
A Methodology Based on Deep Learning for Contact Detection in Radar Images

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Detection System in the Peruvian Navy
2.1. Phase 1: Plot Extractor
2.1.1. Digitization of Radar Turn
2.1.2. Preprocessing
2.1.3. Plot Detection
2.2. Phase 2: Tracking-Prediction
2.3. Radar System Architecture
3. Methodology
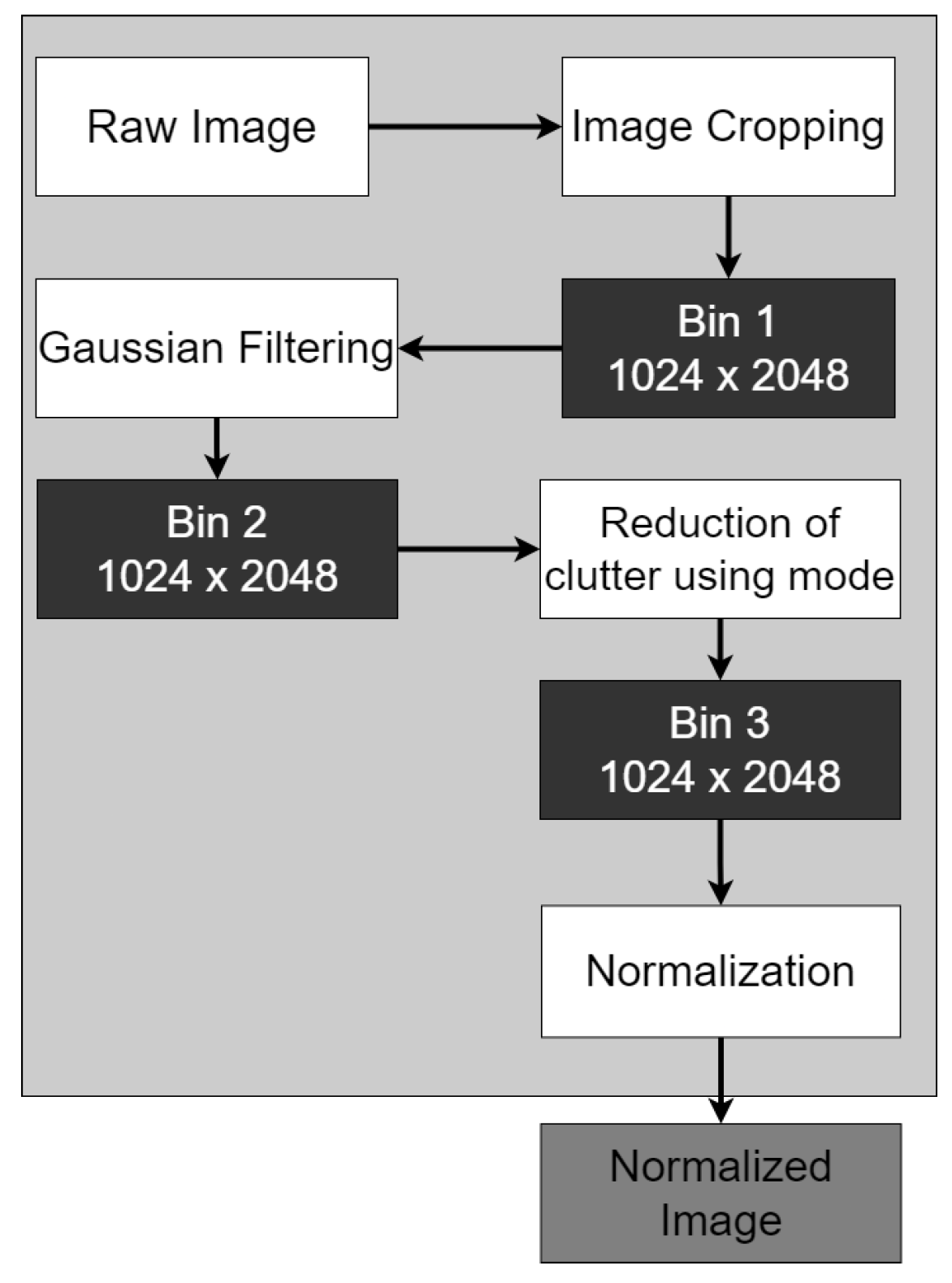
3.1. Phase 1: Preprocessing and Enhancement
3.1.1. Image Cropping
3.1.2. Gaussian Filtering
3.1.3. Reduction of Clutter
- : The statistic mode of the region defined between the 200 and 800 azimuths from samples 300 to 1024.
- : This factor reduces noise and is settled at 2 values.
- : It is a threshold that measures the minimum amount of noise that is affecting the whole image or the minimum values of the image to have a clean final image so that the intensity of the detected objects is the only one that can be observed in the image.
- : It is a decision matrix, where there is a threshold such that values below this threshold become 0, meaning they are not visible in the image. For values above this threshold, the threshold is subtracted from them.
- Consider the default values of 2 and 3 for the radar image’s upper and lower ranges, respectively. The selected range of the radar image comprised of this is represented as (11)
3.1.4. Normalization
3.2. Phase 2: Generation of the Object Detection Model
3.2.1. Automatic Cropping
- Filename: It is the identifier of the radar return.
- Xmin: left horizontal coordinate, between 0 and 2048.
- Xmax: right horizontal coordinate, between 0 and 2048.
- Ymin: upper vertical coordinate, between 0 and 1024.
- Ymax: lower vertical coordinate, between 0 and 1024.
3.2.2. Objects Labeling
- Persistence in three consecutive turns means that the object appearing in the current round must be present in the previous and next round. This translates as follows:The object is present in the current round AND the same object is present in the previous round AND it is also present in the next round.
- Completeness of the object. This translates as follows:The object must contain a single echo AND the echo must be perfectly framed in the object cutout.
The object is not persistent OR the object is not complete OR the object cutout partially contains the object OR the object contains overlapping elements OR any other type of ambiguous elements.
3.2.3. Faster R-CNN Training
3.3. Phase 3: Fine-Tuning of Hyperparameters
3.4. Phase 4: Criteria Filtering
- Persistence criterion: This criterion corresponds to the visibility of the target in three consecutive revolutions. To determine the persistence of the objects, a comparison is made based on a period of two radar revolutions; this measure is sufficient for declaring an object persistent in an oceanic context.
- Area criterion: All objects with dimensions greater than 30 × 30 pixels are discarded. This value corresponds to the maximum Radar Cross-Section area value of the objects of interest.
- Confidence criterion: Only clippings of objects with a probability more significant than the threshold of 0.85 are considered, this being the value established to determine that the object is contained in the clipping.
4. Experiments and Analysis of Results
4.1. Dataset
Cross-Validation
4.2. Experimental Metrics
4.2.1. Cost Function
4.2.2. Confidence Score
4.2.3. Confusion Matrix
- TP: True actual and true predictedIt is the object classified by the expert as a “plot” and predicted as positive, it is a ship.
- FP: False actual and true predictedThe expert classified it as “no” and the algorithm predicted it as “plot” It is a false alarm.
- FN: True actual and false predicted.The expert classified it as a “plot” and has been predicted as “no”. FN represents false negatives, this is missed contacts.
- TN: False actual and false predicted.It is a “no” class predicted; they are hits of the “no” class.
- NI: Unclassified negativeIt is a “no” object and has not been classified by the algorithm.
- PI: Unclassified positiveIt is a “plot” object and the algorithm has not classified it as a ship object.
4.2.4. Recall (TPR)
4.2.5. Accuracy
4.2.6. F1 Score
4.2.7. Misclassification
4.2.8. Specificity (FPR)
4.3. Analysis of Results
4.3.1. Cost Function
4.3.2. Confusion Matrix
4.3.3. Predictions
4.3.4. Processing Time
- Tp: One lap prediction time.
- This is the time required by the model to obtain the predictions, taking into consideration three radar turns, with the outputs of graphs, boxes, and classes being 6.0120687 s. The time required by the algorithm to generate the detected objects from an image is 0.01097893 s. On the other hand, the estimated response time in the tests executed with a single standard processor is equivalent to 4.1 s. Given the technology equipped on the radar vessels, optimizing the estimated response time further is possible.
4.3.5. Future Work
5. Conclusions
- The detection model yields a cost function value equal to 0.0372, a recall rate of 94.5%, and an accuracy rate of 95.1%.
- The detection time is favorable, equivalent to 4.513 s per radar turn. Considering the implementation of the algorithm in an integrated system with a pool of parallel processors, it is feasible to improve the detection time further.
- The modification of weight initialization (; ) and the ADAM optimizer are the determining hyperparameters in improving the training, and consequently the object detection model. The IoU and batch-size hyperparameters influence but are not decisive in the improvement of the performance of the object detection model.
- The cross-validation method is independent in handling partitions and eliminates bias by randomly selecting samples for training and validation datasets. In addition, it allows the best models to be chosen based on rigorous verification that guarantees their implementation in real projects.
- Automatic cropping makes it easy to obtain more precise cuts of objects quickly. These cuts meet the characteristics of the intensity and dimensions of the objects of interest.
- Displaying objects of interest in three consecutive turns allows for a faster and more reliable labeling process. The developed interface increases the efficiency of object labeling.
- Given the results, with the proposed methodology, it is possible to generate a ship detection model that works well despite the noise and clutter reflected in the radar images. The detection model obtained is valid for use with commercial radar images.
- This work is the beginning of future projects with other deep learning algorithms and using an advanced computing infrastructure.
- The findings may be particularly applicable to other coastal regions, where advanced remote sensing applications have not yet been widely explored.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CFAR | Constant False Alarm Rate |
| R-CNN | Region-based Convolutional Neural Network |
| CUT | Cell Under Test |
| API-TFOD | TensorFlow Object Detection Application Programming Interface |
| FPA | False Alarm Rate |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TN | True Negative |
| IP | Unclassified Positive |
| IN | Unclassified Negative |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| IoU | Intersection Over Union |
References
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spacebone optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Kingsley, S.; Quegan, S. Understanding Radar Systems; SciTech Publishing Inc.: Mendham, NJ, USA, 1999. [Google Scholar]
- Purizaga-Céspedes, D. Análisis de un Nuevo Filtro de dos Parámetros para Detección de Contactos en imáGenes de Radares Marinos. Bachelor’s Thesis, Universidad de Piura, Piura, Perú, 13 February 2019. Available online: https://hdl.handle.net/11042/3821 (accessed on 24 May 2024).
- Fulvio, G. Chapter 10—Introduction to the Radar Signal Processing Section. In Academic Press Library in Signal Processing; Sidiropoulos, N., Gini, F., Chellappa, R., Theodoridis, S., Eds.; Elsevier: Oxford, UK, 2014; Volume 2, pp. 505–511. [Google Scholar] [CrossRef]
- Javadi, S.; Farina, A. Radar networks: A review of features and challenges. Inf. Fusion 2020, 61, 48–55. [Google Scholar] [CrossRef]
- Meyer, F.; Hinz, S.; Laika, A.; Weihing, D. Performance analysis of the TerraSAR-X Traffic monitoring concept. Photogramm. Remote Sens. 2006, 61, 225–242. [Google Scholar] [CrossRef]
- Petit, M.; Stretta, J.M.; Farrugio, H.; Wadsworth, A. Synthetic aperture radar imaging of sea surface life and fishing activities. IEEE Trans. Geosci. Remote Sens. 1992, 30, 1085–1089. [Google Scholar] [CrossRef]
- Mazur, A.K.; Wahlin, A.K.; Krezel, A. An object-based SAR image iceberg detection algorithm applied to the Amundsen Sea. Remote Sens. Environ. 2017, 189, 67–83. [Google Scholar] [CrossRef]
- Zhang, J.; Xing, M.; Sun, G. A Fast Target Detection Method for SAR Image Based on Electromagnetic Characteristics. In Proceedings of the International SAR Symposium (CISS), Shanghai, China, 10–12 October 2018; pp. 1–3. [Google Scholar] [CrossRef]
- Koyama, C.; Gokon, H.; Koshimura, S. Disaster debris estimation using high-resolution polarimetric stereo-SAR. ISPRS J. Photogramm. Remote Sens. 2016, 120, 84–98. [Google Scholar] [CrossRef]
- An, W.; Xie, C.; Yuan, X. An Improved Iterative Censoring Scheme for CFAR Ship Detection With SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4585–4595. [Google Scholar] [CrossRef]
- Crisp, D.J. The State-of-the-Art in Ship Detection in Synthetic Aperture Radar Imagery. Defence Science and Technology Organisation Salisbury, Australia. Available online: https://apps.dtic.mil/sti/pdfs/ADA426096.pdf (accessed on 28 May 2024).
- Kang, M.; Leng, X.; Lin, Z.; Ji, K. A modified faster R-CNN based on CFAR algorithm for SAR ship detection. In Proceedings of the International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 19–21 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Qu, H.; Tian, Q. Target Detection and Recognition Based on Convolutional Neural Network for SAR Image. In Proceedings of the 2018 11th International Congress on Image and Signal Processing BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, Z.; Wang, C.; Liang, Y.; Wang, L.; Zhang, J.; Zhang, J.; Lv, C. A User-Centered Framework for Data Privacy Protection Using Large Language Models and Attention Mechanisms. Appl. Sci. 2024, 14, 6824. [Google Scholar] [CrossRef]
- Lee, J.-Y.; Choi, W.-S.; Choi, S.-H. Verification and performance comparison of CNN-based algorithms for two-step helmet-wearing detection. Expert Syst. Appl. 2023, 225, 120096. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Comput. Vis. Pattern Recognit. 2016, 3, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Jiao, J.; Zhang, Y.; Sun, H.; Yang, X.; Gao, X.; Hon, W. A Densely Connected End-to-End Neural Network for Multiscale and Multiscene SAR Ship Detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Pham, M.; Lefèvre, S. Buried Object Detection from B-Scan Ground Penetrating Radar Data Using Faster-RCNN. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 6804–6807. [Google Scholar] [CrossRef]
- Sethu Ramasubiramanian, S.; Sivasubramaniyan, S.; Peer Mohamed, M.F. Aggregate Channel Features and Fast Regions CNN Approach for Classification of Ship and Iceberg. Appl. Sci. 2023, 13, 7292. [Google Scholar] [CrossRef]
- Cai, J.; Zhang, L.; Dong, J.; Guo, J.; Wang, Y.; Liao, M. Automatic identification of active landslides over wide areas from time-series InSAR measurements using Faster RCNN. Int. J. Appl. Earth Obs. Geoinf. 2023, 124, 103516. [Google Scholar] [CrossRef]
- Mduduzi, M.; Chunling, T.; Adewale, O. Preprocessed Faster RCNN for Vehicle Detection. In Proceedings of the 2018 International Conference on Intelligent and Innovative Computing Applications (ICONIC), Mon Tresor, Mauritius, 6–7 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Gavrilescu, R.; Zet, C.; Foșalău, C. Faster R-CNN: An Approach to Real-Time Object Detection. In Proceedings of the 2018 International Conference and Exposition on Electrical And Power Engineering (EPE), Iasi, Romania, 18–19 October 2018; pp. 165–168. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Chen, J.; Shen, Y.; Liang, Y.; Wang, Z.; Zhang, Q. YOLO-SAD: An Efficient SAR Aircraft Detection Network. Appl. Sci. 2024, 14, 3025. [Google Scholar] [CrossRef]
- Guo, J.; Wang, S.; Xu, Q. Saliency Guided DNL-Yolo for Optical Remote Sensing Images for Off-Shore Ship Detection. Appl. Sci. 2022, 12, 2629. [Google Scholar] [CrossRef]
- Liu, J.; Liao, D.; Wang, X.; Li, J.; Yang, B.; Chen, G. LCAS-DetNet: A Ship Target Detection Network for Synthetic Aperture Radar Images. Appl. Sci. 2024, 14, 5322. [Google Scholar] [CrossRef]
- Wang, X.; Hong, W.; Liu, Y.; Hu, D.; Xin, P. SAR Image Aircraft Target Recognition Based on Improved YOLOv5. Appl. Sci. 2023, 13, 6160. [Google Scholar] [CrossRef]
- Yu, J.; Huang, D.; Shi, X.; Li, W.; Wang, X. Real-Time Moving Ship Detection from Low-Resolution Large-Scale Remote Sensing Image Sequence. Appl. Sci. 2023, 13, 2584. [Google Scholar] [CrossRef]
- Botezatu, A.-P.; Burlacu, A.; Orhei, C. A Review of Deep Learning Advancements in Road Analysis for Autonomous Driving. Appl. Sci. 2024, 14, 4705. [Google Scholar] [CrossRef]
- Liang, B.; Wang, Z.; Si, L.; Wei, D.; Gu, J.; Dai, J. A Novel Pressure Relief Hole Recognition Method of Drilling Robot Based on SinGAN and Improved Faster R-CNN. Appl. Sci. 2023, 13, 513. [Google Scholar] [CrossRef]
- Jakubec, M.; Lieskovská, E.; Bučko, B.; Zábovská, K. Comparison of CNN-Based Models for Pothole Detection in Real-World Adverse Conditions: Overview and Evaluation. Appl. Sci. 2023, 13, 5810. [Google Scholar] [CrossRef]
- Altarez, R.D. Faster R–CNN, RetinaNet and Single Shot Detector in different ResNet backbones for marine vessel detection using cross polarization C-band SAR imagery. Remote Sens. Appl. Soc. Environ. 2024, 36, 101297. [Google Scholar] [CrossRef]
- Retallack, A.; Finlayson, G.; Ostendorf, B.; Lewis, M. Using deep learning to detect an indicator arid shrub in ultra-high-resolution UAV imagery. Ecol. Indic. 2022, 145, 109698. [Google Scholar] [CrossRef]
- Li, T.; He, B.; Zheng, Y. Research and Implementation of High Computational Power for Training and Inference of Convolutional Neural Networks. Appl. Sci. 2023, 13, 1003. [Google Scholar] [CrossRef]
- Moreno, V.; Ledezma, A.; Sanchis, A. A Static Images Based-System For Traffic Signs Detection. In Proceedings of the International Conference on Artificial Intelligence and Applications (IASTED), Madrid, Spain, 13–16 February 2006; pp. 445–450. [Google Scholar]
- Moreno, V.; Génova, G.; Alejandres, M.; Fraga, A. Automatic Classification of Web Images as UML Static Diagrams Using Machine Learning Techniques. Appl. Sci. 2020, 10, 2406. [Google Scholar] [CrossRef]
- Gonzales-Martínez, R.; Machacuay, J.; Rotta, P.; Chinguel, C. Real-Time Detection Method of Persistent Objects in Radar Imagery with Deep Learning. In Proceedings of the IEEE Engineering International Research Conference (EIRCON), Lima, Peru, 21–23 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Gonzales-Martínez, R.; Machacuay, J.; Rotta, P.; Chinguel, C. Hyperparameters Tuning of Faster R-CNN Deep Learning Transfer for Persistent Object Detection in Radar Images. IEEE Lat. Am. Trans. 2022, 20, 677–685. [Google Scholar] [CrossRef]
- LabelImg. HumanSignal labelImg. Available online: https://github.com/HumanSignal/labelImg (accessed on 4 September 2024).
- Rubin, B.; Sathiesh, K. Efficient inception V2 based deep convolutional neural network for real-time hand action recognition. IET Image Process. 2020, 14, 688–696. [Google Scholar] [CrossRef]
- Vijiyakumar, K.; Govindasamy, V.; Akila, V. An effective object detection and tracking using automated image annotation with inception based faster R-CNN model. Int. J. Cogn. Comput. Eng. 2024, 5, 343–356. [Google Scholar] [CrossRef]
- Siddiqi, M.D.; Jiang, B.; Asadi, R.; Regan, A. Hyperparameter Tuning to Optimize Implementations of Denoising Autoencoders for Imputation of Missing Spatio-temporal Data. Procedia Comput. Sci. 2021, 184, 107–114. [Google Scholar] [CrossRef]
- Lee, W.Y.; Park, S.M.; Sim, K.B. Optimal hyperparameter tuning of convolutional neural networks based on the parameter-setting-free harmony search algorithm. Optik 2018, 172, 359–367. [Google Scholar] [CrossRef]
- Diederik, P.K.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Schöller, F.; Plenge-Feidenhans’l, M.; Stets, J.; Blanke, M. Assessing Deep-learning Methods for Object Detection at Sea from LWIR Images. IFAC-PapersOnLine 2019, 52, 64–71. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. GPU Comput. Geosci. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef]
- Yuan, Y.; Rosasco, L.; Caponnetto, A. On Early Stopping in Gradient Descent Learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Zhang, G. cPSO-CNN: An efficient PSO-based algorithm for fine-tuning hyper-parameters of convolutional neural networks. Swarm Evol. Comput. 2019, 49, 114–123. [Google Scholar] [CrossRef]
- Dewa, C.K. Suitable CNN Weight Initialization and Activation Function for Javanese Vowels Classification. Procedia Comput. Sci. 2018, 144, 124–132. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009; pp. 389–415. [Google Scholar]
- Paneiro, G.; Rafael, M. Artificial neural network with a cross-validation approach to blast-induced ground vibration propagation modeling. Undergr. Space 2021, 6, 281–289. [Google Scholar] [CrossRef]
- Valente, G.; Lage Castellanos, A.; Hausfeld, L.; De Martino, F.; Formisano, E. Cross-validation and permutations in MVPA: Validity of permutation strategies and power of cross-validation schemes. NeuroImage 2021, 238, 118145. [Google Scholar] [CrossRef] [PubMed]
- Kerbaa, T.H.; Mezache, A.; Oudira, H. Model Selection of Sea CLutter Using Cross Validation Method. Procedia Comput. Sci. 2019, 158, 394–400. [Google Scholar] [CrossRef]
- Gonzales-Martínez, R.; Machacuay, J.; Rotta, P.; Chinguel, C. Faster R-CNN with a cross-validation approach to object detection in radar images. In Proceedings of the 2021 IEEE International Conference on Aerospace and Signal Processing (INCAS), Lima, Peru, 28–30 November 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Padilla, R.; Passos, W.; Dias, T.; Netto, S.; da Silva, E. A Comparative Analysis of Object Detection Metrics with a Companion Open-Source Toolkit. Deep Learn. Based Obj. Detect. 2021, 10, 279. [Google Scholar] [CrossRef]
- Li, Y.; Deng, J.; Wu, Q.; Wang, Y. Eye-Tracking Signals Based Affective Classification Employing Deep Gradient Convolutional Neural Networks. Int. J. Interact. Multimed. Artif. Intell. 2021, 7, 34–43. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Backbone | Accuracy | Processing Time | |||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | mAP | |||
| Faster R-CNN | ResNet34 | 0.90 | 0.68 | 0.77 | 0.21 | 0:50:41 |
| ResNet50 | 0.82 | 0.83 | 0.82 | 0.23 | 00:53:20 | |
| ResNet101 | 0.85 | 0.85 | 0.85 | 0.27 | 01:25:39 | |
| Retina Net | ResNet34 | 0.08 | 0.01 | 0.01 | 0.00 | 00:42:22 |
| ResNet50 | 0 | 0 | 0 | 0.00 | 00:57:52 | |
| ResNet101 | 0.74 | 0.74 | 0.74 | 0.14 | 01:14:46 | |
| SSD | ResNet34 | 0.30 | 0.09 | 0.14 | 0.01 | 00:28:32 |
| ResNet50 | 0.44 | 0.24 | 0.31 | 0.02 | 00:43:19 | |
| ResNet101 | 0.49 | 0.31 | 0.38 | 0.03 | 01:00:25 | |
| Object Detector | CNN Architecture | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Faster R-CNN | ResNet50 | 0.692 | 0.819 | 0.749 |
| ResNet101 | 0.680 | 0.777 | 0.723 | |
| ResNet152 | 0.655 | 0.774 | 0.709 | |
| YOLOv3 | DarkNet53 | 0.592 | 0.659 | 0.619 |
| SSD | ResNet50 | 0.559 | 0.531 | 0.543 |
| ResNet101 | 0.547 | 0.513 | 0.527 | |
| Faster R-CNN | ResNet34 | 0.440 | 0.426 | 0.423 |
| Hyperparameter Configuration | Values |
|---|---|
| Epochs | 100.000 |
| IoU | 0.6 |
| Batch-size | 2 |
| Weight initialization | ; |
| Optimizer | ADAM |
| Real Values (Expert) | |||
|---|---|---|---|
| Positive “Plot” | Negative “No” | ||
| Predicted values (algorithm) | Positive | TP | FP |
| Negative | FN | TN | |
| Unclassified | IP | IN | |
| Cv1 | Cv2 | Cv3 | Cv4 | Cv5 | Cv6 | Cv7 | Cv8 | Cv9 | Cv10 | CV |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0378 | 0.0229 | 0.0175 | 0.0112 | 0.0239 | 0.0528 | 0.0367 | 0.0722 | 0.0538 | 0.0436 | 0.0372 |
| No. Turn | Qty. Box | Qty. “Plot” | Qty. “No” | Recall | Accu. | Plot Dete. | TP | FP | FN | TN | IP | IN | Mis Class | Spec. | F1 Score |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| back67 | 50 | 34 | 16 | 0.967 | 0.879 | 33 | 29 | 4 | 1 | 6 | 4 | 6 | 0.1212 | 0.600 | 0.921 |
| back70 | 50 | 35 | 15 | 0.938 | 0.882 | 34 | 30 | 4 | 2 | 5 | 3 | 6 | 0.1176 | 0.556 | 0.909 |
| back74 | 46 | 37 | 9 | 0.943 | 0.917 | 36 | 33 | 3 | 2 | 2 | 2 | 4 | 0.0833 | 0.400 | 0.930 |
| back80 | 49 | 39 | 10 | 0.971 | 1.000 | 34 | 34 | 0 | 1 | 3 | 4 | 7 | 0.0000 | 1.000 | 0.986 |
| back85 | 52 | 41 | 11 | 0.939 | 1.000 | 31 | 31 | 0 | 2 | 2 | 8 | 9 | 0.0000 | 1.000 | 0.969 |
| back89 | 50 | 35 | 15 | 0.964 | 0.964 | 28 | 27 | 1 | 1 | 2 | 7 | 12 | 0.0357 | 0.667 | 0.964 |
| back94 | 54 | 43 | 11 | 0.789 | 0.909 | 33 | 30 | 3 | 8 | 4 | 5 | 4 | 0.0909 | 0.571 | 0.845 |
| back98 | 45 | 33 | 12 | 0.963 | 1.000 | 26 | 26 | 0 | 1 | 2 | 6 | 10 | 0.0000 | 1.000 | 0.981 |
| back99 | 51 | 38 | 13 | 1.000 | 1.000 | 28 | 28 | 0 | 0 | 5 | 10 | 8 | 0.0000 | 1.000 | 1.000 |
| back100 | 44 | 34 | 10 | 1.000 | 0.967 | 30 | 29 | 1 | 0 | 3 | 5 | 6 | 0.0333 | 0.750 | 0.983 |
| Total | 491 | 369 | 122 | 0.945 | 0.951 | 313 | 297 | 16 | 18 | 34 | 54 | 72 | 0.0488 | 0.754 | 0.947 |
| Real Values (Expert) | |||
|---|---|---|---|
| Positive “Plot” | Negative ”No” | ||
| Predicted values (algorithm) | Positive | 34 | 0 |
| Negative | 1 | 3 | |
| Unclassified | 4 | 7 | |
| Real Values (Expert) | |||
|---|---|---|---|
| Positive “Plot” | Negative “No” | ||
| Predicted values (algorithm) | Positive | 297 | 16 |
| Negative | 18 | 34 | |
| Unclassified | 54 | 72 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gonzales Martínez, R.; Moreno, V.; Rotta Saavedra, P.; Chinguel Arrese, C.; Fraga, A. A Methodology Based on Deep Learning for Contact Detection in Radar Images. Appl. Sci. 2024, 14, 8644. https://doi.org/10.3390/app14198644
Gonzales Martínez R, Moreno V, Rotta Saavedra P, Chinguel Arrese C, Fraga A. A Methodology Based on Deep Learning for Contact Detection in Radar Images. Applied Sciences. 2024; 14(19):8644. https://doi.org/10.3390/app14198644
Chicago/Turabian StyleGonzales Martínez, Rosa, Valentín Moreno, Pedro Rotta Saavedra, César Chinguel Arrese, and Anabel Fraga. 2024. "A Methodology Based on Deep Learning for Contact Detection in Radar Images" Applied Sciences 14, no. 19: 8644. https://doi.org/10.3390/app14198644