Abstract
To enhance the segmentation accuracy of car front face elements such as headlights and grilles for car front face design, and to improve the superiority and efficiency of solutions in automotive partial modification design, this paper introduces MD-TransUNet, a semantic segmentation network based on the TransUNet model. MD-TransUNet integrates multi-scale attention gates and dynamic-channel graph convolution networks to enhance image restoration across various design drawings. To improve accuracy and detail retention in segmenting automotive front face elements, dynamic-channel graph convolution networks model global channel relationships between contextual sequences, thereby enhancing the Transformer’s channel encoding capabilities. Additionally, a multi-scale attention-based decoder structure is employed to restore feature map dimensions, mitigating the loss of detail in the local feature encoding by the Transformer. Experimental results demonstrate that the MSAG module significantly enhances the model’s ability to capture details, while the DCGCN module improves the segmentation accuracy of the shapes and edges of headlights and grilles. The MD-TransUNet model outperforms existing models on the automotive front face dataset, achieving mF-score, mIoU, and OA metrics of 95.81%, 92.08%, and 98.86%, respectively. Consequently, the MD-TransUNet model increases the precision of automotive front face element segmentation and achieves a more advanced and efficient approach to partial modification design.
1. Introduction
The automotive industry has become a critical driver of global economic growth through continuous technological advancements. Studies by Nirmala et al. [] and Manabu et al. [] have shown that the automotive sector has significantly contributed to economic development. Within the entire automotive industrial chain, vehicle design occupies a central upstream position. Volkova et al. [] emphasize that innovation in automotive design is key to successful market promotion, as the degree of innovation directly impacts the automotive industry. A systematic analysis of automotive design reveals its core position within the automotive industrial chain, encompassing key steps in the design process [], such as concept generation, design proposal, model building, full-scale model construction, and final release. In practical production scenarios, even the fastest concept car projects require a minimum of 14 months. Although the design phase only accounts for 5% of the product cost in the automotive product development process, it influences 70% of the overall product impact []. Vehicle design can be divided into full vehicle design and partial modification design []. Among these, car front face design changes are relatively easy to implement, cost-effective, and effectively showcase continuous brand innovation and progress. Moreover, for consumers, the car front face is the most recognizable and visually impactful part of a vehicle’s exterior. As a result, car front face design modifications are commonly used in automotive facelifts. For example, Huang et al. [] identified that headlights are among the most frequently modified elements in vehicle design. They utilized networks such as StyleGAN, CNN, and RNN for the optimization and upgrading of headlight areas, achieving certain improvements. However, their research focused solely on sedans and SUVs, with limited generalizability to other vehicle types. Research in automotive design encompasses traditional product design methods and AI-based design methods. Zhang et al. [] proposed a product form cognition method combining electroencephalography (EEG) and eye-tracking, demonstrating that samples highly matched with target imagery in the form perception stage can trigger stronger EEG signals. Yuan et al. [] established an Aesthetic Measurement Index (AMI) system through Kansei engineering and utilized genetic algorithms and computer vision to propose an electric vehicle car front face design aligned with female aesthetics. Duan et al. [] introduced a complex product design method based on LSTM combined with Kansei engineering, showing that it can address the temporal sequence issues in complex products. In recent years, the rapid development of deep learning has extended across various industries. For instance, GAC Group’s release of GOVE [] demonstrates how designers can generate a large number of diverse concept images through text-to-image generation, selecting the most suitable ones for further refinement. This indicates that deep learning methods have significant potential in automotive design. However, while AI performs well in generating aesthetically pleasing images, it still faces challenges in maintaining subject consistency. Huang et al. [] noted the difficulty of current diffusion methods in preserving character consistency. In related research, Chen et al. [] proposed the ID-Aligner method, introducing feedback learning, identity consistency rewards, and identity aesthetic rewards to effectively maintain character identity consistency in image generation. Wang et al. [] developed the Character Factory framework, which generates consistent virtual characters by incorporating GAN with identity-embedding and contextual consistency loss. Guo et al. [] introduced the PuLID method, incorporating contrastive alignment loss to preserve identity similarity in generated images. Although these methods perform well in maintaining consistency for character images, they can result in distortions when applied to real-world photographs. Consequently, these methods are not suitable for real-world automotive product design. Moreover, while maintaining design consistency across vehicle models, research on the consistent segmentation of headlights and grilles remains sparse. To address the need for consistency across vehicle models and improve the generalization of car front face design elements across different models, this paper proposes a segmentation network for vehicle car front face elements. This network accurately separates elements such as headlights and grilles, providing clear structural data for subsequent design processes.
Taking headlights and grilles as examples, these components are key styling elements in the front face design of a car. Precise segmentation of these elements provides designers with accurate data for further optimization. In the domains of semantic segmentation tasks, Ronneberger et al. [] introduced the U-Net model, which uses skip connections linking the encoder and decoder to transfer high-resolution features, significantly improving segmentation accuracy. Chen et al. [] seamlessly integrated the Transformer architecture with the U-Net framework to form the TransUNet model, addressing U-Net model’s lack of global contextual information. This success led to further research on Transformer-based image segmentation models. For instance, Ji et al. [] developed BGRD-TransUNet for breast lesion segmentation, using DenseNet121 for initial feature extraction, aiding doctors in diagnosis. Pan et al. [] proposed the EG-TransUNet architecture, significantly improving biomedical image segmentation quality. These models have exhibited outstanding effectiveness in the segmentation of medical images and industrial defect detection. TransUNet combines U-Net’s detailed feature extraction and spatial retention with Transformer’s global context modeling, making it effective for complex images. Since car front face segmentation requires an understanding of the entire structure and the relationships between components, the Transformer module captures the global position and context of headlights and grilles, while U-Net’s skip connections retain high-resolution features for accurate boundary segmentation. Therefore, TransUNet enables precise segmentation of car front face elements like headlights and grilles.
Advanced deep learning techniques have significantly enhanced the precision of image semantic segmentation, offering more accurate and efficient tools for automotive design. In automotive segmentation research, Xu et al. [] proposed an improved YOLOv8 segmentation model (EIS-YOLO) for detecting car surface damage, introducing multi-scale feature fusion and high-resolution feature retention, improving accuracy and computational efficiency. Fan et al. [] developed an instance segmentation algorithm based on the SPG model, using the GAM attention mechanism to enhance multi-scale feature fusion for classifying parts in automotive scrap dismantling. Han et al. [] introduced a monocular vision-based approach for detecting and measuring vehicle outlines, achieving high-precision size estimation. Current research mainly focuses on damage detection, component segmentation, and overall vehicle segmentation. However, when it comes to more complex front face details like headlights and grilles, which possess rich details and intricate shapes, they are more susceptible to noise and other factors, often leading to inaccuracies in segmentation.
Therefore, this paper proposes MD-TransUNet, a semantic segmentation network integrating the multi-scale attention gate (MSAG) [] and the dynamic-channel graph convolutional network (DCGCN) [], based on the TransUNet model. The term ‘MD’ is an acronym for the MSAG and DCGCN modules, reflecting their combined role in enhancing the network’s performance. To enhance the edge continuity and overall definition of headlights and grilles, the MSAG module is integrated within the skip connections linking dual encoders and decoders, capturing multi-scale features to enhance detail sensitivity during reconstruction. This provides additional local specific information while suppressing irrelevant interference. The DCGCN module captures channel topological dependencies and aggregates effective features, enhancing information interaction and fusion between channels, thus addressing Transformer’s information loss during sequence encoding. Combining the MSAG and DCGCN modules effectively improves segmentation accuracy and generalization. By first performing image segmentation and then using the stable diffusion model for image restoration, design schemes are quickly generated, thereby improving design process efficiency and effectiveness, and providing a new technical approach for automotive design. The primary contributions of this paper are as follows:
- (1)
- For complex intricate areas such as headlights and grilles, the shortcomings of existing methods in feature extraction, edge information retention, and multi-scale feature fusion are analyzed, and a new car front face segmentation network is proposed.
- (2)
- The improved segmentation model MD-TransUNet has a good segmentation effect on headlights and grilles.
- (3)
- The innovative combination of the segmentation network and image restoration is proposed, which allows details such as the headlights and air intake grille to show diversity while maintaining the overall consistency of the front face of the car. This improves the efficiency and effectiveness of the design process and provides an innovative technical approach for the field of automotive design.
The remaining sections of this paper are outlined below: Section 2 presents the overall architecture of the TransUNet network and two improved modules; Section 3 describes the experimental design process; Section 4 discusses the comparative experiment and the innovative combination of the segmentation network and the stable diffusion model; and Section 5 explains the conclusions of this study.
2. Materials and Methods
2.1. Overall Architecture of the MD-TransUNet Network
The proposed improved network adopts an encoder–decoder structure, as illustrated in Figure 1. The encoder utilizes the R50-ViT-B/16 model [], which combines the Vision Transformer (ViT) with ResNet50. This combination enables the extraction of fine structures and texture information from images, offering robust feature extraction capabilities. In the decoder, the MSAG module is integrated before the two-dimensional sequence is fed into the Transformer layer. The MSAG module enhances the encoder’s ability in multi-scale feature fusion and is concatenated with the upsampled features for precise localization. The DCGCN module is integrated into the connection between high-level and low-level features within the encoder and decoder. It projects image channels into a topological domain and integrates the characteristics of each channel within the topological graph, efficiently capturing the relationships among different feature maps.
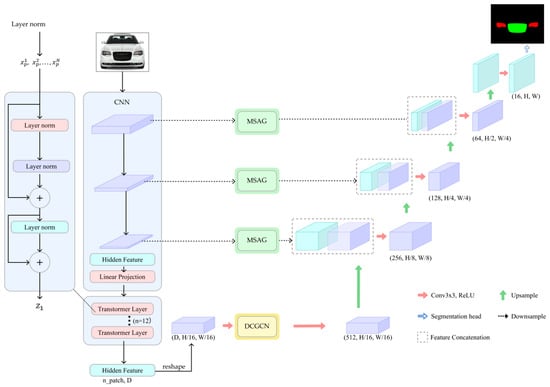
Figure 1.
The overall design of the enhanced TransUNet model.
When the input image has a spatial resolution of and channels, i.e., , it first undergoes local feature extraction via a CNN. The ViT model subsequently extracts features at both low and high levels, which are connected to the feature maps generated by the decoding module through cross-layer connections. This sequence is input into a 12-layer Transformer module for global information extraction. The Transformer module consists of multi-head self-attention (MSA), a multi-layer perceptron (MLP), and layer normalization (LN) []. Within the Transformer module, the image x is reshaped into a sequence of 2D patches of size P × P, represented as , as shown in Equation (1).
In the equation, denotes the patch embedding projection, and denotes the positional embedding.
The sequence patches, serving as an embedded sequence, first undergo layer normalization before being input into the MSA module. The MSA module captures global information by calculating correlations between different positions in the input sequence. The output of the MSA is added to the normalized input through residual connections to retain original information and prevent gradient vanishing. This result is normalized again and fed into the MLP module for further feature extraction and transformation. Ultimately, the output from the MLP is combined with its input through residual connections, resulting in the final output of the -th layer:
In the equation, denotes the layer normalization operator, represents the residual connection between the MSA output and , and represents the encoded image.
The TransUNet network employs sequence-to-sequence prediction with a self-attention mechanism. To address feature resolution loss in the Transformer model, TransUNet uses a CNN–Transformer hybrid encoder. This architecture allows the CNN to extract high-resolution features like the shape and boundaries of headlights, while the Transformer encodes global contextual information more effectively.
The decoder positioned on the right of the TransUNet architecture is a cascaded upsampler (CUP), which decodes the hybrid encoder’s output features to produce the segmentation result. The hidden feature sequence output by the hybrid encoder is reshaped from to . It then passes through cascaded upsampling blocks, each comprising a 2× upsampling operator for scale adjustment, a 3 × 3 convolution layer for feature extraction, and an activation ReLU layer to introduce non-linearity, expanding the feature map from to the original size . The CUP combined with the CNN–Transformer hybrid encoder forms a U-shaped structure, aggregating features at multiple resolution levels through the use of skip connections, ensuring detailed information is preserved.
2.2. MSAG Module
The headlights and grilles in the front of a car exhibit distinct geometric shapes and size characteristics, which are crucial for segmenting automotive front face elements. Traditional image segmentation methods [] often struggle to capture both large-scale structures and fine details simultaneously due to limitations in multi-scale information processing. To address this, we integrated the MSAG module, which computes attention weights at various scales. The architecture of the MSAG module is shown in Figure 2. It captures correlations across different regions of an image at multiple scales. The MSAG module extracts and fuses feature maps at various scales from the input image. Using a self-attention mechanism, it processes these feature maps to capture global and local information at different scales. This multi-scale attention mechanism dynamically adjusts the significance of features at each scale, filtering out irrelevant background noise, and enabling the model to focus on key features like headlights and grilles.
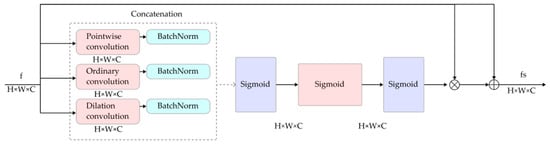
Figure 2.
Structure of the MSAG module.
The MSAG module is integrated with skip connections to enhance the extraction of valuable features. To adaptively select features at different resolutions, three types of convolutions with varying receptive fields are used: 1 × 1 pointwise convolution; 3 × 3 ordinary convolution; and 3 × 3 dilation convolution. The 1 × 1 pointwise convolution is employed for linear transformation and dimensionality reduction, the 3 × 3 ordinary convolution is applied for detailed local feature extraction and enhancement, and the 3 × 3 dilation convolution is utilized to expand the receptive field by introducing strategic gaps, thereby capturing broader and more comprehensive feature information. By combining these convolution operations and applying batch normalization (BN), it is ensured that the resulting feature maps have uniform dimensions, facilitating subsequent feature fusion.
During feature fusion, the input feature is extracted using three different convolution operations: , , . After batch normalization, these three feature maps are represented as:
The three output feature maps of the same size are fused, with the ReLU activation function non-linearly combining features of different scales. This allows the network to adaptively select and enhance valuable features. While retaining the diversity of the original features, the attention mechanism further strengthens the representation of important features. The valuable features are then selected through pointwise convolution, as shown in Equation (7):
In the equation, denotes the merged features, and denotes the ReLU activation function.
After selecting valuable features from the fused feature maps, pointwise convolution is applied to the fused feature maps, generating a weight map through the Sigmoid activation function . The resulting output feature from the multi-scale attention gate, is then obtained:
2.3. DCGCN Module
The shape and edge information of the headlights and grille regions in front images of different car models can vary significantly. Graph convolutional networks (GCNs) map various features onto nodes and edges within a complex topological graph structure [], allowing them to capture dynamic changes in sample intensity sensitively. GCNs are widely used in deep learning tasks for their ability to dynamically adjust learnable parameters to extract spatial information efficiently. By utilizing GCNs, dynamic topological relationships between channels can be captured, optimizing intra-channel functions. To better adjust segmentation areas and capture dynamic topological information between image feature channels, this paper employs the DCGCN module, as shown in Figure 3. By dynamically adjusting the convolution kernels, the DCGCN module adapts flexibly to these differences, thereby improving feature extraction effectiveness and enhancing the fine segmentation performance of headlights and grilles.
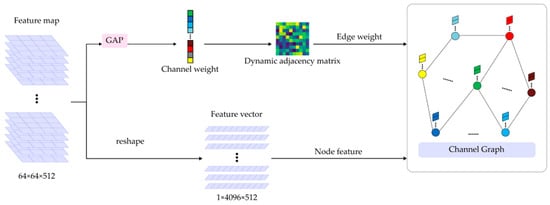
Figure 3.
Structure of the DCGCN module.
Prior to executing graph convolution, the feature map with dimensions 512 × 64 × 64 is converted into a graph. After global average pooling, the initial feature map is transformed into a comprehensive 512-dimensional column vector representation for further processing. To achieve a detailed understanding of the topological relationships among different image channels, the column vector is first processed using a specialized matrix activation function. Following this step, the learned parameter matrix is multiplied to obtain and improve the dynamic properties of the neighborhood matrix. Consequently, the derivation process of adjacency matrix is derived as follows:
In the equation, where and are the -th and -th elements of , the function of represents the matrix activation mechanism used in this context. Additionally, denotes the learnable dynamic parameter structure, which plays a crucial role in the process. The matrix activation mechanism in Equation (9) is defined as a continuous function ranging from 0 to 1, ensuring smooth transitions. It maps the vector of calculated channel weights to a configuration in which the edge weights between the corresponding channel nodes are expressed by non-diagonal elements and the diagonal elements are set to 1 for stability. Equation (10) dynamically adjusts the connection weights based on the input parameters, with fine-tuning the topological relationships to obtain the final matrix configuration.
In a graph convolution network, each node is associated with a corresponding feature vector. In this study, we represent the attributes of each node in a graph-structured data format by reconstructing the features of a single channel into 4096 × 1 vectors. The result of this transformation is the construction of a graph with 512 nodes, where each node has a 4096 × 1 feature vector. To perform an efficient convolution of the processed graph data, a method known as spectral filtering is used []. Spectral filtering can be briefly described as a process in which an signal is modified by a filter in the Fourier domain:
In this formula, the matrix , encompassing the eigenvectors derived from the normalized graph Laplacian, is described by the equation . The matrix is the diagonal matrix containing the eigenvalues of , where represents the degree matrix, denotes the adjacency matrix, and is the identity matrix. The function is treated as a function of denoted . To reduce computational complexity, the function can be closely estimated using a truncated series expansion of Chebyshev polynomials:
In the equation, , where is the largest eigenvalue of , and are the Chebyshev coefficients. The recursive definition of the Chebyshev polynomials is in Equation (13). To compute the filter response, the signal is expanded in terms of these Chebyshev polynomials. This method effectively approximates the spectral graph convolution by using a polynomial of the Laplacian, making it computationally efficient. The approximation allows the convolution operation to be performed in the graph domain without explicitly computing the eigen-decomposition of the Laplacian matrix, thus significantly reducing the computational burden.
In the equation, and . Hence, the signal convolved with the filter can be represented in the following manner:
In the equation, .
In summary, this defines the convolution operation in graph convolution networks. Similarly, an efficient two-layer GCN is employed to conduct convolutional operations on the graph data , avoiding redundant convolution layers that could cause node smoothing. According to the spectral convolution approximation process detailed in graph convolution networks described in references [,,], the rule for forward propagation in a graph convolutional network can be articulated in the following manner:
In the equation, represents the output produced by the -th layer in the neural network architecture, represents the learnable parameters tuned during the training process, represents the nonlinear activation function exemplified by the commonly used ReLU, and represents the node feature matrix of the nodes within the entire graph structure . replaces the original adjacency matrix to effectively mitigate the issue of gradient vanishing or explosion. The formula for the calculation is presented below:
In the equation, the matrix denotes the identity matrix, while signifies the matrix of node degrees in .
3. Experimental Design
3.1. Dataset
This study used a dataset of automotive front face images collected by our research group from The Car Connection, an automotive research website under Internet Brands. The dataset includes cars from 35 brands, covering the years 2007 to 2023, with a resolution of 1024 × 768 pixels per image, totaling 2879 valid samples. In this study, Labelme was used to annotate the headlights and grille on the car front faces. First, the Create Polygons tool was employed to manually draw the polygonal contours of the headlight region point by point, and the label name was entered upon completion. The fill color for the headlight area was then set to red (RGB: 255, 0, 0). The same method was applied to the grille, but to differentiate it from the headlights, the fill color was set to green (RGB: 0, 255, 0). After completing all the annotations, the Save function was used to export the annotation file in .json format, containing both the contour and color information for the headlights and grille.
3.2. Experimental Environment
In this study, the dataset underwent a simple data augmentation, including random rotation and flipping. The CNN–Transformer hybrid encoder combined ResNet-50 and ViT, both pre-trained on ImageNet. In the CUP, four consecutive 2× upsampling blocks were cascaded to achieve full resolution.
The experiments were carried out on an Ubuntu 20.04 (64-bit) system with a Nvidia RTX 3090 Ti GPU. The deep learning model was implemented using the Pytorch 1.12 framework. The input images had a resolution of 512 × 512, with a learning rate of 0.01, a momentum of 0.9, and a weight decay of 1 × 10−4. The default batch size was set to 6, and the model underwent training for 200 epochs utilizing the SGD (Stochastic Gradient Descent) optimizer.
3.3. Evaluation Metrics
In this paper, three evaluation metrics were used to assess the model performance: mFscore, mIOU, and OA. The mFscore (Mean F-score) [] is the average F-score across all categories, where the F-score [] calculated as the harmonic mean of Precision and Recall serves as a robust metric to comprehensively evaluate the classification performance of the model. IoU (Intersection over Union) [] evaluates the extent of overlap between the predicted segmentation results and the ground truth annotations, with mIOU being the average IoU across all categories. OA (Overall Accuracy) [] indicates the overall classification accuracy, indicating the ratio of correctly classified pixels to the total number of pixels, thereby reflecting classification accuracy.
The mathematical expression for calculating the mFscore is presented below:
In the equation, the formulas used to calculate Precision and Recall are given below:
In the equation, TP represents the count of true positives, FP represents the count of false positives, and FN represents the count of false negatives.
The formula for calculating mIOU is presented below:
The formula to calculate OA is provided below:
In the equation, TN denotes the count of true negatives.
4. Experimental Results
4.1. Performance Comparison
In this study, to thoroughly assess the effectiveness and robustness of enhanced networks in segmenting headlights and grilles from car front images, comprehensive experiments were carried out using the dataset detailed in Section 3.1. Six deep learning-based segmentation networks were selected for comparison: DeeplabV3+ [], DNLNet [], SegFormer [], PSPNet [], Segmenter [], and TransUNet []. The results, shown in Table 1, indicate that MD-TransUNet achieved mFscore, mIOU, and OA values of 95.81%, 92.08%, and 98.86%, respectively, outperforming all the compared models. Figure 4 displays the visual segmentation maps of the improved network and the other six networks for the headlights and grilles.

Table 1.
Experimental comparison results.
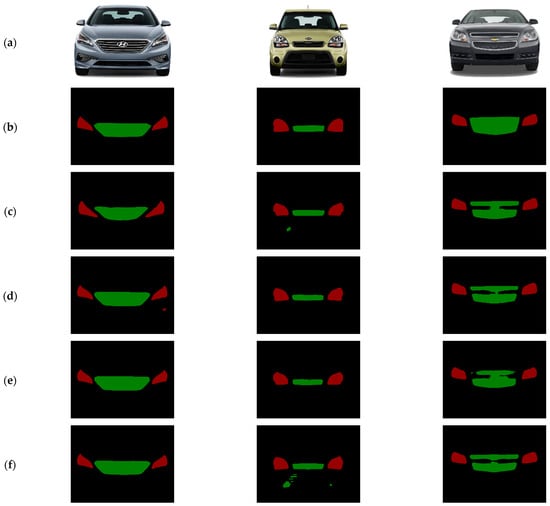

Figure 4.
Comparison of the segmentation results of different algorithms on the automotive front face dataset. (a) Original Image; (b) Labeled Image: (c) DeeplabV3+; (d) DNLNet; (e) SegFormer; (f) PSPNet; (g) Segmenter; (h) TransUNet; and (i) MD-TransUNet.
DeeplabV3+, DNLNet, and PSPNet are CNN-based semantic segmentation models. DeeplabV3+ achieved the highest mIoU value due to its use of Atrous Spatial Pyramid Pooling (ASPP), which captures multi-scale features with different atrous convolution rates, expanding the receptive field and incorporating global context information. SegFormer and Segmenter are Transformer-based semantic segmentation models, with Segmenter performing better due to its powerful, parameter-heavy backbone network, while SegFormer uses a lightweight Transformer. MD-TransUNet enhances TransUNet by introducing dynamic-channel graph convolution (DCGCN), addressing the self-attention mechanism’s limitations in capturing structural information. This improvement boosts segmentation performance with a minimal parameter increase, resulting in the best overall performance.
In summary, the improved network demonstrated excellent segmentation performance across the three evaluation metrics. The DCGCN module dynamically adjusts convolution kernels to adapt to various image features, effectively capturing spatial structures and semantic information. Meanwhile, the MSAG module captures both fine details and global information at different scales, enhancing segmentation accuracy and robustness through multi-scale fusion.
4.2. Ablation Experiments
To enhance the segmentation performance of headlights and grilles in the automotive front face dataset, this study introduces the DCGCN and MSAG modules into the TransUNet network. To further assess the effectiveness of these improvements, four sets of ablation experiments were conducted. The outcomes are presented in Table 2, and the visual representations can be found in Figure 5.
Table 2.
Ablation experiment results.

Figure 5.
Ablation experiment result images. (a) Original Image; (b) Labeled Image; (c) TransUNet; (d) TransUNet + MSAG; (e) TransUNet + DCGCN; and (f) TransUNet + MSAG + DCGCN.
The base model, TransUNet, achieved mFscore, mIOU, and OA values of 95.03%, 90.69%, and 98.61%, respectively. Adding the MSAG module increased the mFscore to 95.30%, mIOU to 91.18%, and OA to 98.70%, indicating that the MSAG module enhances segmentation accuracy and robustness through multi-scale fusion. Incorporating the GCN module raised the mFscore to 95.43%, mIOU to 91.42%, and OA to 98.79%, showing that the GCN module improves segmentation precision by dynamically adjusting convolution kernels to better capture image features. When both the DCGCN and MSAG modules are introduced, the mFscore reached 95.81%, mIOU 92.08%, and OA 98.86%, demonstrating that their combination significantly boosts overall segmentation performance.
In summary, the enhanced TransUNet network shows improvements in mIoU and mFscore metrics, highlighting its high accuracy and robustness in fine-grained segmentation tasks.
4.3. Design of Automotive Front Face Elements Using Semantic Segmentation and Image Restoration
The MD-TransUNet image segmentation network trained in this paper is innovatively combined with the stable diffusion model. These masks are then in fed into the stable diffusion model, which leverages its powerful image generation capabilities to iteratively optimize and refine the image through a diffusion process, creating unique automotive front face designs. This process begins by merging the input mask with a noise image as the initial input. The model then corrects and improves the image through a reverse diffusion process at each layer, gradually generating high-quality images based on the mask features, ensuring that the design of the headlights and grilles meets expectations. The specific steps are illustrated in Figure 6, and the resulting automotive front face element designs are shown in Figure 7.
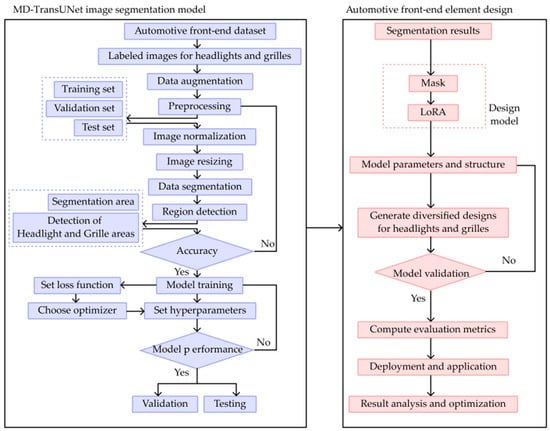
Figure 6.
Applying the trained segmentation model to automotive front face element design.
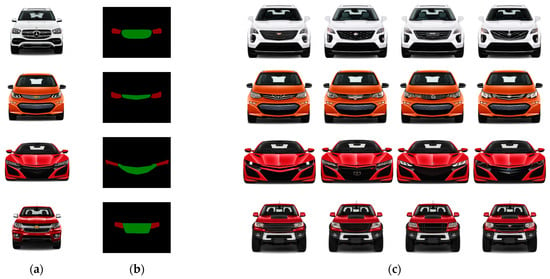
Figure 7.
Diversified designs of headlights and grilles on the automotive front face (a) Original Image; (b) Mask; (c) Front Face Diversified Design Schemes.
This method also shows generalizability in practical applications. Different types of cars, such as sedans, SUVs, and high-performance sports cars, can have front face designs tailored to their unique styles and market demands by adjusting the parameters and input conditions of the stable diffusion model.
For car manufacturers, this automated design generation can significantly shorten the design cycle, reduce costs, and quickly adapt to changing market demands. For designers, it allows them to focus on creativity and high-level design decisions while intelligent algorithms handle the tedious details. During the early design stages, the diffusion model can generate diverse designs, enabling extensive simulation and testing to select the optimal design solution.
5. Conclusions
This paper introduces a MD-TransUNet network, which enhances the TransUNet network with the DCGCN and MSAG modules for segmenting headlights and grilles in automotive front face images. The MSAG module is integrated with skip connections to enhance valuable features, while the DCGCN module bridges high-level and low-level features between the encoder and decoder, dynamically adjusting convolution kernels to capture image details and improve segmentation accuracy. The experimental results indicate that the proposed network surpasses six other models, such as DeeplabV3+, DNLNet, and SegFormer, demonstrating outstanding performance on the dataset. Furthermore, by inputting the precisely segmented car front face image masks from the MD-TransUNet model into a diffusion model, diverse car front face designs can be generated. This approach allows for the flexible adjustment of detailed elements, such as headlights and grilles, while maintaining the overall design consistency of the car front face. This aids in analyzing and comparing the visual effects of different design elements, significantly reducing design iteration time and costs, and improving design efficiency. This approach offers new inspiration and direction for the automotive design industry. For example, various shapes and sizes of headlights and grille layouts can be quickly generated and compared to find the optimal design.
Additionally, the MD-TransUNet model’s ability to accurately segment fine details of car front elements can be extended to autonomous vehicle systems. By refining the segmentation of complex structures, this model could be adapted for detecting critical road elements like pedestrians, vehicles, and traffic signs. The dynamic convolution kernels in the DCGCN module, which adjust based on feature complexity, offer significant advantages in processing diverse road environments, enhancing object detection and classification accuracy. This contributes directly to improving autonomous driving perception systems, enabling more reliable decision-making in real-time traffic scenarios.
Looking ahead, with continuous technological advancements and richer data accumulation, diversified design based on precise image segmentation and generation models will bring more possibilities and breakthroughs to the automotive industry and other industrial design fields.
This study is limited by the lack of diverse environmental variables. The dataset used consists solely of frontal car views at 1024 × 768 resolution, captured under controlled conditions. However, real-world variations in resolution, lighting, and camera angles are common. Current augmentations like random rotation and flipping provide some robustness but may not address real-world challenges. We propose advanced augmentations, such as coordinate transformations, image warping, perspective distortion, and synthetic lighting variations, to better handle viewpoint changes and improve generalization. Future work will explore these methods to enhance model robustness in diverse conditions.
While MD-TransUNet outperforms comparison models across metrics, the visual results show some inconsistencies with annotated images (e.g., Figure 4b vs. Figure 4i, Figure 5b vs. Figure 5f). Possible reasons include:
- Model limitations: Although MSAG and DCGCN enhance global information capture, MD-TransUNet may struggle with fine-grained features like complex edges, leading to less precise segmentation in certain areas;
- Dataset limitations: The dataset, consisting solely of controlled frontal car views, lacks diversity, limiting the model’s ability to generalize to more complex scenarios. Underrepresented features may lead to inaccuracies during testing;
- Loss function limitations: The pixel-based loss function (e.g., cross-entropy loss) focuses on overall classification but is less sensitive to local details, like edge precision, resulting in segmentation discrepancies.
Author Contributions
Conceptualization, J.O. and H.S.; methodology, J.O.; software, H.S.; validation, H.S., J.S. and S.Z.; formal analysis, H.S.; investigation, J.O.; resources, A.Z.; data curation, H.S.; writing—original draft preparation, J.O. and H.S.; writing—review and editing, A.Z.; visualization, H.S.; supervision, J.S. and S.Z.; project administration, J.O. and H.S.; funding acquisition, A.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This study was funded by the National Natural Science Foundation of China, grant number 52165033, and the Gansu Provincial Education Science ‘14th Five-Year Plan’ Project, grant number GS[2021]GHB1996. The APC was funded by these programs.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used and analyzed during this study are available in the GitHub repository: https://github.com/aretsnom/Car-front-face-datasets (accessed on 18 September 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Nirmala, J. Foreign Direct Investment in Automobile Sector in India. Res. Rev. Int. J. Multidiscip. 2023, 8, 71–74. [Google Scholar]
- Furuta, M.; Sato, T.; Otsuka, K. Successful Foreign Direct Investment Through the Development of Parts Supply Industries in the Host Country: A Study of India’s Automobile Manufacturing Sector. Dev. Econ. 2024, 62, 195–237. [Google Scholar] [CrossRef]
- Volkova, N.A.; Katanaev, N.T.; Chebyshev, A.E. End-to-end design of a competitive car with a high level of handling and safety indicators. Вестник Университета 2022, 79–89. [Google Scholar] [CrossRef]
- Shutong, W. Methods of Automotive Design with Artificial Intelligence Intervention. China Sci. Technol. Inf. 2023, 159–162. [Google Scholar]
- Yijiong, S. Vehicle manufacturing efficiency improvement strategy based on full life cycle. Mach. Manuf. 2021, 059, 76–80. [Google Scholar]
- Wang, B. Automotive Styling Creative Design; Tsinghua University Press: Beijing, China, 2019; Chapter 1; p. 1. [Google Scholar]
- Huang, J.; Chen, B.; Yan, Z.; Ounis, I.; Wang, J. GEO: A Computational Design Framework for Automotive Exterior Facelift. ACM Trans. Knowl. Discov. Data 2023, 17, 1–20. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Z.; Yang, B.; Wang, C. Product styling cognition based on Kansei engineering theory and implicit measurement. Appl. Sci. 2023, 13, 9577. [Google Scholar] [CrossRef]
- Yuan, B.; Wu, K.; Wu, X.; Yang, C. Form generative approach for front face design of electric vehicle under female aesthetic preferences. Adv. Eng. Inform. 2024, 62, 102571. [Google Scholar] [CrossRef]
- Duan, J.J.; Luo, P.S.; Liu, Q.; Sun, F.A.; Zhu, L.M. A modeling design method for complex products based on LSTM neural network and Kansei engineering. Appl. Sci. 2023, 13, 710. [Google Scholar] [CrossRef]
- GAC Research Institute. GAC Group Research and Development. Available online: https://www.gac.com.cn/cn/ (accessed on 16 June 2023).
- Huang, J.; Dong, X.; Song, W.; Li, H.; Zhou, J.; Cheng, Y.; Liao, S.; Chen, L.; Yan, Y.; Liao, S.; et al. Consistentid: Portrait generation with multimodal fine-grained identity preserving. arXiv 2024, arXiv:2404.16771. [Google Scholar]
- Chen, W.; Zhang, J.; Wu, J.; Wu, H.; Xiao, X.; Lin, L. ID-Aligner: Enhancing Identity-Preserving Text-to-Image Generation with Reward Feedback Learning. arXiv 2024, arXiv:2404.15449. [Google Scholar]
- Wang, Q.; Li, B.; Li, X.; Cao, B.; Ma, L.; Lu, H.; Jia, X. CharacterFactory: Sampling Consistent Characters with GANs for Diffusion Models. arXiv 2024, arXiv:2404.15677. [Google Scholar]
- Guo, Z.; Wu, Y.; Chen, Z.; Chen, L.; He, Q. PuLID: Pure and Lightning ID Customization via Contrastive Alignment. arXiv 2024, arXiv:2404.16022. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Ji, Z.; Sun, H.; Yuan, N.; Zhang, H.; Sheng, J.; Zhang, X.; Ganchev, I. BGRD-TransUNet: A novel TransUNet-based model for ultrasound breast lesion segmentation. IEEE Access 2024, 12, 31182–31196. [Google Scholar] [CrossRef]
- Pan, S.; Liu, X.; Xie, N.; Chong, Y. EG-TransUNet: A transformer-based U-Net with enhanced and guided models for biomedical image segmentation. BMC Bioinform. 2023, 24, 85. [Google Scholar] [CrossRef]
- Jiang, T.; Zhou, J.; Xie, B.; Liu, L.; Ji, C.; Liu, Y.; Liu, B.; Zhang, B. Improved YOLOv8 Model for Lightweight Pigeon Egg Detection. Animals 2024, 14, 1226. [Google Scholar] [CrossRef]
- Fan, B.; Qin, X.; Wu, Q.; Fu, J.; Hu, Z.; Wang, Z. Instance segmentation algorithm for sorting dismantling components of end-of-life vehicles. Eng. Appl. Artif. Intell. 2024, 133, 108318. [Google Scholar] [CrossRef]
- Han, D.; Zhang, C.; Wang, L.; Xu, X.; Liu, Y. Automatic Outer Contour Detection and Quantification of Vehicles Using Monocular Vision. Struct. Control. Health Monit. 2024, 2024, 6692820. [Google Scholar] [CrossRef]
- Tang, F.; Wang, L.; Ning, C.; Xian, M.; Ding, J. Cmu-net: A strong convmixer-based medical ultrasound image segmentation network. In Proceedings of the 2023 IEEE 20th International Symposium on Biomedical Imaging (ISBI), Cartagena, Colombia, 18–21 April 2023; pp. 1–5. [Google Scholar]
- Li, Y.; Zhang, Y.; Cui, W.; Lei, B.; Kuang, X.; Zhang, T. Dual encoder-based dynamic-channel graph convolutional network with edge enhancement for retinal vessel segmentation. IEEE Trans. Med. Imaging 2022, 41, 1975–1989. [Google Scholar] [CrossRef] [PubMed]
- Song, C.H.; Yoon, J.; Choi, S.; Avrithis, Y. Boosting vision transformers for image retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 107–117. [Google Scholar]
- Courant, R.; Edberg, M.; Dufour, N.; Kalogeiton, V. Transformers and visual Transformers. In Machine Learning for Brain Disorders; Humana: New York, NY, USA, 2023; pp. 193–229. [Google Scholar]
- Basavaprasad, B.; Ravindra, S.H. A survey on traditional and graph theoretical techniques for image segmentation. Int. J. Comput. Appl. 2014, 975, 8887. [Google Scholar]
- Li, Y.; Liu, Y.; Guo, Y.-Z.; Liao, X.-F.; Hu, B.; Yu, T. Spatio-temporal-spectral hierarchical graph convolutional network with semisupervised active learning for patient-specific seizure prediction. IEEE Trans. Cybern. 2021, 52, 12189–12204. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Wan, S.; Gong, C.; Zhong, P.; Du, B.; Zhang, L.; Yang, J. Multiscale dynamic graph convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3162–3177. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, F.; Liu, L.; Liu, W.; Nie, L.; Yang, Y.; Shen, H.T. Graph convolutional network hashing. IEEE Trans. Cybern. 2018, 50, 1460–1472. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Li, J.; Lu, G.; Yu, H.; Zhang, D. Label co-occurrence learning with graph convolutional networks for multi-label chest x-ray image classification. IEEE J. Biomed. Health Inform. 2020, 24, 2292–2302. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Christen, P.; Hand, D.J.; Kirielle, N. A review of the F-measure: Its history, properties, criticism, and alternatives. ACM Comput. Surv. 2023, 56, 1–24. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Azad, R.; Heidari, M.; Shariatnia, M.; Aghdam, E.K.; Karimijafarbigloo, S.; Adeli, E.; Merhof, D. Transdeeplab: Convolution-free transformer-based deeplab v3+ for medical image segmentation. In Predictive Intelligence in Medicine; Springer Nature: Cham, Switzerland, 2022; pp. 91–102. [Google Scholar]
- Yin, M.; Yao, Z.; Cao, Y.; Li, X.; Zhang, Z.; Lin, S.; Hu, H. Disentangled non-local neural networks. In Proceedings of the Computer Vision—ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 191–207. [Google Scholar]
- Safa, A.; Mohamed, A.; Issam, B.; Mohamed-Yassine, H. SegFormer: Semantic segmentation based tranformers for corrosion detection. In Proceedings of the 2023 International Conference on Networking and Advanced Systems (ICNAS), Algiers, Algeria, 21–23 October 2023; pp. 1–6. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).