Figure 1.
A schematic illustration of the limit-state function , safe domain , and failure domain .
Figure 1.
A schematic illustration of the limit-state function , safe domain , and failure domain .
Figure 2.
Illustration of the Kriging (Gaussian process) model and predictions.
Figure 2.
Illustration of the Kriging (Gaussian process) model and predictions.
Figure 3.
Illustration of the proposed hybrid active learning process with the initial five design of experiment (DoE) points (, , the number of points to be added to DoE K= 5, ). Enrichment process (a) initial Kriging and candidate points within and a selected point () designated for addition as a DoE point, positioned as the farthest from the existing DoE points, (b) the second (the Kriging model is updated with the first ), (c) the third , (d) updated Kriging model and candidate points for K-means clustering, centroids of clusters, and determined points based on centroids to be added to the DoE.
Figure 3.
Illustration of the proposed hybrid active learning process with the initial five design of experiment (DoE) points (, , the number of points to be added to DoE K= 5, ). Enrichment process (a) initial Kriging and candidate points within and a selected point () designated for addition as a DoE point, positioned as the farthest from the existing DoE points, (b) the second (the Kriging model is updated with the first ), (c) the third , (d) updated Kriging model and candidate points for K-means clustering, centroids of clusters, and determined points based on centroids to be added to the DoE.
Figure 4.
Flowchart of the HAK algorithm.
Figure 4.
Flowchart of the HAK algorithm.
Figure 5.
Illustration of the limit-state function prediction using multiple DoE points (). (a) Proposed framework with 25 DoE points after three enrichment steps: shapes filled with solid color represent the initial farthest DoE points identified in each enrichment step; (b) AK-MCS with 35 DoE points.
Figure 5.
Illustration of the limit-state function prediction using multiple DoE points (). (a) Proposed framework with 25 DoE points after three enrichment steps: shapes filled with solid color represent the initial farthest DoE points identified in each enrichment step; (b) AK-MCS with 35 DoE points.
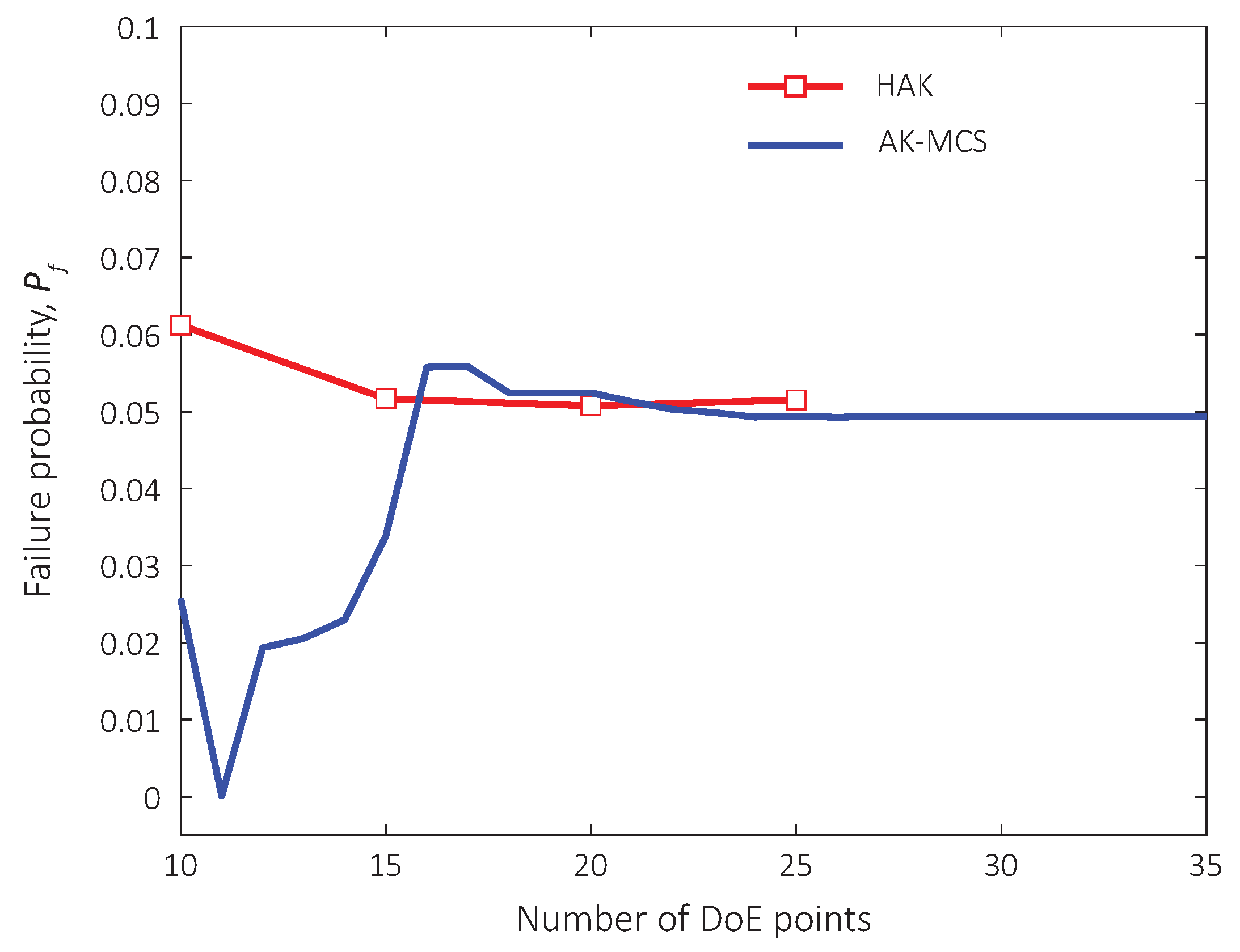
Figure 6.
Convergence history of failure probability ().
Figure 6.
Convergence history of failure probability ().
Figure 7.
Final experimental designs and Kriging predictions for a series system with multiple design points utilizing various learning functions under two scenarios (Case A and B) with randomly generated initial DoE points (). (a) HAK (shapes filled with solid color depict the initial farthest five DoE points identified in each enrichment step), (b) -function with the K-means clustering, (c) -function without the K-means clustering, (d) EFF with the K-means clustering algorithm, (e) EFF without the K-means clustering, and (f) CMM function.
Figure 7.
Final experimental designs and Kriging predictions for a series system with multiple design points utilizing various learning functions under two scenarios (Case A and B) with randomly generated initial DoE points (). (a) HAK (shapes filled with solid color depict the initial farthest five DoE points identified in each enrichment step), (b) -function with the K-means clustering, (c) -function without the K-means clustering, (d) EFF with the K-means clustering algorithm, (e) EFF without the K-means clustering, and (f) CMM function.
Figure 8.
Nonlinear oscillator subjected to a rectangular load pulse.
Figure 8.
Nonlinear oscillator subjected to a rectangular load pulse.
Figure 9.
A truss bridge structure geometry and loading and boundary conditions.
Figure 9.
A truss bridge structure geometry and loading and boundary conditions.
Figure 10.
Correlation matrix of random variables for the truss bridge structure.
Figure 10.
Correlation matrix of random variables for the truss bridge structure.
Figure 11.
Illustration of deformed shape and truss member stresses with mean values of random variables. Tensile stresses are denoted in blue, and compressive stresses are shown in red. The maximum vertical displacement node, its corresponding value, and the maximum stress are highlighted.
Figure 11.
Illustration of deformed shape and truss member stresses with mean values of random variables. Tensile stresses are denoted in blue, and compressive stresses are shown in red. The maximum vertical displacement node, its corresponding value, and the maximum stress are highlighted.
Figure 12.
Probability of failure for the truss structure problem under varying levels of imposed noise variances. (a) AK-MCS, (b) proposed HAK.
Figure 12.
Probability of failure for the truss structure problem under varying levels of imposed noise variances. (a) AK-MCS, (b) proposed HAK.
Figure 13.
(a) A discretized continuum beam structure, depicting its geometry, loading, and boundary conditions, and (b) illustration of the distribution of random variables, specifically the three groups of modulus of elasticity, within the beam.
Figure 13.
(a) A discretized continuum beam structure, depicting its geometry, loading, and boundary conditions, and (b) illustration of the distribution of random variables, specifically the three groups of modulus of elasticity, within the beam.
Figure 14.
(a) Illustration of the assignment of random variables to polygonal elements. (a) , (b) , (c) , and (d) .
Figure 14.
(a) Illustration of the assignment of random variables to polygonal elements. (a) , (b) , (c) , and (d) .
Figure 15.
(a) Comparison of failure probabilities, , obtained by the proposed method (HAK), FORM, SORM, and AK-MCS for varying degrees of freedom (DoF). (b) Normalized computational time, with normalization performed with respect to the computation time for SORM with 5000 elements. The horizontal axis (DoF) is plotted using a base-10 logarithmic scale, corresponding to 500, 1000, 2000, 3000, 5000, 10,000, and 20,000 polygonal elements, respectively.
Figure 15.
(a) Comparison of failure probabilities, , obtained by the proposed method (HAK), FORM, SORM, and AK-MCS for varying degrees of freedom (DoF). (b) Normalized computational time, with normalization performed with respect to the computation time for SORM with 5000 elements. The horizontal axis (DoF) is plotted using a base-10 logarithmic scale, corresponding to 500, 1000, 2000, 3000, 5000, 10,000, and 20,000 polygonal elements, respectively.
Figure 16.
(a) Distribution of material random variables within the discretized beam domain, (b) failure probabilities corresponding to a specific number of material random variables obtained by FORM, SORM, AK-MCS, and the proposed method (HAK).
Figure 16.
(a) Distribution of material random variables within the discretized beam domain, (b) failure probabilities corresponding to a specific number of material random variables obtained by FORM, SORM, AK-MCS, and the proposed method (HAK).
Table 1.
Comparative analysis of results obtained through the proposed HAK and several other reliability analysis methods for the nonlinear limit-state function.
Table 1.
Comparative analysis of results obtained through the proposed HAK and several other reliability analysis methods for the nonlinear limit-state function.
| Case | Method | | | | |
|---|
| FORM | | - | 1.798 | 97 |
| SORM | | - | 1.747 | 109 |
| MCS | | 0.014 | 1.632 | |
| AK-MCS | | 0.014 | 1.651 | 35) |
| HAK | | 0.010 | 1.630 | 25 |
| FORM | | - | 2.715 | 145 |
| SORM | | - | 2.802 | 157 |
| MCS | | 0.03 | 2.615 | 2 |
| AK-MCS | | 0.048 | 2.620 | 35) |
| HAK | | 0.017 | 2.611 | 25 |
| FORM | | - | 3.651 | 192 |
| SORM | | - | 3.778 | 204 |
| MCS | | 0.037 | 3.615 | 5 |
| AK-MCS | | 0.049 | 3.6393 | 42) |
| HAK | | 0.023 | 3.604 | 25 |
| FORM | | - | 4.604 | 349 |
| SORM | | - | 4.743 | 361 |
| MCS | | 0.102 | 4.618 | 5 |
| AK-MCS | - | - | - | |
| HAK | | 0.030 | 4.587 | 25 |
Table 2.
Comparative analysis of results obtained using HAK and various other reliability analysis methods for the series system example.
Table 2.
Comparative analysis of results obtained using HAK and various other reliability analysis methods for the series system example.
| Method | | | |
|---|
| HAK | | 0.018 | 50 |
| MCS | | 0.017 | |
| Meta-IS [38] | | <0.05 | 644 |
Table 3.
Distribution type and parameters of the random variables for the nonlinear oscillator example.
Table 3.
Distribution type and parameters of the random variables for the nonlinear oscillator example.
| Random Variables | Distribution | Mean | Standard Deviation |
|---|
| m | Gaussian | 1 | 0.05 |
| Gaussian | 1 | 0.1 |
| Gaussian | 0.1 | 0.01 |
| R | Gaussian | 0.5 | 0.05 |
| Gaussian | 1 | 0.2 |
| Gaussian | 1 | 0.2 |
Table 4.
Comparative analysis of results: HAK versus various reliability analysis methods for the nonlinear oscillator example.
Table 4.
Comparative analysis of results: HAK versus various reliability analysis methods for the nonlinear oscillator example.
| Method | | | | |
|---|
| FORM | 0.0311 | - | 1.865 | 41 |
| SORM | 0.0287 | - | 1.901 | 128 |
| MCS | 0.0286 | 0.025 | 1.902 | |
| AK-MCS | 0.0294 | 0.018 | 1.889 | |
| IS | 0.0288 | 0.03 | 1.899 | 2670 |
| HAK | 0.0286 | 0.018 | 1.902 | 46 |
Table 5.
Distribution type and parameters of the random variables considered for the reliability analysis of the truss bridge structure.
Table 5.
Distribution type and parameters of the random variables considered for the reliability analysis of the truss bridge structure.
| Random Variables | Distribution | Mean | Moments |
|---|
| (BC) | Gumbel | 29,000 ksi | 2900 ksi |
| (TC) | Gumbel | 29,000 ksi | 5800 ksi |
| (DG) | Gumbel | 29,000 ksi | 8700 ksi |
| Lognormal | 30 kips | 9 kips |
| Lognormal | 50 kips | 10 kips |
| Lognormal | 60 kips | 6 kips |
Table 6.
Cross sectional areas of the truss bridge structure and threshold values of probabilistic constraints.
Table 6.
Cross sectional areas of the truss bridge structure and threshold values of probabilistic constraints.
| Area | Threshold |
|---|
| BC | TC | DG | | |
| 36 in | 25 in | 9 in | 1.0 in | 45 ksi |
Table 7.
Reliability analysis results for the truss bridge structure obtained through various approaches without noise.
Table 7.
Reliability analysis results for the truss bridge structure obtained through various approaches without noise.
| Limit-State Function | Method | | | | |
|---|
| Stress | FORM | | - | 2.673 | 48 |
| SORM | | - | 2.656 | 128 |
| MCS | | 0.05 | 2.659 | |
| AK-MCS | | 0.05 | 2.643 | 52 |
| IS | | 0.05 | 2.634 | 1048 |
| HAK | | 0.02 | 2.650 | 43 |
| Displacement | FORM | | - | 1.329 | 40 |
| SORM | | - | 1.320 | 120 |
| MCS | | 0.01 | 1.315 | |
| AK-MCS | | 0.01 | 1.311 | 166 () |
| IS | | 0.04 | 1.314 | 1040 |
| HAK | | 0.01 | 1.316 | 68 |
Table 8.
Distribution type and parameters of the random variables considered for the reliability analysis of the continuum structure.
Table 8.
Distribution type and parameters of the random variables considered for the reliability analysis of the continuum structure.
| Random Variables | Distribution | Mean | Moments |
|---|
| Lognormal | 29,000 ksi | 29,000 ksi |
| Normal | 3 kips | 0.45 kips |
| Lognormal | 4 kips | 0.6 kips |
| Gamma | 5 kips | 0.75 kips |




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}