
Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms


Abstract
1. Introduction
- We particularly focus on two Transformer-based feature extraction methods, namely Wav2vec and BERT (Bidirectional Encoder Representation from Transformers) [34]. Additionally, we investigate the TIM-Net [35] model and make corresponding improvements to better adapt it to our application scenario in multi-modal emotion recognition tasks.
- We introduce a multi-head attention mechanism, which accurately captures significant emotional features from both speech and text, thereby enhancing the model’s sensitivity and capability to capture emotional information. This innovation gives our model a competitive edge in emotion recognition.
- To validate the effectiveness of our proposed model, we conduct extensive experiments on the IEMOCAP [36] and MELD [37] datasets. The experimental results demonstrate that our MMER-TAB (Multi-Modal Emotion Recognition–Temporal-Aware Block) model exhibits outstanding performance in multi-modal conversation emotion analysis tasks. This not only confirms the effectiveness of the feature extraction methods and model improvements we have adopted but also provides new insights into and methods for research in the field of multi-modal emotion recognition.
2. Methodology
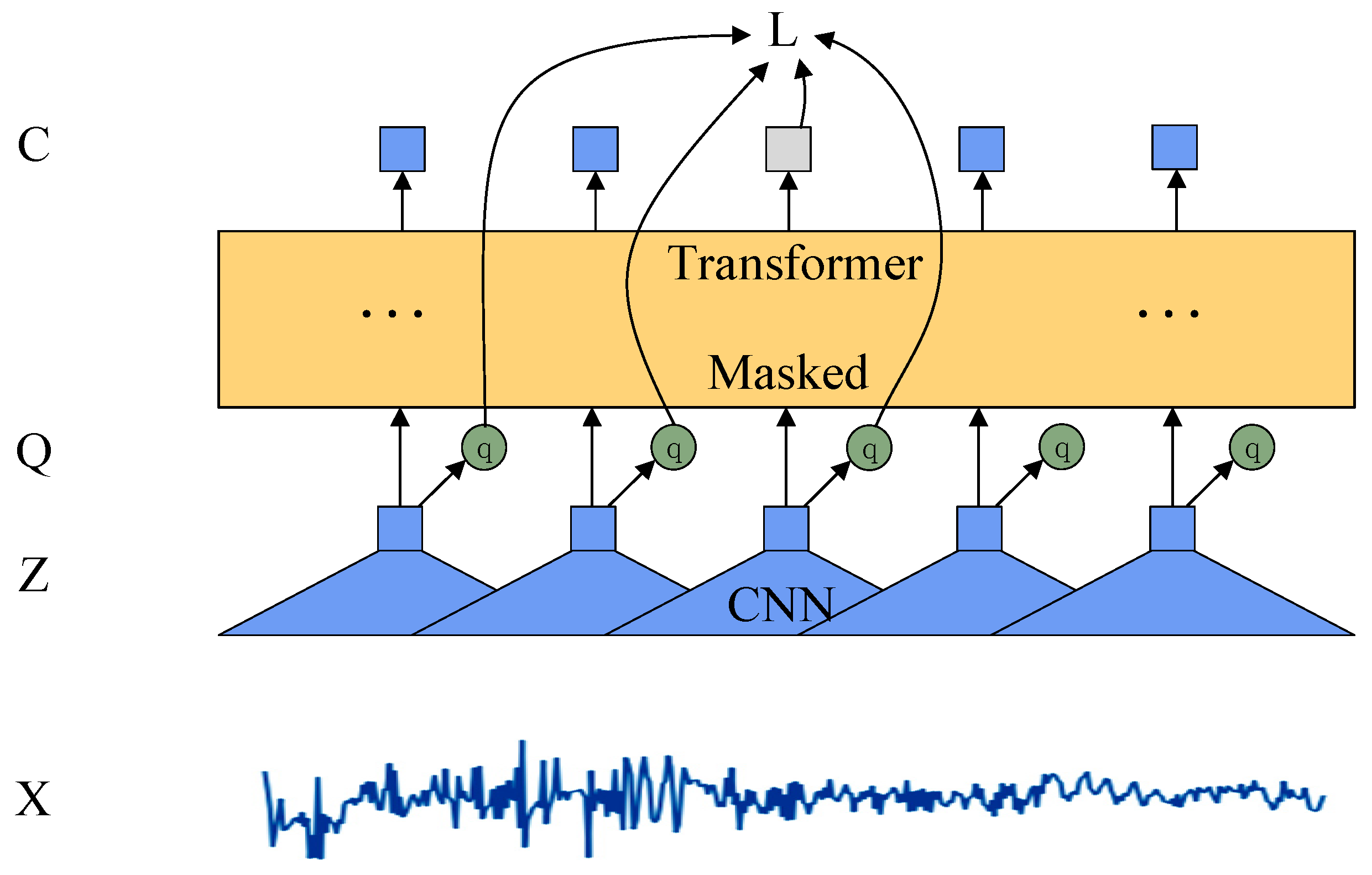
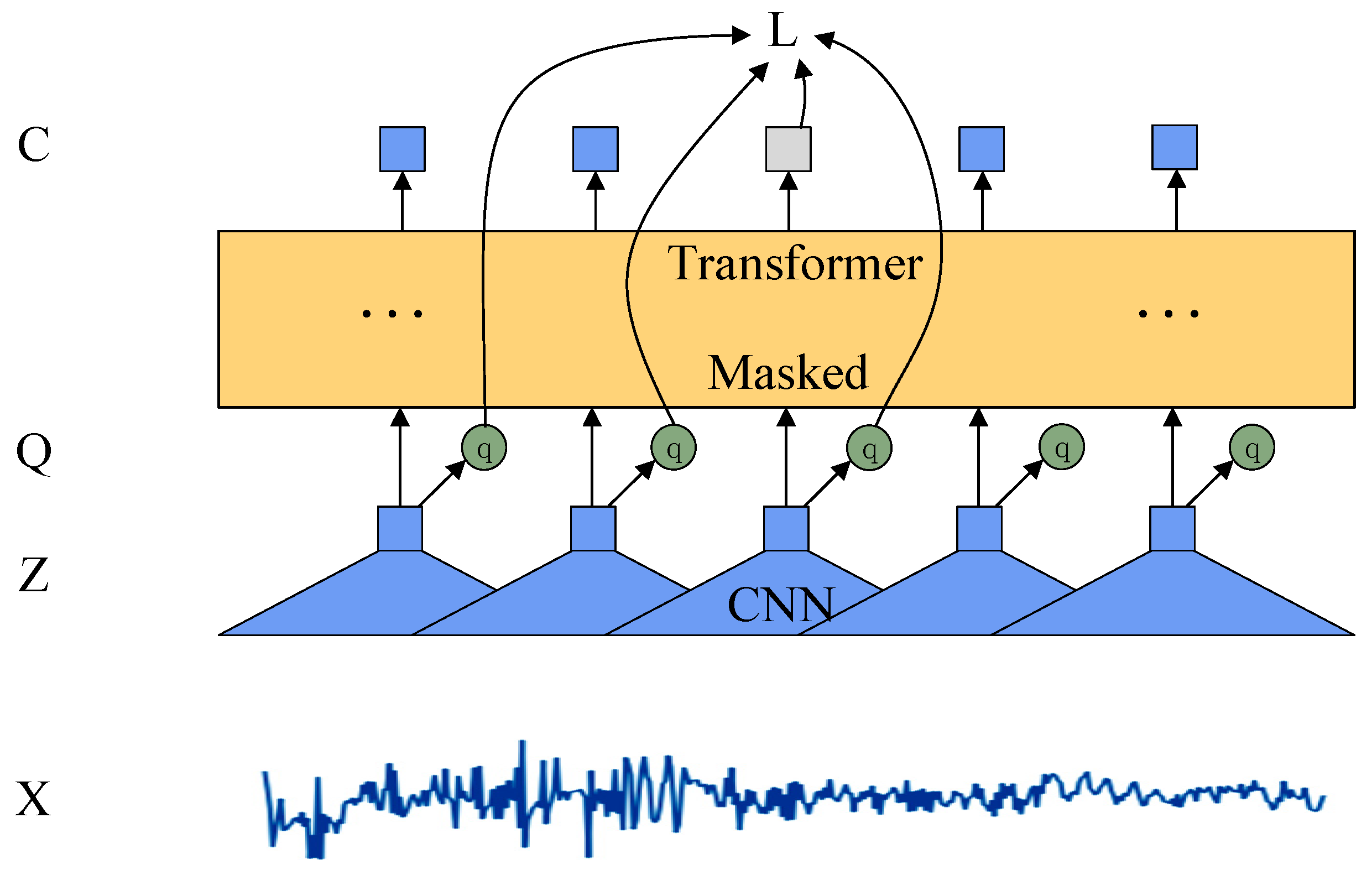
2.1. Wav2vec Speech Features
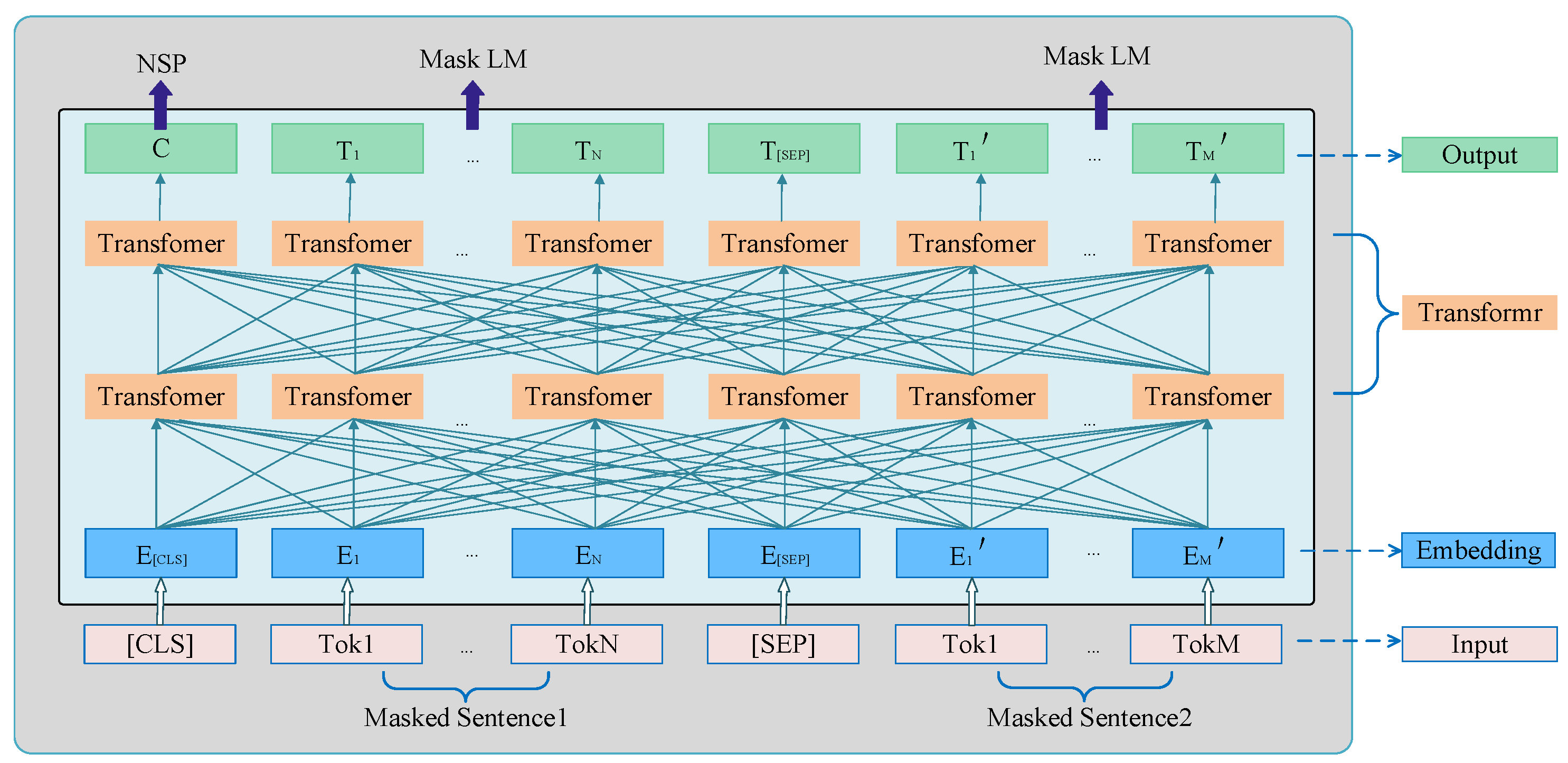
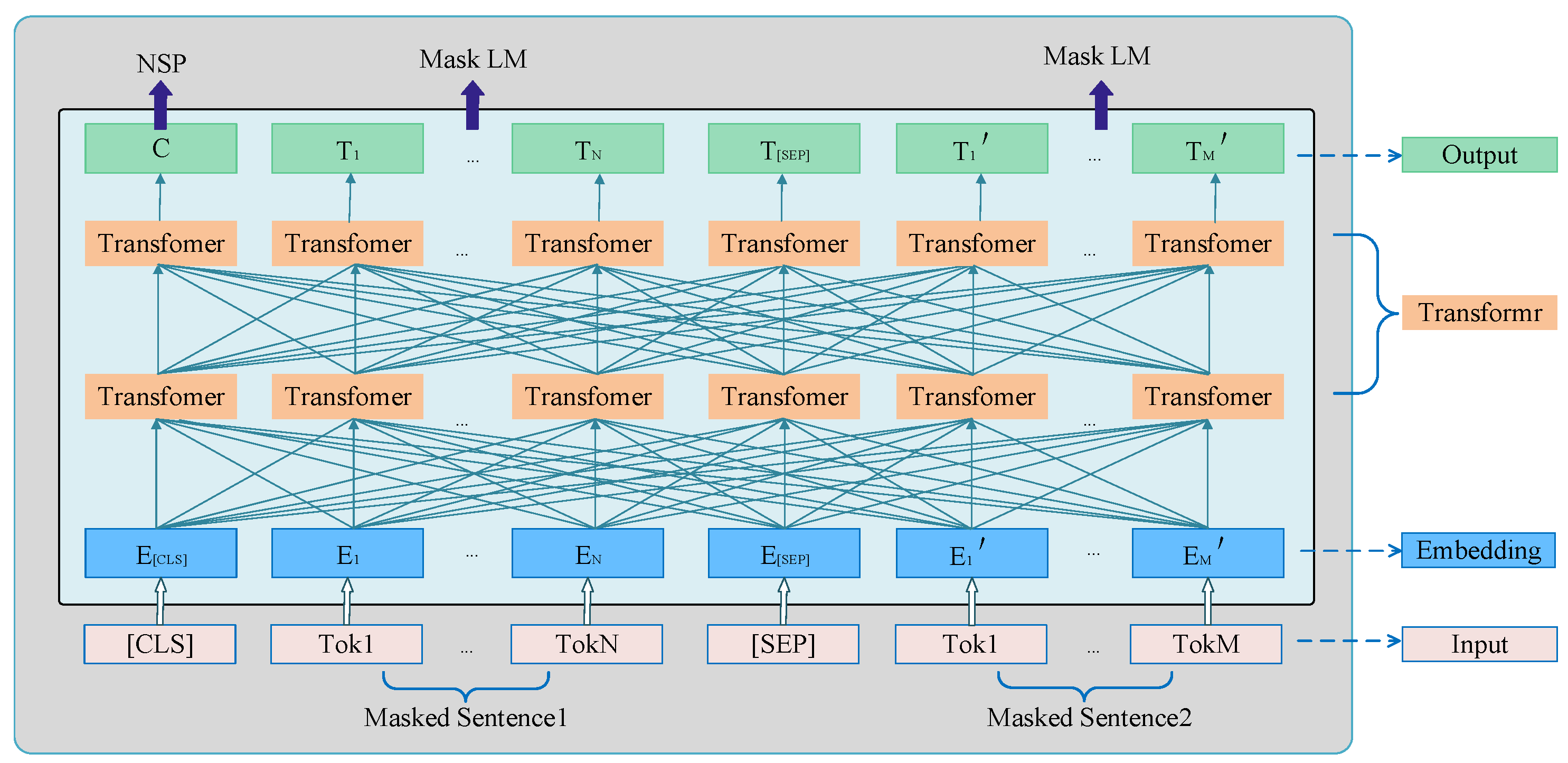
2.2. BERT Text Features
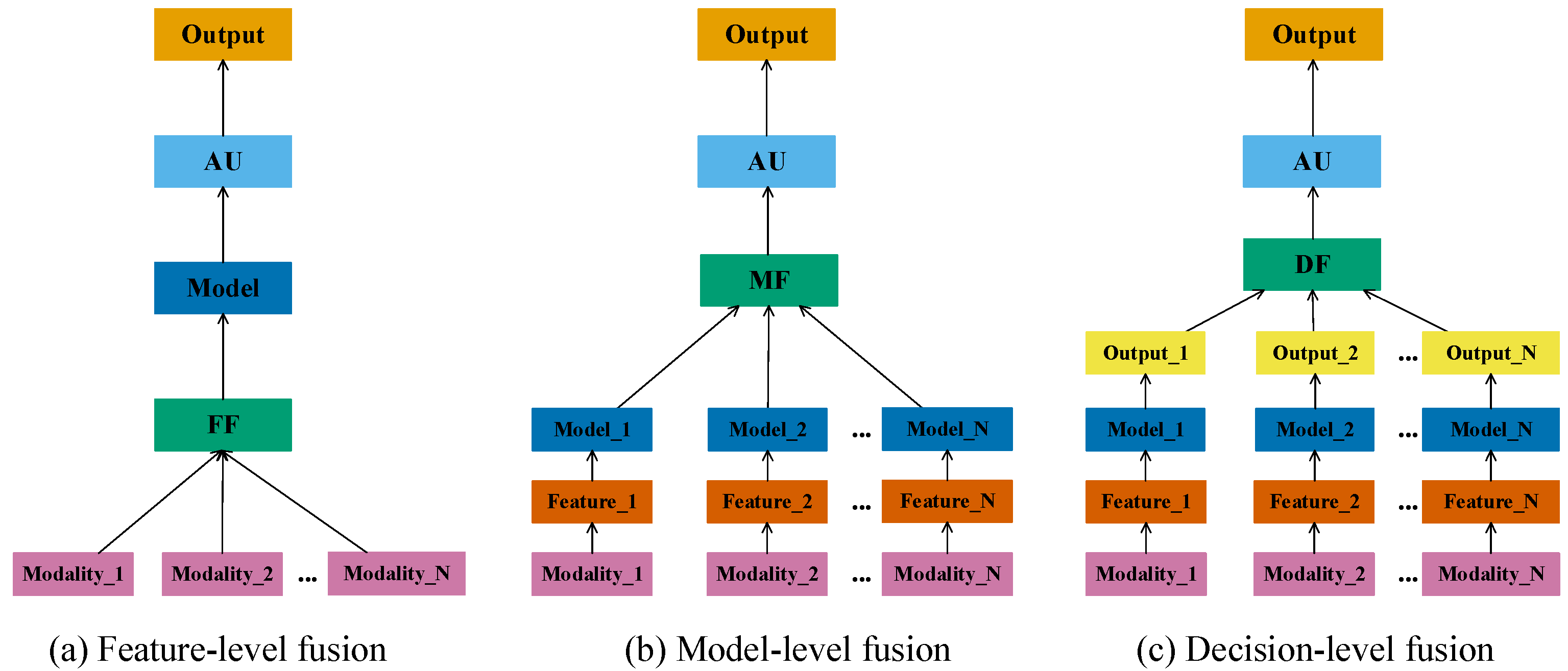
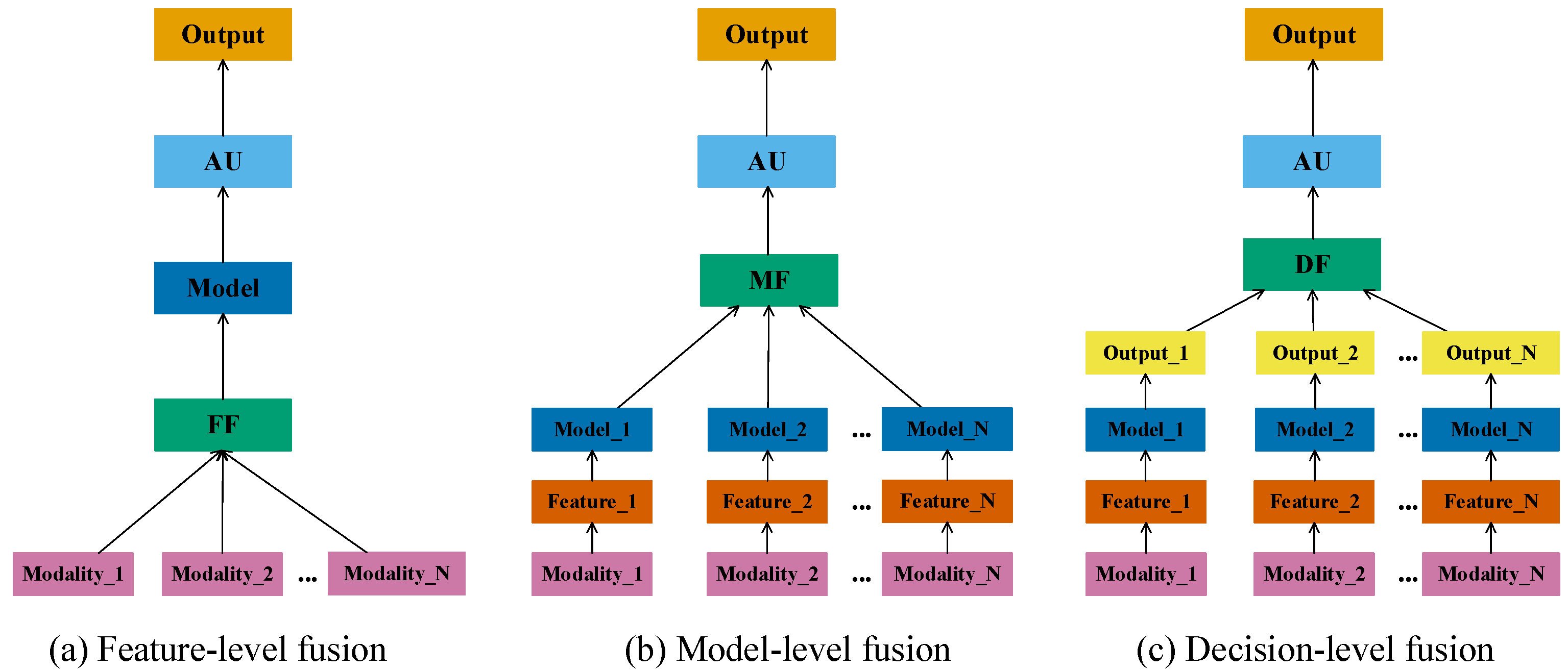
2.3. Multimodal Feature Fusion
2.3.1. Classification Based on the Fusion Stage
2.3.2. Classification Using the Fusion Method
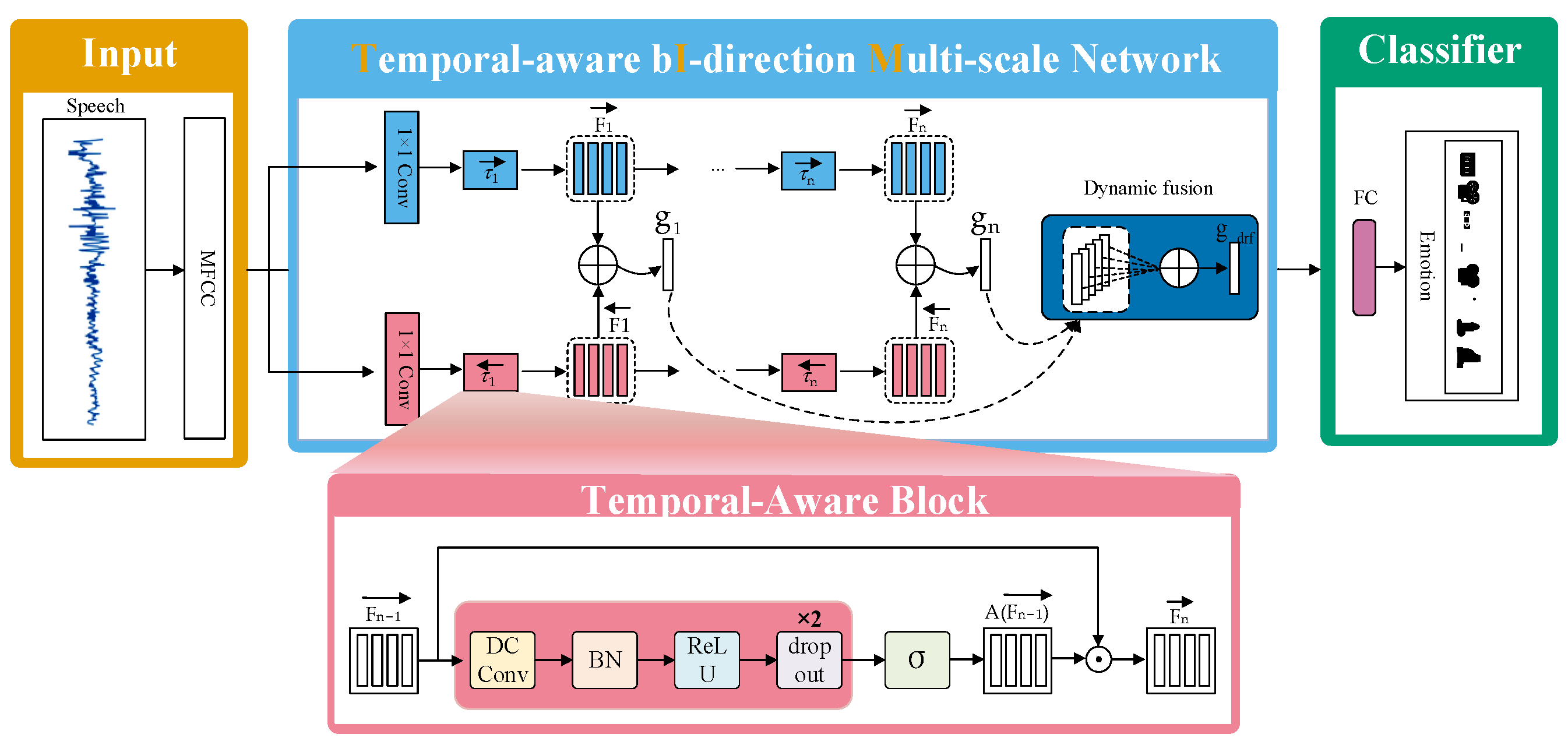
3. TIM-Net and Attention Mechanisms
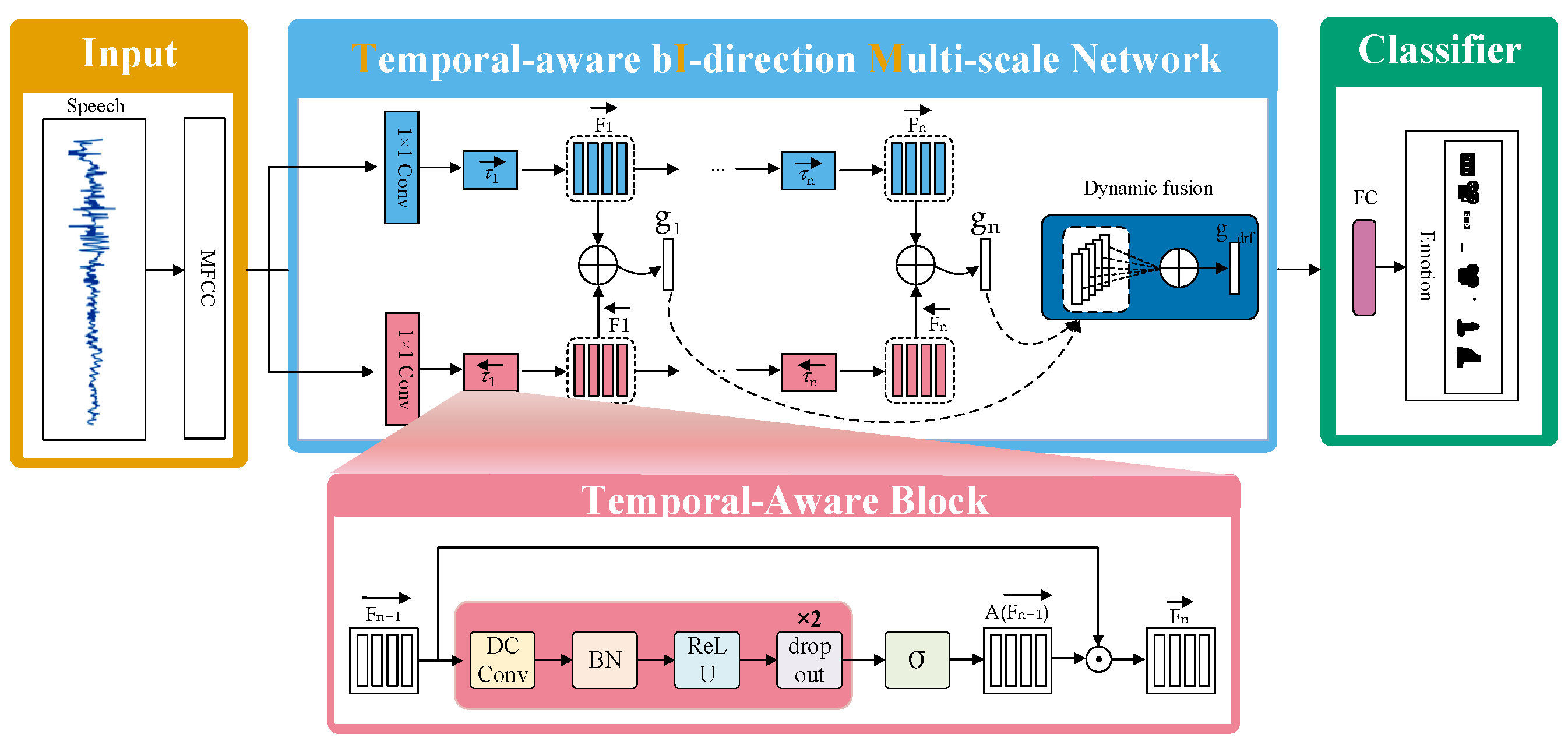
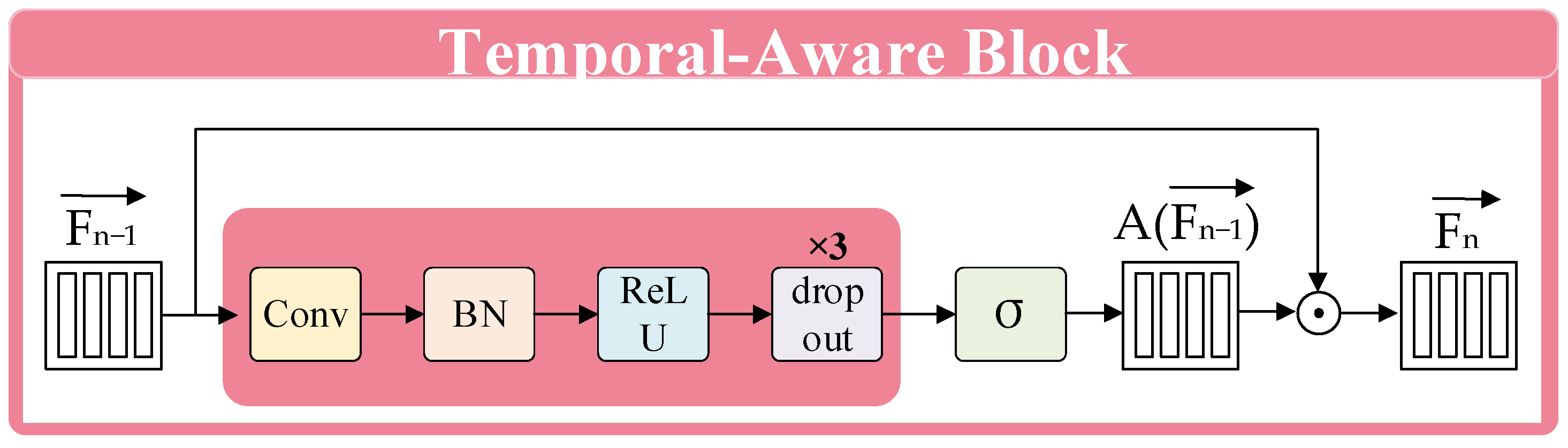
3.1. The TIM-Net Emotion Recognition Network Model
3.2. Attention Mechanism
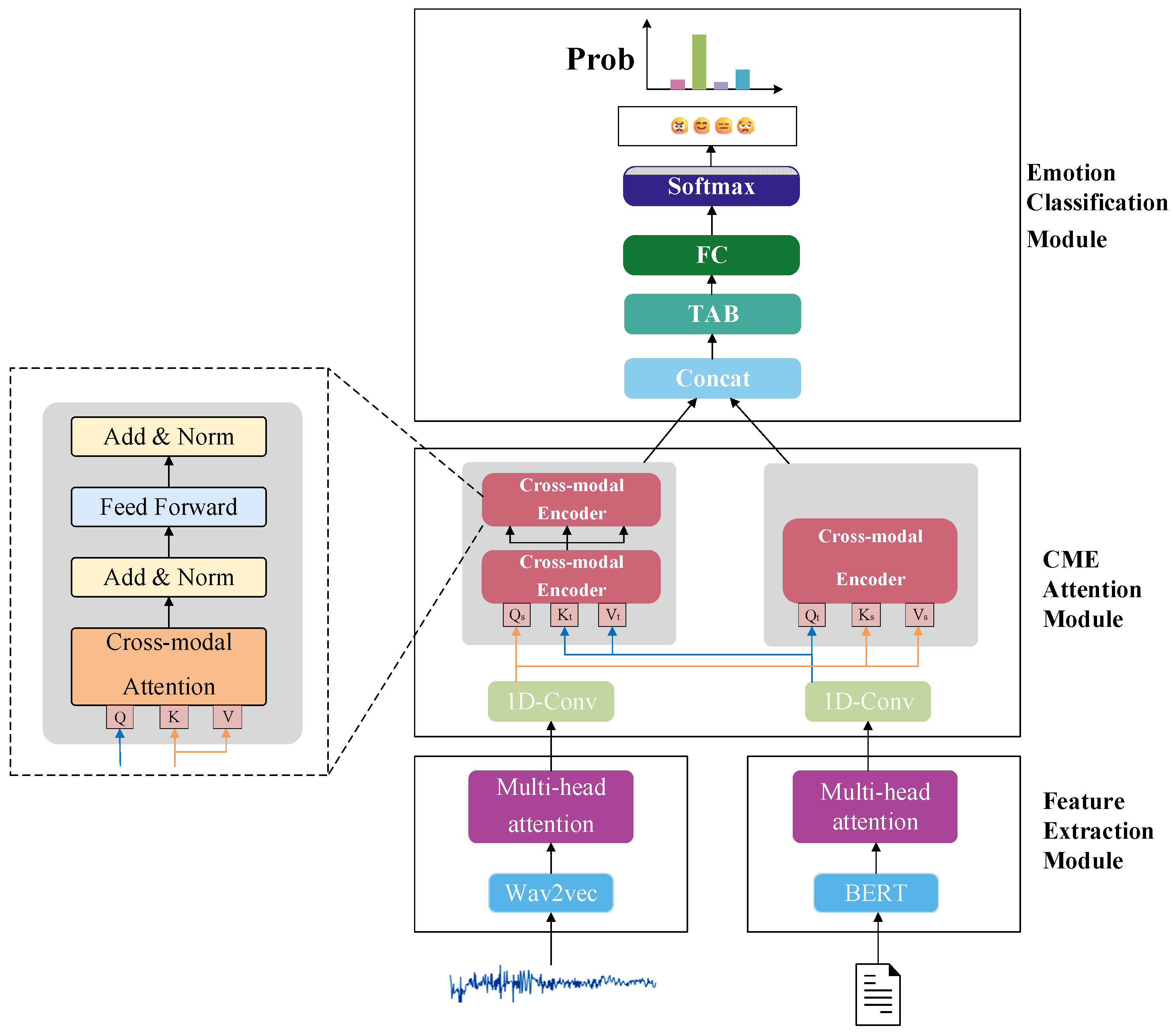
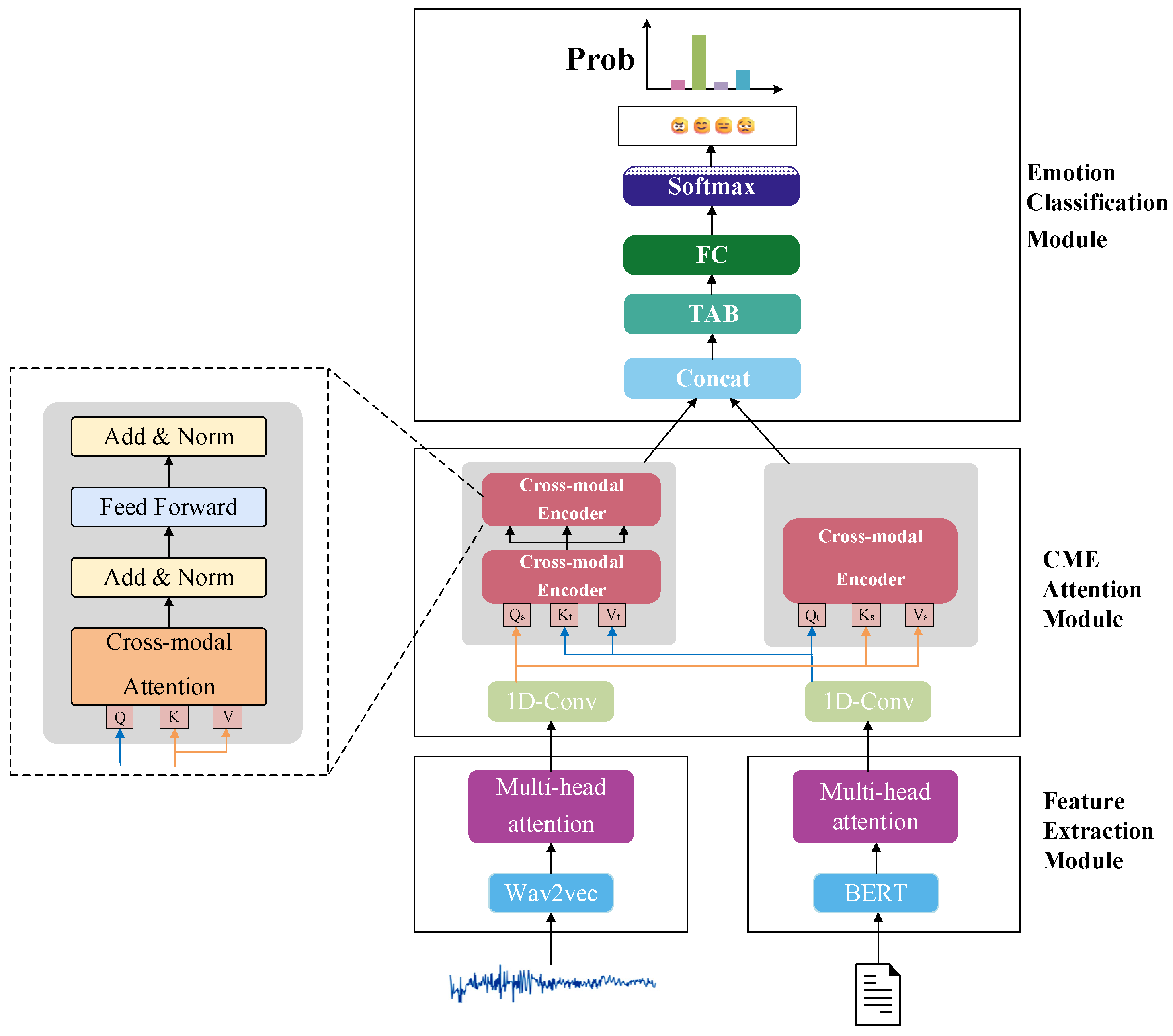
4. Model Design and Interpretation
4.1. Cross-Modal Attention Module
- 1.
- Cross-Modal Transfer
- 2.
- Cross-Modal Transfer
4.2. The Emotion Classification Module
5. Experimental Verification
5.1. Experimental Simulation Parameters
5.2. Experimental Data
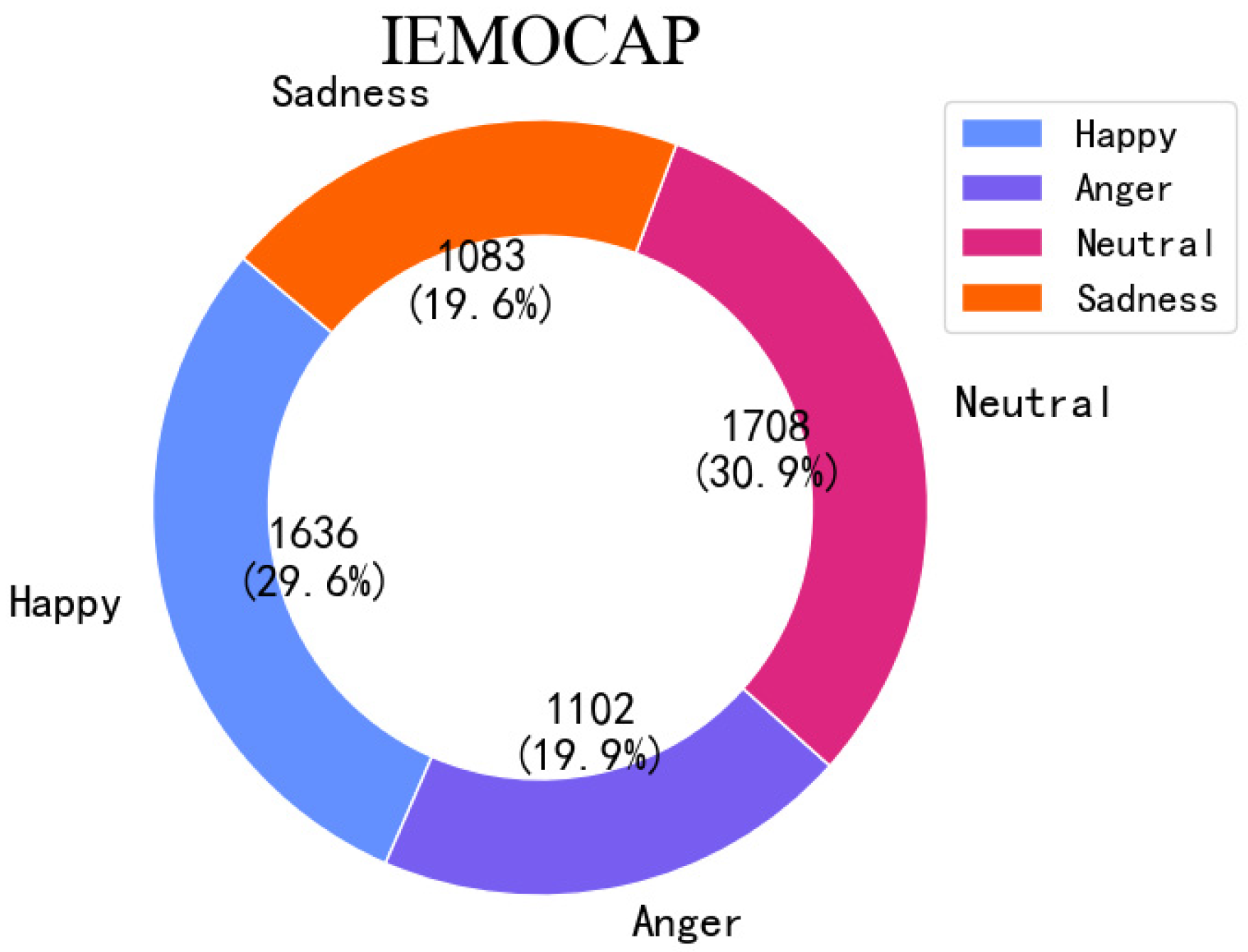
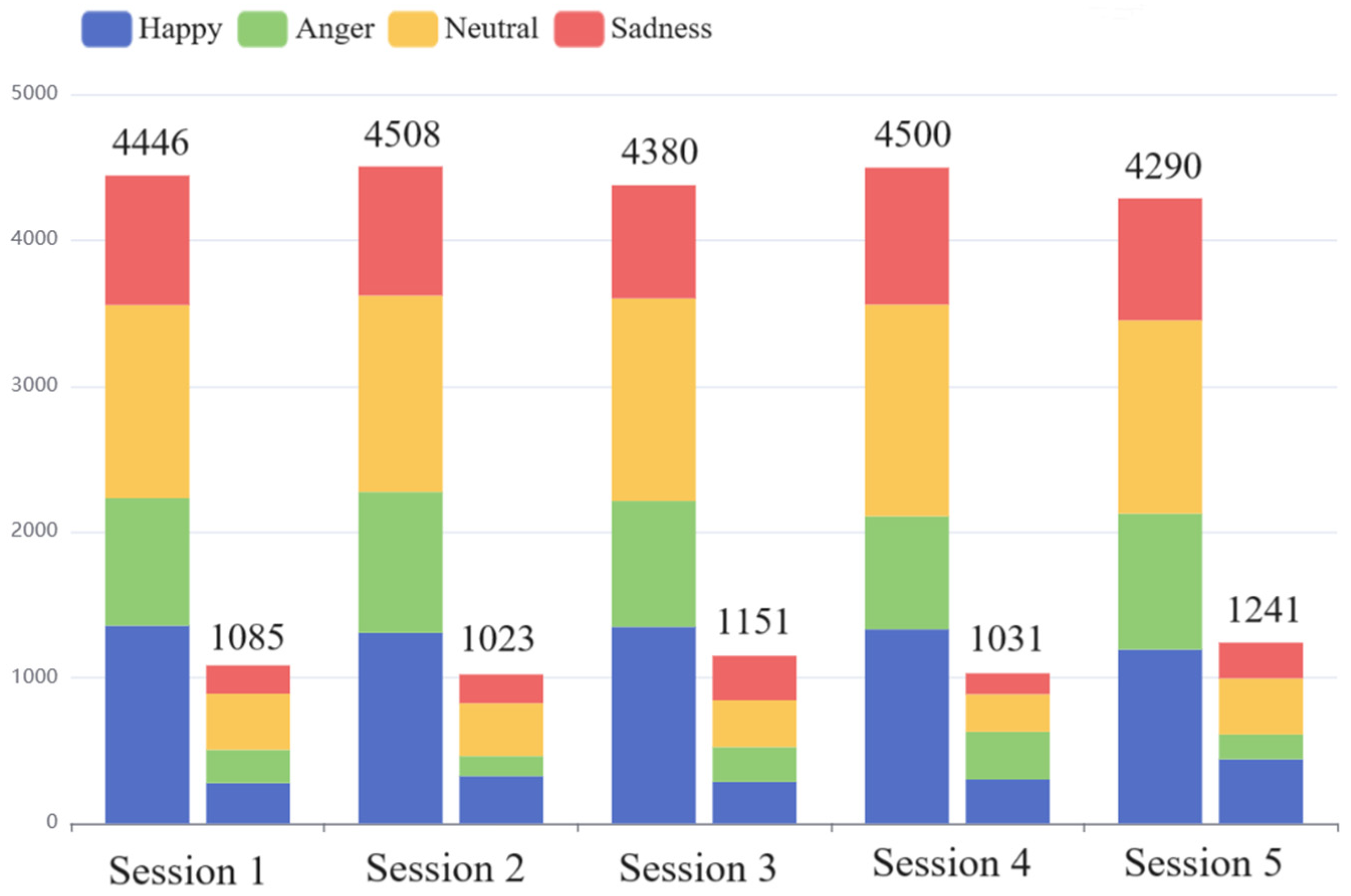
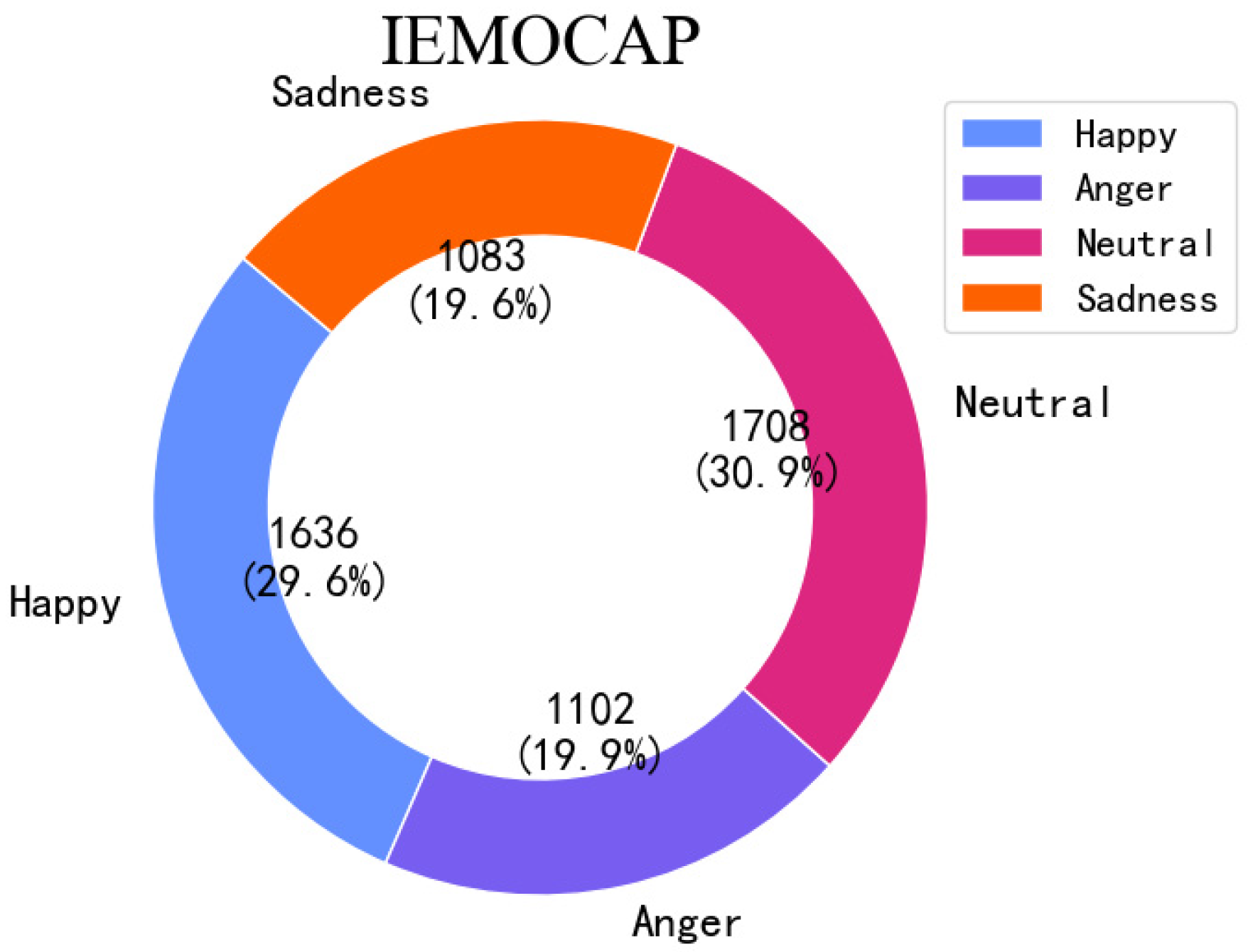
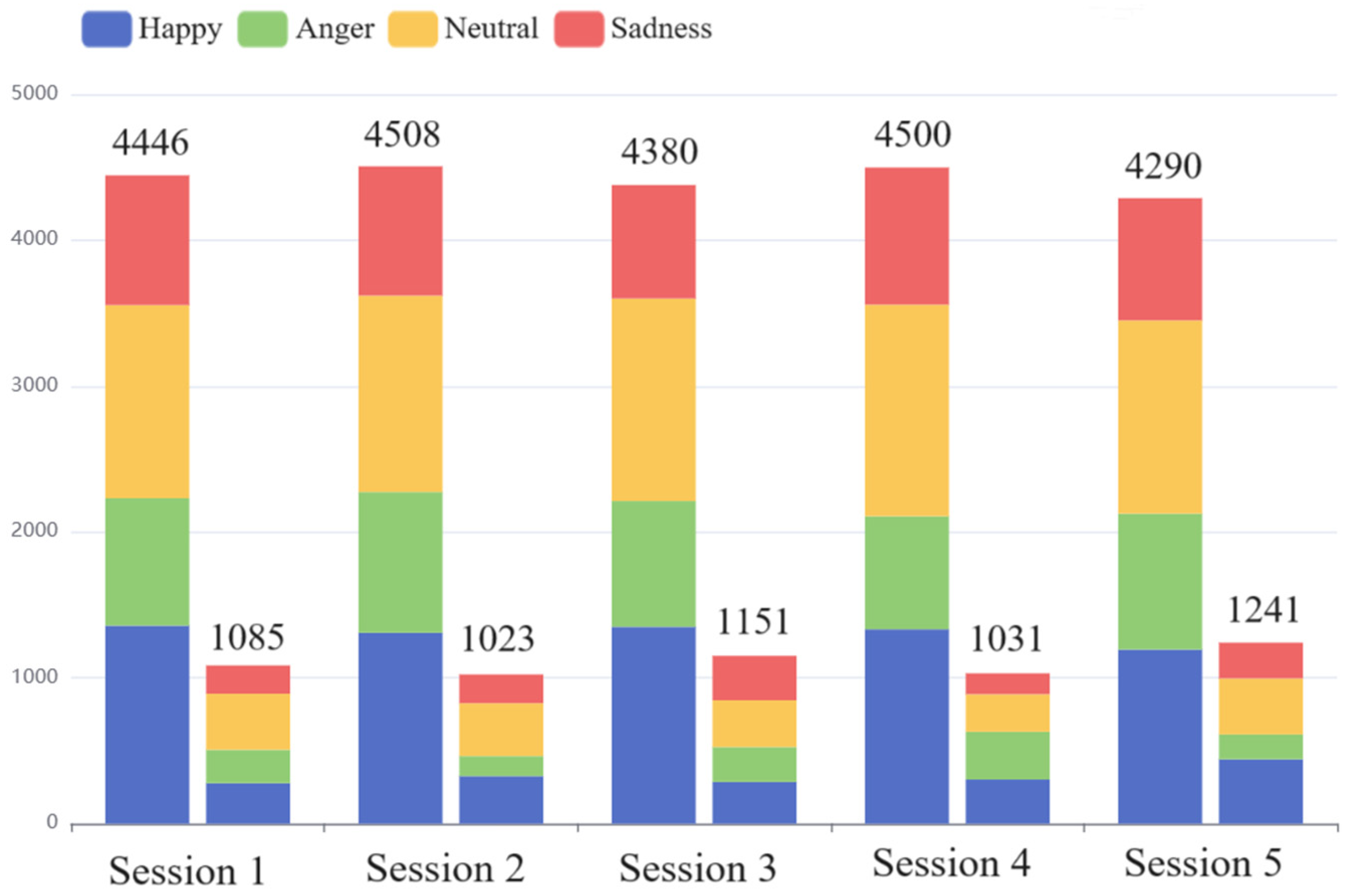
5.2.1. Interactive Emotional Dyadic Motion Capture (IEMOCAP) [36]
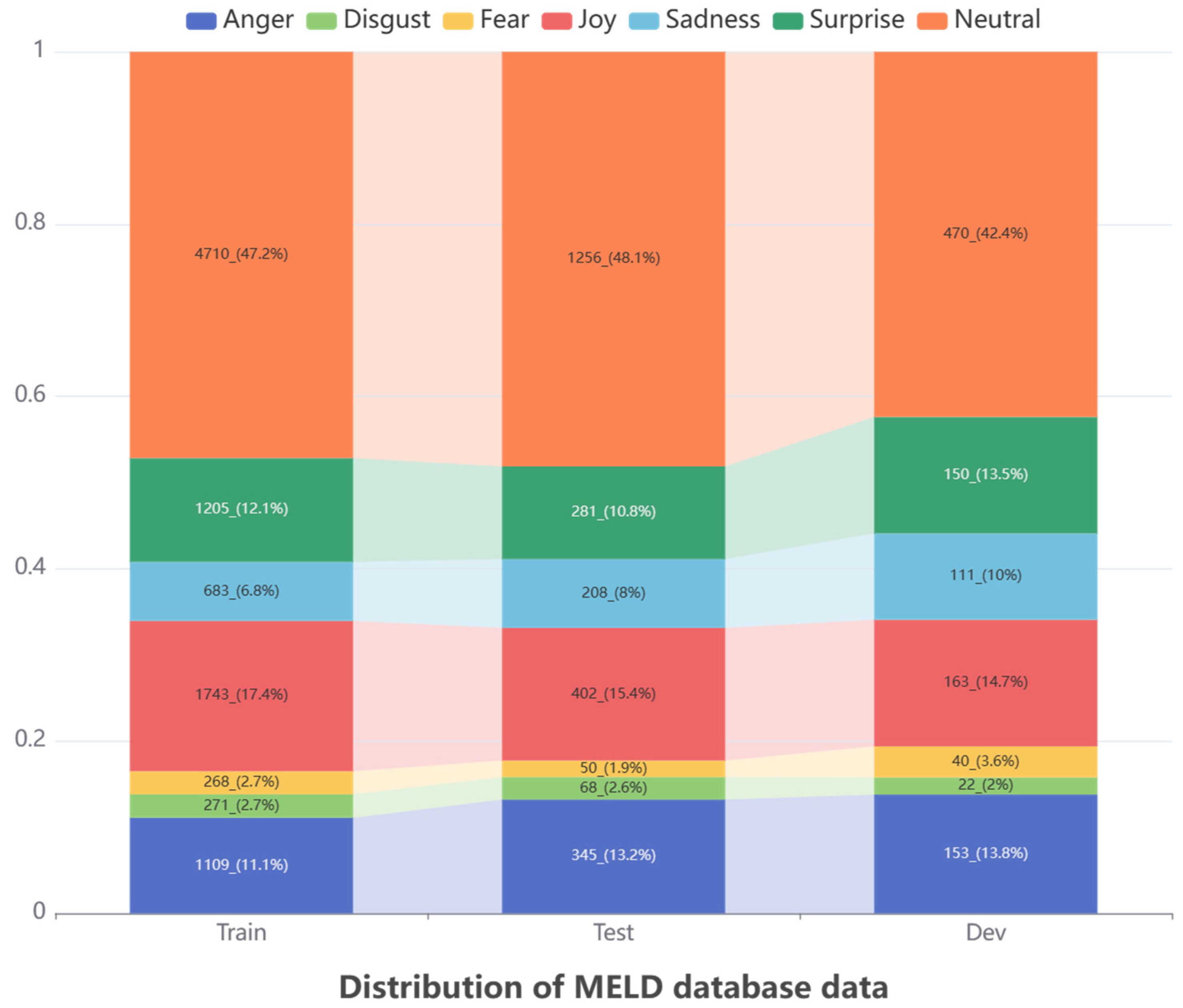
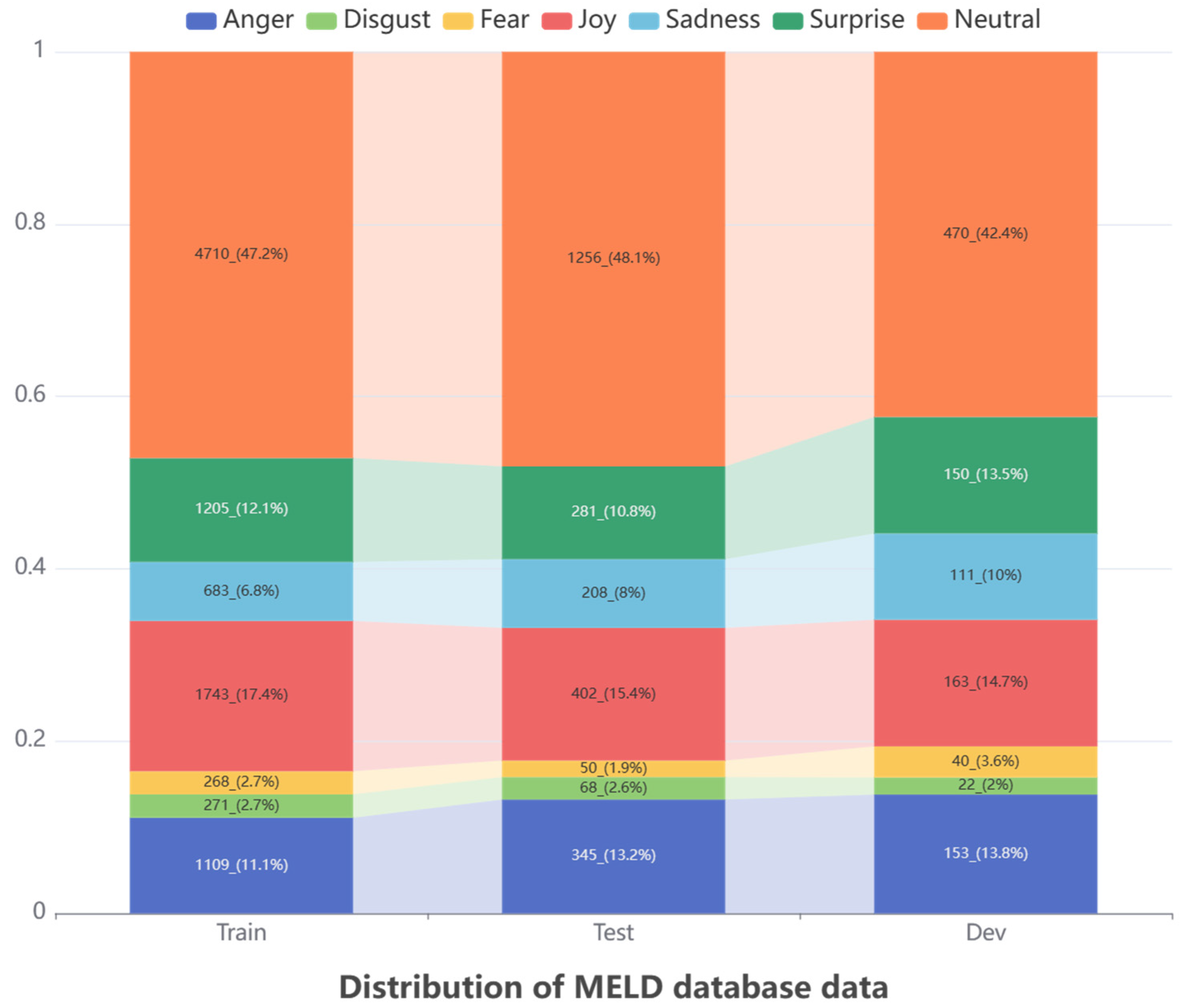
5.2.2. Multimodal EmotionLines Dataset (MELD) [37]
5.3. Experimental Analysis
5.3.1. Evaluation Metrics
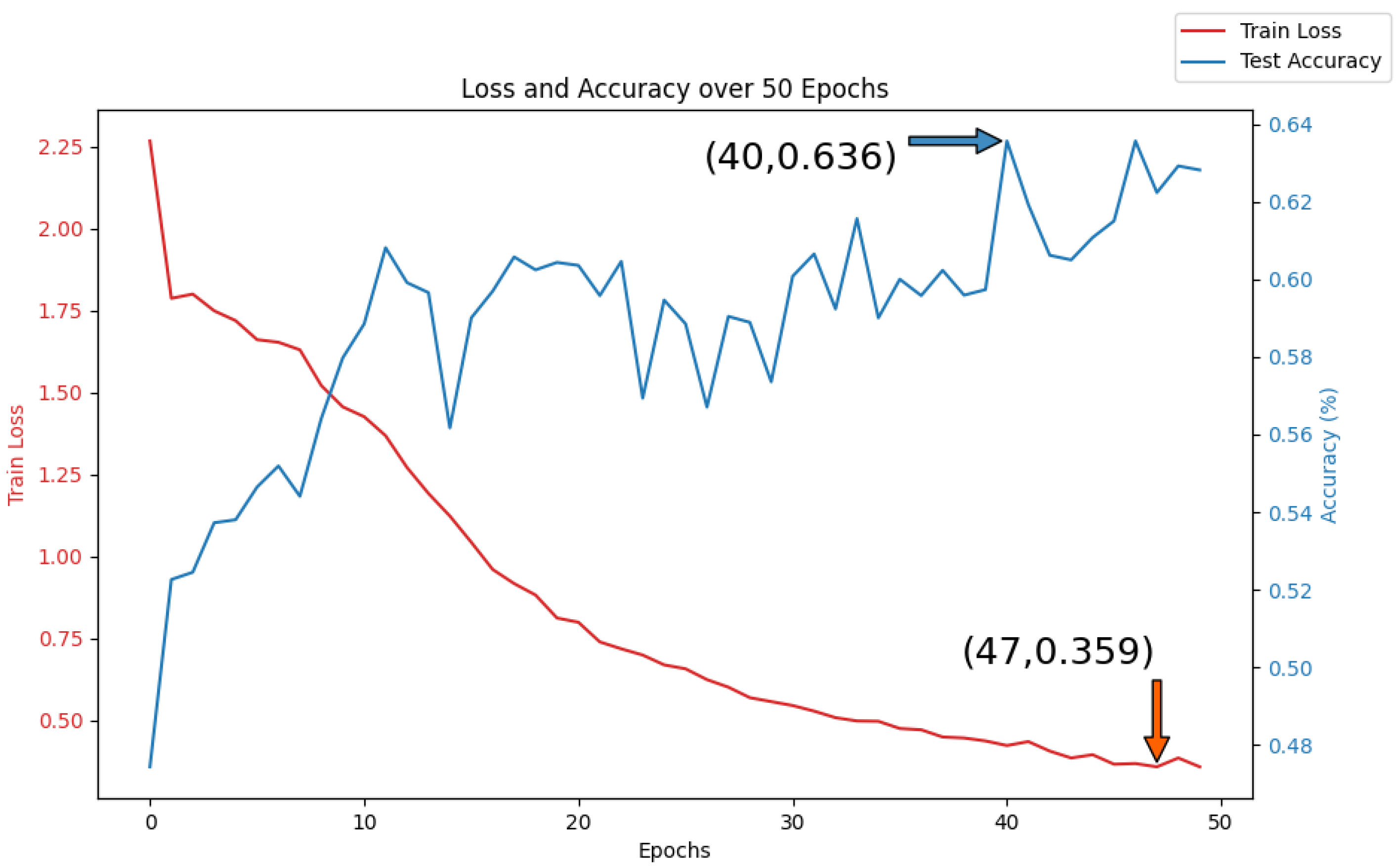
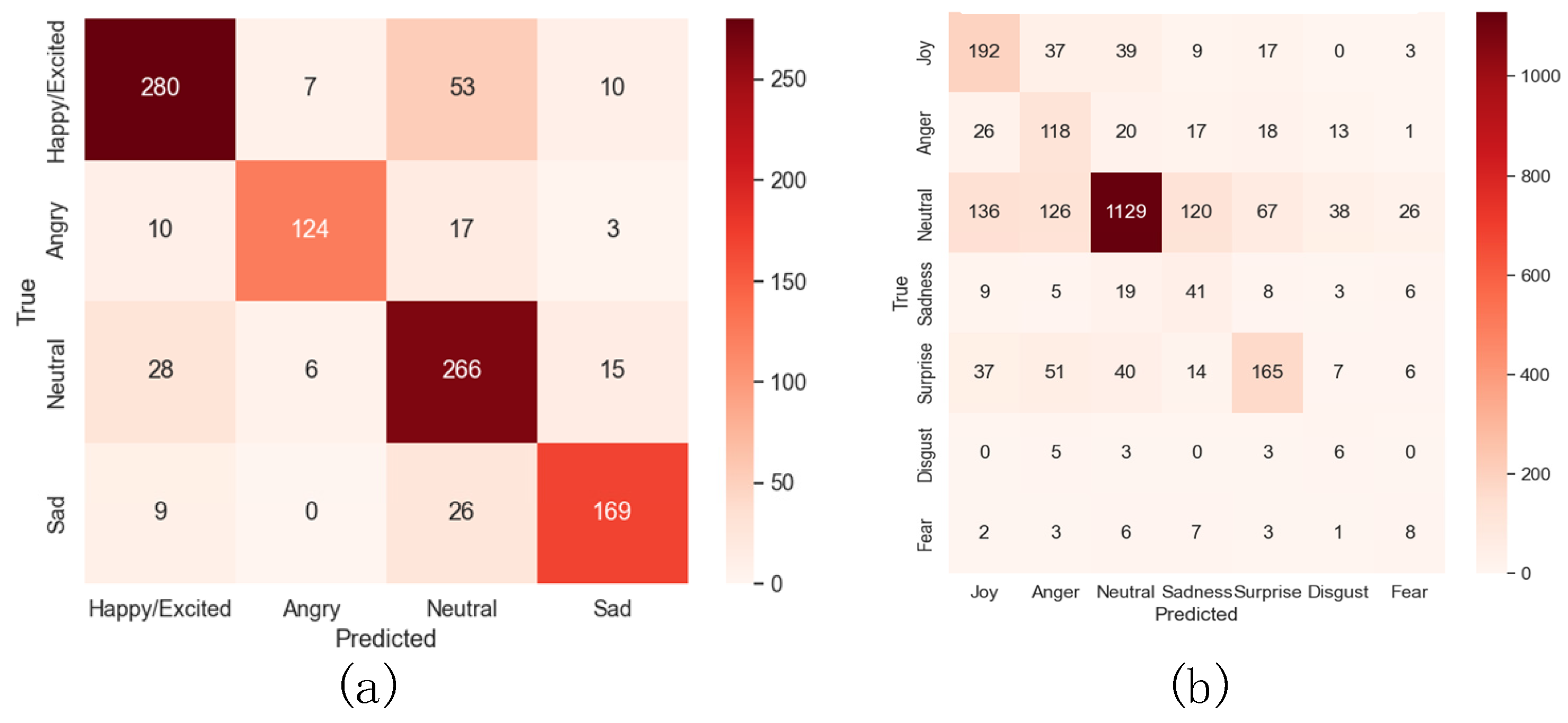
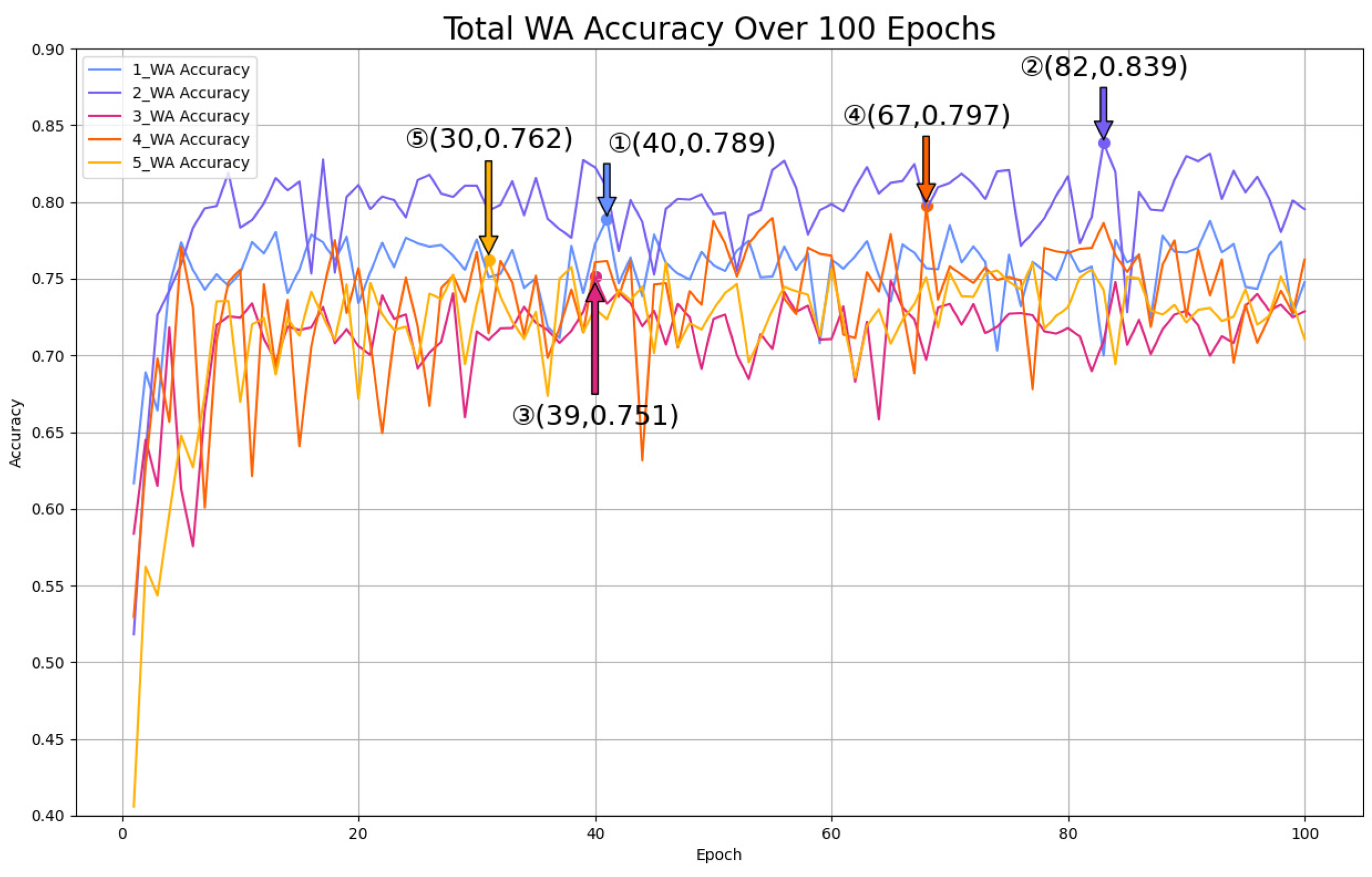
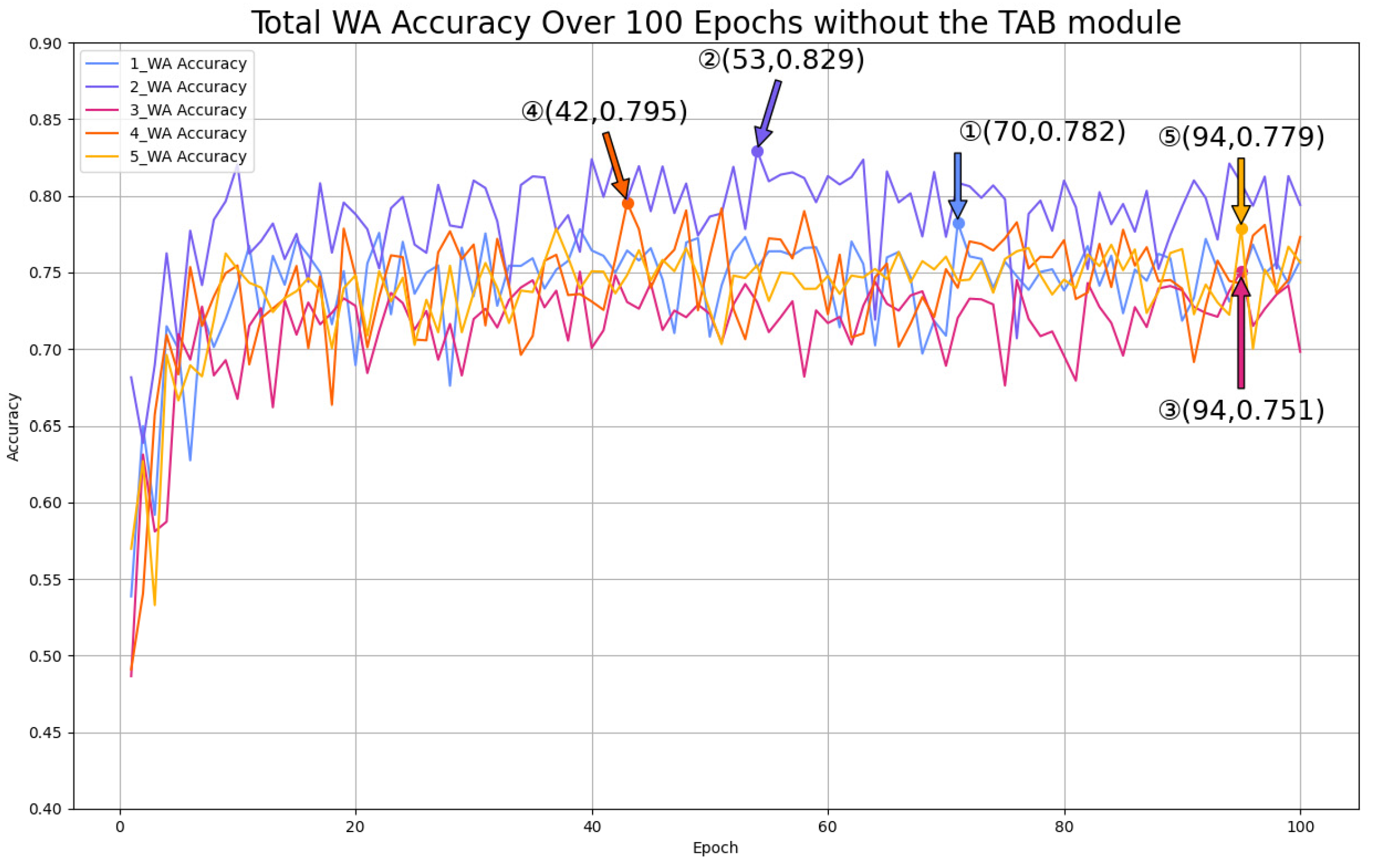
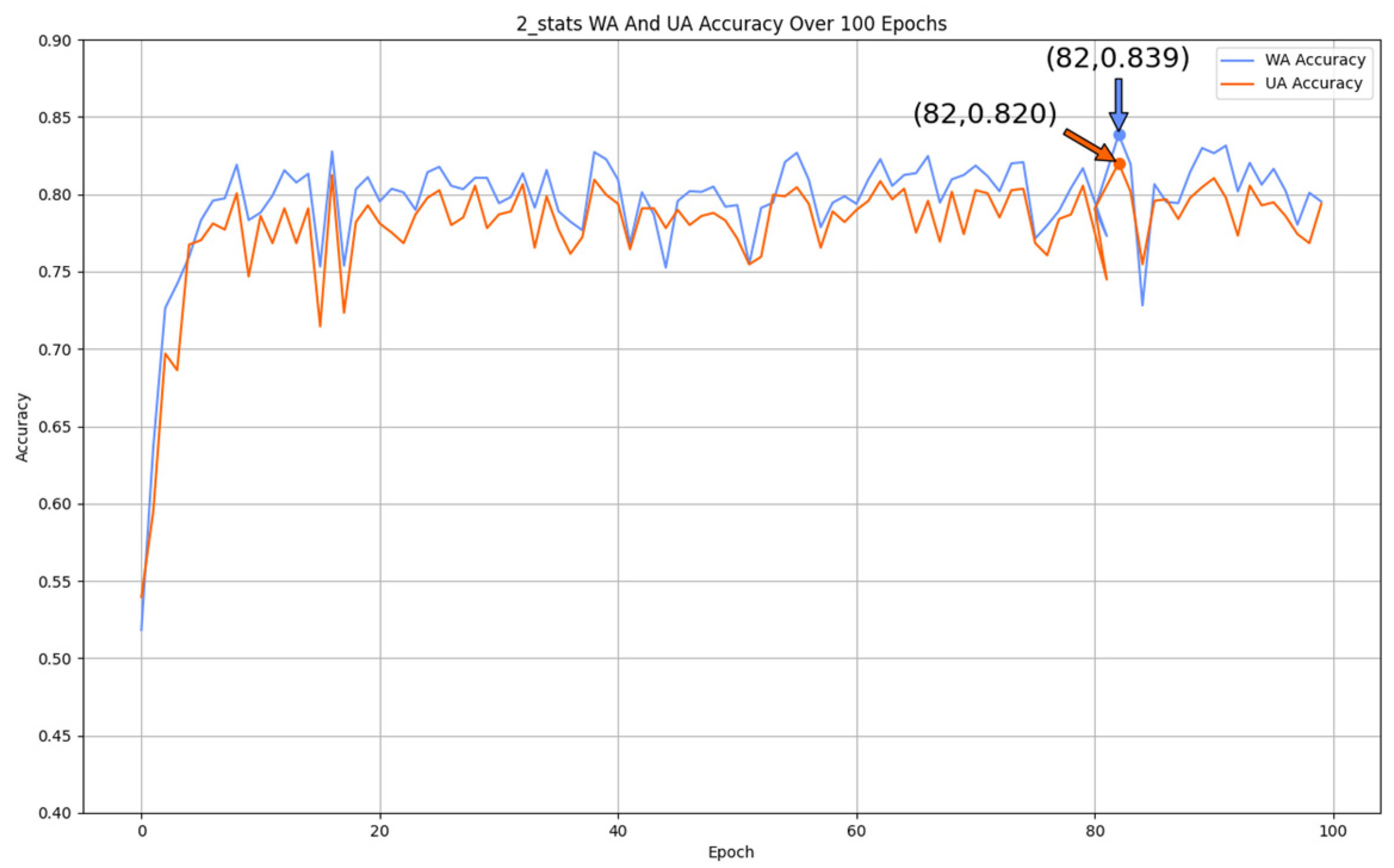
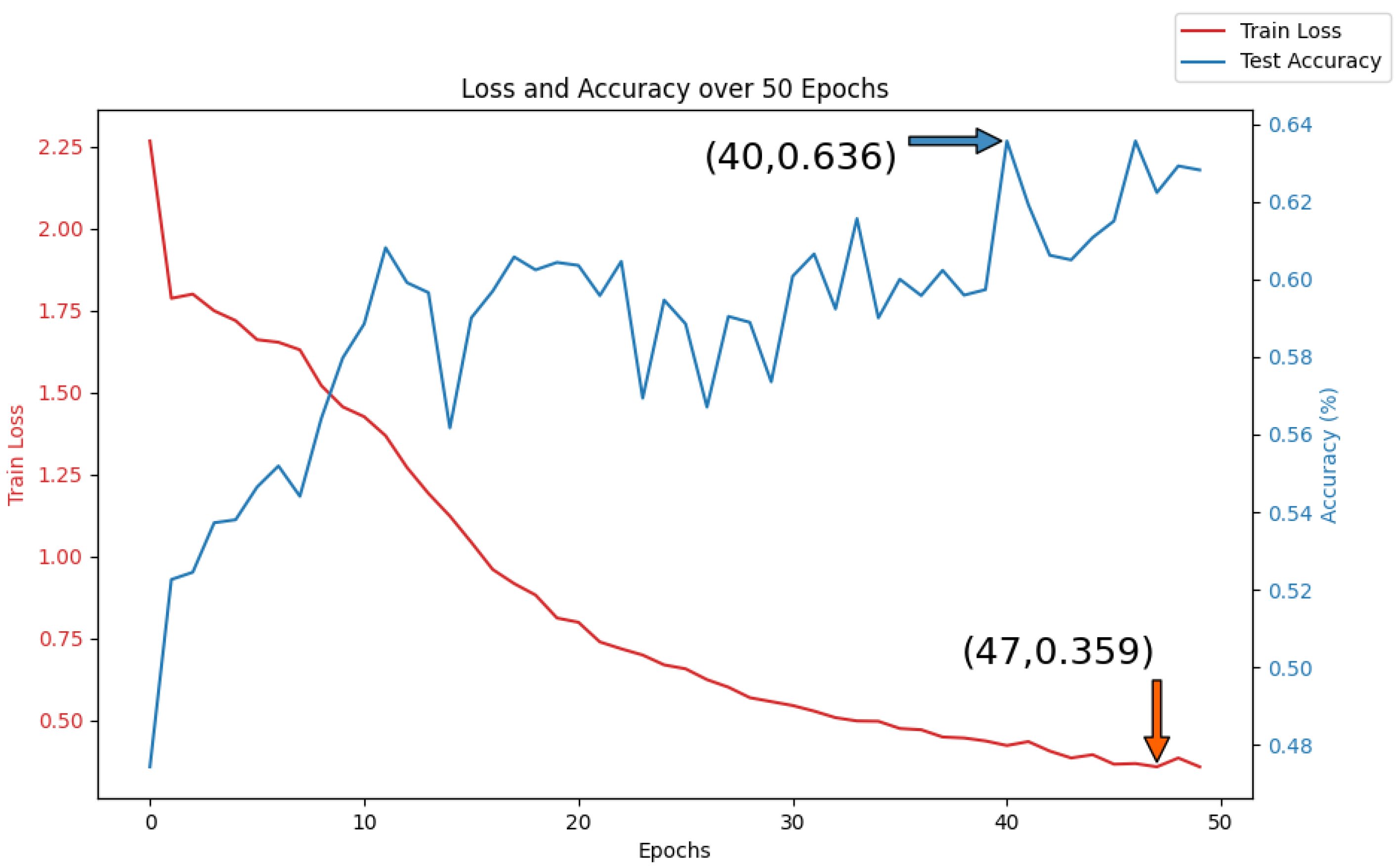
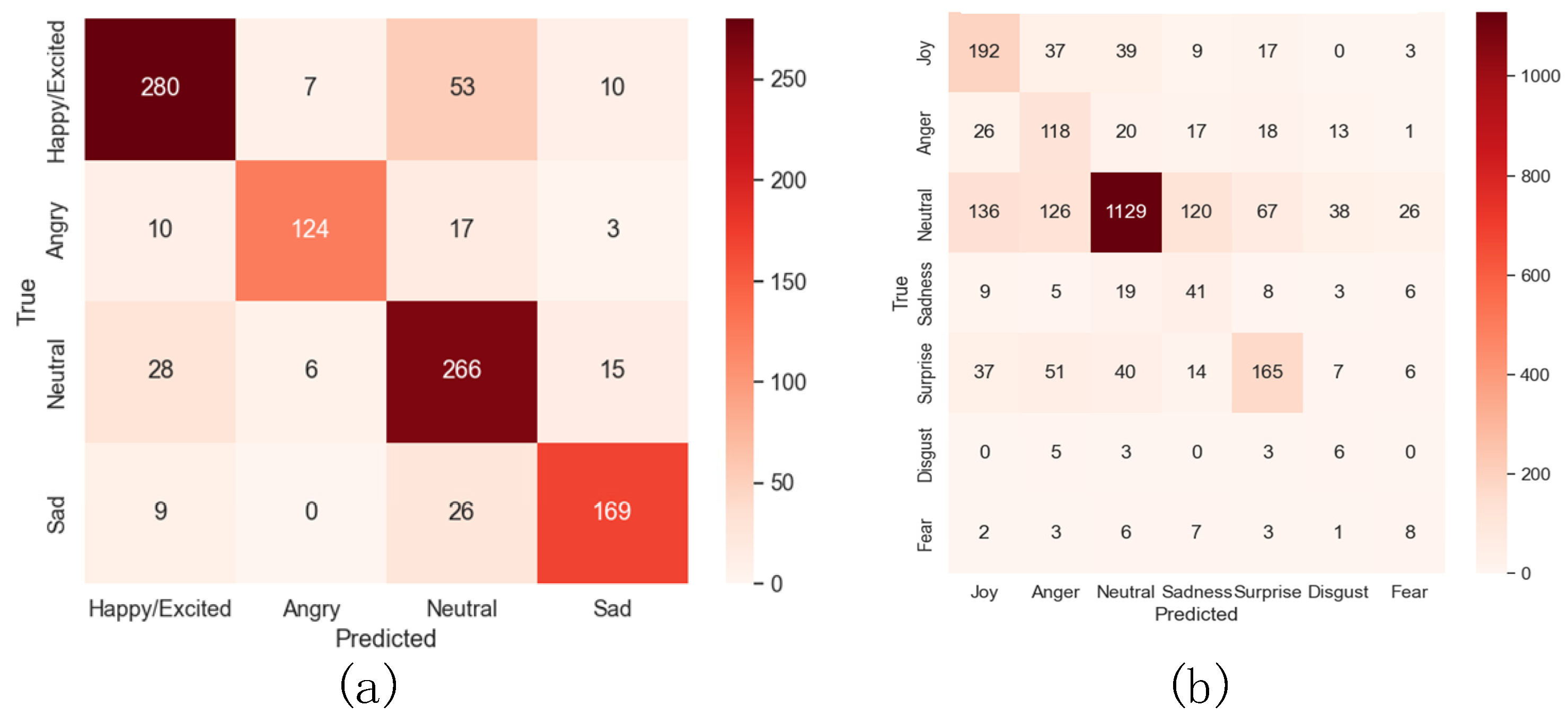
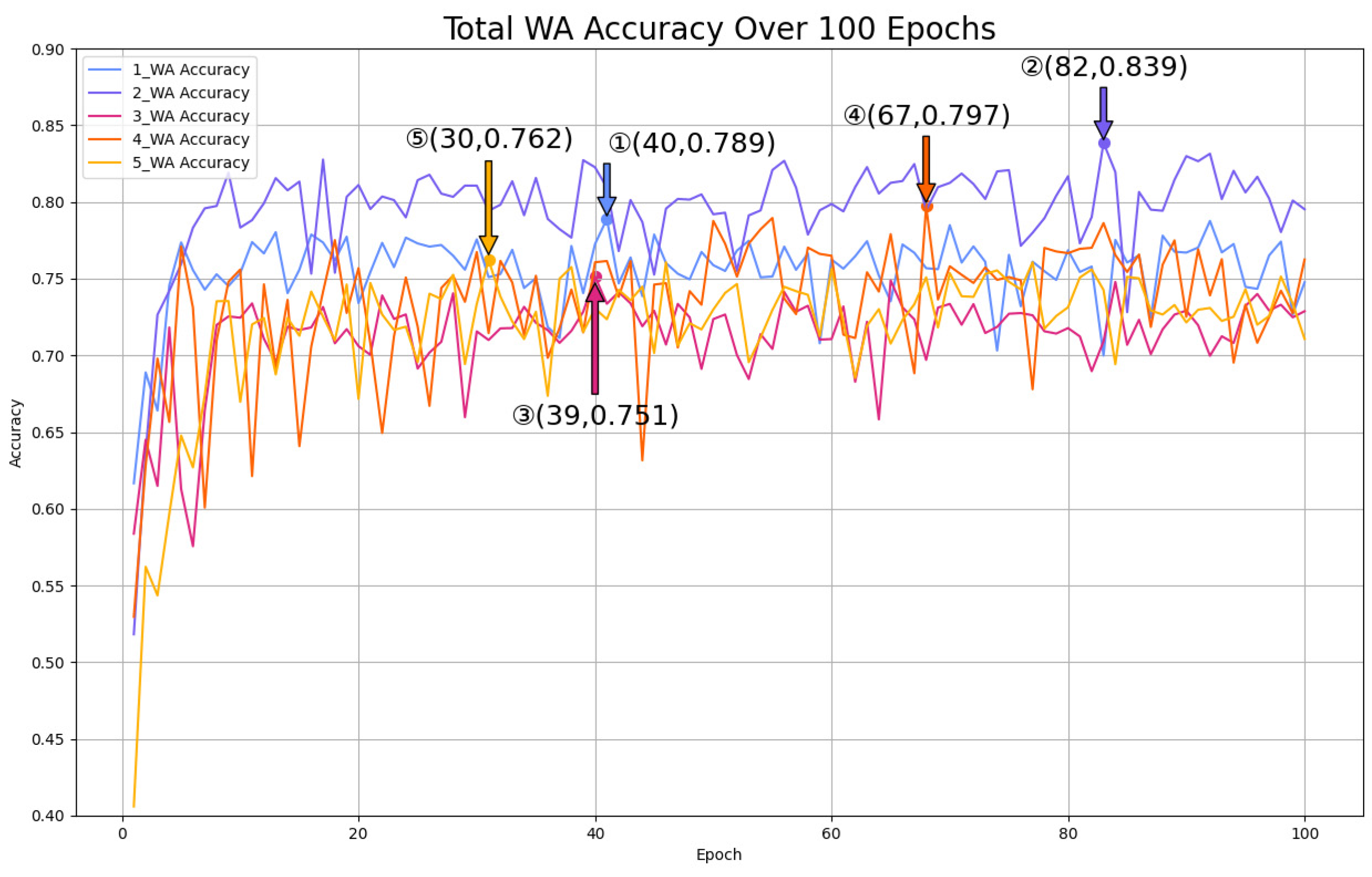
5.3.2. Mul-TAB Result Analysis
- Accuracy Analysis
- 2.
- Robustness Analysis
- 3.
- Hyperparameter Analysis
- 4.
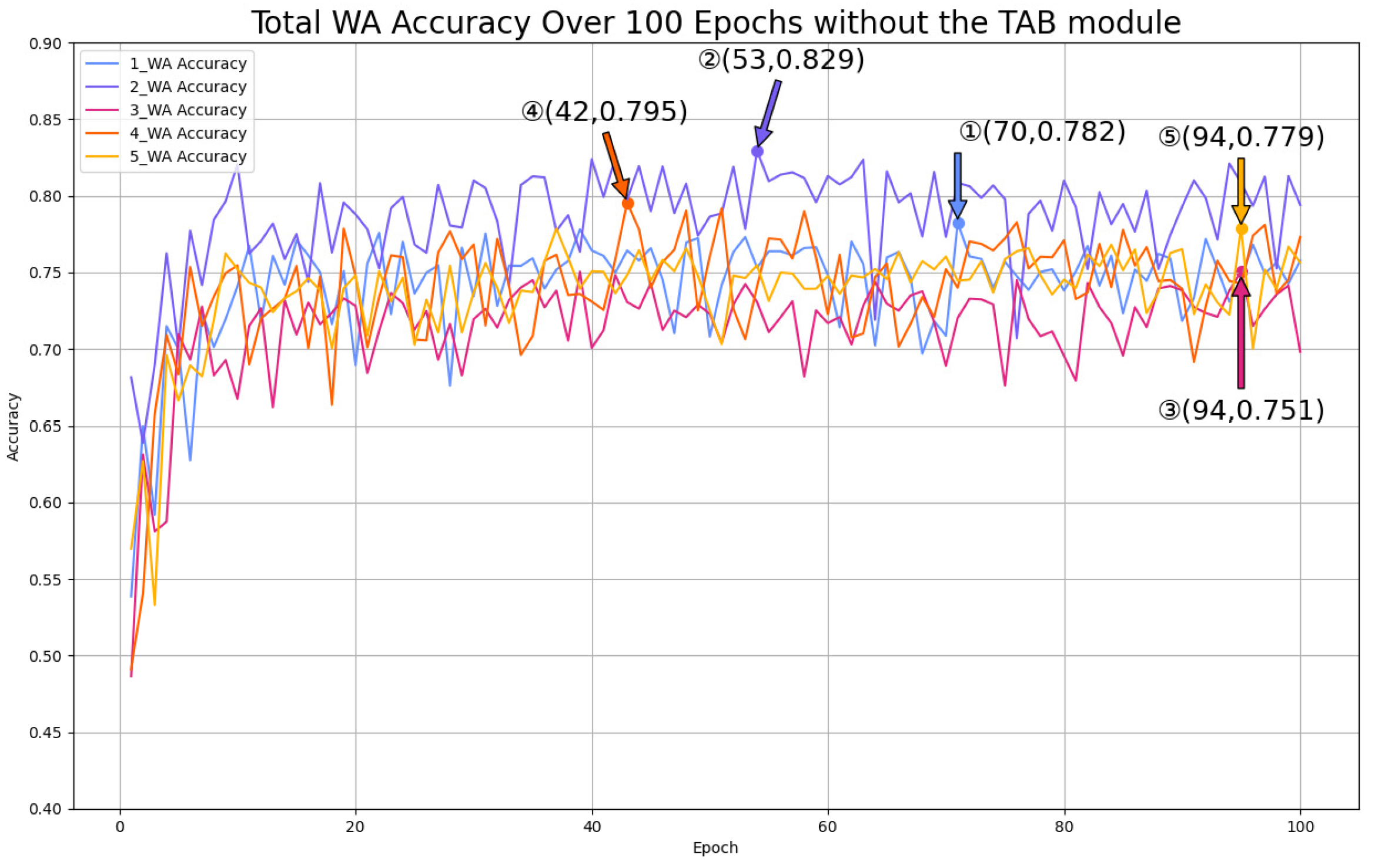
- TAB3 Analysis
- 5.
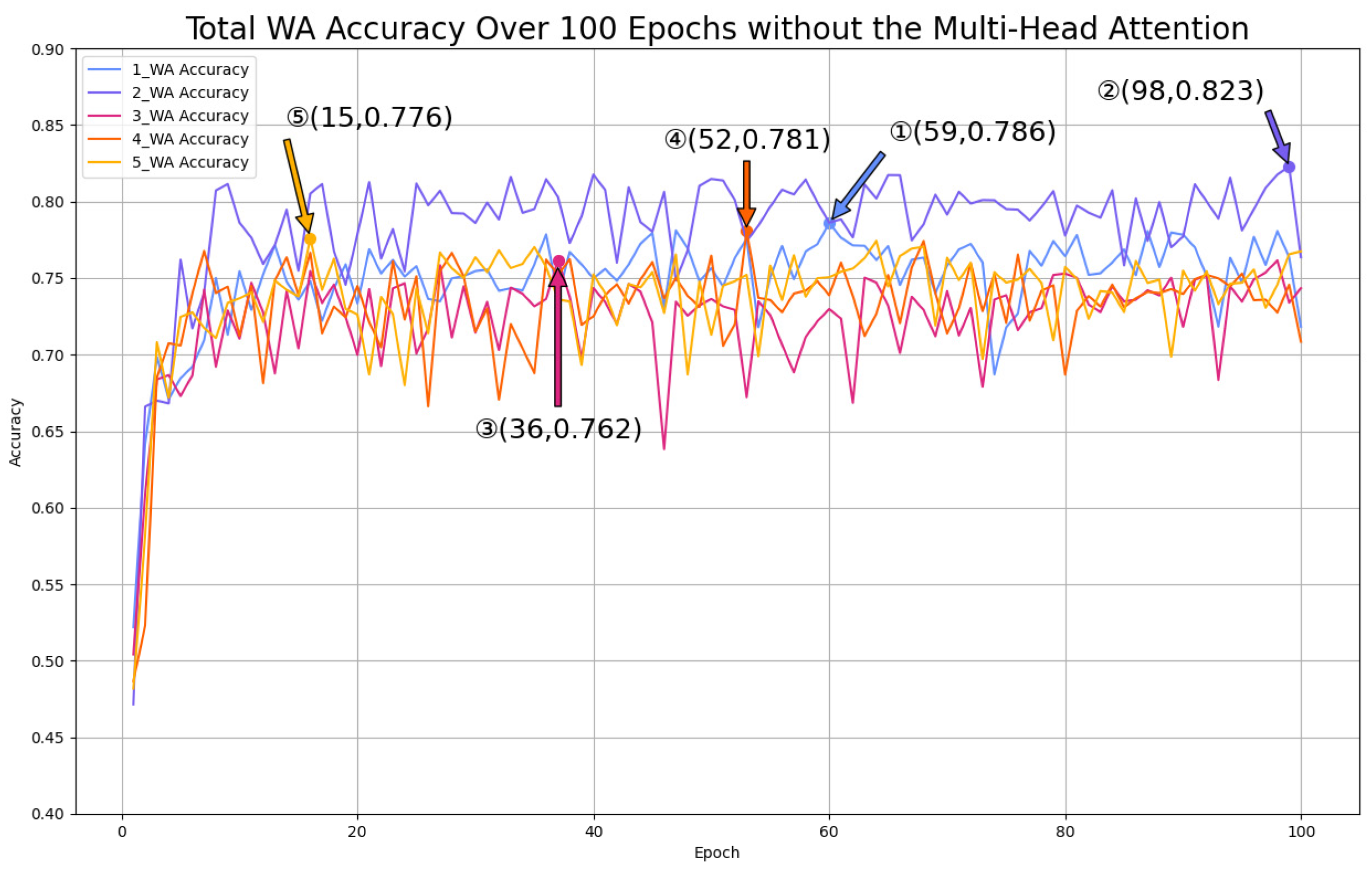
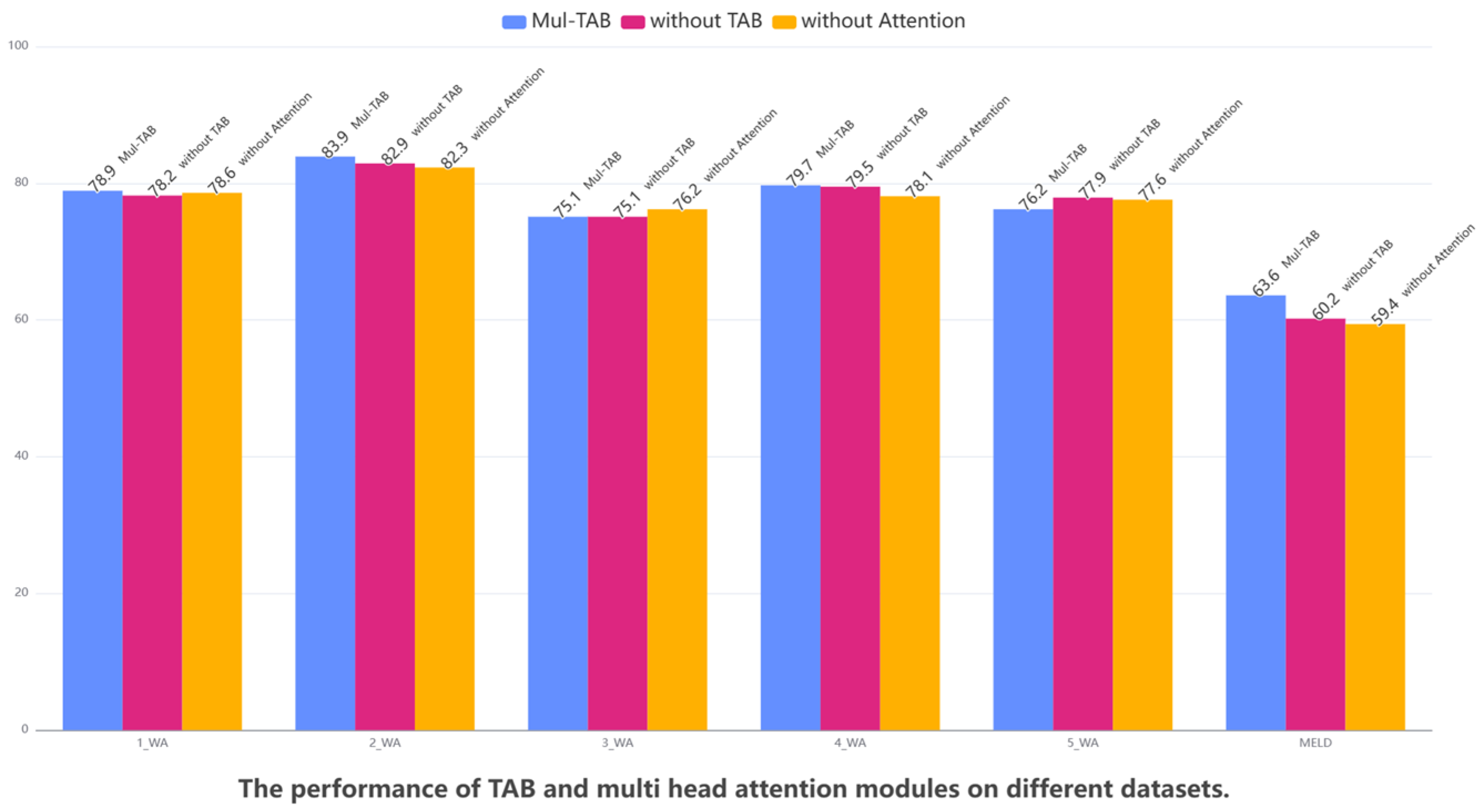
- Multi-Head Attention Mechanism Analysis
5.3.3. Comparison and Analysis with Other Experiments
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| NLP | Natural language processing |
| TIM-Net | Temporal-Aware Bi-direction Multi-Scale Network |
| TAB | Temporal-aware block |
| SER | Speech emotion recognition |
| FER | Facial emotion recognition |
| LLD | Low-Level Descriptor |
| MFCCs | Mel-Frequency Cepstral Coefficients |
| CNN | Convolutional Neural Network |
| RNN | Recurrent Neural Network |
| BiLSTM | Bidirectional Long Short-Term Memory |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| Glove | Global Vectors for Word Representation |
| Elmo | Embeddings from Language Models |
| BERT | Bidirectional Encoder Representation from Transformers |
| MLM | Masked Language Model |
| NSP | Next Sentence Prediction |
| LSTM | Long Short-Term Memory |
| ML-LSTM | Multi-Layer LSTM |
| FC | Fully connected |
| DC Conv | Dilated causal convolution |
| CME | Cross-Modal Encoder |
References
- Ekman, P. An argument for basic emotions. Cogn. Emot. 1992, 6, 169–200. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef]
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R.W. Driver Emotion Recognition for Intelligent Vehicles: A Survey. ACM Comput. Surv. 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Franzoni, V.; Milani, A.; Nardi, D.; Vallverdú, J. Emotional machines: The next revolution. Web Intell. 2019, 17, 1–7. [Google Scholar] [CrossRef]
- Rheu, M.; Shin, J.Y.; Peng, W.; Huh-Yoo, J. Systematic Review: Trust-Building Factors and Implications for Conversational Agent Design. Int. J. Hum. Comput. Interact. 2021, 37, 81–96. [Google Scholar] [CrossRef]
- Suryadevara, N.K.; Mukhopadhyay, S.C. Determining wellness through an ambient assisted living environment. IEEE Intell. Syst. 2014, 29, 30–37. [Google Scholar] [CrossRef]
- Suryadevara, N.K.; Chen, C.-P.; Mukhopadhyay, S.C.; Rayudu, R.K. Ambient assisted living framework for elderly wellness determination through wireless sensor scalar data. In Proceedings of the Seventh International Conference on Sensing Technology, Wellington, New Zealand, 3–5 December 2013; pp. 632–639. [Google Scholar]
- Ghayvat, H.; Awais, M.; Pandya, S.; Ren, H.; Akbarzadeh, S.; Chandra Mukhopadhyay, S.; Chen, C.; Gope, P.; Chouhan, A.; Chen, W. Smart aging system: Uncovering the hidden wellness parameter for well-being monitoring and anomaly detection. Sensors 2019, 19, 766. [Google Scholar] [CrossRef]
- Poorna, S.S.; Nair, G.J. Multistage classification scheme to enhance speech emotion recognition. Int. J. Speech Technol. 2019, 22, 327–340. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, G.; Xu, Y.; Li, J.; Zhao, Z. Learning Mutual Correlation in Multimodal Transformer for Speech Emotion Recognition. In Proceedings of the Annual Conference of the International Speech Communication Association (INTERSPEECH), Brno, Czech Republic, 30 August–3 September 2021; pp. 4518–4522. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Zou, H.; Si, Y.; Chen, C.; Rajan, D.; Chng, E.S. Speech Emotion Recognition with Co-Attention based Multi-level Acoustic Information. In Proceedings of the 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2019, 10, 18–31. [Google Scholar] [CrossRef]
- Bakariya, B.; Singh, A.; Singh, H.; Raju, P.; Rajpoot, R.; Mohbey, K.K. Facial emotion recognition and music recommendation system using cnn-based deep learning techniques. Evol. Syst. 2024, 15, 641–658. [Google Scholar] [CrossRef]
- Meena, G.; Mohbey, K.K.; Indian, A.; Khan, M.Z.; Kumar, S. Identifying emotions from facial expressions using a deep convolutional neural network-based approach. Multimed. Tools Appl. 2024, 83, 15711–15732. [Google Scholar] [CrossRef]
- Lisitsa, E.; Benjamin, K.S.; Chun, S.K.; Skalisky, J.; Hammond, L.E.; Mezulis, A.H. Loneliness among Young Adults during COVID-19 Pandemic: The Mediational Roles of Social Media Use and Social Support Seeking. J. Soc. Clin. Psychol. 2020, 39, 708–726. [Google Scholar] [CrossRef]
- Mohbey, K.K.; Meena, G.; Kumar, S.; Lokesh, K. A CNN-LSTM-Based Hybrid Deep Learning Approach for Sentiment Analysis on Monkeypox Tweets. New Gener. Comput. 2023, 1–19. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, K.; Sridharan, S.; Ghasemi, A.; Dean, D.; Fookes, C. Deep spatio-temporal features for multimodal emotion recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1215–1223. [Google Scholar]
- Guanghui, C.; Xiaoping, Z. Multi-modal emotion recognition by fusing correlation features of speech-visual. IEEE Signal Process. Lett. 2021, 28, 533–537. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7216–7223. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor fusion network for multimodal sentiment analysis. arXiv 2017, arXiv:1707.07250. [Google Scholar]
- Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y.; Kong, X. Multimodal sentiment analysis based on fusion methods: A survey. Inf. Fusion 2023, 95, 306–325. [Google Scholar] [CrossRef]
- Gandhi, A.; Adhvaryu, K.; Poria, S.; Cambria, E.; Hussain, A. Multimodal sentiment analysis: A systematic review of history, datasets, multimodal fusion methods, applications, challenges and future directions. Inf. Fusion 2023, 91, 424–444. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, D.; Zhang, P.; Wang, P.; Li, J.; Li, X.; Wang, B. A quantum-inspired multimodal sentiment analysis framework. Theor. Comput. Sci. 2018, 752, 21–40. [Google Scholar] [CrossRef]
- Liang, P.P.; Zadeh, A.; Morency, L.P. Foundations and recent trends in multimodal machine learning: Principles, challenges, and open questions. arXiv 2022, arXiv:2209.03430. [Google Scholar]
- Hazarika, D.; Zimmermann, R.; Poria, S. Misa: Modality-invariant and-specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Sun, H.; Wang, H.; Liu, J.; Chen, Y.W.; Lin, L. Cubemlp: An MLP-based model for multimodal sentiment analysis and depression estimation. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; pp. 3722–3729. [Google Scholar]
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.P. Multimodal sentiment analysis with word-level fusion and reinforcement learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 163–171. [Google Scholar]
- Bates, J. The role of emotion in believable agents. Commun. ACM 1994, 37, 122–125. [Google Scholar] [CrossRef]
- Hayes-Roth, B.; Doyle, P. Animate characters. Auton. Agents Multi-Agent Syst. 1998, 1, 195–230. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ye, J.; Wen, X.C.; Wei, Y.; Xu, Y.; Liu, K.; Shan, H. Temporal Modeling Matters: A Novel Temporal Emotional Modeling Approach for Speech Emotion Recognition. In Proceedings of the CASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv 2018, arXiv:1810.02508. [Google Scholar]
- Lee, S.; Han, D.K.; Ko, H. Fusion-ConvBERT: Parallel Convolution and BERT Fusion for Speech Emotion Recognition. Sensors 2020, 20, 6688. [Google Scholar] [CrossRef]
- Dai, W.; Cahyawijaya, S.; Liu, Z.; Fung, P. Multimodal end-to-end sparse model for emotion recognition. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2021; pp. 5305–5316. [Google Scholar]
- Huddar, M.G.; Sannakki, S.S.; Rajpurohit, V.S. Attention-based Multi-modal Sentiment Analysis and Emotion Detection in Conversation using RNN. Int. J. Interact. Multimed. Artif. Intell. 2021, 6, 112–121. [Google Scholar] [CrossRef]
- Graves, A.; Fernández, S.; Schmidhuber, J. Bidirectional LSTM networks for improved phoneme classification and recognition. In Proceedings of the Artificial Neural Networks: Formal Models and Their Applications, Warsaw, Poland, 11–15 September 2005; pp. 799–804. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Graves, A.; Schuller, B.; Douglas-Cowie, E.; Cowie, R. On-line emotion recognition in a 3-D activation-valence-time continuum using acoustic and linguistic cues. J. Multimodal User Interfaces 2010, 3, 7–19. [Google Scholar] [CrossRef]
- Wu, Y.; Li, G.; Fu, Q. Non-Intrusive Air Traffic Control Speech Quality Assessment with ResNet-BiLSTM. Appl. Sci. 2023, 13, 10834. [Google Scholar] [CrossRef]
- Chatterjee, A.; Narahari, K.N.; Joshi, M.; Agrawal, P. SemEval-2019 task 3: EmoContext contextual emotion detection in text. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 39–48. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Deng, J.; Ren, F. A survey of textual emotion recognition and its challenges. IEEE Trans. Affect. Comput. 2021, 14, 49–67. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Ilić, S.; Marrese-Taylor, E.; Balazs, J.A.; Matsuo, Y. Deep contextualized word representations for detecting sarcasm and irony. arXiv 2018, arXiv:1809.09795. [Google Scholar]
- D’mello, S.K.; Kory, J. A Review and Meta-Analysis of Multimodal Affect Detection Systems. ACM Comput. Surv. 2015, 47, 1–36. [Google Scholar] [CrossRef]
- Zhang, L.; Na, J.; Zhu, J.; Shi, Z.; Zou, C.; Yang, L. Spatiotemporal causal convolutional network for forecasting hourly PM2.5 concentrations in Beijing, China. Comput. Geosci. 2021, 155, 104869. [Google Scholar] [CrossRef]
- Li, R.; Wu, Z.; Jia, J.; Zhao, S.; Meng, H. Dilated residual network with multi-head self-attention for speech emotion recognition. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6675–6679. [Google Scholar]
- Zhong, Y.; Hu, Y.; Huang, H.; Silamu, W. A Lightweight Model Based on Separable Convolution for Speech Emotion Recognition. In Proceedings of the INTERSPEECH, Shanghai, China, 25–29 November 2020; pp. 3331–3335. [Google Scholar]
- Peng, Z.; Lu, Y.; Pan, S.; Liu, Y. Efficient Speech Emotion Recognition Using Multi-Scale CNN and Attention. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3020–3024. [Google Scholar]
- Aftab, A.; Morsali, A.; Ghaemmaghami, S.; Champagne, B. LIGHT-SERNET: A lightweight fully convolutional neural network for speech emotion recognition. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6912–6916. [Google Scholar]
- Zhao, Z.; Wang, Y.; Wang, Y. Multi-level fusion of wav2vec 2.0 and BERT for multimodal emotion recognition. arXiv 2022, arXiv:2207.04697. [Google Scholar]
- Ghosh, S.; Tyagi, U.; Ramaneswaran, S.; Srivastava, H.; Manocha, D. MMER: Multimodal Multi-task Learning for Speech Emotion Recognition. arXiv 2022, arXiv:2203.16794. [Google Scholar]
- Wang, Y.; Gu, Y.; Yin, Y.; Han, Y.; Zhang, H.; Wang, S.; Li, C.; Quan, D. Multimodal transformer augmented fusion for speech motion recognition. Front. Neurorobot. 2023, 17, 1181598. [Google Scholar] [CrossRef]
- Guo, L.; Wang, L.; Dang, J.; Fu, Y.; Liu, J.; Ding, S. Emotion Recognition with Multimodal Transformer Fusion Framework Based on Acoustic and Lexical Information. IEEE MultiMedia 2022, 29, 94–103. [Google Scholar] [CrossRef]
- Wang, N.; Cao, H.; Zhao, J.; Chen, R.; Yan, D.; Zhang, J. M2R2: Missing-Modality Robust emotion Recognition framework with iterative data augmentation. IEEE Trans. Artif. Intell. 2022, 4, 1305–1316. [Google Scholar] [CrossRef]
- Hu, J.; Liu, Y.; Zhao, J.; Jin, Q. MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. arXiv 2021, arXiv:2107.06779. [Google Scholar]
- Shen, W.; Wu, S.; Yang, Y.; Quan, X. Directed acyclic graph network for conversational emotion recognition. arXiv 2021, arXiv:2105.12907. [Google Scholar]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational transformer network for emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Specific Configuration |
|---|---|
| Operating System | Windows 11 |
| Processor | NVIDIA GeForce RTX 4060 Ti (NVIDIA, Santa Clara, CA, USA) |
| Memory | 16 GB |
| OS Bit | 64-bit |
| Programming Language | Python 3.8 |
| IDE | PyCharm 2023.1.2 |
| Dataset | IEMOCAP and MELD |
| Deep Learning Framework | PyTorch 2.1.0 |
| Model | IEMOCAP | MELD | ||||
|---|---|---|---|---|---|---|
| 1_WA (%) | 2_WA (%) | 3_WA (%) | 4_WA (%) | 5_WA (%) | UA (%) | |
| Mul-TAB | 78.9 | 83.9 | 75.1 | 79.7 | 76.2 | 63.9 |
| Without TAB | 78.2 | 82.9 | 75.1 | 79.5 | 77.9 | 60.2 |
| Without multi-head attention | 78.6 | 82.3 | 76.2 | 78.1 | 77.6 | 59.4 |
| Models | CV Type | Modality | Metrics | |
|---|---|---|---|---|
| UAR (%) | WAR (%) | |||
| MHA + DRN [52] | - | {S} | 67.40 | - |
| CNN + Bi-GRU [53] | - | {S} | 71.72 | 70.39 |
| MSCNN-SPU [54] | 10-fold | {S, T} | 78.20 | 77.40 |
| LightSER [55] | 10-fold | {S} | 70.76 | 70.23 |
| Article [56] | 5-fold | {S, T} | - | 76.31 |
| TIM-Net [35] | 10-fold | {S} | 72.50 | 71.65 |
| MMER [57] | 5-fold | {S, T} | 78.69 | 80.18 |
| Mul-TAB (ours) | 5-fold | {S, T} | 81.92 | 83.85 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Zhang, S.; Li, P. Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms. Appl. Sci. 2024, 14, 3276. https://doi.org/10.3390/app14083276
Wu Y, Zhang S, Li P. Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms. Applied Sciences. 2024; 14(8):3276. https://doi.org/10.3390/app14083276
Chicago/Turabian StyleWu, Yuezhou, Siling Zhang, and Pengfei Li. 2024. "Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms" Applied Sciences 14, no. 8: 3276. https://doi.org/10.3390/app14083276
APA StyleWu, Y., Zhang, S., & Li, P. (2024). Improvement of Multimodal Emotion Recognition Based on Temporal-Aware Bi-Direction Multi-Scale Network and Multi-Head Attention Mechanisms. Applied Sciences, 14(8), 3276. https://doi.org/10.3390/app14083276