
Greenhouse Ventilation Equipment Monitoring for Edge Computing

Abstract
:1. Introduction
2. Methods
2.1. Related Works
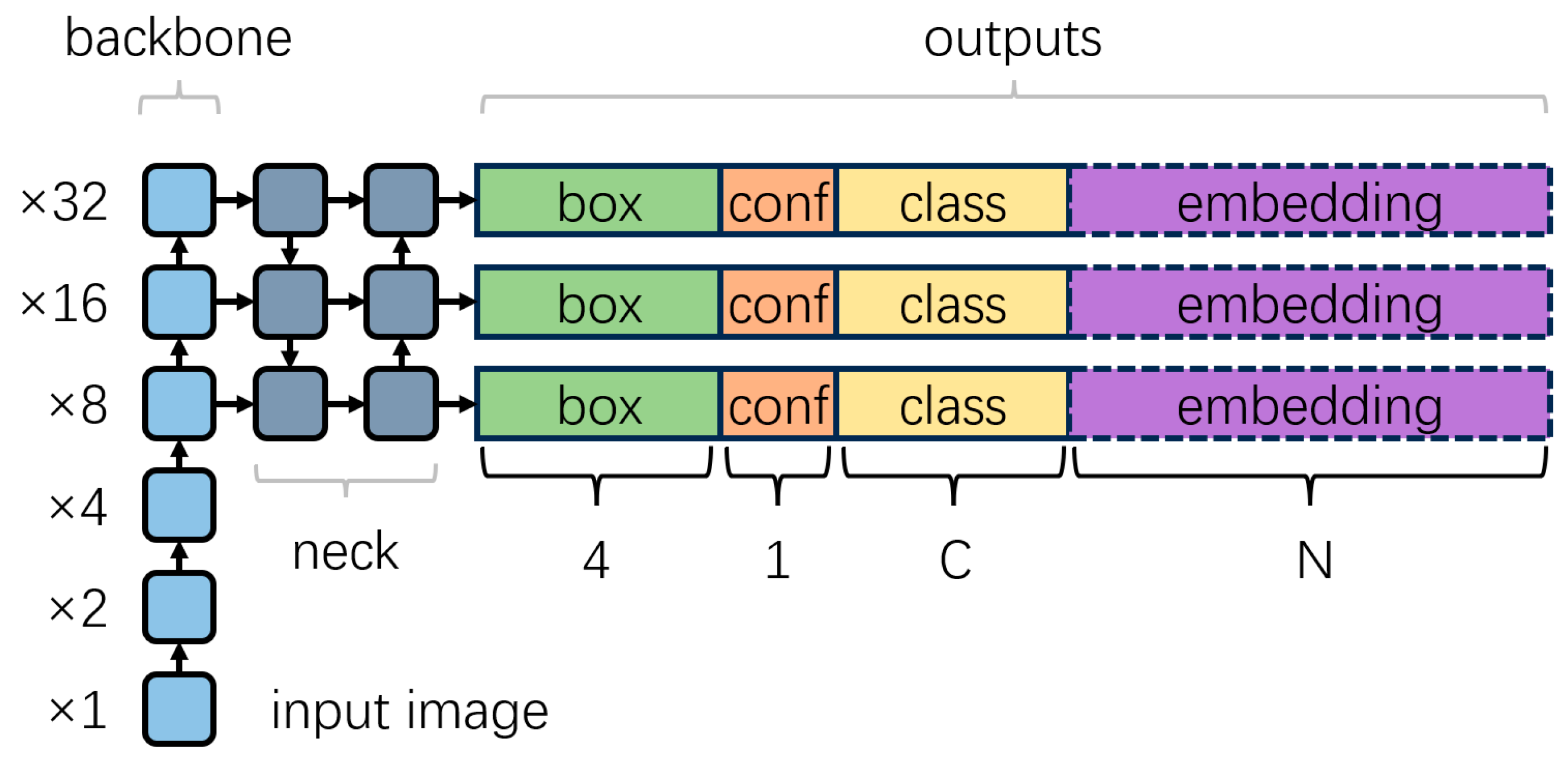
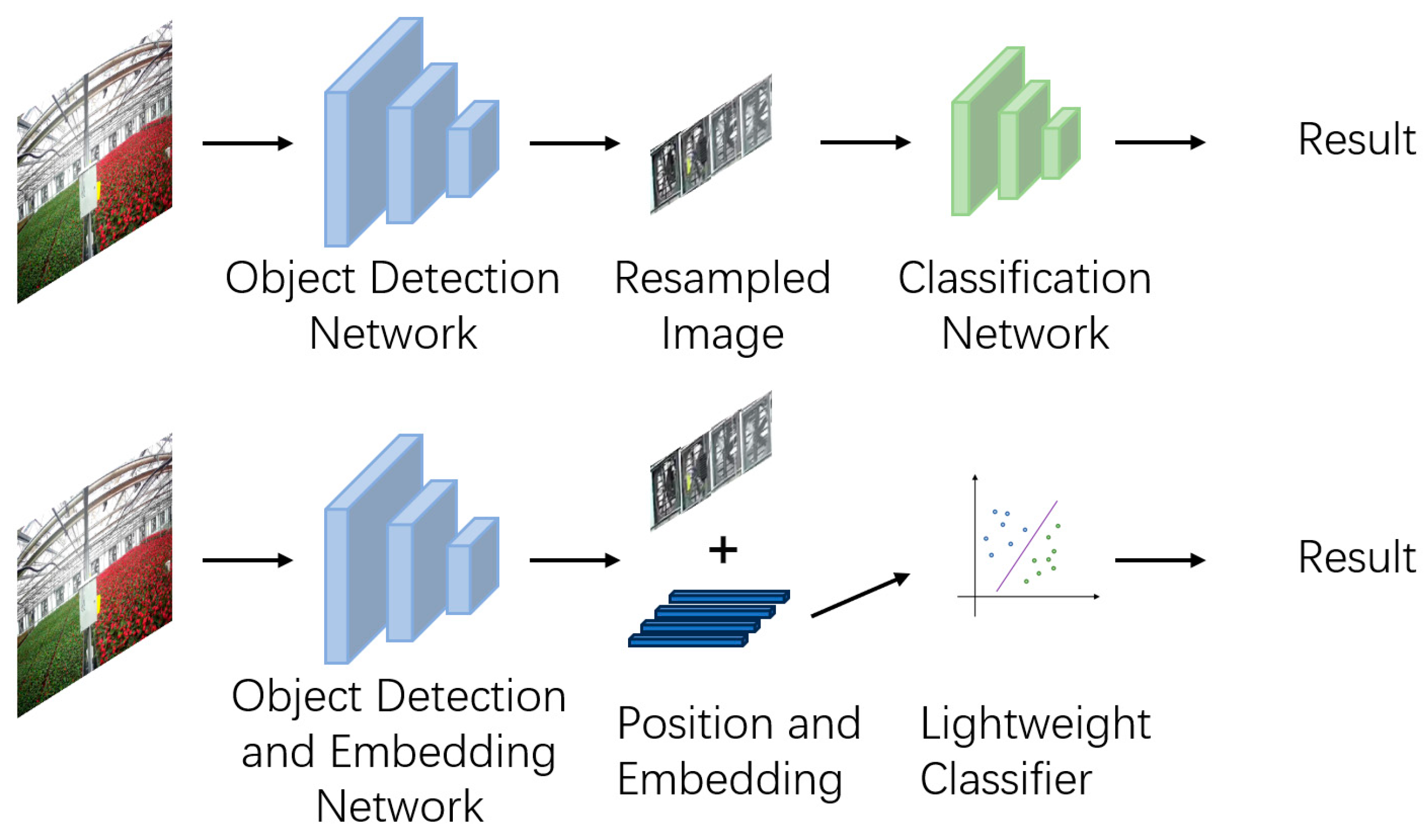
2.2. Integration of Detection and Embedding
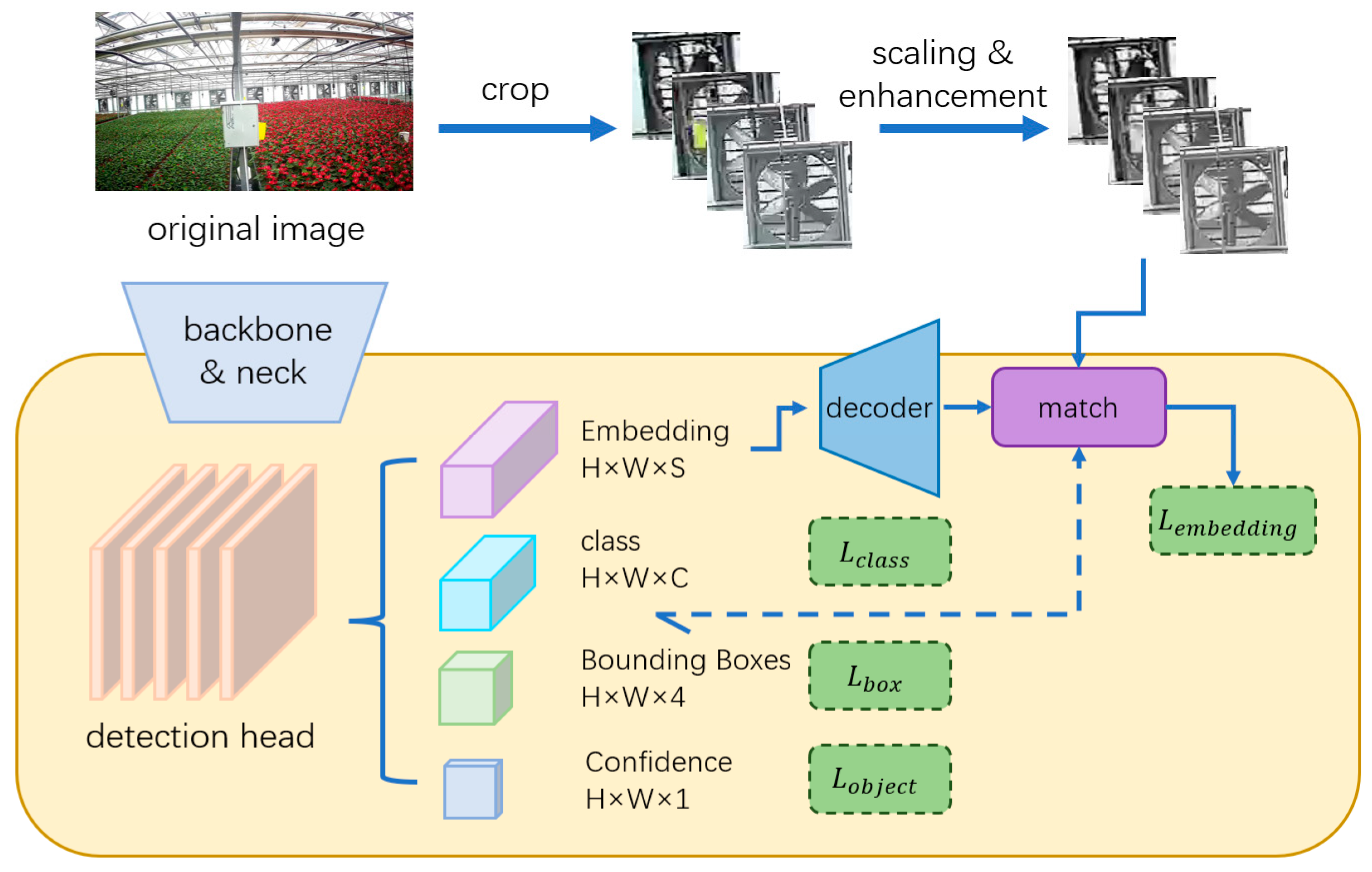
2.2.1. Integration Method
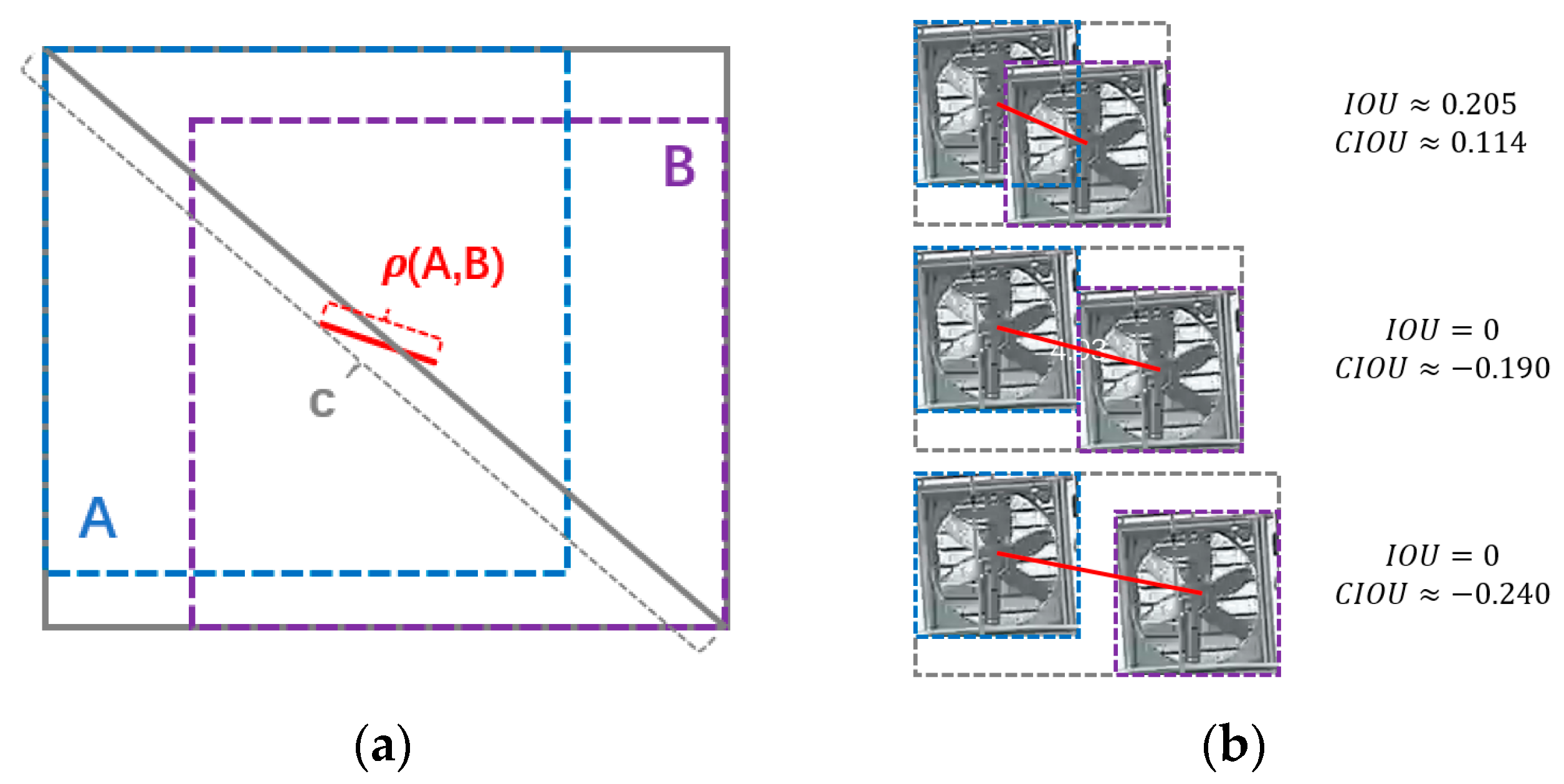
2.2.2. Loss Function
2.2.3. Training Methodology
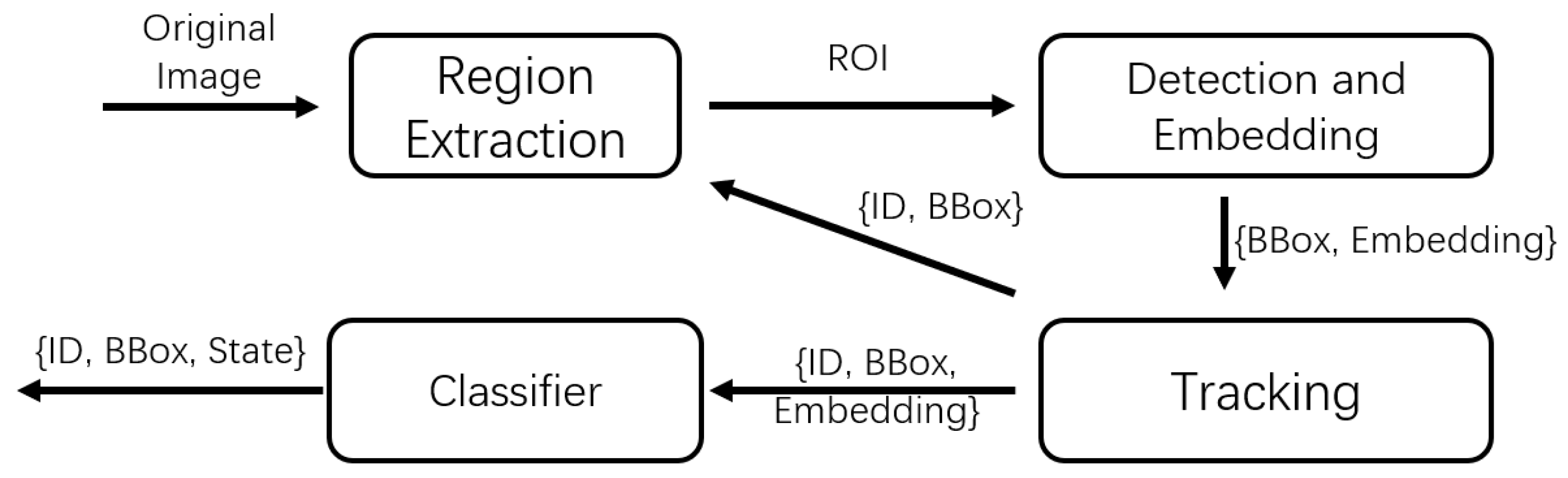
2.3. Extracting Regions of Interest Based on Tracking
3. Experiments
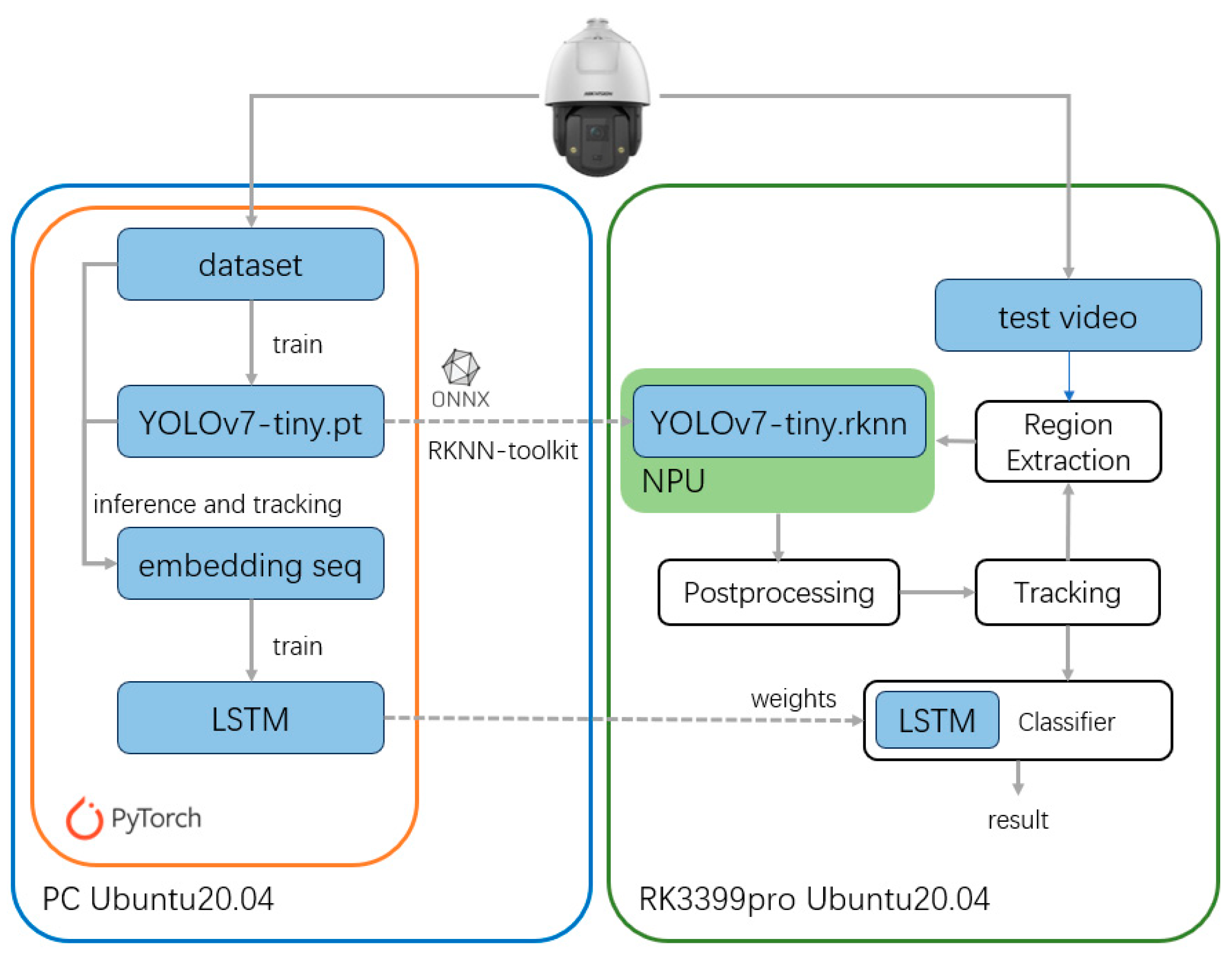
3.1. Experimental Configuration
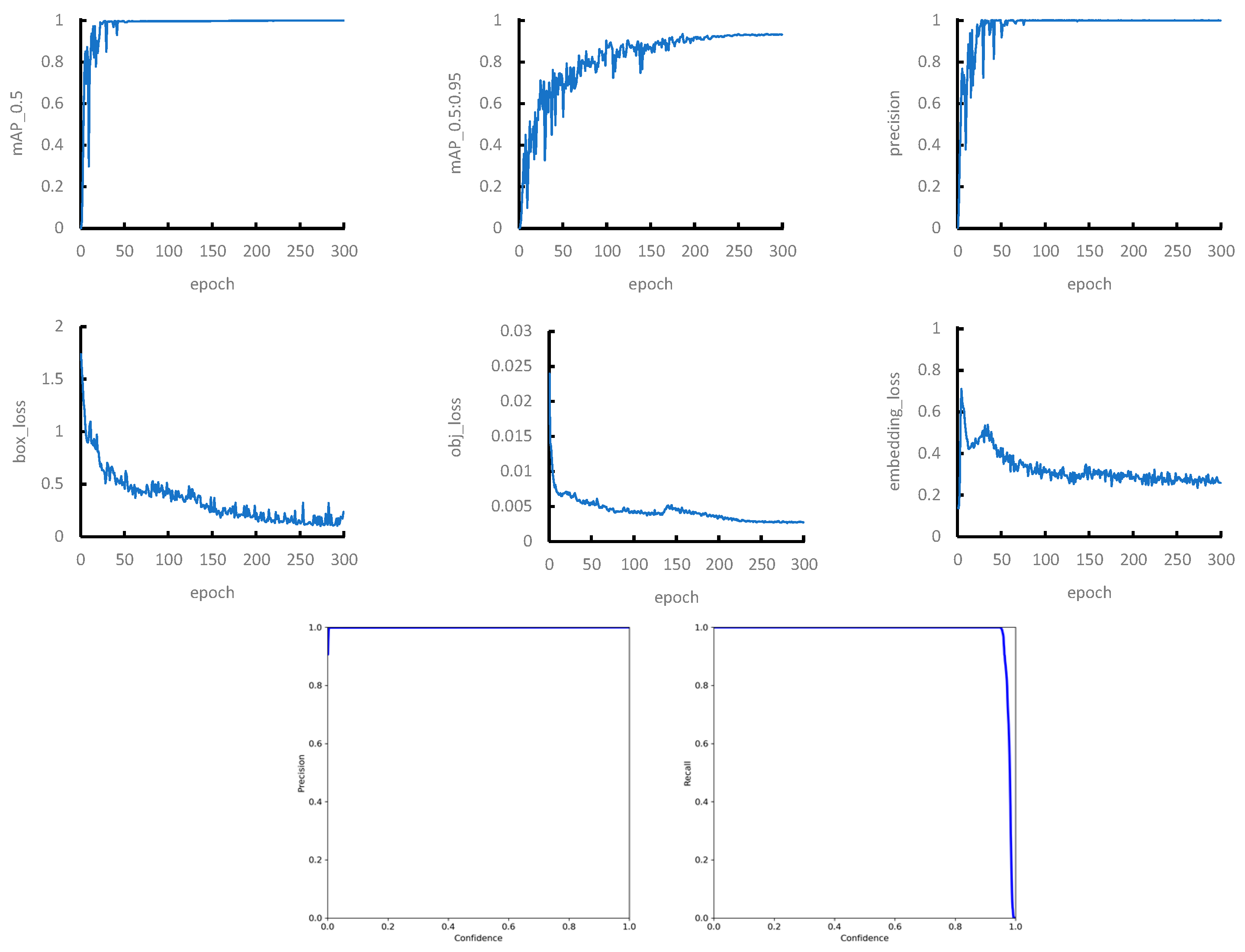
3.2. Training of Object Detection and Embedding Model
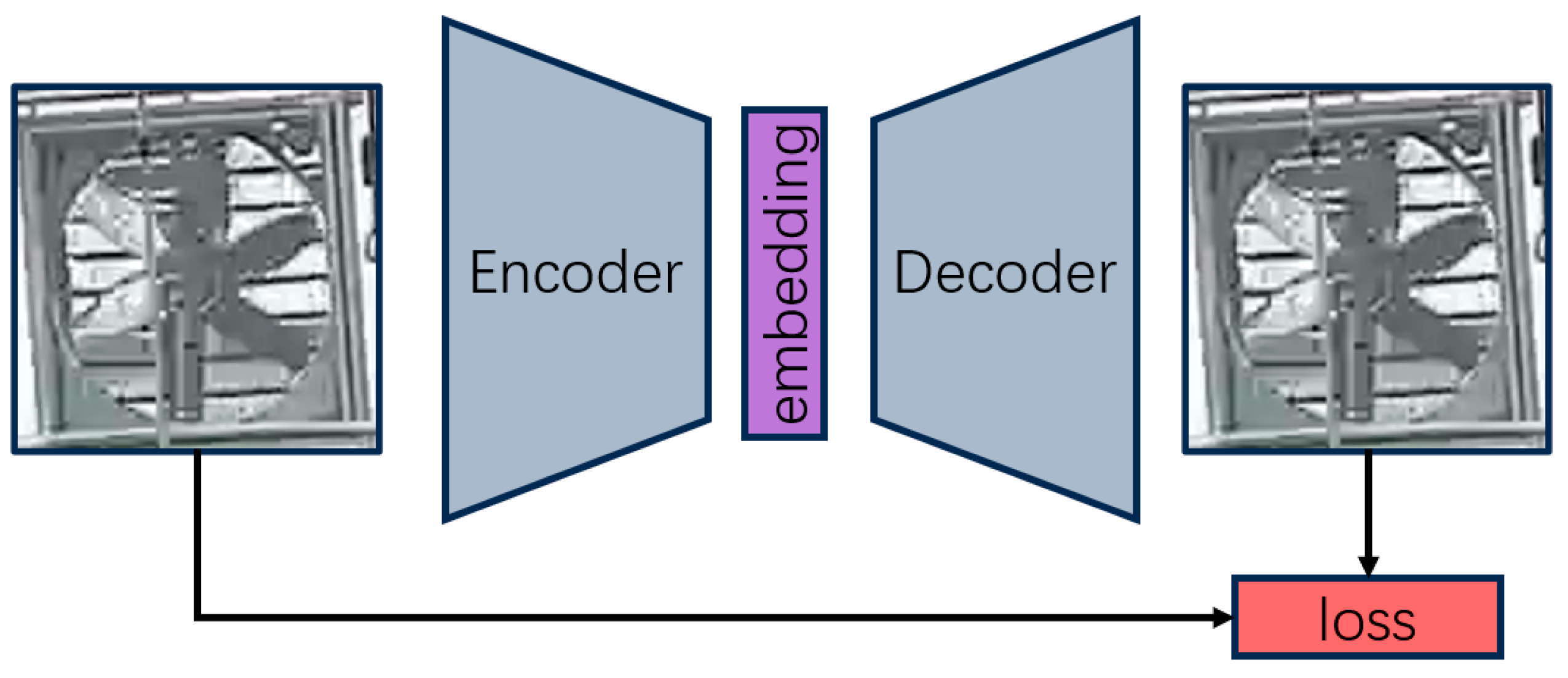
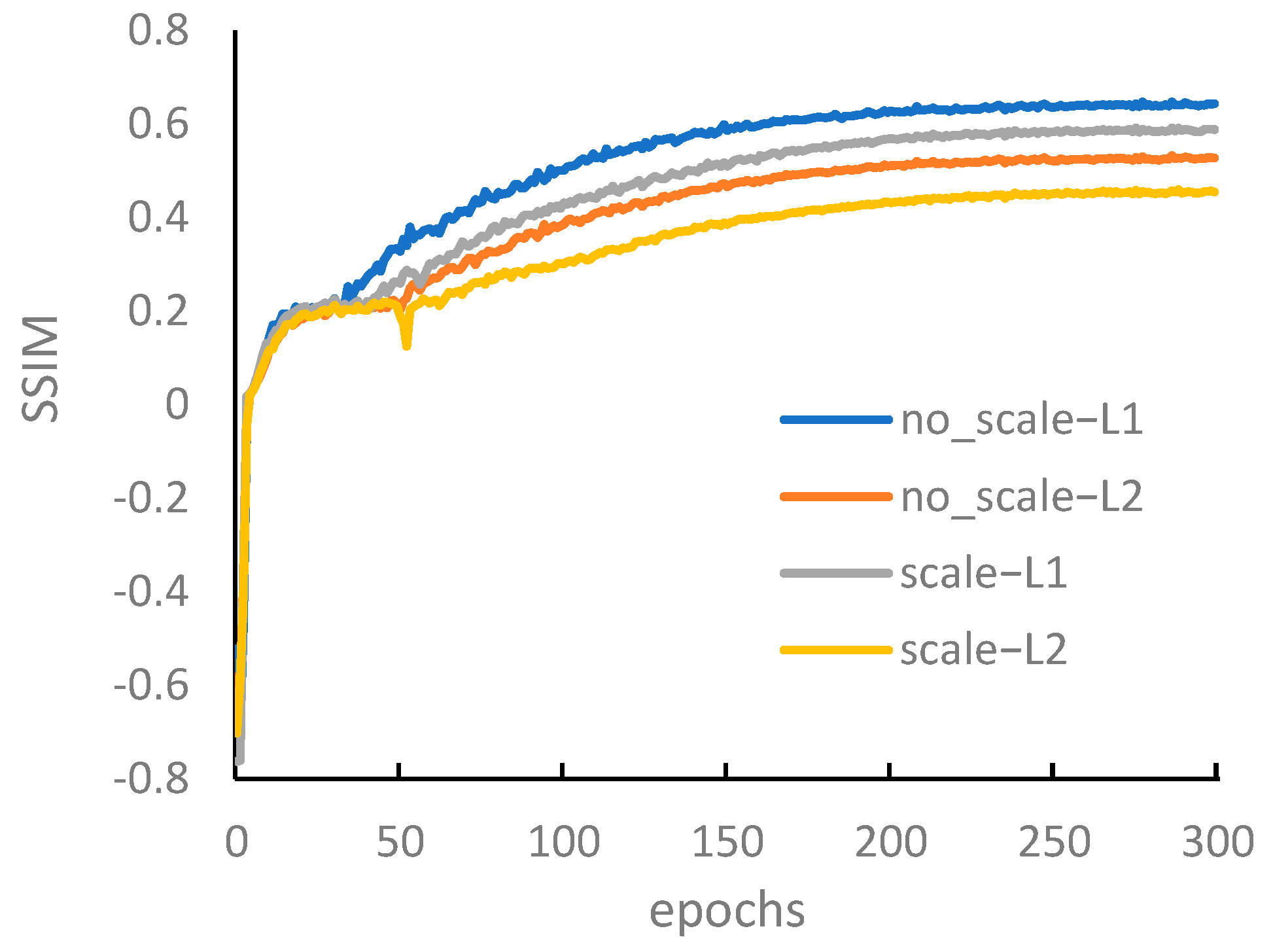
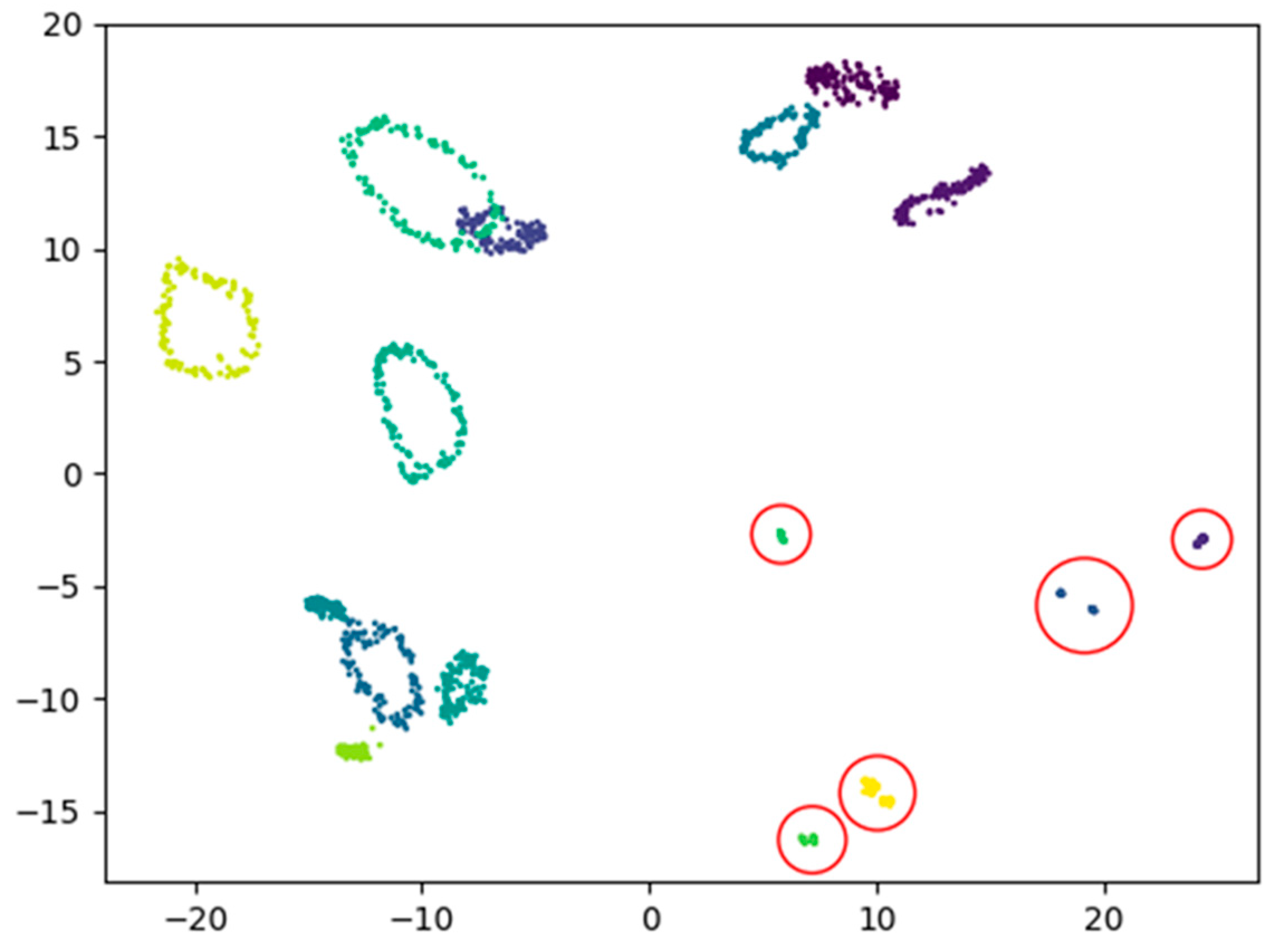
3.2.1. Image Reconstruction Losses
3.2.2. Influence of Various Image Enhancement Techniques
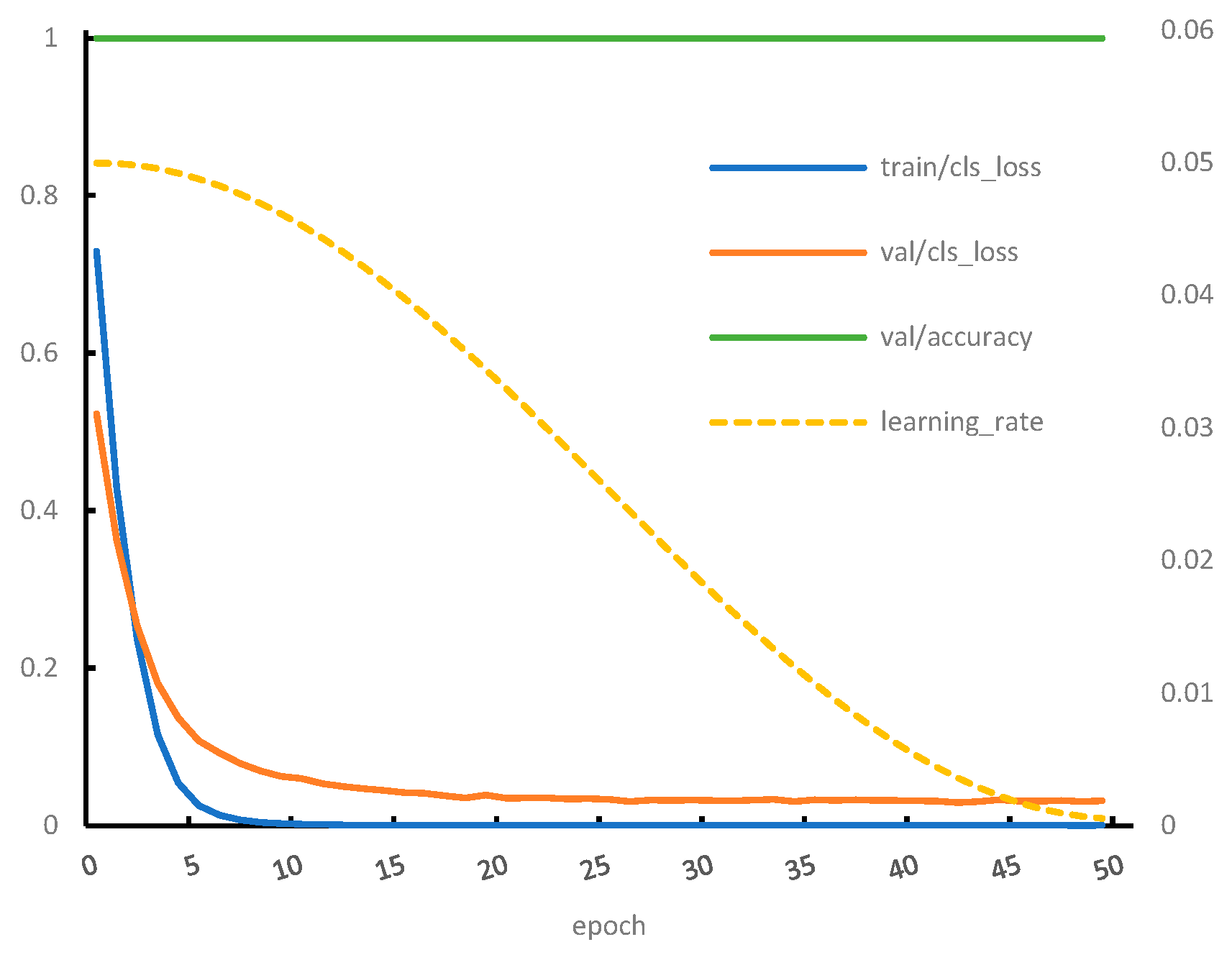
3.2.3. Fan State Recognition
3.2.4. The Convergence of the Model
3.3. Object Tracking and Region Extraction
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, L.; Song, L.; Xie, C.; Zhang, J. Applications of Internet of Things in the Facility Agriculture. In Proceedings of the Computer and Computing Technologies in Agriculture VI, Zhangjiajie, China, 19–21 October 2012; Li, D., Chen, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 297–303. [Google Scholar]
- Chaux, J.D.; Sanchez-Londono, D.; Barbieri, G. A Digital Twin Architecture to Optimize Productivity within Controlled Environment Agriculture. Appl. Sci. 2021, 11, 8875. [Google Scholar] [CrossRef]
- Li, H.; Guo, Y.; Zhao, H.; Wang, Y.; Chow, D. Towards automated greenhouse: A state of the art review on greenhouse monitoring methods and technologies based on internet of things. Comput. Electron. Agric. 2021, 191, 106558. [Google Scholar] [CrossRef]
- Hassan, I.U.; Panduru, K.; Walsh, J. An In-Depth Study of Vibration Sensors for Condition Monitoring. Sensors 2024, 24, 740. [Google Scholar] [CrossRef] [PubMed]
- Qin, L.; Huang, Y.; Yunmeng, G.; Shi, C. Design and Experiment of Status Detection of Greenhouse Ventilation Devices. Trans. Chin. Soc. Agric. Mach. 2021, 52, 303–311. [Google Scholar]
- Liu, W.; Kang, G.; Huang, P.-Y.; Chang, X.; Yu, L.; Qian, Y.; Liang, J.; Gui, L.; Wen, J.; Chen, P. Argus: Efficient Activity Detection System for Extended Video Analysis. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision Workshops (WACVW), Snowmass, CO, USA, 1–5 March 2020; IEEE: New York, NY, USA, 2020; pp. 126–133. [Google Scholar]
- Lao, W.; Cui, C.; Zhang, D.; Zhang, Q.; Bao, Y. Computer Vision-Based Autonomous Method for Quantitative Detection of Loose Bolts in Bolted Connections of Steel Structures. Struct. Control Health Monit. 2023, 2023, 8817058. [Google Scholar] [CrossRef]
- Ting, L.; Khan, M.; Sharma, A.; Ansari, M.D. A secure framework for IoT-based smart climate agriculture system: Toward blockchain and edge computing. J. Intell. Syst. 2022, 31, 221–236. [Google Scholar] [CrossRef]
- Sengupta, A.; Gill, S.S.; Das, A.; De, D. Mobile Edge Computing Based Internet of Agricultural Things: A Systematic Review and Future Directions. In Mobile Edge Computing; Mukherjee, A., De, D., Ghosh, S.K., Buyya, R., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 415–441. ISBN 978-3-030-69893-5. [Google Scholar]
- Zheng, X.; Chen, F.; Lou, L.; Cheng, P.; Huang, Y. Real-Time Detection of Full-Scale Forest Fire Smoke Based on Deep Convolution Neural Network. Remote Sens. 2022, 14, 536. [Google Scholar] [CrossRef]
- Sun, P.; Jiang, Y.; Xie, E.; Shao, W.; Yuan, Z.; Wang, C.; Luo, P. What Makes for End-to-End Object Detection? arXiv 2021, arXiv:2012.05780. [Google Scholar] [CrossRef]
- Lai, T. Real-Time Aerial Detection and Reasoning on Embedded-UAVs in Rural Environments. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4403407. [Google Scholar] [CrossRef]
- Zheng, X.; Lu, C.; Zhu, P.; Yang, G. Visual Multitask Real-Time Model in an Automatic Driving Scene. Electronics. 2023, 12, 2097. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Chen, S.; Guo, W. Auto-Encoders in Deep Learning—A Review with New Perspectives. Mathematics 2023, 11, 1777. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Yang, Y.; Zhou, Y.; Yue, X.; Zhang, G.; Wen, X.; Ma, B.; Xu, L.; Chen, L. Real-time detection of crop rows in maize fields based on autonomous extraction of ROI. Expert Syst. Appl. 2023, 213, 118826. [Google Scholar] [CrossRef]
- Han, C.; Zheng, K.; Zhao, X.; Zheng, S.; Fu, H.; Zhai, C. Design and Experiment of Row Identification and Row-oriented Spray Control System for Field Cabbage Crops. Trans. Chin. Soc. Agric. Mach. 2022, 53, 89–101. [Google Scholar]
- Ghahremannezhad, H.; Shi, H.; Liu, C. A New Adaptive Bidirectional Region-of-Interest Detection Method for Intelligent Traffic Video Analysis. In Proceedings of the 2020 IEEE Third International Conference on Artificial Intelligence and Knowledge Engineering (AIKE), Laguna Hills, CA, USA, 9–13 December 2020; pp. 17–24. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Hotelling, H. Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 1933, 24, 417–441. [Google Scholar] [CrossRef]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. DepGraph: Towards Any Structural Pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pruning Ratio | Window Size | Average Inference Time | Average Post-Processing Time | Number of Target Losses |
|---|---|---|---|---|
| 0% | - | 327.43 | 4.54 | 0 |
| 128 | 162.76 | 8.50 | 18 | |
| 96 | 135.22 | 5.94 | 17 | |
| 64 | 111.32 | 3.58 | 20 | |
| 50% | - | 247.35 | 4.90 | 0 |
| 128 | 128.77 | 7.18 | 9 | |
| 96 | 104.66 | 5.36 | 6 | |
| 64 | 83.06 | 3.02 | 7 | |
| 62.5% | - | 242.01 | 4.87 | 6 |
| 128 | 118.63 | 6.70 | 4 | |
| 96 | 107.70 | 5.62 | 34 | |
| 64 | 80.66 | 2.83 | 7 | |
| 75% | - | 220.15 | 4.70 | 0 |
| 128 | 122.24 | 5.50 | 28 | |
| 96 | 93.36 | 3.36 | 15 | |
| 64 | 58.20 | 0.91 | 48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, G.; Zhang, H.; Chen, M. Greenhouse Ventilation Equipment Monitoring for Edge Computing. Appl. Sci. 2024, 14, 3378. https://doi.org/10.3390/app14083378
Feng G, Zhang H, Chen M. Greenhouse Ventilation Equipment Monitoring for Edge Computing. Applied Sciences. 2024; 14(8):3378. https://doi.org/10.3390/app14083378
Chicago/Turabian StyleFeng, Guofu, Hao Zhang, and Ming Chen. 2024. "Greenhouse Ventilation Equipment Monitoring for Edge Computing" Applied Sciences 14, no. 8: 3378. https://doi.org/10.3390/app14083378