


Remote Sensing Image Segmentation for Aircraft Recognition Using U-Net as Deep Learning Architecture


Abstract
1. Introduction
- The developed architecture presents an end-to-end semantic segmentation model with robust expandability. This model can be effectively employed for the automatic recognition of aircraft, including those that are not present in the initial training dataset. Importantly, this recognition can be achieved without the need to retrain the model.
- This study integrates several strategic approaches, including data preprocessing and data augmentation, with the model designed for aircraft semantic segmentation. These strategies collectively contribute to a substantial improvement in accuracy, enhancing the model’s performance.
- To the best of our knowledge, this study represents the first effort to explore the DLRSD for the development of a semantic segmentation model tailored for aircraft recognition by employing the U-Net architecture. This exploration expands the scope of available resources and insights in the field of aircraft recognition, making a notable contribution to the literature.
2. Background and Related Literature
2.1. Classical Methods for Aircraft Recognition
2.2. Aircraft Recognition Using Image Features Directly
2.3. CNNs for Semantic Segmentation
2.4. CNNs for Semantic Segmentation of Remote Sensing Images
3. Materials and Methods
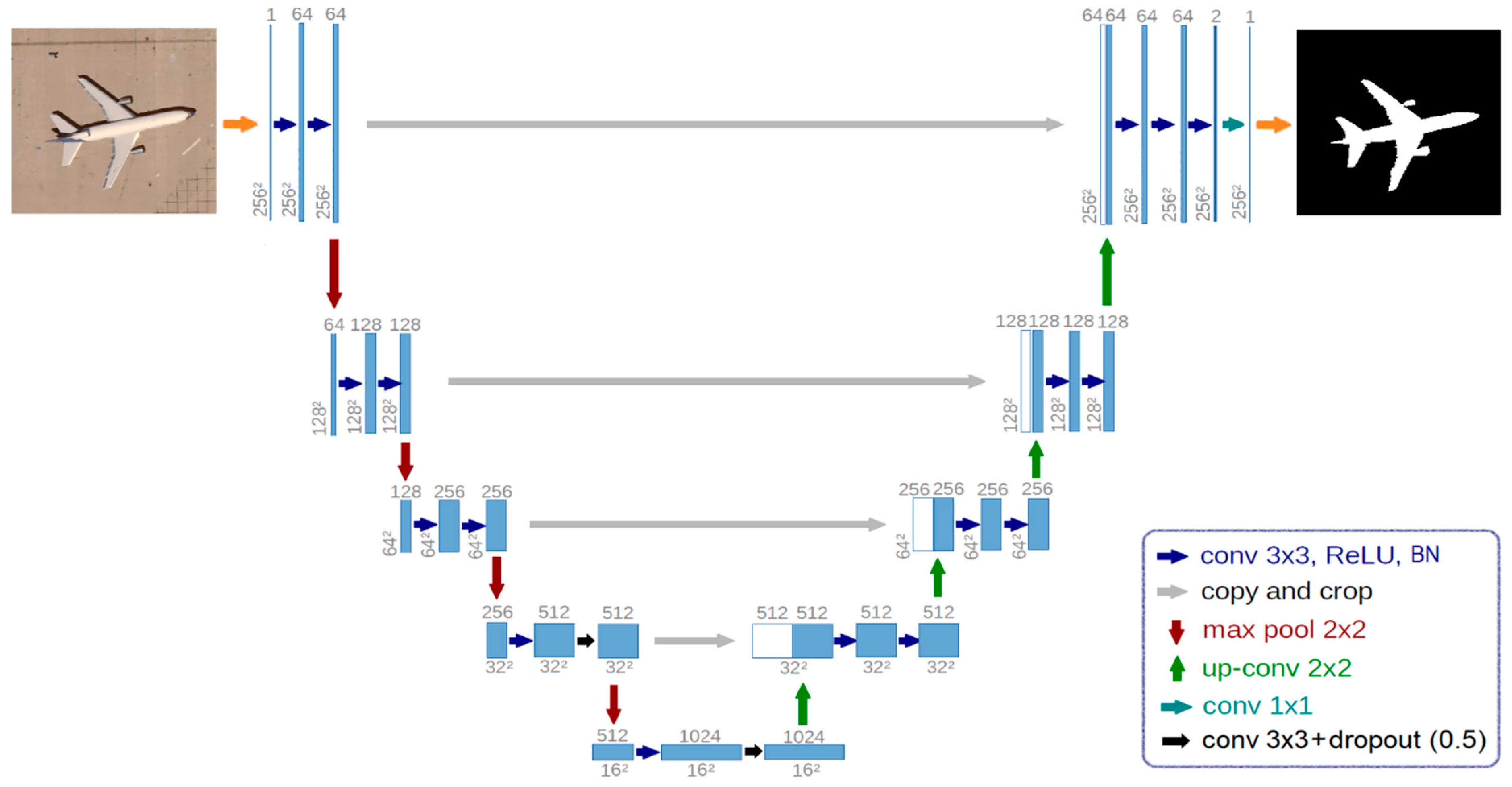
3.1. Architecture of U-Net Used for Aircraft Recognition
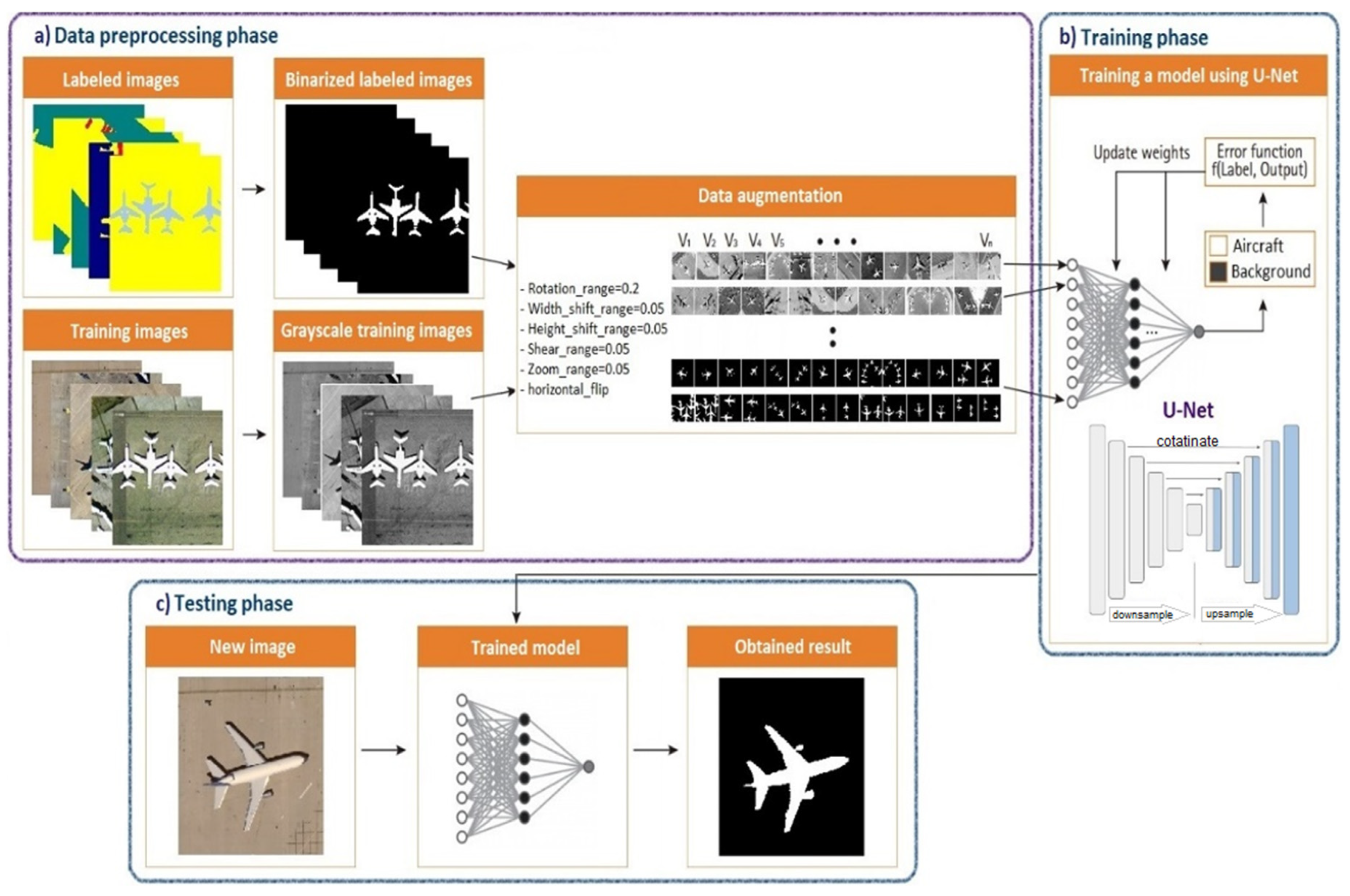
3.2. Semantic Workflow of Proposed Model
3.3. Overview of Dataset Used
3.4. Implementation Tools
4. Results
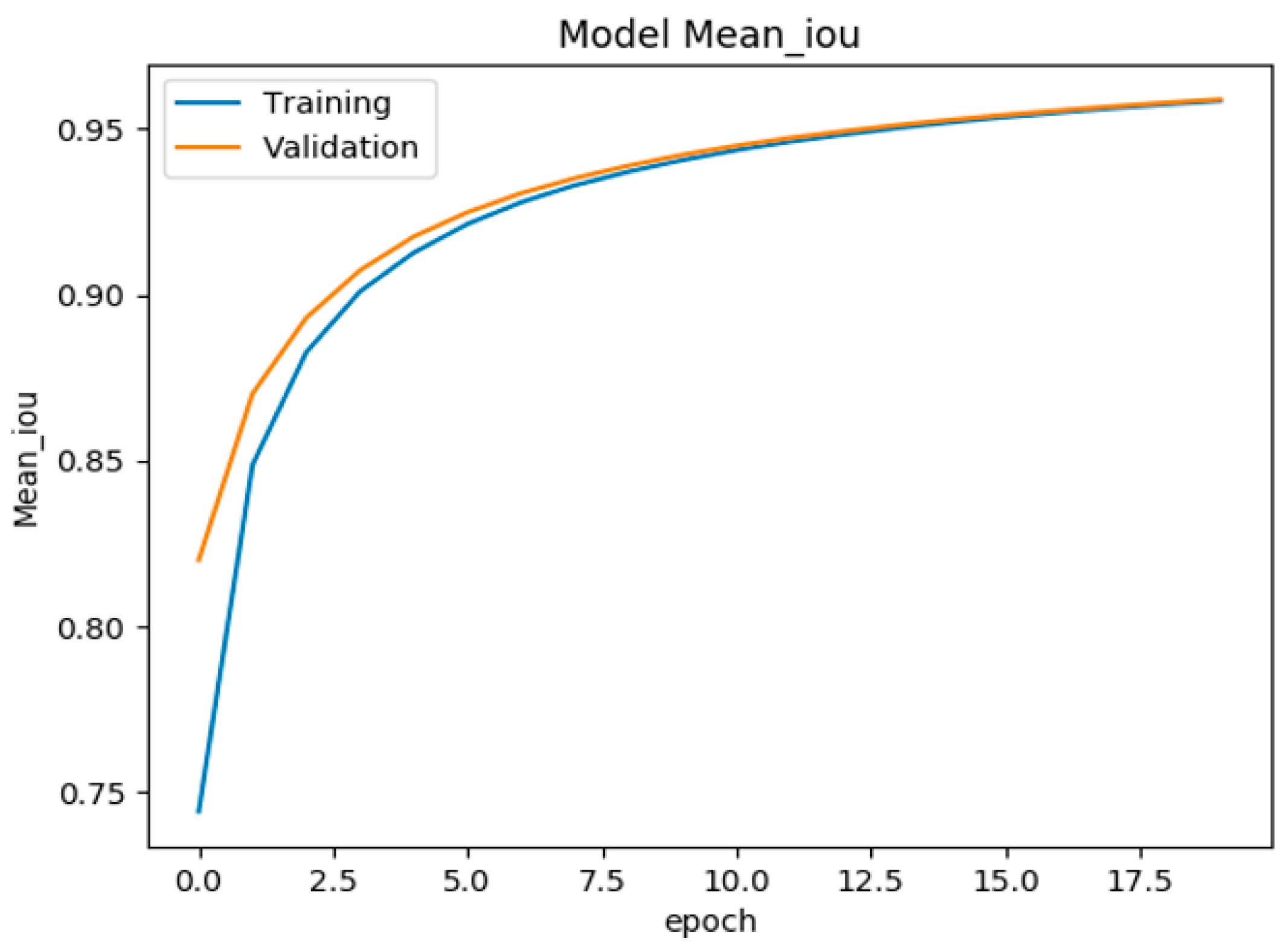
4.1. Training and Evaluation of U-Net Model for Aircraft Semantic Segmentation
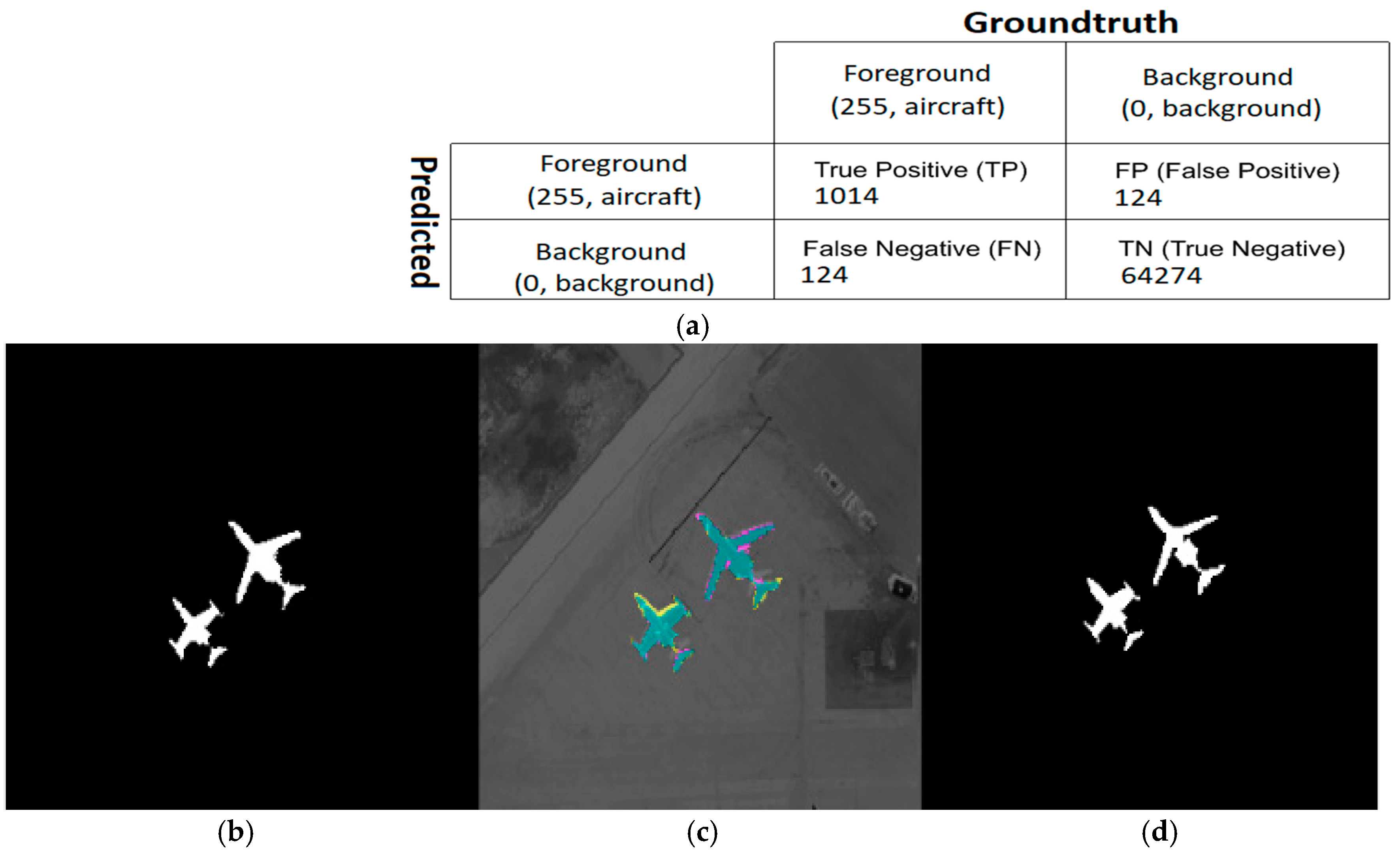
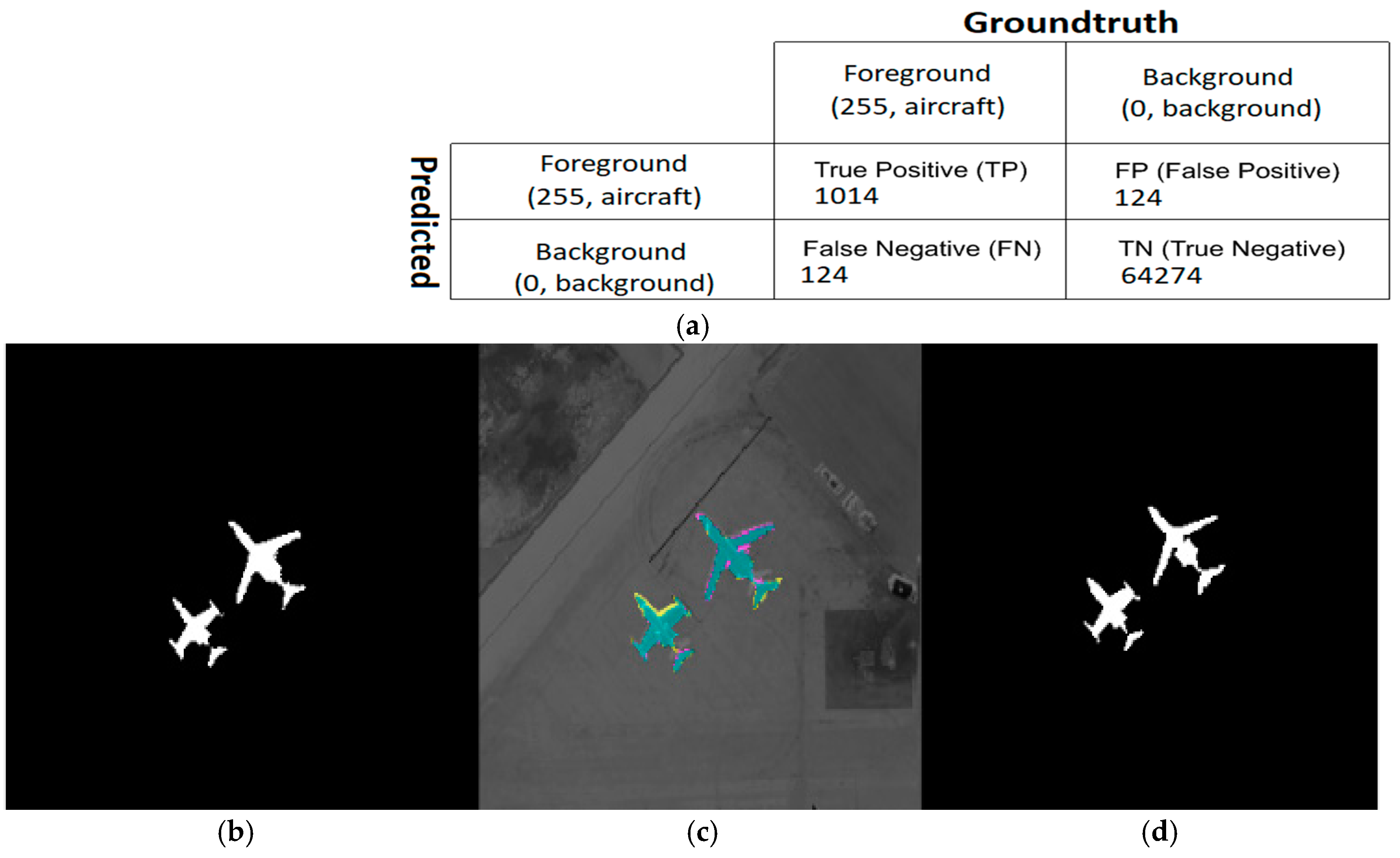
4.2. Evaluation Metrics
4.3. Performance Analysis of Semantic Segmentation
5. Discussion and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, B.; Gao, J.; Chen, S.; Lim, S.; Jiang, H. POI detection of high-rise buildings using remote sensing images: A semantic segmentation method based on multitask attention Res-U-Net. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Hao, X.; Yin, L.; Li, X.; Zhang, L.; Yang, R. A multi-objective semantic segmentation algorithm based on improved U-Net networks. Remote Sens. 2023, 15, 1838. [Google Scholar] [CrossRef]
- Shao, X.; Qiang, Y.; Li, J.; Li, L.; Zhao, X.; Wang, Q. Semantic segmentation of remote sensing image based on Contextual U-Net. In Proceedings of the 2nd International Conference on Applied Statistics, Computational Mathematics, and Software Engineering (ASCMSE 2023), SPIE, Kaifeng, China, 26–28 May 2023; pp. 370–380. [Google Scholar]
- Shao, Z.; Yang, K.; Zhou, W. Performance evaluation of single-label and multi-label remote sensing image retrieval using a dense labeling dataset. Remote Sens. 2018, 10, 964. [Google Scholar] [CrossRef]
- Tummidi, J.R.D.; Kamble, R.S.; Bakliwal, S.; Desai, A.; Lad, B.V.; Keskar, A.G. Salient object detection based aircraft detection for optical remote sensing images. In Proceedings of the 2nd International Conference on Paradigm Shifts in Communications Embedded Systems, Machine Learning and Signal Processing (PCEMS), IEEE, Nagpur, India, 5–6 April 2023; pp. 1–6. [Google Scholar]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. PatternNet: A benchmark dataset for performance evaluation of remote sensing image retrieval. ISPRS J. Photogramm. Remote Sens. 2018, 145, 197–209. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Jégou, H.; Douze, M.; Schmid, C.; Pérez, P. Aggregating local descriptors into a compact image representation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, IEEE, San Francisco, CA, USA, 13–18 June 2010; pp. 3304–3311. [Google Scholar]
- Perronnin, F.; Sánchez, J.; Mensink, T. Improving the fisher kernel for large-scale image classification. In Computer Vision—ECCV 2010. ECCV 2010. Lecture Notes in Computer Science; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Crete, Greece; Berlin/Heidelberg, Germany, 2010; pp. 143–156. [Google Scholar]
- Liu, C.; Wechsler, H. Gabor feature based classification using the enhanced fisher linear discriminant model for face recognition. IEEE Trans. Image Process. 2002, 11, 467–476. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the 9th IEEE International Conference on Computer Vision, IEEE, Nice, France, 13–16 October 2003; Volume 1472, pp. 1470–1477. [Google Scholar]
- Topcu, A.E.; Alzoubi, Y.I.; Elbasi, E.; Camalan, E. Social media zero-day attack detection using TensorFlow. Electronics 2023, 12, 3554. [Google Scholar] [CrossRef]
- Alzoubi, Y.I.; Topcu, A.E.; Erkaya, A.E. Machine learning-based text classification comparison: Turkish language context. Appl. Sci. 2023, 13, 9428. [Google Scholar] [CrossRef]
- Zhao, A.; Fu, K.; Wang, S.; Zuo, J.; Zhang, Y.; Hu, Y.; Wang, H. Aircraft recognition based on landmark detection in remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1413–1417. [Google Scholar] [CrossRef]
- Zuo, J.; Xu, G.; Fu, K.; Sun, X.; Sun, H. Aircraft type recognition based on segmentation with deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 282–286. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015. MICCAI 2015. Lecture Notes in Computer Science; Navab, N., Hornegger, J., Wells, W., Frangi, A., Eds.; Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Topcu, A.E.; Alzoubi, Y.I.; Karacabey, H.A. Text analysis of smart cities: A big data-based model. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 724–733. [Google Scholar]
- Zhang, F.; Liu, S.-q.; Wang, D.-b.; Guan, W. Aircraft recognition in infrared image using wavelet moment invariants. Image Vis. Comput. 2009, 27, 313–318. [Google Scholar] [CrossRef]
- Liu, F.; Yu, P.; Liu, K. Research concerning aircraft recognition of remote sensing images based on ICA Zernike invariant moments. CAAI Trans. Intell. Technol. 2011, 6, 51–56. [Google Scholar]
- Shao, D.; Zhang, Y.; Wei, W. An aircraft recognition method based on principal component analysis and image model matching. Chin. J. Stereol. Image Anal. 2009, 3, 7. [Google Scholar]
- Fang, Z.; Yao, G.; Zhang, Y. Target recognition of aircraft based on moment invariants and BP neural network. In Proceedings of the World Automation Congress 2012, IEEE, Puerto Vallarta, Mexico, 4–28 June 2012; pp. 1–5. [Google Scholar]
- Wang, D.; He, X.; Zhonghui, W.; Yu, H. A method of aircraft image target recognition based on modified PCA features and SVM. In Proceedings of the 9th International Conference on Electronic Measurement and Instruments, IEEE, Beijing, China, 16–19 August 2009; p. 4-177-174-181. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), IEEE, Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Pan, X.; Gao, L.; Marinoni, A.; Zhang, B.; Yang, F.; Gamba, P. Semantic labeling of high resolution aerial imagery and LiDAR data with fine segmentation network. Remote Sens. 2018, 10, 743. [Google Scholar] [CrossRef]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Computer Vision—ECCV 2014. ECCV 2014. Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; Volume 8695, pp. 345–360. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the International Conference on Computer Vision, IEEE, Santiago, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; SegNet, R.C. A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2481–2495. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution aerial image labeling with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef]
- Liu, Y.; Minh Nguyen, D.; Deligiannis, N.; Ding, W.; Munteanu, A. Hourglass-shapenetwork based semantic segmentation for high resolution aerial imagery. Remote Sens. 2017, 9, 522. [Google Scholar] [CrossRef]
- Patravali, J.; Jain, S.; Chilamkurthy, S. 2D-3D fully convolutional neural networks for cardiac MR segmentation. In Statistical Atlases and Computational Models of the Heart. ACDC and MMWHS Challenges, Proceedings of the 8th International Workshop, STACOM 2017, Quebec City, QC, Canada, 10–14 September 2017; Lecture Notes in Computer Science; Pop, M., Sermesant, M., Jodoin, P.-M., Lalande, A., Zhuang, X., Yang, G., Young, A., Bernard, O., Eds.; Springer: Cham, Switzerland, 2018; Volume 10663, pp. 130–139. [Google Scholar]
- Kim, J.H.; Lee, H.; Hong, S.J.; Kim, S.; Park, J.; Hwang, J.Y.; Choi, J.P. Objects segmentation from high-resolution aerial images using U-Net with pyramid pooling layers. IEEE Geosci. Remote Sens. Lett. 2018, 16, 115–119. [Google Scholar] [CrossRef]
- Pyo, J.; Han, K.-j.; Cho, Y.; Kim, D.; Jin, D. Generalization of U-Net semantic segmentation for forest change detection in South Korea using airborne imagery. Forests 2022, 13, 2170. [Google Scholar] [CrossRef]
- Walsh, J.; Othmani, A.; Jain, M.; Dev, S. Using U-Net network for efficient brain tumor segmentation in MRI images. Healthc. Anal. 2022, 2, 100098. [Google Scholar] [CrossRef]
- Shinde, R. Glaucoma detection in retinal fundus images using U-Net and supervised machine learning algorithms. Intell. -Based Med. 2021, 5, 100038. [Google Scholar] [CrossRef]
- Buslaev, A.; Seferbekov, S.; Iglovikov, V.; Shvets, A. Fully convolutional network for automatic road extraction from satellite imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, IEEE, Salt Lake City, UT, USA, 18–22 June 2018; pp. 207–210. [Google Scholar]
- Wang, X.; Zhang, S.; Huang, L. Aircraft segmentation in remote sensing images based on multi-scale residual U-Net with attention. Multimed. Tools Appl. 2023, 38, 17855–17872. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Jeon, G. A real-time efficient object segmentation system based on U-Net using aerial drone images. J. Real-Time Image Process. 2021, 18, 1745–1758. [Google Scholar] [CrossRef]
- Alzoubi, Y.I.; Topcu, A.E.; Ozdemir, E. Enhancing document image retrieval in education: Leveraging ensemble-based document image retrieval systems for improved precision. Appl. Sci. 2024, 14, 751. [Google Scholar] [CrossRef]
- Chollet, F. GitHub Repository. 2015. Available online: https://github.com/keras-team/keras (accessed on 15 March 2023).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Domain | Innovation/Technique | Accuracy Achieved |
|---|---|---|---|
| [31] | Image semantic labeling | Multi-layer perceptron (MLP) was proposed, which outperformed other techniques like CNN | 88.92% |
| [32] | Aerial image semantic segmentation | Hourglass-shaped network (HSN)-based semantic segmentation was proposed | 89.42% |
| [16] | Aircraft classification | Keypoints’ detection network | 95.60% |
| [17] | Biomedical image segmentation | U-Net architecture was deployed | 92.03% |
| [33] | Cardiac MR segmentation | U-Net architecture was deployed | ___ |
| [34] | Satellite image segmentation | U-Net architecture was deployed | 87.61% |
| [2] | Satellite image segmentation | Improved U-Net architecture was deployed | 97.56% |
| [35] | Forest change detection | U-Net architecture was deployed | 99.00% |
| [36] | Brain tumor segmentation in magnetic resonance imaging (MRI) | U-Net architecture was deployed | 99.00% |
| [37] | Glaucoma detection in retinal fundus images | U-Net and supervised ML algorithms | 100% |
| [38] | Satellite image segmentation | ResNet-34 weights within the encoder component | 64.00% |
| [3] | Remote image segmentation | Contextual U-Net architecture | ___ |
| [5] | Aircraft image segmentation | Spatial channel attention U-Net model | ___ |
| [39] | Multi-scale aircraft segmentation | MSRAU-Net | 93.12% |
| [40] | Aerial drone object segmentation | U-Net segmentation model | 95.00% |
| This study | Aircraft image segmentation | U-Net segmentation model | 98.24% |
| Augmentation Methods | Value |
|---|---|
| Horizontal flip | True |
| Height shift | 0.05 |
| Width shift | 0.05 |
| Image zoom | 0.05 |
| Image shear | 0.05 |
| Image rotation | 0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaar, F.; Yılmaz, A.; Topcu, A.E.; Alzoubi, Y.I. Remote Sensing Image Segmentation for Aircraft Recognition Using U-Net as Deep Learning Architecture. Appl. Sci. 2024, 14, 2639. https://doi.org/10.3390/app14062639
Shaar F, Yılmaz A, Topcu AE, Alzoubi YI. Remote Sensing Image Segmentation for Aircraft Recognition Using U-Net as Deep Learning Architecture. Applied Sciences. 2024; 14(6):2639. https://doi.org/10.3390/app14062639
Chicago/Turabian StyleShaar, Fadi, Arif Yılmaz, Ahmet Ercan Topcu, and Yehia Ibrahim Alzoubi. 2024. "Remote Sensing Image Segmentation for Aircraft Recognition Using U-Net as Deep Learning Architecture" Applied Sciences 14, no. 6: 2639. https://doi.org/10.3390/app14062639
APA StyleShaar, F., Yılmaz, A., Topcu, A. E., & Alzoubi, Y. I. (2024). Remote Sensing Image Segmentation for Aircraft Recognition Using U-Net as Deep Learning Architecture. Applied Sciences, 14(6), 2639. https://doi.org/10.3390/app14062639