Abstract
Remote-sensing image dehazing (RSID) is crucial for applications such as military surveillance and disaster assessment. However, current methods often rely on complex network architectures, compromising computational efficiency and scalability. Furthermore, the scarcity of annotated remote-sensing-dehazing datasets hinders model development. To address these issues, a Dual-View Knowledge Transfer (DVKT) framework is proposed to generate a lightweight and efficient student network by distilling knowledge from a pre-trained teacher network on natural image dehazing datasets. The DVKT framework includes two novel knowledge-transfer modules: Intra-layer Transfer (Intra-KT) and Inter-layer Knowledge Transfer (Inter-KT) modules. Specifically, the Intra-KT module is designed to correct the learning bias of the student network by distilling and transferring knowledge from a well-trained teacher network. The Inter-KT module is devised to distill and transfer knowledge about cross-layer correlations. This enables the student network to learn hierarchical and cross-layer dehazing knowledge from the teacher network, thereby extracting compact and effective features. Evaluation results on benchmark datasets demonstrate that the proposed DVKT framework achieves superior performance for RSID. In particular, the distilled model achieves a significant speedup with less than 6% of the parameters and computational cost of the original model, while maintaining a state-of-the-art dehazing performance.
1. Introduction
Remote-sensing image dehazing (RSID), as a critical technique in remote-sensing image processing, aims to eliminate the blurring and degradation caused by atmospheric media [1]. With the widespread application of remote-sensing technology in meteorological monitoring, environmental assessment, and other fields, clear remote-sensing images are crucial for the accuracy and timeliness of information extraction. RSID technology not only enhances image quality but also plays a key role in meteorological monitoring [2], disaster response [3], and military surveillance [4].
In recent years, image-dehazing techniques have been extensively studied, and many dehazing methods have been proposed [5,6]. Currently, these dehazing methods can be categorized into two types [7]: prior-based dehazing methods and learning-based dehazing methods. Prior-based dehazing methods relies on manually extracting statistical differences between haze-degraded images and clear images to establish empirical priors [8,9,10]. The most classical prior-based image-dehazing methods recover the clear image based on the atmospheric scattering model (ASM). For instance, He et al. [11] raised the dark channel prior (DCP) method to estimate the transmission map for image dehazing. To reduce the model complexity, He et al. [12] proposed a guided filtering method for image dehazing subsequently. In addition, Zhu et al. [13] proposed the color attenuation prior (CAP) method to recover depth information so as to conduct image dehazing. Fattal [14] noticed that RGB values follow a color line prior (CLP) within each local patch in an image, and estimated the transmission map based on CLP. Although these prior-based methods are easy to implement, they rely on scene-specific prior assumptions, and when these assumptions are not met, the dehazing results may be unsatisfactory [15].
With the advancement of deep learning, learning-based dehazing methods have been widely explored [16,17,18], which mainly include atmospheric scattering model (ASM)-learning methods and end-to-end learning methods. ASM-learning methods achieve image dehazing by designing suitable deep neural networks to estimate the haze parameters in the ASM. For example, Chi et al. [19] incorporated prior knowledge into a gradient-guided Swin Transformer [20] for haze parameter estimation. To avoid explicitly collecting paired training data, Shyam and Yoo [21] proposed an adversarial auto-augmentation approach by combining extended atmospheric scattering model. End-to-end learning methods achieve effective image dehazing by directly learning the underlying mapping relationship between haze-degraded images and clear images [22]. For example, Qin et al. [23] developed a feature fusion attention network, named FFA-Net, for end-to-end image dehazing. Guo et al. [24] proposed a feature modulation module for effectively integrating Transformer and CNN features. Despite the notable achievements of current learning-based approaches, most of them are designed for dehazing natural scenes [25,26]. Compared to images in natural scenes, remote-sensing images are typically larger, more complex, and exhibit variable and irregular haze intensity distributions. Therefore, the application of existing end-to-end dehazing methods for haze-degraded remote-sensing images may not be ideal [27].
Recently, researchers have explored numerous methods specifically tailored for RSID [28], achieving significant results. For example, Li and Chen [29] designed a two-stage coarse-to-fine dehazing network FCTF-Net for gradually refining dehazing result. Song et al. [30] introduced a detail-compensated split attention to capture global and local regional dependencies for RSID. Zhang and Wang [31] proposed a dynamic collaborative reasoning learning framework for RSID. Zhang et al. [32] developed a frequency-oriented FOTformer for recovering haze-free images. Zheng et al. [33] achieved unsupervised RSID by introducing an enhanced attention-guided GAN network. Yu et al. [34] designed a hierarchical sliced interactive multi-layer collaborative decoding network (HSMD-Net) to achieve image restoration by realizing cross-layer global and local information interaction. In general, most state-of-the-art methods employ heavy backbone networks (e.g., Transformer models [28]) to obtain better performance. However, due to the demanding computational cost and slow running speed, these models are highly inefficient. Therefore, a fundamental question is how to obtain efficient RSID models rather than relying on heavy backbone networks. Furthermore, in comparison to dehazing tasks within natural scenes, there exists a significant scarcity of RSID datasets that incorporate unambiguously labeled images, resulting in suboptimal performance. Although a large number of lightweight techniques, such as quantization [35] and pruning [36], have been explored, there is still no good way to solve the problem of scarcity of RSID datasets. Fortunately, the emergence of knowledge distillation technology provides an alternative for addressing these issues.
As a result, this study proposes a Dual-View Knowledge Transfer (DVKT) framework for simultaneously distilling hierarchical features and cross-layer correlation knowledge. The framework encompasses two innovative modules: Intra-layer Knowledge Transfer (Intra-KT) and Inter-layer Knowledge Transfer (Inter-KT). Specifically, the Intra-KT module leverages representative features extracted from a well-trained teacher network to sequentially guide the corresponding features of the student network. This mechanism progressively corrects the learning bias of the student, enabling its features to exhibit similar visual and semantic patterns to those of the teacher. In contrast, the Inter-KT module calculates the relationships between features of the teacher network layer-by-layer and utilizes this knowledge to aid the student network in modulating its hierarchical features, thereby enabling the student to learn the solution process of the teacher. Based on the proposed DVKT framework, the distilled student network can effectively acquire compact and knowledge-rich features, resulting in high-quality haze-free remote-sensing images. With less than 6% of the parameters of the teacher model, the distilled model achieves nearly an 8-fold speedup while maintaining competitive dehazing performance.
In summary, the main contributions and novelty of this work are three-fold:
- A Dual-View Knowledge Transfer (DVKT) framework is proposed for effective RSID: to the extent of our knowledge, the proposed DVKT framework is the first work to concentrate on transferring shared knowledge from natural scene dehazing models to RSID models and learning remote-sensing scene-specific knowledge for lightweight models.
- Two complementary knowledge transfer modules, Intra-KT and Inter-KT, are integrated to comprehensively transfer the structured knowledge from well-trained natural scene-dehazing models to lightweight RSID models.
- Extensive experiments on benchmark datasets demonstrate the effectiveness of the proposed DVKT framework. In particular, the proposed DVKT framework achieves satisfactory dehazing results while significantly improving processing speed.
2. Materials and Methods
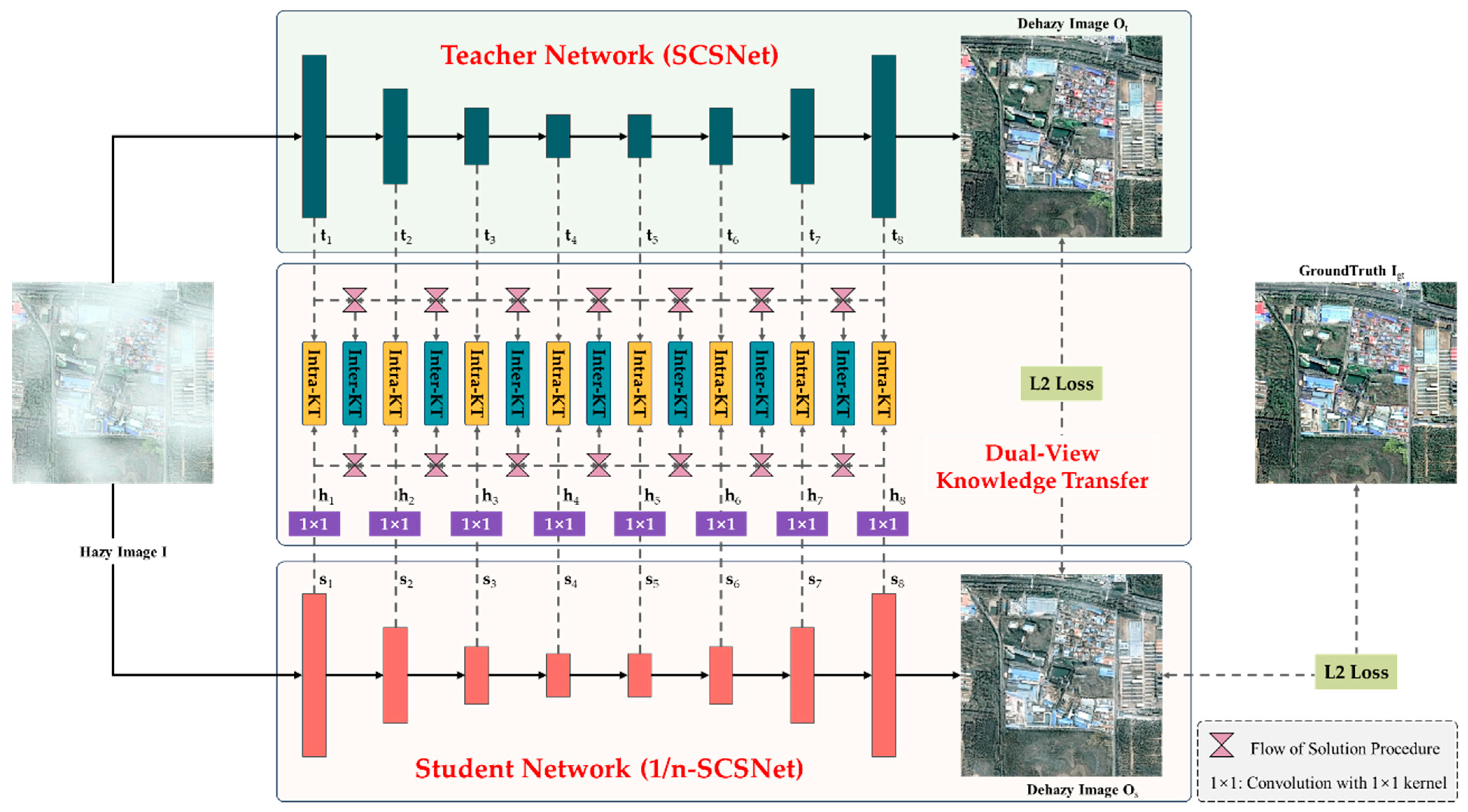
This study proposes a Dual-View Knowledge Transfer (DVKT) framework to address the efficiency and limited labeled data issues in RSID. As depicted in Figure 1, the framework aims to effectively transfer hierarchical and cross-layer knowledge from a well-trained teacher network to a student network based on multiple Intra-KT and Inter-KT modules. The teacher network in the proposed DVKT framework adopts our earlier SCSNet [37]. Differently, the SCSNet used in this study is pre-trained on the natural-scene-dehazing dataset RESIDE [38], instead of limited labeled remote-sensing images. The student network is 1/n-SCSNet, where the number of channels in its convolutional layers (except the last layer) is 1/n of the teacher network. Compared to the complex SCSNet, the 1/n-SCSNet model has only 1/n2 of the parameters and computational cost of SCSNet, but its performance degrades slightly.
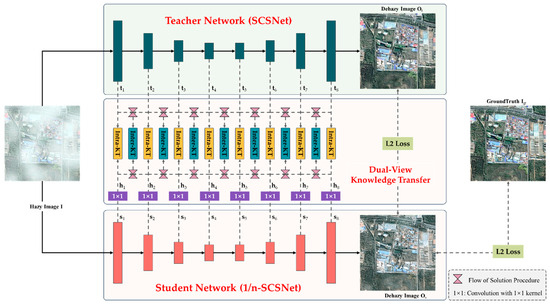
Figure 1.
The framework of the proposed Dual-View Knowledge Transfer (DVKT) for remote-sensing image dehazing.
2.1. Feature Extraction
It is typical for teacher networks to be pre-trained on standard benchmark datasets, and the knowledge they have acquired can be represented explicitly as parameters or implicitly embedded in features. Building on previous research [39], knowledge transfer is conducted at the feature level, using the features of a pre-trained teacher network to guide the learning of a student network’s features hierarchically.
As illustrated in Figure 1, any given hazy image is simultaneously fed into SCSNet and 1/n-SCSNet for feature learning. For the sake of simplicity, the features produced by the i-th block of SCSNet are uniformly represented as , while the features of the corresponding layer in 1/n-SCSNet are denoted as . Note that and have the same resolution, but the number of channels of is 1/n of that of . To reduce the computational cost during training, only some representative features are distilled:
where and represent the feature sets to be distilled from SCSNet and 1/n-SCSNet, respectively.
2.2. Intra-Layer Knowledge Transfer
As discussed in the previous section, the learned features implicitly inherently encompass the knowledge acquired by SCSNet. To enhance the efficiency of the student network 1/n-SCSNet, a simple yet powerful Intra-KT module is designed, which enables the sequential transfer of hierarchical knowledge from SCSNet to 1/n-SCSNet. Specifically, is responsible for learning the semantic patterns of and optimizing the parameters of 1/n-SCSNet by enhancing their distributional similarity.
Concretely, the Intra-KT module consists of two steps: channel reduction and knowledge transfer. Since the number of channels of features and is different, it is not suitable to directly calculate their similarity. To address this issue, a set of embedded features is generated by inputting each feature into a 1 × 1 convolutional layer for channel reduction, which can be expressed as follows:
where denotes the to-be-learned parameters in the 1 × 1 convolutional layer. The output is the embedded feature of , and it has the same channel number with .
The second step entails a similarity calculation and knowledge transfer. Given that the Euclidean distance is excessively strict and may result in mere rote memorization, a relatively relaxed metric, cosine similarity, is employed to quantify the similarity between two features. In particular, the similarity between and at position is calculated as follows:
where denotes the channel number , and indicates the response value at position of the c-th channel in . denotes the length of a vector. Therefore,
where and denote the spatial size of . By minimizing this loss, the parameters in 1/n-SCSNet can be effectively optimized. In comparison to computationally expensive pair-wise distillation that can only be performed on low-resolution high-level features, our Intra-KT is more efficient to transfer implicit knowledge embedded in each layer.
2.3. Inter-Layer Knowledge Transfer
To regularize the student network learning flow of the solution process (FSP) of the teacher network, an Inter-KT module is designed. This module calculates the pair-wise feature relationship within the teacher network layer by layer to regulate features from the student network. A detailed description of the Inter-KT module is as follows:
The Inter-KT module evaluates the feature interdependencies between pairs within the teacher network on a layer-by-layer basis, aiming to govern both the prolonged and immediate development of feature attributes in the student network. Below is an elaborative explanation of the Inter-KT module’s functionality.
Firstly, the FSP matrices need to be generated layer by layer. For any two general features and , their FSP matrix can be calculated through channel-wise inner product:
It is worth noting that the FSP matrix is computed on features with the same resolution. However, the features in have different resolutions. To address this issue, the resolution of all features in is adjusted to that of through max pooling so as to simultaneously reduce the computational cost. The adjusted features of are denoted as . Similarly, corresponding resolution adjustment is applied to features in feature set , so as to align them with the resolution of .
In this study, the FSP matrices of adjacent features are calculated in order to grasp the evolution of features. In particular, an FSP matrix is generated for in the teacher network. Similarly, the FSP matrix is also calculated for of in the student network. Finally, the computation of the loss function for Inter-RT can be carried out using the following:
By reducing the gap among these FSP matrices, the knowledge in the teacher network SCSNet can be effectively transferred into the student network 1/n-SCSNet.
2.4. Loss Function
At the output level, the smooth loss is employed to train the proposed DVKT framework. The smooth loss guarantees proximity between the reconstructed haze-free image and the ground truth, demonstrating superior performance over loss and the traditional loss in numerous low-level visual tasks. Let denote the input haze-degraded image, denote the reconstructed haze-free image obtained by the teacher network, denote the reconstructed haze-free image obtained by the student network, and denote the ground truth clear image. The formula for the smooth loss can be articulated as follows:
where
where is the total number of pixels within the image, and l denotes the l-th color channel.
Ultimately, the optimization of parameters within the 1/n-SCSNet is achieved through the minimization of the overall loss function:
where , , and represent the respective weights assigned to the various loss components.
3. Results and Discussion
To illustrate the efficacy of the proposed DVKT framework, four public datasets are applied for evaluation. Furthermore, the experimental setup, comparison with the state of the art, and some ablation studies are given successively.
3.1. Datasets
Extensive experiments were conducted on four public remote-sensing-image-dehazing datasets: SateHaze1k [40], RS-Haze [28], RSID [19], RRSD300 [41].
- SateHaze1k: The SateHaze1k dataset [40] consists of 1200 image pairs, divided into three sub-datasets with different haze densities. The SateHaze1k-thin sub-dataset contains images with thin haze, the SateHaze1k-moderate sub-dataset contains images with moderate haze, and the SateHaze1k-thick sub-dataset contains images with thick haze. The images in each sub-dataset are split among three categories: 320 for training, 35 for validation, and 45 for testing.
- RS-Haze: The RS-Haze dataset [28] is a comprehensive and challenging dataset designed for image dehazing tasks, featuring 51,300 image pairs. Among these, 51,030 pairs are designated for training purposes, while the remaining 270 pairs are reserved for testing. It encompasses various scenarios and levels of haze density, such as urban landscapes, forests, beaches, and mountain regions.
- RSID: The RSID dataset [19] comprises 1000 image pairs, with each pair consisting of a hazy image and a corresponding haze-free image. In line with prior research [41], 900 of these pairs are randomly chosen for the training set, while the rest are utilized for testing.
- RRSD300: The RRSD300 dataset [41] comprises 300 real-world hazy images collected from DIOR dataset [42] and Microsoft Bing. This dataset is used to verify the generalization of various models.
3.2. Experimental Details and Evaluation Criteria
(1) Experimental Details: The proposed DVKT framework is implemented with PyTorch 1.13, and the experiments are conducted on a PC with NVIDIA RTX 3090 GPU (NVIDIA, Santa Clara, CA, USA). To augment the training dataset, random rotations of 90°, 180°, and 270°, as well as horizontal flipping are applied. The inputs to the DVKT framework are with the spatial size of 256 × 256. For the training process, a batch size of 32 was used, and the number of epochs was set to 20. The DVKT framework was optimized using the Adam optimizer. The initial learning rate configured at 1.0 × 10−4, with a cosine annealing strategy employed to progressively reduce it to 0. To address the high cost associated with tuning weight coefficients, a multi-task learning approach based on equal variance and uncertainty [43] was implemented to determine the optimal weight coefficients , , and . Empirically, the hyperparameter n in 1/n-SCSNet was set to 5.
(2) Evaluation Criteria: To assess the performance of the proposed DVKT framework, the Peak Signal-to-Noise Ratio (PSNR), the Structural Similarity Index Measure (SSIM), and the Learned Perceptual Image Patch Similarity (LPIPS) are used as quantitative metrics. Higher PSNR and SSIM or lower LPIPS values signify superior quality in the restored images. They can be expressed as follows:
where denotes the maximum pixel value of , and MSE represents the mean squared error between the corresponding pixels of and the reconstructed haze-free image . and are the means of and , respectively. and mean the standard deviations of and , respectively. is the covariance between and . means the weight for each image channel. and are constants introduced to maintain stability in the computation.
Furthermore, to evaluate the model size and computational cost, Params and floating-point operations (FLOPs) are adopted:
where represents the channel number for the input feature, and denote the kernel size, and signifies the channel number for the output feature. H and W correspond to the height and width of the feature map. In this study, the units of Params and FLOPs are millions (M) and billions (G), respectively. Furthermore, the model’s inference time, measured in seconds, is determined by averaging the processing times of 100 haze-degraded images. During the experiments, all comparative methods utilize input images with a spatial dimension of 256 × 256.
3.3. Comparison with Other Image Dehazing Methods
This section reports comprehensive quantitative and qualitative comparisons against state-of-the-art methods on the adopted datasets. The compared methods are categorized into two primary groups: (1) those developed for natural image dehazing, encompassing techniques like DCP [11], CEP [44], SLP [45], AOD-Net [46], MOF [47], FFA-Net [23], Light-DehazeNet [48], Restormer [49], DehazeFormer [28], and Trinity-Net [19]; and (2) methods tailored specifically for dehazing remote-sensing images, such as FCTF-Net [29], DCRD-Net [50], and SCSNet [37]. To guarantee a fair assessment, the officially released code for each method was utilized, and a consistent data division strategy was applied during training.
3.3.1. Quantitative Evaluations
(1) Performance Comparison: The quantitative comparison results on the SateHaze1k dataset are summarized in Table 1. As indicated, traditional prior-driven dehazing methods such as DCP, CEP, MOF, and SLP exhibit lower PSNR and SSIM values, suggesting they struggle with the complexities of remote-sensing image dehazing, thus delivering subpar performance. Similarly, AOD-Net and Light-DehazeNet show rather mediocre results when applied to remote-sensing imagery, possibly due to the limitations of early lightweight neural networks in capturing the intricate mappings between hazy and clear images. Conversely, data-driven approaches like FFA-Net, Restormer, Trinity-Net, and DehazeFormer demonstrate higher PSNR and SSIM scores, highlighting their potential in enhancing remote-sensing image dehazing. Models such as DCRD-Net, FCTF-Net, and SCSNet, which are specifically crafted for remote-sensing dehazing tasks, are also included in the comparison. It can be observed that both DCRD-Net and SCSNet achieve very good dehazing performance, and SCSNet performs best among all comparison methods. In contrast, FCTF-Net performs generally, which may be due to its relatively complex network structure, while the data volume in the SateHaze1k dataset is limited, leading to model overfitting. It is worth noting that, except for the teacher network SCSNet used in this study, the proposed DVKT framework delivers a state-of-the-art dehazing performance. Additionally, our DVKT framework matches the dehazing performance of the teacher network, SCSNet, but with a reduced number of parameters and faster inference times.

Table 1.
Qualitative comparison results on the SateHaze1k dataset.
Table 2 illustrates the quantitative comparison results across the RS-Haze and RSID datasets. As indicated, the proposed method demonstrates notable advantages over other compared approaches. Specifically, aside from the teacher network SCSNet utilized in this study, the DVKT framework shows superior dehazing performance. On the RS-Haze dataset, it achieves PSNR and SSIM values of 31.4227 dB and 0.9135, respectively. For the RSID dataset, the PSNR and SSIM values are 24.1082 dB and 0.9426, respectively.
Table 2.
Qualitative results on the RS-Haze and RSID datasets.
(2) Efficiency Comparison: One of the core objectives of this work is to enhance the efficiency of RSID models. To substantiate the effectiveness of the proposed DVKT framework in dehazing tasks, an exhaustive comparison of inference efficiency is conducted with the existing RSID models. Table 3 details the model sizes and inference efficiencies of various models. Concretely, it lists the model parameters (Params), FLOPs, and the average time required to process 100 haze-degraded images (inference time). As observed, while FFA-Net, Restormer, Trinity-Net, and DehazeFormer deliver superior dehazing outcomes, they come with larger Params and FLOPs, which can constrain their practical deployment. On the other hand, AOD-Net and Light-DehazeNet boast smaller parameter sizes, albeit at the expense of considerable performance loss. When compared to FCTF-Net and DCRD-Net, both designed specifically for RSID, the proposed DVKT framework exhibits the lowest computational cost and inference time, underscoring its advantage. Notably, the proposed DVKT framework achieves almost identical PSNR and SSIM values to the teacher model SCSNet but with reduced computational requirements and faster inference times.
Table 3.
Comparison of inference efficiency on the Satehaze1k dataset.
3.3.2. Qualitative Evaluations
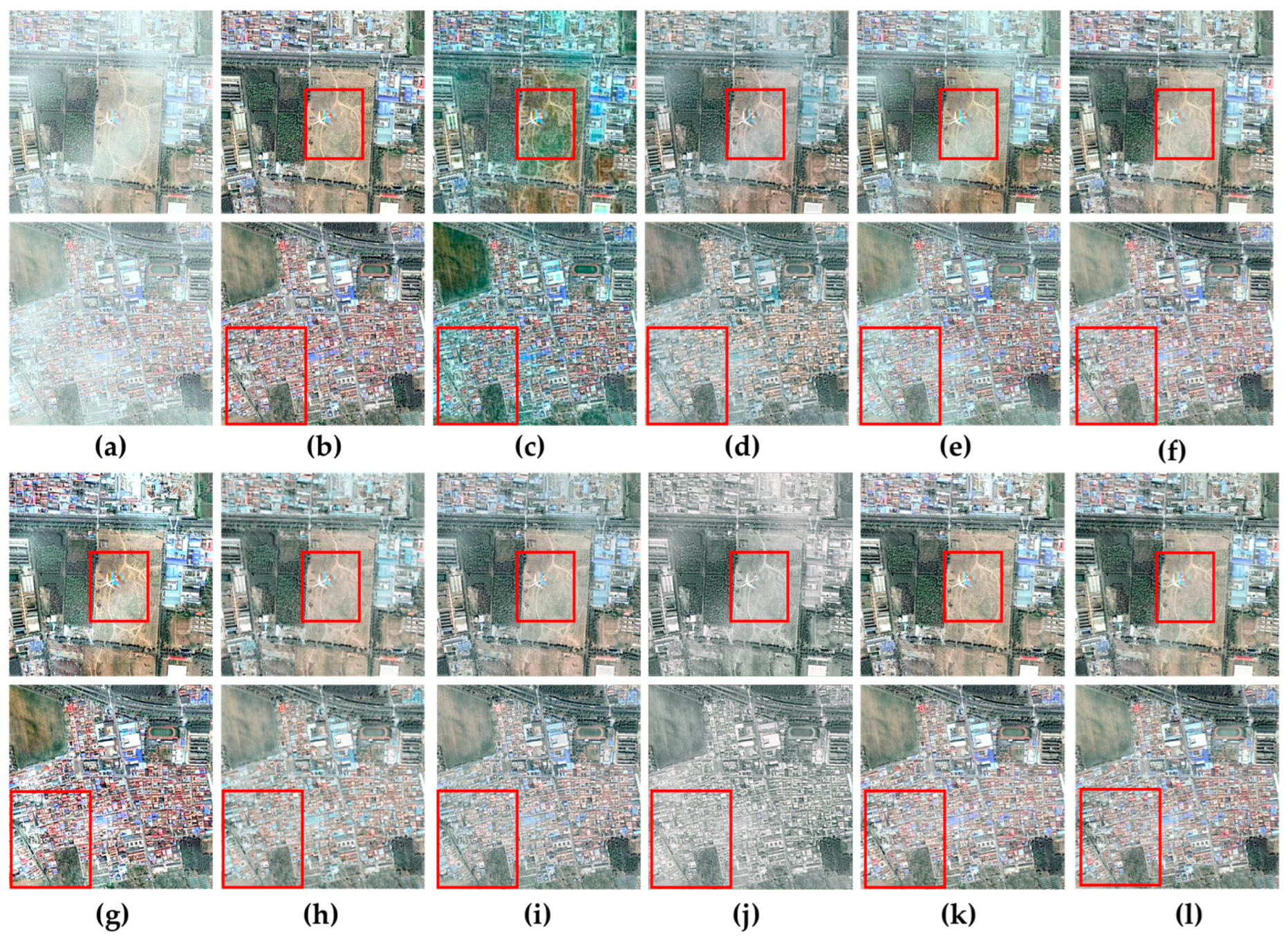
Figure 2 showcases the qualitative results of various methods applied to the SateHaze1k-thin dataset. The dehazed images from DCP and FCTF-Net display noticeable color distortions. A significant amount of haze persists in the images processed by AOD-Net and Light-DehazeNet. Methods such as FCTF-Net and Light-DehazeNet achieve some level of dehazing; however, compared to the ground truth images, there is still a minor presence of haze in the restored images. Similarly, DehazeFormer, SLP, Trinity-Net, and DCRD-Net manage to remove some haze, but the overall restoration still leaves a slight haze residue compared to the ground truth. The dehazed images produced by the teacher model SCSNet and our DVKT framework are more closely aligned with the ground truth images, achieving a higher level of detail recovery. It is important to note that our DVKT framework boasts a smaller model size and higher inference efficiency.
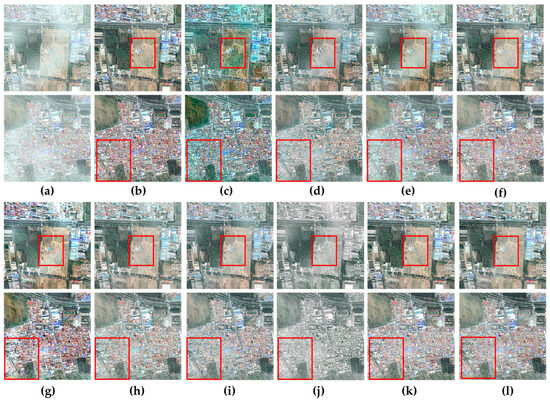
Figure 2.
Visual comparisons of dehazing performance across various methods on the SateHaze1k-thin dataset. The red box emphasizes key areas for comparison. (a) Hazy Image; (b) GroundTruth; (c) DCP [11]; (d) AOD-Net [46]; (e) Light-DehazeNet [48]; (f) DehazeFormer [28]; (g) SLP [45]; (h) Trinity-Net [19]; (i) DCRD-Net [50]; (j) FCTF-Net [29]; (k) SCSNet (Teacher Network) [37]; (l) DVKT (ours).
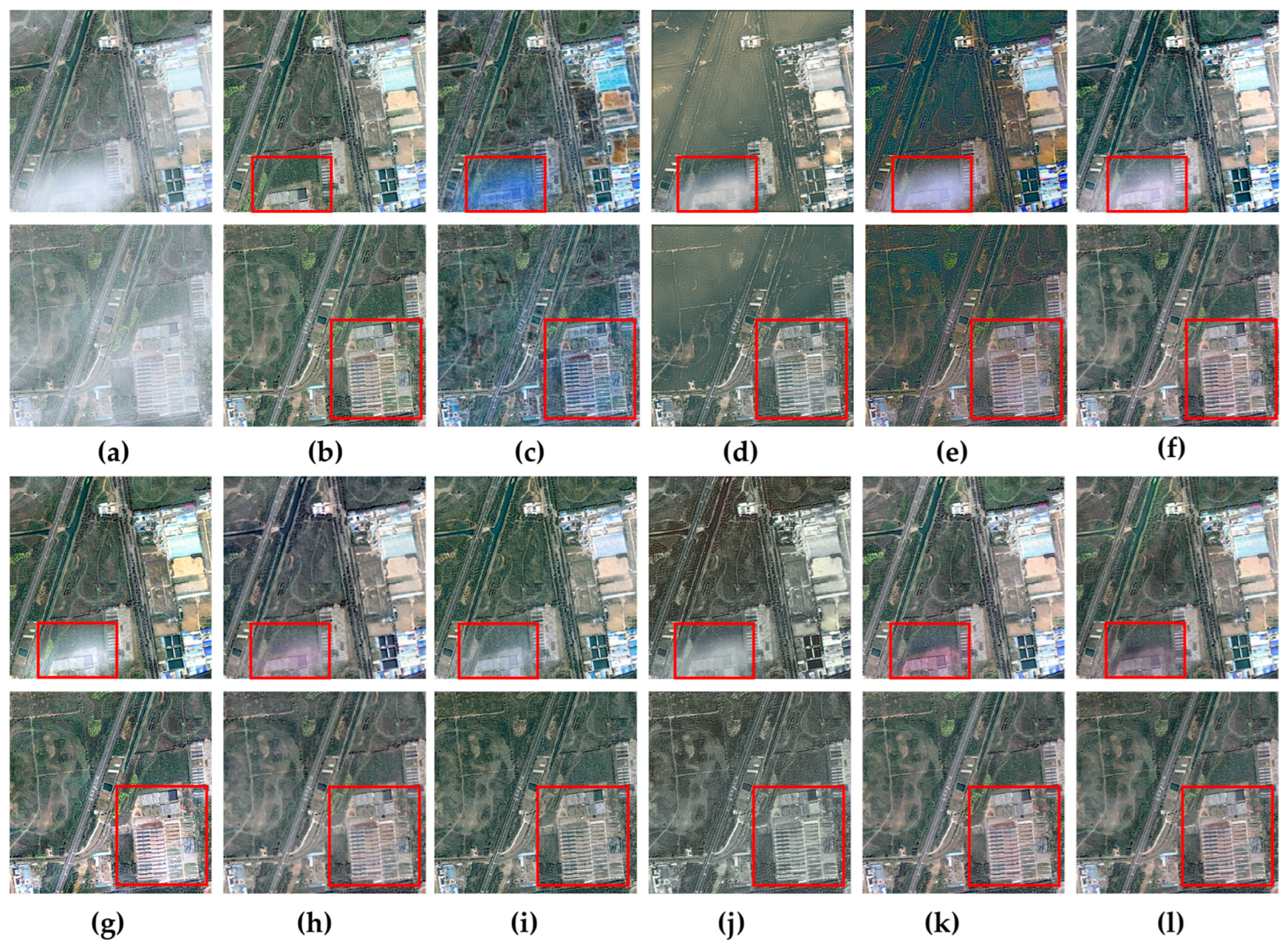
Figure 3 displays the visual results of multiple methods on the SateHaze1k-moderate test set. Under moderate haze conditions, crucial information in remote sensing images can become obscured. Apart from SCSNet and the proposed DVKT framework, other dehazing methods result in images with some residual haze. DCP, AOD-Net, SLP, and Light-DehazeNet show significant color distortion. While DCRD-Net and Trinity-Net achieve a certain level of dehazing, there remain noticeable differences when compared to the ground truth image. In contrast, both the teacher model SCSNet and the proposed DVKT framework produce visually more pleasing results, with enhanced color fidelity and better preservation of texture details.
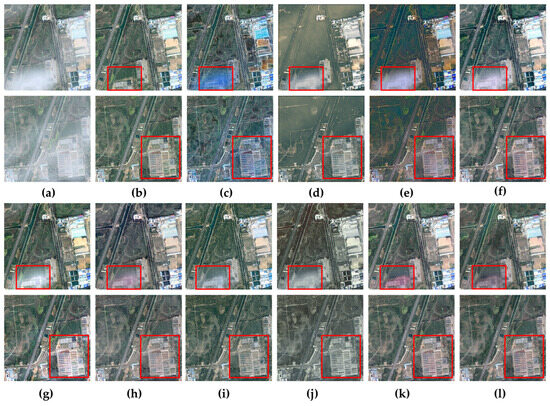
Figure 3.
QVisual comparisons of dehazing performance across various methods on the SateHaze1k-moderate dataset. The red box emphasizes key areas for comparison. (a) Hazy Image; (b) GroundTruth; (c) DCP [11]; (d) AOD-Net [46]; (e) Light-DehazeNet [48]; (f) DehazeFormer [28]; (g) SLP [45]; (h) Trinity-Net [19]; (i) DCRD-Net [50]; (j) FCTF-Net [29]; (k) SCSNet (Teacher Network) [37]; (l) DVKT (ours).
Figure 4 illustrates the qualitative results of different methods when applied to the SateHaze1k-thick test set. This particular set includes remote-sensing images heavily affected by dense haze, causing a significant loss of texture detail information. Methods such as DCP, AOD-Net, Light-DehazeNet, SLP, and FCTF-Net show evident color distortions. Although DehazeFormer, Trinity-Net, and DCRD-Net achieve good dehazing effects, the texture details in the images produced by these methods do not match the ground truth images as closely. In contrast, both the teacher model SCSNet and the proposed DVKT framework effectively preserve the overall structure, local details, and color accuracy of the ground truth images, resulting in visually pleasing and realistic dehazed images.

Figure 4.
Visual comparisons of dehazing performance across various methods on the SateHaze1k-thick dataset. The red box emphasizes key areas for comparison. (a) Hazy Image; (b) GroundTruth; (c) DCP [11]; (d) AOD-Net [46]; (e) Light-DehazeNet [48]; (f) DehazeFormer [28]; (g) SLP [45]; (h) Trinity-Net [19]; (i) DCRD-Net [50]; (j) FCTF-Net [29]; (k) SCSNet (Teacher Network) [37]; (l) DVKT (ours).
Figure 5 showcases the visual results of various methods on the RS-Haze test set. While several methods demonstrate varying degrees of success, some exhibit notable shortcomings. For instance, SLP- and DCP-restored images often suffer from color distortion and residual haze. AOD-Net, DehazeFormer, Trinity-Net, DCRD-Net, and FCTF-Net frequently over-dehaze, leading to a loss of fine details. Light-DehazeNet, on the other hand, struggles with color distortion and detail preservation. In contrast, both SCSNet and the proposed DVKT framework effectively restore texture details and enhance image quality, aligning more closely with the ground truth.

Figure 5.
Visual comparisons of dehazing performance across various methods on the RS-Haze dataset. The red box emphasizes key areas for comparison. (a) Hazy Image; (b) GroundTruth; (c) DCP [11]; (d) AOD-Net [46]; (e) Light-DehazeNet [48]; (f) DehazeFormer [28]; (g) SLP [45]; (h) Trinity-Net [19]; (i) DCRD-Net [50]; (j) FCTF-Net [29]; (k) SCSNet (Teacher Network) [37]; (l) DVKT (ours).
Figure 6 presents the visual comparison of various methods on the RSID test set. Obviously, SLP and DCP-restored images suffer from severe color distortion. The images restored by AOD-Net and Light-DehazeNet suffer from a significant loss of texture details and exhibit notable color distortions. DehazeFormer, Trinity-Net, DCRD-Net, and FCTF-Net can avoid color distortions to some extent, but the generated images still have some haze that cannot be removed. In contrast, both SCSNet and the proposed DVKT framework effectively preserve color fidelity and texture details, producing visually superior results.

Figure 6.
Visual comparisons of dehazing performance across various methods on the RSID dataset. The red box emphasizes key areas for comparison. (a) Hazy Image; (b) GroundTruth; (c) DCP [11]; (d) AOD-Net [46]; (e) Light-DehazeNet [48]; (f) DehazeFormer [28]; (g) SLP [45]; (h) Trinity-Net [19]; (i) DCRD-Net [50]; (j) FCTF-Net [29]; (k) SCSNet (Teacher Network) [37]; (l) DVKT (ours).
To further demonstrate the generalization capability of the proposed method, we conducted performance verification on the RRSD300 dataset. Since the RRSD300 dataset only contains real-world hazy images without corresponding ground truth images, all models are trained on SateHaze1k dataset and trained on the RRSD300 dataset. The visualization results are shown in Figure 7. It can be observed that the dehazing results obtained by DCP and SLP exhibit significant color distortion. AOD-Net and DCRD-Net introduce some artifacts, resulting in poorer dehazing outcomes. Light-DehazeNet’s dehazing results lose considerable detail information. Although FCTF-Net is a dehazing method tailored for remote-sensing images, it also suffers from color distortion. In contrast, the adopted teacher network SCSNet and the proposed DVKT framework achieve better dehazing results, indicating the good generalization and practicality of the proposed DVKT framework method.

Figure 7.
Visual comparisons of dehazing performance across various methods on the RRSD300 dataset. (a) Hazy Image; (b) DCP [11]; (c) AOD-Net [46]; (d) Light-DehazeNet [48]; (e) DehazeFormer [28]; (f) SLP [45]; (g) DCRD-Net [50]; (h) FCTF-Net [29]; (i) SCSNet (Teacher Network) [37]; (j) DVKT (ours).
3.4. Ablation Study
This study focuses on RSID and optimizes the dehazing model by reducing the number of channels in each layer. Typically, for models with the same network architecture, their size and computational cost are positively correlated with dehazing performance. To investigate this further, a study was conducted to evaluate the impact of different Channel Preservation Rates (CPRs) on the dehazing performance of the model. As shown in Table 4, a detailed performance comparison of dehazing models trained with different CPRs was presented. The original teacher model has 1.53 M Params. For further optimization, the experiments were conducted by compressing the model using CPRs of 1/2, 1/3, 1/4, and 1/5. Significant degradation in dehazing performance is not observed when the parameter count is decreased to 0.06 M. Specifically, when CPR was set to 1/5, the PSNR and SSIM reached 23.9271 and 0.9105, respectively, which were nearly comparable to those of the original model (25.1759 and 0.9223). At this time, the Params and FLOPs of the student model are 0.06 M and 0.44 G, respectively, which is a significant optimization compared to the 1.53 M parameters and 10.79 GFLOPs of the teacher model. Overall, our method demonstrates a strong knowledge distillation capability in the field of dehazing and can generate an efficient model that is easy to deploy and apply on edge computing devices and smart terminals.
Table 4.
Ablation study about channel preservation rates (CPR) on SateHaze1k dataset.
Additionally, ablation experiments were conducted to evaluate the effects of different knowledge transfer settings, and the results are presented in Table 5. When no transfer strategy was employed and 1/5-SCSNet was trained directly, the performance was moderate. The incorporation of the Intra-KT strategy led to a significant enhancement in model performance, with PSNR and SSIM metrics increasing to 22.3718 dB and 0.9051, respectively. This indicates that intra-layer knowledge transfer can effectively transfer knowledge from the teacher network to the student network. When only the Inter-KT transfer strategy was used, the model’s PSNR, SSIM, and LPIPS metrics were 21.5281 dB, 0.8937, and 0.0768, respectively. Compared to the results without any transfer strategy, this also showed substantial improvement, suggesting that the proposed Inter-KT transfer module can effectively transfer cross-layer knowledge from the teacher network to the student network. The optimal dehazing performance was achieved when both Intra-KT and Inter-KT were combined. This is because the two proposed transfer modules facilitate knowledge transfer from complementary perspectives, demonstrating the superiority of the proposed approach.
Table 5.
Ablation study about different transfer settings on SateHaze1k dataset.
3.5. Discussion
In this study, we have presented a comprehensive evaluation of the proposed Dual-View Knowledge Transfer (DVKT) framework for RSID. Our results demonstrate the efficacy of the DVKT approach in improving both the performance and efficiency of RSID models.
Firstly, the quantitative and qualitative evaluations on benchmark datasets (SateHaze1k, RS-Haze, and RSID) confirm that the DVKT framework almost achieves a state-of-the-art dehazing performance, comparable to heavy backbone models like SCSNet, while requiring significantly fewer parameters and computational resources. This highlights the effectiveness of our knowledge distillation approach in transferring structured knowledge from a well-trained teacher network to a lightweight student network.
Secondly, the ablation study investigating the impact of different channel preservation rates further validates the robustness of our framework. By progressively reducing the number of channels, we show that the DVKT framework can maintain high dehazing quality even with extremely compressed models. This finding underscores the practicality of our method for deployment on edge devices and mobile platforms with limited computational resources.
Finally, the proposed DVKT framework addresses two critical issues in remote-sensing image dehazing: lack of labeled data and high computational costs. By leveraging the abundance of natural-image-dehazing datasets and transferring knowledge from a pre-trained teacher model, we overcome the data scarcity challenge. Additionally, the lightweight student model generated through DVKT achieves significant speedups compared to heavy backbone networks, demonstrating its potential to enable real-time dehazing for various remote-sensing applications.
4. Conclusions
In summary, this study proposes an innovative Dual-View Knowledge Transfer (DVKT) framework to tackle the challenges of efficiency and dataset scarcity in RSID. The framework includes two innovative modules: Intra-layer Knowledge Transfer (Intra-KT) and Inter-layer Knowledge Transfer (Inter-KT), which can successfully distill hierarchical features and cross-layer correlations from a pre-trained teacher network to a lightweight student network. Specifically, the Intra-KT module can correct the learning bias of the student network by the guidance of representative features from a well-trained teacher network. The Inter-KT module can extract compact and effective features for RSID by distilling and transferring knowledge about cross-layer correlations. Comprehensive evaluations confirm that the proposed DVKT framework successfully compresses RSID models, yielding dual enhancements in both dehazing performance and efficiency.
While the proposed DVKT framework exhibits promising results, it currently relies on a pre-trained teacher model trained on natural-image-dehazing datasets. This may introduce a domain gap between the teacher and student networks, limiting the optimal performance for remote-sensing images. Future work could explore domain adaptation techniques to better bridge this gap.
Author Contributions
Conceptualization, L.Y. and J.C.; methodology, L.Y.; software, H.B.; validation, R.Q.; formal analysis, H.G.; investigation, L.Y.; resources, H.B.; data curation, R.Q.; writing—original draft preparation, L.Y.; writing—review and editing, L.Y.; visualization, H.G.; supervision, J.C. and H.N.; project administration, J.C.; funding acquisition, H.N. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by National Natural Science Foundation of China under Grant 62201452.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study.
Acknowledgments
We would also like to express our gratitude to the anonymous reviewers and the editors for their valuable advice and assistance.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Huang, Y.; Xiong, S. Remote sensing image dehazing using adaptive region-based diffusion models. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8001805. [Google Scholar] [CrossRef]
- Su, H.; Liu, L.; Jeon, G.; Wang, Z.; Guo, T.; Gao, M. Remote Sensing Image Dehazing Based on Dual Attention Parallelism and Frequency Domain Selection Network. IEEE Trans. Consum. Electron. 2024; early access. [Google Scholar]
- Zheng, Y.; Su, J.; Zhang, S.; Tao, M.; Wang, L. Dehaze-TGGAN: Transformer-Guide Generative Adversarial Networks with Spatial-Spectrum Attention for Unpaired Remote Sensing Dehazing. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5634320. [Google Scholar] [CrossRef]
- Kulkarni, A.; Murala, S. Aerial image dehazing with attentive deformable transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 6305–6314. [Google Scholar]
- Wang, Y.; Yan, X.; Wang, F.L.; Xie, H.; Yang, W.; Zhang, X.P.; Qin, J.; Wei, M. Ucl-dehaze: Towards real-world image dehazing via unsupervised contrastive learning. IEEE Trans. Image Process. 2024, 33, 1361–1374. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhan, J.; He, S.; Dong, J.; Du, Y. Curricular contrastive regularization for physics-aware single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5785–5794. [Google Scholar]
- Guo, F.; Yang, J.; Liu, Z.; Tang, J. Haze removal for single image: A comprehensive review. Neurocomputing 2023, 537, 85–109. [Google Scholar] [CrossRef]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1674–1682. [Google Scholar]
- Xu, L.; Zhao, D.; Yan, Y.; Kwong, S.; Chen, J.; Duan, L.Y. IDeRs: Iterative dehazing method for single remote sensing image. Inf. Sci. 2019, 489, 50–62. [Google Scholar] [CrossRef]
- Liang, S.; Gao, T.; Chen, T.; Cheng, P. A Remote Sensing Image Dehazing Method Based on Heterogeneous Priors. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5619513. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. (TOG) 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Zheng, Z.; Ren, W.; Cao, X.; Hu, X.; Wang, T.; Song, F.; Jia, X. Ultra-high-definition image dehazing via multi-guided bilateral learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16180–16189. [Google Scholar]
- Wang, Y.; Xiong, J.; Yan, X.; Wei, M. Uscformer: Unified transformer with semantically contrastive learning for image dehazing. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11321–11333. [Google Scholar] [CrossRef]
- Li, C.; Yu, H.; Zhou, S.; Liu, Z.; Guo, Y.; Yin, X.; Zhang, W. Efficient dehazing method for outdoor and remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 4516–4528. [Google Scholar] [CrossRef]
- Tong, L.; Liu, Y.; Li, W.; Chen, L.; Chen, E. Haze-Aware Attention Network for Single-Image Dehazing. Appl. Sci. 2024, 14, 5391. [Google Scholar] [CrossRef]
- Chi, K.; Yuan, Y.; Wang, Q. Trinity-Net: Gradient-guided Swin transformer-based remote sensing image dehazing and beyond. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4702914. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Shyam, P.; Yoo, H. Data Efficient Single Image Dehazing via Adversarial Auto-Augmentation and Extended Atmospheric Scattering Model. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Paris, France, 2–6 October 2023; pp. 227–237. [Google Scholar]
- Leng, C.; Liu, G. IFE-Net: An Integrated Feature Extraction Network for Single-Image Dehazing. Appl. Sci. 2023, 13, 12236. [Google Scholar] [CrossRef]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Guo, C.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3d position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Huang, P.; Zhao, L.; Jiang, R.; Wang, T.; Zhang, X. Self-filtering image dehazing with self-supporting module. Neurocomputing 2021, 432, 57–69. [Google Scholar] [CrossRef]
- Wang, C.; Shen, H.Z.; Fan, F.; Shao, M.W.; Yang, C.S.; Luo, J.C.; Deng, L.J. EAA-Net: A novel edge assisted attention network for single image dehazing. Knowl.-Based Syst. 2021, 228, 107279. [Google Scholar] [CrossRef]
- Sun, H.; Luo, Z.; Ren, D.; Hu, W.; Du, B.; Yang, W.; Wan, J.; Zhang, L. Partial siamese with multiscale bi-codec networks for remote sensing image haze removal. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4106516. [Google Scholar] [CrossRef]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef]
- Li, Y.; Chen, X. A coarse-to-fine two-stage attentive network for haze removal of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1751–1755. [Google Scholar] [CrossRef]
- Song, T.; Fan, S.; Li, P.; Jin, J.; Jin, G.; Fan, L. Learning an effective transformer for remote sensing satellite image dehazing. IEEE Geosci. Remote Sens. Lett. 2023, 20, 8002305. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S. Dense haze removal based on dynamic collaborative inference learning for remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5631016. [Google Scholar] [CrossRef]
- Zhang, Y.; He, X.; Zhan, C.; Li, J. Frequency-Oriented Transformer for Remote Sensing Image Dehazing. Sensors 2024, 24, 3972. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Su, J.; Zhang, S.; Tao, M.; Wang, L. Dehaze-AGGAN: Unpaired remote sensing image dehazing using enhanced attention-guide generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5630413. [Google Scholar] [CrossRef]
- Yu, M.; Xu, S.; Sun, H.; Zheng, Y.; Yang, W. Hierarchical slice interaction and multi-layer cooperative decoding networks for remote sensing image dehazing. Image Vis. Comput. 2024, 148, 105129. [Google Scholar] [CrossRef]
- Ayazoglu, M. Extremely lightweight quantization robust real-time single-image super resolution for mobile devices. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2472–2479. [Google Scholar]
- Xue, L.; Wang, X.; Wang, Z.; Li, G.; Song, H.; Song, Z. A Lightweight Patch-Level Change Detection Network Based on Multi-layer Feature Compression and Sensitivity-Guided Network Pruning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5624219. [Google Scholar] [CrossRef]
- Yang, L.; Cao, J.; Wang, H.; Dong, S.; Ning, H. Hierarchical Semantic-Guided Contextual Structure-Aware Network for Spectral Satellite Image Dehazing. Remote Sens. 2024, 16, 1525. [Google Scholar] [CrossRef]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- Beyer, L.; Zhai, X.; Royer, A.; Markeeva, L.; Anil, R.; Kolesnikov, A. Knowledge distillation: A good teacher is patient and consistent. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10925–10934. [Google Scholar]
- Huang, B.; Zhi, L.; Yang, C.; Sun, F.; Song, Y. Single satellite optical imagery dehazing using SAR image prior based on conditional generative adversarial networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1806–1813. [Google Scholar]
- Wen, Y.; Gao, T.; Zhang, J.; Li, Z.; Chen, T. Encoder-free multi-axis physics-aware fusion network for remote sensing image dehazing. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4705915. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Kendall, A.; Gal, Y.; Cipolla, R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7482–7491. [Google Scholar]
- Bui, T.M.; Kim, W. Single image dehazing using color ellipsoid prior. IEEE Trans. Image Process. 2017, 27, 999–1009. [Google Scholar] [CrossRef] [PubMed]
- Ling, P.; Chen, H.; Tan, X.; Jin, Y.; Chen, E. Single Image Dehazing Using Saturation Line Prior. IEEE Trans. Image Process. 2023, 32, 3238–3253. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Zhao, D.; Xu, L.; Yan, Y.; Chen, J.; Duan, L.Y. Multi-scale optimal fusion model for single image dehazing. Signal Process. Image Commun. 2019, 74, 253–265. [Google Scholar] [CrossRef]
- Ullah, H.; Muhammad, K.; Irfan, M.; Anwar, S.; Sajjad, M.; Imran, A.S.; de Albuquerque, V.H.C. Light-DehazeNet: A novel lightweight CNN architecture for single image dehazing. IEEE Trans. Image Process. 2021, 30, 8968–8982. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Huang, Y.; Chen, X. Single remote sensing image dehazing using a dual-step cascaded residual dense network. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3852–3856. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).