
Joint Entity and Relation Extraction Model Based on Inner and Outer Tensor Dot Product and Single-Table Filling


Abstract
:1. Introduction
- (1)
- We propose a novel table-filling scheme, which can extract entities with multiple relations and tokens end to end. Even when applied to a simple network architecture, it achieves high accuracy.
- (2)
- We propose a new framework model that combines the attention mechanism inside the transformer with the multi-head tensor dot-product results of sentence representations, enriching the feature vectors of the table and improving accuracy compared to extracting results using only the attention mechanism.
- (3)
- We apply the focal loss function to entity relation extraction table-filling methods. To the best of our knowledge, most current relation extraction models based on table-filling methods use cross-entropy as the loss function for training.
- (4)
2. Related Works
3. Methodology
3.1. Problem Definition
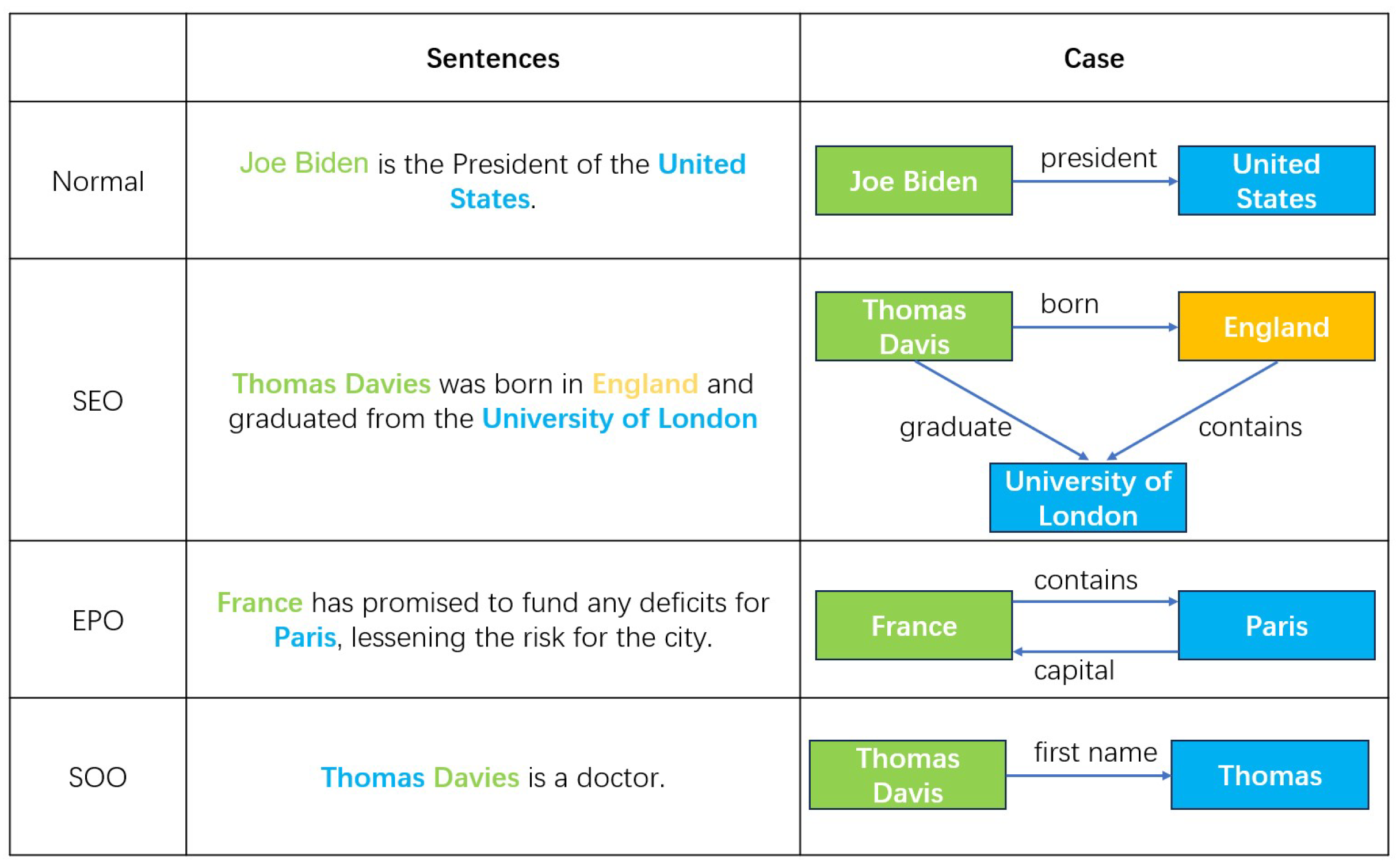
3.2. Table-Filling Schemes
- (1)
- (2)
- It can solve the complex overlapping problems of EPO, SEO, and SOO.
- (3)
- The labels for each part of the relationship not only provide the relative position information of the corresponding entity (i.e., whether the entity is the subject or object) but also provide the span information of the entity (i.e., the specific position of the entity in the sentence). This allows our model to achieve a one-module one-step extraction process, further avoiding exposure bias.
| Algorithm 1 Table decoding strategy |
Input: Table probability matrix , threshold t Output: Triplet T extracted from sentence Z
|
3.3. The Model Framework
3.4. Model Optimization
4. Experiments
4.1. Datasets
4.2. Parameter Settings
4.3. Main Results
- CasRel [8] uses a cascaded framework for sequential extraction, which is relatively slow. Our model can extract all triplets in the text at once.
- TPLinker [10] uses a one-stage token-linking approach for joint relation triplet extraction but requires multiple supporting modules. Our model only needs one module to extract complete triplets.
- PRGC [25] divides joint relation triplet extraction into three subtasks, which can lead to exposure bias. In contrast, our model treats it as a holistic table-filling task, avoiding exposure bias.
- EmRel [30] represents relations as embedding vectors but still requires multiple components. It refines the representation of entities and relations through an attention-based fusion module.
- GRTE [12] is the state-of-the-art method for the NYT dataset, but it requires multiple class labels to determine a complete entity pair. Our method only requires binary classification.
- OneRel [11] is the state-of-the-art method for the WebNLG dataset, achieving improved triplet recognition efficiency through a one-stage single-model approach. However, it still requires triplet extraction in a three-dimensional table, whereas ours only requires extraction in a two-dimensional table, reducing memory usage.
4.4. Detailed Results on Complex Scenarios
4.5. Detailed Results on Different Subtasks
4.6. Efficiency of the Model
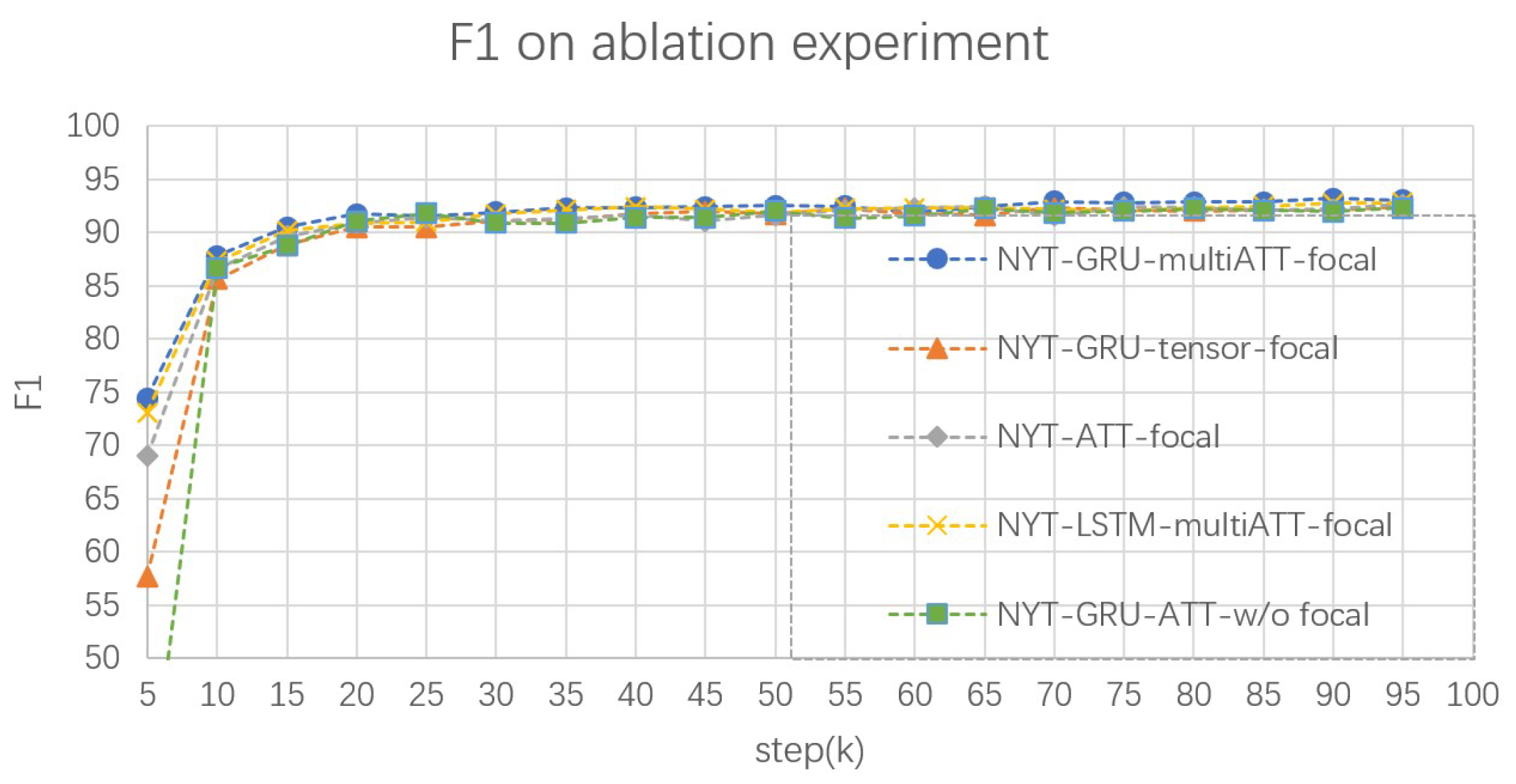
4.7. Ablation Study
4.8. Case Study
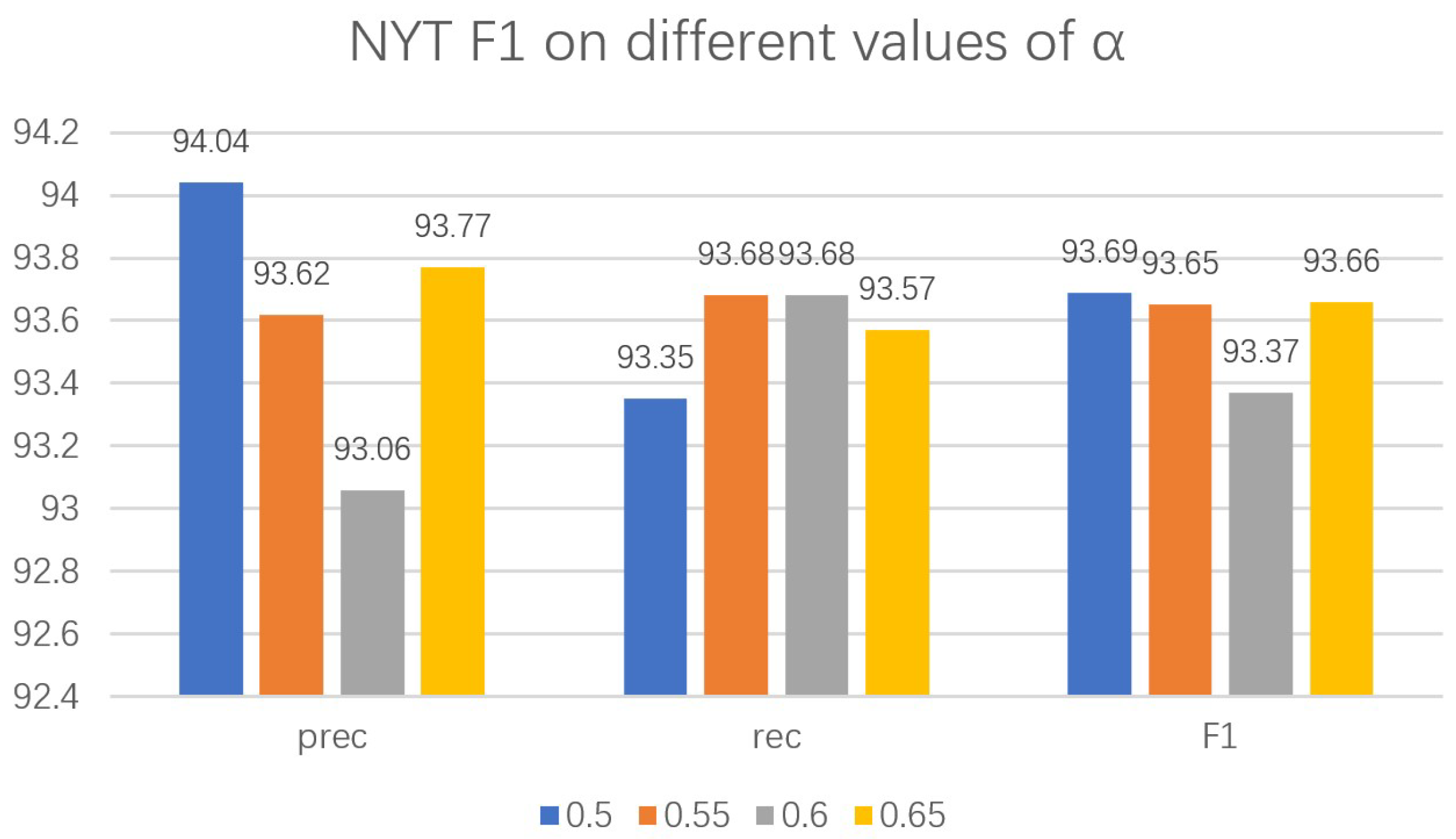
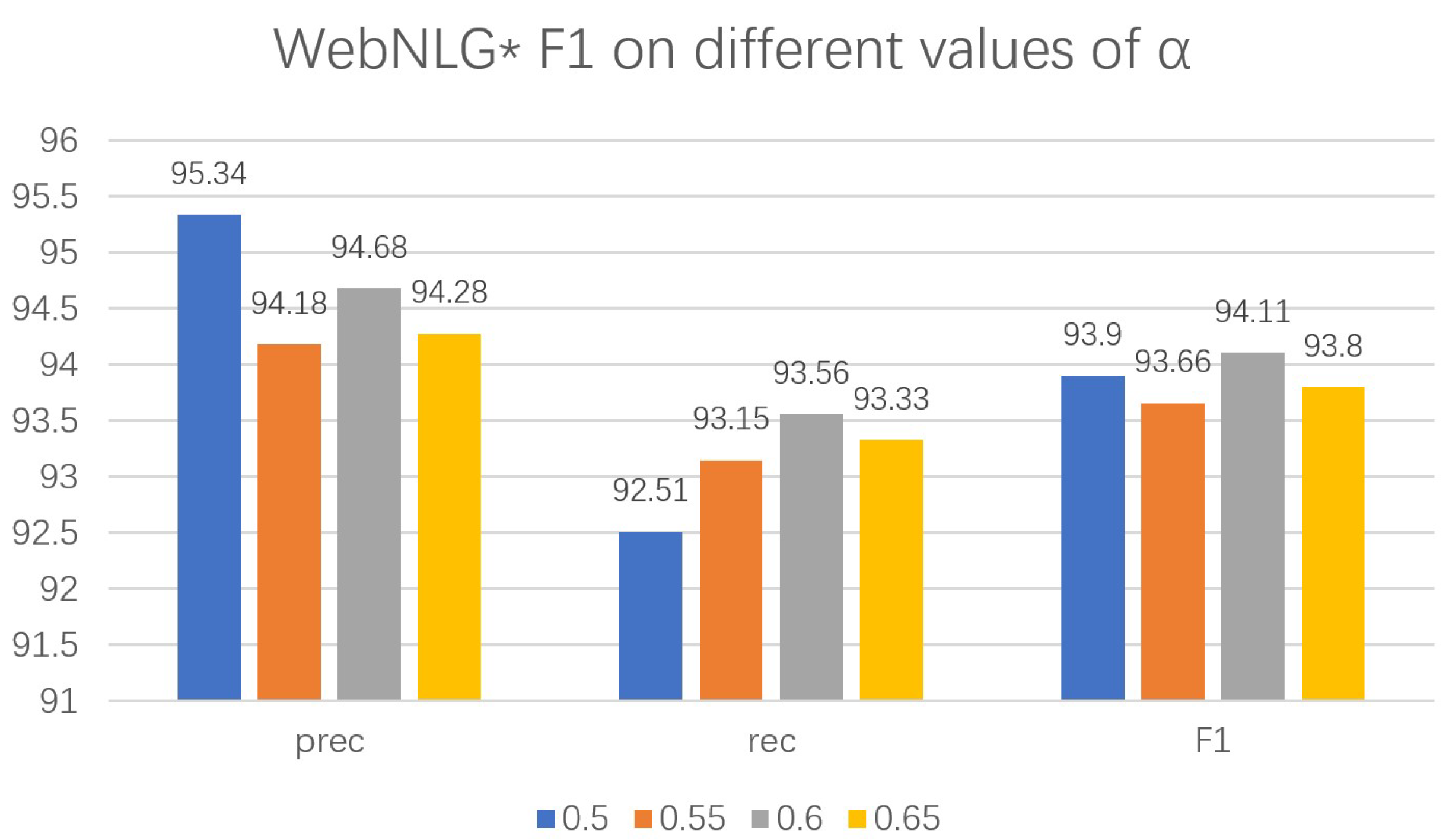
4.9. Parameter Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SEO | Single-Entity Overlap |
| EPO | Entity-Pair Overlap |
| SOO | Subject-Object Overlap |
| RNN | Recurrent Neural Network |
| BERT | Bidirectional Encoder Representations from Transformers |
| NLP | Natural Language Processing |
| BIGRU | Bidirectional Gated Recurrent Unit |
| NYT | New York Times |
| WebNLG | Web Generation from Natural Language Data |
| NER | Named Entity Recognition |
| GRET | Global Feature-Oriented Relational Triple Extraction |
| UniRel | Unified Representation and Interaction for Joint Relational |
| TPlinker | Single-Stage Joint Extraction of Entities and Relations Through Token Pair Linking |
| OneRel | Joint Entity and Relation Extraction with One Module in One Step |
| CasRel | Cascade Binary Tagging Framework for Relational |
| BiLSTM | Bidirectional Long Short-Term Memory |
References
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Chen, Z.Y.; Chang, C.H.; Chen, Y.P.; Nayak, J.; Ku, L.W. UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 3–5 June 2019; pp. 345–356. [Google Scholar]
- Bian, N.; Han, X.; Chen, B.; Sun, L. Benchmarking knowledge-enhanced commonsense question answering via knowledge-to-text transformation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 12574–12582. [Google Scholar]
- Chan, Y.S.; Roth, D. Exploiting syntactico-semantic structures for relation extraction. In Proceedings of the 49th Annual Meeting of the Association for Computationalinguistics: Humananguage Technologies, Portland, OR, USA, 19–24 June 2011; pp. 551–560. [Google Scholar]
- Li, J.; Fei, H.; Liu, J.; Wu, S.; Zhang, M.; Teng, C.; Ji, D.; Li, F. Unified named entity recognition as word-word relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 10965–10973. [Google Scholar]
- Guo, Z.; Zhang, Y.; Lu, W. Attention Guided Graph Convolutional Networks for Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computationalinguistics, Florence, Italy, 28 July–2 August 2019; pp. 241–251. [Google Scholar]
- Wei, Z.; Su, J.; Wang, Y.; Tian, Y.; Chang, Y. A Novel Cascade Binary Tagging Framework for Relational Triple Extraction. In Proceedings of the 58th Annual Meeting of the Association for Computationalinguistics, Virtual, 5–10 July 2020; pp. 1476–1488. [Google Scholar]
- Gupta, P.; Schütze, H.; Andrassy, B. Table filling multi-task recurrent neural network for joint entity and relation extraction. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–16 December 2016; pp. 2537–2547. [Google Scholar]
- Wang, Y.; Yu, B.; Zhang, Y.; Liu, T.; Zhu, H.; Sun, L. TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 1572–1582. [Google Scholar]
- Shang, Y.M.; Huang, H.; Mao, X. Onerel: Joint entity and relation extraction with one module in one step. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 11285–11293. [Google Scholar]
- Ren, F.; Zhang, L.; Yin, S.; Zhao, X.; Liu, S.; Li, B.; Liu, Y. A Novel Global Feature-Oriented Relational Triple Extraction Model based on Table Filling. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2646–2656. [Google Scholar]
- Wang, Z.; Nie, H.; Zheng, W.; Wang, Y.; Li, X. A novel tensor learning model for joint relational triplet extraction. IEEE Trans. Cybern. 2023. [Google Scholar] [CrossRef] [PubMed]
- Zeng, X.; Zeng, D.; He, S.; Liu, K.; Zhao, J. Extracting relational facts by an end-to-end neural model with copy mechanism. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 506–514. [Google Scholar]
- Tang, W.; Xu, B.; Zhao, Y.; Mao, Z.; Liu, Y.; Liao, Y.; Xie, H. UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 7087–7099. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 3–5 June 2019; pp. 4171–4186. [Google Scholar]
- Feng, P.; Zhang, X.; Zhao, J.; Wang, Y.; Huang, B. Relation Extraction Based on Prompt Information and Feature Reuse. Data Intell. 2023, 5, 824–840. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Riedel, S.; Yao, L.; McCallum, A. Modeling relations and their mentions without labeled text. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference—ECML PKDD 2010, Barcelona, Spain, 20–24 September 2010; Proceedings, Part III 21. Springer: Berlin/Heidelberg, Germany, 2010; pp. 148–163. [Google Scholar]
- Gardent, C.; Shimorina, A.; Narayan, S.; Perez-Beltrachini, L. Creating training corpora for nlg micro-planning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Bekoulis, G.; Deleu, J.; Demeester, T.; Develder, C. Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 2018, 114, 34–45. [Google Scholar] [CrossRef]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Zheng, H.; Wen, R.; Chen, X.; Yang, Y.; Zhang, Y.; Zhang, Z.; Zhang, N.; Qin, B.; Ming, X.; Zheng, Y. PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Vrtual, 1–6 August 2021; pp. 6225–6235. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Cabot, P.L.H.; Navigli, R. REBEL: Relation extraction by end-to-end language generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Virtual, 7–11 November 2021; pp. 2370–2381. [Google Scholar]
- Wang, Y.; Sun, C.; Wu, Y.; Zhou, H.; Li, L.; Yan, J. UniRE: A Unified Label Space for Entity Relation Extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual, 1–6 August 2021; pp. 220–231. [Google Scholar]
- Ma, Y.; Hiraoka, T.; Okazaki, N. Named entity recognition and relation extraction using enhanced table filling by contextualized representations. J. Nat. Lang. Process. 2022, 29, 187–223. [Google Scholar] [CrossRef]
- Xu, B.; Wang, Q.; Lyu, Y.; Shi, Y.; Zhu, Y.; Gao, J.; Mao, Z. EmRel: Joint Representation of Entities and Embedded Relations for Multi-triple Extraction. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 659–665. [Google Scholar]
- Zhao, K.; Xu, H.; Cheng, Y.; Li, X.; Gao, K. Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl.-Based Syst. 2021, 219, 106888. [Google Scholar] [CrossRef]
- Liu, J.; Zhao, S.; Wang, G. SSEL-ADE: A semi-supervised ensemble learning framework for extracting adverse drug events from social media. Artif. Intell. Med. 2018, 84, 34–49. [Google Scholar] [CrossRef] [PubMed]
- An, T.; Chen, Y.; Chen, Y.; Ma, L.; Wang, J.; Zhao, J. A machine learning-based approach to ERα bioactivity and drug ADMET prediction. Front. Genet. 2023, 13, 1087273. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Fu, L.; Wang, X.; Zhang, H.; Zhou, C. RFBFN: A relation-first blank filling network for joint relational triple extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, Dublin, Ireland, 22–27 May 2022; pp. 10–20. [Google Scholar]
- An, T.; Wang, J.; Zhou, B.; Jin, X.; Zhao, J.; Cui, G. Impact of strategy conformity on vaccination behaviors. Front. Phys. 2022, 10, 972457. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Approach | Number of Label Types | Supports Multiple Words | Number of Tables |
|---|---|---|---|
| TPlinker | 2 | Yes | |
| OneRel | 4 | Yes | m |
| GRTE | 8 | Yes | m |
| UniRel | 2 | No | 1 |
| Ours | 2 | Yes | 1 |
| Dataset | Train | Valid | Test | Relations |
|---|---|---|---|---|
| NYT* | 56,195 | 4999 | 5000 | 24 |
| NYT | 56,195 | 5000 | 5000 | 24 |
| WebNLG* | 5019 | 500 | 703 | 171 |
| WebNLG | 5019 | 500 | 703 | 216 |
| Dataset | Triples in Test Set | Number of Triplets | ||||
|---|---|---|---|---|---|---|
| Normal | SEO | EPO | SOO | N = 1 | N > 1 | |
| NYT* | 3266 | 1297 | 978 | 45 | 3244 | 1756 |
| NYT | 3222 | 1273 | 969 | 117 | 3089 | 1911 |
| WebNLG* | 245 | 457 | 26 | 84 | 266 | 437 |
| WebNLG | 239 | 448 | 6 | 85 | 256 | 447 |
| Model | NYT* | NYT | WebNLG* | WebNLG | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | Prec. | Rec. | F1 | |
| CasRel | 89.7 | 89.5 | 89.6 | - | - | - | 93.4 | 90.1 | 91.8 | - | - | - |
| TPLinker | 91.3 | 92.5 | 91.9 | 91.4 | 92.6 | 92.0 | 91.8 | 92.0 | 91.9 | 88.9 | 84.5 | 86.7 |
| PRGC | 93.3 | 91.9 | 92.6 | 93.5 | 91.9 | 92.7 | 94.0 | 92.1 | 93.0 | 89.9 | 87.2 | 88.5 |
| EmRel | 91.7 | 92.5 | 92.1 | 92.6 | 92.7 | 92.6 | 92.7 | 93.0 | 92.9 | 90.2 | 87.4 | 88.7 |
| GRTE | 92.9 | 93.1 | 93.0 | 93.4 | 93.5 | 93.4 | 93.7 | 94.2 | 93.9 | 92.3 | 87.9 | 90.0 |
| OneRel | 92.8 | 92.9 | 92.8 | 93.2 | 92.6 | 92.9 | 94.1 | 94.4 | 94.3 | 91.8 | 90.3 | 91.0 |
| Ours | 93.7 | 92.9 | 93.3 | 94.0 | 93.3 | 93.7 | 94.7 | 93.6 | 94.1 | 89.4 | 88.1 | 88.8 |
| Model | NYT* | WebNLG* | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| N = 1 | N = 2 | N = 3 | N = 4 | N > 4 | N = 1 | N = 2 | N = 3 | N = 4 | N > 4 | |
| CasRel | 88.2 | 90.3 | 91.9 | 94.2 | 83.7 | 89.3 | 90.8 | 94.2 | 92.4 | 90.9 |
| TPlinker | 90.0 | 92.8 | 93.1 | 96.1 | 90.0 | 88.0 | 90.1 | 94.6 | 93.3 | 91.6 |
| PRGC | 91.1 | 93.0 | 93.5 | 95.5 | 93.0 | 89.9 | 91.6 | 95.0 | 94.8 | 92.8 |
| GRTE | 90.8 | 93.7 | 94.4 | 96.2 | 93.4 | 90.6 | 92.5 | 96.5 | 95.5 | 94.4 |
| OneRel | 90.5 | 93.4 | 93.9 | 96.5 | 94.2 | 91.4 | 93.0 | 95.9 | 95.7 | 94.5 |
| Ours | 91.4 | 93.4 | 94.7 | 95.6 | 94.9 | 91.7 | 93.3 | 95.4 | 94.1 | 95.3 |
| Model | NYT* | WebNLG* | ||||||
|---|---|---|---|---|---|---|---|---|
| Normal | SEO | EPO | SOO | Normal | SEO | EPO | SOO | |
| CasRel | 87.3 | 91.4 | 92.0 | 77.0 | 89.4 | 92.2 | 94.7 | 90.4 |
| TPlinker | 90.1 | 93.4 | 94.0 | 90.1 | 87.9 | 92.5 | 95.3 | 86.0 |
| PRGC | 91.0 | 94.0 | 94.5 | 81.8 | 90.4 | 93.6 | 95.9 | 94.6 |
| GRTE | 91.1 | 94.4 | 95.0 | - | 90.6 | 94.5 | 96.0 | - |
| OneRel | 90.6 | 94.8 | 95.1 | 90.8 | 91.9 | 94.7 | 95.4 | 94.9 |
| Ours | 91.1 | 94.8 | 95.3 | 93.2 | 91.6 | 94.5 | 94.9 | 96.6 |
| Model | Element | NYT* | WebNLG* | ||||
|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | Prec. | Rec. | F1 | ||
| CasRel | (h, t) | 89.2 | 90.1 | 89.7 | 95.3 | 91.7 | 93.5 |
| r | 96.0 | 93.8 | 94.9 | 96.6 | 91.5 | 94.0 | |
| (h, r, t) | 89.7 | 89.5 | 89.6 | 93.4 | 90.1 | 91.8 | |
| PRGC | (h, t) | 94.0 | 92.3 | 93.1 | 96.0 | 93.4 | 94.7 |
| r | 95.3 | 96.3 | 95.8 | 92.8 | 96.2 | 94.5 | |
| (h, r, t) | 93.3 | 91.9 | 92.6 | 94.0 | 92.1 | 93.0 | |
| OneRel | (h, t) | 93.3 | 93.4 | 93.3 | 96.2 | 96.5 | 96.3 |
| r | 96.7 | 96.9 | 96.8 | 96.7 | 97.0 | 96.8 | |
| (h, r, t) | 92.8 | 92.9 | 92.8 | 94.1 | 94.4 | 94.3 | |
| Ours | (h, t) | 93.9 | 93.5 | 93.7 | 96.2 | 94.6 | 95.4 |
| r | 97.0 | 95.7 | 96.3 | 96.9 | 95.7 | 96.3 | |
| (h, r, t) | 93.7 | 92.9 | 93.3 | 94.7 | 93.6 | 94.1 | |
| Model | NYT | |||
|---|---|---|---|---|
| Params | Training Time(s) | Memory (M) | Inference (ms) | |
| TPLinker | 109,602,962 | 1641 | 4388 | 47.6 |
| OneRel | 112,072,800 | 1758 | 21,254 | 14.4 |
| Ours | 114,810,624 | 1078 | 4246 | 28.3 |
| Model | Prec. | Rec. | F1 |
|---|---|---|---|
| Ours | 94.0 | 93.3 | 93.7 |
| w/o multi-head tensor dot product | 93.3 | 93.7 | 93.5 |
| w/o inside multi-head self-attention of BERT | 93.3 | 93.6 | 93.4 |
| w/o focal loss | 92.1 | 93.5 | 93.3 |
| BiLSTM | 93.4 | 93.5 | 93.5 |
| Instance | |
|---|---|
| Sentence #1 | There were readings about New Orleans from Mark Twain, Tennessee Williams, Truman Capote and others. |
| Ground truth | (Truman Capote, /people/person/place_of_birth, New Orleans) |
| w/o focal loss | (Mark Twain, /people/person/place_of_birth, New Orleans) (Truman Capote, /people/person/place_lived, New Orleans) |
| Ours | (Mark Twain, /people/person/place_of_birth, New Orleans) |
| Sentence #2 | ON Christmas Eve, 1989, a small force of about 100 men led by an obscure former Liberian government official crossed the border from Ivory Coast into Nimba County in northern Liberia. |
| Ground truth | (Liberia, /location/country/a_d *, Nimba County) (Nimba County, /location/a_d/country, Liberia) (Liberia, /location/location/contains, Nimba County) |
| w/o inside attention of BERT | (Liberia, /location/country/a_d, Nimba County) |
| Ours | (Liberia, /location/country/a_d, Nimba County) (Nimba County, /location/a_d/country, Liberia) (Liberia, /location/location/contains, Nimba County) |
| Sentence #3 | A Felton diploma would cost 500 scholarship; we could graduate for $500 from Glenndale -LRB- not to be confused with the Glendale colleges in Arizona and California -RRB-. |
| Ground truth | (California, /location/location/contains, Felton) (California, /location/location/contains, Glendale) |
| w/o tensor dot product | (California, /location/location/contains, Glenndale) (California, /location/location/contains, Felton) |
| Ours | (California, /location/location/contains, Felton) (California, /location/location/contains, Glendale) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, P.; Yang, L.; Zhang, B.; Wang, R.; Ouyang, D. Joint Entity and Relation Extraction Model Based on Inner and Outer Tensor Dot Product and Single-Table Filling. Appl. Sci. 2024, 14, 1334. https://doi.org/10.3390/app14041334
Feng P, Yang L, Zhang B, Wang R, Ouyang D. Joint Entity and Relation Extraction Model Based on Inner and Outer Tensor Dot Product and Single-Table Filling. Applied Sciences. 2024; 14(4):1334. https://doi.org/10.3390/app14041334
Chicago/Turabian StyleFeng, Ping, Lin Yang, Boning Zhang, Renjie Wang, and Dantong Ouyang. 2024. "Joint Entity and Relation Extraction Model Based on Inner and Outer Tensor Dot Product and Single-Table Filling" Applied Sciences 14, no. 4: 1334. https://doi.org/10.3390/app14041334
APA StyleFeng, P., Yang, L., Zhang, B., Wang, R., & Ouyang, D. (2024). Joint Entity and Relation Extraction Model Based on Inner and Outer Tensor Dot Product and Single-Table Filling. Applied Sciences, 14(4), 1334. https://doi.org/10.3390/app14041334