

Connection-Aware Heuristics for Scheduling and Distributing Jobs under Dynamic Dew Computing Environments
 , , , , and
, , , , and
Abstract
:1. Introduction
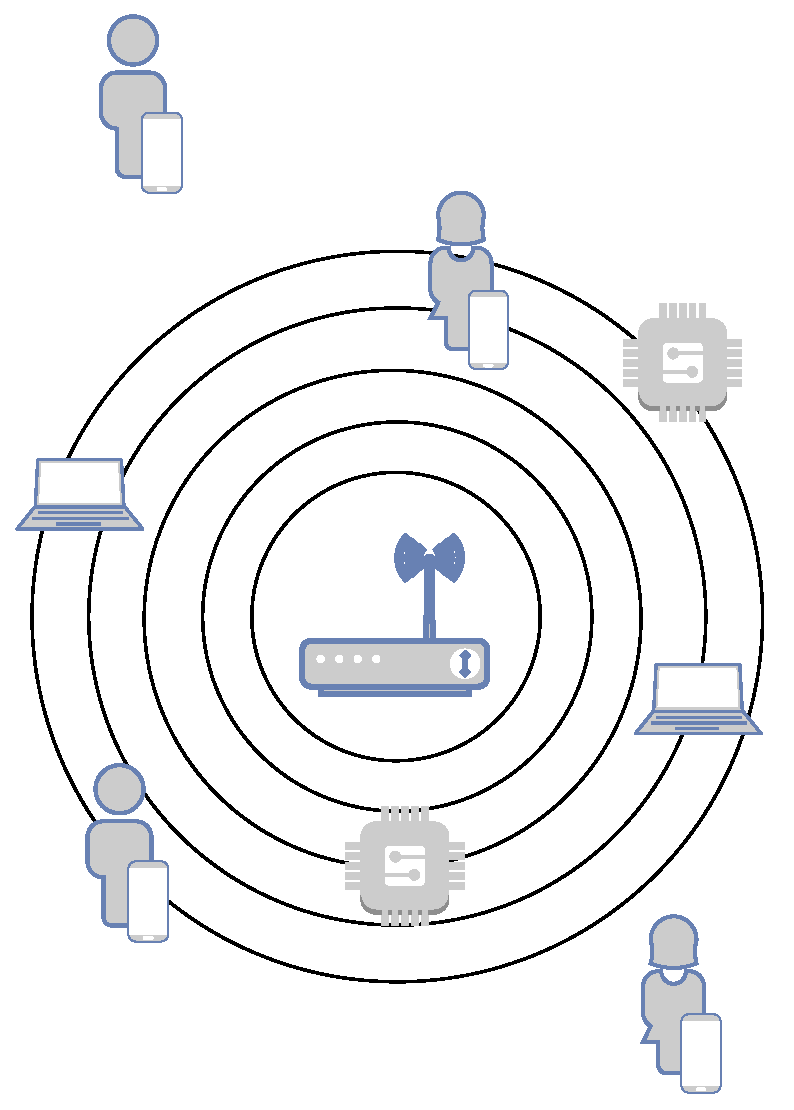
2. Edge and Dew Computing
3. Related Work
RL Methods in Edge and Dew Computing
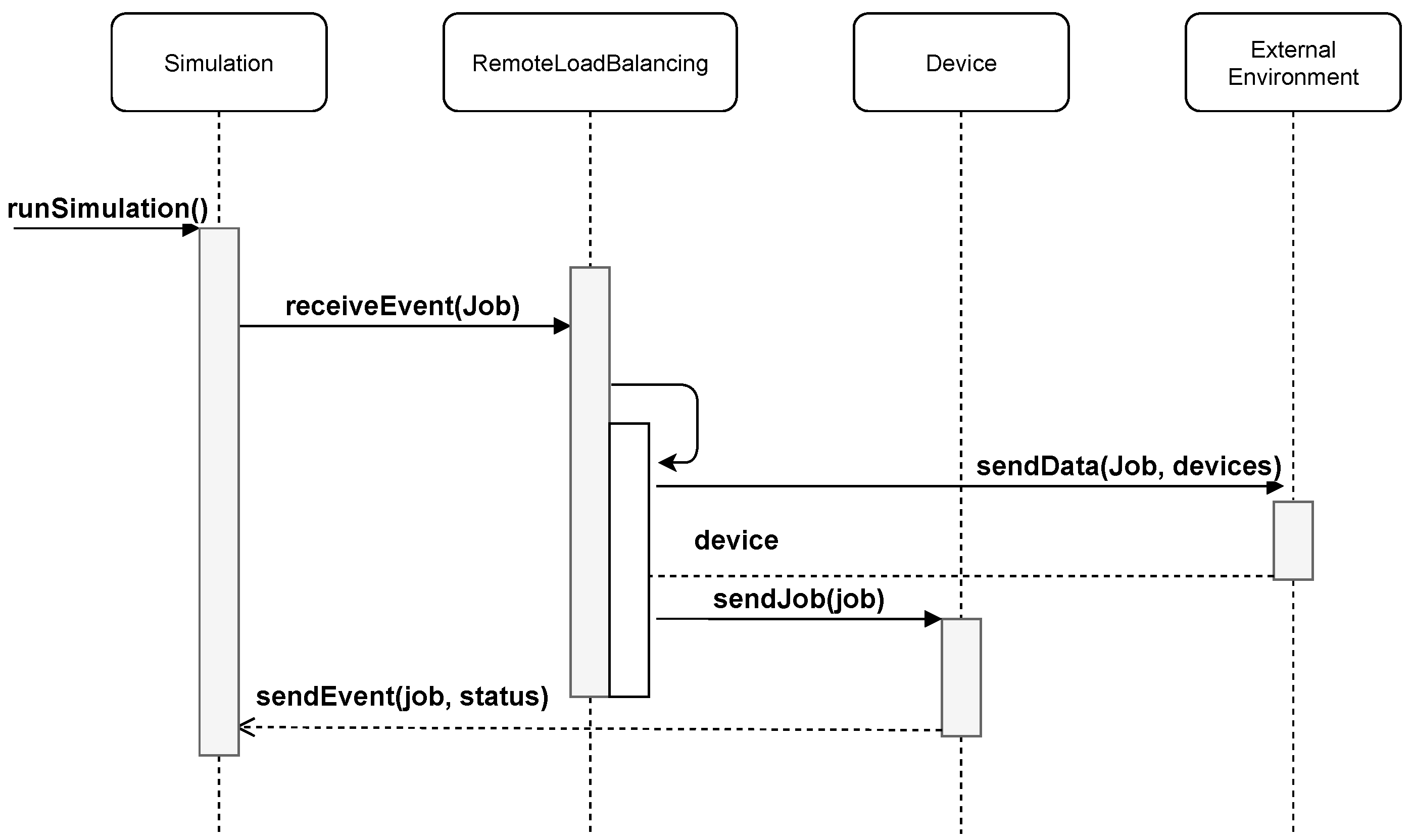
4. EdgeDewSim Extended Simulator
4.1. Device Connection Score
4.2. Device Connection Event
4.3. Device Disconnection Event
5. Human Mobility Modeling
5.1. Random Walk
5.2. Random Waypoint
6. Connection-Aware Scheduling Heuristics
6.1. Reliability Score
6.2. ReleSEAS
6.3. RelBPA
6.4. Connection-Aware Reinforcement Learning Agent
6.4.1. Notation
6.4.2. Problem Definition: Job Scheduling in Dew Computing
6.4.3. Environment Definition: States, Actions, and Rewards
6.4.4. Implementation Details
7. Methodology and Experimentation
7.1. Methodology
7.2. Human-Designed Heuristics
7.3. Reinforcement Learning Agent
7.4. Experimentation
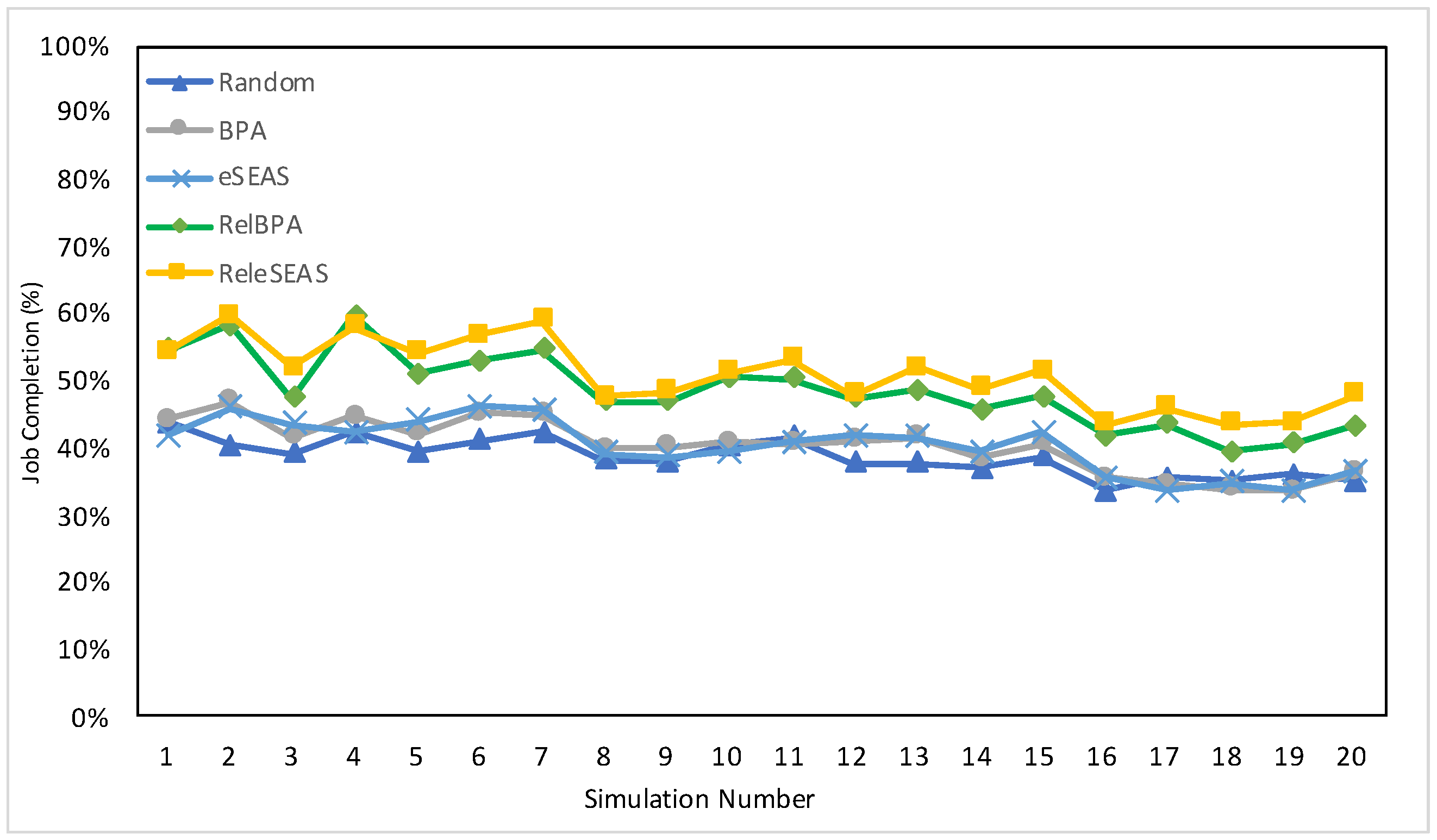
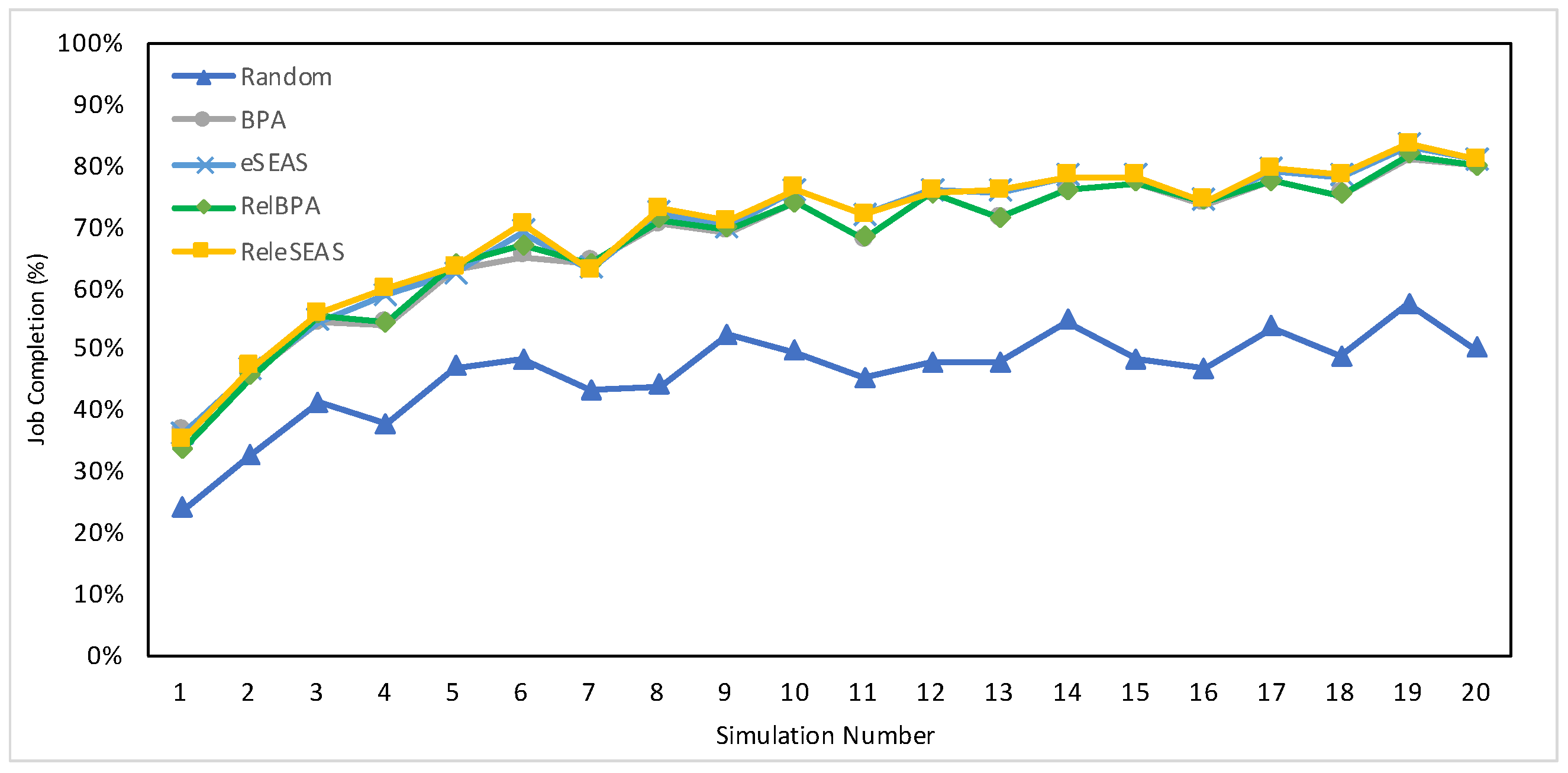
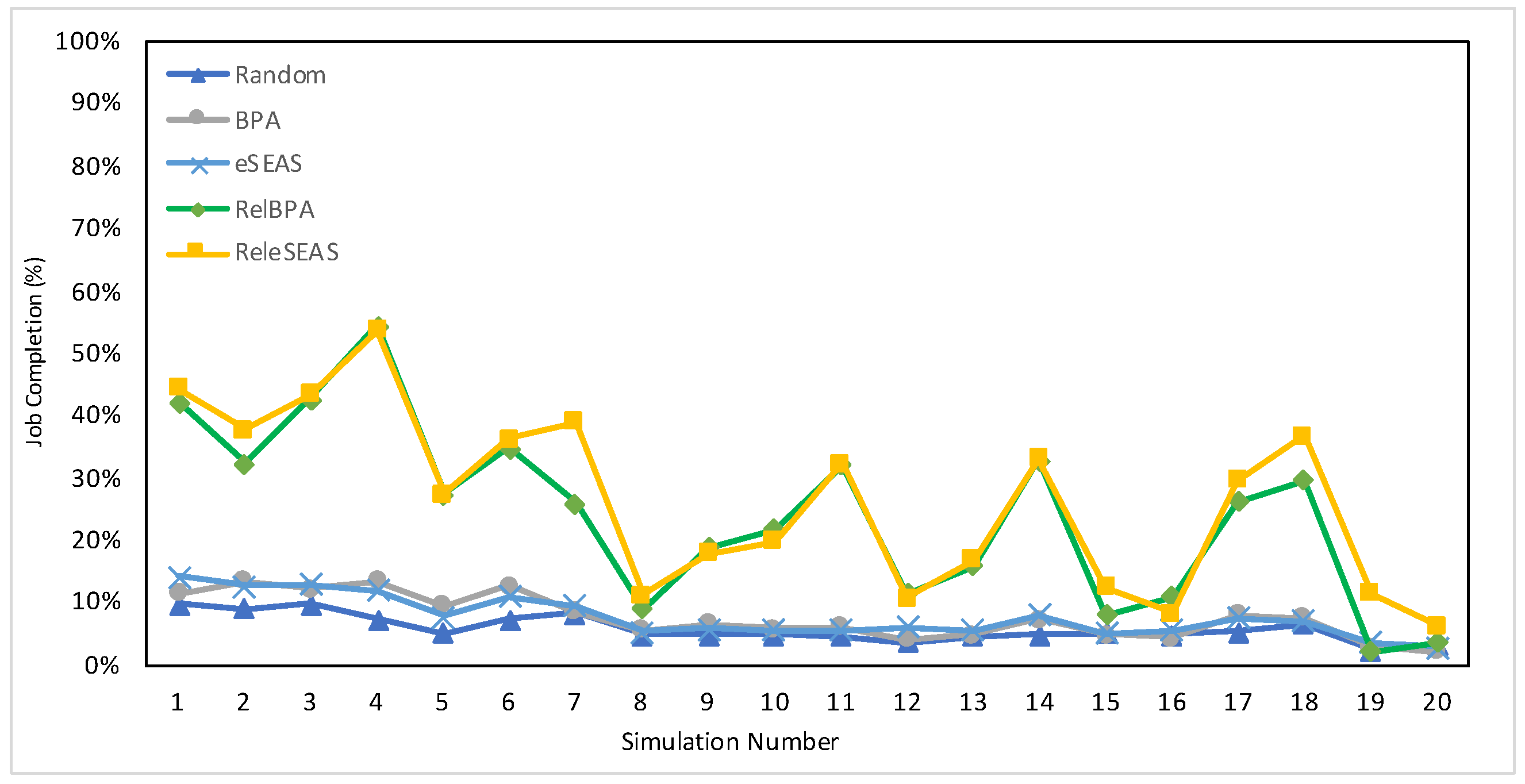
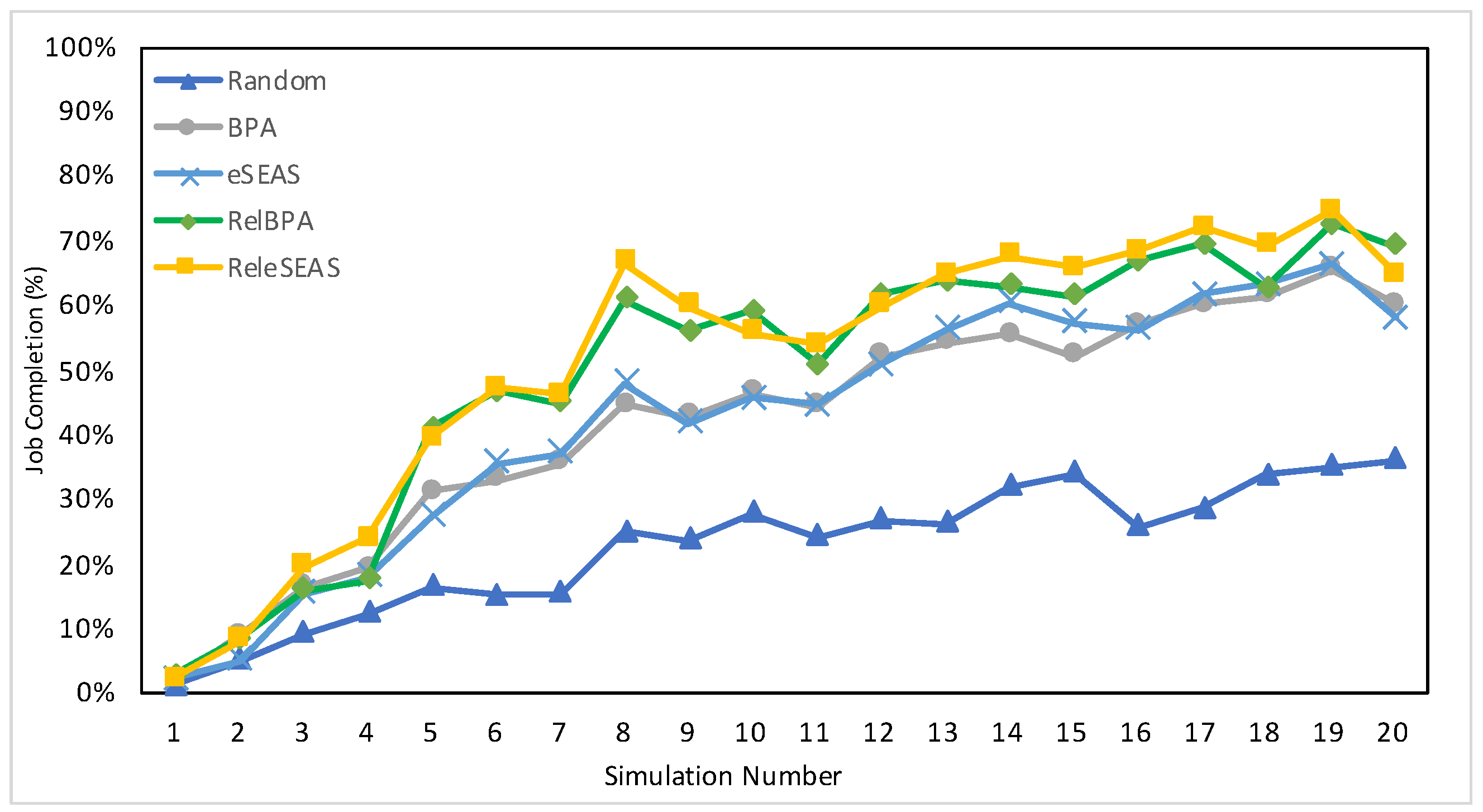
7.4.1. Job Completion
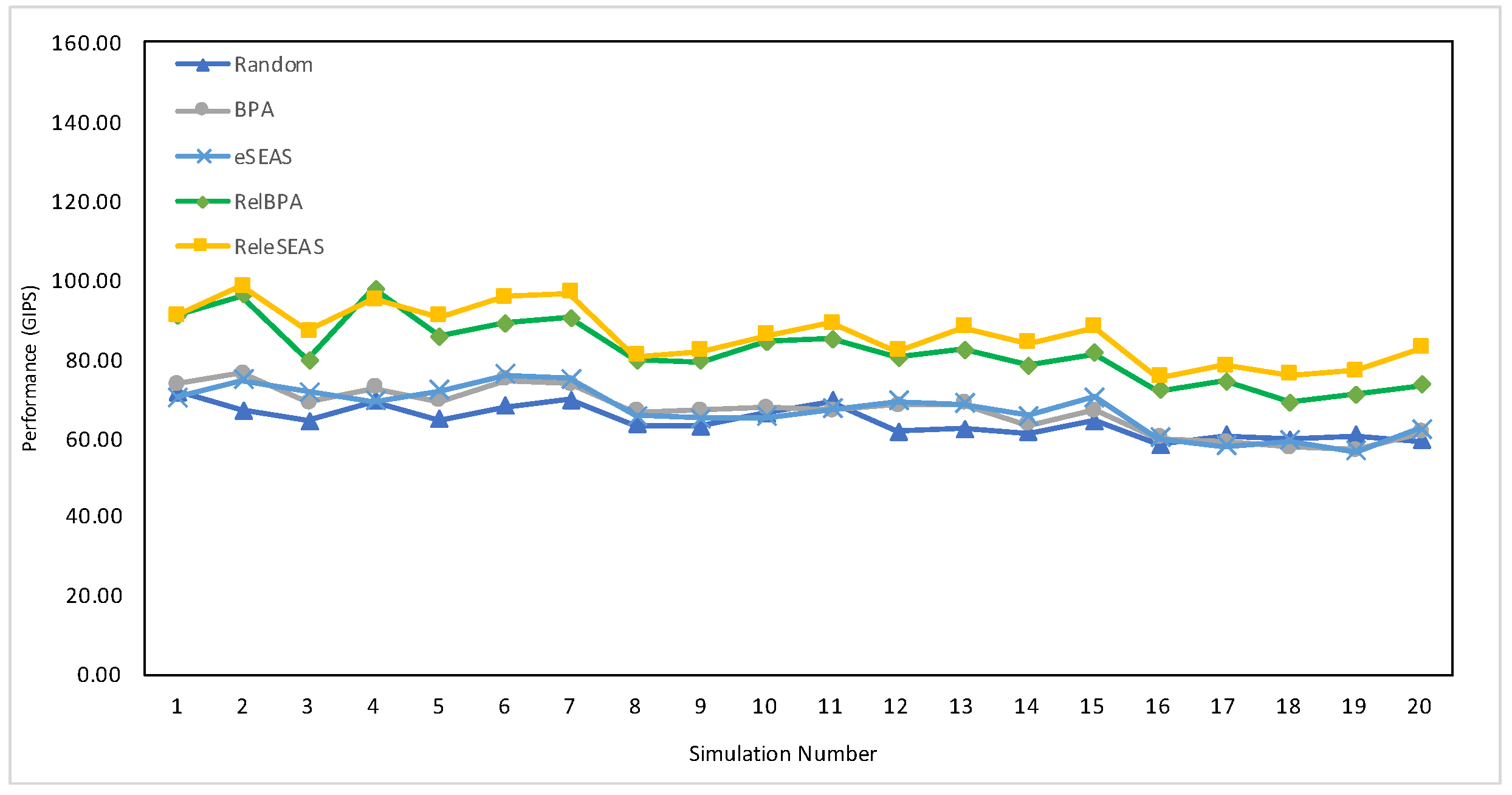
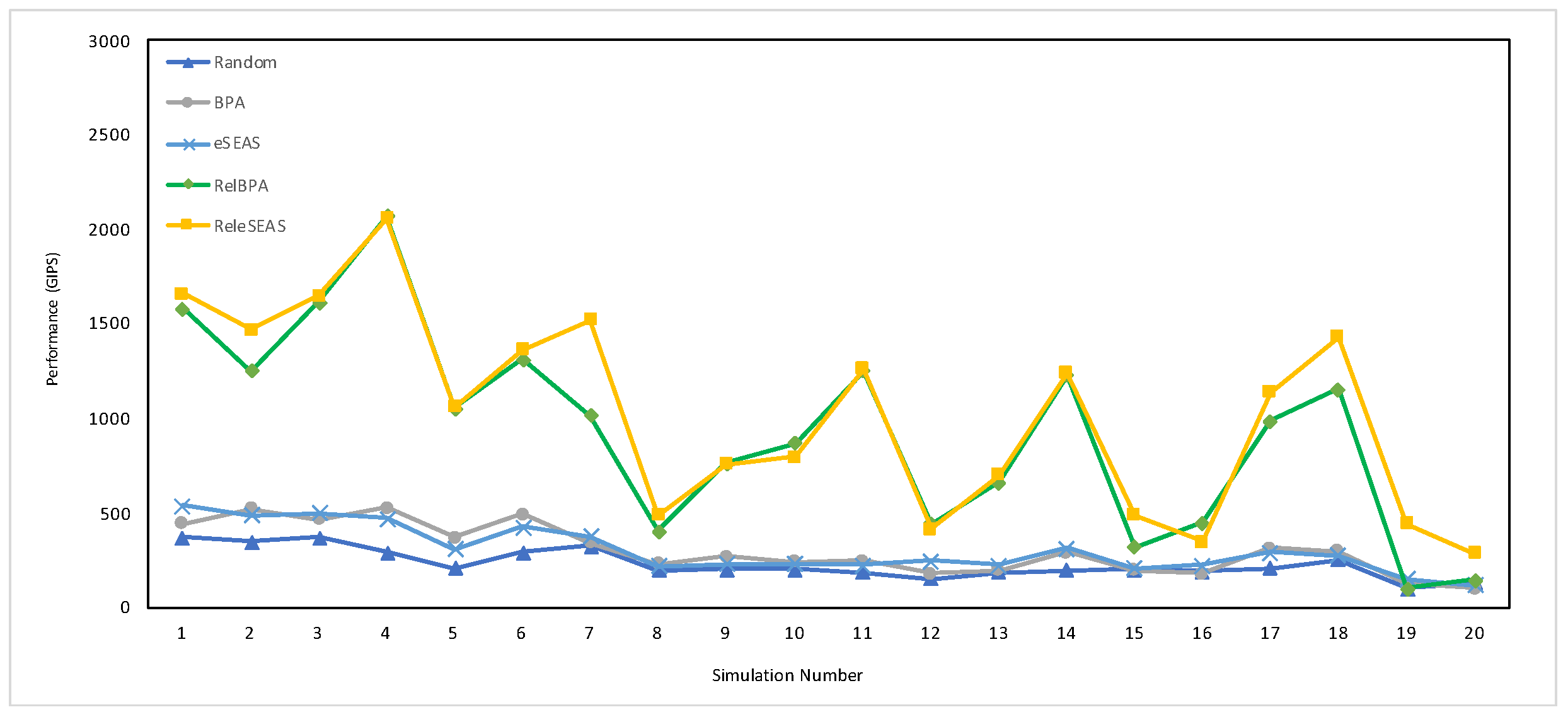
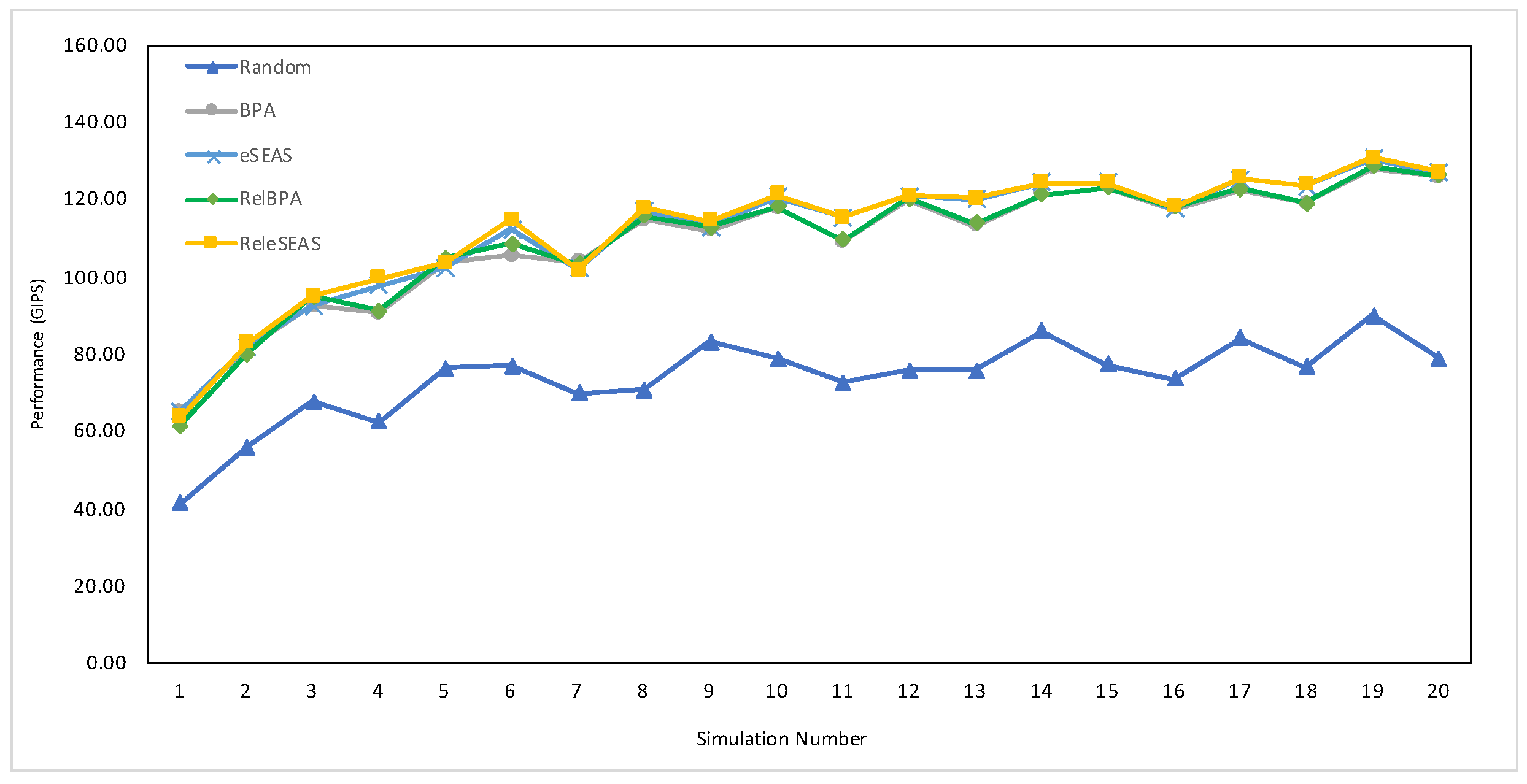
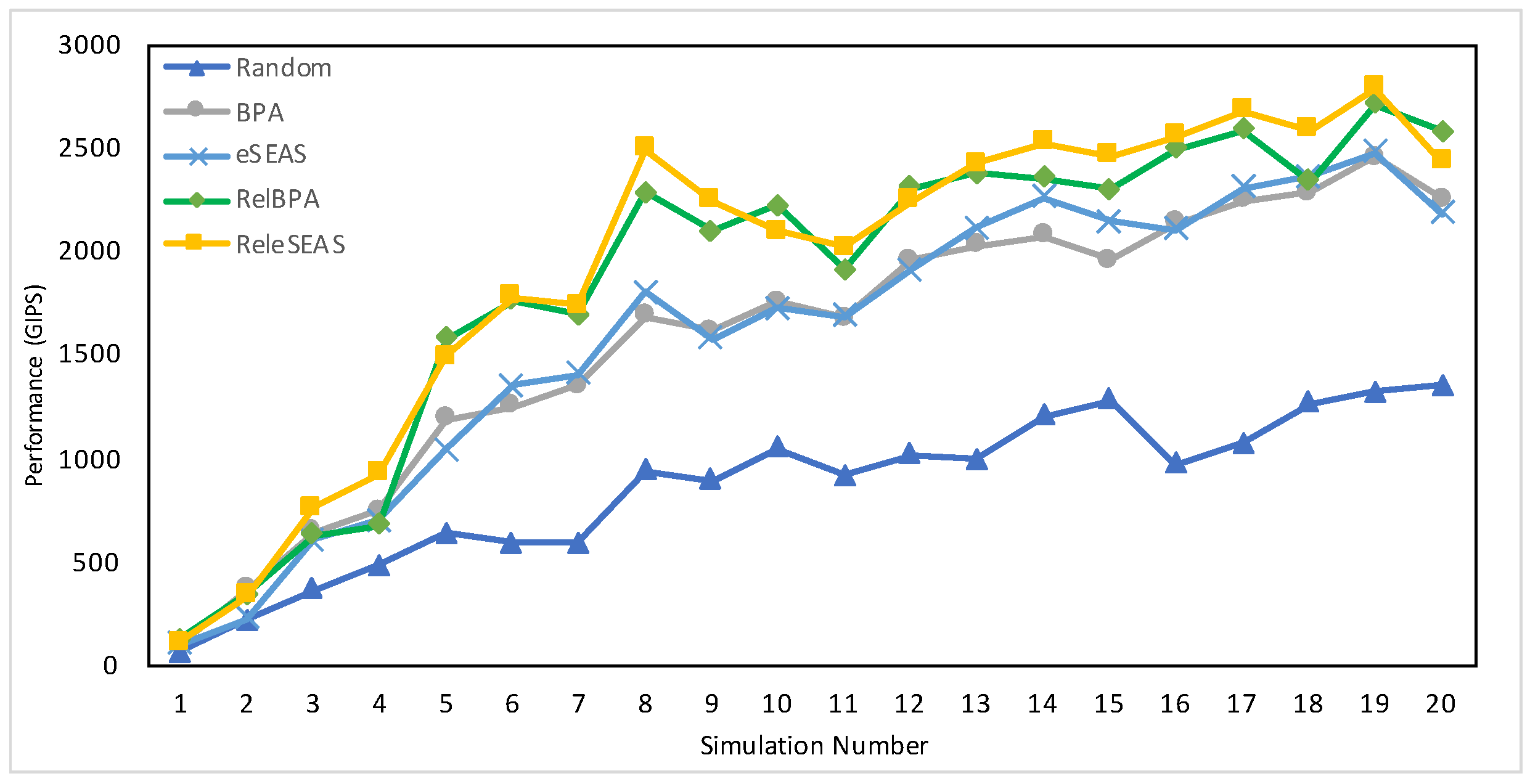
7.4.2. Performance
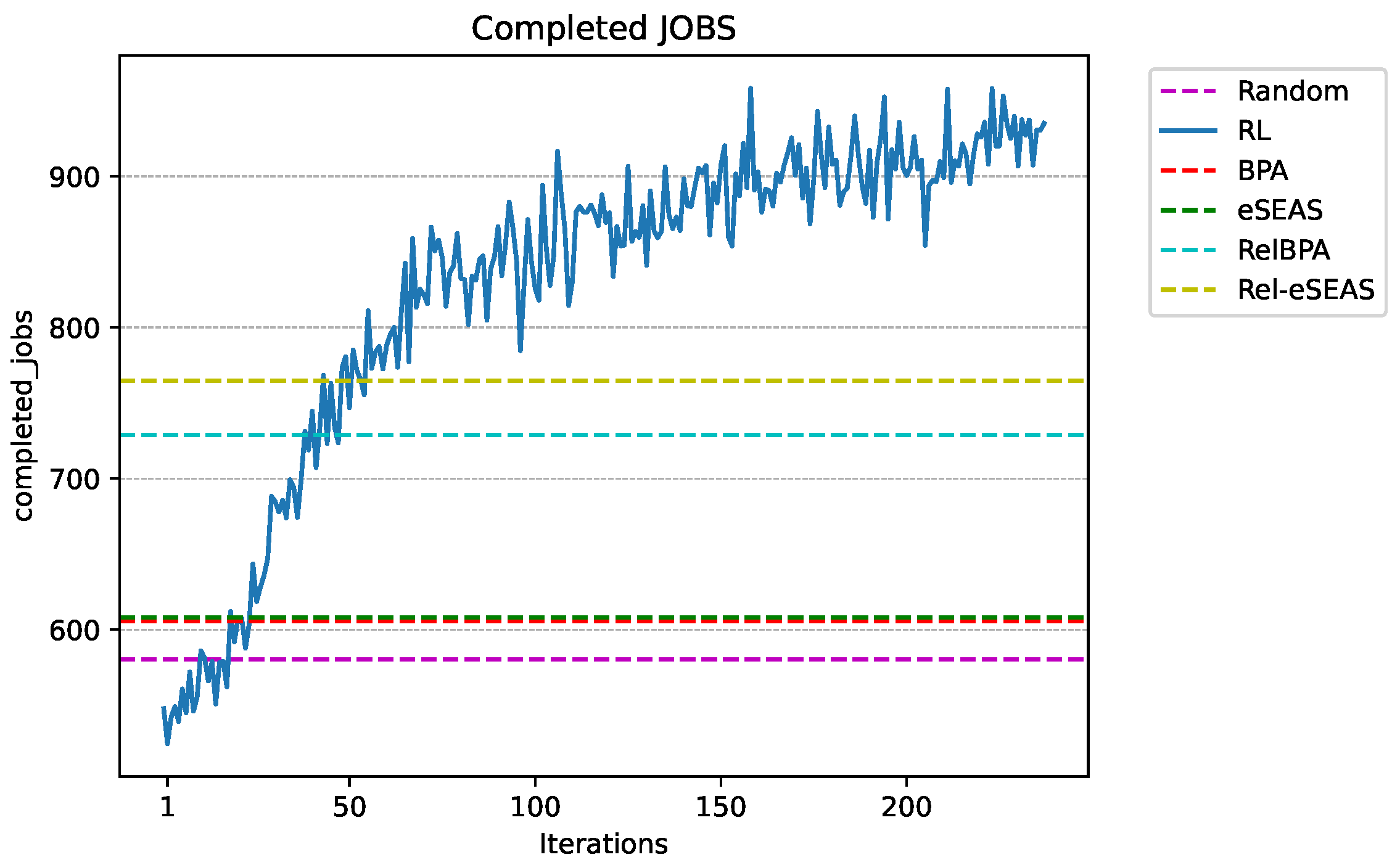
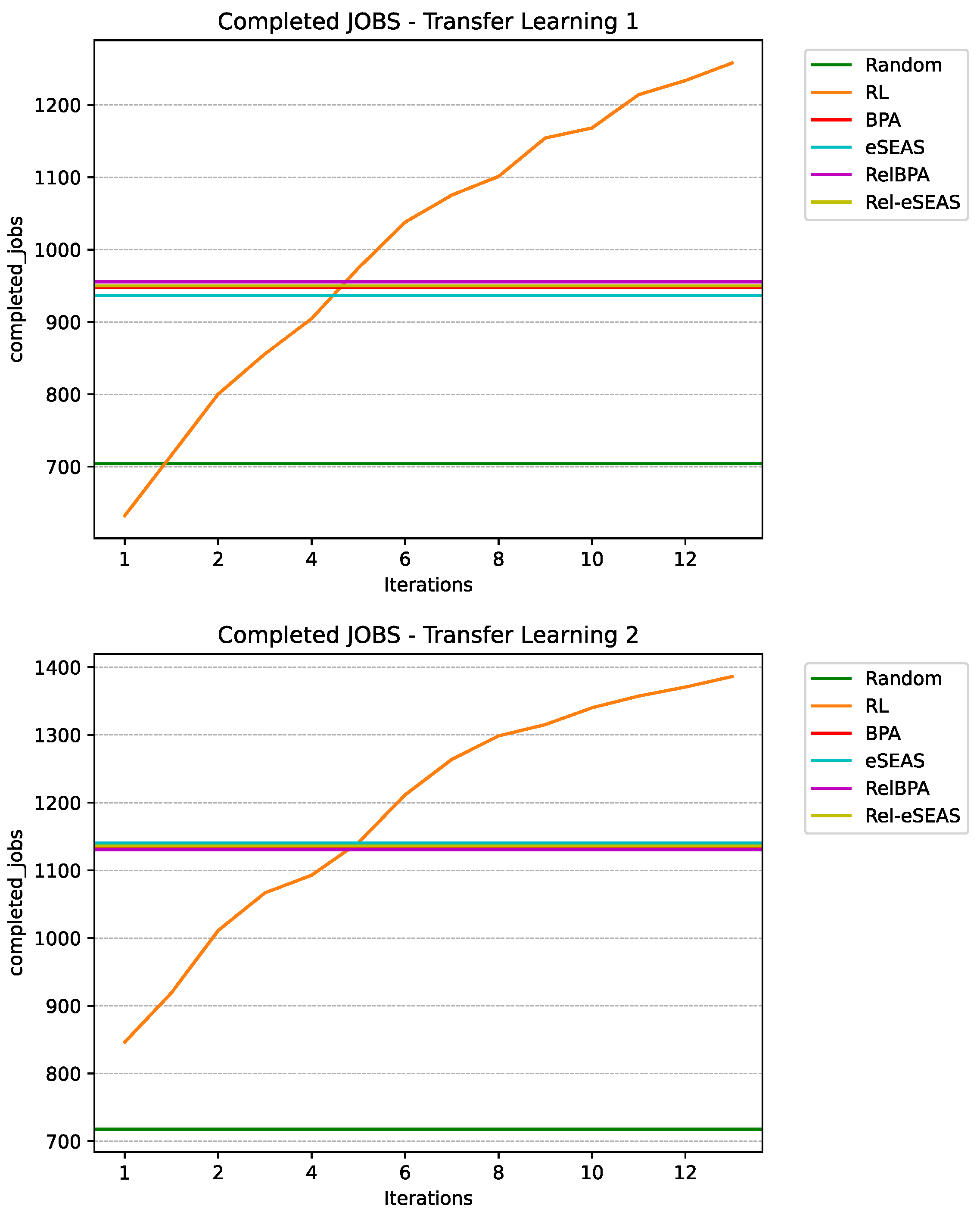
7.5. Reinforcement Learning Agent Results
7.6. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y. Definition and categorization of dew computing. Open J. Cloud Comput. (OJCC) 2016, 3, 1–7. [Google Scholar]
- Ray, P.P. An introduction to dew computing: Definition, concept and implications. IEEE Access 2017, 6, 723–737. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A. Augmenting computing capabilities at the edge by jointly exploiting mobile devices: A survey. Future Gener. Comput. Syst. 2018, 88, 644–662. [Google Scholar] [CrossRef]
- Khalid, M.N.B. Deep Learning-Based Dew Computing with Novel Offloading Strategy. In Proceedings of the International Conference on Security, Privacy and Anonymity in Computation, Communication and Storage, Nanjing, China, 18–20 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 444–453. [Google Scholar]
- Nanakkal, A. A Brief Survey of Future Computing Technologies in Cloud Environment. Ir. Interdiscip. J. Sci. Res. (IIJSR) 2021, 4, 63–70. [Google Scholar] [CrossRef]
- Hirsch, M.; Rodriguez, J.M.; Zunino, A.; Mateos, C. Battery-aware centralized schedulers for CPU-bound jobs in mobile Grids. Pervasive Mob. Comput. 2016, 29, 73–94. [Google Scholar] [CrossRef]
- Sanabria, P.; Tapia, T.F.; Neyem, A.; Benedetto, J.I.; Hirsch, M.; Mateos, C.; Zunino, A. New Heuristics for Scheduling and Distributing Jobs under Hybrid Dew Computing Environments. Wirel. Commun. Mob. Comput. 2021, 2021, 8899660. [Google Scholar] [CrossRef]
- Samal, P.; Mishra, P. Analysis of variants in Round Robin Algorithms for load balancing in Cloud Computing. Int. J. Comput. Sci. Inf. Technol. 2013, 4, 416–419. [Google Scholar]
- Sanabria, P.; Tapia, T.F.; Toro Icarte, R.; Neyem, A. Solving Task Scheduling Problems in Dew Computing via Deep Reinforcement Learning. Appl. Sci. 2022, 12, 7137. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Akkaya, I.; Andrychowicz, M.; Chociej, M.; Litwin, M.; McGrew, B.; Petron, A.; Paino, A.; Plappert, M.; Powell, G.; Ribas, R.; et al. Solving rubik’s cube with a robot hand. arXiv 2019, arXiv:1910.07113. [Google Scholar]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Popova, M.; Isayev, O.; Tropsha, A. Deep reinforcement learning for de novo drug design. Sci. Adv. 2018, 4, eaap7885. [Google Scholar] [CrossRef] [PubMed]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Khan, W.Z.; Ahmed, E.; Hakak, S.; Yaqoob, I.; Ahmed, A. Edge computing: A survey. Future Gener. Comput. Syst. 2019, 97, 219–235. [Google Scholar] [CrossRef]
- Drolia, U.; Martins, R.; Tan, J.; Chheda, A.; Sanghavi, M.; Gandhi, R.; Narasimhan, P. The case for mobile edge-clouds. In Proceedings of the 2013 IEEE 10th International Conference on Ubiquitous Intelligence and Computing and 2013 IEEE 10th International Conference on Autonomic and Trusted Computing, Vietri sul Mare, Italy, 18–21 December 2013; IEEE: Vietri sul Mare, Italy, 2013; pp. 209–215. [Google Scholar]
- Benedetto, J.I.; González, L.A.; Sanabria, P.; Neyem, A.; Navón, J. Towards a practical framework for code offloading in the Internet of Things. Future Gener. Comput. Syst. 2019, 92, 424–437. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yu, W.; Liang, F.; He, X.; Hatcher, W.G.; Lu, C.; Lin, J.; Yang, X. A survey on the edge computing for the Internet of Things. IEEE Access 2017, 6, 6900–6919. [Google Scholar] [CrossRef]
- Olaniyan, R.; Fadahunsi, O.; Maheswaran, M.; Zhani, M.F. Opportunistic edge computing: Concepts, opportunities and research challenges. Future Gener. Comput. Syst. 2018, 89, 633–645. [Google Scholar] [CrossRef]
- Aslam, S.; Michaelides, M.P.; Herodotou, H. Internet of ships: A survey on architectures, emerging applications, and challenges. IEEE Internet Things J. 2020, 7, 9714–9727. [Google Scholar] [CrossRef]
- Hirsch, M.; Rodriguez, J.M.; Mateos, C.; Alejandro, Z. A Two-Phase Energy-Aware Scheduling Approach for CPU-Intensive Jobs in Mobile Grids. J. Grid Comput. 2017, 15, 55–80. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Rodriguez, J.M.; Zunino, A.; Garí, Y.; Monge, D.A. A performance comparison of data-aware heuristics for scheduling jobs in mobile grids. In Proceedings of the 2017 XLIII Latin American Computer Conference (CLEI), Córdoba, Argentina, 4–8 September 2017; IEEE: Córdoba, Argentina, 2017; pp. 1–8. [Google Scholar]
- Chen, X.; Pu, L.; Gao, L.; Wu, W.; Wu, D. Exploiting Massive D2D Collaboration for Energy-Efficient Mobile Edge Computing. IEEE Wirel. Commun. 2017, 24, 64–71. [Google Scholar] [CrossRef]
- Mtibaa, A.; Fahim, A.; Harras, K.A.; Ammar, M.H. Towards resource sharing in mobile device clouds. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 51–56. [Google Scholar] [CrossRef]
- Li, B.; Pei, Y.; Wu, H.; Shen, B. Heuristics to allocate high-performance cloudlets for computation offloading in mobile ad hoc clouds. J. Supercomput. 2015, 71, 3009–3036. [Google Scholar] [CrossRef]
- Chunlin, L.; Layuan, L. Exploiting composition of mobile devices for maximizing user QoS under energy constraints in mobile grid. Inf. Sci. 2014, 279, 654–670. [Google Scholar] [CrossRef]
- Birje, M.N.; Manvi, S.S.; Das, S.K. Reliable resources brokering scheme in wireless grids based on non-cooperative bargaining game. J. Netw. Comput. Appl. 2014, 39, 266–279. [Google Scholar] [CrossRef]
- Loke, S.W.; Napier, K.; Alali, A.; Fernando, N.; Rahayu, W. Mobile Computations with Surrounding Devices. ACM Trans. Embed. Comput. Syst. 2015, 14, 1–25. [Google Scholar] [CrossRef]
- Shah, S.C. Energy efficient and robust allocation of interdependent tasks on mobile ad hoc computational grid. Concurr. Comput. Pract. Exp. 2015, 27, 1226–1254. [Google Scholar] [CrossRef]
- Orhean, A.I.; Pop, F.; Raicu, I. New scheduling approach using reinforcement learning for heterogeneous distributed systems. J. Parallel Distrib. Comput. 2018, 117, 292–302. [Google Scholar] [CrossRef]
- Kaur, P. DRLCOA: Deep Reinforcement Learning Computation Offloading Algorithm in Mobile Cloud Computing. SSRN Electron. J. 2019, 12, 238–246. [Google Scholar] [CrossRef]
- Cheng, M.; Li, J.; Nazarian, S. DRL-cloud: Deep reinforcement learning-based resource provisioning and task scheduling for cloud service providers. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju, Republic of Korea, 22–25 January 2018; IEEE: Jeju, Republic of Korea, 2018; pp. 129–134. [Google Scholar] [CrossRef]
- Huang, L.; Bi, S.; Zhang, Y.J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef]
- Ha, S.; Choi, E.; Ko, D.; Kang, S.; Lee, S. Efficient Resource Augmentation of Resource Constrained UAVs Through EdgeCPS. In Proceedings of the 38th ACM/SIGAPP Symposium on Applied Computing, Tallinn, Estonia, 27–31 March 2023; pp. 679–682. [Google Scholar]
- Ren, J.; Xu, S. DDPG Based Computation Offloading and Resource Allocation for MEC Systems with Energy Harvesting. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Virtual, 25 April–19 May 2021; IEEE: Helsinki, Finland, 2021; pp. 1–5. [Google Scholar]
- Zhao, R.; Wang, X.; Xia, J.; Fan, L. Deep reinforcement learning based mobile edge computing for intelligent Internet of Things. Phys. Commun. 2020, 43, 101184. [Google Scholar] [CrossRef]
- Tefera, G.; She, K.; Shelke, M.; Ahmed, A. Decentralized adaptive resource-aware computation offloading & caching for multi-access edge computing networks. Sustain. Comput. Inform. Syst. 2021, 30, 100555. [Google Scholar] [CrossRef]
- Baek, J.; Kaddoum, G. Heterogeneous Task Offloading and Resource Allocations via Deep Recurrent Reinforcement Learning in Partial Observable Multi-Fog Networks. IEEE Internet Things J. 2020, 8, 1041–1056. [Google Scholar] [CrossRef]
- Lu, H.; Gu, C.; Luo, F.; Ding, W.; Liu, X. Optimization of lightweight task offloading strategy for mobile edge computing based on deep reinforcement learning. Future Gener. Comput. Syst. 2020, 102, 847–861. [Google Scholar] [CrossRef]
- Li, J.; Gao, H.; Lv, T.; Lu, Y. Deep reinforcement learning based computation offloading and resource allocation for MEC. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; IEEE: Barcelona, Spain, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Alfakih, T.; Hassan, M.M.; Gumaei, A.; Savaglio, C.; Fortino, G. Task Offloading and Resource Allocation for Mobile Edge Computing by Deep Reinforcement Learning Based on SARSA. IEEE Access 2020, 8, 54074–54084. [Google Scholar] [CrossRef]
- Zhao, L.; Li, H.; Zhang, E.; Hawbani, A.; Lin, M.; Wan, S.; Guizani, M. Intelligent Caching for Vehicular Dew Computing in Poor Network Connectivity Environments. ACM Trans. Embed. Comput. Syst. 2024, 23, 1–24. [Google Scholar] [CrossRef]
- Khatua, S.; Manerba, D.; Maity, S.; De, D. Dew Computing-Based Sustainable Internet of Vehicular Things. In Dew Computing: The Sustainable IoT Perspectives; Springer: Berlin/Heidelberg, Germany, 2023; pp. 181–205. [Google Scholar]
- Pal, M.N.; Sengupta, D.; Tran, T.A.; De, D. Machine Learning-Based Sustainable Dew Computing: Classical to Quantum. In Dew Computing: The Sustainable IoT Perspectives; Springer: Berlin/Heidelberg, Germany, 2023; pp. 149–177. [Google Scholar]
- Chakraborty, S.; De, D.; Mazumdar, K. DoME: Dew computing based microservice execution in mobile edge using Q-learning. Appl. Intell. 2023, 53, 10917–10936. [Google Scholar] [CrossRef]
- Cobbe, K.; Klimov, O.; Hesse, C.; Kim, T.; Schulman, J. Quantifying generalization in reinforcement learning. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 1282–1289. [Google Scholar]
- Cobbe, K.; Hesse, C.; Hilton, J.; Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual Event, 13–18 July 2020; pp. 2048–2056. [Google Scholar]
- Hirsch, M.; Mateos, C.; Rodriguez, J.M.; Zunino, A. DewSim: A trace-driven toolkit for simulating mobile device clusters in Dew computing environments. Softw. Pract. Exp. 2020, 50, 688–718. [Google Scholar] [CrossRef]
- Manweiler, J.; Santhapuri, N.; Choudhury, R.R.; Nelakuditi, S. Predicting length of stay at wifi hotspots. In Proceedings of the 2013 IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 3102–3110. [Google Scholar]
- Blanford, J.I.; Huang, Z.; Savelyev, A.; MacEachren, A.M. Geo-located tweets. Enhancing mobility maps and capturing cross-border movement. PLoS ONE 2015, 10, e0129202. [Google Scholar] [CrossRef]
- Barbosa, H.; Barthelemy, M.; Ghoshal, G.; James, C.R.; Lenormand, M.; Louail, T.; Menezes, R.; Ramasco, J.J.; Simini, F.; Tomasini, M. Human mobility: Models and applications. Phys. Rep. 2018, 734, 1–74. [Google Scholar] [CrossRef]
- Solmaz, G.; Turgut, D. A Survey of Human Mobility Models. IEEE Access 2019, 7, 125711–125731. [Google Scholar] [CrossRef]
- Falaki, H.; Mahajan, R.; Kandula, S.; Lymberopoulos, D.; Govindan, R.; Estrin, D. Diversity in Smartphone Usage. In Proceedings of the 8th International Conference on Mobile Systems, Applications, and Services (MobiSys’10), New York, NY, USA, 15–18 June 2010; pp. 179–194. [Google Scholar] [CrossRef]
- Keramat Jahromi, K.; Zignani, M.; Gaito, S.; Rossi, G.P. Simulating human mobility patterns in urban areas. Simul. Model. Pract. Theory 2016, 62, 137–156. [Google Scholar] [CrossRef]
- Henderson, T.; Kotz, D.; Abyzov, I. The changing usage of a mature campus-wide wireless network. Comput. Netw. 2008, 52, 2690–2712. [Google Scholar] [CrossRef]
- Gorawski, M.; Grochla, K. Review of mobility models for performance evaluation of wireless networks. In Man-Machine Interactions 3; Springer: Berlin/Heidelberg, Germany, 2014; pp. 567–577. [Google Scholar]
- Panisson, A. Pymobility v0.1—Python Implementation of Mobility Models. 2015. Available online: https://zenodo.org/records/9873 (accessed on 27 November 2023).
- Zhao, K.; Tarkoma, S.; Liu, S.; Vo, H. Urban human mobility data mining: An overview. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 1911–1920. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Zhang, A.; Ballas, N.; Pineau, J. A dissection of overfitting and generalization in continuous reinforcement learning. arXiv 2018, arXiv:1806.07937. [Google Scholar]
- Zhang, C.; Vinyals, O.; Munos, R.; Bengio, S. A study on overfitting in deep reinforcement learning. arXiv 2018, arXiv:1804.06893. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job Set | Random | BPA | eSEAS | RelBPA | ReleSEAS |
|---|---|---|---|---|---|
| 1500 | 38.69% | 40.38% | 40.40% | 48.59% | 50.98% |
| 36,000 (full set) | 5.75% | 7.56% | 7.63% | 24.05% | 26.39% |
| Job Set | Random | BPA | eSEAS | RelBPA | ReleSEAS |
|---|---|---|---|---|---|
| 1500 | 45.97% | 67.58% | 69.17% | 67.75% | 69.51% |
| 36,000 (full set) | 22.74% | 42.21% | 42.60% | 49.73% | 51.52% |
| Job Set | Random | BPA | eSEAS | RelBPA | ReleSEAS |
|---|---|---|---|---|---|
| 1500 | 64.36 | 67.05 | 67.18 | 82.03 | 86.25 |
| 36,000 (full set) | 231.69 | 303.27 | 305.30 | 935.17 | 1029.76 |
| Job Set | Random | BPA | eSEAS | RelBPA | ReleSEAS |
|---|---|---|---|---|---|
| 1500 | 73.68 | 109.30 | 111.60 | 109.65 | 112.23 |
| 36,000 (full set) | 860.52 | 1588.68 | 1604.73 | 1868.67 | 1934.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanabria, P.; Montoya, S.; Neyem, A.; Toro Icarte, R.; Hirsch, M.; Mateos, C. Connection-Aware Heuristics for Scheduling and Distributing Jobs under Dynamic Dew Computing Environments. Appl. Sci. 2024, 14, 3206. https://doi.org/10.3390/app14083206
Sanabria P, Montoya S, Neyem A, Toro Icarte R, Hirsch M, Mateos C. Connection-Aware Heuristics for Scheduling and Distributing Jobs under Dynamic Dew Computing Environments. Applied Sciences. 2024; 14(8):3206. https://doi.org/10.3390/app14083206
Chicago/Turabian StyleSanabria, Pablo, Sebastián Montoya, Andrés Neyem, Rodrigo Toro Icarte, Matías Hirsch, and Cristian Mateos. 2024. "Connection-Aware Heuristics for Scheduling and Distributing Jobs under Dynamic Dew Computing Environments" Applied Sciences 14, no. 8: 3206. https://doi.org/10.3390/app14083206