In this section, our experimental study is presented to demonstrate the effectiveness of FEAT.
Section 5.1 outlines the experimental environment.
Section 5.2 describes the primary settings and research objectives of the experiments.
Section 5.3 presents the main experimental results.
Section 5.4 showcases the ablation study results, primarily focusing on the design functionalities of various components within the algorithm.
5.1. Domain Description
The experimental environment utilized in this study is identified as the Pursuit Domain, which is a setting where numerous studies about the AHT problem have been undertaken. A variant of the Pursuit Domain similar to that utilized by Xing et al. [
12] is employed, with the distinction that in the present environment, a reward of 1 is awarded only when both predators capture the same prey simultaneously, contrasting with their setting, where a reward of 1 is given as soon as one predator captures the prey.
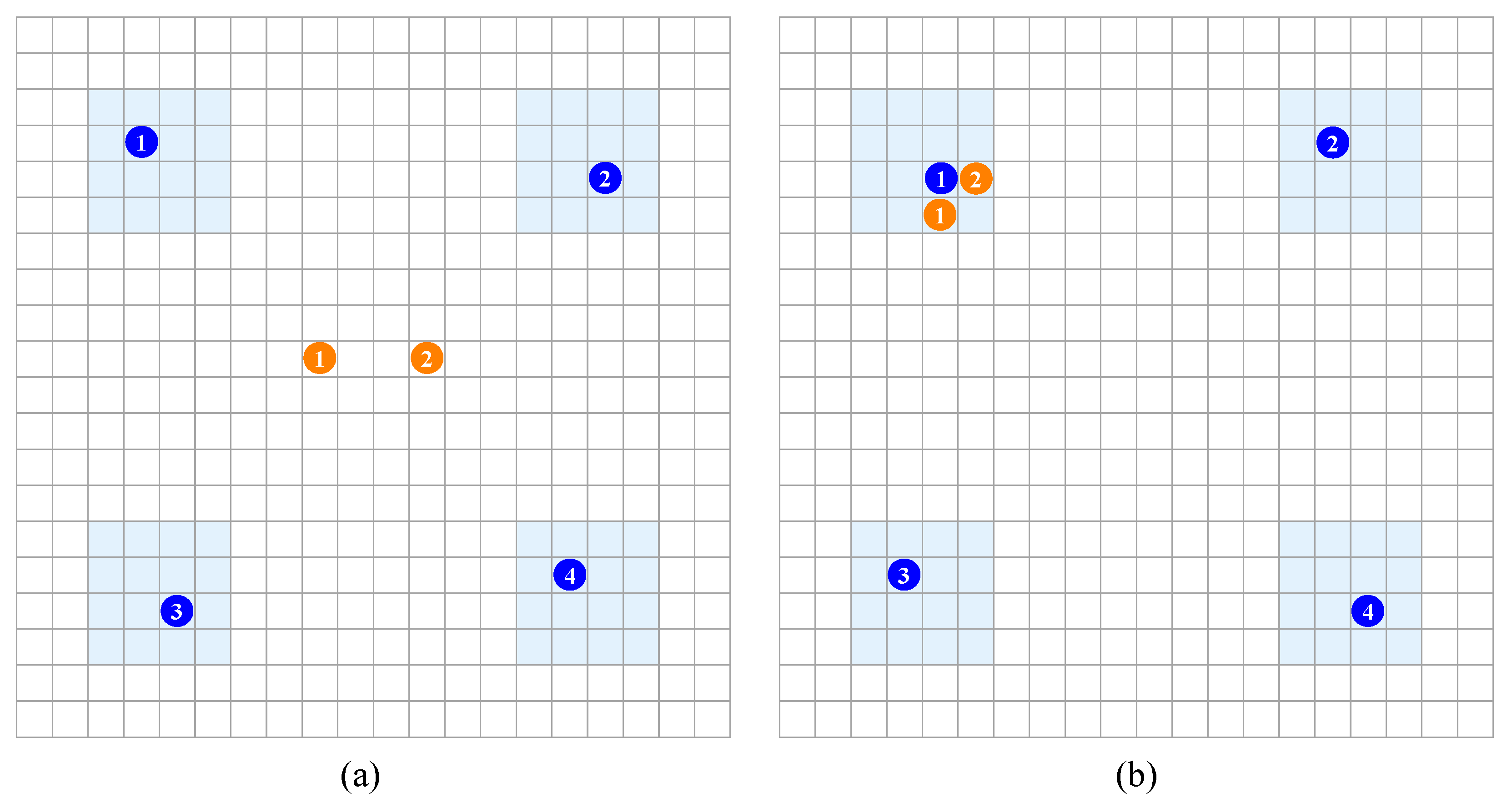
The experimental environment is depicted in
Figure 3a. The map comprises a 20 × 20 square grid, representing a toroidal world. Four light blue regions are present on the map, each hosting one prey that is restricted to move randomly within the confines of its respective region. Two predators are randomly placed at the center of each region with the objective of simultaneously capturing one of the four prey. If a predator occupies one of the four adjacent squares around a prey, the prey is considered captured by that predator, as depicted in
Figure 3b. Subsequently, the predator and prey maintain their positions for the next time step.
The objective of this experimental setting is for two predators to capture a prey simultaneously. A successful capture yields a reward of 1, whereas capturing different prey or exceeding the maximum game steps results in a reward of −1. For all other scenarios, no reward is awarded, defining it as a sparse-reward environment. The task terminates when one of the following conditions is met:
Both predators simultaneously capture the same prey;
Both predators capture different prey;
The task execution steps exceed the maximum step length of the environment.
Predators have five potential actions: moving up, down, left, right, or staying stationary. Movement order for the predators is determined randomly, and should an obstacle obstruct the intended destination, they will remain stationary. Observations encompass their own positions, their teammate’s position, and the position of the nearest prey.
5.2. Experiment Setup
To evaluate the effectiveness of our method, we select PLASTIC-Policy [
9], a highly representative method among type-based approaches within the PLASTIC algorithm. We excluded PLASTIC-Model, another variant within the PLASTIC algorithm, due to its requirement for an accurate model of the environment, which is unavailable in our experiments. Subsequently, we selected the EDRQN [
12] algorithm, representing type-free approaches. In brief, the configuration for the compared algorithms is established as follows:
FEAT: The algorithm proposed in this paper;
PLASTIC-: An implementation of a typical type-based algorithm PLASTIC-Policy under the setting of leveraging a constrained set of types as the known teammate types, on the online testing phase;
PLASTIC-: An implementation of a typical type-based algorithm PLASTIC-Policy under the setting of leveraging the diverse type repository
obtained in
Section 4.2 as the known teammate types, on the online testing phase;
EDRQN: A representative type-free algorithm that the ad hoc agent learns a policy demonstrating diverse behaviors without utilizing any knowledge about known types in the pre-training phase. Subsequently, during the online testing phase, the agent directly cooperates with its teammates;
Random: A baseline wherein the ad hoc agent selects actions randomly at each time step, establishing the lower bound for experimental performance.
This study supplies sets of known teammate types numbered 2, 3, and 4, with their performances documented in
Table 1. At the end of each episode, the teammates collaborating with the ad hoc agent are switched. Additionally, during the online testing phase, we established three configurations for teammate scenarios:
In: Possible teammate types are within ;
In: Possible teammate types are within ;
NFIn: Possible teammate policies are not fully within .
The results of the experiments are detailed in
Section 5.3.
5.3. Main Results
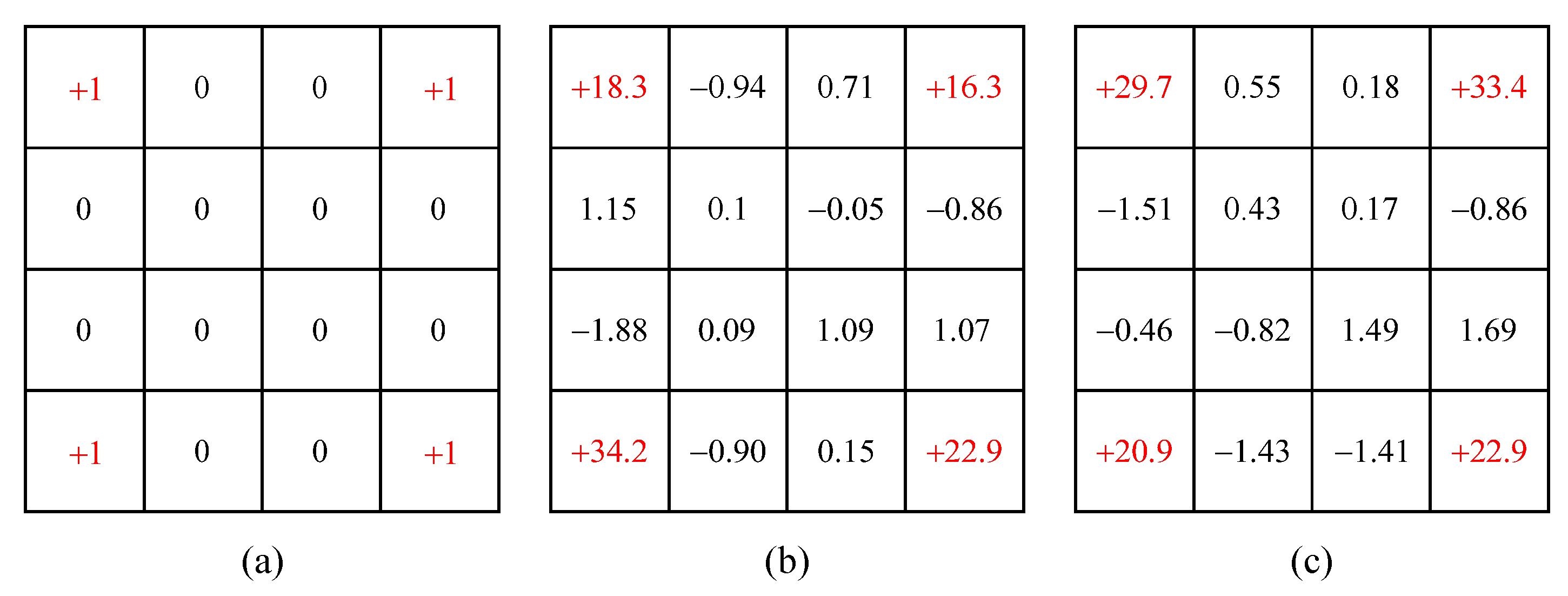
Leveraging prior knowledge from a range of known types, a total of 35 types were generated. The quantity of these types within the constructed type repository is detailed in
Table 2a. Within this table,
denotes the known types,
the type repository generated by the algorithm, and
the externally supplied types of teammates required for collaboration. During the testing phase for various algorithms, combinations involving the known teammate type repository and the required types for collaboration are detailed in
Table 2b. It is noteworthy that neither the EDRQN nor the random algorithms require known teammate types. Additionally, the approach for selecting teammates during testing aligns with that of the aforementioned algorithms.
In the testing phase, we implemented a sampling method without replacement to select a type of teammate from
for collaboration in each episode. Each algorithm and teammate executed ten collaborative interactions, except for EDRQN, which participated in fifty. Based on this methodology, we calculated the win ratios of the ad hoc agent and the average number of steps required to successfully complete their tasks. The detailed results are presented in
Table 3 and
Table 4.
As demonstrated in
Table 3 and
Table 4, the FEAT algorithm exhibits superior performance and robust stability across various experimental setups. It facilitates efficient teamwork even without constraining the actions of teammates to achieve optimality.
The PLASTIC algorithm exhibits high performance when the actual types of teammates fall within a known type repository, as demonstrated by PLASTIC- (In) and PLASTIC- (In, In). However, as the diversity of cooperating teammate types increases, there is a tendency for the performance of the PLASTIC algorithm to decline. This improvement in algorithmic performance from PLASTIC- to PLASTIC- underscores the benefits of automatically generating a diverse type repository.
The EDRQN algorithm displays a lack of stability, as evidenced by its performance in the test with N = 2(In), where the standard deviation of its win rate reached 34.70%. The algorithm’s performance deteriorates significantly when the collaborating agents’ policies are suboptimal. For instance, in fifty collaborations with an agent whose average task completion steps amounted to 43.65, the win rate stood at merely 40%. However, as the diversity of tested teammate types increased, there was an improvement in the win rate. This improvement can be attributed to the increased presence of optimal policy-using teammates in the , resulting in a higher win rate for the EDRQN agents. The findings indicate that the EDRQN algorithm tends to train policies that are responsive to optimal actions by teammates, resulting in poor performance when coupled with suboptimal or inferior teammates. Furthermore, the black-box form of the collaboration policies encountered by the ad hoc agents throughout the pre-training process complicates the comprehensive types of coverage assessment.
The random algorithm acts as the experimental performance baseline, where task completions occur coincidentally.
5.4. Ablation Results
The ablation experiments in this section indicate that each module designed in our experiments contributes to the final experimental outcomes. The issues we aim to explore in the ablation experiments include the following:
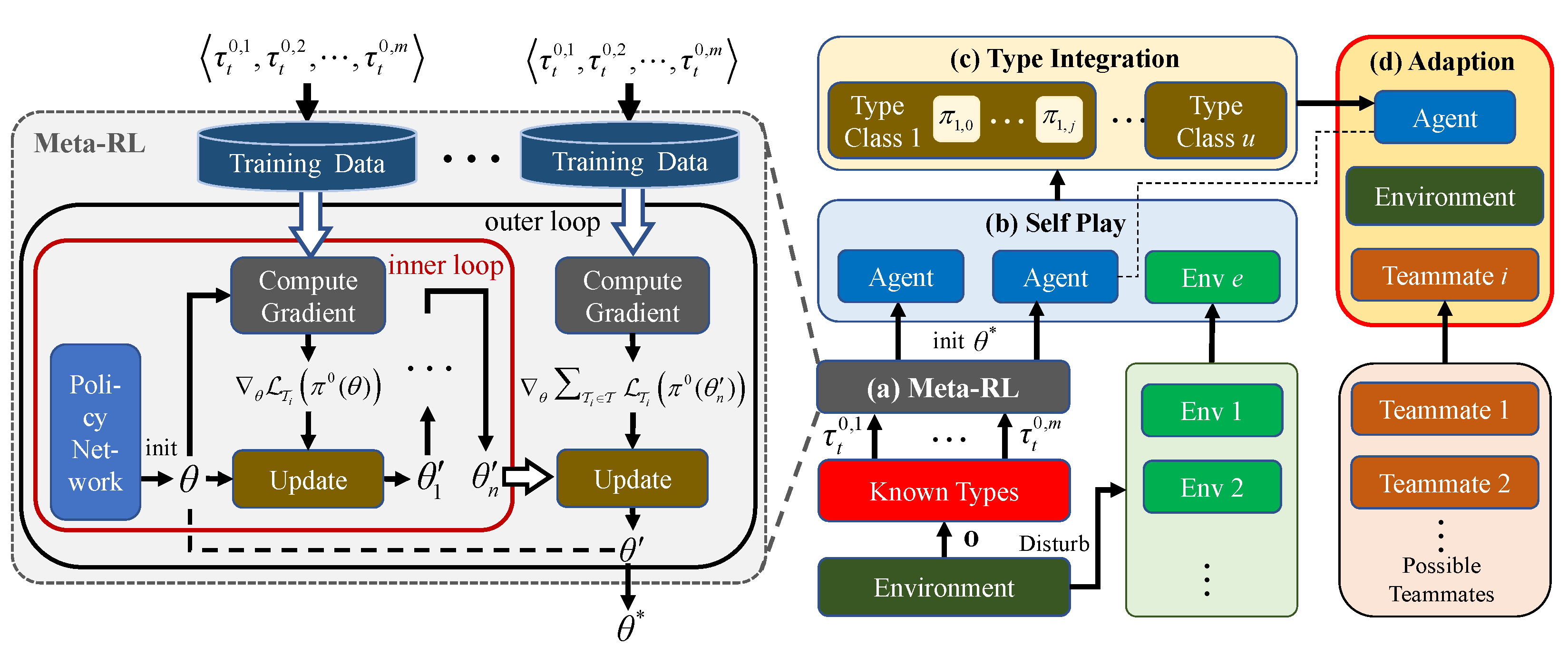
What level of performance does the initially generated Meta-RL policy exhibit?
Does the type repository generated by the Meta-RL policy exhibit diversity and offer an advantage over self-play with the randomly initialized policy in terms of type generation?
What is the performance level of our method in the absence of automatic generation of a substantial type repository?
How significant is the contribution of the module that imitates the current behavior of teammates during an episode?
Initially, to better demonstrate the effectiveness of our experiment, we made tiny adjustments to the environment for this experiment. The environment does not terminate automatically when two predators capture different prey. For example, if both predators capture different prey at the 100th time step, a single predator would accumulate a reward of . Likewise, if both predators capture different prey at the 50th time step, a single predator would accumulate a reward of .
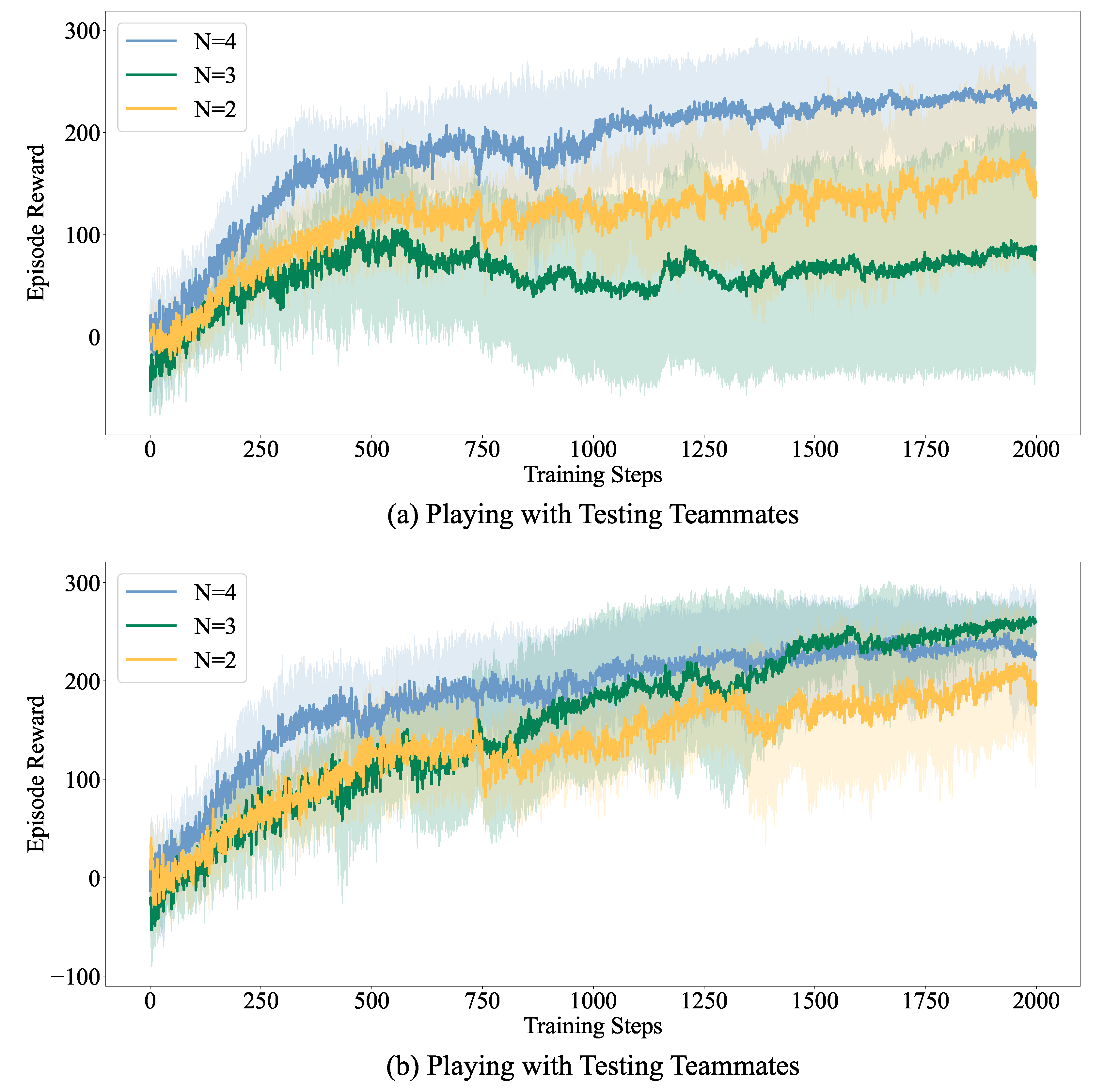
In question 1, we pre-trained the Meta-RL policy using prior knowledge about a predefined number of
N types and evaluated them on a diverse group of 45 teammates with varying performance levels. The results are depicted in
Figure 4. We set
,
, and
, with teammate performance configurations matching those in
Table 1.
As depicted in
Figure 4, testing rewards steadily improve and converge as training steps increase. Obviously, there is an improvement in policy performance after a gradient descent.
Figure 4b clearly indicates that the Meta-RL policy trained with
demonstrates superior performance compared to
and
, with
showing the weakest performance. This suggests that the Meta-RL policy exhibits a parameter-sensitive characteristic, requiring minimal samples and iterations to collaborate effectively with unknown teammates. Furthermore, enhancing pre-training with a broader range of known teammate types can significantly enhance their performance in collaborating with unknown teammates.
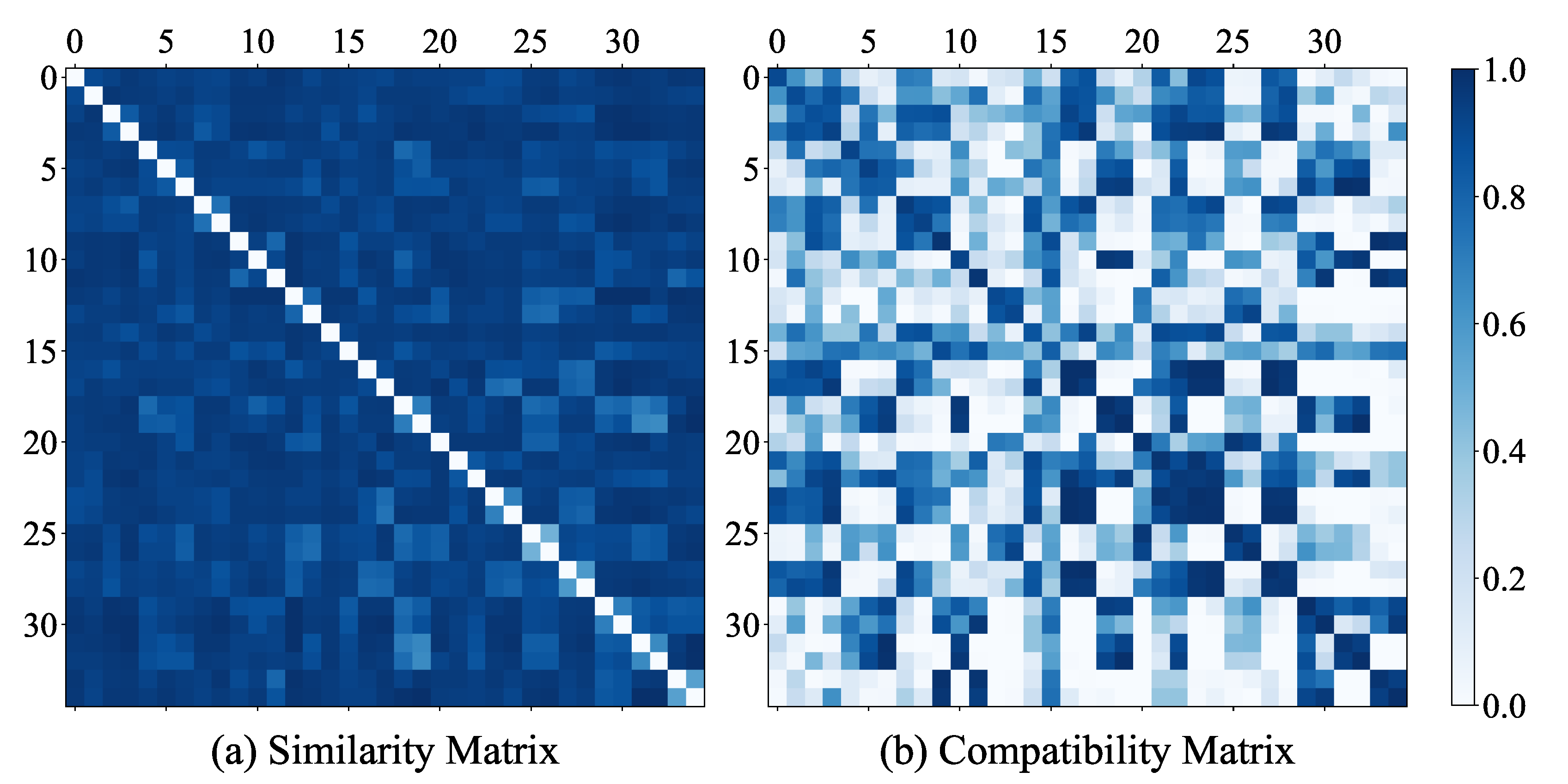
In problem 2, using the policies obtained from
, we acquired an additional 35 types to construct the type repository
. We assessed the type repository using the similarity and compatibility metrics outlined in
Section 4.2. The visualization of similarity and compatibility results is shown in
Figure 5. Herein, the diagonal denotes the outcome of self-play within the same type, indicating the highest similarity and compatibility. The analysis reveals that the types exhibit a moderate level of similarity and substantial differences in compatibility. Furthermore, types with high compatibility tend to have greater similarity, as shown by
and
. This demonstrates the diversity of the type repository.
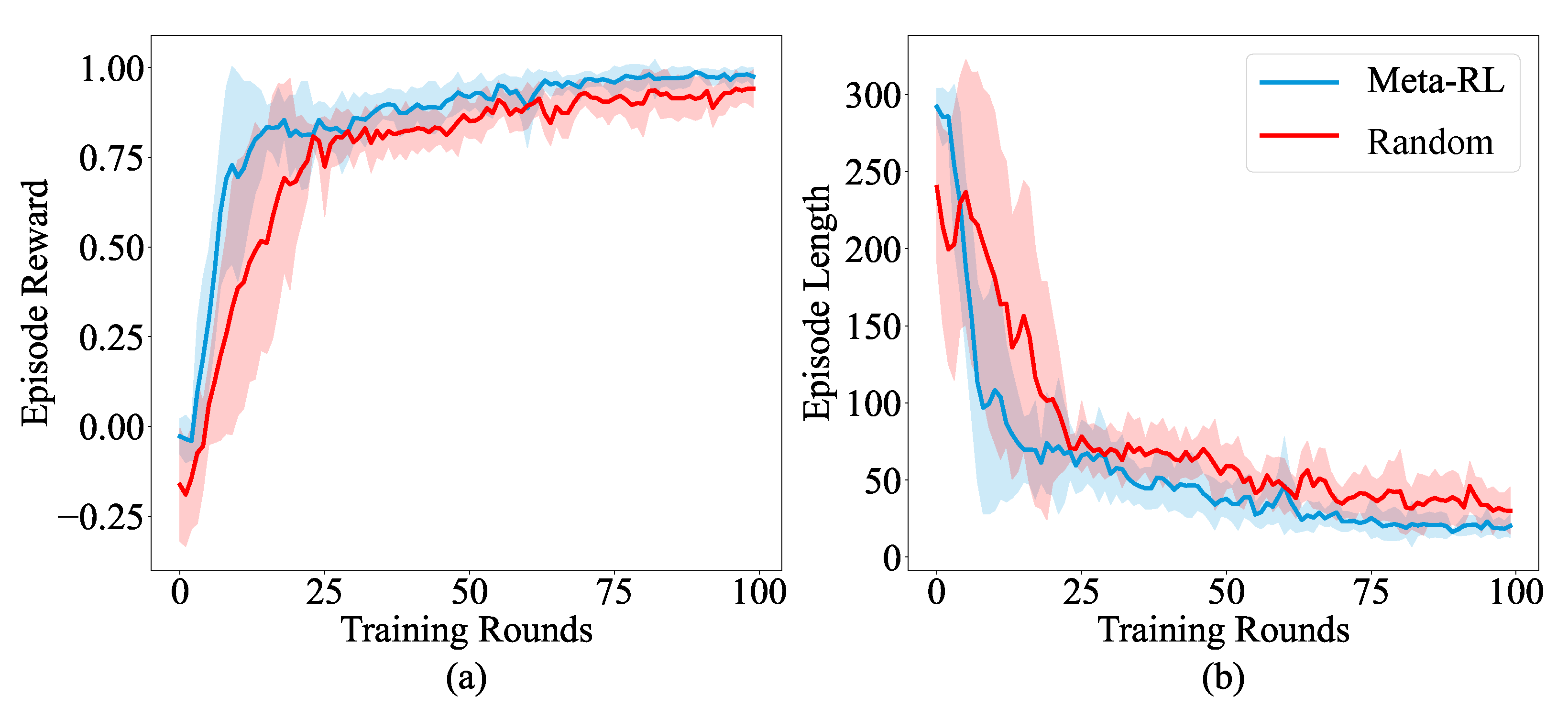
Next, we contrasted the performance of self-play in the environment using policies initialized with the Meta-RL policies and randomly initialized policies using the PPO algorithm, as shown in
Figure 6. The reward configuration corresponds to the environment before adjustments were made. The graph clearly shows that the Meta-RL policy requires fewer steps and achieves higher efficiency in obtaining a reliable policy.
For problem 3, we did not utilize the automatically generated diverse type repository
or utilize the Bayesian formula to identify the actual type of teammates during ad hoc collaboration. The performance of the algorithm is illustrated in
Table 5. A total of 67 possible teammates are in
. Despite this, the algorithm achieves a high success rate and completes tasks in a relatively short number of steps. Moreover, as the number and diversity of known teammate types increase, the algorithm’s performance gradually improves. This improvement can be attributed to the enhanced generalization of the Meta-RL policy, enabling the algorithm to better adapt to unknown teammates.
Regarding problem 4, we initiated the ad hoc agent using known teammate types with
. The agent collaborated with various teammates in the environment for ten episodes and we randomly sampled one of them, which had more than 50 time steps. Throughout this process, we did not utilize the teammate type identification module. Before each episode, the ad hoc agent’s policy was reinitialized using the Meta-RL policy. We sampled 20 trajectories of the ad hoc agent collaborating with the current teammate at each time step and calculated the average reward.
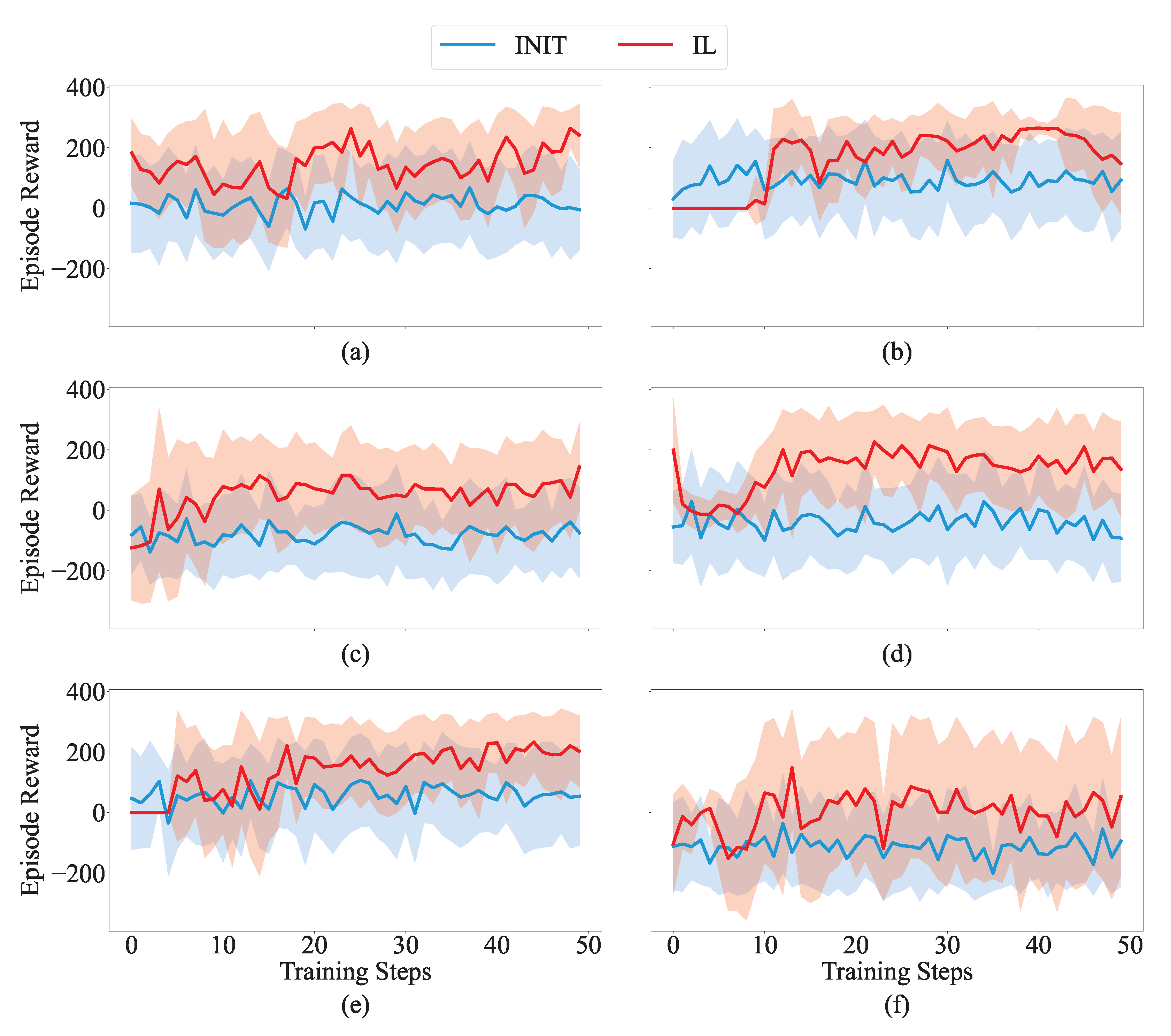
Figure 7 shows the results of the ad hoc agent collaborating with six different types of teammates, and
Table 6 details the performance of each teammate.
From
Table 6, it is clear that the compatibility between the teammate depicted in
Figure 7c and the current Meta-RL policy is minimal. Consequently, as depicted in
Figure 7c, their average cooperation reward is approximately −100, which indicates a significant challenge in completing tasks. However, after imitation learning, their rewards experience a rapid and substantial improvement, highlighting the sensitivity of the Meta-RL policy to parameters and the significance of updating policies through imitation learning. In
Figure 7b, teammates exhibit maximal compatibility with the Meta-RL policy, as evidenced by uniformly positive cooperation rewards and consistent task completion. The performance experienced a modest enhancement following imitation learning.
Further, we analyzed the impact of the cooperative teammates’ performance on the joint outcomes, as depicted in
Figure 7e,f. Notably, when teammates require fewer steps to complete tasks independently, as demonstrated in
Figure 7f, there are fewer samples available for the ad hoc agent to learn from. Despite performance enhancements in the context of previously low compatibility, the limited number of training samples challenges the achievement of superior cooperative performance.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}