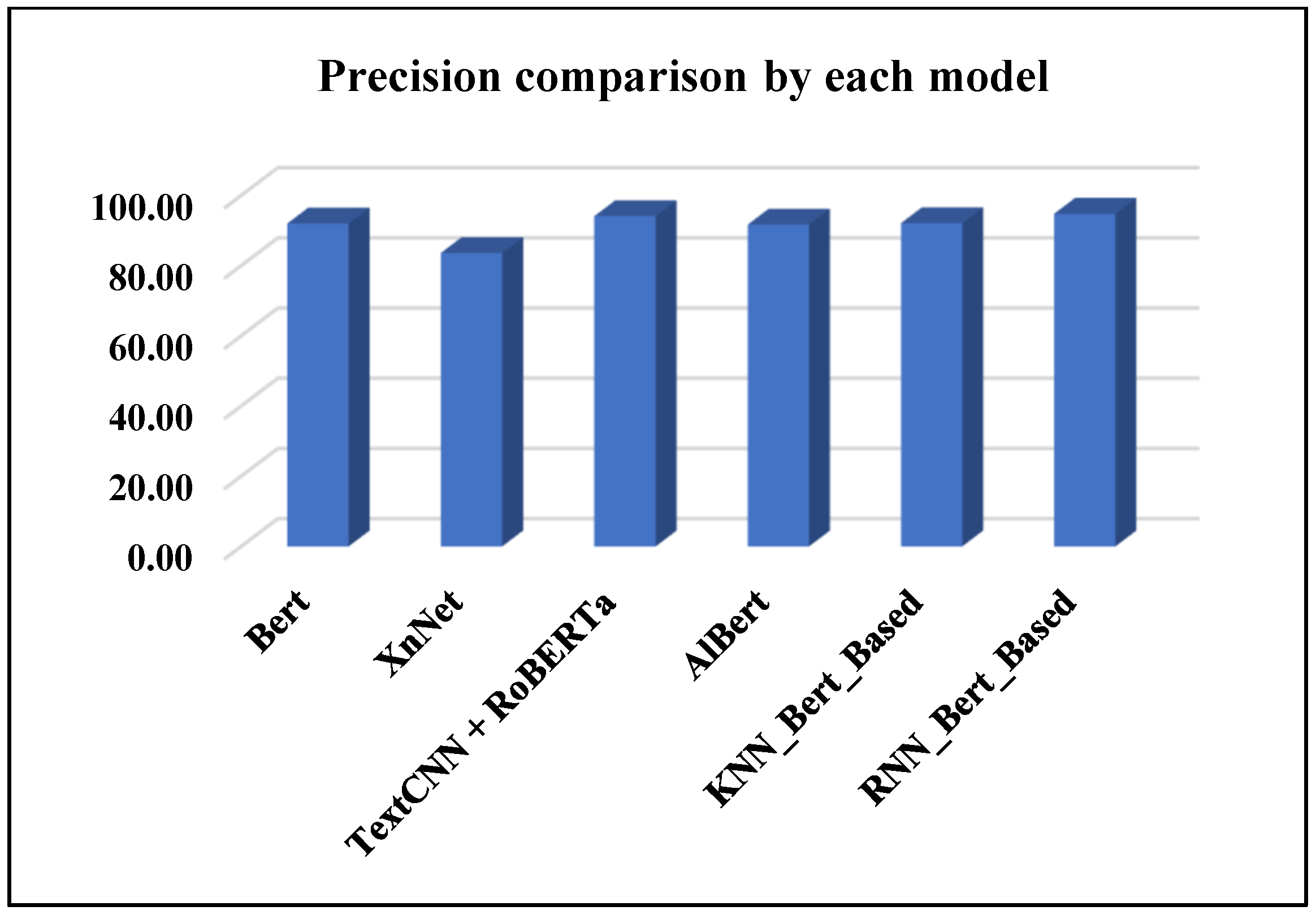
4.3.4. Comparison of Proposed RNN_Bert_Based and Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Munikar, M.; Shakya, S.; Shrestha, A. Fine-grained Sentiment Classification using BERT. arXiv 2019, arXiv:1910.03474. [Google Scholar]
- Shiva Prasad, K.M.; Reddy, H. Text Mining: Classification of Text Documents Using Granular Hybrid Classification Technique. Int. J. Res. Advent Technol. 2019, 7, 1–8. [Google Scholar] [CrossRef]
- Semary, N.A.; Ahmed, W.; Amin, K.; Pławiak, P.; Hammad, M. Enhancing Machine Learning-Based Sentiment Analysis through Feature Extraction Techniques. PLoS ONE 2024, 19, e0294968. [Google Scholar] [CrossRef] [PubMed]
- Manasa, R. Framework for Thought to Text Classification. Int. J. Psychosoc. Rehabil. 2020, 24, 418–424. [Google Scholar] [CrossRef]
- Challenges in text classification using machine learning techniques. Int. J. Recent Trends Eng. Res. 2018, 4, 81–83.
- News Text Classification Model Based on Topic Model. Int. J. Recent Trends Eng. Res. 2017, 3, 48–52.
- Lee, S.A.; Shin, H.S. Combining Sentiment-Combined Model with Pre-Trained BERT Models for Sentiment Analysis. J. KIISE 2021, 48, 815–824. [Google Scholar] [CrossRef]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. BERTScore: Evaluating Text Generation with BERT. arXiv 2020, arXiv:1904.09675. [Google Scholar]
- Sellam, T.; Das, D.; Parikh, A. BLEURT: Learning Robust Metrics for Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 9 April 2020. [Google Scholar] [CrossRef]
- Liu, S.; Tao, H.; Feng, S. Text Classification Research Based on Bert Model and Bayesian network. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 5842–5846. [Google Scholar] [CrossRef]
- Hao, M.; Wang, W.; Zhou, F. Joint Representations of Texts and Labels with Compositional Loss for Short Text Classification. J. Web Eng. 2021, 20, 669–688. [Google Scholar] [CrossRef]
- Bai, J.; Li, X. Chinese Multilabel Short Text Classification Method Based on GAN and Pinyin Embedding. IEEE Access 2024, 12, 83323–83329. [Google Scholar] [CrossRef]
- Jiang, D.; He, J. Tree Framework with BERT Word Embedding for the Recognition of Chinese Implicit Discourse Relations. IEEE Access 2020, 8, 162004–162011. [Google Scholar] [CrossRef]
- Salim, S.; Lahcen, O. A BERT-Enhanced Exploration of Web and Mobile Request Safety through Advanced NLP Models and Hybrid Architectures. IEEE Access 2024, 12, 76180–76193. [Google Scholar] [CrossRef]
- Yu, S.; Su, J.; Luo, D. Improving BERT-Based Text Classification with Auxiliary Sentence and Domain Knowledge. IEEE Access 2019, 7, 176600–176612. [Google Scholar] [CrossRef]
- Zhang, H.; Shan, Y.; Jiang, P.; Cai, X. A Text Classification Method Based on BERT-Att-TextCNN Model. In Proceedings of the 2022 IEEE 5th Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 16–18 December 2022; pp. 1731–1735. [Google Scholar] [CrossRef]
- Alagha, I. Leveraging Knowledge-Based Features with Multilevel Attention Mechanisms for Short Arabic Text Classification. IEEE Access 2022, 10, 51908–51921. [Google Scholar] [CrossRef]
- She, X.; Chen, J.; Chen, G. Joint Learning with BERT-GCN and Multi-Attention for Event Text Classification and Event Assignment. IEEE Access 2022, 10, 27031–27040. [Google Scholar] [CrossRef]
- Meng, Q.; Song, Y.; Mu, J.; Lv, Y.; Yang, J.; Xu, L.; Zhao, J.; Ma, J.; Yao, W.; Wang, R.; et al. Electric Power Audit Text Classification with Multi-Grained Pre-Trained Language Model. IEEE Access 2023, 11, 13510–13518. [Google Scholar] [CrossRef]
- Talaat, A.S. Sentiment Analysis Classification System Using Hybrid BERT Models. J. Big Data 2023, 10, 110. [Google Scholar] [CrossRef]
- Garrido-Muñoz, I.; Montejo-Ráez, A.; Martínez-Santiago, F.; Ureña-López, L.A. A Survey on Bias in Deep NLP. Appl. Sci. 2021, 11, 3184. [Google Scholar] [CrossRef]
- Wu, Y.; Jin, Z.; Shi, C.; Liang, P.; Zhan, T. Research on the Application of Deep Learning-based BERT Model in Sentiment Analysis. arXiv 2024, arXiv:2403.08217. [Google Scholar]
- Li, Q.; Li, X.; Du, Y.; Fan, Y.; Chen, X. A New Sentiment-Enhanced Word Embedding Method for Sentiment Analysis. Appl. Sci. 2022, 12, 10236. [Google Scholar] [CrossRef]
- Chen, X.; Cong, P.; Lv, S. A Long-Text Classification Method of Chinese News Based on BERT and CNN. IEEE Access 2022, 10, 34046–34057. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, W.; Pan, S.; Chen, J. Solving Data Imbalance in Text Classification with Constructing Contrastive Samples. IEEE Access 2023, 11, 90554–90562. [Google Scholar] [CrossRef]
- He, A.; Abisado, M. Text Sentiment Analysis of Douban Film Short Comments Based on BERT-CNN-BiLSTM-Att Model. IEEE Access 2024, 12, 45229–45237. [Google Scholar] [CrossRef]
- Tang, T.; Tang, X.; Yuan, T. Fine-Tuning BERT for Multi-Label Sentiment Analysis in Unbalanced Code-Switching Text. IEEE Access 2020, 8, 193248–193256. [Google Scholar] [CrossRef]
- Zhang, H.; Sun, S.; Hu, Y.; Liu, J.; Guo, Y. Sentiment Classification for Chinese Text Based on Interactive Multitask Learning. IEEE Access 2020, 8, 129626–129635. [Google Scholar] [CrossRef]
- Peng, C.; Wang, H.; Wang, J.; Shou, L.; Chen, K.; Chen, G.; Yao, C. Learning Label-Adaptive Representation for Large-Scale Multi-Label Text Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 2630–2640. [Google Scholar] [CrossRef]
- Lee, D.H.; Jang, B. Enhancing Machine-Generated Text Detection: Adversarial Fine-Tuning of Pre-Trained Language Models. IEEE Access 2024, 12, 65333–65340. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, X.; Zhang, J.; Zhang, M. Three-Branch BERT-Based Text Classification Network for Gastroscopy Diagnosis Text. Int. J. Crowd Sci. 2024, 8, 56–63. [Google Scholar] [CrossRef]
- Rehan, M.; Malik, M.S.I.; Jamjoom, M.M. Fine-Tuning Transformer Models Using Transfer Learning for Multilingual Threatening Text Identification. IEEE Access 2023, 11, 106503–106515. [Google Scholar] [CrossRef]
- Kowsher, M.; Sami, A.A.; Prottasha, N.J.; Arefin, M.S.; Dhar, P.K.; Koshiba, T. Bangla-BERT: Transformer-Based Efficient Model for Transfer Learning and Language Understanding. IEEE Access 2022, 10, 91855–91870. [Google Scholar] [CrossRef]
- Xiao, H.; Luo, L. An Automatic Sentiment Analysis Method for Short Texts Based on Transformer-BERT Hybrid Model. IEEE Access 2024, 12, 93305–93317. [Google Scholar] [CrossRef]
- Olivato, M.; Putelli, L.; Arici, N.; Gerevini, A.E.; Lavelli, A.; Serina, I. Language Models for Hierarchical Classification of Radiology Reports with Attention Mechanisms, BERT, and GPT-4. IEEE Access 2024, 12, 69710–69727. [Google Scholar] [CrossRef]
- Corizzo, R.; Leal-Arenas, S. One-Class Learning for AI-Generated Essay Detection. Appl. Sci. 2023, 13, 7901. [Google Scholar] [CrossRef]
- Perera, P.; Patel, V.M. Learning Deep Features for One-Class Classification. IEEE Trans. Image Process. 2019, 28, 5450–5463. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Socher, R.; Bauer, J.; Manning, C.D.; Ng, A.Y. Parsing with compositional vector grammars. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Volume 1, pp. 455–465, Long Papers. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Parameter | Value |
|---|---|---|
| 1 | Max_length | 256 |
| 2 | Batch_size | 16 |
| 3 | Learning_rate | |
| 4 | Dropout | 0.5 |
| 5 | Epoch | 5 |
| 6 | Activation Function | ReLU |
| 7 | Patience | 1 |
| 8 | max_seq_len | 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eang, C.; Lee, S. Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based). Appl. Sci. 2024, 14, 8388. https://doi.org/10.3390/app14188388
Eang C, Lee S. Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based). Applied Sciences. 2024; 14(18):8388. https://doi.org/10.3390/app14188388
Chicago/Turabian StyleEang, Chanthol, and Seungjae Lee. 2024. "Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based)" Applied Sciences 14, no. 18: 8388. https://doi.org/10.3390/app14188388
APA StyleEang, C., & Lee, S. (2024). Improving the Accuracy and Effectiveness of Text Classification Based on the Integration of the Bert Model and a Recurrent Neural Network (RNN_Bert_Based). Applied Sciences, 14(18), 8388. https://doi.org/10.3390/app14188388