
Remaining Useful Life of the Rolling Bearings Prediction Method Based on Transfer Learning Integrated with CNN-GRU-MHA


Abstract
:1. Introduction
2. Model
2.1. CNN and GRU
2.2. Migration Principle of Model
2.3. MHA Mechanism
2.4. L1 Regularization
2.5. Network Structure and Training Process
- (1)
- In the preprocessing part, firstly, the vibration signal is subjected to noise reduction by discrete wavelet transform; secondly, the vibration signal is normalized to between 0 and 1 as the bearing HI using the maximum–minimum normalization method.
- (2)
- Construct the degradation labels of the receding bearings, in which the training set data and test set data according to all contain labels and the validation set data do not contain labels.
- (3)
- Input the training set data into the CNN-GRU-MHA model, and the spatial information of the degradation features of the rolling bearing is sufficiently obtained by CNN.
- (4)
- Input the CNN extracted features into GRU for further modeling the temporal information of the degraded features.
- (5)
- Input the degraded features into two fully connected layers to realize the RUL prediction of rolling bearings.
- (6)
- Calculate the loss function of the model.
- (7)
- Utilize the loss-tuned parameters of the model to complete the training of the training set data when the number of iterations m of the network reaches N. Otherwise, repeat steps (4) to (6).
- (8)
- Freeze the structure and parameters of the feature extraction layer of the model and continue training the top layer of the model on the test set data.
- (9)
- Repeat steps (4)~(7).
- (10)
- Complete the test set model training.
- (11)
- Output the prediction results of the validation set data.
3. Experiment
3.1. Experimental Data Sources
3.2. Data Processing
3.2.1. Data Noise Reduction
3.2.2. Normalization Process
3.2.3. HI Build
3.3. Label Building
4. Results and Discussion
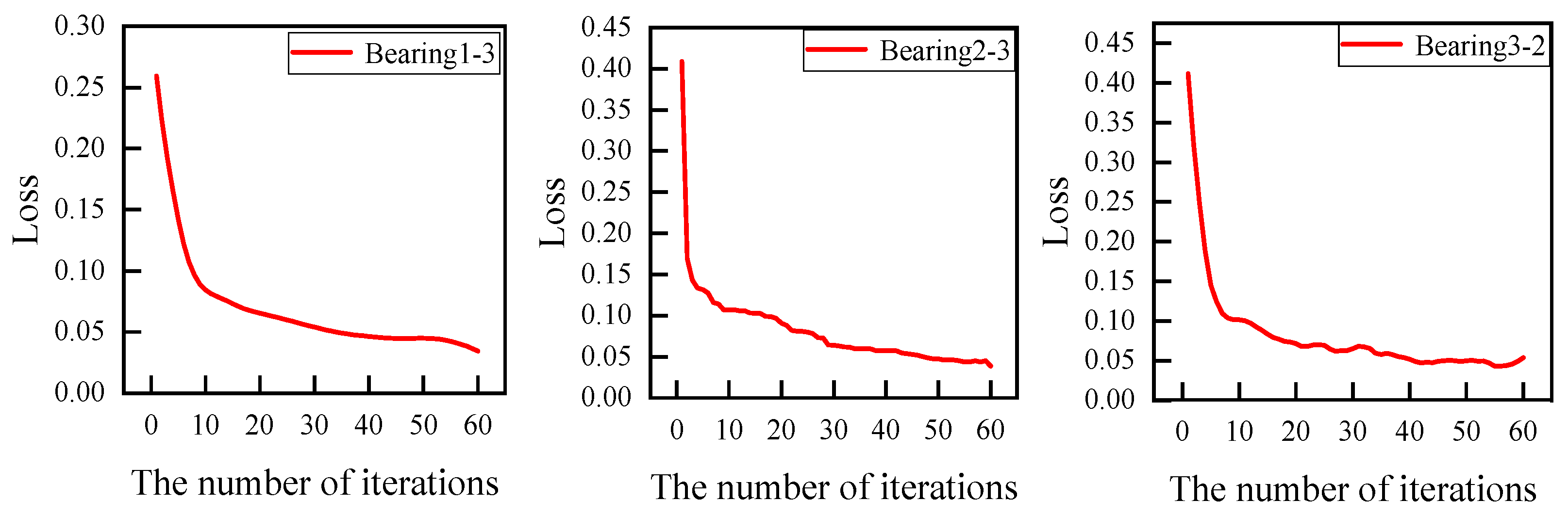
4.1. Training Set Loss
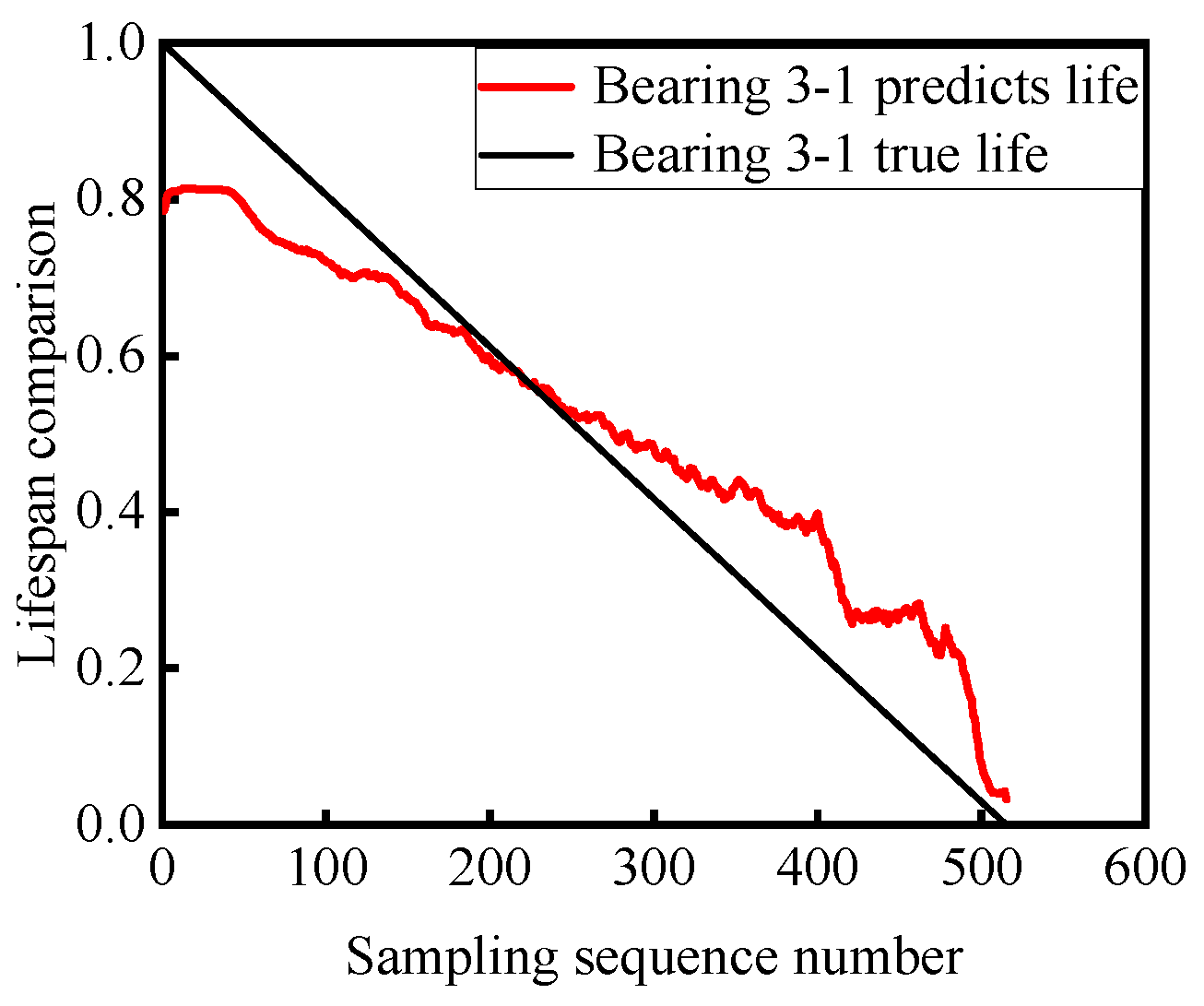
4.2. Prediction Based on Validation Set
4.3. Model Generalizability Validation
5. Conclusions
- (1)
- The method combines CNN and GRU and directly inputs the vibration signals processed by the maximum–minimum normalization method and the discrete wavelets as HIs into the model.
- (2)
- Local features of rolling bearing signals are extracted using CNN, and then the timing information is modeled and predicted using the GRU model; MHA is introduced for weighting, the L1 regularization method is added to reduce the number of features and reduce the computational complexity, and avoid overfitting, and a model-based migration learning method is also introduced to achieve the RUL prediction of rolling bearings with a small amount of data.
- (3)
- Experimental validation was carried out using the PHM2012 and XJTU-SY bearing datasets. The experimental results of PHM2012 data show that the average RMSE of the CNN-GRU-MHA model, with three sets of twelve migration experiments under variable load conditions, is 0.0443; and the results of the XJTU-SY data show that the average RMSE of two sets of four migration experiments under variable load conditions is 0.0691, which verifies the accuracy and good generalization of the model.
- (4)
- In future work, it will be necessary to further collect actual industrial production bearing vibration data to validate the model’s performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, X.; Rong, Y.; Li, L.; He, W.; Lv, M.; Sun, S. Health State Prediction Method Based on Multi-Featured Parameter Information Fusion. Appl. Sci. 2024, 14, 6809. [Google Scholar] [CrossRef]
- Yao, Q.; Dai, L.; Tang, J.; Wu, H.; Liu, T. High-Speed Rolling Bearing Lubrication Reliability Analysis Based on Probability Box Model. Probabilistic Eng. Mech. 2024, 76, 103612. [Google Scholar] [CrossRef]
- Soomro, A.A.; Muhammad, M.B.; Mokhtar, A.A.; Md Saad, M.H.; Lashari, N.; Hussain, M.; Sarwar, U.; Palli, A.S. Insights into Modern Machine Learning Approaches for Bearing Fault Classification: A Systematic Literature Review. Results Eng. 2024, 23, 102700. [Google Scholar] [CrossRef]
- Peng, G.; Zheng, J.; Pan, H.; Tong, J.; Liu, Q. Ensemble holo-Hilbert spectral analysis and its application in fault diagnosis of rolling bearing. J. Vib. Shock 2024, 43, 98–105. [Google Scholar] [CrossRef]
- Cerrada, M.; Sánchez, R.-V.; Li, C.; Pacheco, F.; Cabrera, D.; Valente de Oliveira, J.; Vásquez, R.E. A Review on Data-Driven Fault Severity Assessment in Rolling Bearings. Mech. Syst. Signal Process. 2018, 99, 169–196. [Google Scholar] [CrossRef]
- Yang, G. Practical Techniques for Fault Diagnosis of Rolling Bearings; China Petrochemical Press: Beijing, China, 2012; pp. 20–39. [Google Scholar]
- Chelmiah, E.T.; McLoone, V.I.; Kavanagh, D.F. Low Complexity Non-Linear Spectral Features and Wear State Models for Remaining Useful Life Estimation of Bearings. Energies 2023, 16, 5312. [Google Scholar] [CrossRef]
- Investigation on Rolling Bearing Remaining Useful Life Prediction: A Review. IEEE Conference Publication. IEEE Xplore. Available online: https://ieeexplore.ieee.org/document/8603483 (accessed on 15 August 2024).
- Chen, J.; Huang, R.; Chen, Z.; Mao, W.; Li, W. Transfer Learning Algorithms for Bearing Remaining Useful Life Prediction: A Comprehensive Review from an Industrial Application Perspective. Mech. Syst. Signal Process. 2023, 193, 110239. [Google Scholar] [CrossRef]
- Yin, C.; Hu, Y.; Cao, W. A Review of Methods for Remaining Useful Life Prediction of Motor Bearings. In Proceedings of the 2023 3rd International Joint Conference on Energy, Electrical and Power Engineering, CoEEPE 2023, Lecture Notes in Electrical Engineering, Melbourne, VIC, Australia, 22–24 November 2023; Hu, C., Cao, W., Eds.; Springer: Singapore, 2023; Volume 1208. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, W.; Yang, X.; Zhang, S. RUL Prediction of Rolling Bearings Based on a DCAE and CNN. Appl. Sci. 2021, 11, 11516. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, Y.; Addepalli, S. Remaining Useful Life Prediction Using Deep Learning Approaches: A Review. Procedia Manuf. 2020, 49, 81–88. [Google Scholar] [CrossRef]
- Mogal, S.; Bhandare, R.V.; Phalle, V.M.; Kushare, P.B. Fault Diagnosis and Prediction of Remaining Useful Life (RUL) of Rolling Element Bearing: A Review State of Art. Finn. J. Trib. 2024, 41, 28–42. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Gontarz, S.; Lin, J.; Radkowski, S.; Dybala, J. A Model-Based Method for Remaining Useful Life Prediction of Machinery. IEEE Trans. Rel. 2016, 65, 1314–1326. [Google Scholar] [CrossRef]
- Yu, G.; Li, C.; Zhang, J. A New Statistical Modeling and Detection Method for Rolling Element Bearing Faults Based on Alpha–Stable Distribution. Mech. Syst. Signal Process. 2013, 41, 155–175. [Google Scholar] [CrossRef]
- Deng, L.; Li, W.; Yan, X. An Intelligent Hybrid Deep Learning Model for Rolling Bearing Remaining Useful Life Prediction. Nondestruct. Test. Eval. 2024, 1–28. [Google Scholar] [CrossRef]
- Akpudo, U.E.; Hur, J.-W. Towards Bearing Failure Prognostics: A Practical Comparison between Data-Driven Methods for Industrial Applications. J. Mech. Sci. Technol. 2020, 34, 4161–4172. [Google Scholar] [CrossRef]
- Shutin, D.; Bondarenko, M.; Polyakov, R.; Stebakov, I.; Savin, L. Method for On-Line Remaining Useful Life and Wear Prediction for Adjustable Journal Bearings Utilizing a Combination of Physics-Based and Data-Driven Models: A Numerical Investigation. Lubricants 2023, 11, 33. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Y.; Wang, Y.; Ren, J. An Automatic Algorithm for Software Vulnerability Classification Based on CNN and GRU. Multimed. Tools Appl. 2022, 81, 7103–7124. [Google Scholar] [CrossRef]
- Liu, F.; Zhang, Z.; Zhou, R. Automatic Modulation Recognition Based on CNN and GRU. Tsinghua Sci. Technol. 2022, 27, 422–431. [Google Scholar] [CrossRef]
- Deep Convolutional Neural Network Based Regression Approach for Estimation of Remaining Useful Life. SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-319-32025-0_14 (accessed on 15 August 2024).
- Nie, L.; Zhang, L.; Xu, S.; Cai, W.; Yang, H. Remaining Useful Life Prediction for Rolling Bearings Based on Similarity Feature Fusion and Convolutional Neural Network. J. Braz. Soc. Mech. Sci. Eng. 2022, 44, 328. [Google Scholar] [CrossRef]
- Mo, R.; Li, T.; Si, X.; Zhu, X. A device residual life prediction method using residual network and convolutional attention mechanism. J. Xi’an Jiaotong Univ. 2022, 56, 194–202. [Google Scholar] [CrossRef]
- He, J.; Zhang, X.; Zhang, X.; Shen, J. Remaining Useful Life Prediction for Bearing Based on Automatic Feature Combination Extraction and Residual Multi-Head Attention GRU Network. Meas. Sci. Technol. 2024, 35, 036003. [Google Scholar] [CrossRef]
- Zhang, Q.; Ye, Z.; Shao, S.; Niu, T.; Zhao, Y. Remaining Useful Life Prediction of Rolling Bearings Based on Convolutional Recurrent Attention Network. Assem. Autom. 2022, 42, 372–387. [Google Scholar] [CrossRef]
- Sun, H.; Fan, Y. Fault diagnosis of rolling bearings based on CNN and LSTM networks under mixed load and noise. Multimed Tools Appl. 2023, 82, 43543–43567. [Google Scholar] [CrossRef]
- Gao, X.; Wang, H.; Zhao, Z.; Tian, J.; Zhang, F.; Wang, C. Prediction of Bearing Remaining Useful Life Based on CNN and Gated Recurrent Unit. In Proceedings of the 2023 Global Reliability and Prognostics and Health Management Conference (PHM-Hangzhou), IEEE, Hangzhou, China, 2–15 October 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Guo, J.; Wang, J.; Wang, Z.; Gong, Y.; Qi, J.; Wang, G.; Tang, C. A CNN-BiLSTM-Bootstrap Integrated Method for Remaining Useful Life Prediction of Rolling Bearings. Qual. Reliab. Eng. 2023, 39, 1796–1813. [Google Scholar] [CrossRef]
- Cai, Y. Rolling Bearing Life Prediction Based on CNN-GRU”. Mech. Eng. Autom. 2023, 1, 143–145+148. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11141, pp. 270–279. [Google Scholar] [CrossRef]
- Mercat, J.; Gilles, T.; El Zoghby, N.; Sandou, G.; Beauvois, D.; Gil, G.P. Multi-Head Attention for Multi-Modal Joint Vehicle Motion Forecasting. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), IEEE, Paris, France, 31 May–31 August 2020; pp. 9638–9644. [Google Scholar] [CrossRef]
- Kulkarni, P.; Zepeda, J.; Jurie, F.; Pérez, P.; Chevallier, L. Learning the Structure of Deep Architectures Using L1 Regularization. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015. [Google Scholar] [CrossRef]
- Sun, L.; Yang, Y.; Zhang, N. Research on Bearing State Prediction Using L1 Regularization and BiGRU Model. Electron. Meas. Technol. 2024, 47, 58–65. [Google Scholar] [CrossRef]
- Darwish, A. A Data-Driven Deep Learning Approach for Remaining Useful Life of Rolling Bearings. Syst. Assess. Eng. Manag. 2024, 1, 8–25. [Google Scholar] [CrossRef]
- Qian, M.; Yu, Y.; Guo, L.; Gao, H.; Zhang, R.; Li, S. A New Health Indicator for Rolling Bearings Based on Impulsiveness and Periodicity of Signals. Meas. Sci. Technol. 2022, 33, 105008. [Google Scholar] [CrossRef]
- Lei, Y.; Han, T.; Wang, B.; Li, N.; Yan, T.; Yang, J. XJTU-SY Rolling Element Bearing Accelerated Life Test Datasets: A Tutorial. J. Mech. Eng. 2019, 55, 1–6. [Google Scholar] [CrossRef]
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Working Condition | Rotational Speed (rpm) | Load (N) | Bearing Data |
|---|---|---|---|
| Working condition 1 | 1800 | 4000 | 1_1, 1_2, 1_3, 1_4, 1_5, 1_6, 1_7 |
| Working condition 2 | 1650 | 4200 | 2_1, 2_2, 2_3, 2_4, 2_5, 2_6, 2_7 |
| Working condition 3 | 1500 | 5000 | 3_1, 3_2, 3_3 |
| Test | Source Domain Data | Target Domain Data |
|---|---|---|
| Test 1 | bearing 1-3 | bearing 2-3, bearing 2-4, bearing 3-1, bearing 3-3 |
| Test 2 | bearing 2-3 | bearing 2-4, bearing 2-5, bearing 3-3, bearing 3-3 |
| Test 3 | bearing 3-2 | bearing 1-3, bearing 1-4, bearing 2-3, bearing 2-4 |
| Hyperparameter Name | Hyperparameter Value |
|---|---|
| Learning rate | 0.001 |
| Sample size | 128 |
| Number of iterations | 60/100 |
| Batch size | 128 |
| Source Domain Data | Target Domain Data | Loss | Average Loss |
|---|---|---|---|
| Bearing 1-3 | Bearing 2-3 | 0.0463 | 0.0433 |
| Bearing 1-3 | Bearing 2-4 | 0.0449 | |
| Bearing 1-3 | Bearing 3-1 | 0.0427 | |
| Bearing 1-3 | Bearing 3-3 | 0.0461 | |
| Bearing 2-3 | Bearing 1-3 | 0.0458 | |
| Bearing 2-3 | Bearing 1-4 | 0.0426 | |
| Bearing 2-3 | Bearing 3-3 | 0.0416 | |
| Bearing 3-2 | Bearing 1-3 | 0.0382 | |
| Bearing 3-2 | Bearing 1-4 | 0.0397 | |
| Bearing 3-2 | Bearing 2-3 | 0.0413 | |
| Bearing 3-2 | Bearing 2-4 | 0.0418 |
| Experiment No. | Source Domain Data | Target Domain Data | Loss | Average Loss |
|---|---|---|---|---|
| 1 | bearing1-3 | bearing2-3 | 0.0568 | 0.0691 |
| bearing1-3 | bearing3-2 | 0.0464 | ||
| 2 | bearing2-3 | bearing1-3 | 0.1138 | |
| bearing2-3 | bearing3-2 | 0.0595 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Shao, J.; Peng, X.; Liu, T.; Yao, Q. Remaining Useful Life of the Rolling Bearings Prediction Method Based on Transfer Learning Integrated with CNN-GRU-MHA. Appl. Sci. 2024, 14, 9039. https://doi.org/10.3390/app14199039
Yu J, Shao J, Peng X, Liu T, Yao Q. Remaining Useful Life of the Rolling Bearings Prediction Method Based on Transfer Learning Integrated with CNN-GRU-MHA. Applied Sciences. 2024; 14(19):9039. https://doi.org/10.3390/app14199039
Chicago/Turabian StyleYu, Jianghong, Jingwei Shao, Xionglu Peng, Tao Liu, and Qishui Yao. 2024. "Remaining Useful Life of the Rolling Bearings Prediction Method Based on Transfer Learning Integrated with CNN-GRU-MHA" Applied Sciences 14, no. 19: 9039. https://doi.org/10.3390/app14199039