
A Flexible Hardware Accelerator for Booth Polynomial Multiplier


Abstract
:1. Introduction
1.1. Related Hardware Accelerators and Limitations
1.2. Novelty and Contributions
- We implement a parameterized/flexible hardware accelerator design for the Booth polynomial multiplication method that allows users to perform multiplication over various operand lengths instead of the specified operand sizes. Our flexible accelerator is 1.34× faster in computation time and 1.05× more area-efficient than the most recent dedicated polynomial multiplication accelerator (for operand sizes of ).
- To minimize the area cost of the proposed flexible hardware accelerator of the Booth multiplier, we reuse the hardware resources.
- To provide efficient control functionalities, we implement a dedicated finite-state machine (FSM)-based controller.
- Finally, a comprehensive evaluation of the results concerning the throughput/area ratio is provided.
1.3. Limitation(s) and Significance of This Work
2. Background
2.1. Schoolbook Strategy
| Algorithm 1 Schoolbook Multiplier [1] |
| Require: a and b Ensure: for ()do if () then end if end for |
2.2. Booth Multiplication Approach
| Algorithm 2 Booth Polynomial Multiplication Algorithm [1] |
|
2.3. Schoolbook and Booth Algorithms: Trade-Offs
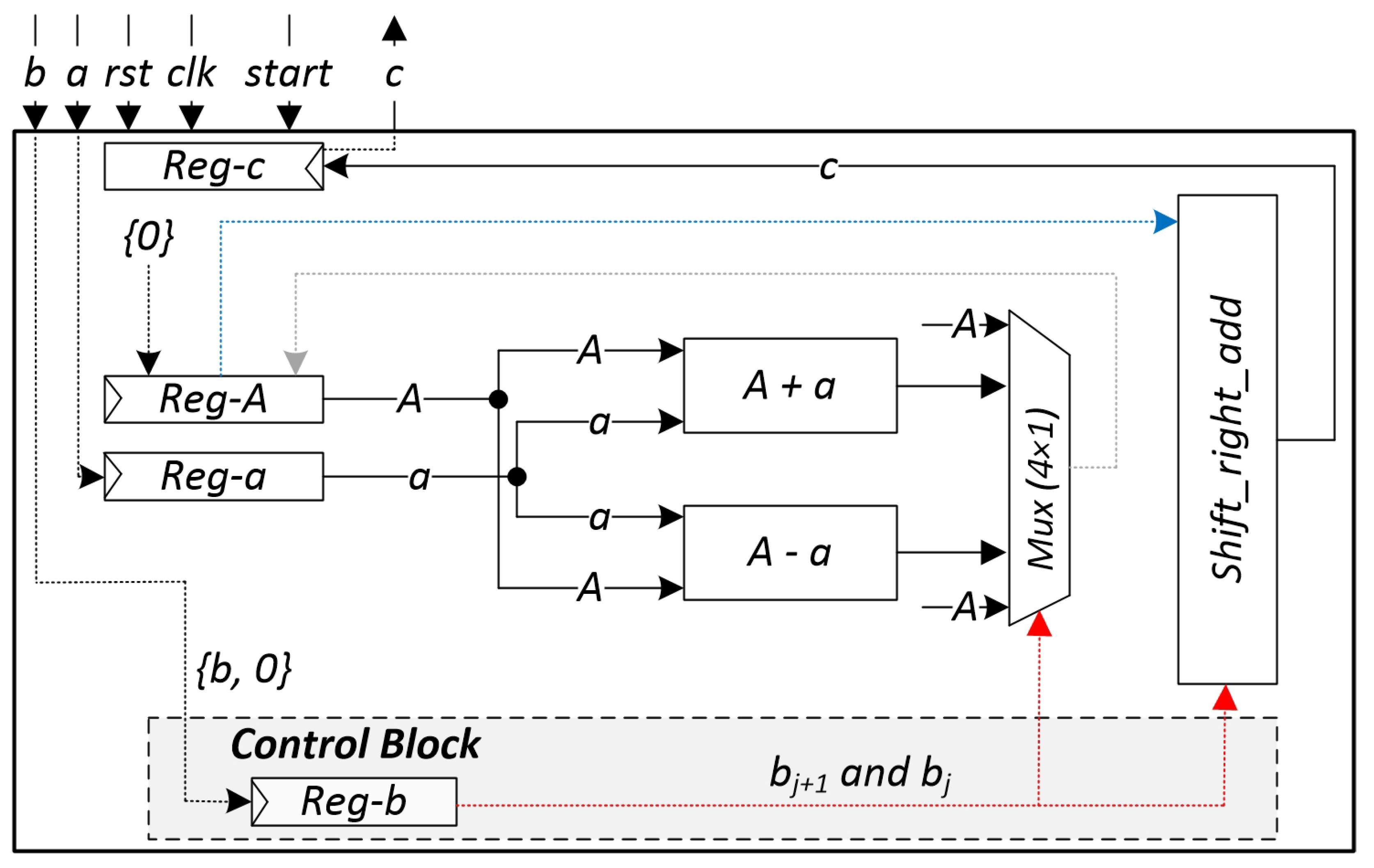
3. Proposed Booth Accelerator Architecture
3.1. Registers (or Buffers)
3.2. Adder and Subtractor
3.3. Multiplexer (4 × 1)
3.4. Shift-Right-Add Block
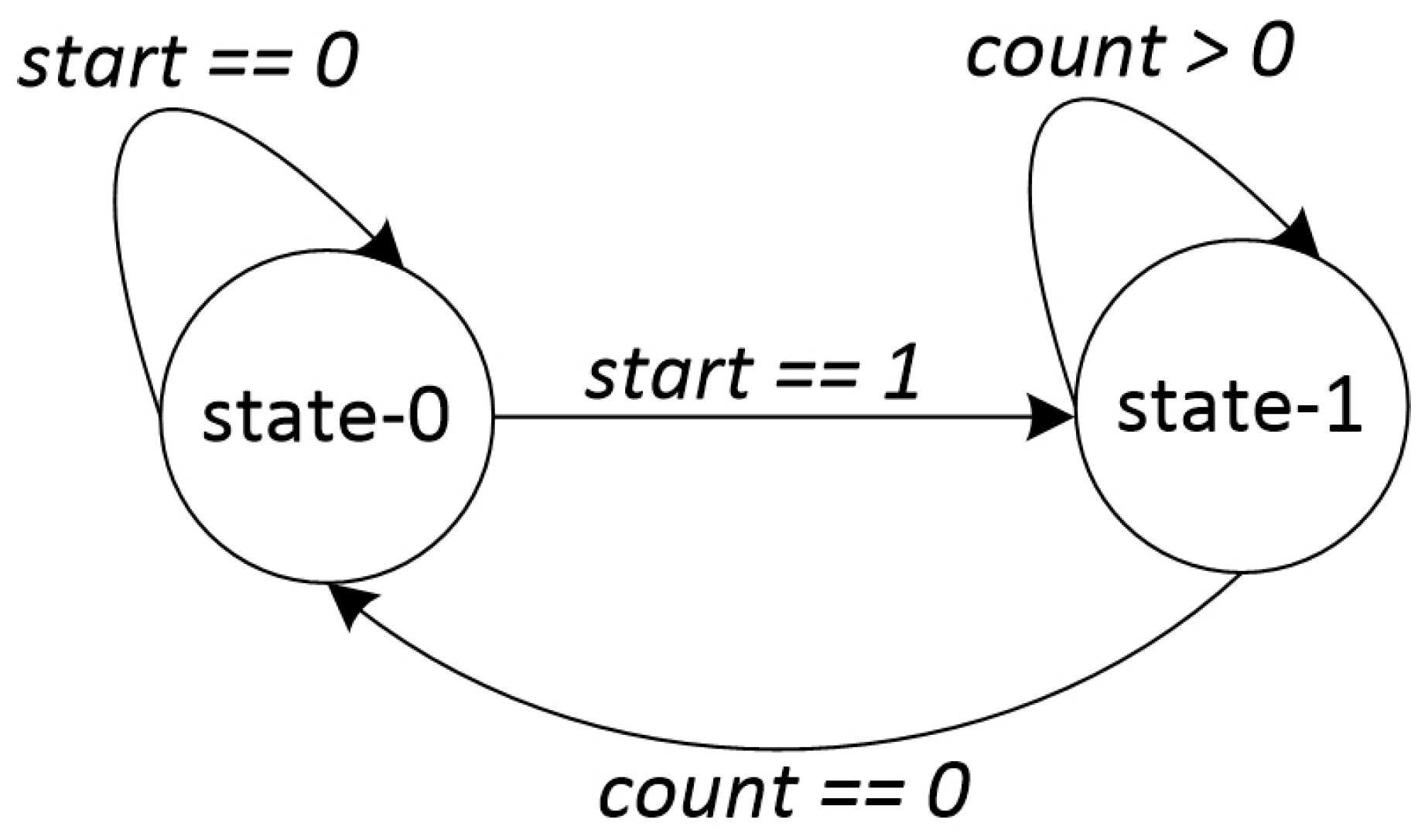
3.5. FSM Controller
4. Results and Comparison
4.1. Results
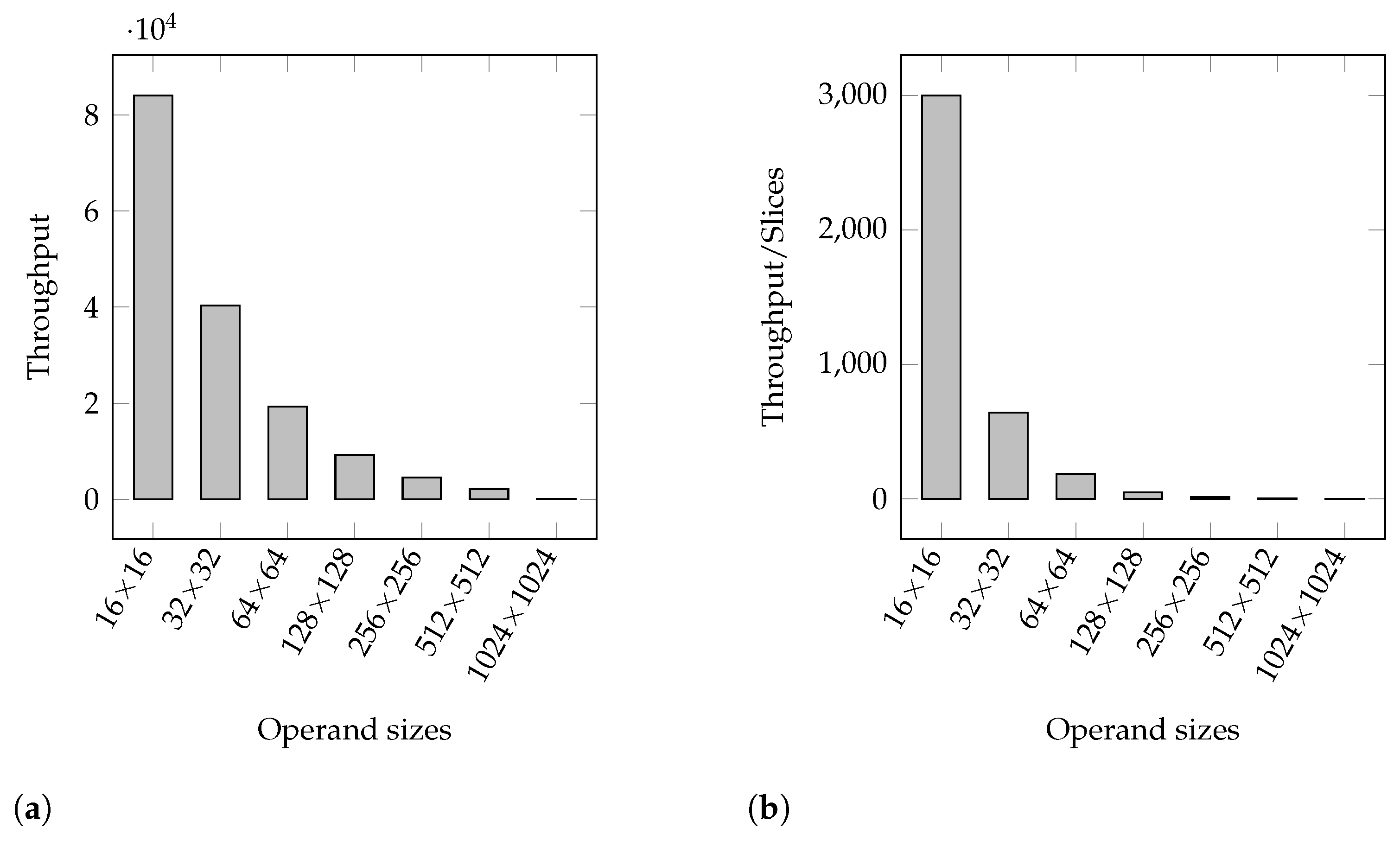
4.1.1. Booth Designs for Operand Sizes in Powers of Two
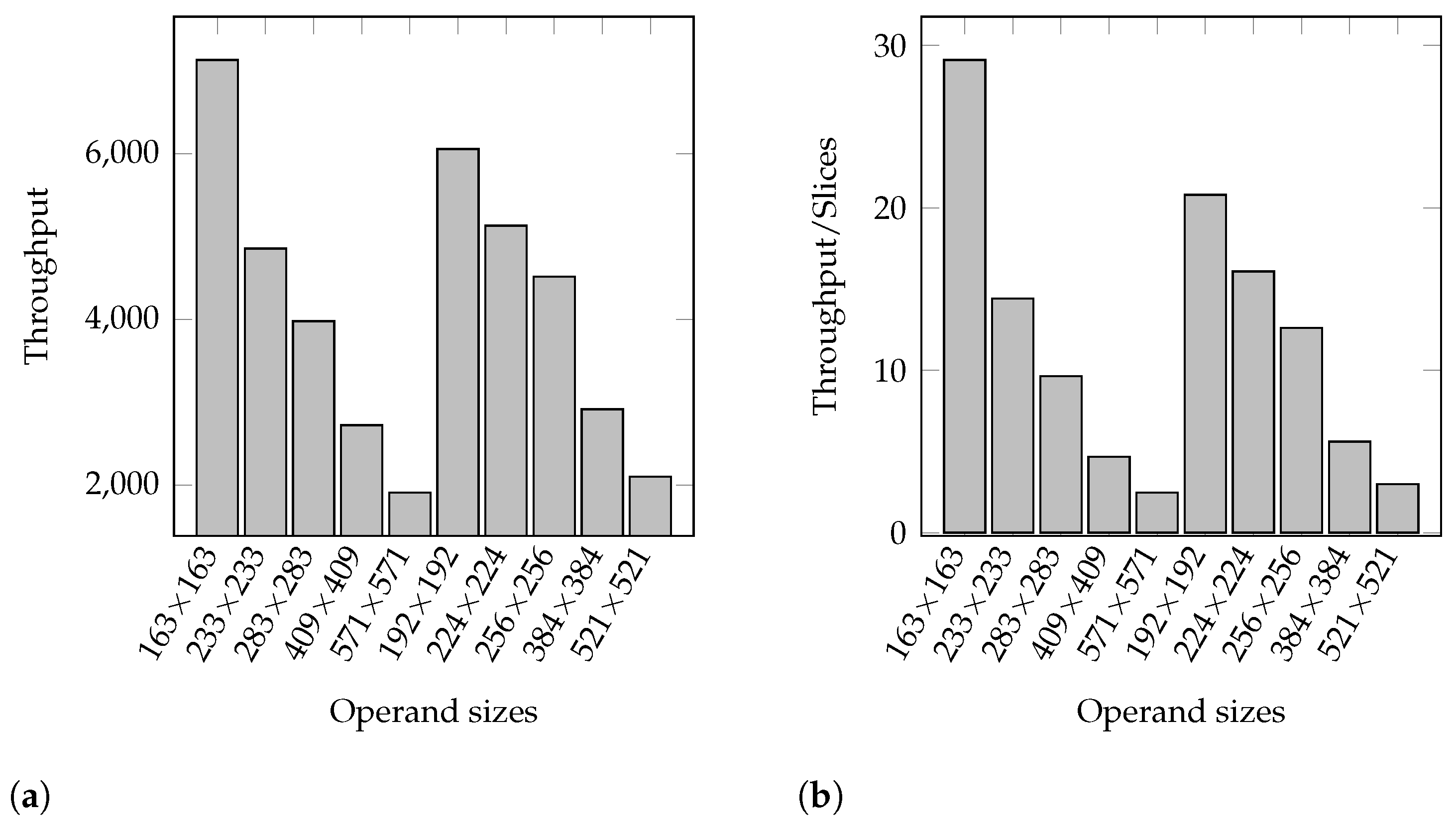
4.1.2. Booth Designs for Operand Sizes Recommended by NIST
4.1.3. Summary of the Results
4.2. Comparisons
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Imran, M.; Abideen, Z.U.; Pagliarini, S. A Versatile and Flexible Multiplier Generator for Large Integer Polynomials. J. Hardw. Syst. Secur. 2023, 7, 55–71. [Google Scholar] [CrossRef]
- Rashid, M.; Imran, M.; Jafri, A.R.; Al-Somani, T.F. Flexible architectures for cryptographic algorithms—A systematic literature review. J. Circuits Syst. Comput. 2019, 28, 1930003. [Google Scholar] [CrossRef]
- Imran, M.; Abideen, Z.U.; Pagliarini, S. An Open-source Library of Large Integer Polynomial Multipliers. In Proceedings of the 24th International Symposium on Design and Diagnostics of Electronic Circuits & Systems (DDECS), Vienna, Austria, 7–9 April 2021; pp. 145–150. [Google Scholar] [CrossRef]
- Abd-Elkader, A.A.; Rashdan, M.; Hasaneen, E.S.A.; Hamed, H.F. Advanced implementation of Montgomery Modular Multiplier. Microelectron. J. 2020, 106, 104927. [Google Scholar] [CrossRef]
- Sajid, A.; Sonbul, O.S.; Rashid, M.; Jafri, A.R.; Arif, M.; Zia, M.Y.I. A Crypto Accelerator of Binary Edward Curves for Securing Low-Resource Embedded Devices. Appl. Sci. 2023, 13, 8633. [Google Scholar] [CrossRef]
- Rashid, M.; Sonbul, O.S.; Arif, M.; Qureshi, F.A.; Alotaibi, S.S.; Sinky, M.H. A Flexible Architecture for Cryptographic Applications: ECC and PRESENT. Comput. Mater. Contin 2023, 76, 1009–1025. [Google Scholar] [CrossRef]
- Imran, M.; Rashid, M. Architectural review of polynomial bases finite field multipliers over GF(2m). In Proceedings of the International Conference on Communication, Computing and Digital Systems (C-CODE), Islamabad, Pakistan, 8–9 March 2017; pp. 331–336. [Google Scholar] [CrossRef]
- Imran, M.; Abideen, Z.U.; Pagliarini, S. An Experimental Study of Building Blocks of Lattice-Based NIST Post-Quantum Cryptographic Algorithms. Electronics 2020, 9, 1953. [Google Scholar] [CrossRef]
- Sajid, A.; Sonbul, O.S.; Rashid, M.; Arif, M.; Jaffar, A.Y. An Optimized Hardware Implementation of a Non-Adjacent Form Algorithm Using Radix-4 Multiplier for Binary Edwards Curves. Appl. Sci. 2023, 14, 54. [Google Scholar] [CrossRef]
- Rashid, M.; Sonbul, O.S.; Zia, M.Y.I.; Arif, M.; Sajid, A.; Alotaibi, S.S. Throughput/Area-Efficient Accelerator of Elliptic Curve Point Multiplication over GF (2233) on FPGA. Electronics 2023, 12, 3611. [Google Scholar] [CrossRef]
- Rashid, M.; Jamal, S.S.; Khan, S.Z.; Alharbi, A.R.; Aljaedi, A.; Imran, M. Elliptic-curve crypto processor for rfid applications. Appl. Sci. 2021, 11, 7079. [Google Scholar] [CrossRef]
- Imran, M.; Abideen, Z.U.; Pagliarini, S. TTech-LIB: Center for Hardware Security. 2020. Available online: https://github.com/Centre-for-Hardware-Security/TTech-LIB (accessed on 11 March 2024).
- Rezai, A.; Keshavarzi, P. High-Throughput Modular Multiplication and Exponentiation Algorithms Using Multibit-Scan–Multibit-Shift Technique. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2015, 23, 1710–1719. [Google Scholar] [CrossRef]
- Machhout, M.; Guitouni, Z.; Torki, K.; Khriji, L.; Tourki, R. Coupled FPGA/ASIC Implementation of Elliptic Curve Crypto-Processor. Int. J. Netw. Secur. Its Appl. 2010, 2, 100–112. [Google Scholar] [CrossRef]
- Venkatachalam, S.; Lee, H.J.; Ko, S.B. Power Efficient Approximate Booth Multiplier. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Boppana, N.V.V.K.; Kommareddy, J.; Ren, S. Low-Cost and High-Performance 8 × 8 Booth Multiplier. Circuits Syst. Signal Process. 2019, 38, 4357–4368. [Google Scholar] [CrossRef]
- Shinde, K.; Kureshi, A. Hardware Implementation of Configurable Booth Multiplier on FPGA. In Proceedings of the International Conference on Communication, Computing and Digital Systems (C-CODE), Pune, India, 21 February 2016; pp. 60–63. [Google Scholar]
- Cheng, X.; Wang, Y.; Liu, J.; Ding, W.; Lou, H.; Li, P. Booth Encoded Bit-Serial Multiply-Accumulate Units with Improved Area and Energy Efficiencies. Electronics 2023, 12, 2177. [Google Scholar] [CrossRef]
- Krishnan T., S.; Chalil, A.; Sreehari, K. VLSI Implementation of Reed Solomon Codes. In Proceedings of the 4th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; pp. 280–284. [Google Scholar] [CrossRef]
- Tang, N.; Lin, Y. Fast Encoding and Decoding Algorithms for Arbitrary (n, k) Reed-Solomon Codes Over . IEEE Commun. Lett. 2020, 24, 716–719. [Google Scholar] [CrossRef]
- Mandelbaum, D. On decoding of Reed-Solomon codes. IEEE Trans. Inf. Theory 1971, 17, 707–712. [Google Scholar] [CrossRef]
- Bai, S.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Schwabe, P.; Seiler, G.; Stehlé, D. CRYSTALS-Dilithium. Selected for NIST PQC Standardization. 2023. Available online: https://pq-crystals.org/dilithium/ (accessed on 4 March 2024).
- Schwabe, P.; Avanzi, R.; Bos, J.; Ducas, L.; Kiltz, E.; Lepoint, T.; Lyubashevsky, V.; Schanck, J.M.; Seiler, G.; Stehle, D. CRYSTALS-KYBER. Proposal to NIST PQC Standardization. 2021. Available online: https://csrc.nist.gov/Projects/post-quantum-cryptography/post-quantum-cryptography-standardization/round-3-submissions (accessed on 9 January 2024).
- Karatsuba, A.; Ofman, Y. Multiplication of Multidigit Numbers on Automata. Sov. Phys. Dokl. 1963, 7, 595. [Google Scholar]
- Carlet, C.; Sunar, B. (Eds.) Arithmetic of Finite Fields. In Proceedings of the WAIFI 2007—International Workshop on the Arithmetic of Finite Fields, Madrid, Spain, 21–22 June 2007; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2007; Volume 4547. [Google Scholar]
- Dutta, S.; Bhattacharjee, D.; Chattopadhyay, A. Quantum circuits for Toom-Cook multiplication. Phys. Rev. A 2018, 98. [Google Scholar] [CrossRef]
- Chung, C.M.M.; Hwang, V.; Kannwischer, M.J.; Seiler, G.; Shih, C.J.; Yang, B.Y. NTT Multiplication for NTT-unfriendly Rings. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2021, 2021, 159–188. [Google Scholar] [CrossRef]
- Liang, Z.; Zhao, Y. Number Theoretic Transform and Its Applications in Lattice-based Cryptosystems: A Survey. 2022. Available online: http://xxx.lanl.gov/abs/2211.13546 (accessed on 27 December 2023).
- NIST. Recommended Elliptic Curves for Federal Government Use. 1999. Available online: https://csrc.nist.gov/csrc/media/publications/fips/186/2/archive/2000-01-27/documents/fips186-2.pdf (accessed on 9 March 2024).
- Hankerson, D.; Menezes, A.J.; Vanstone, S. Guide to Elliptic Curve Cryptography 2004. pp. 1–311. Available online: https://link.springer.com/book/10.1007/b97644 (accessed on 27 July 2023).
- Xilinx Inc. Form 10-K, Annual Report, Filing Date 12 June 2001. Available online: http://edgar.secdatabase.com/1862/101287001501165/filing-main.htm (accessed on 3 March 2024).
- Xilinx Inc. Form 10-K, Annual Report, Filing Date 17 June 2002. Available online: http://edgar.secdatabase.com/2603/101287002002739/filing-main.htm (accessed on 2 March 2024).
- Xilinx Inc. Form 10-K, Annual Report, Filing Date 1 June 2005. Available online: http://edgar.secdatabase.com/669/104746905016238/filing-main.htm (accessed on 2 March 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operand Sizes () | Area Utilization | Timing Details | Power Results | ||
|---|---|---|---|---|---|
| Slices/LUTs/FFs | CCs | Freq (MHz) | Lat (μs) | D/S/TP (mW) | |
| Operand sizes in powers of 2 | |||||
| 16 × 16 | 28/70/82 | 8 | 666 | 0.011 | 17/323/340 |
| 32 × 32 | 63/134/163 | 16 | 645 | 0.024 | 30/323/353 |
| 64 × 64 | 104/260/323 | 32 | 617 | 0.051 | 59/323/382 |
| 128 × 128 | 195/522/649 | 64 | 591 | 0.108 | 114/324/437 |
| 256 × 256 | 358/910/1295 | 128 | 578 | 0.221 | 177/324/502 |
| 512 × 512 | 624/1819/2584 | 256 | 552 | 0.463 | 340/325/666 |
| 1024 × 1024 | 1434/2602/5167 | 512 | 523 | 0.977 | 600/327/927 |
| Key lengths by NIST for use in a binary field ECC (taken from [29]) | |||||
| 163 × 163 | 245/584/827 | 82 | 584 | 0.140 | 153/324/477 |
| 233 × 233 | 337/830/1180 | 117 | 568 | 0.205 | 161/324/485 |
| 283 × 283 | 413/1010/1432 | 142 | 564 | 0.251 | 192/324/516 |
| 409 × 409 | 582/1457/2070 | 205 | 558 | 0.366 | 275/325/600 |
| 571 × 571 | 775/2027/2880 | 286 | 546 | 0.523 | 372/326/698 |
| Key lengths by NIST for use in a prime field ECC (taken from [29]) | |||||
| 192 × 192 | 291/686/973 | 96 | 581 | 0.165 | 184/324/508 |
| 224 × 224 | 319/800/1135 | 112 | 574 | 0.194 | 154/324/478 |
| 256 × 256 | 358/910/1295 | 128 | 578 | 0.221 | 177/324/502 |
| 384 × 384 | 520/1369/1946 | 192 | 560 | 0.342 | 254/325/579 |
| 521 × 521 | 700/1853/2633 | 261 | 549 | 0.475 | 344/325/669 |
| Ref. | Implemented Algorithm | Platform | Operand Sizes () | Freq (MHz) | Lat (s) | Slices/LUTs |
|---|---|---|---|---|---|---|
| [4] | Radix-2 Montgomery | Virtex-6 | 1024 × 1024 | 53.23 | 19.26 | -/2566 |
| [13] | Montgomery | Virtex-5 | 1024 × 1024 | 400 | 0.88 | 6105/- |
| [14] | PCA | Virtex-II | 163 × 163 | 177.8 | 0.91 | 225/- |
| [17] | radix-4 Booth | Spartan-6 | 32 × 32 | 100 | - | -/278 |
| [18] | radix-4 Booth | Kintex-7 | 16 × 16 | - | - | -/110 |
| This Work | Booth | Virtex-6 | 1024 × 1024 | 71.5 | 14.32 | -/2429 |
| Virtex-5 | 1024 × 1024 | 39.35 | 13.01 | 4113/- | ||
| Virtex-4 | 163 × 163 | 131 | 1.24 | 565/- | ||
| Virtex-7 | 32 × 32 | 645.161 | 0.0248 | 30/323 | ||
| Kintex-7 | 16 × 16 | 678.358 | 0.0117 | 30/69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sonbul, O.S. A Flexible Hardware Accelerator for Booth Polynomial Multiplier. Appl. Sci. 2024, 14, 3323. https://doi.org/10.3390/app14083323
Sonbul OS. A Flexible Hardware Accelerator for Booth Polynomial Multiplier. Applied Sciences. 2024; 14(8):3323. https://doi.org/10.3390/app14083323
Chicago/Turabian StyleSonbul, Omar S. 2024. "A Flexible Hardware Accelerator for Booth Polynomial Multiplier" Applied Sciences 14, no. 8: 3323. https://doi.org/10.3390/app14083323
APA StyleSonbul, O. S. (2024). A Flexible Hardware Accelerator for Booth Polynomial Multiplier. Applied Sciences, 14(8), 3323. https://doi.org/10.3390/app14083323