
Migrating from Developing Asynchronous Multi-Threading Programs to Reactive Programs in Java


Abstract
1. Introduction
1.1. Research Overview
1.2. Problem and Approach
1.3. Objectives
2. Theoretical Background
2.1. Concurrency
2.2. Asynchronous Programming
2.3. Non-Blocking I/O
2.4. Event-Driven Architecture
2.5. Reactive Programming
3. Related Work
3.1. Evaluating Hibernate Reactive for Scalable Database Solutions
3.2. Assessing R2DBC in High-Concurrency Web Applications
3.3. Benchmarking Virtual Threads and Reactive WebFlux for Concurrent Web Services
3.4. Reactive and Imperative Approaches in Microservice Performance
3.5. Actor-Oriented Databases for Scalable and Reactive IoT Data Management
3.6. Temporal and Type-Driven Approaches to Asynchronous Reactive Programming
4. Current State of Technology
4.1. Microservices
4.2. The Reactive Manifesto
4.3. Spring Boot and Spring WebFlux
4.4. Performance and Cost Analysis
4.5. Adoption of Reactive Programming
5. Proposed Solution
5.1. Architecture
5.2. Tools and Technologies
- Java and Spring Boot Versions
- Java 21 and Spring Boot 3 were utilized for the development of the asynchronous and reactive applications, ensuring stability and compatibility with mainstream technologies and providing robust support for development and concurrency. These are the latest long-term support versions, which should soon be considered the standard for the current application development and are already a requirement for most of the tools and frameworks actively developed in today’s technology market [13].
- Asynchronous Operations
- CompletableFuture was introduced in Java 8 and provides a robust interface for asynchronous code development, allowing the chaining of multiple steps of the computation process and abstracting multiple aspects of thread management. Compared to its predecessor, the Future interface, it offers a more fluid, non-blocking design and supports other ecosystem advances such as lambda expressions [6].
- ExecutorService allows for granular control over concurrency and asynchronous task execution. It allows the allocation, configuration, and utilization of dedicated thread pools, which can improve application performance in critical scenarios.
- Schedulers are the primary mechanism enabling concurrency management in the reactive model, allowing for enhanced flexibility and granular control through the selection of execution contexts and thread pools such as boundedElastic, parallel, immediate, and single, the appropriate selection is imperative for maintaining low resource consumption and high performance.
- HTTP Clients
- Java HttpClient was utilized in the asynchronous application for delivering a rich interface, abstracting, and enabling communication with external services based on HTTP requests [51]. It provides direct configuration and integration with ExecutorService, which allows asynchronous processing of the response.
- WebClient was utilized in the reactive application due to being part of the WebFlux module, providing a non-blocking implementation, advanced features and support for reactive data flows [28]. The interface is more lightweight and streamlined compared to other implementations given its tight integration within the Spring ecosystem.
- API Gateway
- Zuul v1 is a completely integrated extension within the Java ecosystem, developed by Netflix, picked in the asynchronous model to perform dynamic routing. One main issue with Zuul v1 is its blocking nature, prompting the development of a new variant: Zuul v2, which improves scalability and performance through non-blocking request handling [52].
- Spring Cloud Gateway is the counterpart developed by the Spring team, offering advanced routing capabilities, improved performance, and an extended set of functionalities within the reactive ecosystem [53].
- Database Management
- PostgreSQL was utilized as the relational database in both models, extending conventional SQL with object-oriented capabilities and advanced functionality for data storage and manipulation. It supports complex data types including JSON, arrays, and key–value pairs, while also allowing the definition of custom types and functions [54].
- R2DBC provides streamlined connectivity and non-blocking interactions with the database, representing a specification that provides a reactive driver for PostgreSQL, integrates, and is even preferred in the development of fully reactive applications [9].
- Data Caching
- Redis is used across both models for its high-performance caching capabilities, significantly reducing response times and load on databases and application components. Redis supports both blocking and non-blocking operations, making it a versatile choice for both systems [57].
- Framework Architecture
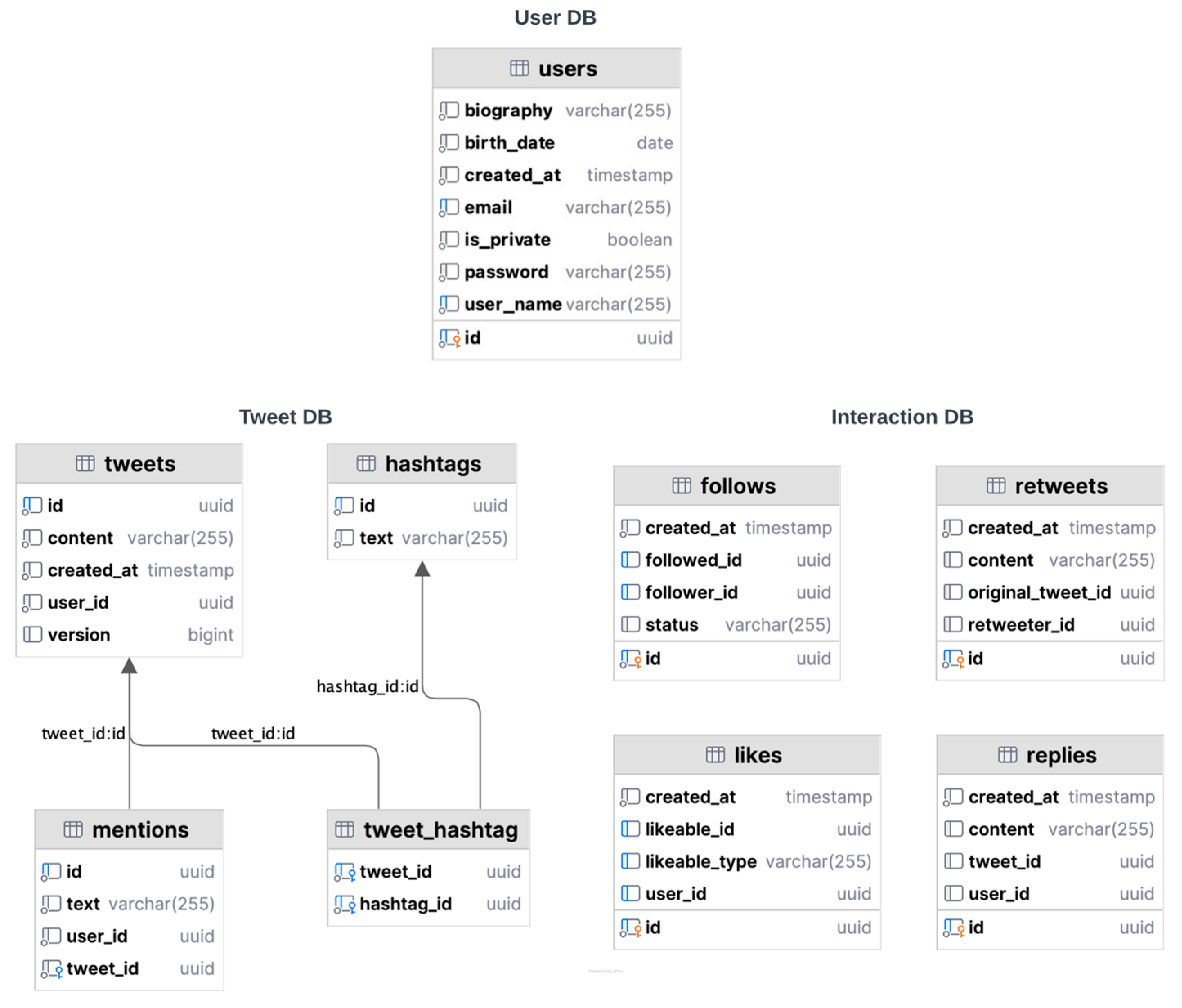
5.3. Project Structure
- Database Structure
- The “users” table defines the list of user accounts within the application.
- The “tweets” define the list of messages within the application. This table has a many-to-one relationship with the “mentions” table, using the foreign key “tweet_id” to reference the associated entity.
- The “hashtags” table defines the list of tags extracted from message contents.
- The “mentions” table defines the user mentions within messages. This table has a many-to-one relationship with the “tweets” table using the foreign key “tweet_id” to reference the associated entity.
- The “tweet_hashtag” table defines the join enabling the many-to-many relationship between messages and tags. This table has a many-to-one relationship with the “tweets” using the foreign key “tweet_id” and with the “hashtags” table using the foreign key “hashtag_id” to reference the associated entities.
- The “follows” table defines the subscriptions between users.
- The “likes” table stores the list of acknowledgments given by users to existing messages or replies.
- The “replies” table stores the list of submitted replies by users to existing messages.
- The “retweets” table stores the list of redistribution of existing messages by the users.
- Project Organization
- The “client” package contains classes for communicating with the other services in the application.
- The “config” package centralizes config classes for various components of the application, such as caching, security, etc.
- The “controller” package includes classes that expose the application’s entry points, receiving and processing user requests.
- The “entity” package contains the entities or data models equivalent to the objects persisted in the database.
- The “exception” package defines specific exceptions used in the application for error handling.
- The “mapper” package groups the classes that provide the conversion between data transfer objects (DTO) and entities.
- The “model” package contains models used for transferring information, without directly exposing persistent entities.
- The “repository” package includes interfaces and implementations for accessing persistent data and managing database operations.
- The “service” package contains the core business logic of the application, which is implemented in classes that organize and sequence calls to repositories and other necessary components.
- The “util” package centralizes utility classes, used in various parts of the application, such as validation methods, conversions, etc.
5.4. Migration Aspects and Stages
6. Implementation Details
6.1. Updating Java and Spring Versions
6.2. Implementation and Management of Components
6.3. Communication Using HTTP Clients
6.4. Handling System Errors
| Listing 1. Example of using Circuit Breaker in reactive applications. |
| @CircuitBreaker( name = “followedIdsCircuitBreaker”, fallbackMethod = “getUserFeedWithCachedFollowed” ) public Flux<TweetDto> getUserFeed(UUID userId) { return interactionClient.getFollowerIds(userId) .collectList() .flatMapMany( tweetRepository::findByUserIdInOrderByCreatedAtDesc ) .flatMap(this::enrichTweetDto); } public Flux<TweetDto> getUserFeedWithCachedFollowed( UUID userId, Throwable t ) { String key = FOLLOWED_CACHE + “::” + userId; return redisTemplate.opsForValue().get(key) .map(v -> { try { return objectMapper.readValue( v, new TypeReference<List<UUID>>() {} ); } catch (JsonProcessingException e) { throw new RuntimeException(e); } }).flatMapMany(Flux::fromIterable) .collectList() .flatMapMany( tweetRepository::findByUserIdInOrderByCreatedAtDesc ) .flatMap(this::enrichTweetDto); } |
6.5. Task Scheduling Mechanisms
6.6. Database Interactions
| Listing 2. Examples of methods for database access in asynchronous applications. |
| List<ReplyEntity> findByTweetIdOrderByCreatedAtDesc(UUID tweetId); @EntityGraph(attributePaths = {“mentions”, “hashtags”}) List<TweetEntity> findByUserIdInOrderByCreatedAtDesc( List<UUID> userIds ); @Query( value = “SELECT * FROM users WHERE user_name ILIKE ‘%:query%’”, nativeQuery = true ) List<UserEntity> searchUsers(String query); @Query( “SELECT NEW ro.tweebyte.interactionservice.model.ReplyDto” + “(r.id, r.userId, r.content, r.createdAt, CAST(COALESCE(COUNT(l), 0) AS long)) “ + “FROM ReplyEntity r “ + “LEFT JOIN LikeEntity l ON r.id = l.likeableId AND l.likeableType = ’REPLY’ “ + “WHERE r.tweetId = :tweetId “ + “GROUP BY r.id, r.userId, r.content, r.createdAt “ + “ORDER BY COUNT(l) DESC, r.createdAt DESC” ) Page<ReplyDto> findTopReplyByLikesForTweetId(@Param(“tweetId”) UUID tweetId, Pageable pageable); |
| Listing 3. Example of loading entity relationships in reactive applications. |
| private Mono<TweetDto> enrichTweetDto(TweetEntity tweetEntity) { Mono<Long> likesMono = interactionClient.getLikesCount(tweetEntity.getId()); Mono<Long> repliesMono = interactionClient .getRepliesCount(tweetEntity.getId()); Mono<Long> retweetsMono = interactionClient .getRetweetsCount(tweetEntity.getId()); Mono<ReplyDto> replyMono = interactionClient .getTopReply(tweetEntity.getId()) Mono<List<HashtagEntity>> hashtagsMono = hashtagRepository .findHashtagsByTweetId(tweetEntity.getId()).collectList(); Mono<List<MentionEntity>> mentionsMono = mentionRepository .findMentionsByTweetId(tweetEntity.getId()).collectList(); return Mono.zip(likesMono, repliesMono, retweetsMono, replyMono, hashtagsMono, mentionsMono) .map(data -> tweetMapper.mapEntityToDto( tweetEntity, data.getT1(), data.getT2(), data.getT3(), data.getT4(), data.getT5(), data.getT6() )); } |
7. Evaluation of Results
7.1. Functional Equivalence
| Listing 4. Example of unit test covering the user login in the asynchronous approach. |
| @Test void testLoginSuccess() throws ExecutionException, InterruptedException { //arrange UserLoginRequest request = new UserLoginRequest( “user@example.com”, “correctpassword” ); UserEntity userEntity = new UserEntity(); userEntity.setEmail(“user@example.com”); userEntity.setPassword(“$2a$10$SomeHashedPasswordHere”); userEntity.setId(UUID.randomUUID()); when(userRepository.findByEmail(any()) ).thenReturn(Optional.of(userEntity)); when( encoder .matches(request.getPassword(), userEntity.getPassword()) ).thenReturn(true); //act AuthenticationResponse result = authenticationService .login(request).get(); //assert assertNotNull(result); assertFalse(result.getToken().isEmpty()); verify(userRepository).findByEmail(request.getEmail()); verify(encoder) .matches(request.getPassword(), userEntity.getPassword()); } |
| Listing 5. Example of a piece of Cucumber feature for message management testing scenarios. |
| Feature: User Tweet Management Scenario: Register a user, create a tweet, and verify tweet existence Given a new user is registered with valid details When the user posts a valid tweet And the user retrieves their tweets Then the user’s tweet should be included in the retrieved tweets Scenario: Attempt to create a tweet with no content Given a new user is registered with valid details When the user attempts to post a tweet with no content Then the response should indicate a content validation error Scenario: Attempt to create a tweet with insufficient content length Given a new user is registered with valid details When the user attempts to post a tweet with insufficient content Then the response should indicate a minimum content length error # other scenarios |
| Listing 6. Example of step implementations for Cucumber feature scenarios. |
| @Given(“a new user is registered with valid details”) public void registerNewUser() throws JsonProcessingException { String url = USER_SERVICE_BASE_URL + “/auth/register”; HttpHeaders headers = new HttpHeaders(); headers.setContentType(MediaType.MULTIPART_FORM_DATA); LinkedMultiValueMap<String, String> body = new LinkedMultiValueMap<>(); body.add(“userName”, generateRandomUsername()); body.add(“email”, generateRandomEmail()); //addition of the other fields HttpEntity<LinkedMultiValueMap<String, String>> requestEntity = new HttpEntity<>(body, headers); ResponseEntity<String> response = restTemplate .postForEntity(url, requestEntity, String.class); assertEquals(HttpStatus.OK, response.getStatusCode()); AuthenticationResponse authResponse = objectMapper .readValue(response.getBody(), AuthenticationResponse.class); userId = UUID.fromString( getClaimFromToken(authResponse.getToken(), “user_id”) ); } @Then(“the user’s tweet should be included in the retrieved tweets”) public void verifyTweetInclusion() throws Exception { TweetDto[] tweetsArray = objectMapper .readValue(response.getBody(), TweetDto[].class); List<TweetDto> tweets = Arrays.asList(tweetsArray); assertTrue( tweets .stream() .anyMatch( tweet -> “This is a valid tweet.” .equals(tweet.getContent()) && tweetId.equals(tweet.getId()) ) ); } |
7.2. Performance Analysis
7.2.1. Static and Initialization Metrics
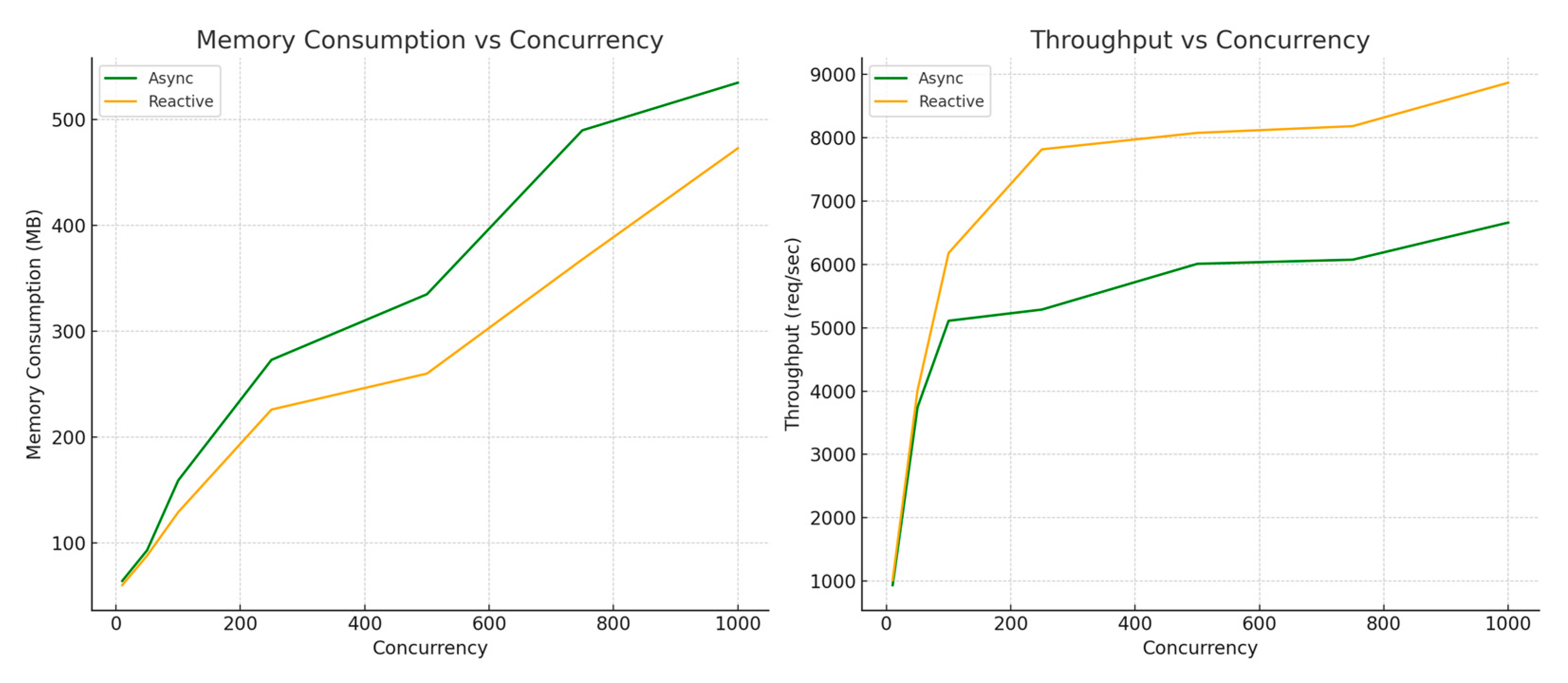
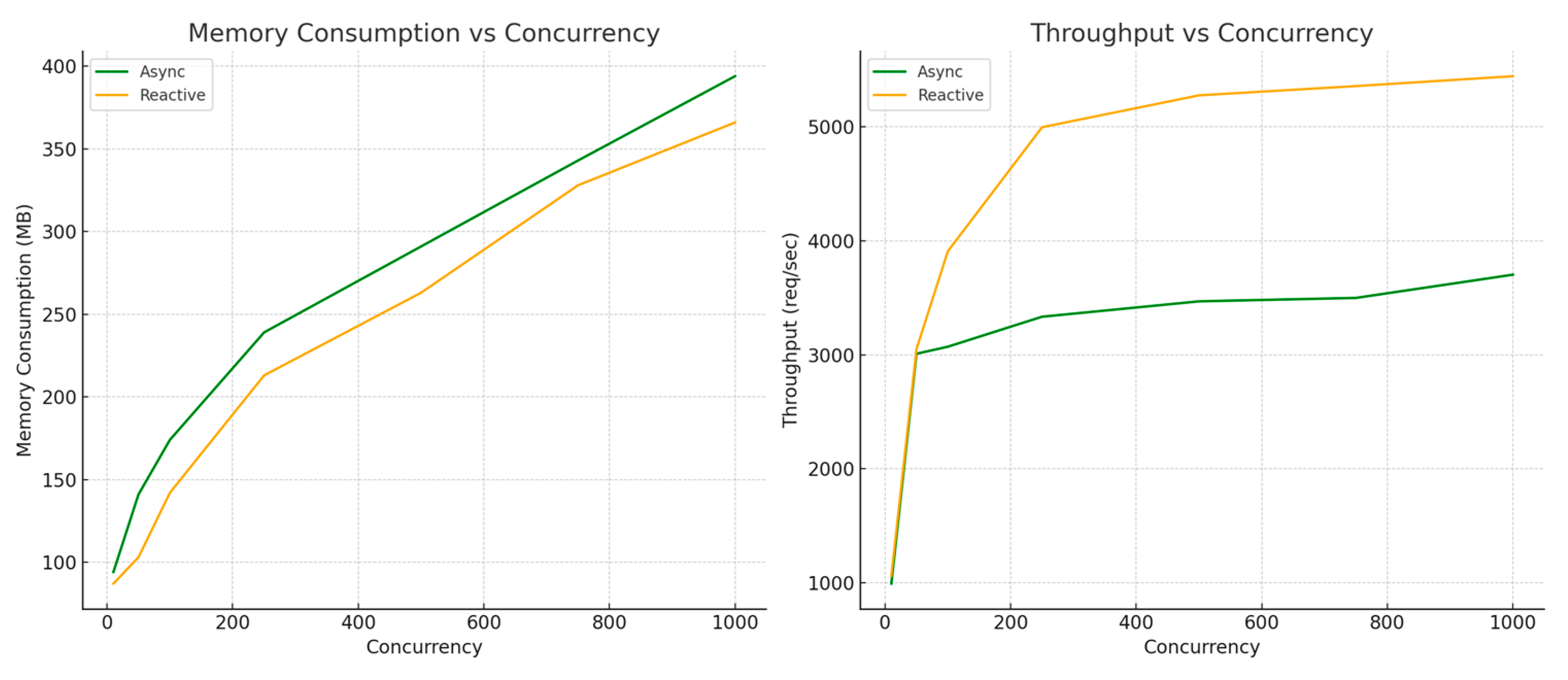
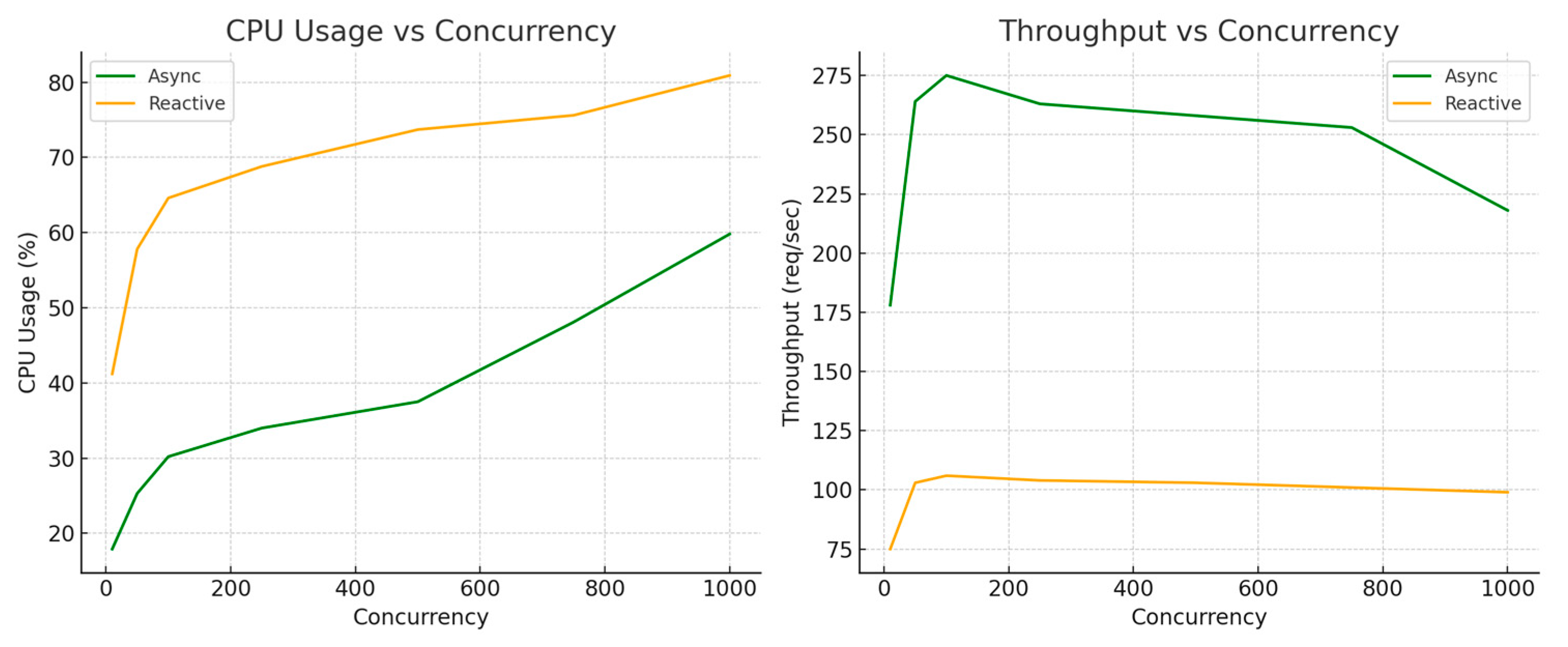
7.2.2. Evaluation Under Concurrent Load Conditions
7.2.3. Discussion of Results
7.2.4. Trade-Offs and Long-Term Impacts
7.2.5. Limitations in Performance Testing
- Server: Intel Core i7 10,700 CPU, 32 GB DDR4 RAM, and 1 TB SSD (Intel, Santa Clara, CA, USA).
- Client: Apple M1 chip, 16 GB unified memory, and 256 GB SSD (Apple, Cupertino, CA, USA).
8. Conclusions and Further Development
8.1. Conclusions
8.2. Further Development
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Erder, M.; Pureur, P.; Woods, E. Continuous Architecture in Practice: Software Architecture in the Age of Agility and DevOps; Addison-Wesley Professional: Boston, MA, USA, 2021. [Google Scholar]
- Ciceri, C.; Farley, D.; Ford, N.; Harmel-Law, A.; Keeling, M.; Lilienthal, C. Software Architecture Metrics: Case Studies to Improve the Quality of Your Architecture; O’Reilly Media: Sebastopol, CA, USA, 2022. [Google Scholar]
- Arnold, K.; Gosling, J.; Holmes, D. The Java Programming Language, 4th ed.; Addison-Wesley Professional: Glenview, IL, USA, 2005. [Google Scholar]
- Sierra, K.; Bates, B.; Gee, T. Head First Java: A Brain-Friendly Guide, 3rd ed.; O’Reilly Media: Sebastopol, CA, USA, 2022. [Google Scholar]
- Davis, A.L. Reactive Streams in Java: Concurrency with RxJava, Reactor, and Akka Streams; Apress: Berkeley, CA, USA, 2018. [Google Scholar]
- Urma, R.G.; Fusco, M.; Mycroft, A. Modern Java in Action: Lambdas, Streams, Functional and Reactive Programming, 2nd ed.; Manning: Hong Kong, 2018. [Google Scholar]
- Hitchens, R. Java NIO: Regular Expressions and High-Performance I/O; O’Reilly Media: Sebastopol, CA, USA, 2002. [Google Scholar]
- Nurkiewicz, T.; Christensen, B. Reactive Programming with RxJava: Creating Asynchronous, Event-Based Applications; O’Reilly Media: Sebastopol, CA, USA, 2016. [Google Scholar]
- Hedgpeth, R. R2DBC Revealed: Reactive Relational Database Connectivity for Java and JVM Programmers; Apress: Berkeley, CA, USA, 2021. [Google Scholar]
- Goetz, B. Java Concurrency In Practice; Pearson: Bengaluru, India, 2016. [Google Scholar]
- Srivastava, R.P.; Nandi, G.C. Controlling Multi Thread Execution Using Single Thread Event Loop. In Proceedings of the 2017 International Conference on Innovations in Control, Communication and Information Systems, Greater Noida, India, 12–13 August 2017; pp. 88–94. [Google Scholar]
- Giebas, D.; Wojszczyk, R. Detection of Concurrency Errors in Multithreaded Applications Based on Static Source Code Analysis. IEEE Access 2021, 9, 61298–61323. [Google Scholar] [CrossRef]
- Malhotra, R. Rapid Java Persistence and Microservices: Persistence Made Easy Using Java EE8, JPA and Spring; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Söderquist, I. Event Driven Data Processing Architecture. In Proceedings of the 2007 Design, Automation & Test In Europe Conference & Exhibition, Nice Acropolis, France, 16–20 April 2007; pp. 972–976. [Google Scholar]
- Laliwala, Z.; Chaudhary, S. Event-Driven Service-Oriented Architecture. In Proceedings of the 2008 5th International Conference on Service Systems and Service Management, Melbourne, Australia, 30 June–2 July 2008; pp. 410–415. [Google Scholar]
- Bellemare, A. Building Event-Driven Microservices: Leveraging Organizational Data at Scale; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- Woodside, M. Performance Models of Event-Driven Architectures. In Proceedings of the Companion of the ACM/Spec International Conference on Performance Engineering, Rennes, France, 19–23 April 2021; pp. 145–149. [Google Scholar]
- Gamma, E.; Helm, R.; Johnson, R.; Vlissides, J. Design Patterns: Elements of Reusable Object-Oriented Software; Addison-Wesley Professional: Boston, MA, USA, 1994. [Google Scholar]
- Grinovero, S. Hibernate Reactive: Is It Worth It? 2021. Available online: https://in.relation.to/2021/10/27/hibernate-reactive-performance/ (accessed on 17 November 2024).
- Ju, L.; Yadav, A.; Yadav, D.; Khan, A.; Sah, A.P. Using Asynchronous Frameworks and Database Connection Pools to Enhance Web Application Performance in High-Concurrency Environments. In Proceedings of the 2024 International Conference on IoT in Social, Mobile, Analytics, and Cloud (I-SMAC 2024), Kirtipur, Nepal, 3–5 October 2024. [Google Scholar]
- Dahlin, K. An Evaluation of Spring WebFlux—With Focus on Built-in SQL Features. Master’s Thesis, Institution of Information Systems and Technology, Mid Sweden University, Östersund, Sweden, 2020. [Google Scholar]
- Joo, Y.H.; Haneklint, C. Comparing Virtual Threads and Reactive WebFlux in Spring: A Comparative Performance Analysis of Concurrency Solutions in Spring. Bachelor’s Thesis, Degree Programme in Computer Engineering, KTH Royal Institute of Technology, Stockholm, Sweden, 2023. [Google Scholar]
- Mochniej, K.; Badurowicz, M. Performance Comparison of Microservices Written Using Reactive and Imperative Approaches. J. Comput. Sci. Inst. 2023, 28, 242–247. [Google Scholar] [CrossRef]
- Wang, Y. Scalable and Reactive Data Management for Mobile Internet-of-Things Applications with Actor-Oriented Databases. Ph.D. Thesis, University of Copenhagen, Copenhagen, Denmark, 2021. [Google Scholar]
- Bansal, S.; Namjoshi, K.S.; Sa’ar, Y. Synthesis of Asynchronous Reactive Programs from Temporal Specifications. In Proceedings of the International Conference on Computer Aided Verification, Oxford, UK, 14–17 July 2018. [Google Scholar]
- Bahr, P.; Houlborg, E.; Rørdam, G.T.S. Asynchronous Reactive Programming with Modal Types in Haskell. In International Symposium on Practical Aspects of Declarative Languages; Gebser, M., Sergey, I., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 18–36. [Google Scholar]
- Spilcă, L. Spring Start Here: Learn What You Need and Learn It Well; Manning: New York, NY, USA, 2021. [Google Scholar]
- Walls, C. Spring in Action; Manning: New York, NY, USA, 2022. [Google Scholar]
- Bogner, J.; Fritzsch, J.; Wagner, S.; Zimmermann, A. Microservices in Industry: Insights into Technologies, Characteristics, and Software Quality. In Proceedings of the 2019 IEEE International Conference on Software Architecture Companion, Hamburg, Germany, 25–26 March 2019. [Google Scholar]
- Fielding, R.T. Architectural Styles and the Design of Network-Based Software Architectures. Ph.D. Thesis, University of California, Irvine, CA, USA, 2000. [Google Scholar]
- Saternos, C. Client-Server Web Apps with JavaScript and Java: Rich, Scalable, and RESTful; O’Reilly Media: Sebastopol, CA, USA, 2014. [Google Scholar]
- Afonso, J.; Caffy, C.; Patrascoiu, M.; Leduc, J.; Davis, M.; Murray, S.; Cortes, P. An HTTP REST API for Tape-backed Storage. EPJ Web Conf. 2024, 295, 01008. [Google Scholar] [CrossRef]
- Nickoloff, J.; Kuenzli, S. Docker in Action, 2nd ed.; Manning: New York, NY, USA, 2019. [Google Scholar]
- Newman, S. Monolith to Microservices: Evolutionary Patterns to Transform Your Monolith; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Vernon, V.; Tomasz, J. Strategic Monoliths and Microservices: Driving Innovation Using Purposeful Architecture; Addison-Wesley Publishing: Boston, MA, USA, 2022. [Google Scholar]
- Bonér, J.; Farley, D.; Kuhn, R.; Thompson, M. The Reactive Manifesto. 2014. Available online: https://www.reactivemanifesto.org (accessed on 17 November 2024).
- Pal, N.; Yadav, D.K. Modeling and verification of software evolution using bigraphical reactive system. Clust. Comput. 2024, 27, 12983–13003. [Google Scholar] [CrossRef]
- Padmanaban, K.; Kalpana, Y.B.; Geetha, M.; Balan, K.; Mani, V.; Sivaraju, S.S. Simulation and modeling in cloud computing-based smart grid power big data analysis technology. Int. J. Model. Simul. Sci. Comput. 2024, 27, 2541005. [Google Scholar] [CrossRef]
- Ullenboom, C. Spring Boot 3 and Spring Framework 6; Rheinwerk Computing: Quincy, MA, USA, 2023. [Google Scholar]
- Rao, R.R.; Swamy, S.R. Review on Spring Boot and Spring Webflux for Reactive Web Development. Int. Res. J. Eng. Technol. 2020, 7, 3834–3837. [Google Scholar]
- Schoop, S.; Hebisch, E.; Franz, T. Improving Comprehensibility of Event-Driven Microservice Architectures by Graph-Based Visualizations. Softw. Archit. ECSA 2024, 14889, 14. [Google Scholar]
- Cabane, H.; Farias, K. On the impact of event-driven architecture on performance: An exploratory study. Future Gener. Comput. Syst. 2024, 153, 52–69. [Google Scholar] [CrossRef]
- Ponge, J.; Navarro, A.; Escoffier, C.; Le Mouël, F. Analysing the Performance and Costs of Reactive Programming Libraries in Java. In Proceedings of the 8th ACM SIGPLAN International Workshop on Reactive and Event-Based Languages and Systems, Chicago, IL, USA, 18 October 2021. [Google Scholar]
- Christensen, B.; Husain, J. Reactive Programming in the Netflix API with RxJava. 2013. Available online: https://netflixtechblog.com/reactive-programming-in-the-netflix-api-with-rxjava-7811c3a1496a (accessed on 17 November 2024).
- Oracle. Java/JDBC Scalability and Asynchrony: Reactive Extension and Fibers. 2019. Available online: https://www.oracle.com/a/tech/docs/dev6323-reactivestreams-fiber.pdf (accessed on 17 November 2024).
- Squbs: A New, Reactive Way for PayPal to Build Applications. 2016. Available online: https://medium.com/paypal-tech/squbs-a-new-reactive-way-for-paypal-to-build-applications-127126bf684b (accessed on 17 November 2024).
- Harris, P.; Hale, B. Designing, Implementing, and Using Reactive APIs. 2018. Available online: https://www.infoq.com/articles/Designing-Implementing-Using-Reactive-APIs/ (accessed on 17 November 2024).
- JSON Web Tokens. Available online: https://jwt.io (accessed on 17 November 2024).
- Spilcă, L. Spring Security in Action, 2nd ed.; Manning: New York, NY, USA, 2024. [Google Scholar]
- Richardson, C. Microservice Architecture Pattern. 2024. Available online: https://microservices.io/patterns/data/database-per-service.html (accessed on 17 November 2024).
- Oracle Java Documentation. Available online: https://docs.oracle.com/en/java/ (accessed on 17 November 2024).
- Zuul Documentation. Available online: https://zuul-ci.org/ (accessed on 17 November 2024).
- Spring Cloud Gateway Documentation. Available online: https://spring.io/projects/spring-cloud-gateway (accessed on 17 November 2024).
- Ferrari, L.; Pirozzi, E. Learn PostgreSQL: Use, manage and build secure and scalable databases with PostgreSQL 16, 2nd ed.; Packt Publishing: Birmingham, UK, 2023. [Google Scholar]
- Tudose, C. Java Persistence with Spring Data and Hibernate; Manning: New York, NY, USA, 2023. [Google Scholar]
- Bonteanu, A.M.; Tudose, C. Performance Analysis and Improvement for CRUD Operations in Relational Databases from Java Programs Using JPA, Hibernate, Spring Data JPA. Appl. Sci. 2024, 14, 2743. [Google Scholar] [CrossRef]
- Redis Official Website. Available online: https://redis.io/ (accessed on 17 November 2024).
- Eclipse Transformer Website. Available online: https://projects.eclipse.org/projects/technology.transformer (accessed on 17 November 2024).
- Reflectoring Website. Available online: https://reflectoring.io/dependency-injection-and-inversion-of-control/ (accessed on 17 November 2024).
- Montesi, F.; Weber, J. From the Decorator Pattern to Circuit Breakers in Microservices. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 1733–1735. [Google Scholar]
- Resilience4j Website. Available online: https://resilience4j.readme.io/docs/getting-started (accessed on 17 November 2024).
- Tudose, C. JUnit in Action; Manning: New York, NY, USA, 2020. [Google Scholar]
- Cucumber Website. Available online: https://cucumber.io/ (accessed on 17 November 2024).
- Van Merode, H. Continuous Integration (CI) and Continuous Delivery (CD): A Practical Guide to Designing and Developing Pipelines; Apress: Berkeley, CA, USA, 2023. [Google Scholar]
- JMeter Website. Available online: https://jmeter.apache.org/ (accessed on 17 November 2024).
- Bonér, J.; Klang, V. Reactive Programming versus Reactive Systems. 2016. Available online: https://gandrille.github.io/tech-notes/Reactive_and_microservices/Reactive/2016%20reactive-programming-vs-reactive-systems.pdf (accessed on 17 November 2024).
- Salvaneschi, G.; Mezini, M. Debugging for Reactive Programming. In Proceedings of the 2016 IEEE/ACM 38th International Conference on Software Engineering (ICSE), Austin, TX, USA, 14–22 May 2016; pp. 796–807. [Google Scholar]
- Holst, G.; Dobslaw, F. On the Importance and Shortcomings of Code Readability Metrics: A Case Study on Reactive Programming. 2021. Available online: https://arxiv.org/abs/2110.15246 (accessed on 17 November 2024).
- Crudu, A.; MoldStud Research Team. The Impact of Reactive Programming on Software Development. 2024. Available online: https://moldstud.com/articles/p-the-impact-of-reactive-programming-on-software-development (accessed on 17 November 2024).
- Köhler, M.; Salvaneschi, G. Automated Refactoring to Reactive Programming. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE), San Diego, CA, USA, 11–15 November 2019; pp. 835–846. [Google Scholar]
- Grottke, M.; Matias, R., Jr.; Trivedi, K.S. The Fundamentals of Software Aging. In Proceedings of the 19th IEEE International Symposium on Software Reliability Engineering Workshops, Redmond, WA, USA, 11–14 November 2008. [Google Scholar]
- Anghel, I.I.; Calin, R.S.; Nedelea, M.L.; Stanica, I.C.; Tudose, C.; Boiangiu, C.A. Software development methodologies: A comparative analysis. UPB Sci. Bull. 2022, 83, 45–58. [Google Scholar]
- Selenium Website. Available online: https://www.selenium.dev/ (accessed on 17 November 2024).
- Server-Sent Events. Available online: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events (accessed on 17 November 2024).
- WebSockets API. Available online: https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API (accessed on 17 November 2024).
- RSocket Website. Available online: https://rsocket.io/ (accessed on 17 November 2024).
- Eclipse Vert.x Website. Available online: https://vertx.io/ (accessed on 17 November 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Section | Summary |
|---|---|
| 3.1. Evaluating Hibernate Reactive for Scalable Database Solutions | Discusses Hibernate Reactive’s scalability and resource efficiency in high-load scenarios, with noted limitations in handling complex transactions. |
| 3.2. Assessing R2DBC in High-Concurrency Web Applications | Highlights R2DBC’s performance in non-blocking environments, emphasizing its efficiency for high-concurrency scenarios with a connection pool. |
| 3.3. Benchmarking Virtual Threads and Reactive WebFlux for Concurrent Web Services | Compares Virtual Threads and WebFlux in Spring applications, showing the benefits of Virtual Threads under specific conditions. |
| 3.4. Reactive and Imperative Approaches in Microservice Performance | Details performance advantages of reactive microservices for I/O-intensive tasks, noting limitations for CPU-heavy operations. |
| 3.5. Actor-Oriented Databases for Scalable and Reactive IoT Data Management | Introduces Actor-Oriented Databases (AODBs) for IoT, emphasizing scalability and low-latency responses in dynamic environments. |
| 3.6. Temporal and Type-Driven Approaches to Asynchronous Reactive Programming | Explores approaches to asynchronous synthesis, offering efficient solutions for reactive systems using compact automaton and type-safe programming. |
| Operation Type | RxJava (ops/ms) | Reactor (ops/ms) | Base (ops/ms) |
|---|---|---|---|
| Map | 33,000 | 10,000 | 63,000 |
| Chain | 23,000 | 13,000 | 63,000 |
| Multiple operators | 12,000 | 5000 | 28,000 |
| Operation Type | RxJava (ops/ms) | Reactor (ops/ms) | Base (ops/ms) |
|---|---|---|---|
| Map | 240 | 250 | - |
| ManyToMany | 130 | 140 | - |
| Filters | 130 | 150 | - |
| Multiple operators | 100 | 100 | 120 |
| Section | Summary |
|---|---|
| 4.1. Microservices | Explores microservices’ benefits for scalability and maintainability, noting challenges in transitioning from monolithic systems. |
| 4.2 The Reactive Manifesto | Summarizes the core principles of reactive systems: responsiveness, resilience, elasticity, and message-driven communication. |
| 4.3 Spring Boot and Spring WebFlux | Highlights WebFlux’s advantages for non-blocking web applications and Spring Boot’s ease of use for rapid development. |
| 4.4 Performance and Cost Analysis | Compares RxJava and Project Reactor, emphasizing their respective strengths in individual operations and event stream processing. |
| 4.5 Adoption of Reactive Programming | Details adoption strategies employed by companies, showcasing reactive programming’s scalability and efficiency. |
| Aspect | Asynchronous | Reactive |
|---|---|---|
| Programming model | Imperative | Reactive |
| Java version | Java 21 | Java 21 |
| Framework | Spring Boot 3 | Spring Boot 3 |
| Single result | CompletableFuture<T> | Mono<T> |
| Collection/Data stream | CompletableFuture<Collection<T>> | Flux<T> |
| Thread pools | ExecutorService | Schedulers |
| API | Standard Java API | Project Reactor, Spring WebFlux |
| Error handling | try-catch, CompletableFuture, exceptionally() | Mono/Flux, onErrorReturn(), onErrorResume(), onErrorMap() |
| Operation retries | Programmatic | Native, Mono/Flux retry() |
| Blocking operations | CompletableFuture get() | Mono/Flux block() |
| Data access | JDBC, Hibernate, JPA | R2DBC |
| Web server | Tomcat | Netty |
| HTTP communication | Java HttpClient | Spring WebClient |
| Microservice (Paradigm) | Heap Memory Consumption (MB) | Startup Time (ms) | JAR Size (MB) |
|---|---|---|---|
| User Service (async) | 61 | 2363 | 52 |
| User Service (reactive) | 38 | 1522 | 37 |
| Tweet Service (async) | 62 | 2921 | 61 |
| Tweet Service (reactive) | 45 | 1874 | 45 |
| Interaction Service (async) | 70 | 3526 | 61 |
| Interaction Service (reactive) | 51 | 2107 | 41 |
| Type | Description | Quantity | Purpose |
|---|---|---|---|
| Unit Tests | Tests focusing on individual code components or methods. | ~150 per service (1023 total) | Ensures correctness and reliability of smaller functional units of the application. |
| Behavior-Driven Tests | Feature-based Cucumber tests, written in Gherkin to validate end-to-end behavior. | 50 scenarios | Validates user-facing functionality, integration, and consistency between asynchronous and reactive implementations. |
| Performance Tests | Simulations of concurrent users performing specific actions. | 4 scenarios × 7 concurrency levels (10, 50, 100, 250, 500, 750, 1000 users) | Measures resource usage (CPU, memory) and throughput under varying load conditions to compare asynchronous and reactive approaches. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zbarcea, A.; Tudose, C. Migrating from Developing Asynchronous Multi-Threading Programs to Reactive Programs in Java. Appl. Sci. 2024, 14, 12062. https://doi.org/10.3390/app142412062
Zbarcea A, Tudose C. Migrating from Developing Asynchronous Multi-Threading Programs to Reactive Programs in Java. Applied Sciences. 2024; 14(24):12062. https://doi.org/10.3390/app142412062
Chicago/Turabian StyleZbarcea, Andrei, and Cătălin Tudose. 2024. "Migrating from Developing Asynchronous Multi-Threading Programs to Reactive Programs in Java" Applied Sciences 14, no. 24: 12062. https://doi.org/10.3390/app142412062
APA StyleZbarcea, A., & Tudose, C. (2024). Migrating from Developing Asynchronous Multi-Threading Programs to Reactive Programs in Java. Applied Sciences, 14(24), 12062. https://doi.org/10.3390/app142412062