Abstract
In a multi-document summarization task, if the user can decide on the summary topic, the generated summary can better align with the reader’s specific needs and preferences. This paper addresses the issue of overly general content generation by common multi-document summarization models and proposes a topic-oriented multi-document summarization (TOMDS) approach. The method is divided into two stages: extraction and abstraction. During the extractive stage, it primarily identifies and retrieves paragraphs relevant to the designated topic, subsequently sorting them based on their relevance to the topic and forming an initial subset of documents. In the abstractive stage, building upon the transformer architecture, the process includes two parts: encoding and decoding. In the encoding part, we integrated an external discourse parsing module that focuses on both micro-level within-paragraph semantic relationships and macro-level inter-paragraph connections, effectively combining these with the implicit relationships in the source document to produce more enriched semantic features. In the decoding part, we incorporated a topic-aware attention mechanism that dynamically zeroes in on information pertinent to the chosen topic, thus guiding the summary generation process more effectively. The proposed model was primarily evaluated using the standard text summary dataset WikiSum. The experimental results show that our model significantly enhanced the thematic relevance and flexibility of the summaries and improved the accuracy of grammatical and semantic comprehension in the generated summaries.
1. Introduction
The Internet’s rapid development and widespread popularity have quickly brought people from an era of information scarcity into an era of information explosion. It has completely changed how people communicate and obtain information and has tremendously impacted many fields, such as business, education, medical care, and government affairs. According to the International Data Corporation (IDC), global data will increase from 33 ZB in 2018 to 175 ZB in 2025 [1], by more than five times. Text data on the Internet are growing exponentially, and how to obtain and quickly refine adequate information is particularly important.
As an effective way to solve the above problems, text summarization is one of the most challenging and exciting problems in natural language processing (NLP). Early text summarization has generally been completed manually, which is time-consuming, labor-intensive, and inefficient. There is an urgent need for automatic summarization methods to replace manual forms. In recent years, with the progress in research on unstructured text data automatic text summarization technology has received widespread attention and research. Much research has been carried out on algorithm technology, datasets, evaluation indicators, and systematic text summarization technology. Nevertheless, in practical applications, the summarization of a single document’s information falls short of fulfilling people’s information acquisition requirements. Therefore, NLP became one possible way to empower multi-document summarization (MDS) technology. Aggarwal [2] emphasized the importance of high-quality data for training complex deep learning models. Due to the lack of large-scale datasets in MDS and the significant increase in computing resources and storage requirements when processing long texts, the research progress was once limited. It was not until 2018 when Zopf proposed a large-scale automatically generated auto-hMDS corpus [3], and the large-scale datasets WikiSum [4] and Multi-News [5] came out one after the other, that multi-document summary technology was widely studied and applied.
The existing MDS technology [6,7,8,9] usually refines and compresses the information of multiple documents under the same topic and presents the primary information in summary form. However, multiple input documents do not necessarily contain only one topic but usually have complex and diverse topic structures in practical applications. If all topics are considered, the critical information of the summary may be overlooked, and the key points cannot be highlighted. Based on the above problems, we propose a topic-oriented two-stage MDS model, which enables users the right to choose summary topics and achieves more personalized information extraction. It meets users’ information acquisition needs, improves the information acquisition efficiency, and promotes user participation and the possibility of customized summary generation.
We conducted an experiment on the WikiSum dataset. The experimental results demonstrate the effectiveness and superiority of our model. To sum up, the contributions of this paper are as follows:
- (1)
- We incorporated and emphasized topic information in the extraction and generation phases of the model to further enhance the focus of multi-document summaries on specific topics.
- (2)
- We designed a discourse parser based on the rhetorical structure theory and analyzed it on the micro- and macro-levels to obtain the primary and secondary relationships between elementary discourse units (EDUs) within and between paragraphs.
- (3)
- We extended the transformer model and added a discourse-aware attention mechanism in the encoder part to combine the intra-paragraph and inter-paragraph relationships with the implicit relationships of the source documents to generate richer semantic features in a complementary manner.
- (4)
- The experimental results of the WikiSum dataset demonstrate that our model achieved advanced performance in recall-oriented understudy for gisting evaluation (ROUGE) scores and human evaluations. While improving the subject focus, it also received high ratings in terms of grammatical accuracy.
2. Literature Review
2.1. Multi-Document Summarization
Russel et al. [10] provided a theoretical basis and practical framework for designing and optimizing MDS models. Depending on the summary implementation method, MDS can be divided into extractive and abstractive methods.
Earlier extractive MDS methods include LexRank [11], proposed by Erkan et al., and TextRank [12], proposed by Mihalcea et al. Both of them are unsupervised methods and graph-based scoring models. The centroid-based method [13] is a typical traditional MDS method. It scores sentences separately according to features such as centrality, position, and term frequency–inverse document frequency (TF-IDF) and then combines all scores linearly into an overall sentence score. Liu et al. [14] proposed a topic-based general multi-document summary sentence sorting method using the latent Dirichlet allocation (LDA) model to calculate the weight of a sentence and the similarity between the sentence topics. Then, the information is integrated into a two-dimensional coordinate system, and the sentence sorting problem is solved as a maximum vector problem. In addition, there are methods based on TF-IDF [15], clustering-based methods [16,17], and methods based on latent semantic analysis (LSA) [18,19]. Most of the above extractive methods adopt the idea of single-document summary processing but overlook the hierarchical relationship between documents, and this relationship plays a crucial role in multi-document summary tasks [20].
As a result, many researchers have turned to more advanced abstractive summarization methods that can understand and integrate the relationships between documents. Barzilay et al. [21] used a sentence fusion method to identify fragments that convey standard information across documents and combine them into sentences. Tan et al. [22] employed the sequence-to-sequence model, using a long short-term memory (LSTM) network as the encoder structure to encode words and sentences in the original document and then using the LSTM-based hierarchical decoder structure to generate the summary. Liu et al. [23] proposed a hierarchical transformer architecture to encode multiple documents hierarchically and represent potential cross-document relationships through an attention mechanism that shares information between multiple documents. Li et al. [9] introduced explicit graph representation in the encoder and decoder of the hierarchical transformer architecture and used the cosine similarity between paragraphs to obtain potential connections between documents better. Ma et al. [24] combined dependency analysis with the transformer architecture, introduced an external parser into the encoding part to capture the dependency tree, and combined the dependency parsing information and source documents through a language-guided multi-head attention mechanism to generate semantic-rich features.
However, capturing cross-document relationships based on word or paragraph representation is not straightforward and flexible, so many researchers have begun to model multiple documents more effectively by mining subtopics. Wan et al. [25] used topic analysis technology to discover explicit or implicit subtopics related to a given topic and then ranked sentences by fusing multiple modalities built on different subtopics through a multimodal learning algorithm. Li et al. [26] took advantage of the topic model and supervised features to generate multi-document summaries by integrating the information of the sentences into the Bayesian topic model. Lee et al. [27] extracted relevant topic words from source documents through topic models and used them as elements of fuzzy sets. Meanwhile, they generated fuzzy relevance rules through sentences in the source documents and, finally, generated multi-document summaries by the fuzzy inference system. Liu et al. [28] used the LDA model and the weighted linear combination strategy to identify important topics in multiple documents, considering statistical features such as word frequency, sentence position, and sentence length. Cui et al. [29] used neural topic models to discover latent topics in multiple documents, thereby capturing cross-document relationships, and explored the impact of topic modeling on summarization. MDS technology based on topic models extracts a comprehensive hierarchical overview. However, it still needs practicality and pertinence for users’ personalized usage needs. Therefore, this paper will systematically explore how to generate topic-oriented multi-document summaries.
2.2. Discourse Structure
Chomsky [30,31] revealed the deep rules behind language expression and provided a theoretical basis for understanding a text’s inherent abstract logical structure. As one of the research directions in NLP, text summarization is essentially the analysis and processing of discourses. It is most appropriate to start with the discourse structure to extract the critical information and topics of the text while capturing the hierarchical relationships. Discourse refers to language composed of continuous paragraphs and sentences according to a specific structure and order [32]. Relation, functionality, and hierarchy are the three characteristics of a discourse. We can divide the discourse into micro- and macro-structures according to the discourse level.
Micro-discourse structure is the structure and relationship between discourse units of sentences, mainly including clauses and clauses, sentences and sentences, and sentence groups. There are many micro-discourse structure theories, including rhetorical structure theory, Pennsylvania discourse tree bank theory, sentence group theory, complex sentence theory, discourse structure theory based on connection dependency trees, etc. Among them, rhetorical structure theory (RST) [33] was founded by Mann and Thompson in 1986 and defined 23 structural relationships. When two or more discourse units are connected through rhetorical relationships, they constitute a structure tree.
Macro-discourse structure mainly refers to the structure and relationship between paragraphs and chapter units, which was proposed by Van Dijk et al. [34]. Related theories include discourse mode, supertheme theory, etc. Most of the existing discourse corpus resources are mainly represented by tree structures. According to rhetorical structure theory, macro-discourse relationships can be divided into parallel, progressive, complementary, contrastive, and causal relationships.
In 2019, Zhang et al. [35] used the primary and secondary relationships in discourse structure analysis to improve the quality of text summaries. Liu et al. [36] extracted summaries based on the rhetorical structure of the text and then modeled the coherence of the summaries. In 2020, Xu et al. [37] proposed a discourse-aware neural extraction summary model based on Bert and constructed a structured discourse graph based on RST trees and coreference relationships to generate a less redundant and informative summary. The above studies all focused on the micro-level of discourse structure, which emphasizes the relationship and structure within or between sentences. There are few studies on the macro-level. This paper uses discourse structure theory to analyze the relationships within paragraphs and between paragraphs at the micro- and macro-levels. It combines them with the implicit relationships in the source document to generate richer semantic features in a complementary manner.
3. Topic-Oriented Multi-Document Summarization (TOMDS) Model
3.1. Overview
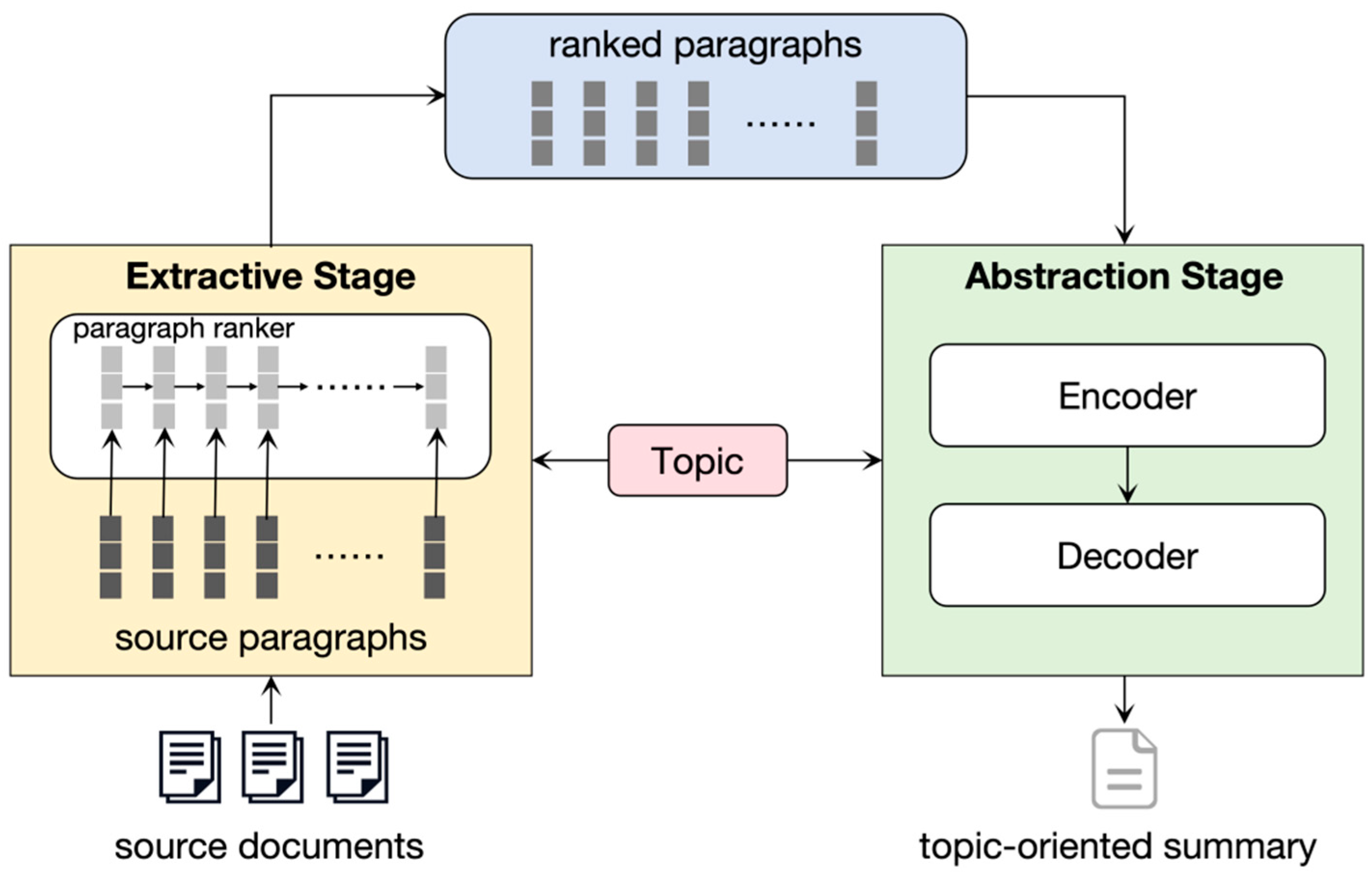
In this paper, we follow the approach of Liu et al. [4] and treat the generation of the main content of Wikipedia as an MDS task. The difference is that we treat the titles of Wikipedia articles as summary topics, and the topics guide summary generation. It is assumed that the model’s input is the source document collection of Wikipedia articles, and the output is the bootstrap part of the Wikipedia articles. Among them, the source documents are the web pages cited in the reference section of the Wikipedia article and the top 10 results returned by searching Google using the article title.
Since the input source document is formed by connecting multiple documents to a piece of a long document, considering the different lengths of multiple documents, a long text may bring immeasurable computational pressure. Therefore, we use line breaks to divide it into paragraphs for processing. Inspired by how humans summarize the main content of multiple documents, we propose a two-stage MDS system. First, we extract topic-related paragraphs and sort them by relevance score, and then integrate the topic information into the summary generation process. The summary system framework is shown in Figure 1. This paper focuses on the summary generation, which follows the transformer architecture. During the coding process, we used the knowledge of discourse structure to design a discourse parser. At the micro-level, we mainly focus on the primary and secondary relationships between EDUs within paragraphs. At the macro-level, we focus on learning the hierarchical structure and primary and secondary relationships between paragraphs. Discourse-aware attention can combine the above primary and secondary relationships with source documents to generate richer semantic features and identify discourse topics in a complementary manner. It also introduces a topic attention module in the decoding process to integrate topic information into the summary generation process, which can generate a summary more aligned with human language expression habits and information acquisition needs.
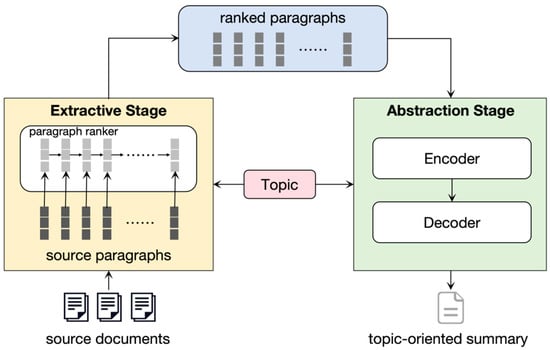
Figure 1.
The overall framework of TOMDS.
3.2. Extractive Stage
The main task of the extractive stage is to extract and sort topic-related paragraphs. Herein, we follow the approach of Liu et al. [23], treating the title of the Wikipedia article as the abstract topic T and then designing a paragraph ranking model to filter out paragraphs with high topic relevance.
First, the input multiple documents Di (i = 1, 2, …, m) are divided into paragraphs according to line breaks, and then a long short-term memory neural (LSTM) network is used to represent the topic T and the source paragraph P, expressed as:
where are the word embedding for tokens in T and P, and and are the update vectors for each token after applying the LSTMs.
We concatenate with the vector of each token in the paragraph and apply a nonlinear transformation to extract features for matching topics and paragraphs.
The max-pooling operation produces the final paragraph vector :
In order to measure whether a paragraph should be selected, we use linear transformation and a sigmoid function to calculate a score s for paragraph P, where s represents the degree of relevance of this paragraph to the topic.
Herein, we train by minimizing the cross-entropy loss between si and the true score yi. Among them, the actual score yi is calculated using ROUGE-2 recall, representing the paragraph’s ROUGE score for the golden summary.
Finally, all input paragraphs {P1, P2, …, PL} obtain corresponding scores {s1, s2, …, sL}. Based on the prediction scores, we sort the input paragraphs and generate the ranking {R1, R2, …, RL}, and then select the first L’ segments {R1, R2, …, RL’} as the next stage’s input.
3.3. Abstractive Stage
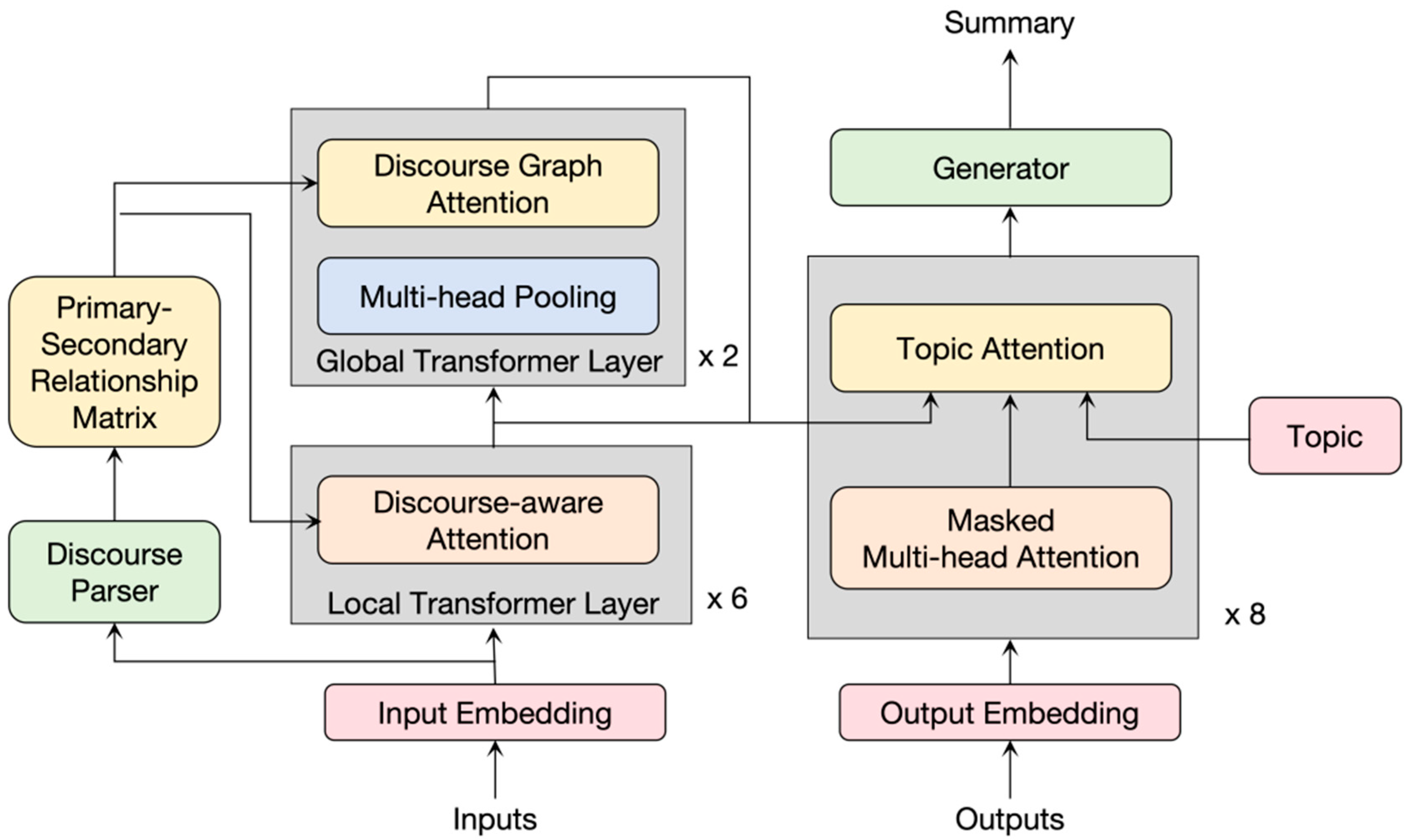
In the abstractive stage, we extend the transformer structure and attention mechanism proposed by Vaswani et al. [38]. This step enables the encoder to learn the internal information of the paragraphs and capture the information between the paragraphs, making it more adaptable to multi-document input tasks and obtaining more accurate encoding and decoding results. The model structure of the abstractive stage is shown in Figure 2.
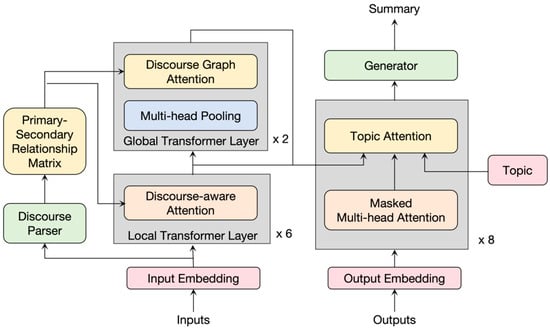
Figure 2.
TOMDS generates partial structure.
3.3.1. Embedding
First, the input token is converted into the corresponding word embedding representation, expressed as:
where represents the j-th token in the i-th ranking paragraph Ri.
Since the transformer model does not have clear order awareness, in order to be able to utilize the order of the input sequence, we follow the method of Vaswani et al. [38] and use sine and cosine functions of different frequencies to inject position information into the sequence. Then, the position embedding of the p-th element in the sequence is:
Among them, d represents the dimension of position embedding, the same as the word embedding dimension. 2i represents the even dimension, and 2i + 1 represents the odd dimension. Since each dimension of the position encoding corresponds to a sinusoid, Ep+o can be expressed as a linear function of for any fixed offset o so that the relative positions of the input elements can be distinguished.
In the multi-document summary task, we need to consider two positions for the input token: the ranking i of the paragraph in which it is located and its position j within the paragraph. Connecting two positions can be expressed as
We use vector to represent input , and then
3.3.2. Primary–Secondary Relationship Matrix
Discourse structure analysis helps to understand the structure and semantics of a discourse. It not only assists in generating concise and informative summary information but also effectively identifies the topic of the discourse. Given a sentence, a paragraph, or a document, we can generate a corresponding discourse parsing tree by discourse structure analysis and determine the nucleus information and rhetorical relationships of its spans to guide generating summaries.
We use an existing rhetorical structure parser [39] to generate an RST discourse parse tree for each input paragraph. First, the input paragraph is split into ni sentences, such that ), and then split the sentences S in the paragraph into -th EDUs, expressed as:
We adopt the scoring method of Kobayashi et al. [40], defined as a scoring function used to set nucleus and rhetorical relationship labels for two adjacent spans at the paragraph or sentence sub-level. Here, two adjacent EDUs ( and ) under the j-th sentence of the i-th paragraph are taken as an example.
where is the nucleus or rhetorical relation label projection layer, and MLP is a multi-layer perceptron that uses a single feed-forward network and a ReLU function as the activation function. Moreover, and are the current left and right spans. We choose the label for the maximum value of the above equation. The label is defined as follows:
where Q represents a set of valid nucleus label combinations {N-S, S-N, N-N} and rhetorical structure labels {Circumstances, Solutionhood, Elaboration, …} for predicting nucleus and rhetorical relationships. Similarly, if we want to determine the nucleus and rhetorical relationship labels of two adjacent sentences ( and ) under the i-th paragraph, then
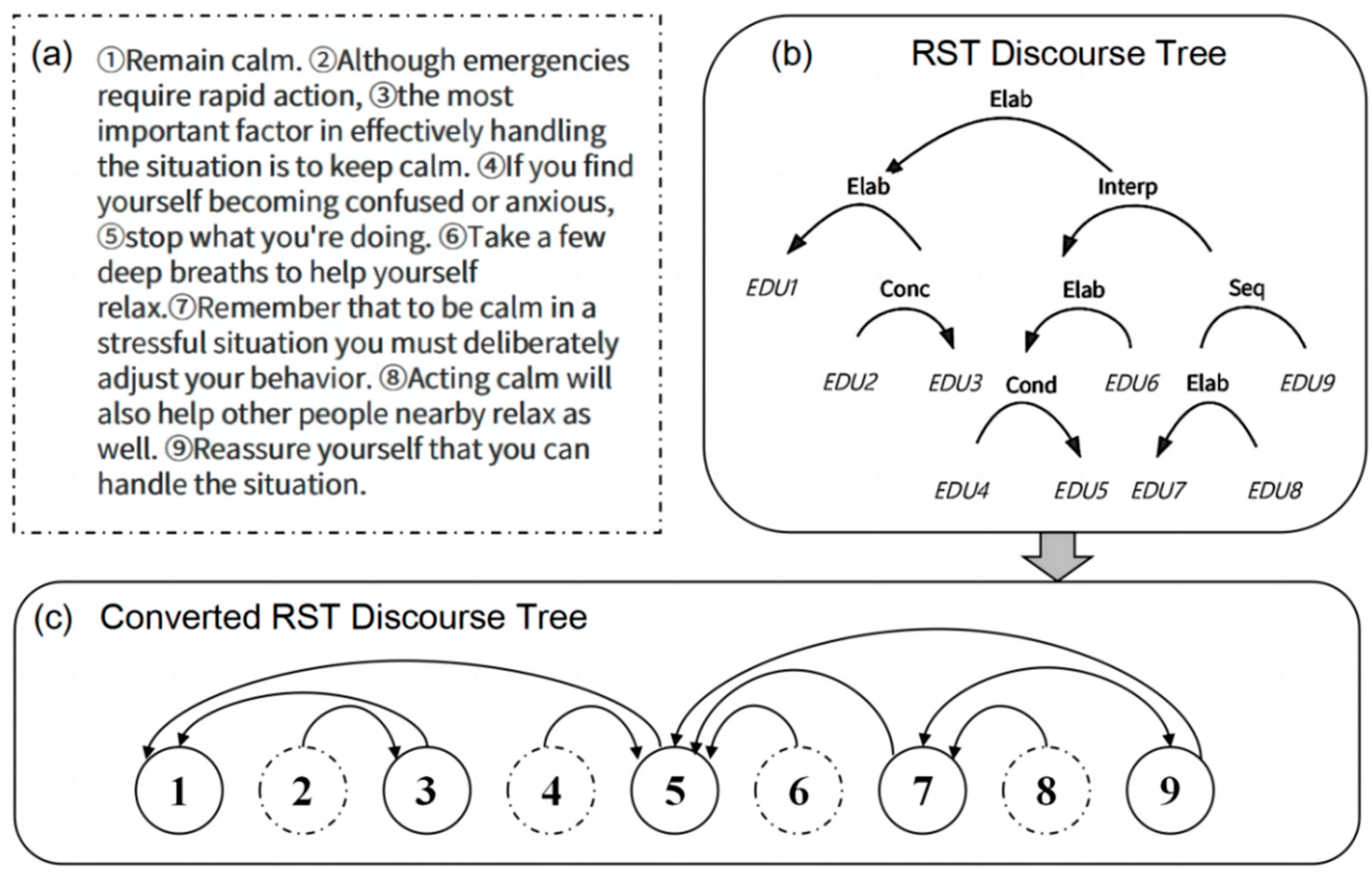
Figure 3 shows the discourse segmentation and RST discourse parse tree construction and conversion. (a) is a paragraph we randomly selected from the WikiSum dataset. (b) is the RST discourse tree constructed based on (a).
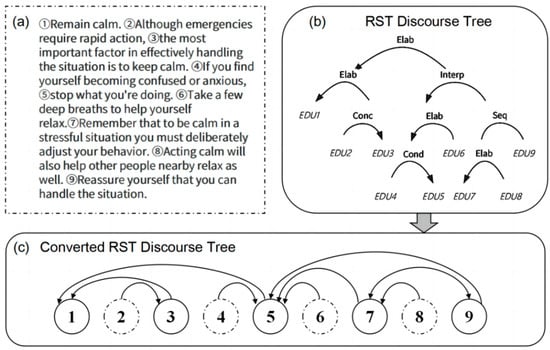
Figure 3.
Example of discourse segmentation and RST tree conversion. The original paragraph is segmented into 9 EDUs in box (a) and then parsed into an RST discourse tree in box (b). Elab, Interp, Conc, Seq, and Cond are relation labels (Elab = elaboration, Interp = interpretation, Conc = concession, Seq = sequence, and Cond = condition). The converted primary–secondary relationship-based RST discourse tree is shown in box (c). Nucleus nodes including ①, ③, ⑤, ⑦, and ⑨, and satellite nodes including ②, ④, ⑥, and ⑧, are denoted by solid lines and dashed lines.
In order to better represent the primary and secondary relationships between EDUs, we use a simple and effective model to convert the RST discourse tree into a discourse tree based on the primary and secondary relationships, as shown in Figure 3c. The serial number in the circle corresponds to the EDU serial number. If there is a directed edge between two serial numbers, we consider that there is a primary and secondary relationship between the two EDUs and the words they contain.
We record the primary and secondary relationships in the matrix as . Let P represent a given input paragraph ’s primary and secondary relationship matrix, where Pxy represents the relationship weight between x-th and y-th words. Here, we simplify the definition of weight, as shown in Equation (14).
In constructing the primary and secondary relationship matrix, our method ignores the concept of individual words. As long as there is a directed edge between two EDUs, the words they contain are assigned a value of 1. Otherwise, it is set to 0. If there is a directed edge from the EDU1 to which word x belongs to the EDU2 to which word y belongs, then Pxy = 1.
Similarly, we treat paragraphs as leaf nodes and then use this method to capture the relationships between input paragraphs and obtain the matrix . Then, represents the relationship weight between paragraphs Ri and Rj (), and also uses 1 and 0 to indicate whether there is a primary and secondary relationship.
3.3.3. Local Transformer Layer
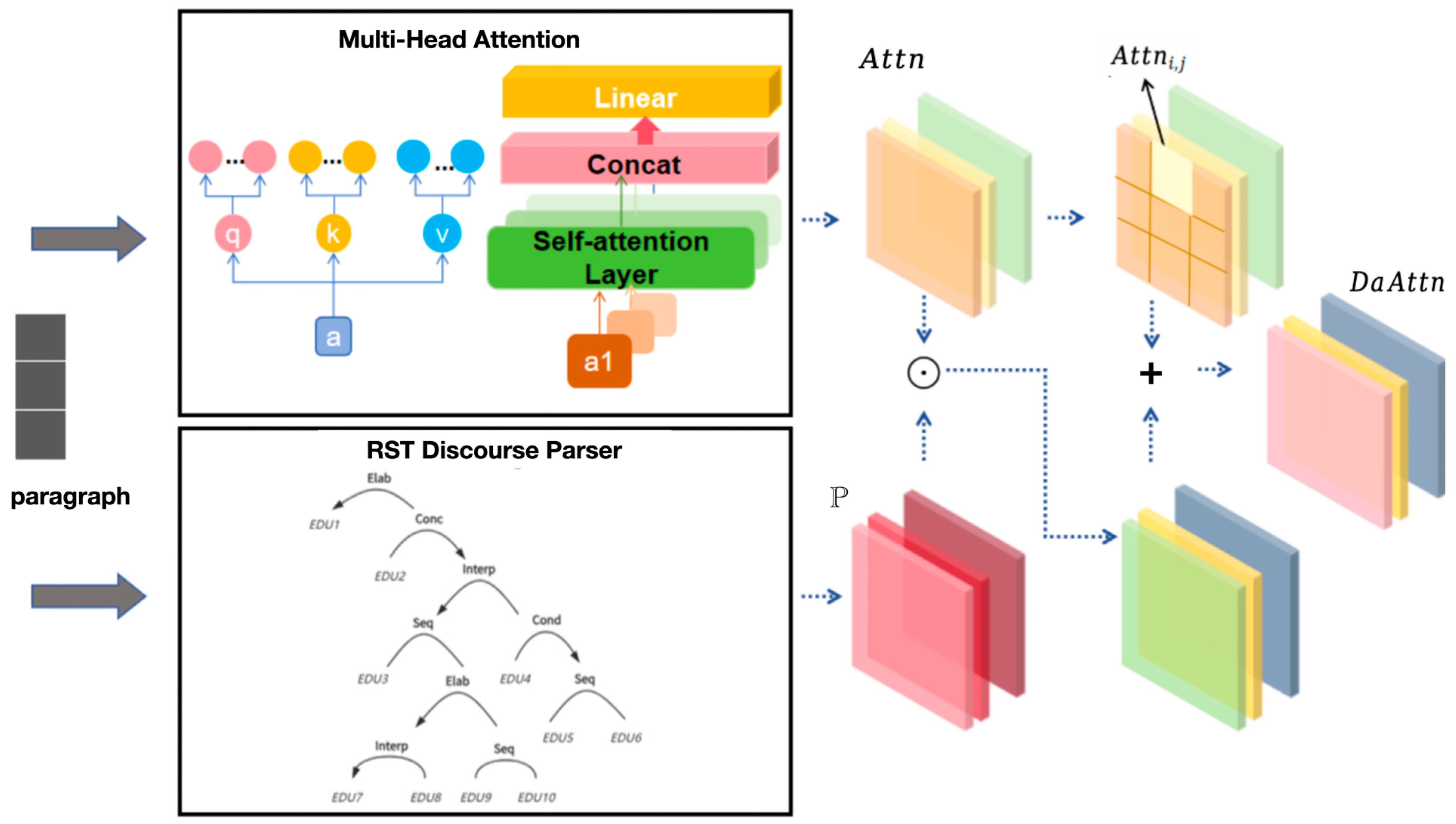
The local transformer layer is used to encode the contextual information of the token within each paragraph. In order to better preserve the primary and secondary relationships of discourses, we expand the coding part of the original transformer model [38] and propose a discourse-aware attention (DaAtt) mechanism. DaAtt integrates the processed primary and secondary relationships of discourses into multi-head attention to generate rich semantic features in a complementary manner, as shown in Figure 4.
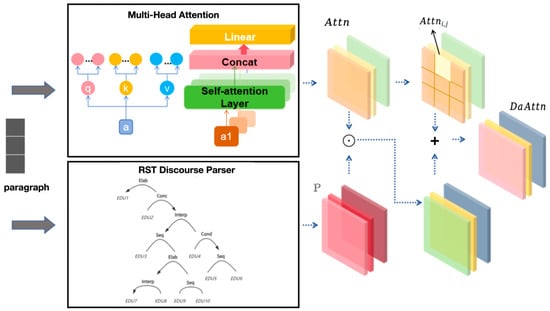
Figure 4.
Discourse-aware attention (DaAtt) mechanism.
In Section 3.3.1, we define the input token as . For the attention head , such that
where , , Rnxm Rzmxn are the weight matrices.
Then, the discourse-aware attention mechanism merges the primary and secondary relationship P with multi-head attention, such that
where is a hyperparameter used to balance the primary and secondary relationship of the discourse and multi-head attention information; ⊙ is the Hadamard product, which represents the numerical multiplication of the corresponding positions in the matrix; Rzxn represents the context vector generated by the discourse-aware attention.
The subsequent processing is the same as the encoder part of the original transformer model, expressed as:
where LayerNorm represents layer normalization, and FFN is a two-layer feed-forward neural network with ReLU as the activation function. For the -th transformer encoder layer, the input is , and the output is .
3.3.4. Global Transformer Layer
The global transformer layer is used to exchange information between paragraphs. Each paragraph of the input can collect information from other paragraphs and then capture global information from the entire input to encode paragraph-level vector representation.
- Multi-head Pooling
In order to obtain paragraph-level vector representation with a fixed length, we use the multi-head pooling mechanism proposed by Liu et al. [22]. Unlike the common max pooling and average pooling, multi-head pooling uses weighted operations to reduce dimensionality. By calculating the weight distribution of tokens for each input paragraph, the model can flexibly encode paragraphs in different representation subspaces by focusing on different words.
Similar to the transformer’s multi-head attention mechanism, each input paragraph has an attention head . Using different dimensional projections for each pooling head separately will translate into attention keys and values , such that:
where and are the weight matrices. =/ is the size of each head, and n is the number of tokens in .
After the softmax transformation of , it is used as the weight of each token in the paragraph, and then the matrix is weighted and added along the dimension of the word, and then pooling heads are connected to obtain a paragraph-level vector representation.
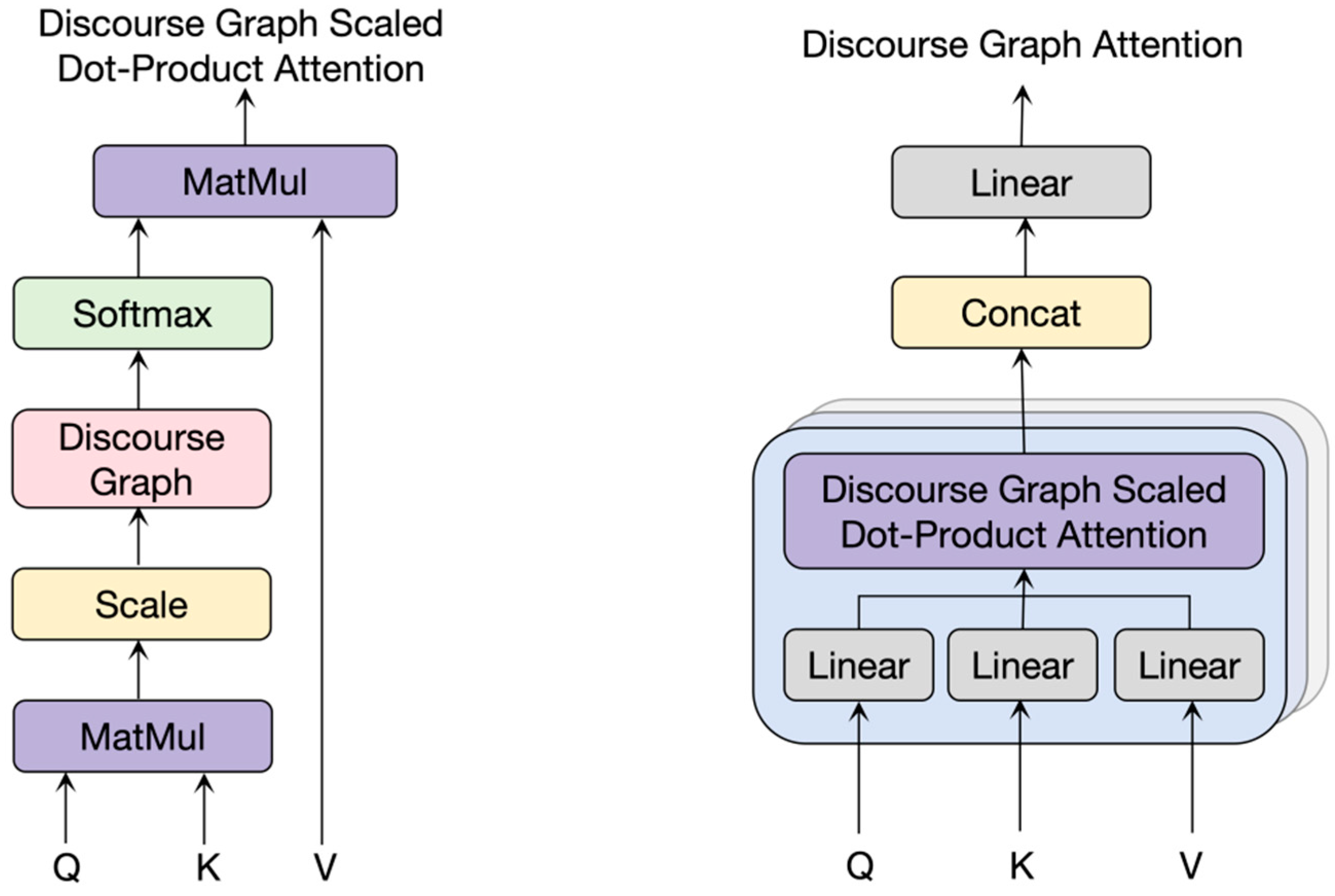
- Discourse Graph Attention
Although the paragraph-level representation vector obtained through the multi-head pooling mechanism considers the words’ information within the paragraph, it does not consider the associated information between paragraphs. Here, we integrate the relationship matrix M between paragraphs in Section 3.3.2 into the global transformer layer to better learn the relationship between paragraphs in multiple documents. The structure of the discourse graph attention mechanism is shown in Figure 5.
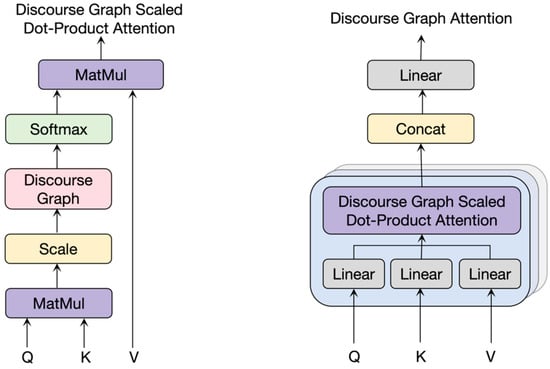
Figure 5.
Discourse graph attention (DGAtt) mechanism.
The input of the discourse graph attention mechanism is a multi-document representation matrix = {, , …, } composed of paragraph-level vectors, where . For each attention head, the paragraph-level vector is first linearly projected into a vector with dimension size , and the subsequent steps are similar to the scaling dot-product attention in the multi-head attention mechanism. The implicit relationship matrix between paragraphs is:
(1,h] represents each attention head of the discourse map attention mechanism and the linear transformation matrix . The linear transformation matrix represents the weights assigned to each paragraph in the attention mechanism of the discourse graph, indicating the attention of each paragraph to other paragraphs from different global perspectives. is the Gaussian deviation of the relationship between paragraphs calculated according to the discourse graph, expressed as:
In Equation (28), is the hyperparameter of the influence intensity of the discourse graph structure in the attention mechanism, and is the relationship matrix between paragraphs. The value of each position in the matrix represents the association between the two paragraphs corresponding to the index. Each element ∈ (−∞, 0] in the matrix represents the closeness between two paragraphs in the multi-document input.
Discourse graph attention introduces a priori discourse perception graph relationship restrictions based on the original implicit inter-paragraph associations, which can capture more comprehensive and rich inter-paragraph relationship information and obtain more accurate paragraph-level representation vectors.
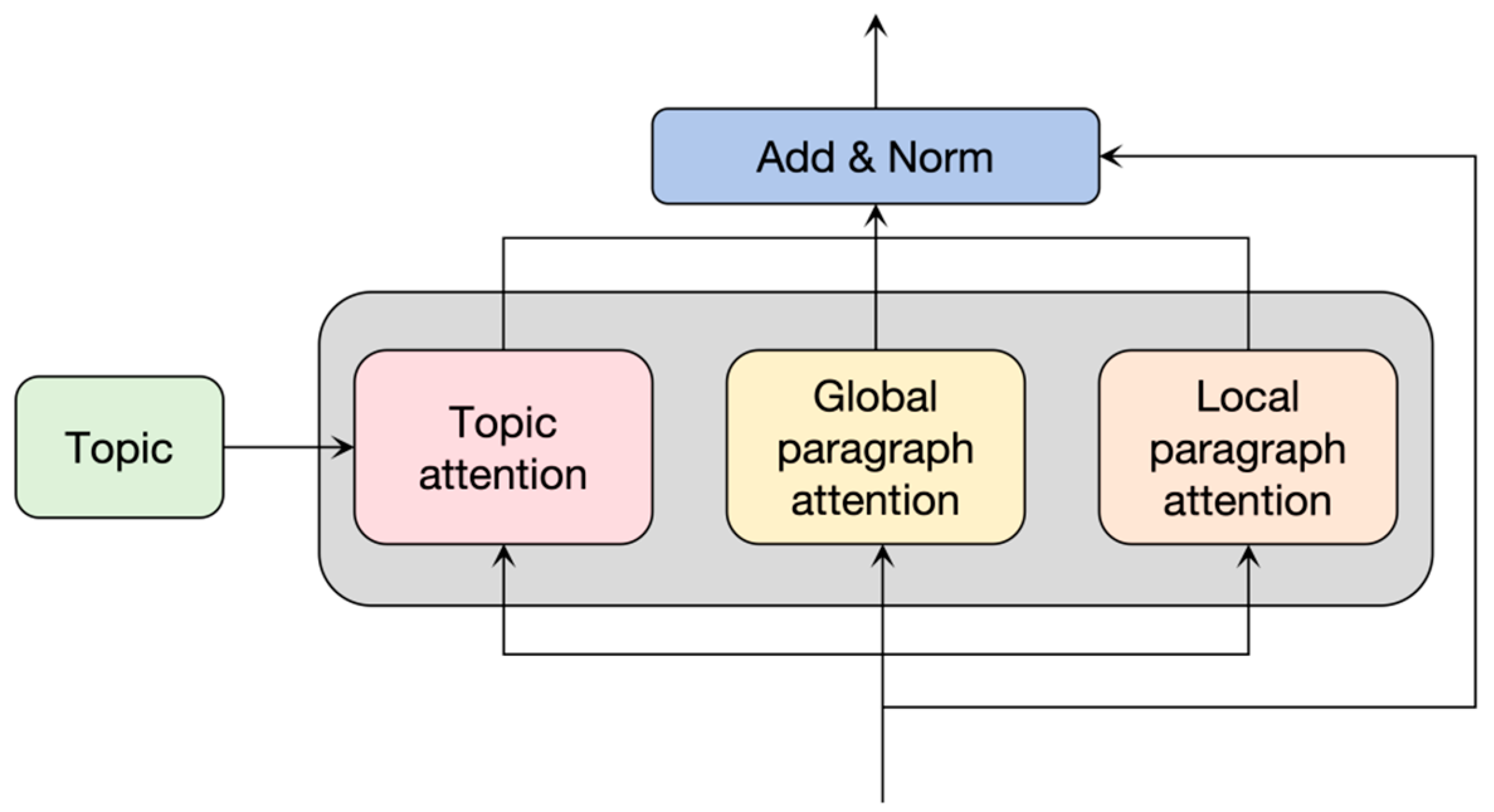
3.3.5. Topic Attention Mechanism
In the decoder, it is necessary to pay attention not only to the information of the summary but also to the topic information input by the user. For the information of the summary itself, we can learn from the self-attention mechanism of the decoder part of the transformer model. For the word-level and paragraph-level representation information output by the encoder and the given topic information, this article proposes a topic attention mechanism to enable the model to simultaneously focus on the multi-granularity representation information output by the encoder and the given topic information. The topic attention mechanism mainly includes the topic attention module, the global paragraph attention module, and the local paragraph attention module. The structure is shown in Figure 6.
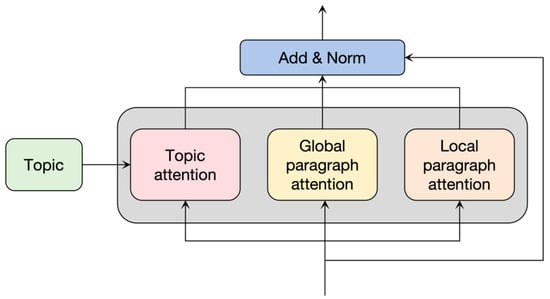
Figure 6.
Topic attention mechanism.
In the topic attention module, the contextual information of the tokens in the summary is encoded. If we define the input token as ∈(i = 1, 2,…, l), then the attention head (j = 1, 2,…, z), and then we obtain
where , ∈Rnxm are the weight matrices. ∈Rnxi are the sub-query, sub-key, and sub-value in different attention heads. After connecting them, we obtain, respectively,
where , , ∈Rzxi are the corresponding key, query, and value, which are used for subsequent attention calculations.
Assume that there are k keywords in the given topic information T, such that }. We assign weights to the importance of keywords, calculate the weighted average, and then obtain the topic vector as
where is the word vector, and is the weight of keyword .
Topic information is introduced into the attention calculation process, such that
where is a parameter matrix that linearly transforms the topic information T, which is mapped onto the same dimension as through .
The global paragraph attention module and the local paragraph attention module allow the decoder to learn the global paragraph information and local intra-paragraph information output by the encoder, respectively. The attention calculation formulas are:
Finally, they are connected in one dimension, and the final topic attention is obtained after linear transformation.
where W is a parameter matrix, which can synthesize all information from topics, global paragraphs, and inter-paragraph attention and incorporate them simultaneously into the summary generation process.
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
Currently, the English multi-document summary datasets include WikiSum proposed by Liu et al. [4] and Multi-News proposed by Fabbri et al. [5]. The dataset in this article’s experiment came from Wikipedia. We crawled the Wikipedia dataset concerning the scripts and URLs [4], eliminated some invalid URLs and repeated paragraphs in the dataset, and made new divisions into the training, test, and validation sets. The specific divisions are shown in the Table 1.

Table 1.
WikiSum dataset scale.
Our model inputs were a collection of multiple Wikipedia text paragraphs and their corresponding topics, and the output we expected was a multi-document summary under a given topic.
4.1.2. Evaluation Method
To evaluate the summary effect of the model, we used the ROUGE evaluation method proposed by Lin et al. [41]. ROUGE evaluates abstracts through the co-occurrence information of n-grams in the abstract. It is an evaluation method oriented to the recall rate of n-grams. In the current multi-document summary task, the ROUGE index with values of 1 and 2 was mainly used, and the calculation formula is shown in Equation (35).
4.1.3. Training Configure
While processing the dataset, we used the sub-word tokenization of sentencepiece to encode the paragraphs and target summaries. At the same time, to divide a paragraph into sentences, we used coreNLP in the paragraph-sorting stage, referring to the sorting method in [4] to classify the target summaries. To train the LSTM model, we calculated the ROUGE-2 recall of each paragraph based on the target summary and used it as the actual score. For the two LSTMs used, the hidden size was set to 256, and the dropout of all linear layers was set to 0.2. Paragraphs filtered out based on the prediction scores were used as input to the generation stage. Our model adopts an encoder–decoder architecture. In the encoding stage, we used the hierarchical coding transformer architecture to obtain the relationship between paragraphs for the best L’ paragraphs filtered after sorting.
During the training phase, all transformer-based models had 256 hidden units, and the feed-forward hidden size was set to 1024. In the discourse parser, we used the self-attention span model (SpanExt) to learn the representation of EDU, constructed a top-down RST parse tree from the learned EDU, and then adjusted the attention inside the paragraph according to the depth of the tree.
The experiments were conducted in a GPU server with 4 NVIDIA Tesla V100 SXM2 GPUs. We set the dropout rate to 0.1, the initial learning rate of the Adam optimizer [42] to 0.0001, the momentum , and the weight decay to 5. During decoding, we used a beam search strategy with a beam size of 5 and a length penalty of α = 0.4.
4.1.4. Model Comparison
We compared our model with the state-of-the-art extractive, abstractive, and topic-based models. The extractive baselines are as follows.
Lead is a simple text summarization method based on fixed rules. It directly extracts the first few sentences of the original document as a summary without any semantic understanding or generation process.
LexRank [11] is a summarization method based on graph algorithms. It treats each sentence as a node in the graph, builds a weighted graph by calculating the similarity between sentences, and then uses the PageRank algorithm to sort sentences to generate a summary.
GraphSum [43] is a text summarization model based on graph neural networks, which uses graph convolutional networks to encode sentences in the input document and performs an attention mechanism on the graph to select the most representative sentences to generate summaries.
We compared with the following abstractive baselines:
T-DMCA [4] is an MDS model based on the transformer architecture. This model introduces a decoder-only architecture and uses the memory-compressed attention mechanism to handle the attention distribution more effectively.
Flat transformer (FT) is a transformer model that directly processes flattened text sequences after merging multiple documents. It splices all documents into a single input sequence and uses standard self-attention mechanisms to capture and integrate information to produce a summary.
Hierarchical transformer (HT) [23] is a variant of the transformer model adapted to handle hierarchical input structures. It encodes the input hierarchically and uses a multi-head attention mechanism to extract semantic features. The model can handle long texts by encoding the texts in layers, thereby avoiding traditional fixed-length input limitations and improving the classification performance.
Most importantly, we also compared with the following topic-based baselines:
TG-MultiSum [30] is a topic-based MDS model. It employs neural topic models to discover common latent topics, and then bridges different documents through them and provides global information to guide summary generation.
S-sLDA [27] is an extended form of the LDA topic model, especially suitable for situations with limited annotated data. It first learns the topic distribution of documents and then optimizes the model parameters with the help of supervised signals.
HierSum [18] is an MDS method based on hierarchical topic modeling. It uses the hierarchical LDA model to represent content specificity as a hierarchical structure of topic vocabulary distribution.
4.2. Experimental Results
WikiSum is a collection of Wikipedia titles and documents under the corresponding titles. We used the ROUGE evaluation method to compare our model with other baseline models on the WikiSum dataset. Table 2 shows our experimental results.
Table 2.
Experimental results.
Lead, LexRank, and GraphSum, in the first part, are extractive baseline models. Compared with Lead and LexRank, GraphSum performed well on the WikiSum dataset because the articles usually contained rich entities, relationships, and knowledge graph information. Since GraphSum is based on a graph structure for modeling and summary generation, it can use this information to extract key content from multiple documents accurately and generate summaries.
In the second part, T-DMCA, FT, and HT are transformer-based variants. Except for T-DMCA, which only uses a decoder, the other variants follow the encoder–decoder architecture. According to the experimental results, the HT model achieved the best results. This shows that hierarchical coding can help obtain relationships between paragraphs.
TG-MultiSum, S-sLDA, and HierSum, in the third part, are topic-based models. Since MDS based on topic models can mine relationships between documents by analyzing latent topics, it solves the topic consistency problem of MDS. Our model did not use a method based on the LDA model but instead used a topic attention mechanism to incorporate continuous and fine-tunable topic attention weights in the decoding process, allowing the model to grasp topic content more flexibly when generating summaries.
The fourth part was an ablation experiment based on our basic model, namely, the discourse parser and the topic attention mechanism, to compare the effects of using them alone and in combination. According to the ROUGE score results, we compared the candidate summaries generated by baseline models with standard summaries. The candidate summaries generated by our model were closer to the standard gold summaries. Adding the discourse parser significantly improved the experiment, and the ROUGE scores increased by 7.02%, 35%, and 17.9%. Since the WikiSum dataset is relatively complete regarding topic-related aspects, adding the topic attention module generated limited improvement in the overall experimental results. We combined a topic attention mechanism with a discourse parser, which outperformed the current baseline models on WikiSum. Compared with GraphSum, which had the best extraction performance, it was improved by 1.4%, 2%, and 2.4%. Compared with the HT model, which had the best performance of the transformers, it was improved by 5.9%, 8.7%, and 7.9%. Compared with the best-performing model based on LDA, the improvement of the transformer model with an added topic attention mechanism and a discourse parser was more prominent. Compared with the standard summary, it increased by 2.1%, 5%, and 5.6% respectively. The experimental results show that the model achieved the best results by adding a discourse parser and a topic attention module.
4.3. Human Evaluation
In addition to automatic evaluation, our experiments also performed human judgment evaluation, simulating human needs for summarizing critical information. We chose the Amazon Mechanical Turk (MTurk) platform, a proven and widely used social crowdsourcing platform with many qualified participants worldwide for human evaluation. We randomly selected 20 test instances from the dataset to evaluate the system performance comprehensively. Initial evaluation studies conduct experiments using the question answering (QA) paradigm [44,45], which quantifies how well a summarization model retains critical information in input documents. Under this paradigm, we created a series of questions based on a gold-standard summary, assuming that the summary contains the most essential details from the input passage. We asked questions about important information in the system summary, and the summary is considered good if it answers the questions we set as perfectly as the gold-standard summary. In order to evaluate the system summary answering effect, we set 50 questions and 2–4 questions for each summary. Table 3 shows the evaluation results.
Table 3.
System scores based on questions answered.
The Lead model is a summary generated based on the first three sentences and cannot completely cover the core content of multiple documents. The HT model augments the transformer architecture with the ability to encode multiple documents in a hierarchical manner, which improves the ability to obtain cross-document relationships and the ability to control the core content of the full text. TG-MultiSum uses topic models to discover potential topics in multiple documents and select key information fragments under each topic in a targeted manner. Among all the current comparison models, our model is a hierarchical transformer model that adds a discourse parser and a topic attention mechanism and achieves the best results.
4.4. Grammar Check
We referred to the method proposed by Xu and Durrett [46] and others to perform syntax checking on the generated summary. Among the indicators of grammar checking, CR is used to check the correctness of grammar, PV to check the passive voice of grammar, PT to check the punctuation marks of compound sentences, and O to check other places where grammar is prone to errors. We selected T-DMCA, FT, and HT as comparative models for grammar checking, and the results are shown in Table 4.
Table 4.
Grammar checking comparison.
The results show that our model performed best regarding the syntax checking results compared with the other transformer variant models. It shows that adding a discourse parser capture the grammatical and semantic information of the input documents better and maintain the discourse structure consistent with the original text. The traditional transformer model usually encodes and decodes each sentence independently without considering the logical relationship between sentences, resulting in the loss of some essential grammatical and semantic information and grammatical errors.
5. Conclusions and Future Work
Inspired by how humans summarize the main content of multiple documents, this paper proposed a two-stage MDS method. First, topic-related paragraphs are extracted and sorted, and then the topic information is integrated into the summary generation process. The abstractive phase follows the transformer architecture and adds an external parser to the encoder. It analyzes the primary and secondary relationships between EDUs within the paragraphs and the hierarchical structure and relationships between paragraphs, generates a relationship matrix, and then uses complementary ways to generate richer semantic features. A topic attention module is introduced into the decoder to integrate topic information into the summary generation process to generate better summaries that meet human language expression habits and information acquisition needs. The experiments on the standard text summary dataset WikiSum showed that the ROUGE indicators of the summary model proposed in this article are better than the current best baseline models, and there are substantial improvements in summary syntax, semantics, and logical structure. In addition, our model highlights the essential principles of the design of artificial intelligence technology, focusing on combining theory and practice, profoundly exploring domain expertise, and strengthening the attention to the core elements. At the research level, we provide new research ideas for researchers and inspire future exploration of theoretical improvements such as MDS and NLP. At the application level, practitioners in fields such as news aggregation, intelligent search engine optimization, and extensive data analysis can use this model to improve the efficiency of information acquisition and processing.
Although the experimental results confirm the significant impact of the TOMDS model on improving the relevance, flexibility, and accuracy of syntactic and semantic understanding in summary topics, we acknowledge that this method still has certain limitations. First, while the model performs well on the WikiSum dataset, further validation is necessary to assess its effectiveness in identifying and extracting topic-related paragraphs when dealing with multi-document sets featuring highly complex topic structures or rare topic content. Secondly, although the discourse parsing module was introduced to enhance contextual association modeling, addressing how to more accurately capture long-distance dependencies and balance global and local information remains an unresolved challenge. Additionally, when applying the topic attention mechanism, the effectiveness of generating summaries for topics that are not clearly defined or whose boundaries may be limited by the quality and diversity of predefined topic tags needs consideration. Therefore, the following research avenues can be pursued to advance this work: exploring more advanced transformer variants to improve the model’s capacity for capturing discourse structures and topic relevance, and investigating ways to enable the model to effectively generate summaries in different fields through a minimal amount of annotated data, thereby strengthening its generalization capability and domain adaptability. It is also worth considering incorporating non-textual information, such as images and tables, into the model to facilitate the generation of multi-modal summaries and enrich the content of the summaries provided.
Author Contributions
Methodology, X.Z.; supervision, X.Z.; validation, Q.W.; writing—original draft, X.Z. and Q.W.; formal analysis, Q.S.; writing—review and editing, P.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Key Research and Development Program of China (No. 2022YFC3302100).
Data Availability Statement
The datasets presented in this article are not readily available because it was generated by applying the data generation methods outlined in the tensor2tensor library’s Wikisum data generator (Tensor2Tensor version 5acf4a4), which can be found at the GitHub repository: https://github.com/tensorflow/tensor2tensor/tree/5acf4a44cc2cbe91cd788734075376af0f8dd3f4/tensor2tensor/data_generators/wikisum (accessed on 16 January 2024).
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- IDC: Expect 175 Zettabytes of Data Worldwide by 2025. Networkworld. 2018. Available online: https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html (accessed on 20 October 2023).
- Aggarwal, C.C. Neural Networks and Deep Learning; Springer: Cham, Switzerland, 2018; p. 3. [Google Scholar]
- Zopf, M. Auto-hmds: Automatic construction of a large heterogeneous multilingual multi-document summarization corpus. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 1 May 2018; Available online: https://aclanthology.org/L18-1510 (accessed on 20 October 2023).
- Liu, P.J.; Saleh, M.; Pot, E.; Goodrich, B.; Sepassi, R.; Kaiser, L.; Shazeer, N. Generating wikipedia by summarizing long sequences. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fabbri, A.R.; Li, I.; She, T.; Li, S.; Radev, D.R. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 4 June 2019. [Google Scholar] [CrossRef]
- Radev, D.R. A common theory of information fusion from multiple text sources step one: Cross-document structure. In Proceedings of the 1st SIGdial Workshop on Discourse and Dialogue, Hong Kong, China, 7–8 October 2000; pp. 74–83. [Google Scholar]
- Antognini, D.; Faltings, B. Learning to create sentence semantic relation graphs for multi-document summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, arXiv: Computation and Language, Association for Computational Linguistics, Hong Kong, China, 20 September 2019. [Google Scholar] [CrossRef]
- Yin, Y.; Song, L.; Su, J.; Zeng, J.; Zhou, C.; Luo, J. Graph-based neural sentence ordering. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 16 December 2019; pp. 5387–5393. [Google Scholar] [CrossRef]
- Li, W.; Xiao, X.; Liu, J.; Wu, H.; Wang, H.; Du, J. Leveraging Graph to Improve Abstractive Multi-Document Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 20 May 2020. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence a Modern Approach; Prentice Hall: London, UK, 2010. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; ACL: Stroudsburg, PA, USA, 2004; pp. 404–411. [Google Scholar]
- Radev, D.R.; Jing, H.; Styś, M.; Tam, D. Centroid-based summarization of multiple documents. Inf. Process. Manag. 2004, 40, 919–938. [Google Scholar] [CrossRef]
- Liu, N.; Peng, X.; Lu, Y.; Tang, X.J.; Wang, H.W. A Topic Approach to Sentence Ordering for Multi-document Summarization. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 1390–1395. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Jabeen, S.; Fiori, A. Multi-document summarization exploiting frequent itemsets. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; pp. 782–786. [Google Scholar]
- Goldstein, J.; Mittal, V.O.; Carbonell, J.G.; Kantrowitz, M. Multi-document summarization by sentence extraction. In Proceedings of the NAACL-ANLP 2000 Workshop: Automatic Summarization, Seattle, WA, USA, 30 April 2000. [Google Scholar]
- Wan, X.; Yang, J. Multi-document summarization using cluster-based link analysis. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 299–306. [Google Scholar]
- Haghigh, A.; Vanderwende, L. Exploring content models for multi-document summarization. In Proceedings of the Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, New York, NY, USA, 4–9 June 2009; pp. 362–370. [Google Scholar]
- Arora, R.; Ravindran, B. Latent dirichlet allocation and singular value decomposition based multi-document summarization. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 713–718. [Google Scholar] [CrossRef]
- Jin, H.; Wang, T.; Wan, X. Multi-granularity interaction network for extractive and abstractive multi-document summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6244–6254. [Google Scholar]
- Barzilay, R.; McKeown, K.R. Sentence fusion for multidocument news summarization. Comput. Linguist. 2005, 31, 297–327. [Google Scholar] [CrossRef]
- Tan, J.; Wan, X.; Xiao, J. Abstractive Document Summarization with a Graph-Based Attentional Neural Model. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1171–1181. [Google Scholar] [CrossRef]
- Liu, Y.; Lapata, M. Hierarchical Transformers for Multi-Document Summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 30 May 2019. [Google Scholar] [CrossRef]
- Ma, C.B.; Zhang, W.E.; Wang, H.; Gupta, S.; Guo, M. Incorporating linguistic knowledge for abstractive multi-document summarization. In Proceedings of the 36th Pacific Asia Conference on Language, Information and Computation, Manila, Philippines, 20–22 October 2022; pp. 147–156. [Google Scholar]
- Wan, X. Subtopic-based multi-modality ranking for topic-focused multi-document summarization. Comput. Intell. 2013, 29, 627–648. [Google Scholar] [CrossRef]
- Li, J.; Li, S. A novel feature-based Bayesian model for query focused multi-document summarization. Trans. Assoc. Comput. Linguist. 2013, 1, 89–98. [Google Scholar] [CrossRef]
- Lee, S.; Belkasim, S.; Zhang, Y. Multi-document text summarization using topic model and fuzzy logic. In Proceedings of the 9th International Conference on Machine Learning and Data Mining in Pattern Recognition (MLDM 13), New York, NY, USA, 23–25 July 2013; pp. 159–168. [Google Scholar]
- Liu, N.; Tang, X.J.; Lu, Y.; Li, M.X.; Wang, H.W.; Xiao, P. Topic-sensitive multi-document summarization algorithm. In Proceedings of the 2014 Sixth International Symposium on Parallel Architectures, Algorithms and Programming, Beijing, China, 13–15 July 2014; pp. 69–74. [Google Scholar]
- Cui, P.; Hu, L. Topic-Guided Abstractive Multi-Document Summarization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Chomsky, N. New Horizons in the Study of Language and Mind; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Chomsky, N. Language and Mind; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Xu, J. Text Linguistics in Contemporary Chinese; The Commercial Press: Beijing, China, 2010; pp. 2–4. [Google Scholar]
- Mann, W.C.; Thompson, S.A. Relational propositions in discourse. Discourse Process. 1986, 9, 57–90. [Google Scholar] [CrossRef]
- Van Dijk, T.A. Macrostructures: An Interdisciplinary Study of Global Structures in Discourse, Interaction, and Cognition; Lawrence Erlbaum Associates, Inc.: Hillsdale, NJ, USA, 2019; pp. 67–93. [Google Scholar]
- Zhang, Y.; Wang, Z.; Wang, H. Single Document Extractive Summarization with Satellite and Nuclear Relations. J. Chin. Inf. Process. 2019, 33, 67–76. [Google Scholar]
- Liu, K.; Wang, H. Research Automatics Summarization Coherence Based on Discourse Rhetoric Structure. J. Chin. Inf. Process. 2019, 33, 77–84. [Google Scholar]
- Xu, J.C.; Gan, Z.; Cheng, Y.; Liu, J. Discourse-Aware Neural Extractive Text Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 5021–5031. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Aidan, N.G.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Zhang, X.; Wei, Q.; Song, Q.; Zhang, P. An Extractive Text Summarization Model Based on Rhetorical Structure Theory. In Proceedings of the 26th ACIS International Winter Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD-Winter), Taiyuan, China, 6–8 July 2023. [Google Scholar]
- Kobayashi, N.; Hirao, T.; Kamigaito, H.; Okumura, M.; Nagata, M. Top-down RST parsing utilizing granularity levels in documents. AAAI Conf. Artif. Intell. 2020, 34, 8099–8106. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. Available online: http://anthology.aclweb.org/W/W04/W04-1013.pdf (accessed on 25 November 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Baralis, E.; Cagliero, L.; Mahoto, N.; Fiori, A. GraphSum: Discovering correlations among multiple terms for graph-based summarization. Inf. Sci. 2013, 249, 96–109. [Google Scholar] [CrossRef]
- Clarke, J.; Lapata, M. Discourse constraints for document compression. Comput. Linguist. 2010, 36, 411–441. [Google Scholar] [CrossRef]
- Narayan, S.; Shay, B.C.; Lapata, M. Ranking sentences for extractive summarization with reinforcement learning. In Proceedings of the NAACL 2018, New Orleans, USA, 1–6 June 2018. [Google Scholar] [CrossRef]
- Xu, J.; Durrett, G. Neural Extractive Text Summarization with Syntactic Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).