
A Chinese Nested Named Entity Recognition Model for Chicken Disease Based on Multiple Fine-Grained Feature Fusion and Efficient Global Pointer

 , ,
, ,  , , and
, , and
Abstract
Featured Application
Abstract
1. Introduction
- We constructed the MFGFF-BiLSTM-EGP model, which connects the fusion output of multi-fine-grained features to the BiLSTM neural network layer, and finally through a fully connected layer into the EGP to predict the entity position.
- In the MFGFF module we designed, the character encoder obtains character features by fine-tuning the RoBERTa pre-trained model, the word encoder acquires word features through word-character matching, word frequency weighting, and multi-head attention mechanism, and the sentence features are output using SBERT. MFGFF effectively integrates multiple fine-grained features. In addition, the introduction of EGP enables the prediction of nested entities by means of positional coding.
- We constructed a comprehensive knowledge base for chicken diseases that included a 20-million-character corpus, a vocabulary containing 6760 specialized terms, a 200-dimensional word vector in the field of chicken diseases, and a high-quality annotated dataset CDNER that was curated under the guidance of veterinarians.
2. Materials and Methods
2.1. Data and Lexicon
2.2. Entity Labeling
2.3. MFGFF-BiLSTM-EGP
| Algorithm 1. Pseudo-code for the MFGFF-BiLSTM-EGP nested named entity recognition mode. | |||
| Input: Pre-trained model RoBERTa, word vectors GloVe, sentence embeddings SBERT, network BiLSTM, efficient global pointer EGP, The number of iterations E. | |||
| . | |||
| 1: | do | ||
| 2: | |||
| 3: | , according to Equations (4) and (5). | ||
| 4: | , according to Equations (6)–(11). | ||
| 5: | |||
| 6: | |||
| 7: | |||
| 8: | |||
| 9: | |||
| 10: | |||
| 11: | |||
| 12: | |||
| 13: | |||
| 14: | |||
| 15: | |||
2.3.1. Character Encoder
2.3.2. Word Encoder
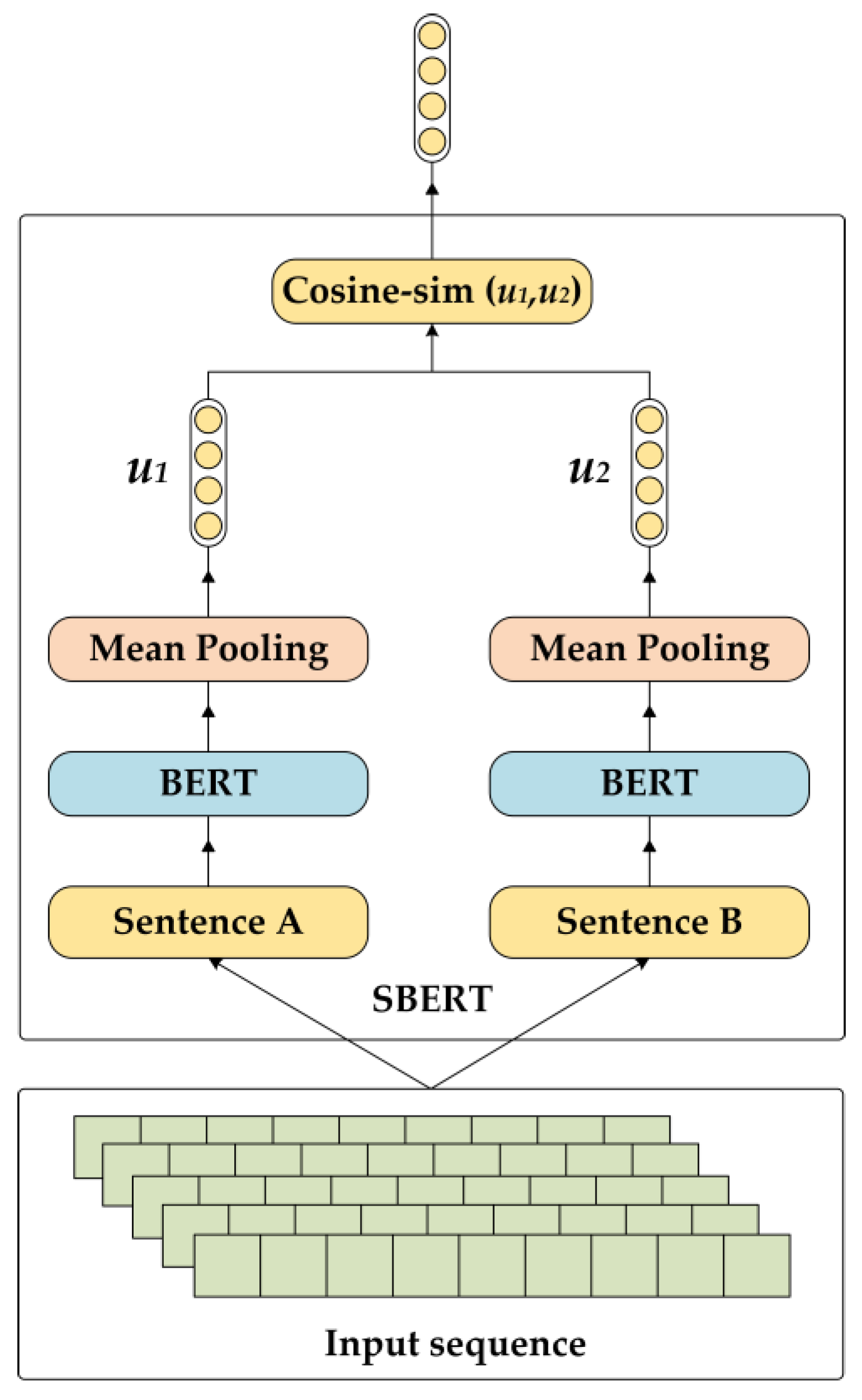
2.3.3. Sentence Encoder
2.3.4. BiLSTM
2.3.5. Efficient Global Pointer
2.4. Experimental Environment and Hyperparameter
2.5. Evaluation Indicators
3. Results
- CDNER (ours): The Chicken Disease Named Entity Recognition dataset comprising 5000 high-quality samples labeled by veterinary experts, containing five types of entities with nested structures.
- CMeEE V2 [50]: A Chinese medicine entity recognition dataset with 20,000 annotated samples across nine categories including nested entities. The categories include diseases (dis), clinical symptoms (sym), drugs (dru), medical equipment (equ), medical procedures (pro), body (bod), medical examination items (ite), microbiology (mic), and departments (dep).
- CLUENER [51]: A general domain NER dataset with 12,091 annotated samples across ten categories: addresses, books, companies, games, government, movies, names, organizations, positions, and scenes.
3.1. Main Results Compared with Other Models
- Lattice LSTM [53]: Encodes input characters and all potential words in the matching dictionary.
- FLAT [54]: A transformer-based model that utilizes unique position encoding to integrate the lattice structure, seamlessly introducing lexical information.
- BERT-CRF: Combines a traditional CRF decoder with the BERT pre-trained model.
- BERT-MRC [55]: Reframes the NER task as a reading comprehension problem.
- SLRBC [56]: Integrates lexical boundary information using the SoftLexicon method with RoBERTa, BiLSTM, and CRF.
3.2. Entity Level Evaluation
3.3. Ablation Study
3.3.1. Effect of Pre-Trained Model
3.3.2. Effect of Word Encoder
3.3.3. Effect of Sentence Encoder
4. Discussion
4.1. Confusion Matrix Analysis
4.2. Visualization of Token Representations in Feature Space
4.3. Nested Entity Predictive Analytic
4.4. Comparative Analysis of Pre-Rained Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, H.; Xue, X.; Li, Q.; Gao, H.; Wang, R.; Jiang, R.; Ren, Z.; Meng, R.; Li, M.; Guo, Y.; et al. Pig-Ear Detection from the Thermal Infrared Image Based on Improved YOLOv8n. Intell. Robot. 2024, 4, 20–38. [Google Scholar] [CrossRef]
- Hou, G.; Jian, Y.; Zhao, Q.; Quan, X.; Zhang, H. Language Model Based on Deep Learning Network for Biomedical Named Entity Recognition. Methods 2024, 226, 71–77. [Google Scholar] [CrossRef] [PubMed]
- Jehangir, B.; Radhakrishnan, S.; Agarwal, R. A Survey on Named Entity Recognition—Datasets, Tools, and Methodologies. Nat. Lang. Process. J. 2023, 3, 100017. [Google Scholar] [CrossRef]
- Li, Y.; Song, L.; Zhang, C. Sparse Conditional Hidden Markov Model for Weakly Supervised Named Entity Recognition. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 978–988. [Google Scholar]
- De Martino, A.; De Martino, D. An Introduction to the Maximum Entropy Approach and Its Application to Inference Problems in Biology. Heliyon 2018, 4, e00596. [Google Scholar] [CrossRef] [PubMed]
- Ramachandran, R.; Arutchelvan, K. Optimized Version of Tree Based Support Vector Machine for Named Entity Recognition in Medical Literature. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3 December 2020; pp. 357–361. [Google Scholar]
- Liu, K.; Hu, Q.; Liu, J.; Xing, C. Named Entity Recognition in Chinese Electronic Medical Records Based on CRF. In Proceedings of the 2017 14th Web Information Systems and Applications Conference (WISA), Liuzhou, China, 11–12 November 2017; pp. 105–110. [Google Scholar]
- Dash, A.; Darshana, S.; Yadav, D.K.; Gupta, V. A Clinical Named Entity Recognition Model Using Pretrained Word Embedding and Deep Neural Networks. Decis. Anal. J. 2024, 10, 100426. [Google Scholar] [CrossRef]
- Zhang, R.; Zhao, P.; Guo, W.; Wang, R.; Lu, W. Medical Named Entity Recognition Based on Dilated Convolutional Neural Network. Cogn. Robot. 2022, 2, 13–20. [Google Scholar] [CrossRef]
- Lerner, I.; Paris, N.; Tannier, X. Terminologies Augmented Recurrent Neural Network Model for Clinical Named Entity Recognition. J. Biomed. Inform. 2020, 102, 103356. [Google Scholar] [CrossRef]
- Jia, C.; Zhang, Y. Multi-Cell Compositional LSTM for NER Domain Adaptation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 28 July–2 August 2020; pp. 5906–5917. [Google Scholar]
- Chang, C.; Tang, Y.; Long, Y.; Hu, K.; Li, Y.; Li, J.; Wang, C.-D. Multi-Information Preprocessing Event Extraction with BiLSTM-CRF Attention for Academic Knowledge Graph Construction. IEEE Trans. Comput. Soc. Syst. 2023, 10, 2713–2724. [Google Scholar] [CrossRef]
- An, Y.; Xia, X.; Chen, X.; Wu, F.-X.; Wang, J. Chinese Clinical Named Entity Recognition via Multi-Head Self-Attention Based BiLSTM-CRF. Artif. Intell. Med. 2022, 127, 102282. [Google Scholar] [CrossRef]
- Deng, N.; Fu, H.; Chen, X. Named Entity Recognition of Traditional Chinese Medicine Patents Based on BiLSTM-CRF. Wirel. Commun. Mob. Comput. 2021, 2021, 6696205. [Google Scholar] [CrossRef]
- Ma, P.; Jiang, B.; Lu, Z.; Li, N.; Jiang, Z. Cybersecurity Named Entity Recognition Using Bidirectional Long Short-Term Memory with Conditional Random Fields. Tinshhua Sci. Technol. 2021, 26, 259–265. [Google Scholar] [CrossRef]
- Baigang, M.; Yi, F. A Review: Development of Named Entity Recognition (NER) Technology for Aeronautical Information Intelligence. Artif. Intell. Rev. 2023, 56, 1515–1542. [Google Scholar] [CrossRef]
- Fantechi, A.; Gnesi, S.; Livi, S.; Semini, L. A spaCy-Based Tool for Extracting Variability from NL Requirements. In Proceedings of the 25th ACM International Systems and Software Product Line Conference-Volume B, Leicester, UK, 6 September 2021; pp. 32–35. [Google Scholar]
- Wang, M.; Hu, F. The Application of NLTK Library for Python Natural Language Processing in Corpus Research. Theory Pract. Lang. Stud. 2021, 11, 1041–1049. [Google Scholar] [CrossRef]
- Kumar, S.; Alam, M.S.; Khursheed, Z.; Bashar, S.; Kalam, N. Enhancing Relational Database Interaction through Open AI and Stanford Core NLP-Based on Natural Language Interface. In Proceedings of the 2024 5th International Conference on Recent Trends in Computer Science and Technology (ICRTCST), Jamshedpur, India, 9 April 2024; pp. 589–602. [Google Scholar]
- Pendleton, S.C.; Slater, K.; Karwath, A.; Gilbert, R.M.; Davis, N.; Pesudovs, K.; Liu, X.; Denniston, A.K.; Gkoutos, G.V.; Braithwaite, T. Development and Application of the Ocular Immune-Mediated Inflammatory Diseases Ontology Enhanced with Synonyms from Online Patient Support Forum Conversation. Comput. Biol. Med. 2021, 135, 104542. [Google Scholar] [CrossRef] [PubMed]
- ElDin, H.G.; AbdulRazek, M.; Abdelshafi, M.; Sahlol, A.T. Med-Flair: Medical Named Entity Recognition for Diseases and Medications Based on Flair Embedding. Procedia Comput. Sci. 2021, 189, 67–75. [Google Scholar] [CrossRef]
- Wang, Y.; Tong, H.; Zhu, Z.; Li, Y. Nested Named Entity Recognition: A Survey. ACM Trans. Knowl. Discov. Data 2022, 16, 1–29. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, T.; Tsai, C.-Y.; Lu, Y.; Yao, L. Evolution and Emerging Trends of Named Entity Recognition: Bibliometric Analysis from 2000 to 2023. Heliyon 2024, 10, e30053. [Google Scholar] [CrossRef]
- Ming, H.; Yang, J.; Gui, F.; Jiang, L.; An, N. Few-Shot Nested Named Entity Recognition. Knowl.-Based Syst. 2024, 293, 111688. [Google Scholar] [CrossRef]
- Huang, H.; Lei, M.; Feng, C. Hypergraph Network Model for Nested Entity Mention Recognition. Neurocomputing 2021, 423, 200–206. [Google Scholar] [CrossRef]
- Jiang, D.; Ren, H.; Cai, Y.; Xu, J.; Liu, Y.; Leung, H. Candidate Region Aware Nested Named Entity Recognition. Neural Netw. 2021, 142, 340–350. [Google Scholar] [CrossRef]
- Wang, B.; Lu, W.; Wang, Y.; Jin, H. A Neural Transition-Based Model for Nested Mention Recognition. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, Brussels, Belgium, 31 October–4 November 2018; pp. 1011–1017. [Google Scholar]
- Huang, P.; Zhao, X.; Hu, M.; Tan, Z.; Xiao, W. T 2-NER: A T Wo-Stage Span-Based Framework for Unified Named Entity Recognition with T Emplates. Trans. Assoc. Comput. Linguist. 2023, 11, 1265–1282. [Google Scholar] [CrossRef]
- Li, F.; Wang, Z.; Hui, S.C.; Liao, L.; Zhu, X.; Huang, H. A Segment Enhanced Span-Based Model for Nested Named Entity Recognition. Neurocomputing 2021, 465, 26–37. [Google Scholar] [CrossRef]
- Jiang, W. A Method for Ancient Book Named Entity Recognition Based on BERT-Global Pointer. Int. J. Comput. Sci. Inf. Technol. 2024, 2, 443–450. [Google Scholar] [CrossRef]
- Zhang, P.; Liang, W. Medical Name Entity Recognition Based on Lexical Enhancement and Global Pointer. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Zhang, X.; Luo, X.; Wu, J. A RoBERTa-GlobalPointer-Based Method for Named Entity Recognition of Legal Documents. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18 June 2023; pp. 1–8. [Google Scholar]
- Cong, L.; Cui, R.; Dou, Z.; Huang, C.; Zhao, L.; Zhang, Y.; Chen, C.; Su, C.; Li, J.; Qu, C. Named Entity Recognition for Power Data Based on Lexical Enhancement and Global Pointer. In Proceedings of the Third International Conference on Electronic Information Engineering, Big Data, and Computer Technology (EIBDCT 2024), Beijing, China, 19 July 2024; Zhang, J., Sun, N., Eds.; p. 61. [Google Scholar]
- Yadav, V.; Bethard, S. A Survey on Recent Advances in Named Entity Recognition from Deep Learning Models. arXiv 2019, arXiv:1910.11470. [Google Scholar]
- Liu, Z.; Jiang, F.; Hu, Y.; Shi, C.; Fung, P. NER-BERT: A Pre-Trained Model for Low-Resource Entity Tagging. arXiv 2021, arXiv:2112.00405. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Zhang, N.; Jia, Q.; Yin, K.; Dong, L.; Gao, F.; Hua, N. Conceptualized Representation Learning for Chinese Biomedical Text Mining. arXiv 2020, arXiv:2008.10813. [Google Scholar]
- Zhang, Z.; Han, X.; Liu, Z.; Jiang, X.; Sun, M.; Liu, Q. ERNIE: Enhanced Language Representation with Informative Entities. arXiv 2019, arXiv:1905.07129. [Google Scholar]
- Ma, R.; Peng, M.; Zhang, Q.; Wei, Z.; Huang, X. Simplify the Usage of Lexicon in Chinese NER. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 28 July–2 August 2020; pp. 5951–5960. [Google Scholar]
- Zhao, J.; Cui, M.; Gao, X.; Yan, S.; Ni, Q. Chinese Named Entity Recognition Based on BERT and Lexicon Enhancement. In Proceedings of the 2022 4th International Conference on Robotics, Intelligent Control and Artificial Intelligence, Dongguan, China, 16 December 2022; pp. 597–604. [Google Scholar]
- Zhang, J.; Guo, M.; Geng, Y.; Li, M.; Zhang, Y.; Geng, N. Chinese Named Entity Recognition for Apple Diseases and Pests Based on Character Augmentation. Comput. Electron. Agric. 2021, 190, 106464. [Google Scholar] [CrossRef]
- Liu, Q.; Zhang, L.; Ren, G.; Zou, B. Research on Named Entity Recognition of Traditional Chinese Medicine Chest Discomfort Cases Incorporating Domain Vocabulary Features. Comput. Biol. Med. 2023, 166, 107466. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Yang, Q.; Wang, H.; Pasquine, M.; Hameed, I.A. Learning the Morphological and Syntactic Grammars for Named Entity Recognition. Information 2022, 13, 49. [Google Scholar] [CrossRef]
- Tian, Y.; Shen, W.; Song, Y.; Xia, F.; He, M.; Li, K. Improving Biomedical Named Entity Recognition with Syntactic Information. BMC Bioinform. 2020, 21, 539. [Google Scholar] [CrossRef] [PubMed]
- Luoma, J.; Pyysalo, S. Exploring Cross-Sentence Contexts for Named Entity Recognition with BERT. arXiv 2020, arXiv:2006.01563. [Google Scholar]
- Jia, B.; Wu, Z.; Wu, B.; Liu, Y.; Zhou, P. Enhanced Character Embedding for Chinese Named Entity Recognition. Meas. Control. 2020, 53, 1669–1681. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar] [CrossRef]
- Hongying, Z.; Wenxin, L.; Kunli, Z.; Yajuan, Y.; Baobao, C.; Zhifang, S. Building a Pediatric Medical Corpus: Word Segmentation and Named Entity Annotation. In Chinese Lexical Semantics; Liu, M., Kit, C., Su, Q., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12278, pp. 652–664. ISBN 978-3-030-81196-9. [Google Scholar]
- Xu, L.; Liu, W.; Li, L.; Liu, C.; Zhang, X. Cluener2020: Fine-Grained Named Entity Recognition Dataset and Benchmark for Chinese. arXiv 2020, arXiv:2001.04351. [Google Scholar]
- Song, Y.; Shi, S.; Li, J.; Zhang, H. Directional Skip-Gram: Explicitly Distinguishing Left and Right Context for Word Embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 175–180. [Google Scholar]
- Zhang, Y.; Yang, J. Chinese NER Using Lattice LSTM. arXiv 2018, arXiv:1805.02023. [Google Scholar] [CrossRef]
- Li, X.; Yan, H.; Qiu, X.; Huang, X. FLAT: Chinese NER Using Flat-Lattice Transformer. arXiv 2020, arXiv:2004.11795. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A Unified MRC Framework for Named Entity Recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Cui, X.; Yang, Y.; Li, D.; Qu, X.; Yao, L.; Luo, S.; Song, C. Fusion of SoftLexicon and RoBERTa for Purpose-Driven Electronic Medical Record Named Entity Recognition. Appl. Sci. 2023, 13, 13296. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity | Labels | Example | Num |
|---|---|---|---|
| Type | TY | Adult chickens, laying hens, flocks, sick chickens | 4503 |
| Disease | DI | Newcastle disease, avian influenza | 4098 |
| Symptom | SY | Clinical warming, edema, congestion | 9265 |
| Body part | BO | Head, eyes, liver, lymphocyte | 5744 |
| Drug | DR | Oxytetracycline, gentamycin, tetracycline | 3201 |
| Total | 26,811 |
| Hyperparameter | Value |
|---|---|
| Optimizer | Adam |
| Warm up | 0.1 |
| LSTM units | 256 |
| Batch size | 32 |
| Dropout | 0.4 |
| Max len | 128 |
| Epoch | 20 |
| Model | CDNER | CMeEE V2 | CLUENER | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P/% | R/% | F1/% | P/% | R/% | F1/% | P/% | R/% | F1/% | |
| Lattice LSTM | 82.43 | 84.51 | 83.46 | 61.26 | 62.33 | 61.79 | 71.69 | 70.78 | 71.23 |
| FLAT | 80.55 | 82.99 | 81.75 | 58.18 | 61.11 | 59.61 | 64.64 | 68.45 | 66.49 |
| BERT-CRF | 87.86 | 89.53 | 88.69 | 70.93 | 73.24 | 71.98 | 79.15 | 81.86 | 80.48 |
| BERT-MRC | 80.16 | 85.91 | 82.93 | 68.00 | 68.35 | 67.97 | 75.60 | 78.22 | 76.89 |
| SLRBC | 88.58 | 90.72 | 89.64 | 71.54 | 72.59 | 72.06 | 81.55 | 80.51 | 81.03 |
| MFGFF-BiLSTM-EGP (ours) | 91.42 | 92.18 | 91.98 | 73.12 | 73.68 | 73.32 | 85.21 | 80.38 | 82.54 |
| Data | Category | P % | R % | F1 % | Macro P % | Macro R % | Macro F1 % |
|---|---|---|---|---|---|---|---|
| CDNER | symptom | 86.99 | 88.26 | 87.6 | 91.42 | 92.18 | 91.98 |
| body part | 92.19 | 92.70 | 92.43 | ||||
| disease | 92.29 | 91.70 | 92.98 | ||||
| drug | 92.50 | 93.97 | 93.22 | ||||
| type | 93.11 | 94.25 | 93.68 | ||||
| CMeEE V2 | bod | 74.56 | 79.05 | 77.30 | 73.12 | 73.68 | 73.32 |
| dis | 78.73 | 87.85 | 83.81 | ||||
| sym | 77.10 | 65.75 | 70.9 | ||||
| ite | 70.87 | 55.58 | 62.04 | ||||
| dru | 77.94 | 83.23 | 81.10 | ||||
| pro | 76.09 | 66.30 | 70.84 | ||||
| mic | 69.56 | 86.60 | 78.19 | ||||
| dep | 77.97 | 68.78 | 73.1 | ||||
| equ | 55.23 | 70.01 | 62.62 | ||||
| CLUENER | address | 76.81 | 80.71 | 78.71 | 85.21 | 80.38 | 82.54 |
| name | 92.67 | 84.76 | 88.54 | ||||
| organization | 84.52 | 84.02 | 84.27 | ||||
| game | 87.42 | 80.98 | 84.08 | ||||
| scene | 81.75 | 76.87 | 79.23 | ||||
| book | 88.04 | 73.64 | 80.20 | ||||
| company | 84.09 | 88.10 | 86.05 | ||||
| position | 86.92 | 81.88 | 84.33 | ||||
| government | 82.72 | 85.90 | 84.28 | ||||
| movie | 87.21 | 66.96 | 75.76 |
| Model | Pre-Trained Model | Word Encoder | Sentence Encoder | F1/% |
|---|---|---|---|---|
| 1 | ✓ | 88.01 | ||
| 2 | ✓ | 82.32 | ||
| 3 | ✓ | ✓ | 82.67 | |
| 4 | ✓ | ✓ | 91.33 | |
| 5 | ✓ | ✓ | 88.34 | |
| 6 | ✓ | ✓ | ✓ | 91.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Peng, C.; Li, Q.; Yu, Q.; Lin, L.; Li, P.; Gao, R.; Wu, W.; Jiang, R.; Yu, L.; et al. A Chinese Nested Named Entity Recognition Model for Chicken Disease Based on Multiple Fine-Grained Feature Fusion and Efficient Global Pointer. Appl. Sci. 2024, 14, 8495. https://doi.org/10.3390/app14188495
Wang X, Peng C, Li Q, Yu Q, Lin L, Li P, Gao R, Wu W, Jiang R, Yu L, et al. A Chinese Nested Named Entity Recognition Model for Chicken Disease Based on Multiple Fine-Grained Feature Fusion and Efficient Global Pointer. Applied Sciences. 2024; 14(18):8495. https://doi.org/10.3390/app14188495
Chicago/Turabian StyleWang, Xiajun, Cheng Peng, Qifeng Li, Qinyang Yu, Liqun Lin, Pingping Li, Ronghua Gao, Wenbiao Wu, Ruixiang Jiang, Ligen Yu, and et al. 2024. "A Chinese Nested Named Entity Recognition Model for Chicken Disease Based on Multiple Fine-Grained Feature Fusion and Efficient Global Pointer" Applied Sciences 14, no. 18: 8495. https://doi.org/10.3390/app14188495
APA StyleWang, X., Peng, C., Li, Q., Yu, Q., Lin, L., Li, P., Gao, R., Wu, W., Jiang, R., Yu, L., Ding, L., & Zhu, L. (2024). A Chinese Nested Named Entity Recognition Model for Chicken Disease Based on Multiple Fine-Grained Feature Fusion and Efficient Global Pointer. Applied Sciences, 14(18), 8495. https://doi.org/10.3390/app14188495