
A Generative Artificial Intelligence Using Multilingual Large Language Models for ChatGPT Applications


Abstract
1. Introduction
- This research contributes to the discussion of how GenAI can be leveraged to maximum effect for SMEs.
- The proposed Expert-B GenAI model provides an effective and flexible basis for bespoke development and implementation of a GenAI-driven chatbot.
- The creation of a chatbot that can adapt to multiple languages; in this study, our focus is on Vietnamese and English.
- The adoption of open-source program code trained using the Expert-B model contributes to a reduction in training time and computational cost.
- The creation of bilingual instruction datasets for English and Vietnamese when combined with the Expert-B model trained using ‘Low-Rank Adaptation’ (LoRA) and ‘DeepSpeed’.
- In this study, we consider the development of a ‘bespoke’ domain-specific GenAI-driven chatbot for SMEs designed to automate question–response interactions.
- This research aims to address the problem by creating a GenAI model for a chatbot complete with a LLM [7] that can adapt to multiple languages (in this research the focus is on Vietnamese and English) for use in GenAI models suitable for resource limited SMEs.
- Turning to potential language difficulties, a multilingual chatbot can cater to the needs of customers who speak different languages [8].
- The proprietary GenAI models are highly resource intensive; by developing an approach that uses public resources combined with low computational costs, SMEs can also take advantage of GenAI chatbot technology.
2. Related Research
2.1. Generative Artificial Intelligence and Chatbots
2.2. Large Language Models and Chatbots
- There is a recognition by OpenAI (OpenAI: https://openai.com/ (accessed on 10 December 2023)) that ChatGPT “sometimes writes plausible sounding but incorrect or nonsensical answers”; a feature common to LLMs often termed “hallucination”. To address (or at least mitigate) hallucination, ChatGPT operates a reward model which is predicated on “human oversight”. However, the reward model can be over-optimised and thus hinder performance, which is an example of an optimisation pathology known as Goodhart’s law [46].
- ChatGPT has limited knowledge of events that occurred after September 2021 resulting in significant errors. Moreover, as discussed in Section 5.4, errors (e.g., inaccurate translation) can be the result of semantic misunderstanding or the language corpus.
- In training ChatGPT, human reviewers preferred longer answers, regardless of actual comprehension or factual content. Additionally, training data also suffers from algorithmic bias, which may be revealed when ChatGPT responds to prompts including descriptors of people. In one instance, ChatGPT generated a rap indicating that women and scientists of colour were inferior to white male scientists.
- In an attempt to mitigate plagiarism, it has been reported that OpenAI (for ChatGPT) has investigated using a digital watermark for text generation systems to combat “bad actors using their services for academic plagiarism or spam”.
3. The Proposed Expert-B Model
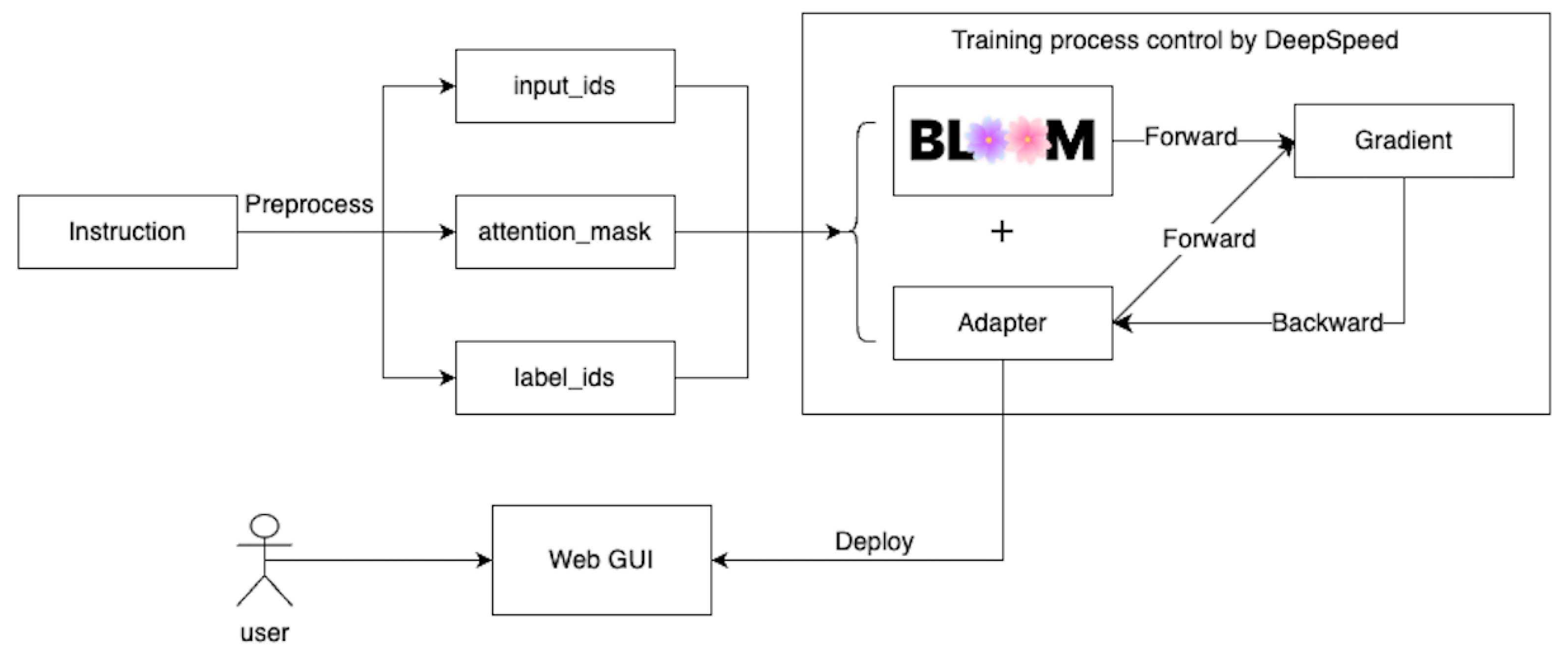
3.1. Overview
3.2. Input–Output
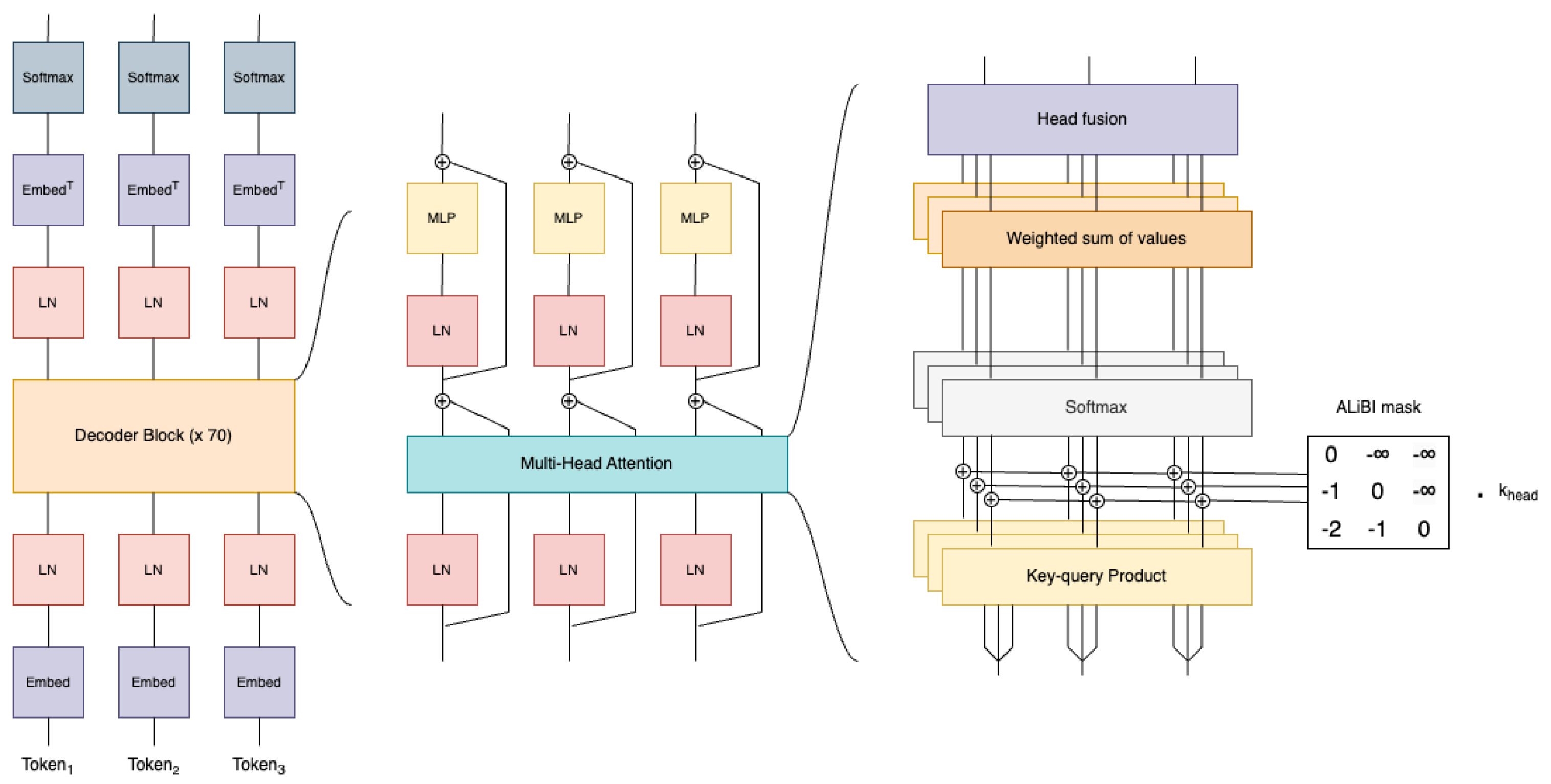
3.3. BLOOM
3.3.1. Architecture
3.3.2. Positional Embeddings
3.3.3. Embedding LayerNorm
3.4. Instruction Dataset
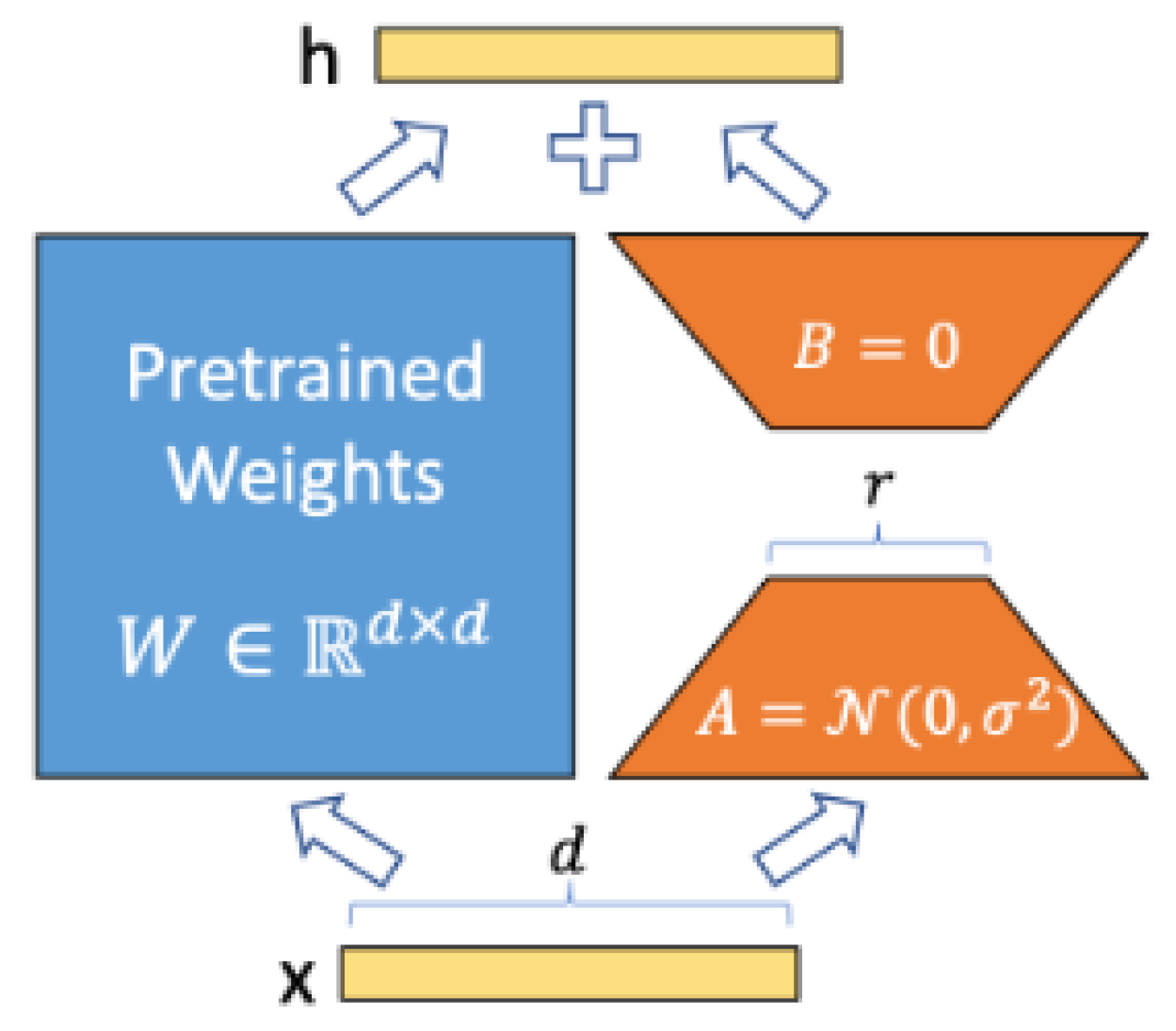
3.5. Low-Rank Adaptation
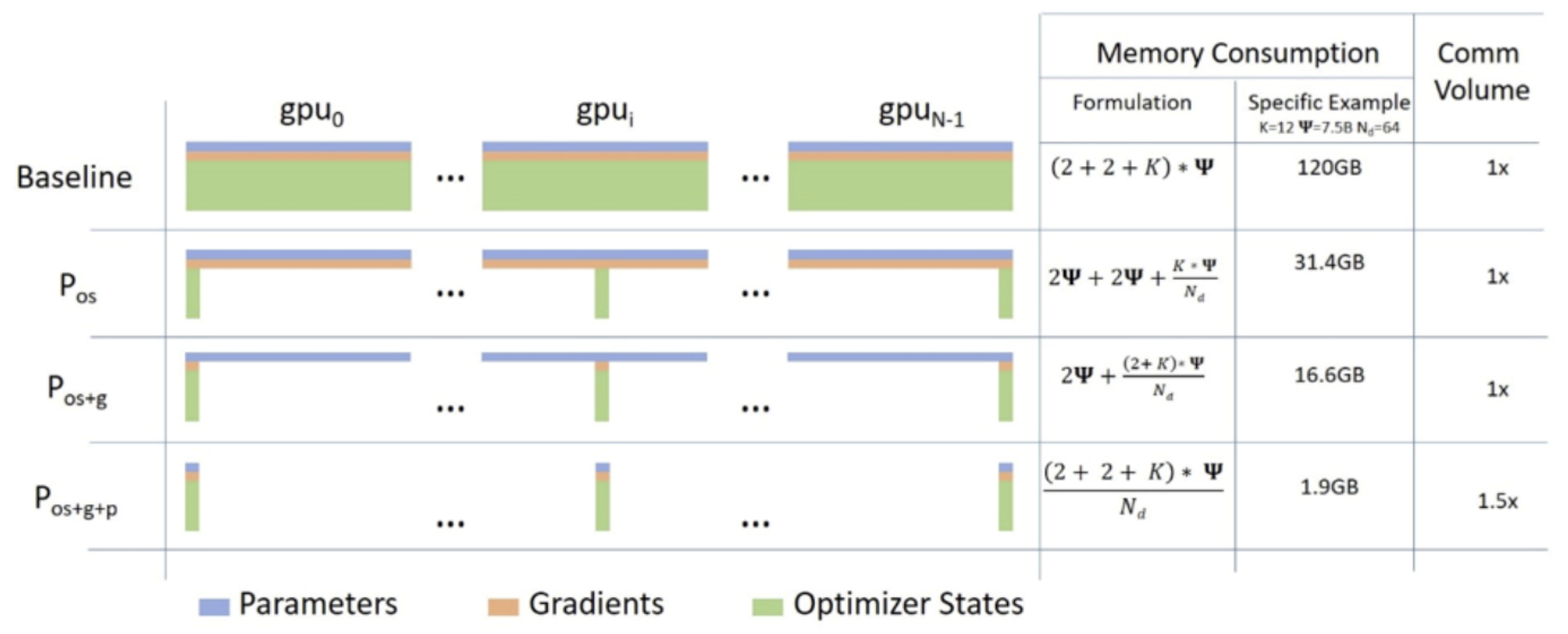
3.6. DeepSpeed
- State 1 (Optimiser States);
- State 2 (Optimiser States + Gradients);
- State 3 (Optimiser States + Gradients + Parameters).
3.7. Phoenix
- Multilingual Instruction: using the Alpaca instruction dataset as a seed, it was translated into various languages and then used with ’GPT-3.5-turbo’ API to generate answers in over 40 different languages.
- User-Centred Instruction: various samples in the form of role, instruction, and input were generated from multiple seeds, which were then passed through ‘GPT-3.5-turbo’ API to generate answers for each sample.
- Conversation: this dataset consists of conversation histories shared on the internet between people and ChatGPT, and each sample can contain multiple turns of consecutive conversation.
4. Experimental Testing
4.1. Training Objectives
- State 1 Map to contextual embeddings ;
- Step 2 Apply an embedding matrix to obtain scores for each token ;
- Step 3 Exponentiate and normalize it to produce the distribution over .
4.2. Theoretical Analysis
4.2.1. Low Rank Adaptation
4.2.2. DeepSpeed ZeRO-Offload
4.2.3. Evaluation Parameters
4.2.4. Simulation Method
4.2.5. Pre-Processing
Prompting
Word Segmentation and Encoding
Decoding Hyperparameters
Evaluation
5. Experimental Results
5.1. Case Study of English Benchmark
- When in a comparison with Phoenix [42] the result is greater than 1, it can be concluded that Expert-B outperformed Phoenix for the English benchmark. This observation is further supported by the category scores shown in Table 4 where our Expert-B model improved on the performance of Phoenix with a total score of 51 wins out of 80 categories, compared to Phoenix which achieved 29 wins.
- The regeneration method used to generate the study dataset has provided more detailed answers compared to the original method used by Alpaca [48]. This suggests that the performance of Expert-B in the English benchmark is even more impressive, as it was able to outperform Phoenix using more detailed answers. In particular, Expert-B dominates Phoenix in the remaining criteria categories, namely writing, knowledge, and generic, with Expert-B taking almost all of the scores in these categories.
- Overall, the results (see Table 4) suggest that Expert-B has a better performance than Phoenix in the English benchmark.
5.2. Case Study of Vietnamese’s Vicuna Benchmark
- The Phoenix model showed a better performance than Expert-B in some categories, particularly in coding and fermi. However, Expert-B demonstrated better performance in several other categories such as common-sense, counter-factual, and writing.
- The overall results for the two models for the Vietnamese benchmark were much closer than in the English benchmark, with the margin for the Phoenix model’s performance improvements being relatively small.
5.3. Case Study of VLSP Benchmark
- Bkai-foundation-models/vietnamese-llama2-7b-40 GB: This model is a LLaMA-2 variant, which has an extended vocabulary size in Vietnamese and has been pretrained on a Vietnamese corpus.
- SeaLLMs/SeaLLM-7B-v1 [58]: Multilingual LLM supported language in South-East Asia Countries, which achieved SOTA on a multi-SEA benchmark.
- Vinai/PhoGPT-7B5-Instruct [59]: A monolingual model that has been developed for an instruction following ability for chatbots operating in Vietnamese.
5.4. Analysis
5.4.1. Dataset
- The Vietnamese data generation process consists of two phases: using ’GPT-3.5-turbo’ API to translate instructions into Vietnamese, and then generating answers using the pipeline dataset introduced in part A.
- If the translated instructions are not semantically accurate and in line with the original Vietnamese, the resulting data can significantly affect the quality and accuracy of the translation. An example of the problem and the disadvantage of using the ‘GPT-3.5-turbo’ API for translation are shown in Figure 11 where the inaccurate (i.e., wrong) translation from English to Vietnamese is demonstrated. The translation shown in Figure 11 was carried out using the Bing Chat function in the Microsoft Edge browser Version 117.0.2045.47 (Official build) (64-bit).
- The inaccuracy is clear and is the result of a fundamental misunderstanding of the semantics in the question “Product of 3 and 5” where the word “product” relates to a mathematical function (i.e., “multiplication”). Frequently in translation software general English is handled well but scientific terms (not part of the language corpus) are incorrectly translated.
- For this study, we believe the reason for the incorrect translation is because Phoenix has a conversation dataset consisting of dialogue between users and ChatGPT with the resulting questions being clearer and created by actual human users. Such inaccuracies are all too common in translation software.
5.4.2. Parameter Efficient Fine-Tuning
5.4.3. Further Investigation Improvement
6. Discussion
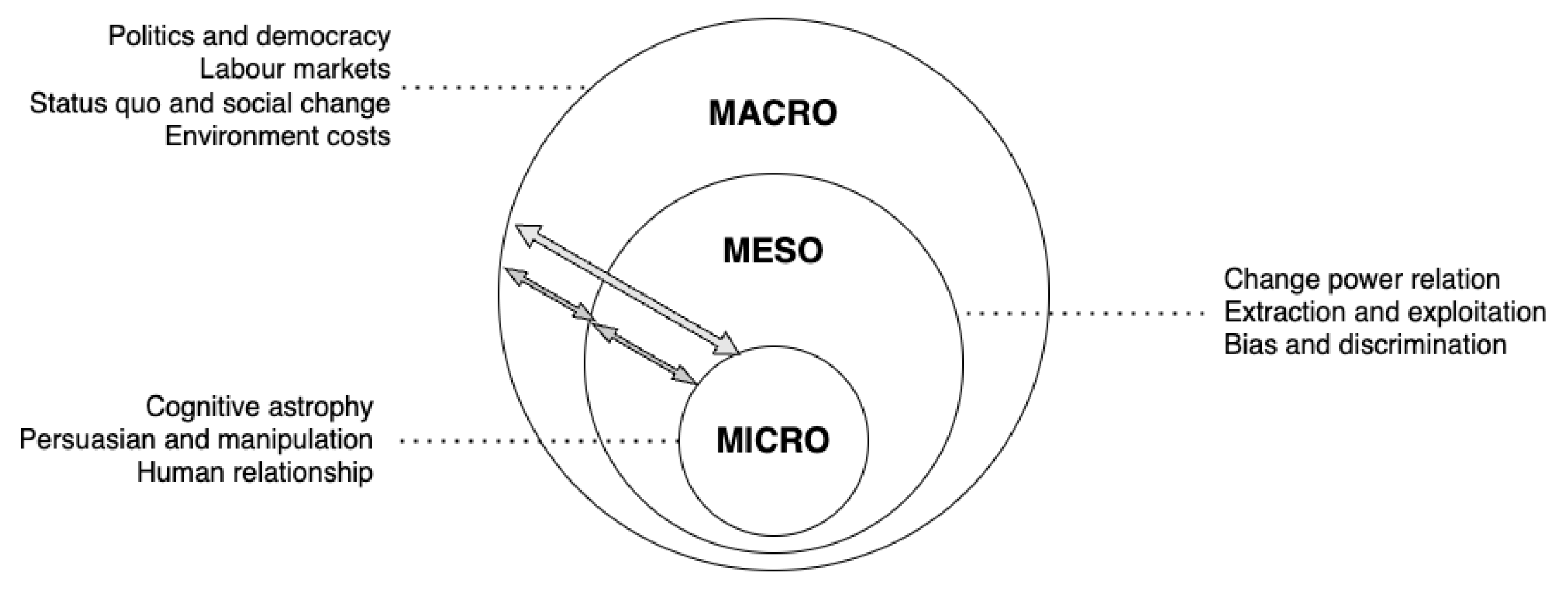
- Prevent them from sharing sensitive or inappropriate information;
- Ensure the safety and privacy of users;
- These considerations are essential to build trust in chatbots and enable their adoption
Open Research Questions
- A Reinforcement Learning from Human Feedback (RLHF) method can be designed to improve the quality and safety of chatbot responses. By receiving feedback on responses in the experiments, we can evaluate the usefulness, safety, and other aspects of each response and then develop a reward model to ensure the quality of the response.
- RLHF may be integrated into the chatbot training process with the chatbot generating responses based on its current model and users provide iterative feedback on the quality and safety of the responses. The chatbot can be trained using reinforcement learning algorithms to maximise the reward score assigned to each response, resulting in higher quality and safer responses.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Thomas, A.M.; Moore, P.; Evans, C.; Shah, H.; Sharma, M.; Mount, S.; Xhafa, F.; Pham, H.V.; Barolli, L.; Patel, A.; et al. Smart care spaces: Pervasive sensing technologies for at-home care. Int. J. Ad Hoc Ubiquitous Comput. 2014, 16, 268–282. [Google Scholar] [CrossRef]
- Pham, H.V.; Le Hoang, T.; Hung, N.Q.; Phung, T.K. Proposed Intelligent Decision Support System Using Hedge Algebra Integrated with Picture Fuzzy Relations for Improvement of Decision-Making in Medical Diagnoses. Int. J. Fuzzy Syst. 2023, 25, 3260–3270. [Google Scholar] [CrossRef]
- Christensen, C.M.; McDonald, R.; Altman, E.J.; Palmer, J.E. Disruptive Innovation: An Intellectual History and Directions for Future Research. J. Manag. Stud. 2018, 55, 1043–1078. [Google Scholar] [CrossRef]
- Van Pham, H.; Kinh Phung, T.; Hung, N.Q.; Dong, L.D.; Trung, L.T.; Dao, N.T.X.; Kieu, P.T.T.; Xuan, T.N. Proposed Distance and Entropy Measures of Picture Fuzzy Sets in Decision Support Systems. Int. J. Fuzzy Syst. 2023, 44, 6775–6791. [Google Scholar] [CrossRef]
- Pham, H.V.; Duong, P.V.; Tran, D.T.; Lee, J.-H. A Novel Approach of Voterank-Based Knowledge Graph for Improvement of Multi-Attributes Influence Nodes on Social Networks. J. Artif. Intell. Soft Comput. Res. 2023, 13, 165. [Google Scholar] [CrossRef]
- Pham, V.H.; Nguyen, Q.H.; Troung, V.P.; Tran, L.P.T. The Proposed Context Matching Algorithm and Its Application for User Preferences of Tourism in COVID-19 Pandemic. In Proceedings of the International Conference on Innovative Computing and Communications, Delhi, India, 19–20 February 2022; Volume 471. [Google Scholar] [CrossRef]
- Crosthwaite, P.; Baisa, V. Generative AI and the end of corpus-assisted data-driven learning? Not so fast! Appl. Corpus Linguist. 2023, 3, 100066. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; Volume 2: Short Papers, pp. 61–68. [Google Scholar] [CrossRef]
- Marjanovic, O.; Skaf-Molli, H.; Molli, P.; Godart, C. Collaborative practice-oriented business processes Creating a new case for business process management and CSCW synergy. In Proceedings of the 2007 International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom 2007), New York, NY, USA, 12–15 November 2007; pp. 448–455. [Google Scholar]
- Clarysse, B.; He, V.F.; Tucci, C.L. How the Internet of Things reshapes the organization of innovation and entrepreneurship. Technovation 2022, 118, 102644. [Google Scholar] [CrossRef]
- Puranam, P.; Alexy, O.; Reitzig, M. What’s “New” About New Forms of Organizing? Acad. Manag. Rev. 2014, 39, 162–180. [Google Scholar] [CrossRef]
- Hagendorff, T.; Fabi, S.; Kosinski, M. Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT. Nat. Comput. Sci. 2023, 3, 833–838. [Google Scholar] [CrossRef]
- Anam Nazir, Z.W. A comprehensive survey of ChatGPT: Advancements, applications, prospects, and challenges. Meta-Radiol. 2023, 1, 100022. [Google Scholar] [CrossRef]
- López Espejel, J.; Ettifouri, E.H.; Yahaya Alassan, M.S.; Chouham, E.M.; Dahhane, W. GPT-3.5, GPT-4, or BARD? Evaluating LLMs reasoning ability in zero-shot setting and performance boosting through prompts. Nat. Lang. Process. J. 2023, 5, 100032. [Google Scholar] [CrossRef]
- Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilić, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. BLOOM A 176B-Parameter Open-Access Multilingual Language Model. arXiv 2022, arXiv:2211.05100. [Google Scholar] [CrossRef]
- Laurençon, H.; Saulnier, L.; Wang, T.; Akiki, C.; Villanova del Moral, A.; Le Scao, T.; Von Werra, L.; Mou, C.; González Ponferrada, E.; Nguyen, H.; et al. The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset. In Proceedings of the Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: New York, NY, USA, 2022; Volume 35, pp. 31809–31826. [Google Scholar]
- Sun, X.; Ji, Y.; Ma, B.; Li, X. A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model. arxiv 2023, arXiv:2304.08109. [Google Scholar]
- Fosso Wamba, S.; Queiroz, M.M.; Chiappetta Jabbour, C.J.; Shi, C.V. Are both generative AI and ChatGPT game changers for 21st-Century operations and supply chain excellence? Int. J. Prod. Econ. 2023, 265, 109015. [Google Scholar] [CrossRef]
- Varghese, J.; Chapiro, J. ChatGPT: The transformative influence of generative AI on science and healthcare. J. Hepatol. 2023, 80. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. Opinion Paper: “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Eke, D.O. ChatGPT and the rise of generative AI: Threat to academic integrity? J. Responsible Technol. 2023, 13, 100060. [Google Scholar] [CrossRef]
- Evans, O.; Wale-Awe, O.; Osuji, E.; Ayoola, O.; Alenoghena, R.; Adeniji, S. ChatGPT impacts on access-efficiency, employment, education and ethics: The socio-economics of an AI language model. BizEcons Q. 2023, 16, 1–17. [Google Scholar]
- Baidoo-Anu, D.; Owusu Ansah, L. Education in the era of generative artificial intelligence (AI): Understanding the potential benefits of ChatGPT in promoting teaching and learning. SSRN 2023. [Google Scholar] [CrossRef]
- Sætra, H.S. Generative AI: Here to stay, but for good? Technol. Soc. 2023, 75, 102372. [Google Scholar] [CrossRef]
- Alabool, H.M. ChatGPT in Education: SWOT analysis approach. In Proceedings of the 2023 International Conference on Information Technology (ICIT), Amman, Jordan, 9–10 August 2023; pp. 184–189. [Google Scholar] [CrossRef]
- Utterback, J.M.; Acee, H.J. Disruptive technologies: An expanded view. Int. J. Innov. Manag. 2005, 9, 1–17. [Google Scholar] [CrossRef]
- Christensen, C.; Raynor, M.E.; McDonald, R. Disruptive Innovation; Harvard Business Review: Brighton, MA, USA, 2013. [Google Scholar]
- Fleck, J.; Howells, J. Technology, the Technology Complex and the Paradox of Technological Determinism. Technol. Anal. Strateg. Manag. 2001, 13, 523–531. [Google Scholar] [CrossRef]
- Wyatt, S. Technological determinism is dead; long live technological determinism. In The Handbook of Science and Technology Studies; MIT Press: Cambridge, MA, USA, 2008; Volume 3, pp. 165–180. [Google Scholar]
- Hallström, J. Embodying the past, designing the future: Technological determinism reconsidered in technology education. Int. J. Technol. Des. Educ. 2020, 32, 17–31. [Google Scholar] [CrossRef]
- Sandrini, L.; Somogyi, R. Generative AI and deceptive news consumption. Econ. Lett. 2023, 232, 111317. [Google Scholar] [CrossRef]
- Möslein, K.M.; Neyer, A.K. Disruptive Innovation. In Wiley Encyclopedia of Management; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 1–3. [Google Scholar] [CrossRef]
- Markides, C. Disruptive Innovation: In Need of Better Theory. J. Prod. Innov. Manag. 2006, 23, 19–25. [Google Scholar] [CrossRef]
- Mackenzie, D. Surprising Advances in Generative Artificial Intelligence Prompt Amazement—And Worries. Engineering 2023, 25, 9–11. [Google Scholar] [CrossRef]
- Checkland, P.; Holwell, S. Information, Systems and Information Systems: Making Sense of the Field; John Wiley and Sons: Chichester, UK, 1997. [Google Scholar]
- Lybaert, C.; Van Hoof, S.; Deygers, B. The influence of ethnicity and language variation on undergraduates’ evaluations of Dutch-speaking instructors in Belgium: A contextualized speaker evaluation experiment. Lang. Commun. 2022, 84, 1–19. [Google Scholar] [CrossRef]
- Li, M.; Wang, R. Chatbots in e-commerce: The effect of chatbot language style on customers’ continuance usage intention and attitude toward brand. J. Retail. Consum. Serv. 2023, 71, 103209. [Google Scholar] [CrossRef]
- Xin, D.; Mao, J.; Liu, M. The Effects of Parasocial Relationships in the Adoption of Mobile Commerce Application: A Conceptual Model. In Proceedings of the 2010 International Conference on E-Business and E-Government, Guangzhou, China, 7–9 May 2010; pp. 149–152. [Google Scholar] [CrossRef]
- Li, R.Y.; Lin, S. Stages of Concern and Parasocial Interaction: Perception, Attitude, and Adoption of Social Media. In Proceedings of the 2018 1st IEEE International Conference on Knowledge Innovation and Invention (ICKII), Jeju, Republic of Korea, 23–27 July 2018; pp. 362–364. [Google Scholar] [CrossRef]
- Hanief, S.; Handayani, P.W.; Azzahro, F.; Pinem, A.A. Parasocial Relationship Analysis on Digital Celebrities Follower’s Purchase Intention. In Proceedings of the 2019 2nd International Conference of Computer and Informatics Engineering (IC2IE), Banyuwangi, Indonesia, 10–11 September 2019; pp. 12–17. [Google Scholar] [CrossRef]
- Chen, W.K.; Wen, H.Y.; Silalahi, A.D.K. Parasocial Interaction with YouTubers: Does Sensory Appeal in the YouTubers’ Video Influences Purchase Intention? In Proceedings of the 2021 IEEE International Conference on Social Sciences and Intelligent Management (SSIM), Taichung, Taiwan, 29–31 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, F.; Chen, J.; Wang, T.; Yu, F.; Chen, G.; Zhang, H.; Liang, J.; Zhang, C.; Zhang, Z.; et al. Phoenix: Democratizing ChatGPT across Languages. arXiv 2023, arXiv:2304.10453. [Google Scholar]
- Kohnke, L.; Moorhouse, B.L.; Zou, D. Exploring generative artificial intelligence preparedness among university language instructors: A case study. Comput. Educ. Artif. Intell. 2023, 5, 100156. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, A.; Lim, C.P. Reconceptualizing ChatGPT and generative AI as a student-driven innovation in higher education. Procedia CIRP 2023, 119, 84–90. [Google Scholar] [CrossRef]
- Yilmaz, R.; Karaoglan Yilmaz, F.G. The effect of generative artificial intelligence (AI)-based tool use on students’ computational thinking skills, programming self-efficacy and motivation. Comput. Educ. Artif. Intell. 2023, 4, 100147. [Google Scholar] [CrossRef]
- Thomas, R.L.; Uminsky, D. Reliance on metrics is a fundamental challenge for AI. Patterns 2022, 3, 100476. [Google Scholar] [CrossRef] [PubMed]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T. Stanford Alpaca: A Strong, Replicable Instruction-Following Model; Center for Research on Foundation Models, Stanford University: Stanford, CA, USA, 2023. [Google Scholar]
- Aghajanyan, A.; Zettlemoyer, L.; Gupta, S. Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. arXiv 2020, arXiv:2012.13255. [Google Scholar]
- Ren, J.; Rajbhandari, S.; Aminabadi, R.Y.; Ruwase, O.; Yang, S.; Zhang, M.; Li, D.; He, Y. ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv 2021, arXiv:2101.06840. [Google Scholar]
- Press, O.; Smith, N.A.; Lewis, M. Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. arXiv 2022, arXiv:2108.12409. [Google Scholar]
- Hu, E.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. arXiv 2022, arXiv:2106.09685. [Google Scholar]
- Han, S.J.; Ransom, K.J.; Perfors, A.; Kemp, C. Inductive reasoning in humans and large language models. Cogn. Syst. Res. 2024, 83, 101155. [Google Scholar] [CrossRef]
- Kunst, J.R.; Bierwiaczonek, K. Utilizing AI questionnaire translations in cross-cultural and intercultural research: Insights and recommendations. Int. J. Intercult. Relations 2023, 97, 101888. [Google Scholar] [CrossRef]
- Zheng, L.; Chiang, W.L.; Sheng, Y.; Zhuang, S.; Wu, Z.; Zhuang, Y.; Lin, Z.; Li, Z.; Li, D.; Xing, E.P.; et al. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. arXiv 2023, arXiv:2306.05685. [Google Scholar]
- Cuong, L.A.; Hieu, N.T.; Cuong, N.V.; Que, N.N.; Nguyen, L.-M.; Nguyen, C.-T. Vlsp 2023 Challenge on Vietnamese Large Language Models 2023. 2023. Available online: https://vlsp.org.vn/vlsp2023/eval/vllm (accessed on 30 March 2024).
- Beeching, E.; Fourrier, C.; Habib, N.; Han, S.; Lambert, N.; Rajani, N.; Sanseviero, O.; Tunstall, L.; Wolf, T. Open LLM Leaderboard. 2023. Available online: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard (accessed on 30 March 2024).
- Nguyen, X.; Zhang, W.; Li, X.; Aljunied, M.; Tan, Q.; Cheng, L.; Chen, G.; Deng, Y.; Yang, S.; Liu, C.; et al. SeaLLMs—Large Language Models for Southeast Asia. arXiv 2023, arXiv:2312.00738. [Google Scholar]
- Nguyen, D.Q.; Nguyen, L.T.; Tran, C.; Nguyen, D.N.; Phung, D.; Bui, H. PhoGPT: Generative Pre-training for Vietnamese. arXiv 2023, arXiv:2311.02945. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar]
- Martínez-Plumed, F.; Gómez, E.; Hernándetz-Orallo, J. Futures of artificial intelligence through technology readiness levels. Telemat. Inform. 2021, 58, 101525. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
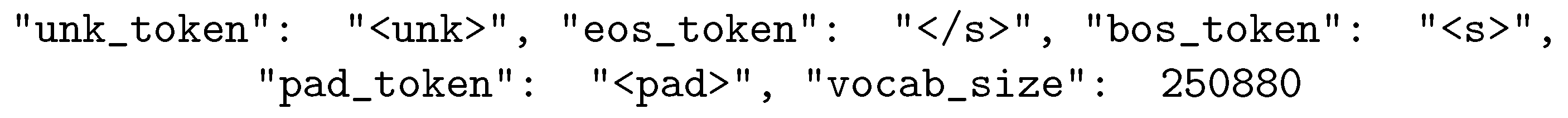{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | BLOOM-560M | BLOOM-1.1B | BLOOM-1.7B | BLOOM-3B | BLOOM-7.1B | BLOOM |
|---|---|---|---|---|---|---|
| Architecture Hyperparameters | ||||||
| Parameters | 559 M | 1065 M | 1722 M | 3003 M | 7069 M | 176,247 M |
| Precision | float16 | bfloat16 | ||||
| Layers | 24 | 24 | 24 | 30 | 30 | 70 |
| Hidden dim | 1024 | 1536 | 2048 | 2560 | 4096 | 14,336 |
| Attention Heads | 16 | 16 | 16 | 32 | 32 | 112 |
| Vocab size | 250,680 | |||||
| Sequence length | 2048 | |||||
| Activation | GELU | |||||
| Position emb | ALiBi | |||||
| Tied emb | TRUE | |||||
| Time/Epoch | Global Batch Size | Memory | |
|---|---|---|---|
| BLOOM | 54 h | 1 | 39 GB |
| BLOOM + LoRA | 4 h | 1 | 39 GB |
| BLOOM + LoRA + DeepSpeed | 4 h | 1 | 36 GB |
| BLOOM + LoRA + DeepSpeed | 3 h | 2 | 39.5 GB |
| Performance Ratio | English | Vietnamese |
|---|---|---|
| Expert-B vs. Phoenix | 107, 89 | 96, 73 |
| English | Vietnamese | ||||
|---|---|---|---|---|---|
| Categorical | Phoenix | Expert-B | Total | Phoenix | Expert-B |
| coding | 5 | 2 | 7 | 6 | 1 |
| common-sense | 2 | 8 | 10 | 4 | 6 |
| counter-factual | 4 | 6 | 6 | 4 | |
| fermi | 9 | 1 | 10 | 8 | 2 |
| generic | 2 | 8 | 10 | 5 | 5 |
| knowledge | 1 | 9 | 10 | 3 | 7 |
| math | 1 | 2 | 3 | 3 | 0 |
| roleplay | 4 | 6 | 10 | 4 | 6 |
| writing | 1 | 9 | 10 | 5 | 5 |
| Total wins | 29 | 51 | 80 | 44 | 36 |
| Model | arc_vi | hellaswag_vi | mmlu_vi | truthfulqa_vi | Average |
|---|---|---|---|---|---|
| vinai/PhoGPT-7B5-Instruct | 26.41 | 40.55 | 26.24 | 45.82 | 34.76 |
| bkai-foundation-models/vietnamese-llama2-7b-40GB | 29.49 | 43.92 | 33.83 | 45.28 | 38.13 |
| sealion-7b | 27.01 | 48.33 | 26.50 | 42.77 | 36.15 |
| Expert-B | 33.68 | 49.10 | 35.57 | 51.4 | 42.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tuan, N.T.; Moore, P.; Thanh, D.H.V.; Pham, H.V. A Generative Artificial Intelligence Using Multilingual Large Language Models for ChatGPT Applications. Appl. Sci. 2024, 14, 3036. https://doi.org/10.3390/app14073036
Tuan NT, Moore P, Thanh DHV, Pham HV. A Generative Artificial Intelligence Using Multilingual Large Language Models for ChatGPT Applications. Applied Sciences. 2024; 14(7):3036. https://doi.org/10.3390/app14073036
Chicago/Turabian StyleTuan, Nguyen Trung, Philip Moore, Dat Ha Vu Thanh, and Hai Van Pham. 2024. "A Generative Artificial Intelligence Using Multilingual Large Language Models for ChatGPT Applications" Applied Sciences 14, no. 7: 3036. https://doi.org/10.3390/app14073036
APA StyleTuan, N. T., Moore, P., Thanh, D. H. V., & Pham, H. V. (2024). A Generative Artificial Intelligence Using Multilingual Large Language Models for ChatGPT Applications. Applied Sciences, 14(7), 3036. https://doi.org/10.3390/app14073036