

Speech Signal Analysis in Patients with Parkinson’s Disease, Taking into Account Phonation, Articulation, and Prosody of Speech

 , and
, and
Abstract
:1. Introduction
2. Related Works
2.1. Evaluation of Clinical Symptoms
2.2. Evaluation of Speech Changes
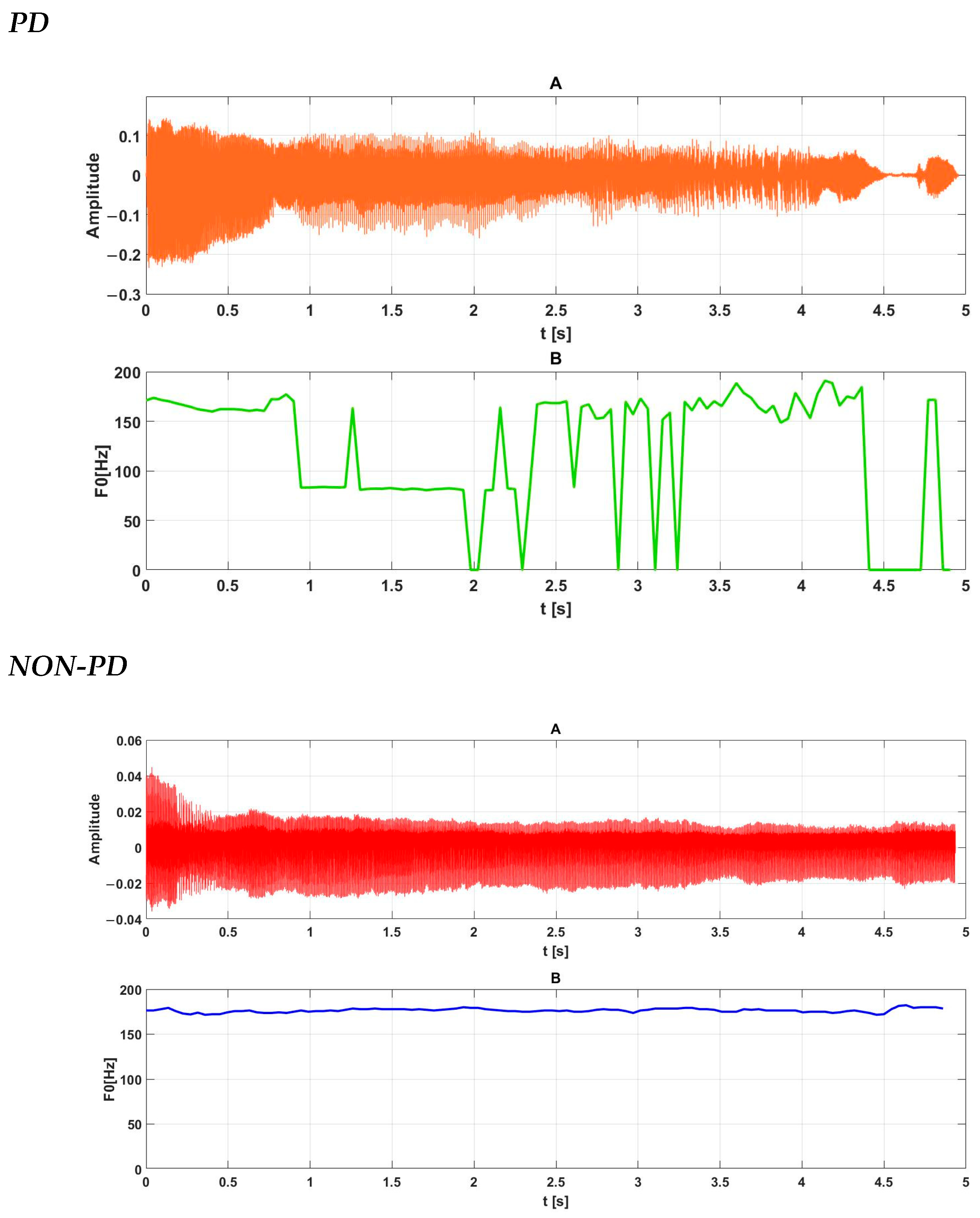
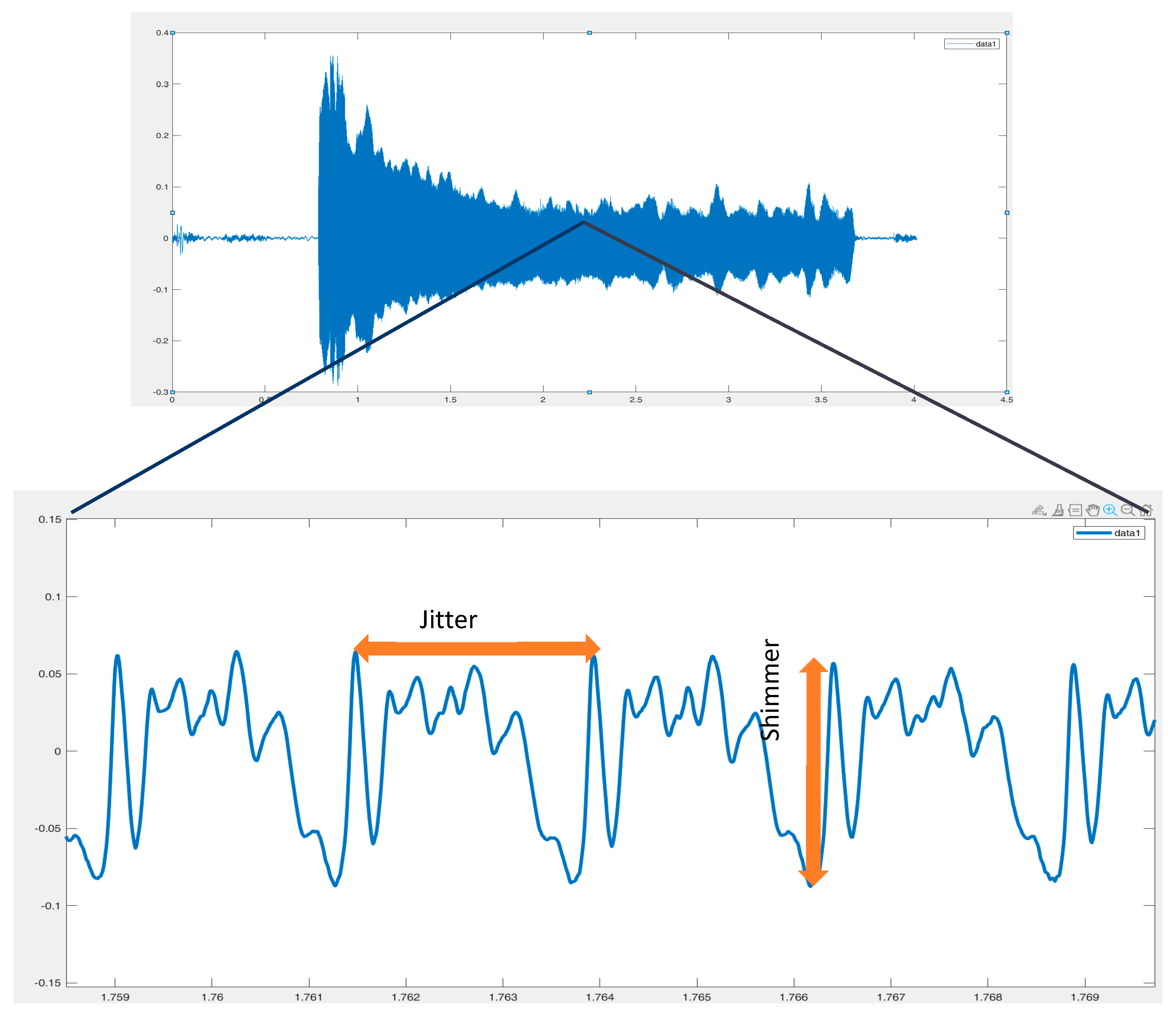
2.2.1. Phonation
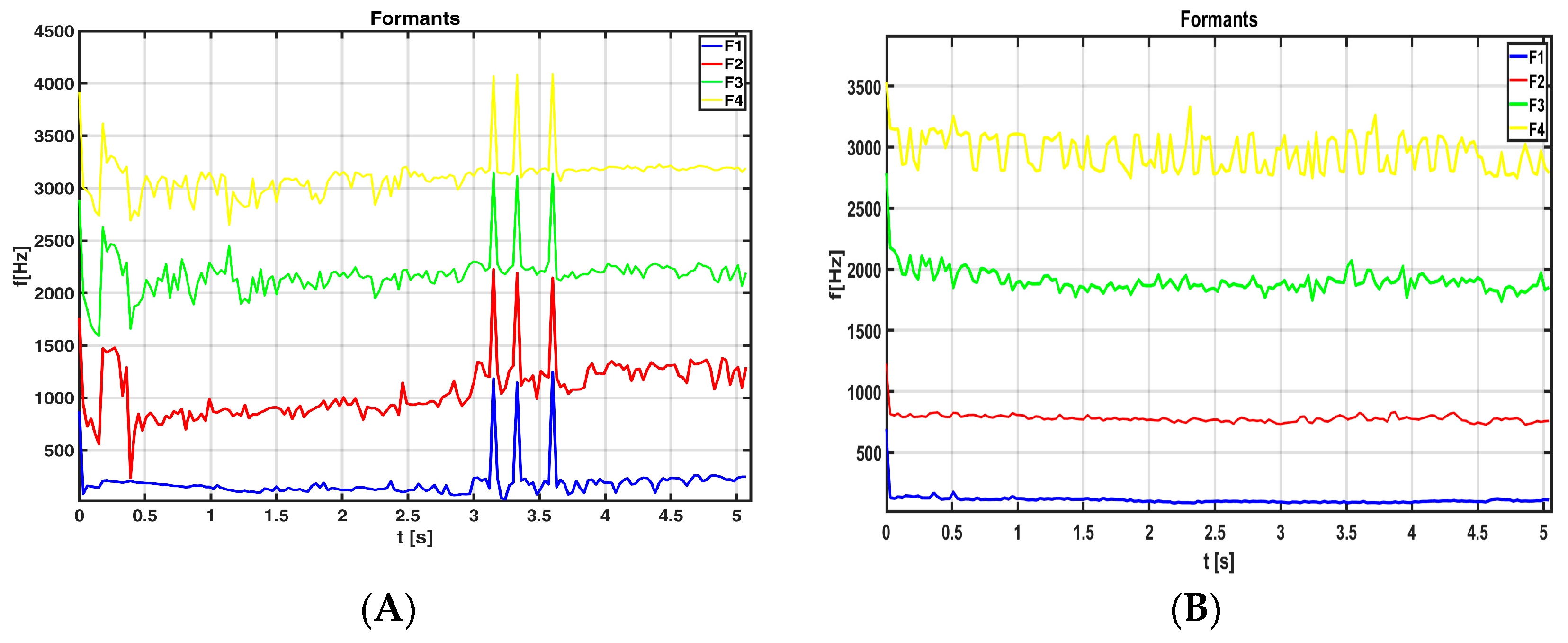
2.2.2. Articulation
2.2.3. Prosody
3. Problem Statement
4. Data Pool
- Two texts of different emotional tone (approximately 176 words);
- Recording the vowel “a” with prolonged phonation, uttered by a patient in one breath (two times);
- Repeating the “pa” syllable in one breath as constantly and for long as possible, for 5 s.
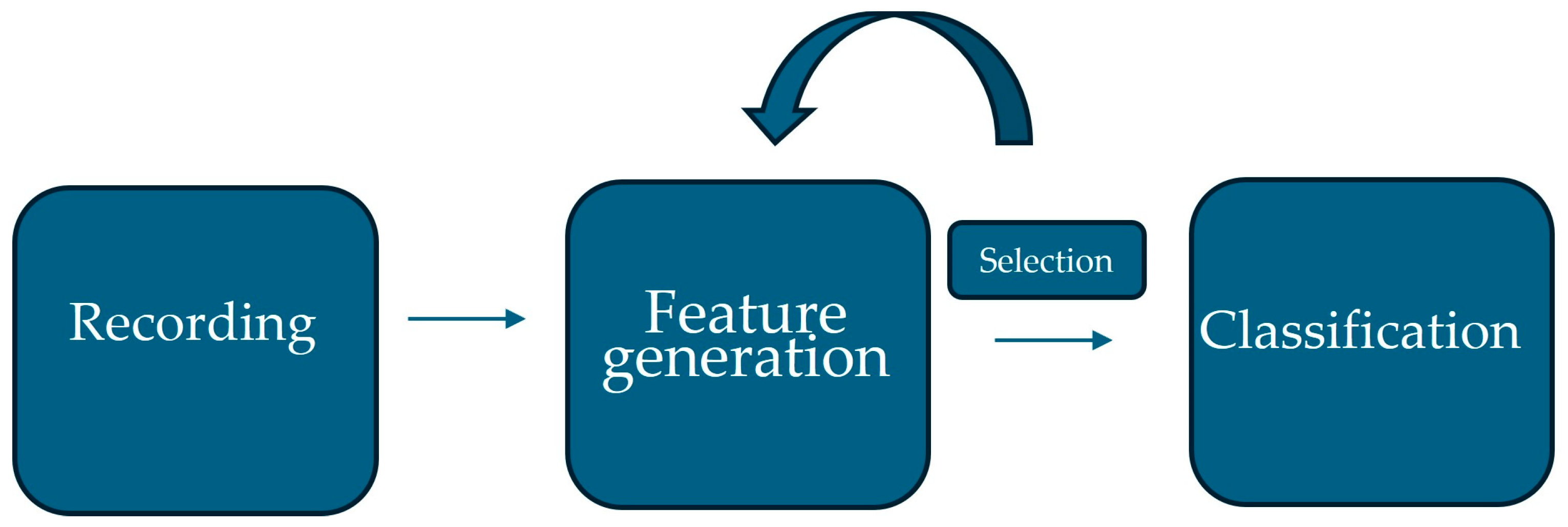
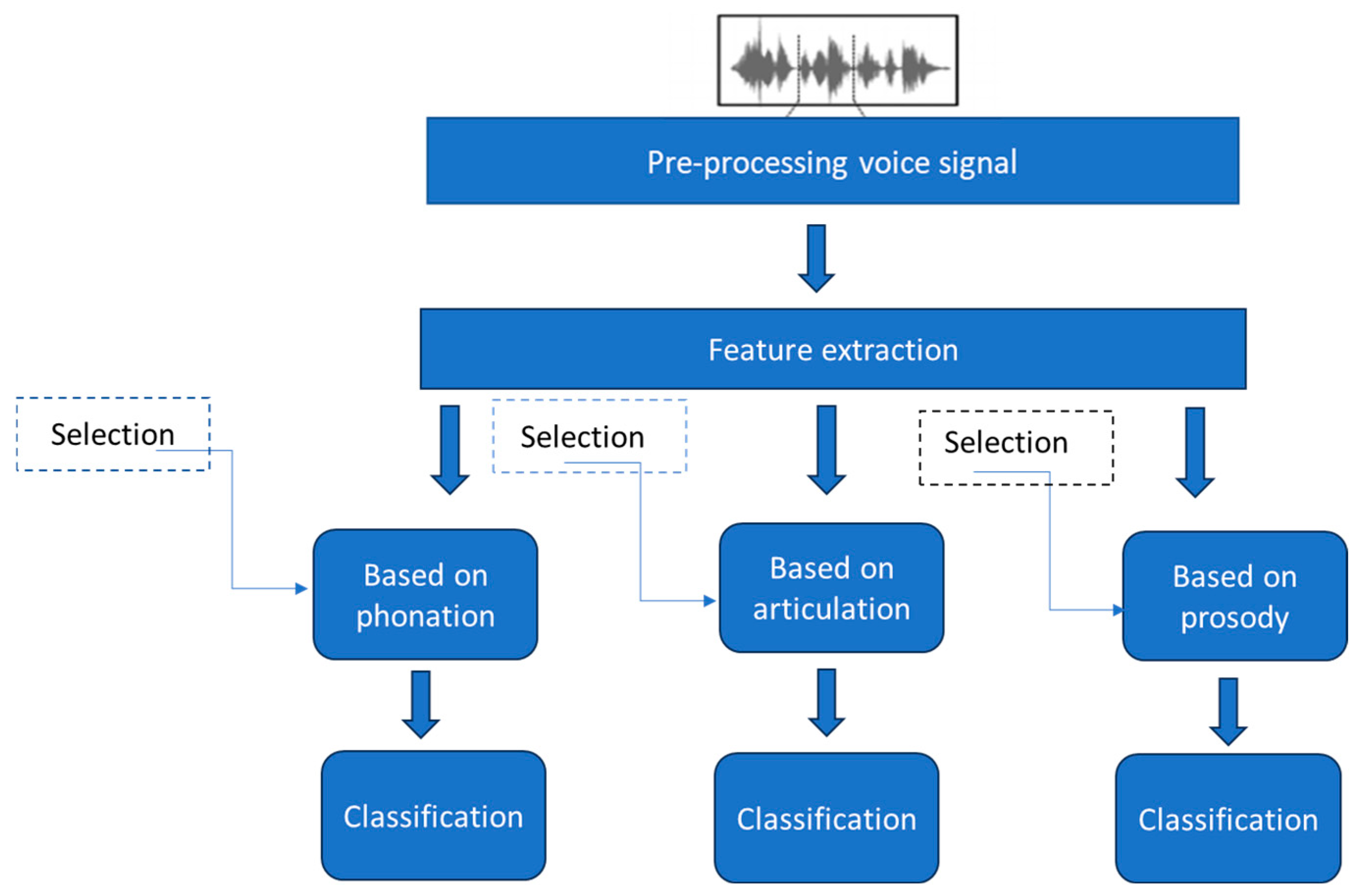
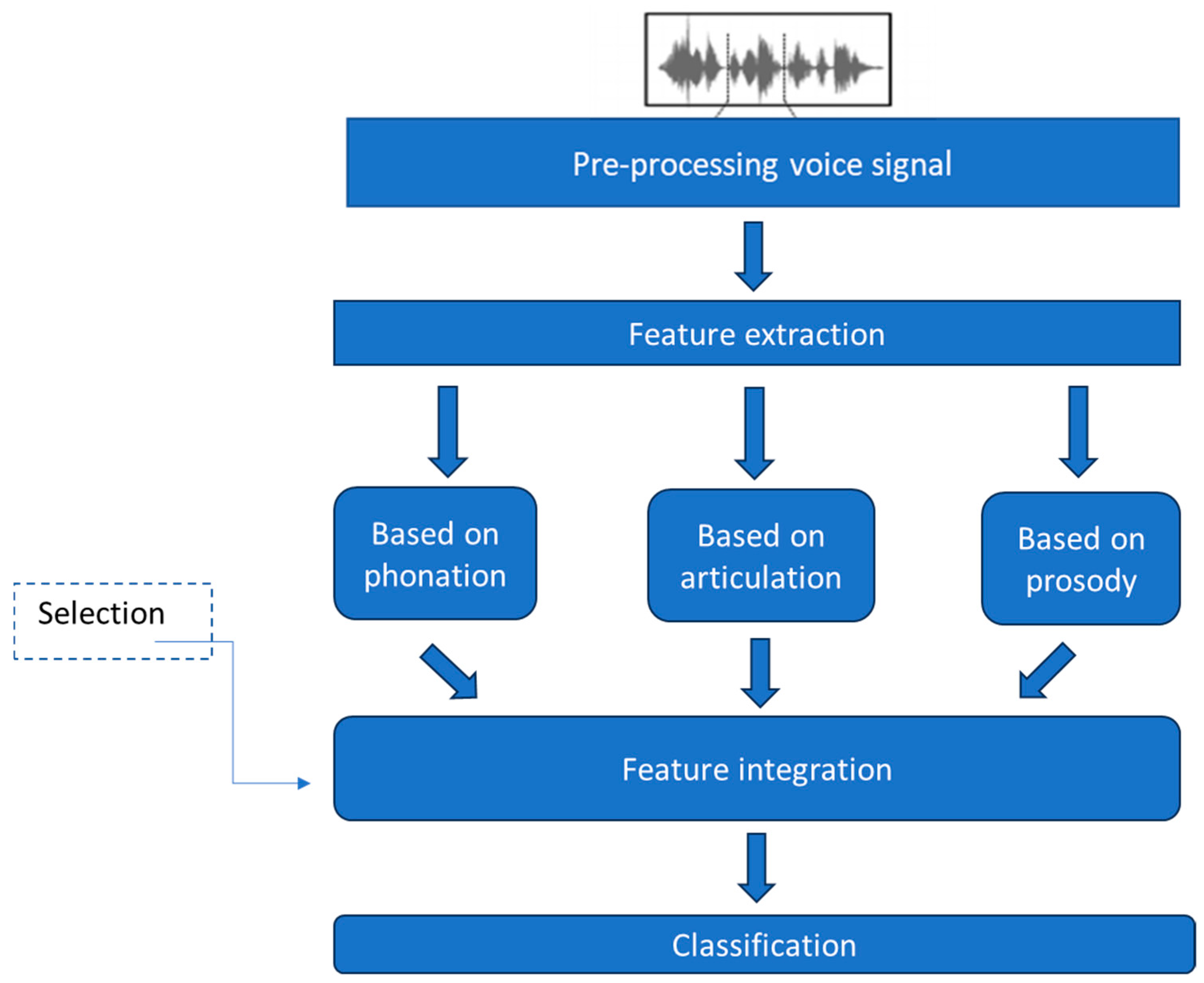
5. Architecture of the Proposed System
5.1. Pre-Processing
5.2. Feature Extraction
- A. Evaluation of the phonation process
- Jitter group parameters (Jitter [%], Jitta [μs], RAP [%], PPQ5 [%]);
- Shimmer group parameters (shimmer [%], APQ3 [%], APQ5 [%], APQ11 [%];
- PVI (pathology vibrato index).
- B. Assessment of the articulation process
- Evaluating resonant cavities within specific frequency bands (formant analysis);
- Speech signal frequency analysis.
- Fraction of locally unvoiced pitch frames, which defines which part of the analyzed speech signal is unvoiced;
- Sonorousness coefficient, which is the quotient of voiced to unvoiced frames in the analyzed speech signal.
- C. Prosody process assessment
- Fundamental tone (laryngeal, F0), or more specifically, an analysis of the changes in this parameter for a specific recording;
- Individual recording durations, including the duration of a sad statement or the duration of a joyful statement;
- The number of “pa” syllables uttered during a 5 s speech fragment;
- The duration of the intervals between “pa” syllables.
5.3. Feature Selection
5.4. Classification
5.5. Integration of Subsystems
6. Experiment
7. Results of Experiments
- Subset 1—three separate systems based on full dimensional vectors of various models of speech;
- Subset 2—three separate systems based on vectors of selected feature of various models of speech;
- Subset 3—raw feature integration data using the features of subset 2;
- Subset 4—feature integration after the selection of subset 3.
7.1. Effectiveness of Individual Model
7.2. Feature Pre-Selection
7.3. Raw Feature Integration
7.4. Feature Integration After the Selection of Descriptors
8. Discussion
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lang, A.E.; Lozano, A.M. Parkinson’s disease. N. Engl. J. Med. 1998, 339, 1044–1053. [Google Scholar] [CrossRef]
- Stewart, A.F.; William, J.W. Parkinson’s Disease: Diagnosis & Clinical Management, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Grover, S.; Somaiya, M.; Kumar, S.; Avasthi, A. Psychiatric aspects of Parkinson’s disease. J. Neurosci. Rural. Pract. 2015, 6, 65–76. [Google Scholar] [CrossRef]
- Singh, N.; Pillay, V.; Choonara, Y.E. Advances in the treatment of parkinsons disease. Prog. Neurobiol. 2007, 81, 29–44. [Google Scholar] [CrossRef]
- Fahn, S.; Elton, R.L.; Members of the UPDRS Develoment Committee. Unified Parkinson’s Disease rating scale. In Recent Developments in Parkinson’s Disease; Goetz, C.G., Tilley, B.C., Shaftman, S.R., Eds.; Macmillan Health Care Information: Florham Park, NJ, USA, 1987; Volume 2, pp. 153–164. [Google Scholar]
- Goetz, C.G.; Tilley, B.C.; Shaftman, S.R.; Stebbins, G.T.; Fahn, S.; Martinez-Martin, P.; Poewe, W.; Sampaio, C.; Stern, M.B.; Dodel, R.; et al. Movement Disorder Society-sponsored revision of the Unified Parkinson’s Disease Rating Scale (MDS-UPD-RS): Scale presentation and clinimetric testing results. Mov. Disord. 2008, 23, 2129–2170. [Google Scholar] [CrossRef] [PubMed]
- Siuda, J.; Boczarska-Jedynak, M.; Budrewicz, S.; Dulski, J.; Figura, M.; Fiszer, U. Validation of the Polish version of the Movement Disorder Society-Unified Parkinson’s Disease Rating Scale (MDS-UPDRS). Pol. J. Neurol. Neurosurg. 2020, 54, 416–425. [Google Scholar] [CrossRef]
- Poewe, W.; Antonini, A.; Zijlmans, J.C.; Burkhard, P.R.; Vingerhoets, F. Levodopa in the treatment of Parkinson’s disease: An old drug still going strong. Clin. Interv. Aging. 2010, 5, 229–238. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Pawlukowska, W.; Honczarenko, K.; Gołąb-Janowska, M. Charakter zaburzeń mowy w chorobie Parkinsona. Neurol. Neurochir. Pol. 2013, 47, 263–270. [Google Scholar] [CrossRef] [PubMed]
- Meka, S.S.L.; Kandadai, R.M.; Borgohain, R. Quantitative Evaluation of Parkinsonian Tremor and the Impact on it by DBS and Drugs. In Proceedings of the 2022 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 19–20 February 2022; pp. 1–4. [Google Scholar]
- Fujikawa, J.; Morigaki, R.; Yamamoto, N.; Nakanishi, H.; Oda, T.; Izumi, Y.; Takagi, Y. Diagnosis and Treatment of Tremor in Parkinson’s Disease Using Mechanical Devices. Life 2023, 13, 78. [Google Scholar] [CrossRef] [PubMed]
- Mailankody, P.; Thennarasu, K.; Nagaraju, B.C.; Yadav, R.; Pal, P.K. Re-emergent tremor in Parkinson’s disease: A clinical and electromyographic study. J. Neurol. Sci. 2016, 366, 33–36. [Google Scholar] [CrossRef]
- Hellwig, B.; Häussler, S.; Lauk, M.; Guschlbauer, B.; Köster, B.; Kristeva-Feige, R.; Timmer, J.; Lücking, C.H. Tremor-correlated cortical activity detected by electroencephalography. Clin. Neurophysiol. 2000, 11, 806–809. [Google Scholar] [CrossRef] [PubMed]
- Barrantes, S.; Sánchez Egea, A.J.; González Rojas, H.A.; Martí, M.J.; Compta, Y.; Valldeoriola, F.; Simo Mezquita, E.; Tolosa, E.; Valls-Solè, J. Differential diagnosis between Parkinson’s disease and essential tremor using the smartphone’s accelerometer. PLoS ONE 2017, 12, e0183843. [Google Scholar] [CrossRef]
- De Stefano, C.; Fontanella, F.; Impedovo, D.; Pirlo, G.; di Freca, A.S. Handwriting analysis to support neurodegenerative diseases diagnosis: A review. Pattern Recogn. Lett. 2019, 121, 37–45. [Google Scholar] [CrossRef]
- Junior, E.P.; Delmiro, I.L.D.; Magaia, N.; Maia, F.M.; Hassan, M.M.; Albuquerque, V.H.C.; Fortino, G. Intelligent sensory pen for aiding in the diagnosis of parkinson’s disease from dynamic handwriting analysis. Sensors 2020, 20, 5840. [Google Scholar] [CrossRef]
- Drotár, P.; Mekyska, J.; Rektorová, I.; Masarová, L.; Smékal, M. Faundez-Zanuy, Evaluation of handwriting kinematics and pressure for differential diagnosis of parkinson’s disease. Artif. Intell. Med. 2016, 67, 39–46. [Google Scholar] [CrossRef] [PubMed]
- Rios-Urrego, C.D.; Vásquez-Correa, J.C.; Vargas-Bonilla, J.F.; Nöth, E.; Lopera, F.; Orozco-Arroyave, J.R. Analysis and evaluation of handwriting in patients with Parkinson’s disease using kinematic, geometrical, and non-linear features. Comput. Methods Programs Biomed. 2019, 173, 43–52. [Google Scholar] [CrossRef] [PubMed]
- Pereira, C.R.; Pereira, D.R.; Rosa, G.H.; Albuquerque, V.H.; Weber, S.A.; Hook, C.; Papa, J. Handwritten dynamics assessment through convolutional neural networks: An application to parkinson’s disease identification. Artif. Intell. Med. 2018, 87, 67–77. [Google Scholar] [CrossRef]
- Jakubowski, J.; Potulska-Chromik, A.; Białek, K.; Nojszewska, M.; Kostera-Pruszczyk, A. A Study on the Possible Diagnosis of Parkinson’s Disease on the Basis of Facial Image Analysis. Electronics 2021, 10, 2832. [Google Scholar] [CrossRef]
- Su, G.; Lin, B.; Yin, J.; Luo, W.; Xu, R.; Xu, J.; Dong, K. Detection of hypomimia in patients with Parkinson’s disease via smile videos. Ann. Transl. Med. 2021, 9, 1307. [Google Scholar] [CrossRef] [PubMed]
- Purup, M.M.; Knudsen, K.; Karlsson, P.; Terkelsen, A.J.; Borghammer, P. Skin Temperature in Parkinson’s Disease Measured by Infrared Thermography. Parkinson’s Dis. 2020, 2020, 2349469. [Google Scholar] [CrossRef] [PubMed]
- Pierleoni, P. A Smart Inertial System for 24h Monitoring and Classification of Tremor and Freezing of Gait in Parkinson’s Disease. IEEE Sens. J. 2019, 19, 11612–11623. [Google Scholar] [CrossRef]
- Khan, M.A.; Kadry, S.; Parwekar, P.; Damaševičius, R.; Mehmood, A.; Khan, J.A.; Naqvi, S.R. Human gait analysis for osteoarthritis prediction: A framework of deep learning and kernel extreme learning machine. Complex. Intell. Syst. 2021, 9, 2665–2683. [Google Scholar] [CrossRef]
- Liu, P.; Yu, N.; Yang, Y.; Yu, Y.; Sun, X.; Yu, H.; Han, J.; Wu, J. Quantitative assessment of gait characteristics in patients with Parkinson’s disease using 2D video. Park. Relat. Disord. 2022, 101, 49–56. [Google Scholar] [CrossRef] [PubMed]
- Borzì, L.; Sigcha, L.; Rodríguez-Martín, D.; Olmo, G. Real-time detection of freezing of gait in Parkinson’s disease using multi-head convolutional neural networks and a single inertial sensor. Artif. Intell. Med. 2023, 135, 102459. [Google Scholar] [CrossRef] [PubMed]
- Yu, T.; Park, K.W.; McKeown, M.J.; Wang, Z.J. Clinically Informed Automated Assessment of Finger Tapping Videos in Parkinson’s Disease. Sensors 2023, 23, 9149. [Google Scholar] [CrossRef] [PubMed]
- Sano, Y.; Kandori, A.; Shima, K.; Tamura, Y.; Takagi, H.; Tsuji, T.; Noda, M.; Higashikawa, F.; Yokoe, M.; Sakoda, S. Reliability of Finger Tapping Test Used in Diagnosis of Movement Disorders. In Proceedings of the 2011 5th International Conference on Bioinformatics and Biomedical Engineering, Wuhan, China, 10–12 May 2011; pp. 1–4. [Google Scholar]
- Fernandez, L.D.; Mateo, C.G. Speech production. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Boston, MA, USA, 2009. [Google Scholar]
- Factor, S.; Weiner, W.J. Parkinson’s Disease Diagnosis and Clinical Management; Medical Publishing: New York, NY, USA, 2002. [Google Scholar]
- Adams, S.G.; Dykstra, A. Hypokinetic dysarthria. In Clinical Management of Sensorimotor Speech Disorders; Mc-Neil, M.R., Ed.; Thieme: New York, NY, USA, 2008. [Google Scholar]
- Darley, F.L.; Aronson, A.E.; Brown, J.R. Clusters of deviants speech dimensions in the dysarthrias. J. Speech Hear. Res. 1969, 12, 462–469. [Google Scholar] [CrossRef] [PubMed]
- Logemann, J.; Fisher, H.; Boshes, B. The steps in the degeneration of speech and voice control in Parkinson’s disease. In Parkinson’s Disease: Refidity, Akinesia, Behavior; Siegfried, J., Ed.; Hans Huber: Vienna, Austria, 1973. [Google Scholar]
- Blanchet, P.G.; Snyder, G.J. Speech rate deficits in individuals with parkinson’s disease: A review of the literature. J. Med. Speech Lang. Pathol. 2009, 17, 1–7. [Google Scholar]
- Jauer-Niworowska, O. Zaburzenia mowy u osób z chorobą Parkinsona—Nie tylko dyzartria. In Złożoność Uwarunkowań Trudności w Komunikacji Werbalnej; Wydział Polonistyki Uniwersytetu Warszawskiego: Warszawa, Poland, 2016. (In Polish) [Google Scholar]
- Ma, A.; Lau, K.K.; Thyagarajan, D. Voice changes in Parkinson’s disease: What are they telling us? J. Clin. Neurosci. 2020, 72, 1–7. [Google Scholar] [CrossRef]
- Skodda, S.; Schlegel, U. Speech rate and rhythm in parkinson’s disease. Mov. Disord. 2008, 23, 985–992. [Google Scholar] [CrossRef] [PubMed]
- Van Borsel, J.; Bontinck, C.; Coryn, M.; Paemeleire, F.; Vandemaele, P. Acoustic features of palilalia: A case study. Brain Lang. 2007, 101, 90–96. [Google Scholar] [CrossRef] [PubMed]
- Moro-Velazquez, L.U.; Gomez-Garcia, J.A.; Arias-Londoño, J.D.; Dehak, N.; Godino-Llorente, J.I. Advances in Parkinson’s disease detection and assessment using voice and speech: A review of the articulatory and phonatory aspects. Biomed. Signal Process. Control 2021, 66, 102418. [Google Scholar] [CrossRef]
- Guimarães, I. A Ciência e a Arte da Voz Humana; Escola Superior de Saúde de Alcoitão: Alcabideche, Portugal, 2007. [Google Scholar]
- Vizza, P.; Tradigo, G.; Mirarchi, D.; Bossio, R.B.; Lombardo, N.; Arabia, G.; Quattrone, A.; Veltri, P. Methodologies of speech analysis for neuro-degenerative diseases evaluation. Int. J. Med. Inform. 2019, 122, 45–54. [Google Scholar] [CrossRef]
- Holmes, R.J.; Oates, J.M.; Phyland, D.J.; Hughes, A.J. Voice characteristics in the progression of Parkinson’s disease. Int. J. Lang. Commun. Disord. 2000, 35, 407–418. [Google Scholar] [CrossRef] [PubMed]
- Thomas, M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Atalar, M.S.; Oguz, O.; Genc, G. Hypokinetic Dysarthria in Parkinson’s Disease: A Narrative Review. Sisli Etfal Hastanesi tip bulteni 2023, 57, 163–170. [Google Scholar] [CrossRef] [PubMed]
- Xiu, N.; Li, W.; Liu, L.; Liu, Z.; Cai, Z.; Li, L.; Vaxelaire, B.; Sock, R.; Ling, Z.; Chen, J.; et al. A Study on Voice Measures in Patients with Parkinson’s Disease. J. Voice, 2024; in press. [Google Scholar] [CrossRef]
- Cuong Ngo, Q.; Motin Mohammod, A.; Nemuel, D.P.; Drotár, P.; Kempster, P.; Kumar, D. Computerized analysis of speech and voice for Parkinson’s disease: A systematic review. Comput. Methods Programs Biomed. 2022, 226, 107133. [Google Scholar]
- Logemann, J.A.; Fisher, H.B.; Boshes, B.; Blonsky, E.R. Frequency and cooccurrence of vocal tract dysfunctions in the speech of a large sample of parkinson patients. J. Speech Hear. Disord 1978, 43, 47–57. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, J.; Rahn, D.A. Studying vocal fold vibrations in Parkinson’s disease with a nonlinear model. Chaos 2005, 15, 033903. [Google Scholar] [CrossRef] [PubMed]
- Zwirner, P.; Barnes, G.J. Vocal tract steadiness: A measure of phonatory and upper airway motor control during phonation in dysarthria. J. Speech Lang. Hear. Res. 1992, 35, 761–768. [Google Scholar] [CrossRef]
- Harel, B.; Cannizzaro, M.; Snyder, P.J. Variability in fundamental frequency during speech in prodromal and incipient Parkinson’s disease: A longitudinal case study. Brain Cogn. 2004, 56, 24–29. [Google Scholar] [CrossRef]
- Chiaramonte, R.; Bonfiglio, M. Acoustic analysis of voice in Parkinson’s disease: A systematic review of voice disability and meta-analysis of studies. Rev. Neurol. 2020, 70, 393–405. [Google Scholar]
- Mekyska, J.; Janousova, E.; Gomez-Vilda, P.; Smekal, Z.; Rektorova, I.; Eliasova, I.; Lopez-de-Ipina, K. Robust and complex approach of pathological speech signal analysis. Neurocomputing 2015, 167, 94–111. [Google Scholar] [CrossRef]
- Erdogdu Sakar, B.; Serbes, G.; Sakar, C. Analyzing the effectiveness of vocal features in early telediagnosis of Parkinson’s disease. PLoS ONE 2017, 12, 8. [Google Scholar] [CrossRef] [PubMed]
- Khojasteh, P.; Viswanathan, R.; Aliahmad, B.; Ragnav, S.; Zham, P.; Kumar, D. Parkinson’s disease diagnosis based on multivariate deep features of speech signal. In Proceedings of the 2018 IEEE Life Sciences Conference (LSC), Montreal, QC, Canada, 28–30 October 2018; pp. 187–190. [Google Scholar]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Godino-Llorente, J.I.; Grandas-Perez, F.; Shattuck-Hufnagel, S.; Yagüe-Jimenez, V.; Dehak, N. Phonetic relevance and phonemic grouping of speech in the automatic detection of parkinson’s disease. Sci. Rep. 2019, 9, 19066. [Google Scholar] [CrossRef] [PubMed]
- Benba, A.; Jilbab, A.; Hammouch, A. Voice analysis for detecting persons with parkinson’s disease using PLP and VQ. J. Theor. Appl. Inf. Technol. 2014, 70, 443. [Google Scholar]
- Schoentgen, J.; Kacha, A. Grenez, Joint analysis of vocal jitter, flutter and tremor in vowels sustained by normophonic and parkinson speakers. In Proceedings of the Models and Analysis of Vocal Emissions for Biomedical Applications 11th International Workshop 2019, Firense, Italy, 17–19 December 2019. [Google Scholar]
- Skodda, S.; Visser, W.; Schlegel, U. Vowel Articulation in Parkinson’s Disease. J. Voice 2011, 25, 467–472. [Google Scholar] [CrossRef] [PubMed]
- Ackermann, H.; Hertrich, I.; Hehr, T. Oral diadochokinesis in neurological dysarthrias. Folia Phoniatr. Logop. 1995, 47, 15–23. [Google Scholar] [CrossRef]
- Canter, G.J. Speech characteristics of patients with Parkinson’s disease: III. Articulation, diadochokinesis, and overall speech adequacy. J. Speech Hear. Disord. 1965, 30, 217–224. [Google Scholar] [CrossRef]
- Skodda, S.; Grönheit, W.; Schlegel, U. Impairment of vowel articulation as a possible marker of disease progression in parkinson’s disease. PLoS ONE 2012, 7, e32132. [Google Scholar] [CrossRef]
- Whitfield, J.; Goberman, A. Articulatory acoustic vowel space: Application to clear speech in individuals with parkinson’s disease. J. Commun. Disord. 2014, 51, 19–28. [Google Scholar] [CrossRef] [PubMed]
- Vásquez-Correa, J.; Arias-Vergara, T.; Orozco-Arroyave, J.; Nöth, E. A multitask learning approach to assess the dysarthria severity in patients with parkinson’s disease. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH 2018, Hyderabad, India, 2–6 September 2018; pp. 456–460. [Google Scholar]
- Moro-Velazquez, L.; Gomez-Garcia, J.A.; Godino-Llorente, J.I.; Villalba, J.; Orozco-Arroyave, J.R.; Dehak, N. Analysis of speaker recognition methodologies and the influence of kinetic changes to automatically detect parkinson’s disease. Appl. Soft Comput. 2018, 62, 649–666. [Google Scholar] [CrossRef]
- Orozco-Arroyave, R.F.; Hönig, J.D.; Arias-Londoño, J.F.; Vargas-Bonilla, K.; Daqrouq, S.; Skodda, J.; Rusz, E. Nöth, Automatic detection of parkinson’s disease in running speech spoken in three different languages. J. Acoust. Soc. Am. 2016, 139, 48. [Google Scholar] [CrossRef] [PubMed]
- Vásquez-Correa, J.C.; Arias-Vergara, T.; Orozco-Arroyave, J.R.; Vargas-Bonilla, J.F.; Arias-Londoño, J.D.E. Nöth Automatic detection of parkinson’s disease from continuous speech recorded in non-controlled noise conditions. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association 2015, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Breitenstein, C.; Van Lancker, D.; Daum, I.; Waters, C.H. Impaired perception of vocal emotions in Parkinson’s disease: Influence of speech time processing and executive functioning. Brain Cogn 2001, 45, 277–314. [Google Scholar] [CrossRef] [PubMed]
- Martens, H.; Van Nuffelen, G.; Cras, P.; Pickut, B.; De Letter, M.; De Bodt, M. Assessment of prosodic communicative efficiency in Parkinson’s disease as judged by professional listeners. Park. Dis. 2011, 2011, 129310. [Google Scholar] [CrossRef]
- Shahouzaei, N.; Ghayoumi-Anaraki, Z.; Maleki Shahmahmood, T.; Ladani, N.T.; Shoeibi, A. Changes in speech prosody perception during Parkinson’s disease: A comprehensive analysis. J. Commun. Disord. 2024, 110, 106430. [Google Scholar] [CrossRef]
- Albuquerque, L.; Martins, M.; Coelho, L.; Guedes, J.J.; Ferreira, M.; Rosa, I.P. Martins, Advanced Parkinson disease patients have impairment in prosody processing. J. Clin. Exp. Neuropsychol. 2016, 38, 208–216. [Google Scholar] [CrossRef]
- Basirat, A.; Schwartz, J.-L.; Moreau, C. Word segmentation based on prosody in Parkinson’s Disease. Clin. Linguist. Phon. 2021, 35, 534–541. [Google Scholar] [CrossRef] [PubMed]
- Steinhauer, K.; Abada, S.H.; Pauker EItzhak, I.; Baum, S.R. Prosody–syntax interactions in aging: Event-related potentials reveal dissociations between on-line and off-line measures. Neurosci. Lett. 2010, 472, 133–138. [Google Scholar] [CrossRef] [PubMed]
- Dara, C.; Monetta, L.; Pell, M.D. Vocal emotion processing in Parkinson’s disease: Reduced sensitivity to negative emotions. Brain Res. 2008, 1188, 100–111. [Google Scholar] [CrossRef] [PubMed]
- Ariatti, A.F.; Benuzzi, P. Nichelli, Recognition of emotions from visual and prosodic cues in Parkinson’s disease. Neurol. Sci. 2008, 29, 219–227. [Google Scholar] [CrossRef] [PubMed]
- Martens, H.; Van Nuffelen, G.; Wouters, K.; De Bodt, M. Reception of communicative functions of prosody in hypokinetic dysarthria due to Parkinson’s disease. J. Park. Dis. 2016, 6, 219–229. [Google Scholar] [CrossRef] [PubMed]
- Blesić, M.; Georgiev, D.; Manouilidou, C. Perception of linguistic and emotional prosody. In Parkinson’s Disease-Evidence from Slovene; Blesić, M., Ed.; 2020; Available online: https://www.academia.edu/download/61772364/IJS_Blesic_et_al_201920200113-53227-tv5i3w.pdf (accessed on 21 November 2024).
- Kodali, M.; Kadiri, S.R.; Alku, P. Automatic classification of the severity level of Parkinson’s disease: A comparison of speaking tasks, features, and classifiers. Comput. Speech Lang. 2024, 83, 101548. [Google Scholar] [CrossRef]
- Ho, A.K.; Bradshaw, J.L.; Iansek, R. For better or worse: The effect of levodopa on speech in Parkinson’s disease. Mov. Disord. 2008, 23, 574–580. [Google Scholar] [CrossRef]
- Chmielińska, J.; Białek, K.; Potulska-Chromik, A.; Jakubowski, J.; Majda-Zdancewicz, E.; Nojszewska, M.; Kostera-Pruszczyk, A.; Dobrowolski, A. Multimodal data acquisition set for objective assessment of Parkinson’s disease; SPIE 11442. In Proceedings of the Radioelectronic Systems Conference, Jachranka, Poland, 20–21 November 2019. [Google Scholar]
- Zhang, Z. Mechanics of human voice production and control. J. Acoust. Soc. Am. 2016, 140, 4. [Google Scholar] [CrossRef] [PubMed]
- Teixeira, J.P.; Oliveira, C.; Lopes, C. Vocal Acoustic Analysis—Jitter, Shimmer and HNR Parameters. Procedia Technol. 2013, 9, 1112–1122. [Google Scholar] [CrossRef]
- Brockmann, M.; Drinnan, M.J.; Storck, P.N. Carding, “Reliable Jitter and Shimmer Measurements in Voice Clinics: The Relevance of Vowel, Gender, Vocal Intensity, and Fundamental Frequency Effects in a Typical Clinical Task. J. Voice 2011, 25, 44–53. [Google Scholar] [CrossRef] [PubMed]
- Brockmann-Bauser, M. Improving Jitter and Shimmer Measurements in Normal Voices. Ph.D. Thesis, Newcastle University, Newcastle, UK, 2011. [Google Scholar]
- Little, M.A.; McSharry, P.E.; Hunter, E.J.; Spielman, J.; Ramig, L.O. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Trans. Biomed. Eng. 2015, 56, 1015. [Google Scholar]
- Tsanas, A.; Little, M.A.; Lorraine, O. Ramig, Remote Assessment of Parkinson’s Disease Symptom Severity Using the Simulated Cellular Mobile Telephone Network. IEEE Access Pract. Innov. Open Solut. 2021, 9, 11024–11036. [Google Scholar]
- Moran, R.J.; Reilly, R.B.; de Chazal, P.; Lacy, P.D. Telephony-based voice pathology assessment using automated speech analysis. IEEE Trans. Biomed. Eng. 2006, 53, 468–477. [Google Scholar] [CrossRef]
- Vashkevich, M.Y. Rushkevich, Classification of ALS patients based on acoustic analysis of sustained vowel phonations. Biomed. Signal Process. Control. 2021, 65, 102350. [Google Scholar] [CrossRef]
- Madhu Keerthana, Y.; Sreenivasa Rao, K.; Mitra, P. Dysarthric speech detection from telephone quality speech using epoch-based pitch perturbation features. Int. J. Speech Technol. 2022, 25, 967–973. [Google Scholar] [CrossRef]
- Wang, M.; Wen, Y.; Mo, S.; Yang, L.; Chen, X.; Luo, M.; Yu, H.; Xu, F.; Zou, X. Distinctive acoustic changes in speech in Parkinson’s disease. Comput. Speech Lang. 2022, 75, 101384. [Google Scholar] [CrossRef]
- Maryn, Y.; Roy, N.; De Bodt, M.; Van Cauwenberge, P.; Corthals, P. Acoustic measurement of overall voice quality: A meta-analysis. J. Acoust. Soc. Am. 2009, 126, 2619–2634. [Google Scholar] [CrossRef]
- Kumar, D.; Satija, U.; Kumar, P. Automated classification of pathological speech signals. In Proceedings of the IEEE 19th India Council International Conference (INDI-CON), Kochi, India, 24–26 November 2022; pp. 1–5. [Google Scholar]
- Peeters, G. A Large Set of Audio Features for Sound Description (Similarity and Classification) in the CUIDADO Project; CUIDADO: Paris, French, 2014. [Google Scholar]
- Misra, H.; Ikbal, S.; Bourlard, H.; Hermansky, H. Spectral Entropy Based Feature for Robust ASR. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Montreal, QC, Canada, 17–21 May 2004. [Google Scholar]
- Alías, F.; Socoró, J.C.; Sevillano, X. A Review of Physical and Perceptual Feature Extraction Techniques for Speech, Music and Environmental Sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Majda-Zdancewicz, E.; Dobrowolski, A.; Potulska-Chromik, A.; Jakubowski, J.; Chmielińska, J.; Białek, K.; Nojszewska, M.; Kostera-Pruszczyk, A. The use of voice processing techniques in the assessment of patients with Parkinson’s disease. In Proceedings of the SPIE 11442, Radioelectronic Systems Conference, Jachranka, Poland, 20–21 November 2019. [Google Scholar]
- Osowski, S. Metody i Narzędzia Eksploracji Danych; BTC Publishing House: Legionowo, Poland, 2017. (In Polish) [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Brzostowski, K. Zastosowanie Przetwarzania Sygnałów w Fuzji Danych Strumieniowych; Oficyna Wydawnicza Politechniki Wroclawskiej: Wrocław, Poland, 2018. (In Polish) [Google Scholar]
- Azadi, H.; Akbarzadeh, T.M.; Shoeibi, A.; Kobravi, H.R. Evaluating the effect of Parkinson’s disease on jitter and shimmer speech features. Adv. Biomed. Res. 2021, 10, 54. [Google Scholar] [CrossRef] [PubMed]
- Tsanas, M.A.; Little, P.E.; McSharry, J.; Spielman, L.O. Ramig, Novel speech sig-nal processing algorithms fo A. r high-accuracy classification of Parkinson’s dis-ease. IEEE Trans. Biomed. Eng. 2012, 59, 1264–1271. [Google Scholar] [CrossRef] [PubMed]
- Montaña, D.; Campos-Roca, Y.; Pérez, C.J. A Diadochokinesis-based expert sys-tem considering articulatory features of plosive consonants for early de-tection of Parkinson’s disease. Comput. Methods Program Biomed. 2018, 154, 89–97. [Google Scholar] [CrossRef] [PubMed]
- Moro-Velázquez, L.; Gómez-García, J.A.; Dehak, N.; Godino-Llorente, J.I. Analysis of phonatory features for the automatic detection of parkinson’s disease in two different corpora. In Proceedings of the Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA) (2019), Florence, Italy, 17–19 December 2019; p. 33. [Google Scholar]
- Faragó, P.; Ștefănigă, S.-A.; Cordoș, C.-G.; Mihăilă, L.-I.; Hintea, S.; Peștean, A.-S.; Beyer, M.; Perju-Dumbravă, L.; Ileșan, R.R. CNN-Based Identification of Parkinson’s Disease from Continuous Speech in Noisy Environments. Bioengineering 2023, 10, 531. [Google Scholar] [CrossRef] [PubMed]
- Er, M.B.; Isik, E.; Isik, I. Parkinson’s detection based on combined CNN and LSTM using enhanced speech signals with Variational mode decomposition. Biomed. Signal Process. Control. 2021, 70, 103006. [Google Scholar] [CrossRef]
- Narendra, N.P.; Schuller, B.; Alku, P. The Detection of Parkinson’s Disease From Speech Using Voice Source Information. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1925–1936. [Google Scholar] [CrossRef]
- Arias-Vergara, T.; Vásquez-Correa, J.C.; Orozco-Arroyave, J.R.; Klumpp, P.; Nöth, E. Unobtrusive monitoring of speech impairments of Parkinson’s disease patients through mobile devices. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Sakar, B.E.; Isenkul, M.E.; Sakar, C.O.; Sertbas, A.; Gurgen, F.; Sakir, D.; Apaydin, H.; Kursun, O. Collection and analysis of a Parkinson speech dataset with multiple types of sound recordings. IEEE J. Biomed. Health Inform. 2013, 19, 828–834. [Google Scholar] [CrossRef]
- Moro-Velazquez, L.; Gomez-Garcia, J.; Godino-Llorente, J.I.; Rusz, J.; Skodda, S.; Grandas, F.; Velazquez, J.-M.; Orozco-Arroyave, J.R.; Noth, E.; Dehak, N. Study of the automatic detection of Parkison’s disease based on speaker recognition technologies and allophonic distillation. In Proceedings of the 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1404–1407. [Google Scholar]
- Vásquez-Correa, J.C.; Orozco-Arroyave, J.R.; Nöth, E. Convolutional neural network to model articulation impairments in patients with Parkinson’s disease. In Proceedings of the Interspeech, Stockholm, Swede, 20–24 August 2017; pp. 314–318. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | PD Patients | NON-PD Patients |
|---|---|---|
| Male | 8 | 19 |
| Female | 16 | 5 |
| Age (average) | 55.5 | 40.0 |
| The disease duration (average) | 5.3 | N/A |
| The symptom severity—based on part III UPDRS | 20.25 | N/A |
| Features | Symptoms of PD | Measured Feature | Additional Information |
|---|---|---|---|
| Phonation | Dysphonia Unstable vibrations of vocal folds | Jitter [%] Jitta [μs] RAP [%], PPQ5 [%] | Irregular contraction of laryngeal muscles during sound production |
| Roughness Hoarseness Dysphonia | Shimmer [%] APQ3 [%] APQ5 [%] APQ11 [%] | Reduced laryngeal control and degenerative changes in laryngeal tissue | |
| Exaggerated vocal tremor | PVI | Rapid and regular fluctuation of the fundamental frequency | |
| Dysphonia | PPE | New measure of dysphonia, which is robust to many uncontrollable confounding effects | |
| Dysphonia | PPF | Unstable vibrations of vocal folds | |
| Dysphonia | PFR | The degree of variability in fundamental frequency contour that characterizes the functioning of the phonatory subsystem | |
| Dysphonia | NHR | Incomplete vocal fold closure | |
| Hoarseness Vocal weakness | HNR, | Assessment of the ratio between periodic components and non-periodic components | |
| Articulation | Hypokinetic Dysarthria | Spectral parameters (11 features) | Articulator movements |
| Hypokinetic dysarthria | F1, F2, F3, F4 formants | Articulator movements Physical characteristics of the sound channel (resonant cavity) | |
| Dysfluency | Sonorousness coefficient Fraction of locally unvoiced pitch frames | Information about the amount of aperiodicity in the phonation | |
| Prosody | Monotonicity, Monoloudness Hypoprosodia Bradylalia | Fundamental tone, Duration of a sad statement, Duration of a joyful statement, Number of “pa” syllables uttered during a 5 s speech fragment, Duration of the intervals between “pa” syllables |
| Classifier | ||||||
|---|---|---|---|---|---|---|
| Modalities | 1-nn | SVM | ||||
| ACC [%] | Se [%] | Sp [%] | ACC [%] | Se [%] | Sp [%] | |
| Phonation | 87.5 | 95.8 | 79.2 | 83.1 | 100 | 66.7 |
| Articulation | 87.8 | 88.9 | 86.7 | 82.2 | 84.4 | 80.0 |
| Prosody | 60.4 | 54.2 | 66.7 | 70.8 | 75.0 | 66.7 |
| Classifier | ||||||
|---|---|---|---|---|---|---|
| Modalities | 1-nn | SVM | ||||
| ACC [%] | Se [%] | Sp [%] | ACC [%] | Se [%] | Sp [%] | |
| Phonation | 91.7 | 91.7 | 91.7 | 85.4 | 100 | 70.8 |
| Articulation | 89.8 | 89.4 | 88.1 | 88.9 | 88.9 | 88.9 |
| Prosody | 64.6 | 66.7 | 62.5 | 72.9 | 75.0 | 70.8 |
| Method | Number of Descriptors | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
| Relief | 0.059 | 0.064 | 0.054 | −0.0002 | 0.017 | 0.049 | 0.003 | 0.049 | 0.046 | 0.024 | 0.010 |
| Chi-square | 11.87 | 0.045 | 2.95 | 0.5182 | 0.704 | 3.816 | 0.704 | 3.816 | 4.939 | 1.142 | 0.518 |
| Fischer score | 0.13 | 0.067 | 0.21 | 0.0716 | 0.098 | 0.241 | 0.135 | 0.241 | 0.284 | 0.154 | 0.173 |
| F-test | 26.87 | 0.031 | 3.28 | 0.4389 | 0.619 | 4.500 | 0.619 | 4.500 | 6.286 | 1.071 | 0.438 |
| Classifier | |||
|---|---|---|---|
| ACC [%] | Se [%] | Sp [%] | |
| Fusion model based on pre-selection (11 features) | |||
| SVM (Linear kernel) | 72.9 | 58.3 | 87.5 |
| SVM (Quadratic kernel) | 79.1 | 62.5 | 95.8 |
| SVM (Cubic kernel) | 75.0 | 58.3 | 91.7 |
| SVM (Gaussian kernel) | 77.1 | 58.3 | 95.8 |
| 1-nn (Euclidean Distance) | 83.3 | 70.8 | 95.8 |
| 1-nn (Chebyshev Distance) | 75.0 | 62.5 | 87.5 |
| 1-nn (Minkowski Distance) | 70.8 | 75.0 | 66.7 |
| 1-nn (Spearman Distance) | 77.1 | 54.2 | 100.0 |
| Fusion model based on final selection (5 features) | |||
| SVM (Linear kernel) | 70.8 | 50.0 | 91.7 |
| SVM (Quadratic kernel) | 77.1 | 66.7 | 87.5 |
| SVM (Cubic kernel) | 79.2 | 70.8 | 87.5 |
| SVM (Gaussian kernel) | 89.6 | 95.8 | 83.3 |
| 1-nn (Euclidean Distance) | 83.3 | 79.2 | 87.5 |
| 1-nn (Chebyshev Distance) | 92.2 | 91.1 | 93.3 |
| 1-nn (Minkowski Distance) | 68.8 | 41.7 | 95.8 |
| 1-nn (Spearman Distance) | 85.4 | 83.3 | 87.5 |
| Classifier | 1-nn | SVM | ||||
|---|---|---|---|---|---|---|
| ACC [%] | Se [%] | Sp [%] | ACC [%] | Se [%] | Sp [%] | |
| Fusion model based on pre-selection | 83.3 | 70.8 | 95.8 | 79.1 | 62.5 | 95.8 |
| AUC | 0.85 | 0.82 | ||||
| Fusion model based on final selection | 92.2 | 91.1 | 93.3 | 89.6 | 95.8 | 83.3 |
| AUC | 0.89 | 0.92 | ||||
| Reference | ACC [%] | Se [%] | Sp [%] | Additional Information |
|---|---|---|---|---|
| [107] | 85.0 | 80.0 | 90.0 | SVM methods |
| 82.5 | 850 | 80.0 | K-NN classifier | |
| [105] | 65.57 | 63.29 | 67.86 | Baseline features (phonation + articulation + prosody) |
| 67.93 | 69.71 | 66.14 | Baseline features + Glottal (QCP) | |
| [106] | 66.0 | 88.0 | 14.0 | SVM method. Telephonic speech The best results were obtained when the prosody features were considered. |
| 61.0 | 82.0 | 0 | CNN | |
| [103] | 93/96/92 | - | - | Continuous speech, speech denoising |
| 83/87/86 | - | - | Original signal | |
| this paper | 92.2% | 91.1% | 93.3% | 1-nn method |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majda-Zdancewicz, E.; Potulska-Chromik, A.; Nojszewska, M.; Kostera-Pruszczyk, A. Speech Signal Analysis in Patients with Parkinson’s Disease, Taking into Account Phonation, Articulation, and Prosody of Speech. Appl. Sci. 2024, 14, 11085. https://doi.org/10.3390/app142311085
Majda-Zdancewicz E, Potulska-Chromik A, Nojszewska M, Kostera-Pruszczyk A. Speech Signal Analysis in Patients with Parkinson’s Disease, Taking into Account Phonation, Articulation, and Prosody of Speech. Applied Sciences. 2024; 14(23):11085. https://doi.org/10.3390/app142311085
Chicago/Turabian StyleMajda-Zdancewicz, Ewelina, Anna Potulska-Chromik, Monika Nojszewska, and Anna Kostera-Pruszczyk. 2024. "Speech Signal Analysis in Patients with Parkinson’s Disease, Taking into Account Phonation, Articulation, and Prosody of Speech" Applied Sciences 14, no. 23: 11085. https://doi.org/10.3390/app142311085
APA StyleMajda-Zdancewicz, E., Potulska-Chromik, A., Nojszewska, M., & Kostera-Pruszczyk, A. (2024). Speech Signal Analysis in Patients with Parkinson’s Disease, Taking into Account Phonation, Articulation, and Prosody of Speech. Applied Sciences, 14(23), 11085. https://doi.org/10.3390/app142311085