

A Simplified Query-Only Attention for Encoder-Based Transformer Models


Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
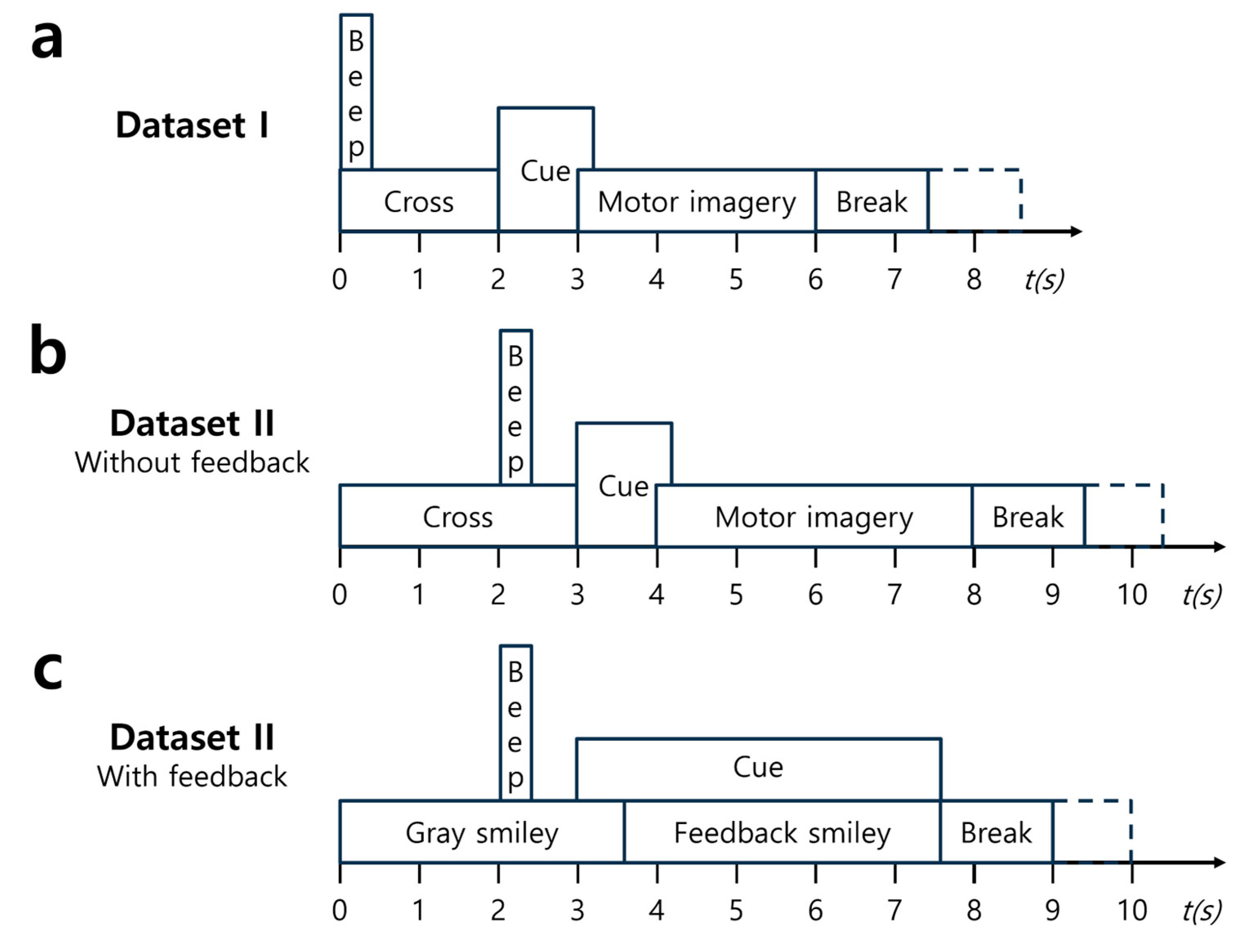
3.1. Dataset
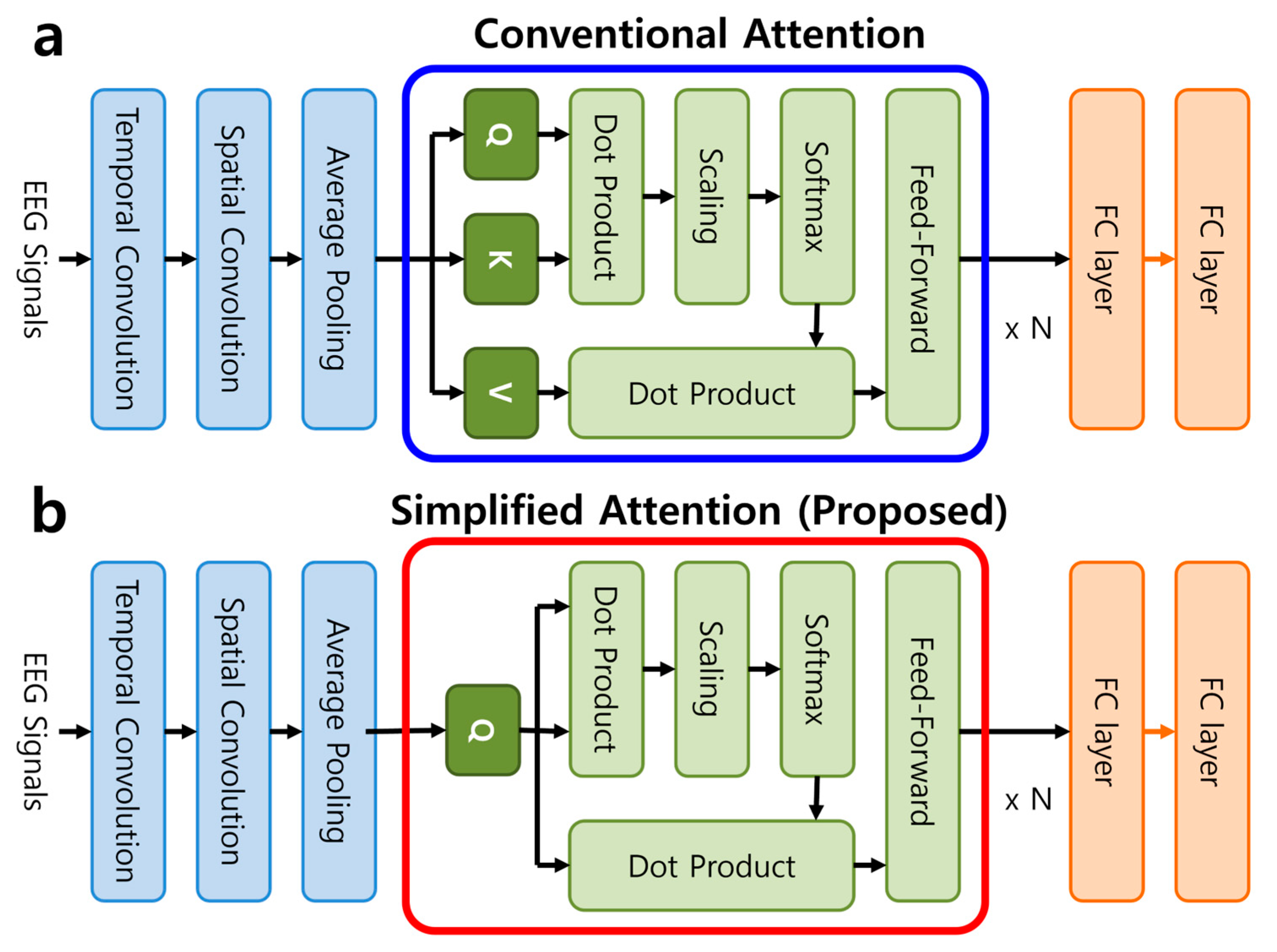
3.2. Transformer Architecture
3.3. Evaluation
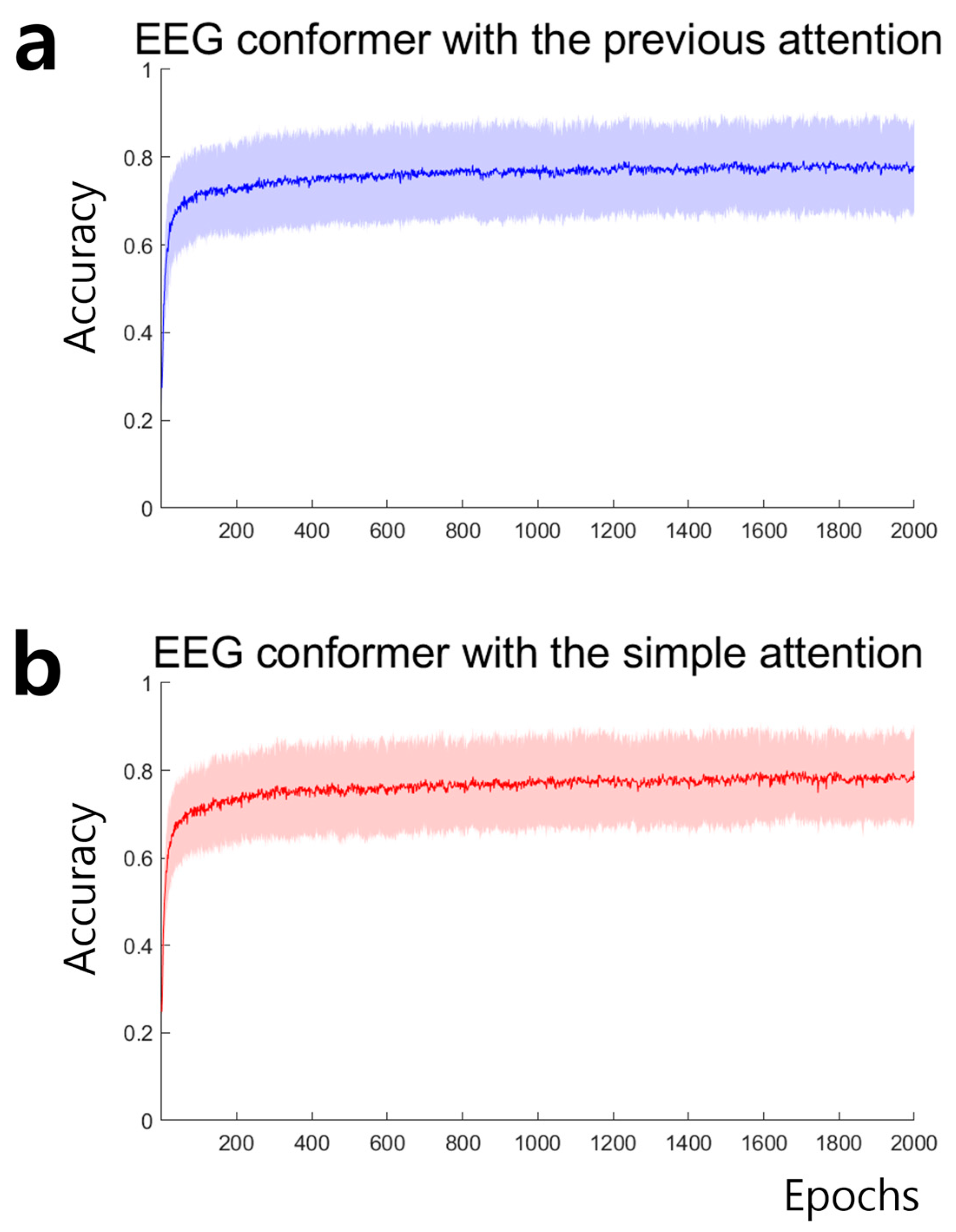
4. Results
5. Discussion
5.1. Model Simplification and Its Implications
5.2. Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 20 September 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Wu, Y.; Alayrac, J.-B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Reid, M.; Savinov, N.; Teplyashin, D.; Lepikhin, D.; Lillicrap, T.; Alayrac, J.-b.; Soricut, R.; Lazaridou, A.; Firat, O.; Schrittwieser, J. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv 2024, arXiv:2403.05530. [Google Scholar]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A survey on multimodal large language models. arXiv 2023, arXiv:2306.13549. [Google Scholar]
- OpenAI. Hello GPT-4o. Available online: https://openai.com/index/hello-gpt-4o (accessed on 20 September 2024).
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. arXiv 2019, arXiv:1906.01787. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2023, 241, 122666. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Text summarization with pretrained encoders. arXiv 2019, arXiv:1908.08345. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.-C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12113–12132. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Guo, M.-H.; Xu, T.-X.; Liu, J.-J.; Liu, Z.-N.; Jiang, P.-T.; Mu, T.-J.; Zhang, S.-H.; Martin, R.R.; Cheng, M.-M.; Hu, S.-M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape transformer for underwater image enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Zhou, H.-Y.; Guo, J.; Zhang, Y.; Han, X.; Yu, L.; Wang, L.; Yu, Y. nnformer: Volumetric medical image segmentation via a 3d transformer. IEEE Trans. Image Process. 2023, 32, 4036–4045. [Google Scholar] [CrossRef]
- Kim, S.; Gholami, A.; Shaw, A.; Lee, N.; Mangalam, K.; Malik, J.; Mahoney, M.W.; Keutzer, K. Squeezeformer: An efficient transformer for automatic speech recognition. Adv. Neural Inf. Process. Syst. 2022, 35, 9361–9373. [Google Scholar]
- Li, Y.; Lai, L.; Shangguan, Y.; Iandola, F.N.; Ni, Z.; Chang, E.; Shi, Y.; Chandra, V. Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11901–11905. [Google Scholar]
- Song, Y.; Zheng, Q.; Liu, B.; Gao, X. EEG conformer: Convolutional transformer for EEG decoding and visualization. IEEE Trans. Neural Syst. Rehabil. Eng. 2022, 31, 710–719. [Google Scholar] [CrossRef] [PubMed]
- Abibullaev, B.; Keutayeva, A.; Zollanvari, A. Deep Learning in EEG-Based BCIs: A Comprehensive Review of Transformer Models, Advantages, Challenges, and Applications. IEEE Access 2023, 11, 127271–127301. [Google Scholar] [CrossRef]
- Jiang, W.-B.; Zhao, L.-M.; Lu, B.-L. Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. In Proceedings of the ICLR, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Chen, W.; Wang, C.; Xu, K.; Yuan, Y.; Bai, Y.; Zhang, D. D-FaST: Cognitive Signal Decoding with Disentangled Frequency-Spatial-Temporal Attention. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1476–1493. [Google Scholar] [CrossRef]
- Tangermann, M.; Müller, K.-R.; Aertsen, A.; Birbaumer, N.; Braun, C.; Brunner, C.; Leeb, R.; Mehring, C.; Miller, K.J.; Müller-Putz, G.R. Review of the BCI competition IV. Front. Neurosci. 2012, 6, 55. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4015–4026. [Google Scholar]
- Peebles, W.; Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4195–4205. [Google Scholar]
- Wang, W.; Bao, H.; Dong, L.; Bjorck, J.; Peng, Z.; Liu, Q.; Aggarwal, K.; Mohammed, O.K.; Singhal, S.; Som, S. Image as a foreign language: Beit pretraining for vision and vision-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19175–19186. [Google Scholar]
- Lu, M.Y.; Chen, B.; Williamson, D.F.; Chen, R.J.; Liang, I.; Ding, T.; Jaume, G.; Odintsov, I.; Le, L.P.; Gerber, G. A visual-language foundation model for computational pathology. Nat. Med. 2024, 30, 863–874. [Google Scholar] [CrossRef]
- Ang, K.K.; Chin, Z.Y.; Wang, C.; Guan, C.; Zhang, H. Filter bank common spatial pattern algorithm on BCI competition IV datasets 2a and 2b. Front. Neurosci. 2012, 6, 21002. [Google Scholar] [CrossRef] [PubMed]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef]
- Zhao, H.; Zheng, Q.; Ma, K.; Li, H.; Zheng, Y. Deep representation-based domain adaptation for nonstationary EEG classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 535–545. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Schrittwieser, J.; Antonoglou, I.; Hubert, T.; Simonyan, K.; Sifre, L.; Schmitt, S.; Guez, A.; Lockhart, E.; Hassabis, D.; Graepel, T. Mastering atari, go, chess and shogi by planning with a learned model. Nature 2020, 588, 604–609. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| Model | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Average | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ConvConformer | 82.29 | 60.69 | 90.31 | 71.02 | 72.57 | 60.68 | 81.94 | 83.55 | 79.30 | 75.82 | 0.6776 |
| SimpleConformer | 81.11 | 60.96 | 90.12 | 73.87 | 73.06 | 61.05 | 82.58 | 85.03 | 77.41 | 76.13 | 0.6817 |
| FBCSP | 76.00 | 56.50 | 81.25 | 61.00 | 55.00 | 45.25 | 82.75 | 81.25 | 70.75 | 67.75 | 0.5700 |
| ConvNet | 76.39 | 55.21 | 89.24 | 74.65 | 56.94 | 54.17 | 92.71 | 77.08 | 76.39 | 72.53 | 0.6337 |
| EEGNet | 85.76 | 61.46 | 88.54 | 67.01 | 55.90 | 52.08 | 89.58 | 83.33 | 86.81 | 74.50 | 0.6600 |
| DRDA | 83.19 | 55.14 | 87.43 | 75.28 | 62.29 | 57.15 | 86.18 | 83.61 | 82.00 | 74.75 | 0.6633 |
| Model | S01 | S02 | S03 | S04 | S05 | S06 | S07 | S08 | S09 | Average | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ConvConformer | 72.80 | 67.81 | 80.07 | 94.76 | 93.98 | 82.80 | 89.56 | 92.53 | 88.17 | 84.72 | 0.6944 |
| SimpleConformer | 71.79 | 66.18 | 79.49 | 96.63 | 93.91 | 82.40 | 89.52 | 92.66 | 88.98 | 84.62 | 0.6924 |
| FBCSP | 70.00 | 60.36 | 60.94 | 97.50 | 93.12 | 80.63 | 78.13 | 92.50 | 86.88 | 80.00 | 0.6000 |
| ConvNet | 76.56 | 50.00 | 51.56 | 96.88 | 93.13 | 85.31 | 83.75 | 91.56 | 85.62 | 79.37 | 0.5874 |
| EEGNet | 75.94 | 57.64 | 58.43 | 98.13 | 81.25 | 88.75 | 84.06 | 93.44 | 89.69 | 80.48 | 0.6096 |
| DRDA | 81.37 | 62.86 | 63.63 | 95.94 | 93.56 | 88.19 | 85.00 | 95.25 | 90.00 | 83.98 | 0.6796 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeom, H.-g.; An, K.-m. A Simplified Query-Only Attention for Encoder-Based Transformer Models. Appl. Sci. 2024, 14, 8646. https://doi.org/10.3390/app14198646
Yeom H-g, An K-m. A Simplified Query-Only Attention for Encoder-Based Transformer Models. Applied Sciences. 2024; 14(19):8646. https://doi.org/10.3390/app14198646
Chicago/Turabian StyleYeom, Hong-gi, and Kyung-min An. 2024. "A Simplified Query-Only Attention for Encoder-Based Transformer Models" Applied Sciences 14, no. 19: 8646. https://doi.org/10.3390/app14198646