
SISGAN: A Generative Adversarial Network Pedestrian Trajectory Prediction Model Combining Interaction Information and Scene Information

Abstract
1. Introduction
2. Related Work
2.1. Social Interactions for Pedestrian Trajectories
2.2. Scene Interaction Modeling Between Pedestrians and Environment
- (1)
- The interaction attention module is designed from the perspective of target pedestrians. It illustrates the influence mechanism of pedestrian interactions through four types of interaction information: repulsive force, pedestrian direction, motion direction, and speed difference. By utilizing a multi-head attention mechanism, this module calculates the interaction weights of different pedestrians, providing a more comprehensive summary of the social interaction information that influences the target pedestrian’s next decision.
- (2)
- This study establishes a potential connection between pedestrians and their environment using historical trajectory data. By applying a Gaussian function to calculate the spatial probability density of the trajectory data, this density value reflects the pedestrian’s walking preferences and the degree of aggregation in specific areas. The scene density map is then integrated with the scene convolution map in the spatial domain, allowing for the extraction of significant spatial information.
3. Methods
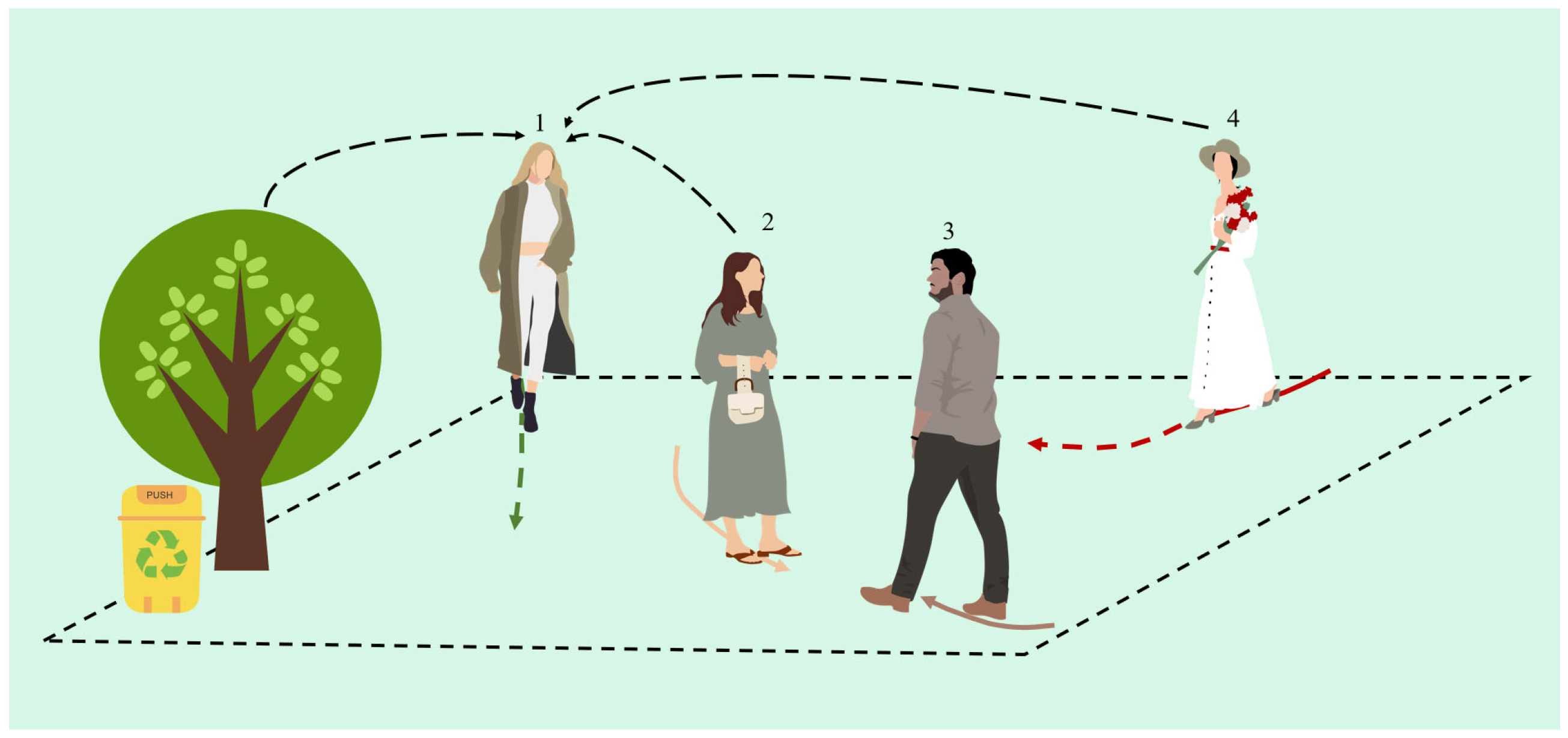
3.1. Pedestrian Trajectory Prediction Problem Definition
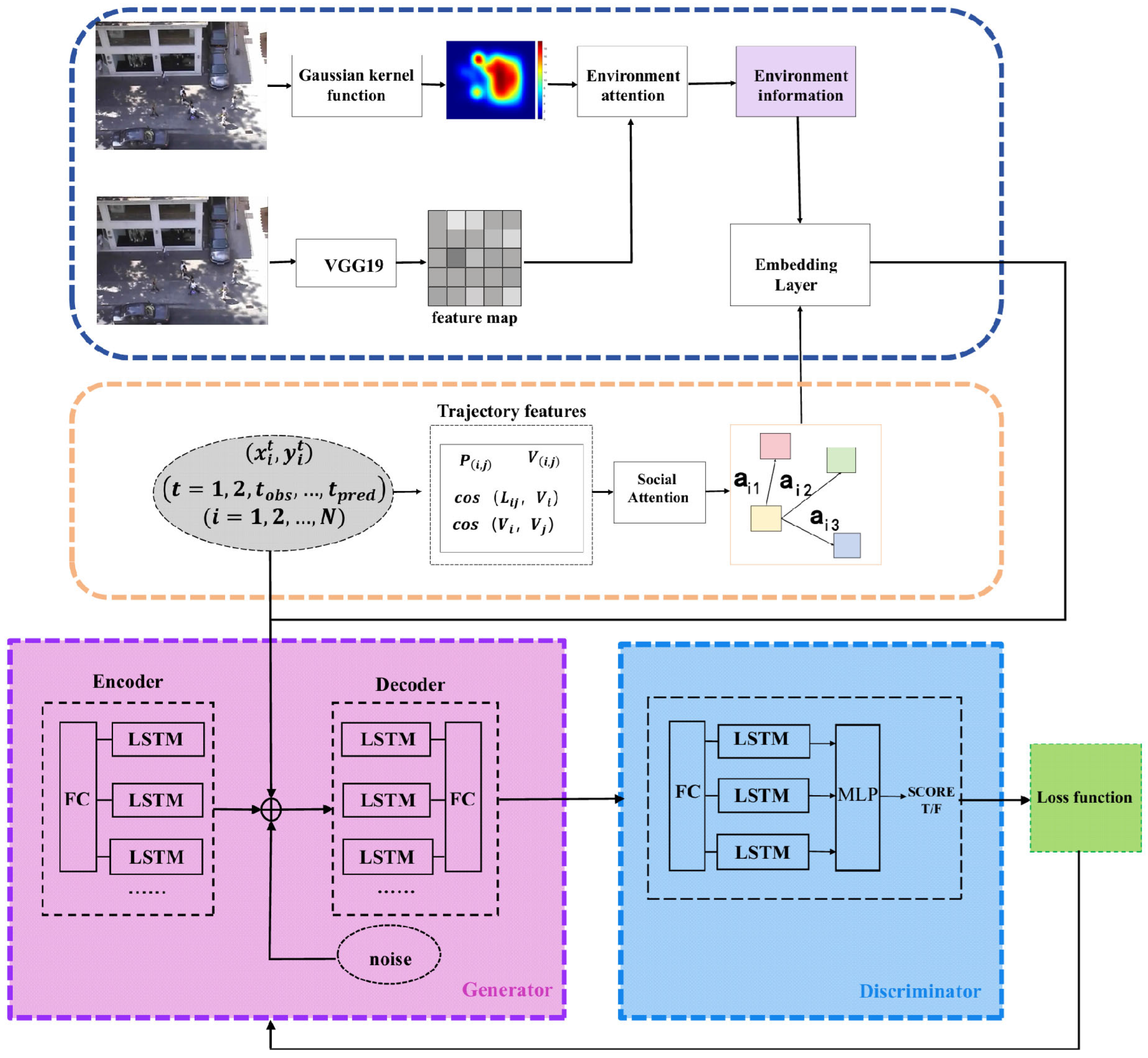
3.2. Overall Network Architecture
3.3. Social Attention Module
3.3.1. Information Extraction for Pedestrian Interaction Features
3.3.2. Pedestrian Weight Calculation Based on Multiple Attention Mechanism
3.4. Environment Attention Module
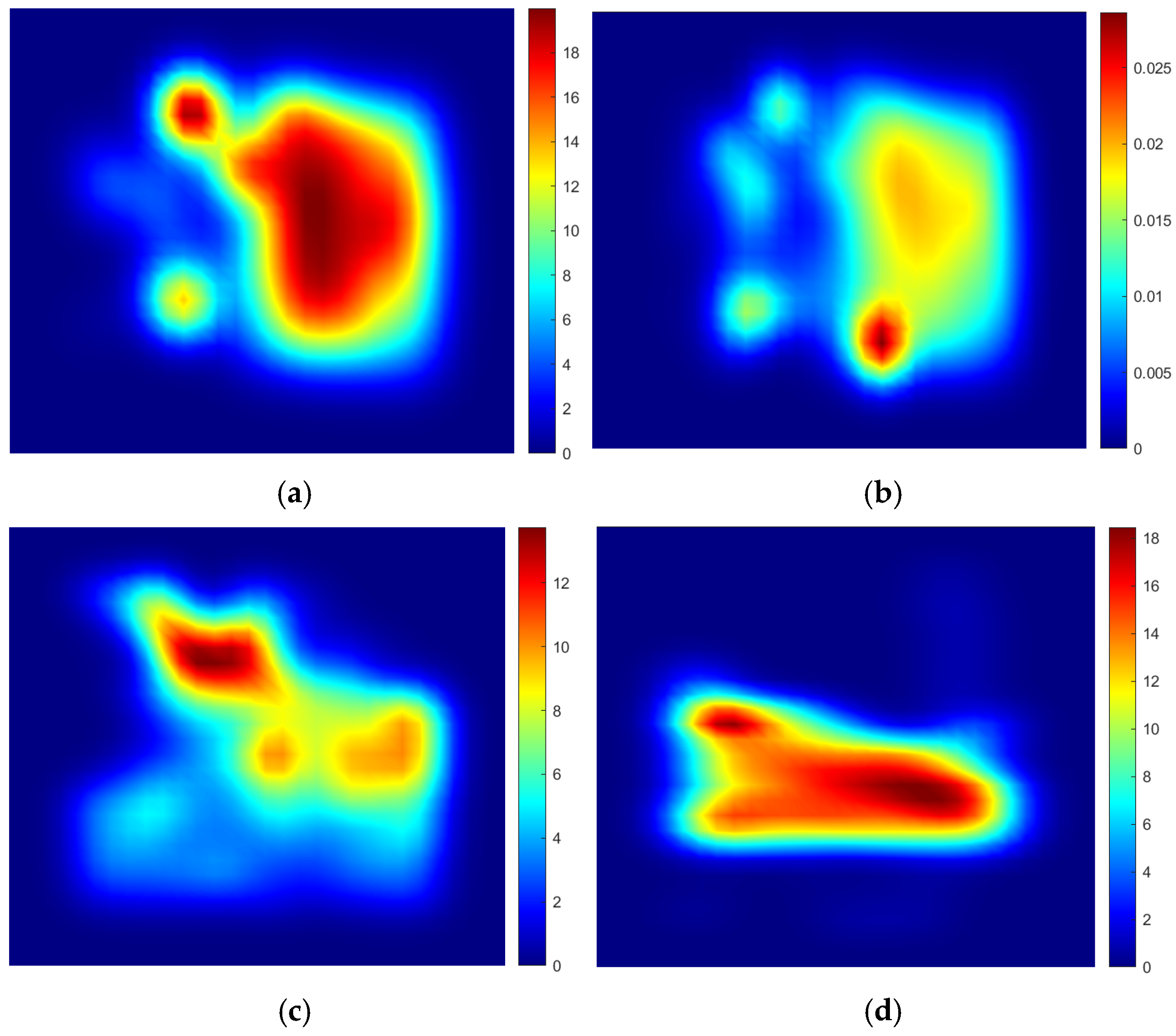
3.4.1. Trajectory Density Map
3.4.2. Scene Semantic Module
3.5. Pedestrian Trajectory Prediction
3.5.1. The Generator
3.5.2. The Discriminator
3.5.3. The Loss Function
4. Experiment and Analysis
4.1. Datasets
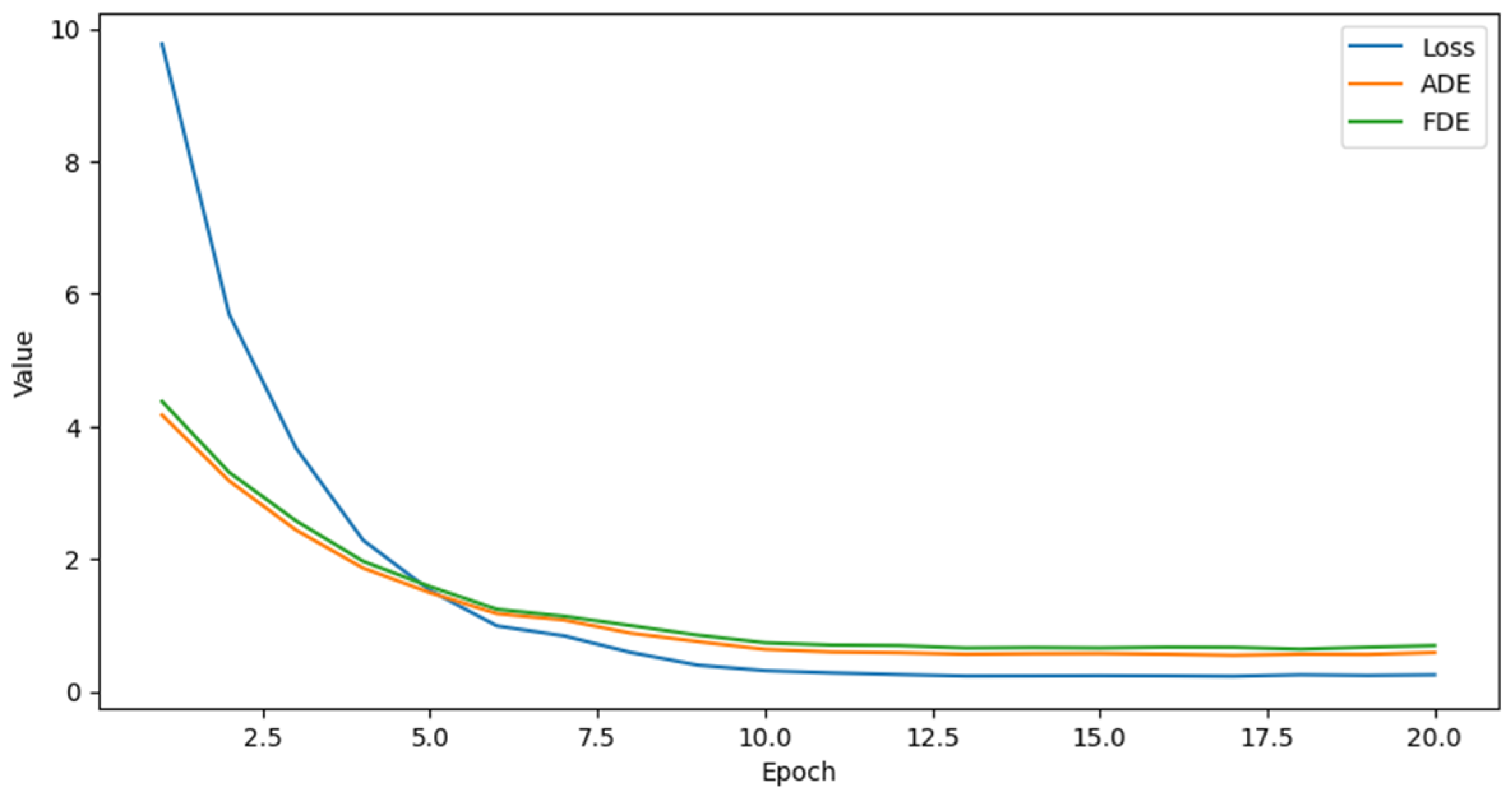
4.2. Experimental Details
4.3. Metrics
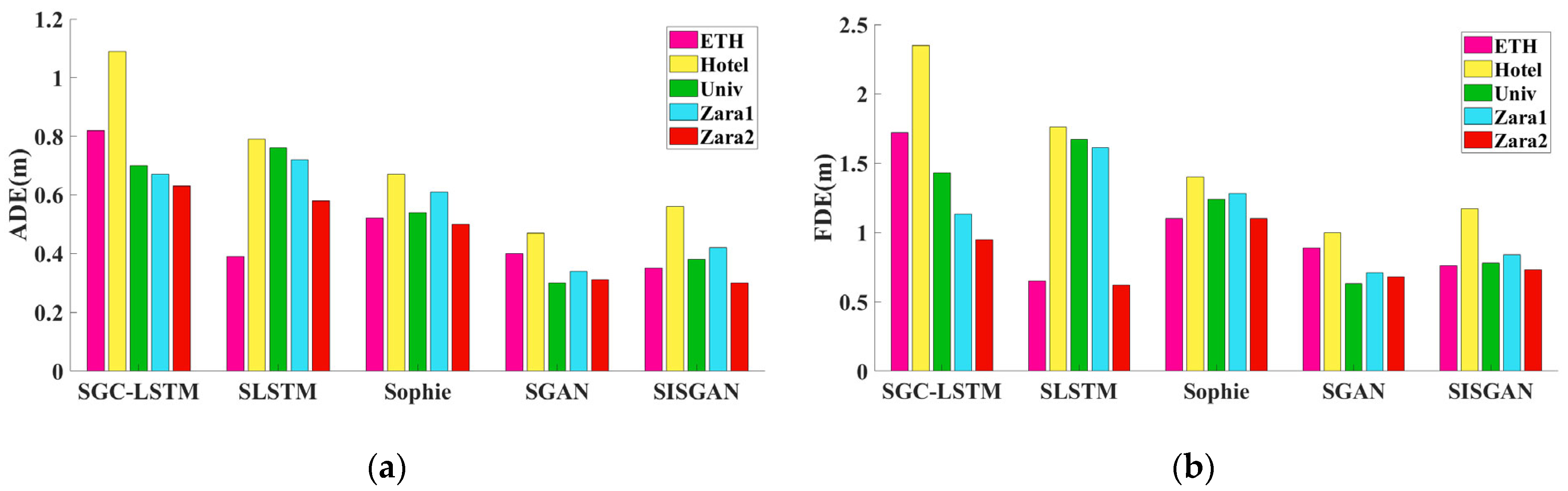
4.4. Analysis of Results
4.4.1. Quantitative Results
4.4.2. Qualitative Results
4.4.3. Results of Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E Stat. Phys. Plasmas Fluids Relat. Interdiscip. Top. 1995, 51, 4282–4286. [Google Scholar] [CrossRef] [PubMed]
- Pellegrini, S.; Ess, A.; Schindler, K.; van Gool, L. You’ll never walk alone: Modeling social behavior for multi-target tracking. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 261–268. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 961–971. [Google Scholar] [CrossRef]
- Xu, K.; Qin, Z.; Wang, G.; Huang, K.; Ye, S.; Zhang, H. Collision-Free LSTM for Human Trajectory Prediction. In Proceedings of the MultiMedia Modeling: 24th International Conference, MMM 2018, Bangkok, Thailand, 5–7 February 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 106–116. [Google Scholar] [CrossRef]
- Haddad, S.; Wu, M.; Wei, H.; Lam, S.K. Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model. In Proceedings of the 24th Computer Vision Winter Workshop Friedrich Fraundorfer, Stift Vorau, Austria, 6–8 February 2019; Volume 25, pp. 4–13. [Google Scholar] [CrossRef]
- Kim, S.; Chi, H.-G.; Lim, H.; Ramani, K.; Kim, J.; Kim, S. Higher-order Relational Reasoning for Pedestrian Trajectory Prediction. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15251–15260. [Google Scholar]
- Su, Y.; Li, Y.; Wang, W.; Zhou, J.; Li, X. A Unified Environmental Network for Pedestrian Trajectory Prediction. Proc. AAAI Conf. Artif. Intell. 2024, 38, 4970–4978. [Google Scholar] [CrossRef]
- Cheng, H.; Liu, M.; Chen, L.; Broszio, H.; Sester, M.; Yang, M.Y. GATraj: A graph- and attention-based multi-agent trajectory prediction model. ISPRS J. Photogramm. Remote Sens. 2023, 205, 163–175. [Google Scholar] [CrossRef]
- Giuliari, F.; Hasan, I.; Cristani, M.; Galasso, F. Transformer Networks for Trajectory Forecasting. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10335–10342. [Google Scholar]
- Chen, X.; Zhang, H.; Hu, Y.; Liang, J.; Wang, H. VNAGT: Variational Non-Autoregressive Graph Transformer Network for Multi-Agent Trajectory Prediction. IEEE Trans. Veh. Technol. 2023, 72, 12540–12552. [Google Scholar] [CrossRef]
- Czech, P.; Braun, M.; Kreßel, U.; Yang, B. On-Board Pedestrian Trajectory Prediction Using Behavioral Features. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; Volume 48, pp. 437–443. [Google Scholar]
- Wang, J.; Sang, H.; Chen, W.; Zhao, Z. VOSTN: Variational One-Shot Transformer Network for Pedestrian Trajectory Prediction. Phys. Scr. 2024, 99, 026002. [Google Scholar] [CrossRef]
- Sadeghian, A.; Kosaraju, V.; Hirose, N.; Rezatofighi, H.; Savarese, S. SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar]
- Lai, W.-C.; Xia, Z.-X.; Lin, H.-S.; Hsu, L.-F.; Shuai, H.-H.; Jhuo, I.-H.; Cheng, W.-H. Trajectory Prediction in Heterogeneous Environment via Attended Ecology Embedding. In Proceedings of the MM ‘20: The 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Xue, H.; Huynh, D.Q.; Reynolds, M. SS-LSTM: A Hierarchical LSTM Model for Pedestrian Trajectory Prediction. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1186–1194. [Google Scholar]
- Manh, H.; Alaghband, G. Scene-LSTM: A Model for Human Trajectory Prediction. arXiv 2019. [Google Scholar] [CrossRef]
- Syed, A.; Morris, B.T. SSeg-LSTM: Semantic Scene Segmentation for Trajectory Prediction. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2504–2509. [Google Scholar]
- Chen, W.; Sang, H.; Wang, J.; Zhao, Z. WTGCN: Wavelet transform graph convolution network for pedestrian trajectory prediction. Int. J. Mach. Learn. Cybern. 2024, 1–18. [Google Scholar] [CrossRef]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-BiGAT: Multimodal Trajectory Forecasting using Bicycle-GAN and Graph Attention Networks. Adv. Neural Inf. Process. Syst. 2019, 137–146. [Google Scholar] [CrossRef]
- Zhao, Y.; Lu, T.; Su, W.; Wu, P.; Fu, L.; Li, M. Quantitative measurement of social repulsive force in pedestrian movements based on physiological responses. Transp. Res. Part B Methodol. 2019, 130, 1–20. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. Advances in Neural Information Processing Systems. arXiv 2017. [Google Scholar] [CrossRef]
- Bolya, D.; Fu, C.Y.; Dai, X.; Zhang, P.; Hoffman, J. Hydra attention: Efficient attention with many heads. In Proceedings of the Computer Vision–ECCV 2022 Work Shops, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2023; pp. 35–49. [Google Scholar] [CrossRef]
- Lerner, A.; Chrysanthou, Y.; Lischinski, D. Crowds by Example. Comput. Graph. Forum 2007, 26, 655–664. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, H.; Cheng, H.; Qi, K.; Hu, K.; Kang, C.; Zheng, J. Social graph convolutional LSTM for pedestrian trajectory prediction. IET Intell. Transp. Syst. 2021, 15, 396–405. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Site 1 | Site 2 |
|---|---|---|
| ETH |  |  |
| UCY |  |  |
| Dataset | ADE/FDE (Meter) | ||||
|---|---|---|---|---|---|
| SGC-LSTM | SLSTM | Sophie | SGAN | SISGAN | |
| ETH | 0.82/1.72 | 1.09/2.35 | 0.70/1.43 | 0.67/1.13 | 0.63/0.95 |
| hotel | 0.45/0.65 | 0.79/1.76 | 0.76/1.67 | 0.72/1.61 | 0.58/1.62 |
| Univ | 0.53/1.10 | 0.67/1.40 | 0.54/1.24 | 0.61/1.28 | 0.50/1.10 |
| zara1 | 0.40/0.92 | 0.47/1.00 | 0.30/0.63 | 0.34/0.71 | 0.31/0.68 |
| zara2 | 0.36/0.78 | 0.56/1.17 | 0.38/0.78 | 0.42/0.84 | 0.30/0.73 |
| Average | 0.51/1.03 | 0.72/1.54 | 0.54/1.15 | 0.58/1.19 | 0.46/1.01 |
| Dataset | ADE/FDE (Meter) | ||
|---|---|---|---|
| SGAN | SIGAN | SISGAN | |
| ETH | 0.67/1.13 | 0.79/1.43 | 0.63/0.95 |
| hotel | 0.72/1.61 | 0.58/1.21 | 0.58/1.62 |
| Univ | 0.61/1.28 | 0.65/1.41 | 0.50/1.10 |
| zara1 | 0.34/0.71 | 0.32/0.80 | 0.31/0.68 |
| zara2 | 0.42/0.84 | 0.42/0.78 | 0.30/0.73 |
| Average | 0.58/1.19 | 0.51/1.10 | 0.46/1.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dou, W.; Lu, L. SISGAN: A Generative Adversarial Network Pedestrian Trajectory Prediction Model Combining Interaction Information and Scene Information. Appl. Sci. 2024, 14, 9537. https://doi.org/10.3390/app14209537
Dou W, Lu L. SISGAN: A Generative Adversarial Network Pedestrian Trajectory Prediction Model Combining Interaction Information and Scene Information. Applied Sciences. 2024; 14(20):9537. https://doi.org/10.3390/app14209537
Chicago/Turabian StyleDou, Wanqing, and Lili Lu. 2024. "SISGAN: A Generative Adversarial Network Pedestrian Trajectory Prediction Model Combining Interaction Information and Scene Information" Applied Sciences 14, no. 20: 9537. https://doi.org/10.3390/app14209537
APA StyleDou, W., & Lu, L. (2024). SISGAN: A Generative Adversarial Network Pedestrian Trajectory Prediction Model Combining Interaction Information and Scene Information. Applied Sciences, 14(20), 9537. https://doi.org/10.3390/app14209537