Abstract
Similarity measures in heterogeneous information networks (HINs) have become increasingly important in recent years. Most measures in such networks are based on the meta path, a relation sequence connecting object types. However, in real-world scenarios, there exist many complex semantic relationships, which cannot be captured by the meta path. Therefore, a meta structure is proposed, which is a directed acyclic graph of object and relation types. In this paper, we explore the complex semantic meanings in HINs and propose a meta-structure-based similarity measure called StructSim. StructSim models the probability of subgraph expansion with bias from source node to target node. Different from existing methods, StructSim claims that the subgraph expansion is biased, i.e., the probability may be different when expanding from the same node to different nodes with the same type based on the meta structure. Moreover, StructSim defines the expansion bias by considering two types of node information, including out-neighbors of current expanded nodes and in-neighbors of next hop nodes to be expanded. To facilitate the implementation of StructSim, we further designed the node composition operator and expansion probability matrix with bias. Extensive experiments on DBLP and YAGO datasets demonstrate that StructSim is more effective than the state-of-the-art approaches.
1. Introduction
A heterogeneous information network (HIN) is a powerful way of modeling real-world relationships [1,2]. Due to the capability of containing rich inter-dependency between objects, HINs have recently attracted a lot of research attention [3]. HINs consist of multiple types of objects and relations. Figure 1 is a toy example of HINs.
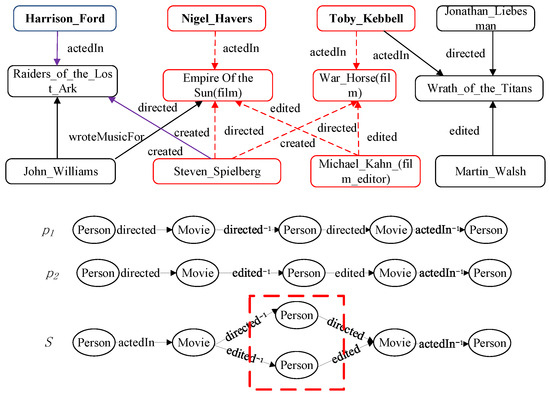
Figure 1.
A toy example of a heterogeneous information network, meta path, and meta structure.
In the real world, HINs are very ubiquitous, including DBLP [4] and Yago [5]. HINs analysis can help discover interesting knowledge [6]. A wide variety of data mining problems have also been studied in HINs [7,8]. A similarity measure is the basis of many data mining tasks, such as clustering, classification and product recommendation. In this paper, we mainly focus on the similarity measure in HINs.
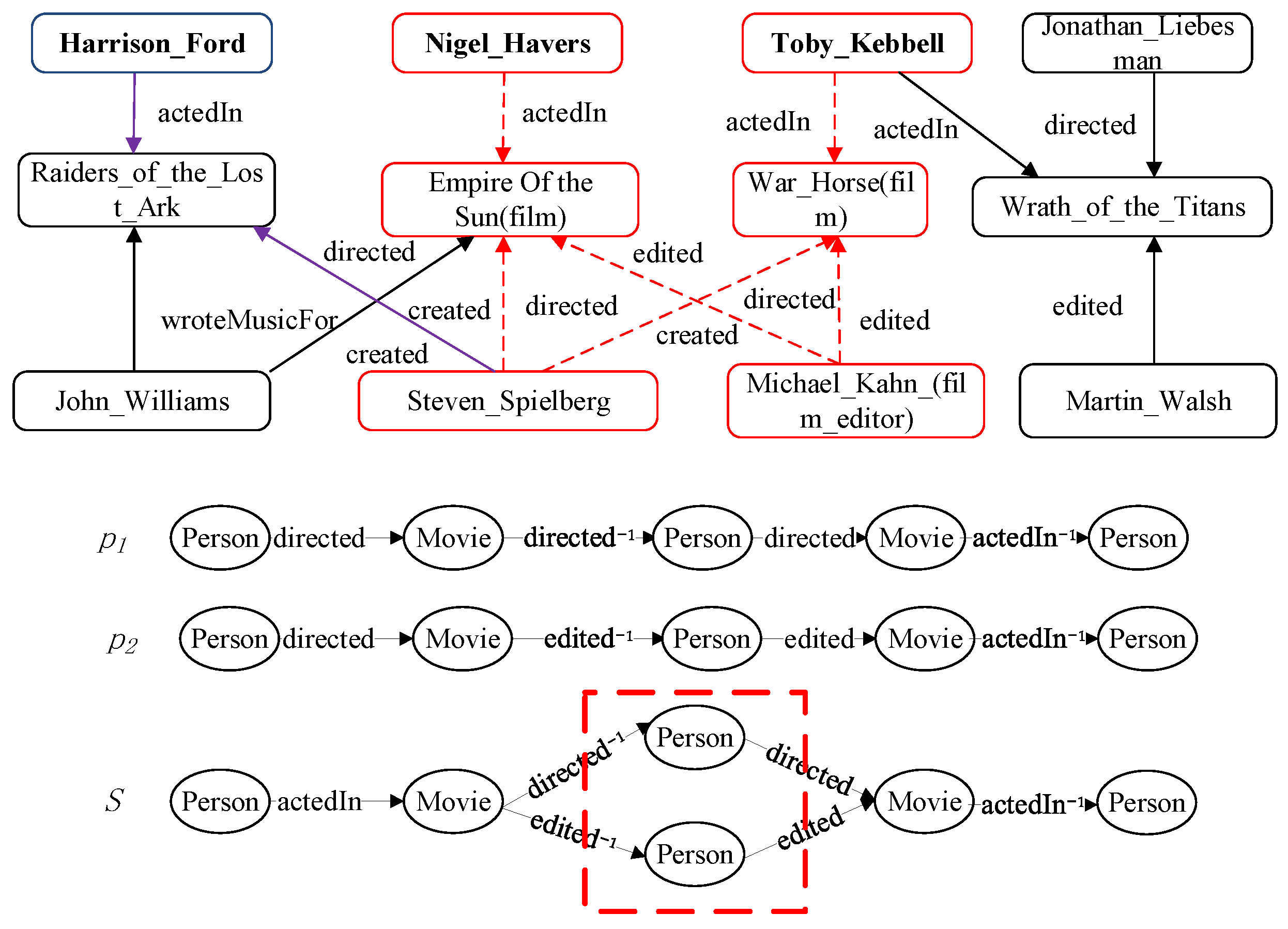
As an important tool of capturing semantics in HINs, a meta path is a sequence of relations connecting object types [9], which embodies rich semantic meanings. In HINs, different meta paths denote different semantic meanings. For instance, in Figure 1, there exists a meta path between Toby Kebbel and Steven Spielberg, which means the actor acts in the movie directed by a specific director. The meta path between Toby Kebbel and Michael Kahn (film editor) denotes that the actor acts in the movie edited by a specific film editor. It is obvious that the semantic similarity between objects is different based on different meta paths. Therefore, the similarity measure in HINs is related to the meta path.
So far, many meta-path-based similarity methods have been proposed in HINs, such as Path-Constrained Random Walk (PCRW) [10], PathSim [9] and HeteSim [11]. These methods can only capture the simple semantic meaning between objects in HINs. However, there exist a wide variety of complex semantic relationships in large-scale HINs like knowledge graphs [12,13], which were originally introduced by Google in 2012 to optimize search results. These complex semantic relationships, such as the complex semantic relationships in Figure 1, cannot be well captured by a simple meta path. Therefore, the concept of a meta structure is proposed, which is a directed acyclic graph (DAG) [14]. For example, in Figure 1, Toby Kebbell and Nigel Havers not only act in the movies directed by Steven Spielberg, but also act in the movies edited by Michael Kahn (film editor). This kind of complex semantic relationship can be illustrated by the meta structure in Figure 1 rather than a meta path or .
However, research on meta-structure-based similarity has, up until now, been relatively. Although BSCSE [14] has been proposed to measure such complex semantic similarities between objects, it does not fully leverage the structure information of a network. What is more, BSCSE holds that the probability of subgraph expansion is the same from the same node to different nodes with the same type based on the meta structure. In fact, the probability may be different.
Therefore, in this paper, we further consider the structure information of a network and introduce the bias of expansion to propose a novel meta-structure-based similarity measure called StructSim. In addition, to facilitate the implementation of StructSim, we further design the node composition operator and expansion probability matrix with bias. As illustrated by the dotted box in in Figure 1, node-composition operator means that we combine two nodes in a layer of a meta structure into a composite node. In this way, we can also easily conduct subgraph expansion in a way similar to random walk.
The main contributions of our work can be summarized as follows.
- We explore the complex semantic meaning analysis in large-scale HINs (e.g., knowledge graph) and propose a novel meta-structure-based similarity measure named StructSim, which can well capture the complex similarity semantics between objects in HINs.
- We design the subgraph expansion with bias by considering comprehensive structure information of the network, which includes out-neighbor information on current expansion nodes and in-neighbor information on the next-hop nodes to be expanded.
- We propose the Node-Composition Operator and expansion probability matrix with bias so as to conveniently implement StructSim and conduct subgraph expansion in a way similar to random walk.
- We conduct extensive experiments on DBLP and YAGO datasets, which demonstrate that StructSim is more effective than the state-of-the-art methods.
2. Related Work
In this paper, we mainly summarize similarity measure methods in homogeneous information networks and those in HINs.
The similarity measure in homogeneous information networks calculates the similarity of objects based on the link structure of a network. Personalized PageRank [15] is a classic representative, which employs the probability of random walk with restart to evaluate the similarity between objects. However, it is an asymmetrical approach. SimRank [16] is a representative of symmetric measures, which adopts the neighbors’ similarity to measure the similarity between objects. Several researchers are also devoted to the study of improving the efficiency due to the computational complexity [17]. RoleSim [18] is proposed to measure the role of object similarity. SCAN [19] leverages the immediate neighbor set to measure the similarity of objects. All these approaches just consider the objects with the same type and do not consider the heterogeneity of a network.
The similarity measure in HINs mainly includes similarity based on the meta path and that based on the meta structure [20,21,22,23]. The former captures the simple semantics between objects while the latter expresses the complex meanings between objects.
The approaches based on the meta path include PathCount [9], PCRW [10], PathSim [9], HeteSim [11], DPRel [22] and so on. PathSim can only measure the similarity between the same-type objects, while other methods can measure the similarity between different-type objects. PathSim, PCRW and HeteSim are based on random walk model; the difference lies in the method of random walk. DPRel [22] is a meta-path-based semi-metric measure for relevance measurement on objects in a general heterogeneous information network with a specified network schema. Recently, Shi et al. [24] presented a new-path-based measure called PReP, which is studied from a probabilistic perspective. HowSim [23] is a newly proposed similarity measure which has the property of being meta-path-free and capturing the structure and semantic similarity simultaneously. In addition, RelSim [25] employs the meta path to measure the similarity between relation instances, such as <Google, Larry Page> and <Microsoft, BillGates> (Organization and Founder).
The approaches based on the meta structure include BSCSE [14] and MGP [21]. BSCSE employs the subgraph expansion model to capture complex semantic meanings among objects. MGP introduces the idea of PathSim to measure the proximity of distinct classes. Recently, RecurMS [26] has been proposed as a schematic structure in HINs and provides a unified framework for integrating all the meta paths and meta structures. The RecurMS-based similarity RMSS is defined as the weighted sum of the commuting matrices of the decomposed recurrent meta paths and meta trees. RMSS is robust to different meta paths or meta structures. Table 1 demonstrates a comparison of different similarity measures based on the meta path and meta structure in HINs.

Table 1.
A comparison of measures based on the meta path and meta structure in HINs.
3. The Proposed Method
In this section, we will introduce the proposed method. More specifically, we first describe the definition of the layer of the meta structure. Then, we elaborate upon the strategy of subgraph expansion with bias and its semantic meaning. Finally, we propose the general formula of StructSim, analyze the characteristics and discuss its implementation.
3.1. Layer of Meta Structure
The layer of the meta structure denotes its depth, which is defined as follows.
Definition 1
(Layer of meta structure [14]). Given the meta structure , we can divide the nodes in the meta structure into different levels according to its topological characteristics. is a set of nodes and is a set of edges. To be specific, denotes the nodes’ set of the i-th layer in the meta structure. means the nodes’ set from the i-th layer to the j-th layer in the meta structure . denotes the total number of layers in the meta structure, with .
In Figure 1, is an example of a meta structure. The number of layers of is 5, that is, . The nodes’ set of the first layer is denoted by , with . The nodes’ set of the second layer is , with . Then, we can easily obtain , with . There is only one node in the first layer of , while there are two nodes in the third layer of .In this paper, is regarded as a whole when expanding the subgraph, which will be illustrated in the implementation section.
3.2. Subgraph Expansion with Bias
In HINs, similarity measures based on the meta structure employ the subgraph expansion to model the complex semantic meanings between objects. The subgraph expansion strategy claims that the expansion probability is the same when expanding to a different node of the same type from the same layer of the meta structure in each step. In fact, the expansion probability may be different due to the difference between objects. Therefore, we propose a novel strategy of subgraph expansion with bias in this paper, which has an essential difference from current subgraph expansion. Based on the subgraph expansion with bias, we can easily calculate the subgraph expansion probability with bias.
We firstly describe the process of subgraph expansion and then focus on the bias factor in subgraph expansion. Similar to random walk based on the meta path, the subgraph expansion based on the meta structure means that we traverse the network starting from a given source node until the target node along the given meta structure is reached to. Owing to the complexity of the meta structure, the traversing result refers to the subgraph rather than the path. We will describe the process with an example.
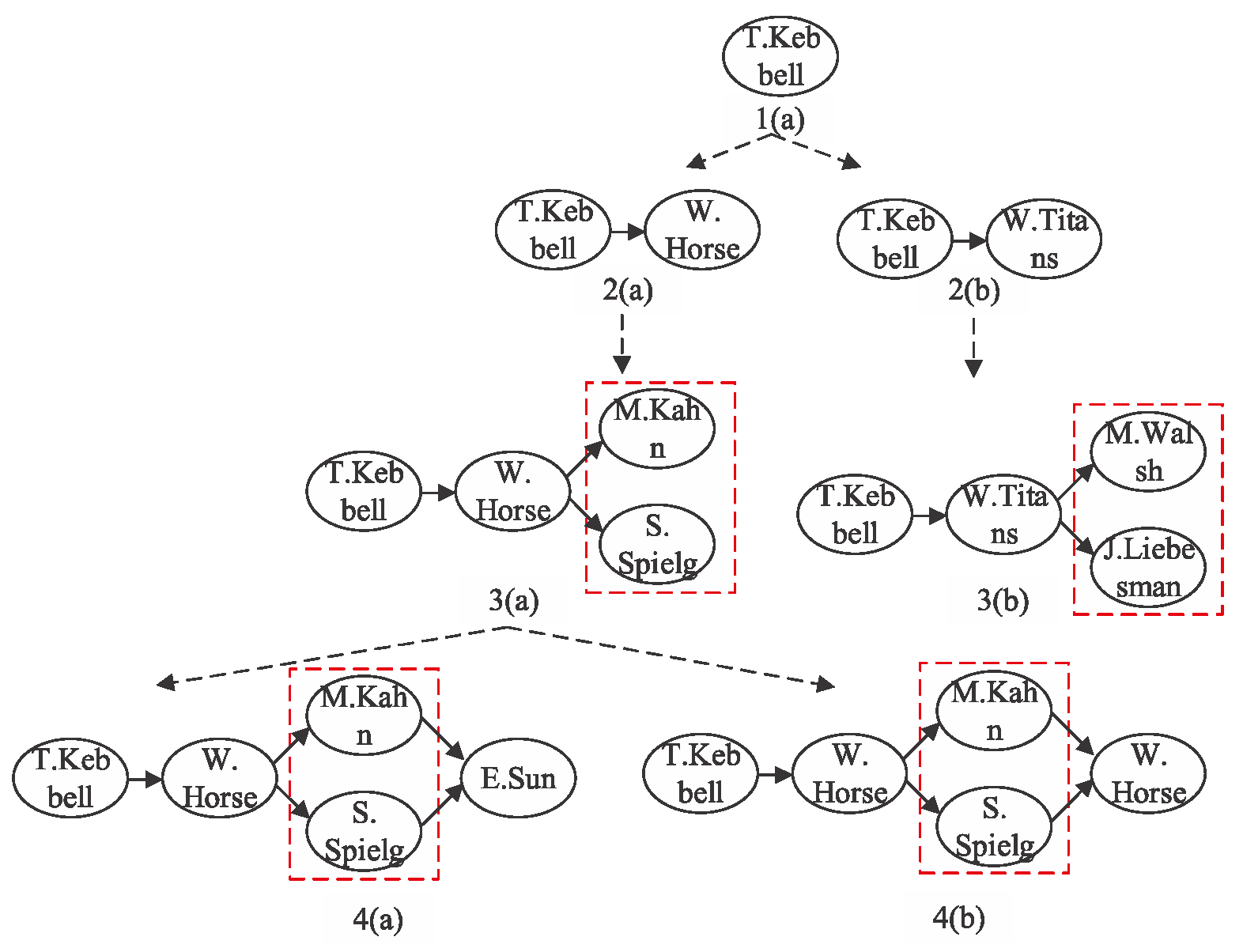
Figure 2 shows an example of the detailed process of subgraph expansion. To be specific, given the source node Toby Kebbell and the meta structure in Figure 1, starting from Toby Kebbell, along the relation of the first layer of meta structure S, we can expand to two nodes, namely, War Horse (film) and Wrath of the Titans, and then obtain the two subgraphs shown by 2(a) and 2(b) in Figure 2.
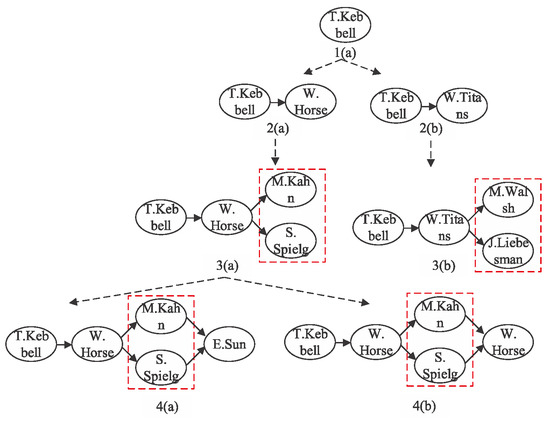
Figure 2.
The process of subgraph expansion based on the meta structure.
We continue to make the second layer expansion from 2(a) and 2(b), and then we can obtain subgraphs 3(a) and 3(b), respectively. Different from the first layer expansion, we need, meanwhile, to expand two nodes in the second layer, as shown by the dotted rectangle in 3(a) and 3(b) of Figure 2. In this situation, where two nodes are, meanwhile, expanded at a layer of the meta structure, we regard these two nodes as a whole to generate subgraph expansion in this study. To facilitate the expansion of this kind of complex structure, we further design the node composition operator, which will be introduced in detail in the next section.
After the two nodes are looked at as a whole, we can make the subgraph expansion in a similar way to random walk. Then, we expand to 4(a) and 4(b) from 3(a) of Figure 2. In a similar way, we generate subsequent subgraph expansion along different relations in every layer of the meta structure. Finally, we finish the expansion when meeting the target node.
Based on the subgraph expansion, we introduce the bias factor, which denotes that we make the subgraph expansion with different probabilities starting from the source node to the target node along the layer of the meta structure in the whole network. More specifically, the bias means that the probability is different when expanding to different nodes with the same type from the same layer of the meta structure in each step. That is, we need, meanwhile, to consider two kinds of node neighbor information, including the out-neighbors information on the current node and the in-neighbors information on the next hop node to be expanded. In other words, the probability of expanding to some nodes is high, while the probability of expanding to other nodes may be low in each step, namely, the expansion is biased.
Figure 2 is an example; there are two nodes, (War Horse (film) and Wrath of the Titans), when we traverse the network starting from Toby Kebbell along the relation of the first layer of the meta structure . If we do not consider the bias, then the probability of expanding to War Horse (film) or Wrath of the Titans is equal to 1/2. In fact, the probability is not always the same. That is, the probability of expanding to one node is high, while the probability of expanding to another one may be low. Therefore, we devise the strategy of subgraph expansion with bias. For example, the probability from Toby Kebbell to War Horse (film) may be ¾, while the probability from Toby Kebbell to Wrath of the Titans may be 1/4. The movie role may be a vital reason for this bias. Just as Toby Kebbell acts as the leading role in one film, and may only make a guest appearance in another movie. It is obvious that Toby Kebbell will pay more attention to the movie in which he acts as the leading role, which also further reveals that he has different biases for both movies.
3.3. General Formula of Similarity Measure Based on Meta Structure
In this section, we first describe the basic idea of the proposed method. Then, we propose the general formula of similarity measure based on the meta structure. Finally, we describe the semantic meanings with a detailed example.
3.3.1. Basic Idea
To explore the complicated semantics between objects, we propose a novel meta-structure-based similarity measure called StructSim. The basic idea is that two objects are more similar if the probability of expansion from the source node to the target node along a given meta structure is greater.
Different from random walk based on the meta path, subgraph expansion based on the meta structure involves a more complex structure than the path. Moreover, we introduce the subgraph expansion with bias to make full use of leveraging the structure information of the network in this study, which has an essential difference from the existing subgraph expansion.
Specifically, StructSim claims that the expansion probability from the same node to different nodes with the same type is different in each step when the subgraph is expanded along the meta structure. That is, the probability of expanding to some nodes is high, while the probability of expanding to other nodes may be low. Here, to embody the bias of subgraph expansion, StructSim, meanwhile, considers the node information at both ends of the expansion, including the out-neighbor information on the current node, and the in-neighbor information on the next-hop node to be expanded. In a word, the expansion is biased and StructSim models the probability of subgraph expansion with bias.
3.3.2. The Formula of StructSim
In this section, we clarify the formula definition of StructSim. Let and be the source and target nodes, respectively. Based on the meta structure we can define the general formula of StructSim as follows:
where denotes the similarity score between the source node and target node based on an instance of the meta structure. Here, has several different definitions, such as the number of subgraphs and the expansion probability. In general, the number of subgraphs can be a special case of expansion probability. Therefore, we define the general formula of as follows:
where denotes the number of layers of instance s of the meta structure. is the subgraph expansion probability with bias in the ith layer, which can be obtained by subgraph expansion with bias starting from the source node to the target node along a given meta structure in the whole network. Here, the subgraph expansion with bias is a kind of novel strategy proposed to make full use of the structure information of the network. Equation (2) shows that can be regarded as the product of expansion probability with bias of all layers of instance s of the meta structure.
The function in Equation (2) is the subgraph expansion probability with bias and it depends on two factors: and . Specifically, is the set of expanded subgraphs in the ith layer, which controls the extent of depending on their out-neighbor information. denotes the set of forward subgraphs of the next-hop nodes expanded from the ith layer, which controls the extent of dependence on their in-neighbor information. Through combining both types of information above, we can determine the bias in subgraph expansion and then obtain the subgraph expansion probability with bias, as shown in Equation (3).
where is the set of expanded subgraphs in the ith layer during the process of subgraph expansion. The number of expanded subgraphs is . denotes the set of forward subgraphs of next-hop nodes expanded from the ith layer; is the number of forward subgraphs. ω means the weight which controls the proportion of out-neighbors and in-neighbors in expansion probability with bias.
3.3.3. Semantic Meaning Explanation with an Example
In this section, we use an example to describe the semantic meaning of subgraph expansion probability with bias . Figure 1 is an HIN example. The given source node is Toby Kebbell and the meta structure is S. Figure 2 denotes the process of subgraph expansion based on the meta structure. It is obvious that there exist two nodes connecting with Toby Kebbell through relation , namely, War Horse (film) and Wrath of the Titans. Hence, the number of subgraphs in the first layer is . For subgraph 2(a), the forward subgraph of next-hop node W. Horse is 1(a); the number of the forward subgraph is . By a weighted combination of and , we can obtain the expansion probability with bias . In this paper, we set out-neighbors and in-neighbors to have the same important weight in the expansion probability with bias, which means ω = 0.5. Consequently, we can obtain the expansion probability with bias from 1(a) to 2(a), that is . The different values for ω mean that the proportion of the weight of out-neighbor and in-neighbor information is different in the expansion probability with bias. We can adjust the range of ω to determine the optimal value for a specific task.
In the same way, we can compute the subgraph expansion probability with bias of the remaining layers of the meta structure. Based on the expansion probability with bias, given an instance s of the meta structure, the product of probabilities with bias of all the layers of is the similarity between the source node and the target node based on , denoted by . In general, given the source node , HIN G = (V, E) and the meta structure , we can obtain all instances of through expanding the subgraph along the layer of the meta structure in graph G. For instance, in Figure 1, through subgraph expansion starting from source node Toby Kebbell along the meta structure S, we can obtain the instance of the meta structure shown by a dashed line. For each instance, we compute the and then accumulate the similarity scores based on all instances of the meta structure to obtain the final similarity . It is obvious that StructSim models the probability of subgraph expansion with bias from the source node x to the target node y along a given meta structure . Two objects are more similar if they are connected by more instances of the meta structure.
3.4. The Implementation of StructSim
In this section, we study how to perform similarity computation based on a given meta structure. We first present two novel mechanisms, including a Node-Composition operator and an expansion probability matrix with bias. Then, we describe the implementation of StructSim based on both strategies proposed above.
3.4.1. Node-Composition Operator
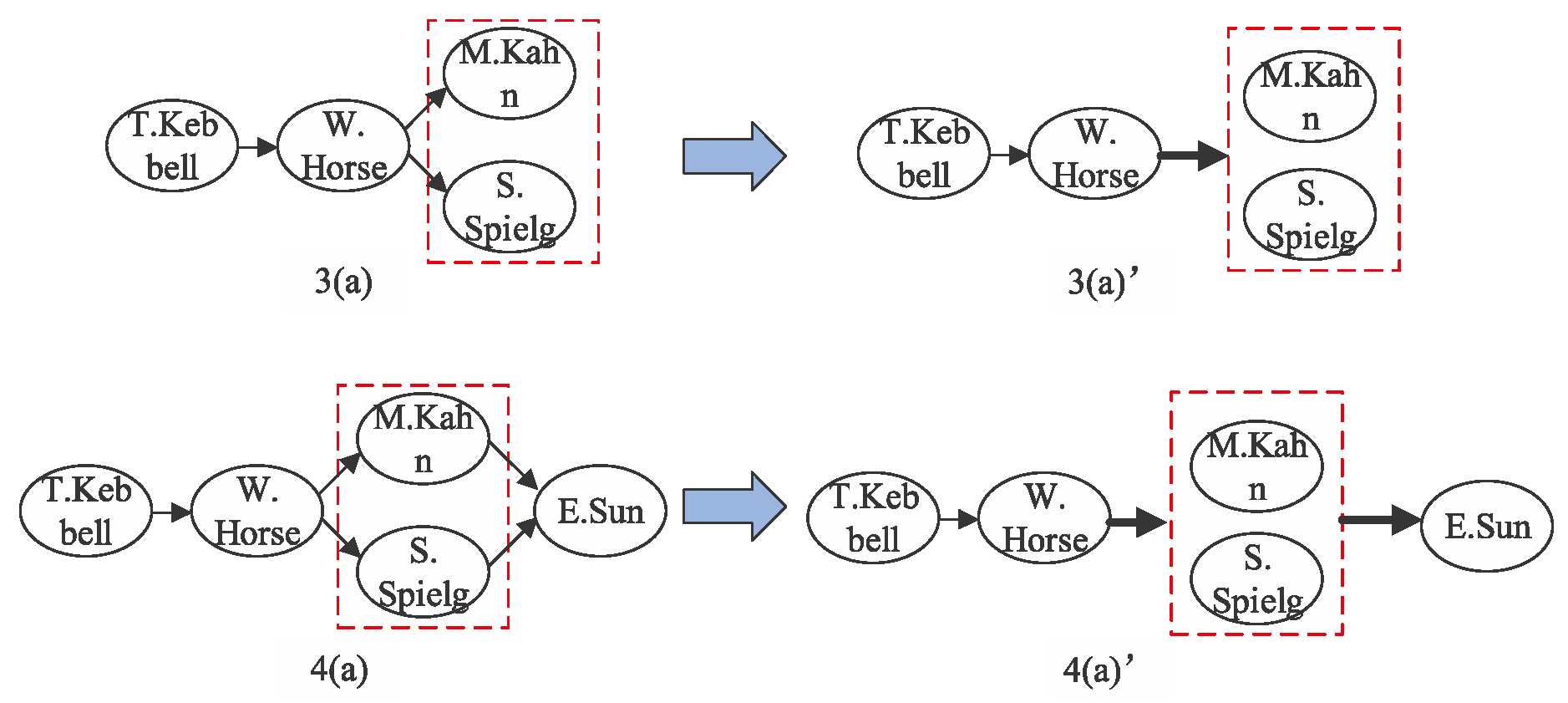
In Figure 2, we describe the detailed process of subgraph expansion. However, the expansion is different in different layers of the meta structure. For instance, we can easily find the difference between the first layer expansion and the second layer expansion by carefully observing Figure 2. At the first layer expansion, only a single node is expanded, as shown by the subgraph expansion from (1)a to (2)a in Figure 2. However, at the second layer expansion, two nodes need, meanwhile, to be expanded, as shown by the subgraph expansion from (2)a to (3)a in Figure 2. It is not easy to calculate the expansion probability in the situation of the second complicated expansion. Therefore, an effective solution is needed to solve this problem.
Inspired by the literature [11], we designed the Node-Composition Operator to facilitate the expansion of the complex structure and computation of the expansion probability matrix with bias. To be specific, we combine two nodes into a composition node. The relation connecting the composition node can also be called the composition edge. Based on the operation of Node-Composition, we regard the composition node as a whole to create subgraph expansion in a way similar to single node expansion. Then, we can easily compute the subgraph expansion probability with bias in this situation.
Figure 2 is an example to clearly illustrate the Node-Composition Operator. From the process of subgraph expansion based on the meta structure in Figure 2, we can see that, in the second layer of subgraph expansion, we need expand two nodes of Person type at the same time from the node with Movie type. The process from 2(a) to 3(a) in Figure 2 shows the expansion from W.Horse (film) to M.Kahn (film editor) and S.Spielg (director). After the Node-Composition operation, we obtain subgraph (3)a’ in Figure 3. The relation connecting W.Horse (film) and composition node (M.Kahn (film editor) and S.Spielg (director)) is also adjusted to be a composition edge, which is revealed by the bold arrow in (3)a’ of Figure 3. Then, in the third layer expansion, it is the expansion from a composition node to a single node. As illustrated by the process from 3(a) to 4(a) in Figure 2, we generate subgraph expansion from M.Kahn and S.Spielg (a composition node) to E.Sun (a single node). After the operation of Node Composition, we obtain the subgraph exhibited by (4)a’ in Figure 3.
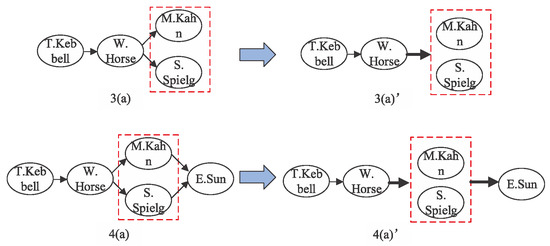
Figure 3.
A toy example of the Node-Composition operator.
Based on the Node-Composition Operator, the node sets in every layer of the meta structure can be regarded as a whole. Then, we can adopt the matrix to conveniently calculate the expansion probability, which is similar to the transition probability matrix in random walk. Finally, we can apply the matrix multiplication to the implementation of StructSim.
3.4.2. Expansion Probability Matrix with Bias
Based on the Node-Composition Operator, we can easily define the expansion probability matrix with bias as follows.
Definition 2.
Expansion probability matrix with bias. is an adjacent matrix between and . The normalized matrix of along the row vector is denoted as , which is the expansion probability matrix of layer relation . Suppose there exists bias for expanding to different objects in of the same layer j. The expansion probability matrix with bias of layer relation is . is the function of matrics and and is the bias matrix of object type in the ith layer based on layer relation .
denotes that the object in the ith layer of the meta structure S has a different bias for various objects in the (i+1)th layer. The probability is the same in each row of the expansion probability matrix , while the probability may be different in each row of the expansion probability matrix with bias . denotes the node sets in the ith layer of the meta structure . It is obvious that has two different situations. One is that only contains a node. The other is that contains more than one node. In the first situation, it is easy to compute the expansion probability matrix with bias by adopting the existing transition probability matrix. However, it is very difficult to calculate the expansion probability matrix with bias in the second situation. As illustrated in the Node-Composition Operator, is regarded as a whole when making subgraph expansion based on a meta structure. Therefore, we first use the Node-Composition Operator for . Then, we adopt a strategy similar to the first situation to calculate the probability matrix.
In this paper, we present the weighted combination operation to determine the function f. That is, . Based on the expansion probability matrix with bias , we have the following relevance matrix between the type of source node and the type of target node based on the meta structure S for StructSim.
where denotes the total number of layers in the meta structure S. We can obtain the final similarity score based on the meta structure by way of matrix multiplication, which refers to the in Equation (1).
3.5. Discussion
In this section, we analyze the computational complexity, characteristics and limitation of the proposed method. The time complexity mainly lies in matrix multiplication. What is more, the dimension and sparsity of the matrix also have a certain impact on efficiency. The complexity is O ( for an instance of a meta structure S with depth, while m is the average matrix dimension. In addition, the Node-Composition Operator may also cause an increase in matrix dimensions, especially in a large-scale information network.
In order to better analyze the characteristics of the proposed method, we have concluded the overall relations between different measures and the computation formulas in Table 1. They are based on some basic strategies including path/graph count or walking/expansion probability. Although these methods can also capture semantics between objects, it is not sufficient for the utilization of the structure information of a network. Therefore, we present the strategy of expansion with bias in this paper in order to make full use of network information. Moreover, for the complex structure expansion, one must also face the problem that multiple nodes expand at the same time. To solve this, some strategies need to be devised. In this paper, we design the operator of Node-Composition. Based on the operation, we can make the subgraph expansion much easier.
These above strategies reveal the difference between StructSim and BSCSE. BSCSE simulates the process of structure-constrained subgraph expansion. StructSim further introduces the bias and operator of Node-Composition based on BSCSE, which can well capture comprehensive information between objects with complex semantic meanings. This property also implies that StructSim is more effective than BSCSE, since StructSim, meanwhile, considers both kinds of information for probability computation, not solely out-neighbor information. The limitation is that the efficiency of matrix multiplication is a vital issue that needs to be addressed. Besides this, by adopting the Node-Composition Operator in some layer of the meta structure, the number of composition nodes with the same type could be large, which is inefficient both in terms of space to store them and in terms of the operation of matrix multiplication. Fortunately, there have been several quick computation solutions, including dynamic programming and Monte Carlo [11].
4. Experiments
4.1. Datasets
In order to verify the effectiveness of StructSim, we conducted extensive experiments on the classic datasets YAGO [5] and DBLP [11]. YAGO is a huge semantic knowledge base system derived from Wikipedia, WordNet and GeoNames [5]. Now, it contains more than 10 million entities and 120 million facts. In this paper, we mainly adopt the “Core Facts” part in YAGO, denoted by Yago-Core [27], which includes the fact tuples of entity and relationship such as <Steven Spielberg, directed, War Horse (film)>, and tuples of entity type. Table 2 shows the statistics of the Yago-Core dataset. DBLP contains the major conferences in four research fields including database, data mining, information retrieval and artificial intelligence. It has 14,475 authors, 14,376 papers, 8593 terms and 20 conferences, the labelled data of which is 4057 authors, 20 conferences and 100 papers.
Table 2.
Yago-Core dataset statistics.
4.2. Baselines
To validate the effectiveness of StructSim, we selected seven representative approaches as baselines, which included PathCount (the number of path instances) [9], PathSim (a standardized version of PathCount) [9], PCRW (the sum of probability based on random walk of all path instances) [10], StructCount (the number of instances of meta structure) [14], SCSE (the probability of subgraph expansion) [14] and MGP [21] (the shared characteristic meta-graphs).
4.3. Effectiveness Experiments
In order to evaluate the effectiveness of StructSim, we conducted extensive experiments on entity resolution and clustering tasks. We adopted two popular criteria of Area Under the Curve (AUC) and Normalized Mutual Information (NMI) [28] to evaluate the performance of StructSim on both tasks, respectively. Then, we further analyzed the traits of StructSim through a case study.
4.3.1. Entity Resolution Task
Entity resolution refers to finding the same entity pairs with different descriptions, which can achieve the purpose of data cleaning. For example, in YAGO, Presidency of Ronald Reagan and Ronald Reagan denote the same person but have different descriptions. Entity resolution aims to find Presidency of Ronald Reagan and Ronald Reagan so as to clean the data by deduplicating this entry.
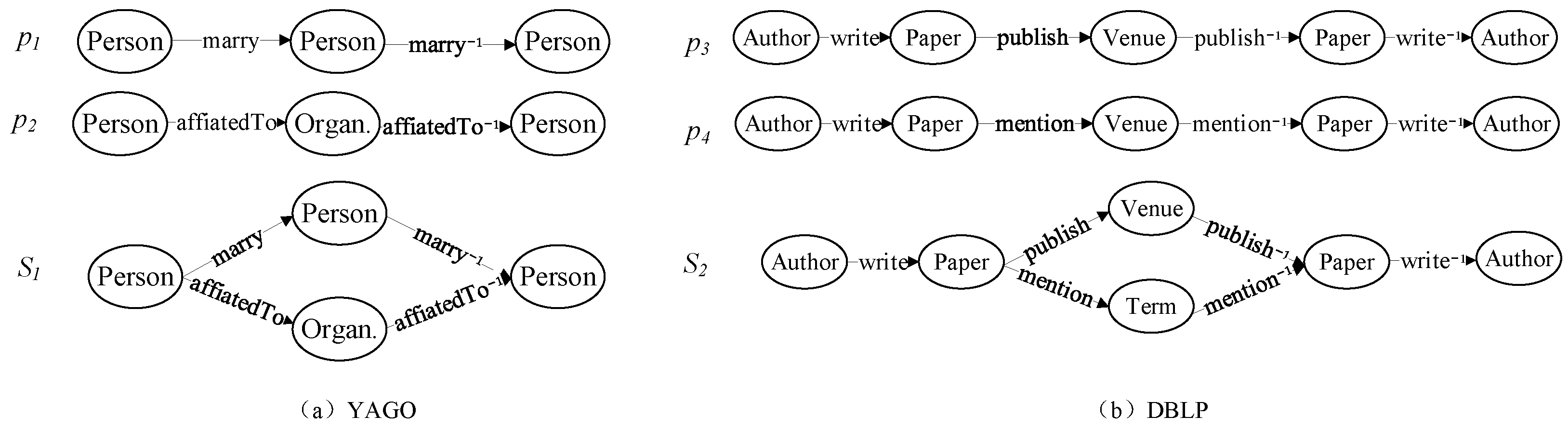
We extracted experiment data from YAGO for an entity resolution task. To be specific, we leverage yago-fact tuples and entity types to obtain 2687 pairs of objects satisfying the semantic meaning revealed by the meta path p1 in Figure 4. These extracted data, in total, included 4521 different people. Then, we manually labeled the data with the help of Wikipedia and obtained 46 pairs of entities which denoted the same object. The remaining 2641 pairs of entities were regarded as negative samples.
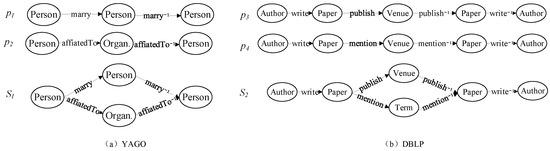
Figure 4.
Meta path and meta structure on entity resolution and clustering tasks.
For the entity resolution task, we employed the meta structure and meta paths , in Figure 4 to compute the similarity between objects. For each object, we regarded it as a source node to find the duplicated target node. Based on the similarity score, we ranked the other entities except for the source node. The higher the similarity score, the more likely it was to belong to the same object. Here, the same object was the pairs of objects that referred to the same entity. For example, Presidency of Ronald Reagan and Ronald Reagan refer to the same entity. We drew the ROC curve through adapting the threshold of the similarity score and computed the AUC value.
Table 3 demonstrates the results of different similarity measures in the entity resolution task. is the similarity formula of a linear combination of the meta path; and denote the similarity score based on the meta path and , respectively.
Table 3.
Effectiveness results of different similarity measures on entity resolution task.
From Table 3, we can observe that (1) the similarity measures based on the meta structure have a better performance compared with those based on the meta path, which reveals that the meta structure can capture more complex semantic meaning than the meta path. Here, means two people are not only subordinate to the same organization but also have a marital relationship with the same people. However, both and cannot express the complicated semantics. (2) StructSim performs better than StructCount, SCSE, BSCSE and MGP, which indicates that StructSim considers more rich semantics by incorporating the out-neighbor and in-neighbor information when expanding the subgraph, rather than just considering the out-neighbor information that most similarity measures do. (3) The linear combination of the meta path outperforms the approaches based on the meta path but is inferior to meta-structure-based approaches. This demonstrates that the linear combination can capture more comprehensive information than a single meta path; nevertheless, it cannot capture more complicated semantics than the meta structure. (4) has some superiority over in the entity resolution task, which may be due to the fact that two objects with a martial relationship with the same person have higher probability to be the same people than two objects being subordinate to the same organization.
4.3.2. Clustering Task
For the clustering task, we clustered authors based on the meta structure and the meta paths in Figure 4. According to the research field, we set the number of clusters to four. Based on the similarity matrices derived by different similarity measures, we applied Normalized Cut [29] to cluster authors. We ran this 100 times for each algorithm and recorded the average accuracy.
Table 4 demonstrates the results of different similarity measures in the clustering task, and also lists the experimental results based on the linear combination of the meta path. We can obtain the following several conclusions from Table 4. (1) StructSim outperforms StructCount, SCSE, BSCSE and MGP, which indicates that StructSim considers more rich semantics than StructCount and SCSE. (2) p3 has a better performance than p4 in the clustering task, which reveals that can capture more semantic meaning information compared with . That is, authors who have published papers in the same venue are more likely to be classified into a cluster. (3) The linear combination of the meta path performs better than the approaches based on the meta path. This demonstrates that the linear combination can capture more comprehensive information than any single meta path.
Table 4.
Effectiveness results of different similarity measures in clustering task.
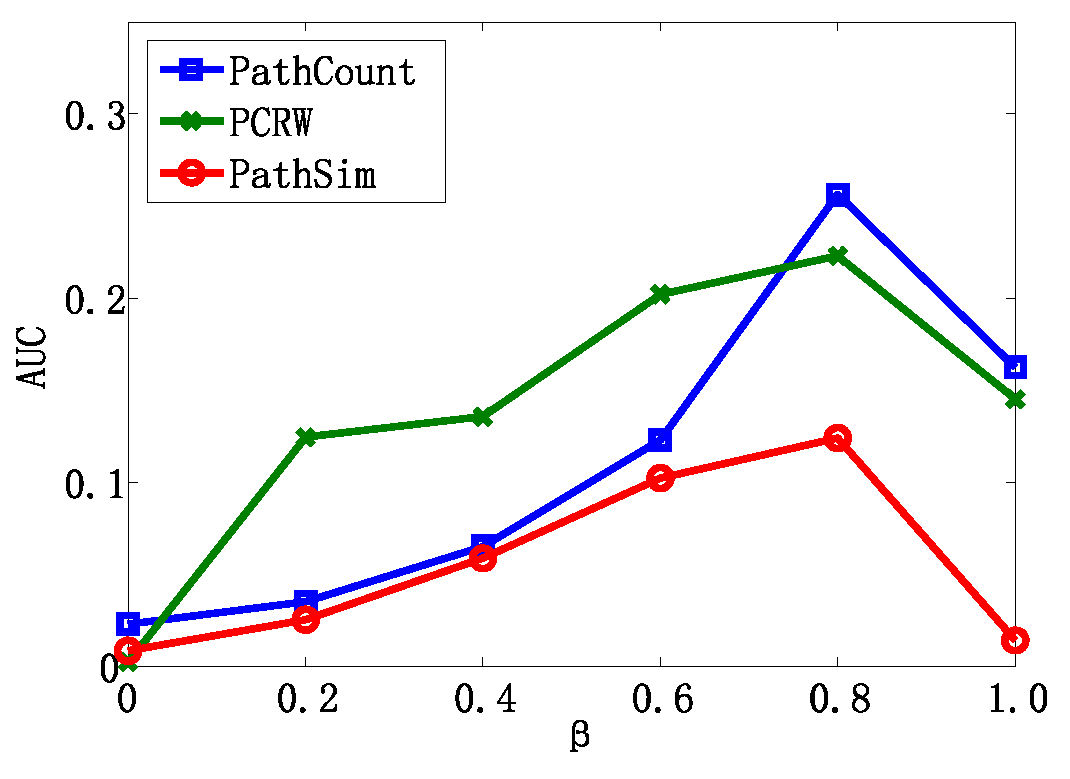
We also further studied how parameter β influenced the performance of algorithms in the entity resolution task. We varied the parameter β from 0 to 1 and recorded the AUC value, which is depicted in Figure 5. The experimental results on various β show that different weight combinations of the meta path have a significant effect on performance. With the increase in β, the performance first gradually increases and then decreases. Algorithms achieve the best AUC value when β = 0.8, which indicates that the meta path p1 has a more significant impact than p2 in the entity resolution task. This is also consistent with our intuition. In addition, it is very meaningful to determine the proper weight of the meta path so as to achieve a better performance, which will be studied in future work.
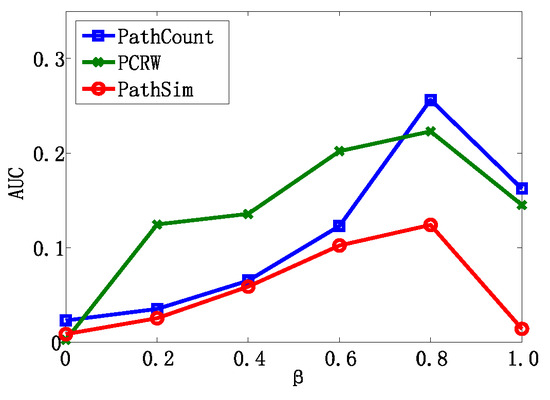
Figure 5.
The results of the linear combination of the meta path in the entity resolution task.
4.3.3. Case Study
In order to illustrate the traits of StructSim, we show the top five most similar authors to “Christos Faloutsos” based on different meta paths, the linear combination of the meta paths and the meta structure for PCRW, PathSim and StructSim in Table 5.
Table 5.
Top 5 most similar authors to “Christos Faloutso” under different meta paths and meta structures in DBLP dataset.
From the results, we can see that StructSim obtains some similar authors to Christos Faloutsos and these authors contain more complex semantic meanings than those authors obtained using other methods. However, other methods just focus on partial semantics. For example, in the ranking result generated by PCRW based on APCPA, Charu C. Aggarwal is just an author who has published papers in the same conference that Christos Faloutsos published, but does not pursue the same research topics as him. Charu C. Aggarwal and Jiawei Han have published more papers in the same conference than Christos Faloutsos has published. Therefore, they are ranked in the top two. PathSim finds similar peer–authors, such as Jiawei Han, who has the same reputation as Christos Faloutsos in the data mining field. Both PCRW and PathSim are mainly concentrated on the same conference or the same terms. Nevertheless, StructSim can pay close attention to these two kinds of semantics. As a consequence, StructSim gives the best ranking quality with complicated semantics, which is consistent with human intuition.
5. Conclusions
In this article, we studied the complex semantic similarity measure in HINs. We proposed a meta-structure-based similarity measure approach called StructSim, which employs the subgraph expansion probability with bias to define the similarity between objects. Moreover, we designed the Node-Composition Operator and expansion probability matrix with bias so as to facilitate the implementation of StructSim. Experiments on Yago and DBLP show that StructSim has a better performance compared with the baselines. In addition, we also analyzed the traits of StructSim through a case study.
In the future, we will further study the semantics analysis approach based on more complicated structures, such as motifs, which may be beneficial in various data mining tasks. We are also interested in methodological complexity, which is very important in making an approach practical.
Author Contributions
Conceptualization, Y.Z.; methodology, Y.Z.; software, Y.Z.; validation, Y.Z., J.Q. and J.Y.; formal analysis, Y.Z.; investigation, Y.Z.; resources, Y.Z.; data curation, J.Y.; writing—original draft preparation, Y.Z.; writing—review and editing, J.Q. and Y.Z.; visualization, J.Y.; supervision, Y.Z.; project administration, Y.Z.; funding acquisition, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 62102236).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used and analyzed during the current study is available from the corresponding author on reasonable request. You can also acquire the detailed data material from the webpage http://www.shichuan.org/index.html (accessed on 25 December 2023).
Acknowledgments
We appreciate Yang Xiao’s contribution to revising the English language, grammar and relevant data analysis in this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Shi, C.; Li, Y.; Zhang, J.; Sun, Y.; Philip, S.Y. A survey of heterogeneous information network analysis. IEEE Trans. Knowl. Data Eng. 2017, 29, 17–37. [Google Scholar] [CrossRef]
- Sun, Y.; Han, J. Mining heterogeneous information networks: A structural analysis approach. ACM SIGKDD Explor. Newsl. 2013, 14, 20–28. [Google Scholar] [CrossRef]
- Yang, C.; Gong, X.; Shi, C.; Yu, P. A post-training framework for improving heterogeneous graph neural networks. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 251–262. [Google Scholar]
- Ley, M. Dblp Computer Science Bibliography. Available online: http://dblp.uni-trier.de/ (accessed on 20 November 2023).
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the WWW’07: 16th International World Wide Web Conference, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Zhou, L.H.; Wang, J.L.L.Z.; Chen, H.M.; Kong, B. Heterogeneous Information Network Representation Learning: A Survey. J. Comput. Sci. 2022, 45, 160–189. (In Chinese) [Google Scholar]
- Liu, J.; Shi, C.; Yang, C.; Lu, Z.; Yu, P.S. A survey on heterogeneous information network-based recommender systems: Concepts, methods, applications and resources. AI Open 2022, 3, 40–57. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, H.; Liang, F.; Shi, C. Node-dependent semantic search over heterogeneous graph neural networks. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 2646–2655. [Google Scholar]
- Sun, Y.; Han, J.; Yan, X.; Yu, P.S.; Wu, T. Pathsim: Meta path-based top-k similarity search in heterogeneous information networks. Int. J. Very Large Data Bases 2011, 4, 992–1003. [Google Scholar] [CrossRef]
- Lao, N.; Cohen, W.W. Relational retrieval using a combination of path-constrained random walks. Mach. Learn. 2010, 81, 53–67. [Google Scholar] [CrossRef]
- Shi, C.; Kong, X.; Huang, Y.; Philip, S.Y.; Wu, B. Hetesim: A general framework for relevance measure in heterogeneous networks. IEEE Trans. Knowl. Data Eng 2014, 26, 2479–2492. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. Official Google Blog. 2012. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 22 November 2023).
- Alkhamees, M.A.; Alnuem, M.A.; Al-Saleem, S.M.; Al-Ssulami, A.M. A semantic metric for concepts similarity in knowledge graphs. J. Inf. Sci. 2023, 49, 778–791. [Google Scholar] [CrossRef]
- Huang, Z.; Zheng, Y.; Cheng, R.; Sun, Y.; Mamoulis, N.; Li, X. Meta structure: Computing relevance in large heterogeneous information networks. In Proceedings of the KDD’16: The 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1595–1604. [Google Scholar]
- Jeh, G.; Widom, J. Scaling personalized web search. In Proceedings of the WWW’03: The 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 271–279. [Google Scholar]
- Jeh, G.; Widom, J. Simrank: A measure of structural-context similarity. In Proceedings of the KDD’02: The Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 538–543. [Google Scholar]
- Li, C.; Han, J.; He, G.; Xin, J.; Wu, T. Fast computation of sim-rank for static and dynamic information networks. In Proceedings of the EDBT/ICDT’10 Joint Conference, Lausanne, Switzerland, 22–26 March 2010; pp. 465–476. [Google Scholar]
- Jin, R.; Lee, V.E.; Hong, H. Axiomatic ranking of network role similarity. In Proceedings of the KDD’11: The 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 922–930. [Google Scholar]
- Xu, X.; Yuruk, N.; Feng, Z.; Schweiger, T.A.J. Scan: A structural clustering algorithm for networks. In Proceedings of the KDD07: The 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 12–15 August 2007; pp. 824–833. [Google Scholar]
- Wang, C.; Song, Y.; Li, H.; Sun, Y.; Han, J. Distant meta-path similarities for text-based heterogeneous information networks. In Proceedings of the CIKM’17: ACM Conference on Information and Knowledge Management, Singapore, 6–10 November 2017. [Google Scholar]
- Yuan, F.; Lin, W.; Zheng, V.W.; Min, W.; Li, X.L. Semantic proximity search on graphs with meta graph-based learning. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 277–288. [Google Scholar]
- Gupta, M.; Kumar, P.; Bhasker, B. Dprel: A meta-path-based relevance measure for mining heterogeneous networks. Inf. Syst. Front. 2019, 21, 979–995. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Z.; Zhao, Z.; Li, Z.; Zhao, M. Effective similarity search on heterogeneous networks: A meta-path free approach. IEEE Trans. Knowl. Data Eng. 2020, 34, 3225–3240. [Google Scholar] [CrossRef]
- Shi, Y.; Chan, P.-W.; Zhuang, H.; Gui, H.; Han, J. Prep: Path-based relevance from a probabilistic perspective in heterogeneous information networks. In Proceedings of the KDD’17: The 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 425–434. [Google Scholar]
- Wang, C.; Sun, Y.; Song, Y.; Han, J.; Song, Y.; Wang, L.; Zhang, M. Relsim: Relation similarity search in schema-rich heterogeneous information networks. In Proceedings of the 2016 SIAM International Conference on Data Mining, Miami, FL, USA, 5–7 May 2016; pp. 621–629. [Google Scholar]
- Zhou, Y.; Huang, J.; Sun, H.; Sun, Y.; Wambura, S. Recurrent meta-structure for robust similarity measure in heterogeneous information networks. ACM Trans. Knowl. Discov. Data 2019, 13, 1–33. [Google Scholar] [CrossRef]
- Meng, C.; Cheng, R.; Maniu, S.; Senellart, P.; Zhang, W. Discovering meta-paths in large heterogeneous information networks. In Proceedings of the WWW’15: 24th International World Wide Web Conference, Florence, Italy, 18–22 May 2015; pp. 754–764. [Google Scholar]
- Jia, X.S.; Zhao, Z.Y.; Li, C.; Luan, W.J.; Liang, Y.Q. Heterogeneous network Representation learning method Fusin Mutual Information and Multiple Meta-paths. Ruan Jian Xue Bao J. Softw. 2023, 34, 3256–3271. (In Chinese) [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 22, 888–905. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).