Abstract
With the development of deep learning foundation model technology, the types of computing tasks have become more complex, and the computing resources and memory required for these tasks have also become more substantial. Since it has long been revealed that task offloading in cloud servers has many drawbacks, such as high communication delay and low security, task offloading is mostly carried out in the edge servers of the Internet of Things (IoT) network. However, edge servers in IoT networks are characterized by tight resource constraints and often the dynamic nature of data sources. Therefore, the question of how to perform task offloading of deep learning foundation model services on edge servers has become a new research topic. However, the existing task offloading methods either can not meet the requirements of massive CNN architecture or require a lot of communication overhead, leading to significant delays and energy consumption. In this paper, we propose a parallel partitioning method based on matrix convolution to partition foundation model inference tasks, which partitions large CNN inference tasks into subtasks that can be executed in parallel to meet the constraints of edge devices with limited hardware resources. Then, we model and mathematically express the problem of task offloading. In a multi-edge-server, multi-user, and multi-task edge-end system, we propose a task-offloading method that balances the tradeoff between delay and energy consumption. It adopts a greedy algorithm to optimize task-offloading decisions and terminal device transmission power to maximize the benefits of task offloading. Finally, extensive experiments verify the significant and extensive effectiveness of our algorithm.
1. Introduction
Recent years have witnessed the explosive growth of IoT devices and the emergence of MaaS (Model as a Service) in IoT application types [1], and the lack of memory and computing resources of edge computing [2,3] is insufficient to satisfy the inference of the DNN or CNN [4]. However, placing it on traditional cloud server computing will not only lead to a huge delay caused by frequent communication but also expose private and sensitive information in the process of data transmission and remote processing [5,6]. The rapid explosion and the scale of data collection will make the cloud-based centralized data processing infeasible in the near future [7].
In addition, fog computing [8] or edge computing has also been proposed to utilize the computing resources closer to the data collection endpoints, such as gateways and edge node devices. However, the question of how to effectively partition, distribute, and schedule CNN inference in a locally connected but severely resource-constrained cluster of IoT edge devices is a challenging problem that has not been fully resolved. The existing hierarchical partitioning methods for deep neural network inference applications lead to a significant amount of local processing of intermediate-feature map data. This brings about significant memory occupancy that exceeds the capabilities of typical IoT devices. Furthermore, existing distributed DNN/CNN [9,10] edge-processing solutions based on static partitioning and distribution schemes cannot optimally explore the availability of dynamically changing data sources and computing resources in typical IoT edge clusters [11].
Existing research on service deployment [12,13] and task offloading [14,15] often focuses on how to offload some ordinary, computationally lightweight tasks to servers for processing. However, the above methods are not applicable to the offloading of large model inference tasks in the large-scale edge computing network studied in this paper because most of them are limited to task offloading and do not fully consider task splitting, let alone the computing characteristics of large model tasks. Therefore, this paper innovatively combines distributed computing for large model application tasks with partitioning the large model before task offloading so that edge devices can also complete DNN/CNN inference [16] with limited memory and computing resources. In addition, most of the existing task offloading methods also adopt batch processing, but in reality, most tasks arrive in real-time. We innovatively propose a task offloading method for real-time task arrival.
Inspired by [17], we decided to adopt a method based on matrix convolution for the division of DNN/CNN inference. In this context, how to offload these partition tasks to various servers for execution has become a major problem. This paper proposes a solution to this problem based on this premise.
In this article, we propose a horizontal partitioning method for DNN/CNN and design a real-time greedy algorithm to seek the optimal real-time offloading solution. This method includes the following main innovations and contributions:
- (1)
- We formulate the problem of partitioning and offloading DNN/CNN inference tasks into a real-time integer linear programming program and consider the dependency relationship between different partitioning granularity and offloading schemes.
- (2)
- We propose a real-time Greedy Partitioning and Offloading Algorithm (GPOA) for effectively finding the optimal granularity partitioning and unloading scheme that can achieve minimum latency and energy consumption. We achieve our goals and achieve good performance by utilizing the coupling between particle size partitioning and unloading schemes.
- (3)
- We focus on finding the optimal partitioning and offloading solution in real-time when tasks arrive and evaluate the performance of the GPOA based on data. We compare three baseline algorithms, and the results showed that our algorithm is superior in terms of latency, energy consumption, and overall performance.
The remainder of this paper is organized as follows. In Section 2, we briefly review related work. Section 3 describes the system model and problem formulation. In Section 4, we present the greedy partitioning and task offloading algorithm. In Section 5, we evaluate the performance of our algorithms through extensive simulations, followed by presenting the conclusions of our work in Section 6.
2. Related Work
We aimed to offload the tasks that are disassembled from the foundation model inference to edge servers with limited computing resources and memory, thus reducing latency and improving security. Therefore, we have conducted investigations from the following aspects.
2.1. Foundation Model Inference Partitioning
Due to the mismatch between the computing power required for foundation model inference and the computational resources of edge servers, how to decompose foundation model inference has become a crucial issue that urgently needs to be addressed. To solve this problem, several related solutions have been proposed.
In response to the above issues, many people have put forward the idea of cloud-edge collaboration. Li et al. [18] proposed the JALAD method, a joint accuracy and latency-aware execution framework. By decoupling the structure of deep neural networks, JALAD enables part of the model to be executed on edge devices and the rest to run in the cloud, minimizing data transmission. This method aims to reduce latency while maintaining model accuracy, improving the performance and user experience of deep learning services. Li et al. [19] proposed a real-time DNN inference acceleration method based on edge computing. The core idea of this method is to utilize the powerful computing capabilities of edge servers to offload part or all of the DNN inference tasks to the edge servers for processing, thereby reducing the computational burden of mobile devices and improving inference speed and accuracy.
However, numerous researchers and practitioners also believe that the effect of direct dismantling large model inference is better. Hu et al. [20] proposed the EdgeFlow method. EdgeFlow is a distributed inference system that provides natural support for DAG (Directed Acyclic Graph) structural models. The main design goal of this system is to divide and distribute the model to different devices while maintaining complex layer dependencies to ensure correct inference results. Mao et al. [21] proposed MoDNN—A locally distributed mobile computing system for deep neural network applications. MoDNN can divide trained DNN models into multiple mobile devices to accelerate DNN calculations by reducing device-level computing costs and memory usage. Two model partitioning schemes are designed to minimize non-parallel data transmission time, including wake-up time and transmission time. Zhang et al. [22] introduced DeepSlicing, a collaborative and adaptive inference system that adapts to various CNNs and supports customized flexible fine-grained scheduling. By dividing the model and data, they also designed an efficient scheduler—Proportional Synchronous Scheduler (PSS), which realizes the trade-off between computation and synchronization. Zhao et al. [17] proposed DeepThings, a framework for adaptive distributed execution of CNN-based inference applications on resource-constrained IoT edge clusters. DeepThings used fused tile partitioning to minimize memory occupancy while exposing parallelism.
2.2. Task Offloading
Current task offloading algorithms include three types: minimum energy consumption, minimum latency, and the trade-off between energy consumption and latency. We will compare these algorithms and analyze their advantages and disadvantages.
For algorithms that optimize execution time, we have found the following two options: Liu et al. [23] adopt a Markov decision process framework to tackle the given problem, wherein the scheduling of computational tasks is dictated by the queuing status of the task buffer, the operational state of the local processing unit, and the status of the transmission unit. Furthermore, they introduce an efficient one-dimensional search algorithm to identify the optimal task scheduling policy. The advantage of this algorithm is the greatly reduced execution time compared to the case of not using computing offloading. The disadvantage is that it is very complex. Mao et al. [24] proposed a low-complexity online algorithm, namely the dynamic computation offloading algorithm based on Lyapunov optimization, which jointly determines the offloading decision, the CPU cycle frequency for mobile execution, and the transmit power for computation offloading. The unique advantage of this algorithm is that the decision-making only relies on the current system state, without the need to calculate the distribution information of task requests, wireless channels, and EH processes. The disadvantage is that it has weak applicability because the data are completely offloaded.
According to the Computing and Offloading Algorithm Based on Minimization of Energy Consumption, we found that Shi et al. [25] introduced a computing offloading algorithm for distributed mobile cloud computing environments. This algorithm examined the node movement patterns and developed a network access prediction method based on subsequence tail matching. One of its primary advantages lies in its energy-saving capabilities, rendering it suitable for various scenarios. However, it fell short in overlooking the crucial aspects of time delay implementation and data processing efficiency, as well as the instability perceived by mobile devices.
Lastly, we investigated the model and algorithm for the tradeoff between energy consumption and latency. The algorithm proposed by Chen et al. [26] comprehensively addresses the factors that impact the algorithm’s efficiency, incorporating the system’s actual conditions to effectively offload task data. One significant advantage of this algorithm lies in its ability to conserve at least 50% of the energy compared to solutions that do not employ partial offloading techniques. However, a potential drawback is that it fails to take into account the energy consumption and time expenditure associated with data transmission. Lu et al. [27] introduced a computing offloading algorithm that leverages specific information within the Internet of Things (IoT) environment to optimize the number of feedback transmissions from nodes to the Mobile Edge Computing (MEC) server. Employing Lyapunov optimization, the algorithm ensures energy equilibrium and stability in the overall system data throughput. This approach transformed the balancing challenge of energy consumption, data backlog, and time consumption into a knapsack problem. A key advantage of this algorithm is its ability to restrict the number of nodes requiring feedback transmission in a wireless sensor network comprising 5000 IoT devices to less than 60. However, a limitation lies in the fact that the solution to the knapsack problem does not guarantee a global optimal solution, potentially rendering the offloading decisions of this algorithm suboptimal in terms of efficiency.
We can observe that decision-making for task offloading can be achieved from various perspectives, but in order to consider all aspects comprehensively, we chose to create our own energy consumption and execution time trade-off model for handling the offloading of large model inference tasks.
3. Problem Formulation
3.1. System Model
In the edge network, we divide the large model inference tasks, which require a huge amount of computation, into many subtasks based on the model mentioned in Section 3.2 to match the computing power of our edge servers, and the system model described in this chapter is used to offload these subtasks to the servers. In order to clearly demonstrate our partitioning and offloading methods, the following discussion will use CNN inference tasks as examples.
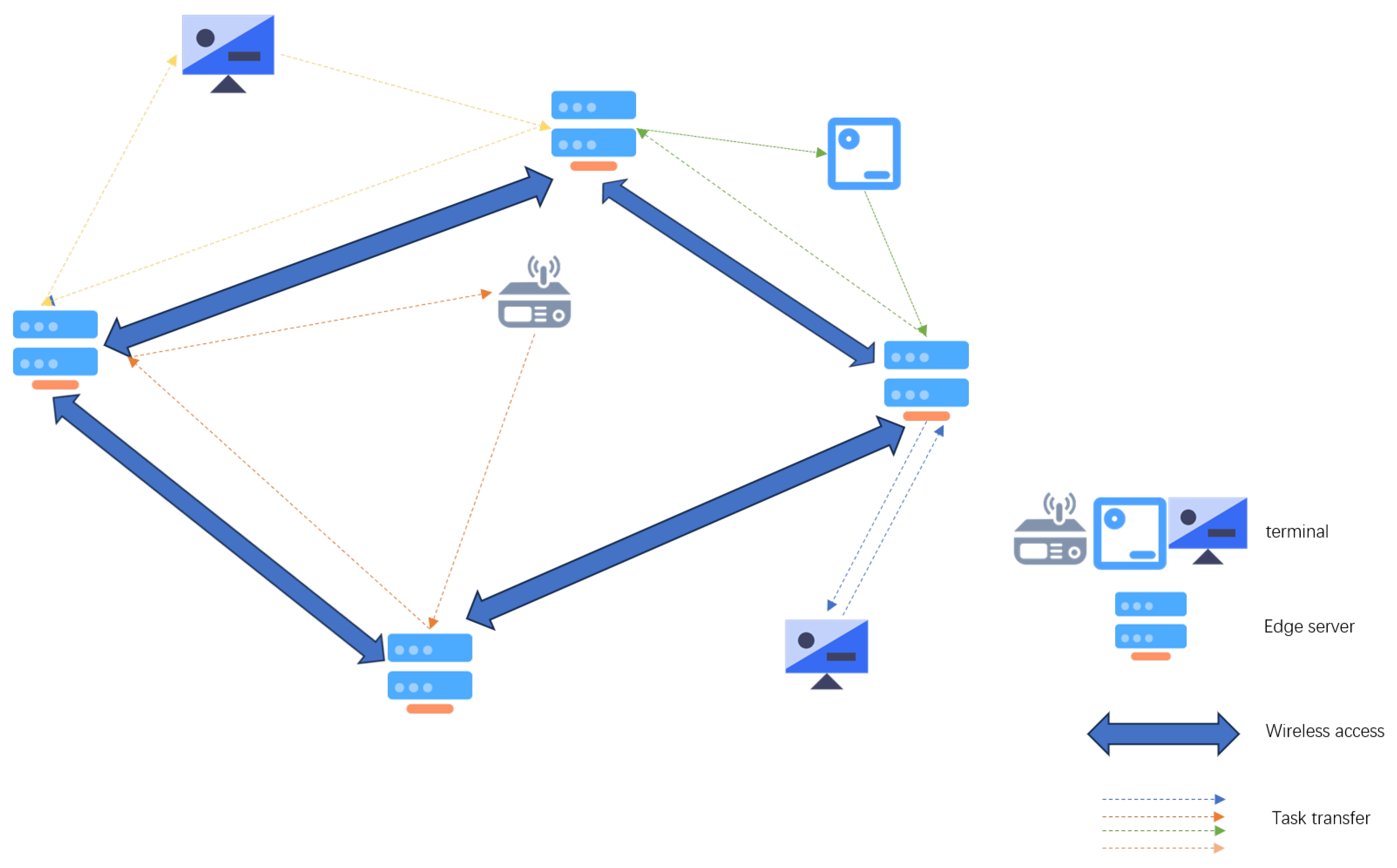
As shown in Figure 1, we demonstrate a multi-user multi-edge server-edge computing system. These edge servers are devices installed on wireless access points, with computing and storage capabilities similar to the cloud. In this edge computing system, we have multiple CNN inference tasks that need to be offloaded to the server for processing, denoted as: , and an edge network: connected by multiple edge servers.
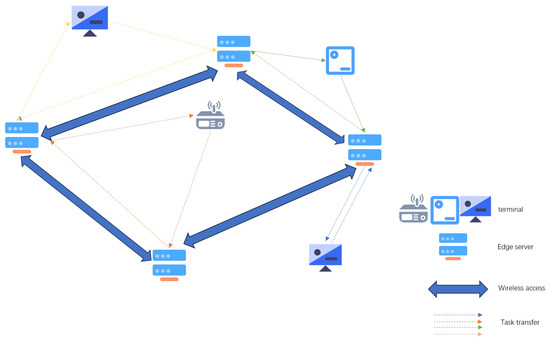
Figure 1.
A multi-user multi-edge server-edge computing system.
On the edge network S, there are edge servers , and each edge server can be expressed as , where represents the computation frequency of the i-th server’s core, represents the storage resources of the i-th server, represents the number of cores of the i-th server, and represents the working power of this server when performing inference tasks.
In this scenario, the CNN inference tasks arrive in real-time, and we use to represent the arrival time of each large task. Additionally, we divide each large task into smaller subtasks for easier processing, denoted as: , where represents the k-th task (this task is a divided subtask) of the j-th user. These tasks can also be expressed as , where represents the computing resources required for this task, represents the data volume of this task, and is an m-dimensional decision variable, . When the value is 1, it indicates that the k-th task of the j-th user is offloaded to the i-th server, and when the value is 0, it is the opposite. In addition, we have also created a variable to represent the server closest to the j-th user in order to find the shortest propagation delay.
3.2. Partitioning Model
Firstly, it should be pointed out that our partitioning method is not only designed for specific CNN architectures but is applicable to all neural networks with convolutional neural network layer structures, such as RNN and Transformer. For complex and numerous convolutional neural network architectures, our method is also applicable, as long as the granularity of partitioning is designed to be smaller, or large CNN networks can be first partitioned into vertical layers and then parallelized through our method.
In DNN architectures, multiple convolutional and pooling layers are usually stacked together to gradually extract hidden features from input data. In a CNN with L layers, for layer , the input feature map dimensions for each layer are , and each layer has corresponding learnable filters with dimensions . The filters slide across input feature maps with a stride of to perform convolution calculations and then generate output feature maps with dimensions , which, in turn, form the input maps for layer l + 1.
Note that in such convolution chains of CNN, due to the large dimensions of the input and intermediate feature maps, the data and computational complexity of each layer are very large. This results in extremely large memory footprints. Ordinary edge devices are unable to meet such memory and computing power requirements.
However, we can observe that each output data element only depends on a local region in the input feature maps. Thus, each original convolutional layer can be partitioned into multiple parallel execution tasks with smaller input and output regions and hence a reduced memory footprint for each layer.
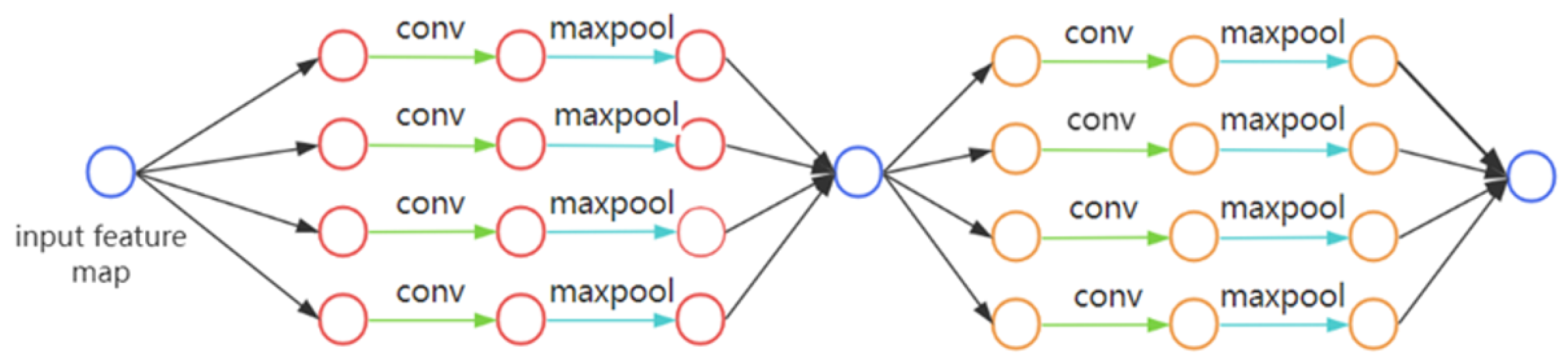
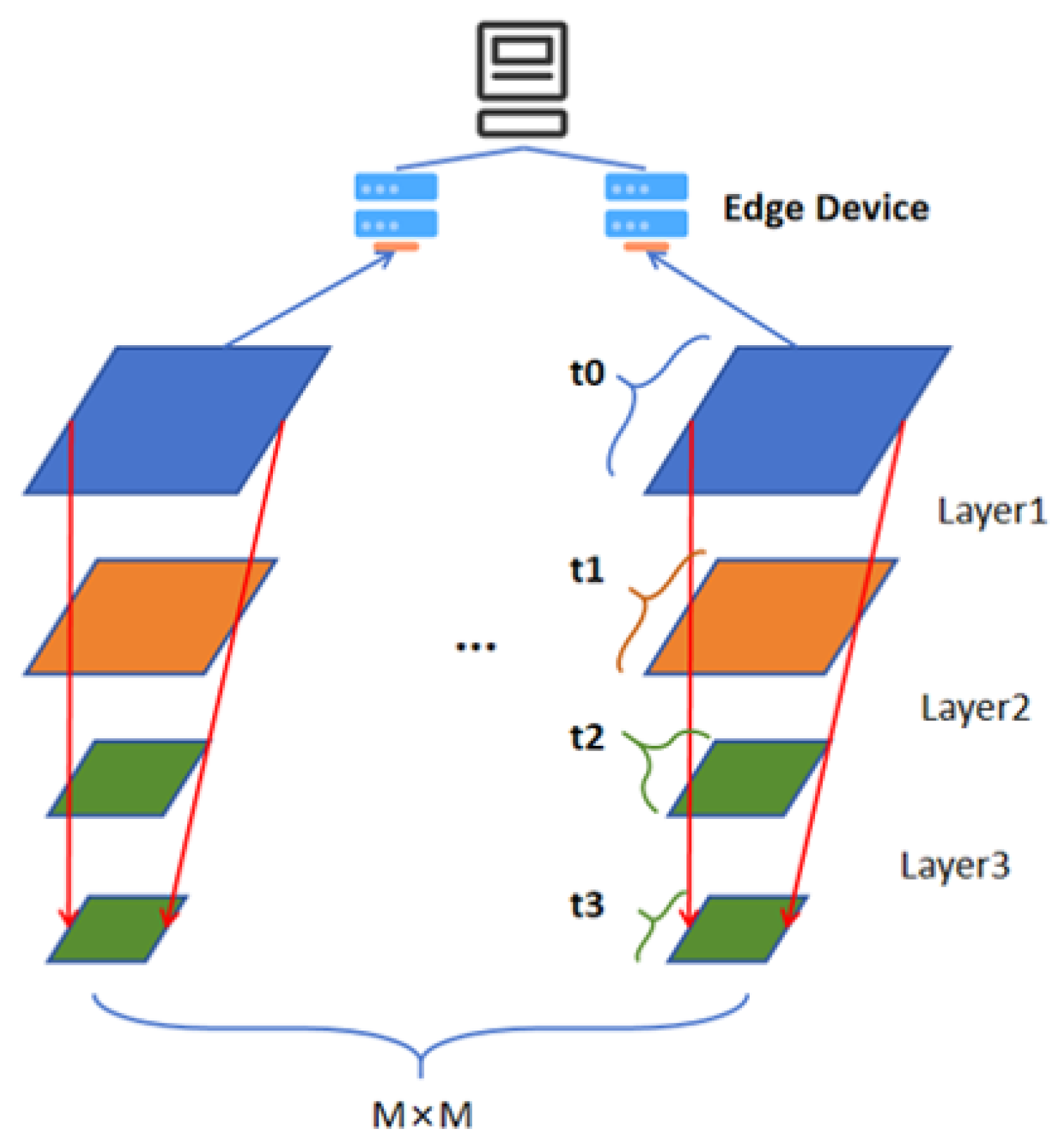
Inspired by [17], we decided to adopt a method based on matrix convolution for the division of DNN/CNN inference to parallelize the convolutional operation and reduce the memory footprint. In our method, the original CNN is divided into tiled stacks of convolution and pooling operations. The feature maps of each layer are divided into small tiles in a grid fashion, where corresponding feature map tiles and operations across layers are vertically fused together to constitute an execution partition and stack. Figure 2 shows the DAG of the partitioned CNN process. As shown in Figure 3, the original set of layers is thus partitioned into M × M independent execution stacks. By dividing the fusion stack along the grid, the size of the intermediate feature maps associated with each partition can be reduced to any desired footprint based on the grid granularity. Then, multiple partitions can be iteratively executed within one device, reducing memory requirements to a maximum of one partition at a time instead of the entire convolutional feature map. In order to distribute the inference operations and input data, each partition’s intermediate feature tiles’ size and input region’s size need to be correctly calculated based on the output partition’s size.
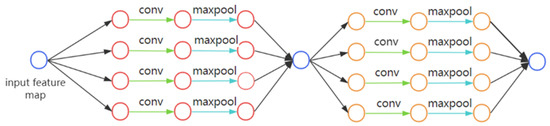
Figure 2.
DAG for the partitioning process of the general CNN network framework.
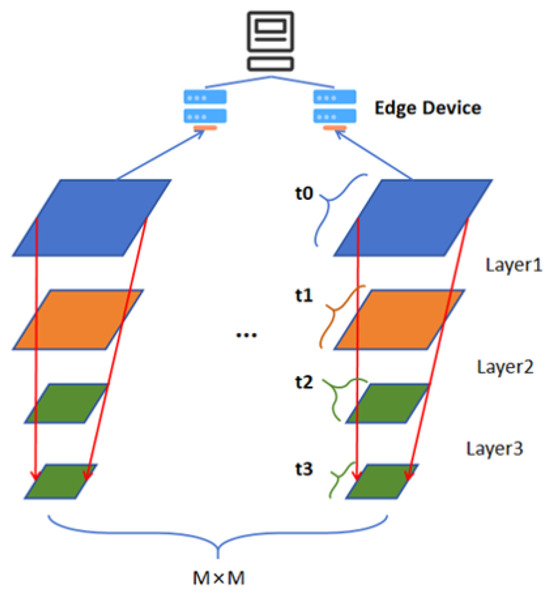
Figure 3.
Partitioning method for CNN.
In our method, the region’s size for a tile in the output map of layer l is represented by . During the process, the output data are first partitioned equally into nonoverlapping grid tiles with a given grid dimension. Then, with the output offset parameters, a recursive backward traversal is performed for each partition to calculate the required tile region’s size in each layer as follows:
For a CNN with L layers, the final input offsets for each partition in the CNN input map at can be obtained by applying (1) recursively starting from partition offsets in the output map at with an initial size of . For the l layer, the partitioned CNN convolution task’s calculation times can be calculated by the following formulas:
By using the two Formulas (1) and (2), we can obtain the amount of data and calculation times required by each convolution layer in the partitioned CNN framework, which can be used as evaluation parameters for unloading CNN tasks.
3.3. Offloading Model
In this section, we first define the notations to be used in this paper. Subsequently, we briefly introduce the system model, describe the decision variables, and formulate the problem.
3.3.1. Execution Time of Task Offloading
Since this model is an optimization model based on latency and energy consumption balancing, we inevitably need to establish a model to measure latency. We know that propagation delay is negligible compared to the total latency, so we only need to consider three components: transmission delay, computational processing delay, and queuing delay arising from the real-time arrival of tasks.
Regarding the computational processing delay, we can represent it based on the ratio of the computational resource required by the task to total computation frequency of server cores :
In this context, “core” represents the number of server cores.
Considering the transmission delay of each task between different servers and users, we can express it by the ratio of the amount of data required for transmission, , to the transmission rate or , where represents the link transmission rate for tasks offloaded to the server closest to the user, and represents the link transmission rate for tasks offloaded to other servers. Both rates can be calculated using the Shannon formula:
After determining the transmission rate, we next discuss the transmission delay and obtain the total delay by adding it to the computational processing delay and queuing delay t’:
- (1)
- When the user offloads the task to the local server, i.e., , the total delay for a single task is calculated as follows:
- (2)
- When the local server closest to the user is busy and the task needs to be offloaded to other edge servers, i.e., , the total delay for a single task is calculated as follows:
In summary, the total delay for a single task can be summarized as follows:
From this, we can write the total delay for all tasks of a single user:
However, since this paper discusses the offloading and processing of multiple batches of tasks on multiple edge servers, we can further take the maximum value of the offloading and processing delays of all single-user tasks as the total delay for all users and all tasks:
3.3.2. Energy Consumption
Since this paper discusses the task offloading method balancing delay and energy consumption, establishing a reasonable energy consumption model is crucial. We can also divide energy consumption into two parts as the delay model: the energy consumption of users sending tasks and the energy consumption required for task offloading computation.
Regarding the energy consumption for tasks sent by users, we can also follow a similar discussion pattern as that for latency, addressing two scenarios:
Firstly, when , which means the user offloads the task to the local server, we can sum up the energy consumption required for transmitting each task of the users:
However, when i is not equal to y, indicating that the local server is busy and the task needs to be sent to another server, we must take into account the energy consumption for transmission between servers:
In summary, our total transmission energy consumption can be summarized as:
Similarly, for the computation energy consumption of task offloading, we can also perform a summation:
In summary, our energy consumption optimization model can combine the two parts of energy consumption to represent the total energy consumption of each user processing tasks:
3.4. Optimization Objective
We formulate the offloading problem of large-model inference subtasks as a linear programming problem to improve the overall performance in a stable state. The first goal is to minimize latency, i.e., maximize the quality of service, under the premise of successful process task offloading and computing. The second optimization goal is to minimize energy consumption. The specific task offloading model is as follows:
where and are linear weighting coefficients that can control whether the overall optimization goal is to achieve the lowest latency or minimize total energy consumption. By adjusting the values assigned to these coefficients, the optimization process can be tuned to prioritize either low latency or energy efficiency. Given the actual deployment scenario and mathematical reasoning, the deployment strategy is subject to some key constraints. Equation (16) represents the constraint on the weighting coefficients. Equation (17) indicates that the total amount of data required for the task should not exceed the server’s storage capacity. Equation (18) imposes constraints on the 0, 1 matrix. Finally, Equation (19) states that the number of offloaded tasks should not exceed the number of cores on the server. Equations (17) and (19) are the constraints related to storage resources.
4. Algorithm
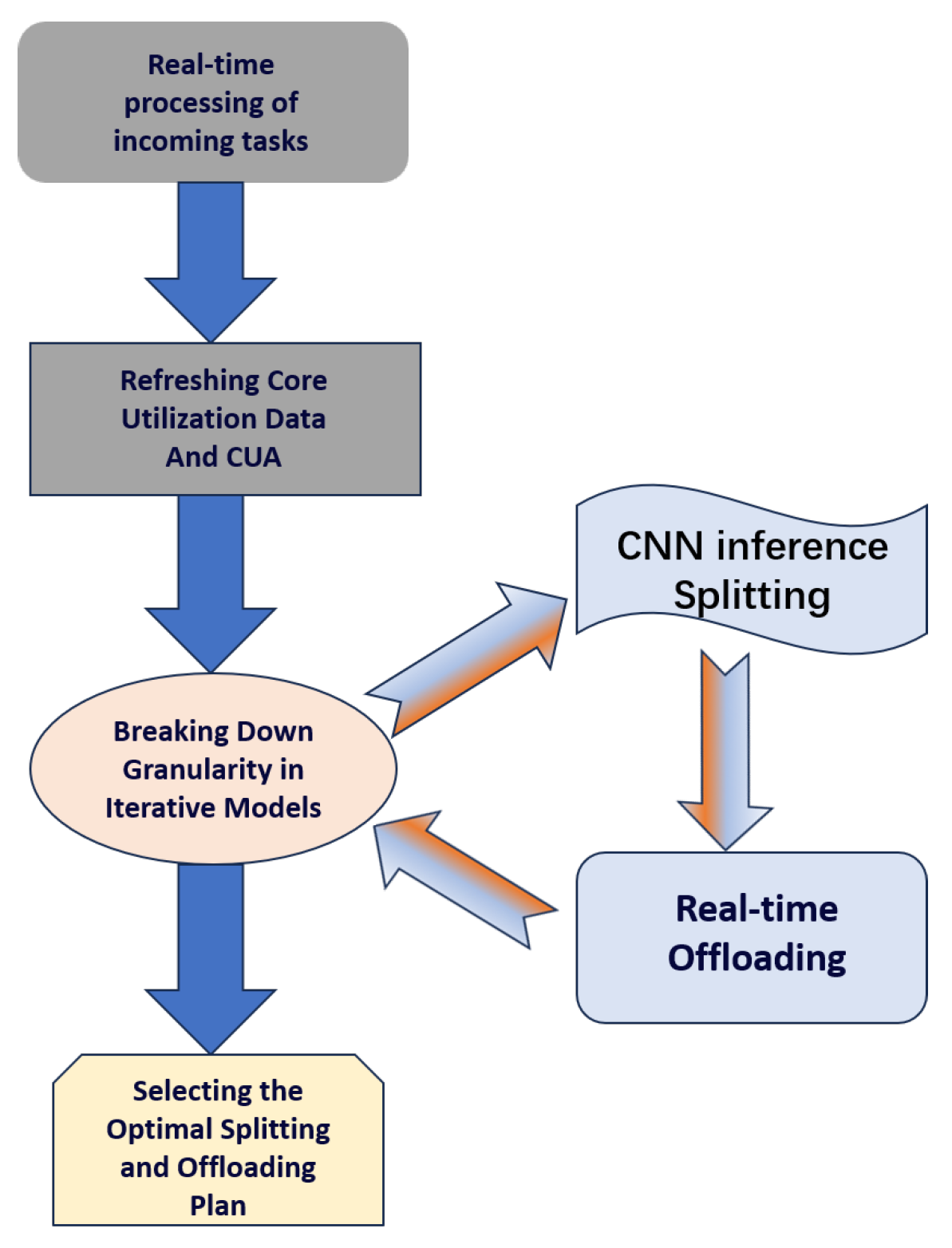
As described in the third section, we establish separate partitioning and offloading models to model the problem. In order to solve the decision-making problem of real-time task partitioning and offloading, we propose Greedy Partitioning and Offloading Algorithms (GPOA). The algorithm process is shown in Figure 4. This algorithm mainly has two decision-making parts—the granularity of the model’s partitioning and the unloading scheme of the partition task. Different model partitioning schemes can lead to different optimal offloading schemes, and similarly, changes in offloading schemes can also affect the optimal partitioning scheme, and the two are coupled. Therefore, our proposed GPOA simultaneously makes decisions for both. At the same time, due to the real-time arrival of tasks, it is necessary to estimate the queuing time when deciding on the unloading plan for each task. Therefore, we need to maintain and update the core usage and queuing queue in real-time for each edge server. We have designed a Core Refreshing Algorithm (CRA) to address this issue.
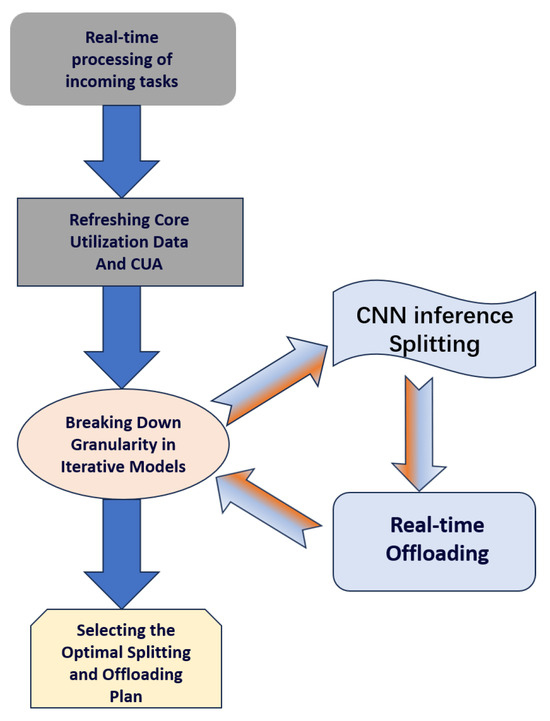
Figure 4.
Flowchart of GPOA.
4.1. Core Refreshing Algorithm
As mentioned in Algorithm 1. When it is necessary to update the core state of the edge server, the core that has already completed the task is first released based on the current time and the usage of the core maintained by the system (line 3). Then, iterate through the subtasks that are currently in queue. If the idle core can meet the requirements of the subtask in the queue, allocate the core to this task and check whether the remaining cores continue to meet the requirements of the next task (line 6). If it cannot meet the requirements of queuing tasks, then this part of the core remains idle. Through this algorithm, we maintain a series of tables that play an important role in estimating the queue duration of tasks.
| Algorithm 1 CRA |
|
4.2. Greedy Partitioning and Offloading Algorithms
The specific explanation for Algorithm 2 is as follows: When a large CNN inference task arrives at the system, the first step is to partition the inference task according to a certain granularity (line 4). For different partition granularities, we will obtain different numbers of subtasks. We need to find a solution that balances latency and power requirements to offload these subtasks to this edge network. In this algorithm, we first sort these subtasks by computational complexity (line 5). Starting from the task with the highest computational complexity, calculate the latency and energy consumption that would occur if subtasks are offloaded to a server (line 6). Then, offload this task to the server with the lowest latency and energy consumption. Finally, we obtain an uninstallation scheme with specific partition granularity and corresponding latency and energy consumption (line 9). Then, we compare the energy consumption and latency of different partition granularities and select the optimal partition scheme (line 11).
| Algorithm 2 GPOA |
|
4.3. Complexity Analysis
CRA: The outermost loop is to traverse all servers, with a time complexity of . The inner loop may execute times in the worst-case scenario, as each iteration may involve the deletion and addition of one or more tasks. Each iteration’s internal operation is . Thus, the time complexity of this algorithm is , where is the number of servers and is the length of the usage sequence of the server’s cores.
GPOA: As mentioned above, the time complexity of updating the state is . For each subtask, the estimated queuing delay function will traverse the usage sequence of the kernel, with a time complexity of . At the same time, each subtask will traverse each server, so the time complexity is . Assuming the number of subtasks is , the total time complexity is
5. Performance Evaluation
In this section, we evaluate the performance of our partitioning model and task offloading algorithm through simulation experiments. We consider the following influencing factors: data size, number of Edge Node CPU Cores, and request arrival rate. Moreover, in our simulation experiments, we compare our model with three baseline algorithms and use the method of controlling variables to evaluate the impact of influencing factors on our model and algorithm.
5.1. Experiment Settings
We build a simulation environment for CNN task partitioning and offloading on the Python platform. All simulations are performed on a PC with an Intel (R) Core (TM) i7-11370H CPU @ 3.30GHz, NVIDIA GeForce RTX 3050 Ti GPU, 8GB RAM and Windows 10. The detailed experimental data settings are as follows:
Edge computing network: Our edge network consists of 10 nodes, each with distinct regional characteristics, thus forming a collaborative network. Each node is assigned a specific service area. The data of our edge network nodes and structures are abstracted from the edge computing dataset [28] of Shanghai Telecom. The dataset shows the distribution of 3233 base stations in the Shanghai area, which constitute the infrastructure of mobile communication networks. The density and distribution of base stations reflect the coverage capability and service quality of mobile communication networks in Shanghai. The CPU cores of each edge node are evenly distributed within the range of [8, 16], the core computing frequency is 1.12 GHz and the data transmission rates between nodes are randomly distributed within [5, 20] Gbps. To account for the heterogeneity in propagation paths within the edge system, we utilized a 10 × 10 bandwidth matrix to represent the diverse bandwidth conditions among the edge nodes.
Inference workload: Our partitioning model divides the linear chain structure into a nonlinear DAG structure, enabling parallel execution of the partitioned subtasks. This method can be applied to most large model inference tasks with convolutional layer structures, such as Transformer and RNN. Here, our simulation experiment takes the classic CNN model, VGG-16 [29], as an example to discuss the partitioning of inference tasks. VGG-16 consists of a total of 16 layers, but during the partitioning process, the workload of each subtask increases uniformly as the number of layers increases. Therefore, to demonstrate the performance of our partitioning model and task offloading algorithm, we can select one of the layers for simulation of partitioning and offloading. For VGG-16, the piece of input data is a 224 × 224 image with 3 channels.
The banded distribution figures, constructed from gathered data across repeated experiments, provide a comprehensive visualization that underscores the robust consistency and validity of the derived conclusions. This approach ensures a heightened level of scientific rigor and credibility in the interpretation of the experimental outcomes.
5.2. Baseline Algorithm and Metrics
In order to qualitatively and effectively evaluate the performance of our algorithm, we use the following baseline algorithms for comparison.
- (1)
- Randomized algorithm. The random algorithm randomly selects edge network nodes for microservice deployment in response to each application request. If the initially selected node lacks the necessary resources, the algorithm repeats the selection process until a suitable node is found. However, the random algorithm here is not simply random but also involves the process of selecting the optimal solution.
- (2)
- Genetic algorithm. Generate a set of initial solutions that satisfy the constraints using a random algorithm. Subsequently, the optimization objective is used as a fitness function to evaluate the quality of each solution. Perform iterative crossover, mutation, and selection operations to search for the best task offloading solution. The genetic algorithm here includes selection strategies.
- (3)
- Fixed partition granularity. Using a fixed granularity to partition all CNN tasks without considering the characteristics of the task and the condition of the edge server.
The following metrics are used to evaluate the performance of our partitioning and offloading algorithm.
- (1)
- Average delay: The average delay of all tasks from request to completion, which is defined in Equation (9).
- (2)
- Energy consumption: The energy consumed during transmission and computation processes, which is defined in Equation (14).
- (3)
- Combined metric: Combined metric based on delay and energy consumption, which is defined in Equation (15).
5.3. Experimental Results
5.3.1. The Influence of the Number of Edge Node CPU Cores
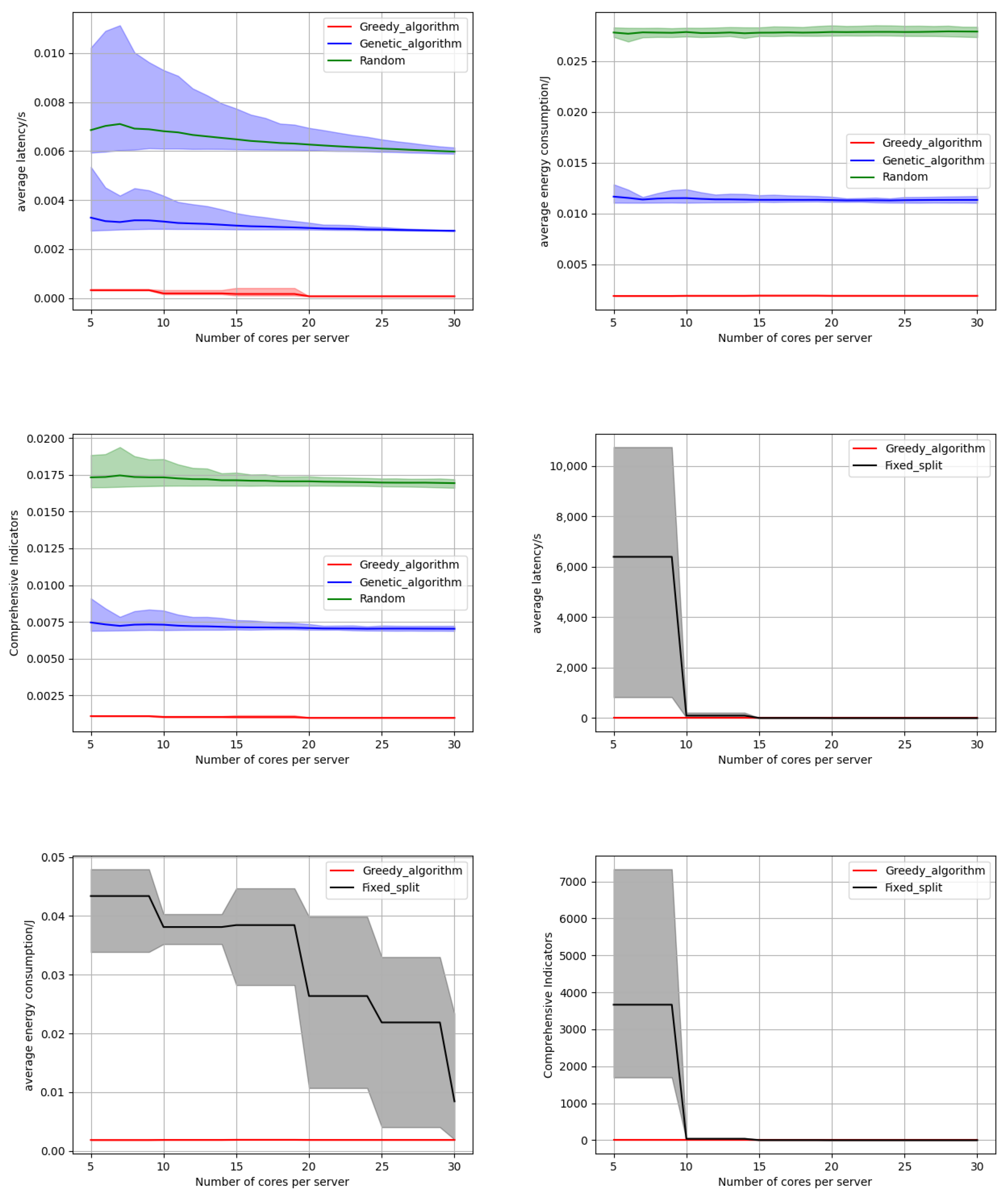
We conducted an in-depth study on the impact of the number of available cores on edge servers on the algorithm results. The number of cores on each edge server is investigated within the range of 5 to 30, with an interval of 1, as shown in Figure 5. The results indicate that as the number of server cores increases, the latency of all three algorithms gradually decreases. This is because the number of available idle cores per server increases, enabling each algorithm to better allocate corresponding cores for incoming tasks, enhancing task efficiency and parallelism, and subsequently reducing computation time and waiting time. Notably, regardless of the variation in the number of server cores, our offloading algorithm consistently exhibits the lowest latency compared to the random algorithm and genetic algorithm. Moreover, Figure 5 demonstrates that as the number of server cores increases, our algorithm maintains a declining trend in average energy consumption, consistently outperforming the other two baseline algorithms. This characteristic underscores the capability of our algorithm to minimize energy usage. Figure 5 also illustrates that our offloading algorithm surpasses the other two baseline algorithms in terms of comprehensive metrics encompassing latency and energy consumption. It can also be seen intuitively from Figure 5 that the strip distribution of multiple experimental results shows that our algorithm always outperforms the baseline algorithm, indicating the consistency of our experimental results. The specific experimental data on latency and energy consumption as the number of Edge Node CPU cores increases are presented in Table 1. The superiority of our algorithm can be specifically seen from the table. From Figure 5, we can see that as the number of cores increases, the energy consumption of our algorithm and baseline algorithm remains basically unchanged. This is because an increase in the number of cores will only reduce the queuing probability and latency of reaching subtasks. In our energy consumption calculation method, only transmission energy consumption and calculation energy consumption are included, and the reduction in queuing delay does not affect the calculation of energy consumption, so the energy consumption remains basically unchanged. For fixed partition granularity, energy consumption decreases as the number of cores increases. This is because the granularity of the split remains constant, which means that as the number of cores increases, the method cannot achieve optimal partitioning. Figure 5 further compares the performance of our method against a fixed partitioning granularity model for task partitioning. As evident from the figure, when running the same task offloading algorithm, the latency, energy consumption, and comprehensive metrics associated with fixed partitioning granularity are significantly inferior to those achieved by our method. This disparity stems from the fact that our method exhaustively explores various partitioning granularities and ultimately selects the one that optimizes the comprehensive metrics for peak performance. The rationale behind this approach is that excessively large partitioning granularities result in oversized subtasks that fail to fully capitalize on the parallelism benefits of task partitioning, while excessively small granularities increase data redundancy and subsequently expand the task workload. Our method addresses these issues by striking a balance between the two extremes to achieve optimal performance.
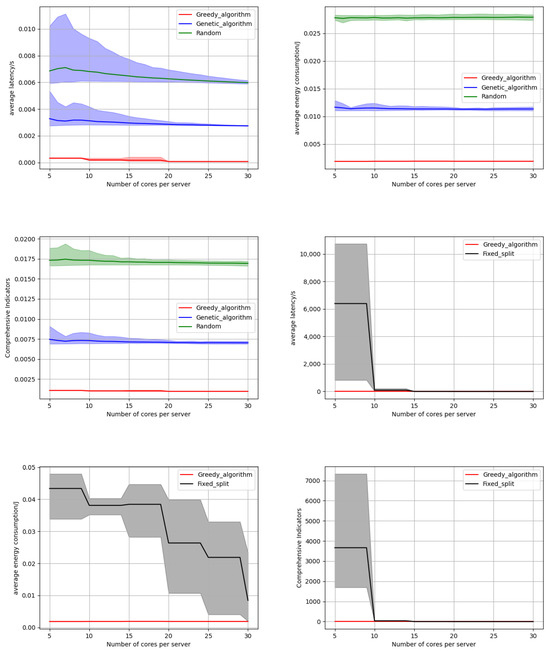
Figure 5.
The influence of the number of Edge Node CPU Cores.

Table 1.
The influence of the number of Edge Node CPU Cores.
5.3.2. The Influence of the Data Size
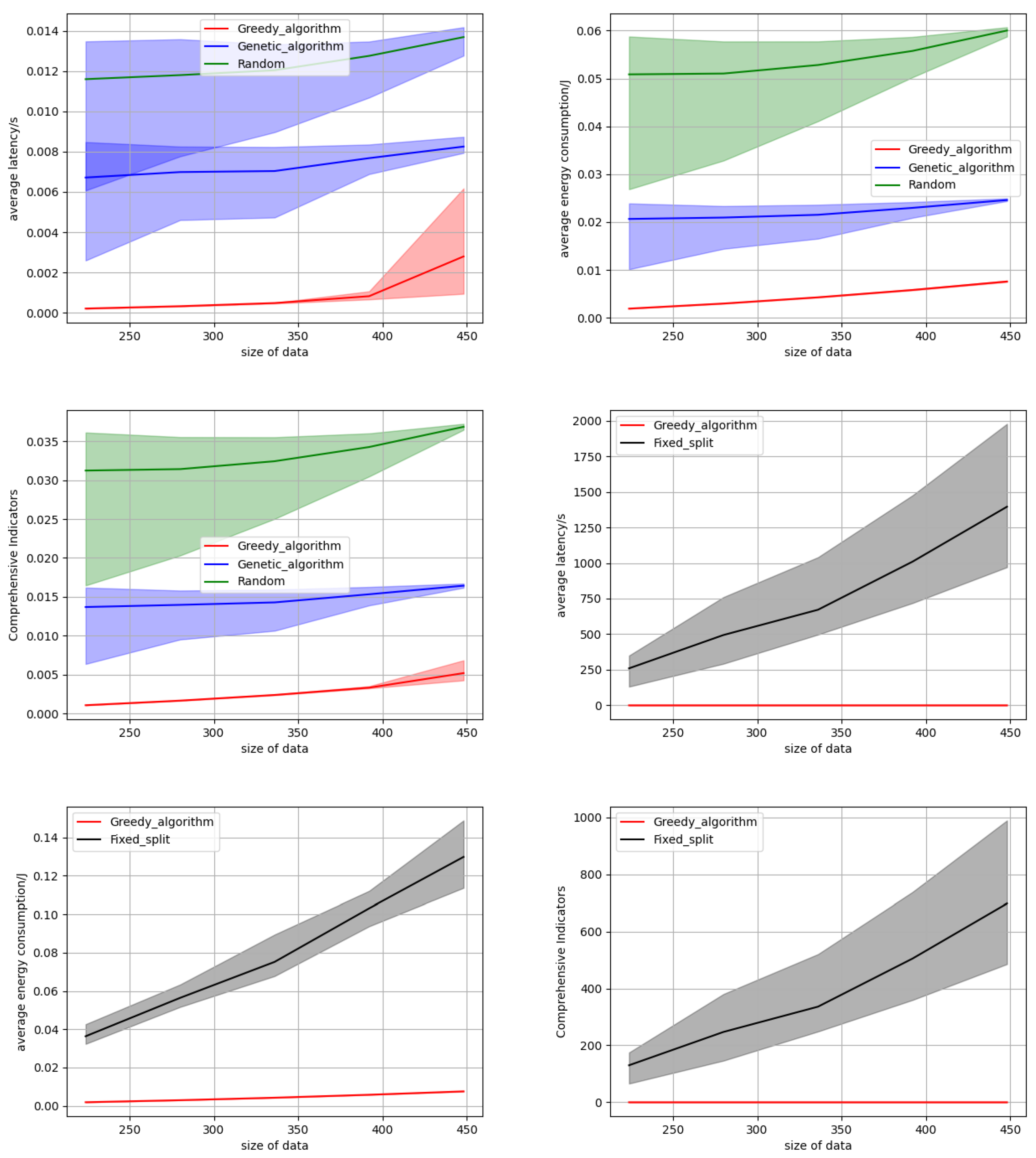
Subsequently, we delve into the performance of the three algorithms under varying task data sizes. We change the size of the input data from 224 × 224 to 504 × 504 with a step length of 56. When the size of the data is large, it is equivalent to simulating the performance of our algorithm under high task loads. As the data size increases, the time and power consumption required for servers to complete tasks escalate, leading to a higher likelihood and duration of task queuing, which in turn elevates the average latency and energy consumption across all tasks. This investigation is conducted using 10 edge servers, each equipped with 8 to 15 cores. As depicted in Figure 6, the experimental results reveal a consistent trend in the performance metrics of all three algorithms: as the task data size grows, the average latency, average energy consumption, and the composite indicator all increase. However, our algorithm consistently outperforms the two baseline algorithms. As shown in the strip distribution figure, the superiority of our algorithm is consistent. This superiority can be attributed to our greedy algorithm, which dynamically determines the optimal queuing sequence and assigns the most suitable server for each task upon the arrival of multiple tasks. Such adaptability enables our algorithm to alleviate latency and energy consumption issues, ultimately enhancing overall performance. Furthermore, Figure 6 compares the performance of our method against that of fixed partition granularity. It is evident that our method surpasses the fixed partition granularity approach in terms of latency, energy consumption, and the composite indicator. This underscores the advantage of dynamically selecting the optimal partition granularity for each task. The specific experimental data on latency and energy consumption as the data size increases are presented in Table 2.
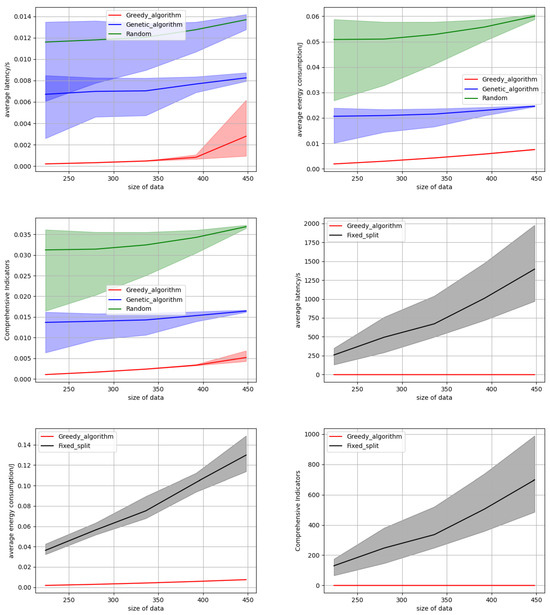
Figure 6.
The influence of the data size.
Table 2.
The influence of the data size.
5.3.3. The Influence of the Request Arrival Rate
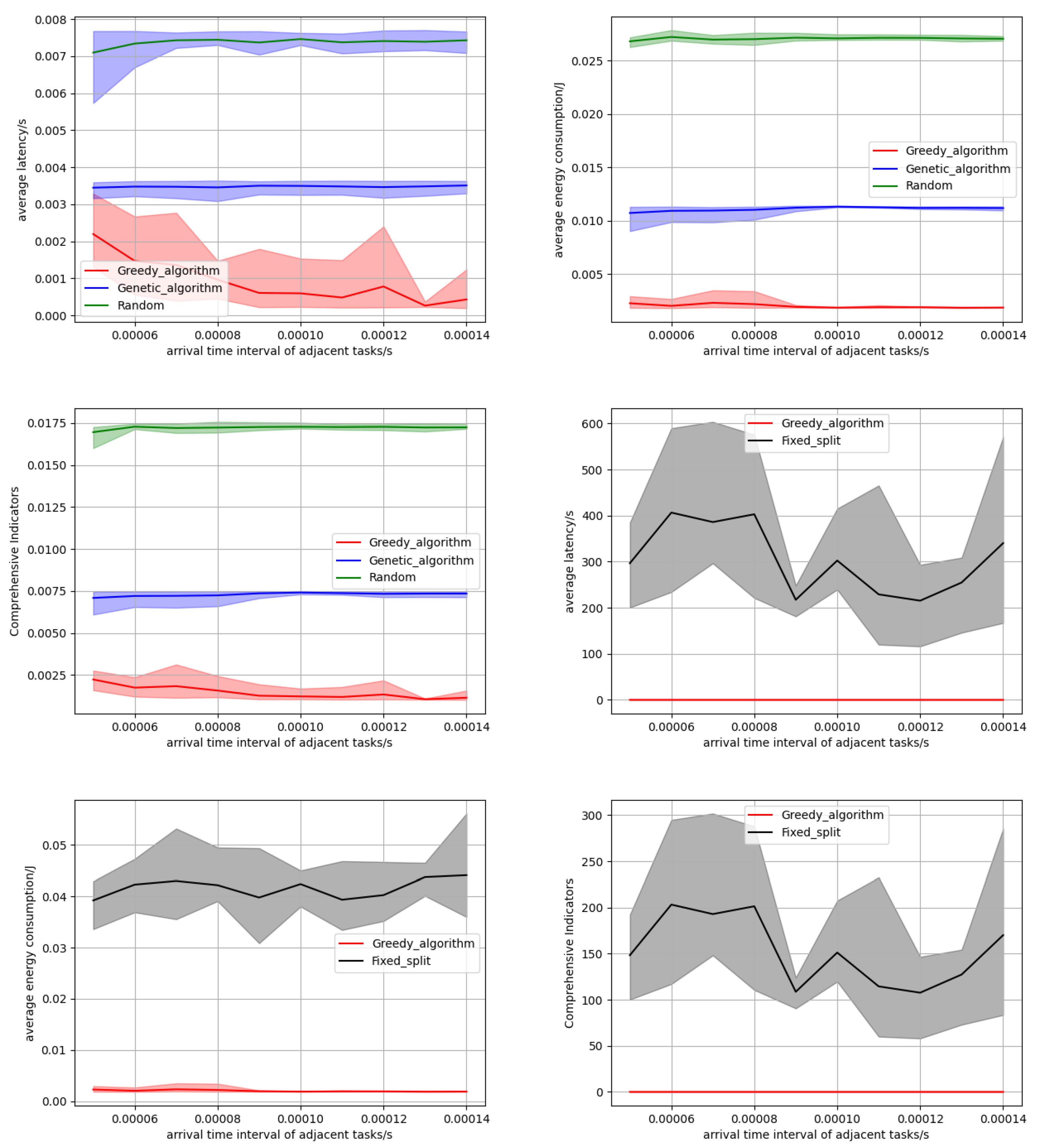
Finally, we investigated the performance of three algorithms when the time interval between adjacent inference tasks changed. We study the performance of our method under high task loads by increasing the arrival rate of the request. As the time interval increases, the number of idle kernels for the next arriving task also increases, resulting in a decrease in the likelihood and duration of task queuing, thereby reducing the average latency of all tasks. This survey is conducted on 10 edge servers, each equipped with a specific number of cores. As shown in Figure 7, the experimental results reveal the performance indicator trends of three algorithms: for the average delay, as the time interval increases, the greedy algorithm always searches for the optimal solution, the possibility and duration of task queuing decrease, and the average delay continues to decrease. And the band distribution graph in Figure 7 demonstrates the consistency of our algorithm’s performance over other baseline algorithms. For average energy consumption, increasing the time interval can only change the queue delay, so the impact on average energy consumption is minimal. Overall, compared to the two baseline algorithms, our algorithm consistently maintains excellent performance and consistent results. In Figure 7, we compare the performance of our method with that of fixed partition granularity. It is evident that our algorithm has significant advantages over fixed partitioning in terms of latency, energy consumption, and overall metrics, highlighting the advantage of our dynamic partitioning in selecting the optimal partition granularity for each task. Table 3 presents specific experimental data on latency and energy consumption as the request arrival rate increases.
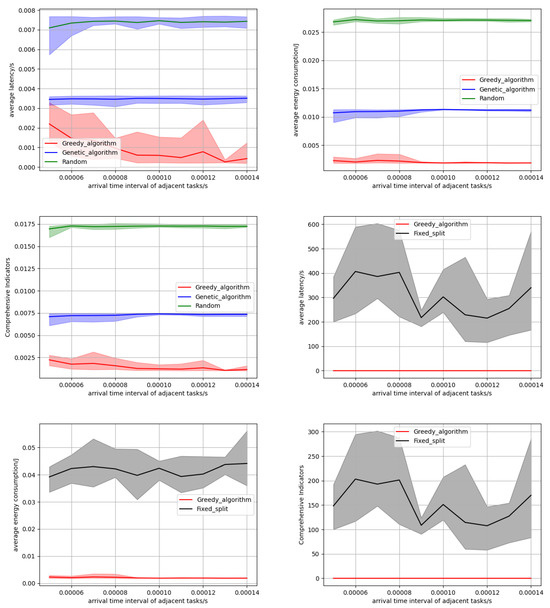
Figure 7.
The influence of the request arrival rate.
Table 3.
The influence of the request arrival rate.
6. Conclusions
This paper has investigated the issues of CNN task partitioning and task offloading in edge computing networks to enable the deployment of large CNN tasks on edge servers with limited hardware resources while minimizing task latency and energy consumption. Our approach has comprised two main components: task partitioning and offloading. Instead of the conventional vertical partitioning method, we have opted for horizontal partitioning during partitioning, leveraging the characteristic that convolutional results are only relevant to part of the input data. This approach has divided the CNN task into multiple subtasks that can be executed in parallel. In modeling task offloading, we have accounted for the random arrival of tasks and employed a greedy algorithm to dynamically allocate servers in real-time, aiming to minimize task latency and energy consumption. Finally, we have designed simulation experiments to compare our algorithm with two baseline algorithms, and we have also compared scenarios with fixed partitioning granularity. The experimental results indicate that our method consistently identifies the optimal partitioning granularity for each task, achieving optimal performance when considering both latency and energy consumption.
Lastly, it should be noted that our partitioning method is not designed for a specific CNN architecture but is applicable to all neural networks with a convolutional neural network layer structure, such as RNN and Transformer. This is because our resolution method determines the corresponding resolution scale according to the size of the characteristic graph output of the inference task and the hardware conditions of the device, while considering the coupling of the resolution and offloading process, and then determines the specific partition granularity based on the comprehensive index of delay and energy consumption, which is suitable for most existing CNN models. Furthermore, our partitioning method is designed based on the data locality of convolution computation. The result of the multi-layer convolution operation in CNN is only related to a specific region of the input feature graph data, and the size of this specific region can be calculated by the calculation formula given by us. For convolutional neural network architectures with complex structures and large numbers, our method is also applicable, just the granularity of the partition needs to be designed to be smaller, or large CNN networks can be divided into vertical hierarchies first, and then partitioned in parallel by our method.
Author Contributions
Conceptualization, Y.Y. and K.P.; methodology, Z.Z.; software, Y.Y.; validation, Z.W., Y.Y. and Y.X.; formal analysis, B.L.; investigation, Y.X.; resources, K.L.; data curation, C.Y.; writing—original draft preparation, Z.Z.; writing—review and editing, Z.W.; visualization, B.X.; supervision, K.P.; project administration, Z.Z.; funding acquisition, K.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the Key Research and Development Program of Hubei Province under grant 2022BAA038, in part by the Key Research and Development Program of Hubei Province under grant 2023BAB074, in part by the special fund for Wuhan Artificial Intelligence Innovation under grant 2022010702040061.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
Author Zhiyong Zha was employed by the company State Grid Information Telecommunication Co., Ltd. Authors Yongjun Xia, Bin Luo were employed by the company Hubei Huazhong Electric Power Technology Development Co., Ltd. Author Bo Xu was employed by the company Hubei ChuTianYun Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Nomenclatures
The following abbreviations are used in this manuscript:
| Notation | Definition |
| S | A set of edge servers |
| The computing frequency of a single kernel on the i-th edge server | |
| The storage capacity of the i-th edge server | |
| The number of cores in the i-th edge server | |
| U | A group of users who need to use large model inference |
| The nearest edge server for the j-th user | |
| The k-th task of the j-th user | |
| The computing resources required for the k-th task of the j-th user | |
| The amount of data for the k-th task of the j-th user | |
| Binary decision variables | |
| The width of the feature map for the l-th layer | |
| The height of the feature map for the l-th layer | |
| The dimension of the filter for the l-th layer | |
| The number of output feature maps for the l-th layer | |
| The region’s size for a tile in the output map of layer l | |
| The calculation times for the l-th layer | |
| M | Partition the feature map into parts |
References
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things(IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef]
- Chien, S.Y.; Chan, W.K.; Tseng, Y.H.; Lee, C.; Somayazulu, V.S.; Chen, Y. Distributed computing in IoT: System-on-a-chip for smart cameras as an example. In Proceedings of the 20th Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 19–22 January 2015; pp. 130–135. [Google Scholar]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar]
- Lane, N.D.; Bhattacharya, S.; Georgiev, P.; Forlivesi, C.; Kawsar, T.F. An early resource characterization of deep learning on wearables, smartphones and Internet-of-Things devices. In Proceedings of the International Workshop Internet Things Towards Appl. (IoT-A), Seoul, Republic of Korea, 26–28 October 2015; pp. 7–12. [Google Scholar]
- Kang, A.M.; Hauswald, J.; Gao, C.; Rovinski, A.; Mudge, T.; Mars, J.; Tang, L. Neurosurgeon: Collaborative intelligence between the cloud and mobile edge. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Xi’an, China, 8–12 April 2017; pp. 615–629. [Google Scholar]
- Teerapittayanon, S.; McDanel, B.; Kung, H.-T. Distributed deep neural networks over the cloud, the edge and end devices. In Proceedings of the International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 328–339. [Google Scholar]
- Zhang, B.; Mor, N.; Kolb, J.; Chan, D.S.; Lutz, K.; Allman, E.; Wawrzynek, J.; Lee, E.; Kubiatowicz, J. The cloud is not enough: Saving IoT from the cloud. In Proceedings of the USENIX Workshop Hot Topics Cloud Computing (HotCloud), Santa Clara, CA, USA, 6–7 July 2015; p. 21. [Google Scholar]
- Ribeiro, F.M.; Kamienski, C.A. Timely Anomalous Behavior Detection in Fog-IoT Systems using Unsupervised Federated Learning. In Proceedings of the IEEE 8th World Forum on Internet of Things (WF-IoT), Yokohama, Japan, 26 October–11 November 2022. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Samie, F.; Tsoutsouras, V.; Xydis, S.; Bauer, L.; Soudris, D.; Henkel, J. Distributed QoS management for Internet of Things under resource constraints. In Proceedings of the 2016 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ISSS), Pittsburgh, PA, USA, 2–7 October 2016; pp. 1–10. [Google Scholar]
- Jiao, Z.; Zhang, J.; Yao, P.; Wan, L.; Ni, L. Service Deployment of C4ISR Based on Genetic Simulated Annealing Algorithm. IEEE Access 2020, 8, 65498–65512. [Google Scholar] [CrossRef]
- Fan, W.; Cui, Q.; Li, X.; Huang, X.; Tao, X. On Credibility-Based Service Function Chain Deployment. IEEE Open J. Comput. Soc. 2021, 2, 152–163. [Google Scholar] [CrossRef]
- Li, R.; Lim, C.S.; Rana, M.E.; Zhou, X. A Trade-Off Task-Offloading Scheme in Multi-User Multi-Task Mobile Edge Computing. IEEE Access 2022, 10, 129884–129898. [Google Scholar]
- Mahjoubi, A.; Ramaswamy, A.; Grinnemo, K.J. An Online Simulated Annealing-Based Task Offloading Strategy for a Mobile Edge Architecture. IEEE Access 2024, 12, 70707–70718. [Google Scholar]
- Liu, C.S.W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Zhao, Z.; Barijough, K.M.; Gerstlauer, A. DeepThings: Distributed adaptive deep learning inference on resource-constrained IoT edge clusters. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2348–2359. [Google Scholar]
- Li, H.; Hu, C.; Jiang, J.; Wang, Z.; Wen, Y.; Zhu, W. JALAD: Joint Accuracy- and Latency-Aware Deep Structure Decoupling for Edge-Cloud Execution. In Proceedings of the IEEE 24th International Conference on Parallel and Distributed Systems (ICPADS), Singapore, 11–13 December 2018; pp. 671–678. [Google Scholar]
- Li, E.; Zeng, L.; Zhou, Z.; Chen, X. Edge AI: On-Demand Accelerating Deep Neural Network Inference via Edge Computing. IEEE Trans. Wirel. Commun. 2020, 19, 447–457. [Google Scholar] [CrossRef]
- Hu, C.; Li, B. Distributed Inference with Deep Learning Models across Heterogeneous Edge Devices. In Proceedings of the IEEE Infocom, London, UK, 2–5 May 2022; pp. 330–339. [Google Scholar]
- Mao, J.; Chen, X.; Nixon, K.W.; Krieger, C.; Chen, Y. MoDNN: Local distributed mobile computing system for deep neural network. In Proceedings of the IEEE Infocom, Atlanta, GA, USA, 1–4 May 2017; pp. 1396–1401. [Google Scholar]
- Zhang, S.; Zhang, S.; Qian, Z.; Wu, J.; Jin, Y.; Lu, S. DeepSlicing: Collaborative and Adaptive CNN Inference With Low Latency. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 2175–2187. [Google Scholar] [CrossRef]
- Liu, J.; Mao, Y.; Zhang, J. Delay-optimal computation task scheduling for mobile-edge computing systems. In Proceedings of the IEEE International Symposium on Information Theory, Barcelona, Spain, 10–15 July 2016; pp. 1451–1455. [Google Scholar]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic Computation Offloading for Mobile-Edge Computing With Energy Harvesting Devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Shi, Y.; Chen, S.; Xu, X. MAGA: A Mobility-Aware computation Decision for Distributed Mobile Cloud Computing. IEEE Internet Things J. 2018, 5, 164–174. [Google Scholar] [CrossRef]
- Chen, M.H.; Liang, B.; Dong, M. A semidefinite relaxation approach to mobile cloud offloading with computing access point. In Proceedings of the IEEE International Workshop on Signal Processing Advances in Wireless Communications, Stockholm, Sweden, 28 June–1 July 2015; pp. 186–190. [Google Scholar]
- Lu, W.; Ni, W.; Tian, H.; Liu, R.P.; Wang, X.; Giannakis, G.B.; Paulraj, A. Optimal Schedule of Mobile Edge Computing for Internet of Things using Partial Information. IEEE J. Sel. Areas Commun. 2017, 35, 2606–2615. [Google Scholar] [CrossRef]
- Wang, S.; Zhao, Y.; Xu, J.; Yuan, J.; Hsu, C.-H. Edge server placement in mobile edge computing. J. Parallel Distrib. 2019, 127, 160–168. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional net works for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).