

Harvesting Insights from the Sky: Satellite-Powered Automation for Detecting Mowing Based on Predicted Compressed Sward Heights
 , , ,
, , ,
Abstract
:Featured Application
Abstract
1. Introduction
2. Materials and Methods
2.1. Initial Data
2.2. Data Preparation
2.3. Unsupervised Analysis to Detect Mowing Events
2.4. Description of the Validation Set
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gourlez de la Motte, L.; Jérôme, E.; Mamadou, O.; Beckers, Y.; Bodson, B.; Heinesch, B.; Aubinet, M. Carbon Balance of an Intensively Grazed Permanent Grassland in Southern Belgium. Agric. For. Meteorol. 2016, 228–229, 370–383. [Google Scholar] [CrossRef]
- Erb, K.-H.; Kastner, T.; Plutzar, C.; Bais, A.L.S.; Carvalhais, N.; Fetzel, T.; Gingrich, S.; Haberl, H.; Lauk, C.; Niedertscheider, M.; et al. Unexpectedly Large Impact of Forest Management and Grazing on Global Vegetation Biomass. Nature 2018, 553, 73–76. [Google Scholar] [CrossRef] [PubMed]
- Lessire, F.; Jacquet, S.; Veselko, D.; Piraux, E.; Dufrasne, I. Evolution of Grazing Practices in Belgian Dairy Farms: Results of Two Surveys. Sustainability 2019, 11, 3997. [Google Scholar] [CrossRef]
- European Comission EU Agrees to Increase Carbon Removals. Available online: https://ec.europa.eu/commission/presscorner/detail/en/IP_22_6784 (accessed on 1 February 2023).
- Dillon, P.; Hennessy, T.; Shalloo, L.; Thorne, F.; Horan, B. Future Outlook for the Irish Dairy Industry: A Study of International Competitiveness, Influence of International Trade Reform and Requirement for Change. Int. J. Dairy Technol. 2008, 61, 16–29. [Google Scholar] [CrossRef]
- Fulkerson, W.J.; Michell, P.J. The Effect of Height and Frequency of Mowing on the Yield and Composition of Perennial Ryegrass—White Clover Swards in the Autumn to Spring Period. Grass Forage Sci. 1987, 42, 169–174. [Google Scholar] [CrossRef]
- Rotz, C.A. How to Maintain Forage Quality during Harvest and Storage. Adv. Dairy Tecnol. 2003, 15, 227–239. [Google Scholar]
- Impact of Mowing Frequency on Arthropod Abundance and Diversity in Urban Habitats: A Meta-Analysis—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/pii/S1618866722002576 (accessed on 16 January 2024).
- Influence of Mowing on the Persistence of Two Endangered Large Blue Butterfly Species—JOHST—2006—Journal of Applied Ecology—Wiley Online Library. Available online: https://besjournals.onlinelibrary.wiley.com/doi/full/10.1111/j.1365-2664.2006.01125.x (accessed on 16 January 2024).
- Effectiveness of Mowing for the Flora Diversity Preservation: A Case Study of Steppe-like Grassland in Croatia (NATURA 2000 Site)|Biodiversity and Conservation. Available online: https://link.springer.com/article/10.1007/s10531-016-1252-1 (accessed on 16 January 2024).
- Kołos, A.; Banaszuk, P. Mowing May Bring about Vegetation Change, but Its Effect Is Strongly Modified by Hydrological Factors. Wetl. Ecol. Manag. 2018, 26, 879–892. [Google Scholar] [CrossRef]
- Michaud, A.; Plantureux, S.; Baumont, R.; Delaby, L. Les prairies, une richesse et un support d’innovation pour des élevages de ruminants plus durables et acceptables. INRAE Prod. Anim. 2020, 33, 153–172. [Google Scholar] [CrossRef]
- Chilliard, Y.; Ferlay, A.; Mansbridge, R.M.; Doreau, M. Ruminant Milk Fat Plasticity: Nutritional Control of Saturated, Polyunsaturated, Trans and Conjugated Fatty Acids. Ann. Zootech. 2000, 49, 181–205. [Google Scholar] [CrossRef]
- Elgersma, A.; Tamminga, S.; Ellen, G. Modifying Milk Composition through Forage. Anim. Feed Sci. Technol. 2006, 131, 207–225. [Google Scholar] [CrossRef]
- Caraes, C.; Hebert, J. Agriculture et Élevage de Précision: Comptabiliser Le Temps de Pâturage Grâce à Un Collier Connecté: Chronopâture 2020. Available online: https://normandie.chambres-agriculture.fr/ (accessed on 20 July 2020).
- Soyeurt, H.; Gerards, C.; Nickmilder, C.; Bindelle, J.; Franceschini, S.; Dehareng, F.; Veselko, D.; Bertozzi, C.; Gengler, N.; Marvuglia, A.; et al. Prediction of Indirect Indicators of a Grass-Based Diet by Milk Fourier Transform Mid-Infrared Spectroscopy to Assess the Feeding Typologies of Dairy Farms. Animals 2022, 12, 2663. [Google Scholar] [CrossRef]
- De Vroey, M.; Radoux, J.; Defourny, P. Grassland Mowing Detection Using Sentinel-1 Time Series: Potential and Limitations. Remote Sens. 2021, 13, 348. [Google Scholar] [CrossRef]
- Reinermann, S.; Gessner, U.; Asam, S.; Ullmann, T.; Schucknecht, A.; Kuenzer, C. Detection of Grassland Mowing Events for Germany by Combining Sentinel-1 and Sentinel-2 Time Series. Remote Sens. 2022, 14, 1647. [Google Scholar] [CrossRef]
- Garioud, A.; Giordano, S.; Valero, S.; Mallet, C. Challenges in Grassland Mowing Event Detection with Multimodal Sentinel Images. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar]
- Lobert, F.; Holtgrave, A.-K.; Schwieder, M.; Pause, M.; Vogt, J.; Gocht, A.; Erasmi, S. Mowing Event Detection in Permanent Grasslands: Systematic Evaluation of Input Features from Sentinel-1, Sentinel-2, and Landsat 8 Time Series. Remote Sens. Environ. 2021, 267, 112751. [Google Scholar] [CrossRef]
- Holtgrave, A.-K.; Lobert, F.; Erasmi, S.; Röder, N.; Kleinschmit, B. Grassland Mowing Event Detection Using Combined Optical, SAR, and Weather Time Series. Remote Sens. Environ. 2023, 295, 113680. [Google Scholar] [CrossRef]
- Komisarenko, V.; Voormansik, K.; Elshawi, R.; Sakr, S. Exploiting Time Series of Sentinel-1 and Sentinel-2 to Detect Grassland Mowing Events Using Deep Learning with Reject Region. Sci. Rep. 2022, 12, 983. [Google Scholar] [CrossRef]
- De Vroey, M.; de Vendictis, L.; Zavagli, M.; Bontemps, S.; Heymans, D.; Radoux, J.; Koetz, B.; Defourny, P. Mowing Detection Using Sentinel-1 and Sentinel-2 Time Series for Large Scale Grassland Monitoring. Remote Sens. Environ. 2022, 280, 113145. [Google Scholar] [CrossRef]
- Wang, Z.; Ma, Y.; Zhang, Y.; Shang, J. Review of Remote Sensing Applications in Grassland Monitoring. Remote Sens. 2022, 14, 2903. [Google Scholar] [CrossRef]
- Tiscornia, G.; Baethgen, W.; Ruggia, A.; Do Carmo, M.; Ceccato, P. Can We Monitor Height of Native Grasslands in Uruguay with Earth Observation? Remote Sens. 2019, 11, 1801. [Google Scholar] [CrossRef]
- Cimbelli, A.; Vitale, V. Grassland Height Assessment by Satellite Images. Adv. Remote Sens. 2017, 6, 40–53. [Google Scholar] [CrossRef]
- Nickmilder, C.; Tedde, A.; Dufrasne, I.; Lessire, F.; Tychon, B.; Curnel, Y.; Bindelle, J.; Soyeurt, H. Development of Machine Learning Models to Predict Compressed Sward Height in Walloon Pastures Based on Sentinel-1, Sentinel-2 and Meteorological Data Using Multiple Data Transformations. Remote Sens. 2021, 13, 408. [Google Scholar] [CrossRef]
- Wrage, N.; Şahin Demirbağ, N.; Hofmann, M.; Isselstein, J. Vegetation Height of Patch More Important for Phytodiversity than That of Paddock. Agric. Ecosyst. Environ. 2012, 155, 111–116. [Google Scholar] [CrossRef]
- Nickmilder, C.; Tedde, A.; Dufrasne, I.; Lessire, F.; Glesner, N.; Tychon, B.; Bindelle, J.; Soyeurt, H. Creation of a Walloon Pasture Monitoring Platform Based on Machine Learning Models and Remote Sensing. Remote Sens. 2023, 15, 1890. [Google Scholar] [CrossRef]
- Obermeyer, K.; Komainda, M.; Kayser, M.; Isselstein, J. Exploring the Potential of Rising Plate Meter Techniques to Analyse Ecosystem Services from Multi-Species Grasslands. Crop Pasture Sci. 2022, 74, 378–391. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Posit Posit. Available online: https://www.posit.co/ (accessed on 20 July 2023).
- van Rossum, G. Python Reference Manual; Department of Computer Science [CS]; CWI: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Spyder Welcome to Spyder’s Documentation—Spyder 5 Documentation. Available online: https://docs.spyder-ide.org/current/index.html (accessed on 20 July 2023).
- OS Os—Miscellaneous Operating System Interfaces. Available online: https://docs.python.org/3/library/os.html (accessed on 20 July 2023).
- Hijmans, R.J.; van Etten, J.; Sumner, M.; Cheng, J.; Baston, D.; Bevan, A.; Bivand, R.; Busetto, L.; Canty, M.; Fasoli, B.; et al. Raster: Geographic Data Analysis and Modeling. Available online: https://cran.r-project.org/web/packages/raster/ (accessed on 20 July 2023).
- RE 6.2. Re—Regular Expression Operations—Python 3.6.15 Documentation. Available online: https://docs.python.org/3.6/library/re.html (accessed on 20 July 2023).
- Pebesma, E.; Bivand, R.; Racine, E.; Sumner, M.; Cook, I.; Keitt, T.; Lovelace, R.; Wickham, H.; Ooms, J.; Müller, K.; et al. Sf: Simple Features for R. Available online: https://cran.r-project.org/web/packages/sf/ (accessed on 20 July 2023).
- Pandas Pandas Documentation—Pandas 2.0.3 Documentation. Available online: https://pandas.pydata.org/docs/index.html (accessed on 20 July 2023).
- Dowle, M.; Srinivasan, A.; Gorecki, J.; Chirico, M.; Stetsenko, P.; Short, T.; Lianoglou, S.; Antonyan, E.; Bonsch, M.; Parsonage, H.; et al. Data.Table: Extension of “Data.Frame”. Available online: https://cran.r-project.org/web/packages/data.table/ (accessed on 20 July 2023).
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array Programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B. Caret: Classification and Regression Training. Available online: https://cran.r-project.org/web/packages/caret/ (accessed on 20 July 2023).
- Dask Dask—Dask Documentation. Available online: https://docs.dask.org/en/stable/ (accessed on 20 July 2023).
- Scikit-Learn Scikit-Learn: Machine Learning in Python—Scikit-Learn 1.3.0 Documentation. Available online: https://scikit-learn.org/stable/index.html (accessed on 20 July 2023).
- ESA Open Access Hub. Available online: https://scihub.copernicus.eu/ (accessed on 16 January 2024).
- ESA Copernicus Data Space Ecosystem|Europe’s Eyes on Earth. Available online: https://dataspace.copernicus.eu/ (accessed on 16 January 2024).
- CRA-W Agromet.Be. Available online: https://agromet.be/fr/pages/home/ (accessed on 16 January 2024).
- Liu, F.T.; Ting, K.M.; Zhou, Z.-H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Forton, F.; Meniger, G. Cours Sur Les Prairies. 2019. Available online: https://www.fourragesmieux.be/Documents_telechargeables/ (accessed on 13 March 2023).
- [Chiffres-clé] Quelles Sont les Céréales et Cultures Cultivées en Wallonie? Celagri 2019. Available online: https://www.celagri.be/quelles-cereales-et-cultures-cultive-t-on-en-wallonie/ (accessed on 20 July 2023).
- Herman-Saffar, O. An Approach for Choosing Number of Clusters for K-Means. Available online: https://towardsdatascience.com/an-approach-for-choosing-number-of-clusters-for-k-means-c28e614ecb2c (accessed on 20 July 2023).
- Grelet, C.; Larsen, T.; Crowe, M.A.; Wathes, D.C.; Ferris, C.P.; Ingvartsen, K.L.; Marchitelli, C.; Becker, F.; Vanlierde, A.; Leblois, J.; et al. Prediction of Key Milk Biomarkers in Dairy Cows through Milk MIR Spectra and International Collaborations. J. Dairy Sci. 2023, in press. [Google Scholar] [CrossRef] [PubMed]
- Vogel, A.; Scherer-Lorenzen, M.; Weigelt, A. Grassland Resistance and Resilience after Drought Depends on Management Intensity and Species Richness. PLoS ONE 2012, 7, e36992. [Google Scholar] [CrossRef] [PubMed]
- Moinet, G.Y.K.; Midwood, A.J.; Hunt, J.E.; Rumpel, C.; Millard, P.; Chabbi, A. Grassland Management Influences the Response of Soil Respiration to Drought. Agronomy 2019, 9, 124. [Google Scholar] [CrossRef]



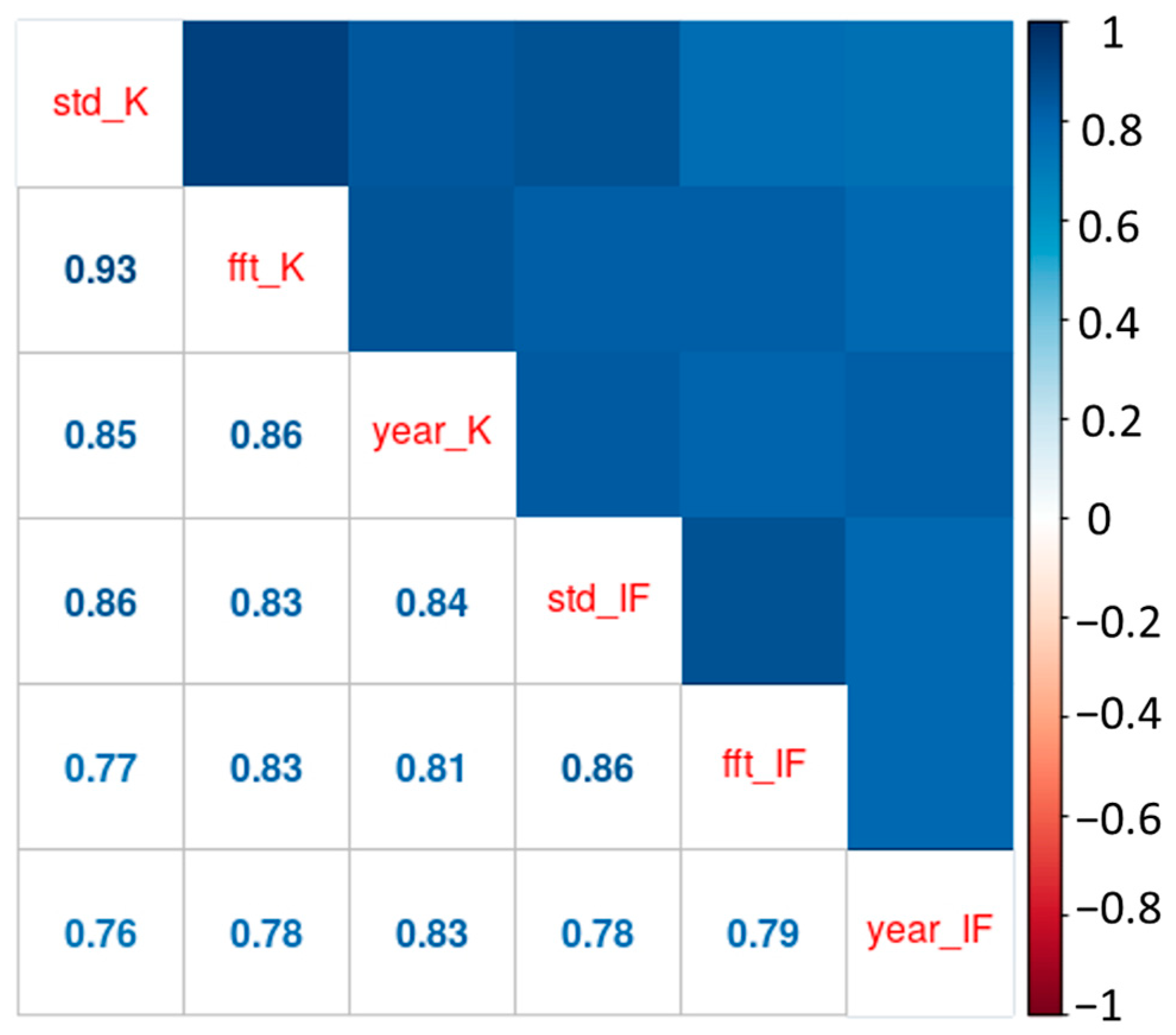

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| R | Python | |||
|---|---|---|---|---|
| Software | Version | Reference | Software | Reference |
| R | 4.1.1 | [31] | os v3.9 | [35] |
| raster | 3.4-13 | [36] | Re v3.9 | [37] |
| sf | 1.0-2 | [38] | Pandas v1.4.1 | [39] |
| data.table | 1.14.0 | [40] | Numpy v1.21.5 | [41] |
| caret | 6.0-93 | [42] | Dask v2023.4.1 | [43] |
| scikit-learn v1.0.1 | [44] |
| Year | Nparcels 1 | Pixel CSH (mm) | MEAN_DAY (mm) | SD_DAY (mm) |
|---|---|---|---|---|
| 2018 | 86,218 | 56.0 ± 19.9 | 56.2 ± 17.5 | 7.0 ± 5.3 |
| 2019 | 86,617 | 63.8 ± 21.6 | 62.8 ± 17.6 | 8.1 ± 6.2 |
| 2020 | 91,224 | 60.1 ± 20.1 | 59.6 ± 16.6 | 7.5 ± 6.0 |
| 2021 | 136,892 | 59.2 ± 18.5 | 58.8 ± 15.7 | 7.3 ± 5.0 |
| Temporality | Category | 2018 | 2019 | 2020 | 2021 |
|---|---|---|---|---|---|
| With a precise date | N events | 12 | 11 | 44 | 0 |
| N farms | 2 | 4 | 5 | 0 | |
| N parcels | 12 | 11 | 11 | 0 | |
| N refusal mowing 1 | 0 | 0 | 8 | 0 | |
| Without the precise date | N events = N parcels | 3 | 3 | 3 | 3 |
| week_fft | week_std | yearstats | |||||
|---|---|---|---|---|---|---|---|
| Year | IF | MEAN_YEAR | SD_YEAR | MEAN_YEAR | SD_YEAR | MEAN_YEAR | SD_YEAR |
| 2018 | Group 0 | 55.21 | 6.8 | 55.04 | 6.71 | 55.58 | 6.99 |
| Group 1 | 59.05 | 8.64 | 59.78 | 9.01 | 57.85 | 8 | |
| 2019 | Group 0 | 61.41 | 7.71 | 61.17 | 7.5 | 61.86 | 7.83 |
| Group 1 | 68.19 | 10.35 | 69.2 | 11.21 | 66.7 | 10.02 | |
| 2020 | Group 0 | 58.78 | 7.33 | 58.22 | 6.93 | 58.69 | 7.26 |
| Group 1 | 62.77 | 9.01 | 64.99 | 10.58 | 63.12 | 9.29 | |
| 2021 | Group 0 | 57.21 | 6.76 | 56.77 | 6.53 | 57.54 | 6.85 |
| Group 1 | 63.18 | 9.26 | 64.51 | 9.95 | 62.2 | 9.03 | |
| week_fft | week_std | yearstats | |||||
|---|---|---|---|---|---|---|---|
| Year | K-Means | MEAN_YEAR | SD_YEAR | MEAN_YEAR | SD_YEAR | MEAN_YEAR | SD_YEAR |
| 2018 | Cluster 0 | 53.3 | 5.92 | 56.67 | 10.58 | 57.65 | 8.12 |
| Cluster 1 | 57.03 | 7.14 | 57.92 | 7.69 | 57.26 | 6.8 | |
| Cluster 2 | 55.43 | 7.18 | 53.35 | 6.86 | 60.68 | 9.38 | |
| Cluster 3 | 54.73 | 5.96 | 54.73 | 5.96 | 54.73 | 5.96 | |
| Cluster 4 | 59.09 | 8.86 | 59.09 | 8.86 | 59.09 | 8.86 | |
| 2019 | Cluster 0 | 61.47 | 7.35 | 65.18 | 9.08 | 57.93 | 6.3 |
| Cluster 1 | 58.18 | 6.39 | 62.82 | 7.57 | 58.61 | 6.37 | |
| Cluster 2 | 62.84 | 8.29 | 69.54 | 11.38 | 64.74 | 9.17 | |
| Cluster 3 | 62.75 | 8.25 | 62.75 | 8.25 | 62.75 | 8.25 | |
| Cluster 4 | 62.87 | 8.27 | 62.87 | 8.27 | 62.87 | 8.27 | |
| 2020 | Cluster 0 | 53.28 | 5.68 | 63.38 | 9.56 | 55.48 | 5.67 |
| Cluster 1 | 63.61 | 9.47 | 55.6 | 5.93 | 62.73 | 8.12 | |
| Cluster 2 | 57.54 | 6.95 | 61.24 | 7.37 | 61.33 | 8.75 | |
| Cluster 3 | 59.76 | 7.73 | 59.76 | 7.73 | 59.76 | 7.73 | |
| Cluster 4 | 59.74 | 7.71 | 59.74 | 7.71 | 59.74 | 7.71 | |
| 2021 | Cluster 0 | 56.3 | 6.28 | 54 | 6.03 | 59.02 | 6.61 |
| Cluster 1 | 62.71 | 8.72 | 58.76 | 10.8 | 64.81 | 10.32 | |
| Cluster 2 | 59.87 | 7.7 | 58.93 | 6.75 | 62.82 | 8.18 | |
| Cluster 3 | 58.7 | 7.34 | 58.7 | 7.34 | 58.7 | 7.34 | |
| Cluster 4 | 58.66 | 7.36 | 58.66 | 7.36 | 58.66 | 7.36 | |
| K-Means | Isolation Forest | |||
|---|---|---|---|---|
| Year | Seemingly Mown Parcels | Seemingly Grazed Parcels | Seemingly Mown Parcels | Seemingly Grazed Parcels |
| 2018 | 2901 | 3086 | 5343 | 54,267 |
| 2019 | 4335 | 19,880 | 5923 | 54,904 |
| 2020 | 8082 | 1296 | 5610 | 56,698 |
| 2021 | 750 | 2454 | 10,601 | 88,201 |
| TOTAL | 16,068 | 26,716 | 27,477 | 250,070 |
| Year | K-Means | Isolation Forest | ||||
|---|---|---|---|---|---|---|
| Weekstd | Weekfft | Yearstats | Weekstd | Weekfft | Yearstats | |
| 2018 | 0.38 | 0.42 | 0.44 | 0.20 | 0.21 | 0.28 |
| 2019 | 0.38 | 0.41 | 0.39 | 0.20 | 0.21 | 0.22 |
| 2020 | 0.56 | 0.57 | 0.50 | 0.18 | 0.19 | 0.27 |
| 2021 | 0.23 | 0.21 | 0.29 | 0.17 | 0.17 | 0.14 |
| Mean | 0.39 | 0.40 | 0.40 | 0.19 | 0.19 | 0.23 |
| Algorithm | Dataset | N Components | Calibration Accuracy | Validation Accuracy (N = 68) |
|---|---|---|---|---|
| K-means | week_std | 4 | 0.99 ± 0.0004 (N = 42,784) | 0.48 (N = 33) |
| week_fft | 7 | 0.99 ± 0.0004 (N = 42,784) | 0.66 (N = 45) | |
| yearstats | 6 | 0.98 ± 0.0011 (N = 42,784) | 0.54 (N = 37) | |
| Isolation forest | week_std | 7 | 0.95 ± 0.0006 (N = 277,547) | 0.18 (N = 12) |
| week_fft | 9 | 0.95 ± 0.0005 (N = 277,547) | 0.31 (N = 21) | |
| yearstats | 6 | 0.94 ± 0.0006 (N = 277,547) | 0.40 (N = 27) |
| Year | Total Parcels | Percentage of Parcels Flagged as Mown | ||||
|---|---|---|---|---|---|---|
| week_fft (0.50) | week_fft (0.45) | week_fft (0.40) | week_fft (0.35) | week_fft (0.30) | ||
| 2018 | 86,218 | 42 | 53 | 65 | 77 | 88 |
| 2019 | 86,617 | 41 | 48 | 57 | 66 | 78 |
| 2020 | 91,224 | 57 | 66 | 75 | 84 | 91 |
| 2021 | 136,892 | 21 | 27 | 36 | 47 | 65 |
| Total | 400,915 | 40 | 49 | 58 | 68 | 80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dichou, K.; Nickmilder, C.; Tedde, A.; Franceschini, S.; Brostaux, Y.; Dufrasne, I.; Lessire, F.; Glesner, N.; Soyeurt, H. Harvesting Insights from the Sky: Satellite-Powered Automation for Detecting Mowing Based on Predicted Compressed Sward Heights. Appl. Sci. 2024, 14, 1923. https://doi.org/10.3390/app14051923
Dichou K, Nickmilder C, Tedde A, Franceschini S, Brostaux Y, Dufrasne I, Lessire F, Glesner N, Soyeurt H. Harvesting Insights from the Sky: Satellite-Powered Automation for Detecting Mowing Based on Predicted Compressed Sward Heights. Applied Sciences. 2024; 14(5):1923. https://doi.org/10.3390/app14051923
Chicago/Turabian StyleDichou, Killian, Charles Nickmilder, Anthony Tedde, Sébastien Franceschini, Yves Brostaux, Isabelle Dufrasne, Françoise Lessire, Noémie Glesner, and Hélène Soyeurt. 2024. "Harvesting Insights from the Sky: Satellite-Powered Automation for Detecting Mowing Based on Predicted Compressed Sward Heights" Applied Sciences 14, no. 5: 1923. https://doi.org/10.3390/app14051923