


Transformer-Based High-Speed Train Axle Temperature Monitoring and Alarm System for Enhanced Safety and Performance

Abstract
1. Introduction
2. Data Processing
2.1. Missing Data Handling
2.2. Outlier Treatment
2.3. Normalization Processing
3. Screening and Regeneration of Strong Thermal Grade Characteristic Data
3.1. Selection of Axle Temperature Features
3.2. Generation of Intense Heat-Level Axle Temperature Feature Data
3.3. Discriminative Model Optimization for the Adversarial Generative Model
3.4. Generation of the Strong Thermal Signature Data
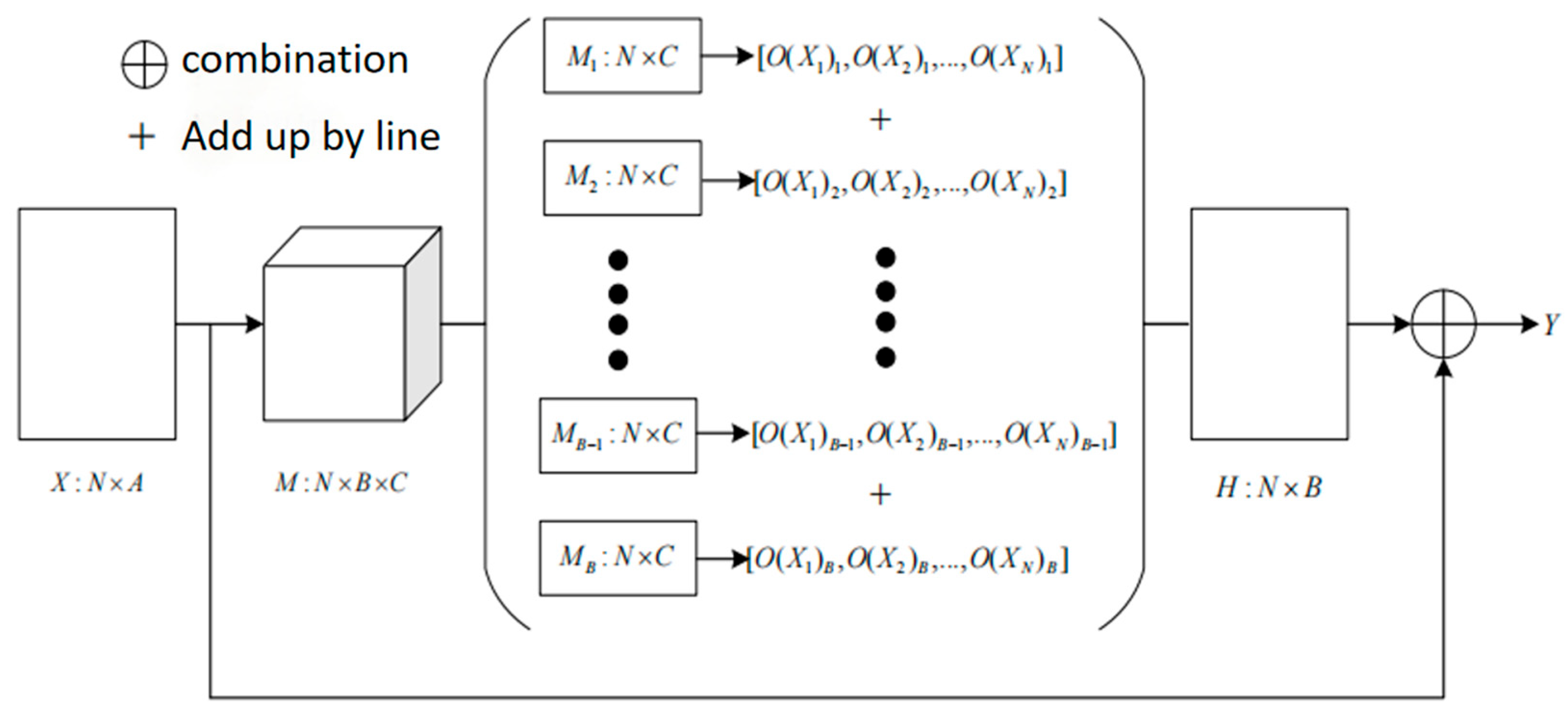
4. Intelligent Algorithm Model for Determination of the Axle Temperature Alarm Level
4.1. Training the Axle Temperature Alarm-Level Discrimination Model
4.2. Axle Temperature Alarm-Level Discrimination
4.3. Optimization of the Axle Temperature Alarm-Level AdamW-Based Discriminator Model
5. Conclusions and Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lukianenko, N. Epistemological research problems of rail transport as a social institution. Transp. Res. Proceed. 2022, 63, 1826–1833. [Google Scholar] [CrossRef]
- Chen, X. Cross-cultural communication in the belt and road strategy. Front. Soc. Sci. Technol. 2021, 3, 48–56. [Google Scholar] [CrossRef]
- Tang, W.C.; Wang, M.J.; Chen, G.D. Analysis on temperature distribution of failure axle box bearings of high speed train. J. China Railw. Soc. 2016, 38, 50–56. [Google Scholar] [CrossRef]
- Randall, R.B. Vibration-Based Condition Monitoring: Industrial, Aerospace and Automotive Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 13–20. [Google Scholar]
- Yi, C.; Lin, J.; Zhang, W.; Ding, J. Faults diagnostics of railway axle bearings based on IMF’s confidence index algorithm for ensemble EMD. Sensors 2015, 15, 10991–11011. [Google Scholar] [CrossRef]
- Henao, H.; Kia, S.H.; Capolino, G.-A. Torsional-vibration assessment and gear-fault diagnosis in railway traction system. IEEE Trans. Ind. Electron. 2011, 58, 1707–1717. [Google Scholar] [CrossRef]
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind turbine condition monitoring: State-of-the-art review, new trends, and future challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef]
- Kilundu, B.; Chiementin, X.; Duez, J.; Mba, D. Cyclostationarity of Acoustic Emissions (AE) for monitoring bearing defects. Mech. Syst. Signal Process. 2011, 25, 2061–2072. [Google Scholar] [CrossRef]
- Eftekharnejad, B.; Carrasco, M.R.; Charnley, B.; Mba, D. The application of spectral kurtosis on acoustic emission and vibrations from a defective bearing. Mech. Syst. Signal Process. 2011, 25, 266–284. [Google Scholar] [CrossRef]
- Sun, H.; Zi, Y.; He, Z. Wind turbine fault detection using multiwavelet denoising with the data-driven block threshold. Appl. Acoust. 2014, 77, 122–129. [Google Scholar] [CrossRef]
- Ming, A.B.; Zhang, W.; Qin, Z.Y.; Chu, F.L. Envelope calculation of the multi-component signal and its application to the deterministic component cancellation in bearing fault diagnosis. Mech. Syst. Signal Process. 2015, 50, 70–100. [Google Scholar] [CrossRef]
- Zimroz, R.; Bartelmus, W.; Barszcz, T.; Urbanek, J. Diagnostics of bearings in presence of strong operating conditions non-stationarity—A procedure of load-dependent features processing with application to wind turbine bearings. Mech. Syst. Signal Process. 2014, 46, 16–27. [Google Scholar] [CrossRef]
- Kharche, P.P.; Kshirsagar, S.V. Review of fault detection in rolling element bearing. Int. J. Innov. Res. Adv. Eng. 2014, 1, 169–174. [Google Scholar]
- Liu, C.; Wang, F. A review of current condition monitoring and fault diagnosis methods for low-speed and heavy-load slewing bearings. In Proceedings of the 2017 9th International Conference on Modelling, Identification and Control (ICMIC), Kunming, China, 10–12 July 2017; pp. 104–109. [Google Scholar]
- Corni, I.; Symonds, N.; Wood, R.J.K.; Wasenczuk, A.; Vincent, D. Real-time on-board condition monitoring of train axle bearings. In Proceedings of the Stephenson Conference, London, UK, 21–23 April 2015; p. 14. [Google Scholar]
- Jayaswal, P.; Wadhwani, A.K.; Mulchandani, K.B. Machine fault signature analysis. Int. J. Rotat. Mach. 2008, 2008, 583982. [Google Scholar] [CrossRef]
- Singh, K. Smart Components: Creating a Competitive Edge through Smart Connected Drive Train on Mining Machines. Master’s Thesis, KTH, School of Industrial Engineering and Management (ITM), Stockholm, Sweden, 2021. [Google Scholar]
- Xu, Q.; Sun, S.; Xu, Y.; Hu, C.; Chen, W.; Xu, L. Influence of temperature gradient of slab track on the dynamic responses of the train-CRTS III slab track on subgrade nonlinear coupled system. Sci. Rep. 2022, 12, 14638. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Xu, P.; Yang, C.; Guo, W.; Yao, S. High-temperature mechanical properties and microstructure of 2.5 DC/C–SiC composites applied for the brake disc of high-speed train. J. Eur. Ceram. Soc. 2024, 44, 116683. [Google Scholar] [CrossRef]
- Kebede, Y.B.; Yang, M.-D.; Huang, C.-W. Real-time pavement temperature prediction through ensemble machine learning. Eng. Appl. Artif. Intell. 2024, 135, 108870. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Chai, T. Multi-directional reconstruction based contributions for root-cause diagnosis of dynamic processes. In Proceedings of the 2014 American Control Conference, Portland, OR, USA, 4–6 June 2014; pp. 3500–3505. [Google Scholar]
- Song, Y.; Ma, Q.; Zhang, T.; Li, F.; Yu, Y. Research on fault diagnosis strategy of air-conditioning systems based on DPCA and machine learning. Processes 2023, 11, 1192. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis? J. ACM 2011, 58, 1–37. [Google Scholar] [CrossRef]
- Li, Z.; He, Q. Prediction of railcar remaining useful life by multiple data source fusion. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2226–2235. [Google Scholar] [CrossRef]
- Yan, G.; Yu, C.; Bai, Y. A new hybrid ensemble deep learning model for train axle temperature short term forecasting. Machines 2021, 9, 312. [Google Scholar] [CrossRef]
- Pan, Z.; Xu, D.; Zhang, Y.; Wang, M.; Wang, Z.; Yu, J.; Zhang, G. New energy transmission line fault location method based on Pearson correlation coefficient. In Proceedings of the 2nd International Conference on Smart Energy, Fenghuang, China, 29–30 July 2024; p. 012007. [Google Scholar]
- Wang, C.; Liu, J.; Zio, E. A modified generative adversarial network for fault diagnosis in high-speed train components with imbalanced and heterogeneous monitoring data. J. Dyn. Monit. Diagn. 2022, 1, 84–92. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A survey on generative adversarial networks: Variants, applications, and training. ACM Comput. Surv. (CSUR) 2021, 54, 1–49. [Google Scholar] [CrossRef]
- Yildirim, M.; Sun, X.A.; Gebraeel, N.Z. Sensor-driven condition-based generator maintenance scheduling—Part I: Maintenance problem. IEEE Trans. Power Syst. 2016, 31, 4253–4262. [Google Scholar] [CrossRef]
- Matetić, I.; Štajduhar, I.; Wolf, I.; Ljubic, S. A review of data-driven approaches and techniques for fault detection and diagnosis in HVAC systems. Sensors 2022, 23, 1. [Google Scholar] [CrossRef]
- Lv, H.; Chen, J.; Pan, T.; Zhang, T.; Feng, Y.; Liu, S. Attention mechanism in intelligent fault diagnosis of machinery: A review of technique and application. Measurement 2022, 199, 111594. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Fold Times k | Loss Value/% | Precision/% |
|---|---|---|
| 1 | 4.63 | 98.62 |
| 2 | 9.52 | 97.88 |
| 3 | 7.36 | 98.03 |
| Average | 7.17 | 98.17 |
| Layer Type | Output Type | Parameter Value |
|---|---|---|
| Embedding | (Batch, 3, 3) | 256 |
| Multi-head attention | (Batch, 3, 64) | 16,640 |
| Add | (Batch, 3, 64) | 0 |
| Layer norm | (Batch, 3, 64) | 0 |
| FFN | (Batch, 3, 64) | 33,088 |
| Add | (Batch, 3, 64) | 0 |
| Layer norm | (Batch, 3, 64) | 0 |
| Output | (Batch, 3, 4) | 260 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, W.; Xie, K.; Zou, J.; Huang, K.; Mu, F.; Chen, L. Transformer-Based High-Speed Train Axle Temperature Monitoring and Alarm System for Enhanced Safety and Performance. Appl. Sci. 2024, 14, 8643. https://doi.org/10.3390/app14198643
Li W, Xie K, Zou J, Huang K, Mu F, Chen L. Transformer-Based High-Speed Train Axle Temperature Monitoring and Alarm System for Enhanced Safety and Performance. Applied Sciences. 2024; 14(19):8643. https://doi.org/10.3390/app14198643
Chicago/Turabian StyleLi, Wanyi, Kun Xie, Jinbai Zou, Kai Huang, Fan Mu, and Liyu Chen. 2024. "Transformer-Based High-Speed Train Axle Temperature Monitoring and Alarm System for Enhanced Safety and Performance" Applied Sciences 14, no. 19: 8643. https://doi.org/10.3390/app14198643
APA StyleLi, W., Xie, K., Zou, J., Huang, K., Mu, F., & Chen, L. (2024). Transformer-Based High-Speed Train Axle Temperature Monitoring and Alarm System for Enhanced Safety and Performance. Applied Sciences, 14(19), 8643. https://doi.org/10.3390/app14198643